Download as KEY, PPTX






















![0.2) Serialize events from streams class GmailSlurper(object): ... def init_imap(self, username, password): self.username = username self.password = password try: imap.shutdown() except: pass self.imap = imaplib.IMAP4_SSL('imap.gmail.com', 993) self.imap.login(username, password) self.imap.is_readonly = True ... def write(self, record): self.avro_writer.append(record) ... def slurp(self): if(self.imap and self.imap_folder): for email_id in self.id_list: (status, email_hash, charset) = self.fetch_email(email_id) if(status == 'OK' and charset and 'thread_id' in email_hash and 'froms' in email_hash): print email_id, charset, email_hash['thread_id'] self.write(email_hash) © Hortonworks Inc. 2012 Scrape your own gmail in Python and Ruby. 36](https://image.slidesharecdn.com/agileanalyticsapplicationsonhadoop-121026175305-phpapp01/75/Agile-analytics-applications-on-hadoop-36-2048.jpg)


![1.1) cat our Avro serialized events me$ cat_avro ~/Data/enron.avro { u'bccs': [], u'body': u'scamming people, blah blah', u'ccs': [], u'date': u'2000-08-28T01:50:00.000Z', u'from': {u'address': u'bob.dobbs@enron.com', u'name': None}, u'message_id': u'<1731.10095812390082.JavaMail.evans@thyme>', u'subject': u'Re: Enron trade for frop futures', u'tos': [ {u'address': u'connie@enron.com', u'name': None} ] } © Hortonworks Inc. 2012 Get cat_avro in python, ruby 40](https://image.slidesharecdn.com/agileanalyticsapplicationsonhadoop-121026175305-phpapp01/75/Agile-analytics-applications-on-hadoop-40-2048.jpg)

![1.5) Check events in our ‘database’ $ mongo enron MongoDB shell version: 2.0.2 connecting to: enron > show collections emails system.indexes > db.emails.findOne({message_id: "<1731.10095812390082.JavaMail.evans@thyme>"}) { " "_id" : ObjectId("502b4ae703643a6a49c8d180"), " "message_id" : "<1731.10095812390082.JavaMail.evans@thyme>", " "date" : "2001-01-09T06:38:00.000Z", " "from" : { "address" : "bob.dobbs@enron.com", "name" : "J.R. Bob Dobbs" }, " "subject" : Re: Enron trade for frop futures, " "body" : "Scamming more people...", " "tos" : [ { "address" : "connie@enron", "name" : null } ], " "ccs" : [ ], " "bccs" : [ ] } © Hortonworks Inc. 2012 44](https://image.slidesharecdn.com/agileanalyticsapplicationsonhadoop-121026175305-phpapp01/75/Agile-analytics-applications-on-hadoop-44-2048.jpg)
![1.6) Publish events on the web require 'rubygems' require 'sinatra' require 'mongo' require 'json' connection = Mongo::Connection.new database = connection['agile_data'] collection = database['emails'] get '/email/:message_id' do |message_id| data = collection.find_one({:message_id => message_id}) JSON.generate(data) end © Hortonworks Inc. 2012 45](https://image.slidesharecdn.com/agileanalyticsapplicationsonhadoop-121026175305-phpapp01/75/Agile-analytics-applications-on-hadoop-45-2048.jpg)
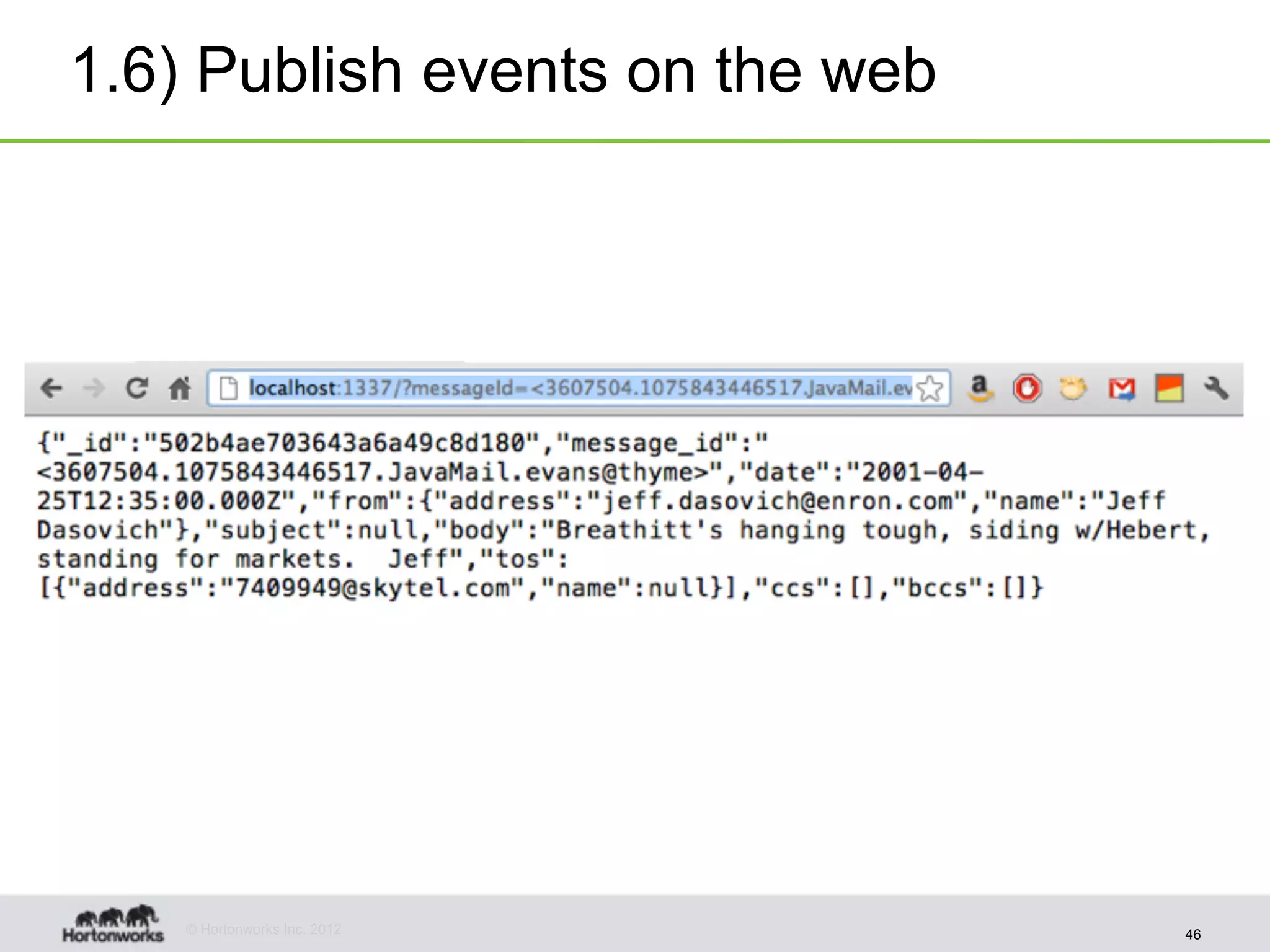

![1.7) Wrap events with Bootstrap <link href="/static/bootstrap/docs/assets/css/bootstrap.css" rel="stylesheet"> </head> <body> <div class="container" style="margin-top: 100px;"> <table class="table table-striped table-bordered table-condensed"> <thead> {% for key in data['keys'] %} <th>{{ key }}</th> {% endfor %} </thead> <tbody> <tr> {% for value in data['values'] %} <td>{{ value }}</td> {% endfor %} </tr> </tbody> </table> </div> </body> Complete example here with code here. © Hortonworks Inc. 2012 48](https://image.slidesharecdn.com/agileanalyticsapplicationsonhadoop-121026175305-phpapp01/75/Agile-analytics-applications-on-hadoop-48-2048.jpg)
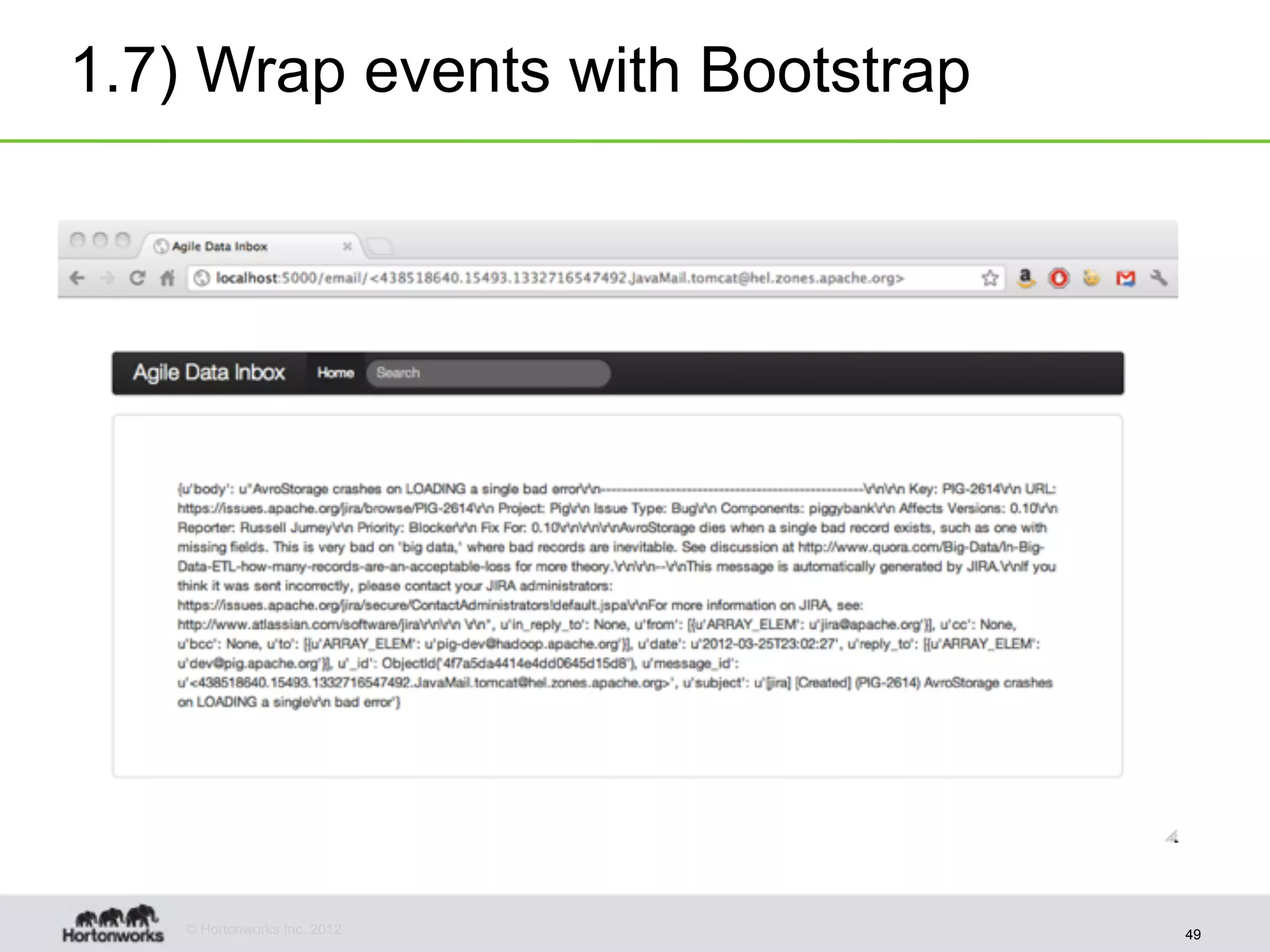
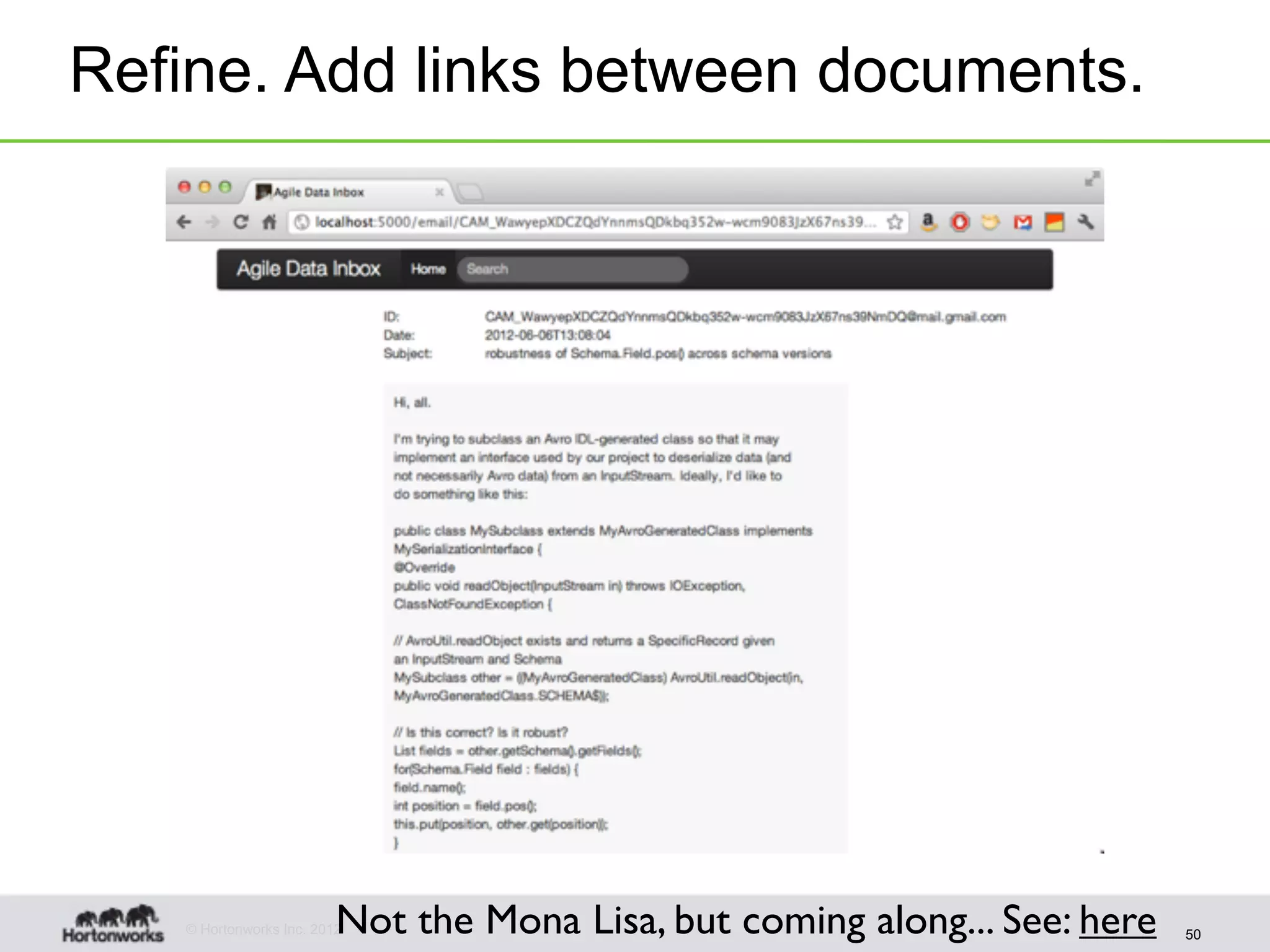


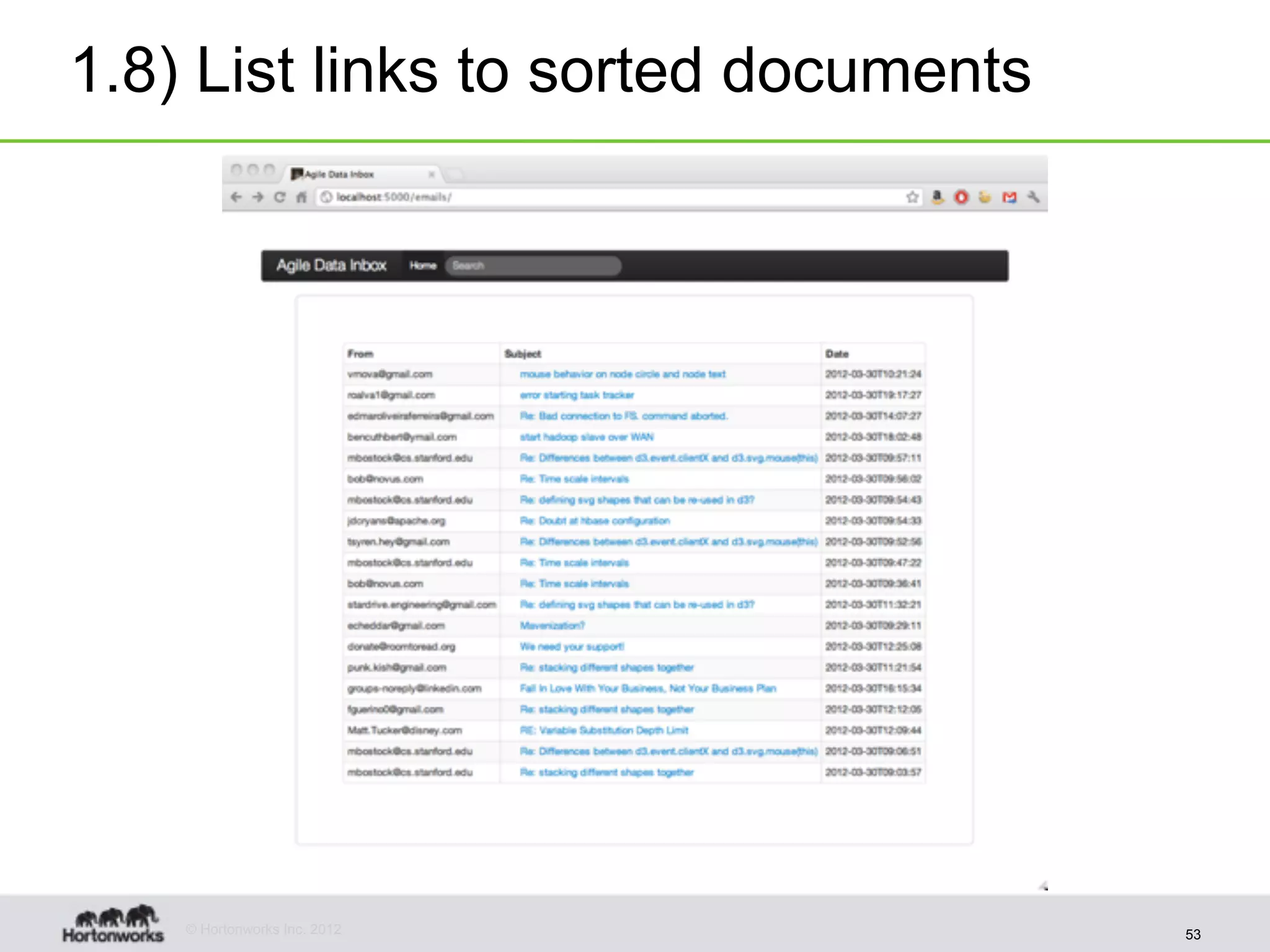








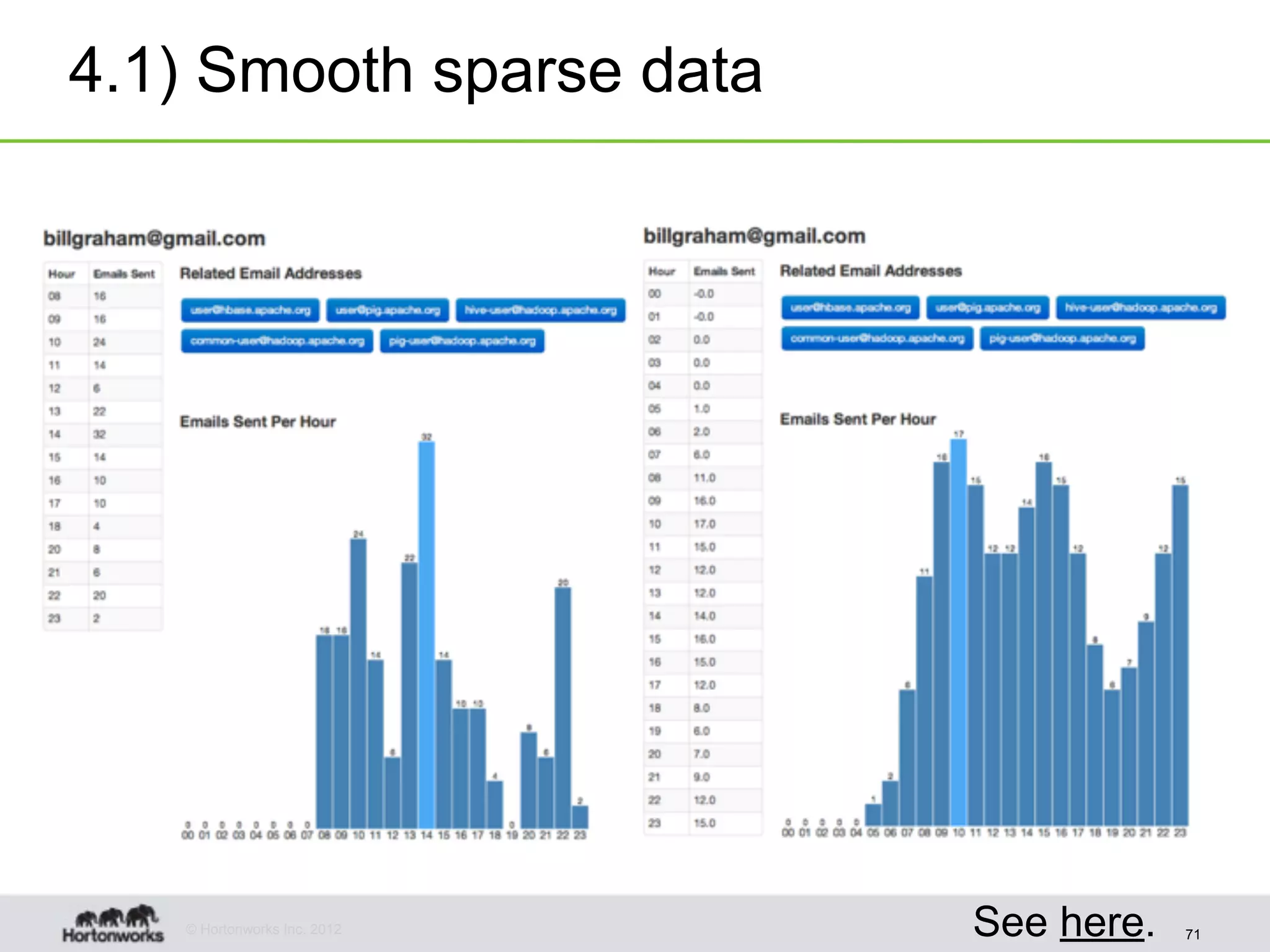


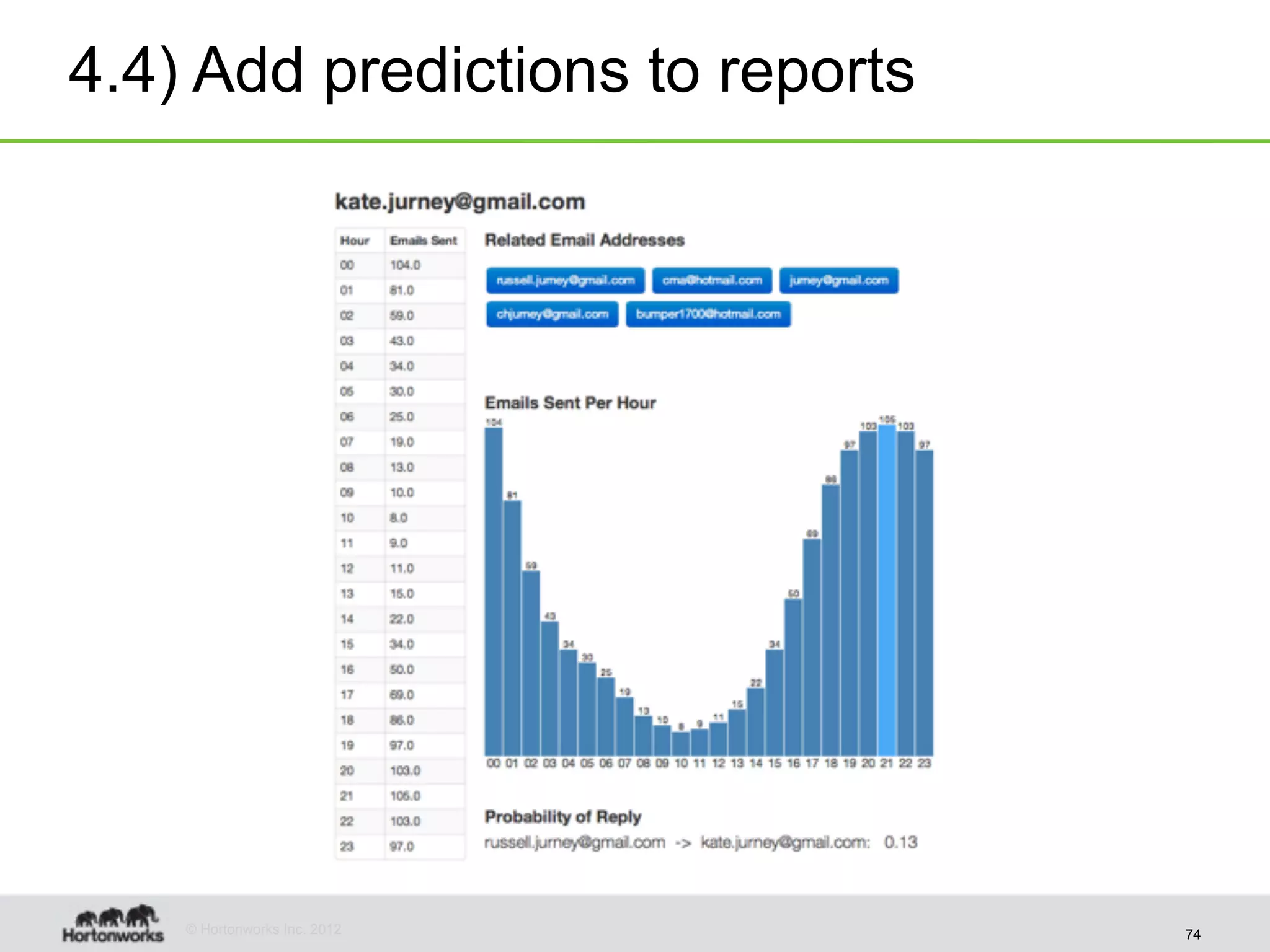


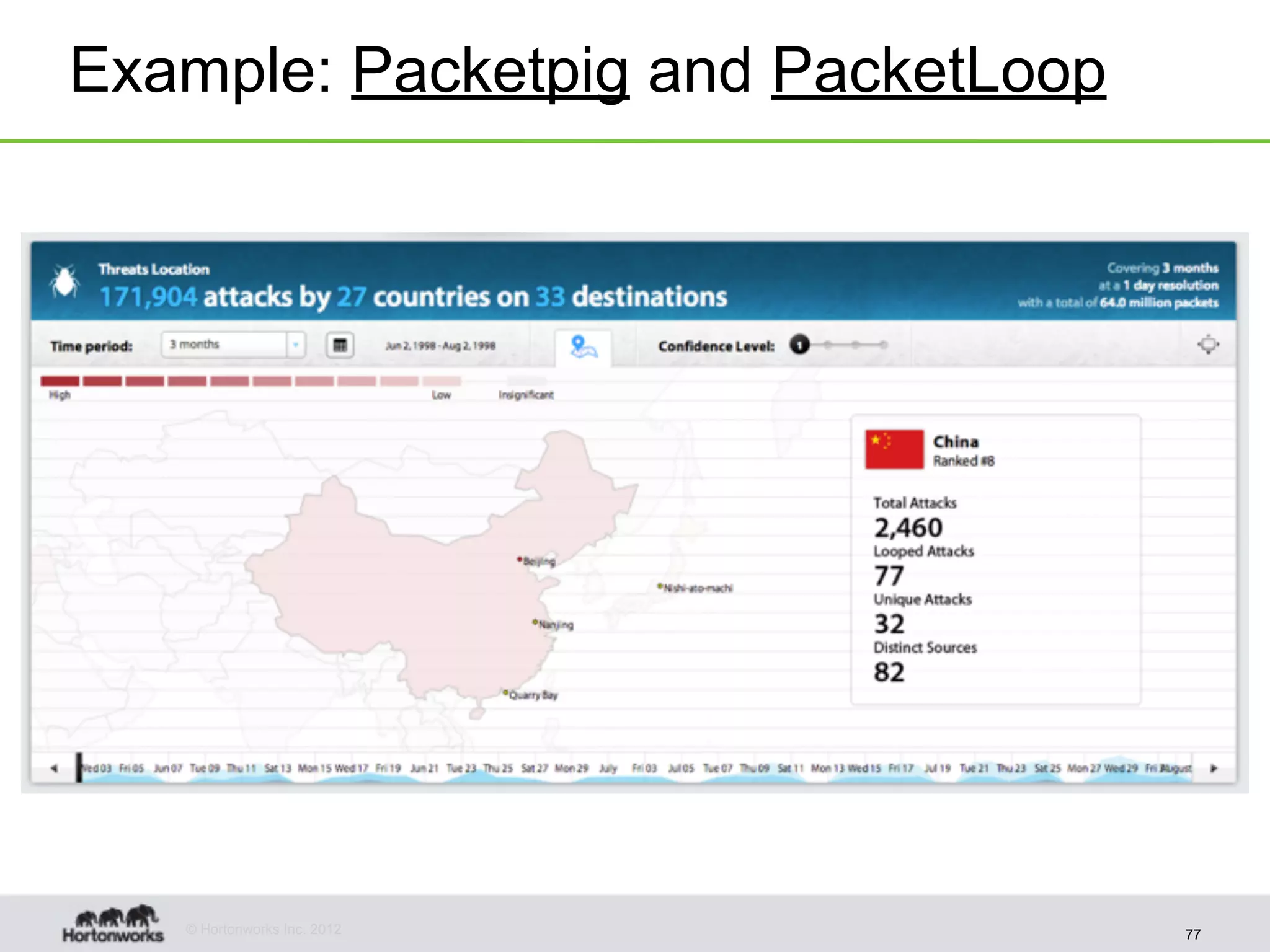




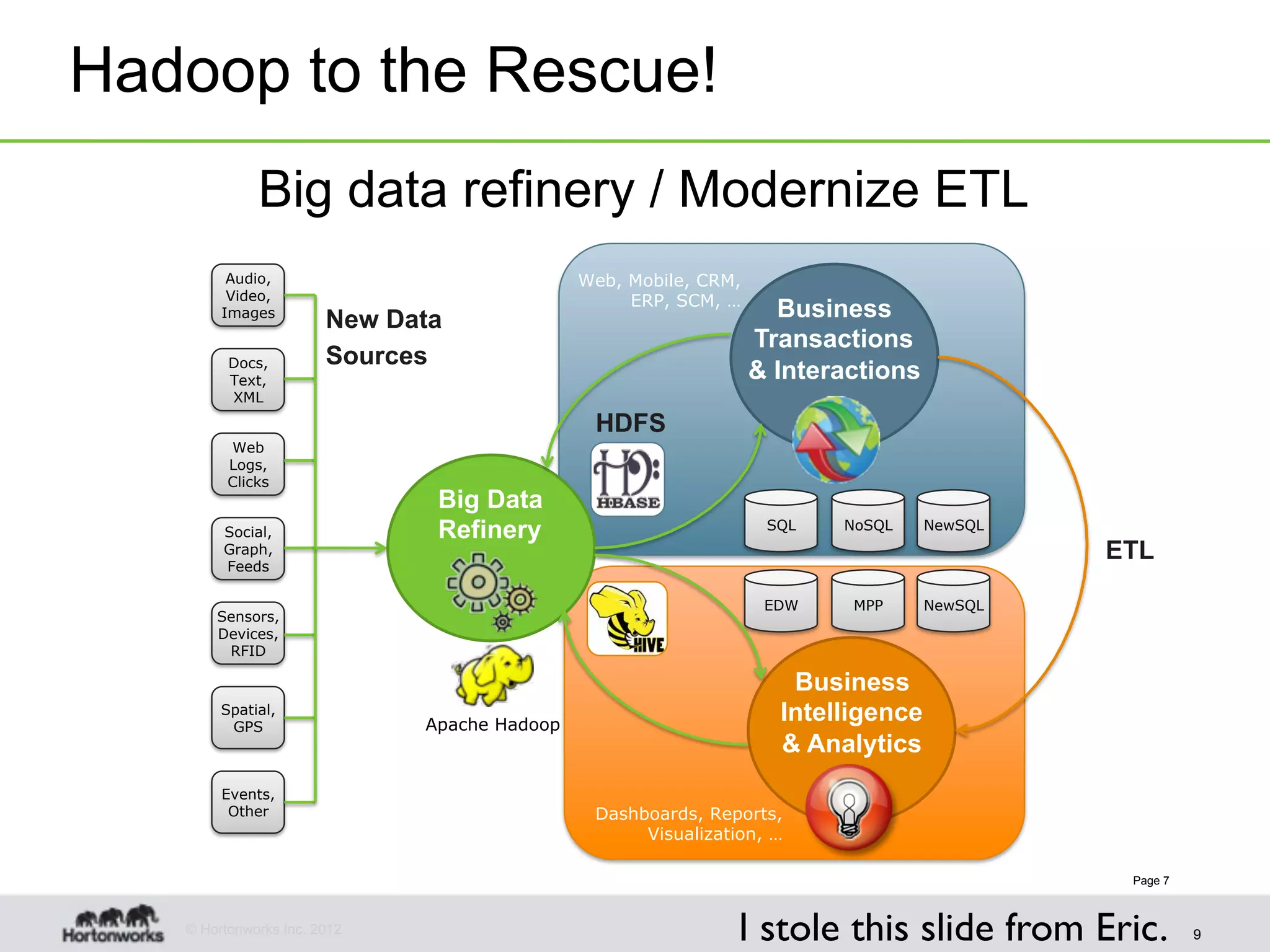
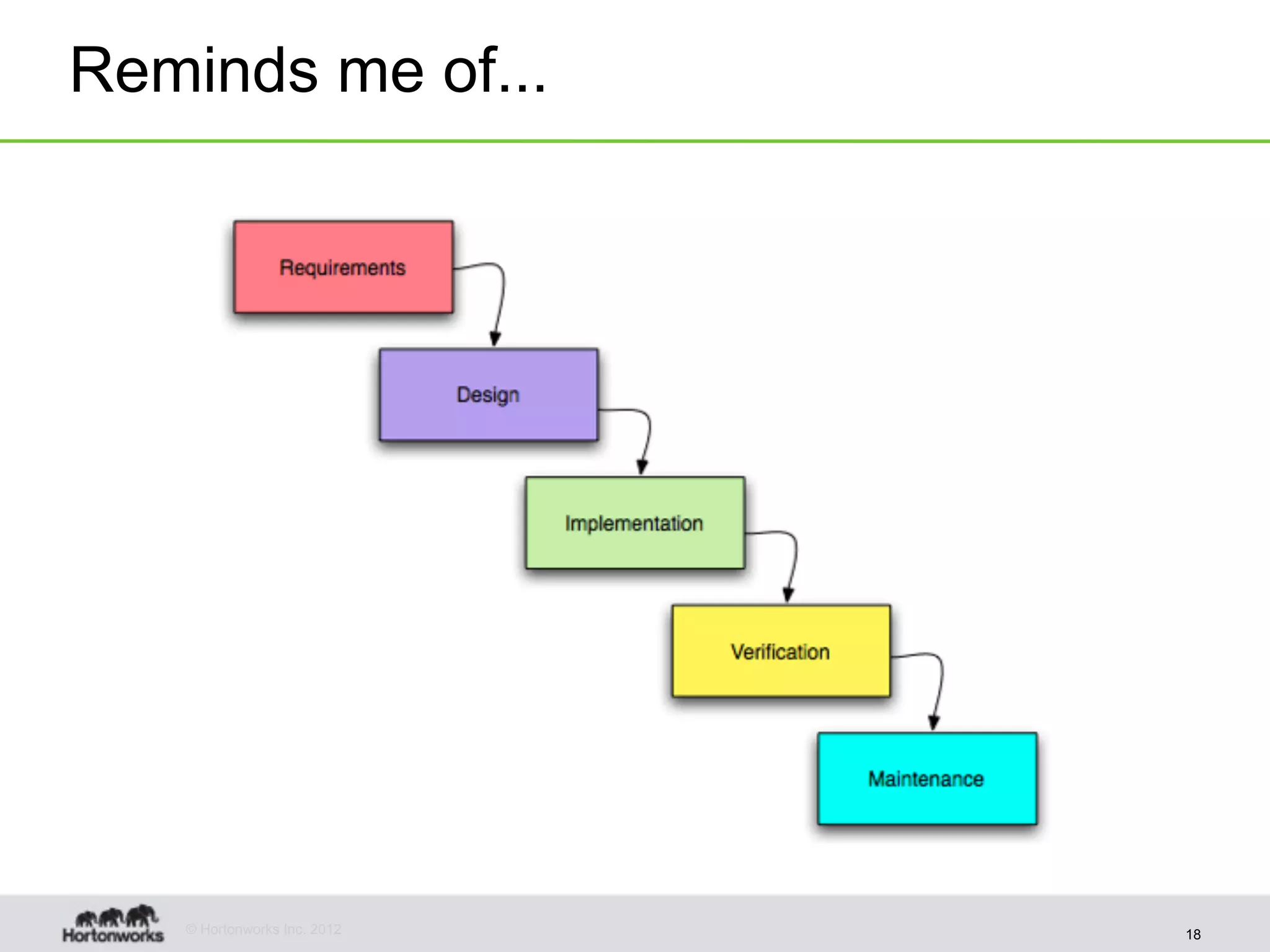
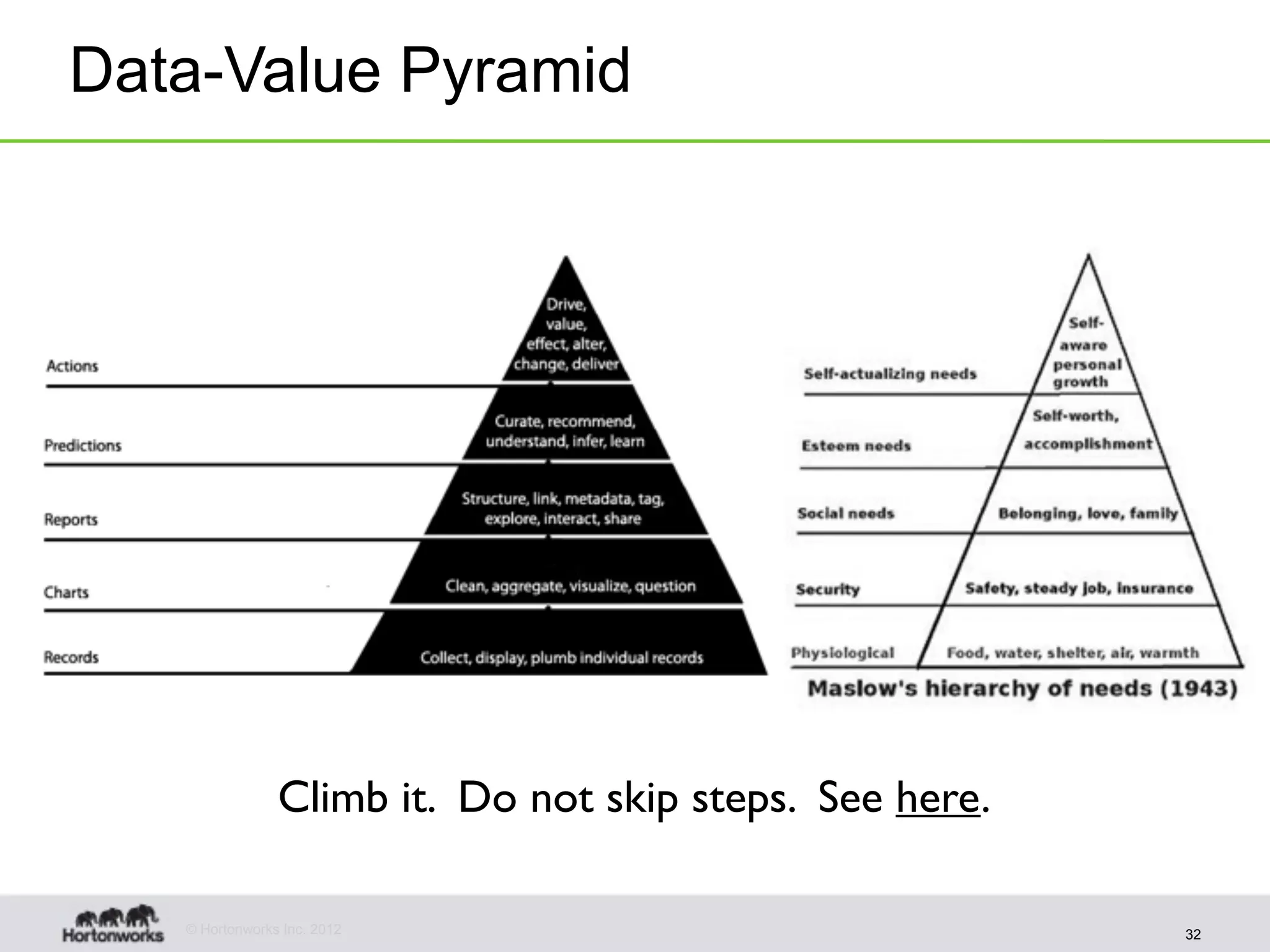
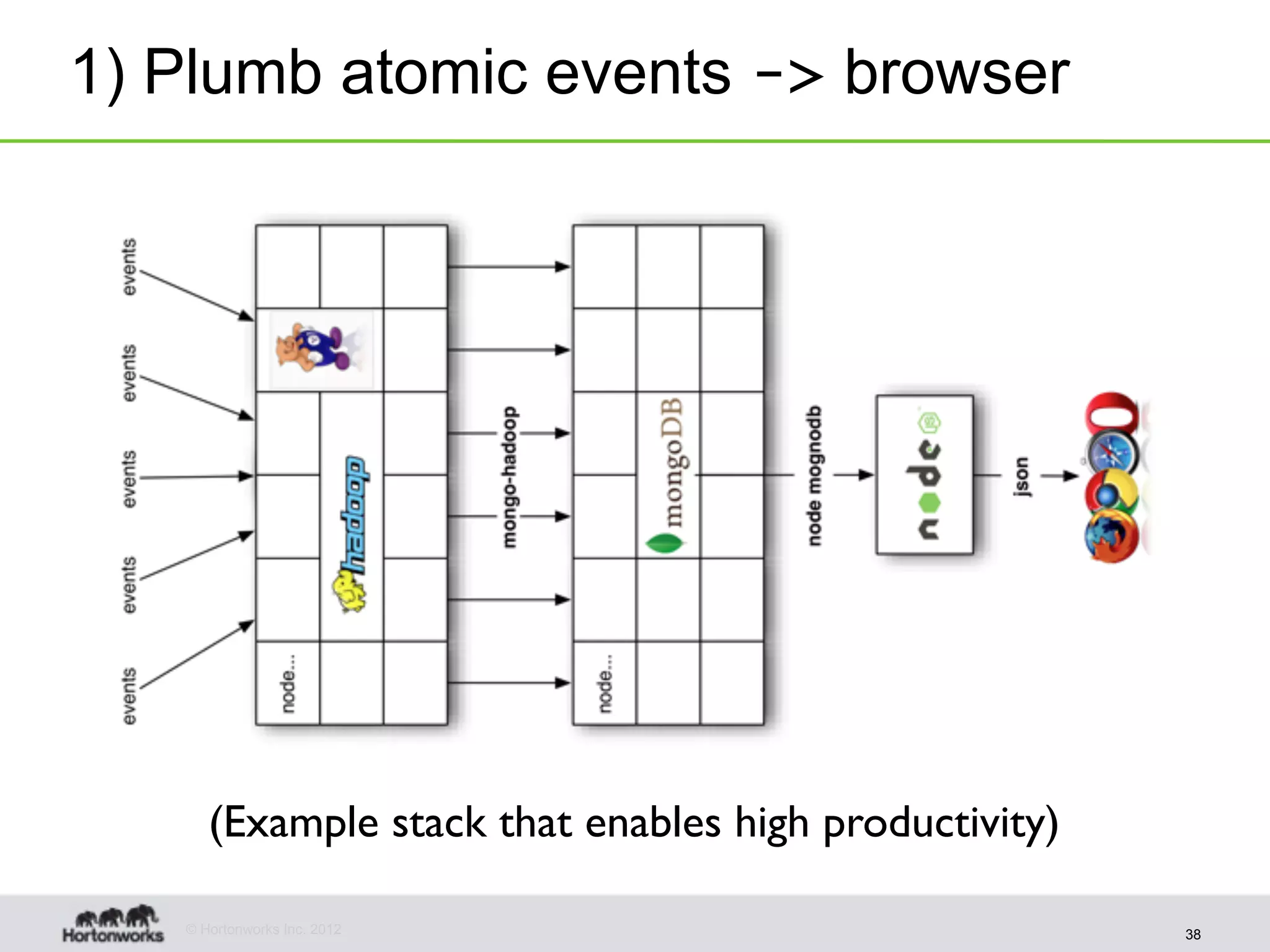
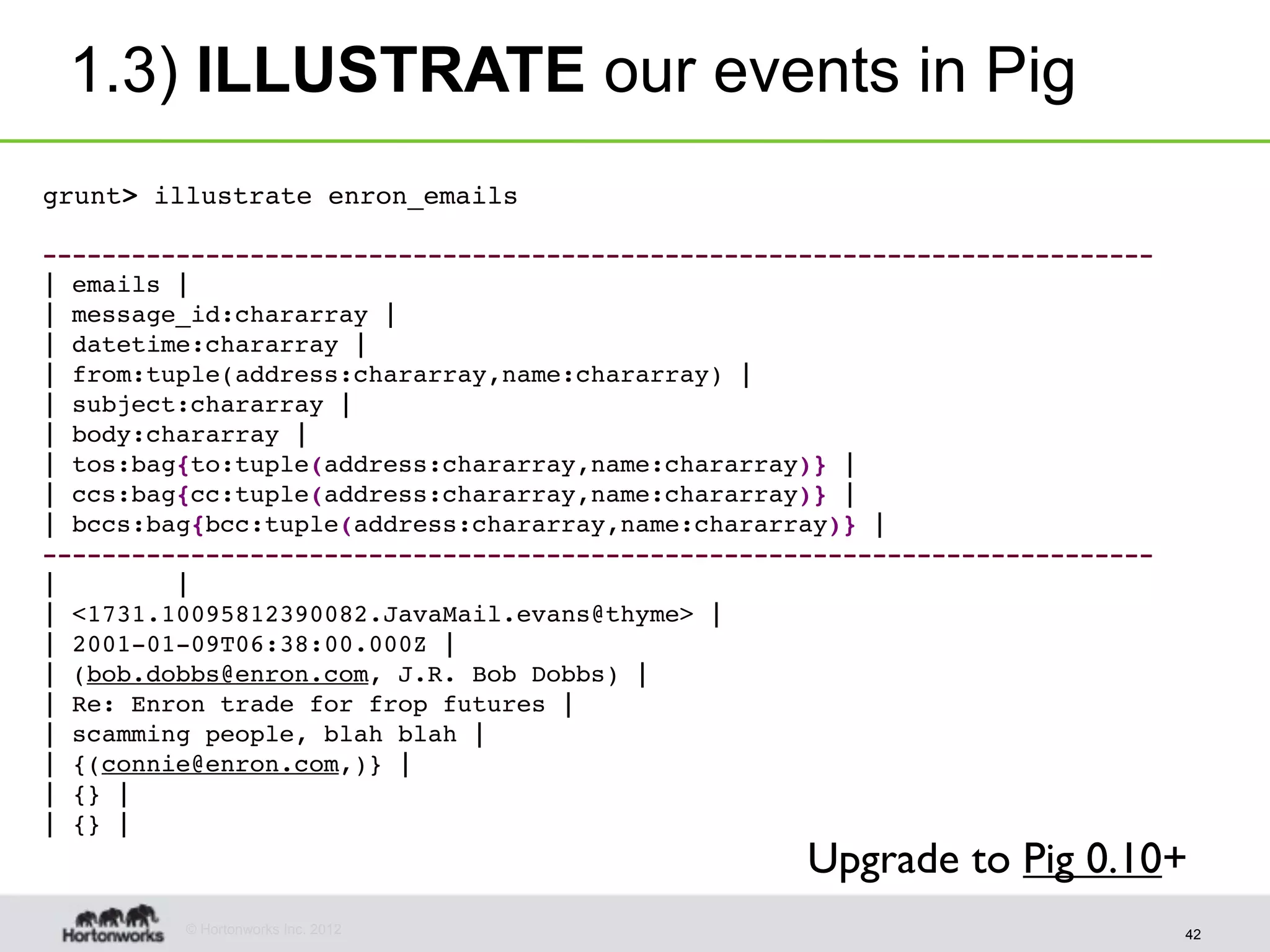
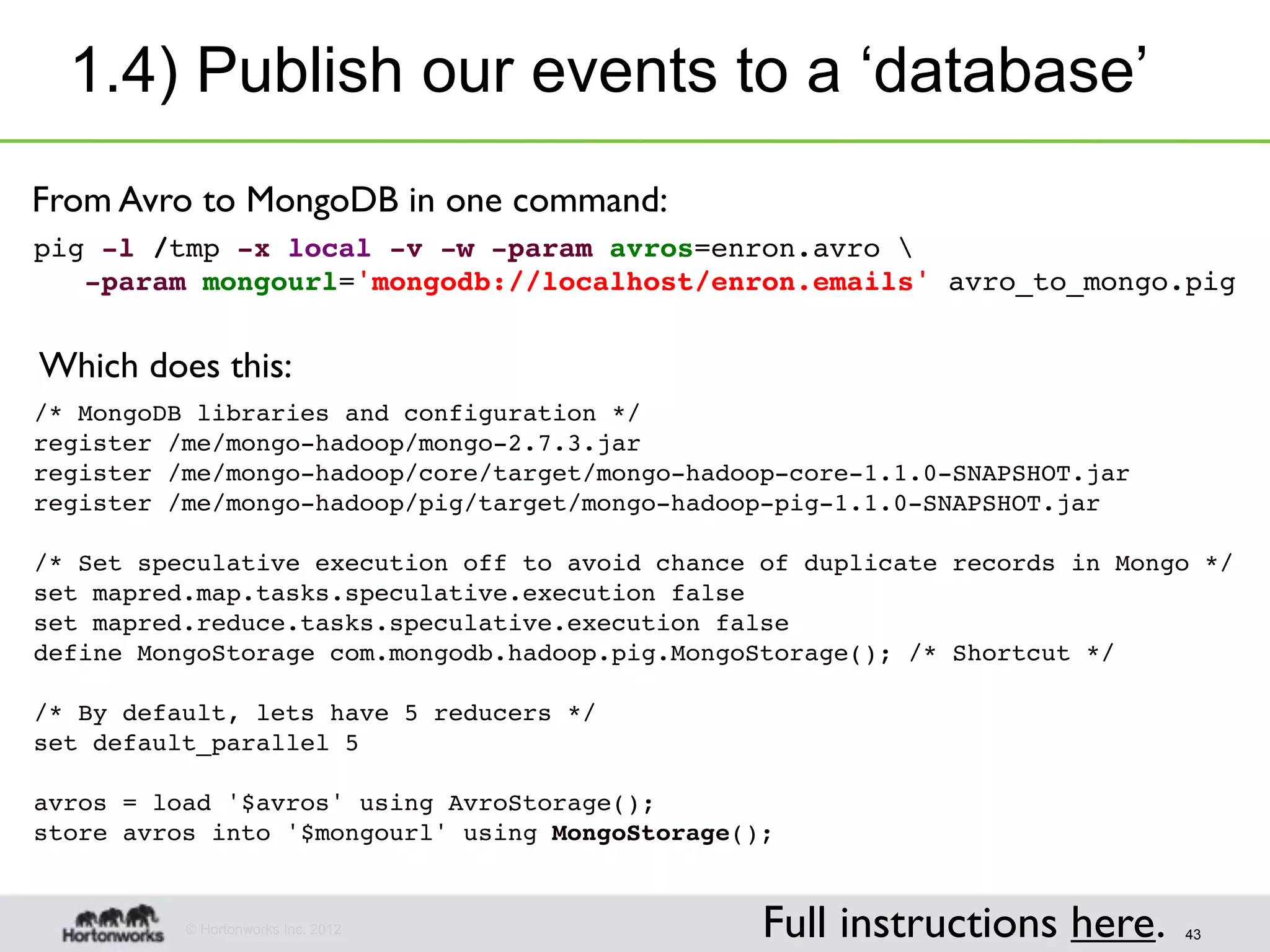
The document discusses strategies for developing agile analytics applications using Hadoop, emphasizing an iterative approach where data is explored interactively to discover insights which then form the basis for shipped applications, rather than trying to design insights up front. It recommends setting up an environment where insights are repeatedly produced and shared with the team using an interactive application from the start to facilitate collaboration between data scientists and developers.