Download as PDF, PPTX





































![Indexing Paths Path Description / Default path for the collection. Recursive /name/? Hash or Range Indexes for predicates and sorts /name/* Index path for all paths under the specified label. (multiple levels down) /name/[]/prop/? Index path required to serve iteration and JOIN queries against arrays of objects like [{prop: "a"}, {prop: "b"}]:](https://image.slidesharecdn.com/cosmosdbfordbadev-171130161429/75/CosmosDB-for-DBAs-Developers-54-2048.jpg)



![Indexes Inclusion / Exclusion includedPaths: [ { “path”: “/mainContent/*”, “indexes”:[ { “kind”: “Hash”, “dataType”: “String”, “precision”: 20 } ] } ] excludedPaths: [ { “path”: “/nonIndexedContent/*” } ]](https://image.slidesharecdn.com/cosmosdbfordbadev-171130161429/75/CosmosDB-for-DBAs-Developers-58-2048.jpg)

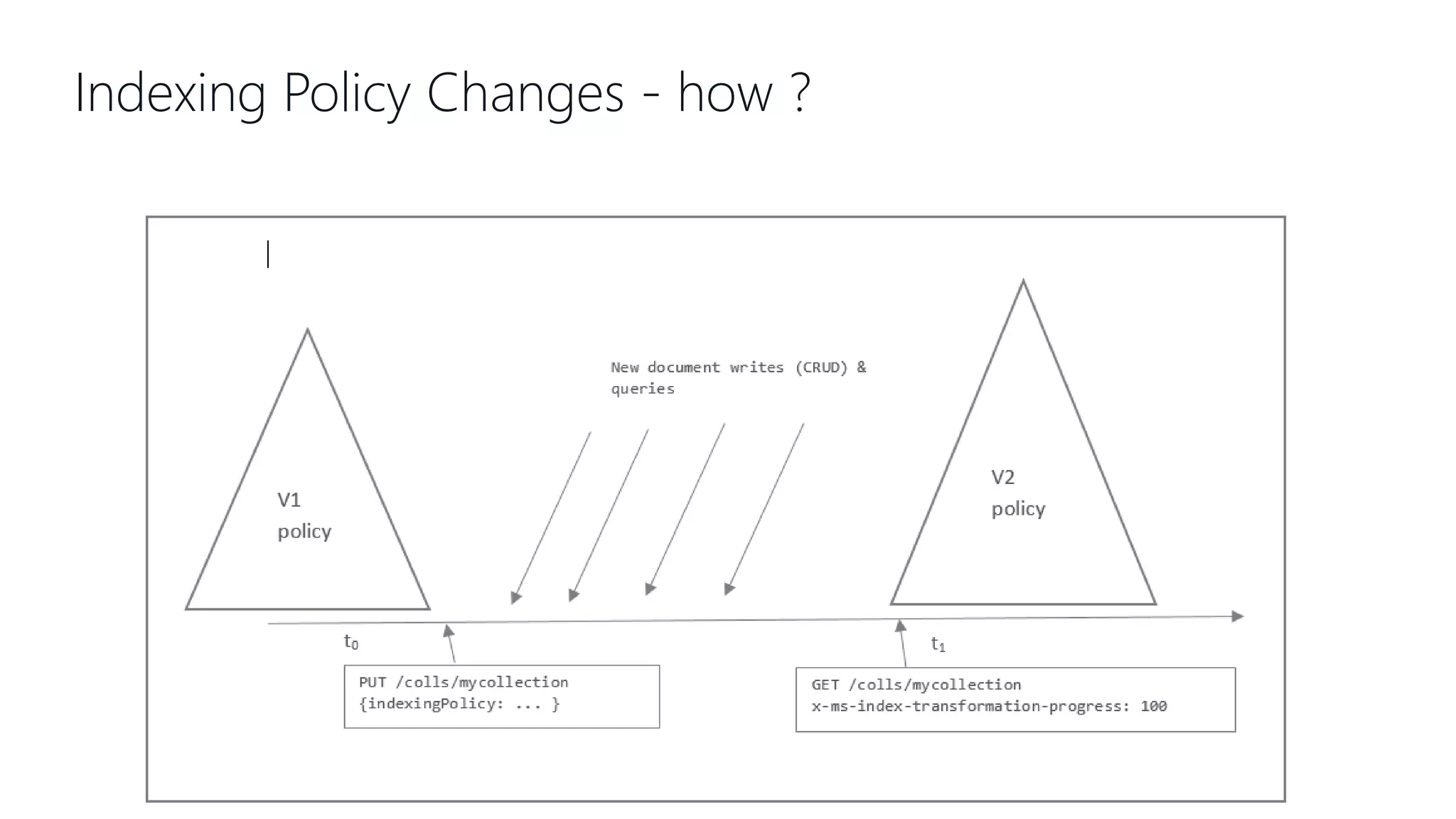

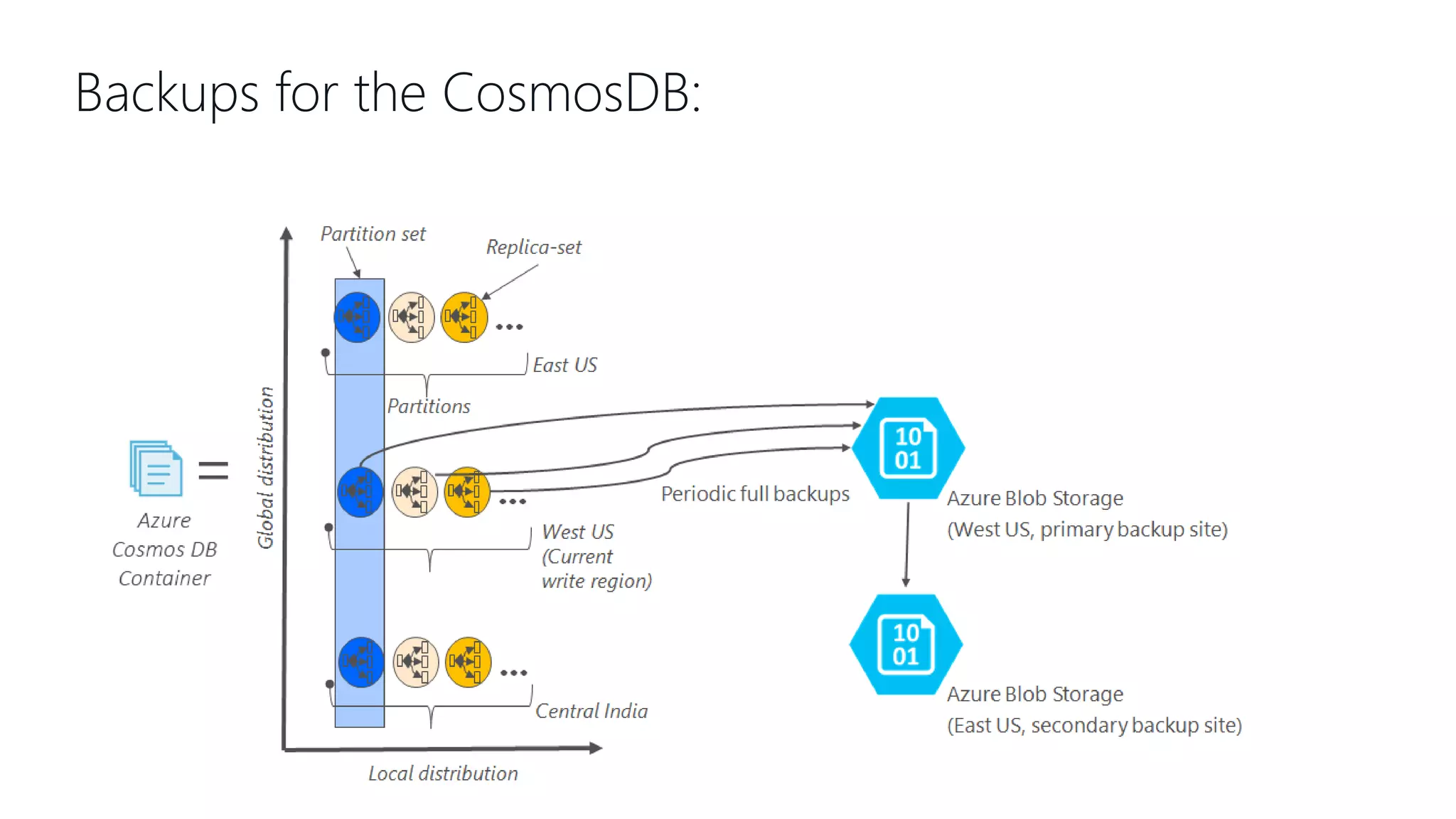
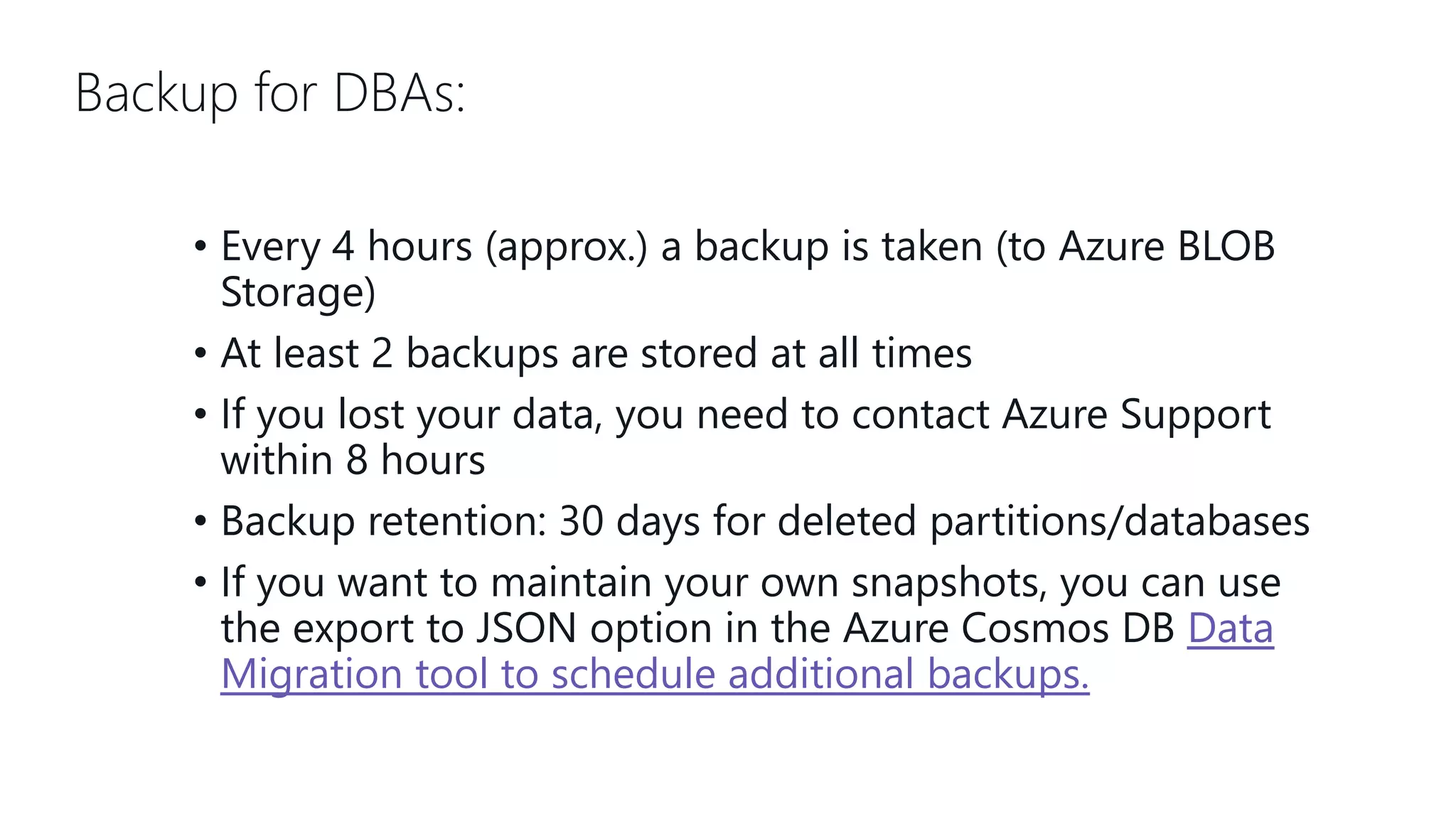
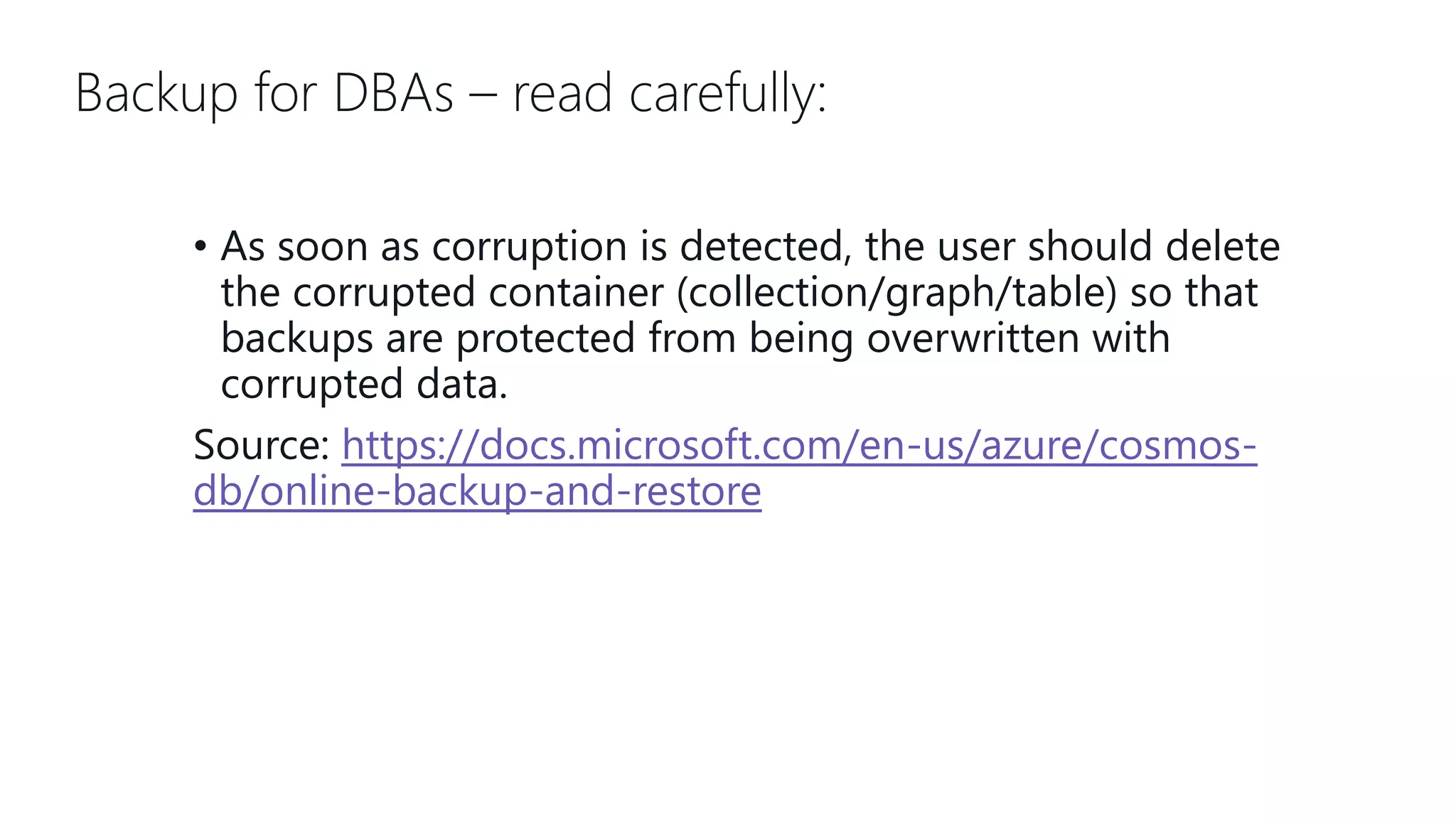


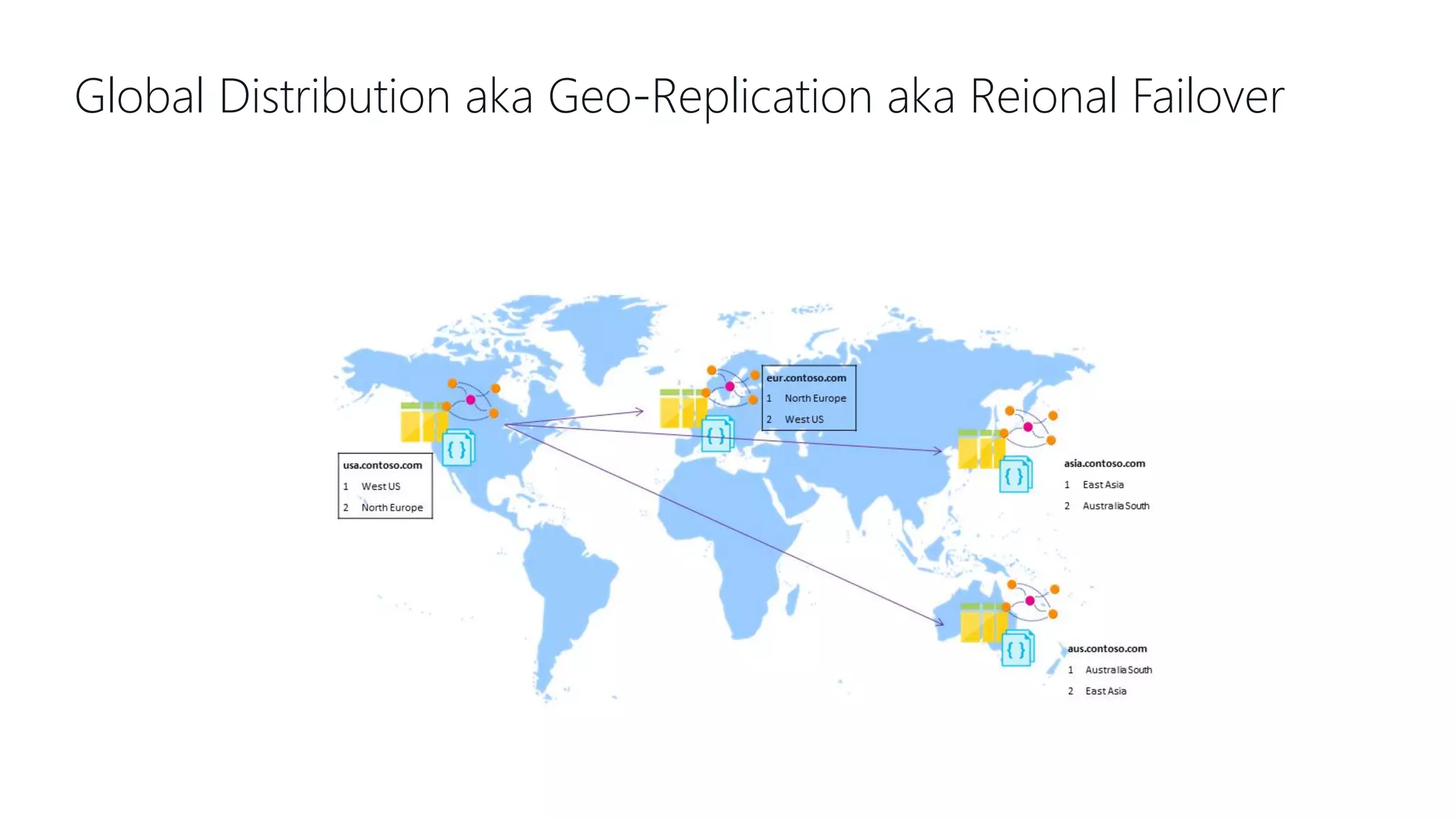
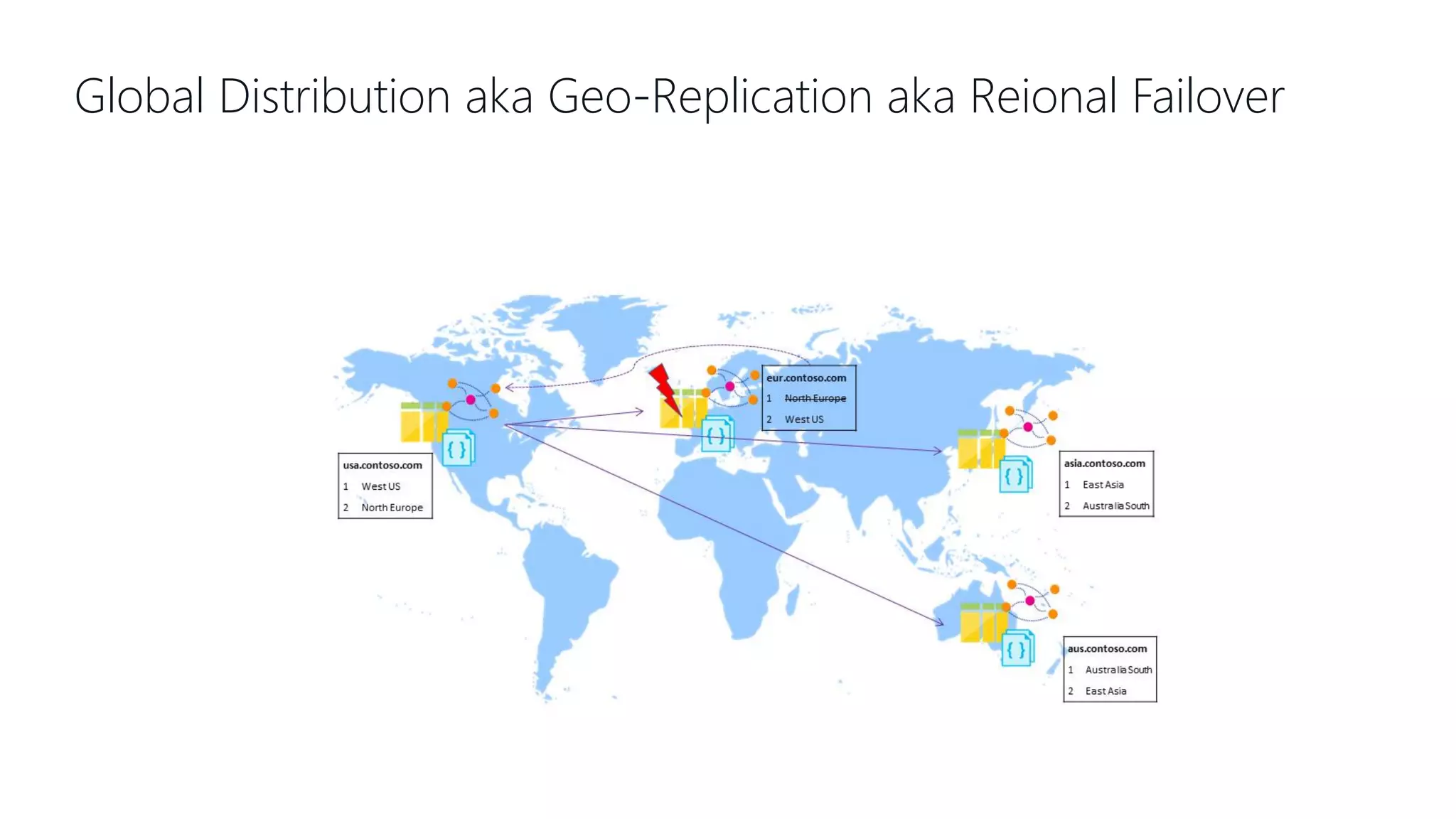
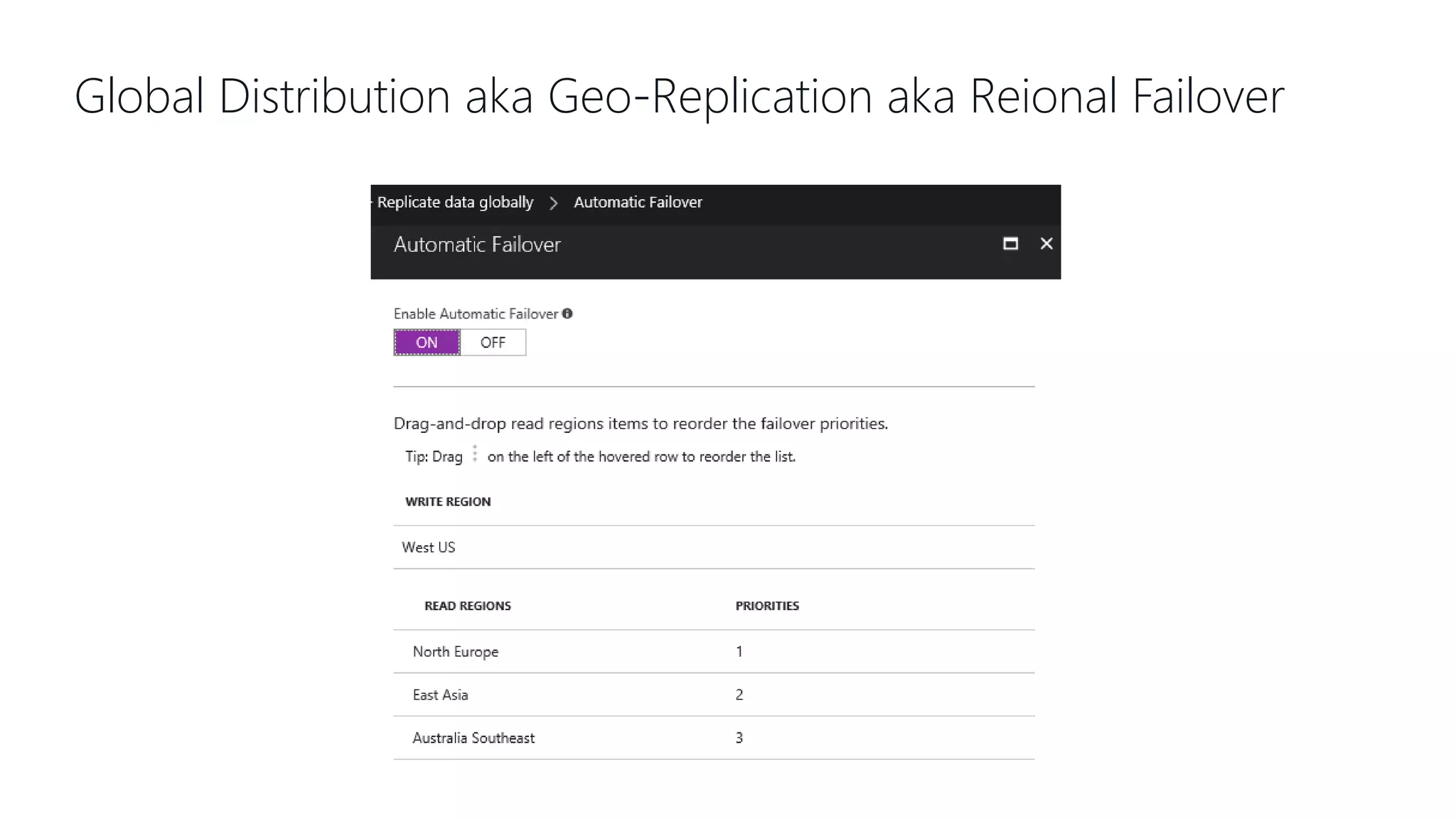
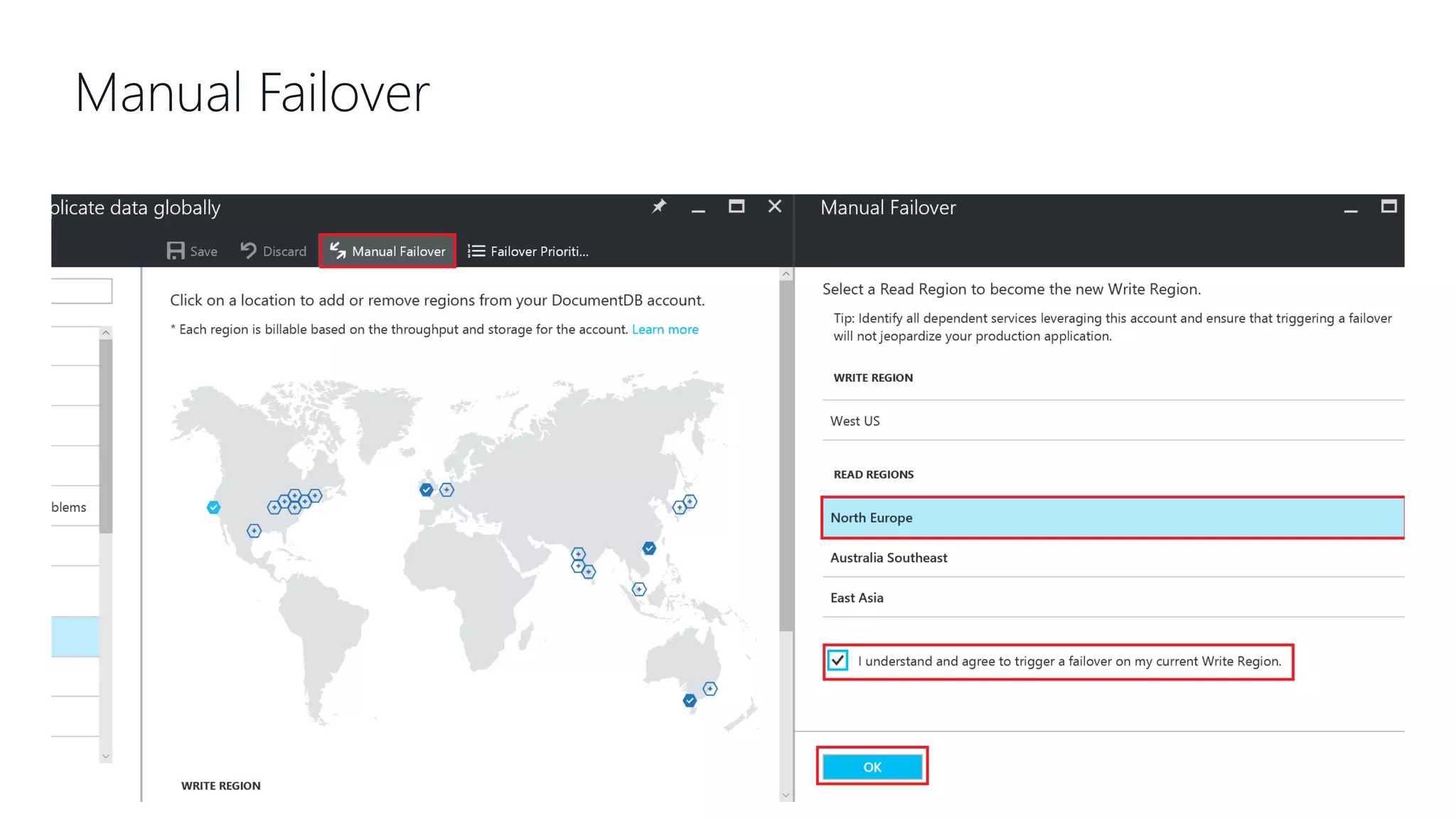

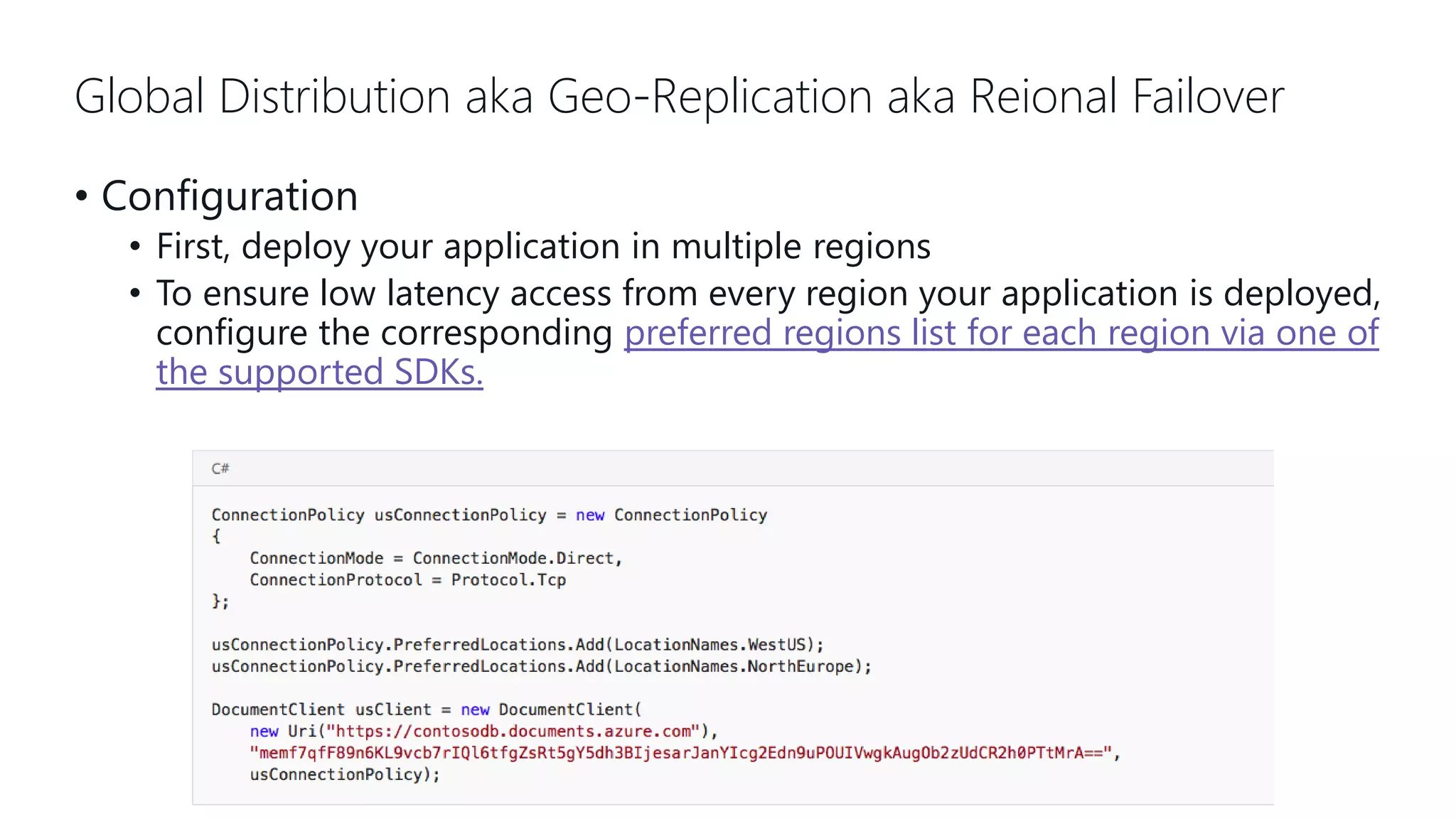













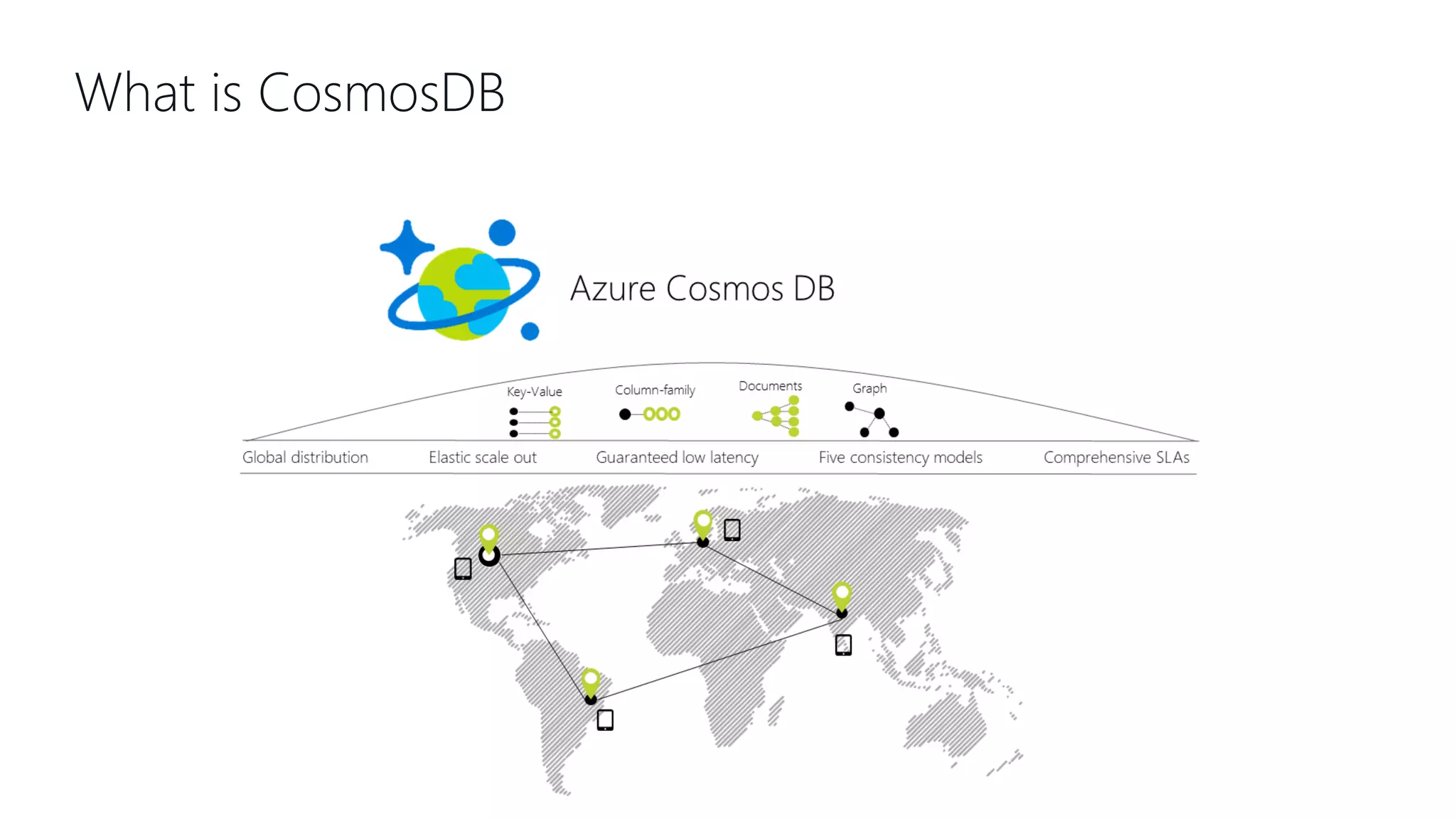
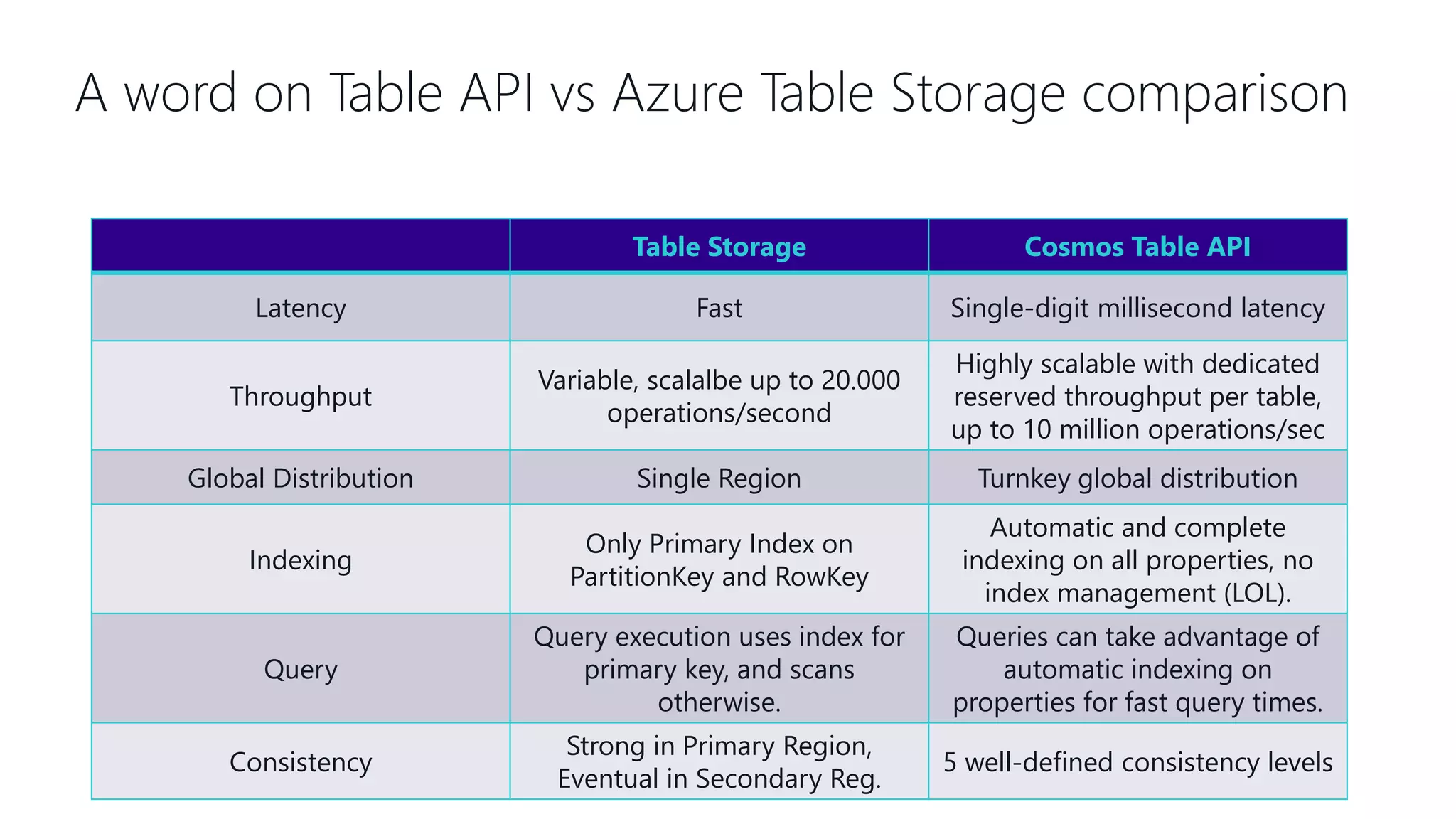
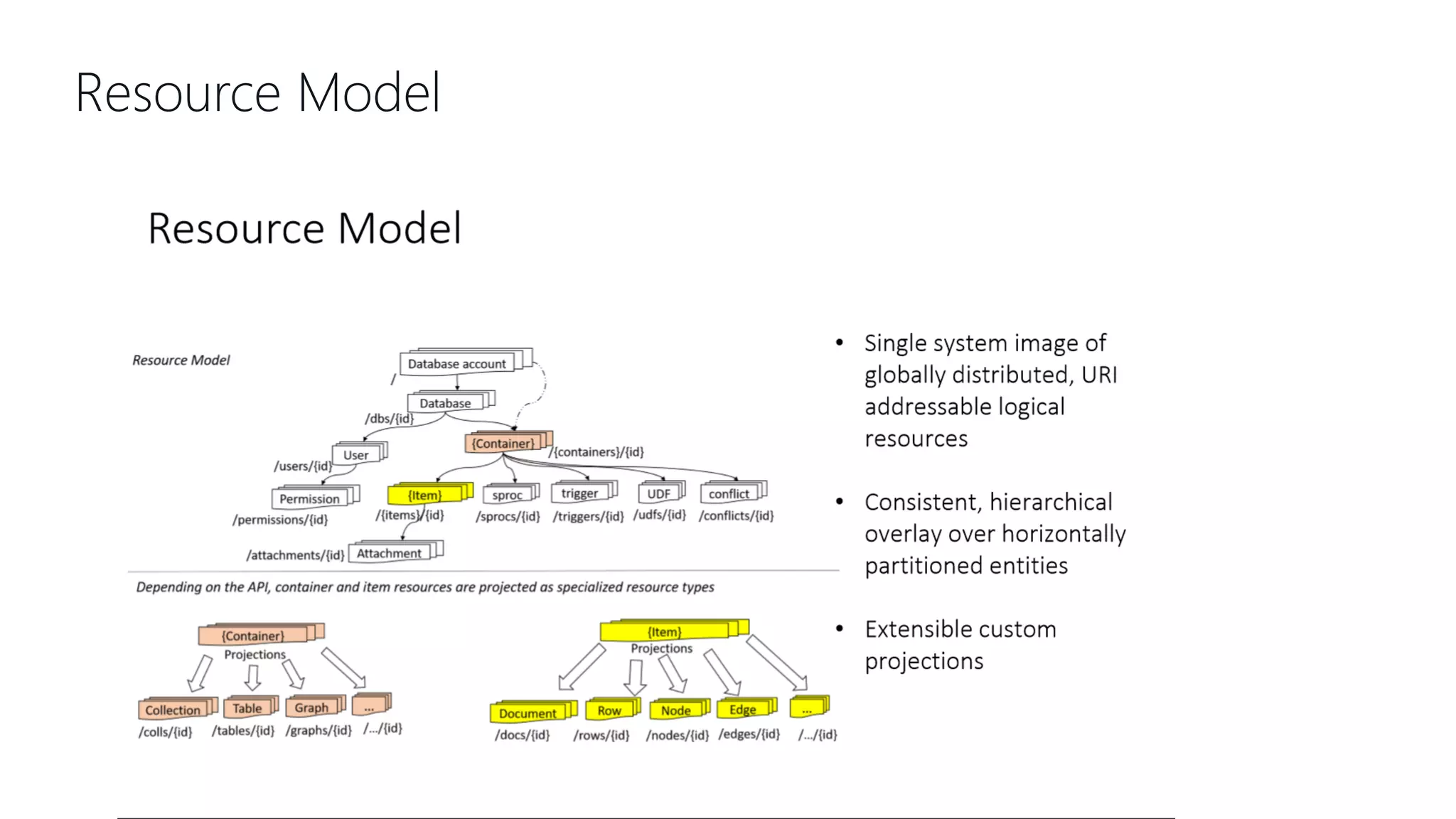
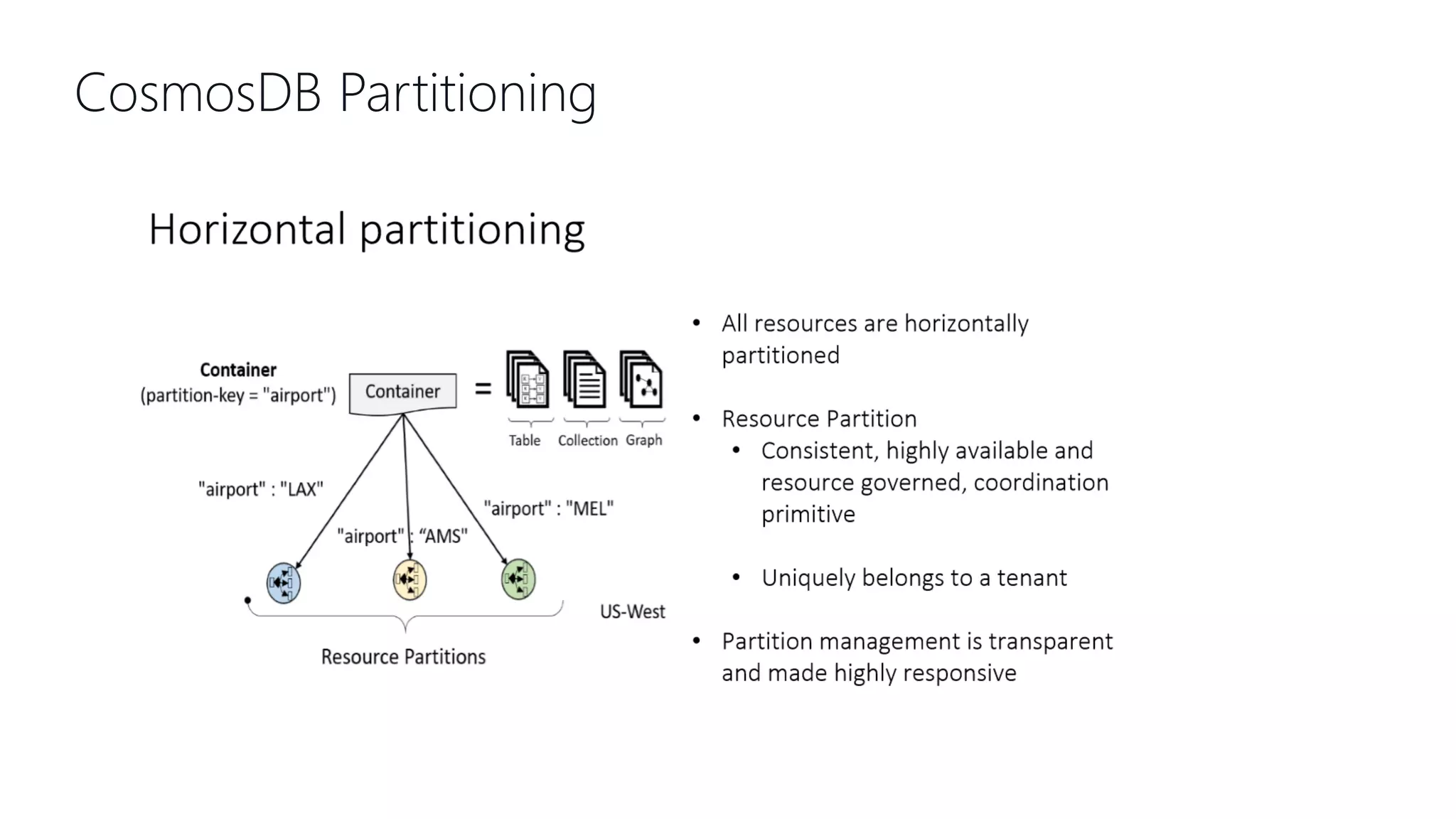
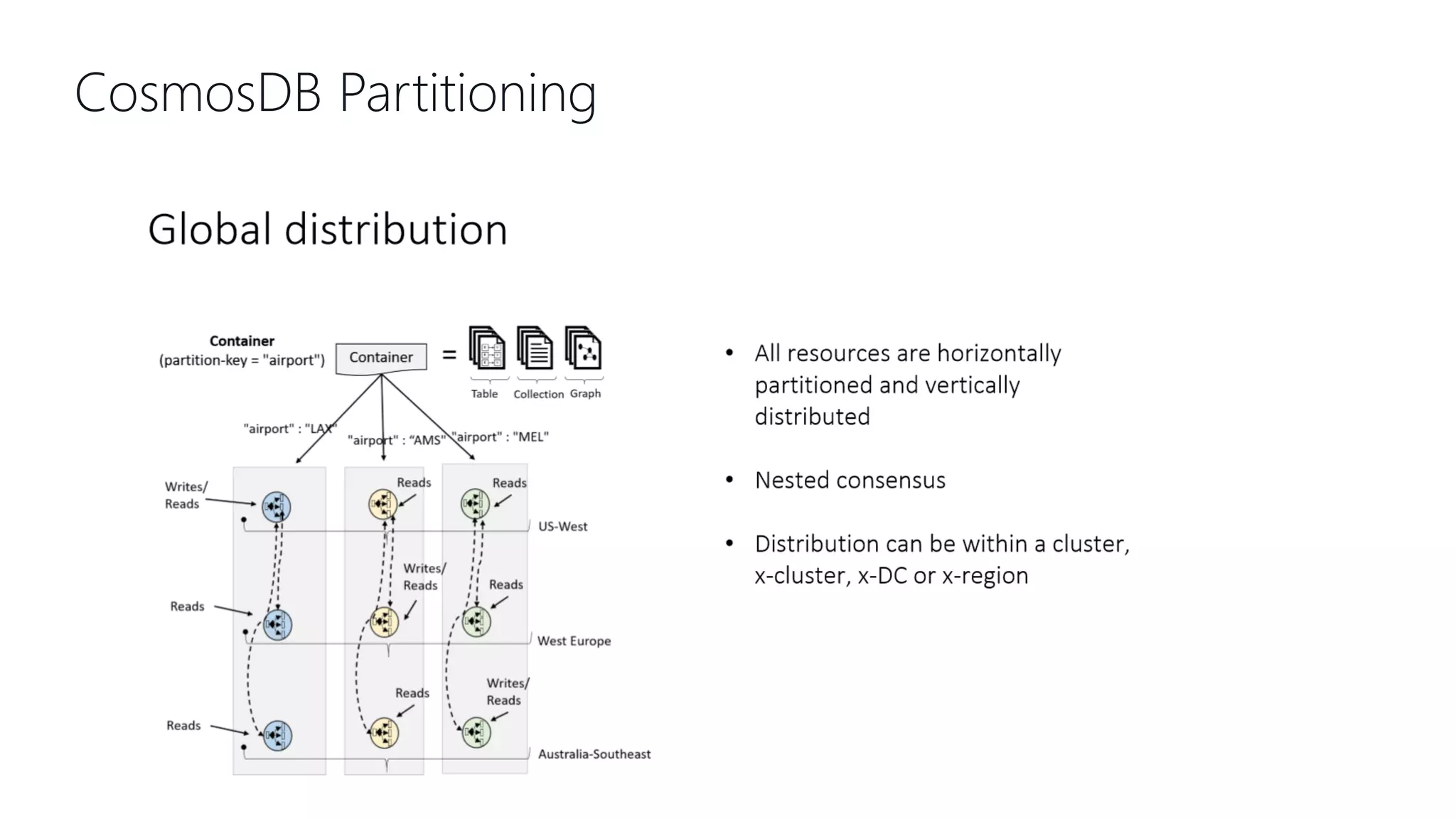
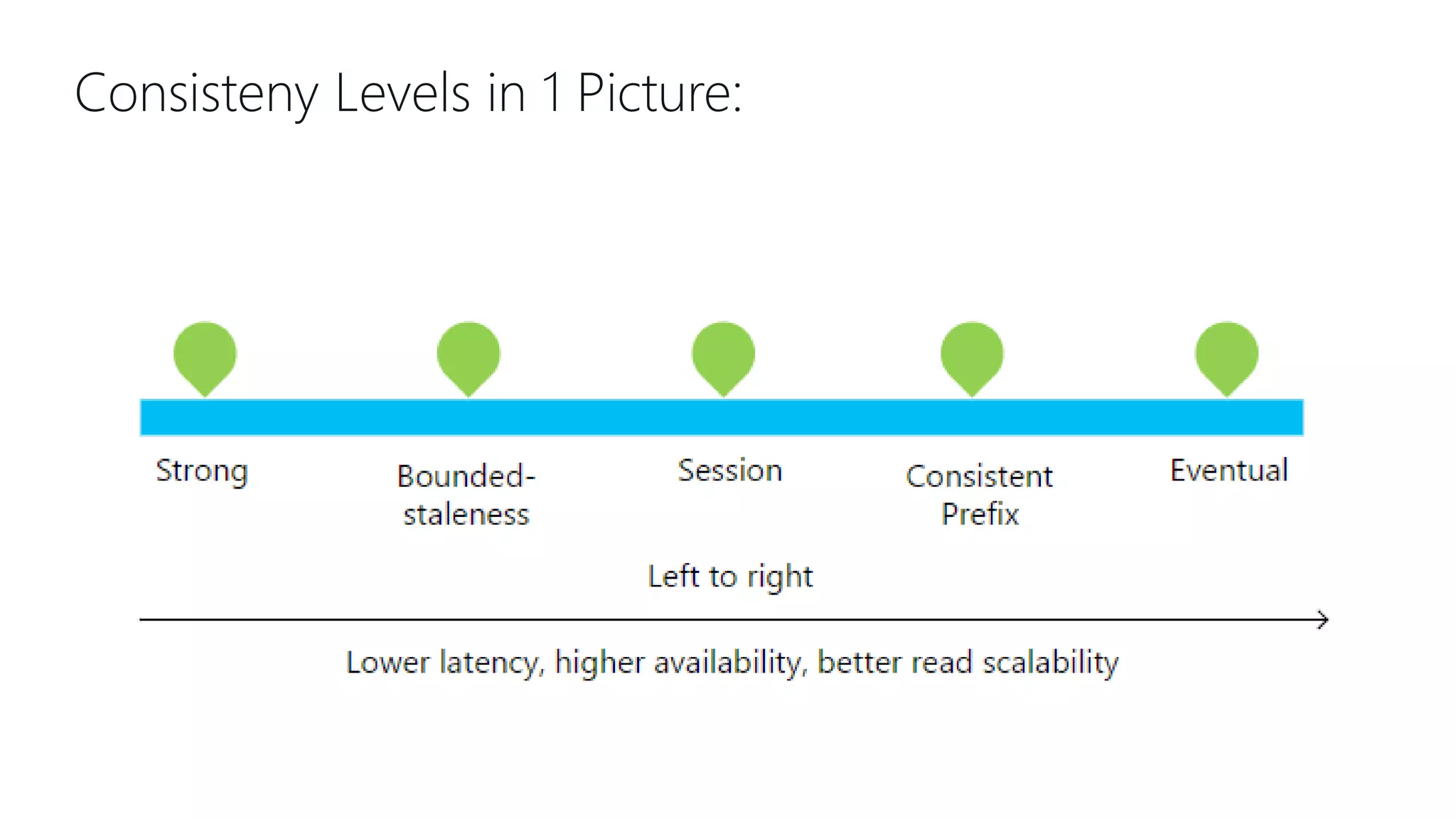
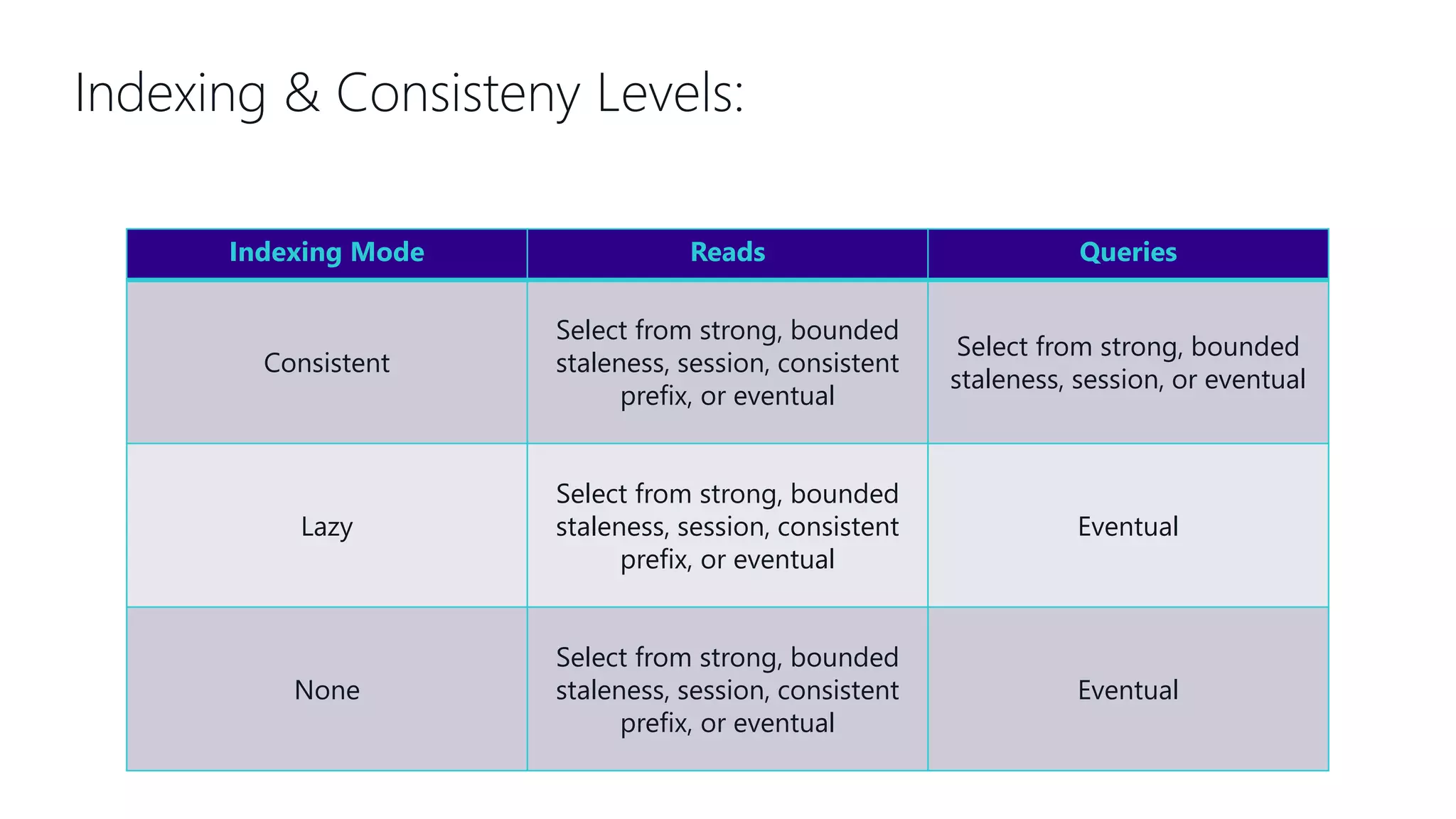
This document provides an overview and introduction to Cosmos DB. It discusses what Cosmos DB is, its data models, APIs, partitioning, and global distribution. It explains why Cosmos DB was created to address limitations of traditional databases. Key aspects covered include throughput and consistency levels, indexing, backups, failovers, and using Cosmos DB for developers and database administrators. The document also discusses migration tools, limitations, and integrations with PowerBI and geospatial data.