







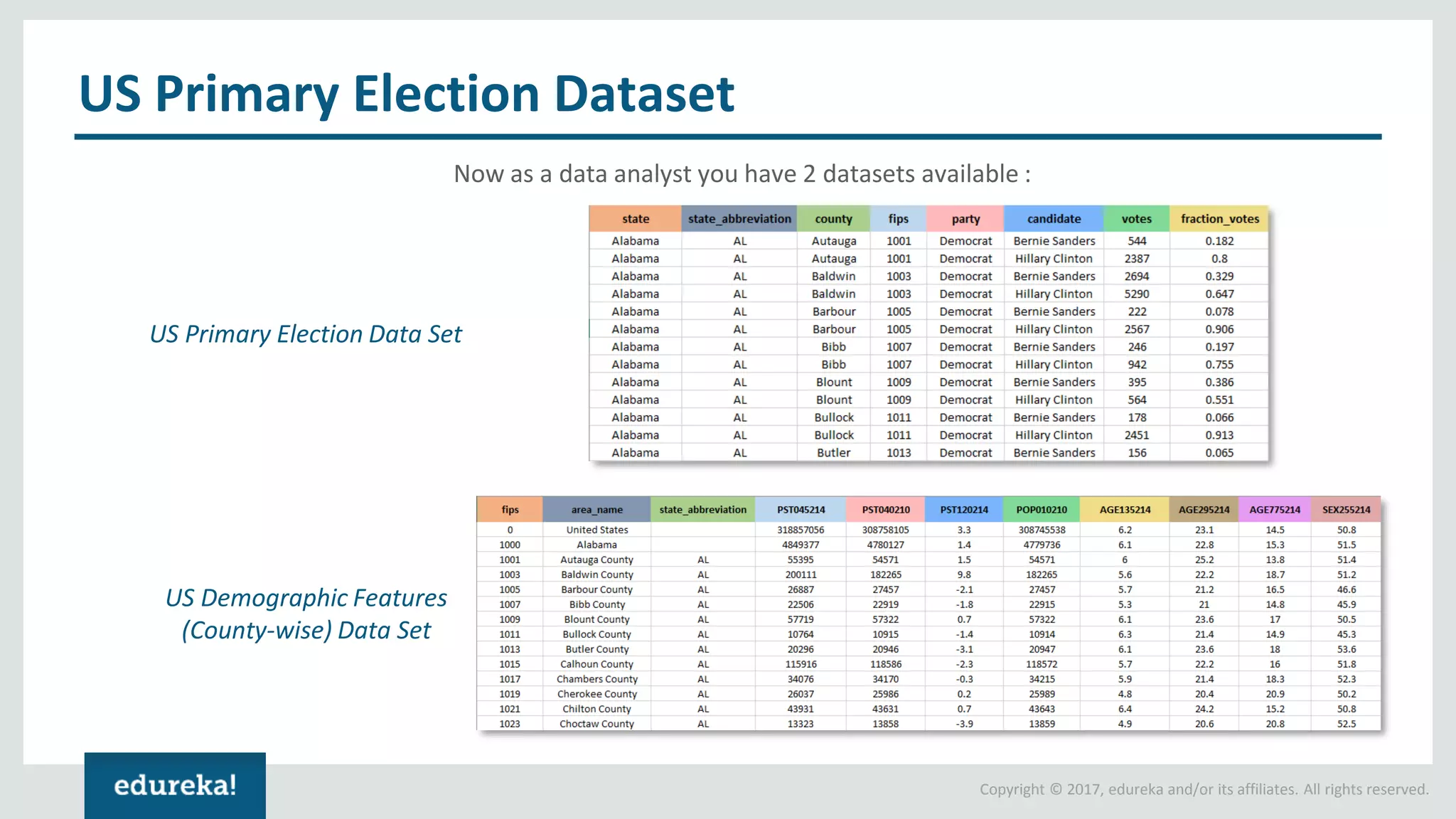
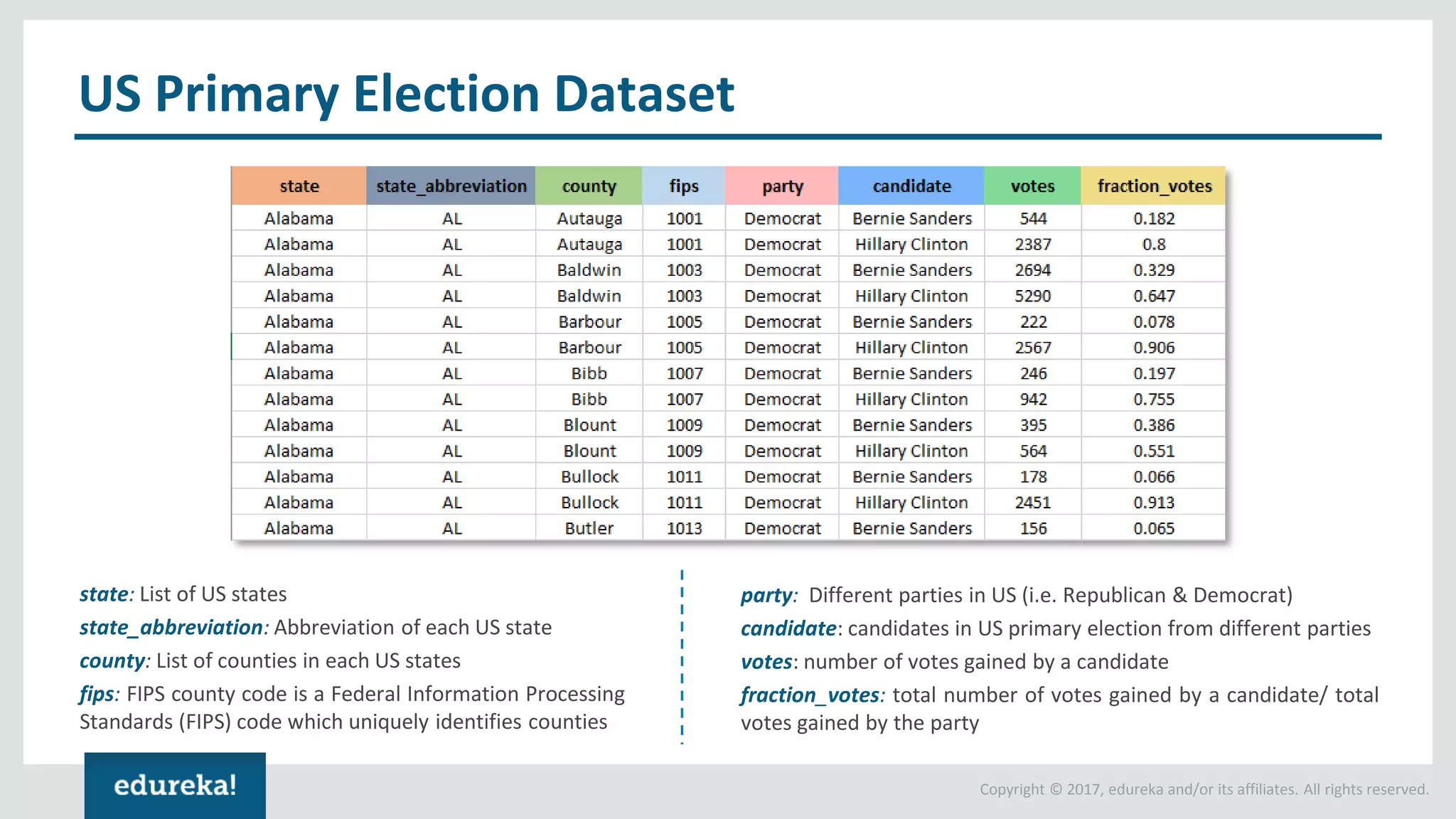
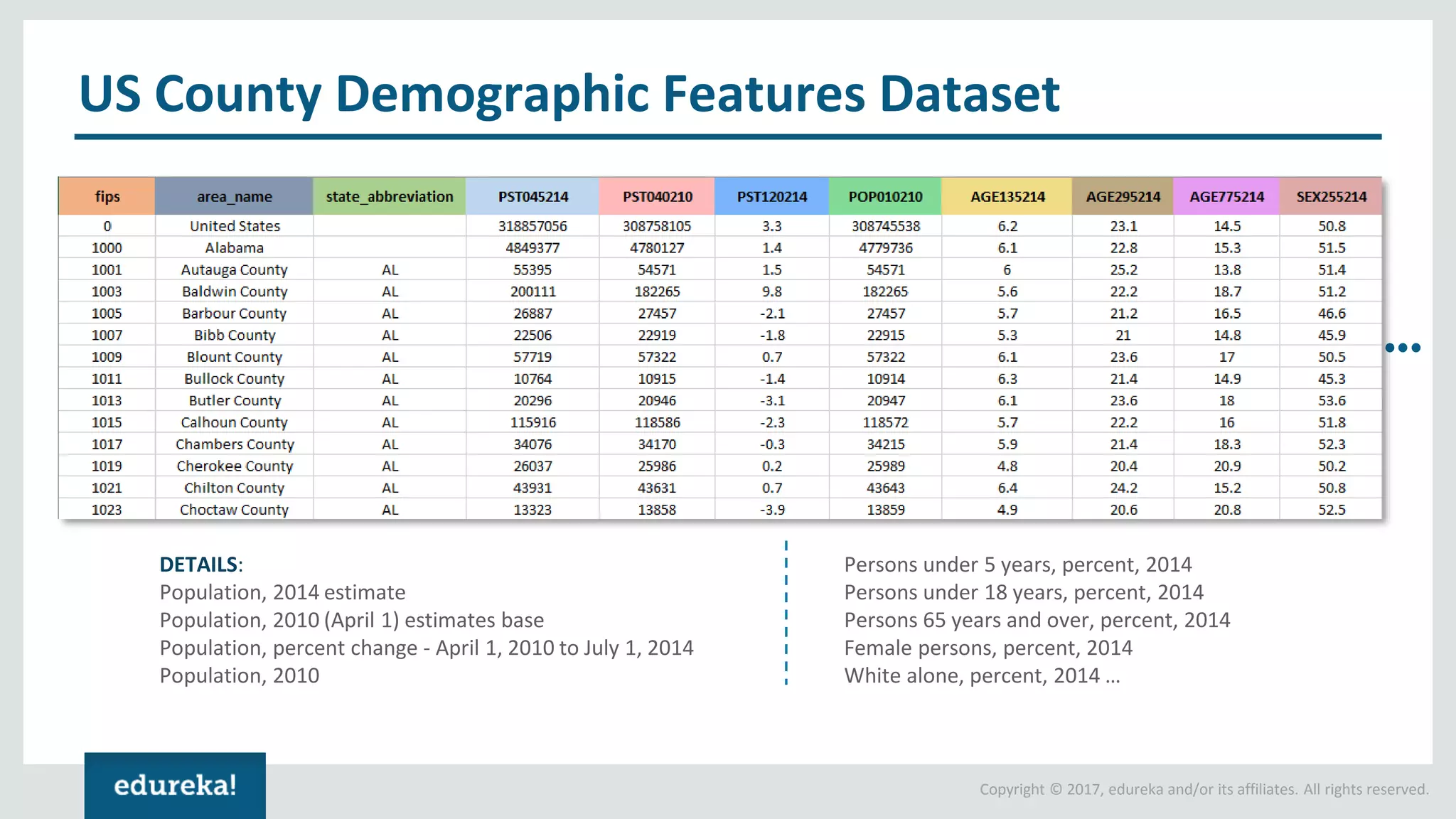
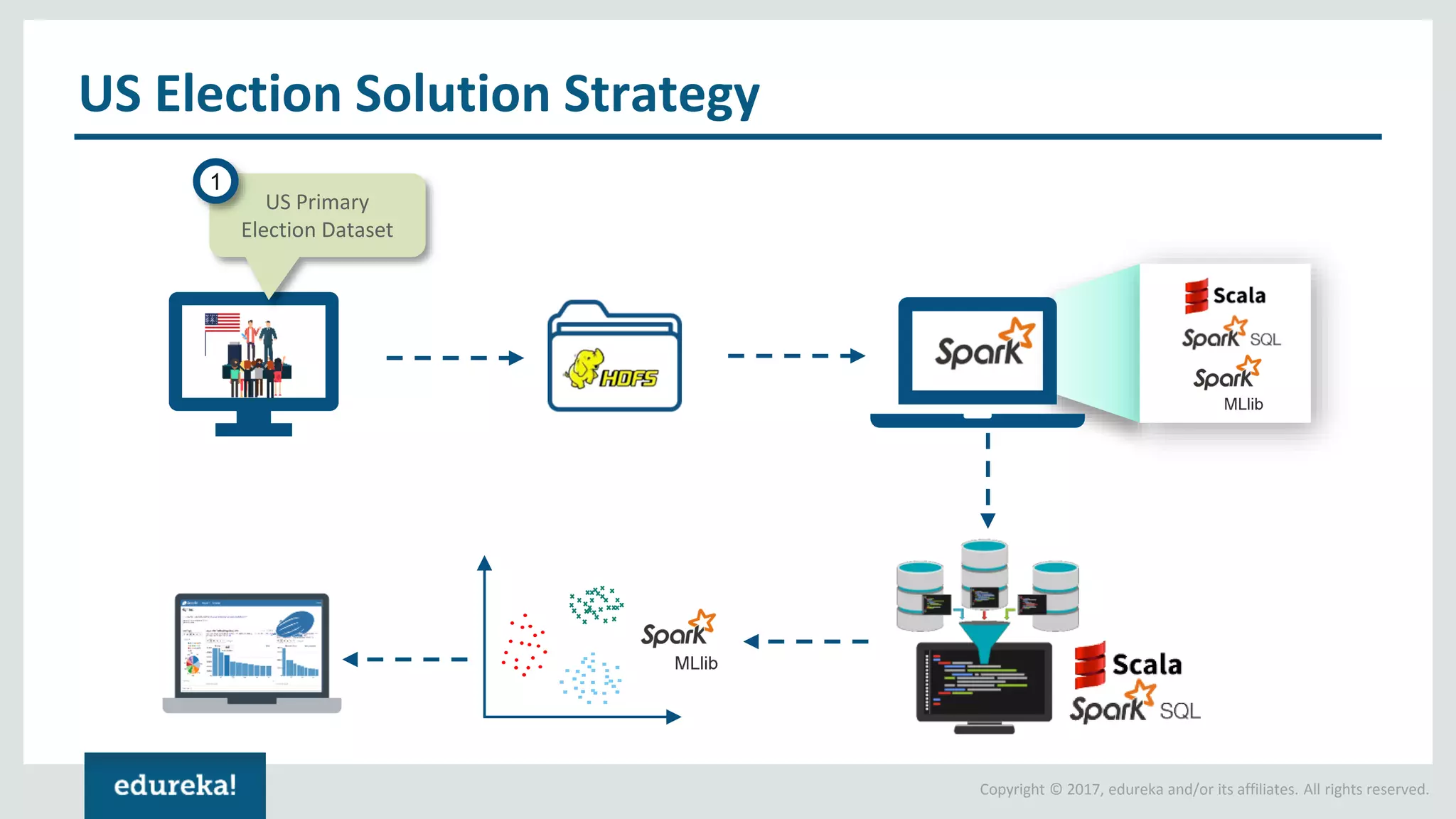
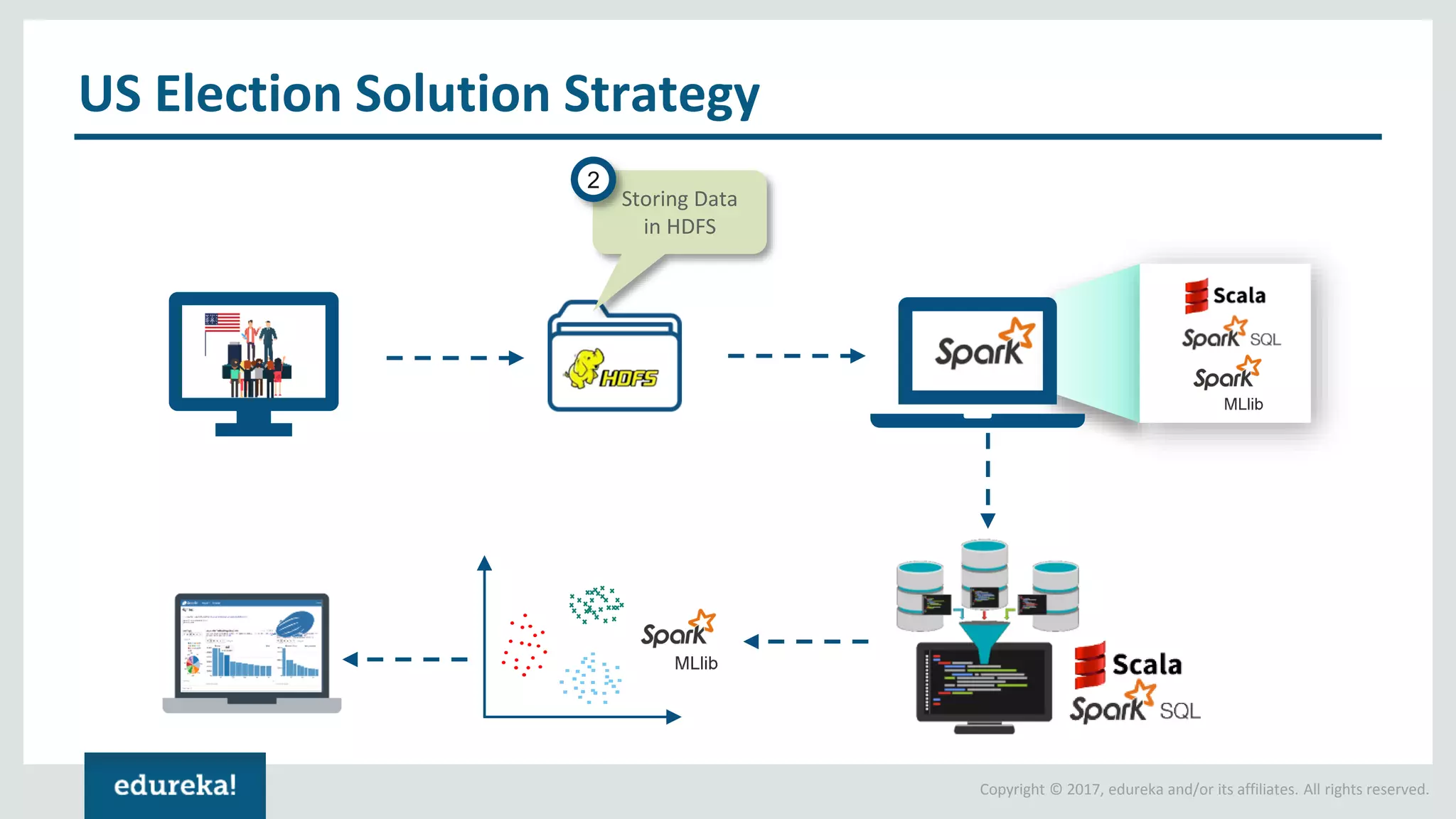
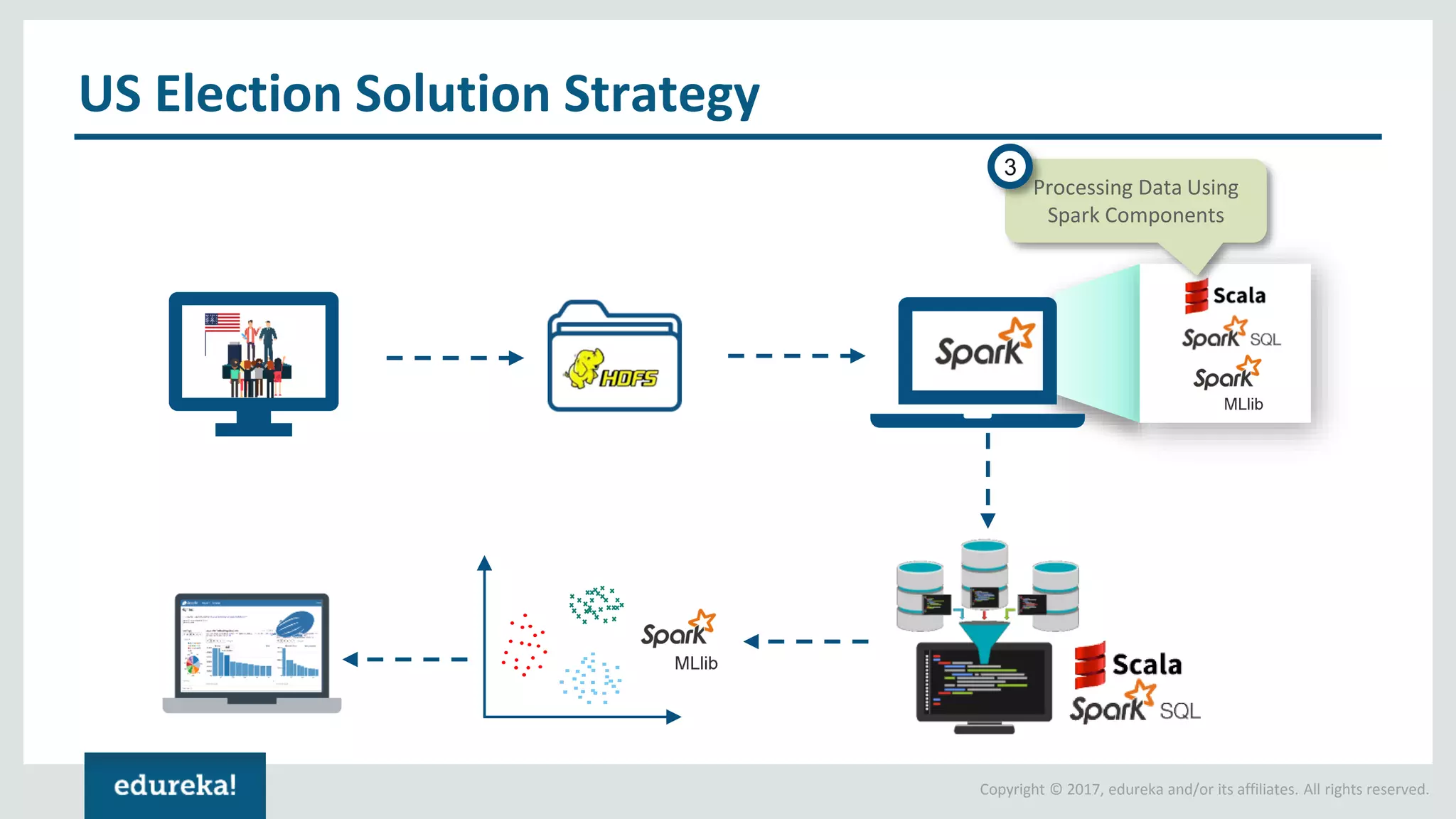
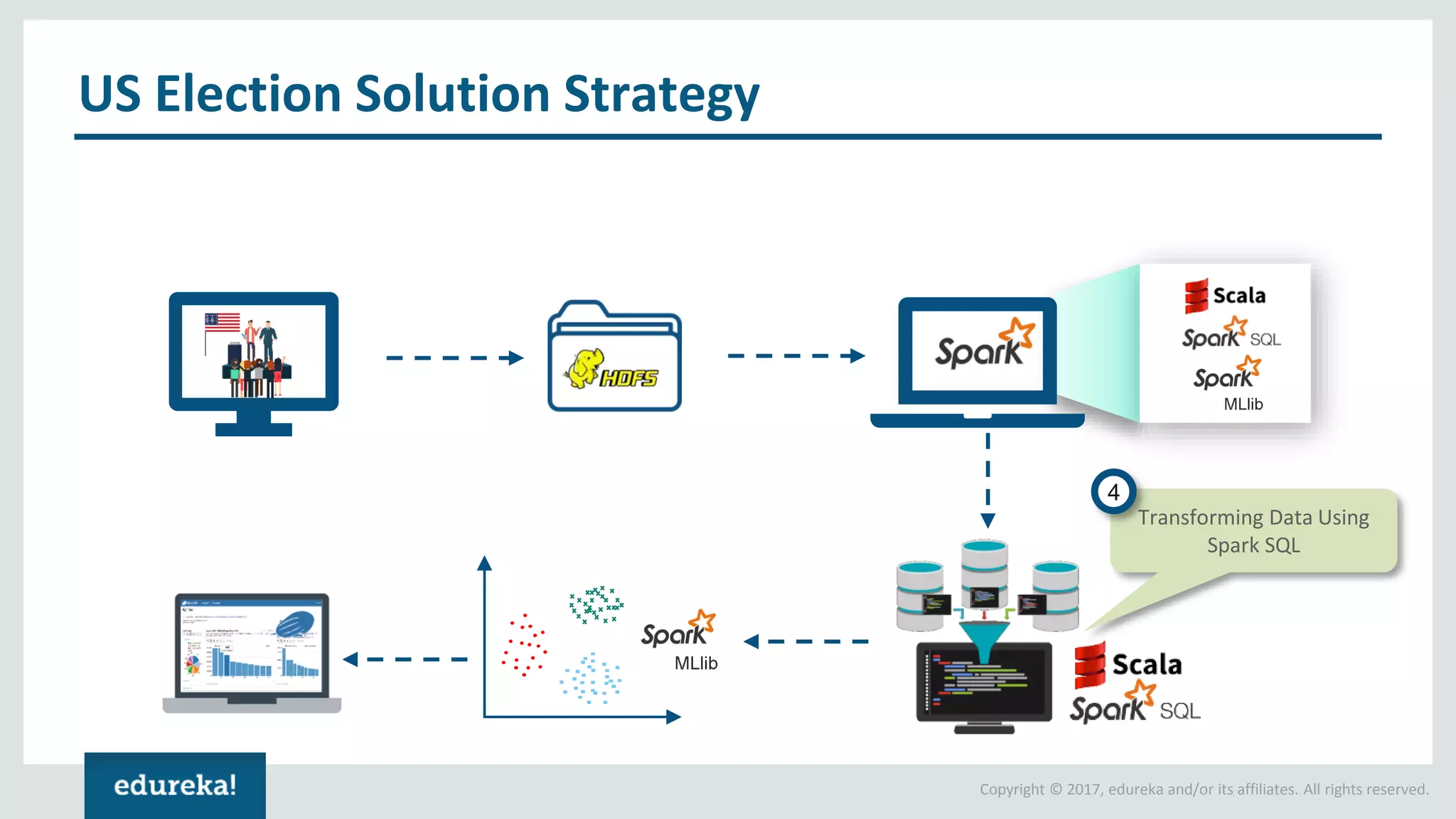
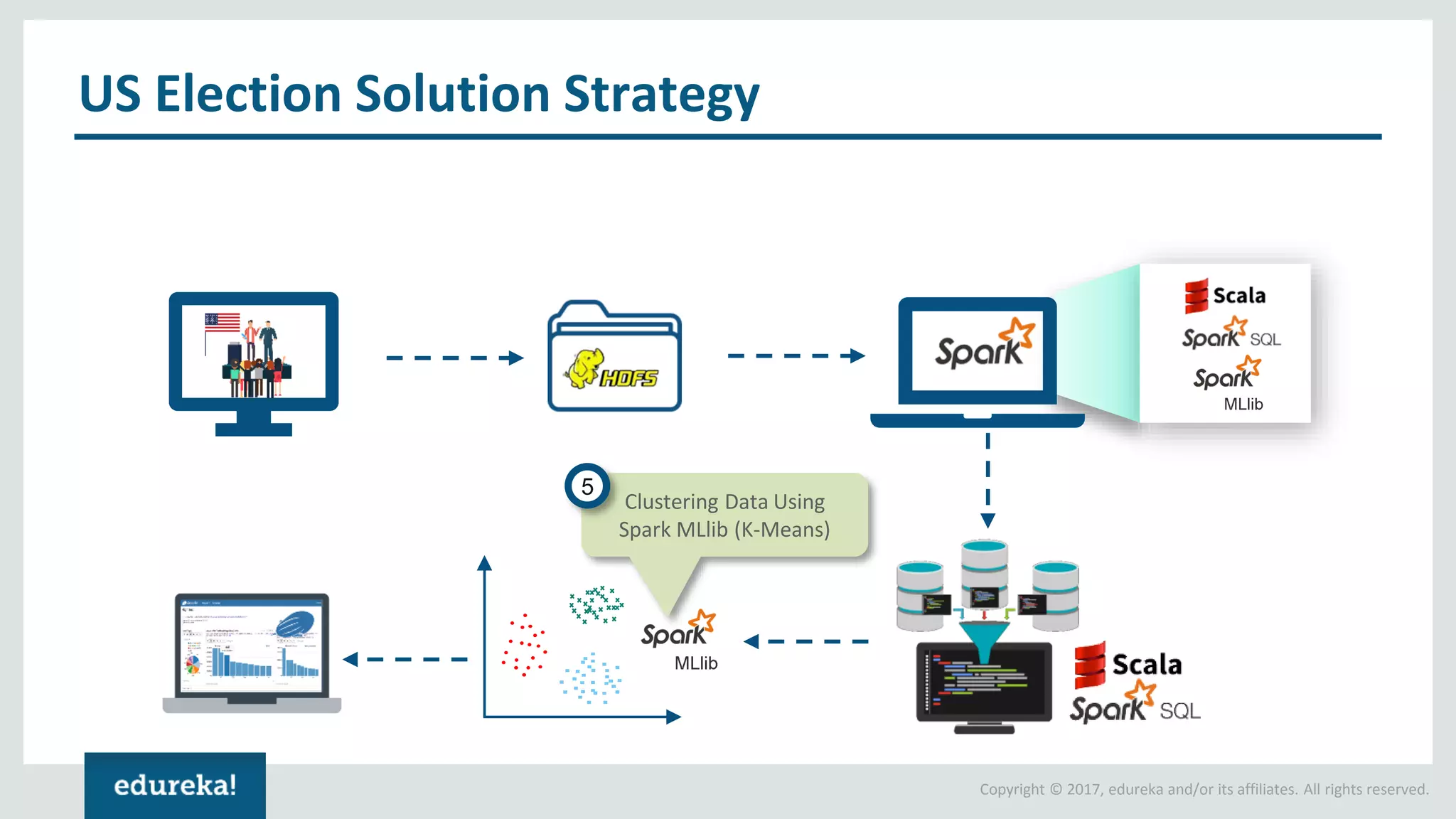
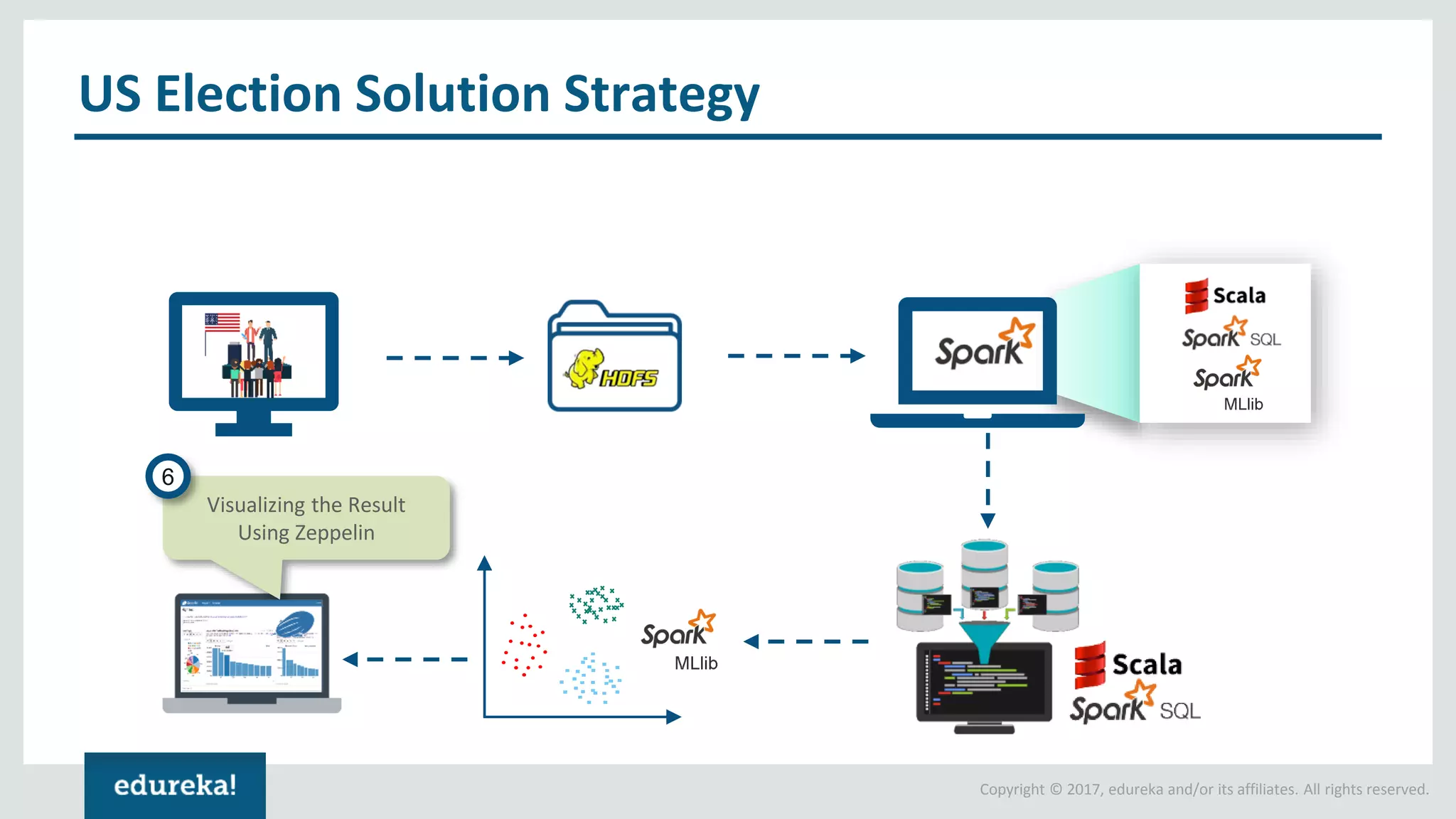
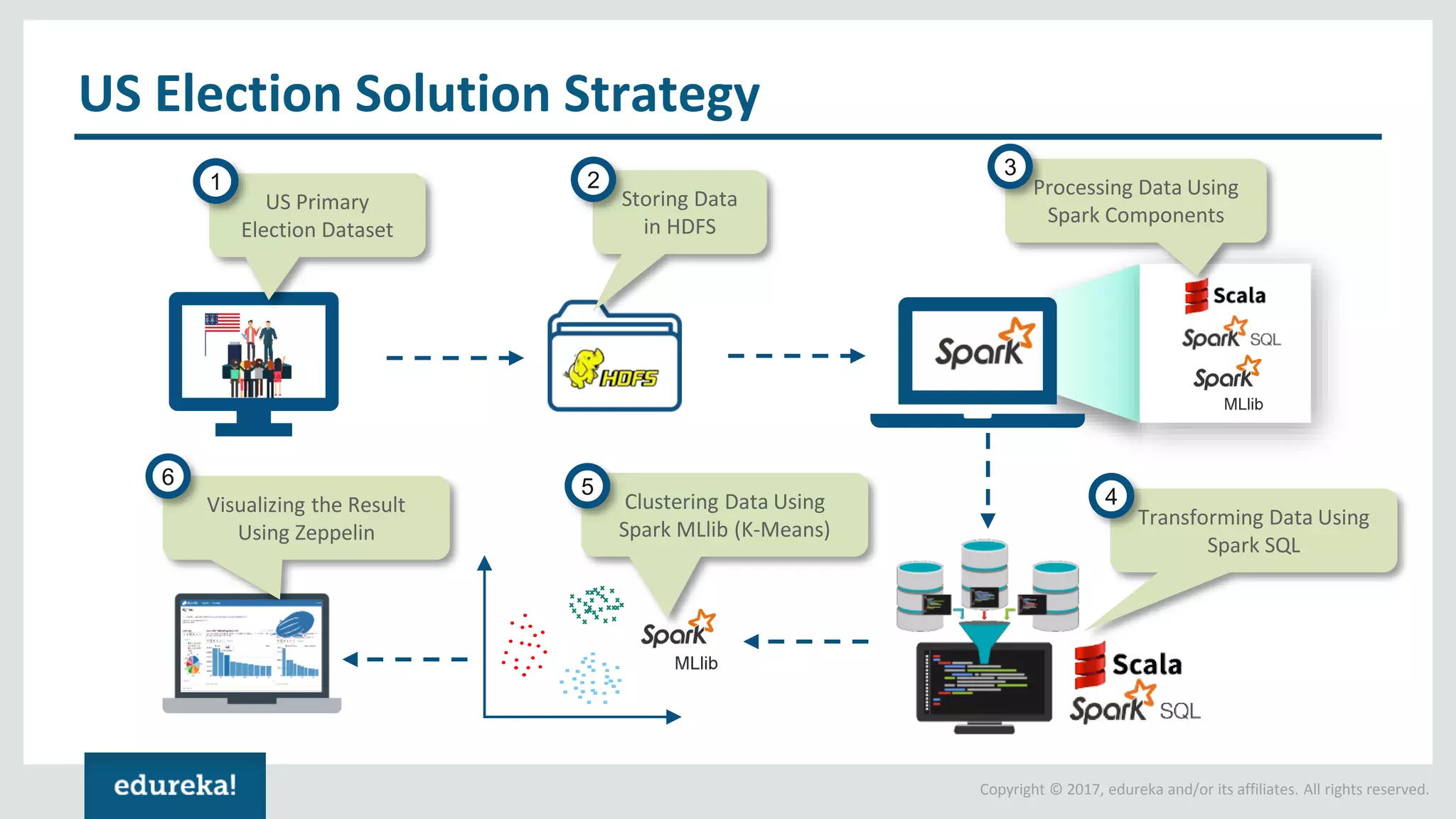


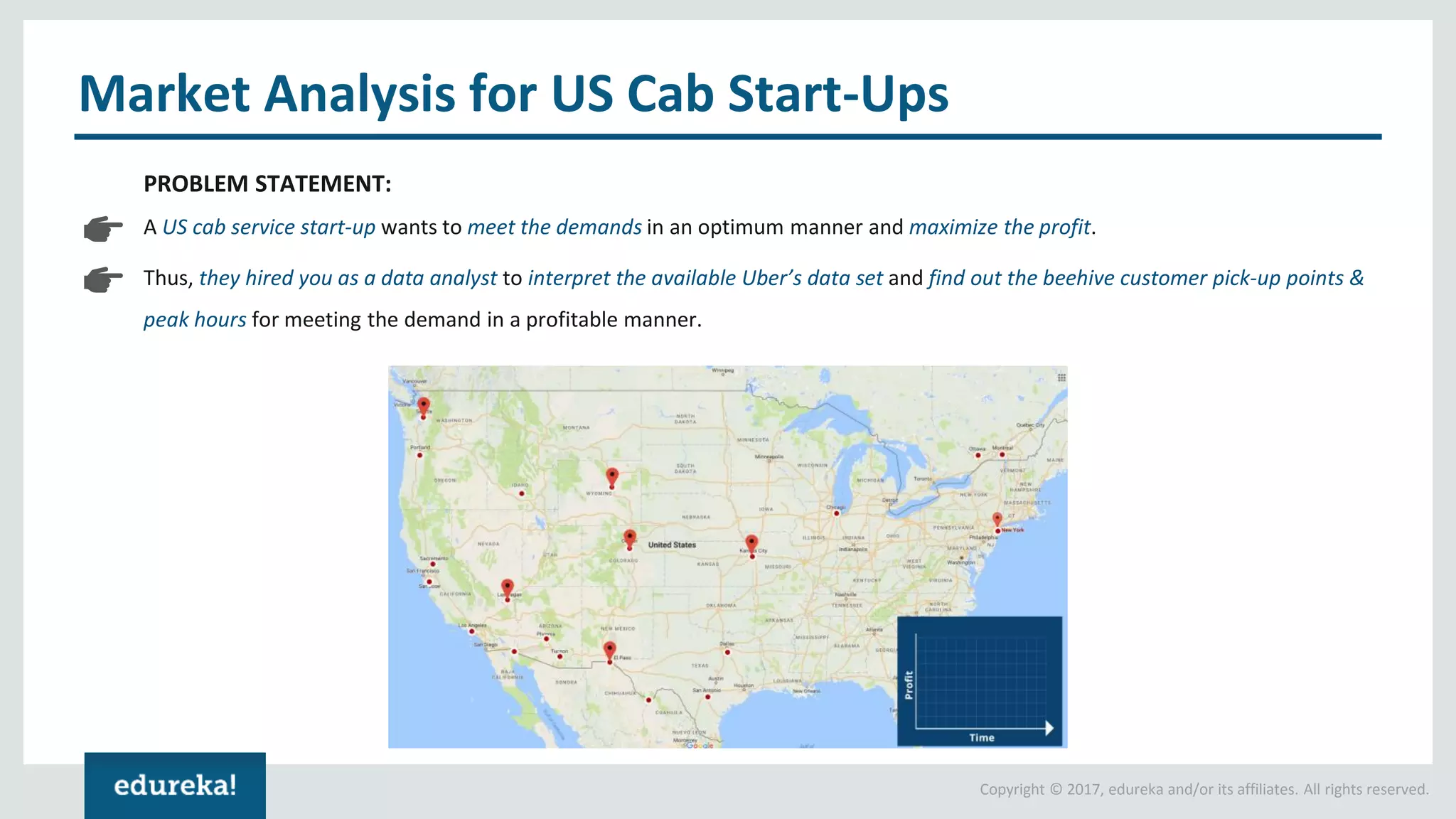
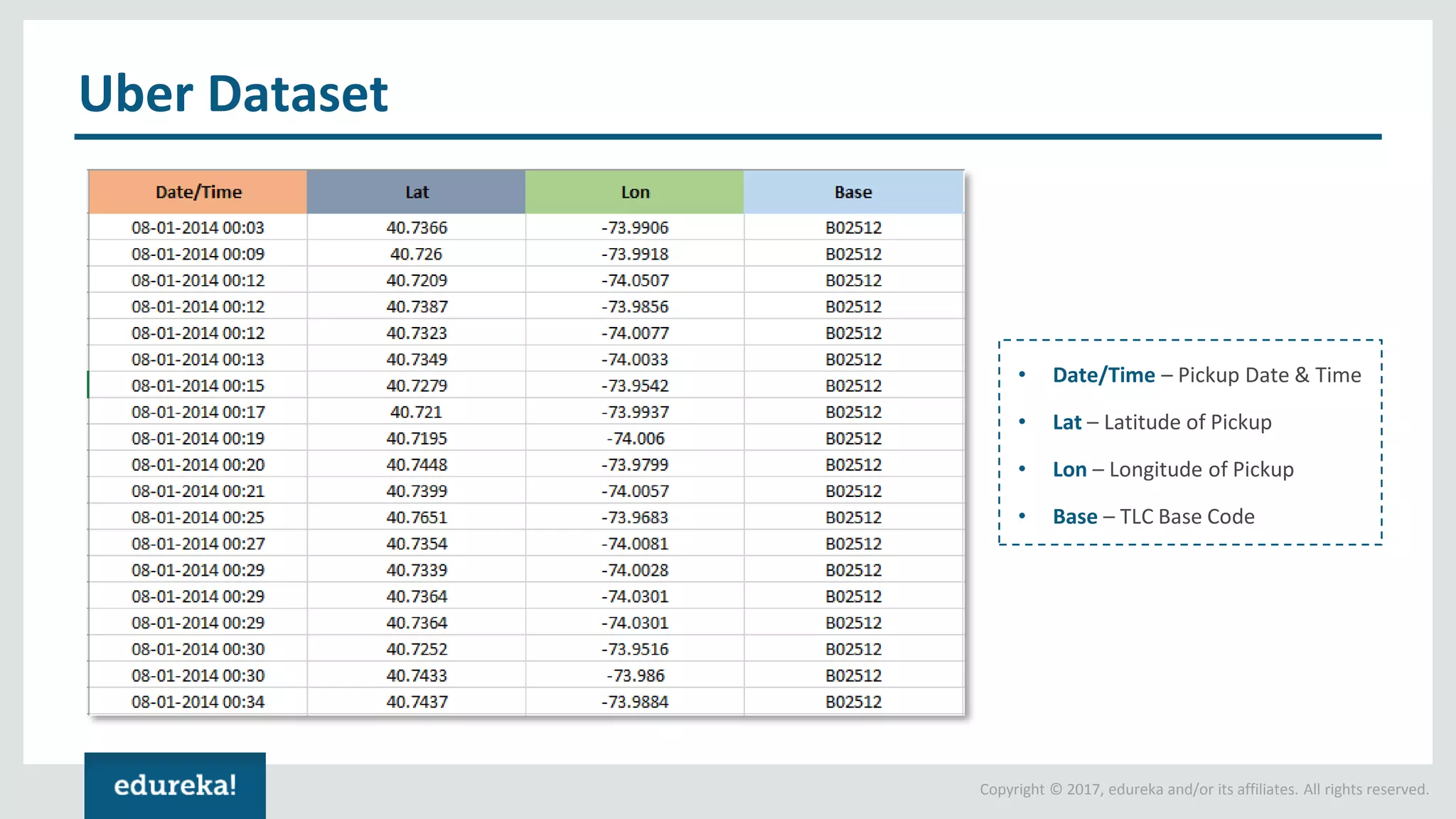
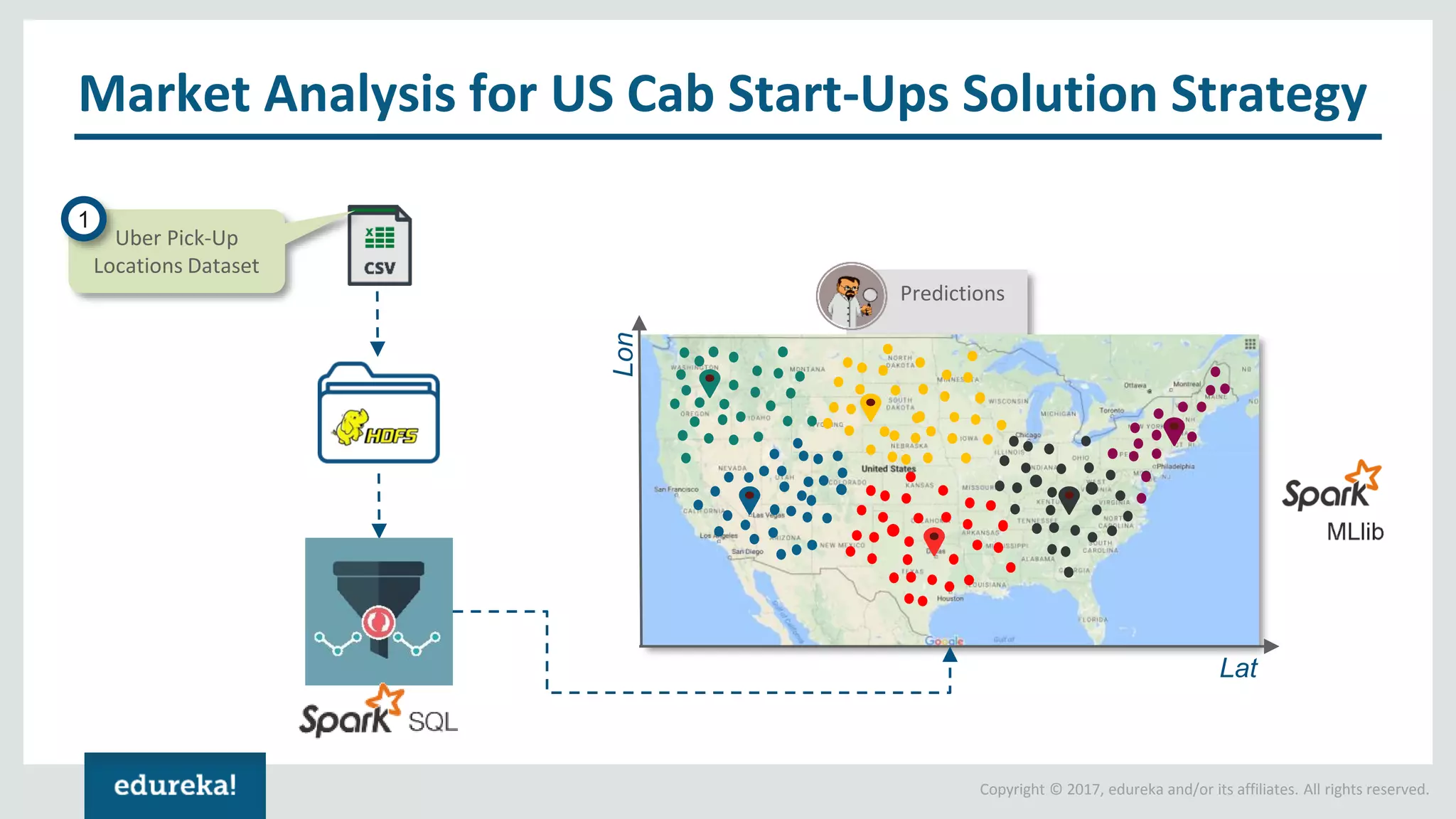
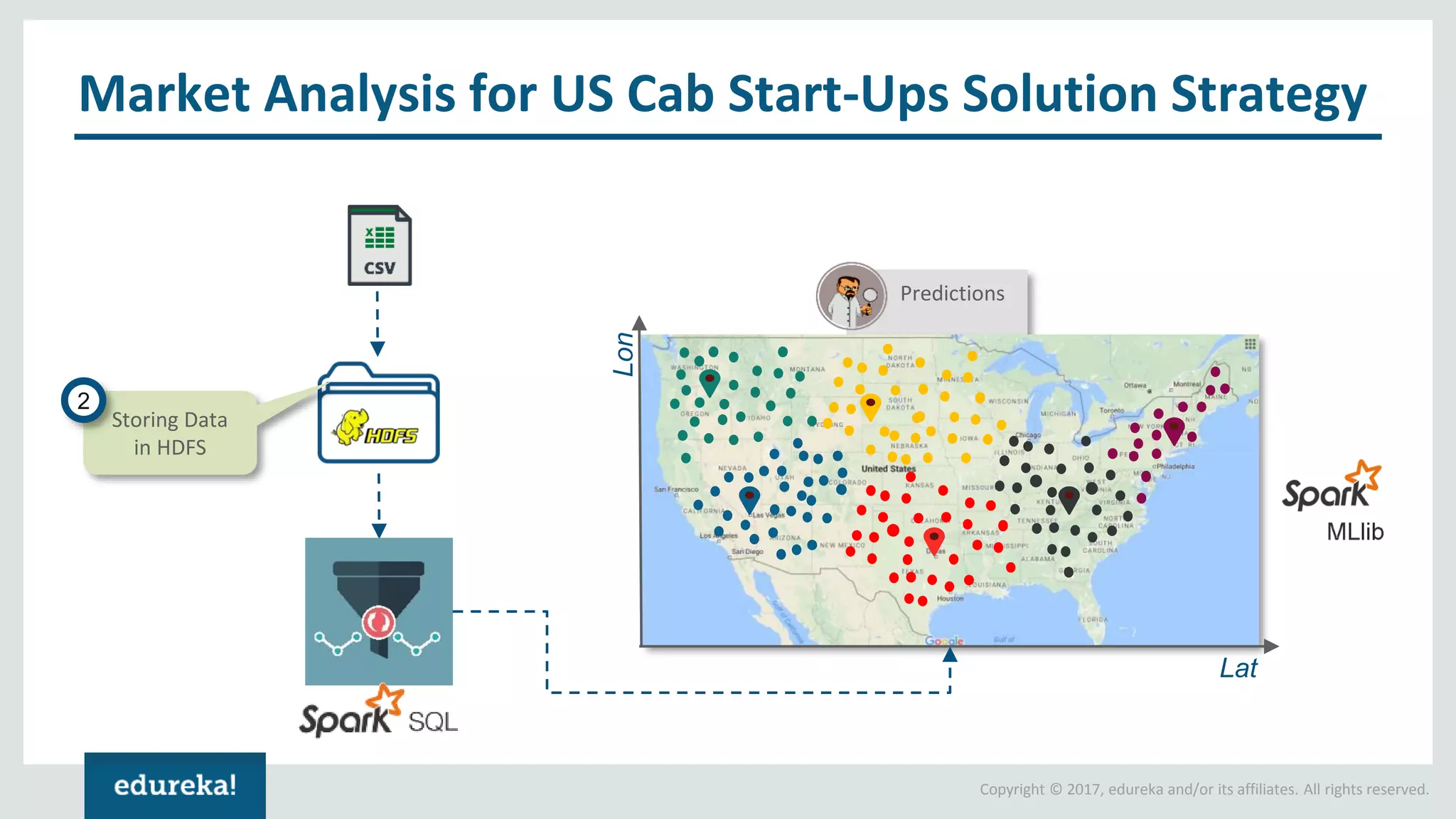
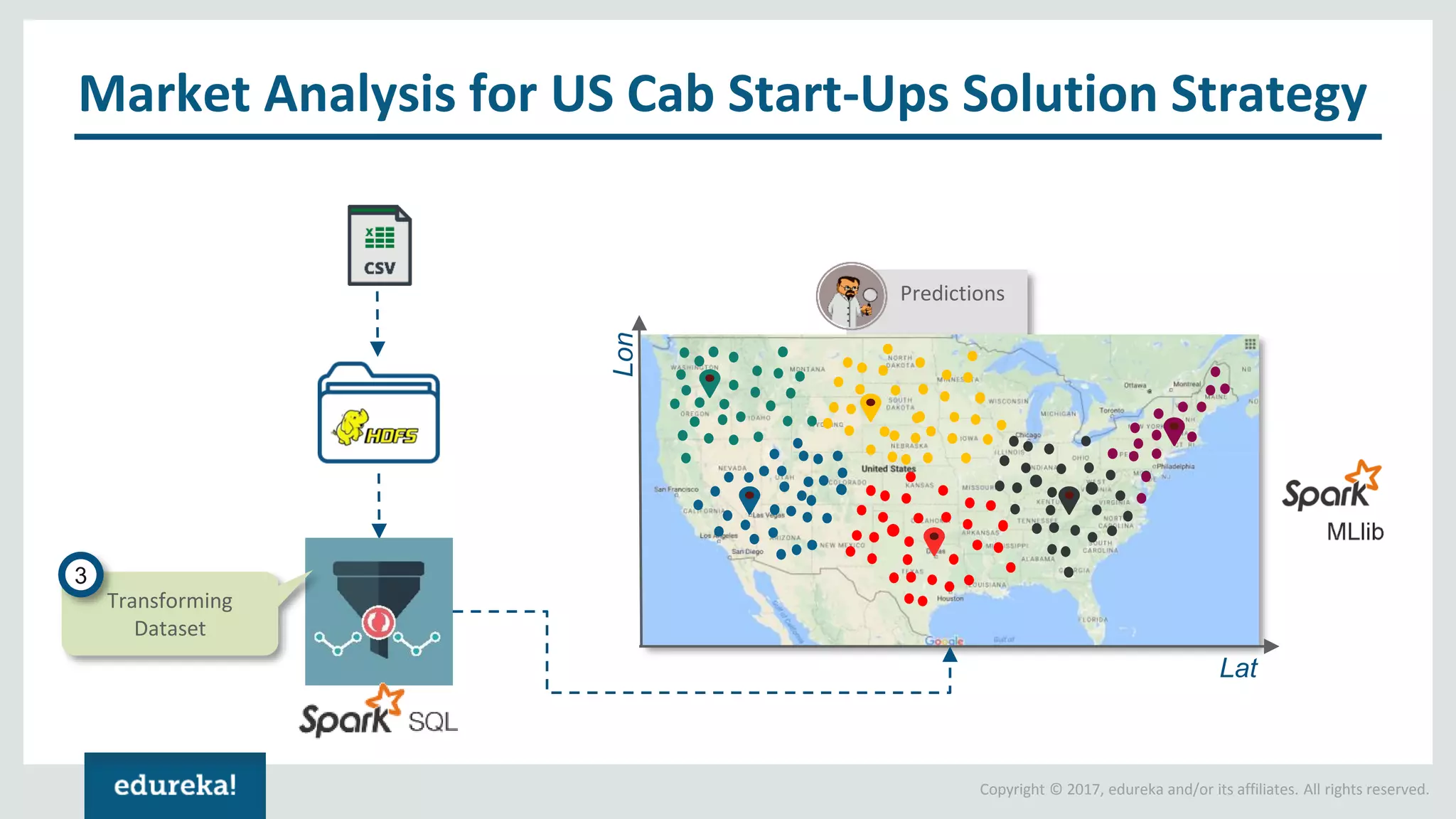
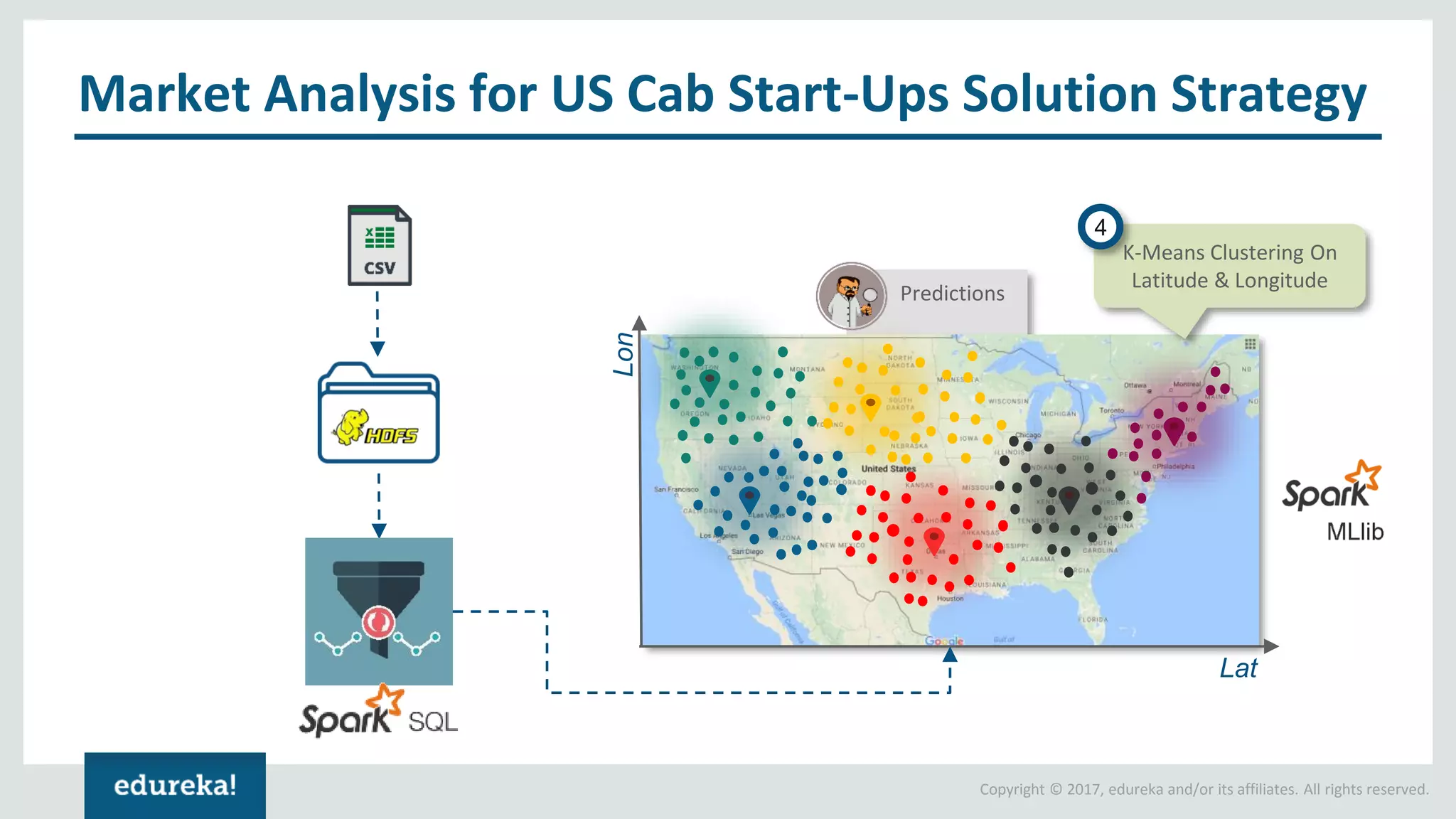
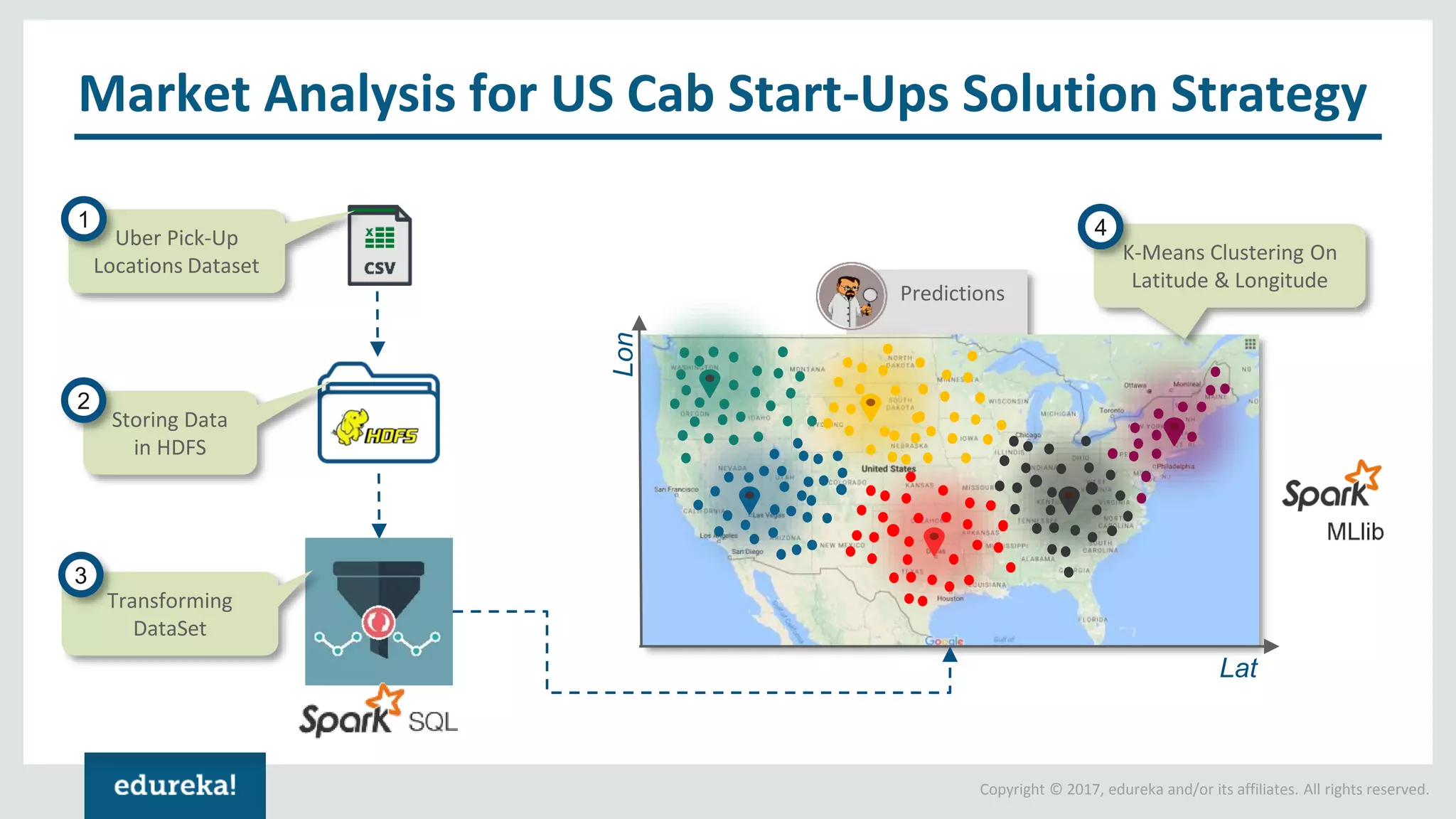

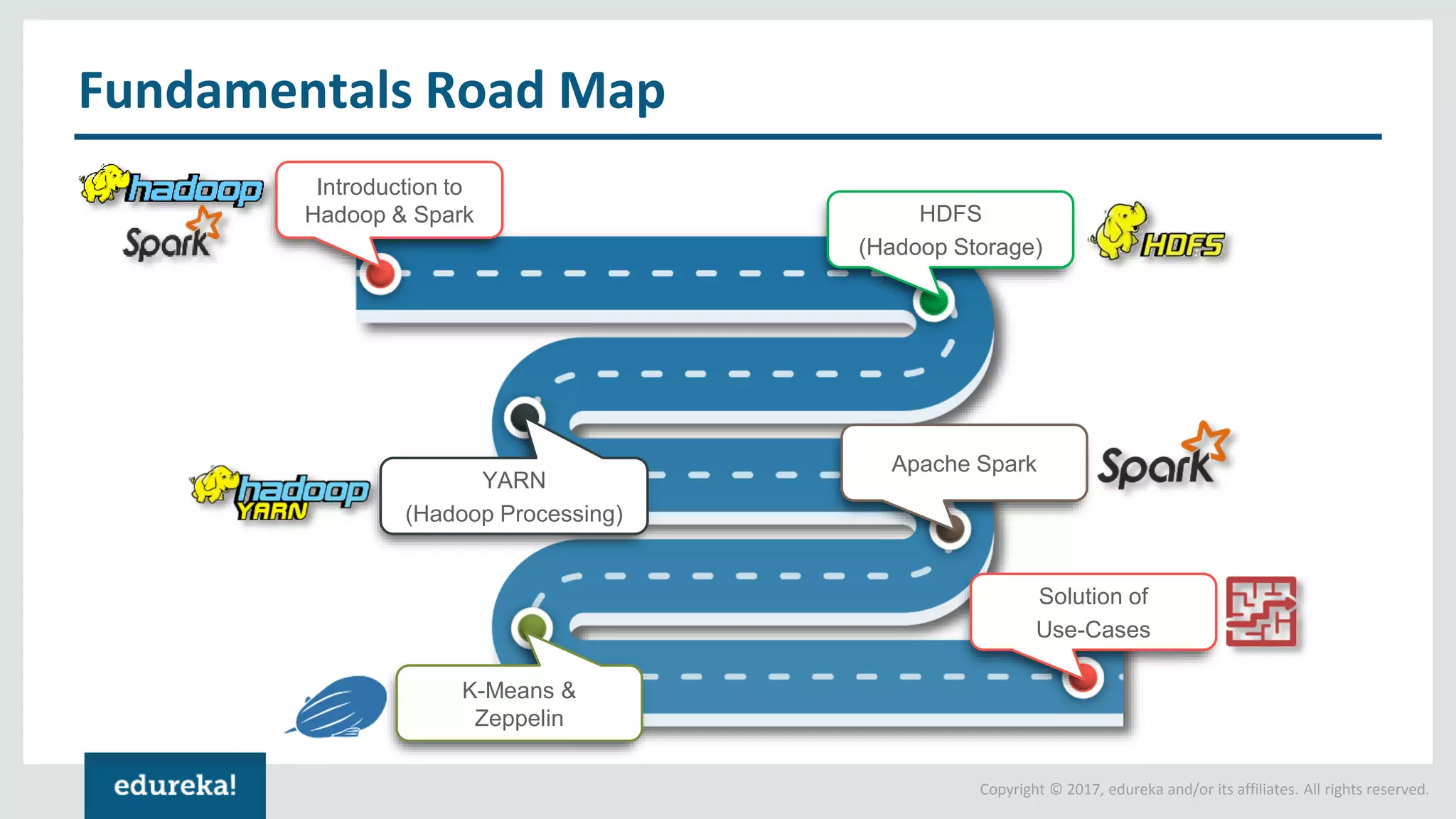
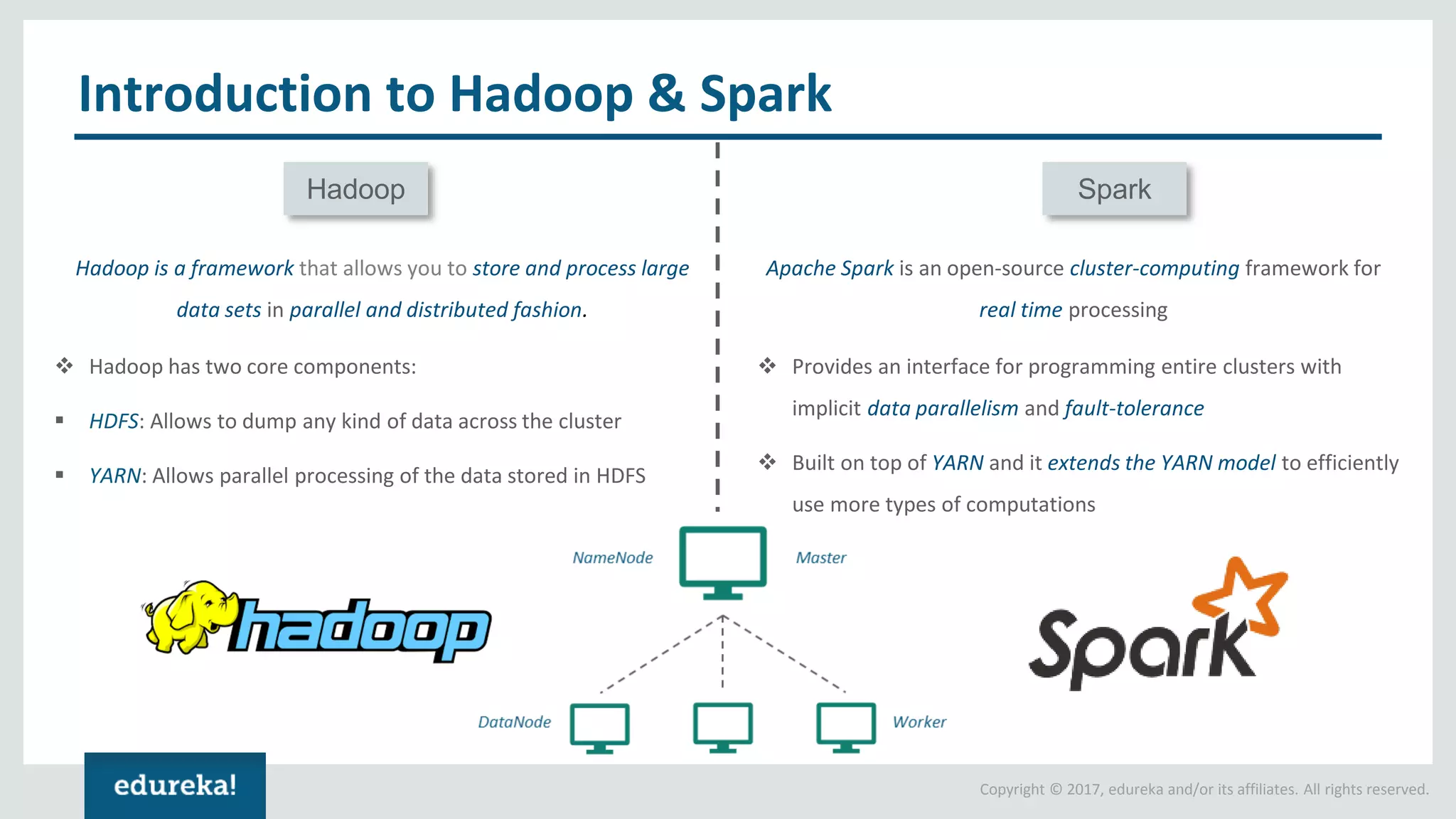

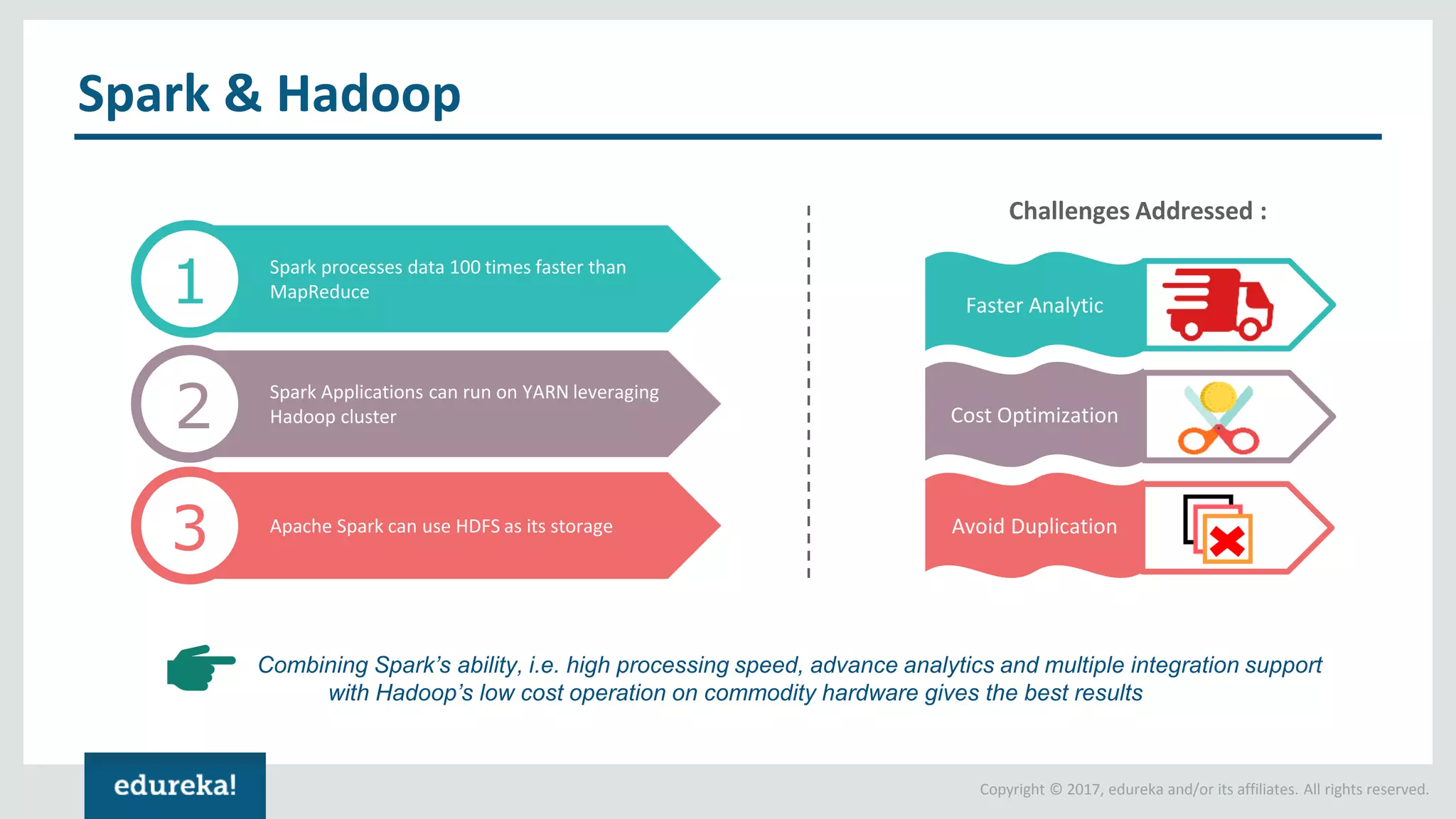



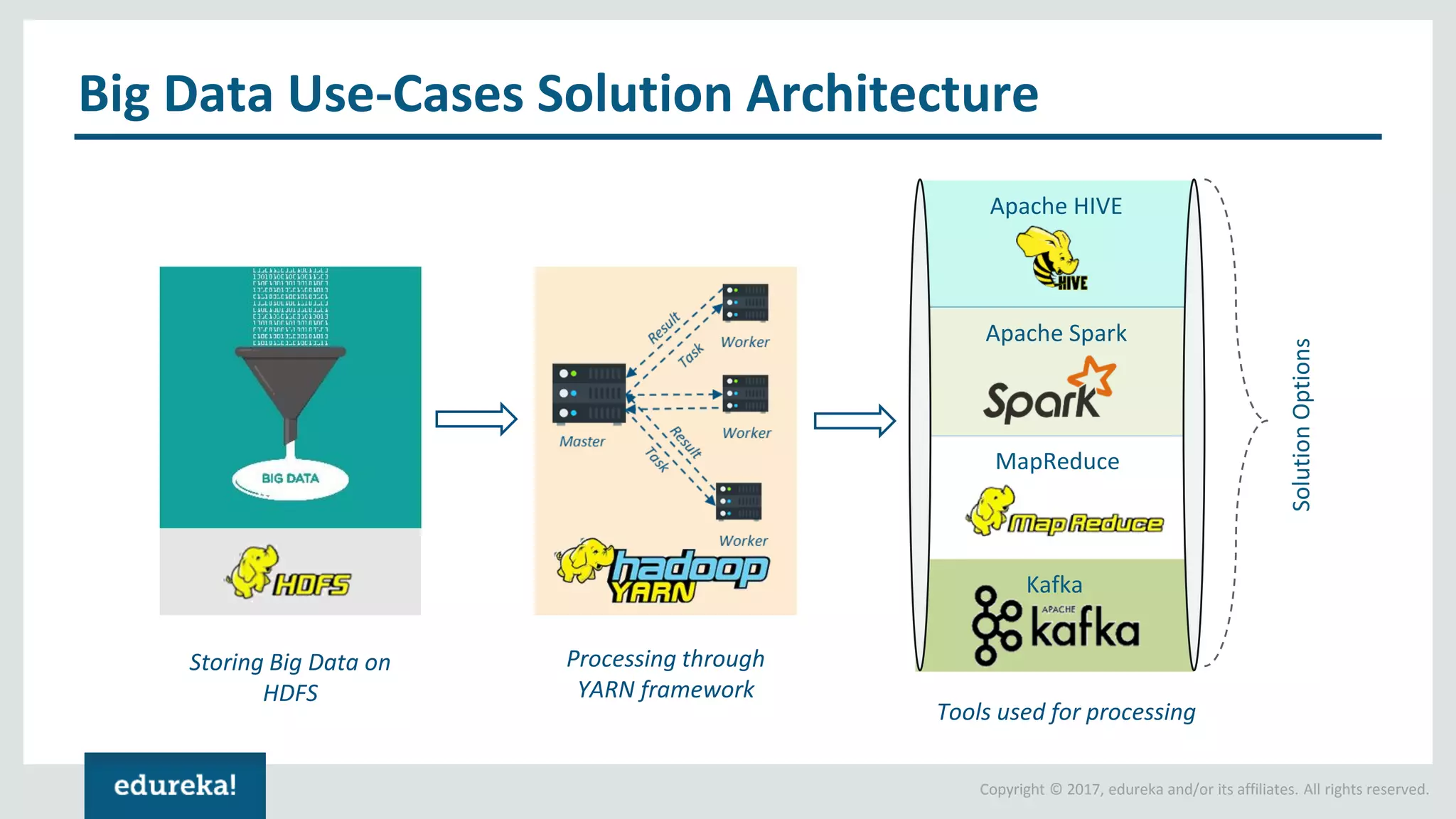
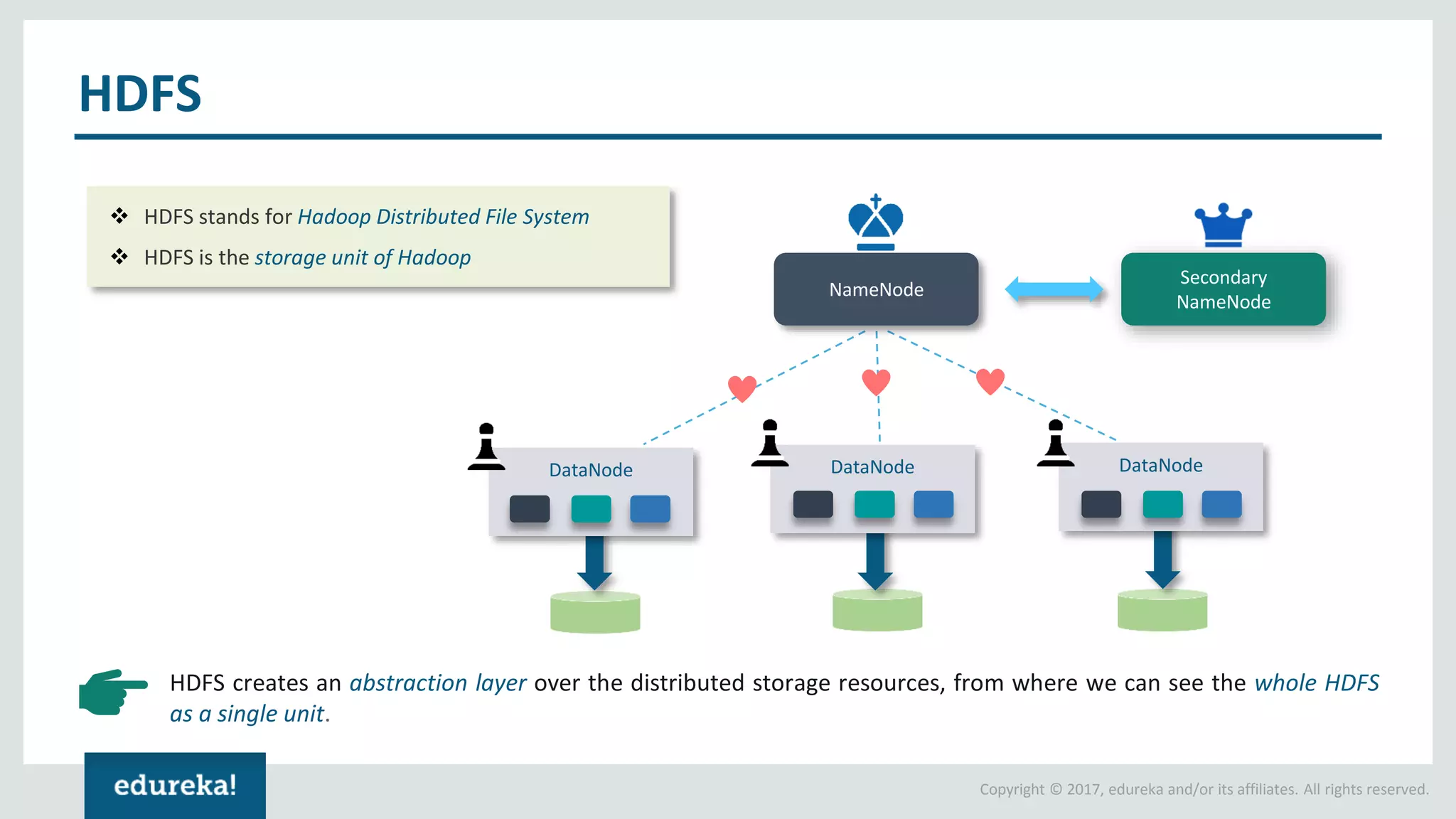
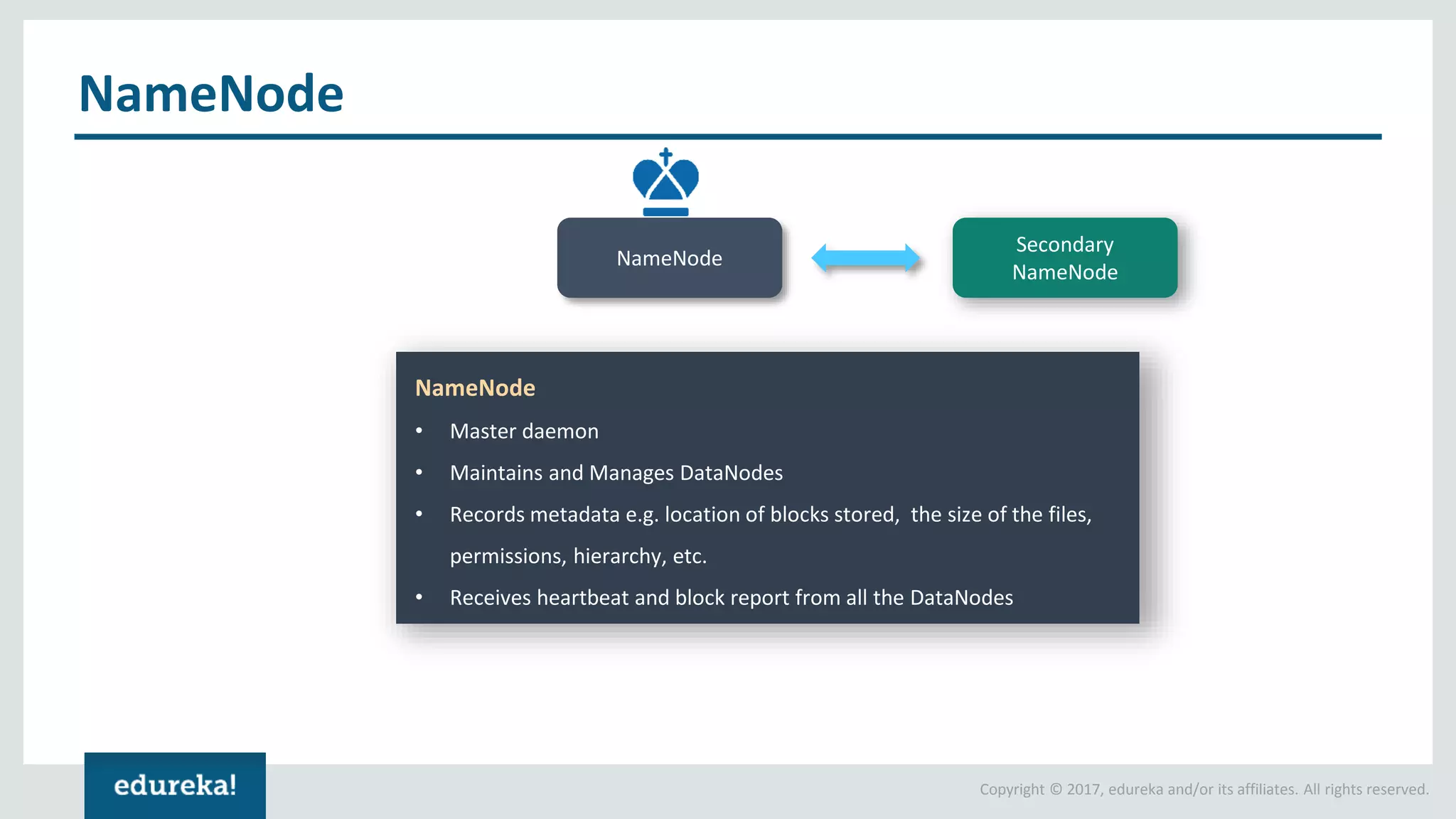
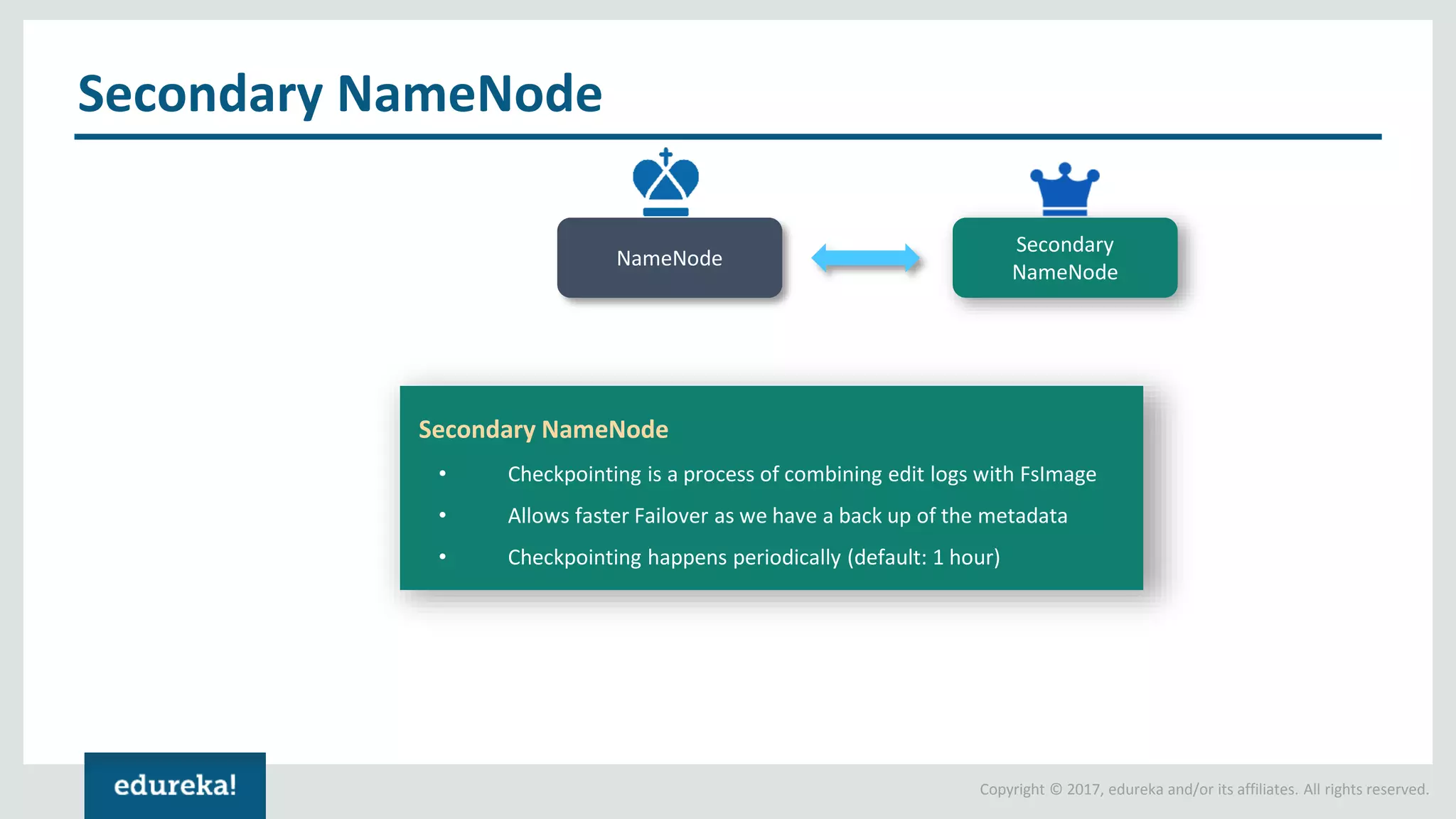
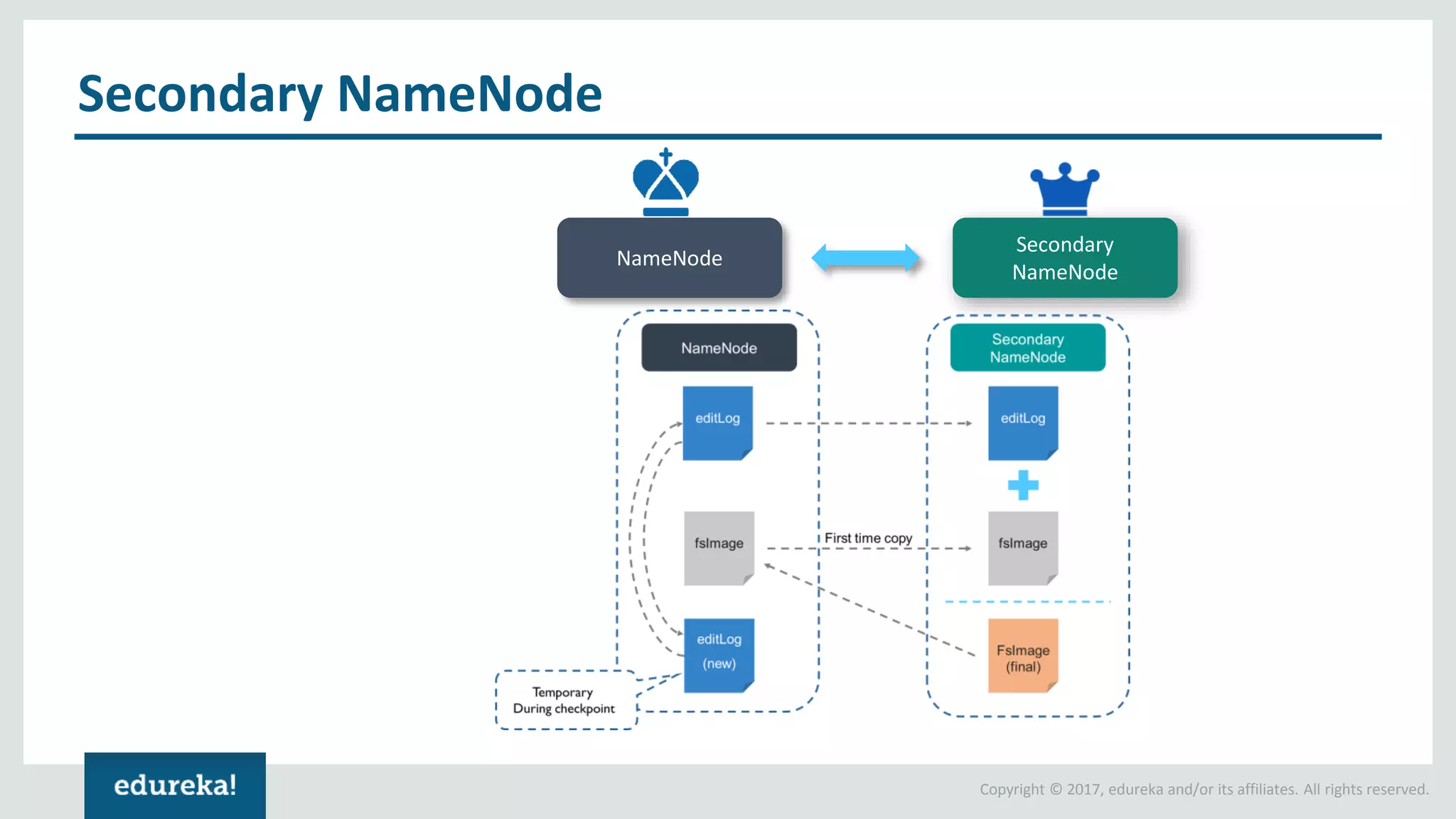
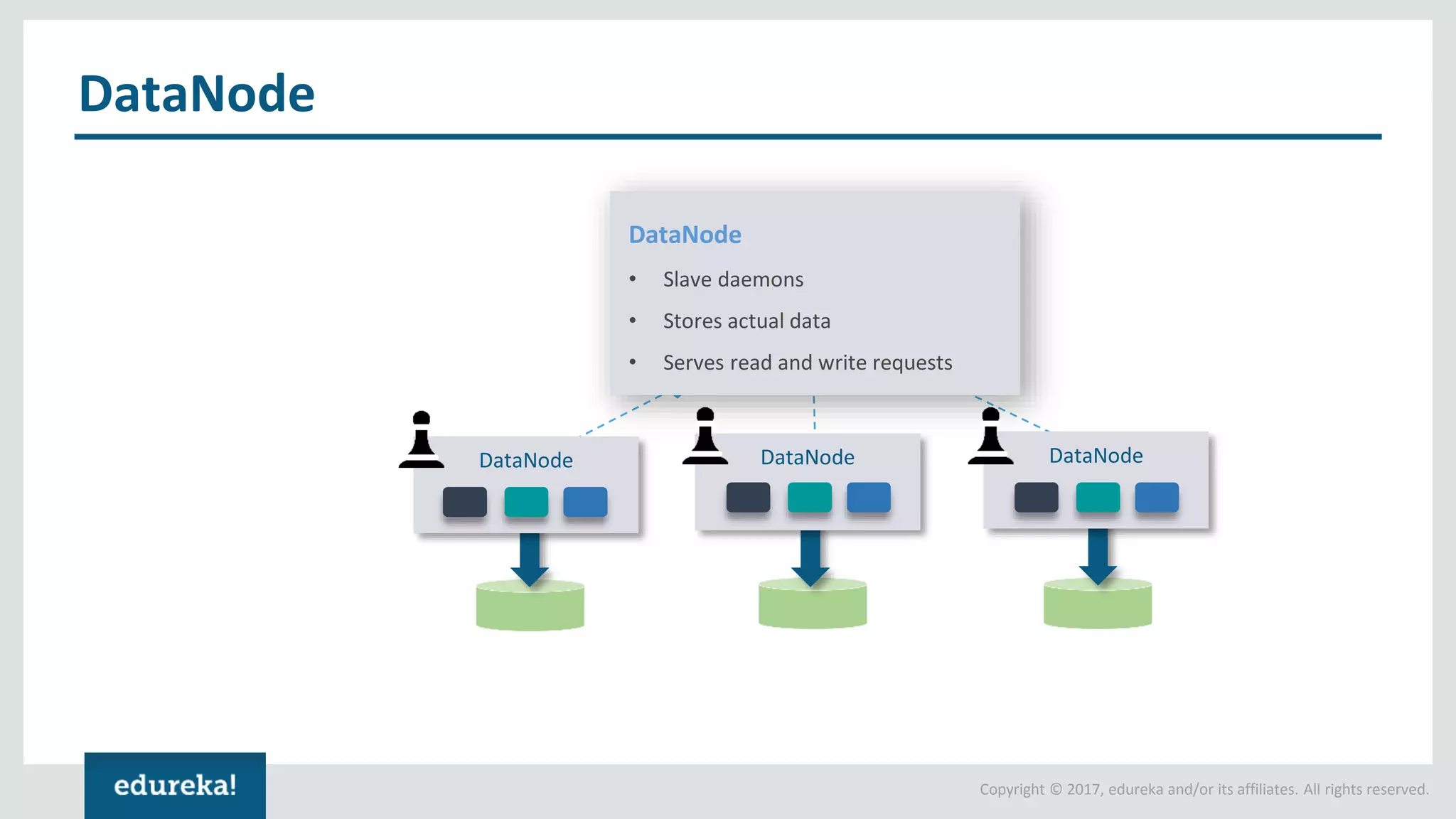
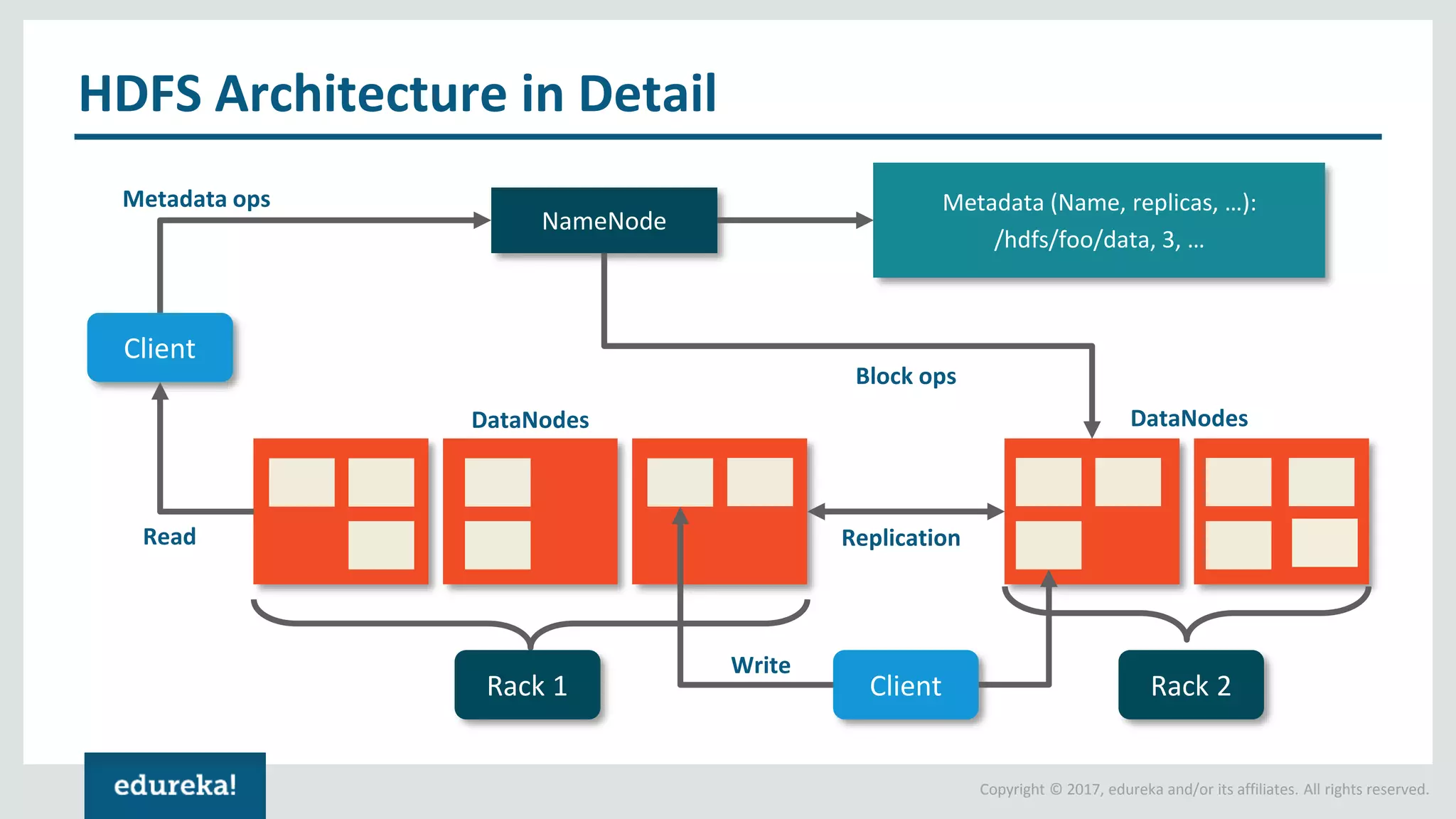


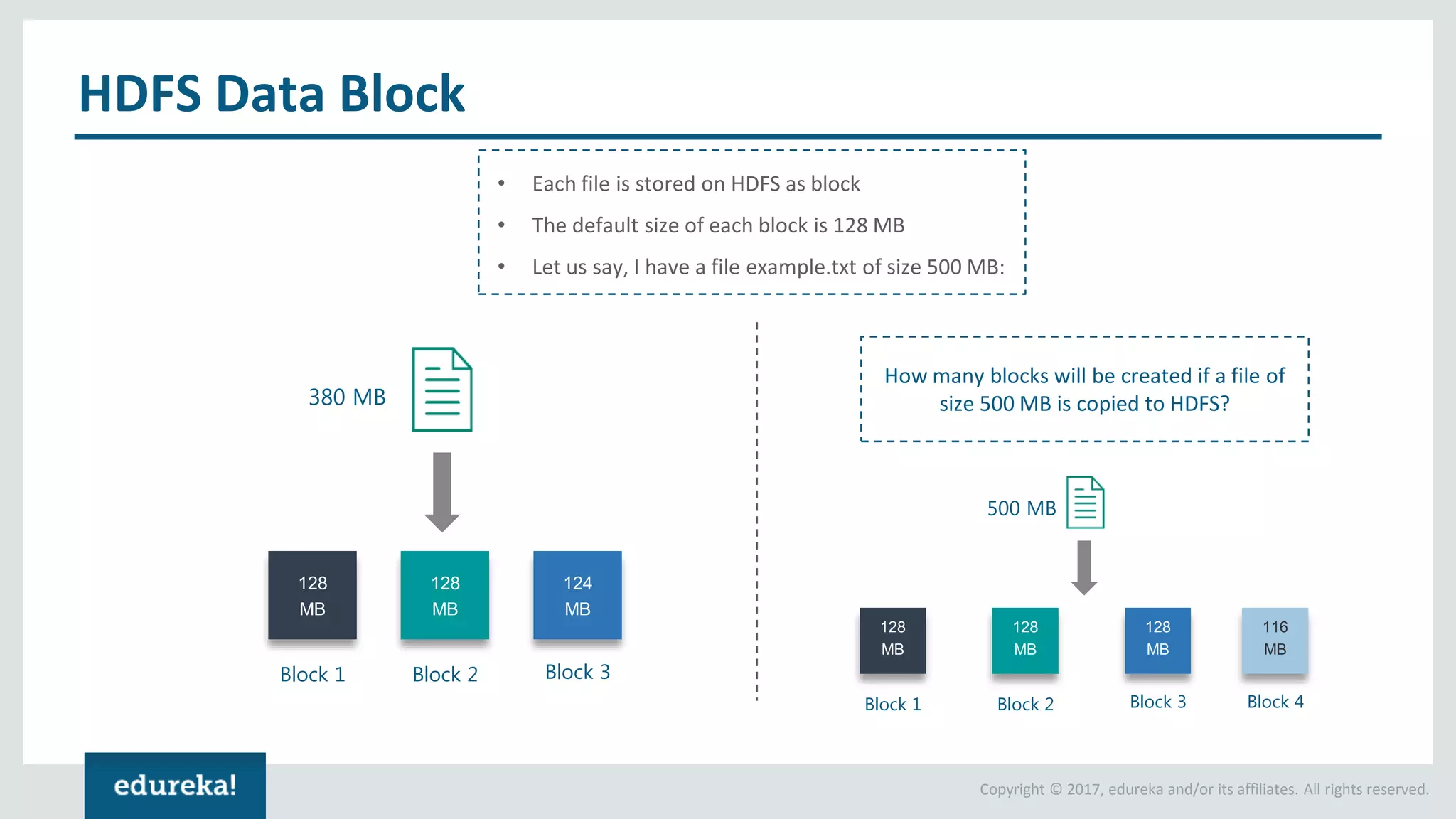
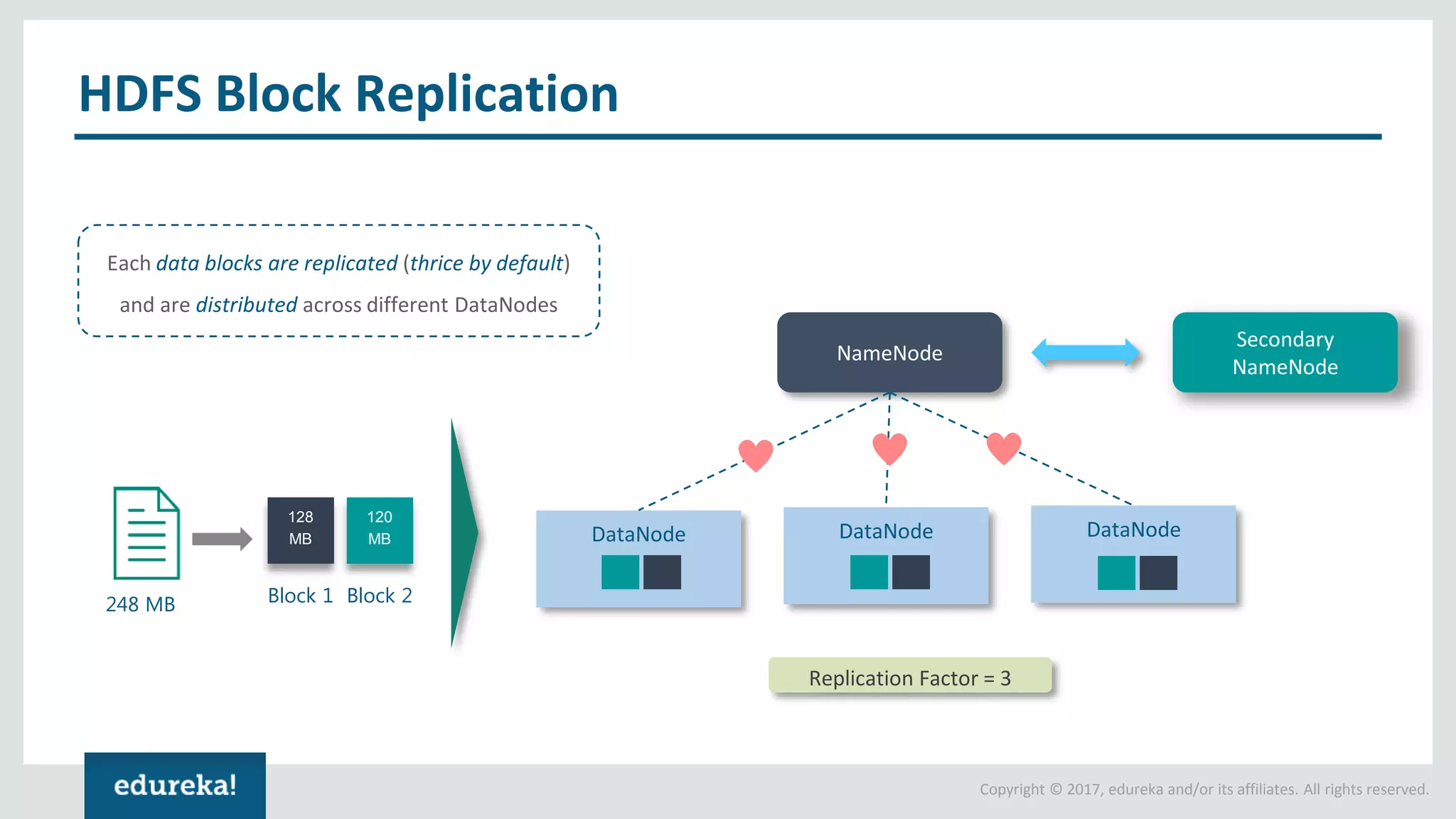
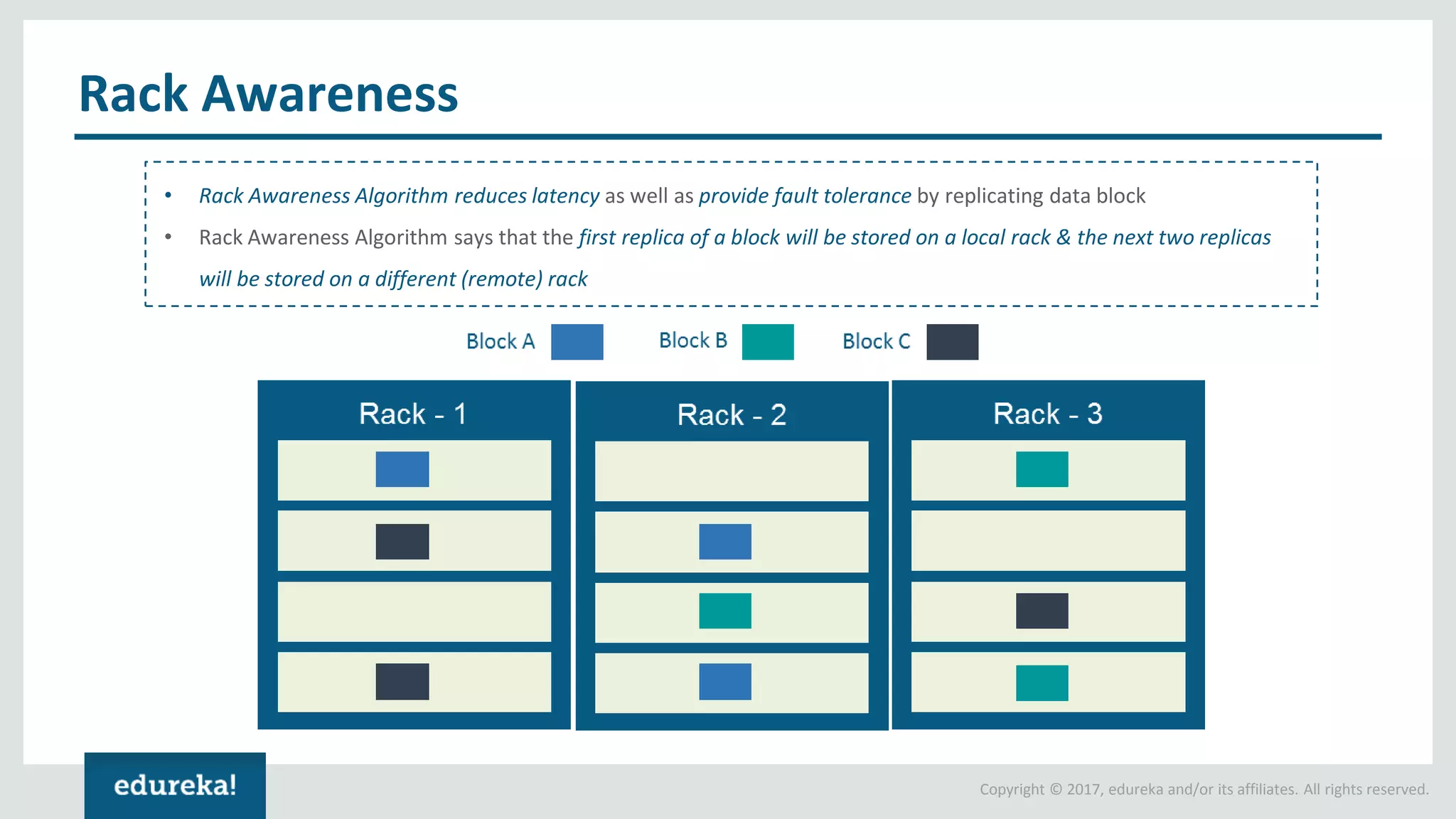


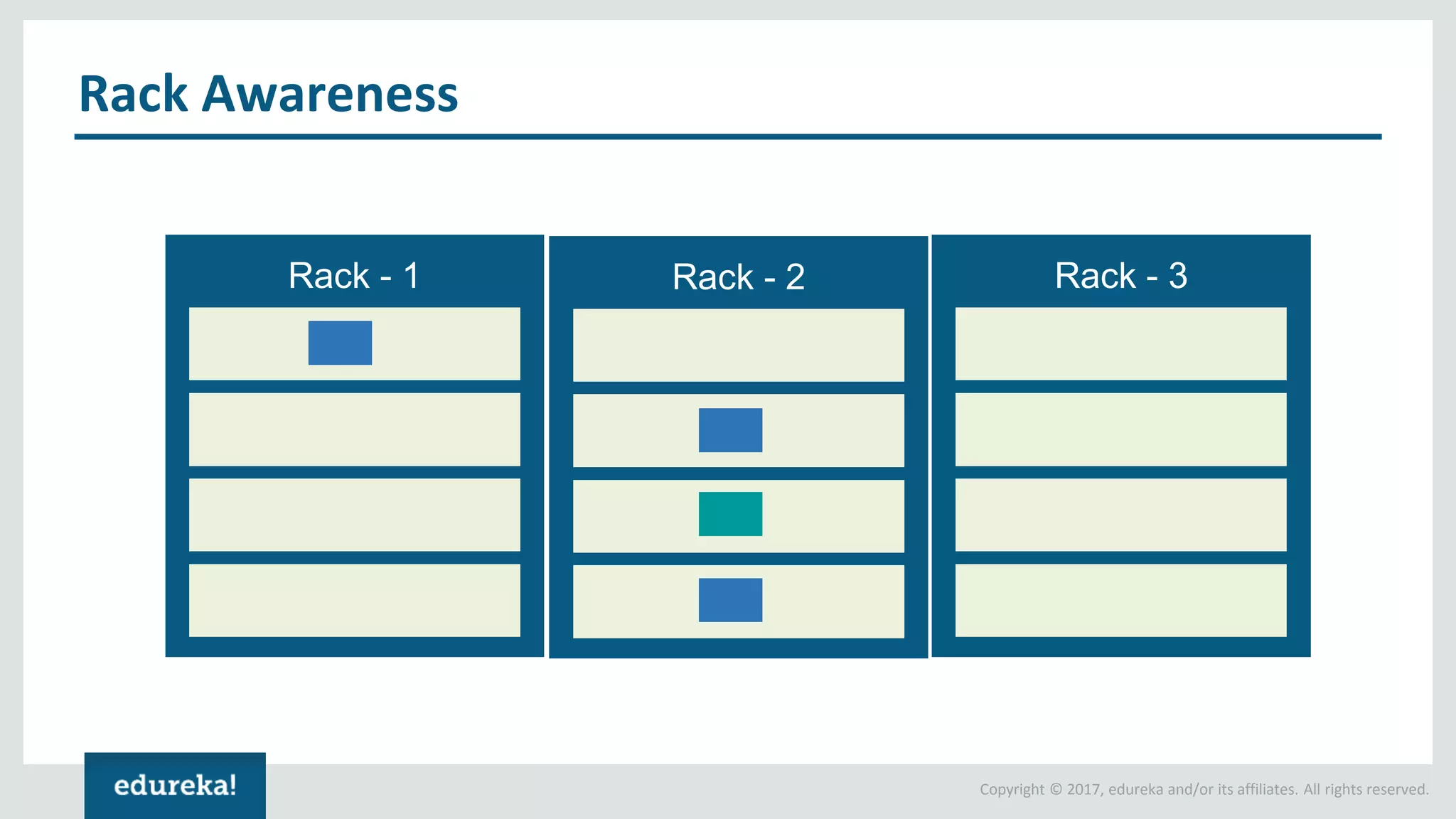
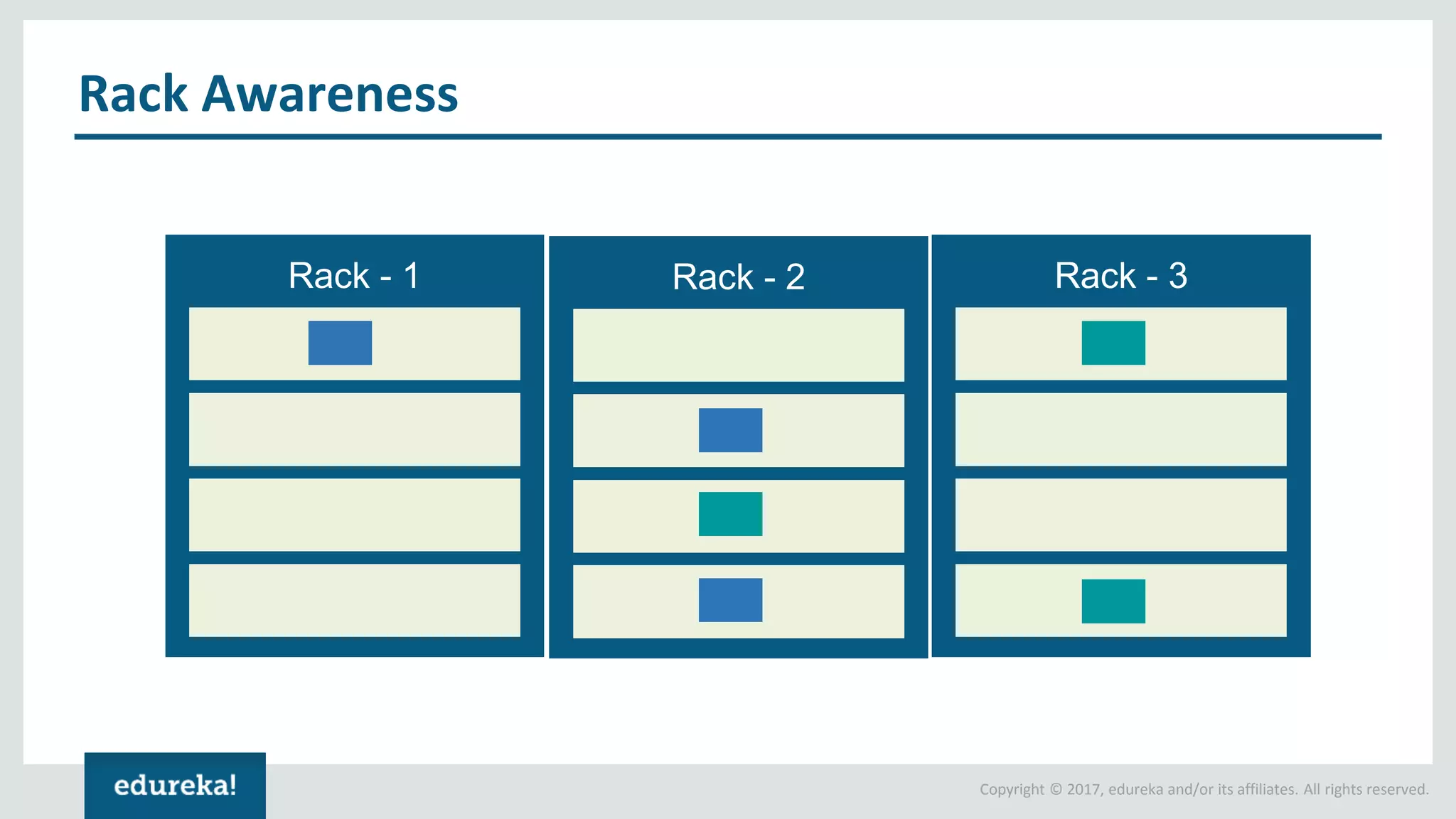
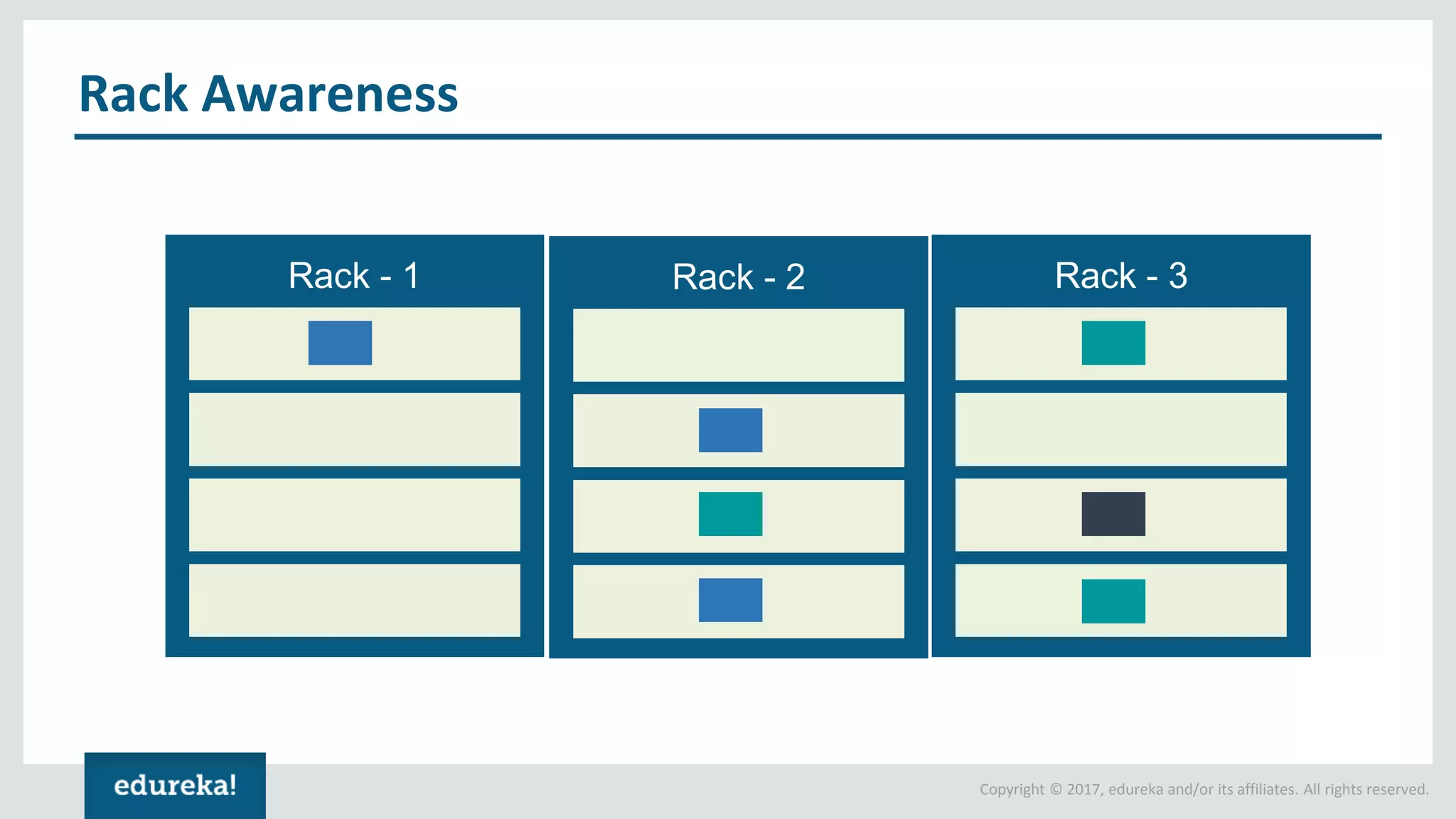
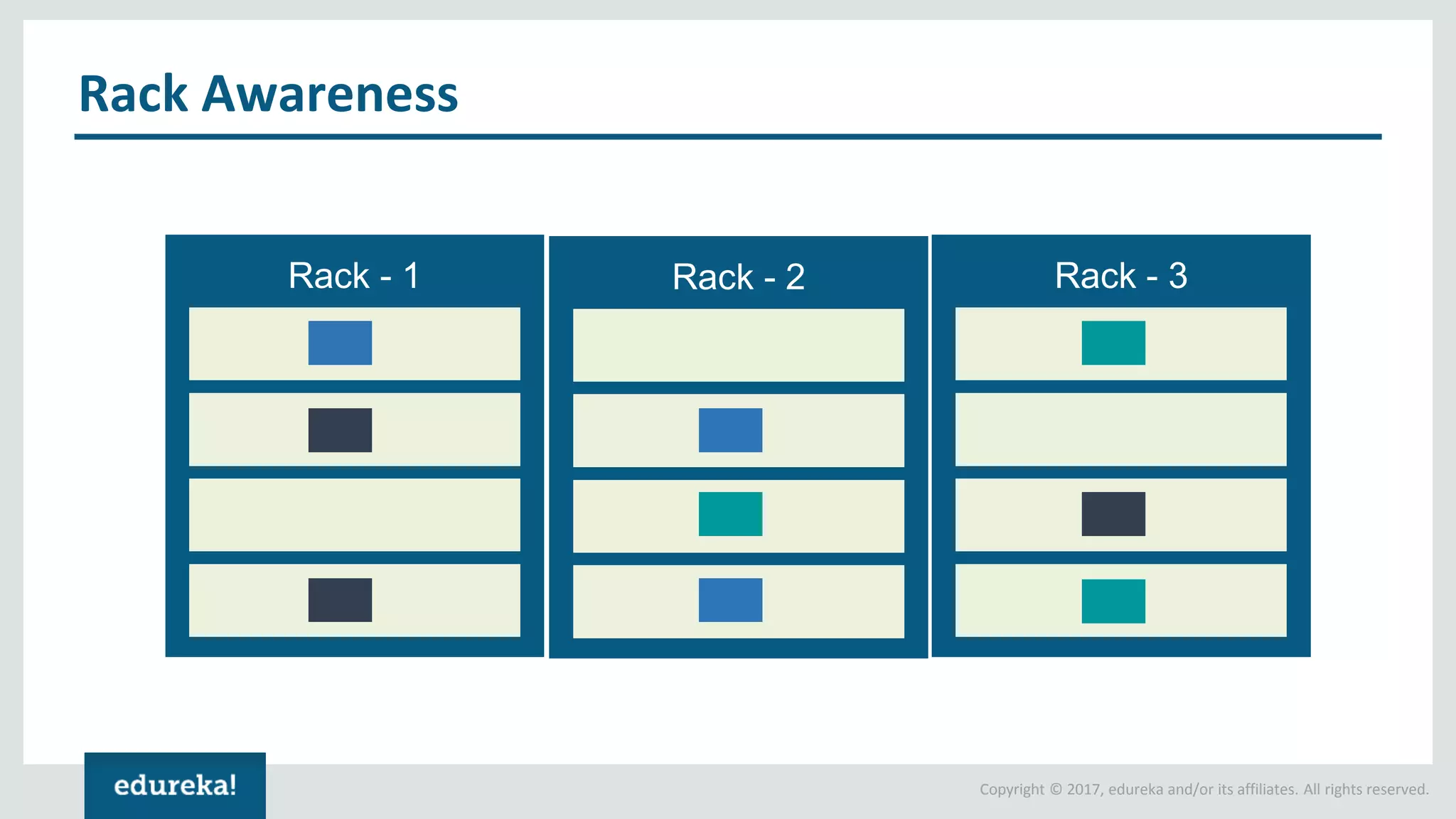
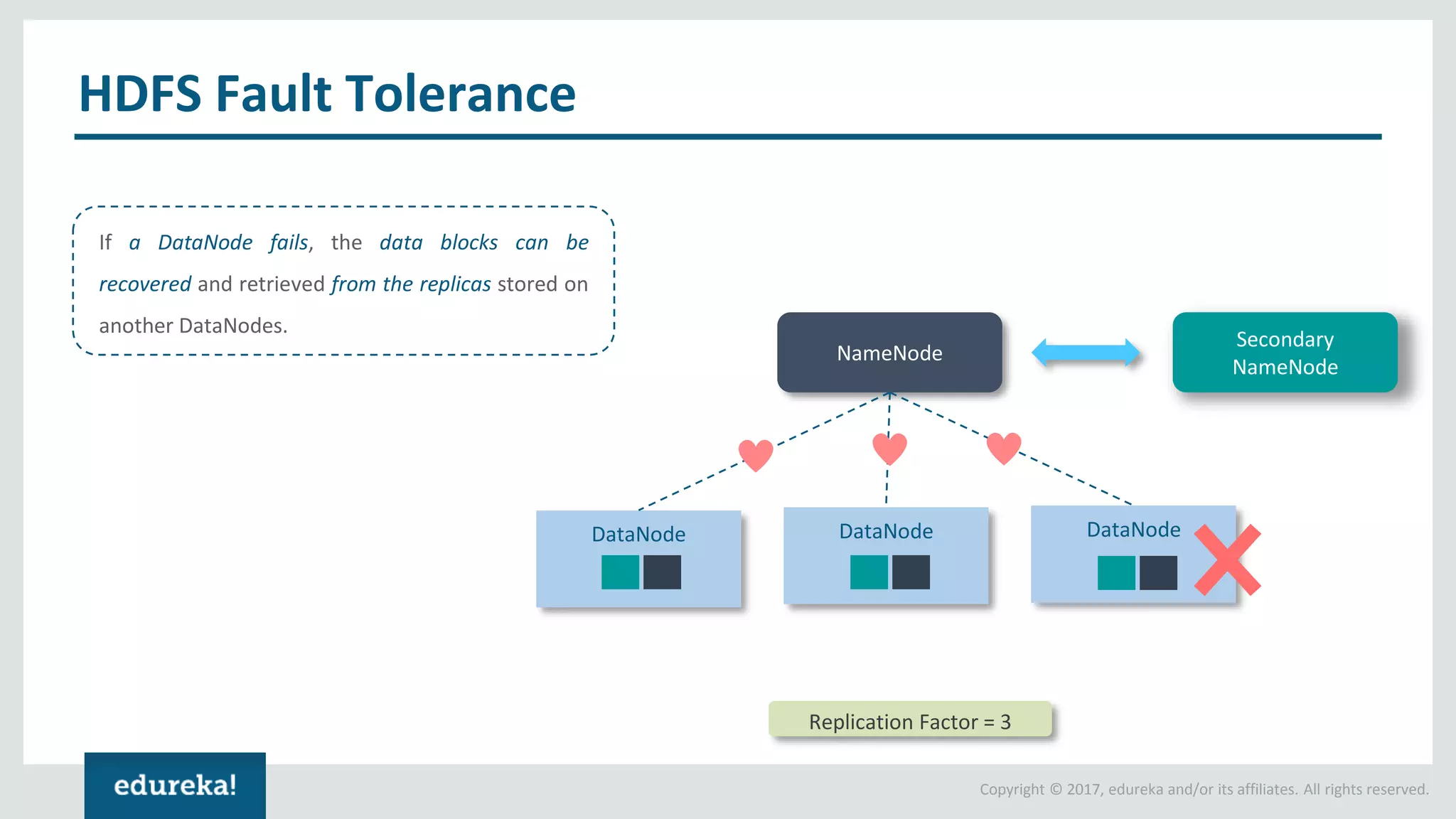
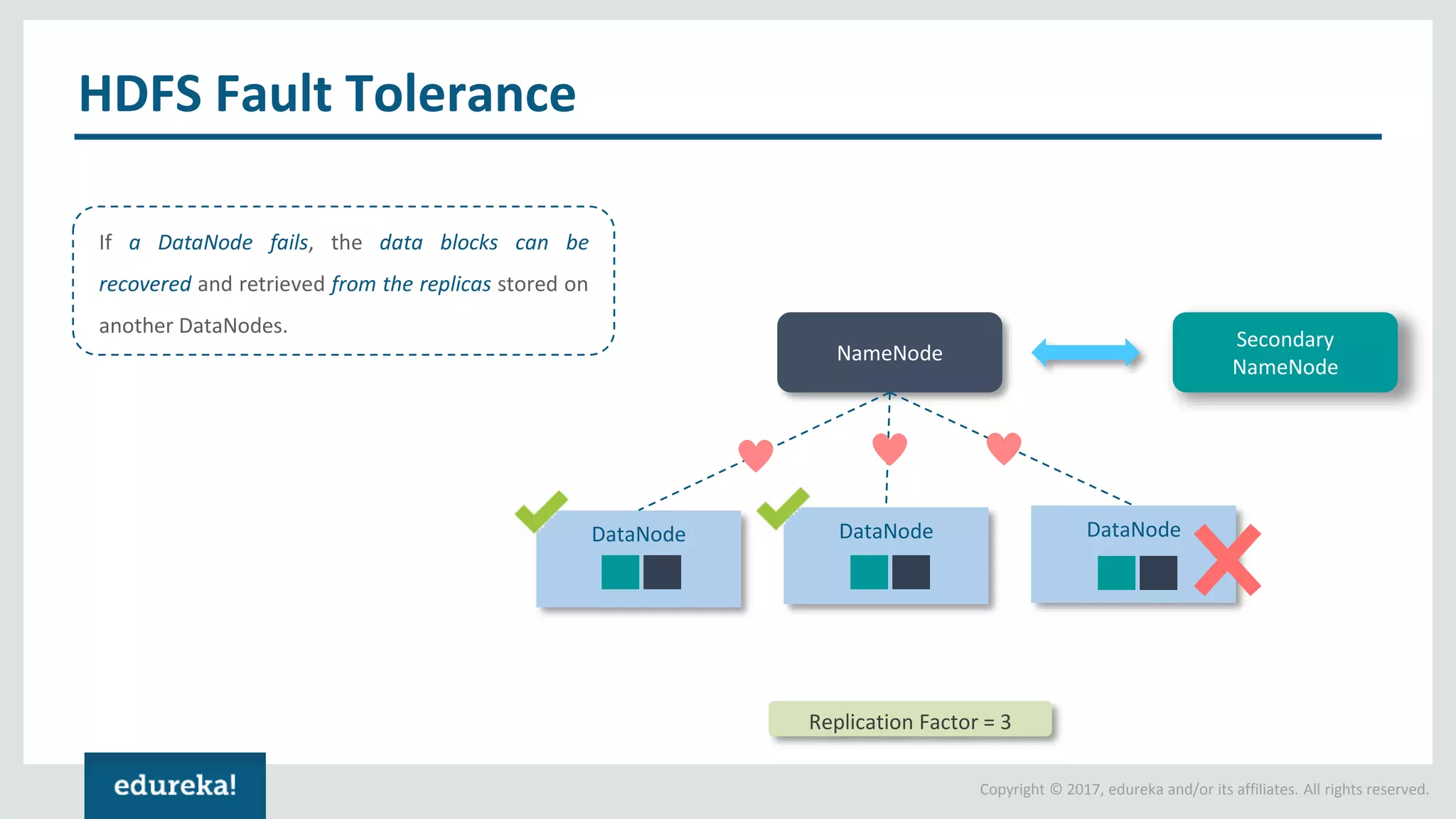
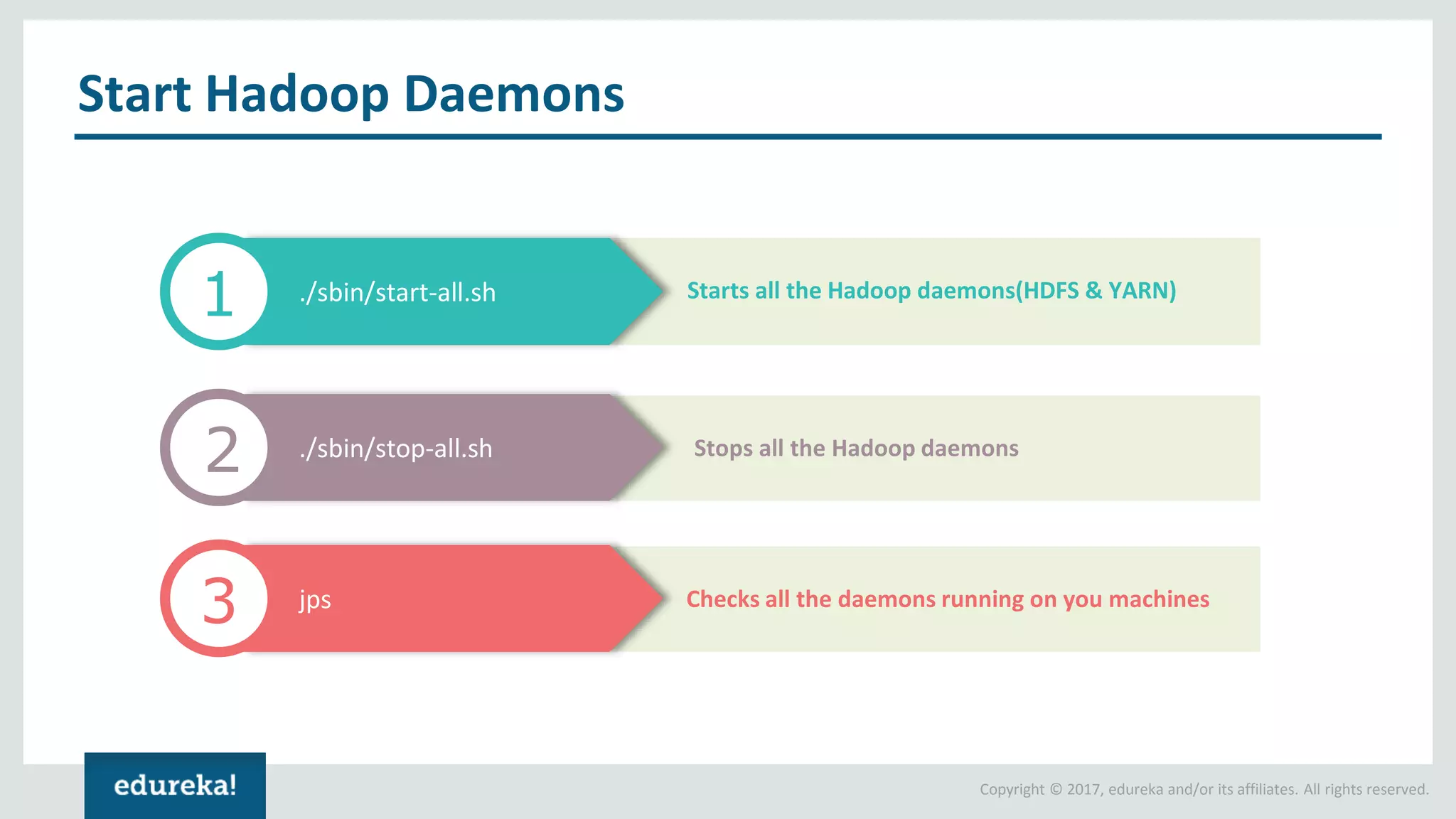

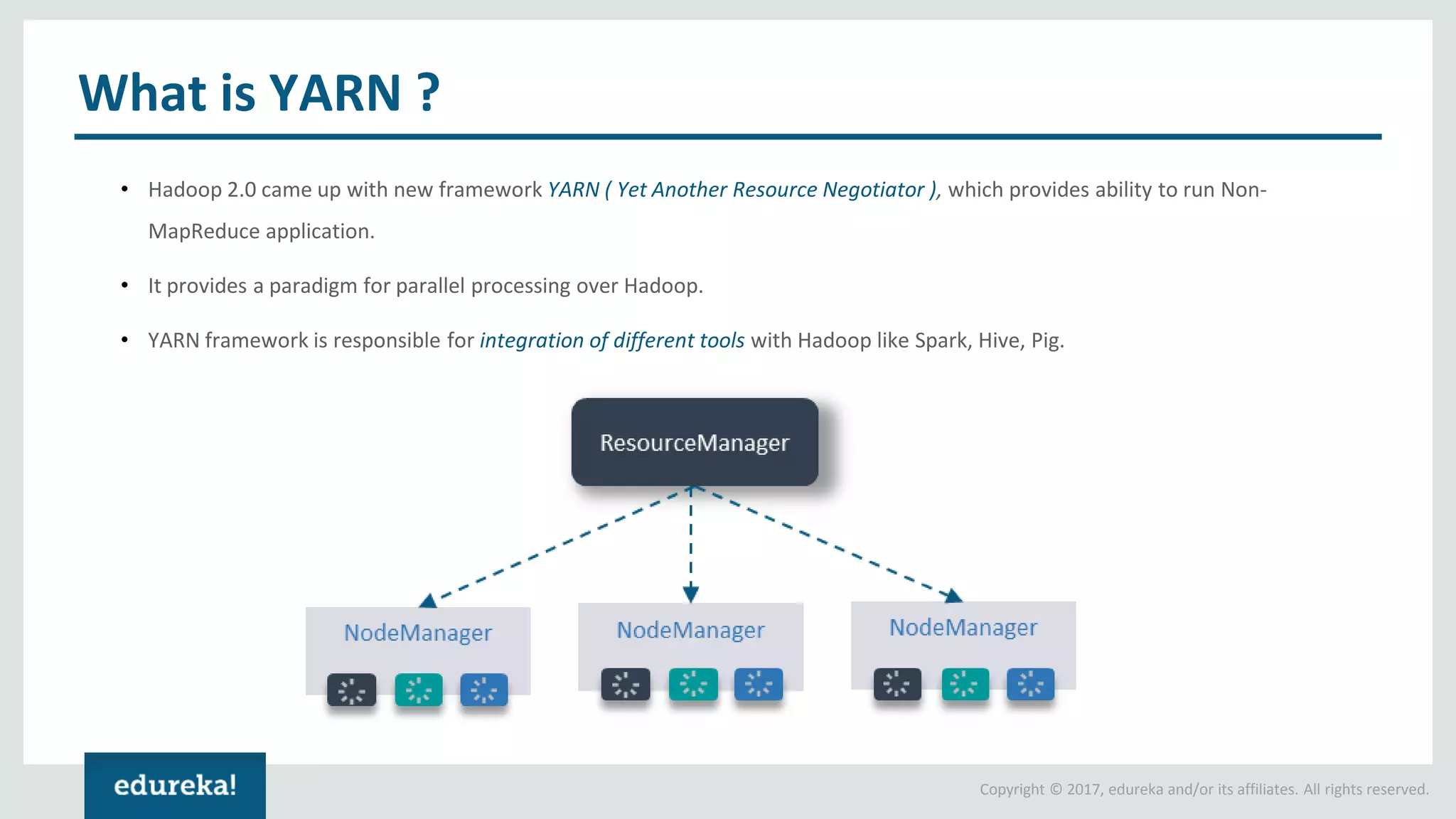


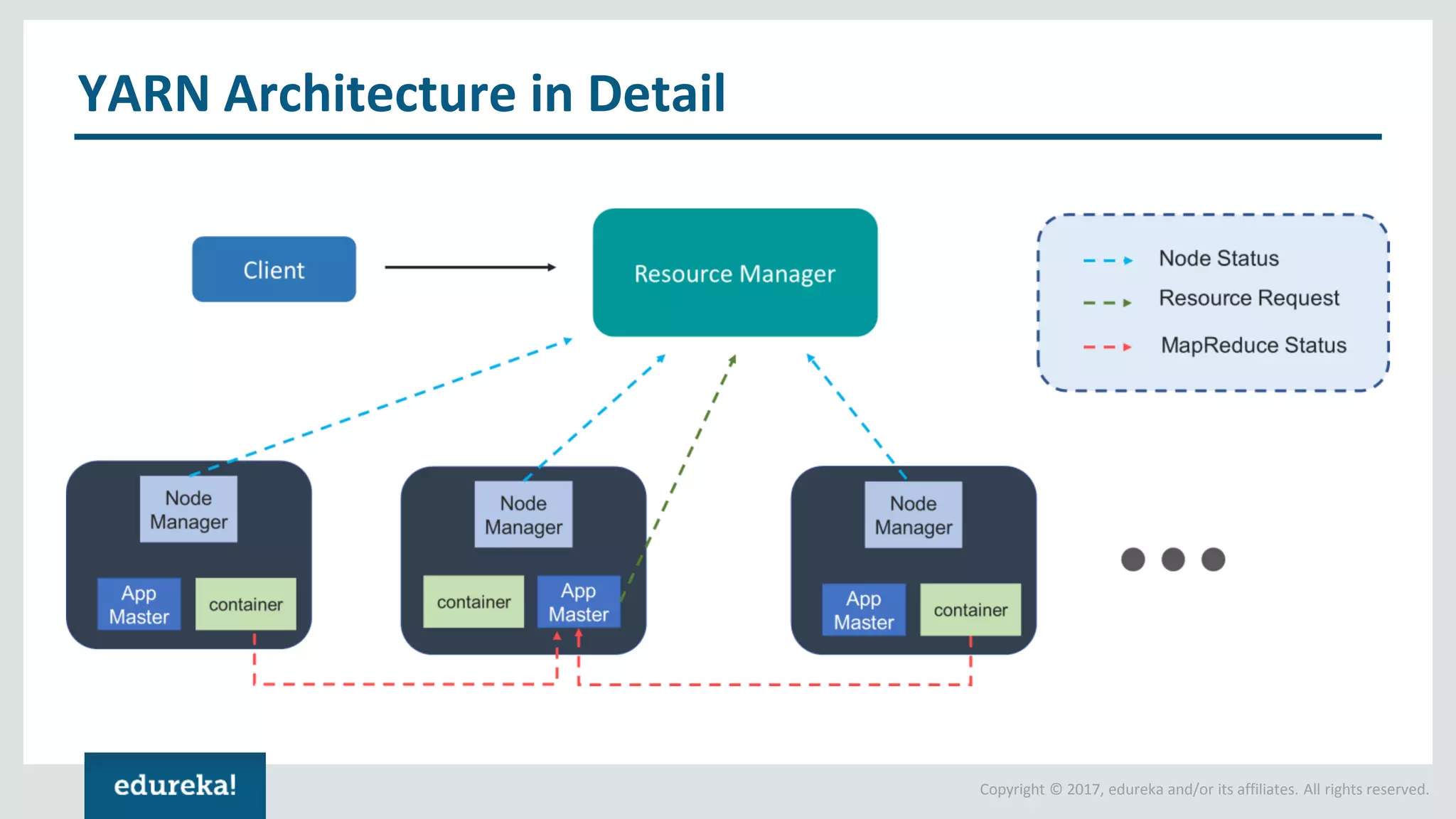

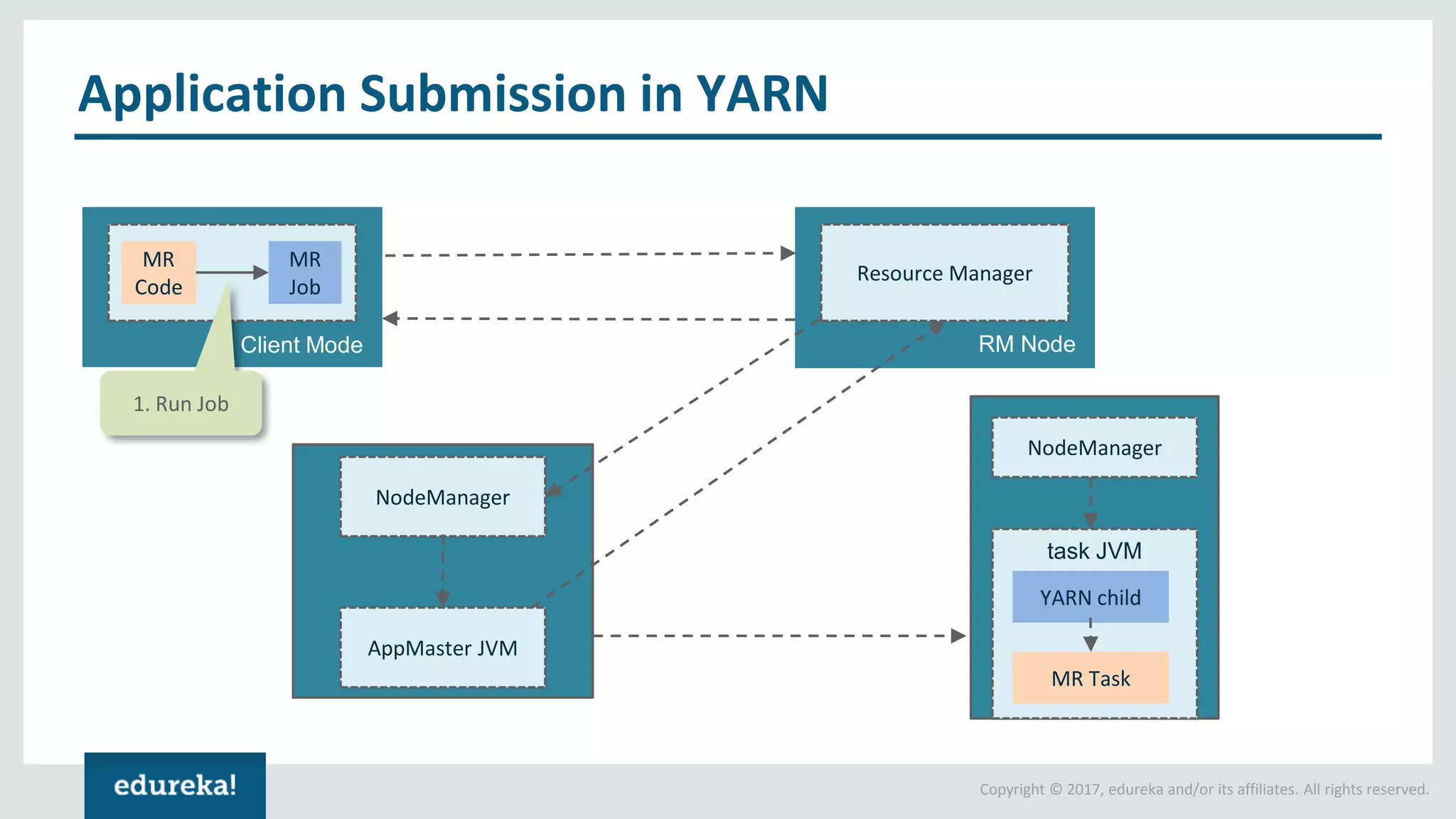
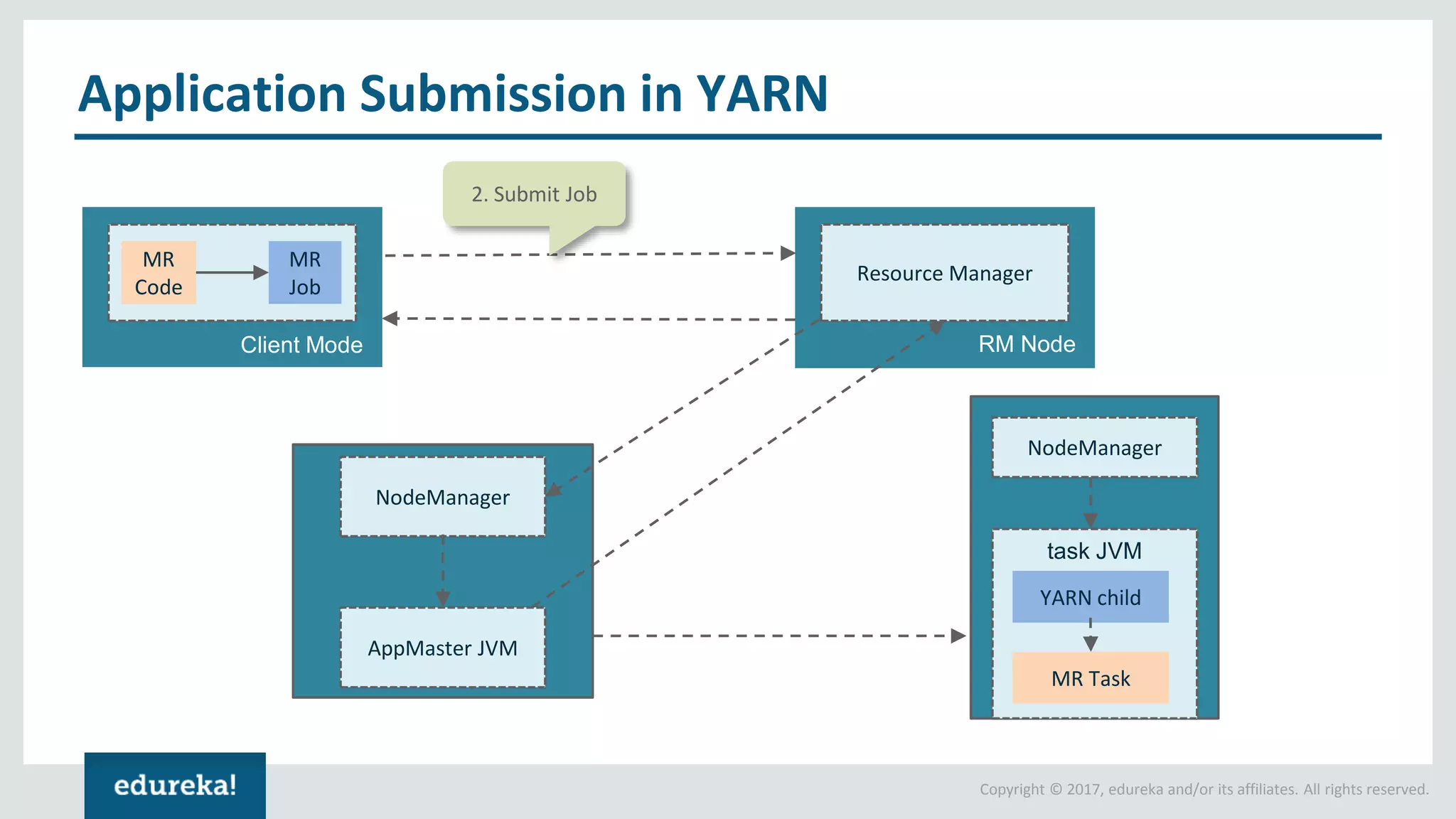
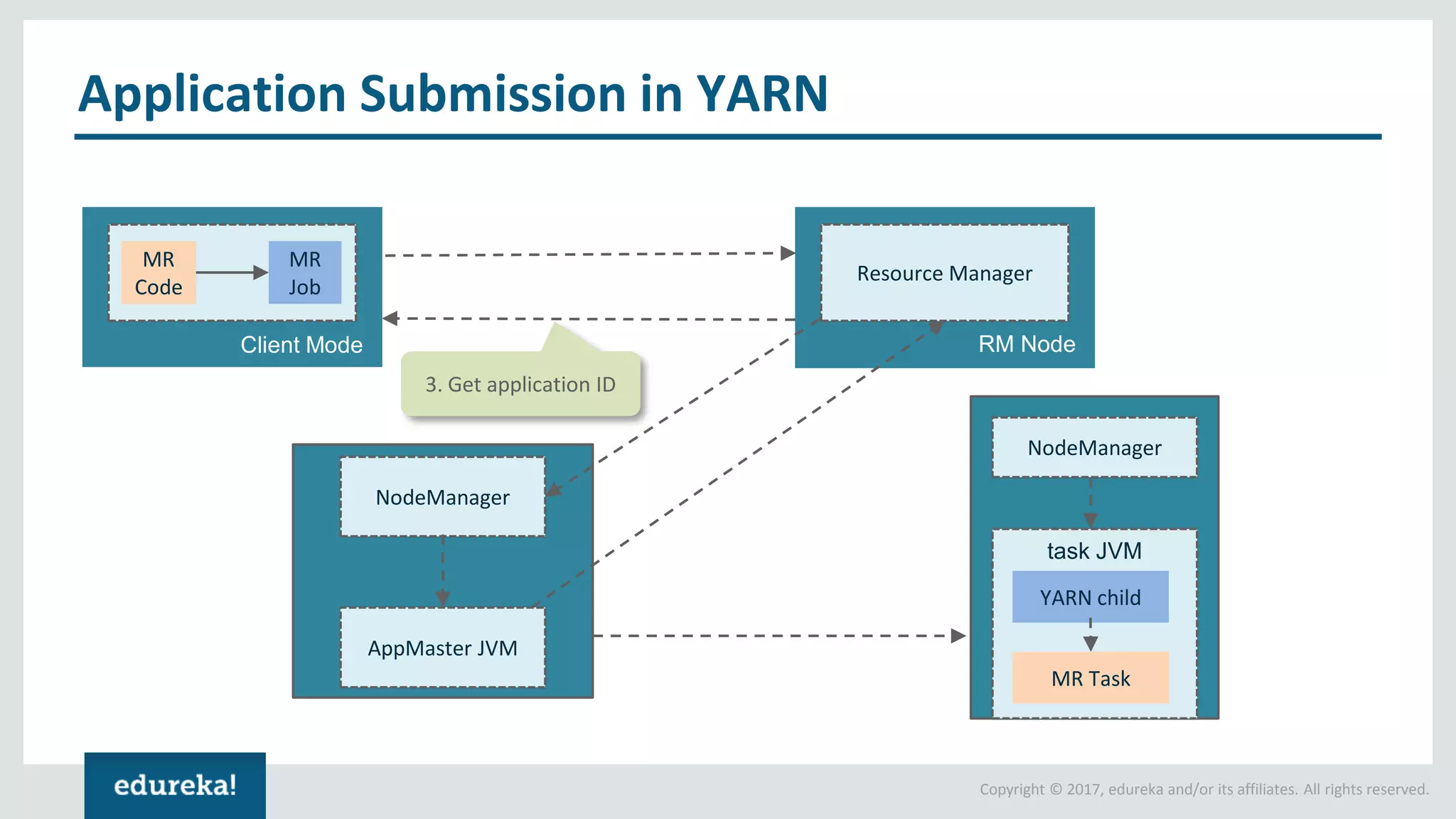
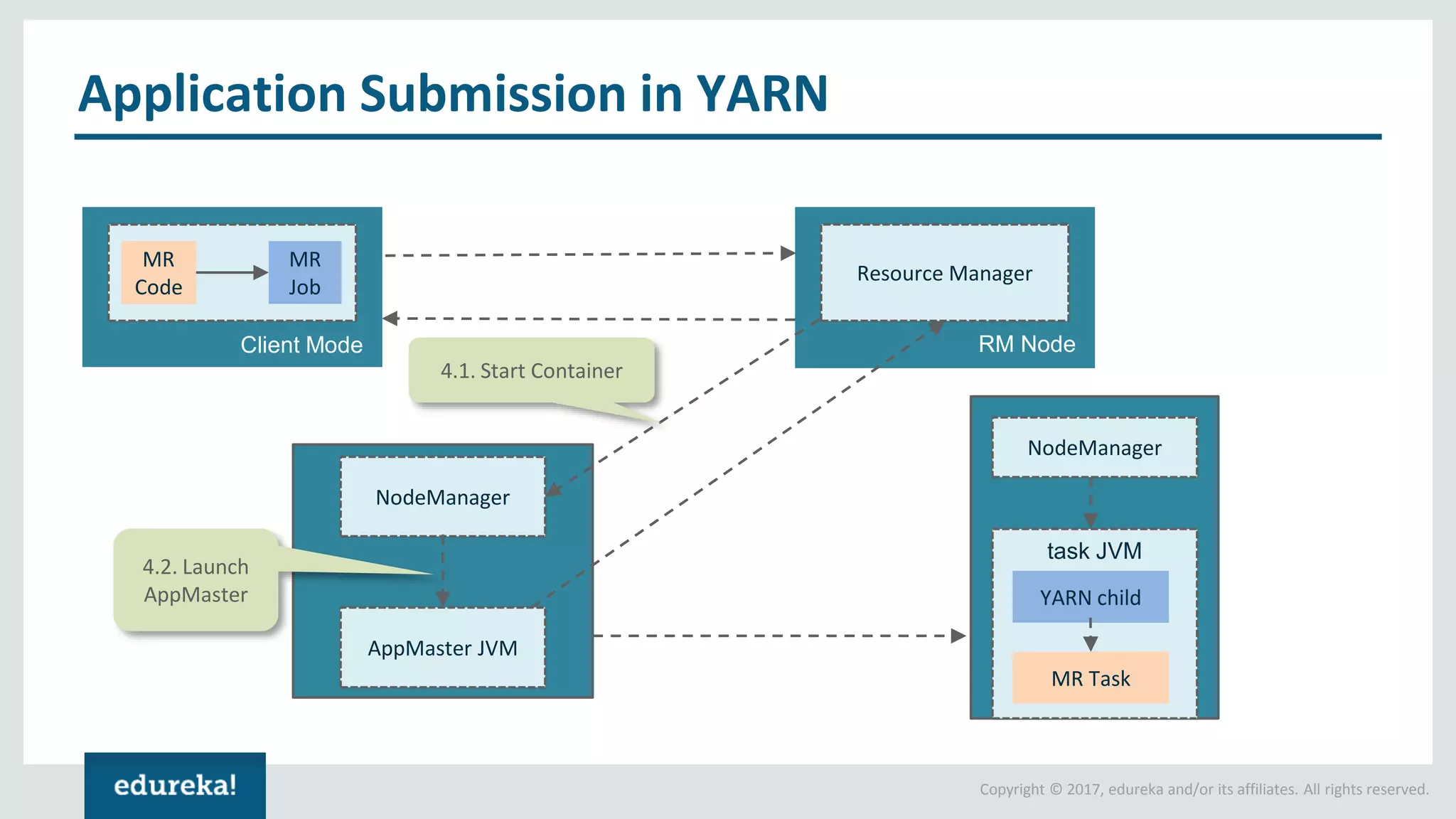
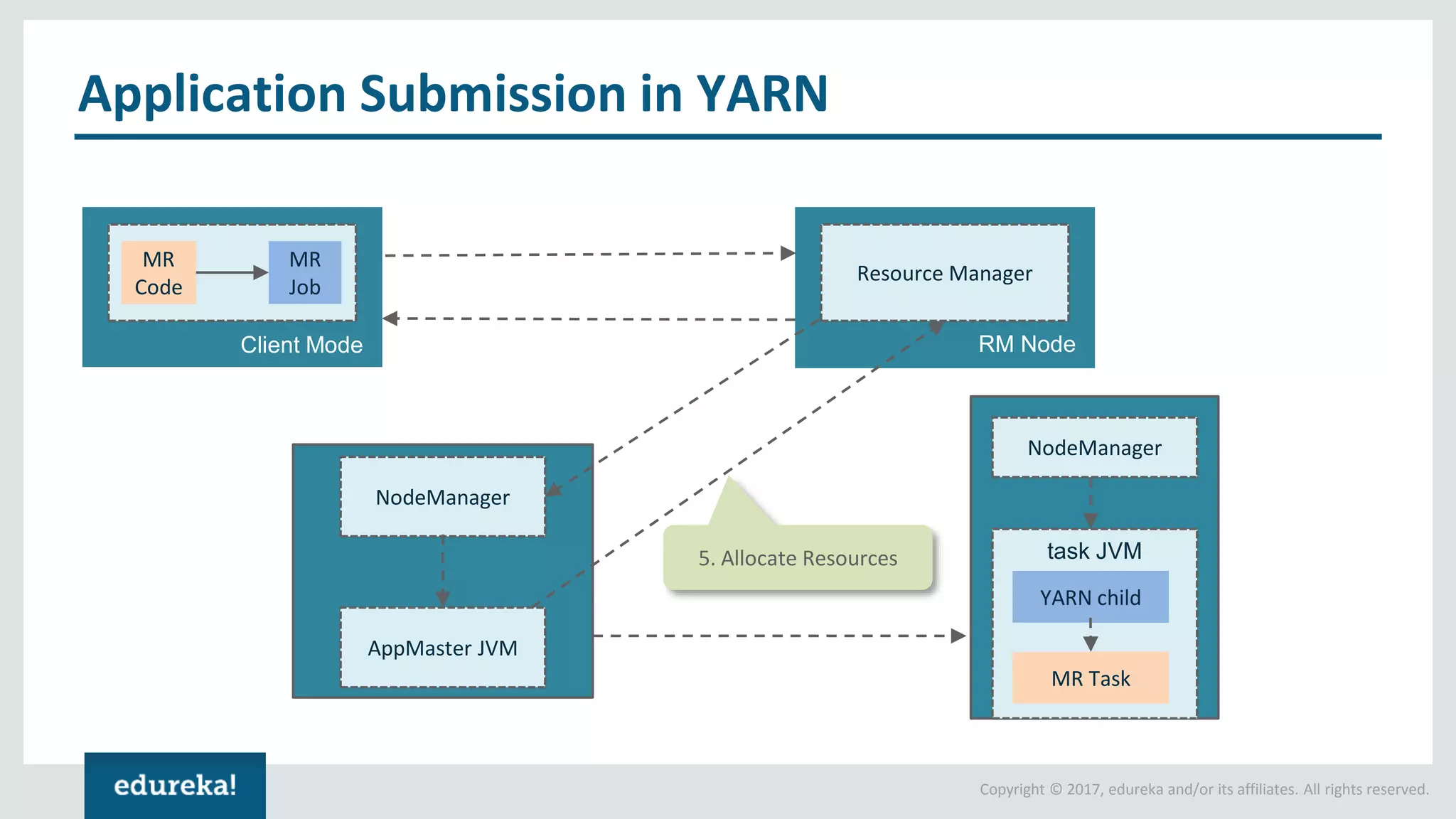
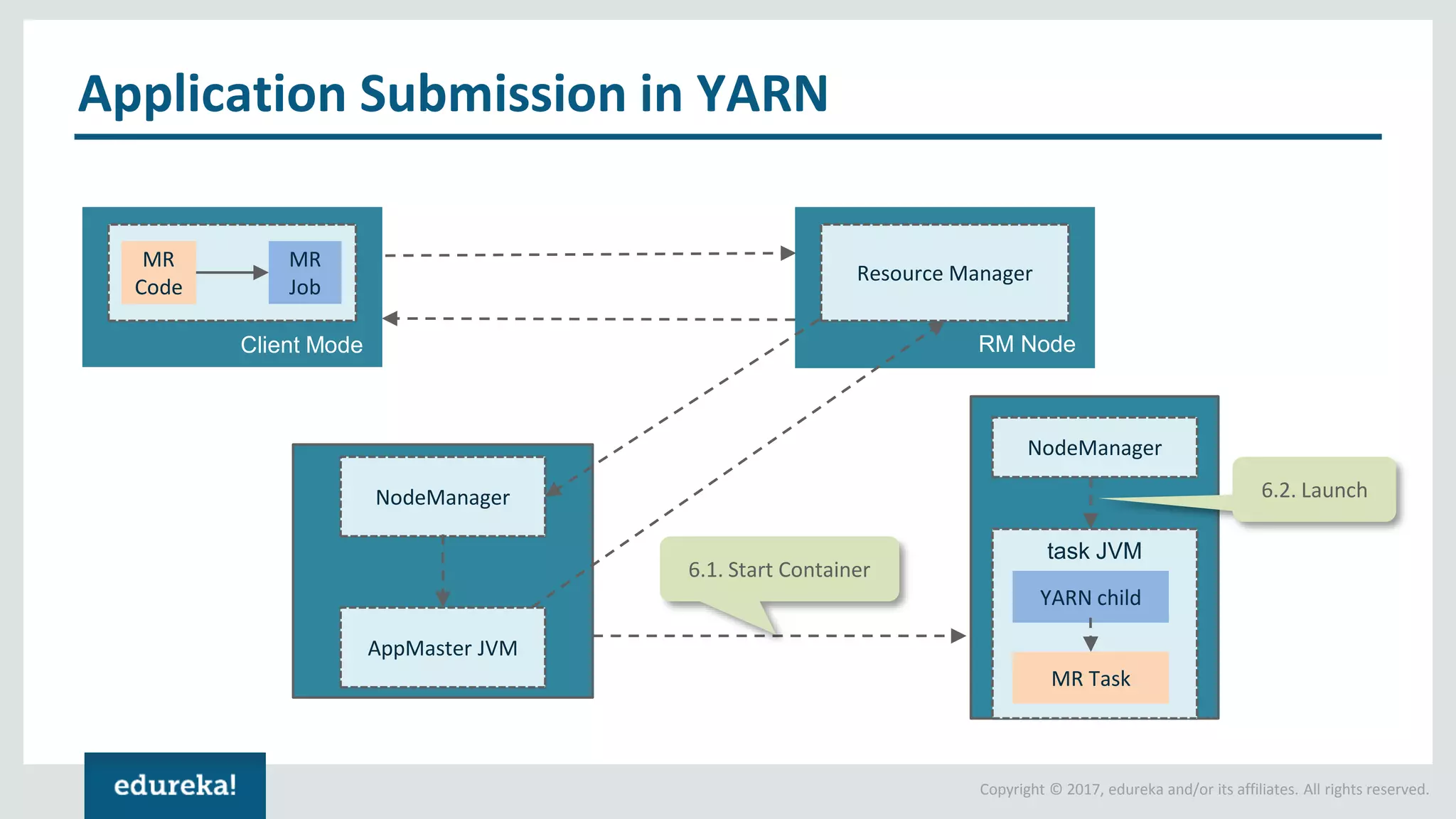
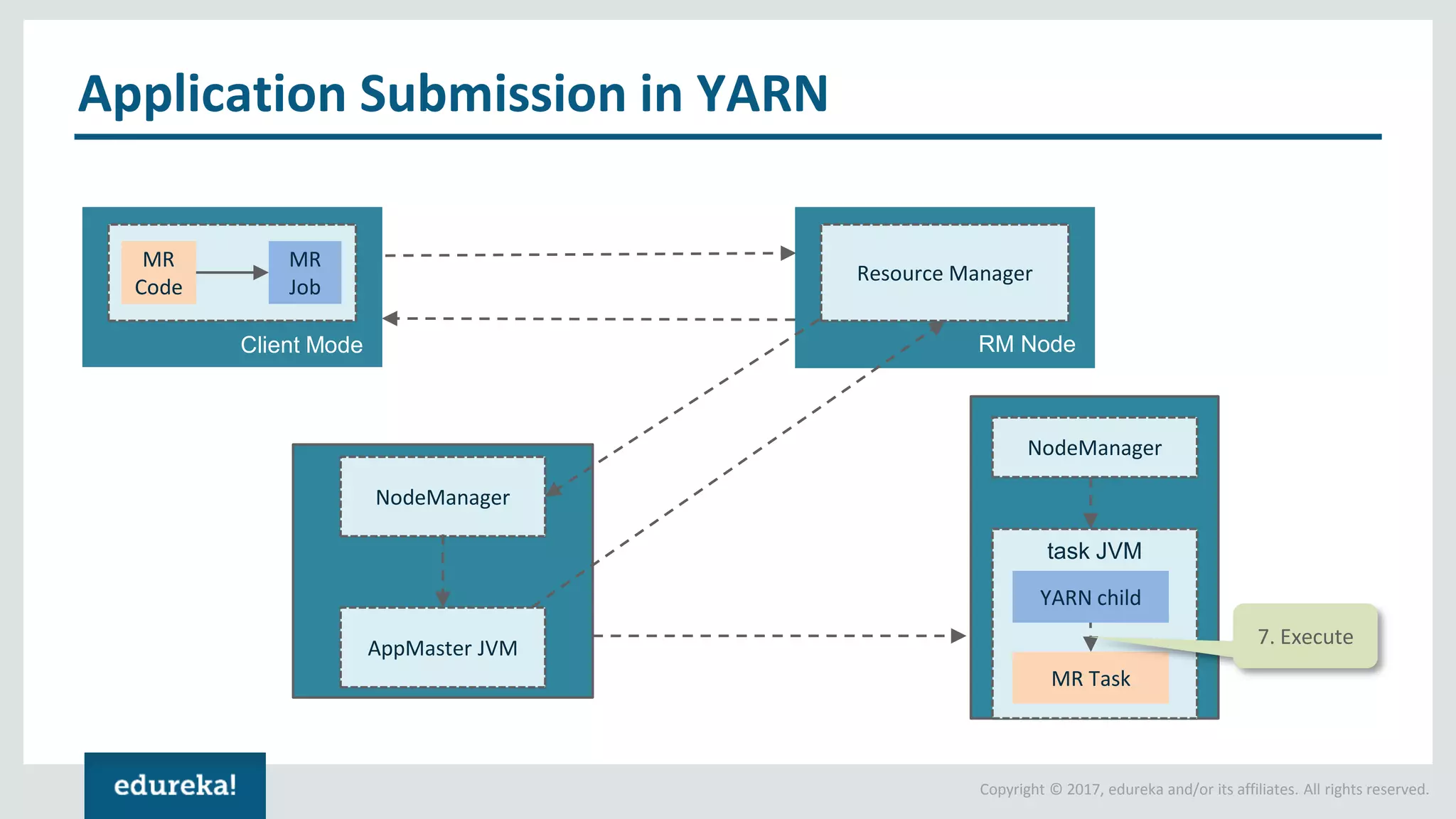
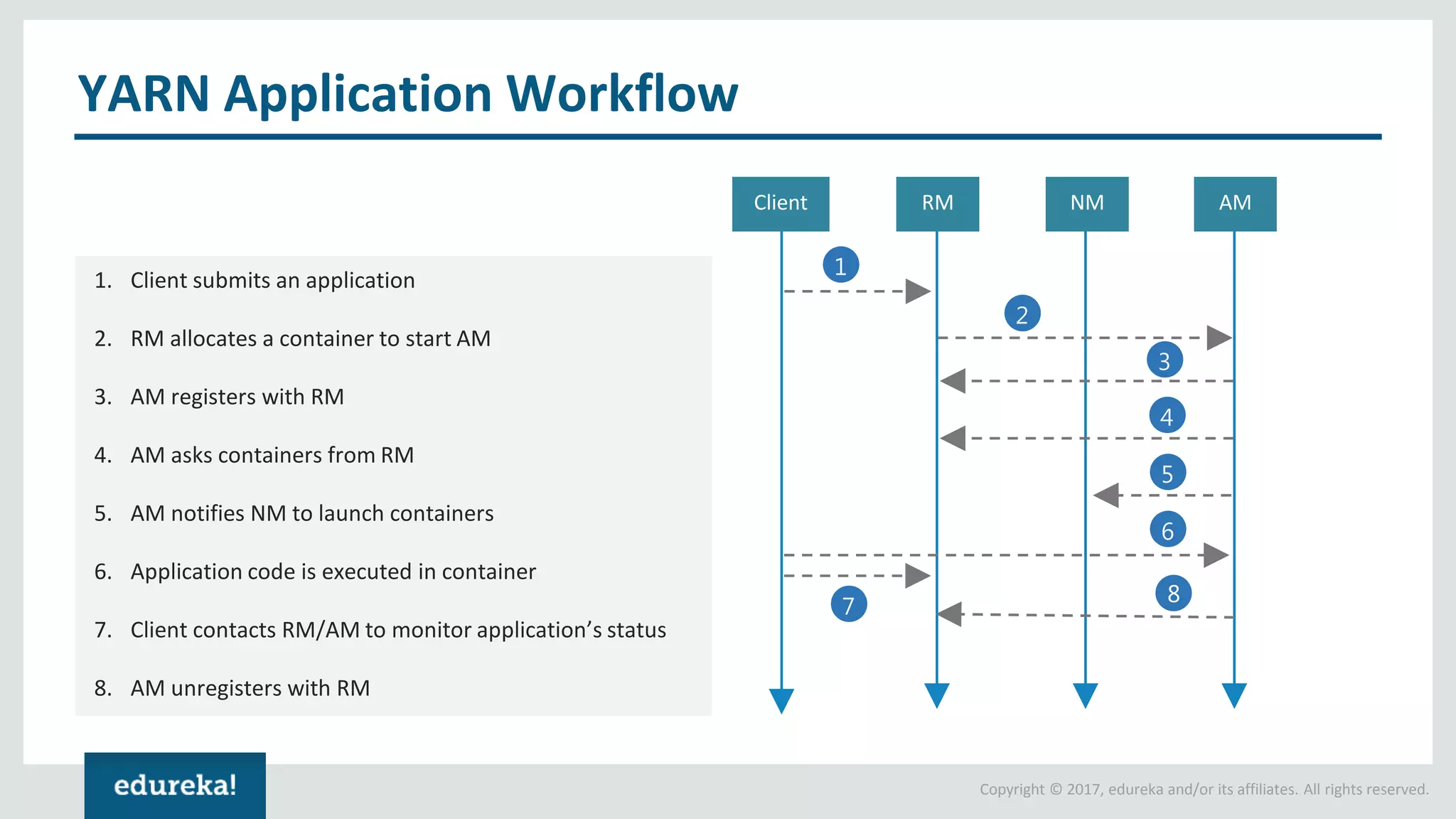

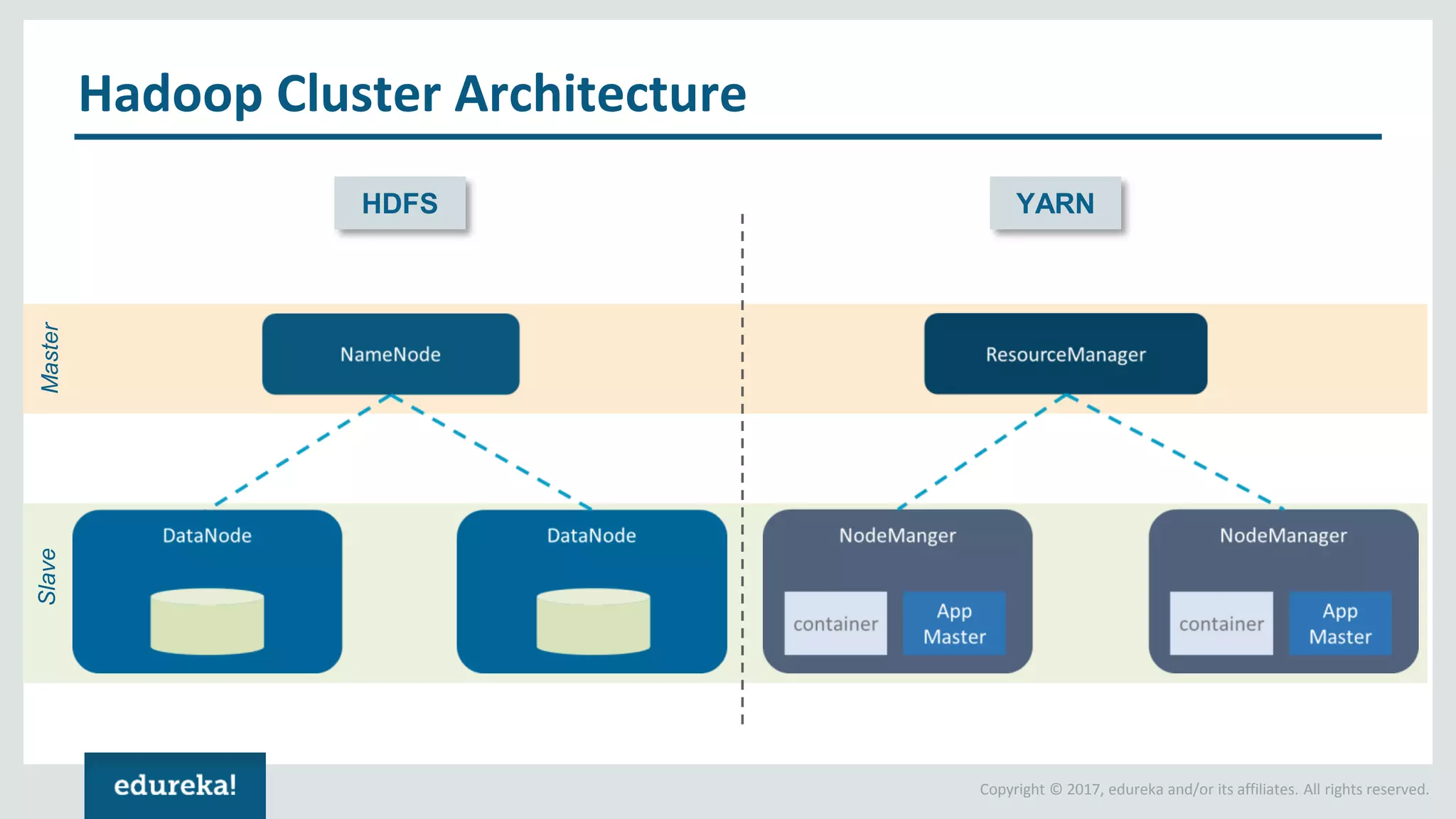

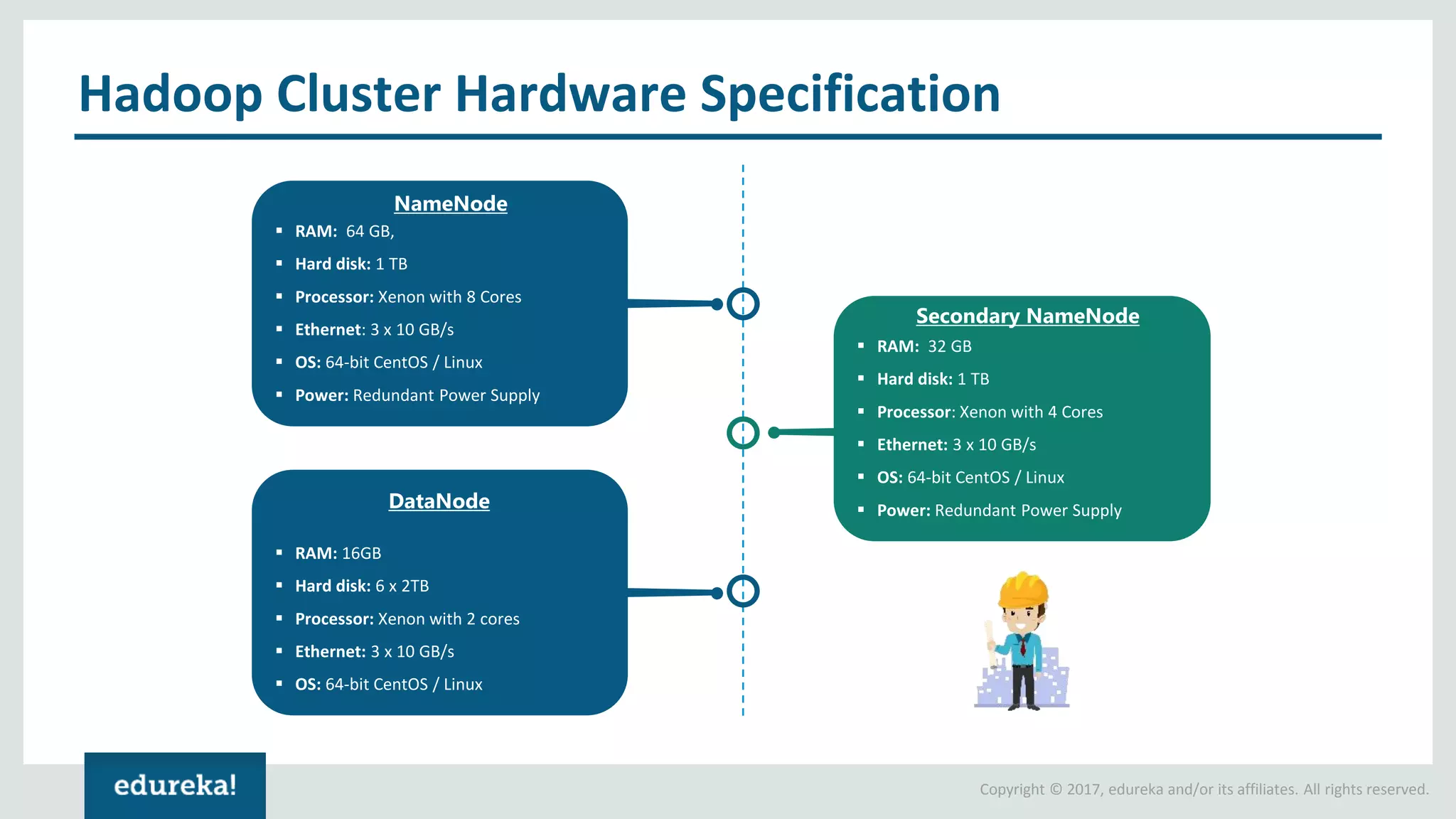

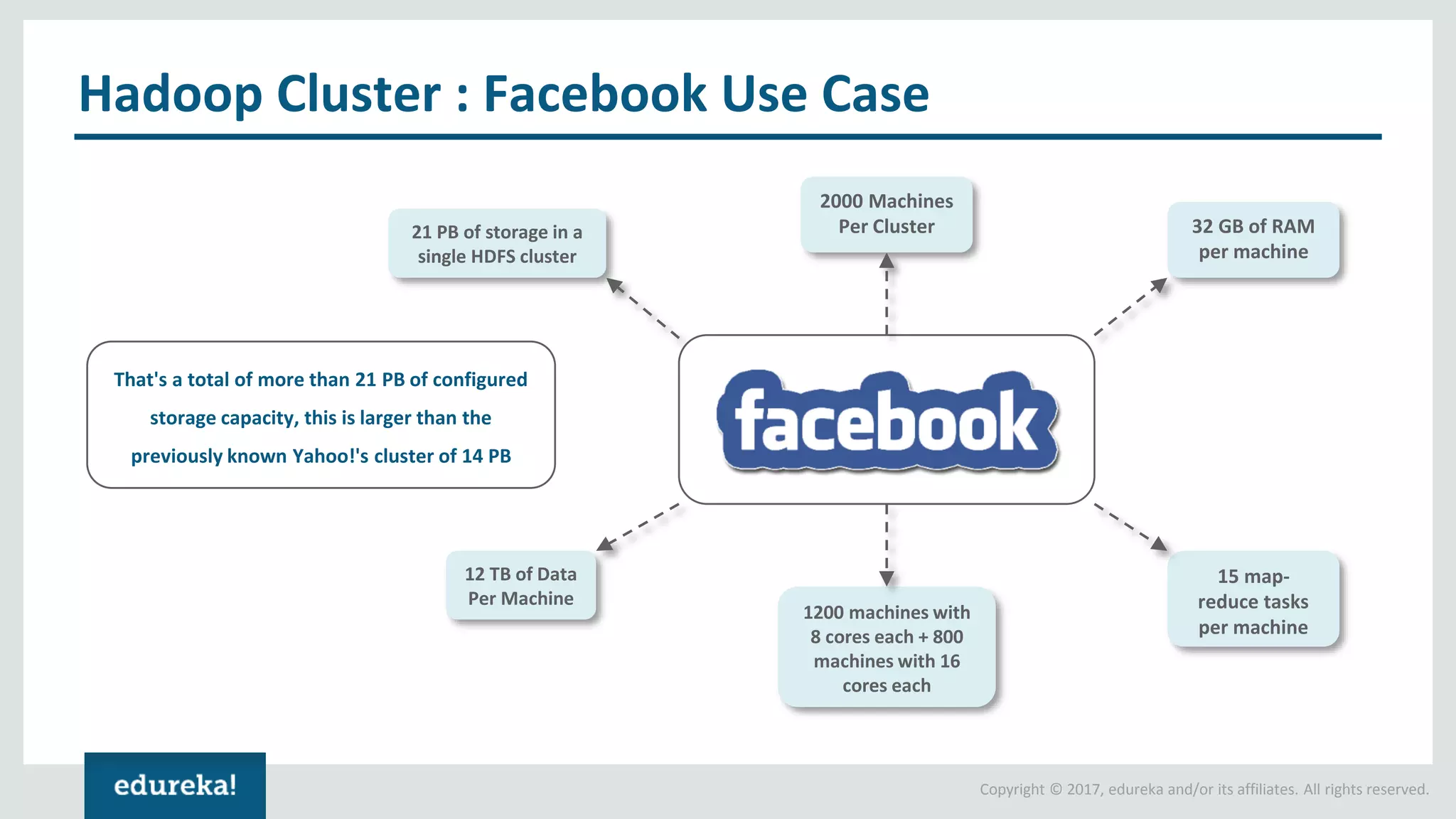
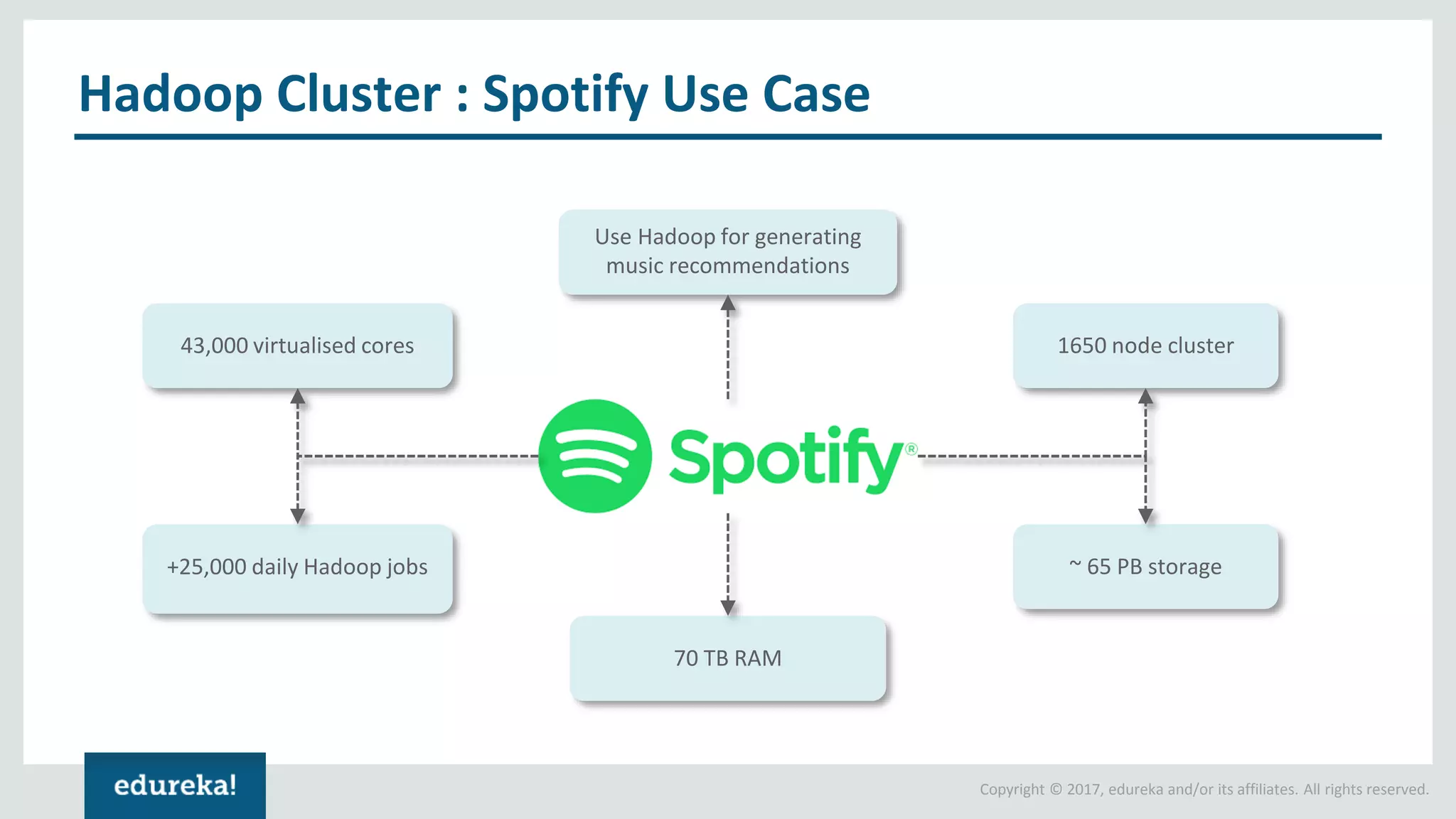
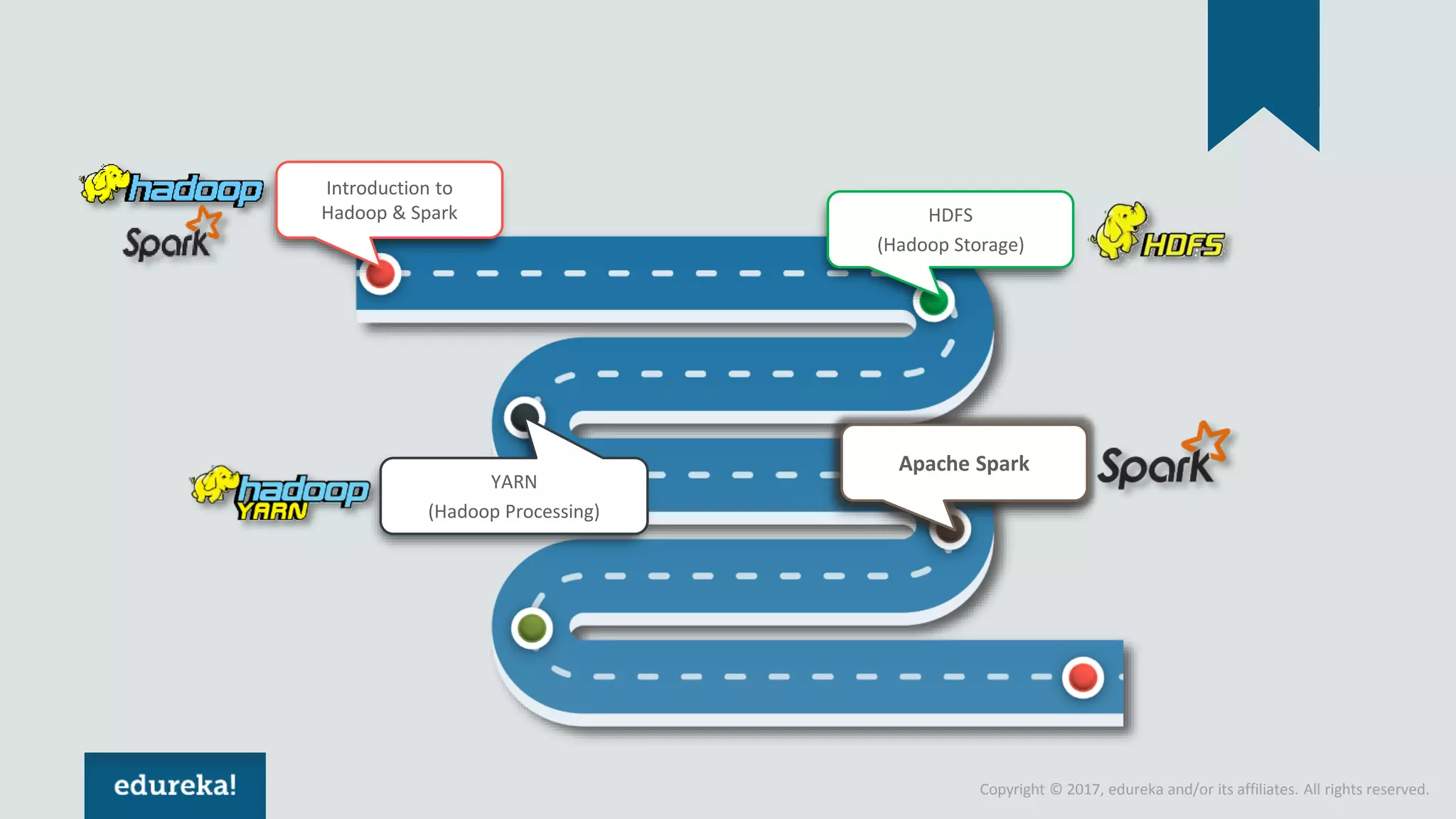
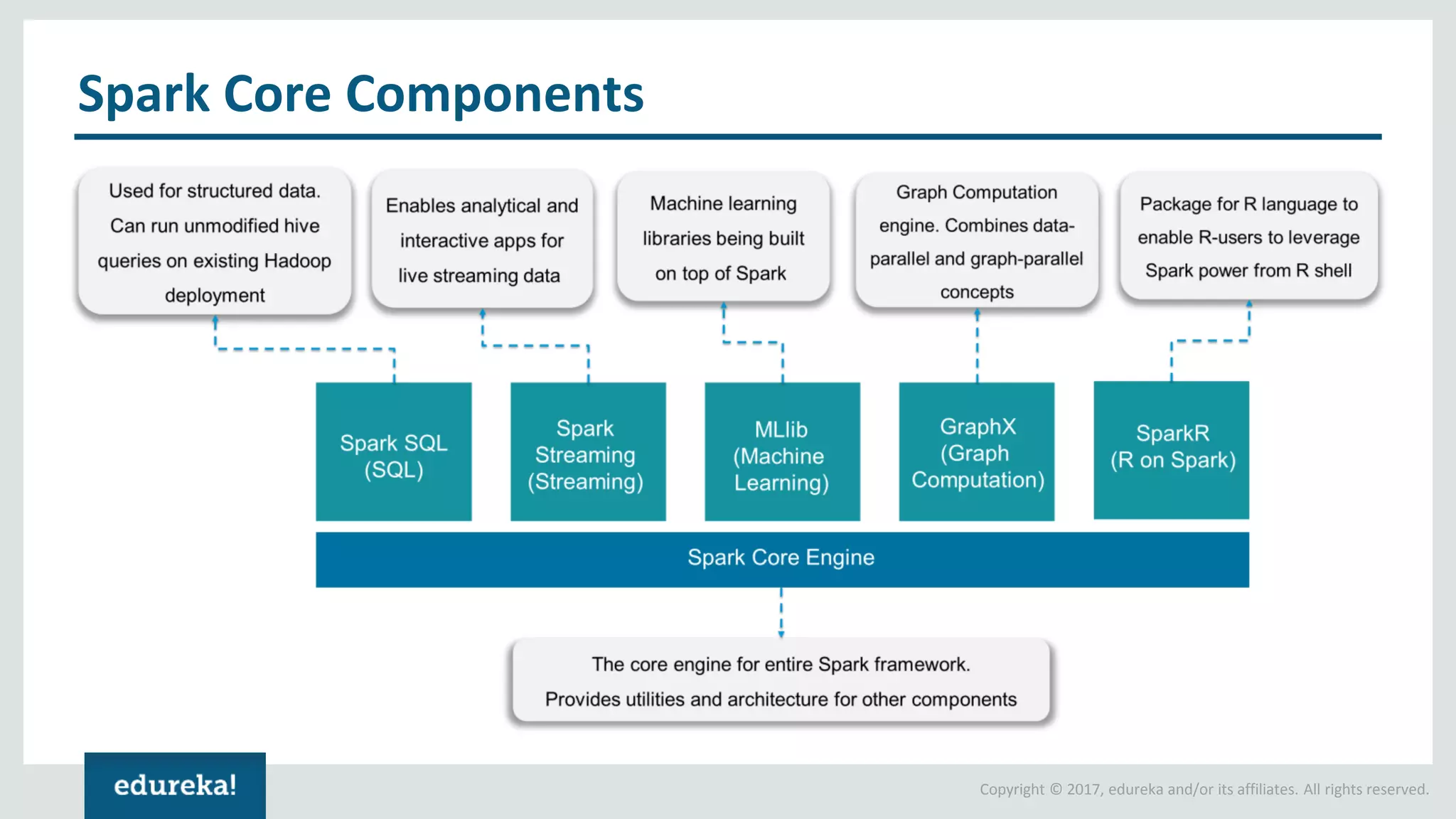

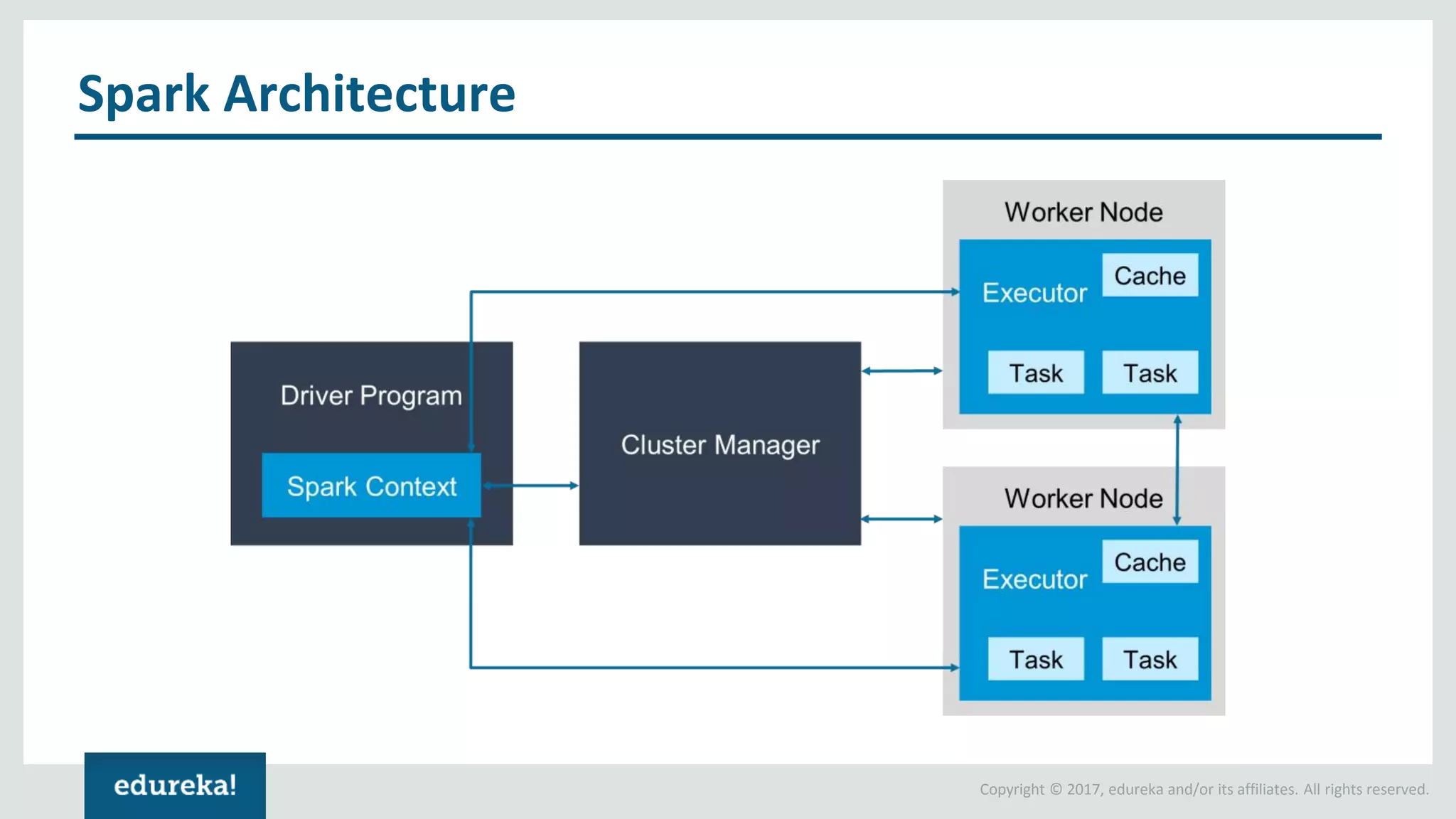
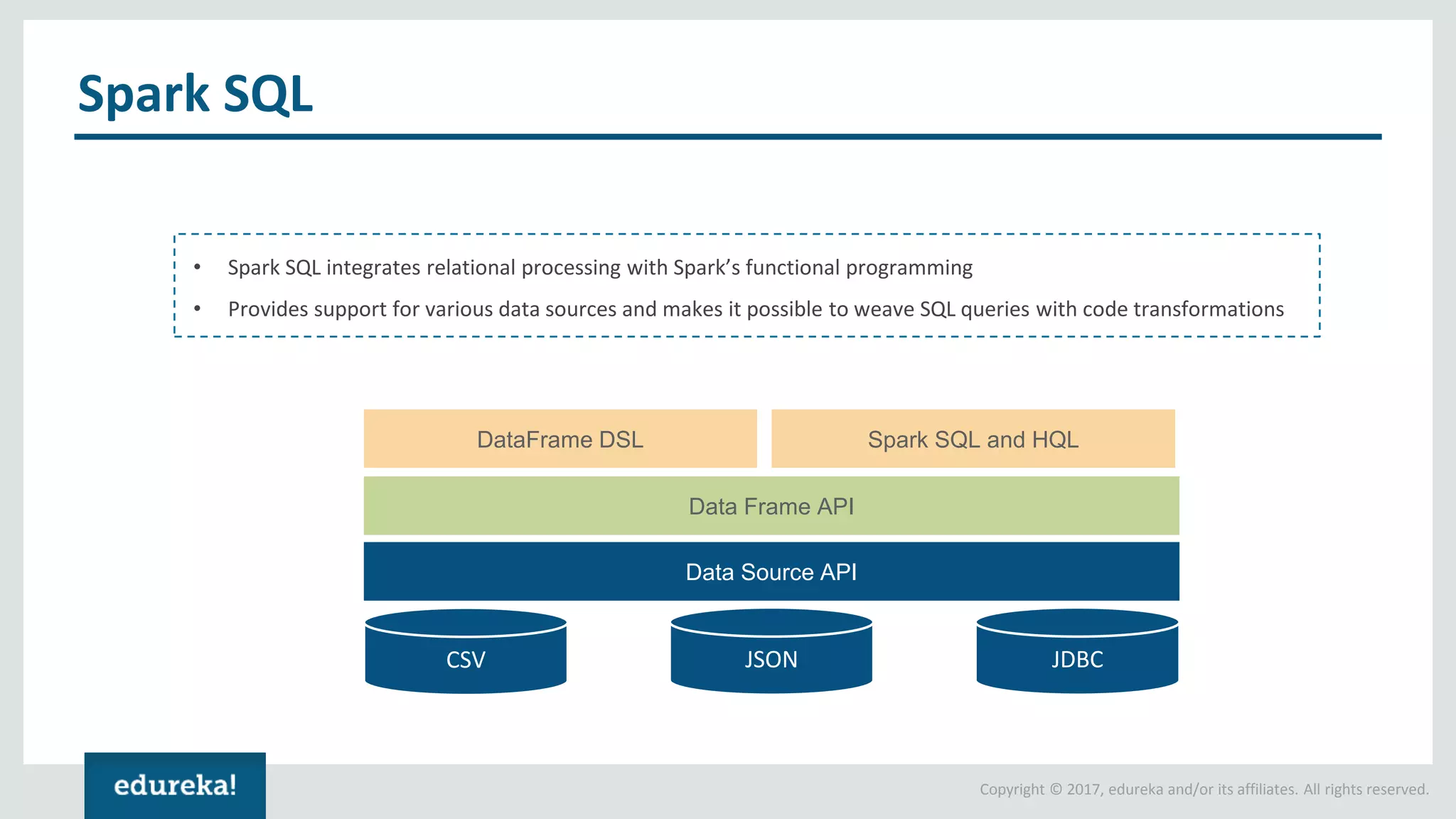

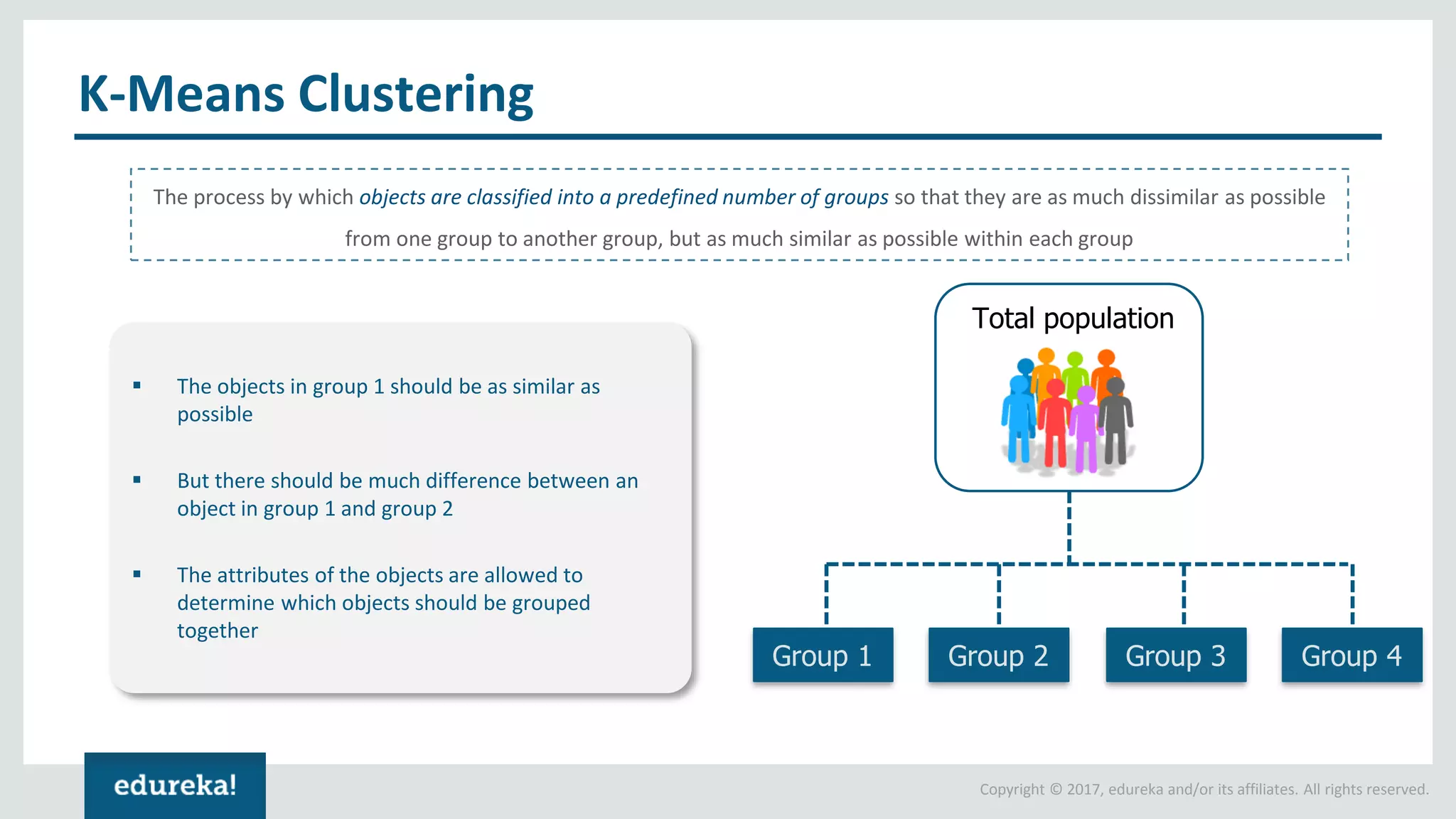
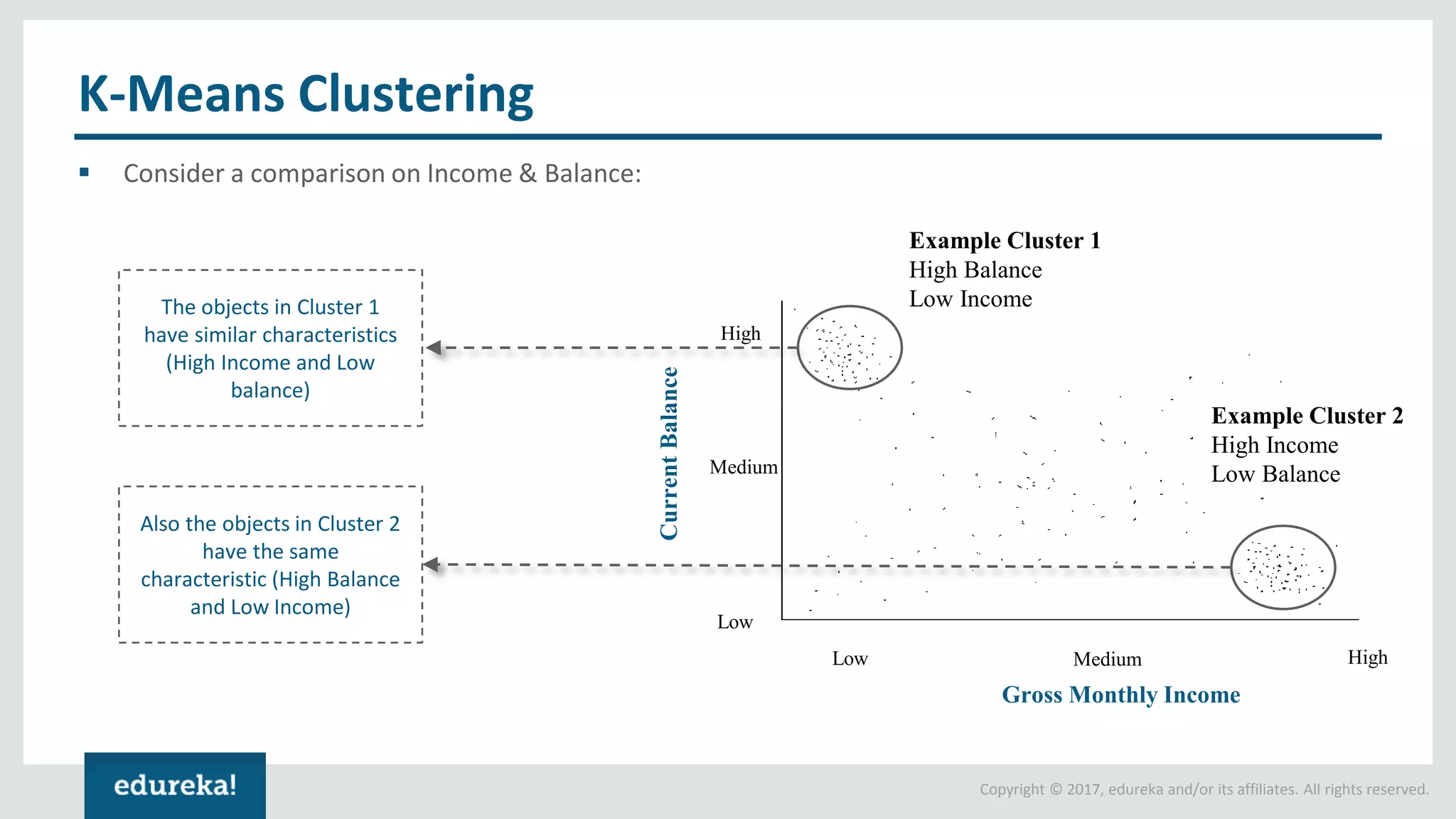
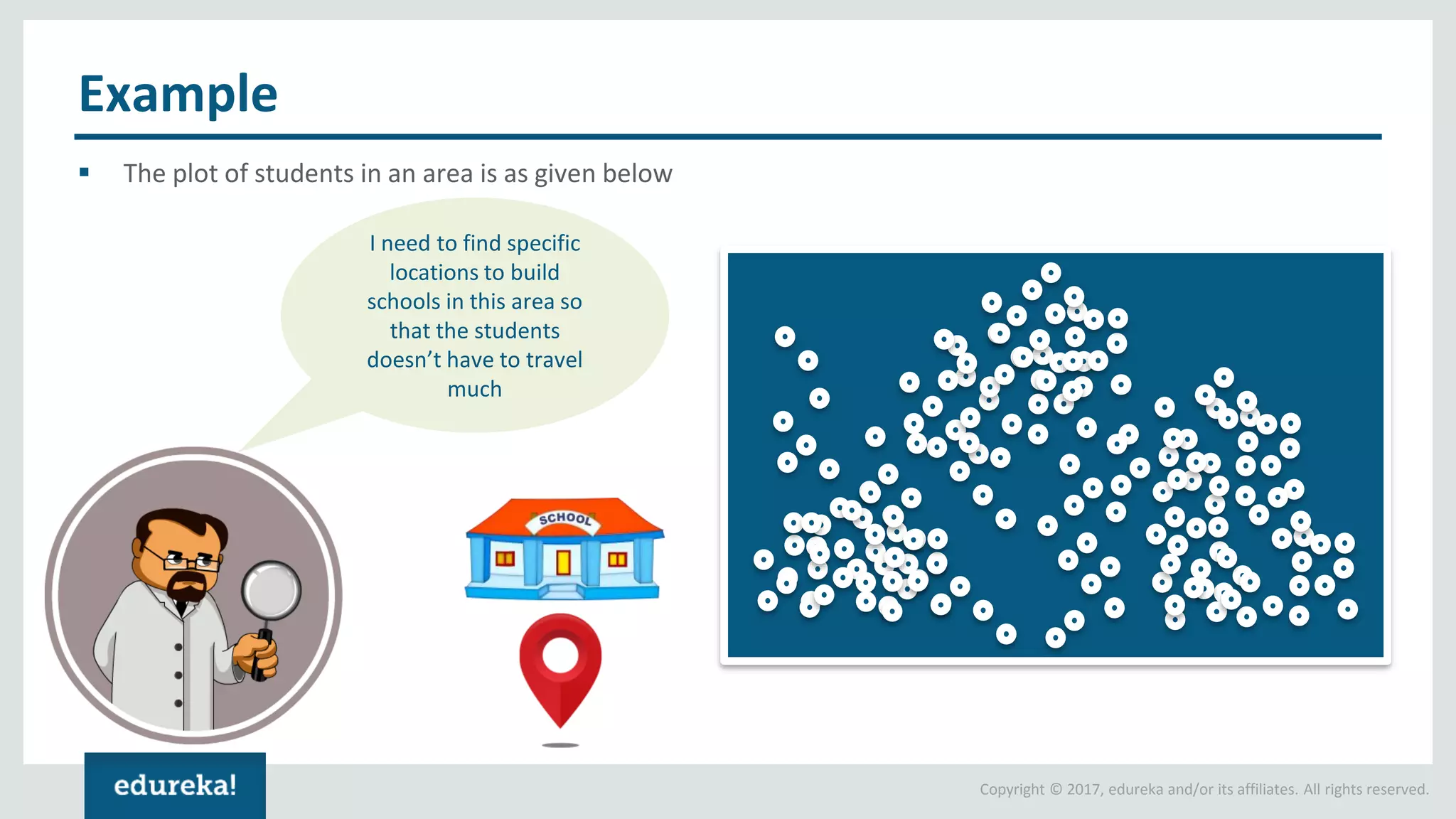
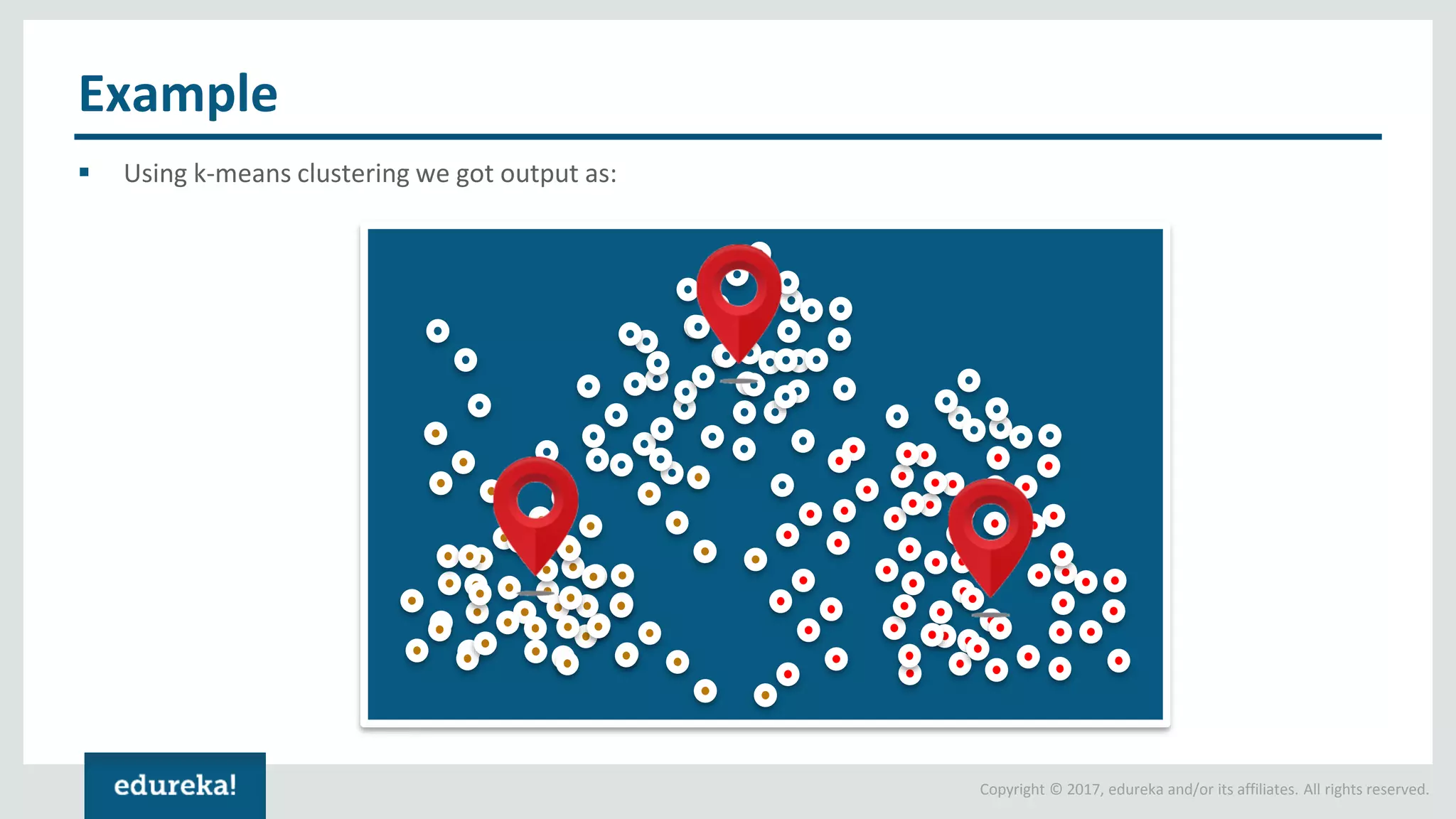

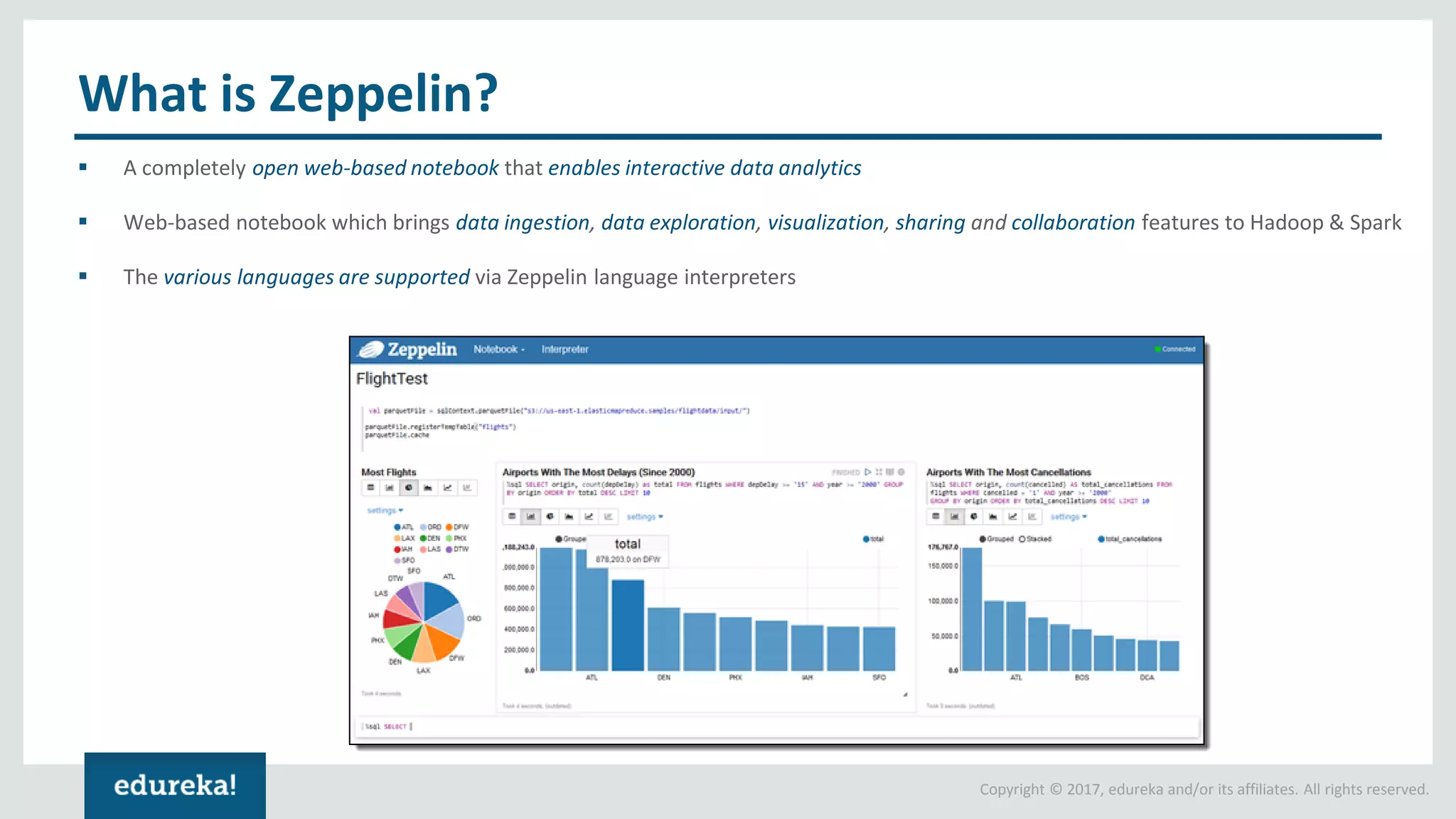
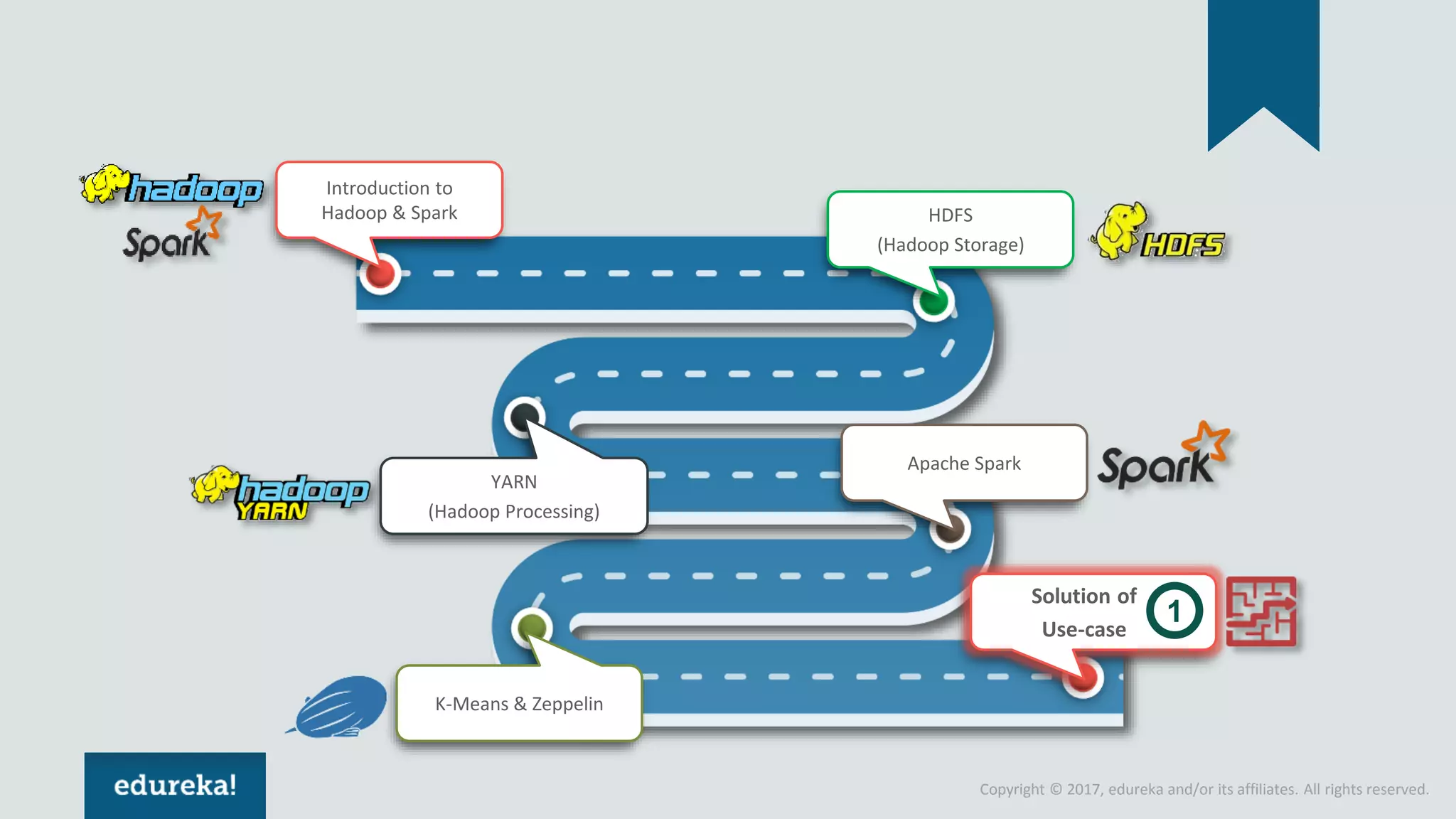
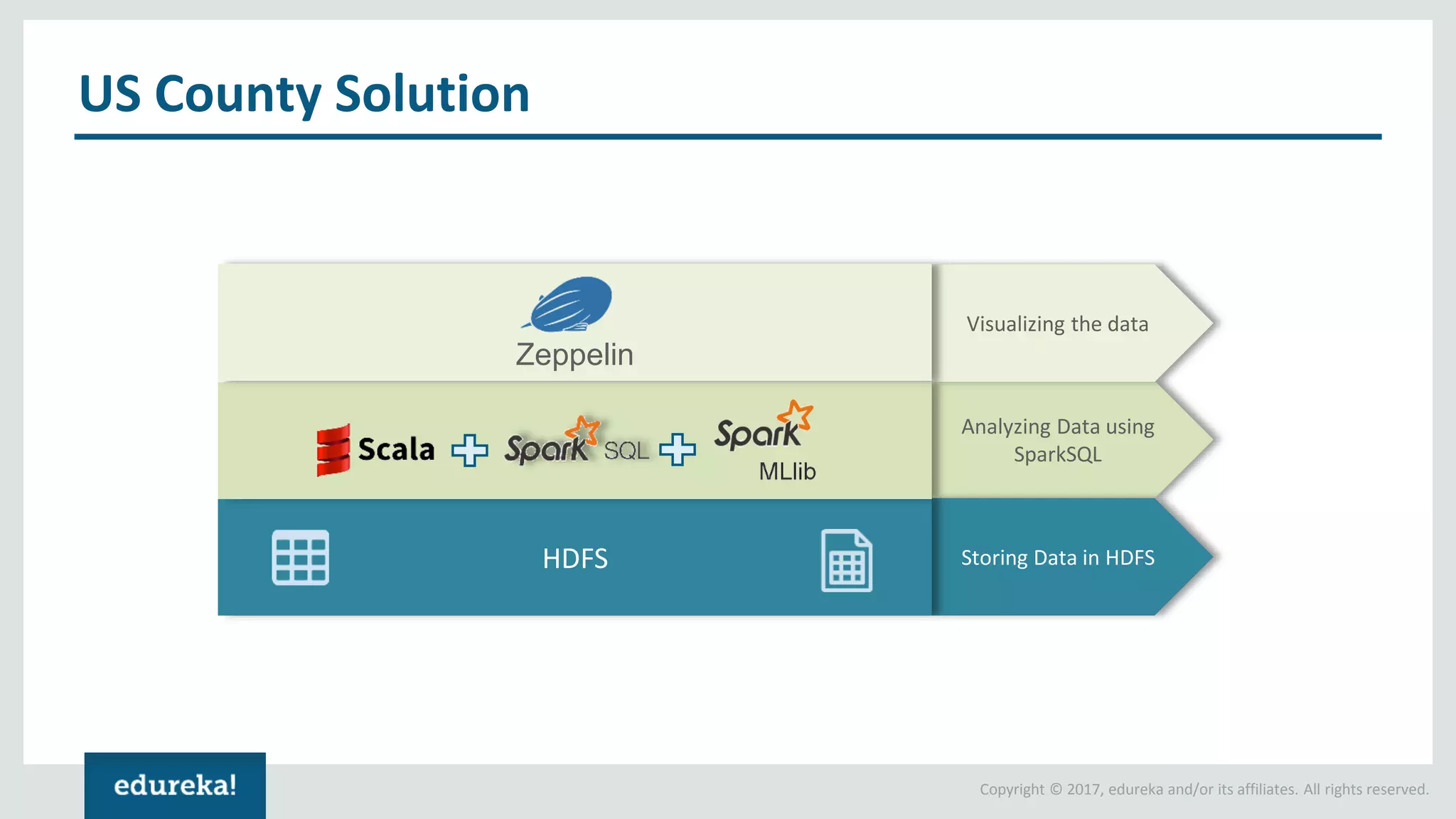
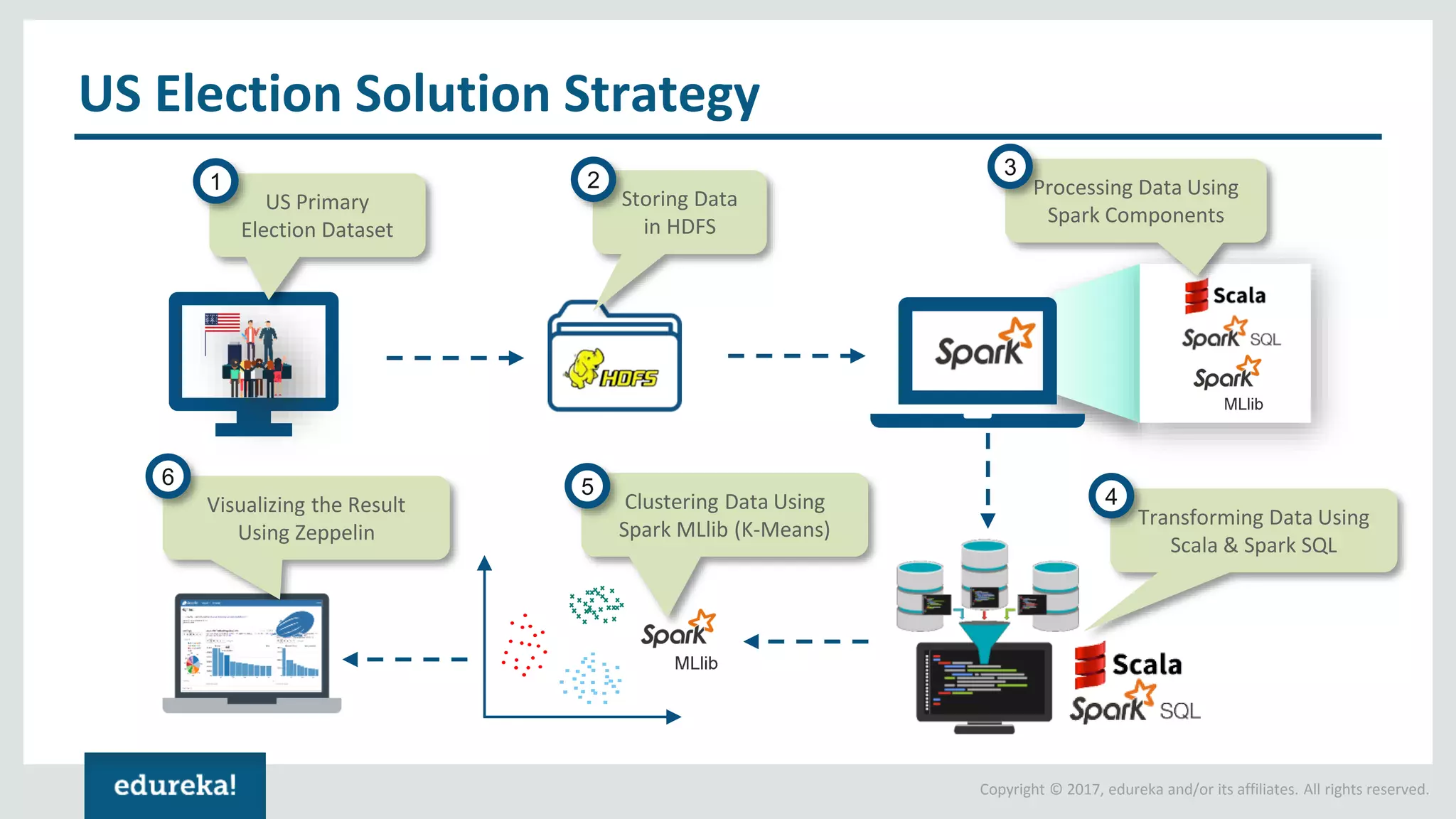
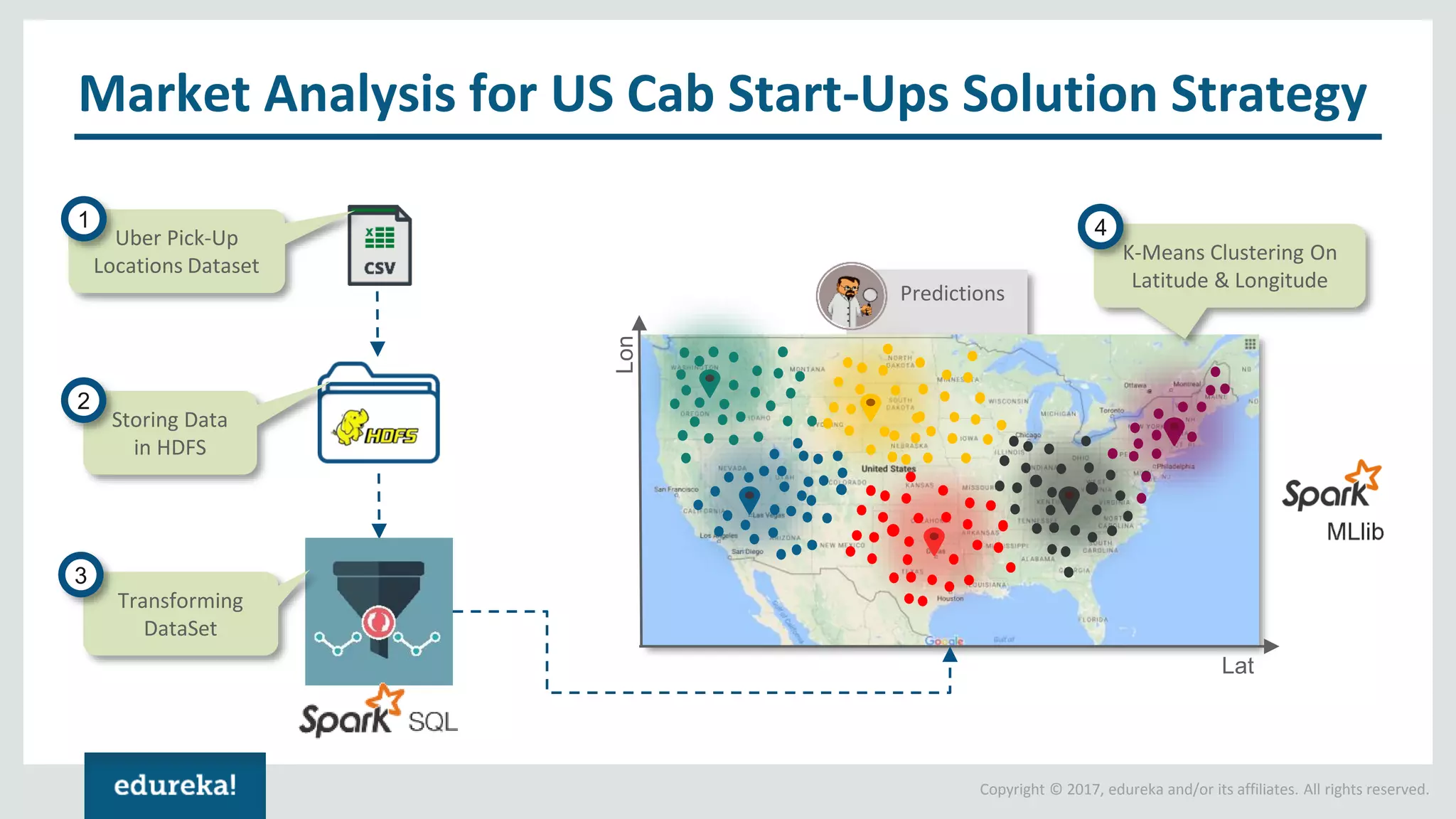

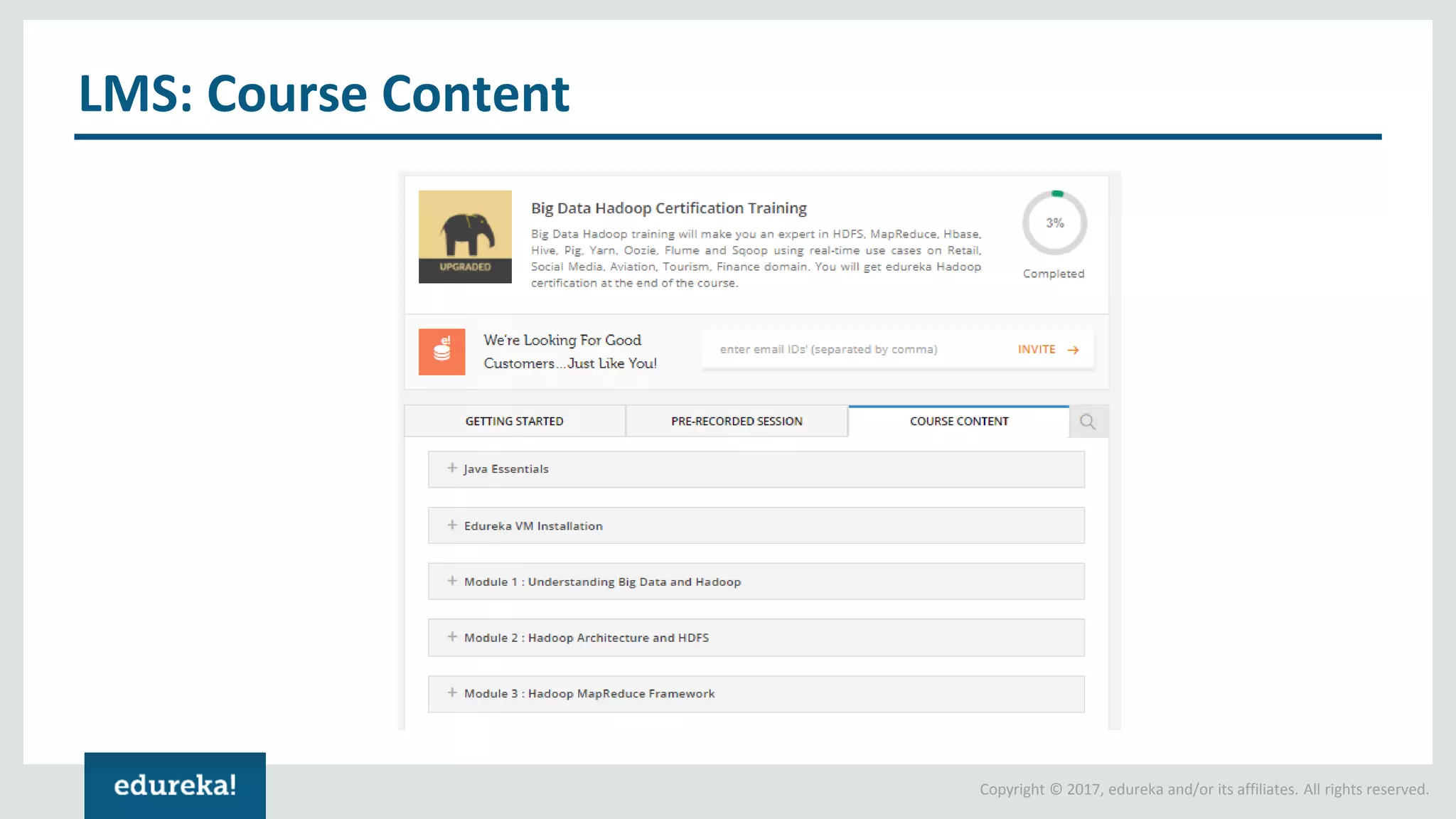
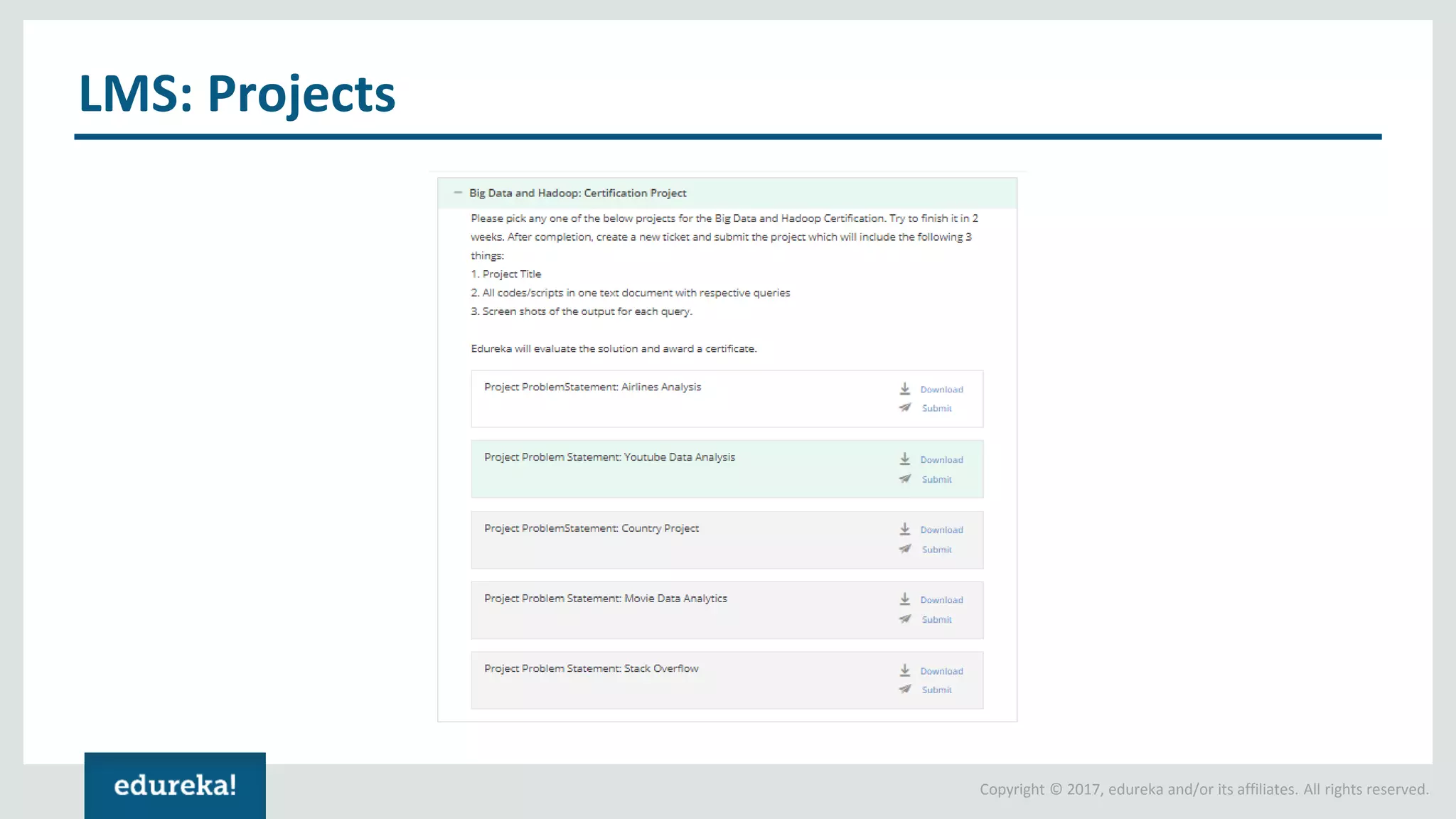



The document outlines various data analytics projects related to the US primary elections and the market analysis for US cab startups, detailing problem statements, available datasets, and solution strategies using Hadoop and Spark technologies. It provides a comprehensive overview of data processing techniques, including storage in HDFS, data transformation using Spark SQL, clustering with Spark MLlib, and visualizing results. Additionally, it covers the architecture of Hadoop, the function of YARN in resource management, and error handling in HDFS.