






















![akka { actor { deployment { /services-manager/handler_registry/segment_handler { router = round-robin-pool optimal-size-exploring-resizer { enabled = on action-interval = 5s downsize-after-underutilized-for = 2h } } } provider = "akka.cluster.ClusterRefActorProvider" } cluster { seed-nodes = ["akka.tcp://Hydra@127.0.0.1:2552","akka.tcp://hydra@172.0.0.1:2553"] } }](https://image.slidesharecdn.com/strata-hadoop-sjc-2016-170510180210/75/Designing-a-Scalable-Data-Platform-38-2048.jpg)


![trait KafkaMessage[K, P] { val timestamp = System.currentTimeMillis def key: K def payload: P def retryOnFailure: Boolean = true } case class JsonMessage(key: String, payload: JsonNode) extends KafkaMessage[String, JsonNode] object JsonMessage { val mapper = new ObjectMapper() def apply(key: String, json: String) = { val payload: JsonNode = mapper.readTree(json) new JsonMessage(key, payload) } } case class AvroMessage(val schema: SchemaHolder, key: String, json: String) extends KafkaMessage[String, GenericRecord] { def payload: GenericRecord = { val converter: JsonConverter[GenericRecord] = new JsonConverter[GenericRecord](schema.schema) converter.convert(json) } }](https://image.slidesharecdn.com/strata-hadoop-sjc-2016-170510180210/75/Designing-a-Scalable-Data-Platform-44-2048.jpg)








![override val supervisorStrategy = OneForOneStrategy(maxNrOfRetries = 10, withinTimeRange = 1.minute) { case _: ActorInitializationException => akka.actor.SupervisorStrategy.Stop case _: FailedToSendMessageException => Restart case _: ProducerClosedException => Restart case _: NoBrokersForPartitionException => Escalate case _: KafkaException => Escalate case _: ConnectException => Escalate case _: Exception => Escalate } val kafkaProducerSupervisor = BackoffSupervisor.props( Backoff.onFailure( kafkaProducerProps, childName = actorName[KafkaProducerActor], minBackoff = 3.seconds, maxBackoff = 30.seconds, randomFactor = 0.2 ))](https://image.slidesharecdn.com/strata-hadoop-sjc-2016-170510180210/75/Designing-a-Scalable-Data-Platform-57-2048.jpg)
![class KafkaProducerActor extends Actor with LoggingAdapter with ActorConfigSupport with NotificationSupport[KafkaMessage[Any, Any]] { import KafkaProducerActor._ implicit val ec = context.dispatcher override def preRestart(cause: Throwable, message: Option[Any]) = { //send it to itself again after the exponential delays, no Ack from Kafka message match { case Some(rp: RetryingProduce) => { notifyObservers(KafkaMessageNotDelivered(rp.msg)) val nextBackOff = rp.backOff.nextBackOff val retry = RetryingProduce(rp.topic, rp.msg) retry.backOff = nextBackOff context.system.scheduler.scheduleOnce(nextBackOff.waitTime, self, retry) } case Some(produce: Produce) => { notifyObservers(KafkaMessageNotDelivered(produce.msg)) if (produce.msg.retryOnFailure) { context.system.scheduler.scheduleOnce(initialDelay, self, RetryingProduce(produce.topic, produce.msg)) } } } } }](https://image.slidesharecdn.com/strata-hadoop-sjc-2016-170510180210/75/Designing-a-Scalable-Data-Platform-58-2048.jpg)





![@throws(classOf[Exception]) override def init: Future[Boolean] = Future { val useProxy = config.getBoolean(“message.proxy”,false) val ingestorPath = config.getRequiredString("ingestor.path") ingestionActor = if (useProxy) context.actorSelection(ingestorPath) else context.actorOf(ReliableIngestionProxy.props(ingestorPath)) val cHeaders = config.getOptionalList("headers") topic = config.getRequiredString("kafka.topic") headers = cHeaders match { case Some(ch) => List( ch.unwrapped.asScala.map { header => { val sh = header.toString.split(":") RawHeader(sh(0), sh(1)) } }: _* ) case None => List.empty[HttpHeader] } true }](https://image.slidesharecdn.com/strata-hadoop-sjc-2016-170510180210/75/Designing-a-Scalable-Data-Platform-66-2048.jpg)








![Persistent Context Jobs #Required for related jobs #Create a new context curl -X POST 'localhost:9091/contexts/video-032116-ctx?num-cpu-cores=10&memory-per- node=512m' OK #Verify creation curl localhost:9091/contexts ["video-032116-ctx"] #Run job using the context curl -d "kafka.topic=segment" 'localhost:9091/jobs? appName=segment&classPath=hydra.SegmentJob&sync=true&context=video-032116-ctx' { "result":{ "active-sessions":24476221 } }](https://image.slidesharecdn.com/strata-hadoop-sjc-2016-170510180210/75/Designing-a-Scalable-Data-Platform-81-2048.jpg)




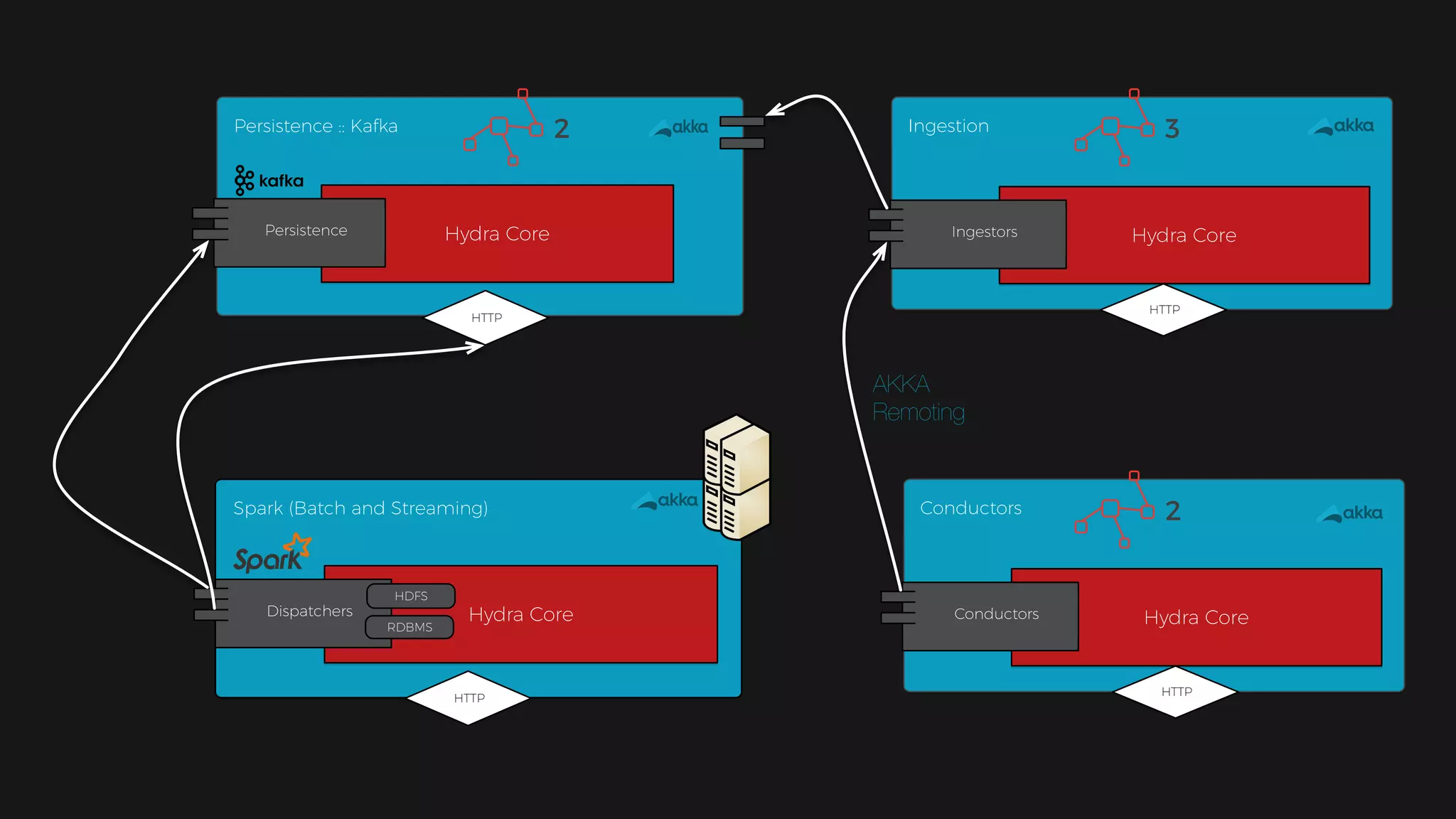









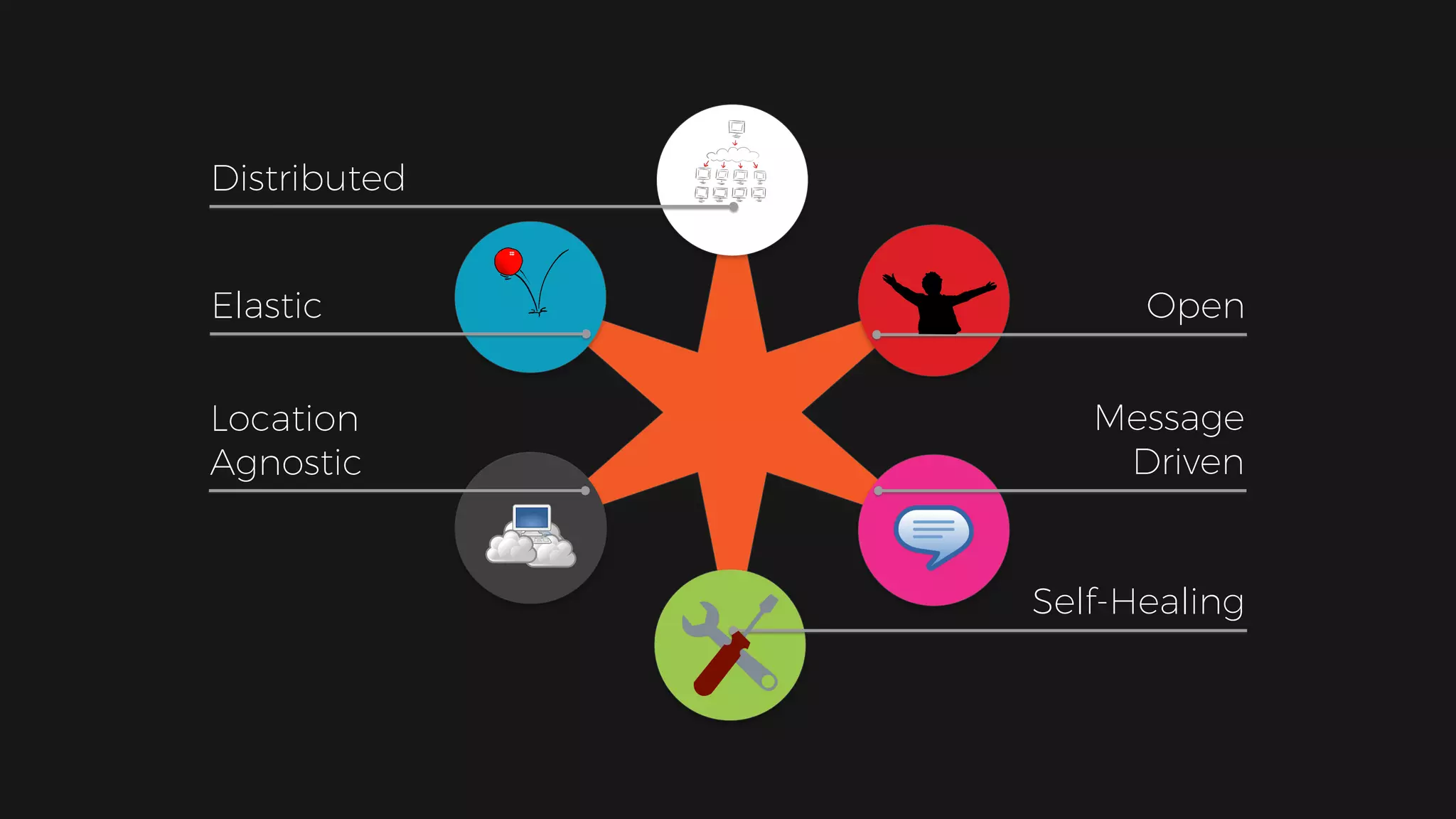
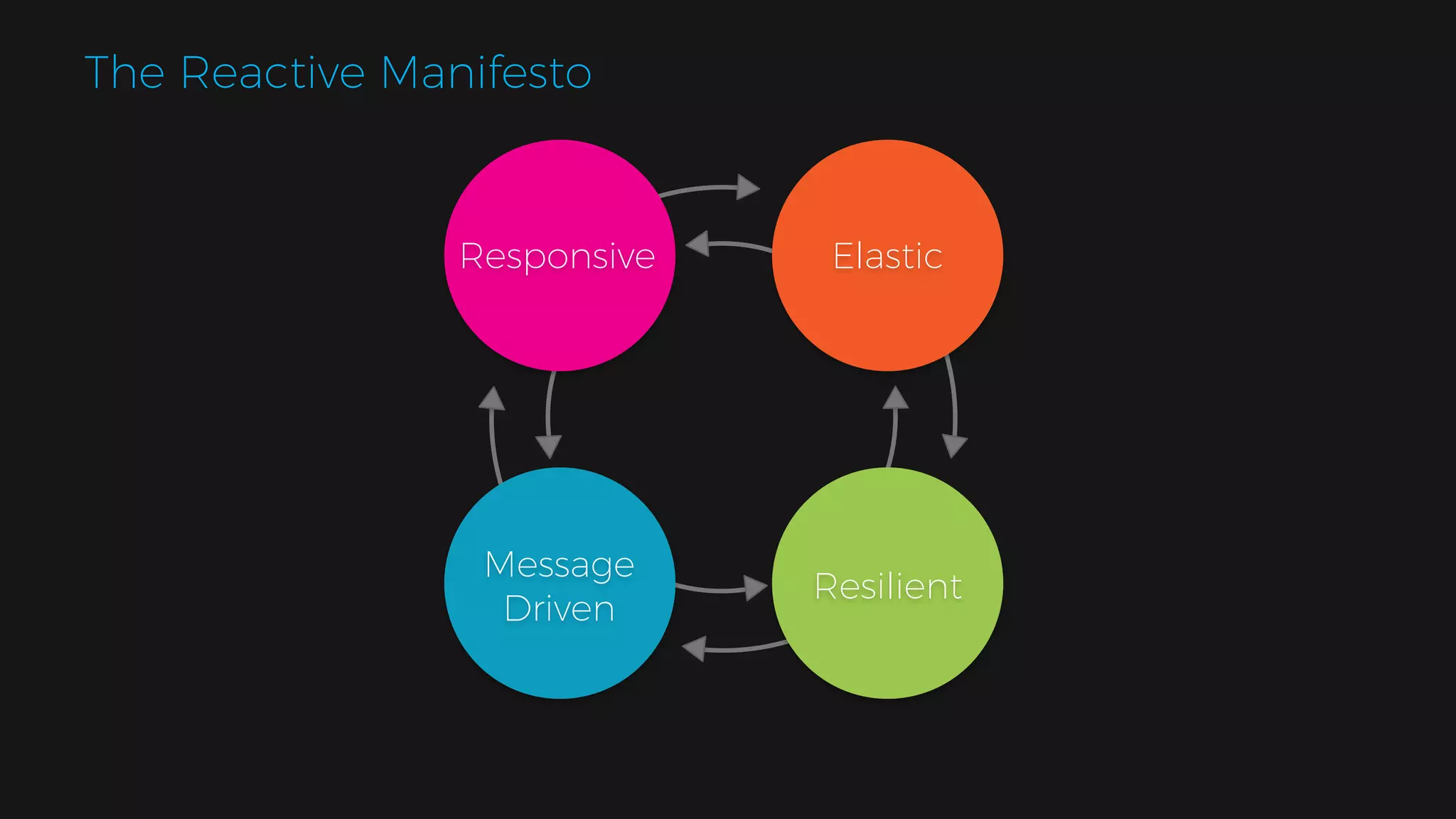
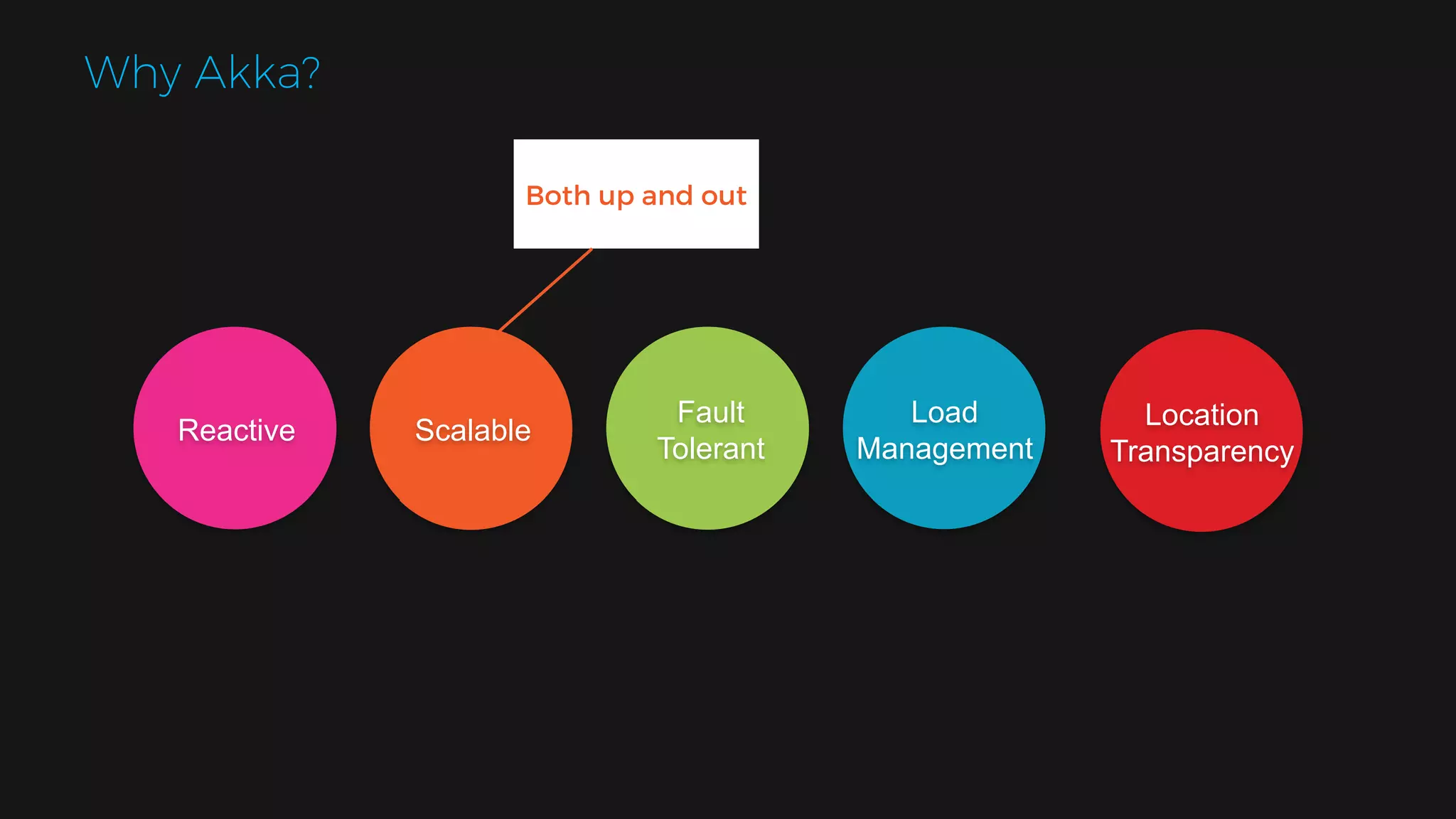
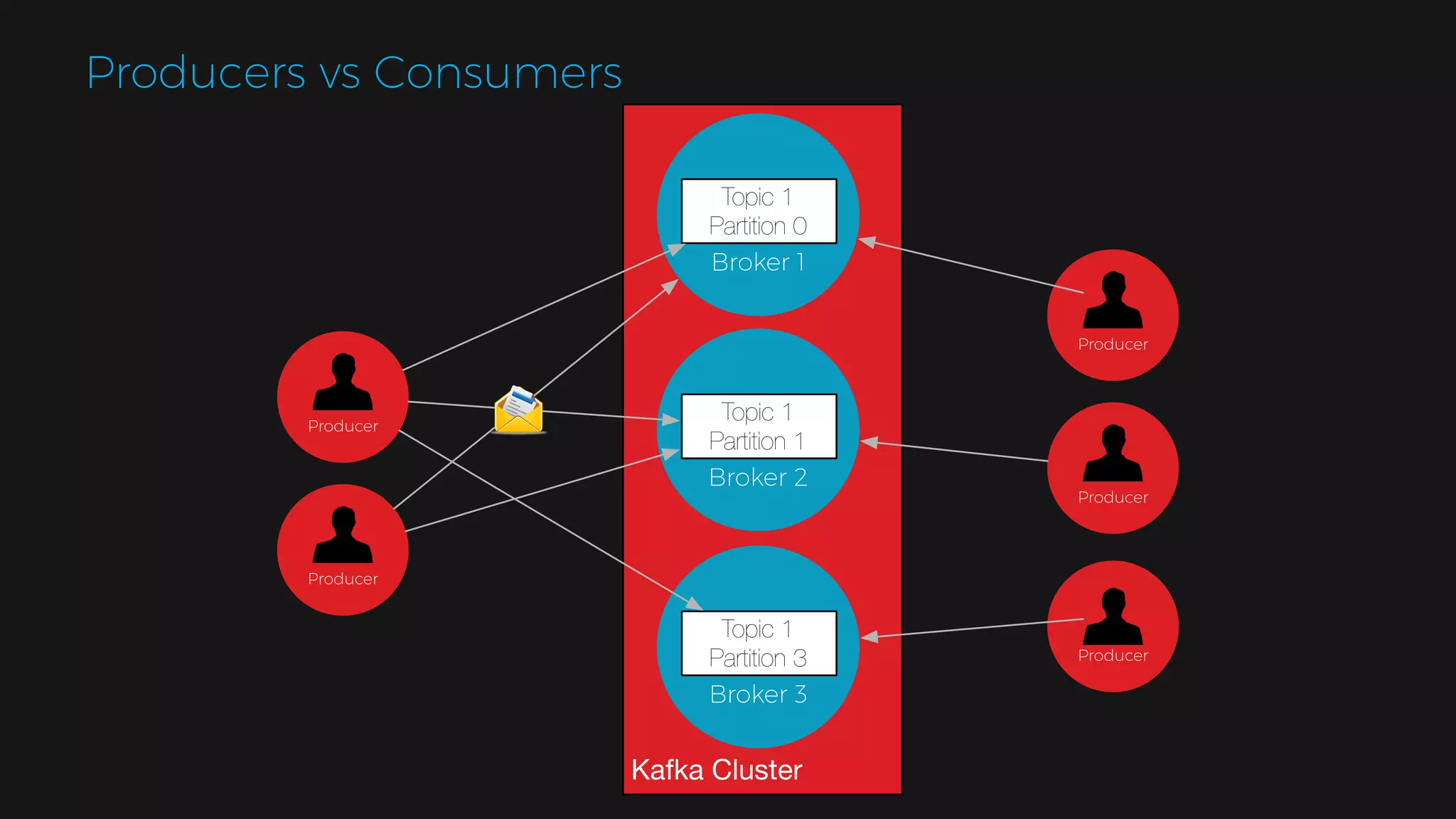
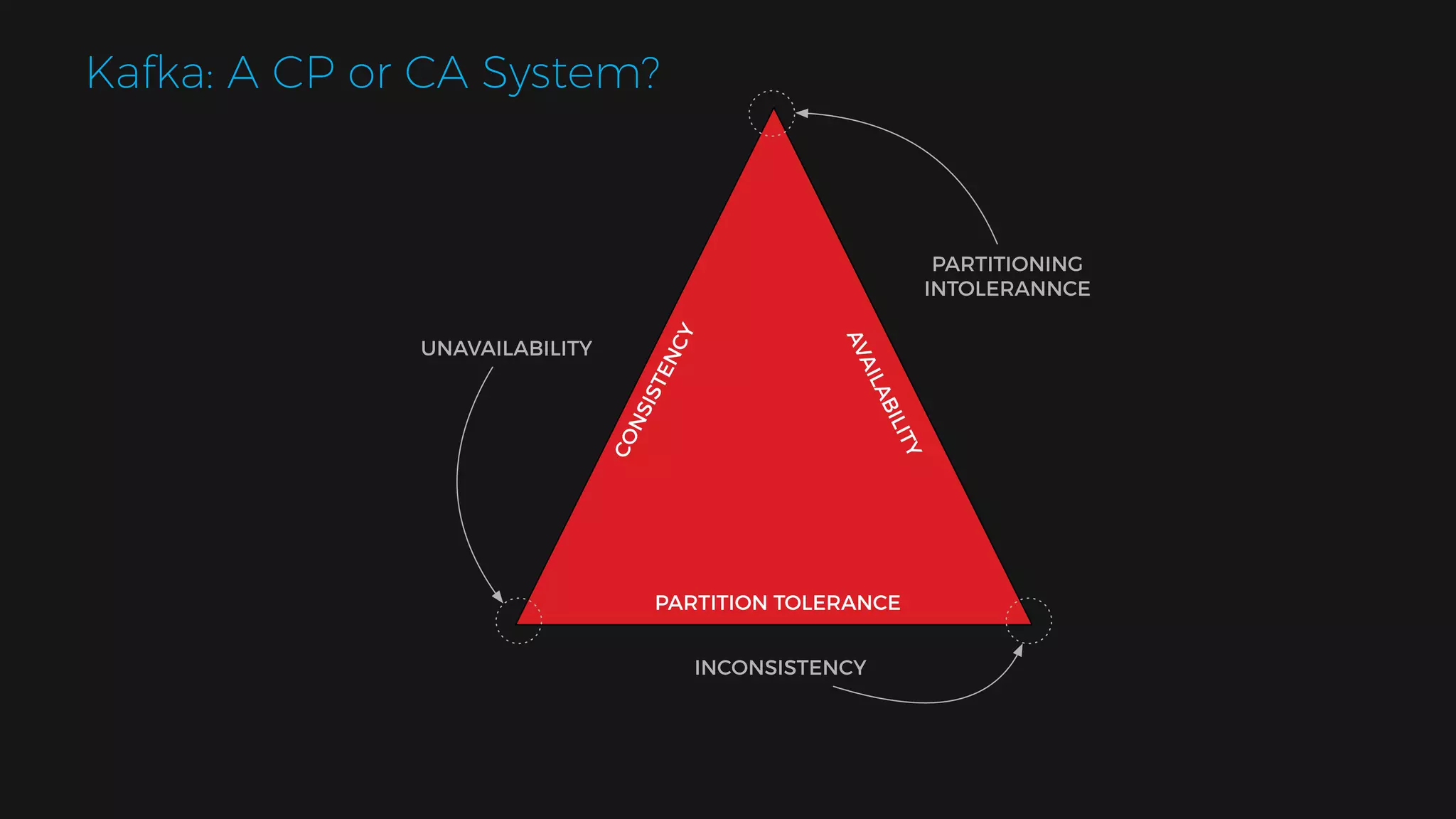
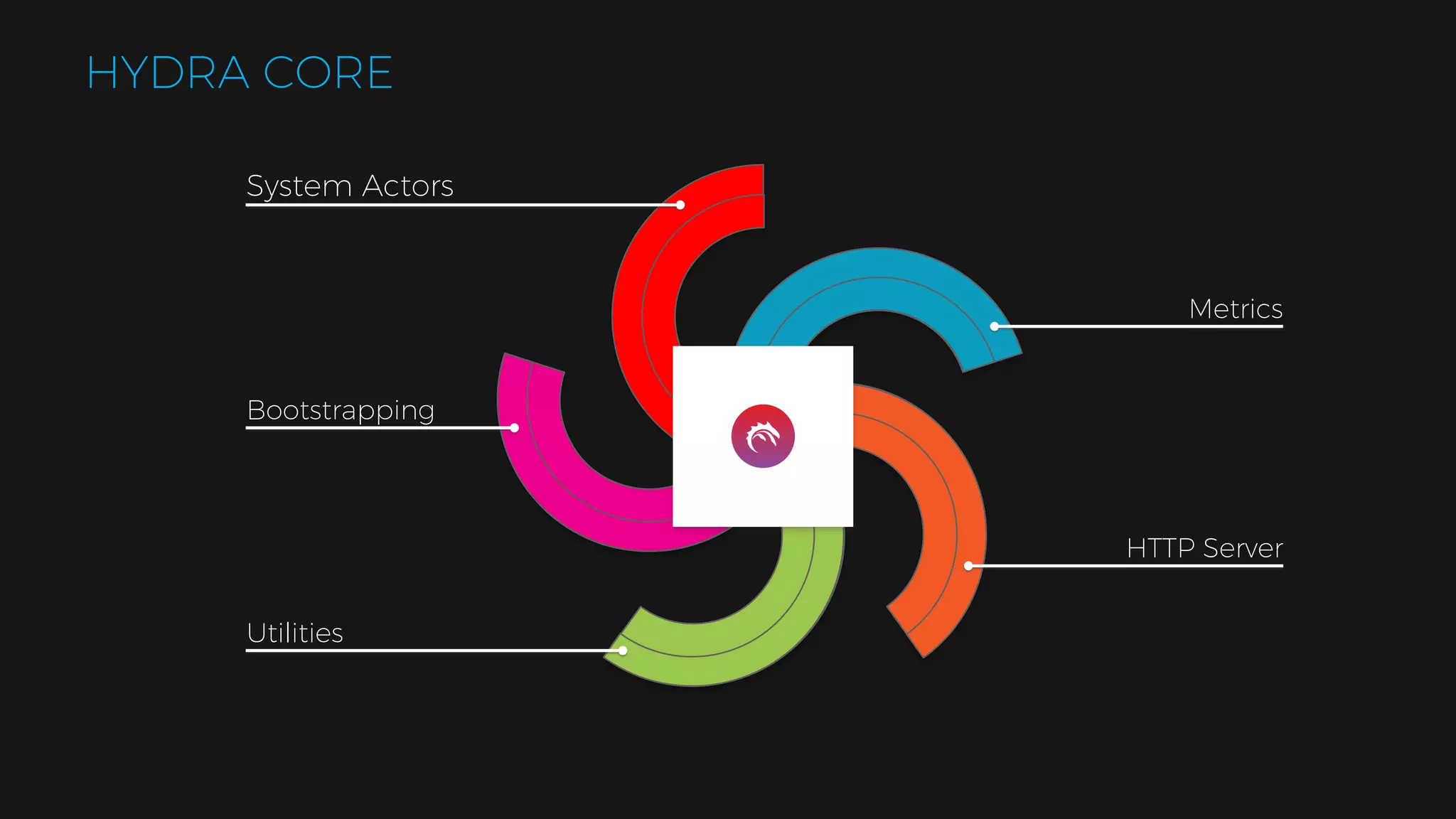
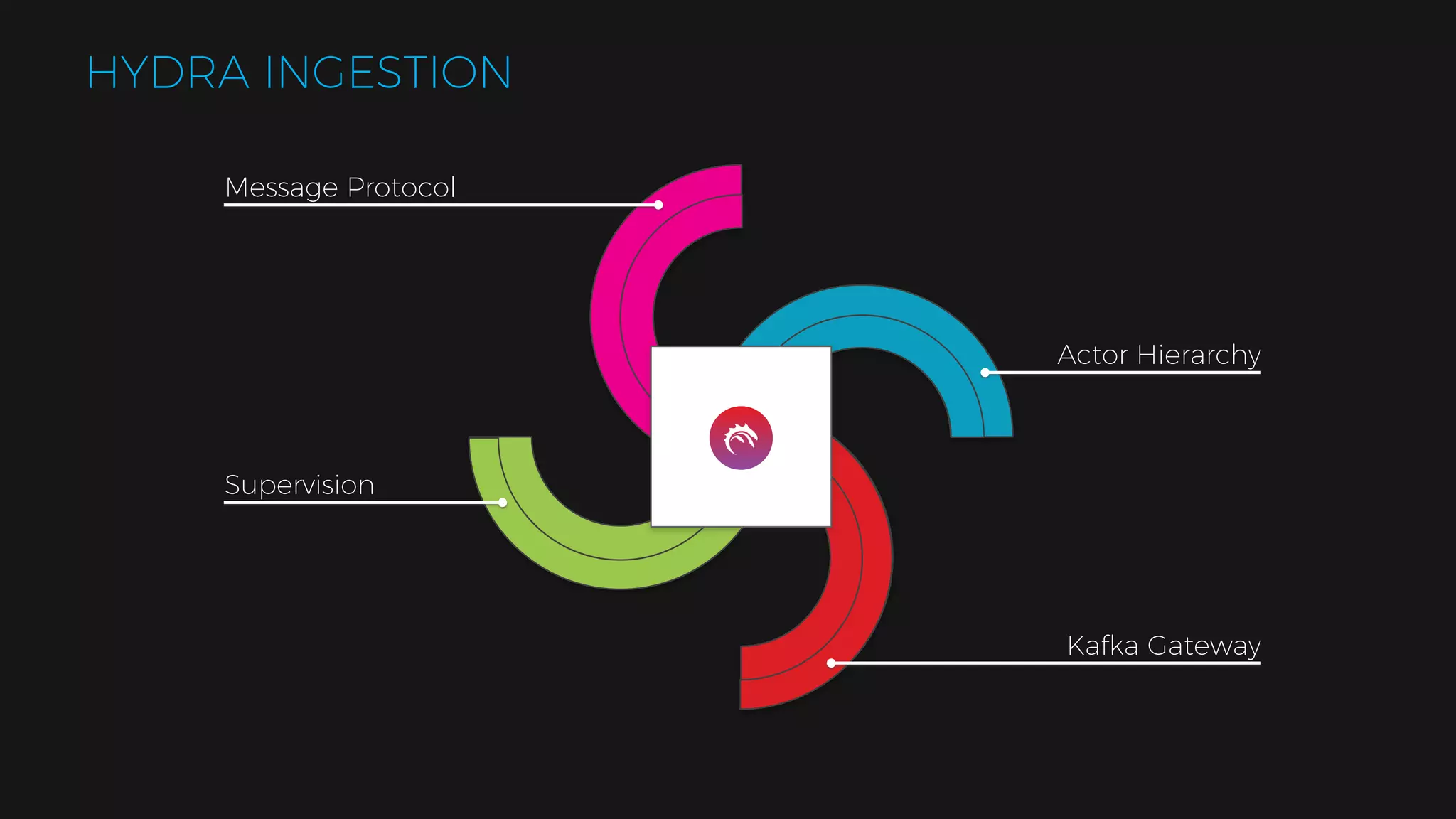
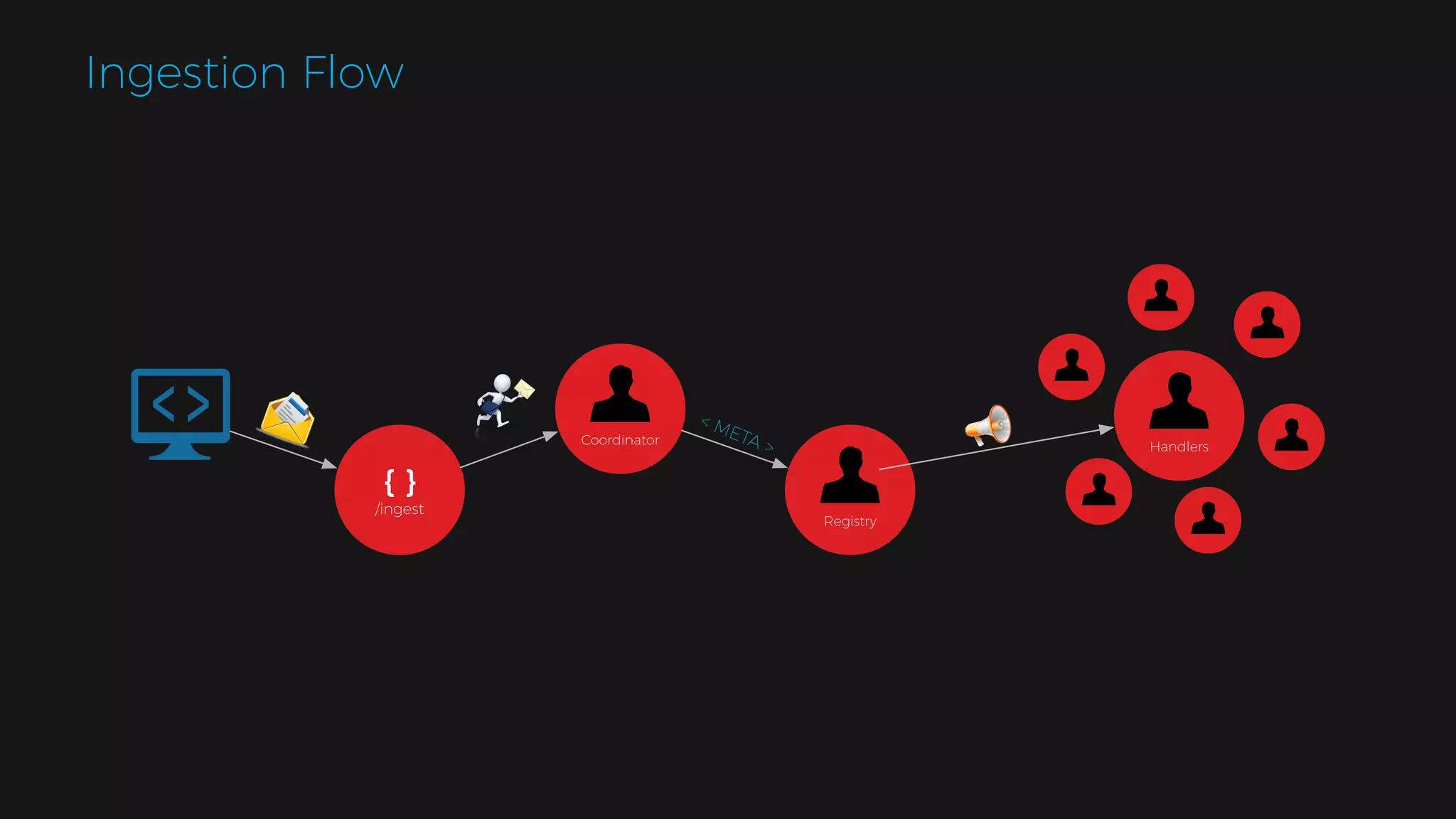
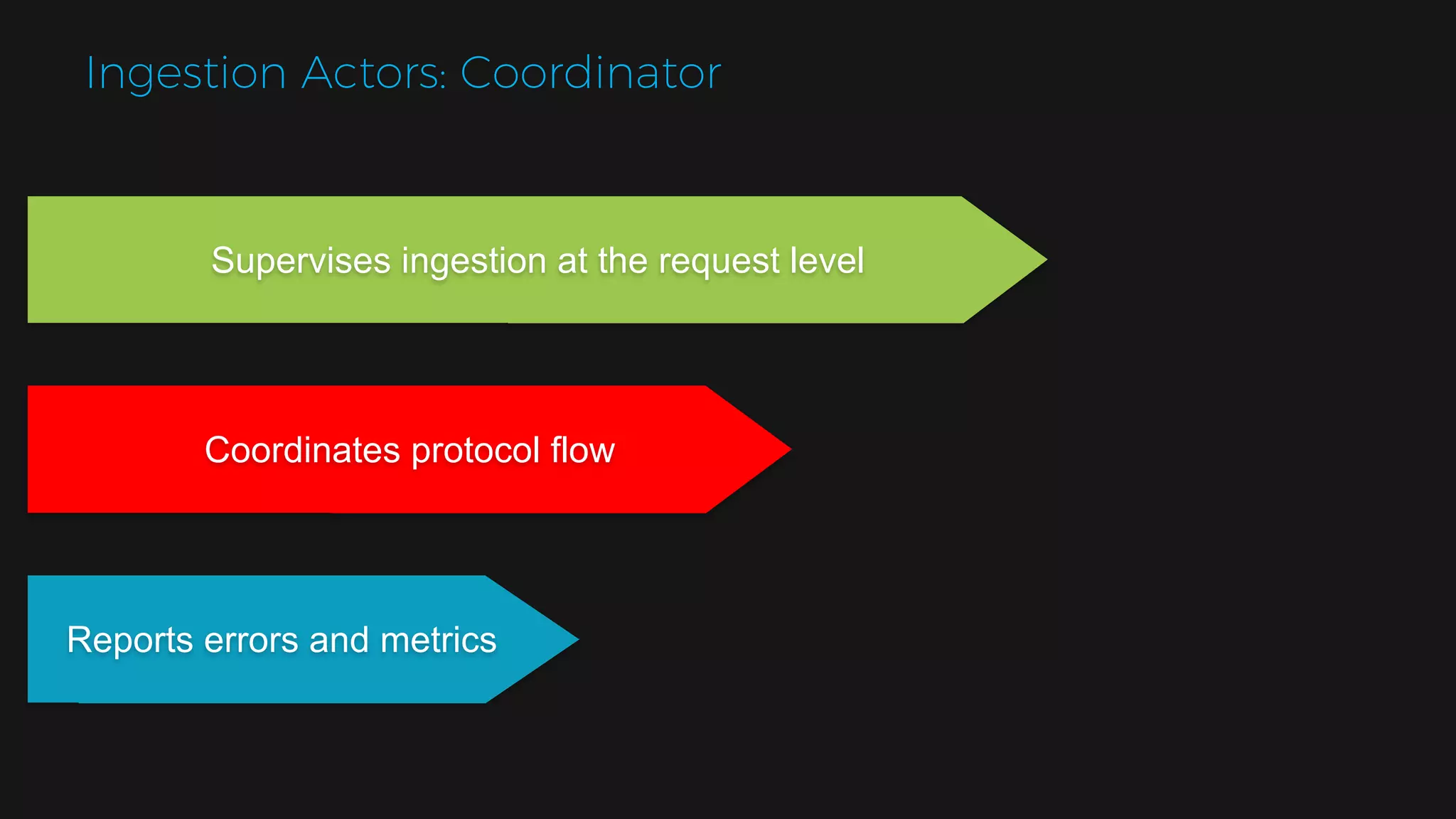
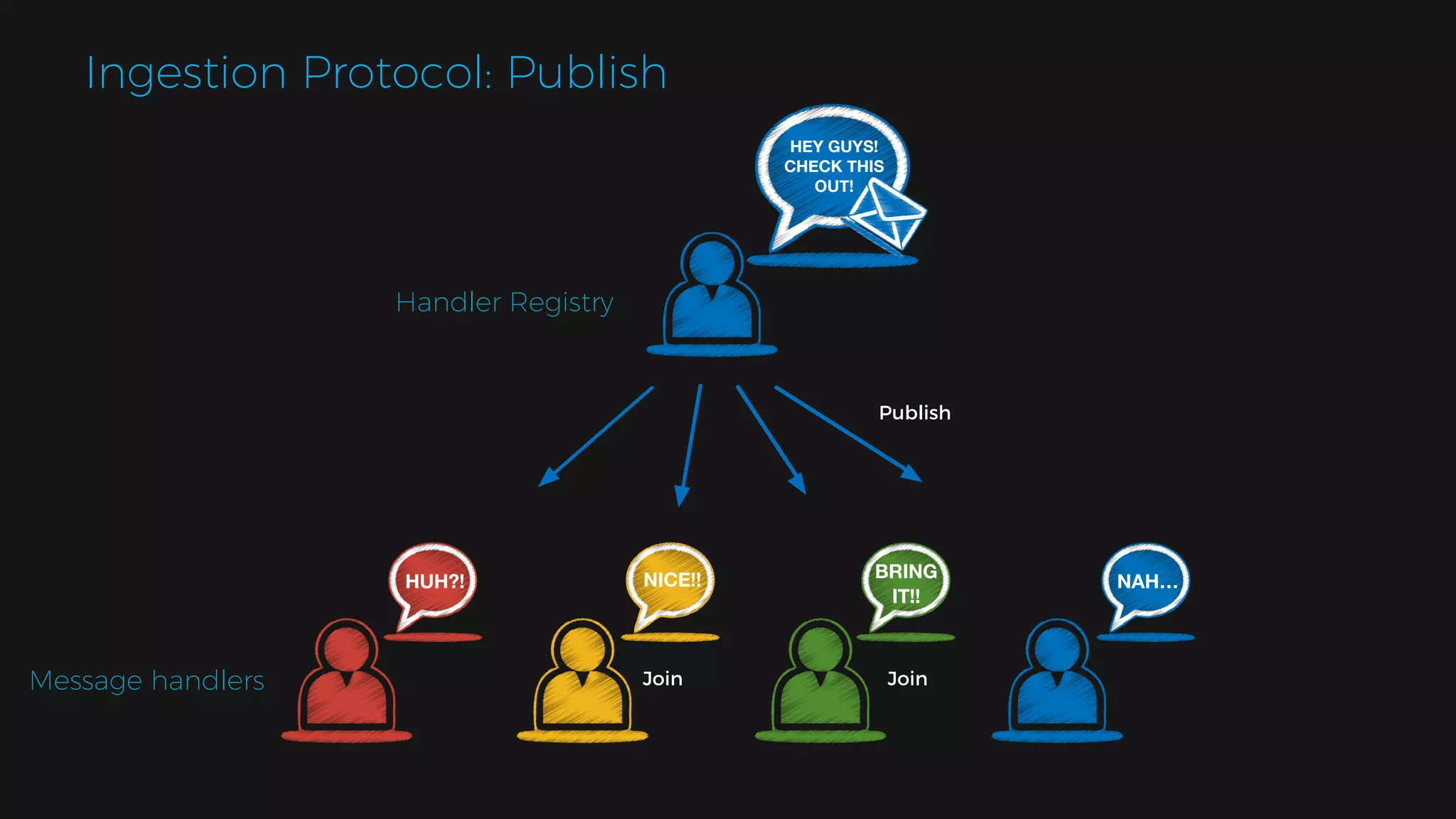
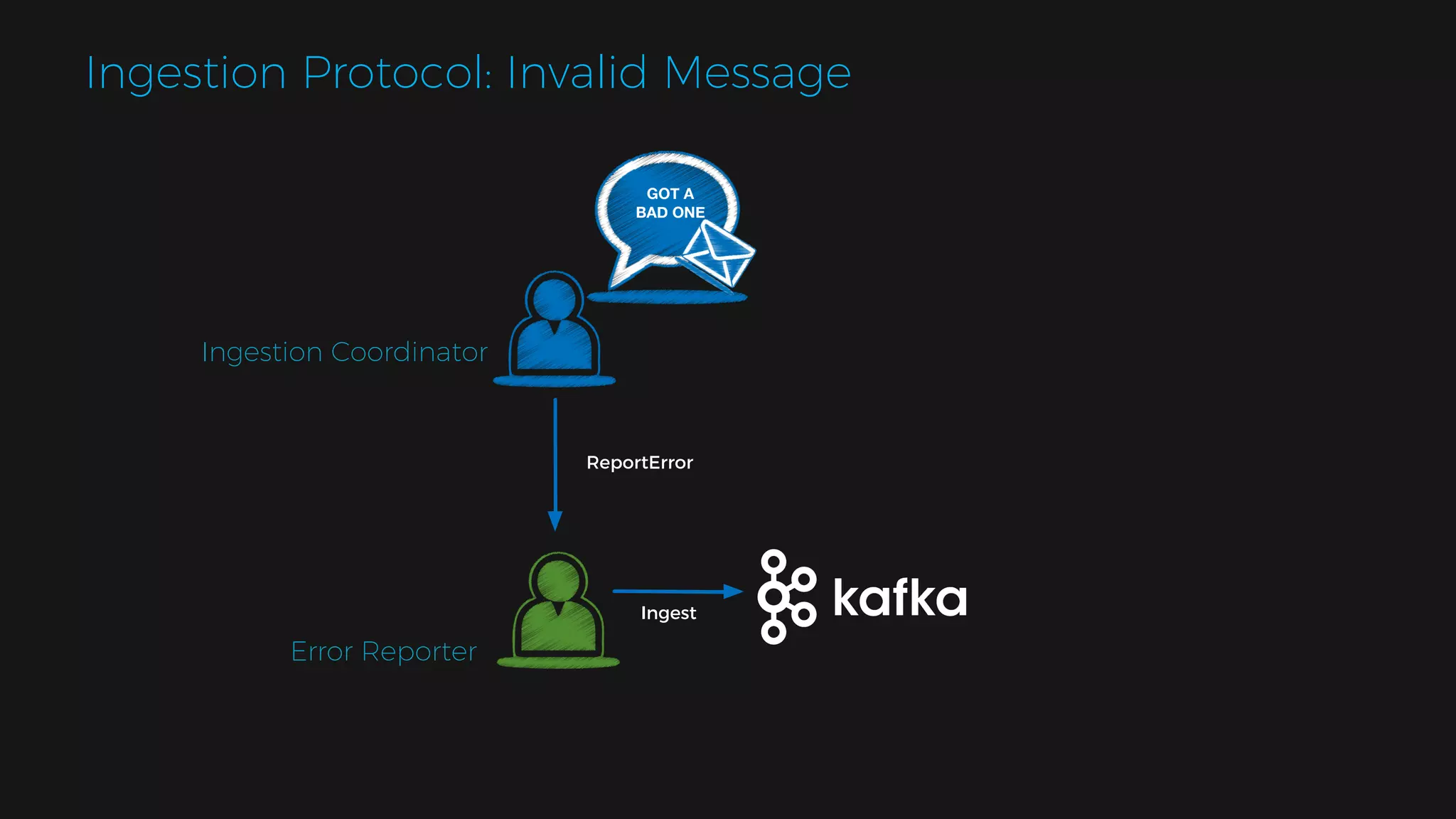
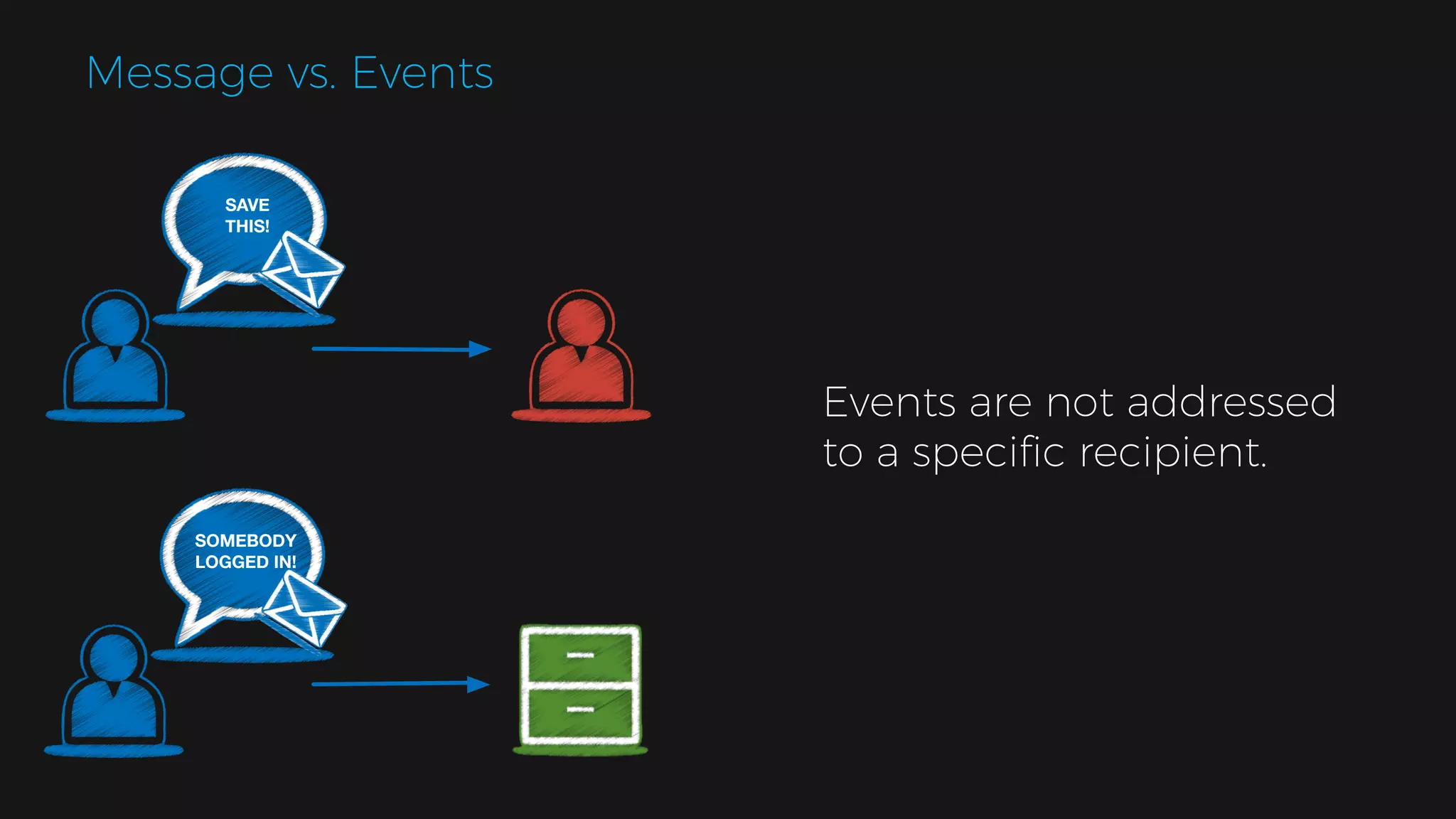
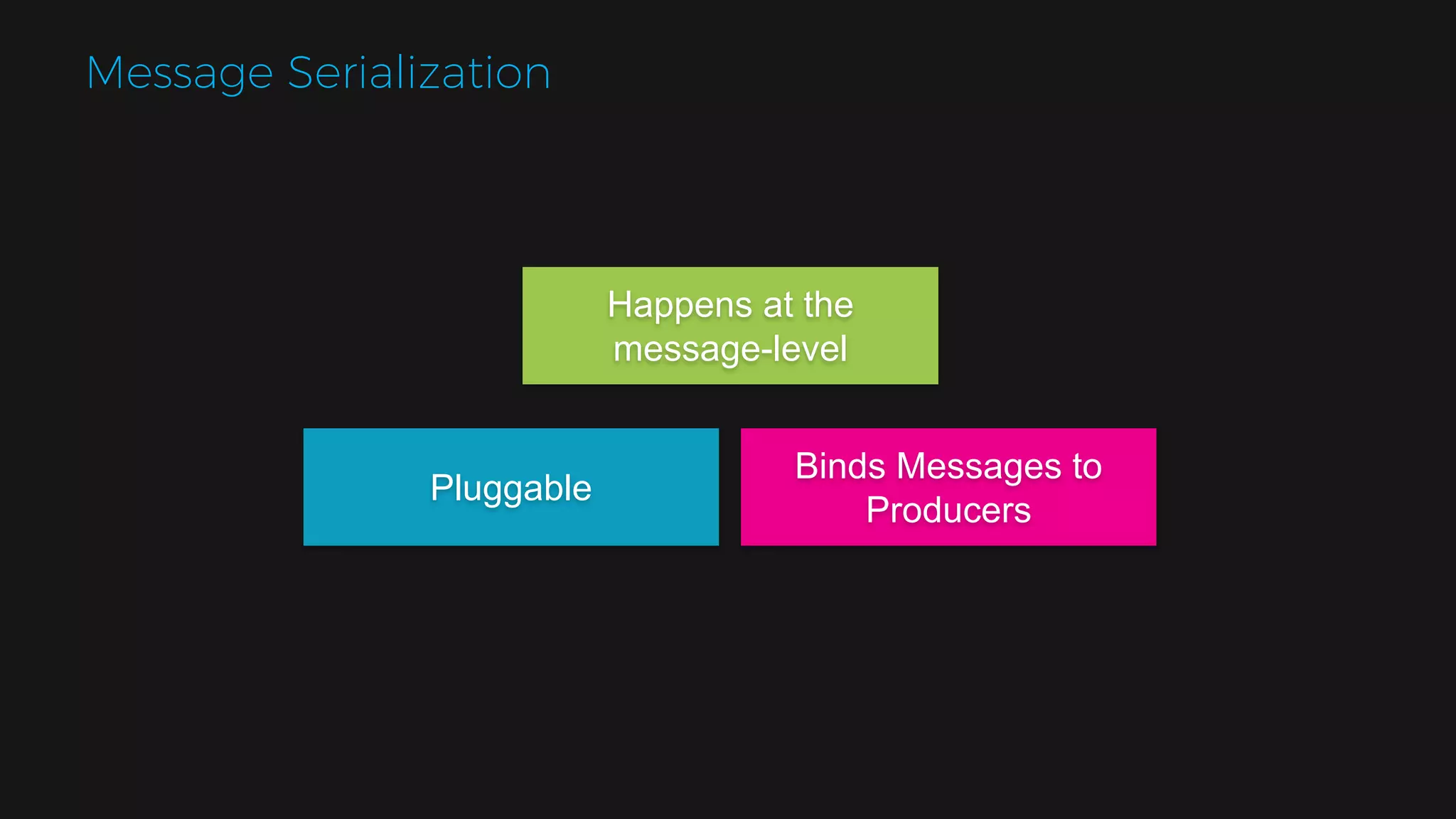
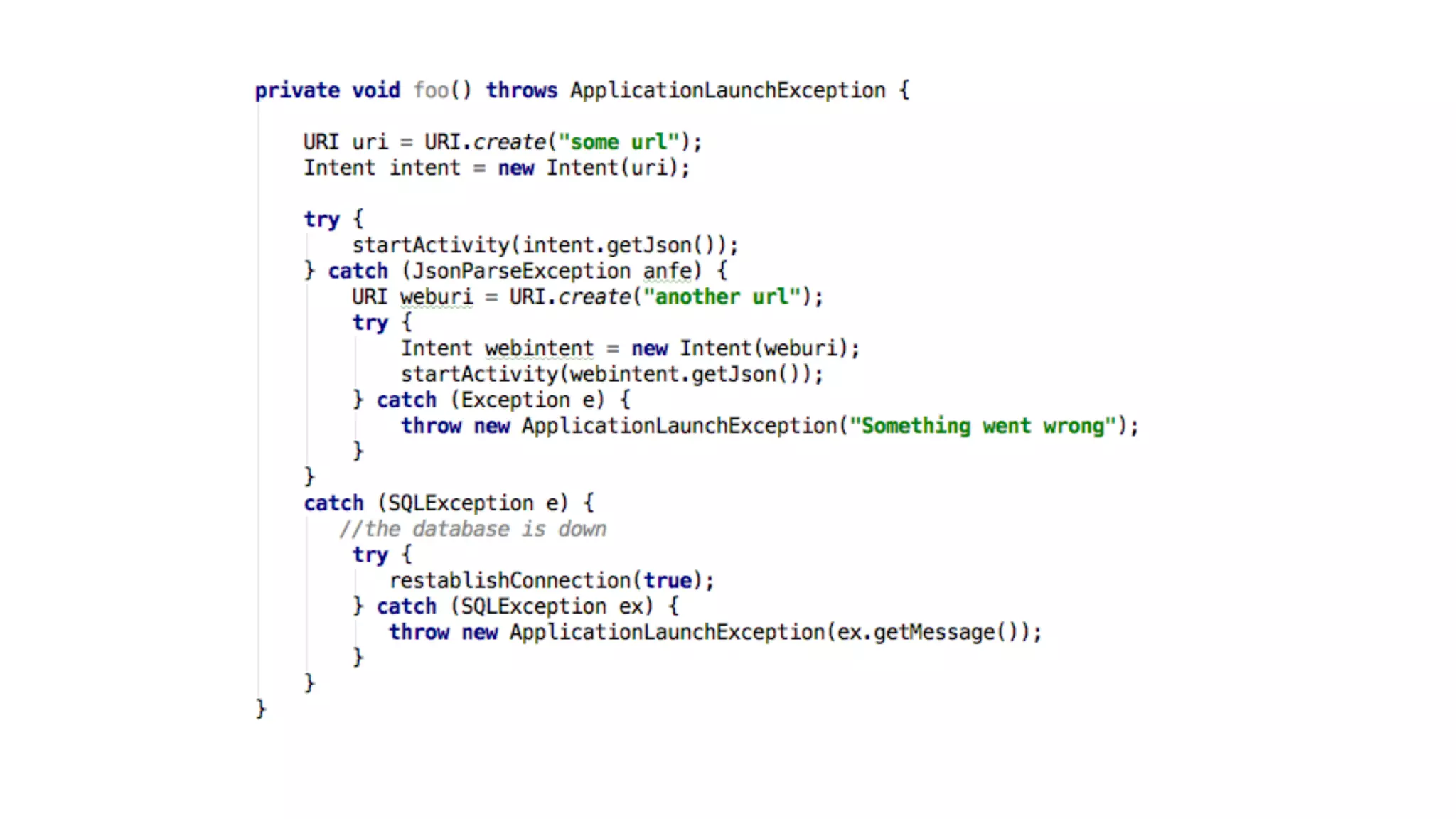
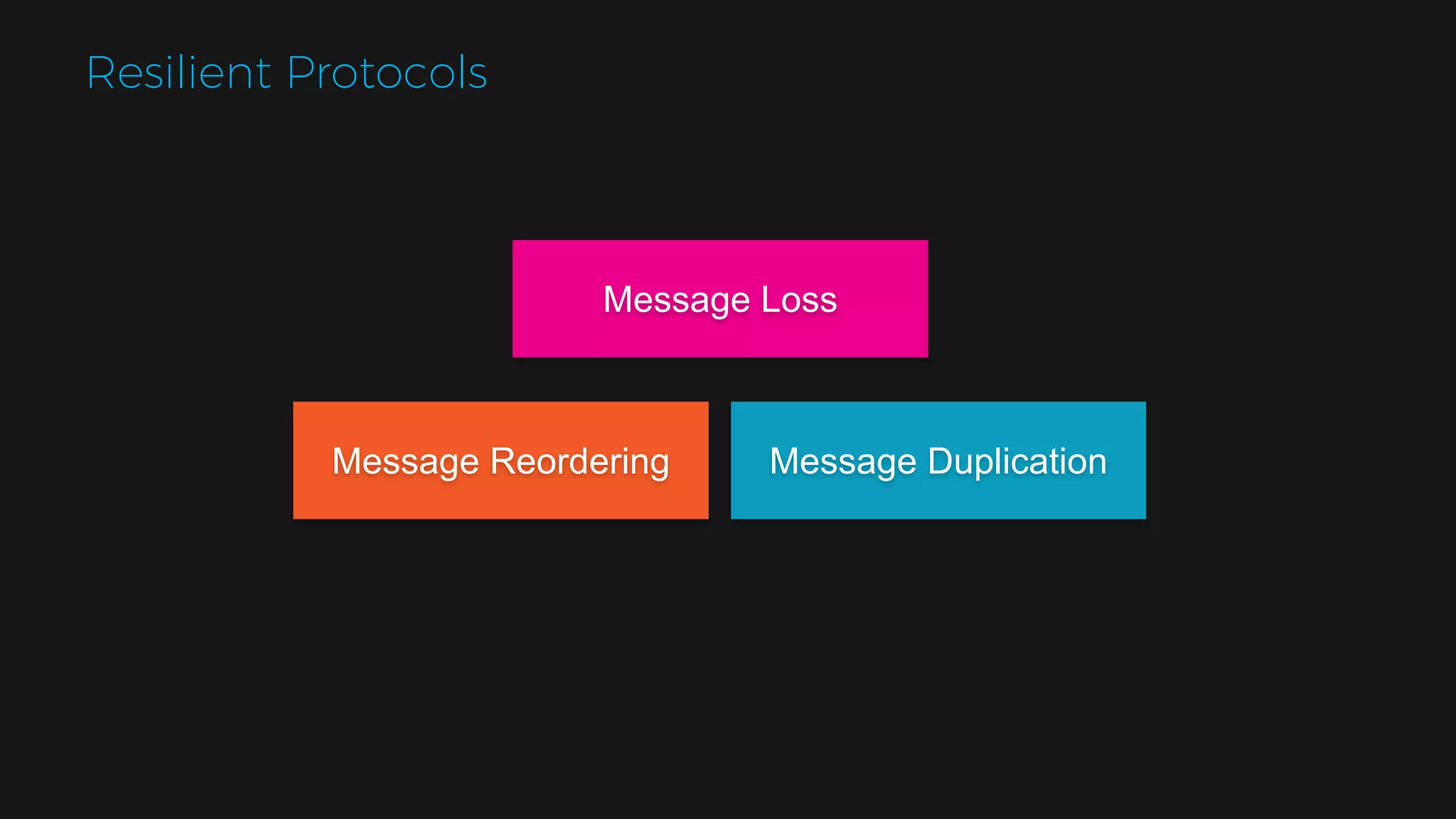
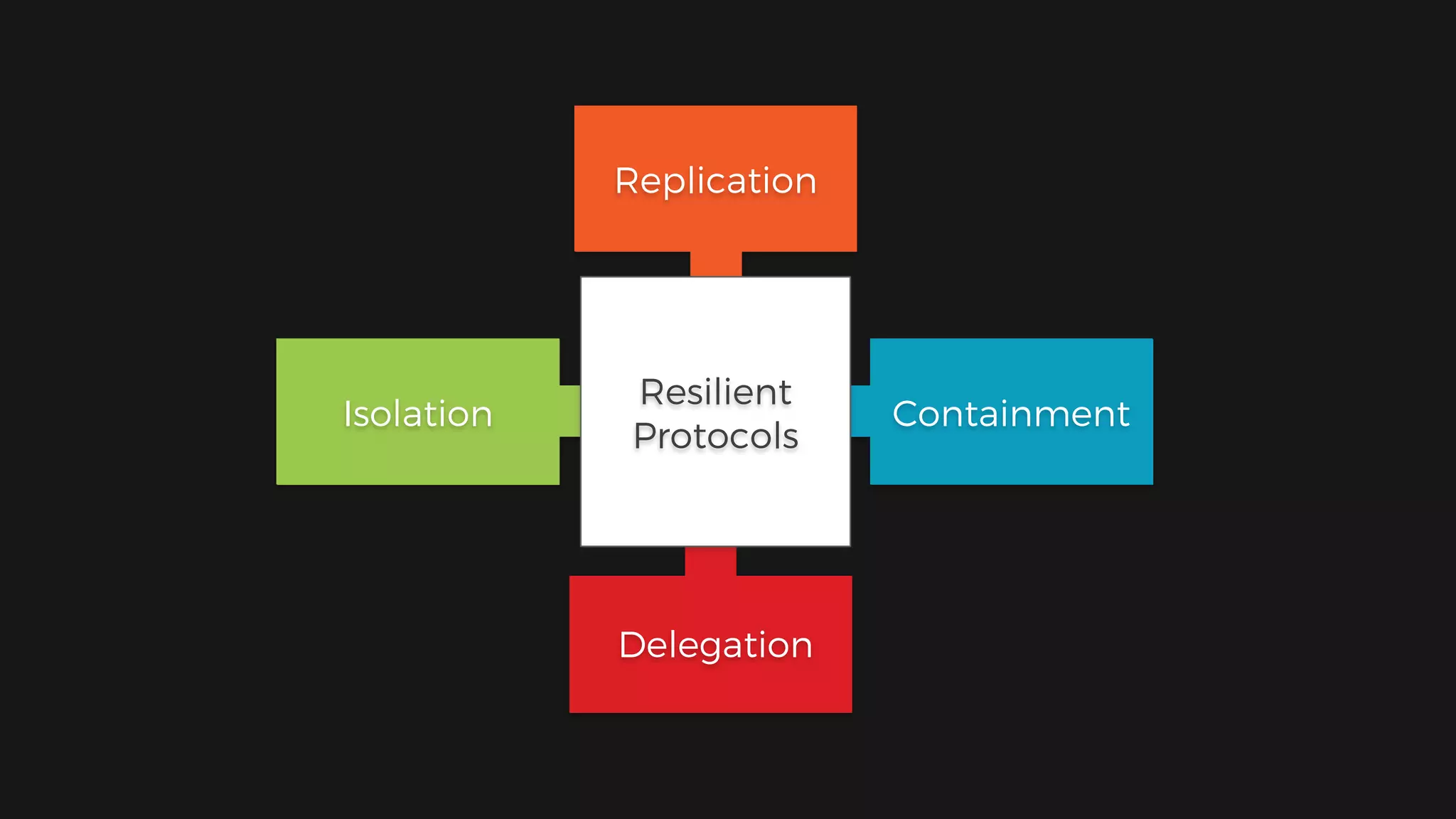
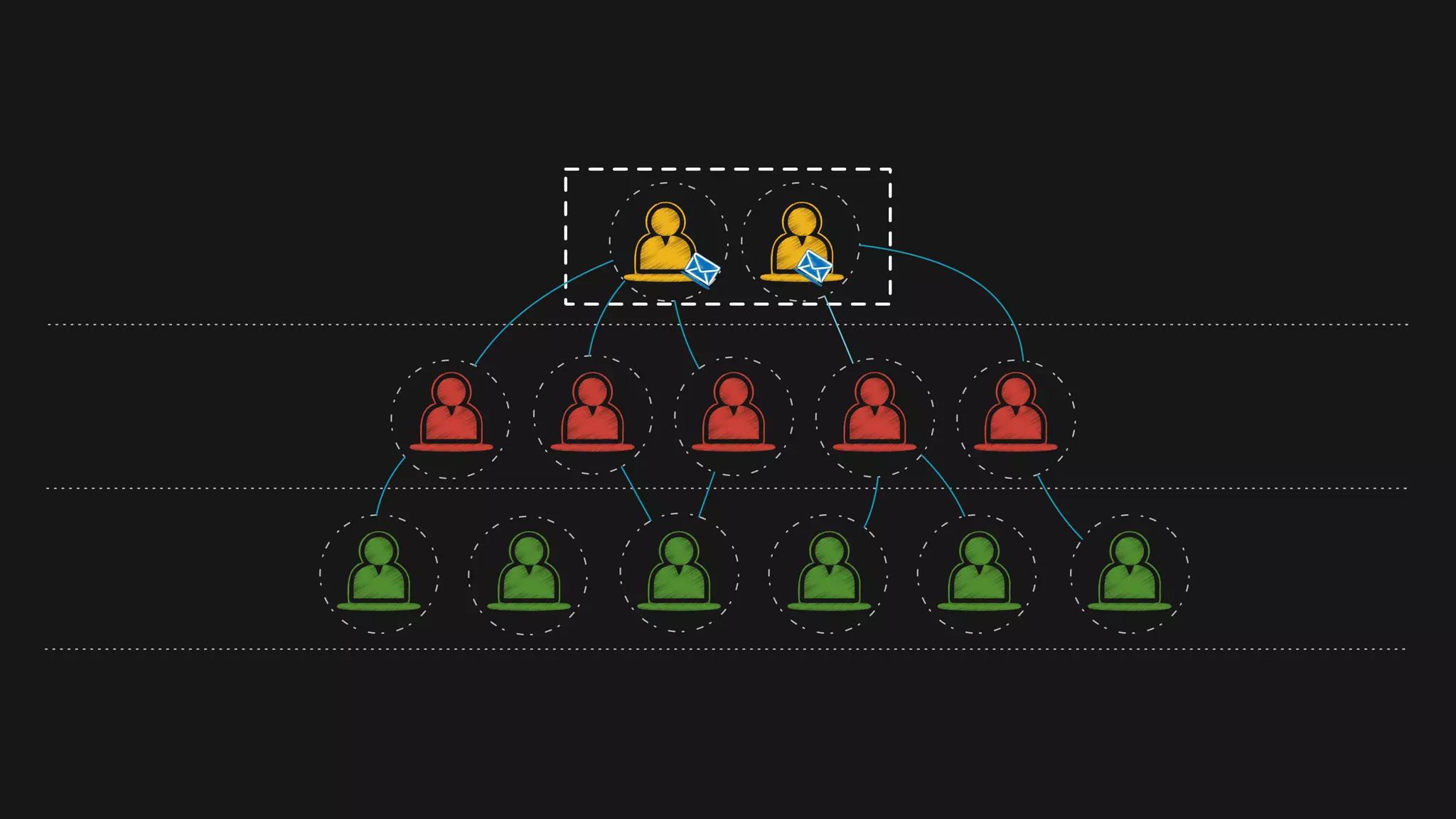
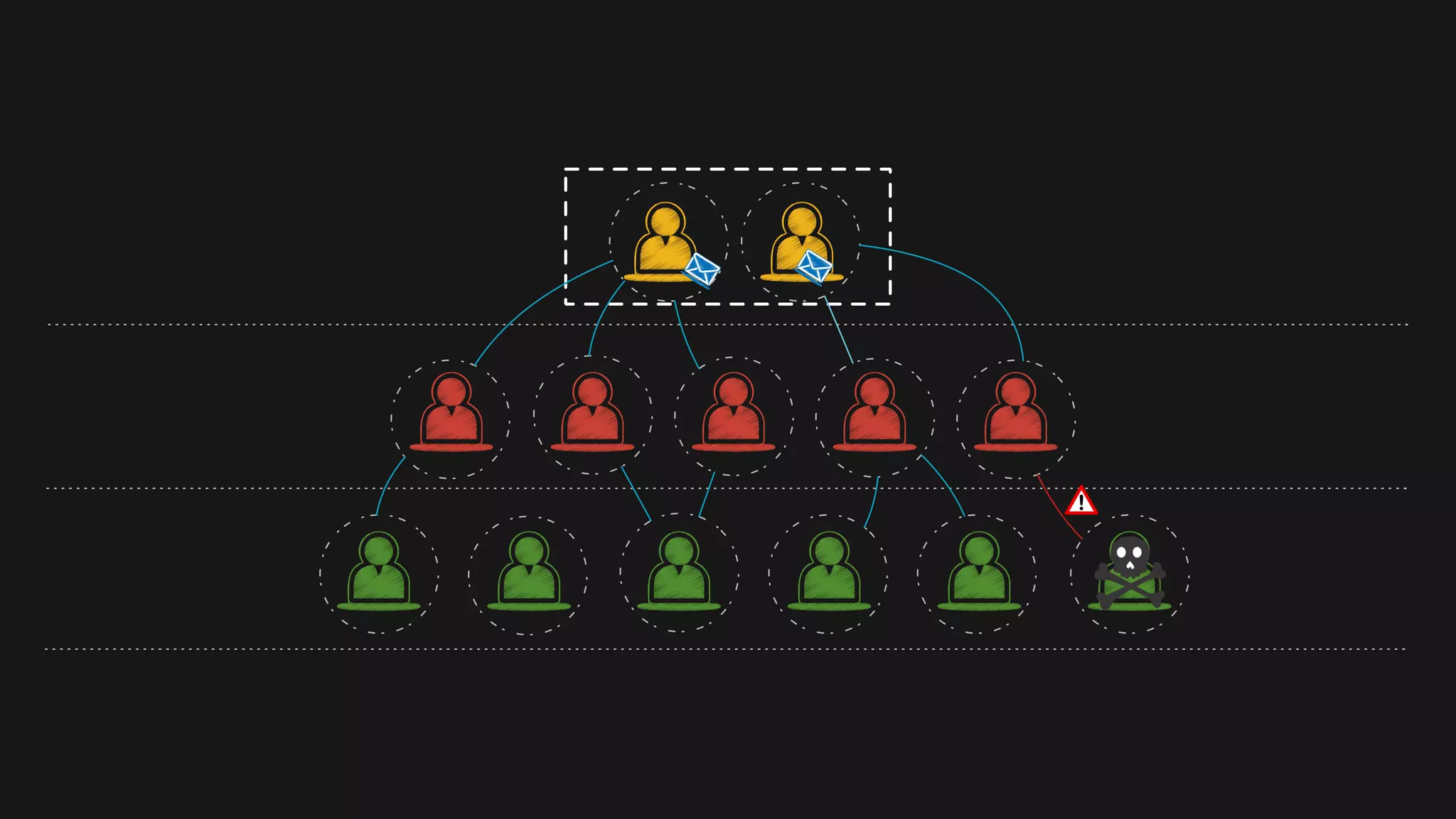
The document outlines the design of a scalable data platform using Akka, Spark Streaming, and Kafka, focusing on real-time data ingestion and processing. It describes the architecture, including components like Akka actors, Kafka producers, and the ingestion protocol, as well as challenges and considerations such as fault tolerance, message serialization, and event handling. The platform aims to provide a responsive, resilient, and distributed system for processing video and analytics data efficiently.