Download as PDF, PPTX




































![akka { actor { deployment { /services-manager/handler_registry/segment_handler { router = round-robin-pool optimal-size-exploring-resizer { enabled = on action-interval = 5s downsize-after-underutilized-for = 2h } } } provider = "akka.cluster.ClusterRefActorProvider" } cluster { seed-nodes = ["akka.tcp://Hydra@127.0.0.1:2552","akka.tcp://hydra@172.0.0.1:2553"] } }](https://image.slidesharecdn.com/software-arch-nyc-2016-slideshare-160413140942/75/Designing-a-reactive-data-platform-Challenges-patterns-and-anti-patterns-63-2048.jpg)
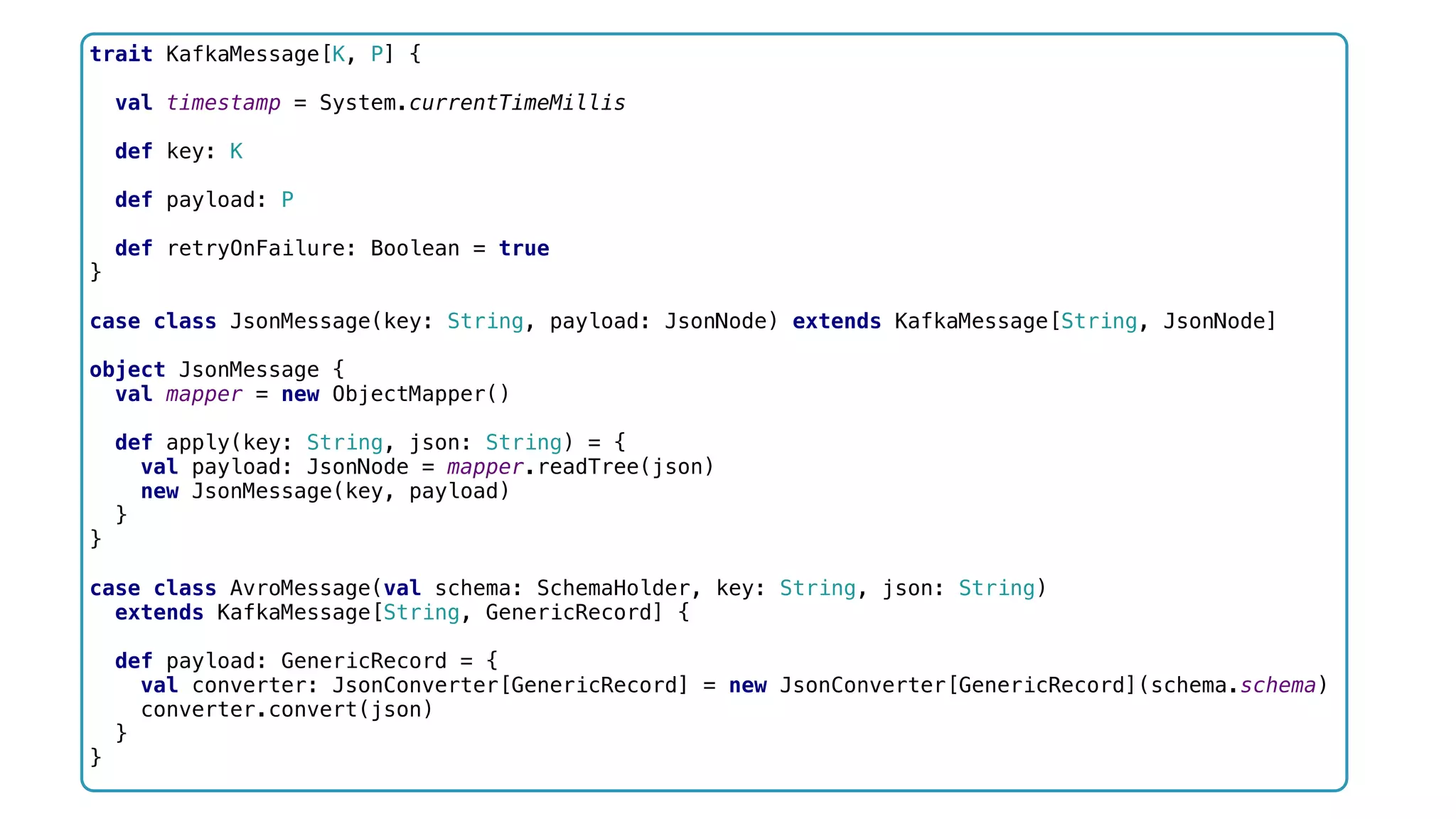


![trait KafkaMessage[K, P] { val timestamp = System.currentTimeMillis def key: K def payload: P def retryOnFailure: Boolean = true } case class JsonMessage(key: String, payload: JsonNode) extends KafkaMessage[String, JsonNode] object JsonMessage { val mapper = new ObjectMapper() def apply(key: String, json: String) = { val payload: JsonNode = mapper.readTree(json) new JsonMessage(key, payload) } } case class AvroMessage(val schema: SchemaHolder, key: String, json: String) extends KafkaMessage[String, GenericRecord] { def payload: GenericRecord = { val converter: JsonConverter[GenericRecord] = new JsonConverter[GenericRecord](schema.schema) converter.convert(json) } }](https://image.slidesharecdn.com/software-arch-nyc-2016-slideshare-160413140942/75/Designing-a-reactive-data-platform-Challenges-patterns-and-anti-patterns-67-2048.jpg)





![override val supervisorStrategy = OneForOneStrategy(maxNrOfRetries = 10, withinTimeRange = 1.minute) { case _: ActorInitializationException => akka.actor.SupervisorStrategy.Stop case _: FailedToSendMessageException => Restart case _: ProducerClosedException => Restart case _: NoBrokersForPartitionException => Escalate case _: KafkaException => Escalate case _: ConnectException => Escalate case _: Exception => Escalate } val kafkaProducerSupervisor = BackoffSupervisor.props( Backoff.onFailure( kafkaProducerProps, childName = actorName[KafkaProducerActor], minBackoff = 3.seconds, maxBackoff = 30.seconds, randomFactor = 0.2 ))](https://image.slidesharecdn.com/software-arch-nyc-2016-slideshare-160413140942/75/Designing-a-reactive-data-platform-Challenges-patterns-and-anti-patterns-77-2048.jpg)
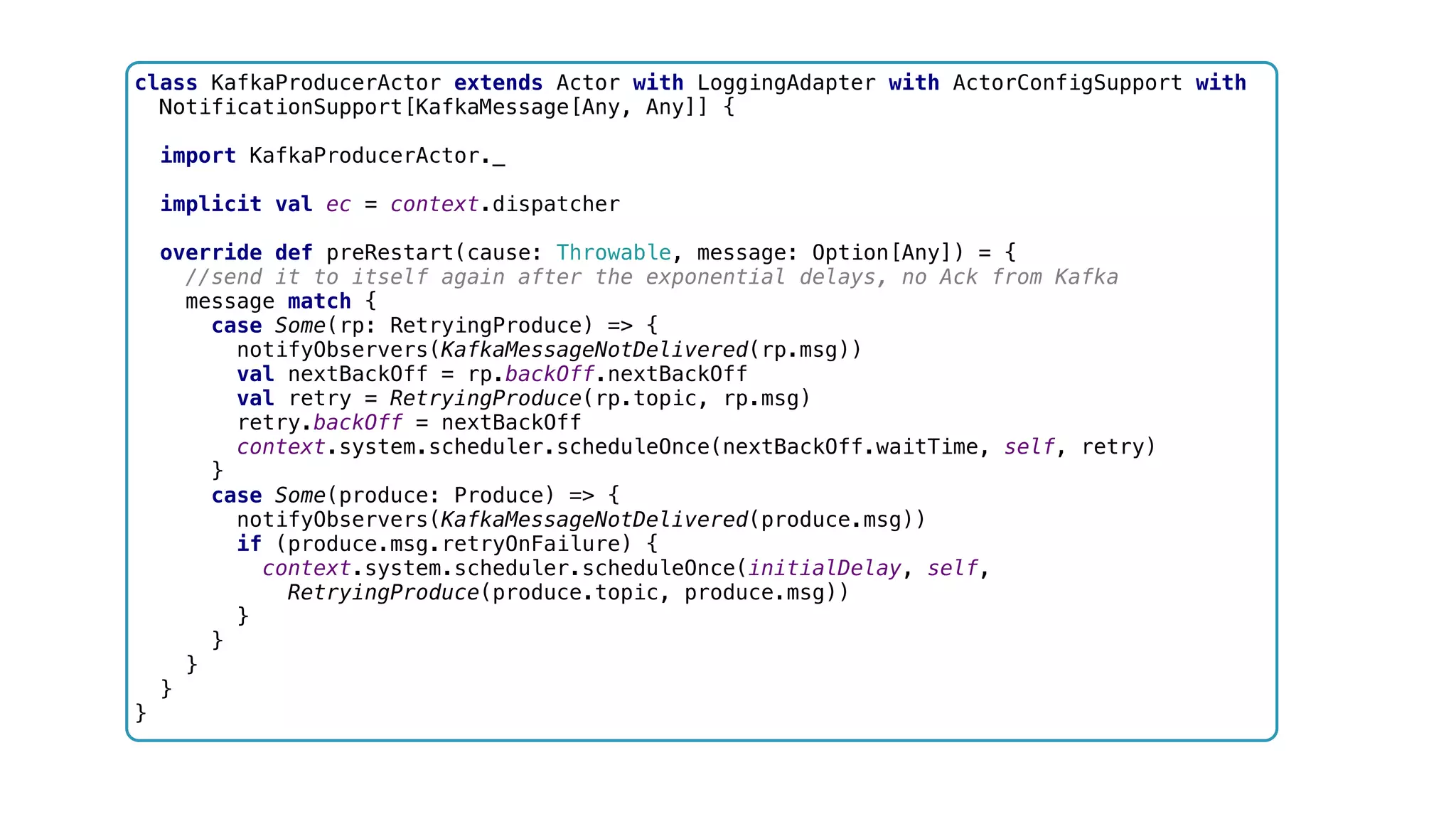
![class KafkaProducerActor extends Actor with LoggingAdapter with ActorConfigSupport with NotificationSupport[KafkaMessage[Any, Any]] { import KafkaProducerActor._ implicit val ec = context.dispatcher override def preRestart(cause: Throwable, message: Option[Any]) = { //send it to itself again after the exponential delays, no Ack from Kafka message match { case Some(rp: RetryingProduce) => { notifyObservers(KafkaMessageNotDelivered(rp.msg)) val nextBackOff = rp.backOff.nextBackOff val retry = RetryingProduce(rp.topic, rp.msg) retry.backOff = nextBackOff context.system.scheduler.scheduleOnce(nextBackOff.waitTime, self, retry) } case Some(produce: Produce) => { notifyObservers(KafkaMessageNotDelivered(produce.msg)) if (produce.msg.retryOnFailure) { context.system.scheduler.scheduleOnce(initialDelay, self, RetryingProduce(produce.topic, produce.msg)) } } } } }](https://image.slidesharecdn.com/software-arch-nyc-2016-slideshare-160413140942/75/Designing-a-reactive-data-platform-Challenges-patterns-and-anti-patterns-78-2048.jpg)

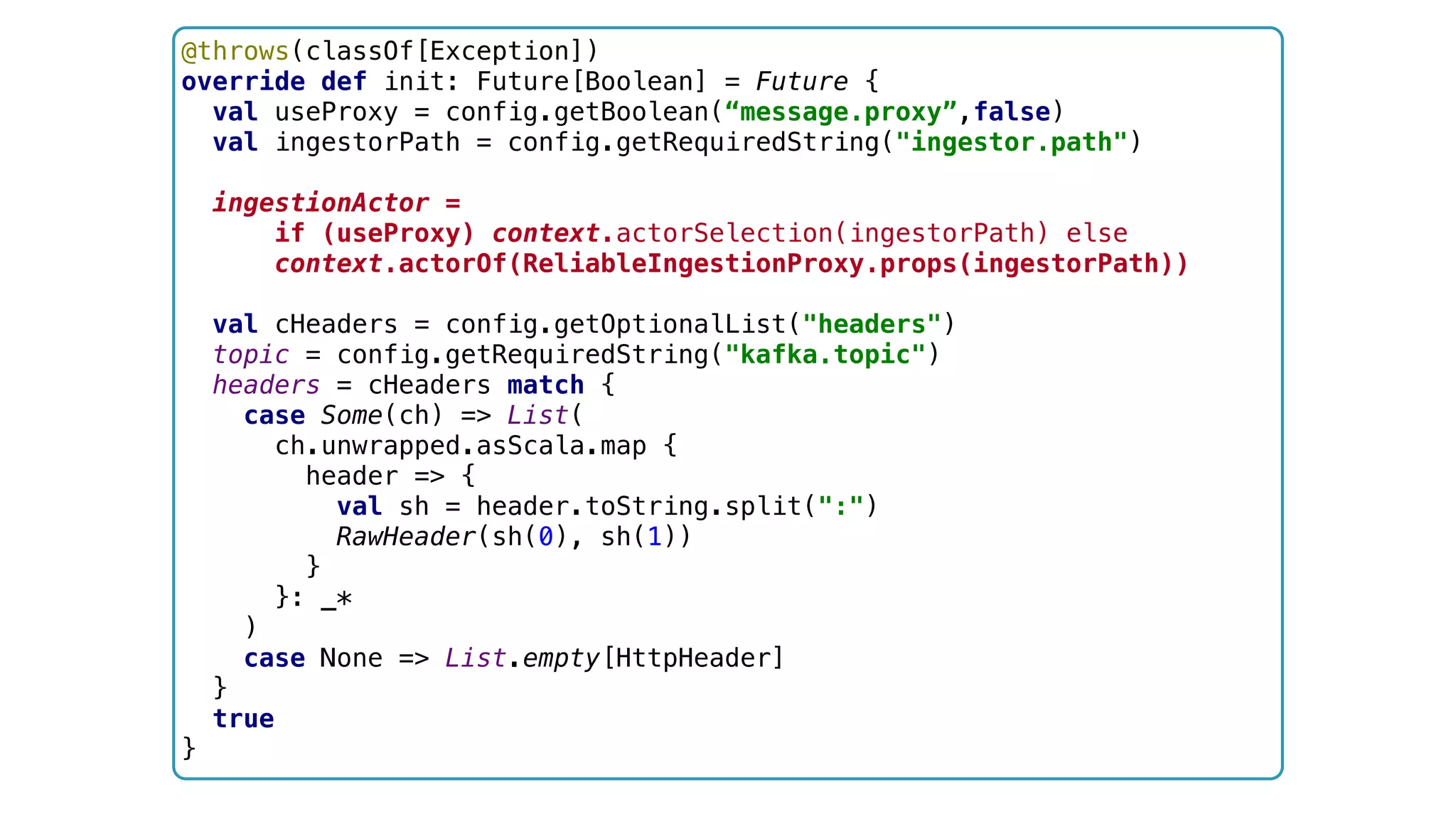


![@throws(classOf[Exception]) override def init: Future[Boolean] = Future { val useProxy = config.getBoolean(“message.proxy”,false) val ingestorPath = config.getRequiredString("ingestor.path") ingestionActor = if (useProxy) context.actorSelection(ingestorPath) else context.actorOf(ReliableIngestionProxy.props(ingestorPath)) val cHeaders = config.getOptionalList("headers") topic = config.getRequiredString("kafka.topic") headers = cHeaders match { case Some(ch) => List( ch.unwrapped.asScala.map { header => { val sh = header.toString.split(":") RawHeader(sh(0), sh(1)) } }: _* ) case None => List.empty[HttpHeader] } true }](https://image.slidesharecdn.com/software-arch-nyc-2016-slideshare-160413140942/75/Designing-a-reactive-data-platform-Challenges-patterns-and-anti-patterns-87-2048.jpg)

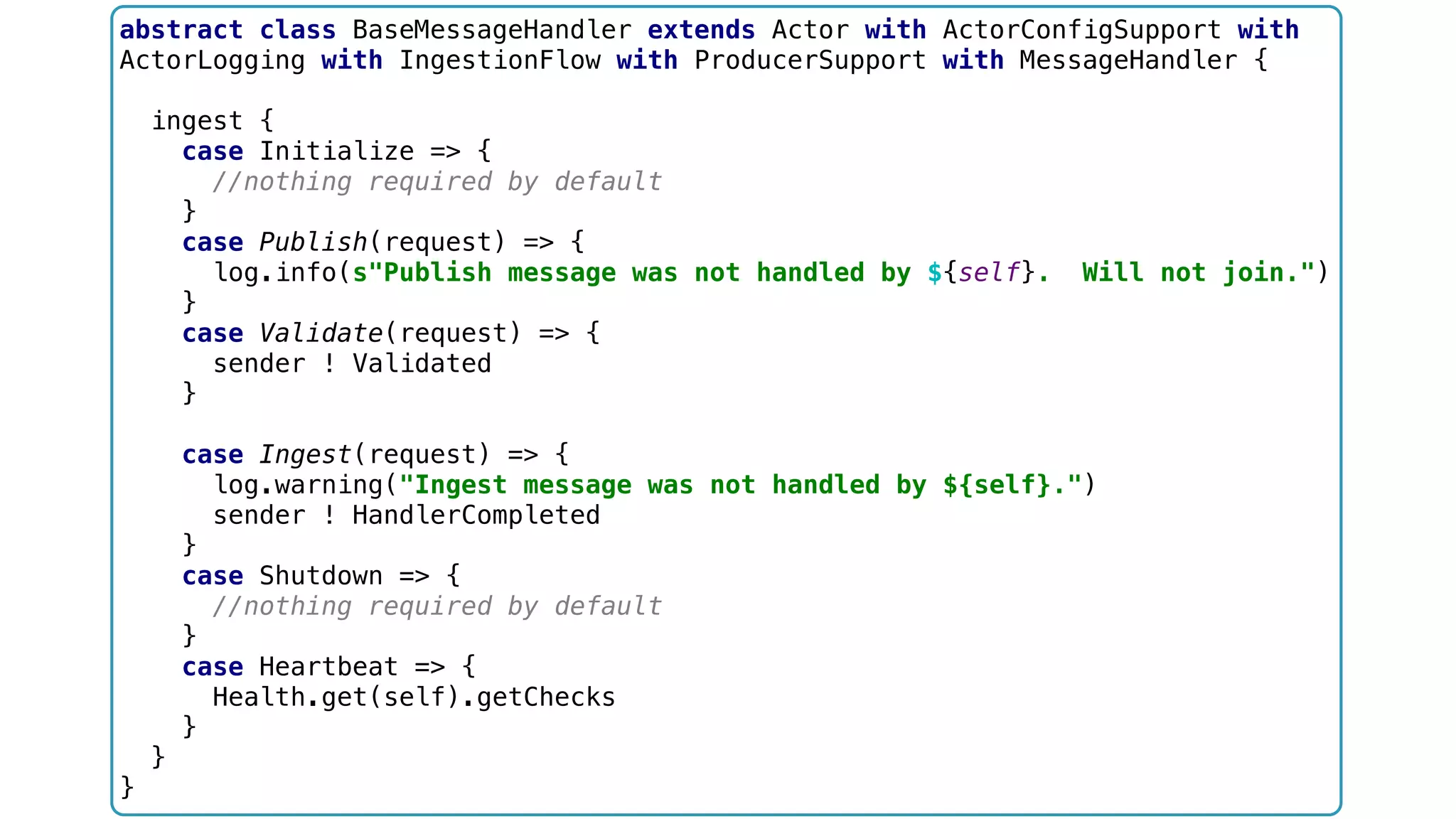
![object Messages { case object ServiceStarted case class RegisterHandler(info: ActorRef) case class RegisteredHandler(name: String, handler: ActorRef) case class RemoveHandler(path: ActorPath) case object GetHandlers case object InitiateIngestion extends HydraMessage case class RequestCompleted(s: IngestionSummary) extends HydraMessage case class IngestionSummary(name:String) case class Produce(topic: String, msg: KafkaMessage[_, _], ack: Option[ActorRef]) extends HydraMessage case object HandlerTimeout extends HydraMessage case class Validate(req: HydraRequest) extends HydraMessage case class Validated(req: HydraRequest) extends HydraMessage case class NotValid(req: HydraRequest, reason: String) extends HydraMessage case object HandlingCompleted extends HydraMessage case class Publish(request: HydraRequest) case class Ingest(request: HydraRequest) case class Join(r: HydraRequest) extends HydraMessage }](https://image.slidesharecdn.com/software-arch-nyc-2016-slideshare-160413140942/75/Designing-a-reactive-data-platform-Challenges-patterns-and-anti-patterns-89-2048.jpg)









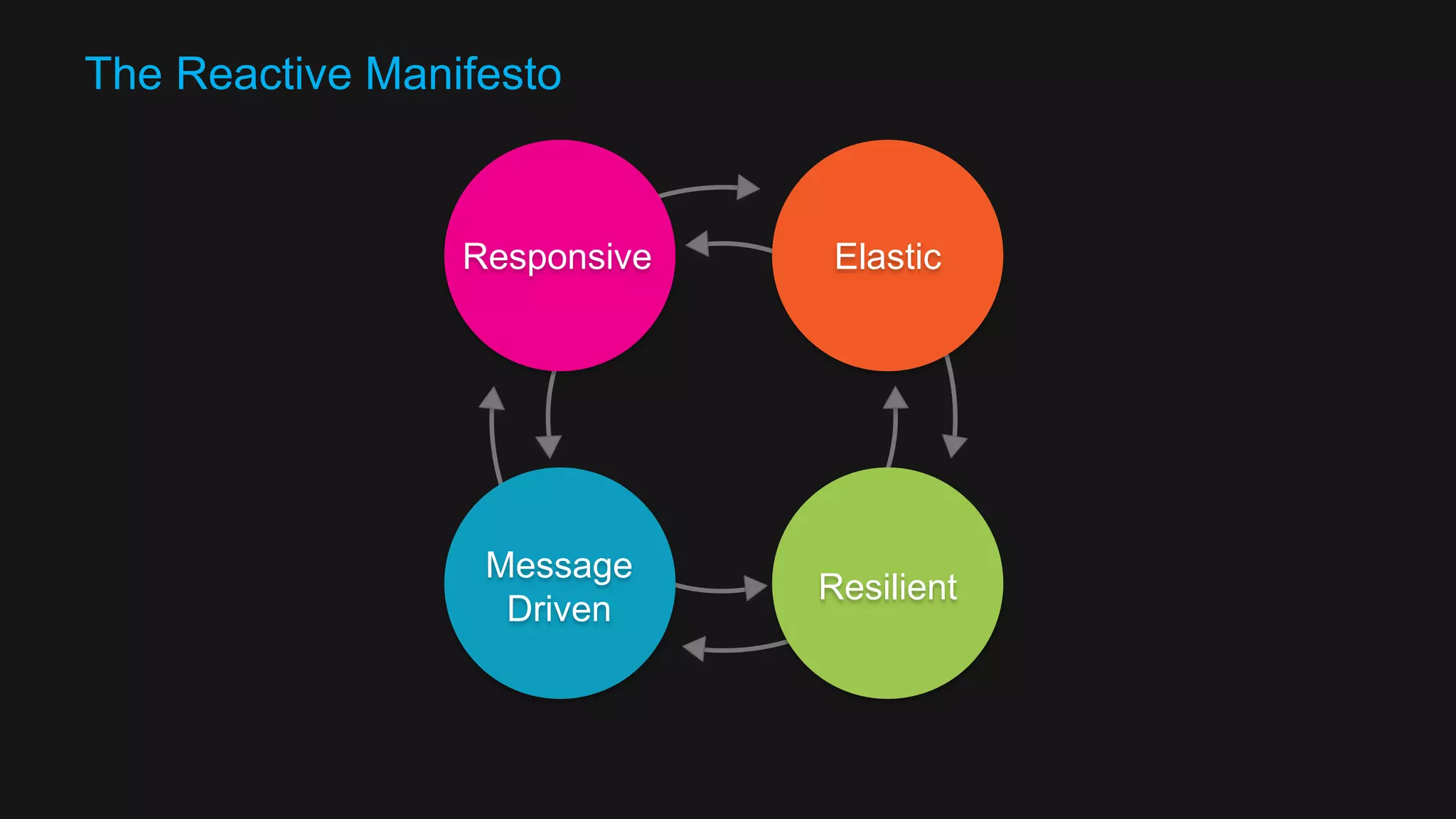
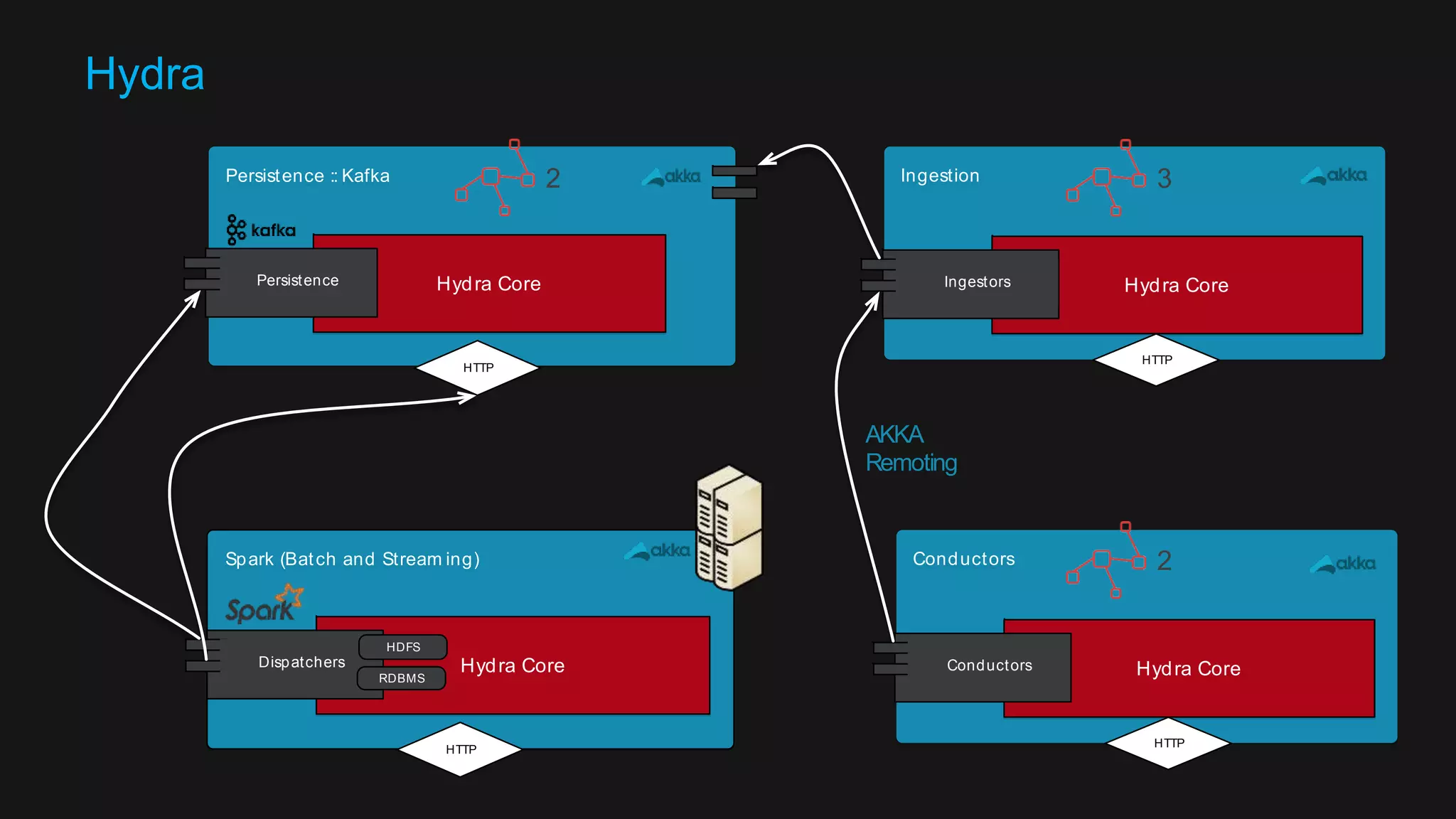
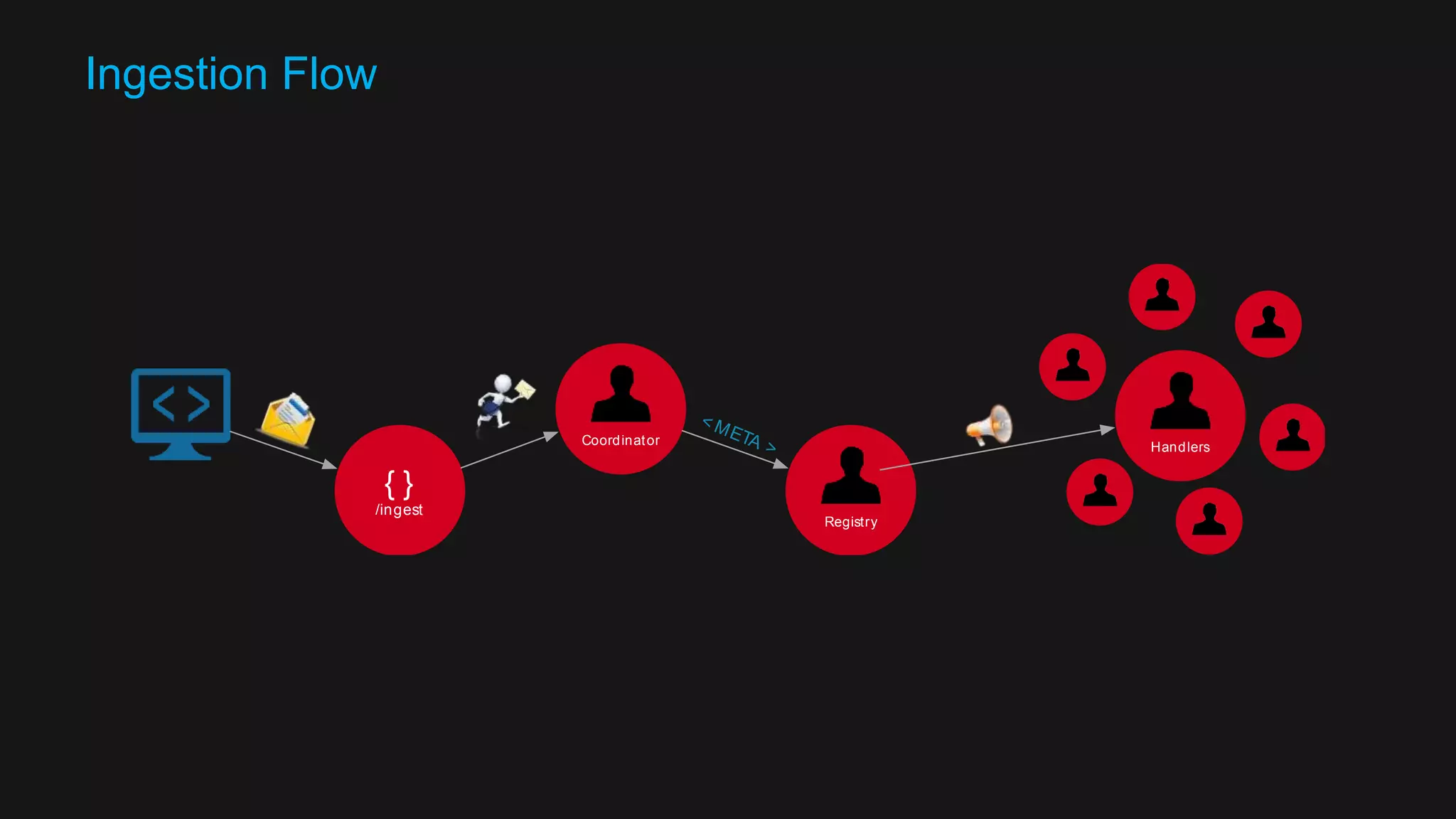
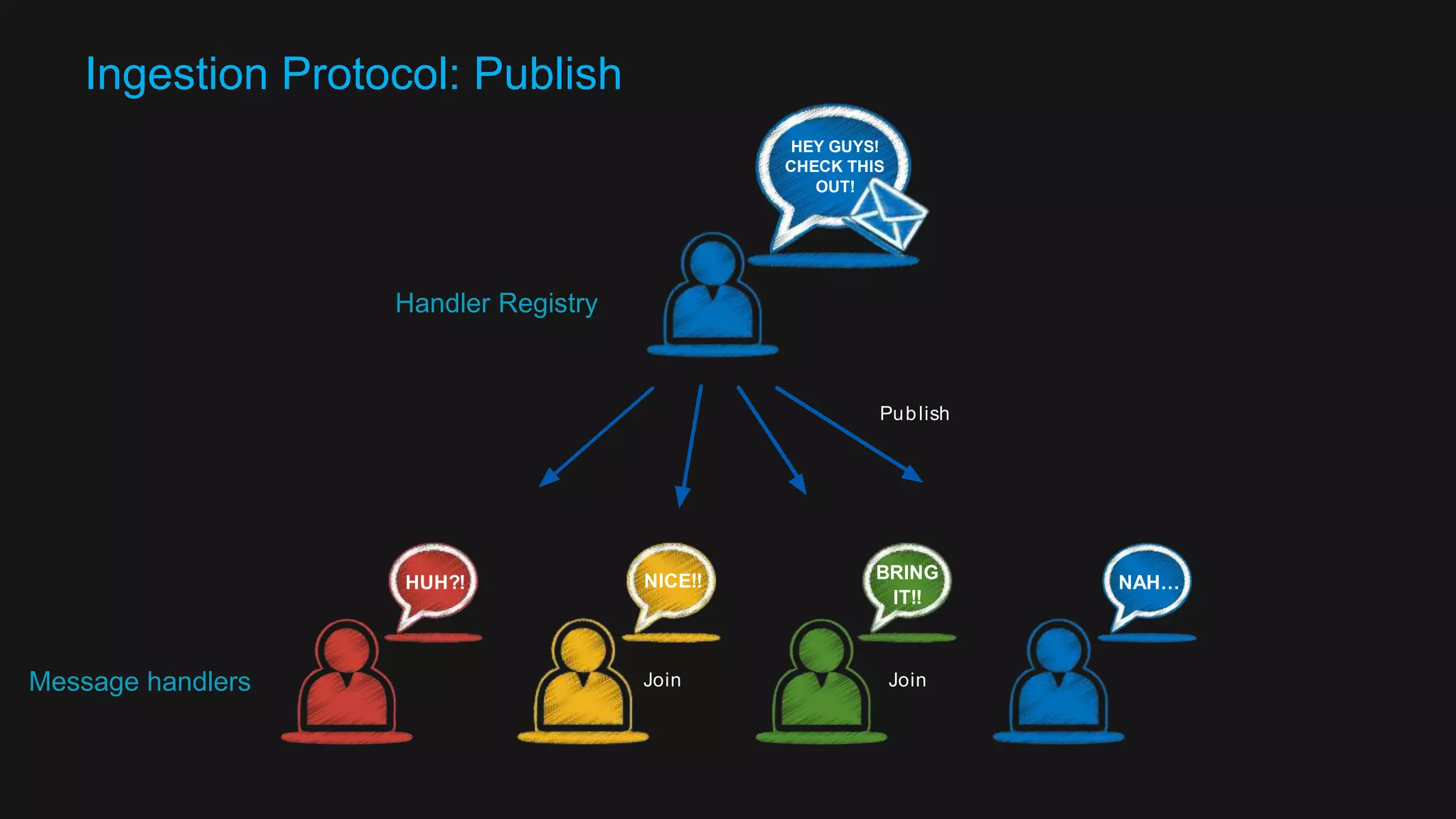
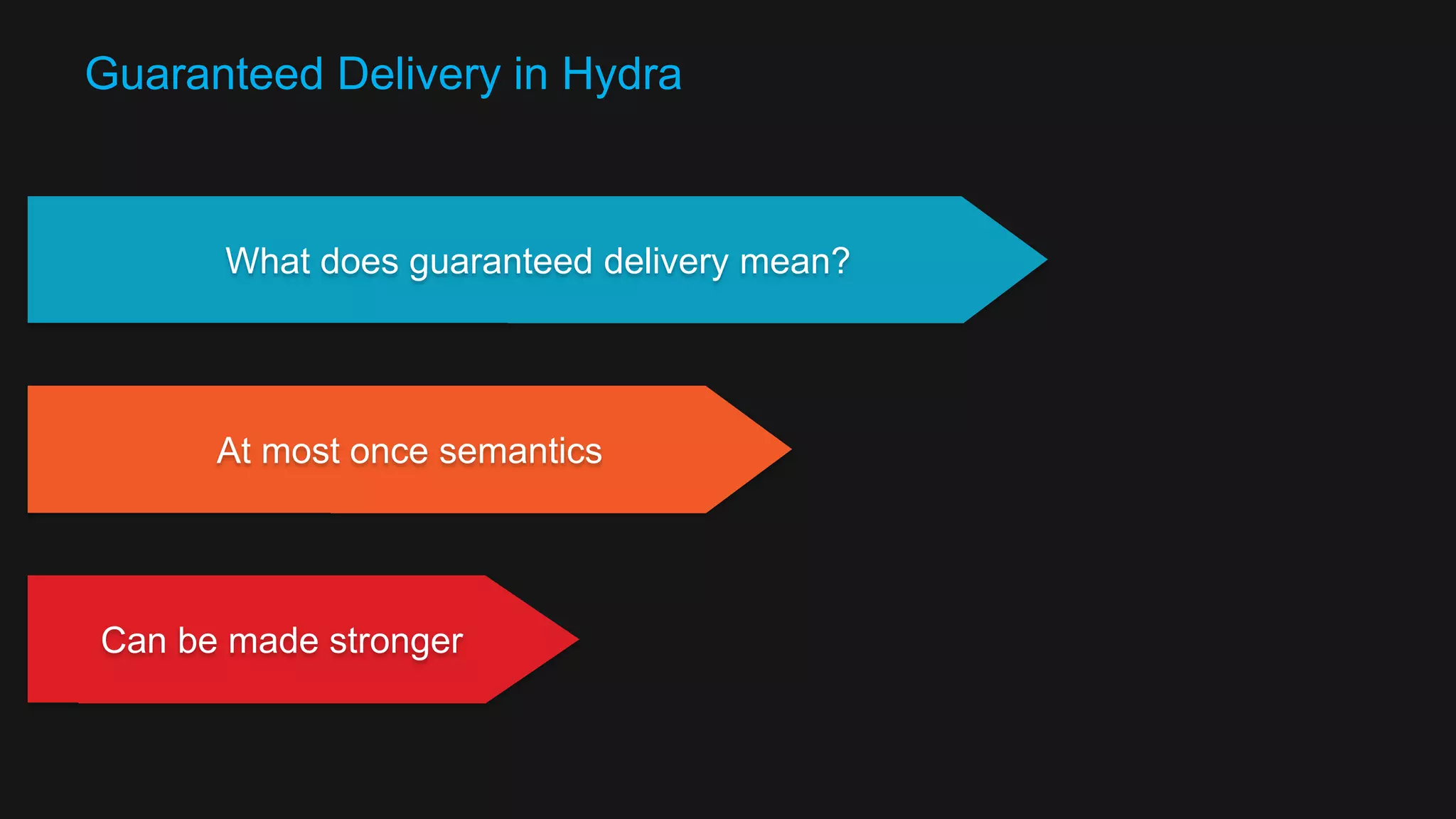
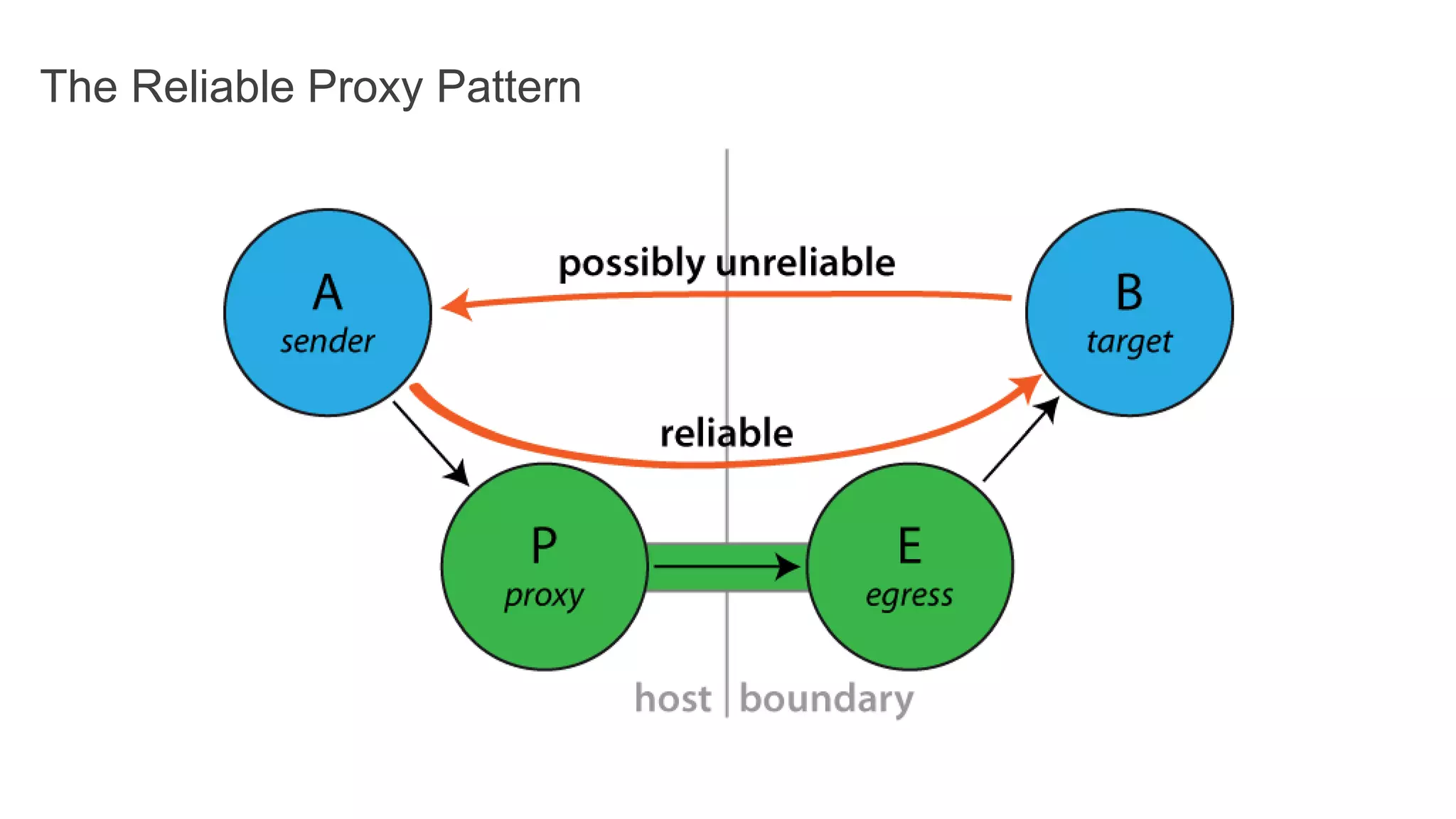
The document discusses the design of a reactive data platform, emphasizing challenges and good practices in building resilient systems using tools like Akka, Kafka, and Spark. It covers asynchronous communication, eventual consistency, and patterns for effective data ingestion, as well as anti-patterns to avoid. The focus is on employing strategies that ensure efficient processing, error handling, and system scalability in complex software architectures.