Download as PDF, PPTX




















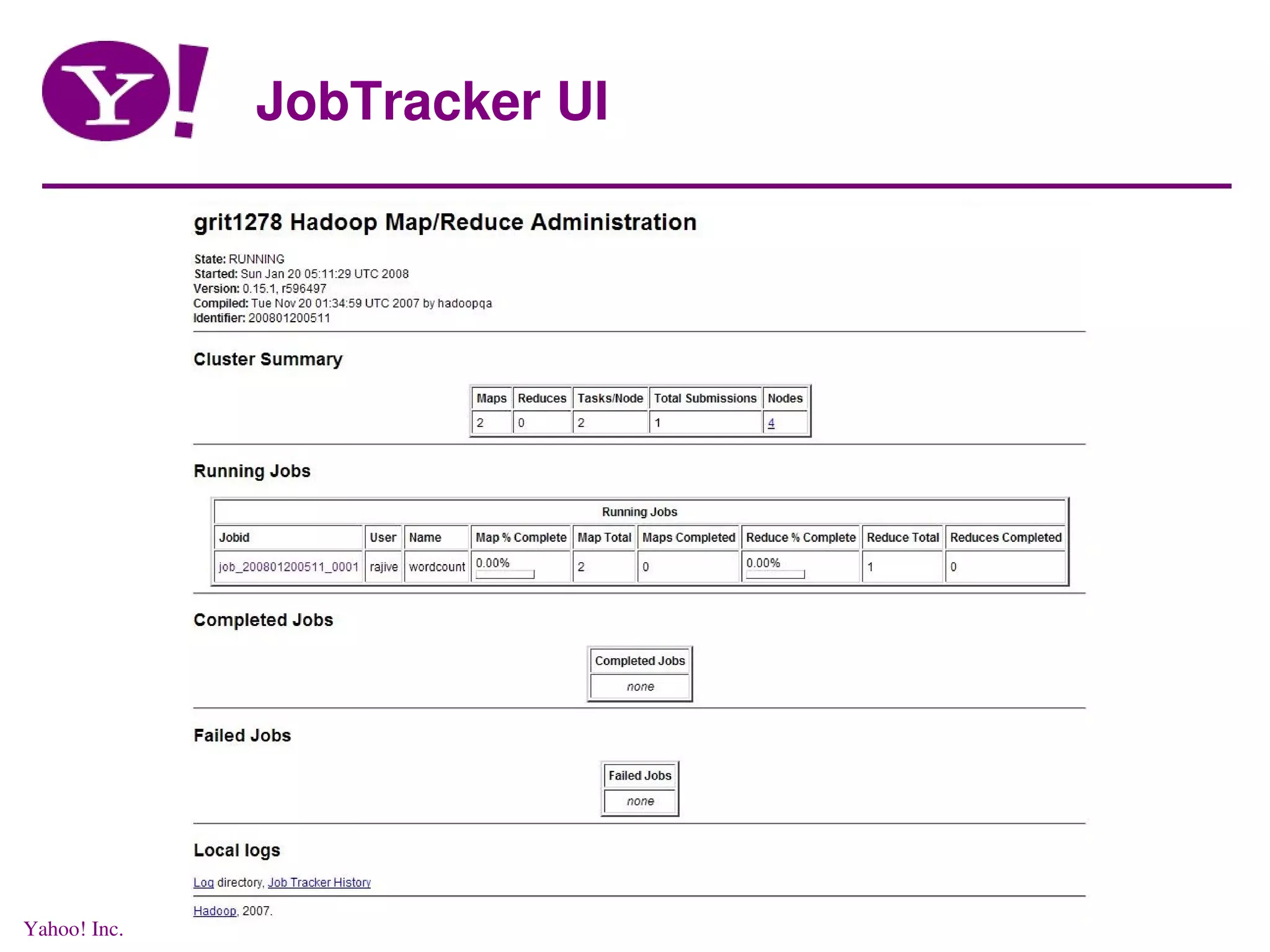
![Running Jobs gritgw1004:/grid/0/tmp/rajive$ hod -m 5 HDFS UI on grit1002.yahooresearchcluster.com:50070 Mapred UI on grit1278.yahooresearchcluster.com:55118 Hadoop config file in: /grid/0/kryptonite/hod/tmp/hod-15575-tmp/hadoop- site.xml allocation information: 1 job tracker node 4 task tracker nodes 5 nodes in total [hod] (rajive) >> Yahoo! Inc.](https://image.slidesharecdn.com/rajiveyahoosaas-090712085256-phpapp01/75/Distributed-Data-processing-in-a-Cloud-27-2048.jpg)
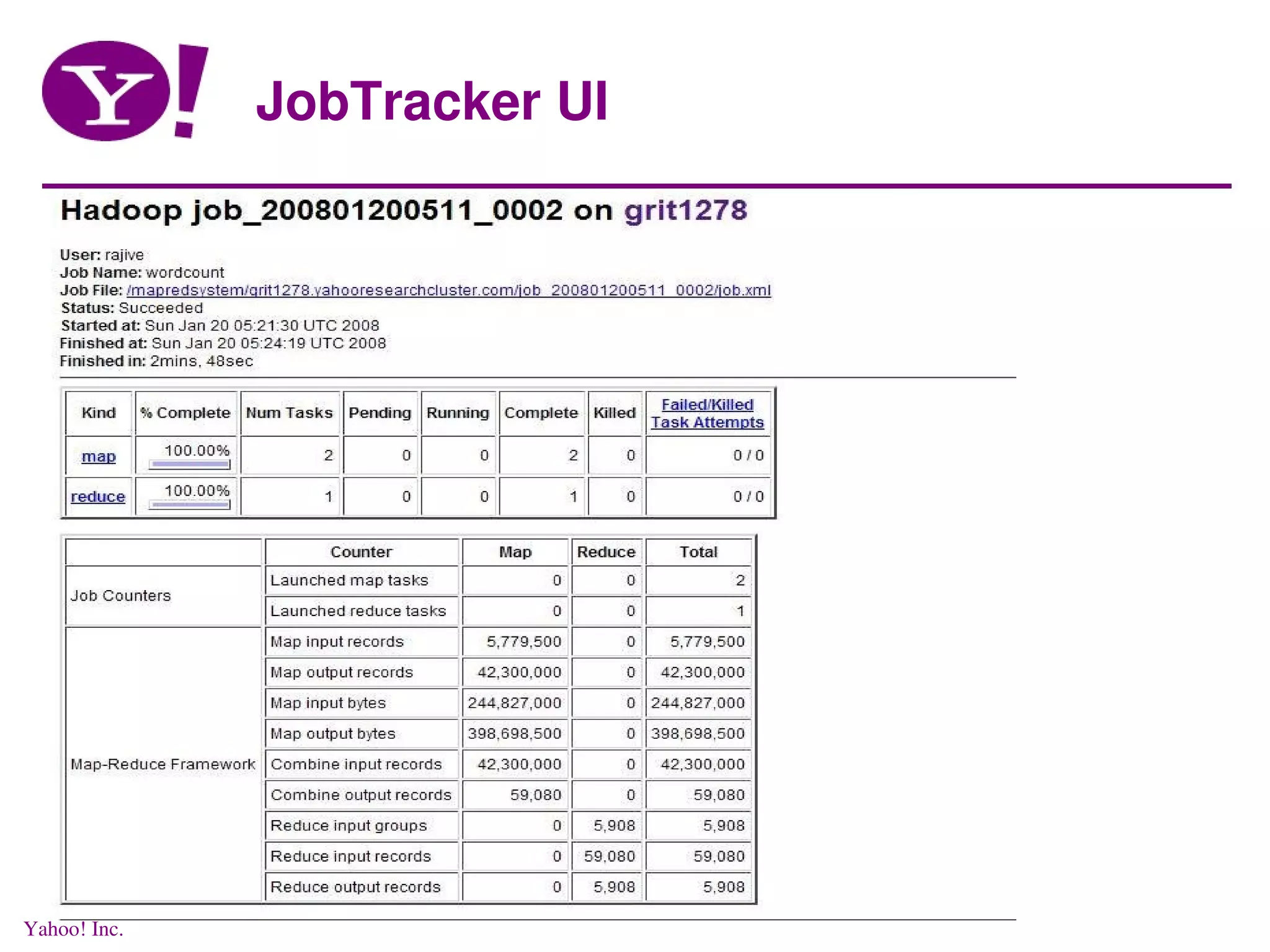
![Running Jobs run jar /grid/0/hadoop/current/hadoop-examples.jar wordcount [hod] (rajive) >> /user/rajive/alice-1.5k /user/rajive/wcout2 08/01/20 05:21:26 WARN mapred.JobConf: Deprecated resource 'mapred-default.xml' is being loaded, please discontinue its usage! 08/01/20 05:21:27 INFO mapred.FileInputFormat: Total input paths to process : 1 08/01/20 05:21:30 INFO mapred.JobClient: Running job: job_200801200511_0002 08/01/20 05:21:31 INFO mapred.JobClient: map 0% reduce 0% 08/01/20 05:21:38 INFO mapred.JobClient: map 3% reduce 0% 08/01/20 05:21:42 INFO mapred.JobClient: map 12% reduce 0% 08/01/20 05:21:48 INFO mapred.JobClient: map 20% reduce 0% 08/01/20 05:22:12 INFO mapred.JobClient: map 27% reduce 0% 08/01/20 05:22:18 INFO mapred.JobClient: map 37% reduce 0% 08/01/20 05:22:21 INFO mapred.JobClient: map 41% reduce 0% 08/01/20 05:22:41 INFO mapred.JobClient: map 45% reduce 0% 08/01/20 05:22:48 INFO mapred.JobClient: map 54% reduce 0% 08/01/20 05:22:51 INFO mapred.JobClient: map 59% reduce 0% 08/01/20 05:22:59 INFO mapred.JobClient: map 62% reduce 0% 08/01/20 05:23:19 INFO mapred.JobClient: map 71% reduce 0% 08/01/20 05:23:22 INFO mapred.JobClient: map 76% reduce 0% 08/01/20 05:23:29 INFO mapred.JobClient: map 83% reduce 0% 08/01/20 05:23:49 INFO mapred.JobClient: map 88% reduce 0% 08/01/20 05:23:52 INFO mapred.JobClient: map 93% reduce 0% 08/01/20 05:23:59 INFO mapred.JobClient: map 100% reduce 0% 08/01/20 05:24:19 INFO mapred.JobClient: map 100% reduce 100% 08/01/20 05:24:20 INFO mapred.JobClient: Job complete: job_200801200511_0002 08/01/20 05:24:20 INFO mapred.JobClient: Counters: 11 08/01/20 05:24:20 INFO mapred.JobClient: Job Counters 08/01/20 05:24:20 INFO mapred.JobClient: Launched map tasks=2 08/01/20 05:24:20 INFO mapred.JobClient: Launched reduce tasks=1 08/01/20 05:24:20 INFO mapred.JobClient: Map-Reduce Framework 08/01/20 05:24:20 INFO mapred.JobClient: Map input records=5779500 08/01/20 05:24:20 INFO mapred.JobClient: Map output records=42300000 08/01/20 05:24:20 INFO mapred.JobClient: Map input bytes=244827000 08/01/20 05:24:20 INFO mapred.JobClient: Map output bytes=398698500 08/01/20 05:24:20 INFO mapred.JobClient: Combine input records=42300000 08/01/20 05:24:20 INFO mapred.JobClient: Combine output records=59080 08/01/20 05:24:20 INFO mapred.JobClient: Reduce input groups=5908 08/01/20 05:24:20 INFO mapred.JobClient: Reduce input records=59080 08/01/20 05:24:20 INFO mapred.JobClient: Reduce output records=5908 [hod] (rajive) >> Yahoo! Inc.](https://image.slidesharecdn.com/rajiveyahoosaas-090712085256-phpapp01/75/Distributed-Data-processing-in-a-Cloud-28-2048.jpg)

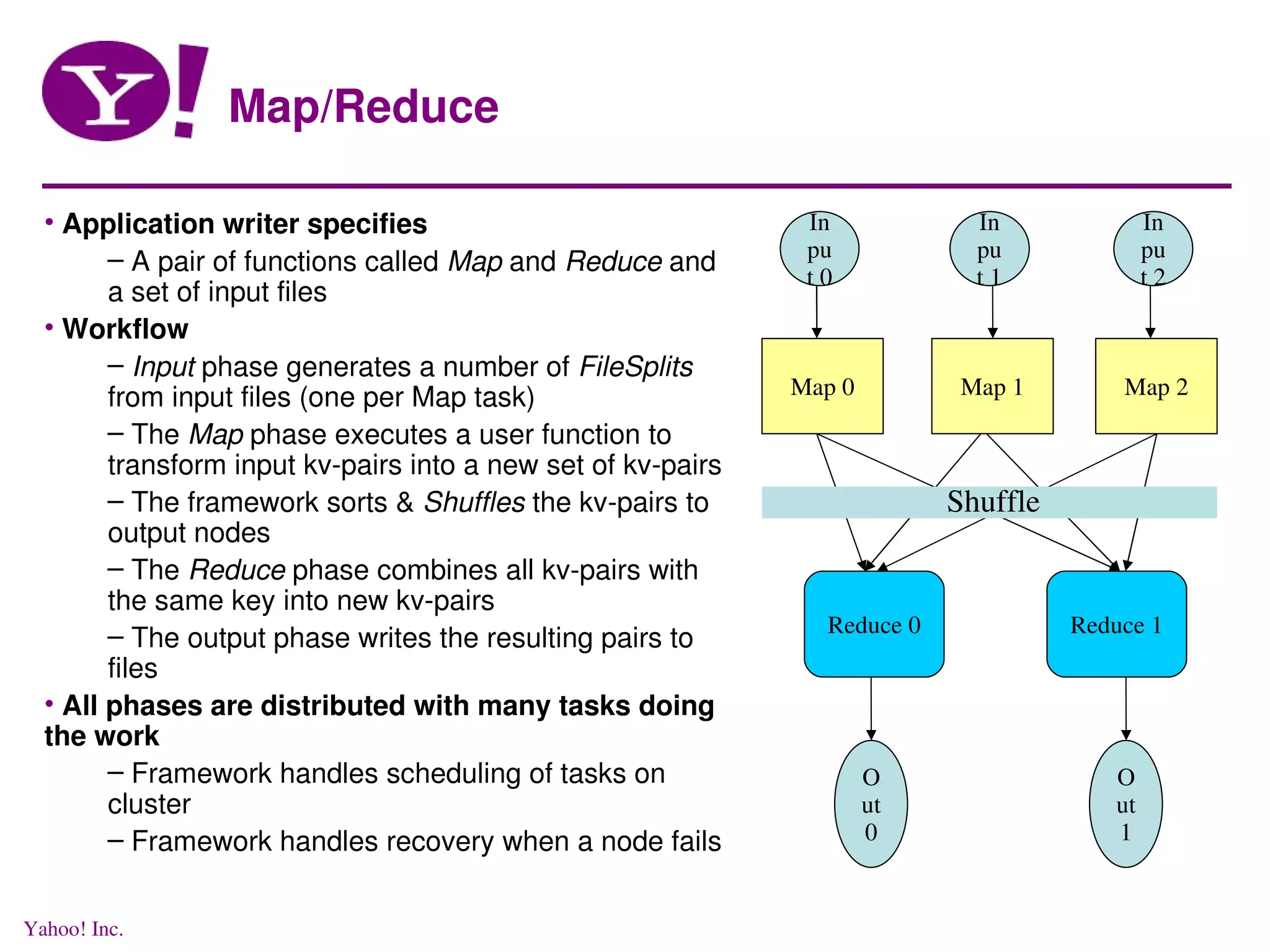
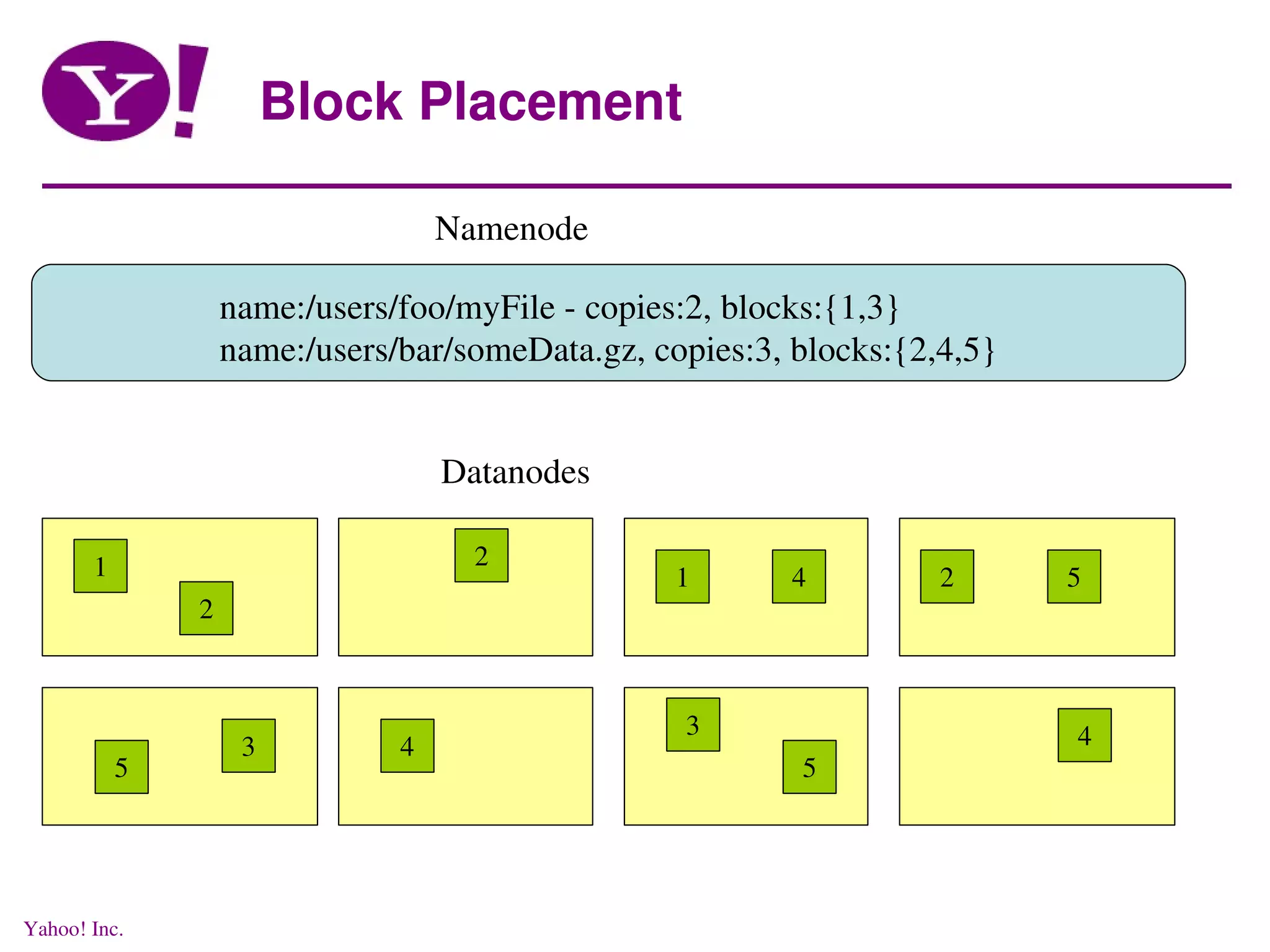
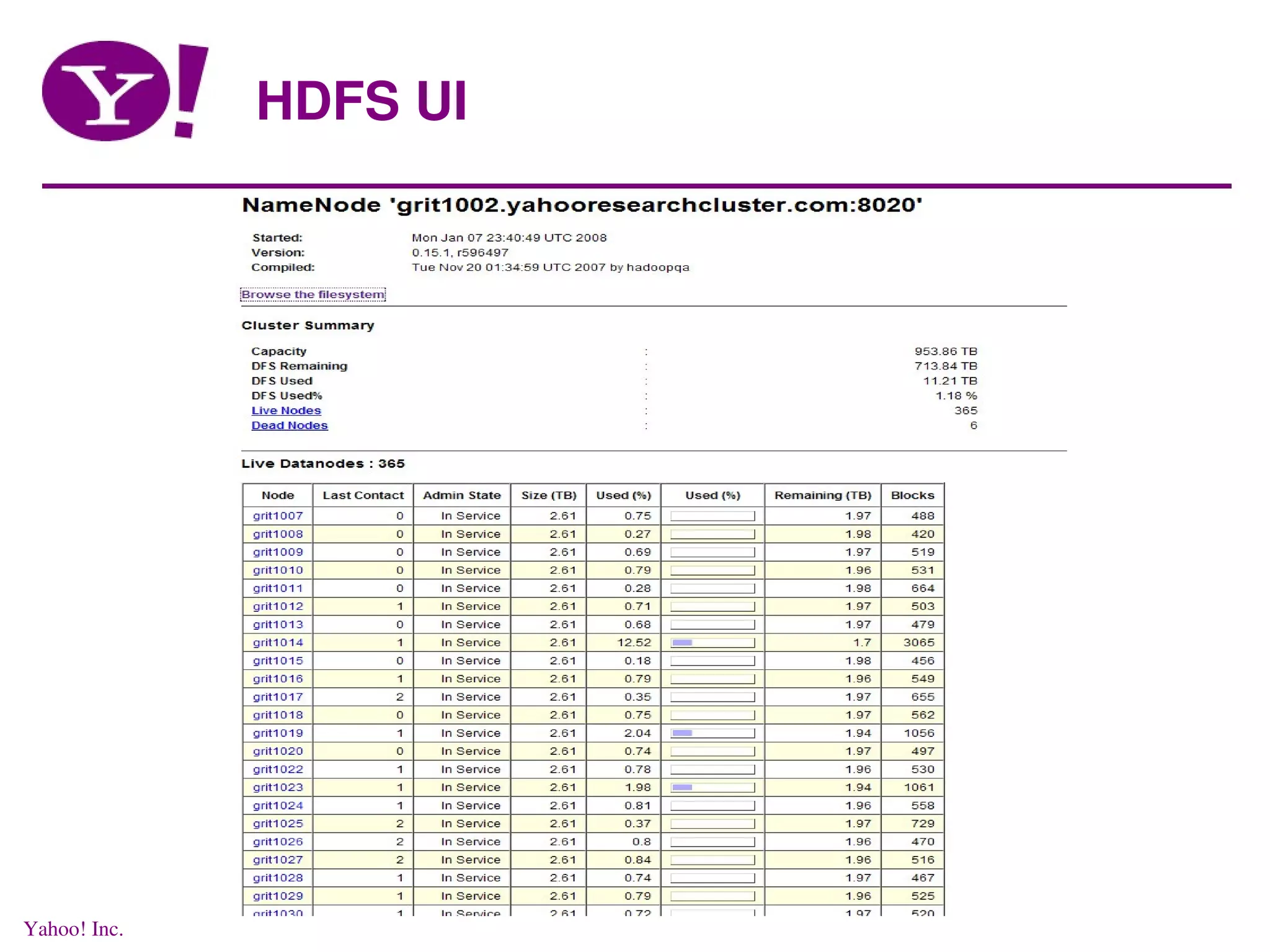
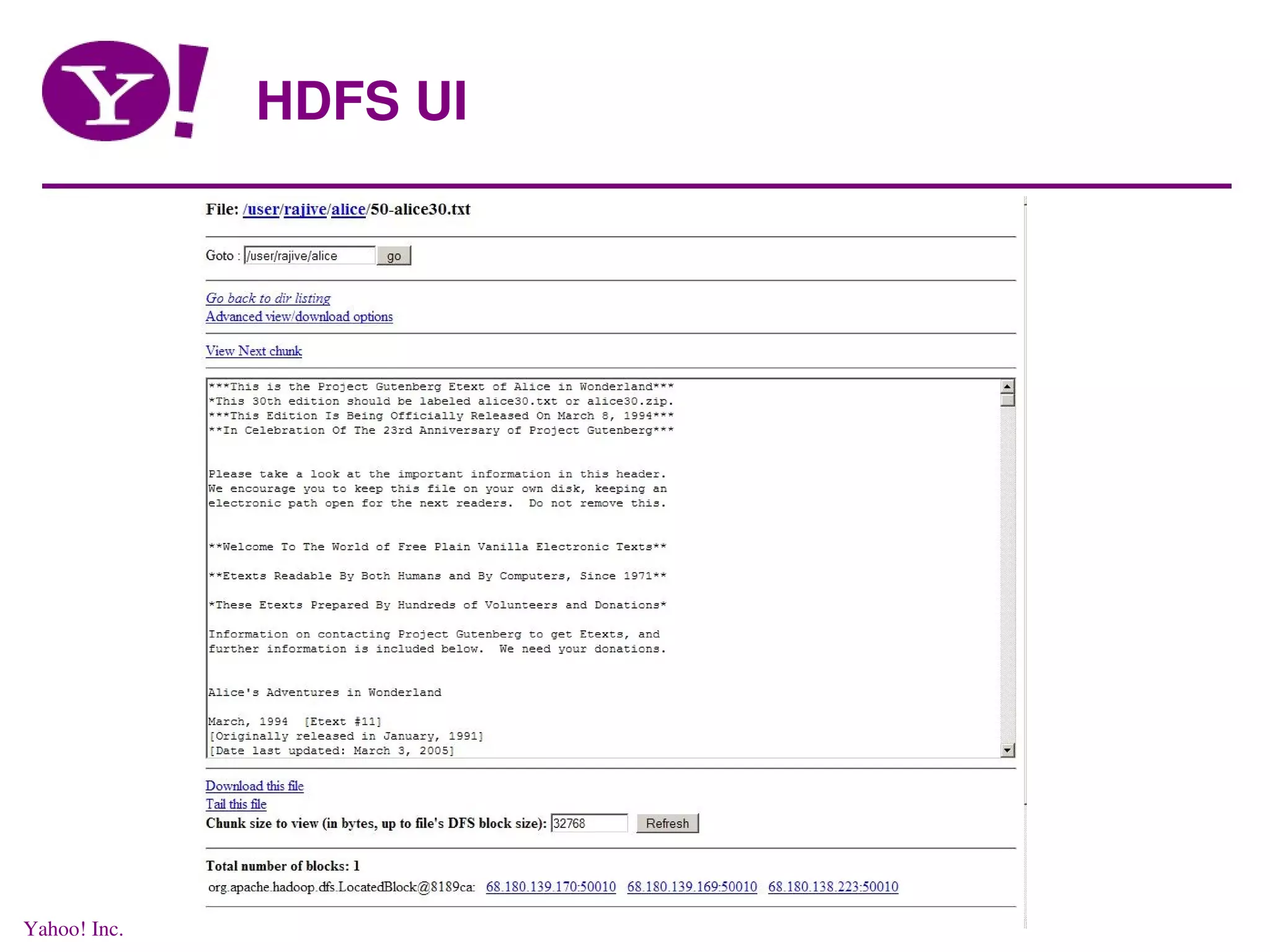
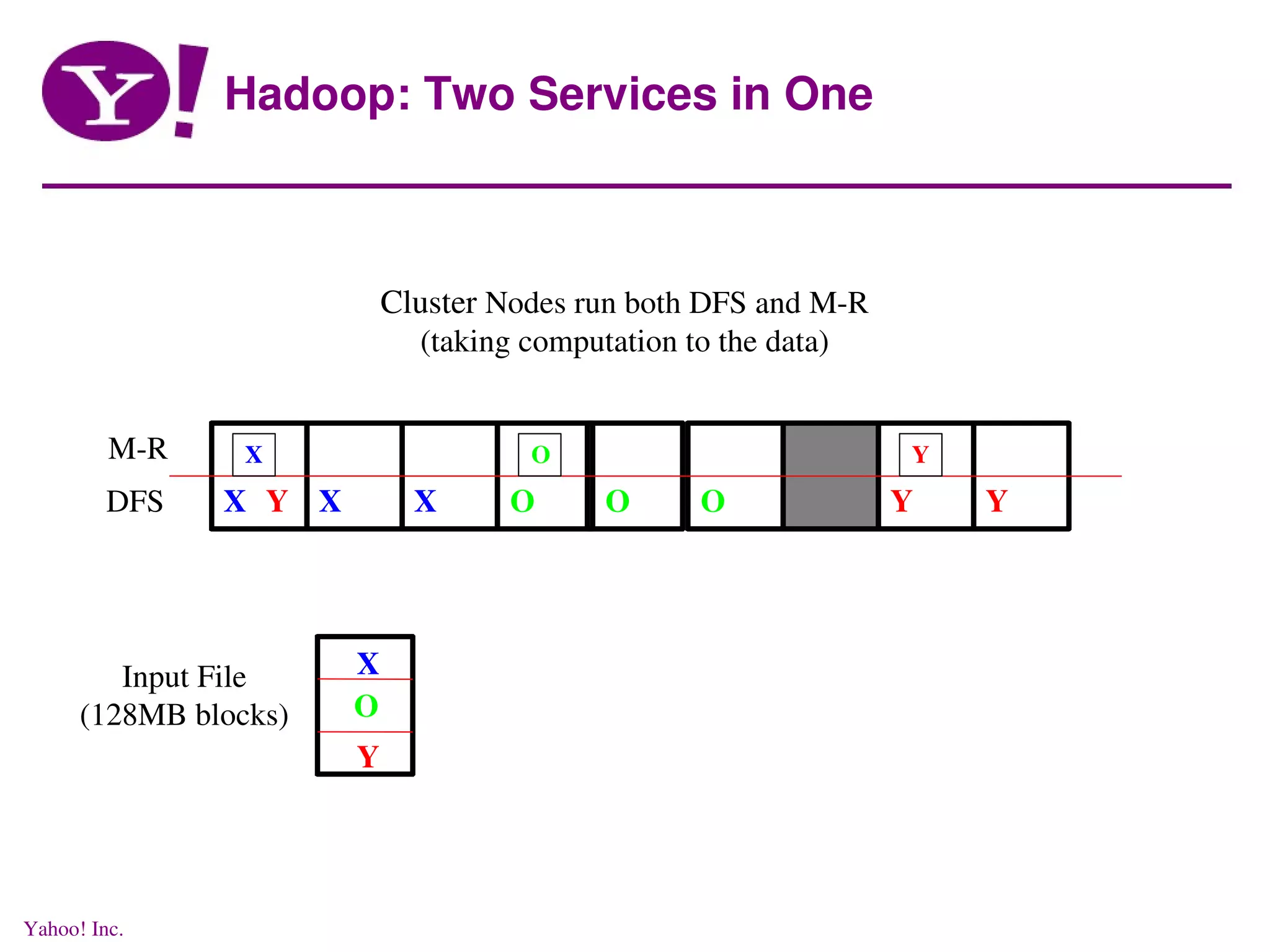
This document discusses distributed data processing using MapReduce and Hadoop in a cloud computing environment. It describes the need for scalable, economical, and reliable distributed systems to process petabytes of data across thousands of nodes. It introduces Hadoop, an open-source software framework that allows distributed processing of large datasets across clusters of computers using MapReduce. Key aspects of Hadoop discussed include its core components HDFS for distributed file storage and MapReduce for distributed computation.