Downloaded 90 times



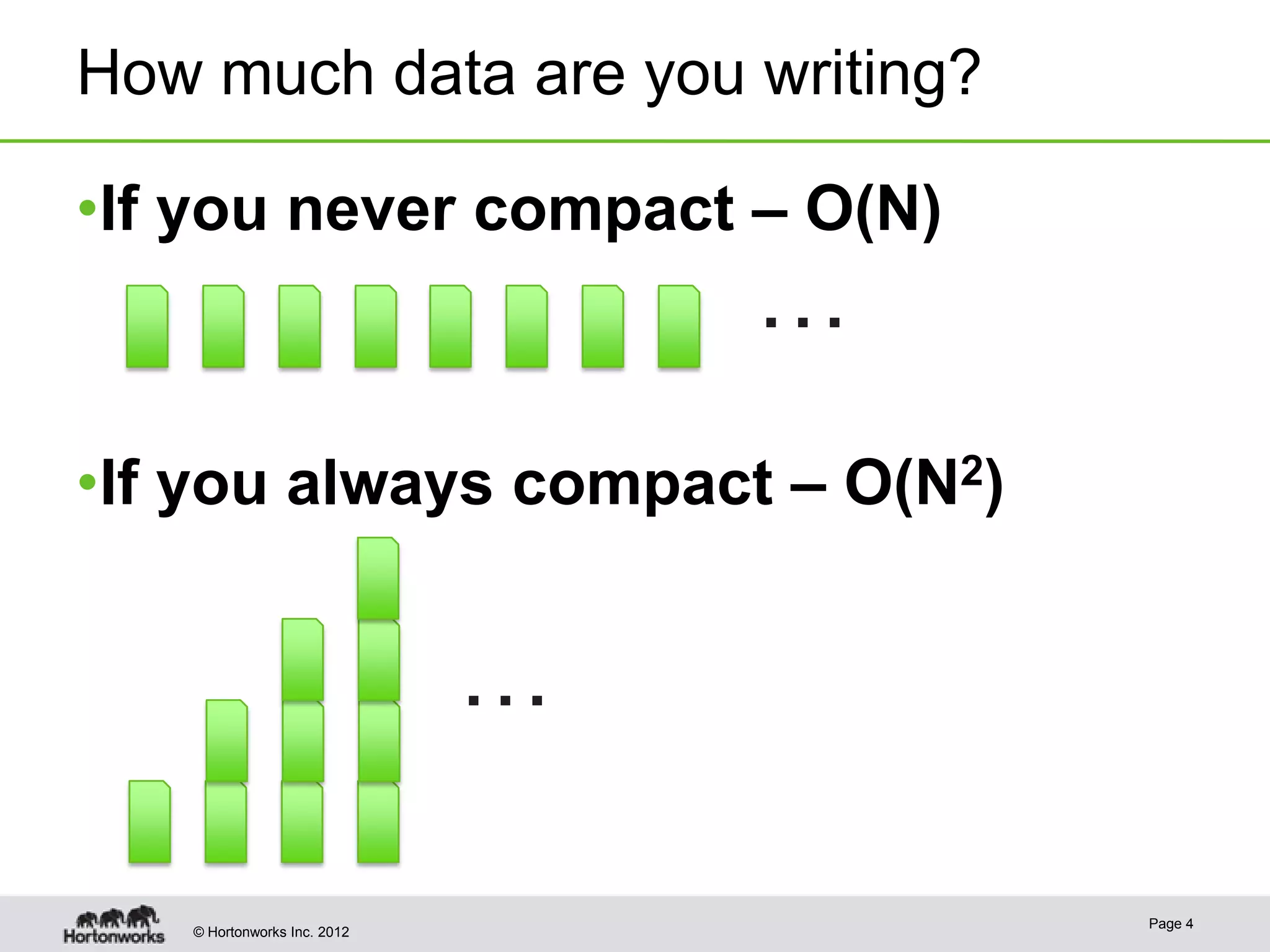






















The document discusses compaction and splitting in Apache Accumulo distributed key-value stores. It explains that Accumulo tables are divided into non-overlapping ranges called tablets, and that compaction merges sorted files within a tablet into a single file to improve read performance. Splitting divides large tablets into two in order to balance workload. The document provides details on Accumulo's and HBase's compaction algorithms and how they determine when to compact and split tablets.