Introduction to ParallelComputing Ananth Grama, Anshul Gupta, George Karypis, and Vipin Kumar To accompany the text ``Introduction to Parallel Computing'', Addison Wesley
2.
Course Objectives &Outcomes To understand different parallel programming models CO1: Understand various Parallel Paradigm
3.
1: Introduction toParallel Computing Syllabus: Introduction to Parallel Computing: Motivating Parallelism Modern Processor: Stored-program computer architecture, General-purpose Cache-based Microprocessor architecture Parallel Programming Platforms: Implicit Parallelism, Dichotomy of Parallel Computing Platforms, Physical Organization of Parallel Platforms, Communication Costs in Parallel Machines. Levels of parallelism, Models: SIMD, MIMD, SIMT, SPMD, Data Flow Models, Demand-driven Computation, Architectures: N-wide superscalar architectures, multi-core, multi-threaded.
4.
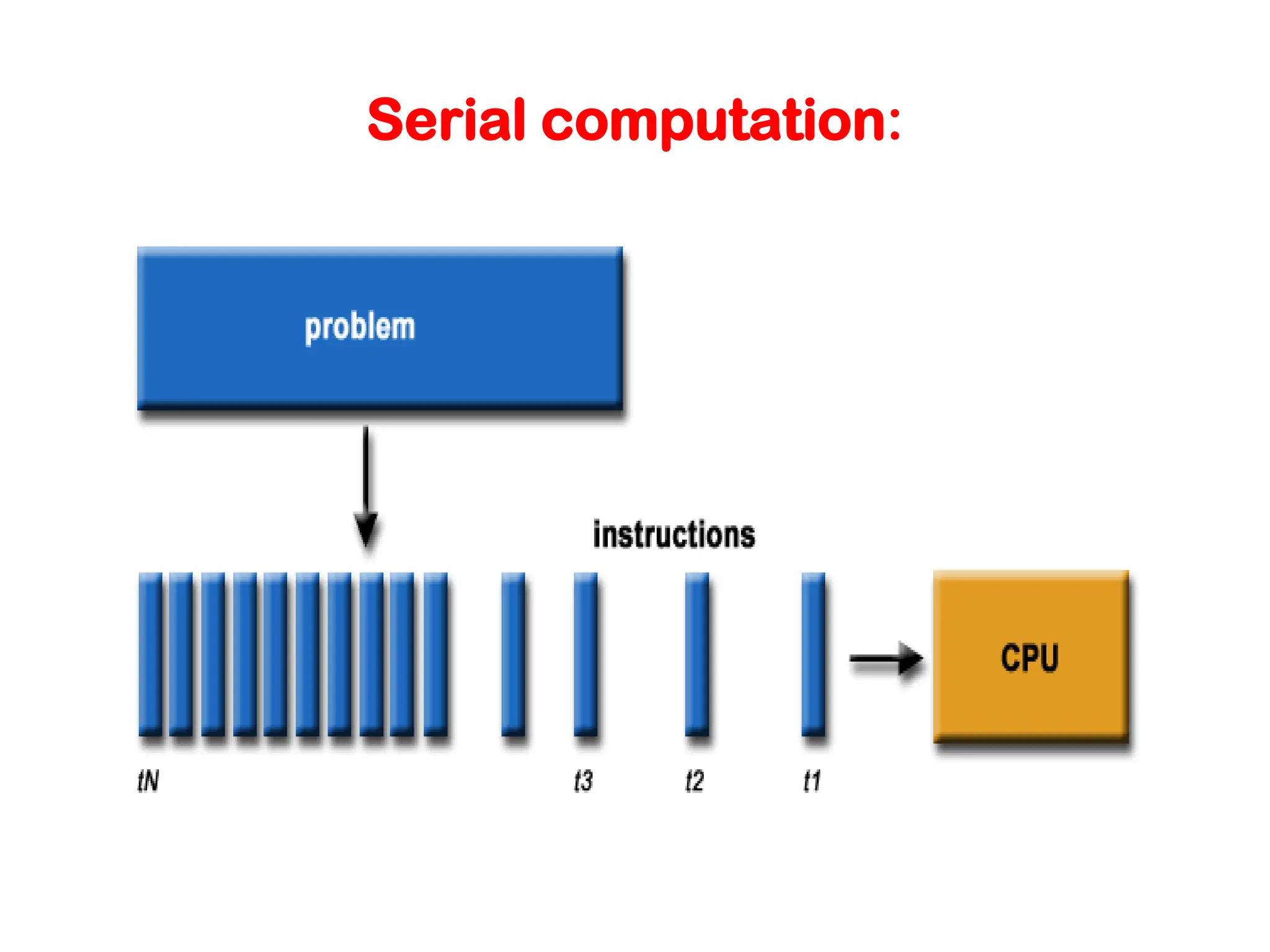
Introduction to Parallel Computing Traditionally,software has been written for serial computation: – To be run on a single computer having a single Central Processing Unit (CPU); – A problem is broken into a discrete series of instructions. – Instructions are executed one after another. – Only one instruction may execute at any moment in time.
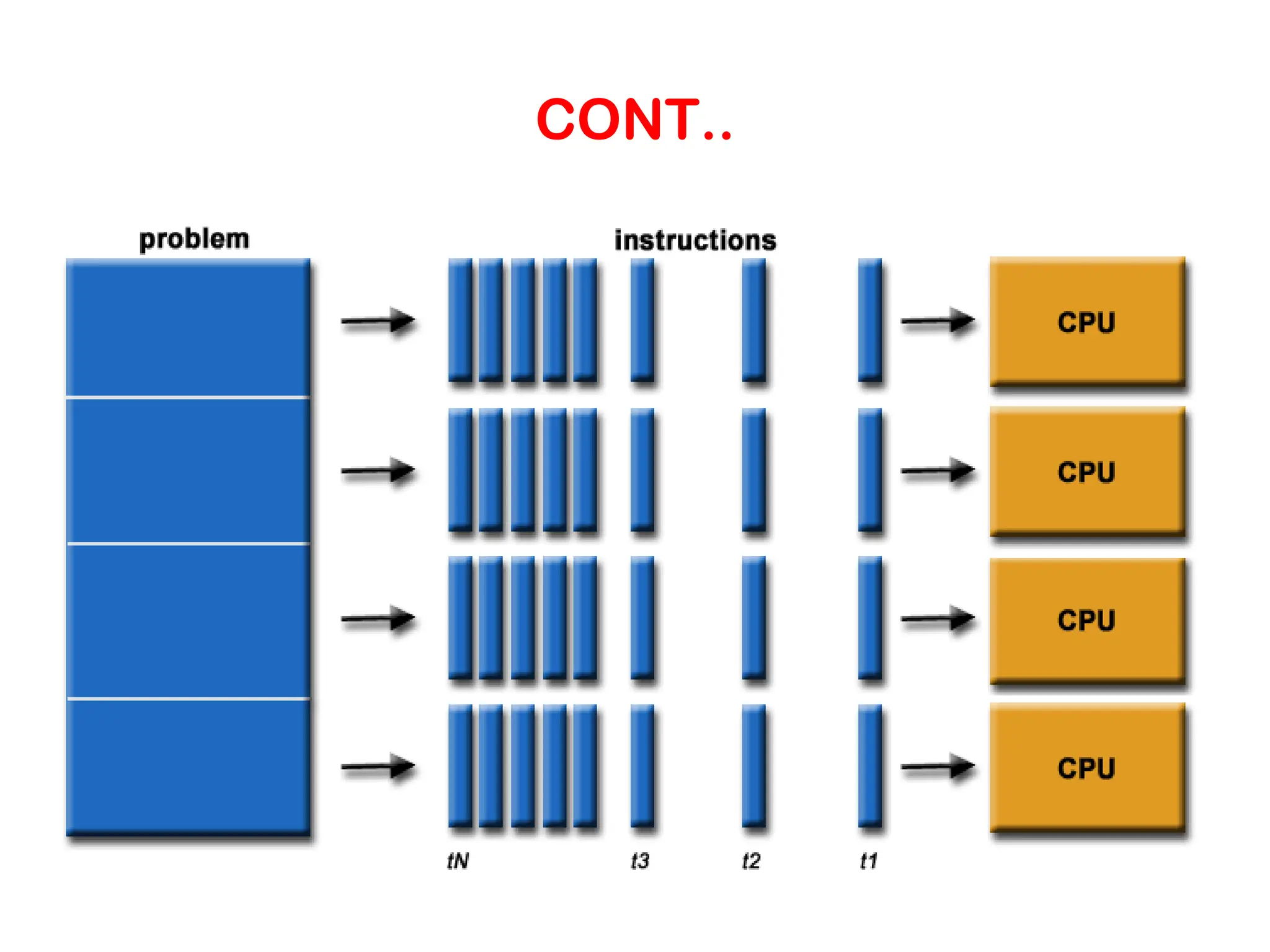
Parallel Computing – Inthe simplest sense, parallel computing is the simultaneous use of multiple compute resources to solve a computational problem. – To be run using multiple CPUs – A problem is broken into discrete parts that can be solved concurrently – Each part is further broken down to a series of instructions – Instructions from each part execute simultaneously on different CPUs
Motivating Parallelism • Developmentof parallel software has traditionally been thought of as time and effort intensive. • This can be largely attributed to the inherent complexity of specifying and coordinating concurrent tasks, a lack of portable algorithms, standardized environments, and software development toolkits. 1. The Computational Power Argument – from Transistors to FLOPS 2. The Memory/Disk Speed Argument 3. The Data Communication Argument
9.
The Computational PowerArgument – from Transistors to FLOPS … • In 1965, Gordon Moore made the following simple observation: "The complexity for minimum component costs has increased at a rate of roughly a factor of two per year. Certainly over the short term this rate can be expected to continue, if not to increase. Over the longer term, the rate of increase is a bit more uncertain, although there is no reason to believe it will not remain nearly constant for at least 10 years. That means by 1975, the number of components per integrated circuit for minimum cost will be 65,000."
10.
The Memory/Disk SpeedArgument The overall speed of computation is determined not just by the speed of the processor, but also by the ability of the memory system to feed data to it. While clock rates of high-end processors have increased at roughly 40% per year over the past decade, DRAM access times have only improved at the rate of roughly 10% per year over this interval. • The overall performance of the memory system is determined by the fraction of the total memory requests that can be satisfied from the cache
11.
The Data Communication Argument •In many applications there are constraints on the location of data and/or resources across the Internet. • An example of such an application is mining of large commercial datasets distributed over a relatively low bandwidth network. • In such applications, even if the computing power is available to accomplish the required task without resorting to parallel computing, it is infeasible to collect the data at a central location. • In these cases, the motivation for parallelism comes not just from the need for computing resources but also from the infeasibility or undesirability of alternate (centralized) approaches. Reference Book: Ananth
12.
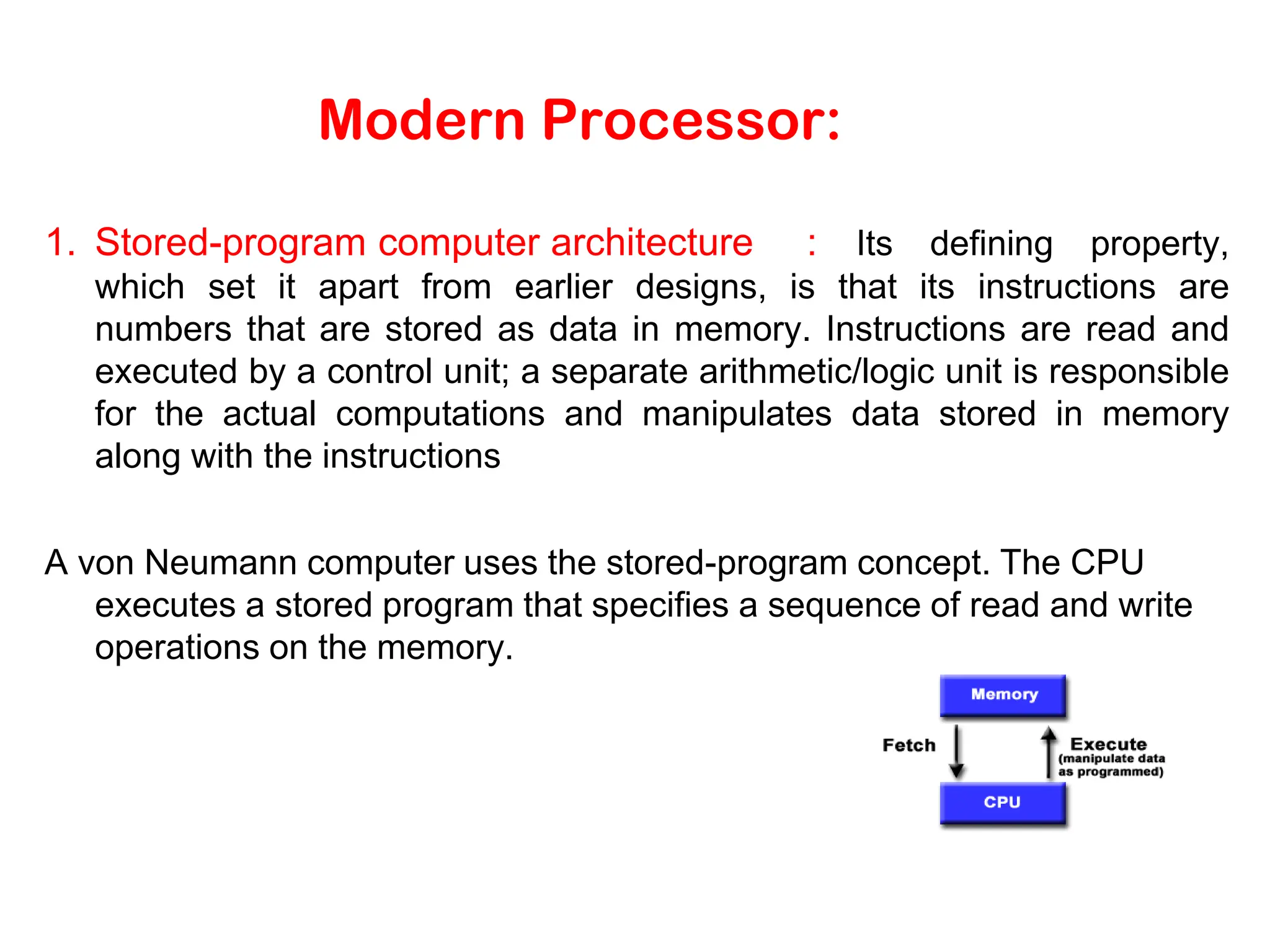
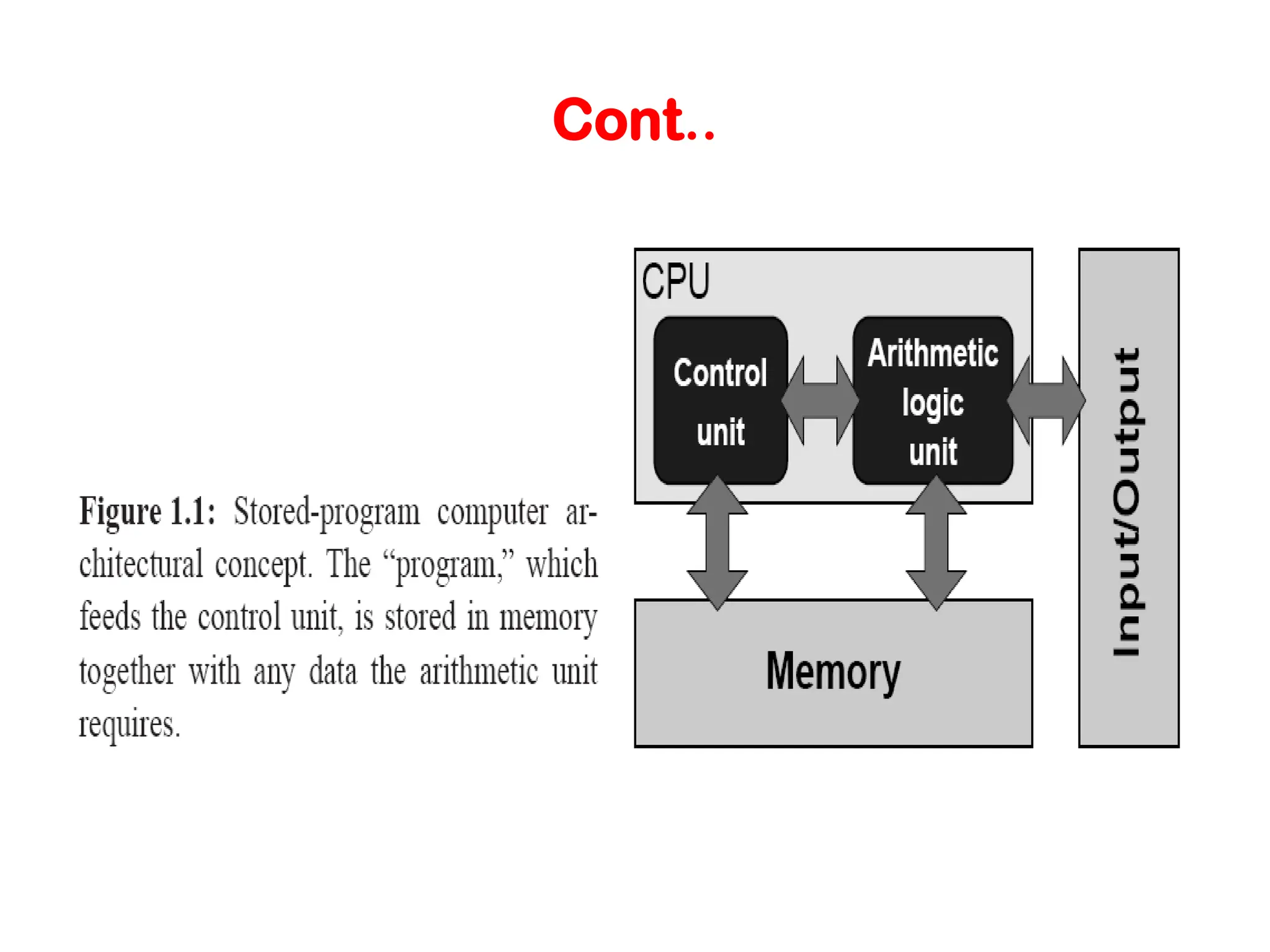
Modern Processor: 1. Stored-programcomputer architecture : Its defining property, which set it apart from earlier designs, is that its instructions are numbers that are stored as data in memory. Instructions are read and executed by a control unit; a separate arithmetic/logic unit is responsible for the actual computations and manipulates data stored in memory along with the instructions A von Neumann computer uses the stored-program concept. The CPU executes a stored program that specifies a sequence of read and write operations on the memory.
Cont.. Instructions and datamust be continuously fed to the control and arithmetic units, so that the speed of the memory interface poses a limitation on compute performance. The architecture is inherently sequential, processing a single instruction with (possibly) a single operand or a group of perands from memory.(SISD)
15.
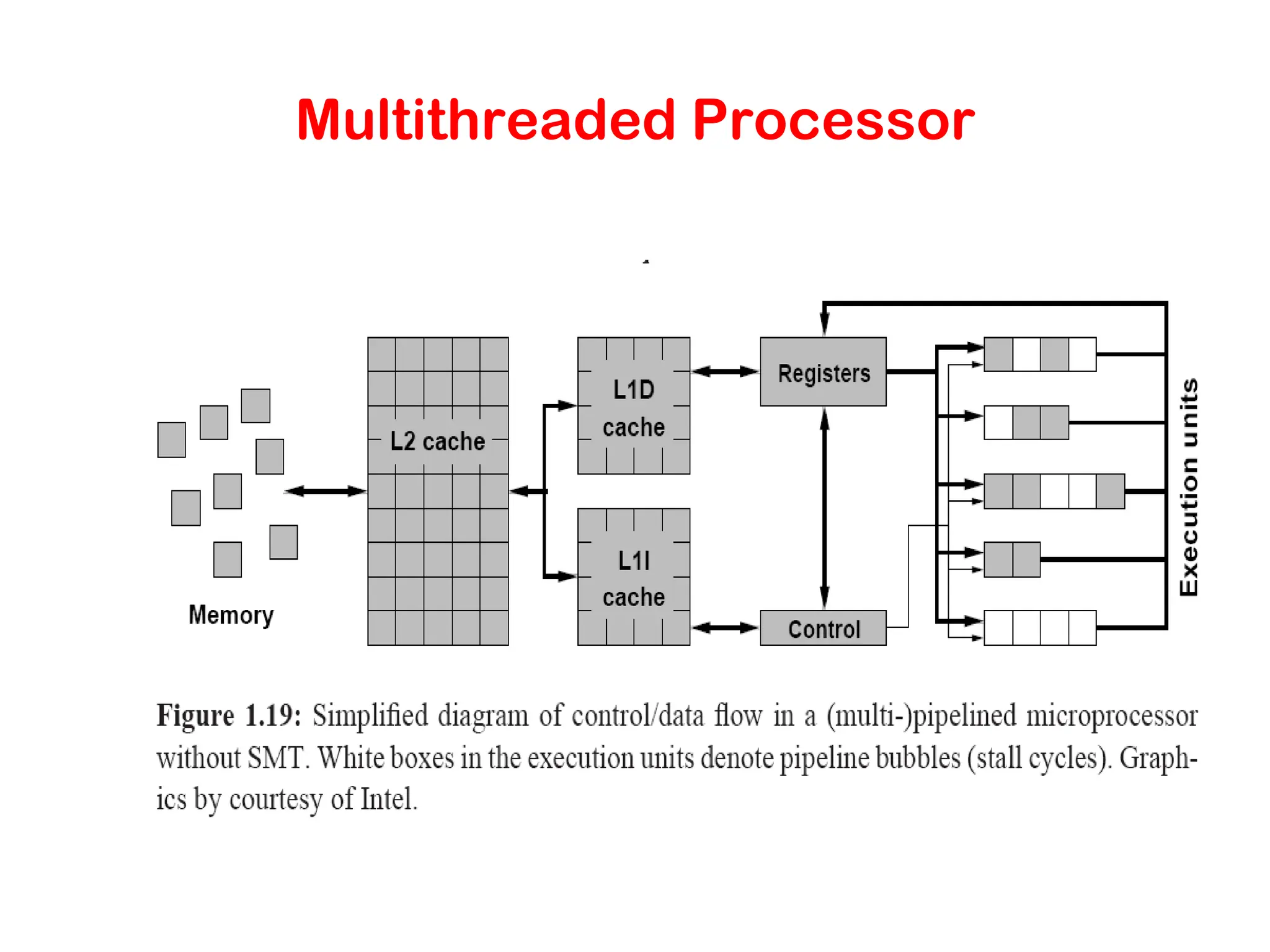
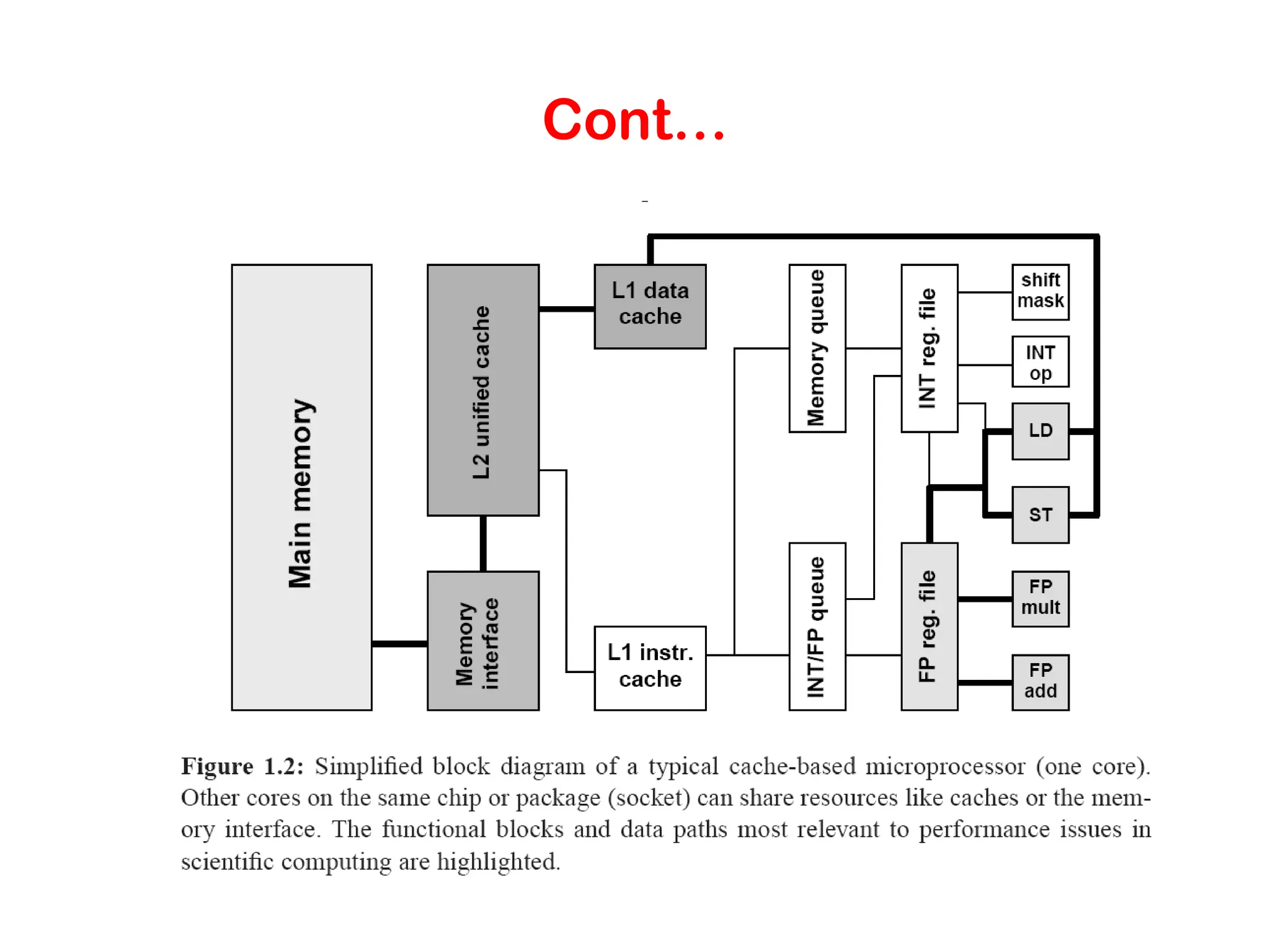
Cont.. 2. General-purpose Cache-basedMicroprocessor architecture : • Microprocessors implement stored pgm.... • Modern processors have lot of componets but only a small part does the actual work -AU for fp and int operations. • Rest are CPU regs, nowdays processors req all operands to reside in regs. • LD(load) and ST(store) units handle instruction transfer. • Queues for instructions • Finally Cache
References Book Title: Introductionto High Performance Computing for Scientist and Engineers Authors: George and Wellien • Reference: http://prdrklaina.weebly.com/uploads/5/7/7/3/5773421/int roduction_to_high_performance_computing_for_scientist s_and_engineers.pdf
18.
Scope of Parallelism •Conventional architectures coarsely comprise of a processor, memory system, and the datapath. • Each of these components present significant performance bottlenecks. • Parallelism addresses each of these components in significant ways. • Different applications utilize different aspects of parallelism - e.g., data itensive applications utilize high aggregate throughput, server applications utilize high aggregate network bandwidth, and scientific applications typically utilize high processing and memory system performance. • It is important to understand each of these performance bottlenecks.
19.
Implicit Parallelism: Trendsin Microprocessor Architectures • Microprocessor clock speeds have posted impressive gains over the past two decades (two to three orders of magnitude). • Higher levels of device integration have made available a large number of transistors. • The question of how best to utilize these resources is an important one. • Current processors use these resources in multiple functional units and execute multiple instructions in the same cycle. • The precise manner in which these instructions are selected and executed provides impressive diversity in architectures.
20.
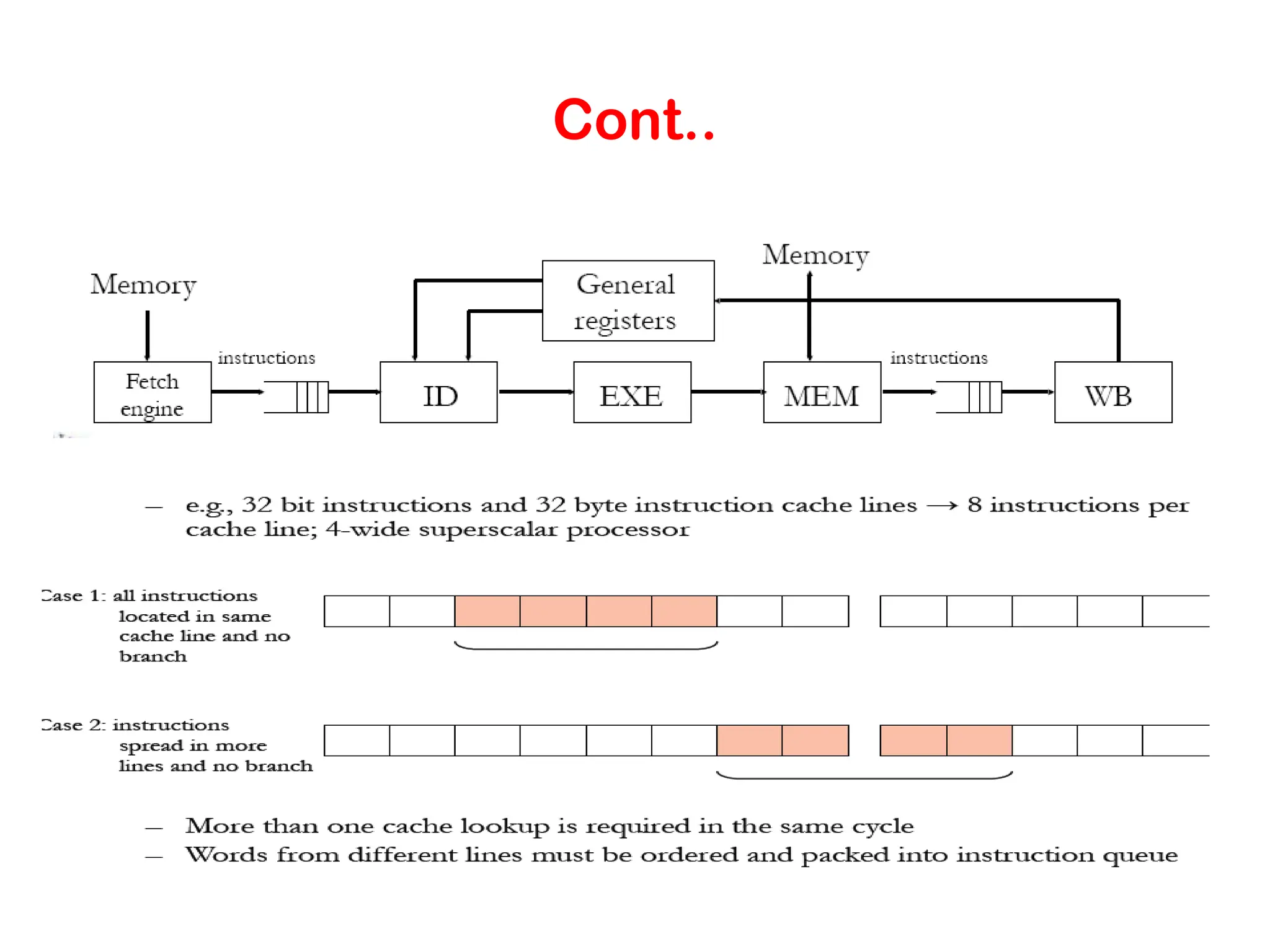
Pipelining and SuperscalarExecution • Pipelining overlaps various stages of instruction execution to achieve performance. • At a high level of abstraction, an instruction can be executed while the next one is being decoded and the next one is being fetched. • This is akin to an assembly line for manufacture of cars.
21.
Pipelining and SuperscalarExecution • Pipelining, however, has several limitations. • The speed of a pipeline is eventually limited by the slowest stage. • For this reason, conventional processors rely on very deep pipelines (20 stage pipelines in state-of-the-art Pentium processors). • However, in typical program traces, every 5-6th instruction is a conditional jump! This requires very accurate branch prediction. • The penalty of a misprediction grows with the depth of the pipeline, since a larger number of instructions will have to be flushed.
22.
Pipelining and SuperscalarExecution • One simple way of alleviating these bottlenecks is to use multiple pipelines. • The question then becomes one of selecting these instructions. • In Below example, there is some wastage of resources due to data dependencies.
Superscalar Execution: AnExample • In the above example, there is some wastage of resources due to data dependencies. • The example also illustrates that different instruction mixes with identical semantics can take significantly different execution time.
25.
Superscalar Execution • Schedulingof instructions is determined by a number of factors: – True Data Dependency: The result of one operation is an input to the next. – Resource Dependency: Two operations require the same resource. – Branch Dependency: Scheduling instructions across conditional branch statements cannot be done deterministically a-priori. – The scheduler, a piece of hardware looks at a large number of instructions in an instruction queue and selects appropriate number of instructions to execute concurrently based on these factors. – The complexity of this hardware is an important constraint on superscalar processors.
26.
Superscalar Execution: Issue Mechanisms •In the simpler model, instructions can be issued only in the order in which they are encountered. That is, if the second instruction cannot be issued because it has a data dependency with the first, only one instruction is issued in the cycle. This is called in-order issue. • In a more aggressive model, instructions can be issued out of order. In this case, if the second instruction has data dependencies with the first, but the third instruction does not, the first and third instructions can be co- scheduled. This is also called dynamic issue. • Performance of in-order issue is generally limited.
27.
Superscalar Execution: Efficiency Considerations •Not all functional units can be kept busy at all times. • If during a cycle, no functional units are utilized, this is referred to as vertical waste. • If during a cycle, only some of the functional units are utilized, this is referred to as horizontal waste. • Due to limited parallelism in typical instruction traces, dependencies, or the inability of the scheduler to extract parallelism, the performance of superscalar processors is eventually limited. • Conventional microprocessors typically support four-way superscalar execution.
28.
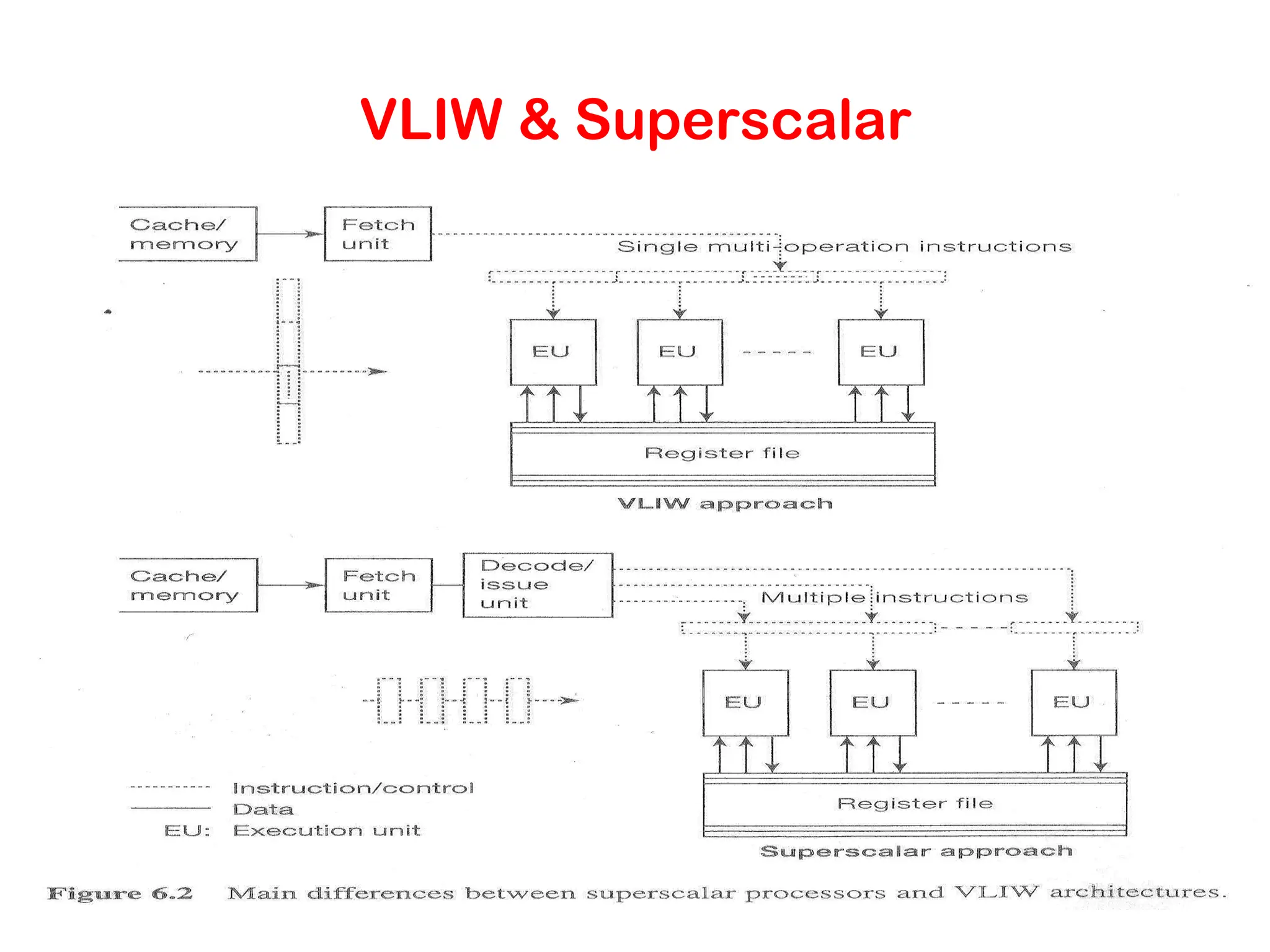
Very Long InstructionWord (VLIW) Processors • The hardware cost and complexity of the superscalar scheduler is a major consideration in processor design. • To address this issues, VLIW processors rely on compile time analysis to identify and bundle together instructions that can be executed concurrently. • These instructions are packed and dispatched together, and thus the name very long instruction word. • This concept was used with some commercial success in the Multiflow Trace machine (circa 1984). • Variants of this concept are employed in the Intel IA64 processors.
29.
Very Long InstructionWord (VLIW) Processors: Considerations • Issue hardware is simpler. • Compiler has a bigger context from which to select co- scheduled instructions. • Compilers, however, do not have runtime information such as cache misses. Scheduling is, therefore, inherently conservative. • Branch and memory prediction is more difficult. • VLIW performance is highly dependent on the compiler. A number of techniques such as loop unrolling, speculative execution, branch prediction are critical. • Typical VLIW processors are limited to 4-way to 8-way parallelism.
Limitations of Memory SystemPerformance • Memory system, and not processor speed, is often the bottleneck for many applications. • Memory system performance is largely captured by two parameters, latency and bandwidth. • Latency is the time from the issue of a memory request to the time the data is available at the processor. • Bandwidth is the rate at which data can be pumped to the processor by the memory system.
32.
Dichotomy of ParallelComputing Platforms • An explicitly parallel program must specify concurrency and interaction between concurrent subtasks. • The former is sometimes also referred to as the control structure and the latter as the communication model.
33.
Control Structure ofParallel Programs • Parallelism can be expressed at various levels of granularity - from instruction level to processes. • Between these extremes exist a range of models, along with corresponding architectural support.
34.
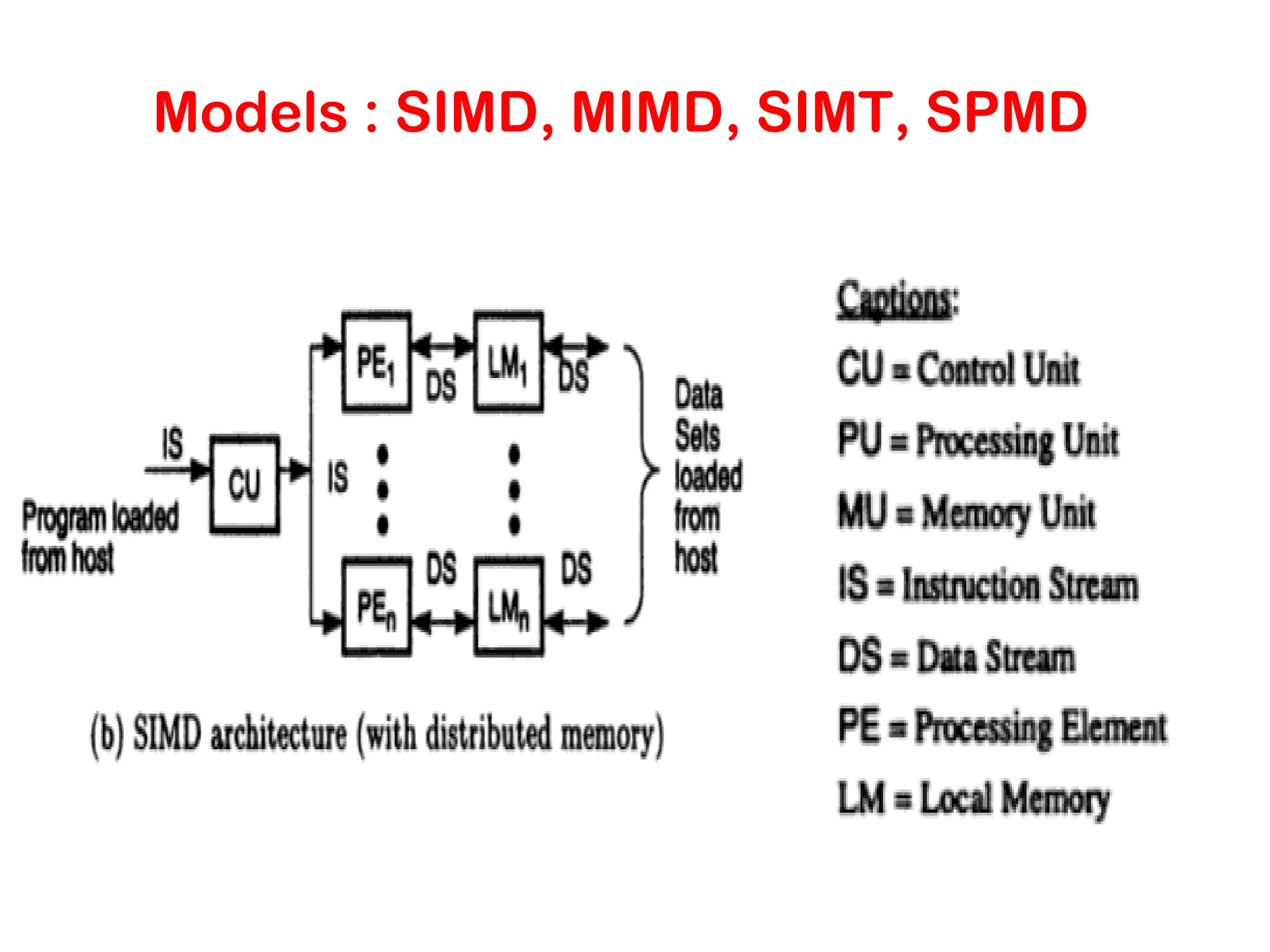
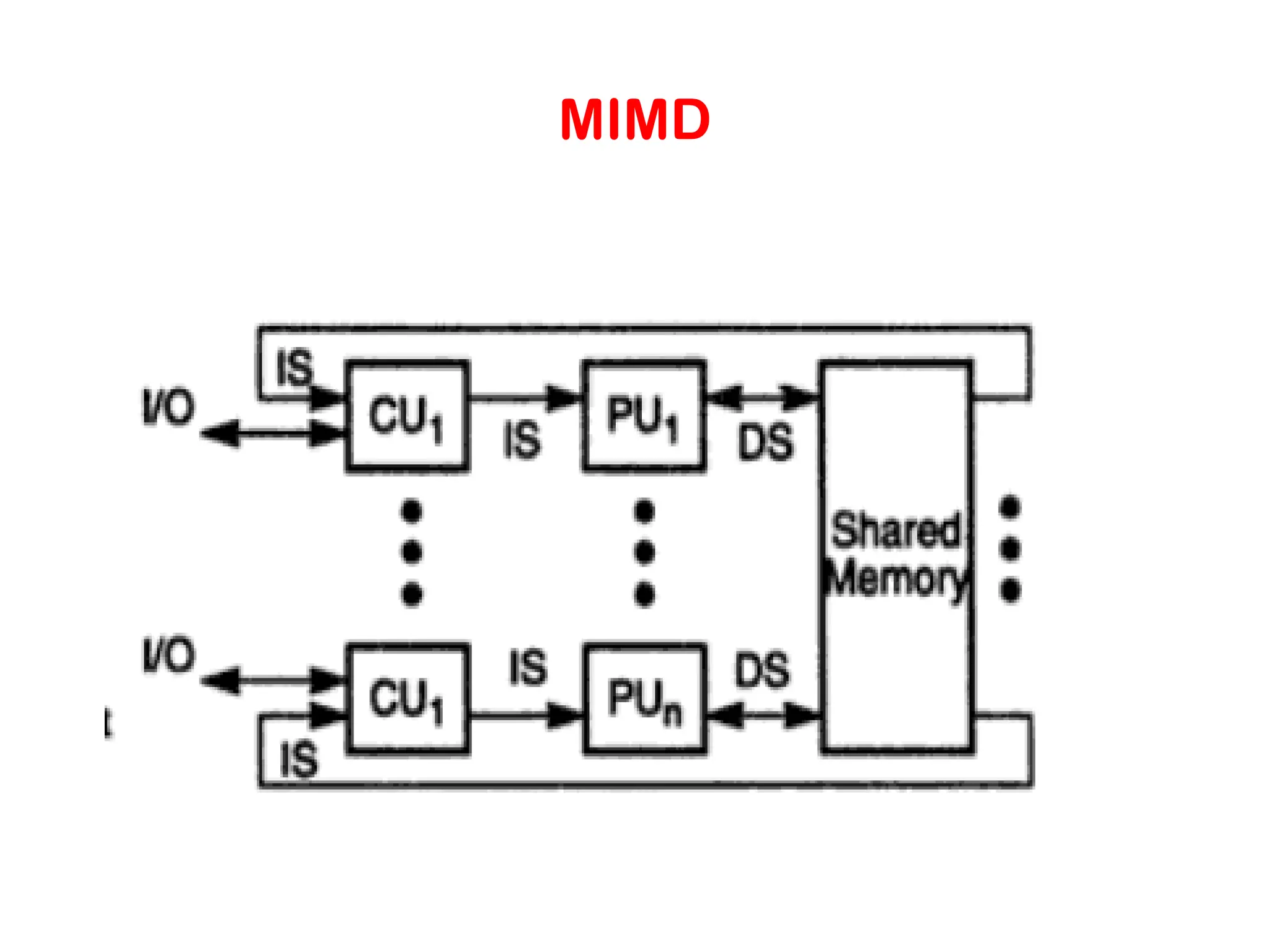
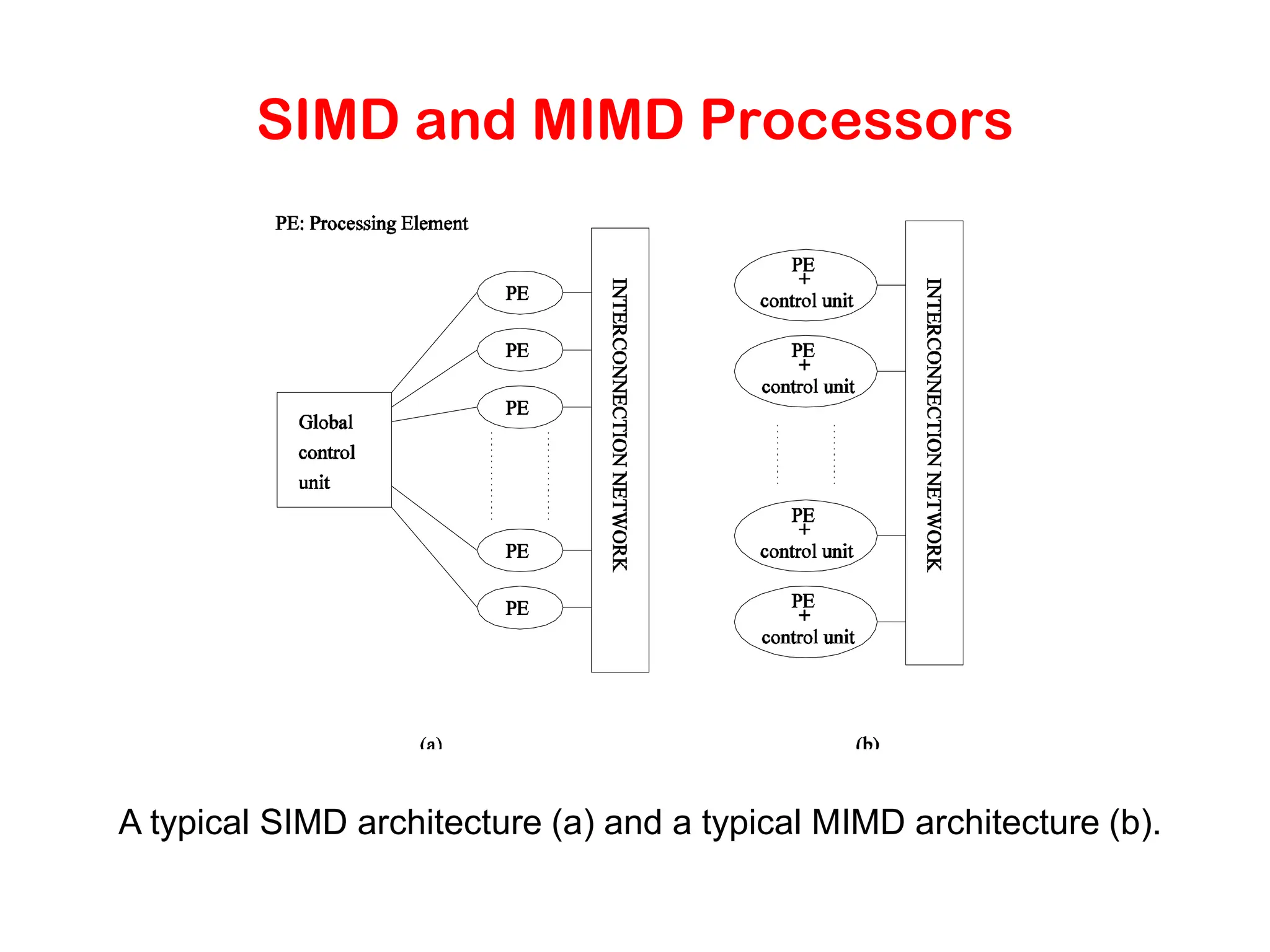
Control Structure ofParallel Programs • Processing units in parallel computers either operate under the centralized control of a single control unit or work independently. • If there is a single control unit that dispatches the same instruction to various processors (that work on different data), the model is referred to as single instruction stream, multiple data stream (SIMD). • If each processor has its own control control unit, each processor can execute different instructions on different data items. This model is called multiple instruction stream, multiple data stream (MIMD).
35.
SIMD and MIMDProcessors A typical SIMD architecture (a) and a typical MIMD architecture (b).
36.
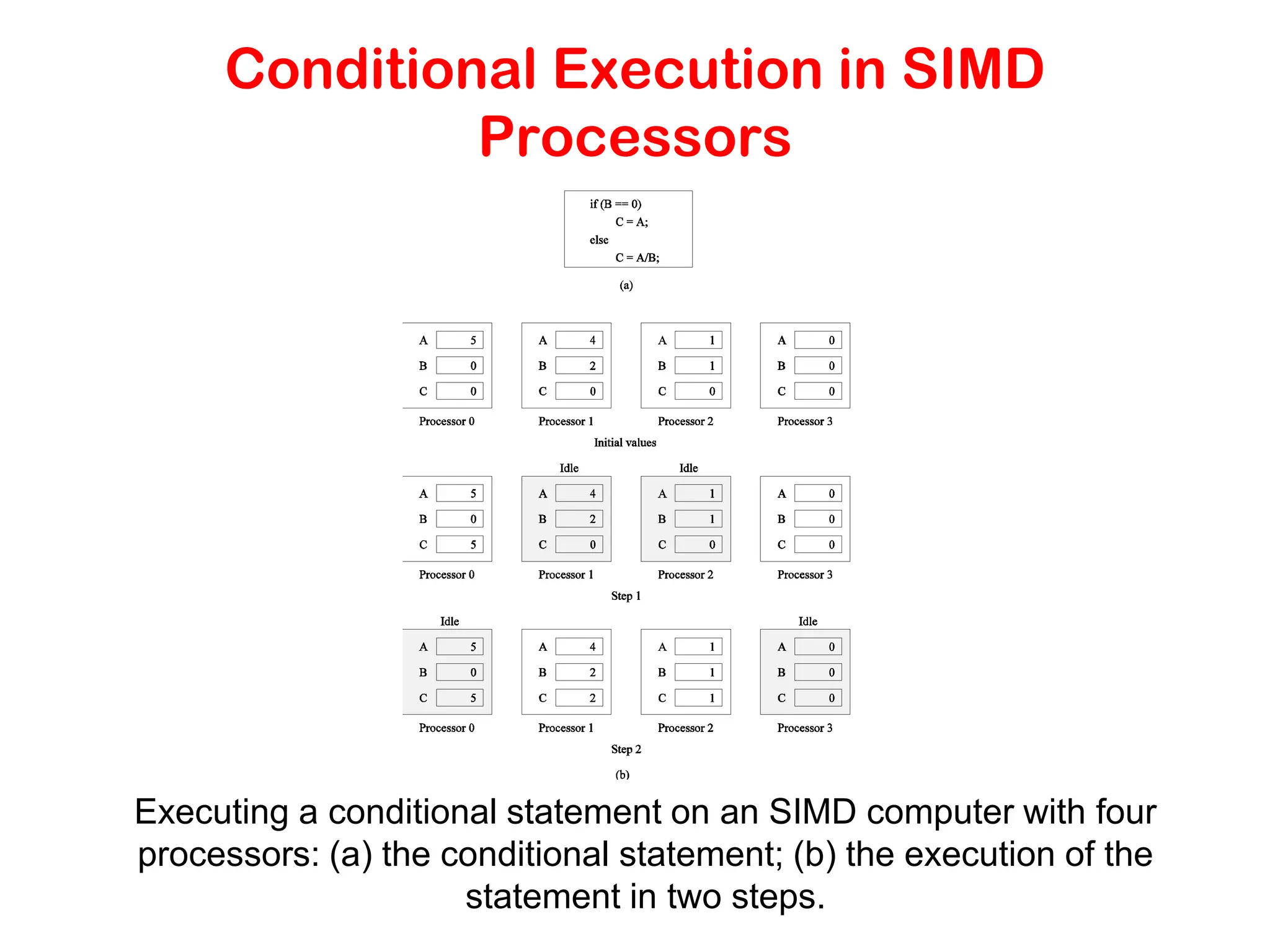
SIMD Processors • Someof the earliest parallel computers such as the Illiac IV, MPP, DAP, CM-2, and MasPar MP-1 belonged to this class of machines. • Variants of this concept have found use in co-processing units such as the MMX units in Intel processors and DSP chips such as the Sharc. • SIMD relies on the regular structure of computations (such as those in image processing). • It is often necessary to selectively turn off operations on certain data items. For this reason, most SIMD programming paradigms allow for an ``activity mask'', which determines if a processor should participate in a computation or not.
37.
Conditional Execution inSIMD Processors Executing a conditional statement on an SIMD computer with four processors: (a) the conditional statement; (b) the execution of the statement in two steps.
38.
MIMD Processors • Incontrast to SIMD processors, MIMD processors can execute different programs on different processors. • A variant of this, called single program multiple data streams (SPMD) executes the same program on different processors. • It is easy to see that SPMD and MIMD are closely related in terms of programming flexibility and underlying architectural support. • Examples of such platforms include current generation Sun Ultra Servers, SGI Origin Servers, multiprocessor PCs, workstation clusters, and the IBM SP.
39.
SIMD-MIMD Comparison • SIMDcomputers require less hardware than MIMD computers (single control unit). • However, since SIMD processors ae specially designed, they tend to be expensive and have long design cycles. • Not all applications are naturally suited to SIMD processors. • In contrast, platforms supporting the SPMD paradigm can be built from inexpensive off-the-shelf components with relatively little effort in a short amount of time.
40.
Communication Model of ParallelPlatforms • There are two primary forms of data exchange between parallel tasks - accessing a shared data space and exchanging messages. • Platforms that provide a shared data space are called shared-address-space machines or multiprocessors. • Platforms that support messaging are also called message passing platforms or multicomputers.
41.
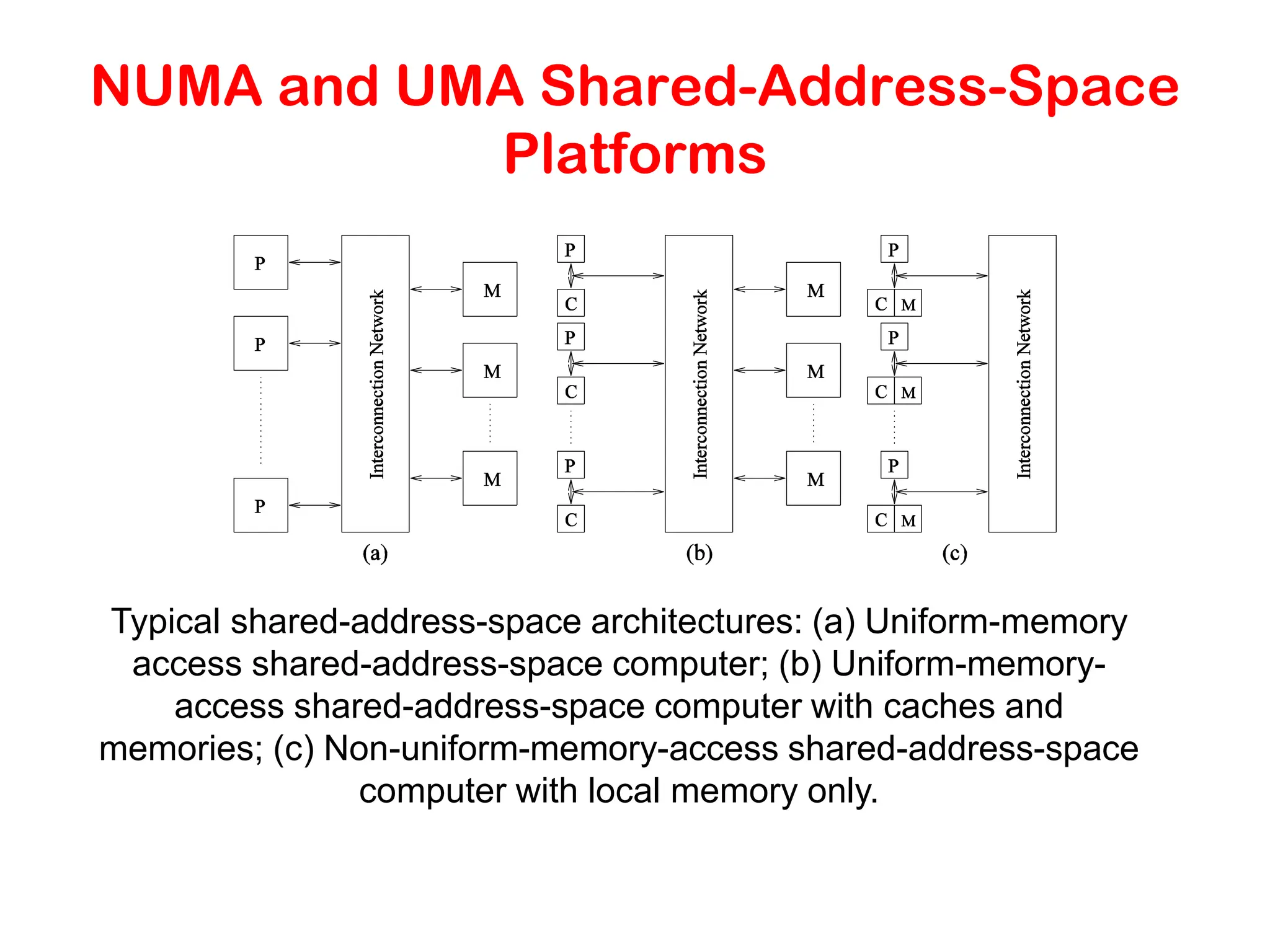
Shared-Address-Space Platforms • Part(or all) of the memory is accessible to all processors. • Processors interact by modifying data objects stored in this shared-address-space. • If the time taken by a processor to access any memory word in the system global or local is identical, the platform is classified as a uniform memory access (UMA), else, a non-uniform memory access (NUMA) machine.
42.
NUMA and UMAShared-Address-Space Platforms Typical shared-address-space architectures: (a) Uniform-memory access shared-address-space computer; (b) Uniform-memory- access shared-address-space computer with caches and memories; (c) Non-uniform-memory-access shared-address-space computer with local memory only.
43.
NUMA and UMA Shared-Address-SpacePlatforms • The distinction between NUMA and UMA platforms is important from the point of view of algorithm design. NUMA machines require locality from underlying algorithms for performance. • Programming these platforms is easier since reads and writes are implicitly visible to other processors. • However, read-write data to shared data must be coordinated (this will be discussed in greater detail when we talk about threads programming). • Caches in such machines require coordinated access to multiple copies. This leads to the cache coherence problem. • A weaker model of these machines provides an address map, but not coordinated access. These models are called non cache coherent shared address space machines.
44.
Shared-Address-Space vs. Shared Memory Machines •It is important to note the difference between the terms shared address space and shared memory. • We refer to the former as a programming abstraction and to the latter as a physical machine attribute. • It is possible to provide a shared address space using a physically distributed memory.
45.
Message-Passing Platforms • Theseplatforms comprise of a set of processors and their own (exclusive) memory. • Instances of such a view come naturally from clustered workstations and non-shared-address-space multicomputers. • These platforms are programmed using (variants of) send and receive primitives. • Libraries such as MPI and PVM provide such primitives.
46.
Message Passing vs. Shared AddressSpace Platforms • Message passing requires little hardware support, other than a network. • Shared address space platforms can easily emulate message passing. The reverse is more difficult to do (in an efficient manner).
47.
Physical Organization of ParallelPlatforms We begin this discussion with an ideal parallel machine called Parallel Random Access Machine, or PRAM.
48.
Architecture of an IdealParallel Computer • A natural extension of the Random Access Machine (RAM) serial architecture is the Parallel Random Access Machine, or PRAM. • PRAMs consist of p processors and a global memory of unbounded size that is uniformly accessible to all processors. • Processors share a common clock but may execute different instructions in each cycle.
49.
Architecture of an IdealParallel Computer • Depending on how simultaneous memory accesses are handled, PRAMs can be divided into four subclasses. – Exclusive-read, exclusive-write (EREW) PRAM. – Concurrent-read, exclusive-write (CREW) PRAM. – Exclusive-read, concurrent-write (ERCW) PRAM. – Concurrent-read, concurrent-write (CRCW) PRAM.
50.
Cont.. 2. Interconnection Networksfor Parallel Computers Classification of interconnection networks: (a) a static network; and (b) a dynamic network. 3. Network Topologies: Bus-Based Networks, Crossbar Networks, Multistage Networks, Star-Connected Network, Linear Arrays, Meshes, and k-d Meshes etc 4. Evaluating Static Interconnection Networks : Diameter, connection and Bisection Width 5. Evaluating Dynamic Interconnection Networks 6. Cache Coherence in Multiprocessor Systems: Snoopy cache based and Directory based
51.
Interconnection Networks for ParallelComputers • Interconnection networks carry data between processors and to memory. • Interconnects are made of switches and links (wires, fiber). • Interconnects are classified as static or dynamic. • Static networks consist of point-to-point communication links among processing nodes and are also referred to as direct networks. • Dynamic networks are built using switches and communication links. Dynamic networks are also referred to as indirect networks.
52.
Evaluating Static Interconnection Networks NetworkDiameter Bisection Width Arc Connectivity Cost (No. of links) Completely-connected Star Complete binary tree Linear array 2-D mesh, no wraparound 2-D wraparound mesh Hypercube Wraparound k-ary d-cube
53.
Evaluating Dynamic InterconnectionNetworks Network Diameter Bisection Width Arc Connectivity Cost (No. of links) Crossbar Omega Network Dynamic Tree
54.
Cache Coherence in MultiprocessorSystems • Interconnects provide basic mechanisms for data transfer. • In the case of shared address space machines, additional hardware is required to coordinate access to data that might have multiple copies in the network. • The underlying technique must provide some guarantees on the semantics. • This guarantee is generally one of serializability, i.e., there exists some serial order of instruction execution that corresponds to the parallel schedule.
55.
Cache Coherence in MultiprocessorSystems Cache coherence in multiprocessor systems: (a) Invalidate protocol; (b) Update protocol for shared variables. When the value of a variable is changes, all its copies must either be invalidated or updated.
56.
Communication Costs in ParallelMachines • Along with idling and contention, communication is a major overhead in parallel programs. • The cost of communication is dependent on a variety of features including the programming model semantics, the network topology, data handling and routing, and associated software protocols.
57.
Message Passing Costsin Parallel Computers • The total time to transfer a message over a network comprises of the following: – Startup time (ts): Time spent at sending and receiving nodes (executing the routing algorithm, programming routers, etc.). – Per-hop time (th): This time is a function of number of hops and includes factors such as switch latencies, network delays, etc. – Per-word transfer time (tw): This time includes all overheads that are determined by the length of the message. This includes bandwidth of links, error checking and correction, etc.
58.
Store-and-Forward Routing • Amessage traversing multiple hops is completely received at an intermediate hop before being forwarded to the next hop. • The total communication cost for a message of size m words to traverse l communication links is • In most platforms, th is small and the above expression can be approximated by
59.
Routing Techniques Passing amessage from node P0 to P3 (a) through a store-and- forward communication network; (b) and (c) extending the concept to cut-through routing. The shaded regions represent the time that the message is in transit. The startup time associated with this message transfer is assumed to be zero.
Levels of parallelism 1.Data Parallelism: Many problems in scientific computing involve processing of large quantities of data stored on a computer. If this manipulation can be performed in parallel, i.e., by multiple processors working on different parts of the data, we speak of data parallelism. As a matter of fact, this is the dominant parallelization concept in scientific computing on MIMD-type computers. It also goes under the name of SPMD (Single Program Multiple Data), as usually the same code is executed on all processors, with independent instruction pointers. Ex: Medium-grained loop parallelism, Coarse-grained parallelism by domain decomposition
62.
Levels of Parallelism 2.Functional Parallelism: Sometimes the solution of a “big” numerical problem can be split into more or less disparate subtasks, which work together by data exchange and synchronization. In this case, the subtasks execute completely different code on different data items, which is why functional parallelism is also called MPMD (Multiple Program Multiple Data). Ex: Master Worker Scheme, Functional decomposition Ref:http://prdrklaina.weebly.com/uploads/5/7/7/3/5773421/introduction_to_high_perf ormance_computing_for_scientists_and_engineers.pdf
SIMT Single instruction, multiplethreads (SIMT) is an execution model used in parallel computing where single instruction, multiple data (SIMD) is combined with multithreading. It is different from SPMD in that all instructions in all "threads" are executed in lock-step. The SIMT execution model has been implemented on several GPUs and is relevant for general-purpose computing on graphics processing units (GPGPU), e.g. some supercomputers combine CPUs with GPUs.
66.
SPMD • In contrastto SIMD processors, MIMD processors can execute different programs on different processors. • A variant of this, called single program multiple data streams (SPMD) executes the same program on different processors. • It is easy to see that SPMD and MIMD are closely related in terms of programming flexibility and underlying architectural support. • Examples of such platforms include current generation Sun Ultra Servers, SGI Origin Servers, multiprocessor PCs, workstation clusters, and the IBM SP.
67.
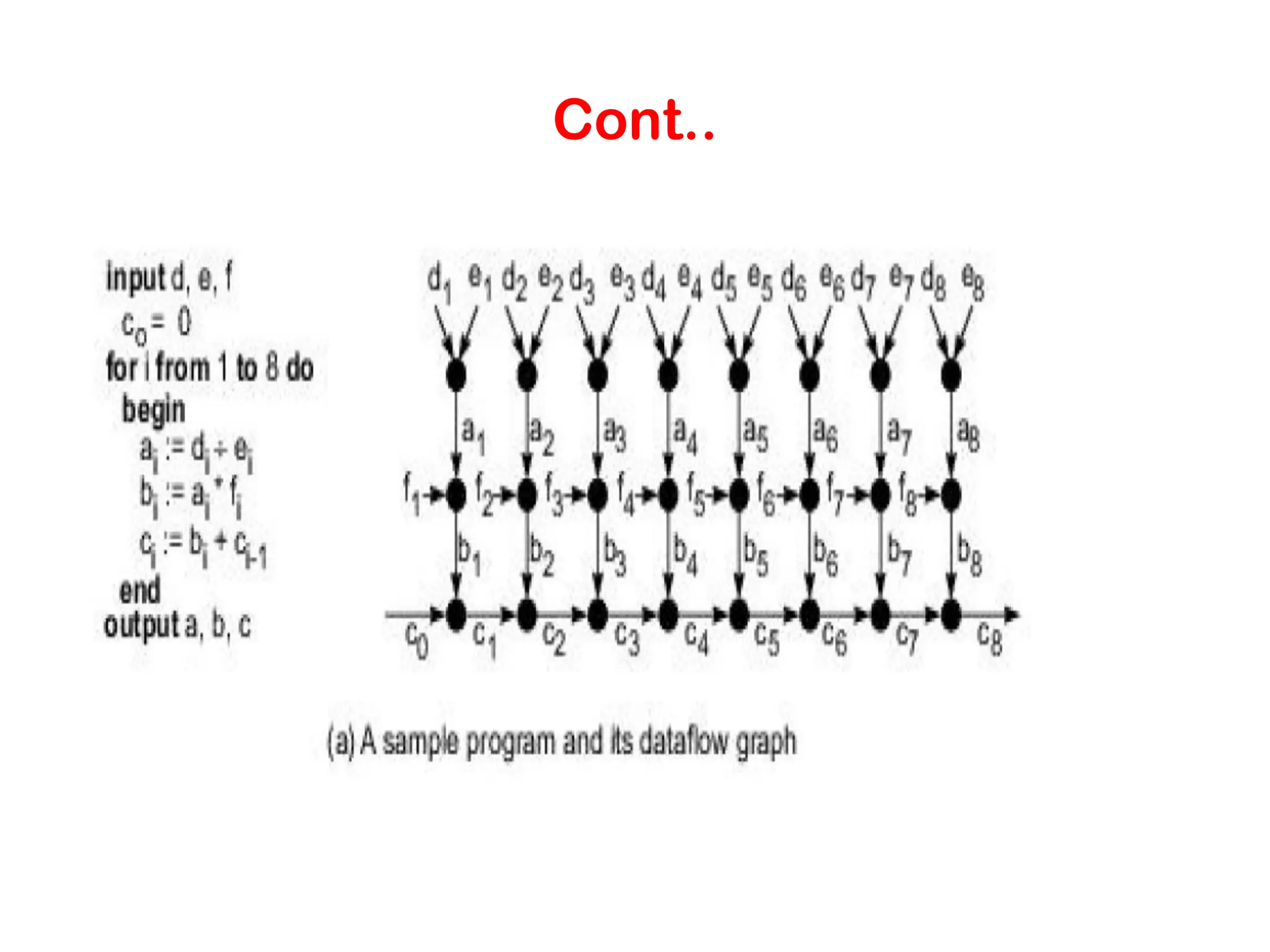
Data Flow • lna daraflow computer, the execution of an instruction is driven by data availability instead of being guided by a program counter, ln theory, any instruction should be ready for execution whenever operands become available. • The instructions in a data-driven program are not ordered in any way. instead of being stored separately in a main memory, data are directly held inside instructions. • This data-driven scheme requires no program counter, and no eonlrol sequencer. However, it requires special mechanisms to detect data availability, to match data tokens with needy instructions, and to enable the chain reaction of asynchronous instruction executions. No memory sharing between instructions results in no side effects.
N-Wide Superscalar • Ideally:in an n-issue superscalar, n instructions are fetched, decoded, executed, and committed per cycle In practice: – Data, control, and structural hazards spoil issue flow – Multi-cycle instructions spoil commit flow • Buffers at issue (issue queue) and commit (reorder buffer) decouple these stages from the rest of the pipeline and regularize somewhat breaks in the flow
Modern Processor andArchitecture Book Title: Introduction to High Performance Computing for Scientist and Engineers Authors: George and Wellien • Refernce:http://prdrklaina.weebly.com/uploads/5/7/7/3/5773421/introduction_to_high_ performance_computing_for_scientists_and_engineers.pdf
75.
Demand Driven andData flow • Book Name: • ADVANCED COMPUTER ARCHITECTURE Author name: Kai Hwang


















































![B]Communication Costs in Shared-Address- Space Machines](https://image.slidesharecdn.com/parallelcomputing-unit-i-ppt2019-250816221705-b9bbe9a6/75/Cloud-Computing-Parallel-computing-unit-i-60-2048.jpg)