Download as PDF, PPTX











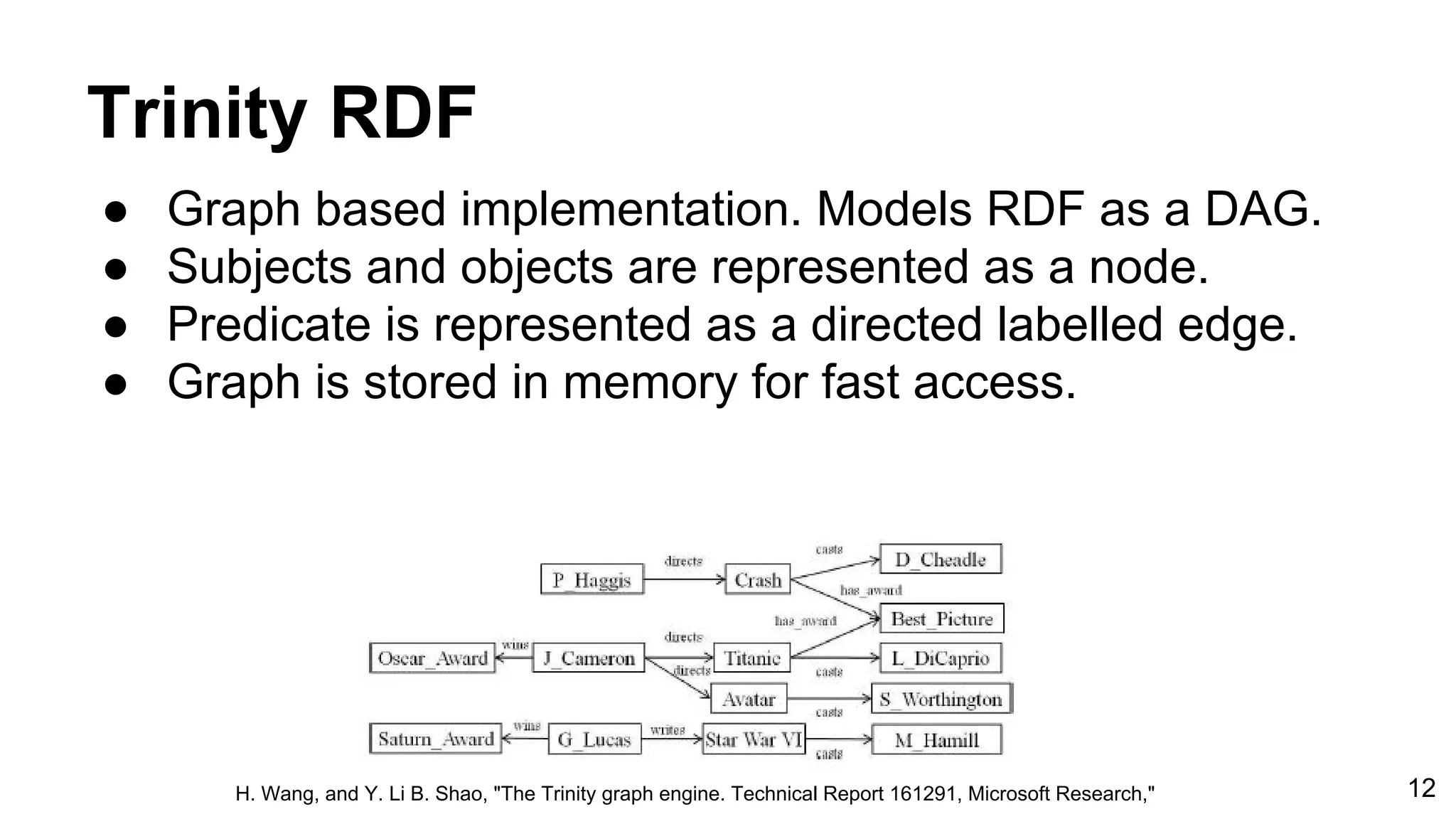
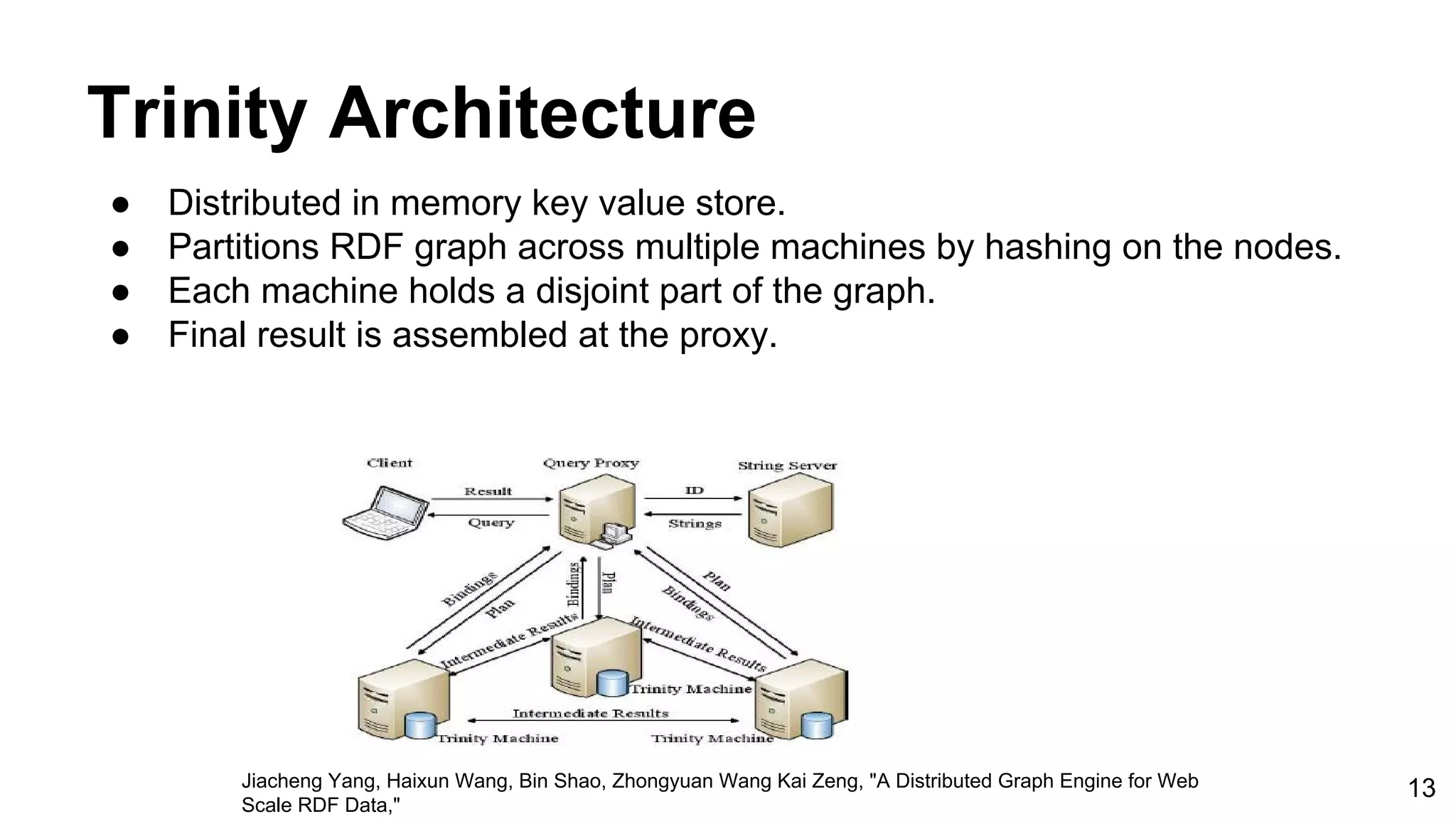


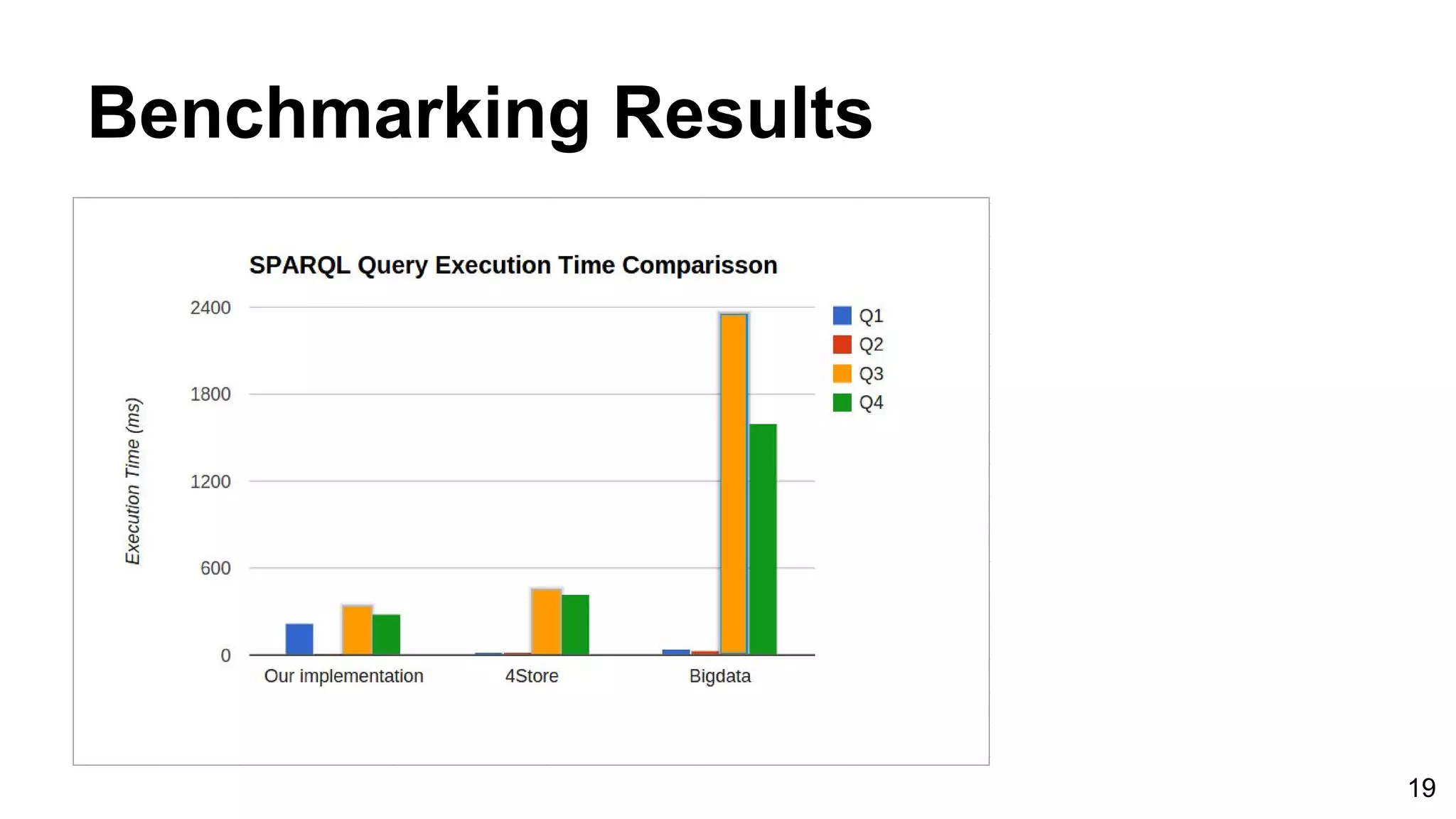
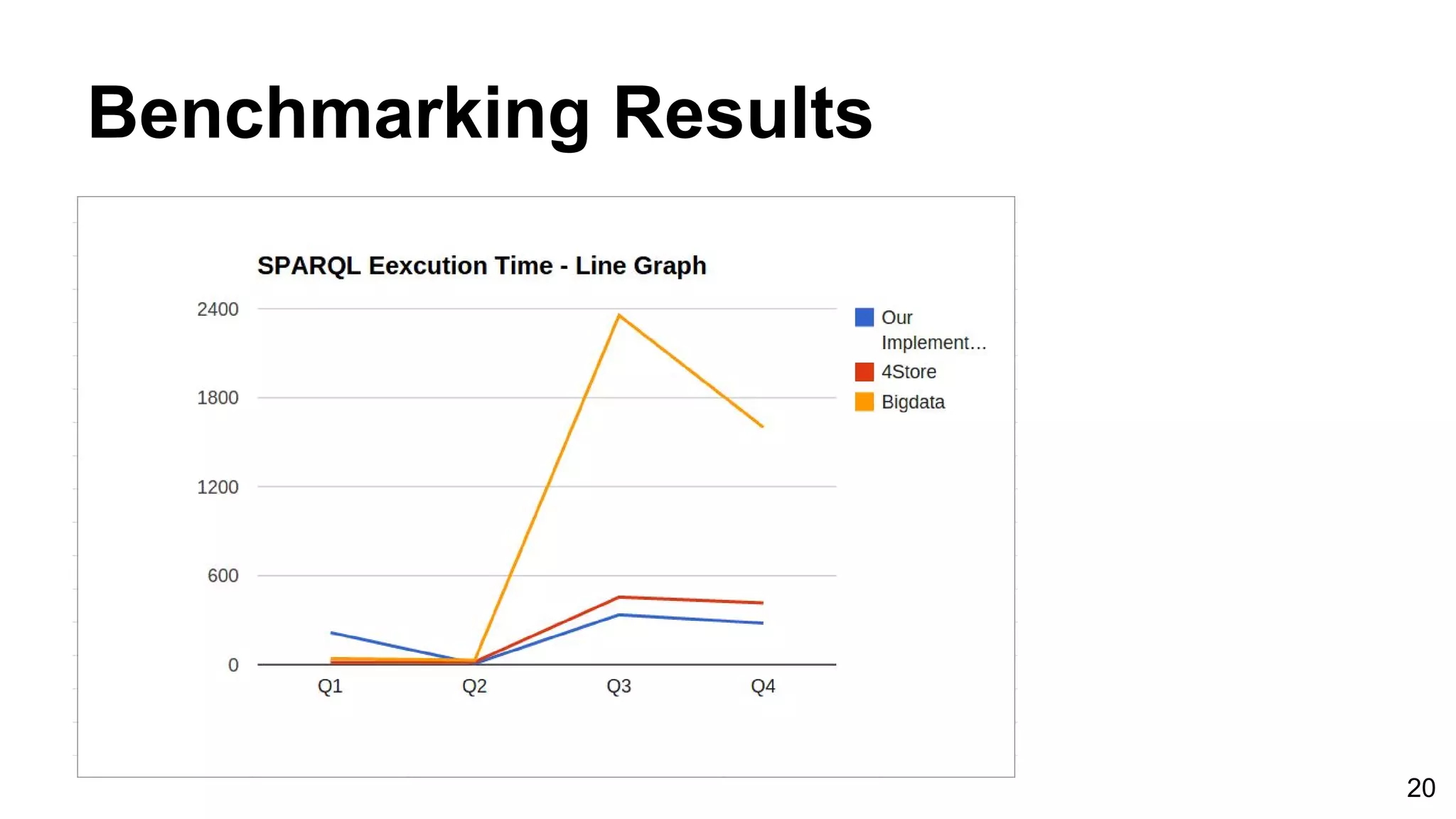
![Benchmark Results ● Query complexity increases from Q1 through Q4. ● The execution time taken by different RDF stores, to execute above four queries. ● Query execution time is measured in ms. Q1 Q2 Q3 Q4 Our implementation 216ms 7ms 336ms 279ms 4Store 16ms 18ms 455ms 416ms Bigdata 41ms 30ms 2sec, 355ms 1sec, 600ms DBpedia. (2008, Jan 10.) RDF Store Benchmarks with DBpedia [Online]. Available: http://wifo5-03.informatik.uni-mannheim.de/benchmarks-200801/ 18](https://image.slidesharecdn.com/graphbasedrdfstoreforapachecassandra-viva-170103151736/75/Graph-basedrdf-storeforapachecassandra-18-2048.jpg)

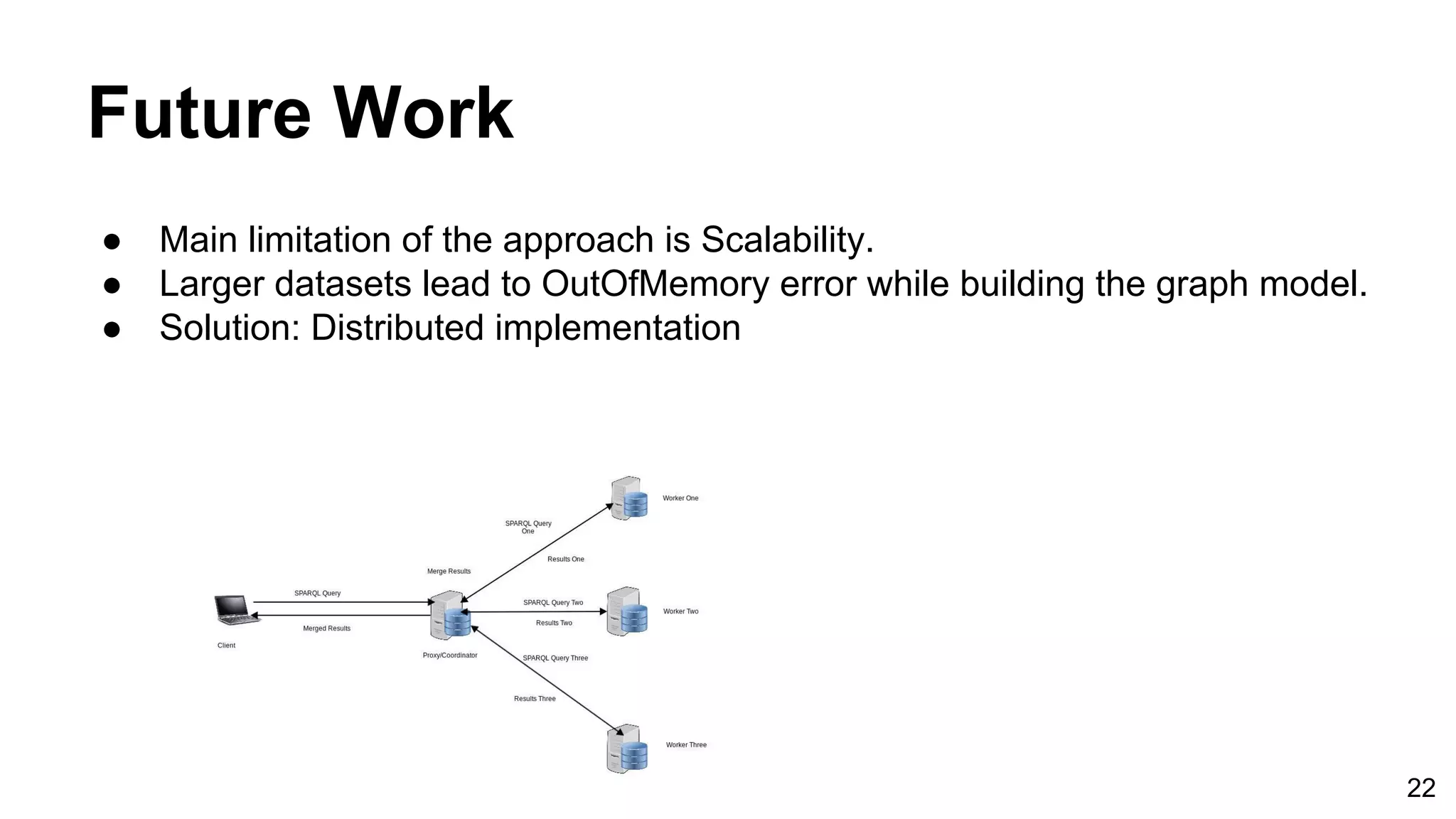


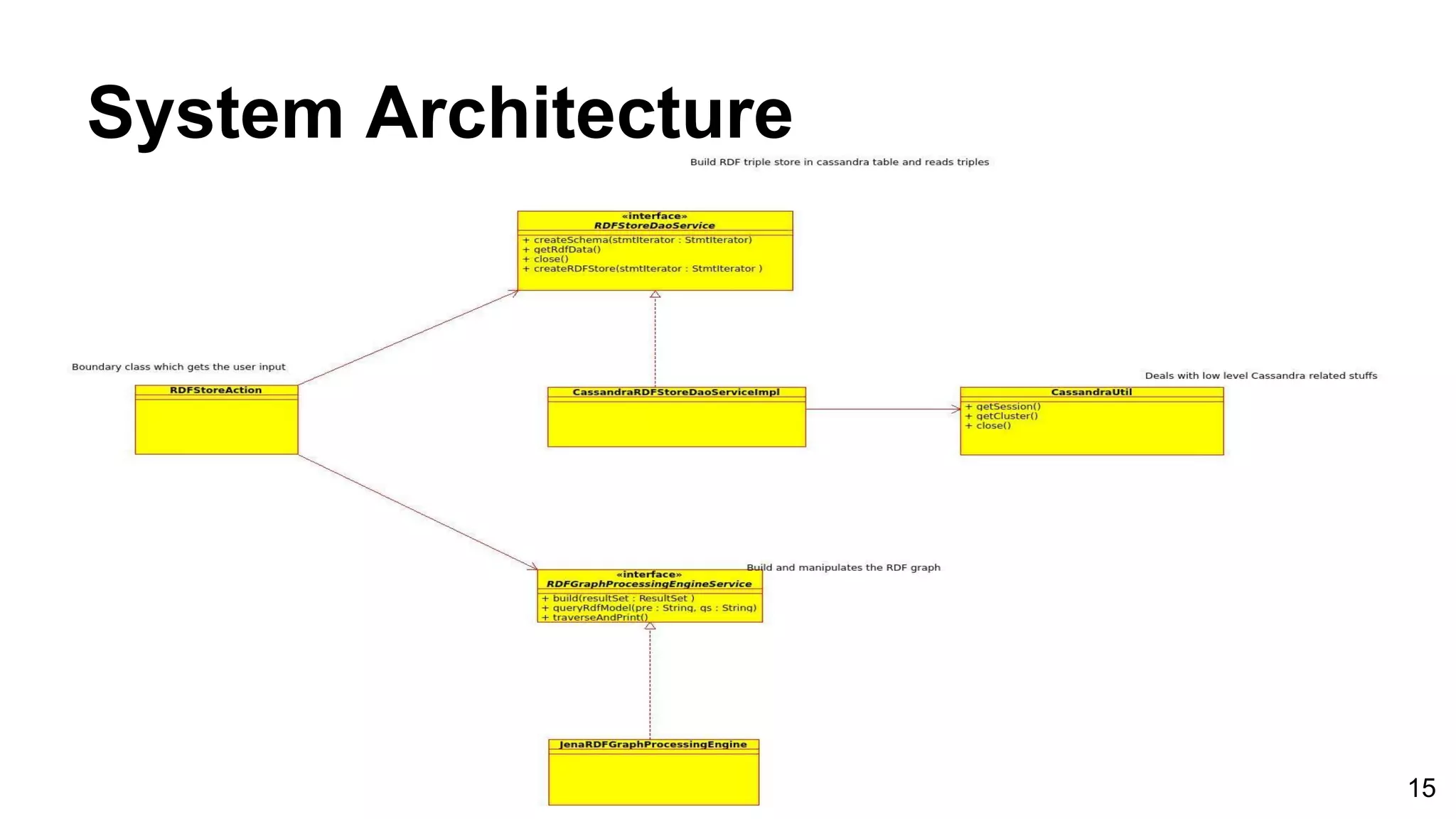
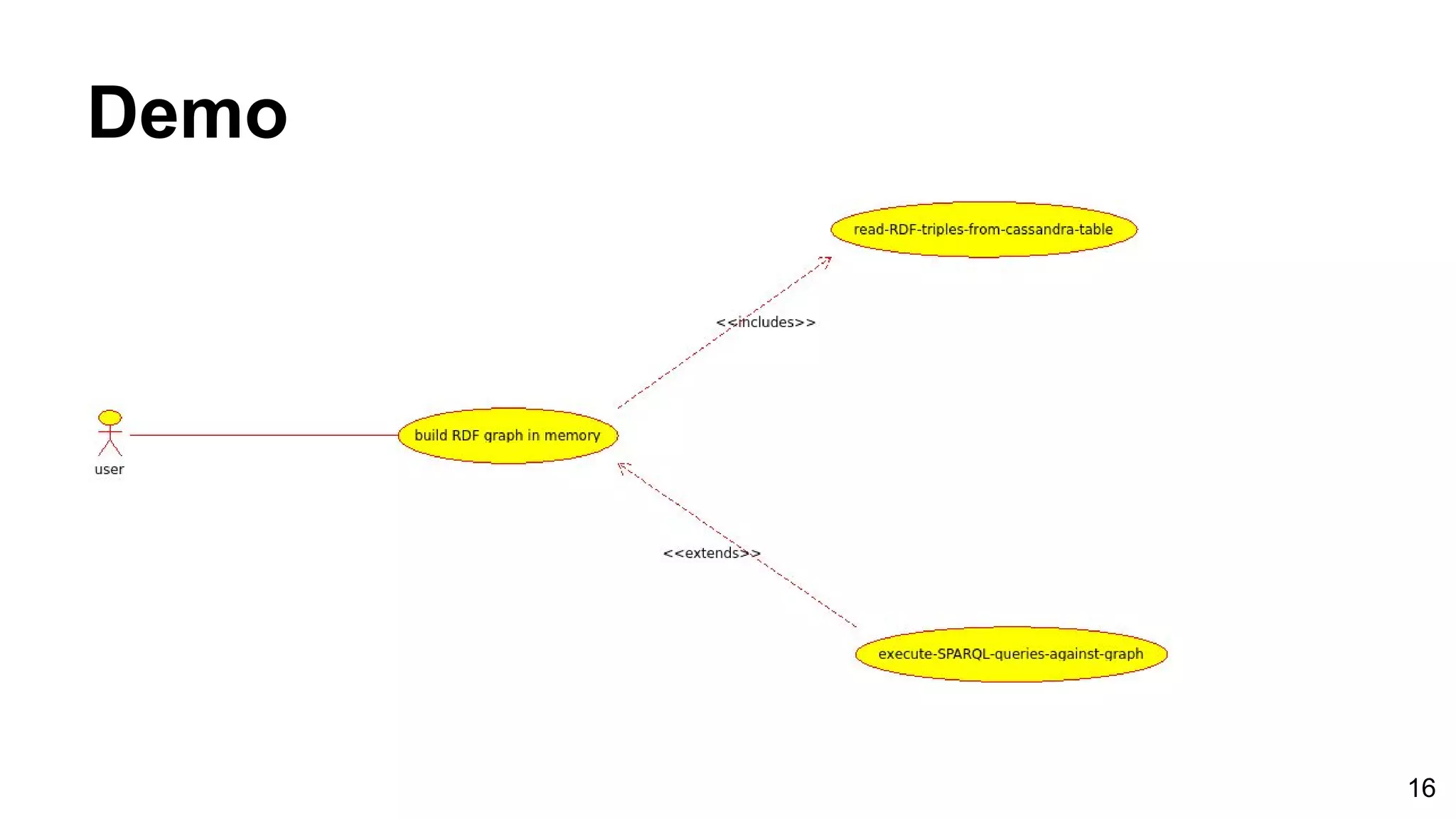
This document discusses building a graph-based RDF store on Apache Cassandra. It first introduces RDF data and triple stores, then discusses challenges in building a scalable triple store on Cassandra. It reviews existing approaches like relational and graph-based models. The methodology builds a prototype RDF store on Cassandra using a graph model. Evaluation benchmarks it against other stores on DBPedia data, showing it outperforms them on more complex queries. Future work could improve scalability with a distributed implementation.