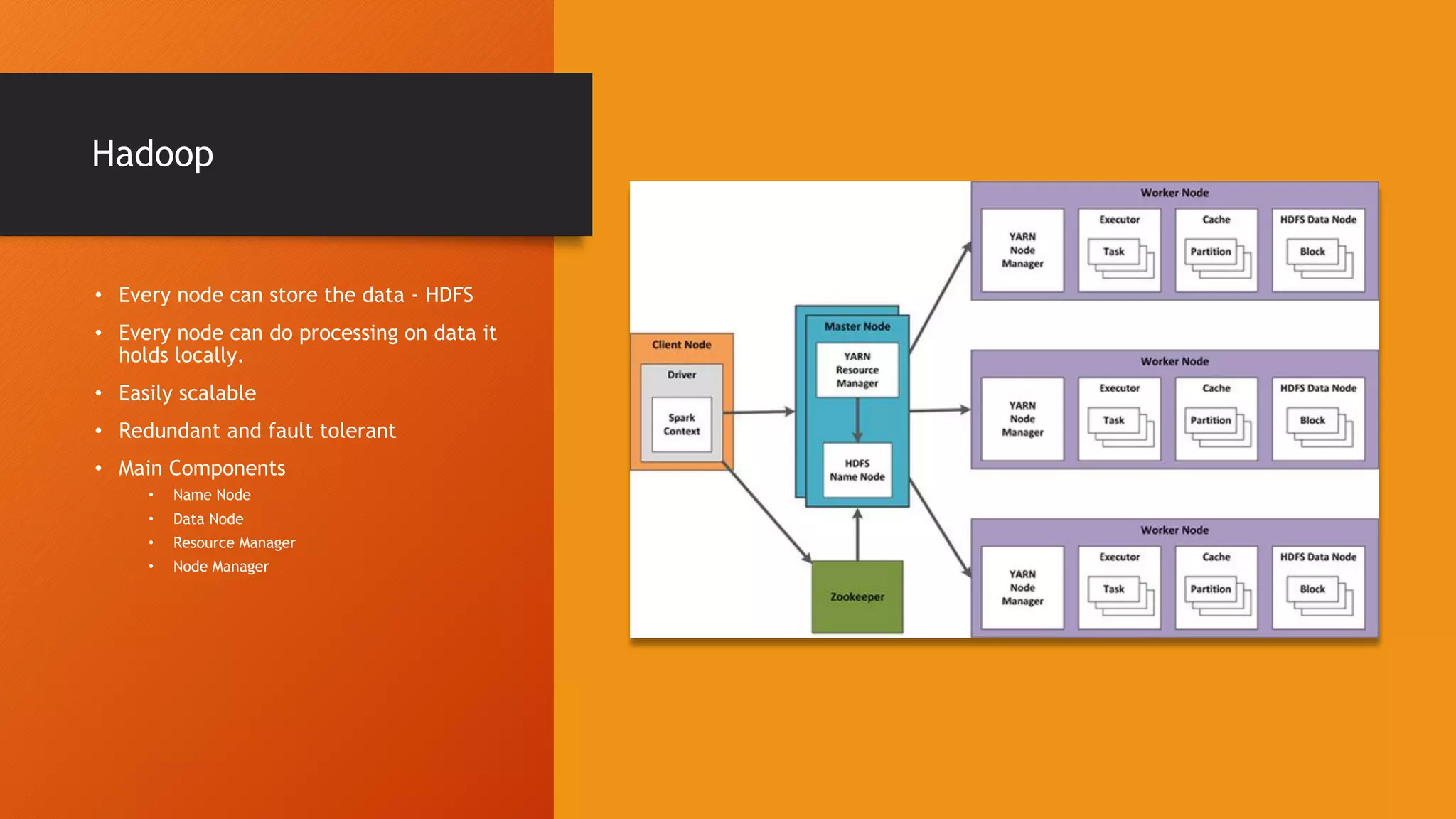
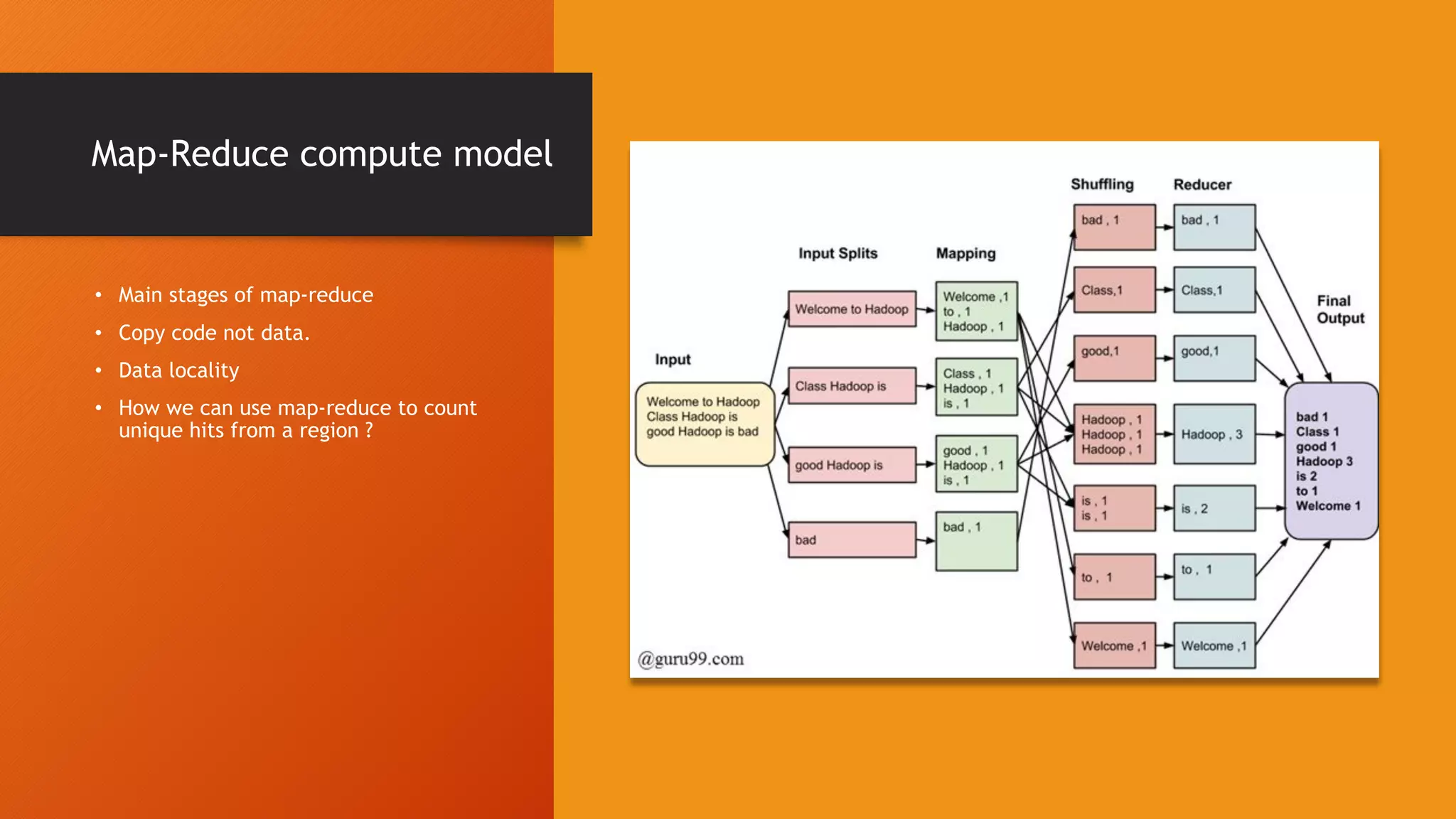
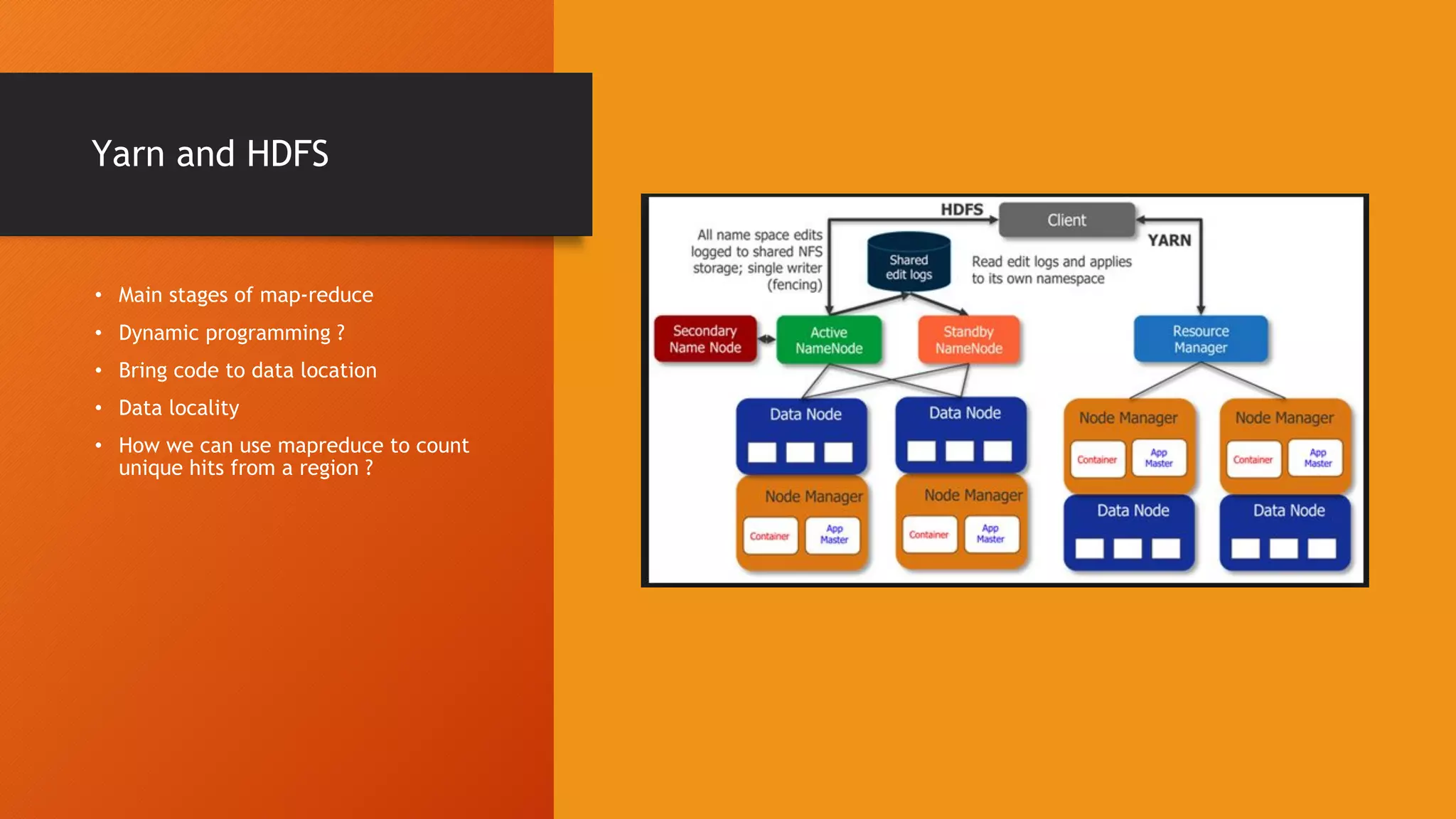
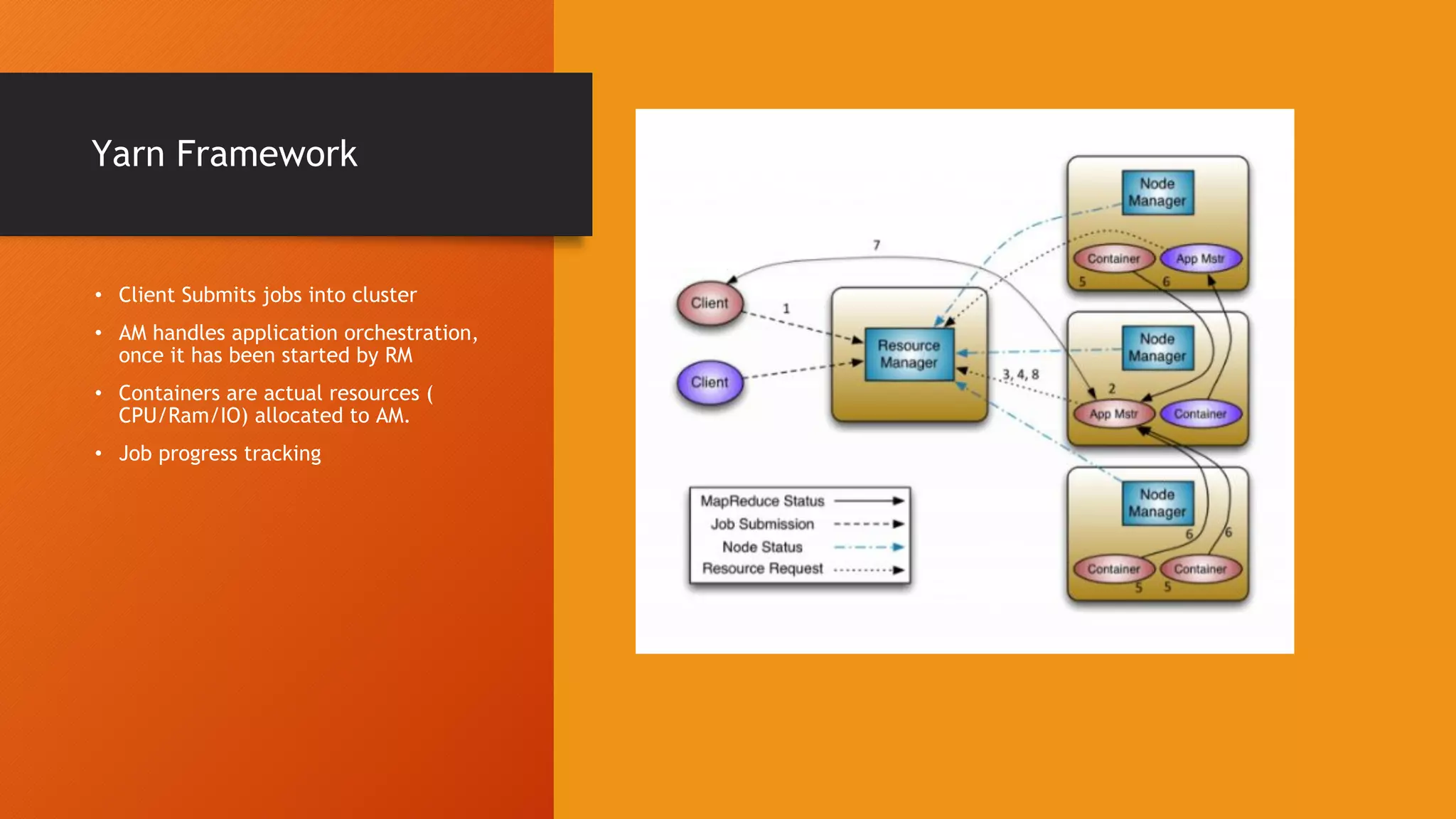
This document provides an introduction to big data and Hadoop. It discusses how distributed systems can scale to handle large data volumes and discusses Hadoop's architecture. It also provides instructions on setting up a Hadoop cluster on a laptop and summarizes Hadoop's MapReduce programming model and YARN framework. Finally, it announces an upcoming workshop on Spark and Pyspark.