Download as PDF, PPTX



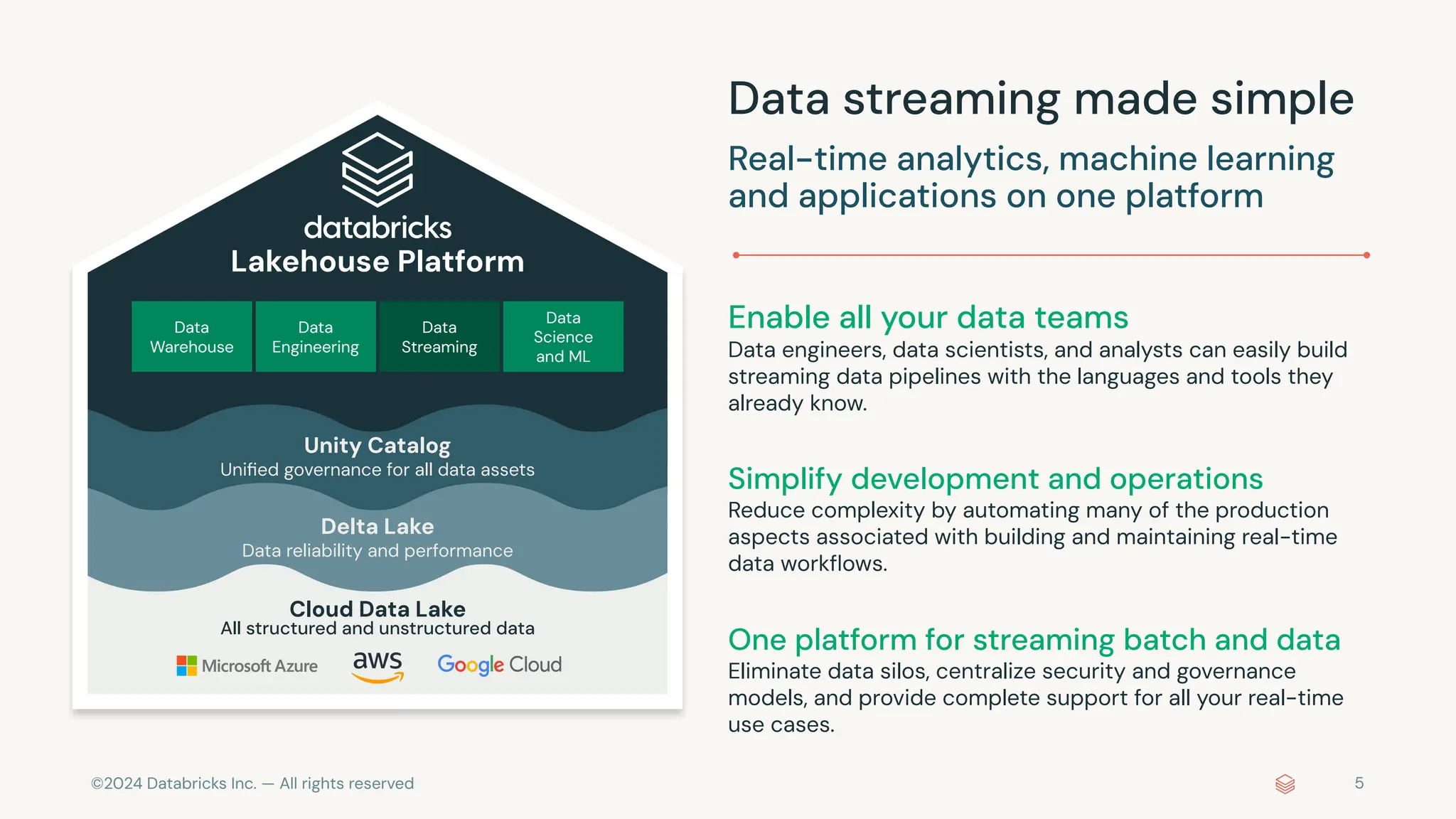


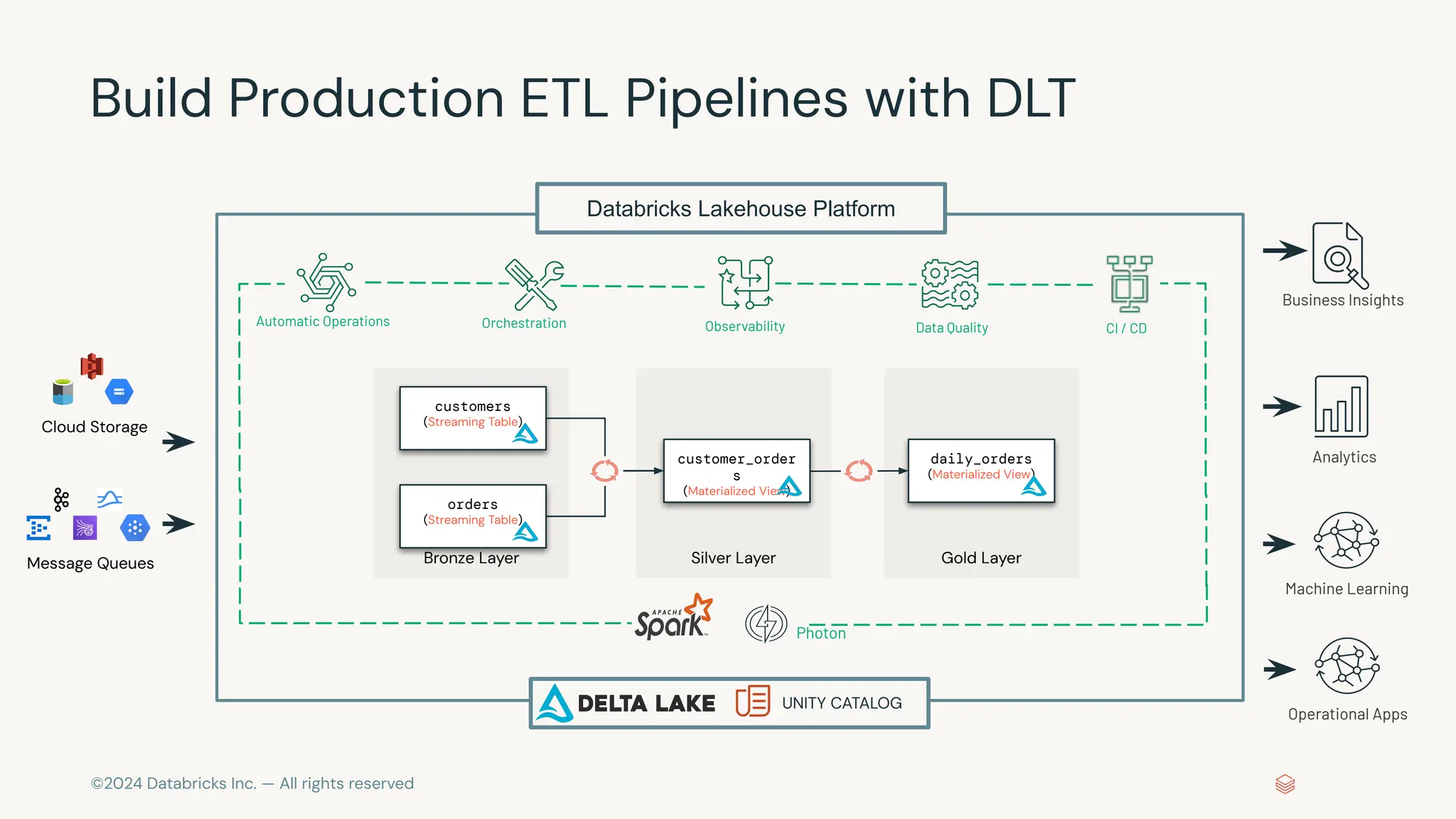

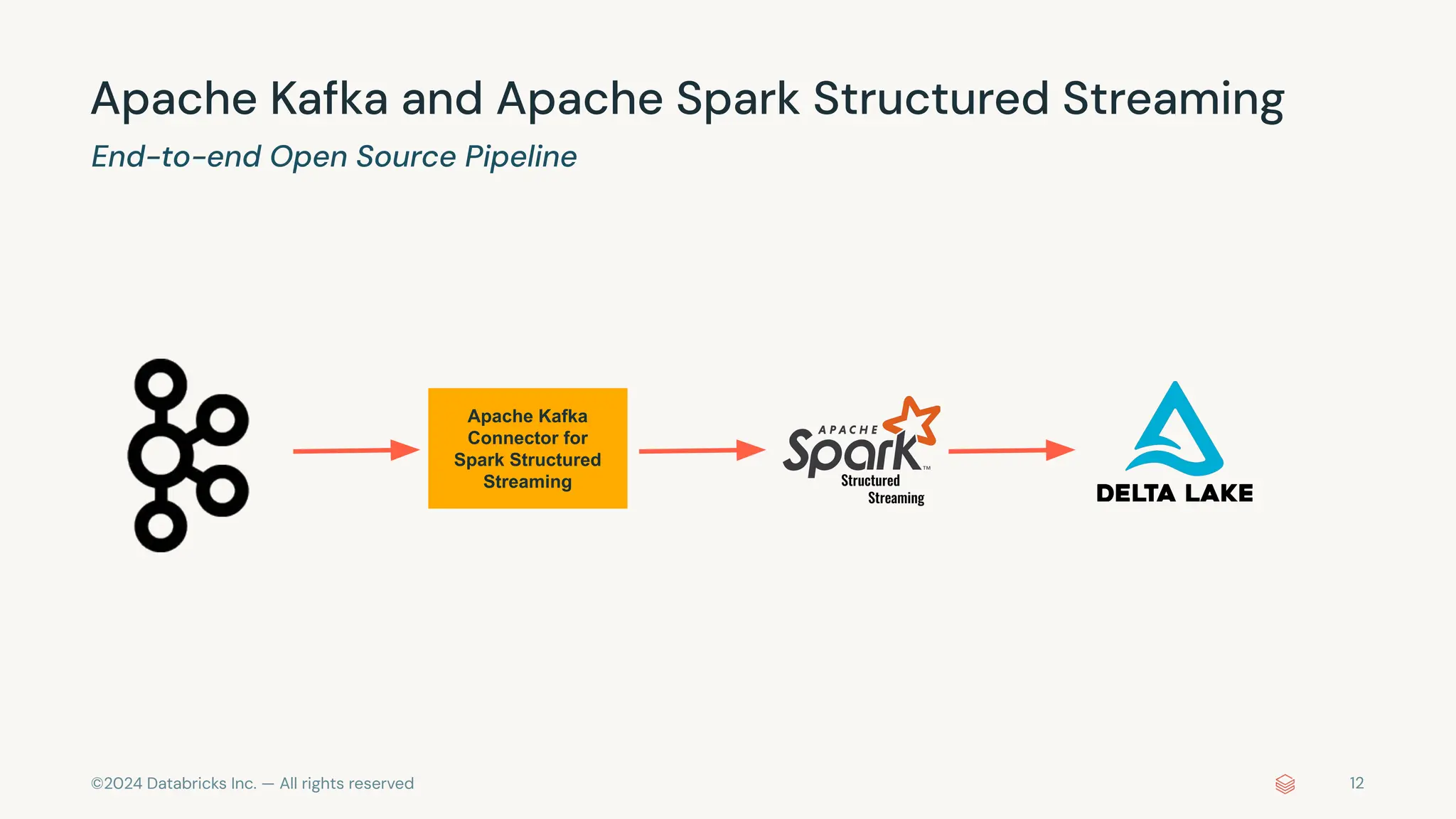
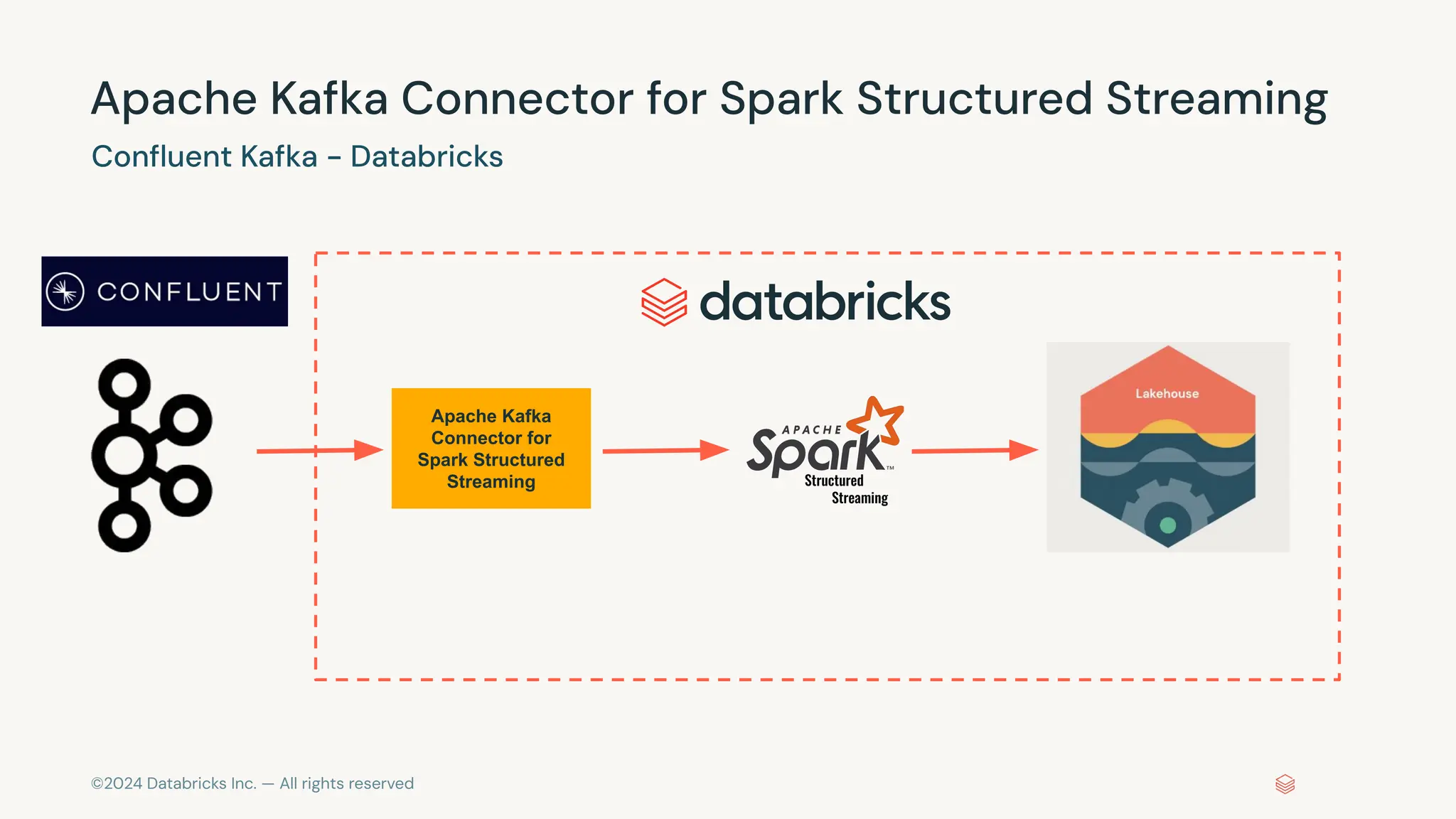
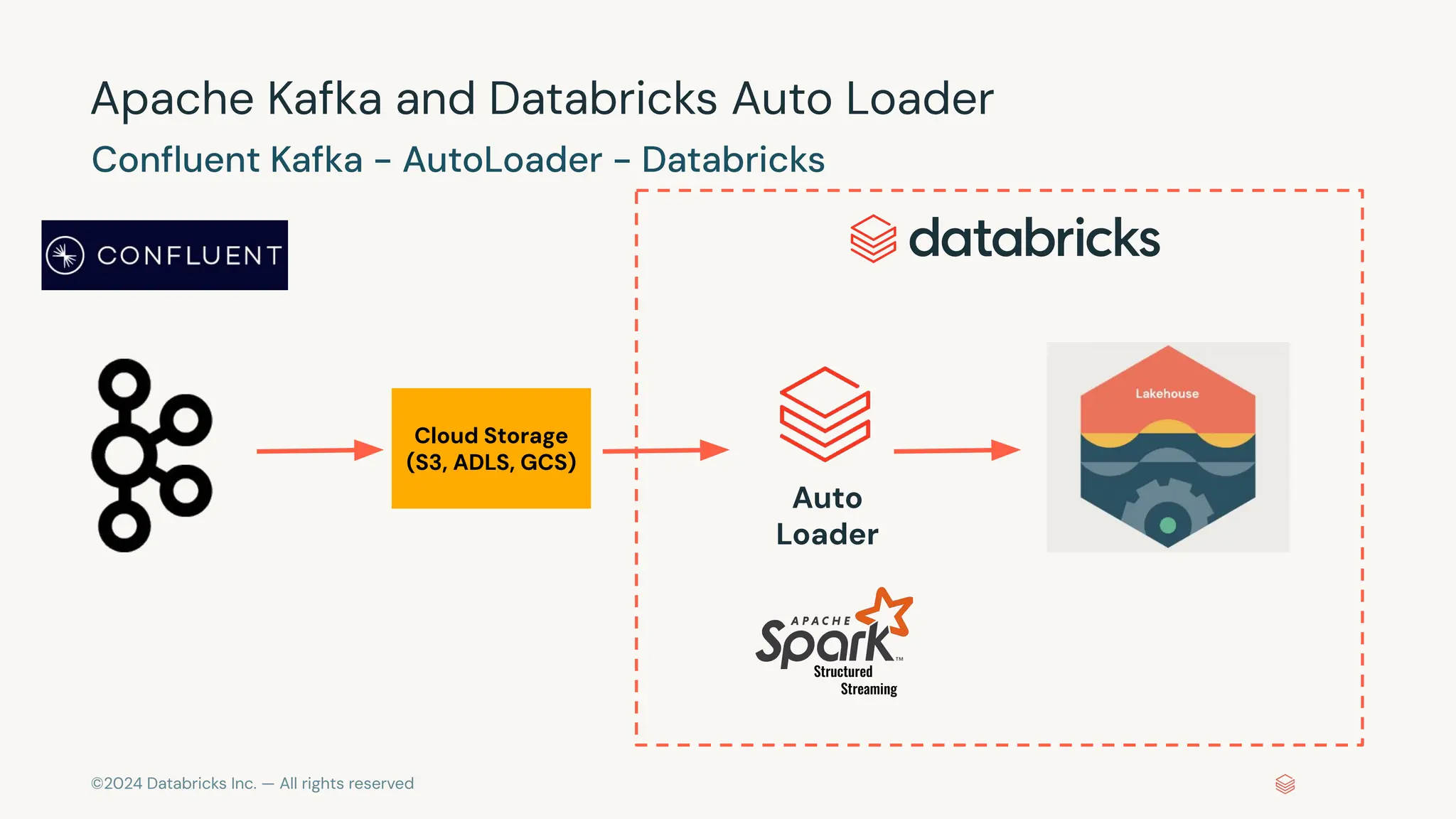
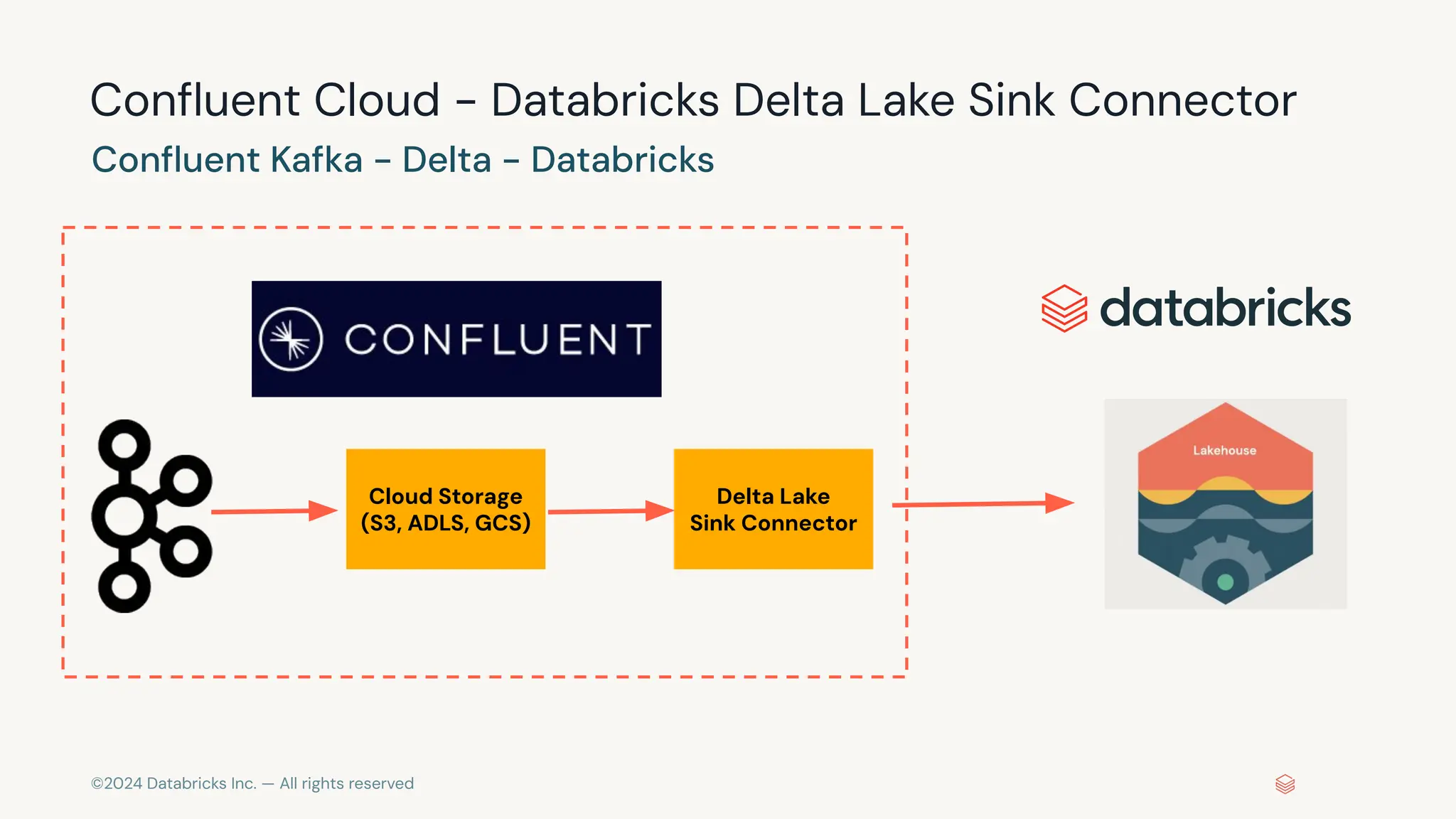

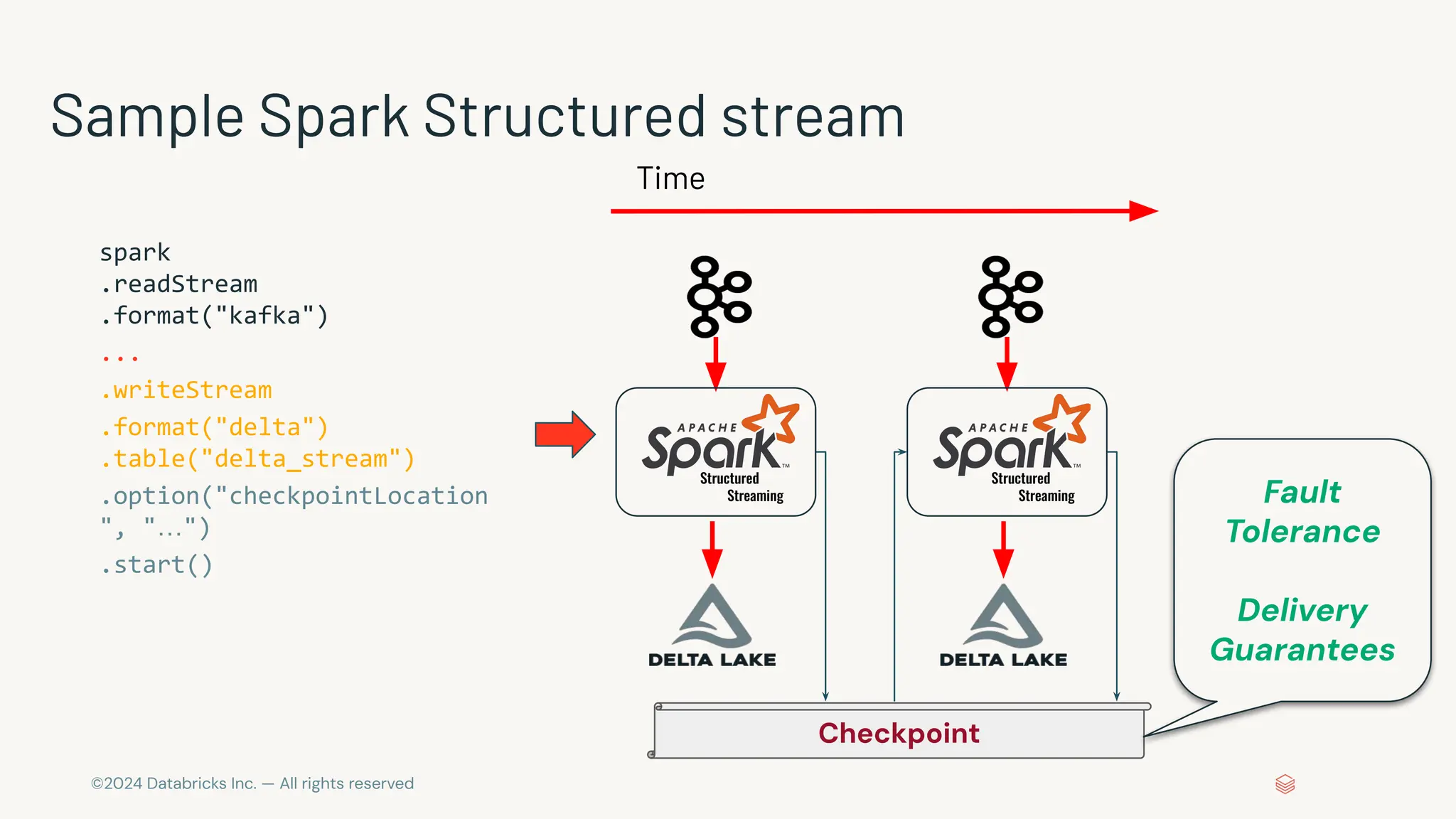

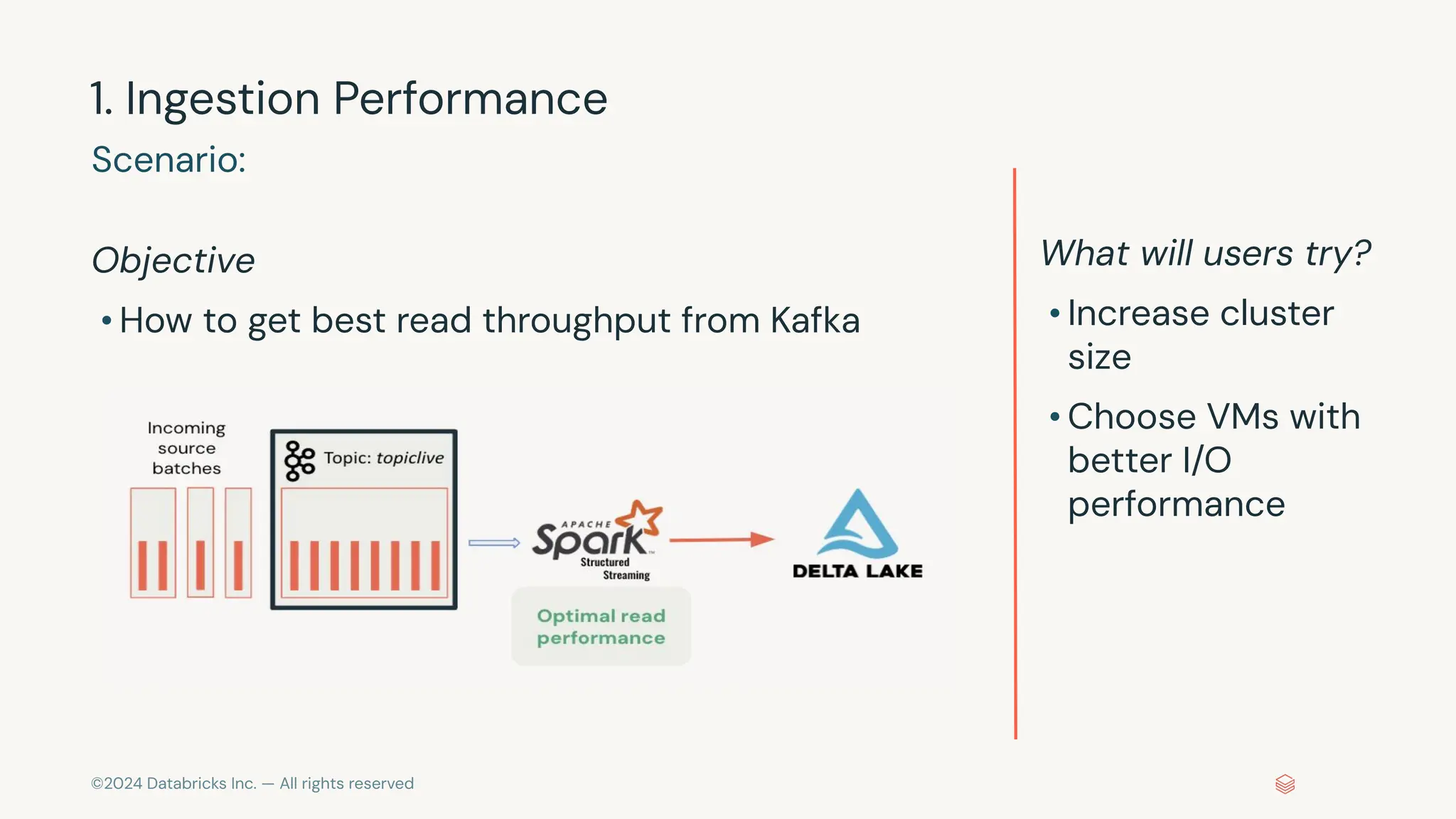
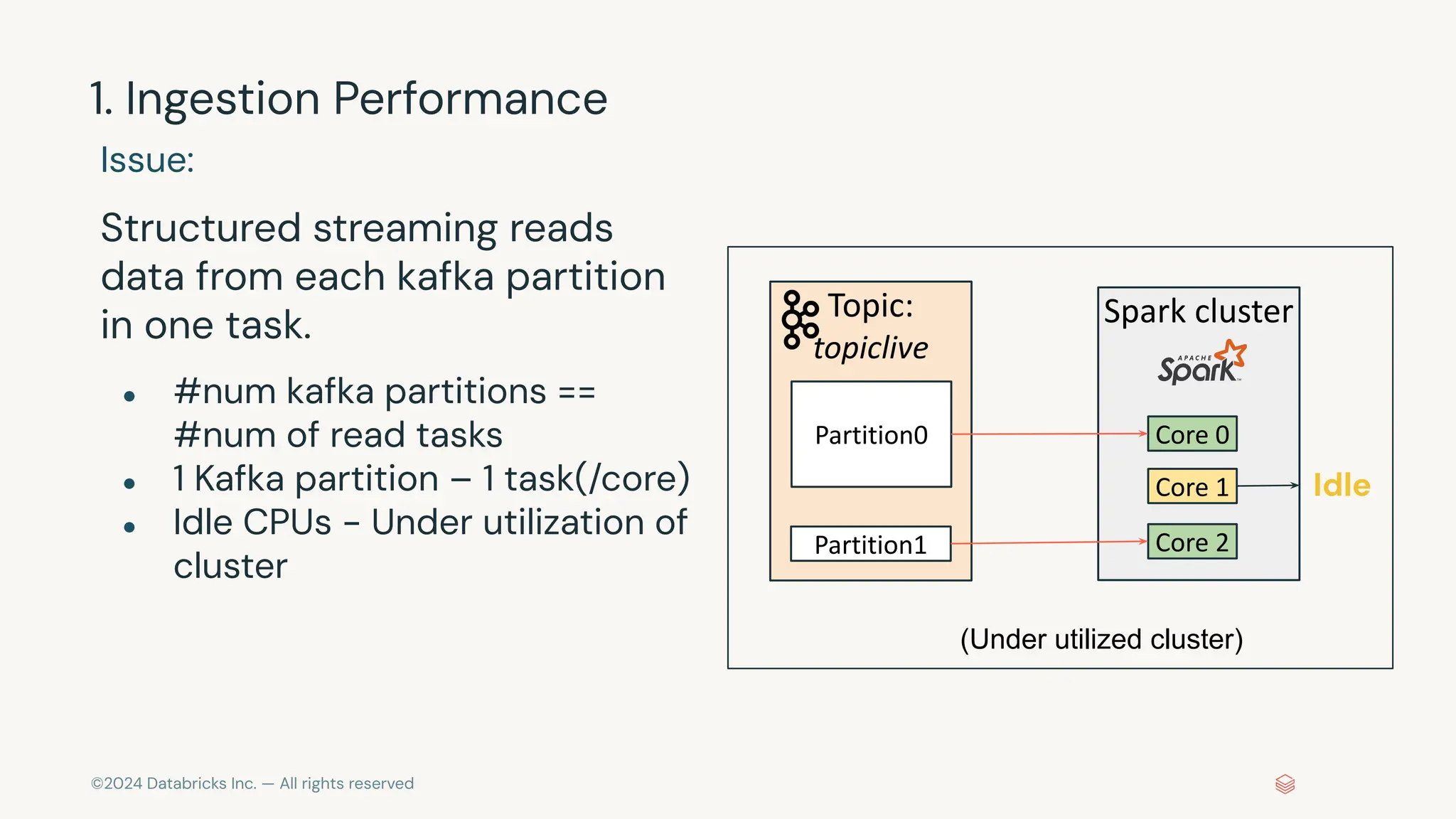
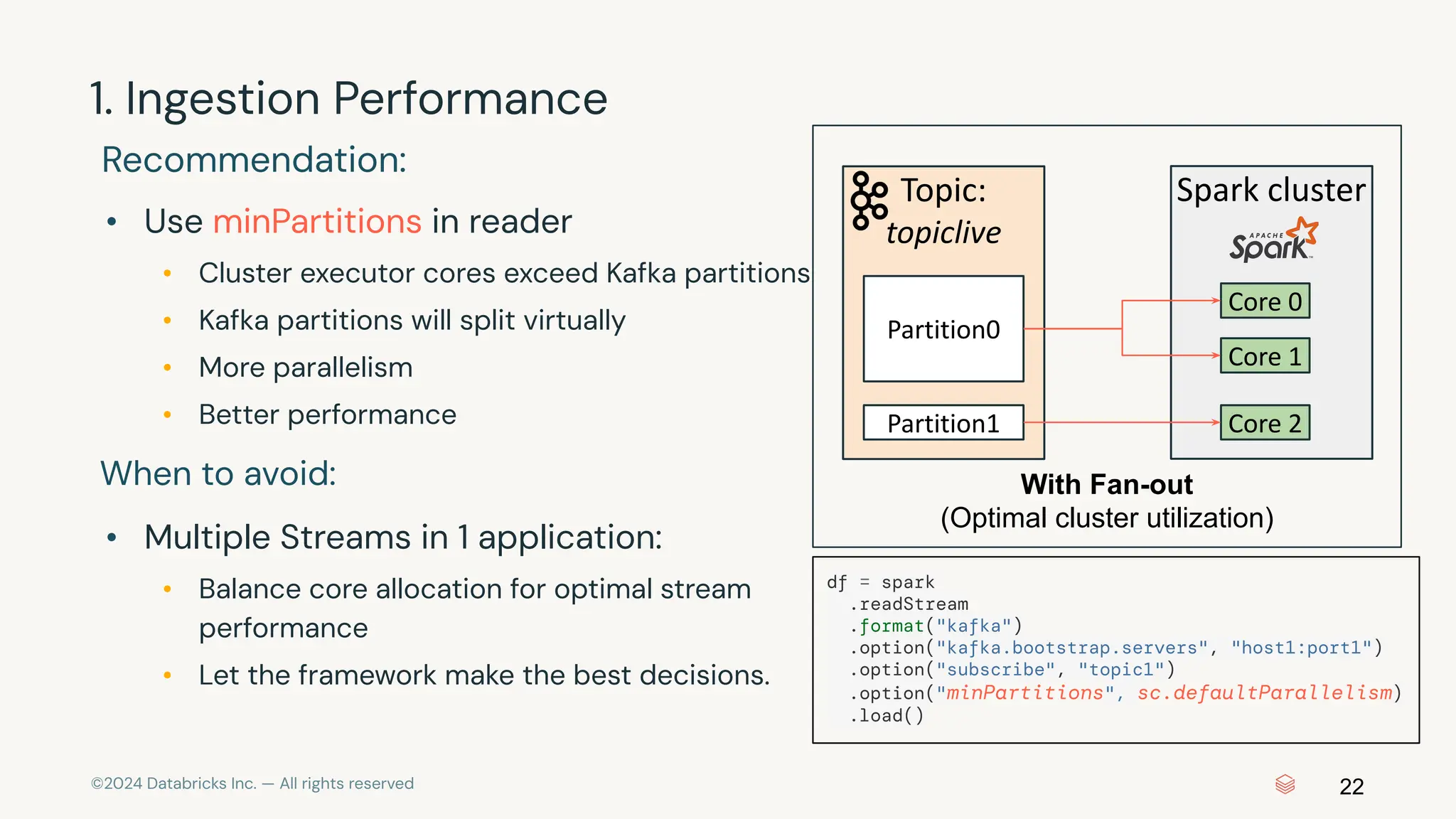
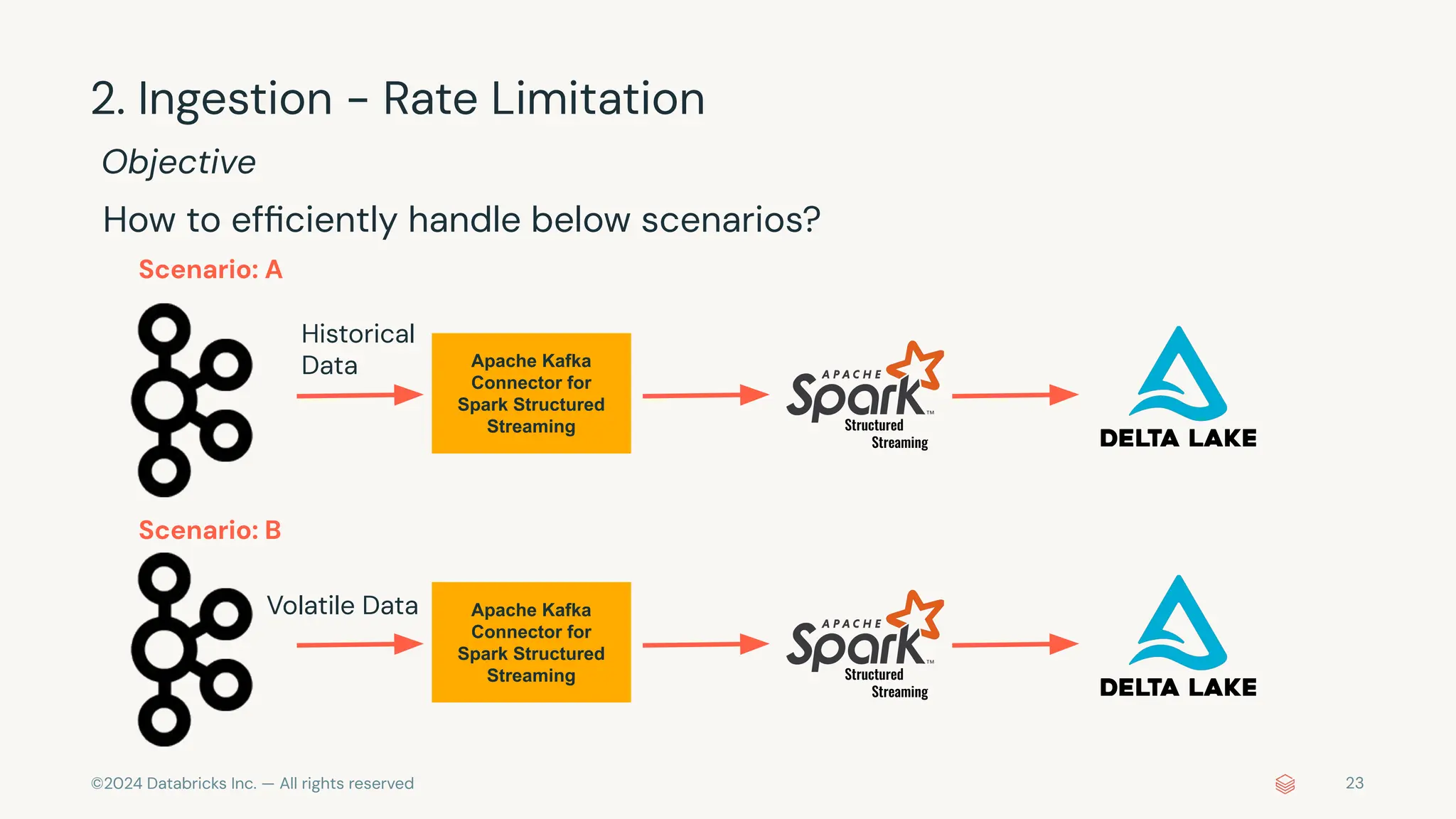
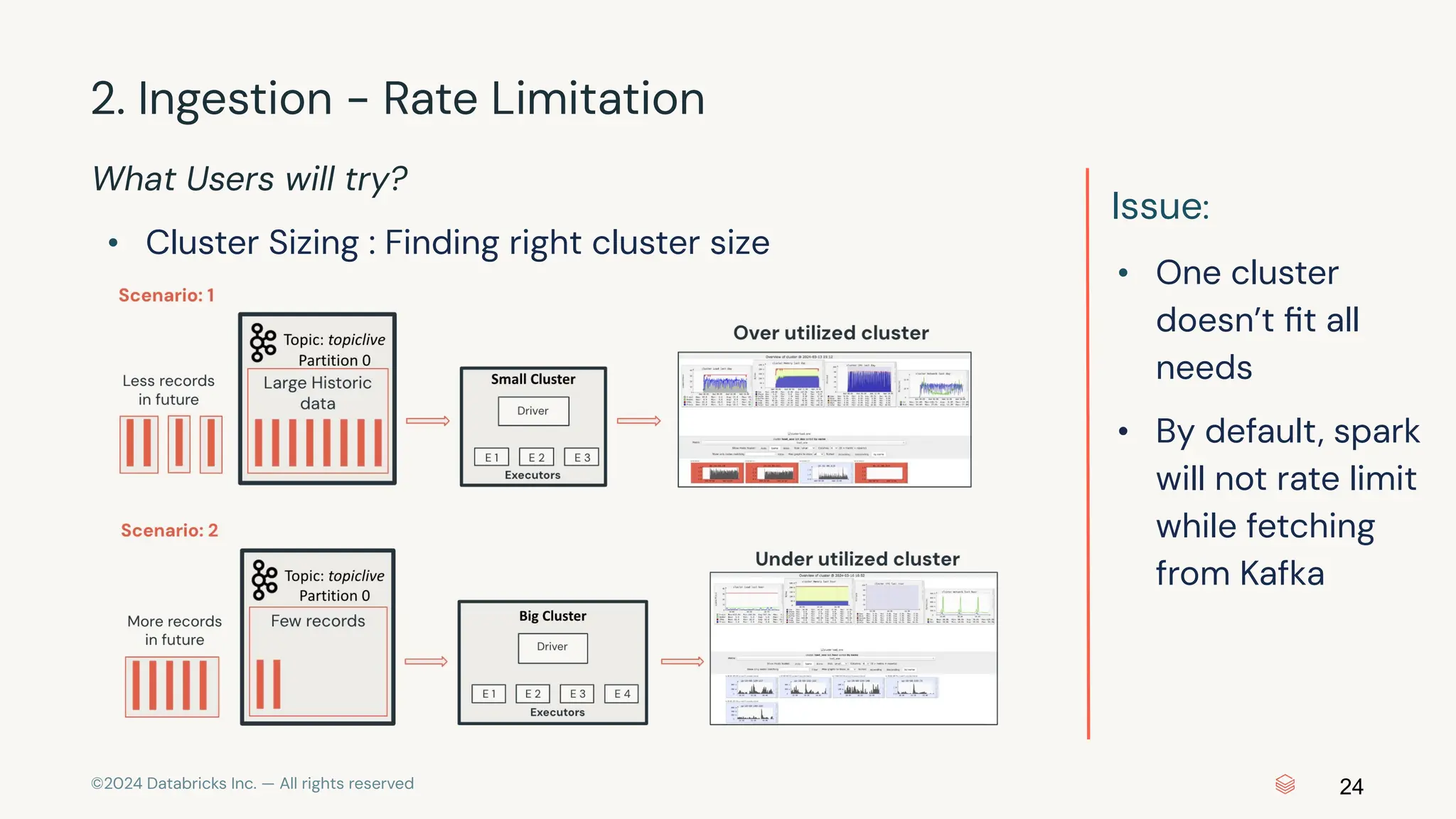






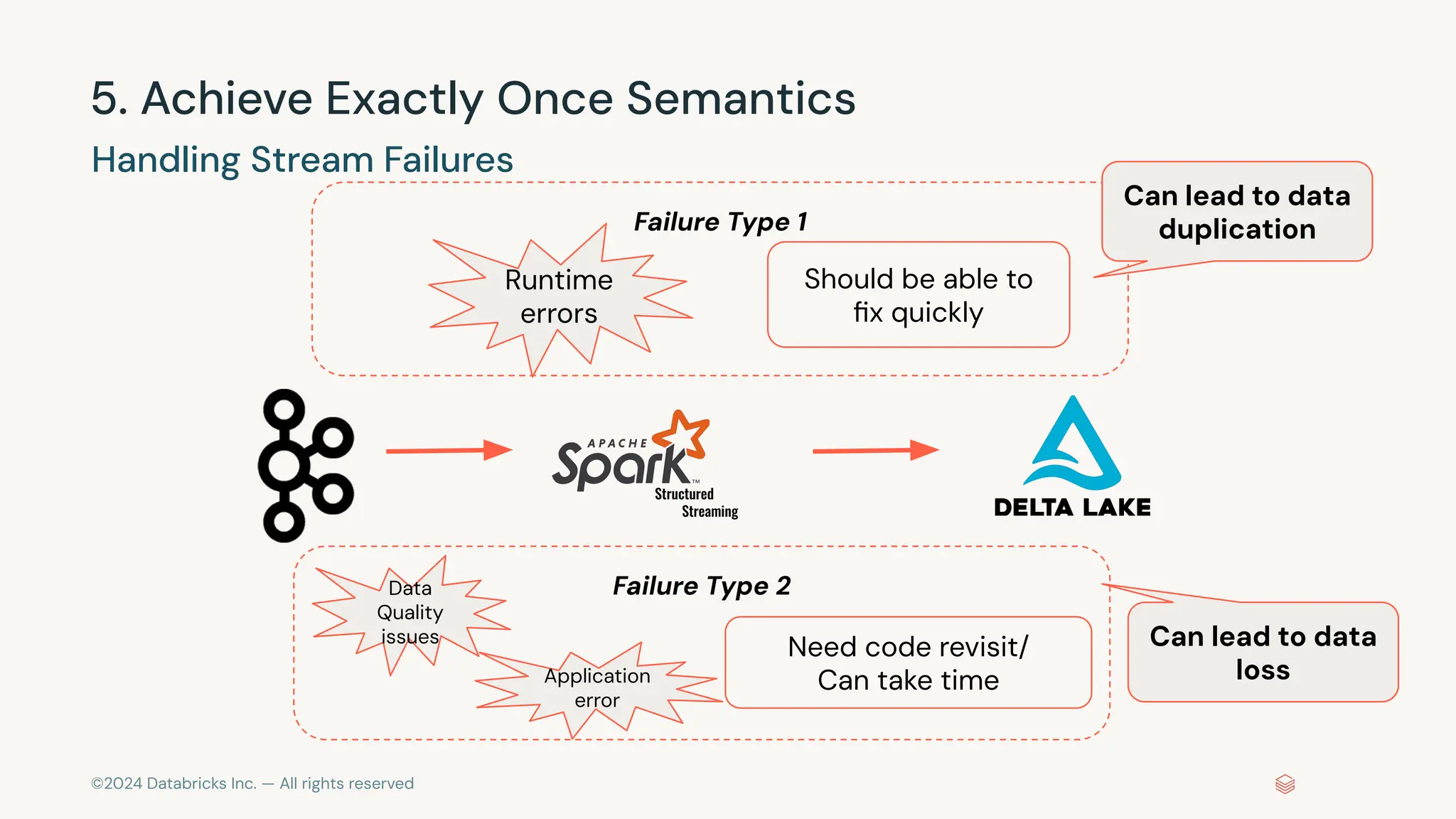
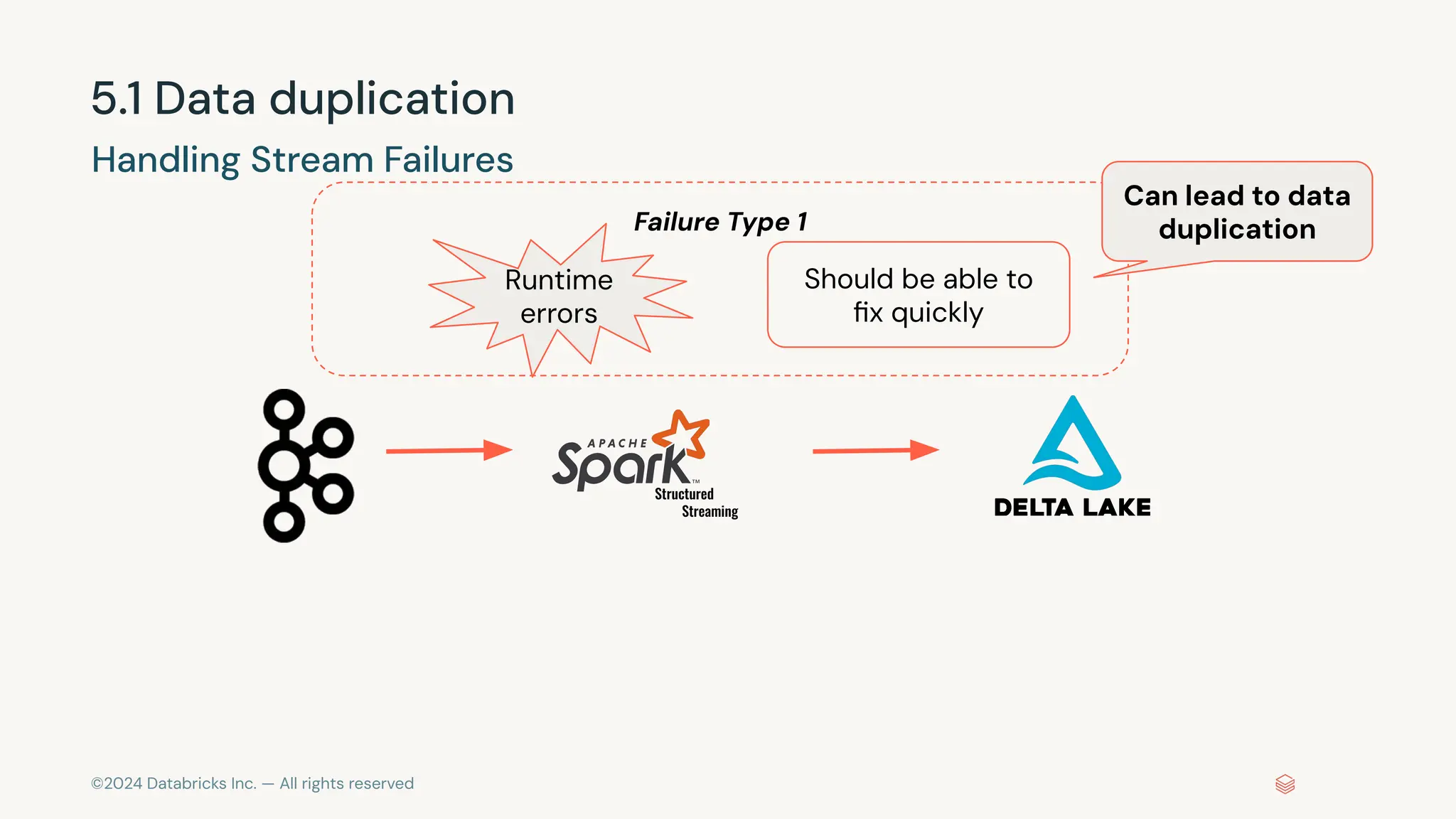


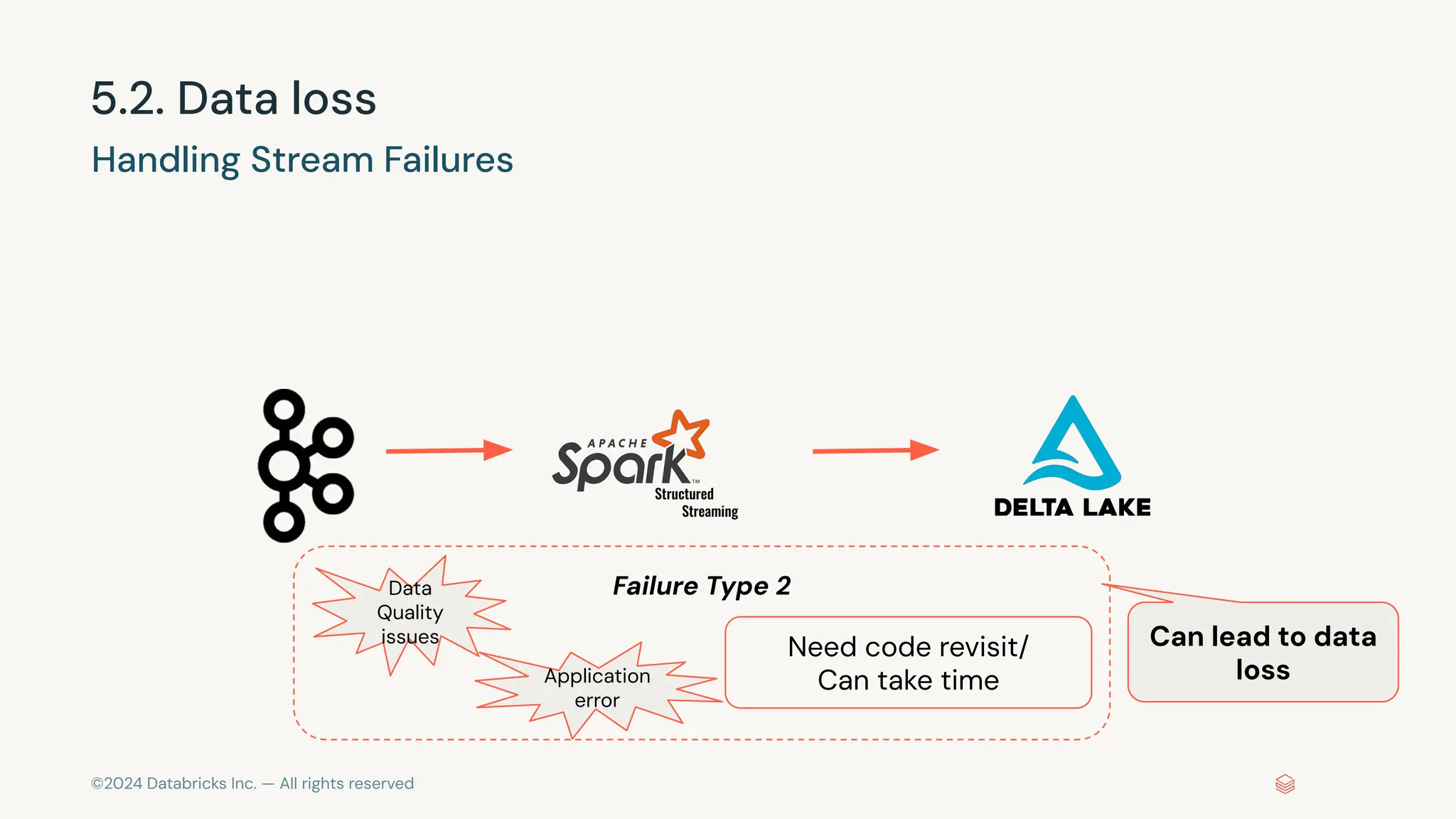


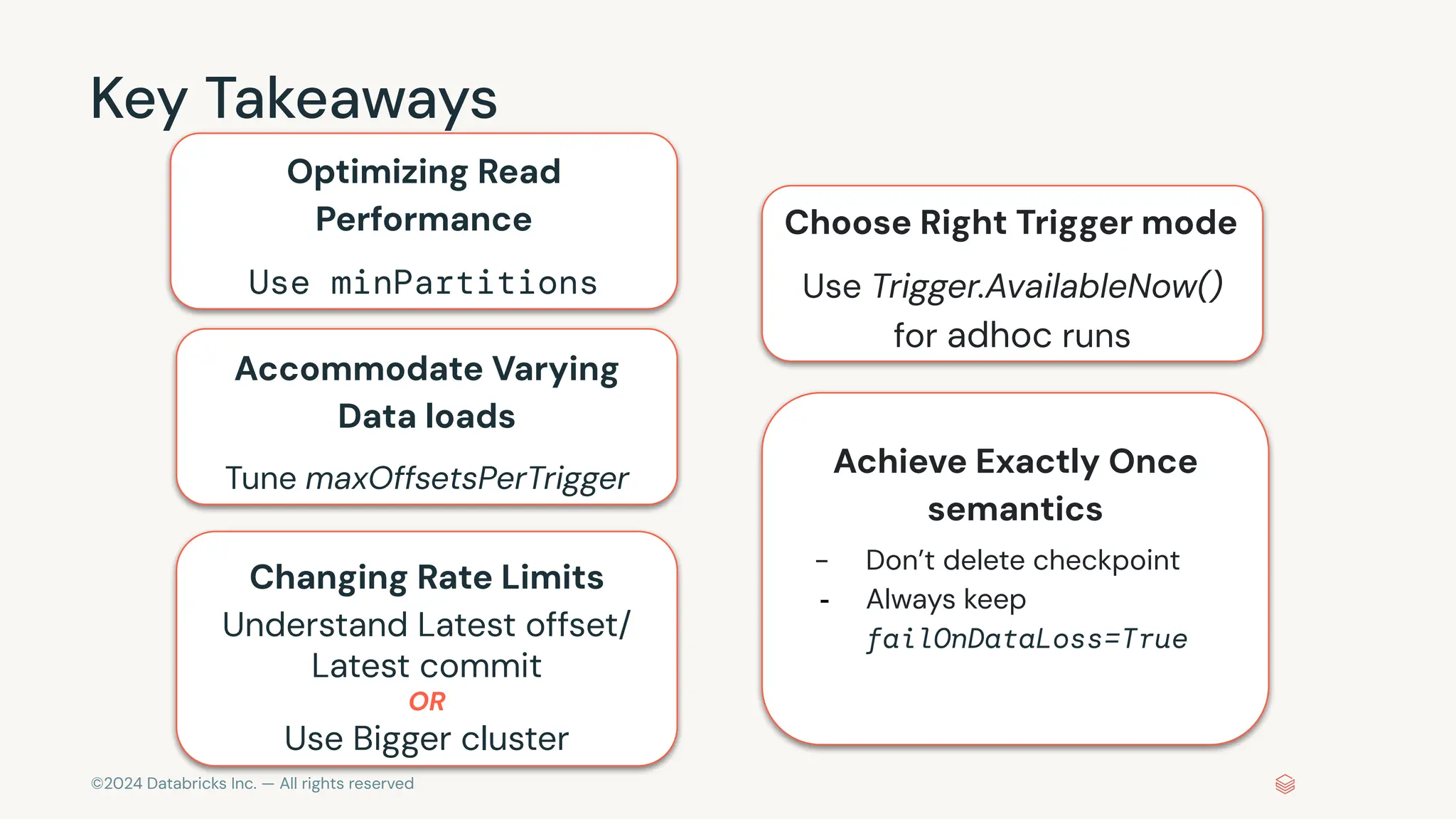


The document provides an overview of best practices and common pitfalls when using Apache Kafka with Spark Structured Streaming. Key topics include optimizing read performance, handling varying data loads, managing rate limits, and achieving exactly-once semantics. It emphasizes the importance of understanding system configurations and using appropriate trigger modes to ensure reliable and efficient streaming applications.