Download as PDF, PPTX



























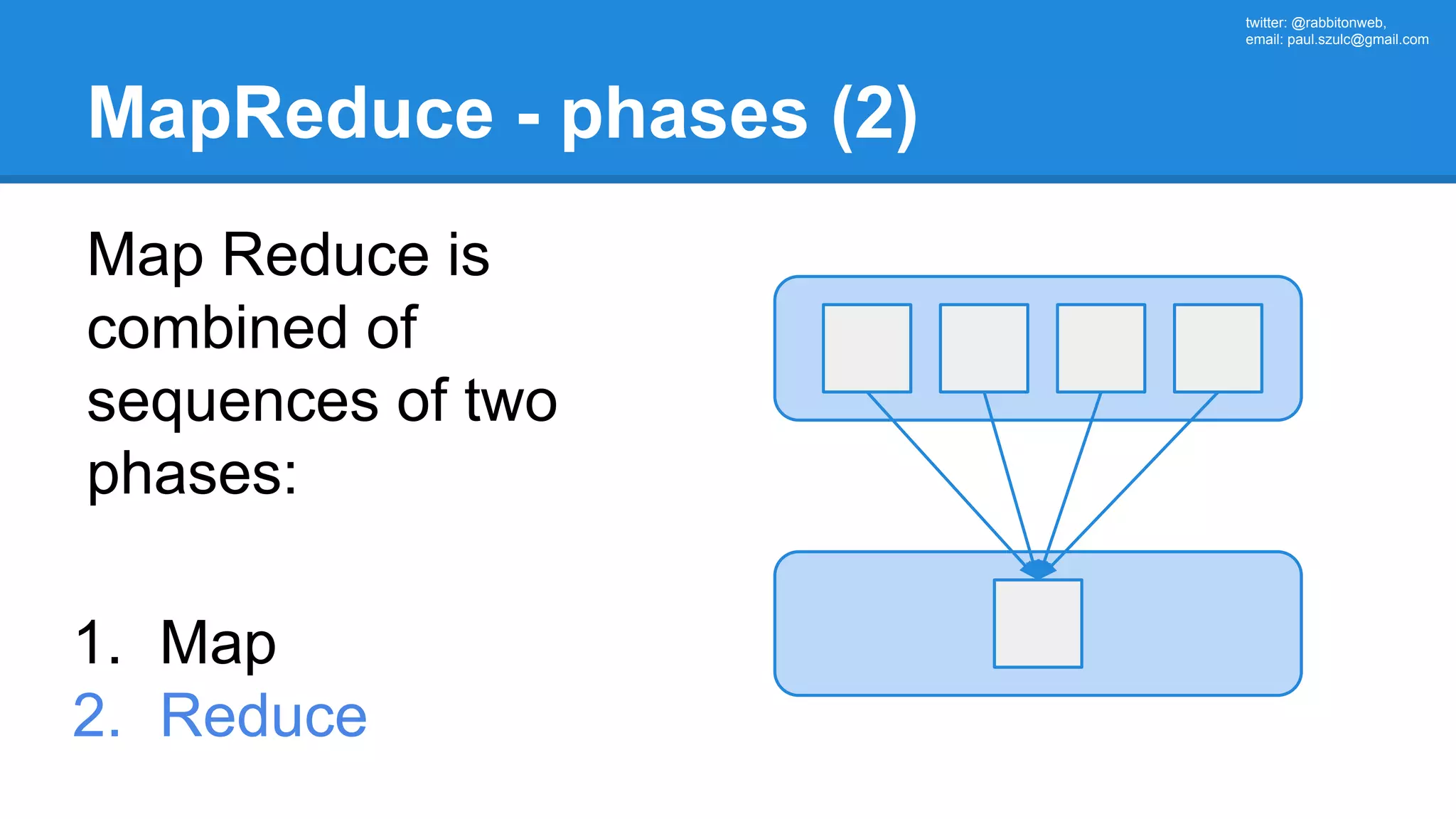












![twitter: @rabbitonweb, email: paul.szulc@gmail.com Word count: Hadoop implementation 15 public class WordCount { 16 17 public static class Map extends Mapper<LongWritable, Text, Text, IntWritable> { 18 private final static IntWritable one = new IntWritable(1); 19 private Text word = new Text(); 20 21 public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { 22 String line = value.toString(); 23 StringTokenizer tokenizer = new StringTokenizer(line); 24 while (tokenizer.hasMoreTokens()) { 25 word.set(tokenizer.nextToken()); 26 context.write(word, one); 27 } 28 } 29 } 30 31 public static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable> { 33 public void reduce(Text key, Iterable<IntWritable> values, Context context) 34 throws IOException, InterruptedException { 35 int sum = 0; 36 for (IntWritable val : values) { sum += val.get(); } 39 context.write(key, new IntWritable(sum)); 40 } 41 } 43 public static void main(String[] args) throws Exception { 44 Configuration conf = new Configuration(); 46 Job job = new Job(conf, "wordcount"); 48 job.setOutputKeyClass(Text.class); 49 job.setOutputValueClass(IntWritable.class); 51 job.setMapperClass(Map.class); 52 job.setReducerClass(Reduce.class); 54 job.setInputFormatClass(TextInputFormat.class);](https://image.slidesharecdn.com/apachesparkworkshops-160527153959/75/Apache-spark-workshop-49-2048.jpg)












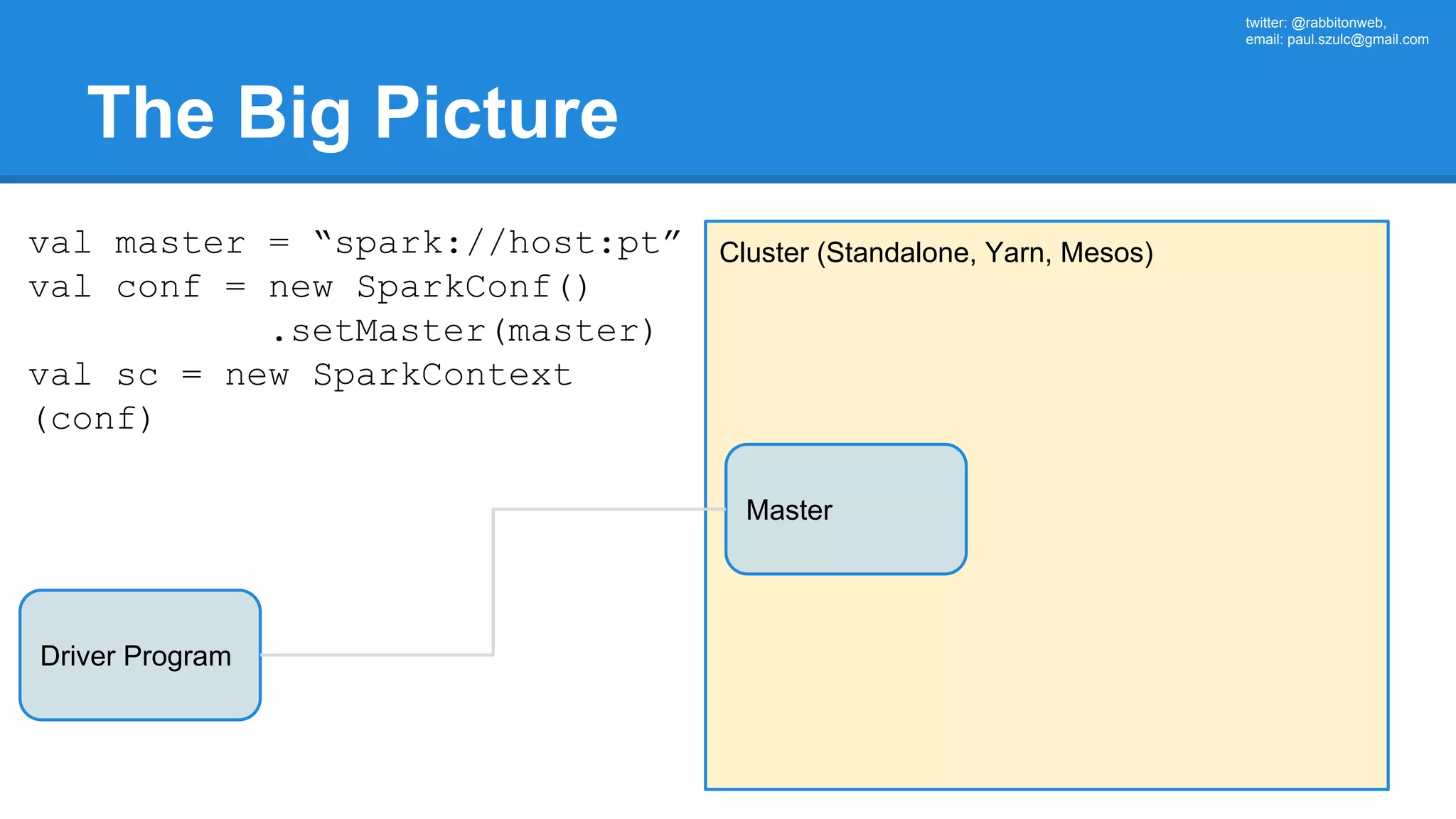
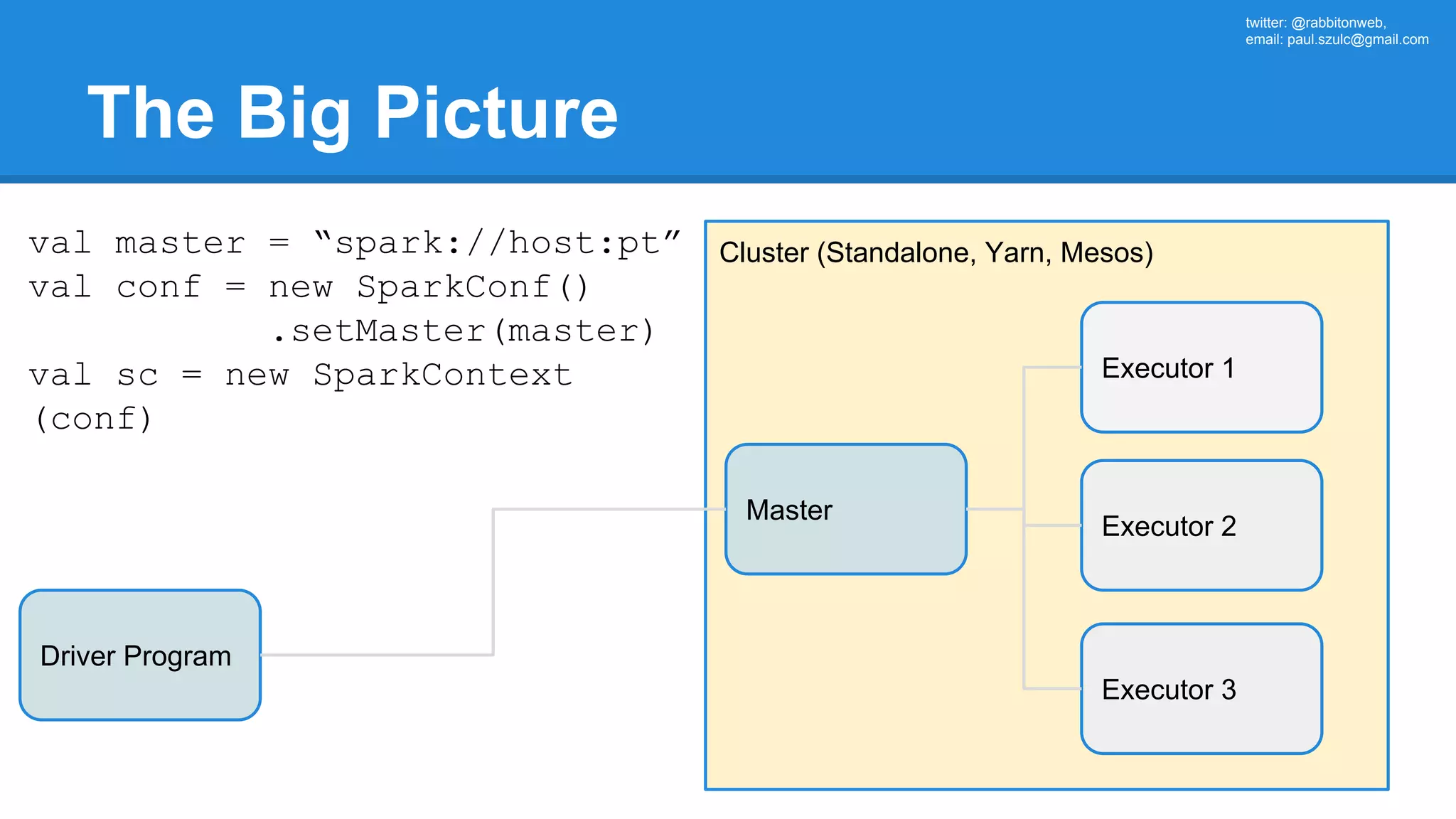









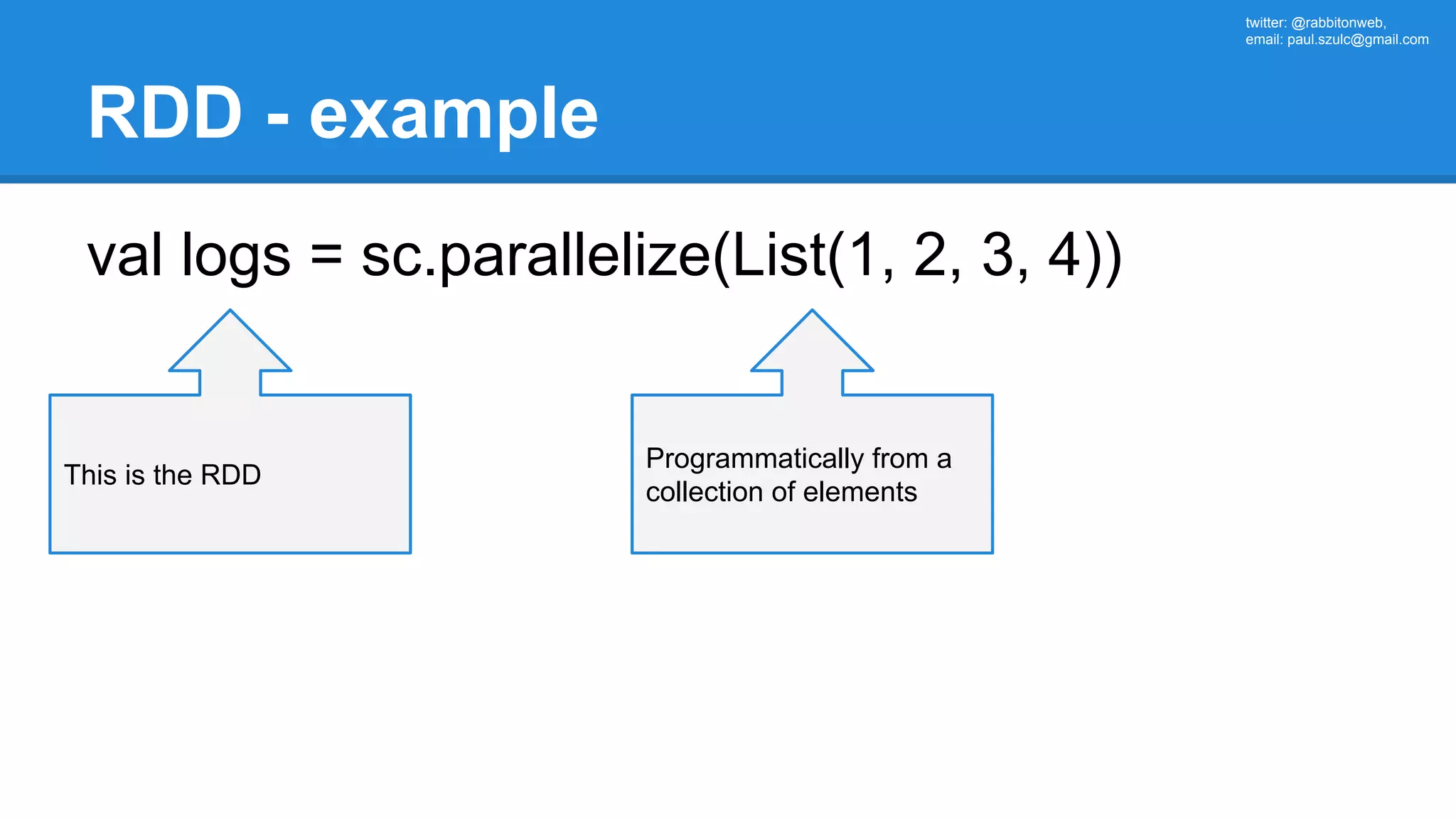


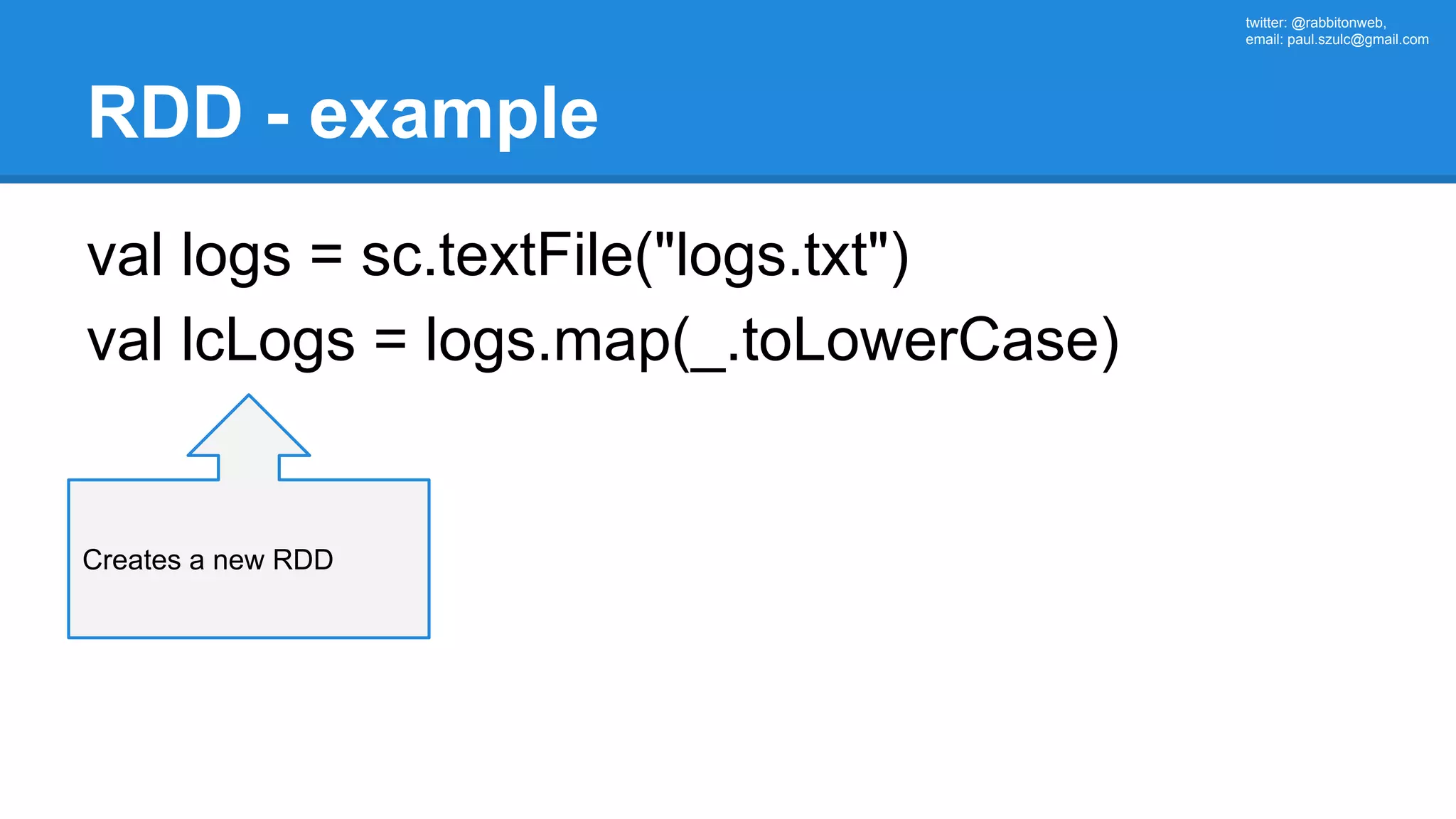














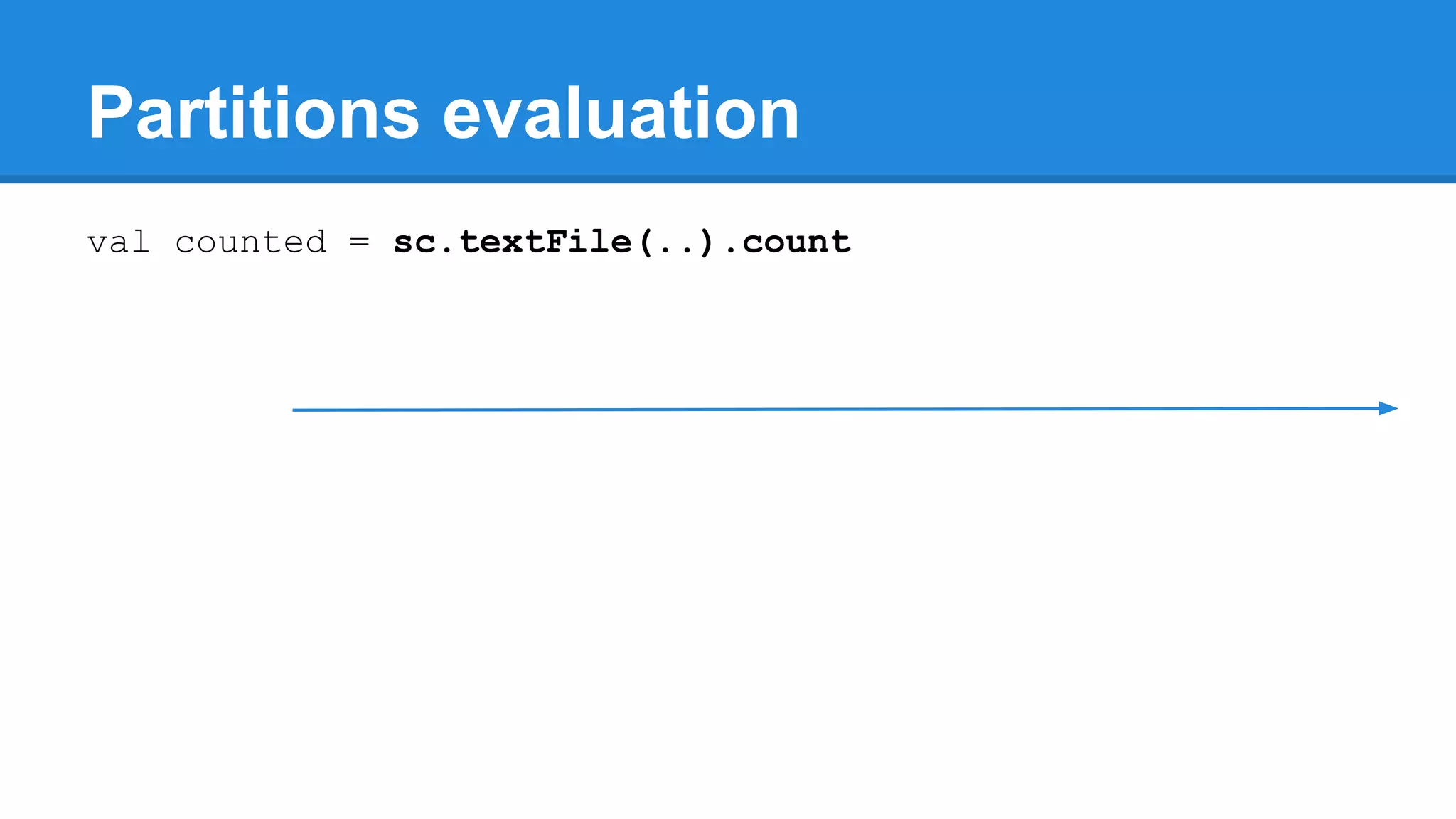


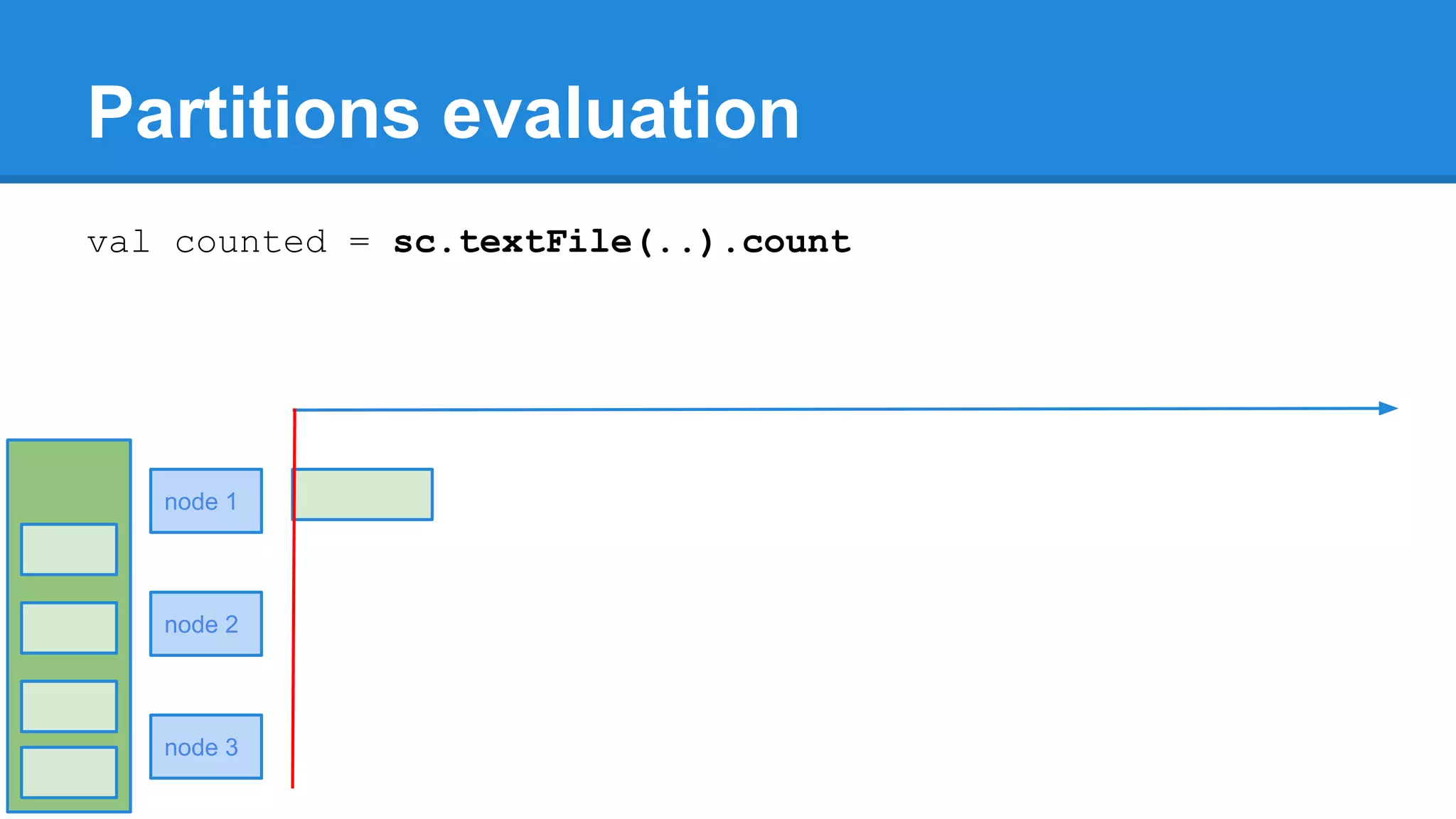
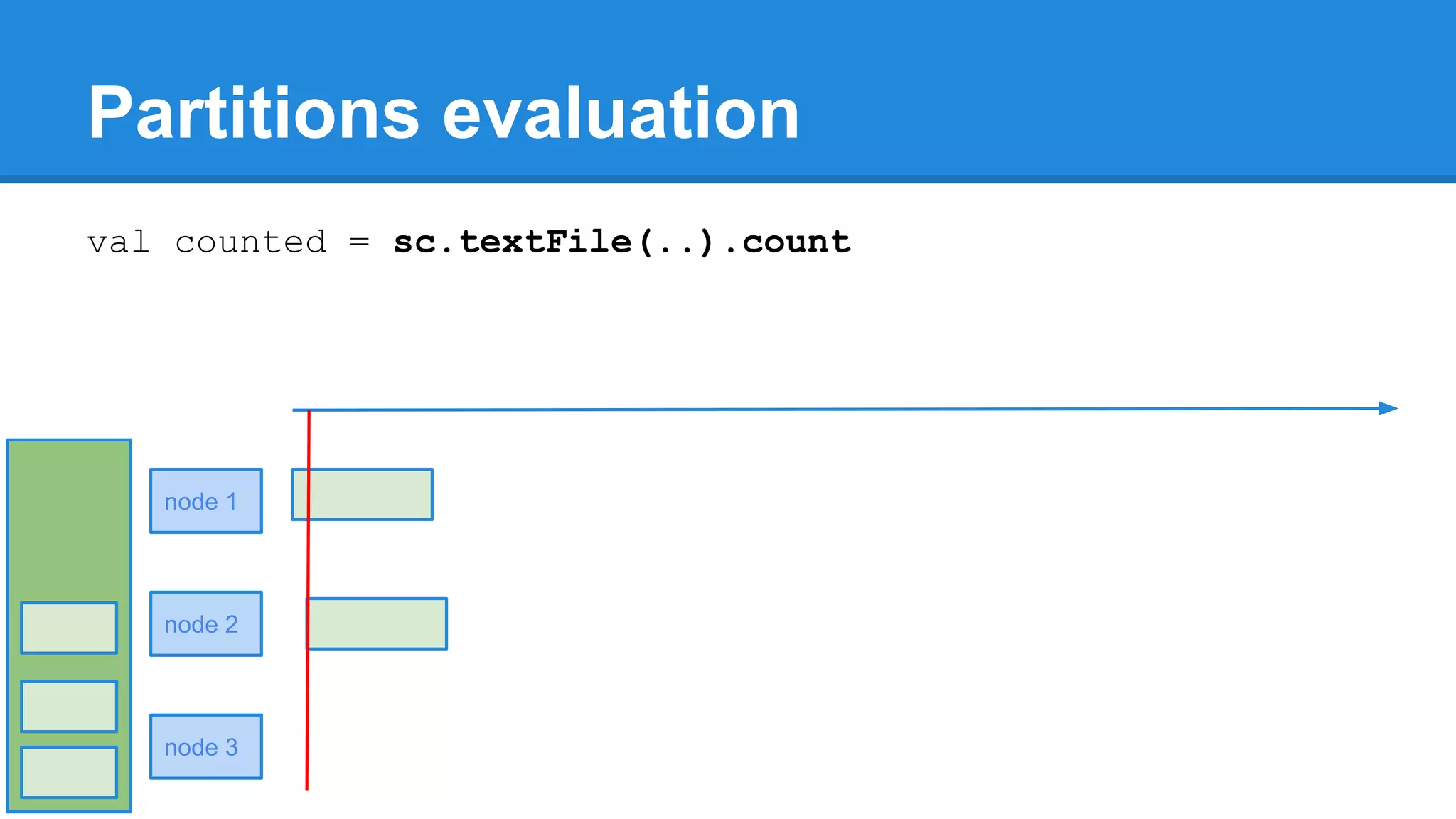









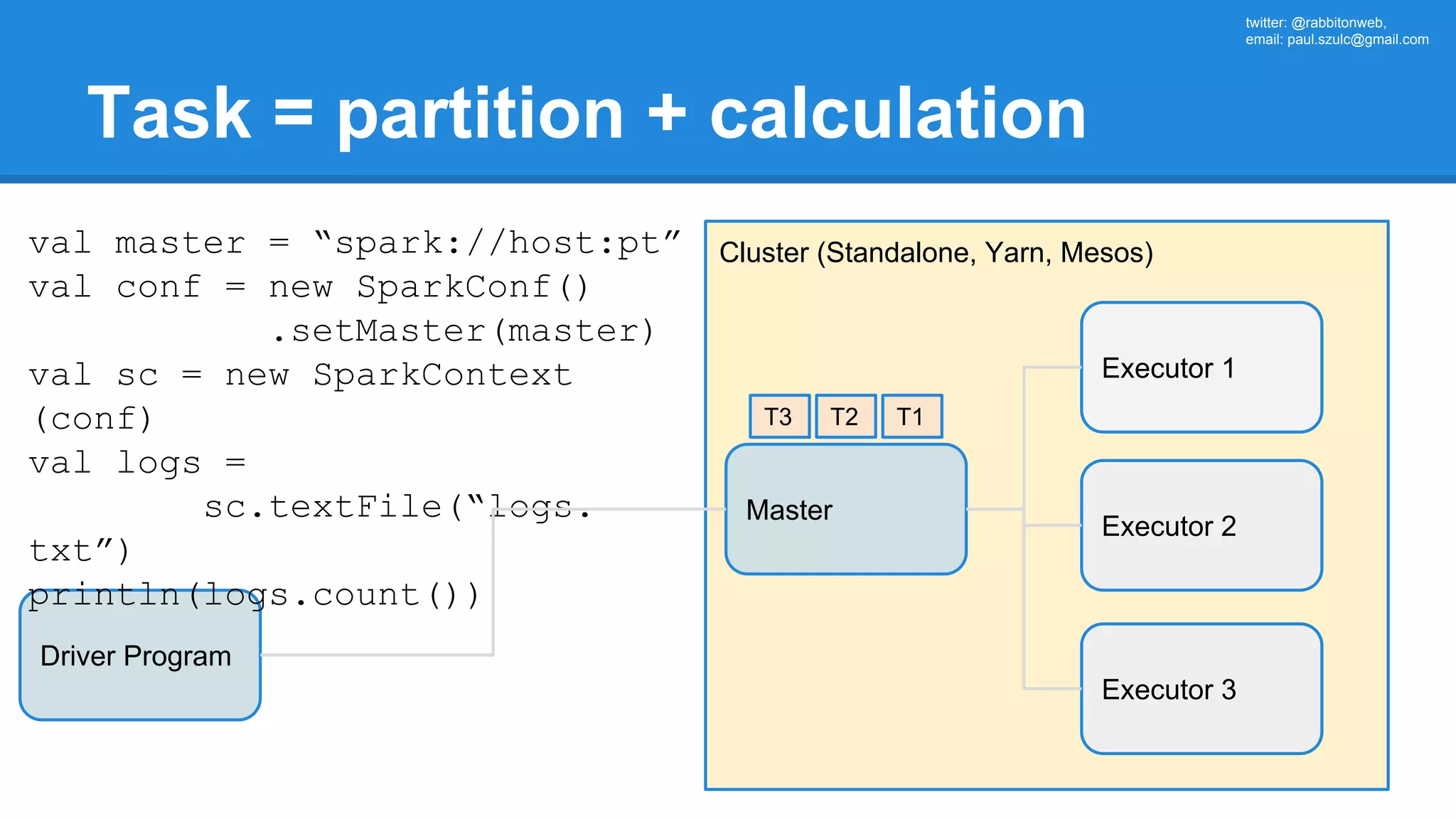
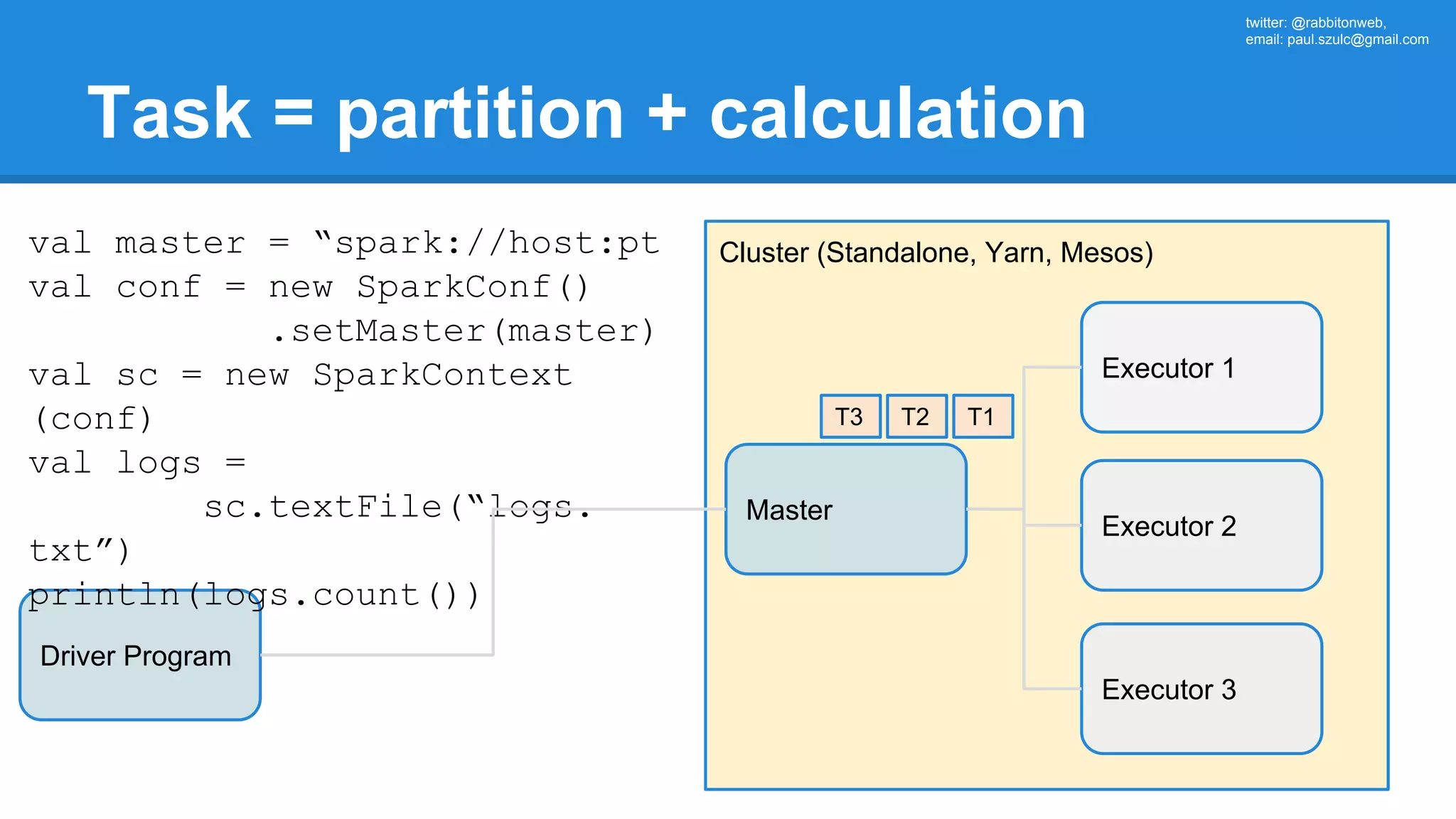
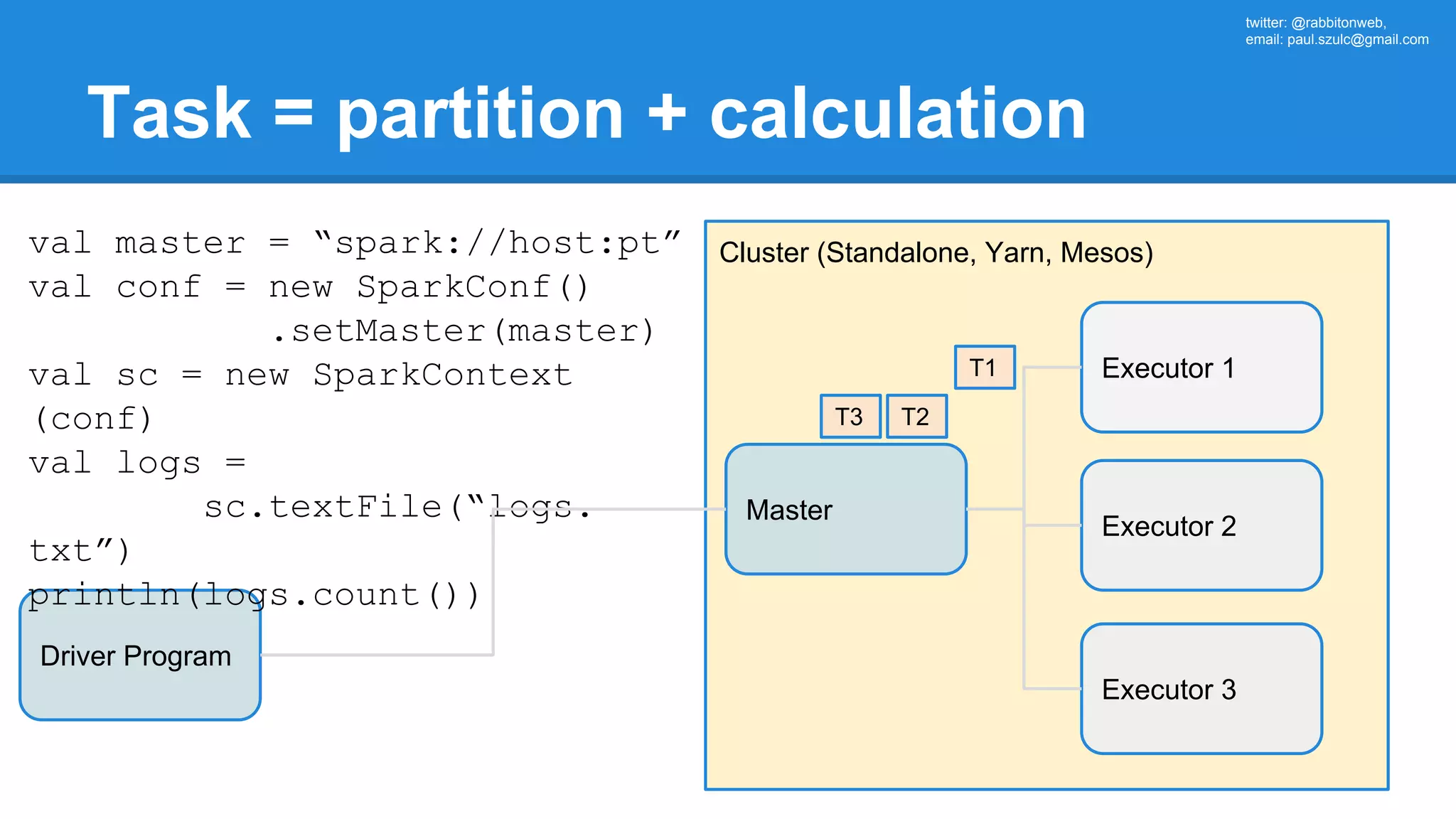
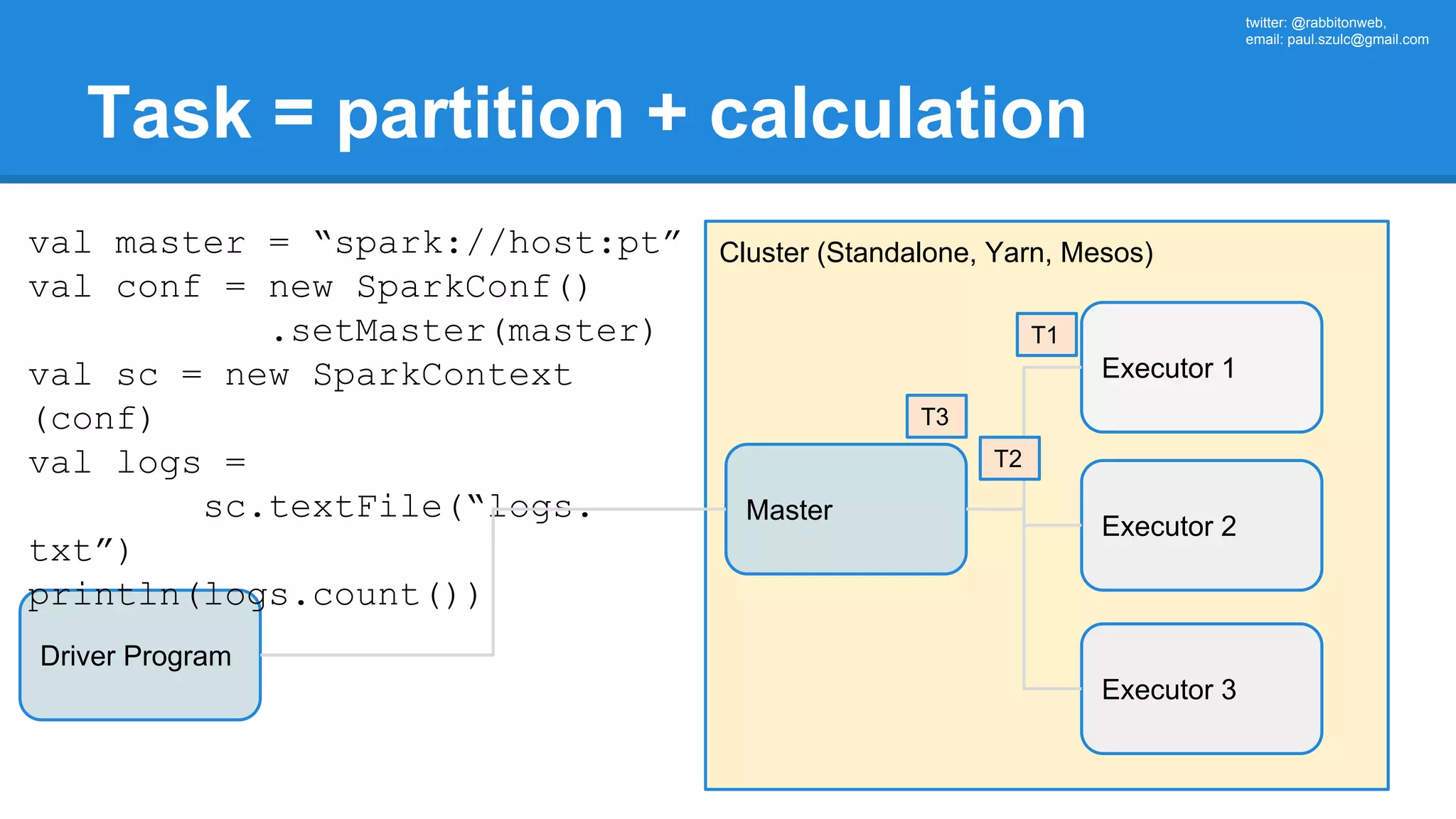
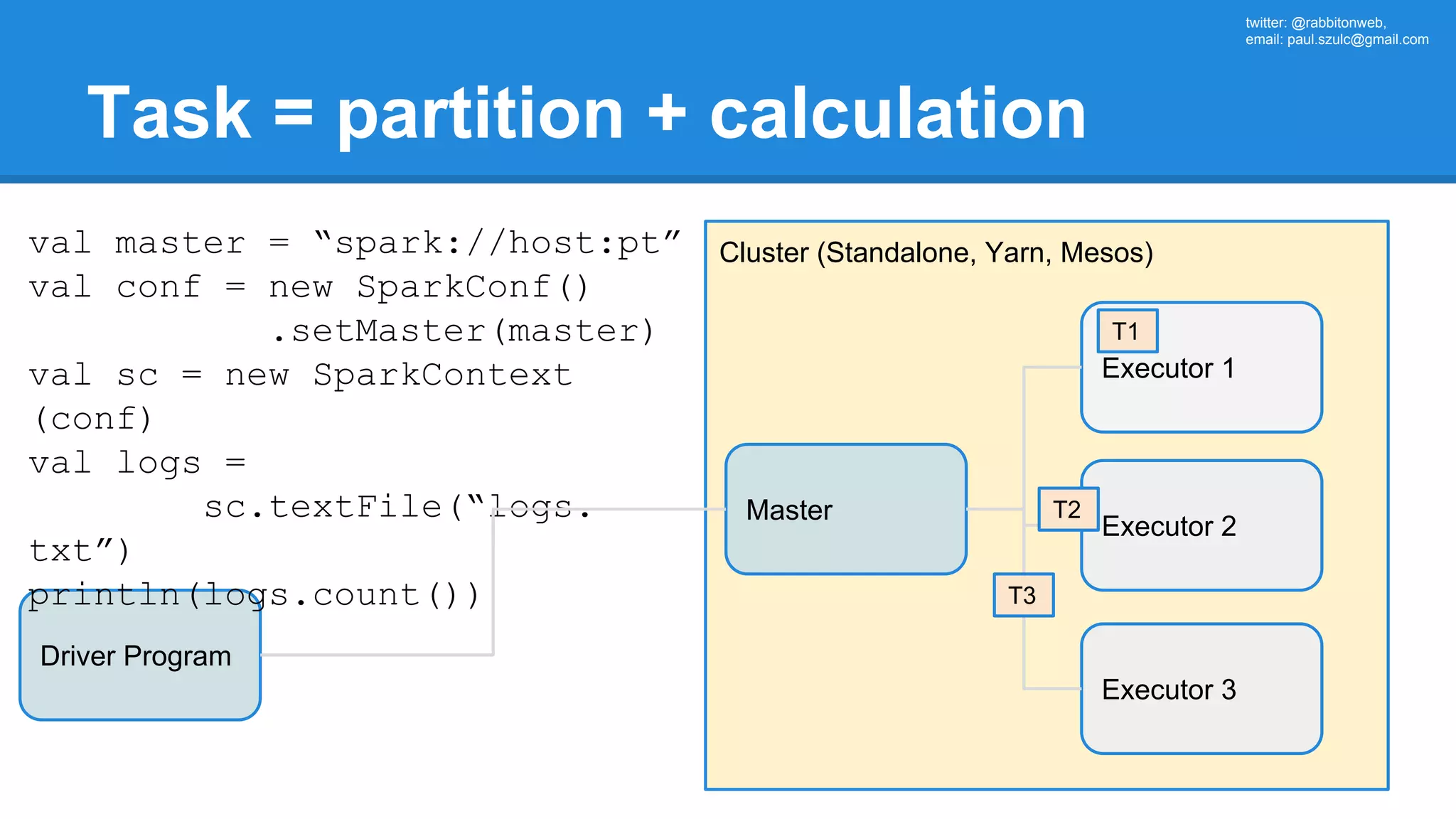
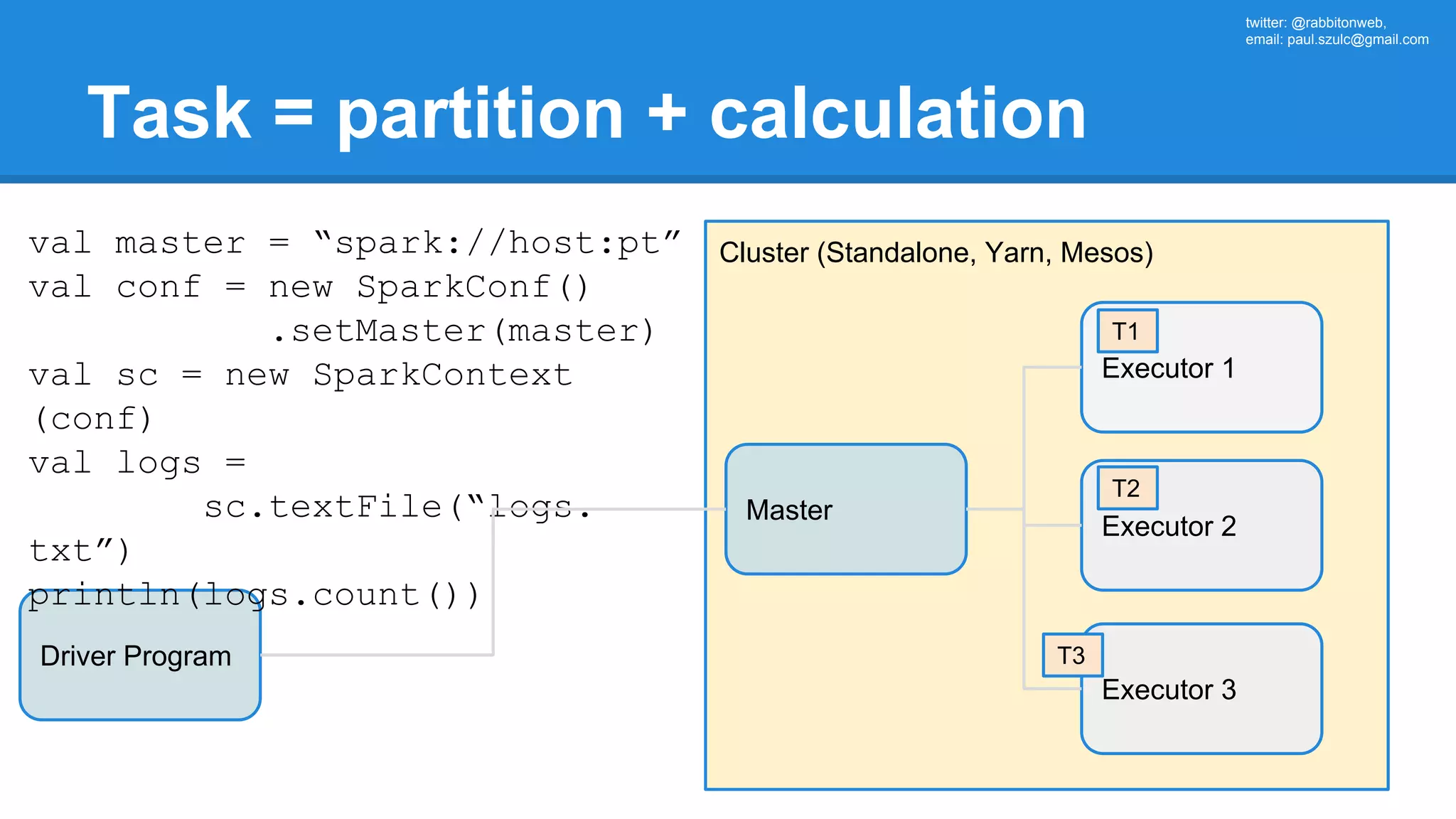
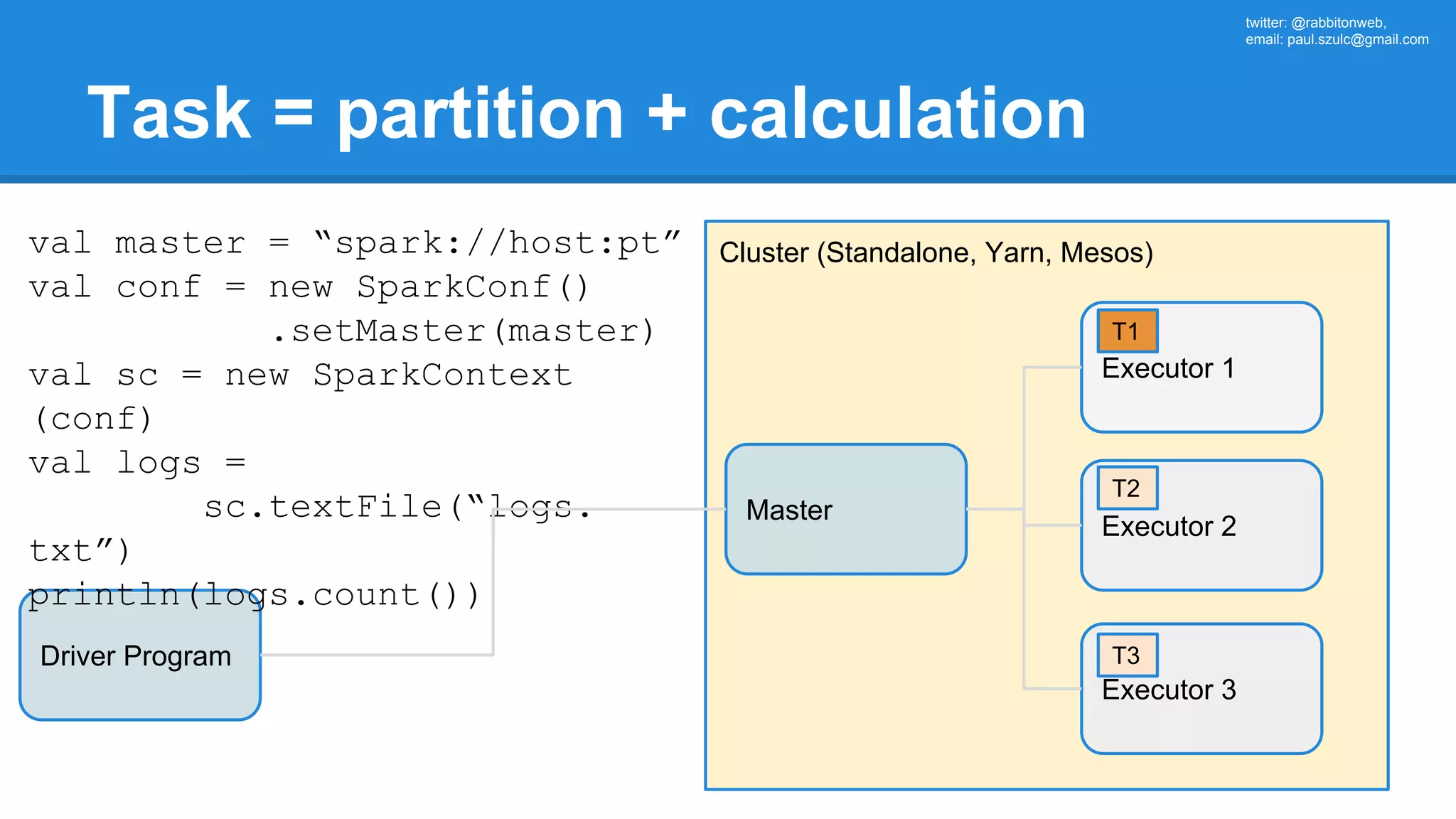
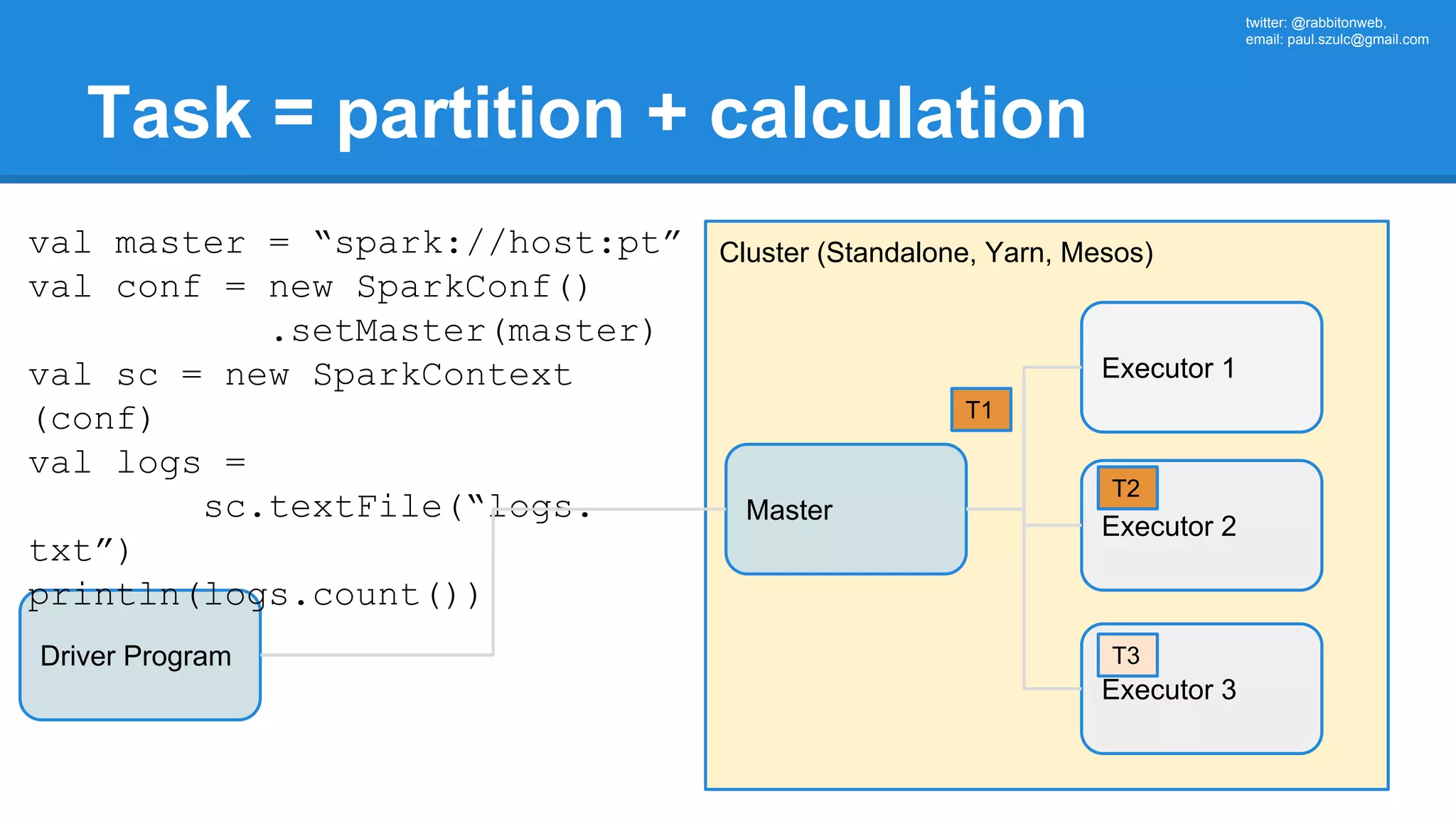




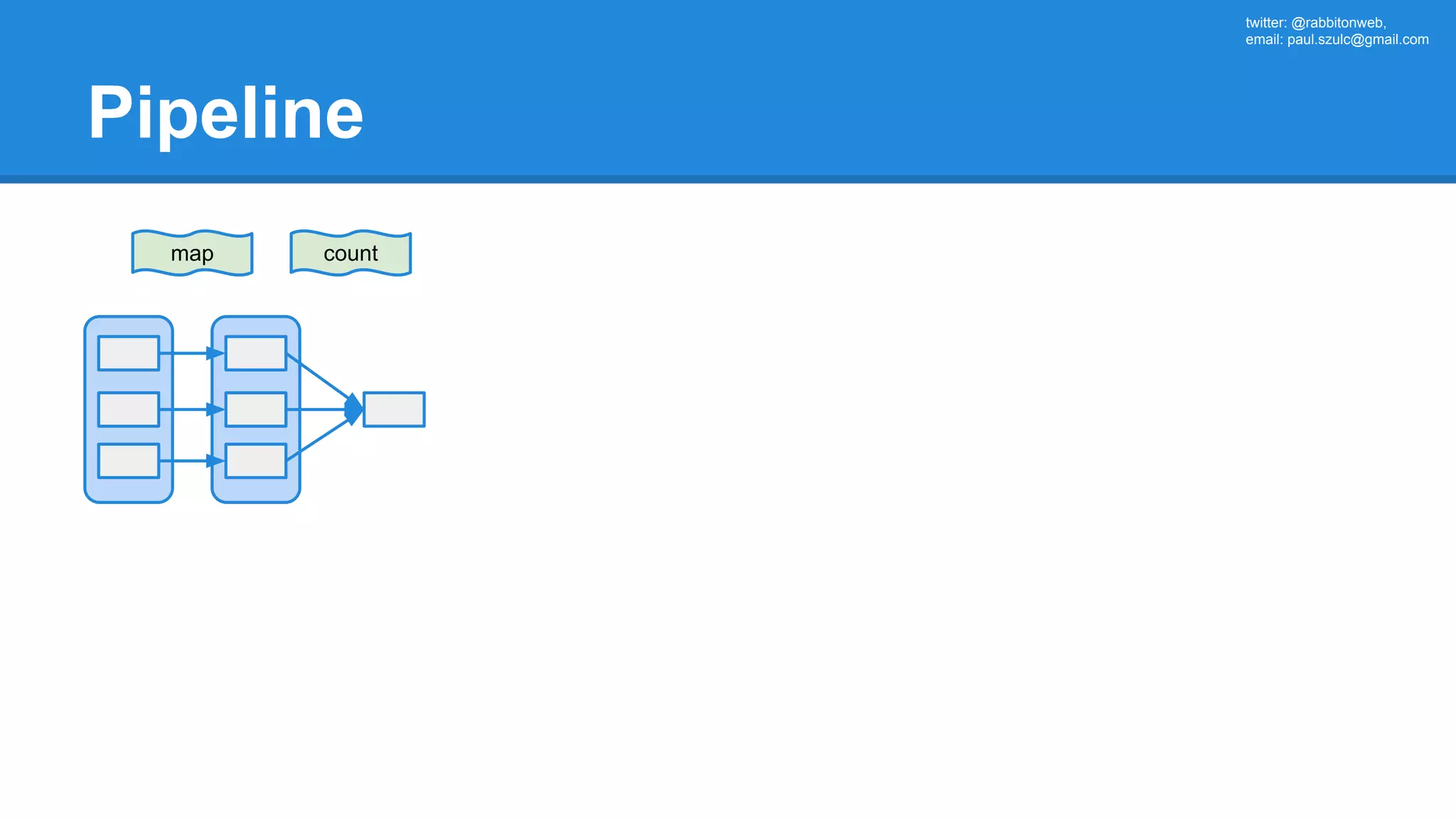
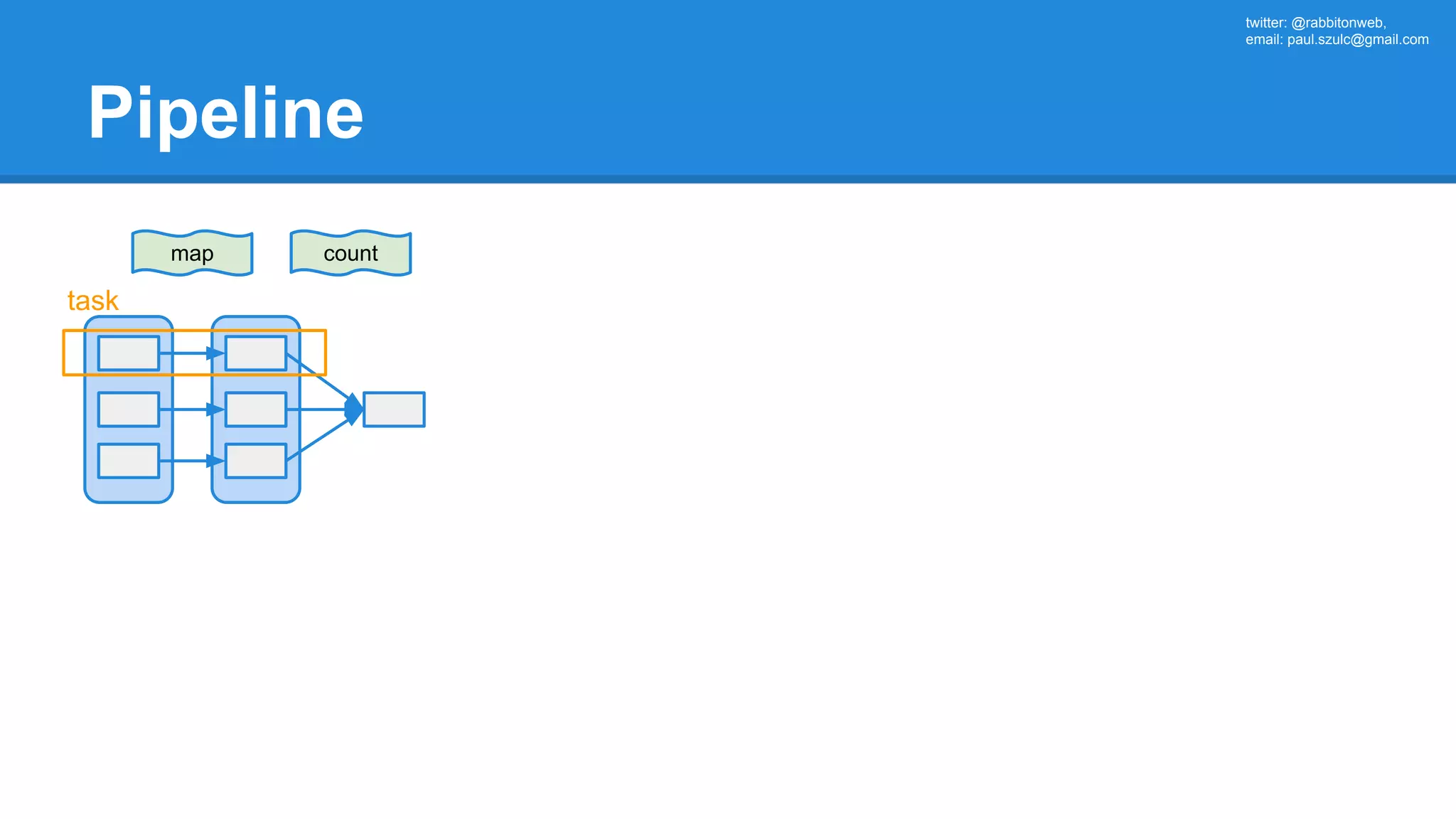
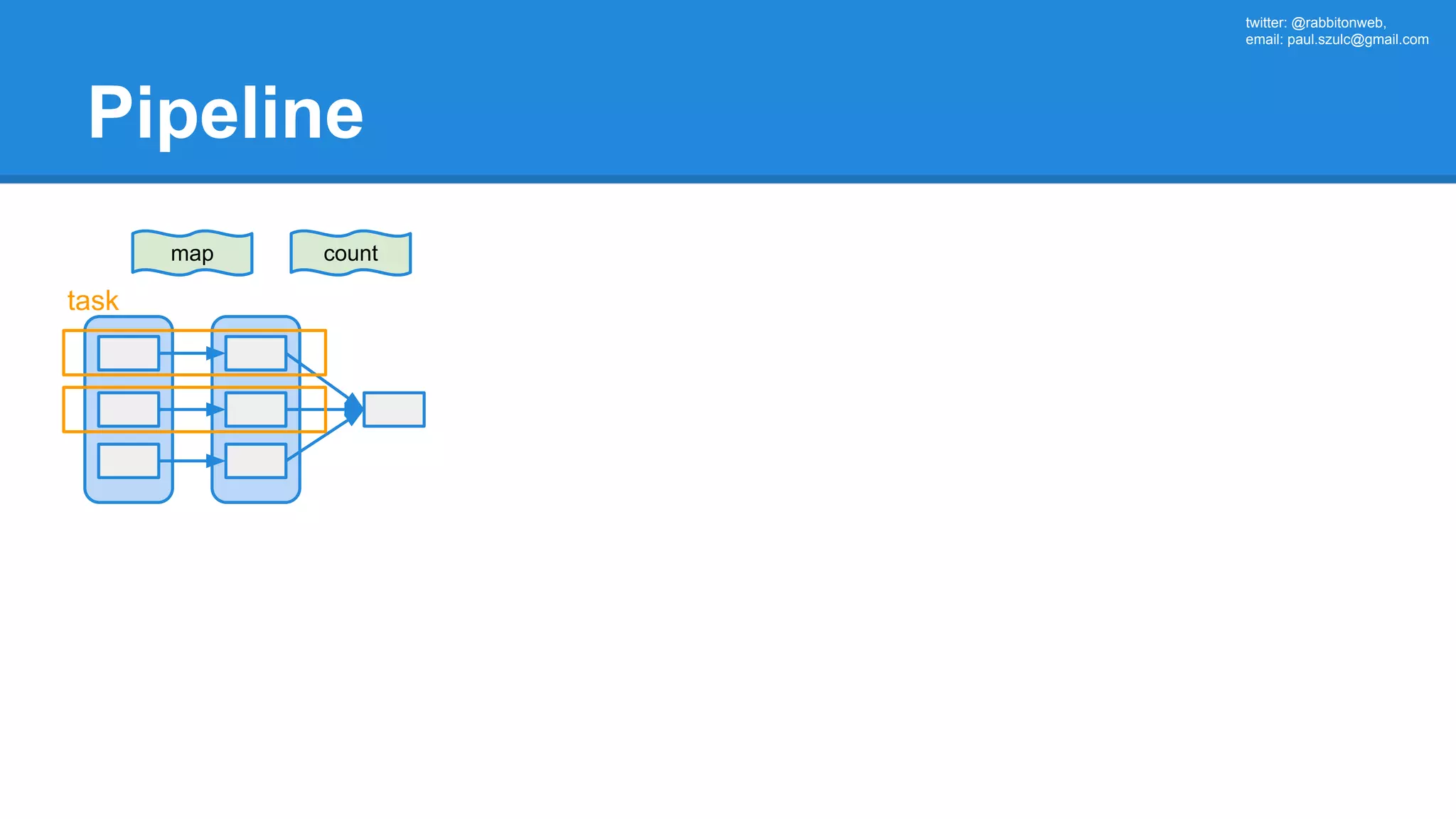
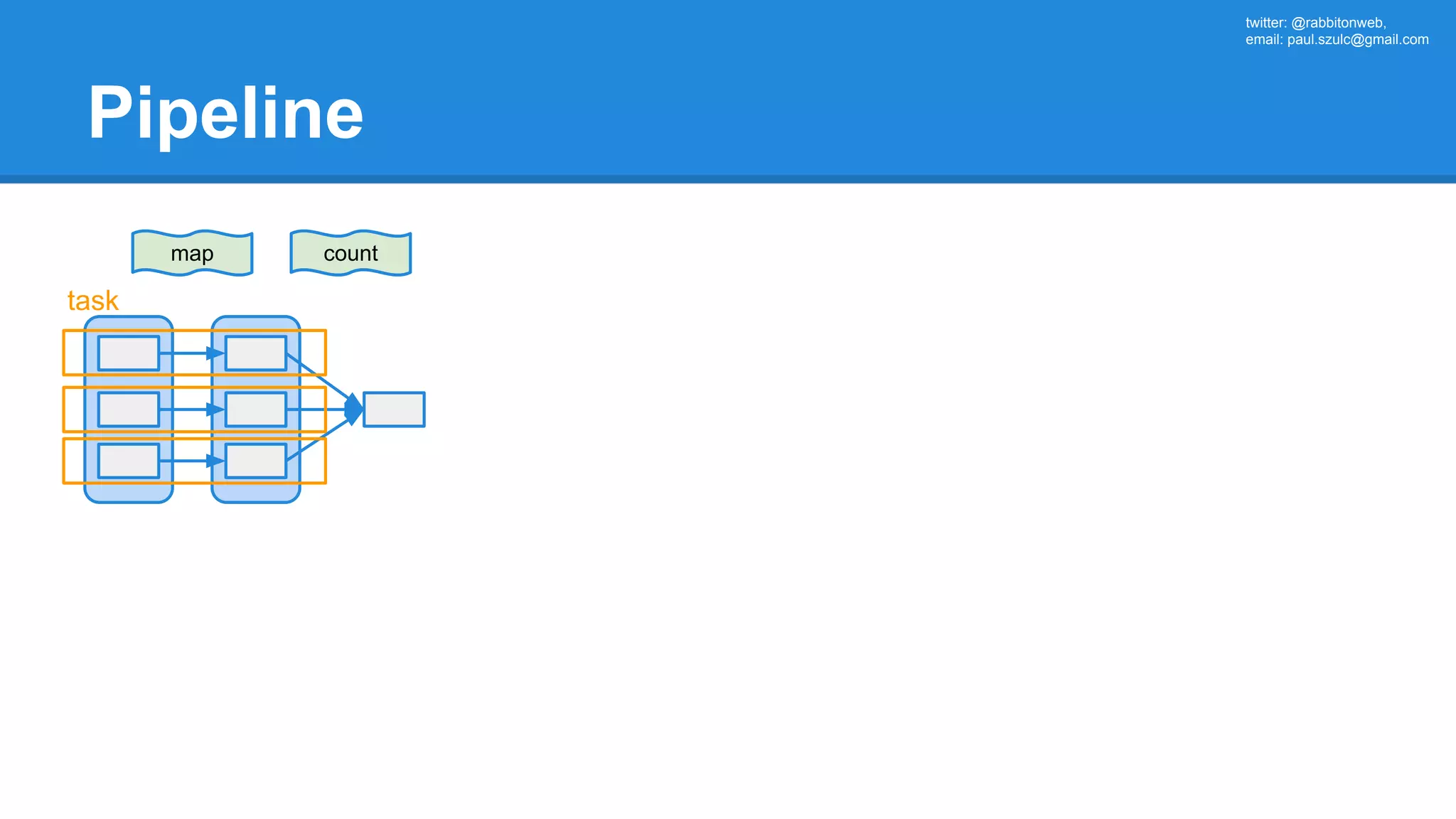






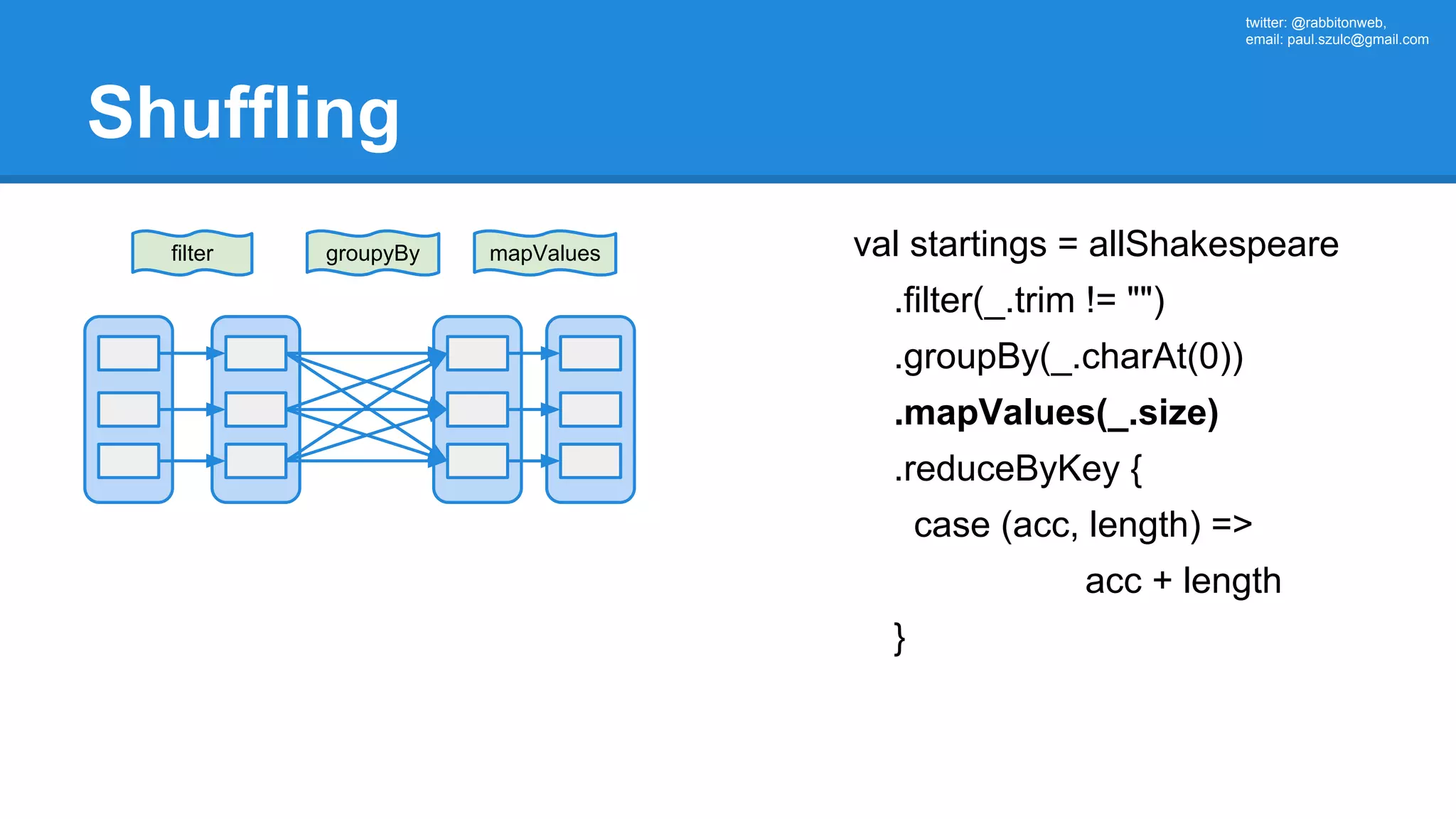
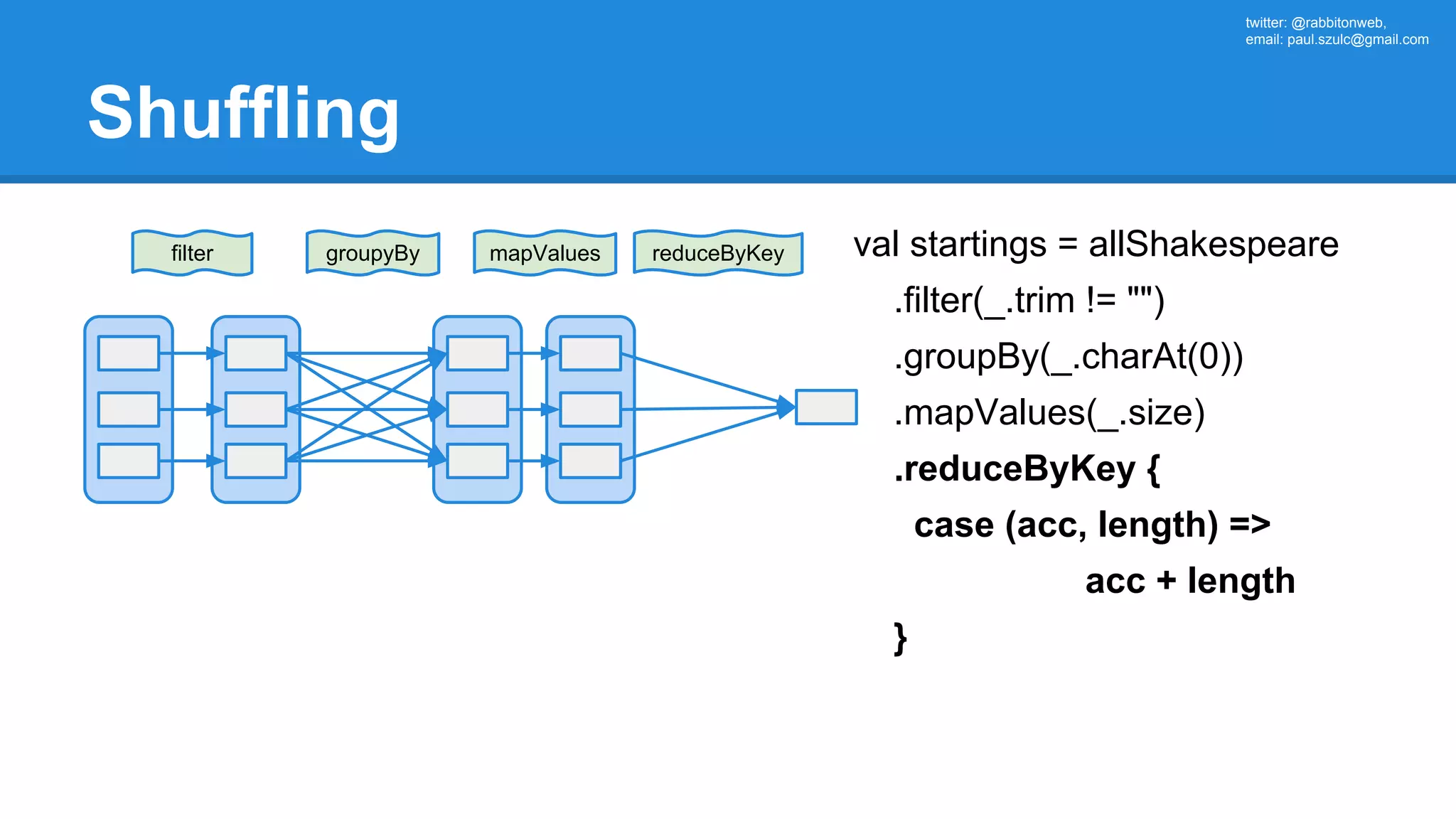
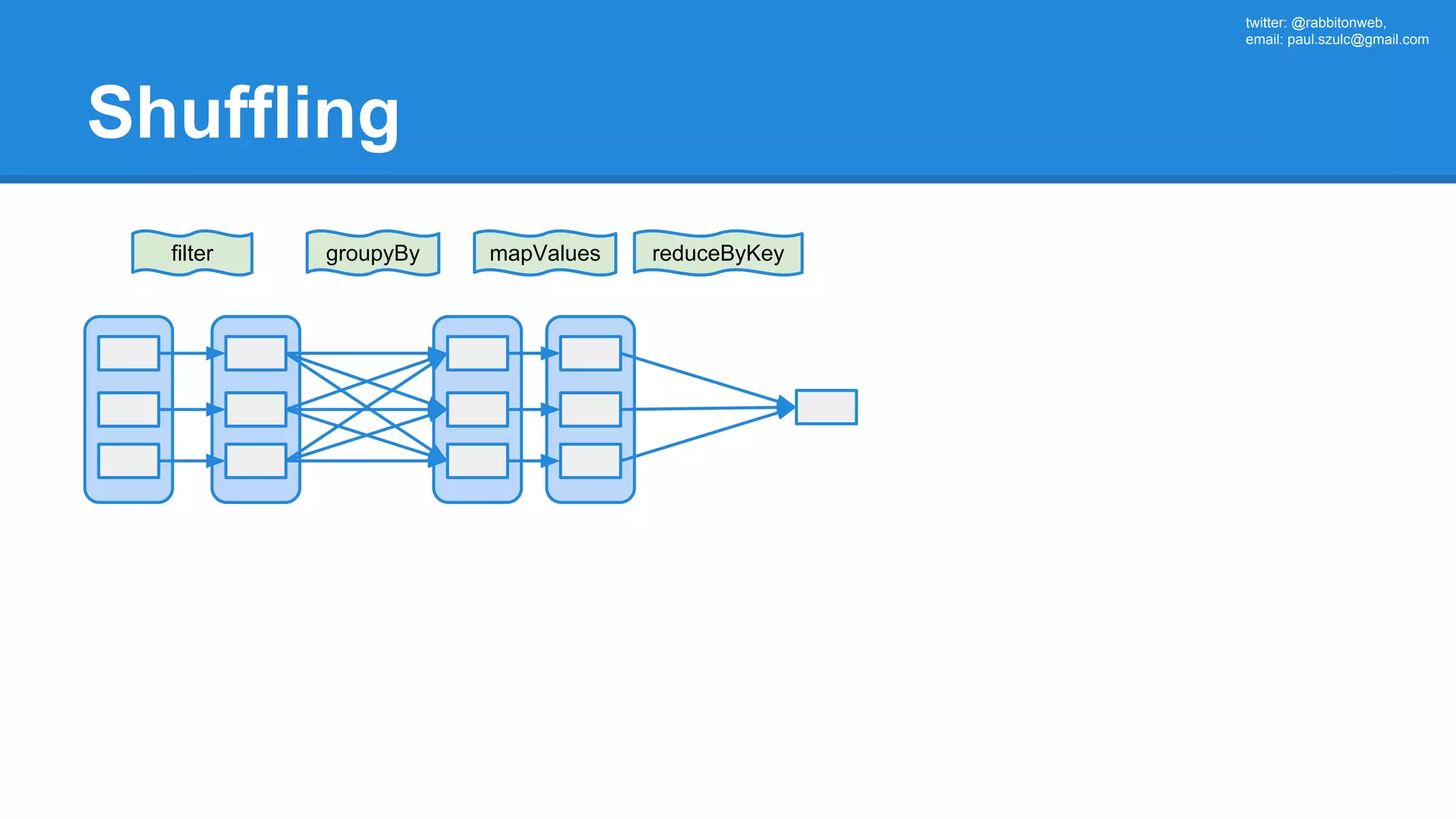
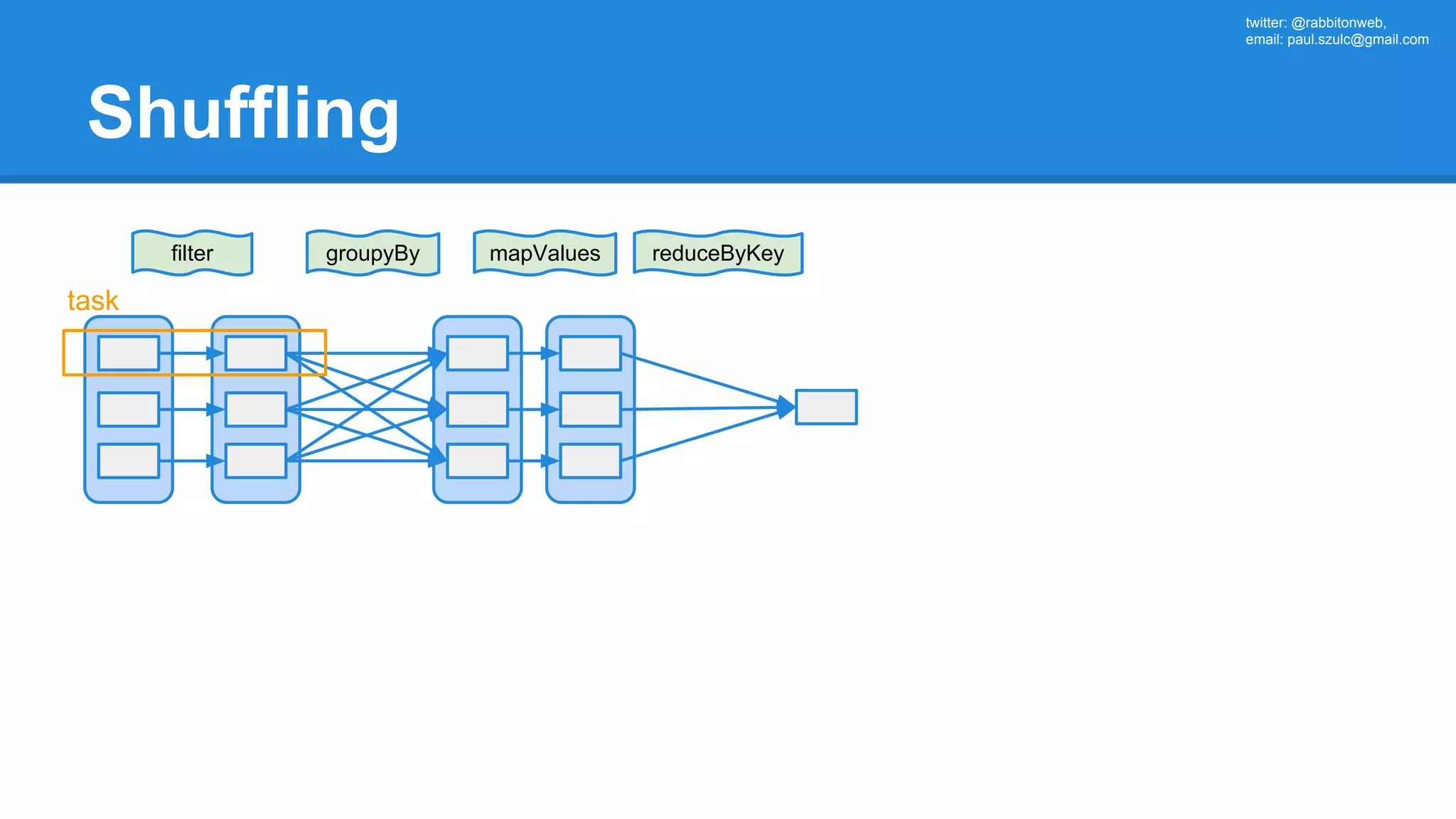
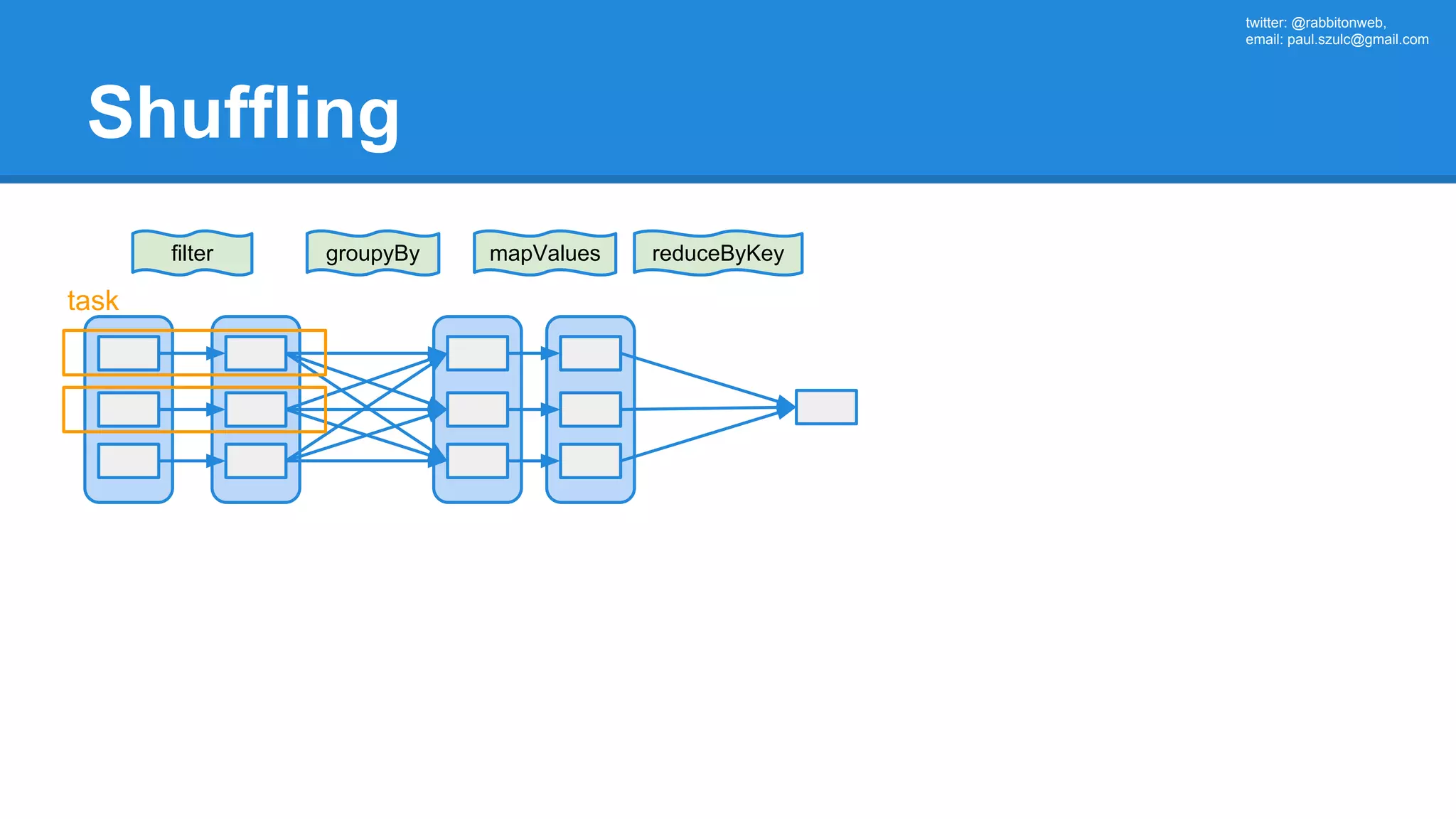
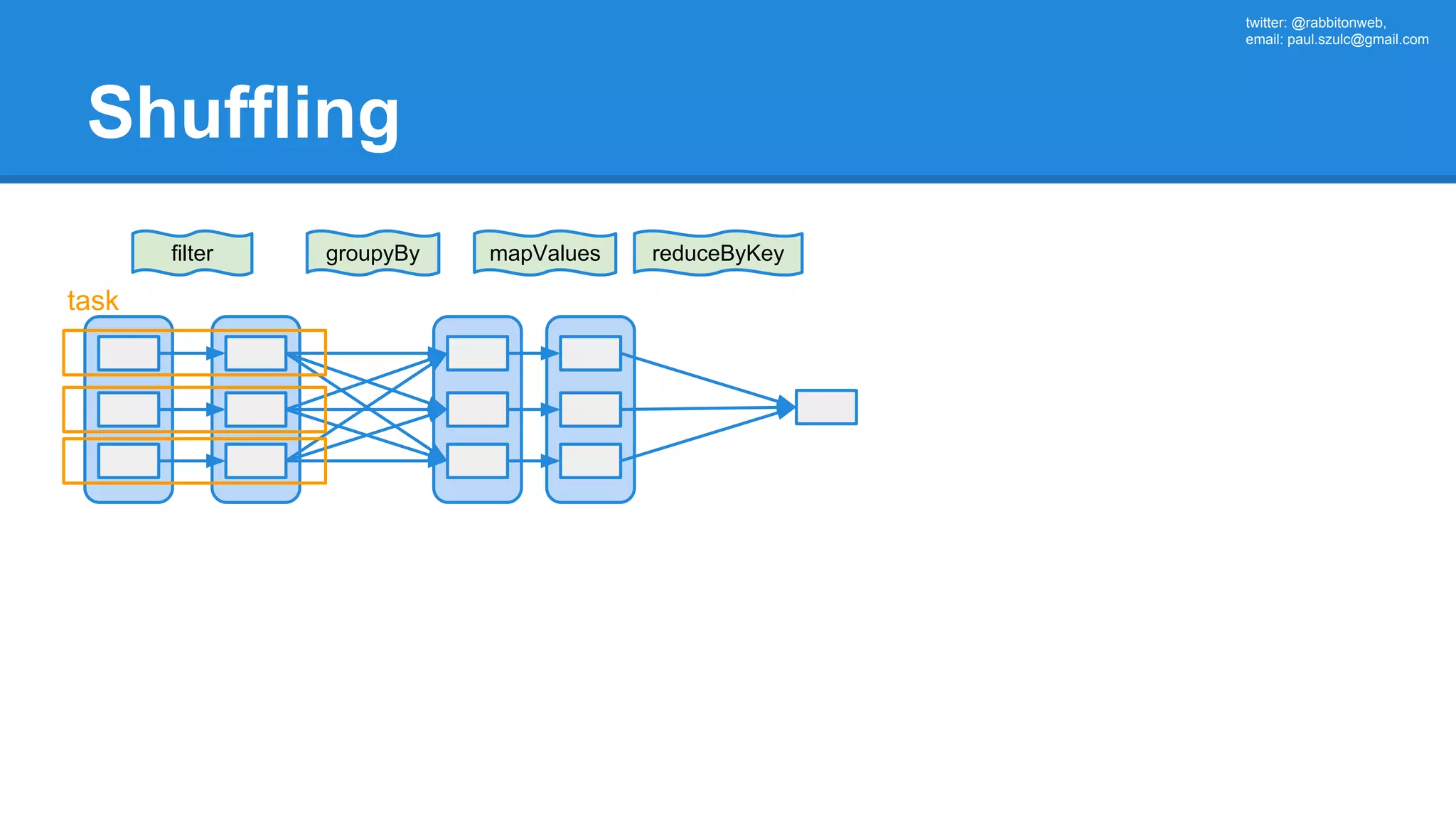
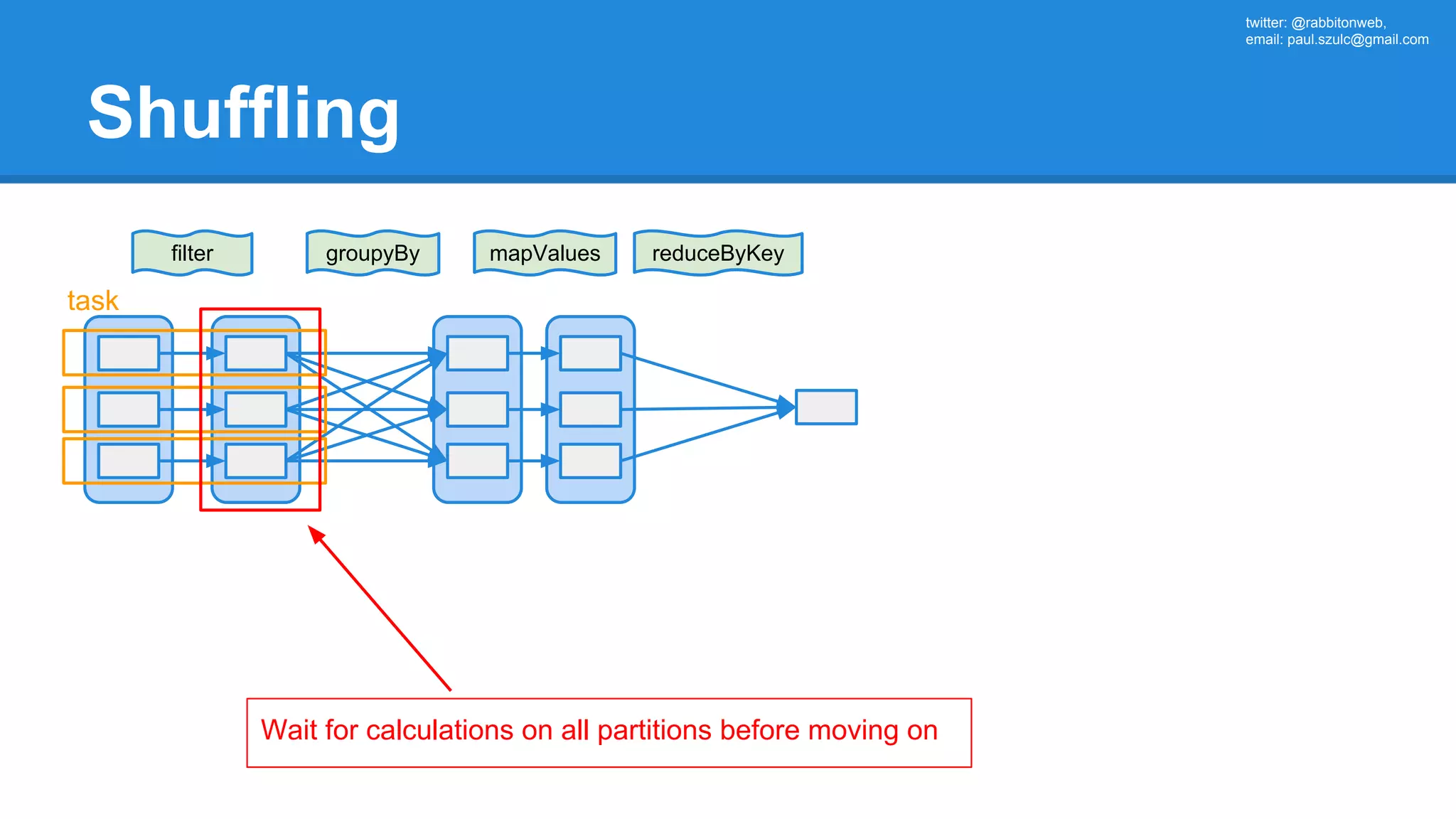
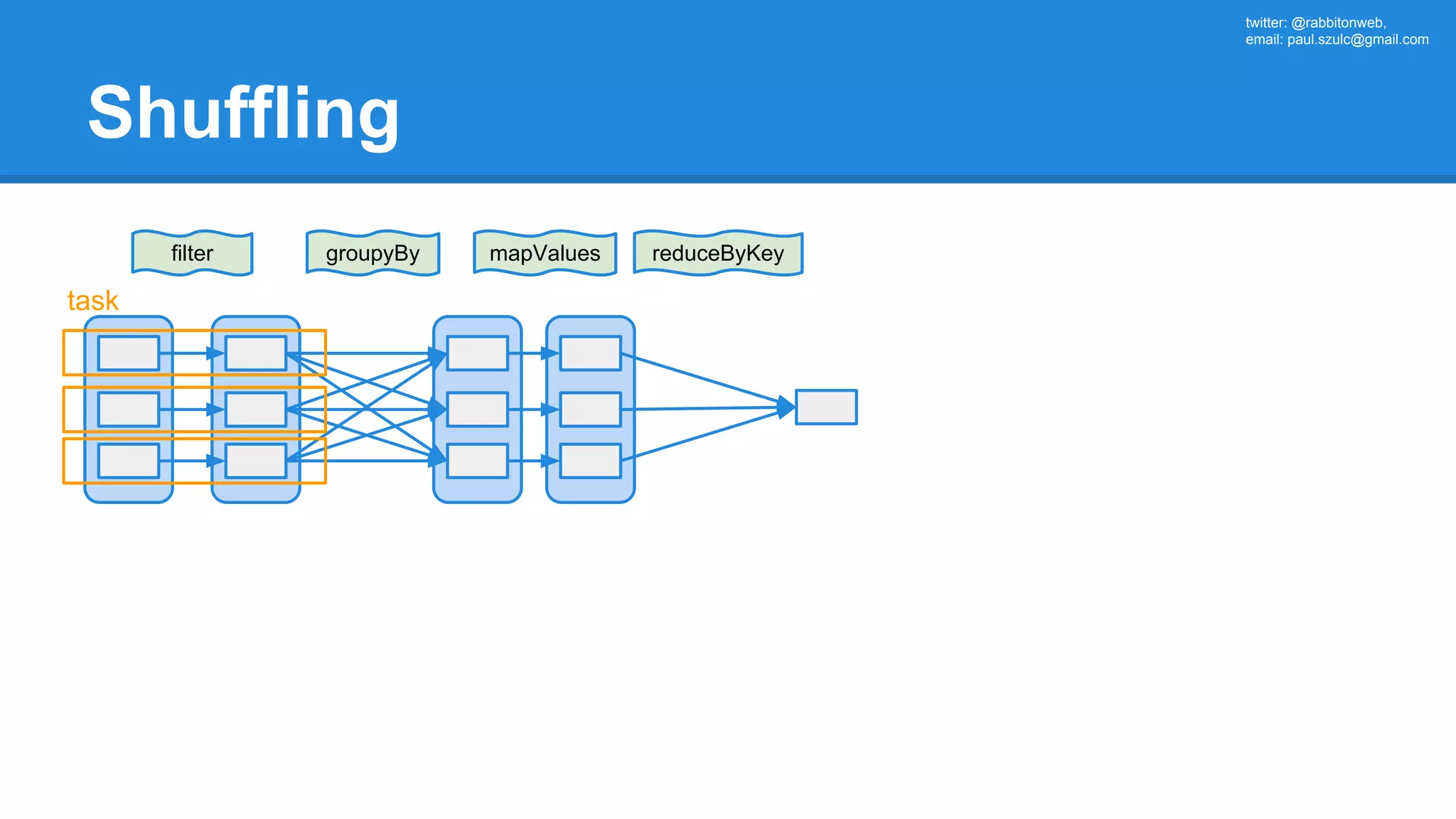
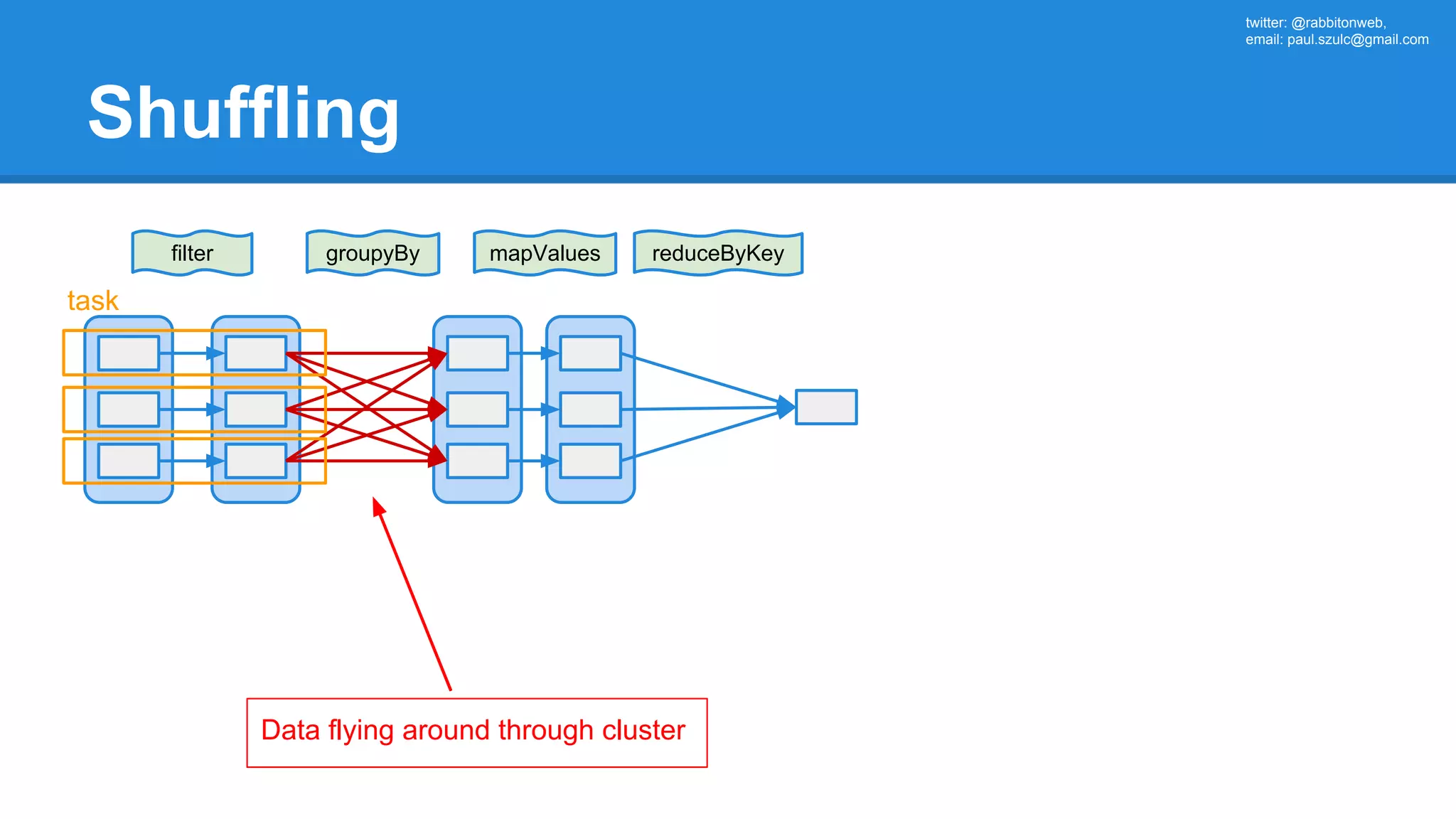
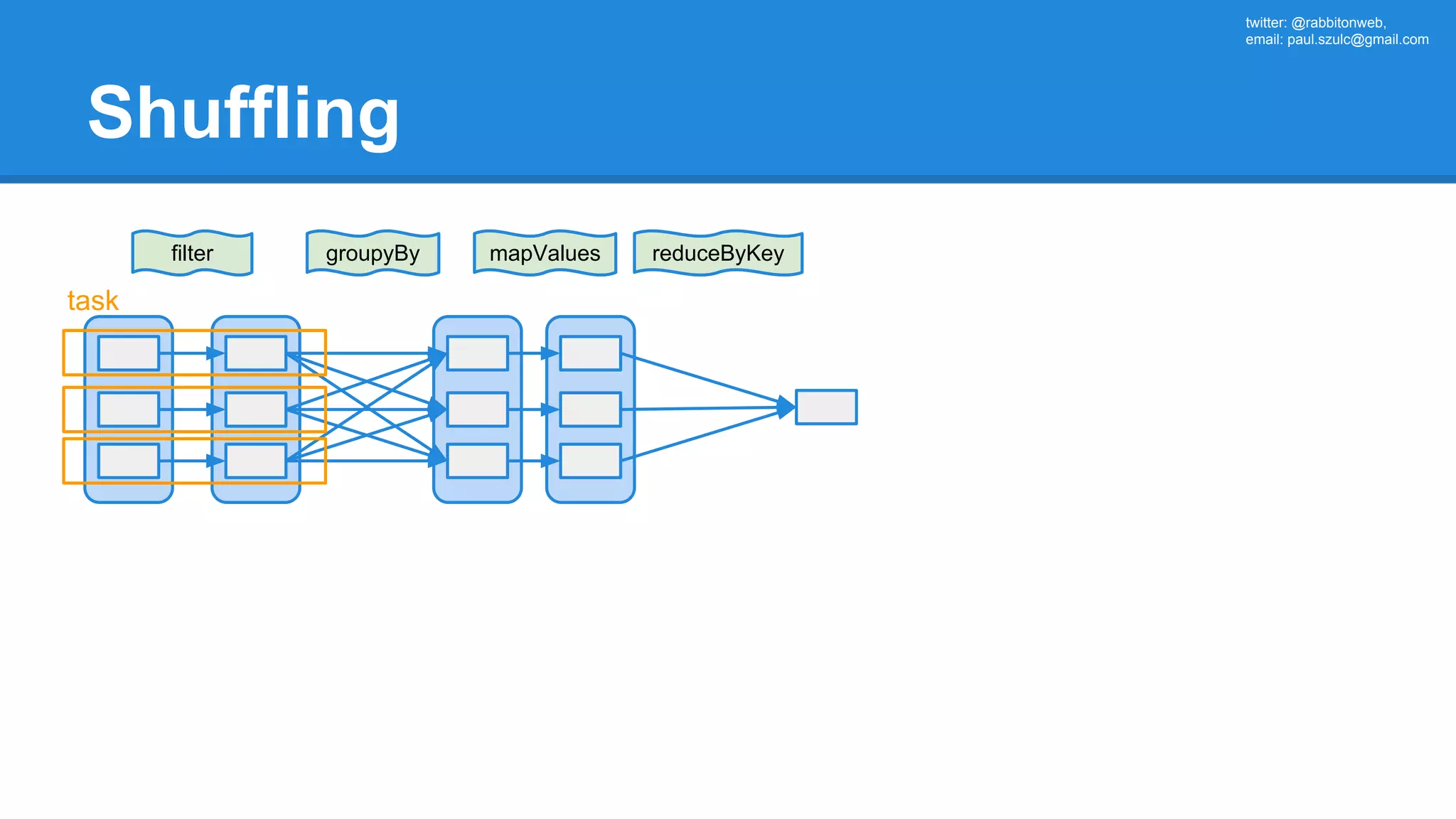
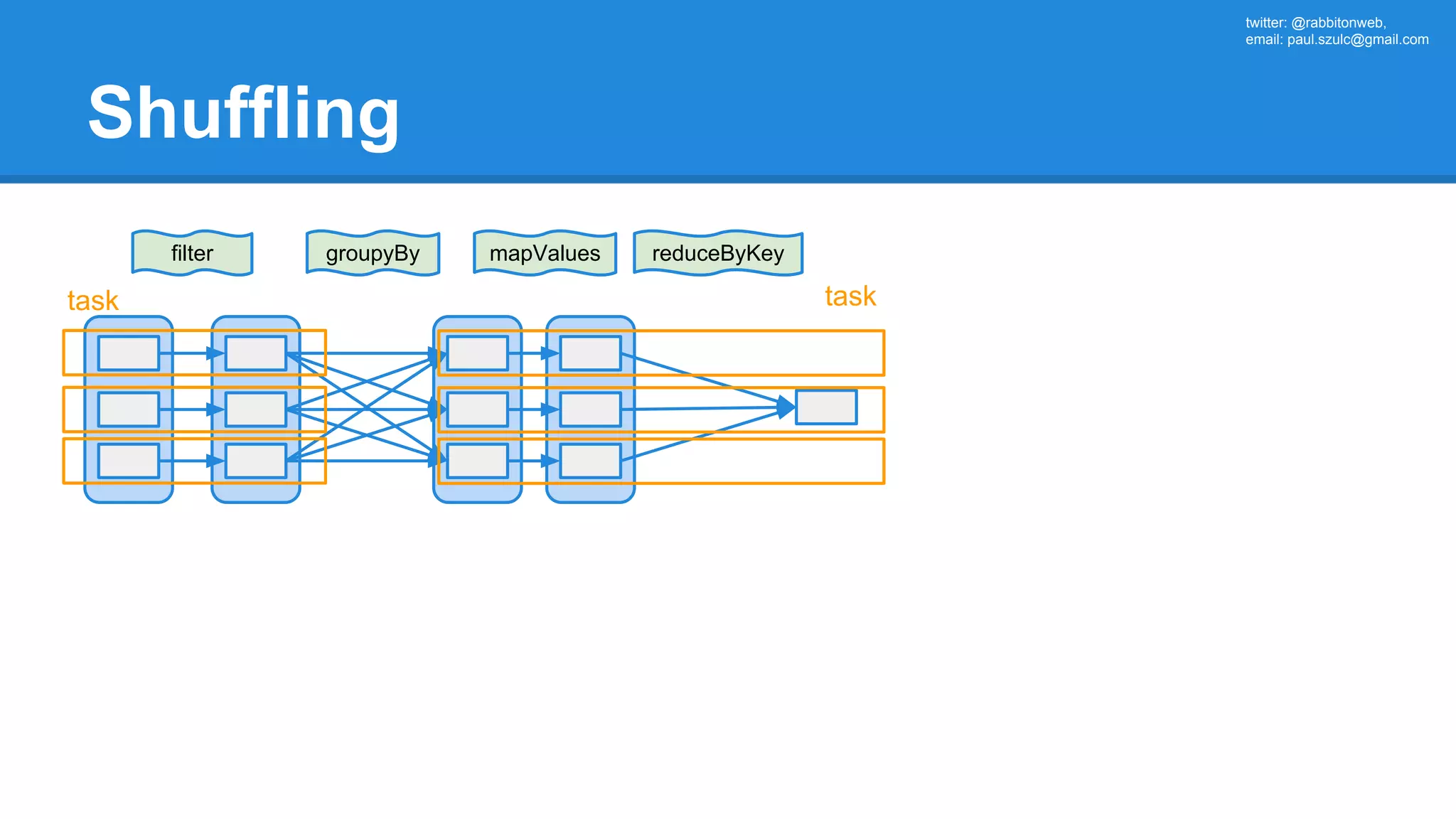
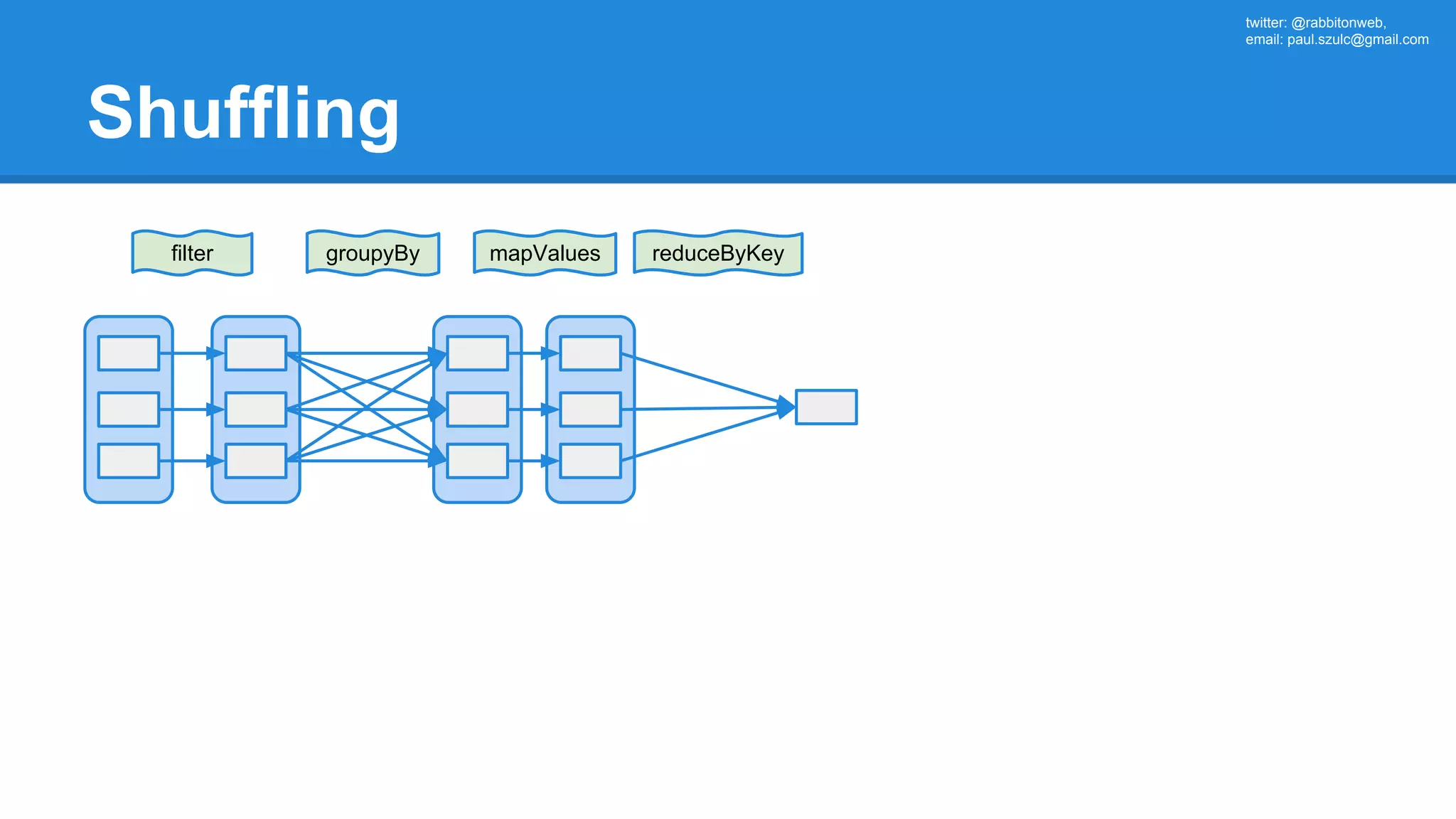
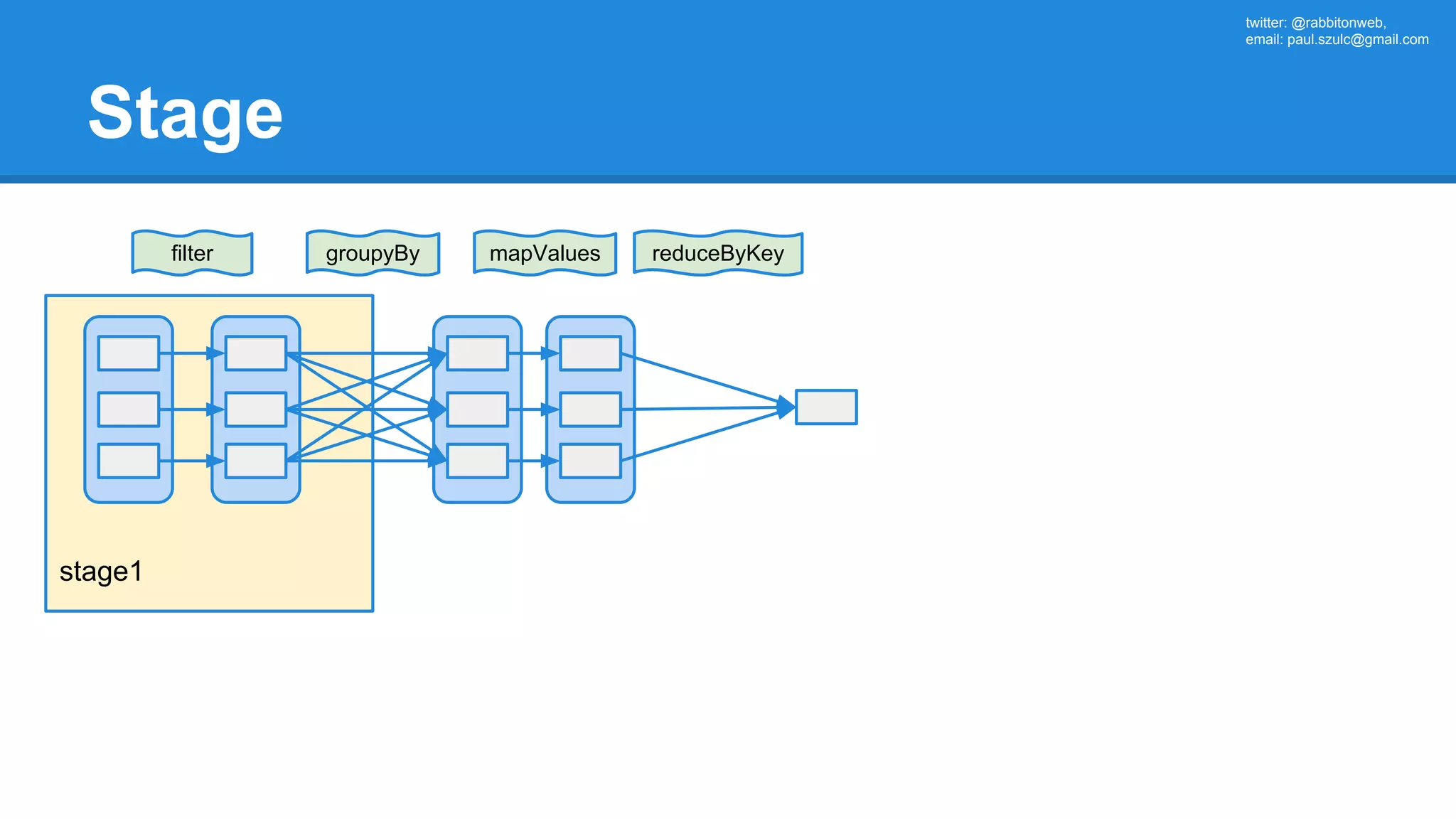
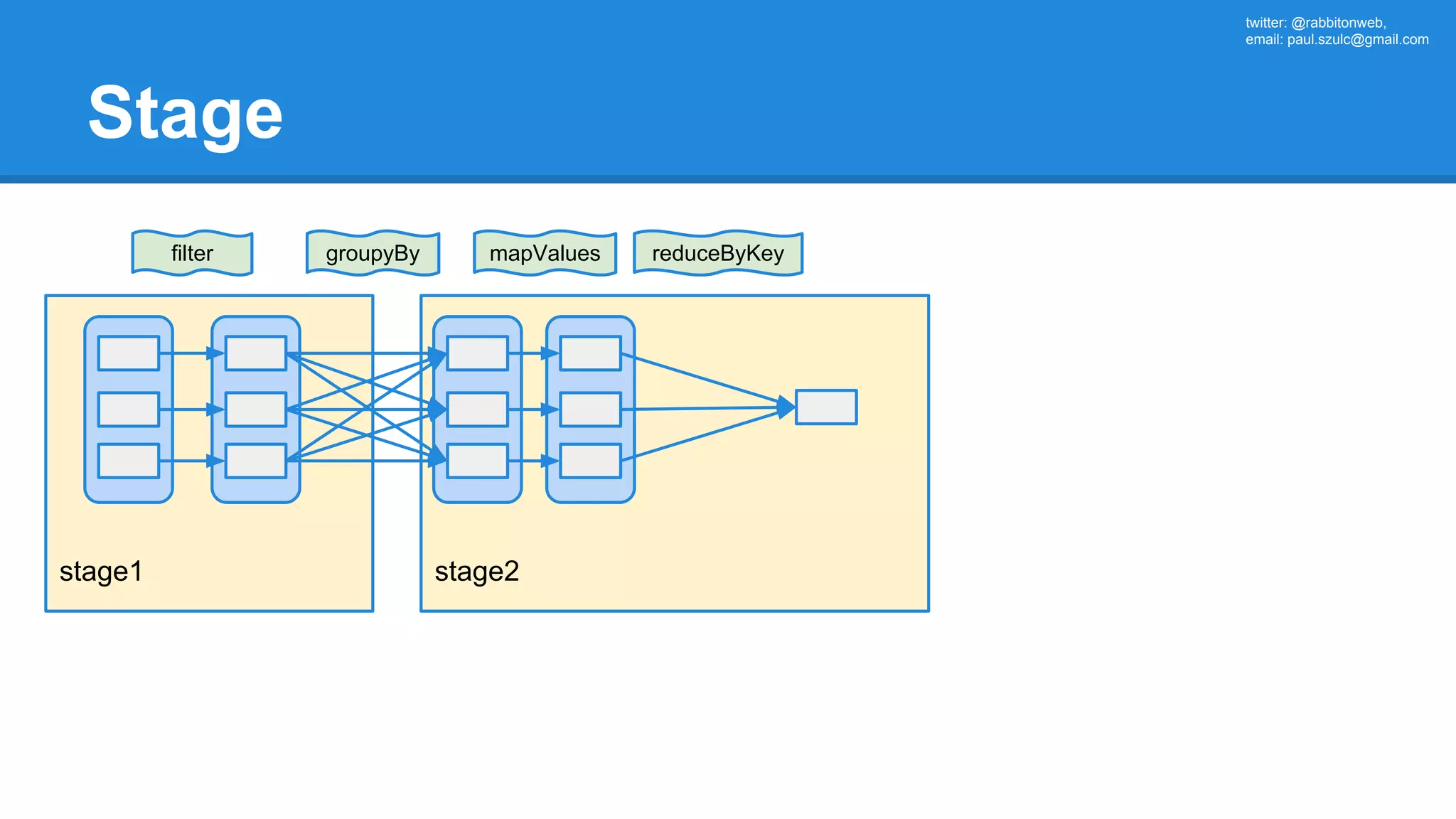
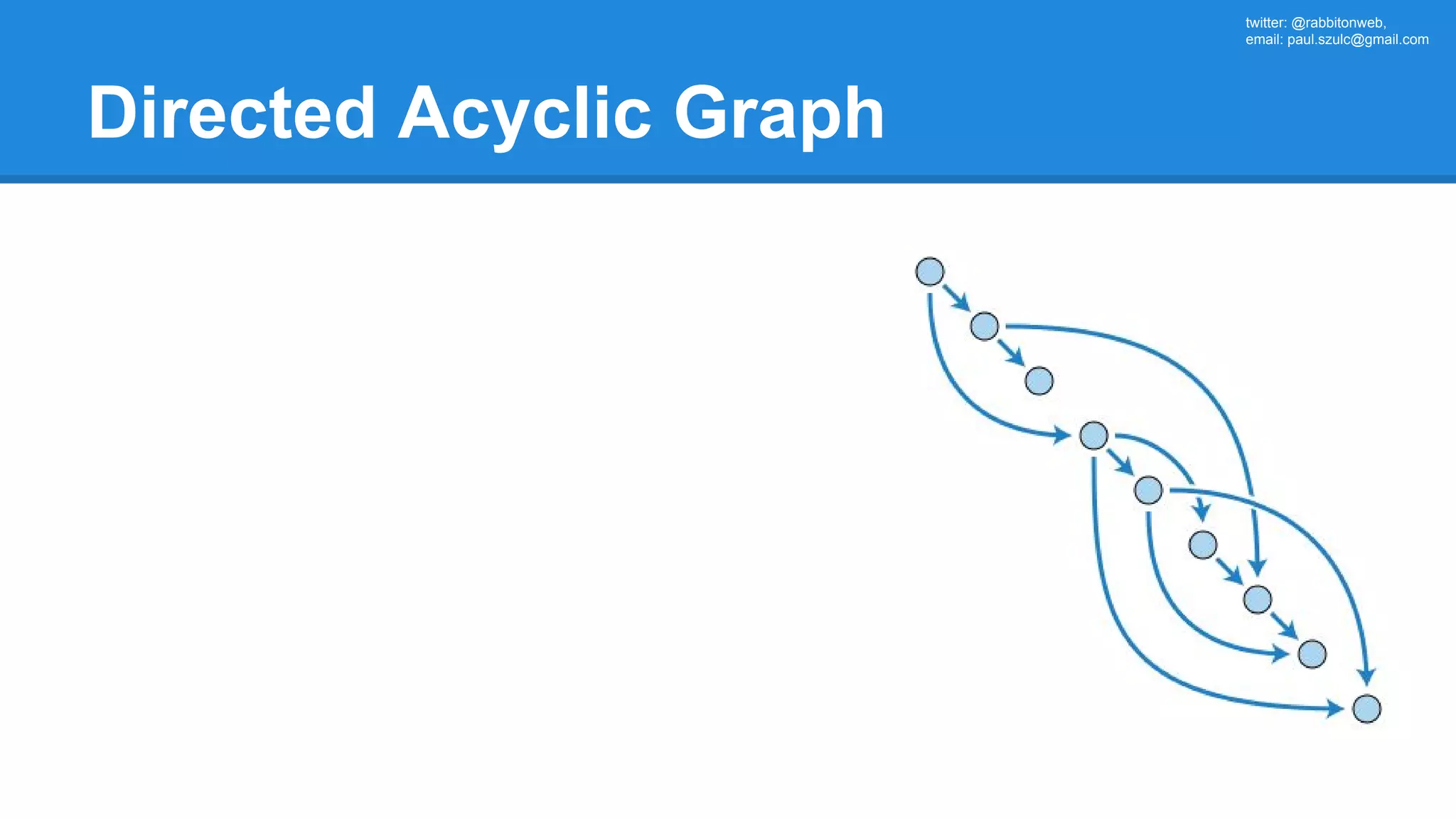


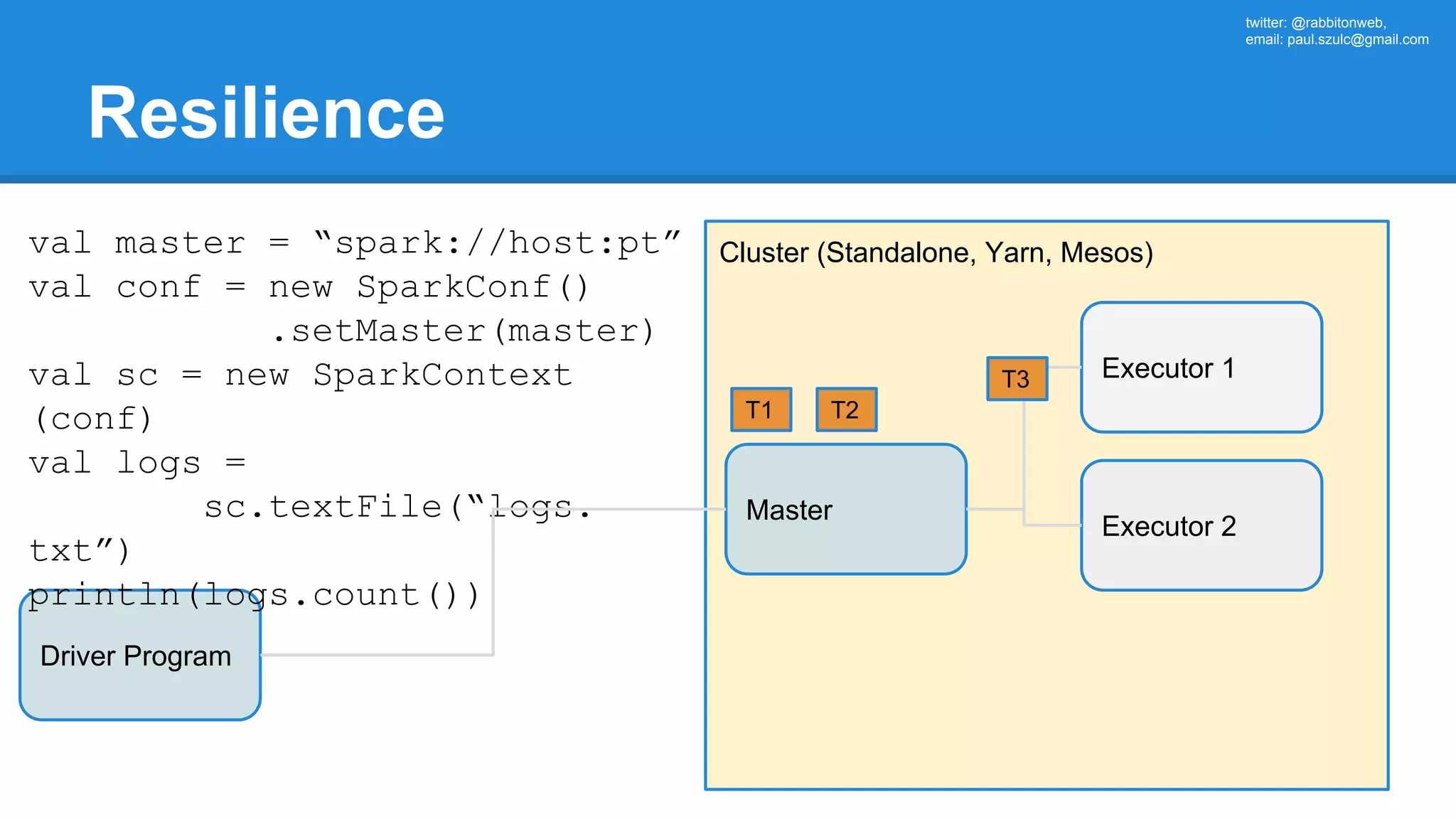
![twitter: @rabbitonweb, email: paul.szulc@gmail.com Directed Acyclic Graph val startings = allShakespeare .filter(_.trim != "") .map(line => (line.charAt(0), line)) .mapValues(_.size) .reduceByKey { case (acc, length) => acc + length } println(startings.toDebugString) (2) ShuffledRDD[5] at reduceByKey at Ex3.scala:18 [] +-(2) MapPartitionsRDD[4] at mapValues at Ex3.scala:17 [] | MapPartitionsRDD[3] at map at Ex3.scala:16 [] | MapPartitionsRDD[2] at filter at Ex3.scala:15 [] | src/main/resources/all-shakespeare.txt MapPartitionsRDD[1] | src/main/resources/all-shakespeare.txt HadoopRDD[0] at textFile](https://image.slidesharecdn.com/apachesparkworkshops-160527153959/75/Apache-spark-workshop-160-2048.jpg)
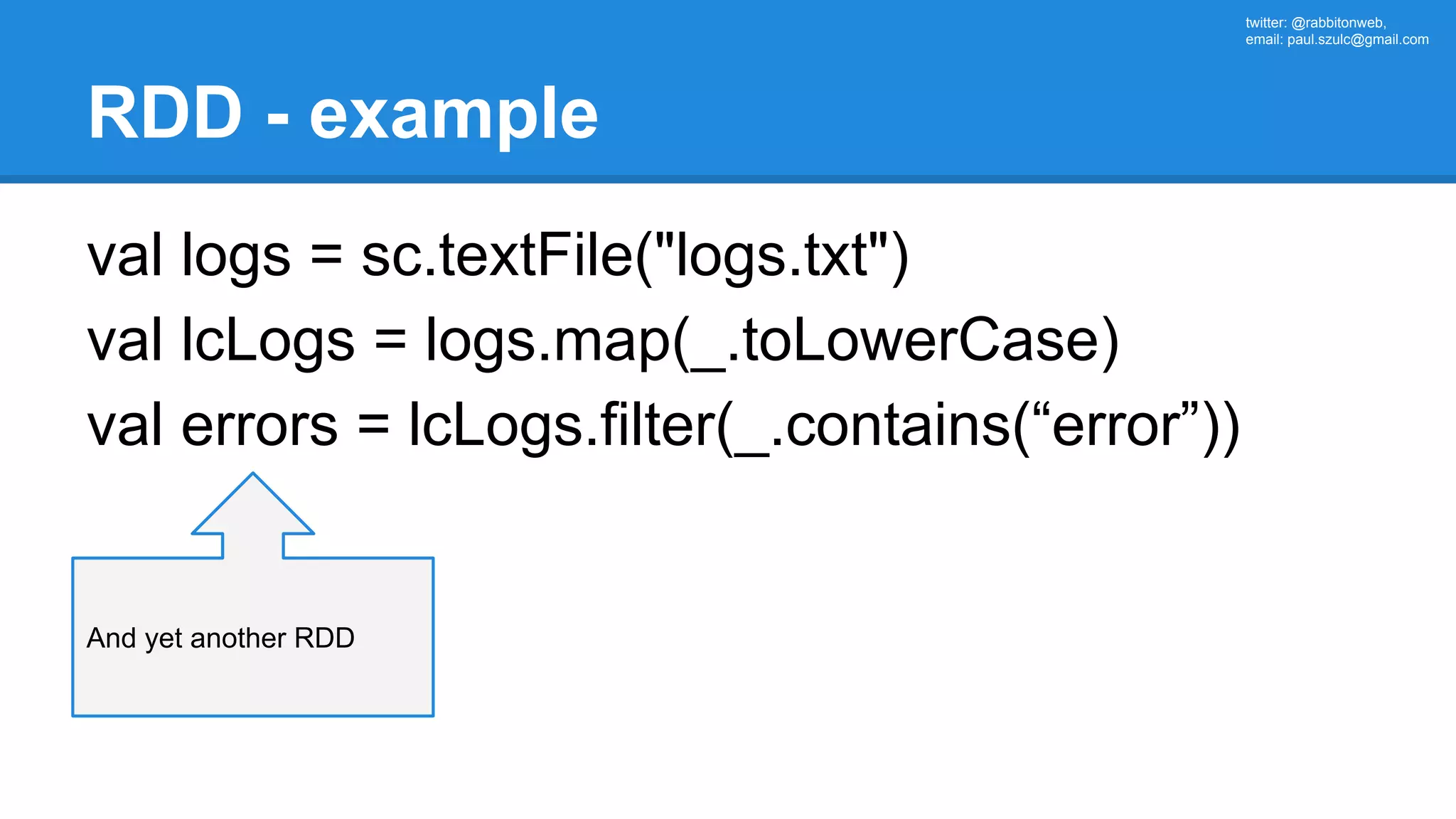
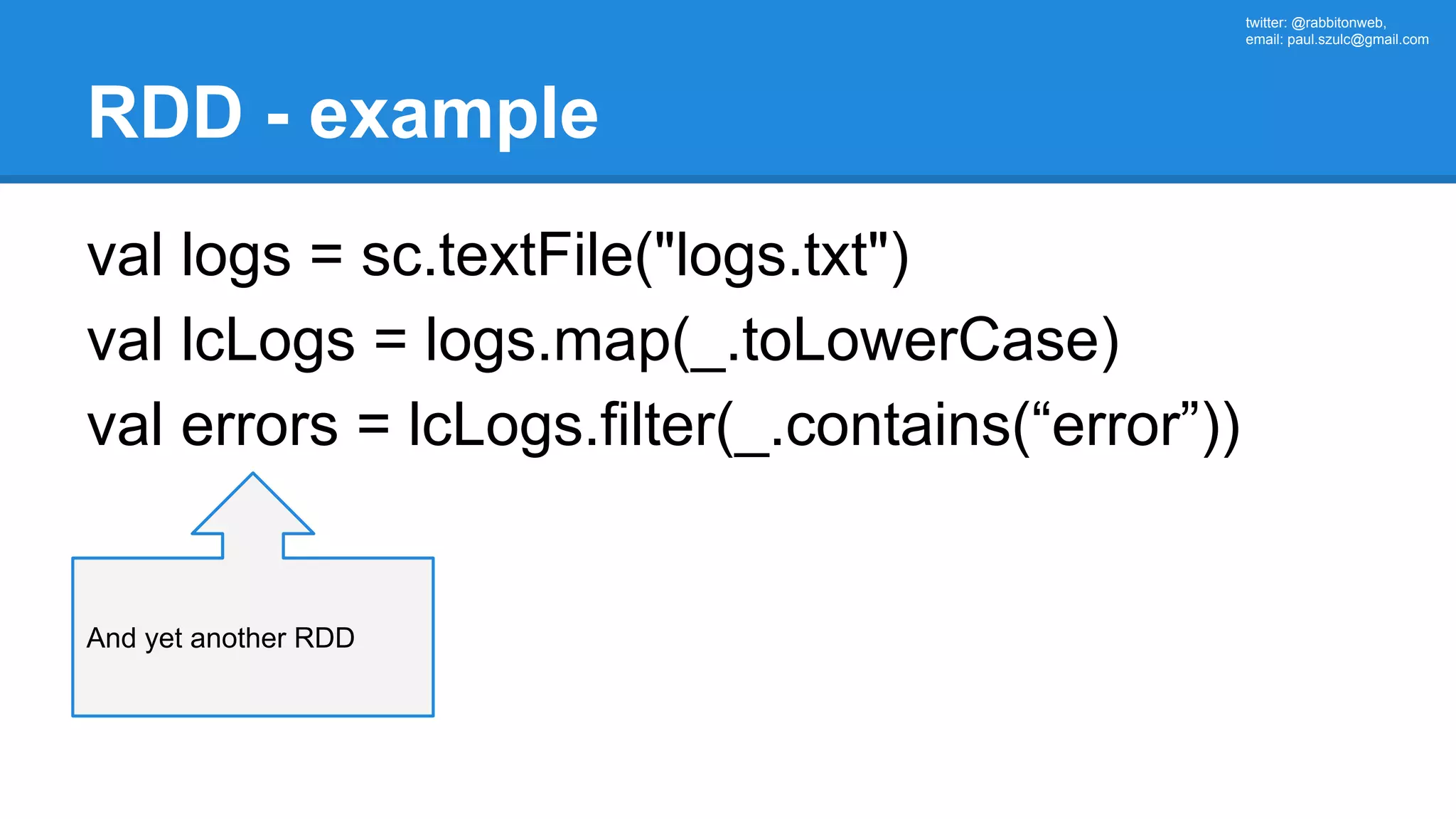
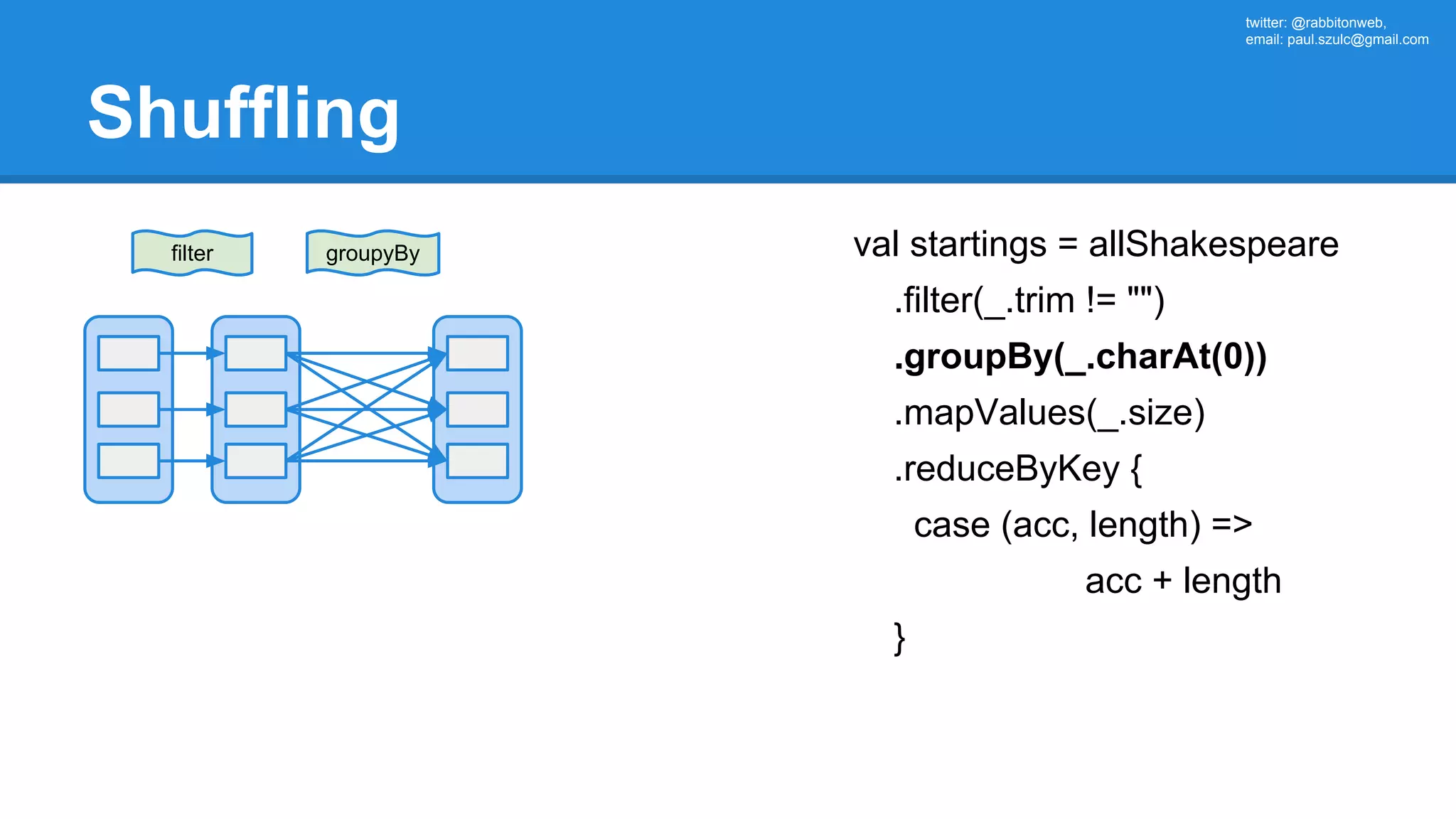
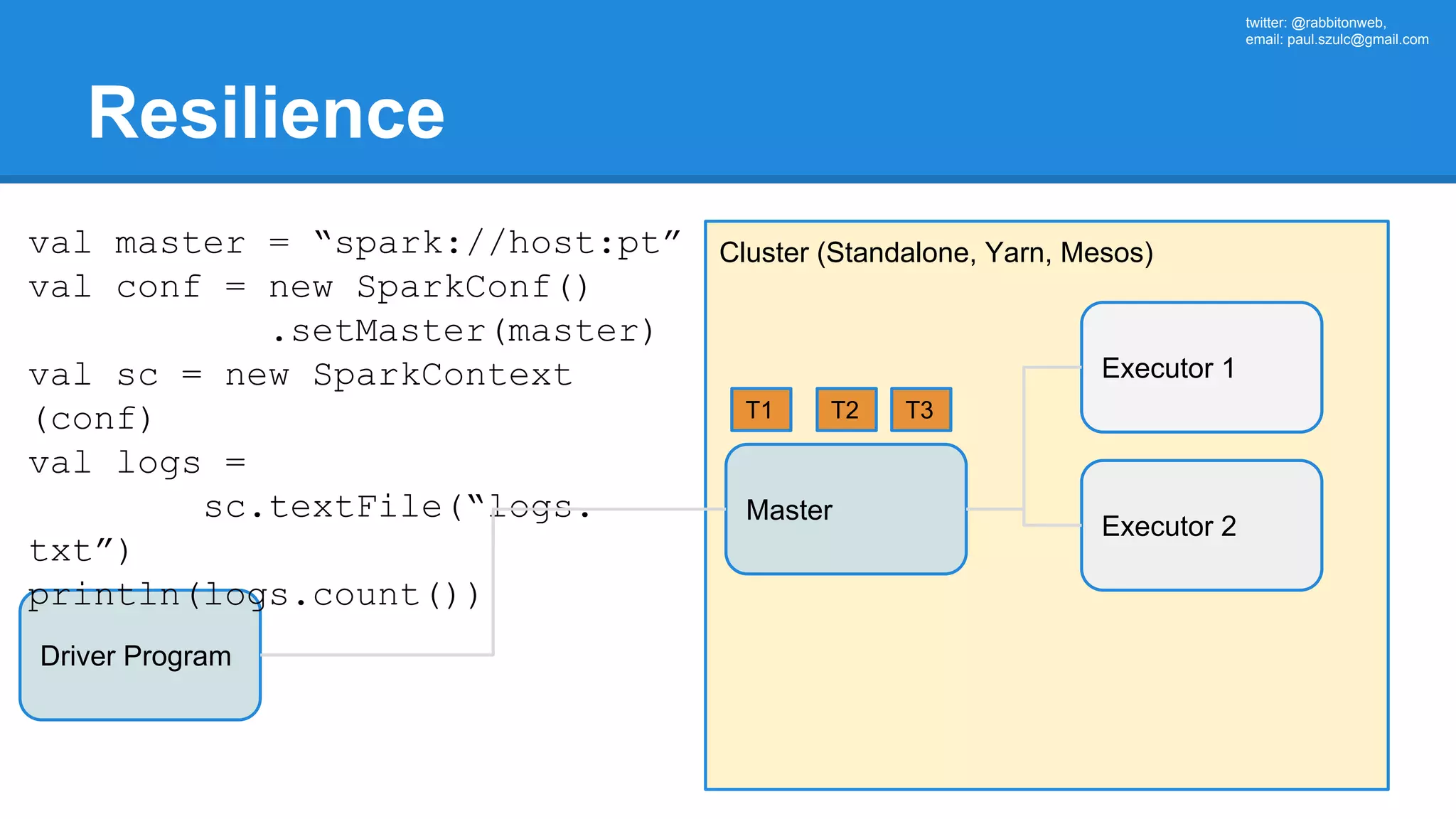
![twitter: @rabbitonweb, email: paul.szulc@gmail.com Directed Acyclic Graph val startings = allShakespeare .filter(_.trim != "") .groupBy(_.charAt(0)) .mapValues(_.size) .reduceByKey { case (acc, length) => acc + length } println(startings.toDebugString) (2) MapPartitionsRDD[6] at reduceByKey at Ex3.scala:42 | MapPartitionsRDD[5] at mapValues at Ex3.scala:41 | ShuffledRDD[4] at groupBy at Ex3.scala:40 +-(2) MapPartitionsRDD[3] at groupBy at Ex3.scala:40 | MapPartitionsRDD[2] at filter at Ex3.scala:39 | src/main/resources/all-shakespeare.txt MapPartitionsRDD[1] | src/main/resources/all-shakespeare.txt HadoopRDD[0]](https://image.slidesharecdn.com/apachesparkworkshops-160527153959/75/Apache-spark-workshop-161-2048.jpg)
























![What is a partition? A partition represents subset of data within your distributed collection. override def getPartitions: Array[Partition] = ???](https://image.slidesharecdn.com/apachesparkworkshops-160527153959/75/Apache-spark-workshop-223-2048.jpg)
![What is a partition? A partition represents subset of data within your distributed collection. override def getPartitions: Array[Partition] = ??? How this subset is defined depends on type of the RDD](https://image.slidesharecdn.com/apachesparkworkshops-160527153959/75/Apache-spark-workshop-224-2048.jpg)




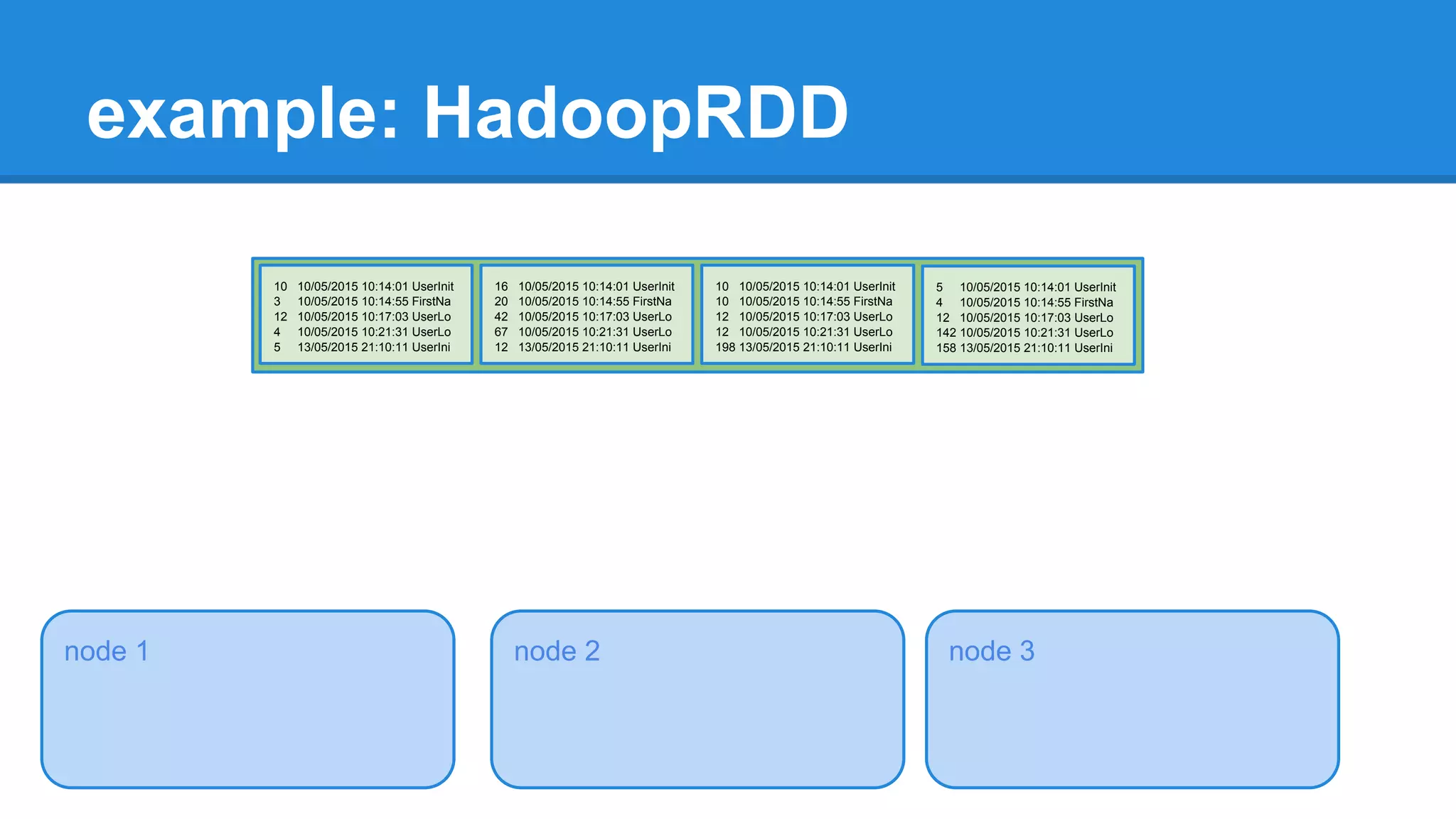
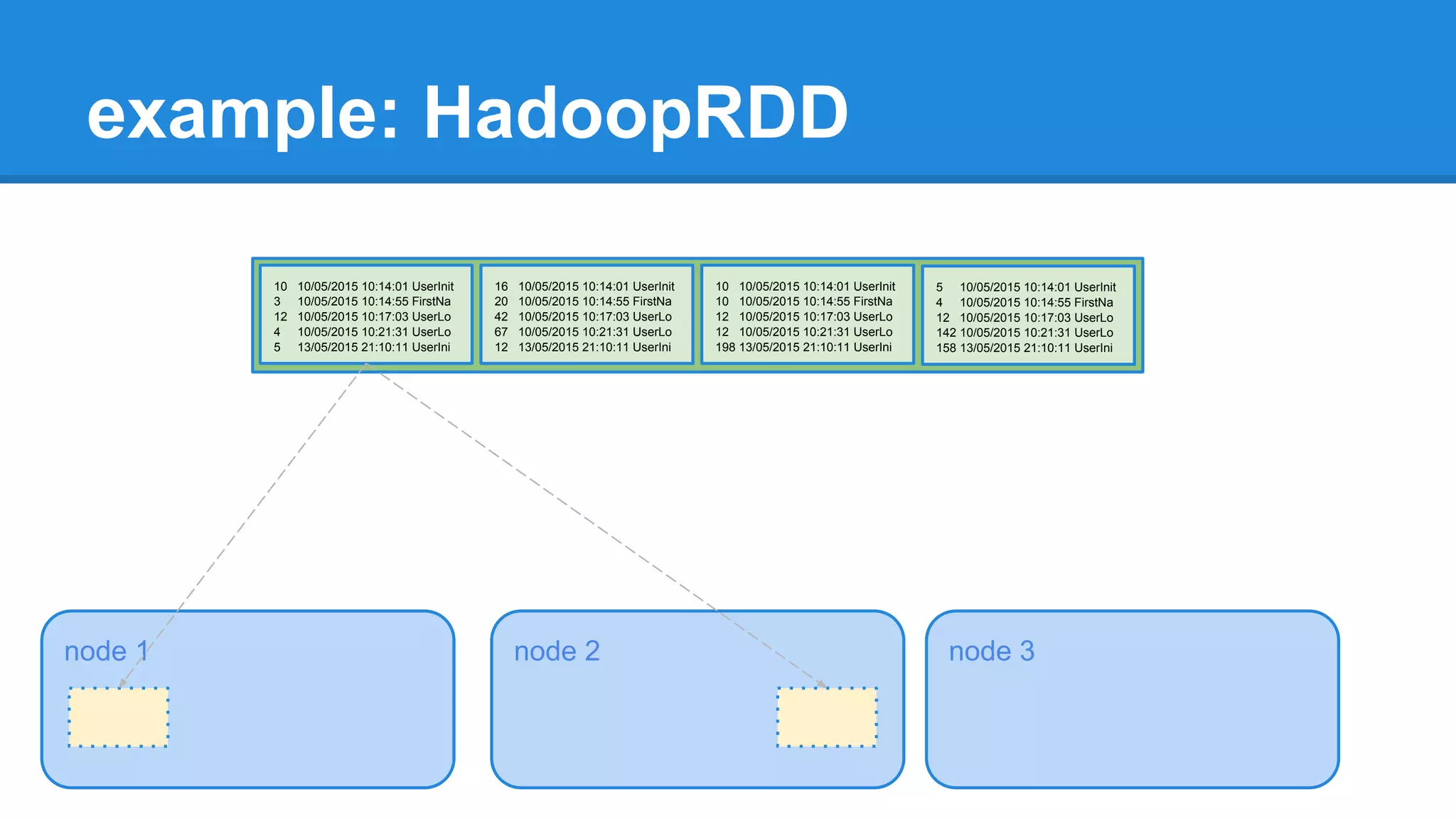
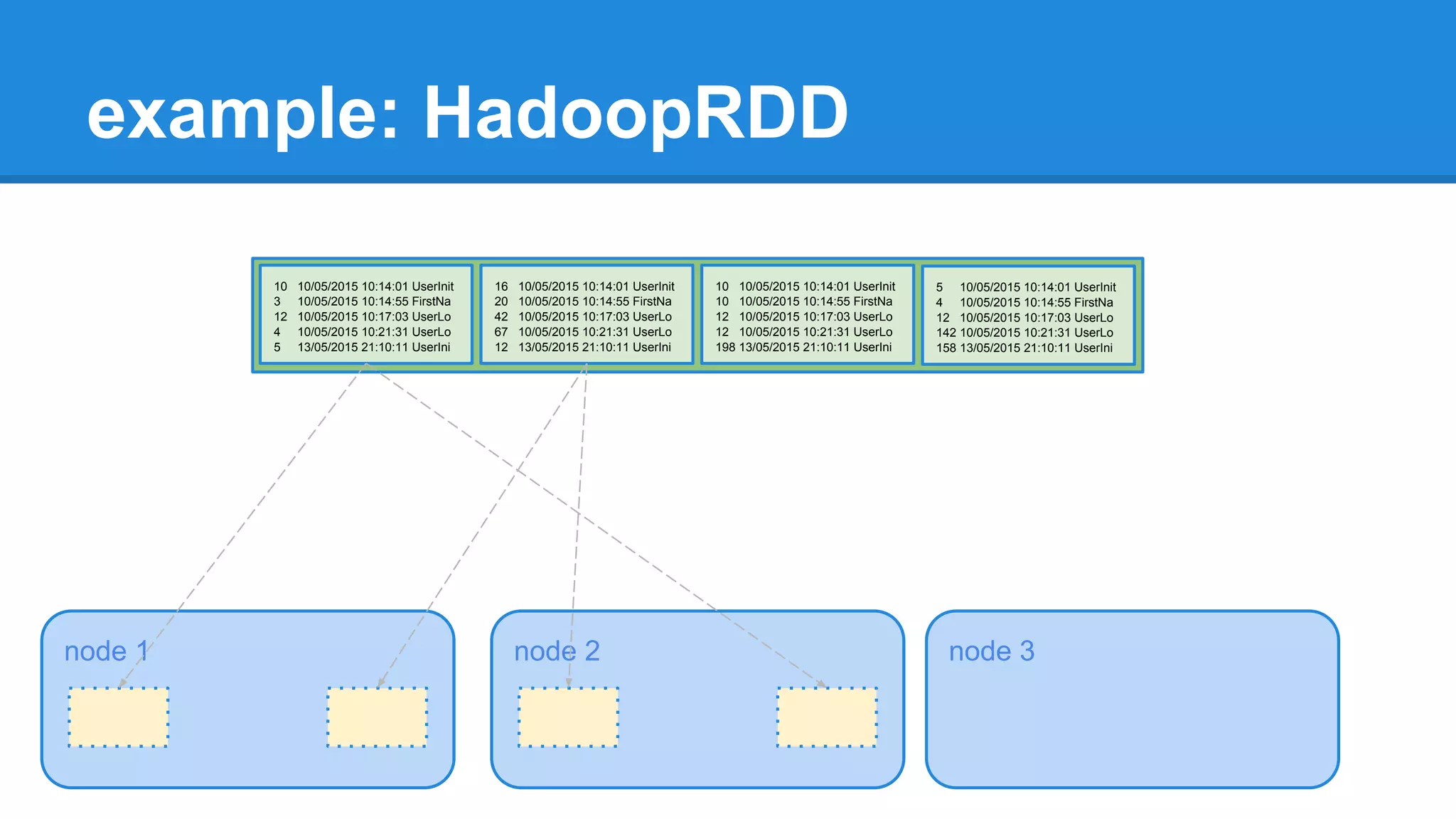
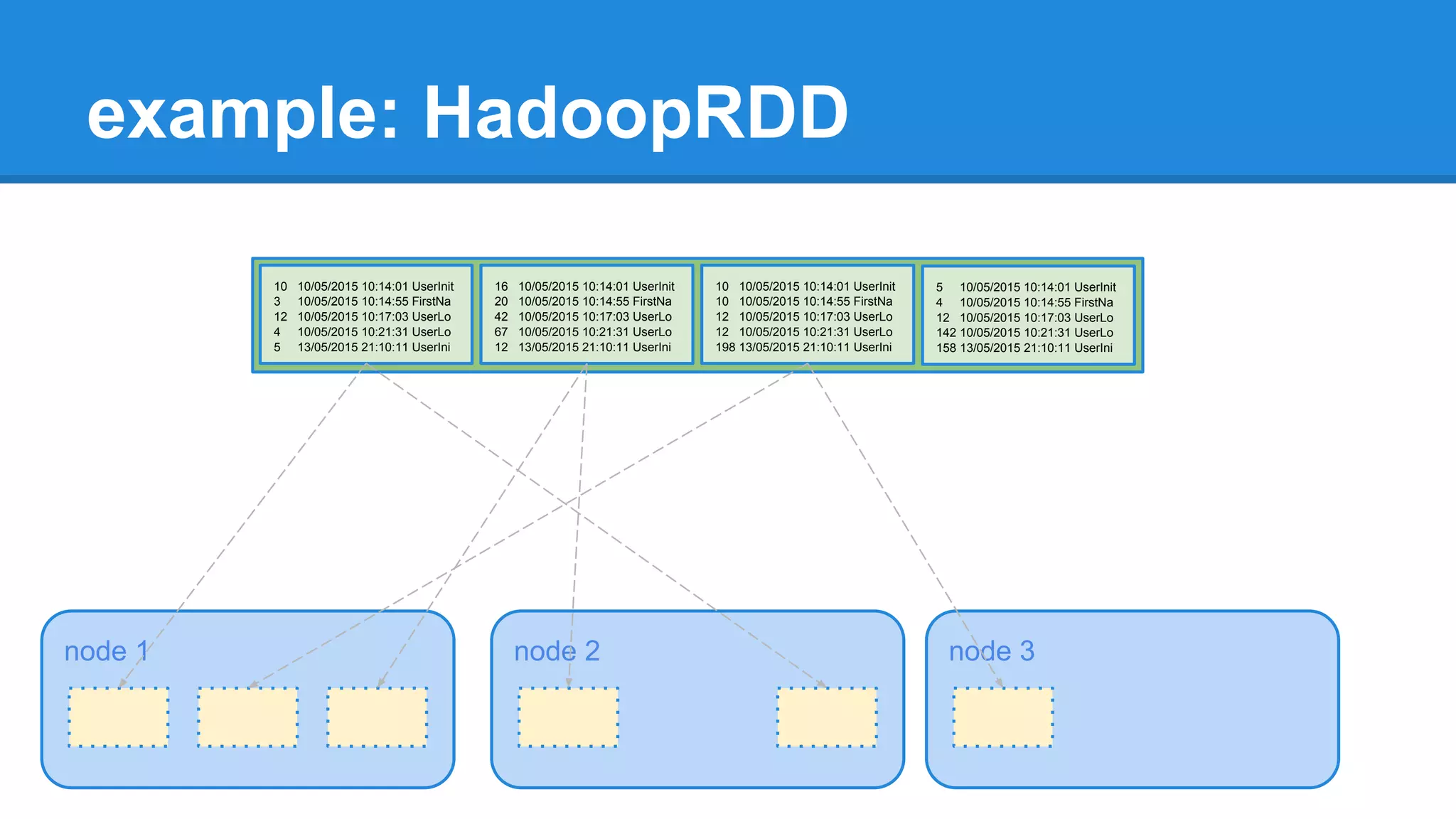
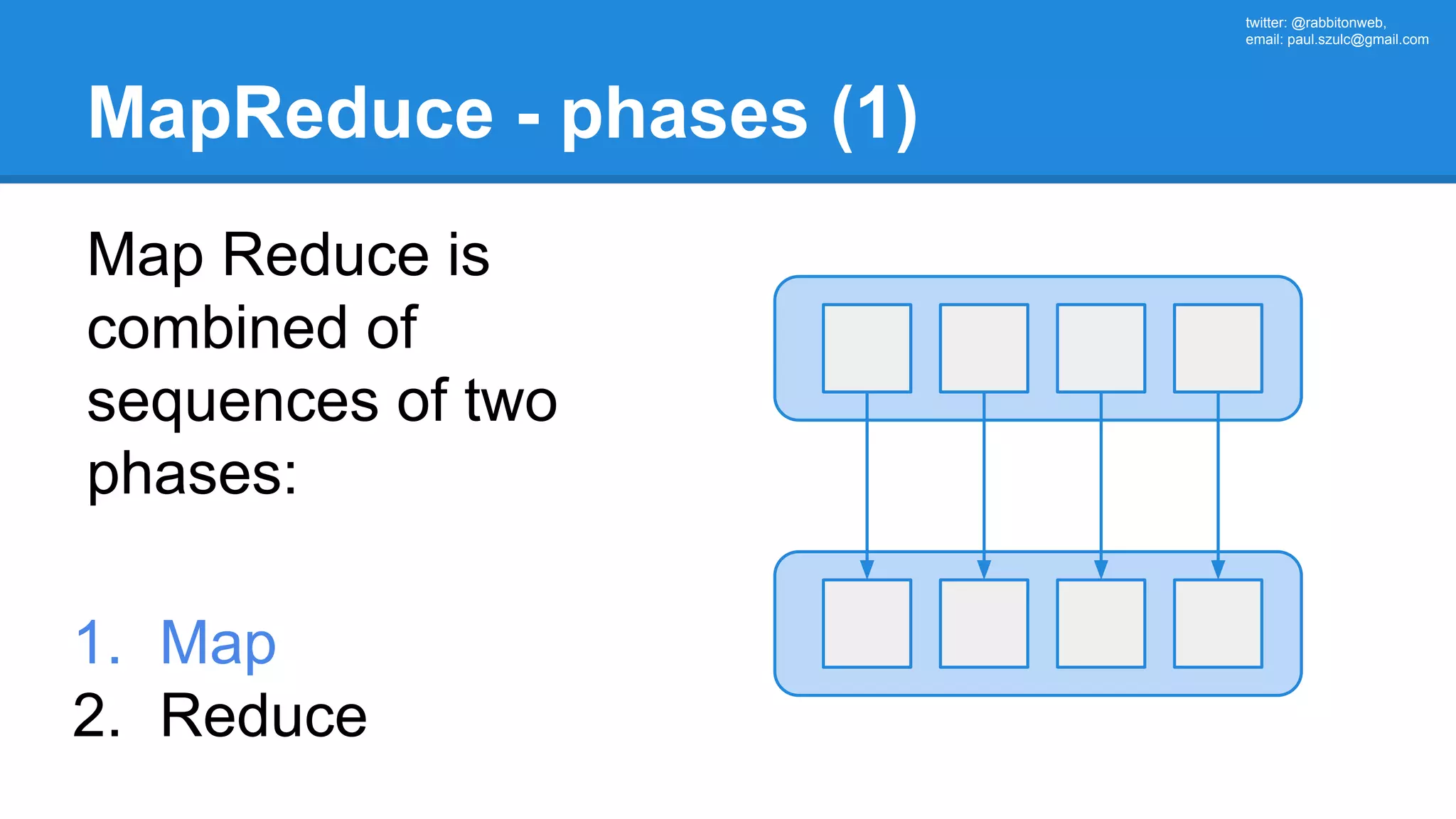
 extends RDD[(K, V)](sc, Nil) with Logging { ... override def getPartitions: Array[Partition] = { val jobConf = getJobConf() SparkHadoopUtil.get.addCredentials(jobConf) val inputFormat = getInputFormat(jobConf) if (inputFormat.isInstanceOf[Configurable]) { inputFormat.asInstanceOf[Configurable].setConf(jobConf) } val inputSplits = inputFormat.getSplits(jobConf, minPartitions) val array = new Array[Partition](inputSplits.size) for (i <- 0 until inputSplits.size) { array(i) = new HadoopPartition(id, i, inputSplits(i)) } array }](https://image.slidesharecdn.com/apachesparkworkshops-160527153959/75/Apache-spark-workshop-234-2048.jpg)
 extends RDD[(K, V)](sc, Nil) with Logging { ... override def getPartitions: Array[Partition] = { val jobConf = getJobConf() SparkHadoopUtil.get.addCredentials(jobConf) val inputFormat = getInputFormat(jobConf) if (inputFormat.isInstanceOf[Configurable]) { inputFormat.asInstanceOf[Configurable].setConf(jobConf) } val inputSplits = inputFormat.getSplits(jobConf, minPartitions) val array = new Array[Partition](inputSplits.size) for (i <- 0 until inputSplits.size) { array(i) = new HadoopPartition(id, i, inputSplits(i)) } array }](https://image.slidesharecdn.com/apachesparkworkshops-160527153959/75/Apache-spark-workshop-235-2048.jpg)
 extends RDD[(K, V)](sc, Nil) with Logging { ... override def getPartitions: Array[Partition] = { val jobConf = getJobConf() SparkHadoopUtil.get.addCredentials(jobConf) val inputFormat = getInputFormat(jobConf) if (inputFormat.isInstanceOf[Configurable]) { inputFormat.asInstanceOf[Configurable].setConf(jobConf) } val inputSplits = inputFormat.getSplits(jobConf, minPartitions) val array = new Array[Partition](inputSplits.size) for (i <- 0 until inputSplits.size) { array(i) = new HadoopPartition(id, i, inputSplits(i)) } array }](https://image.slidesharecdn.com/apachesparkworkshops-160527153959/75/Apache-spark-workshop-236-2048.jpg)



 extends RDD[U](prev) { ... override def getPartitions: Array[Partition] = firstParent[T].partitions](https://image.slidesharecdn.com/apachesparkworkshops-160527153959/75/Apache-spark-workshop-240-2048.jpg)









: Array[U]](https://image.slidesharecdn.com/apachesparkworkshops-160527153959/75/Apache-spark-workshop-268-2048.jpg)
: Array[U]](https://image.slidesharecdn.com/apachesparkworkshops-160527153959/75/Apache-spark-workshop-269-2048.jpg)
: Array[U]](https://image.slidesharecdn.com/apachesparkworkshops-160527153959/75/Apache-spark-workshop-270-2048.jpg)
: Array[U]](https://image.slidesharecdn.com/apachesparkworkshops-160527153959/75/Apache-spark-workshop-271-2048.jpg)
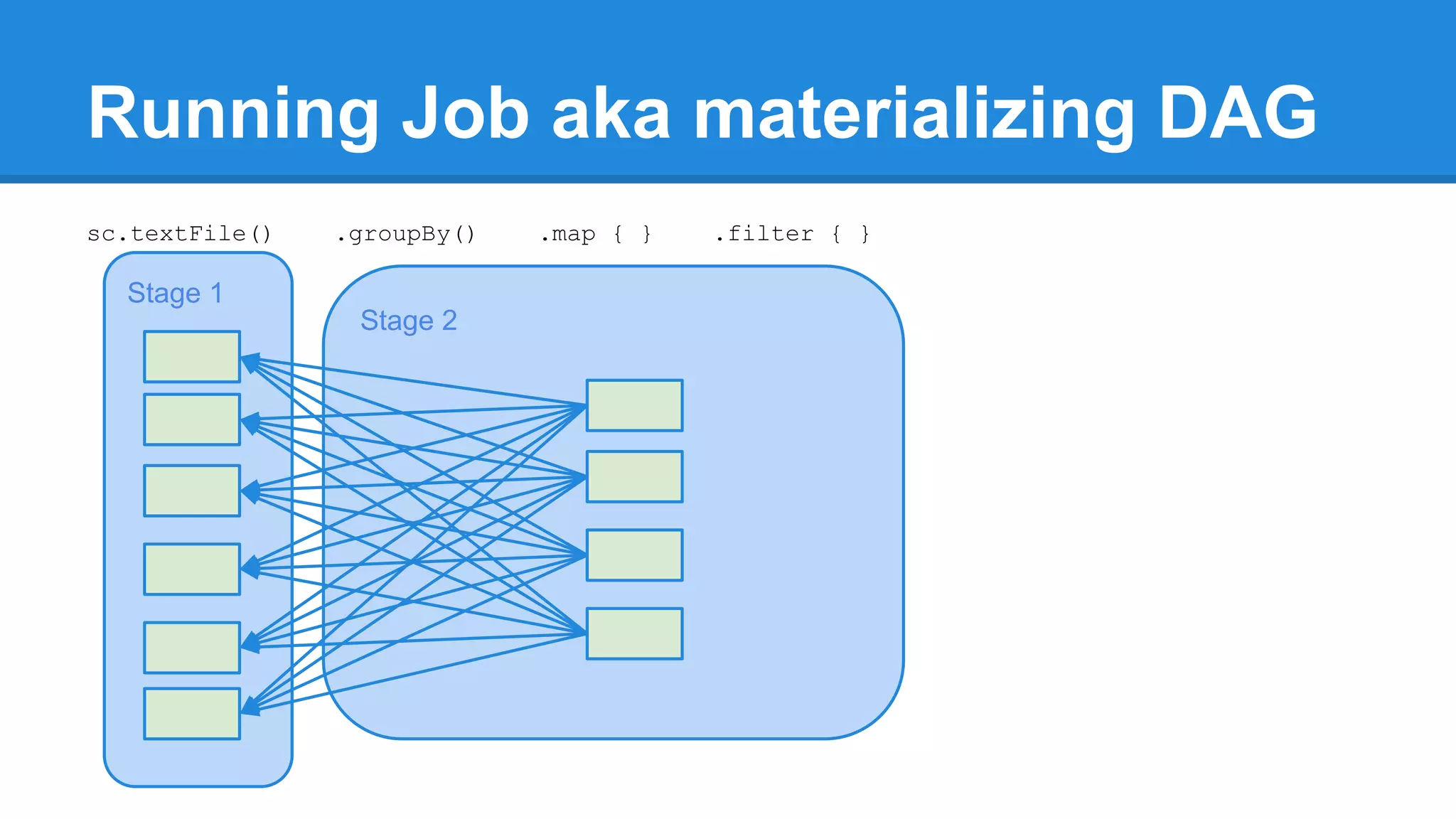
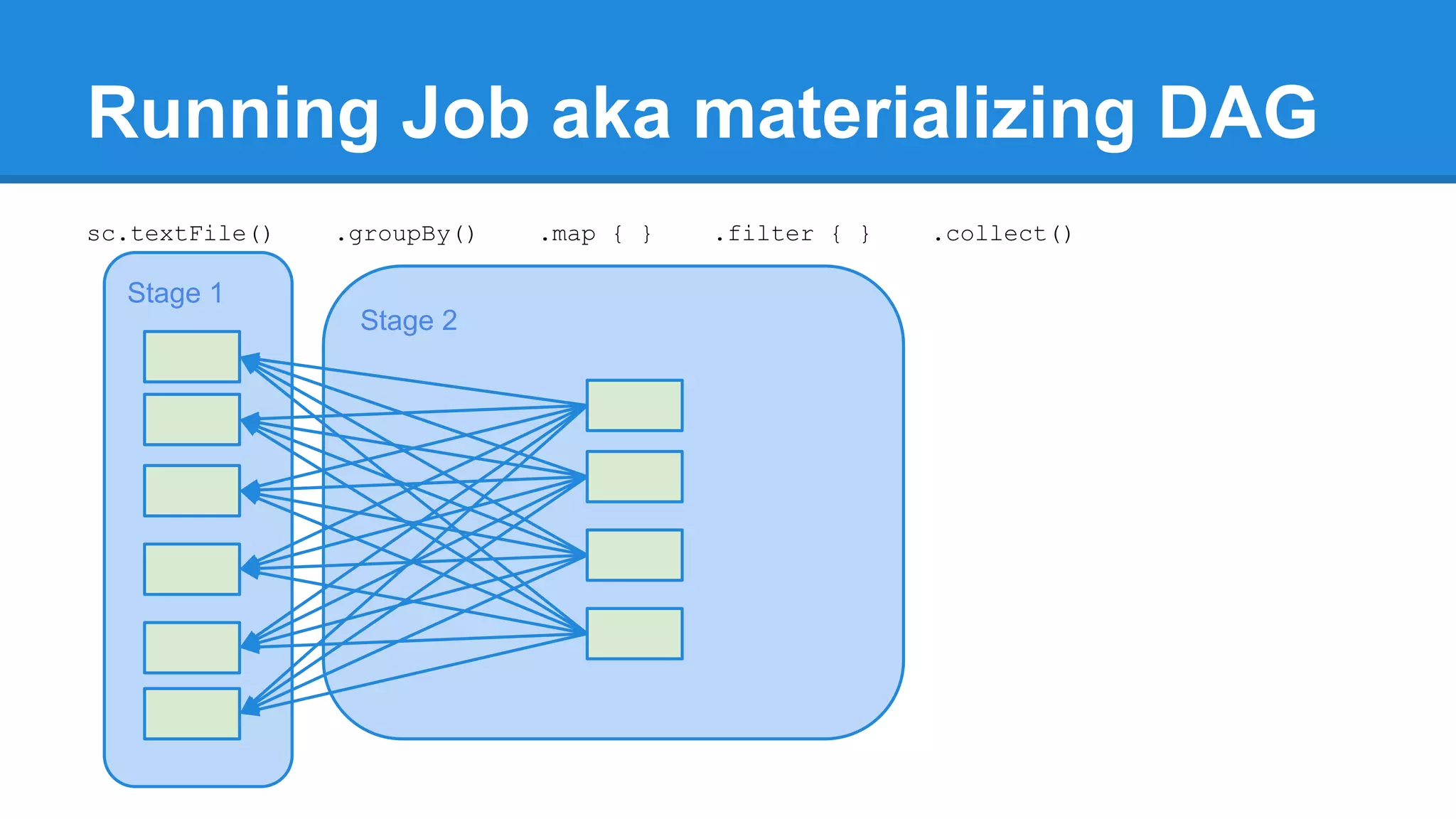
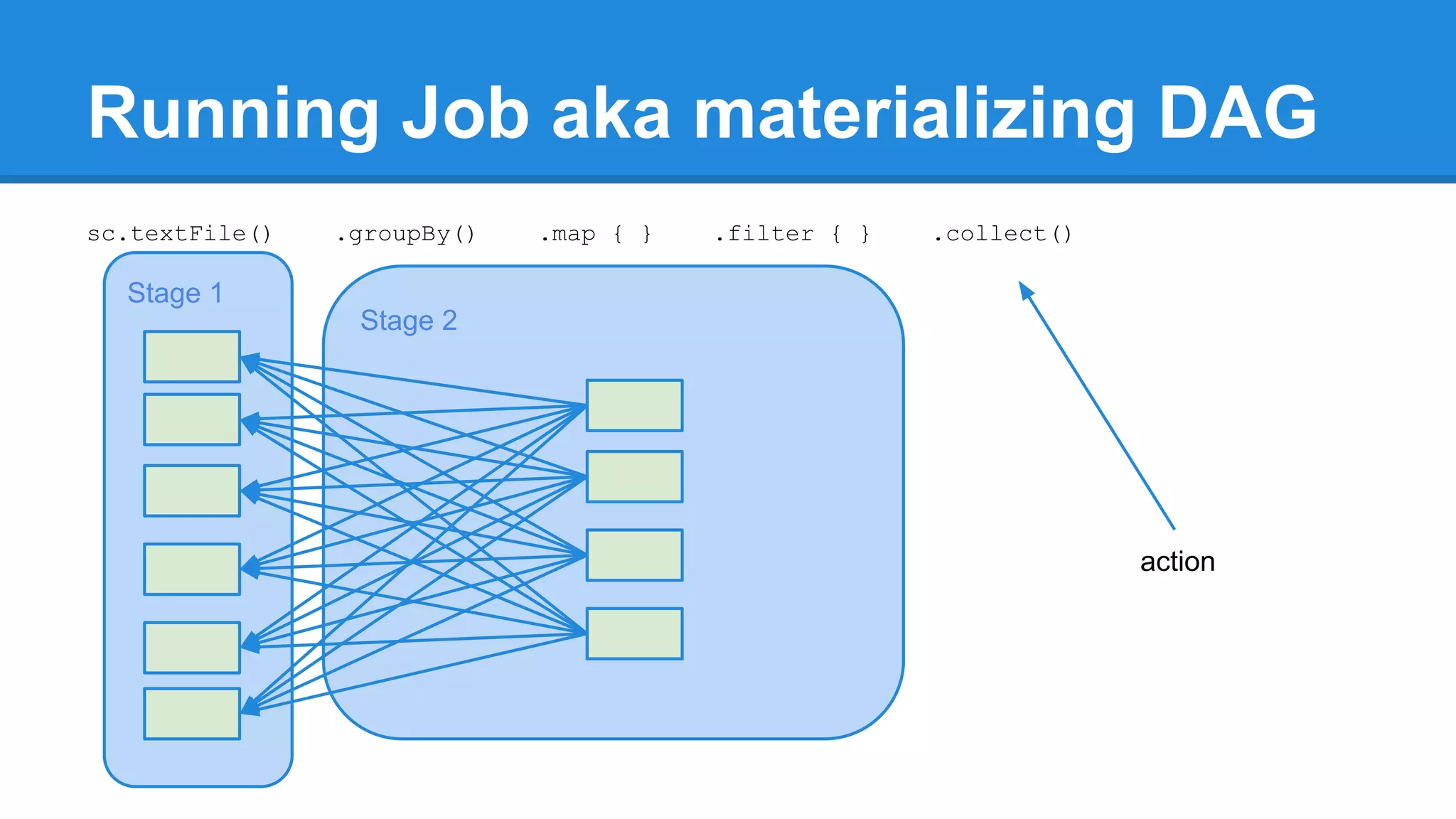
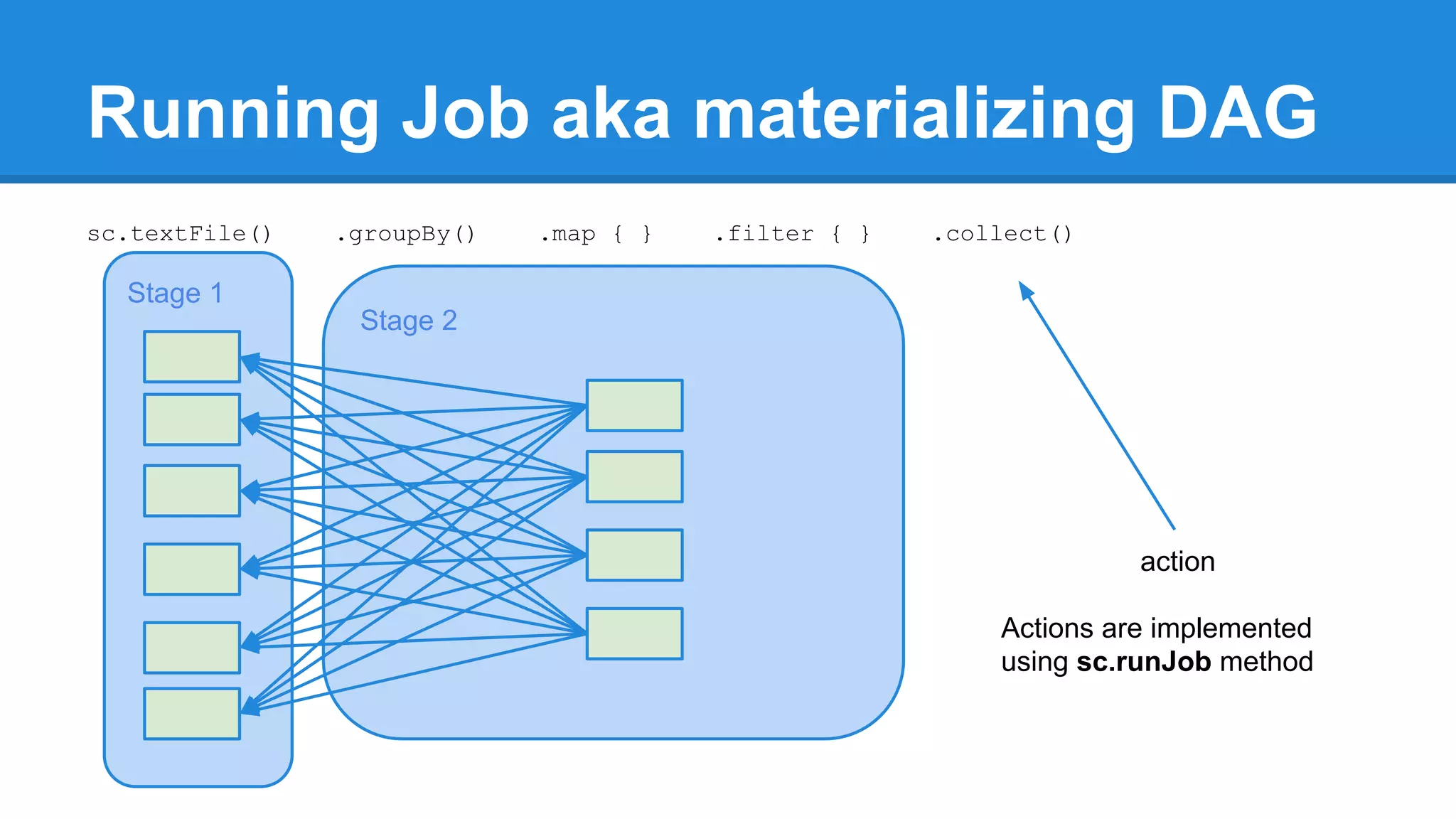
![Running Job aka materializing DAG /** * Return an array that contains all of the elements in this RDD. */ def collect(): Array[T] = { val results = sc.runJob(this, (iter: Iterator[T]) => iter.toArray) Array.concat(results: _*) }](https://image.slidesharecdn.com/apachesparkworkshops-160527153959/75/Apache-spark-workshop-272-2048.jpg)
![Running Job aka materializing DAG /** * Return an array that contains all of the elements in this RDD. */ def collect(): Array[T] = { val results = sc.runJob(this, (iter: Iterator[T]) => iter.toArray) Array.concat(results: _*) } /** * Return the number of elements in the RDD. */ def count(): Long = sc.runJob(this, Utils.getIteratorSize _).sum](https://image.slidesharecdn.com/apachesparkworkshops-160527153959/75/Apache-spark-workshop-273-2048.jpg)
![Multiple jobs for single action /** * Take the first num elements of the RDD. It works by first scanning one partition, and use the results from that partition to estimate the number of additional partitions needed to satisfy the limit. */ def take(num: Int): Array[T] = { (….) val left = num - buf.size val res = sc.runJob(this, (it: Iterator[T]) => it.take(left).toArray, p, allowLocal = true) (….) res.foreach(buf ++= _.take(num - buf.size)) partsScanned += numPartsToTry (….) buf.toArray }](https://image.slidesharecdn.com/apachesparkworkshops-160527153959/75/Apache-spark-workshop-274-2048.jpg)


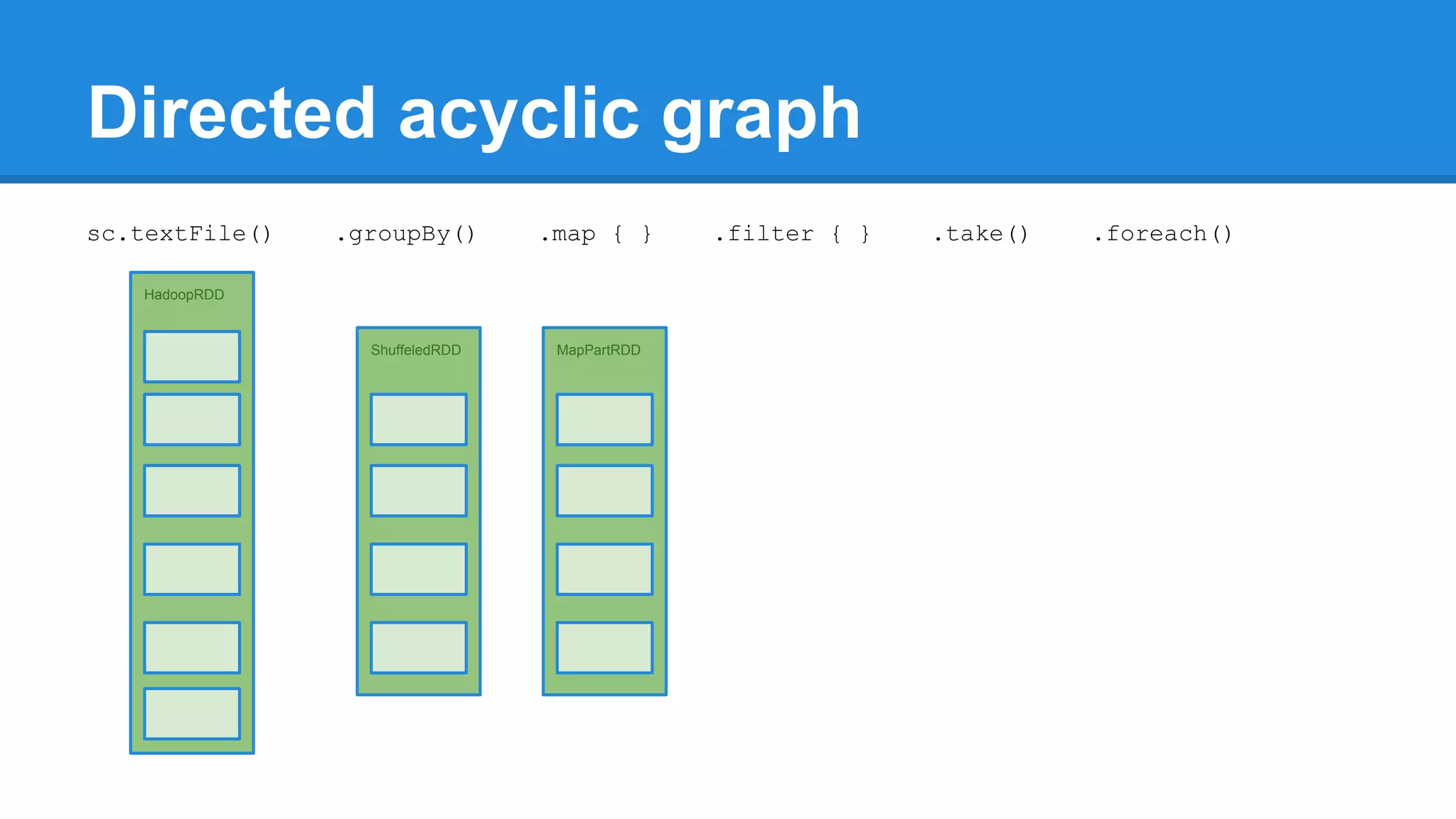
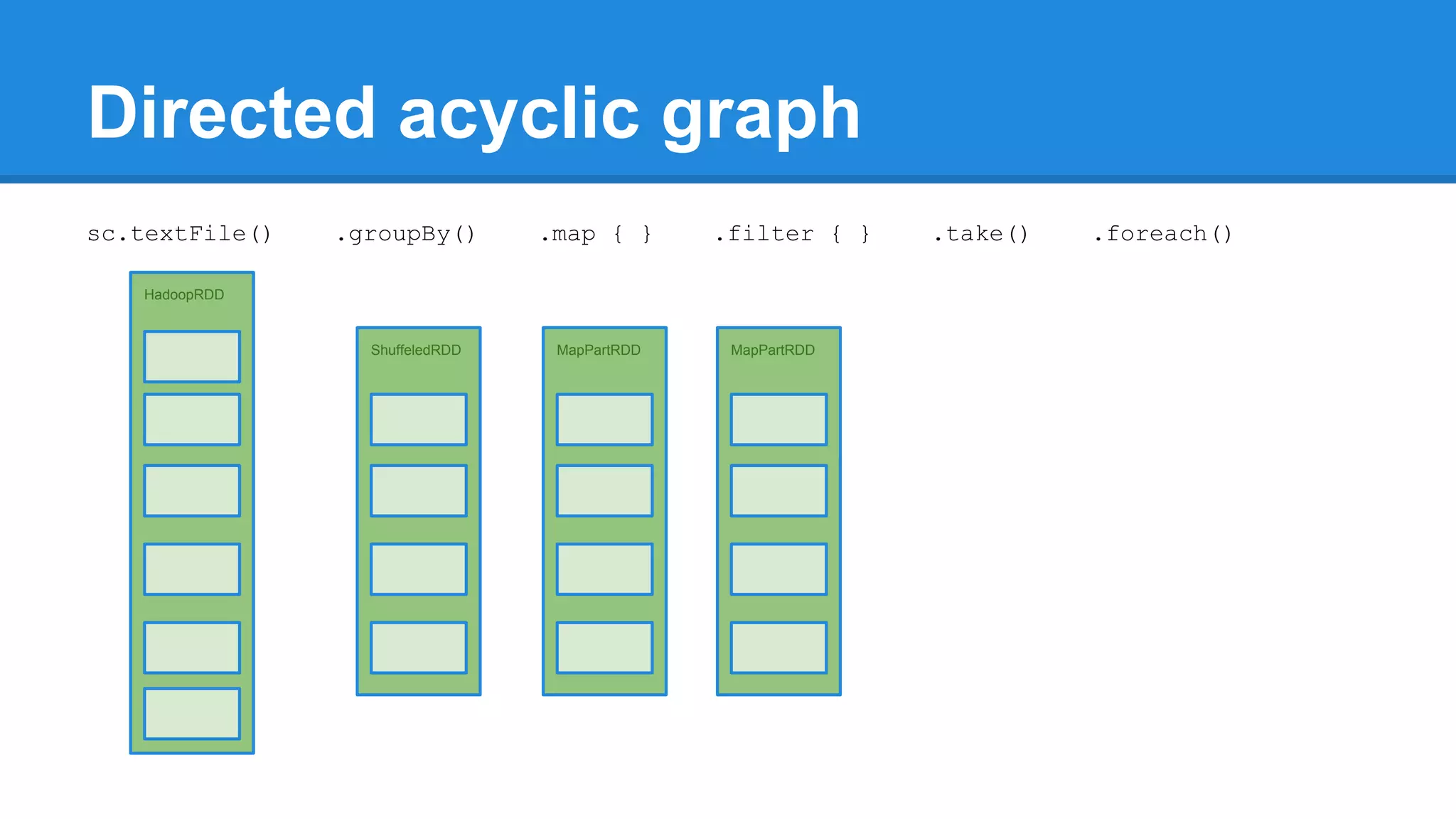
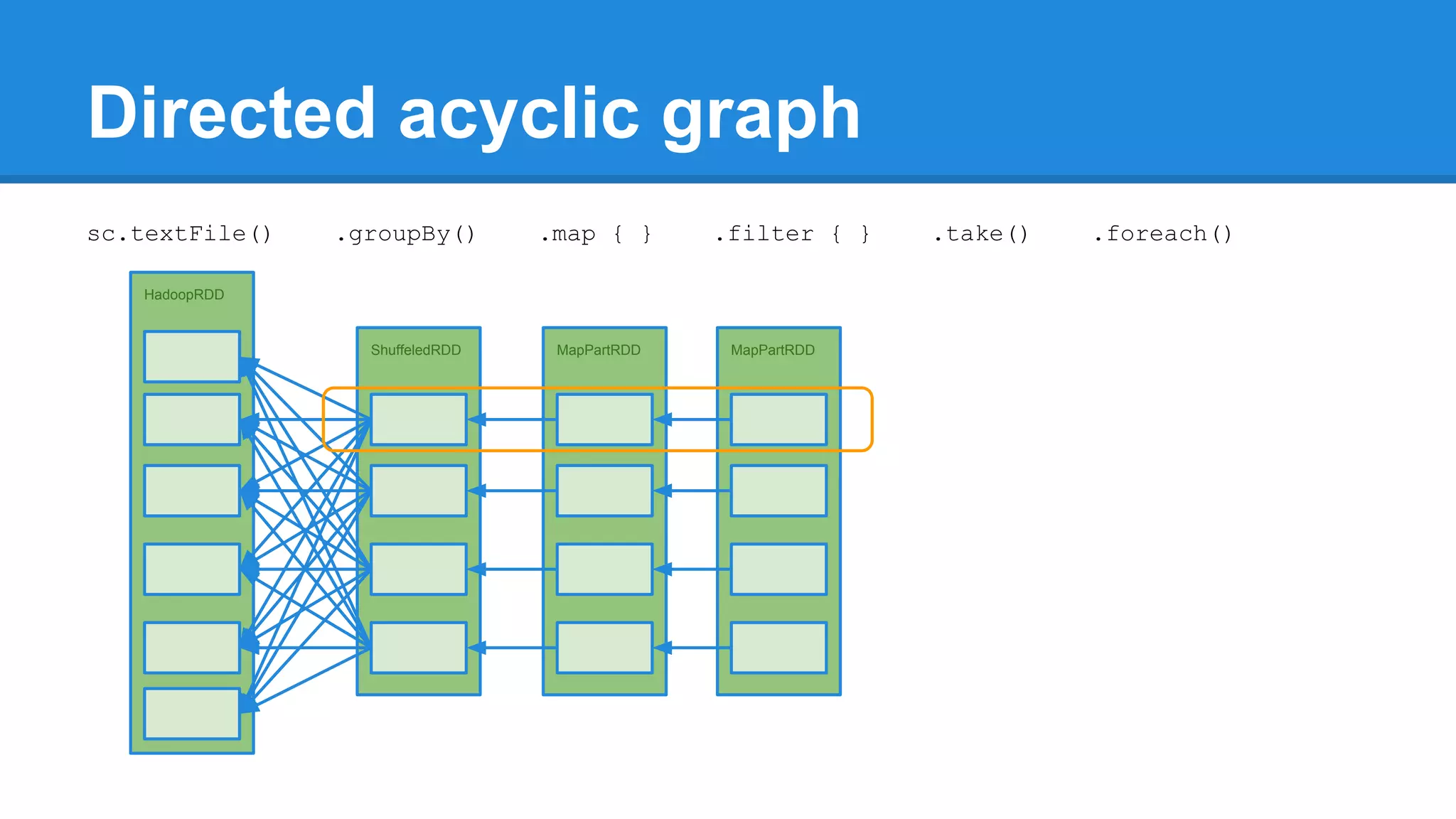
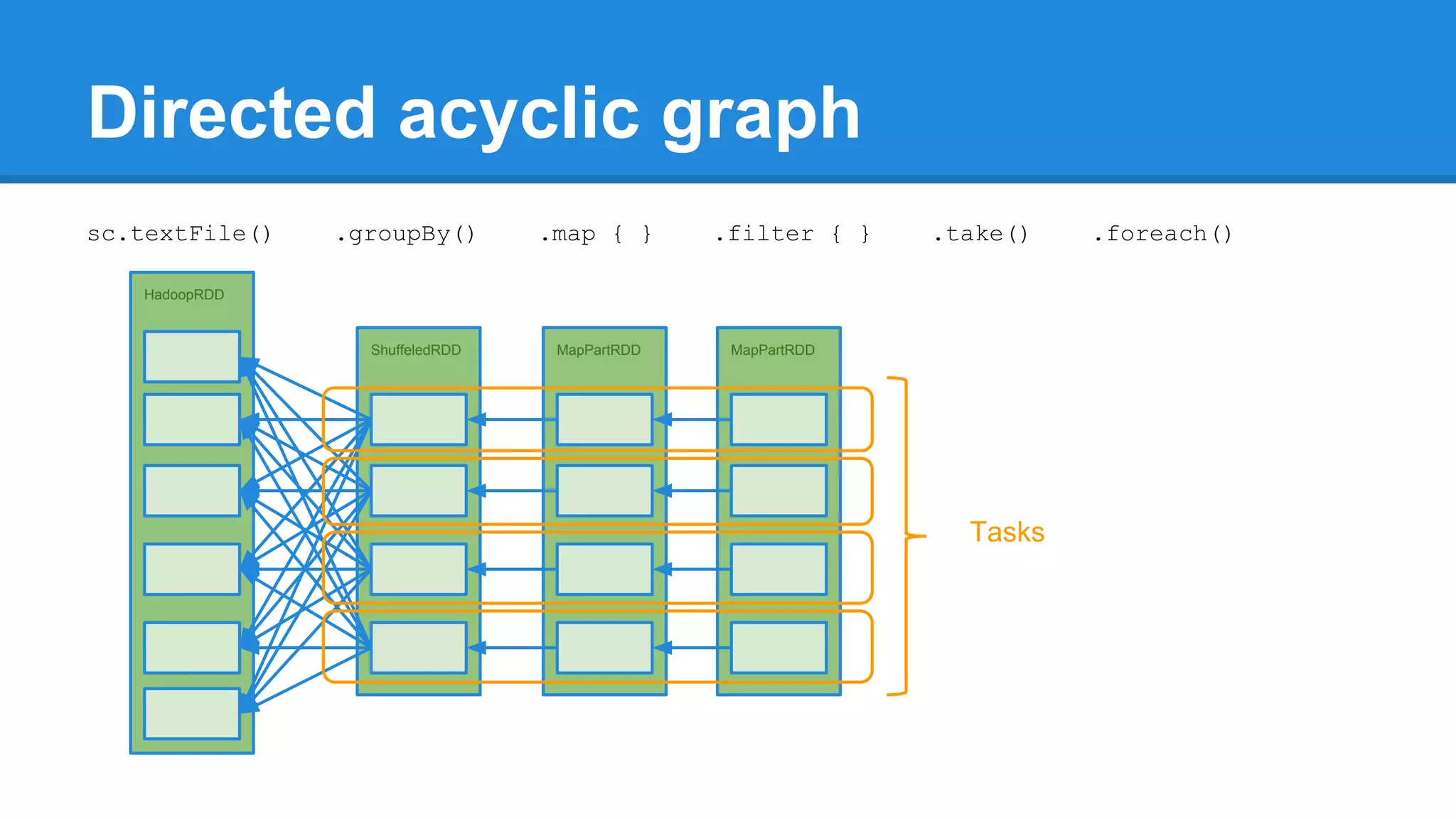
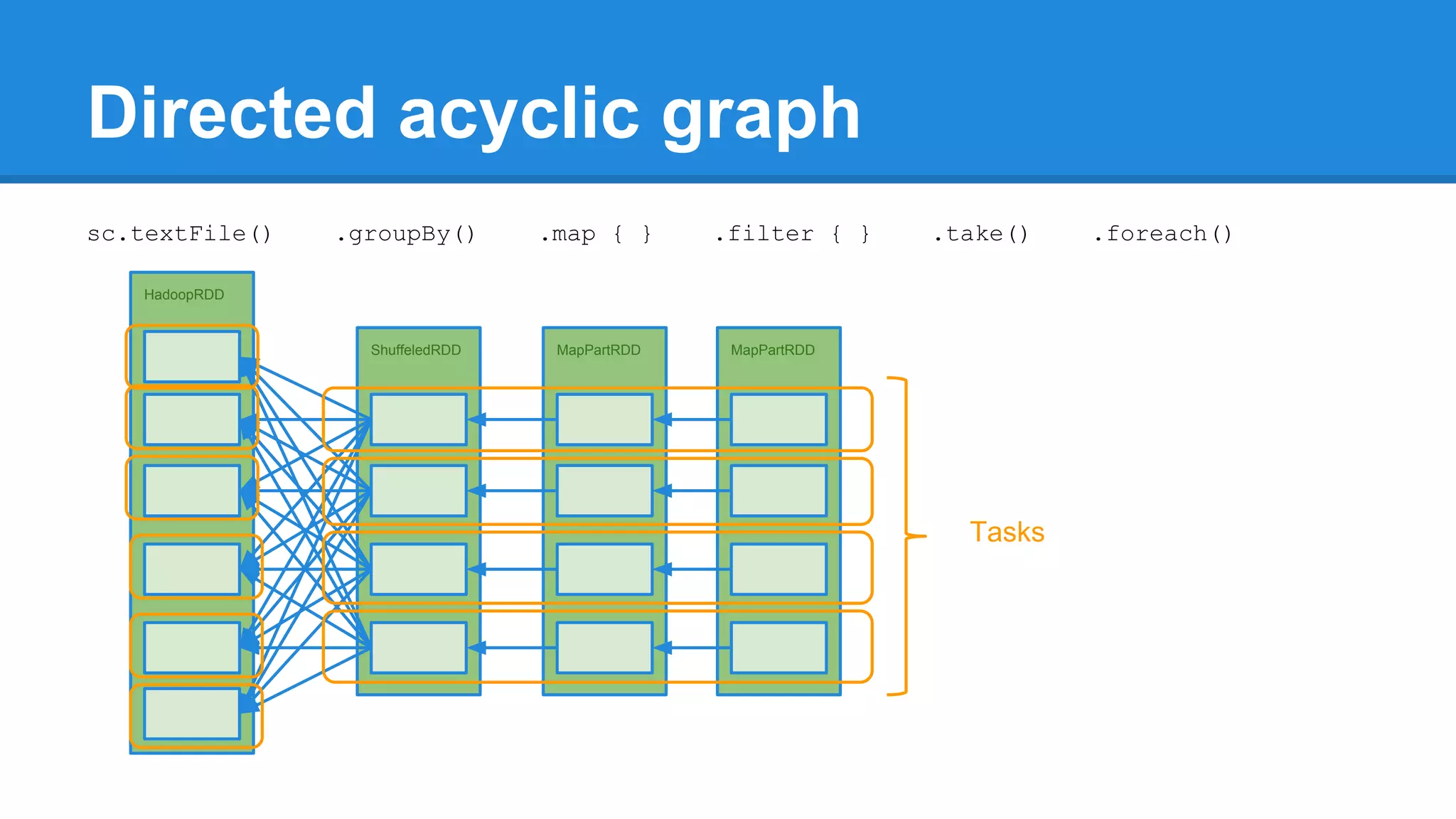
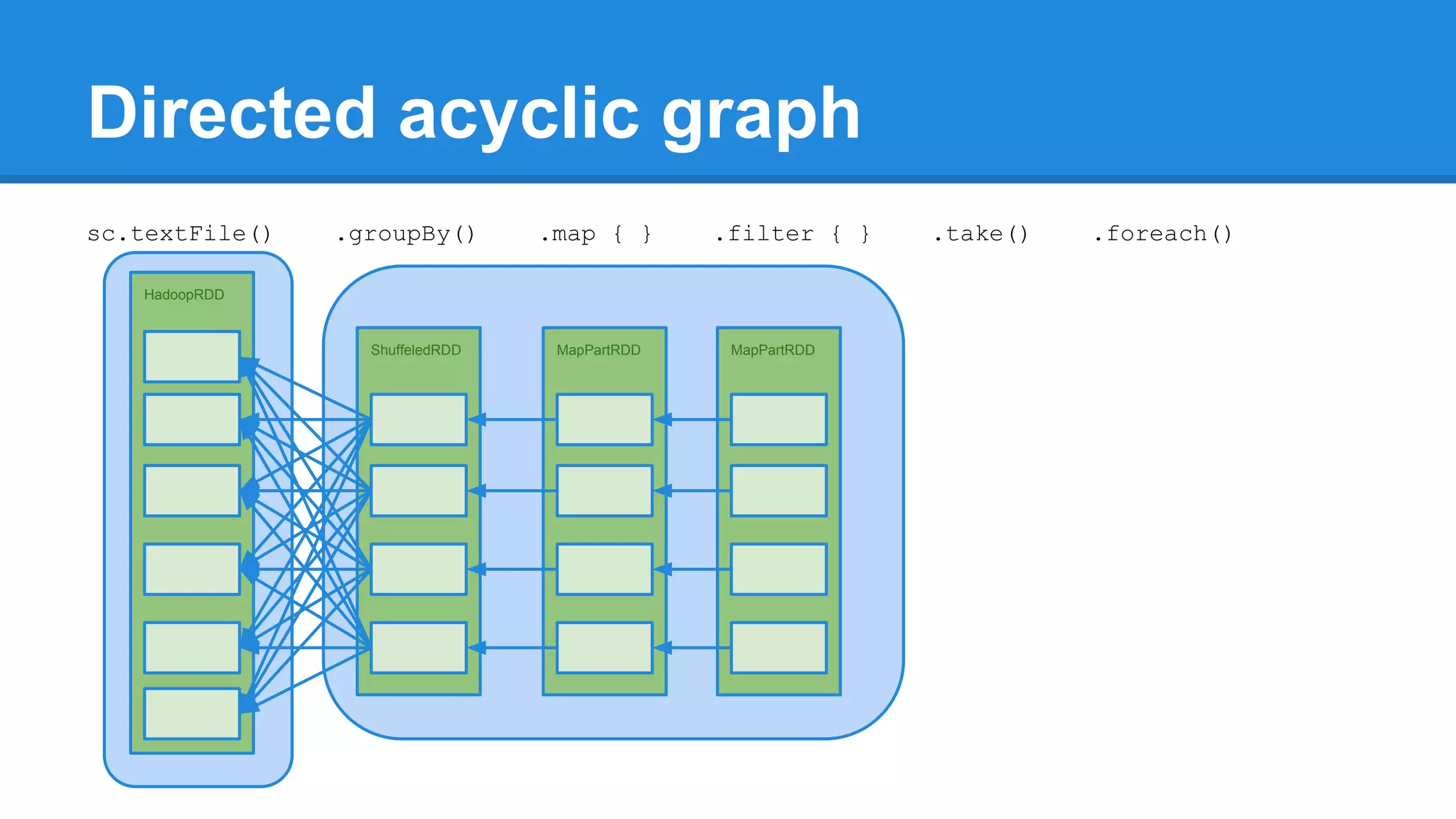
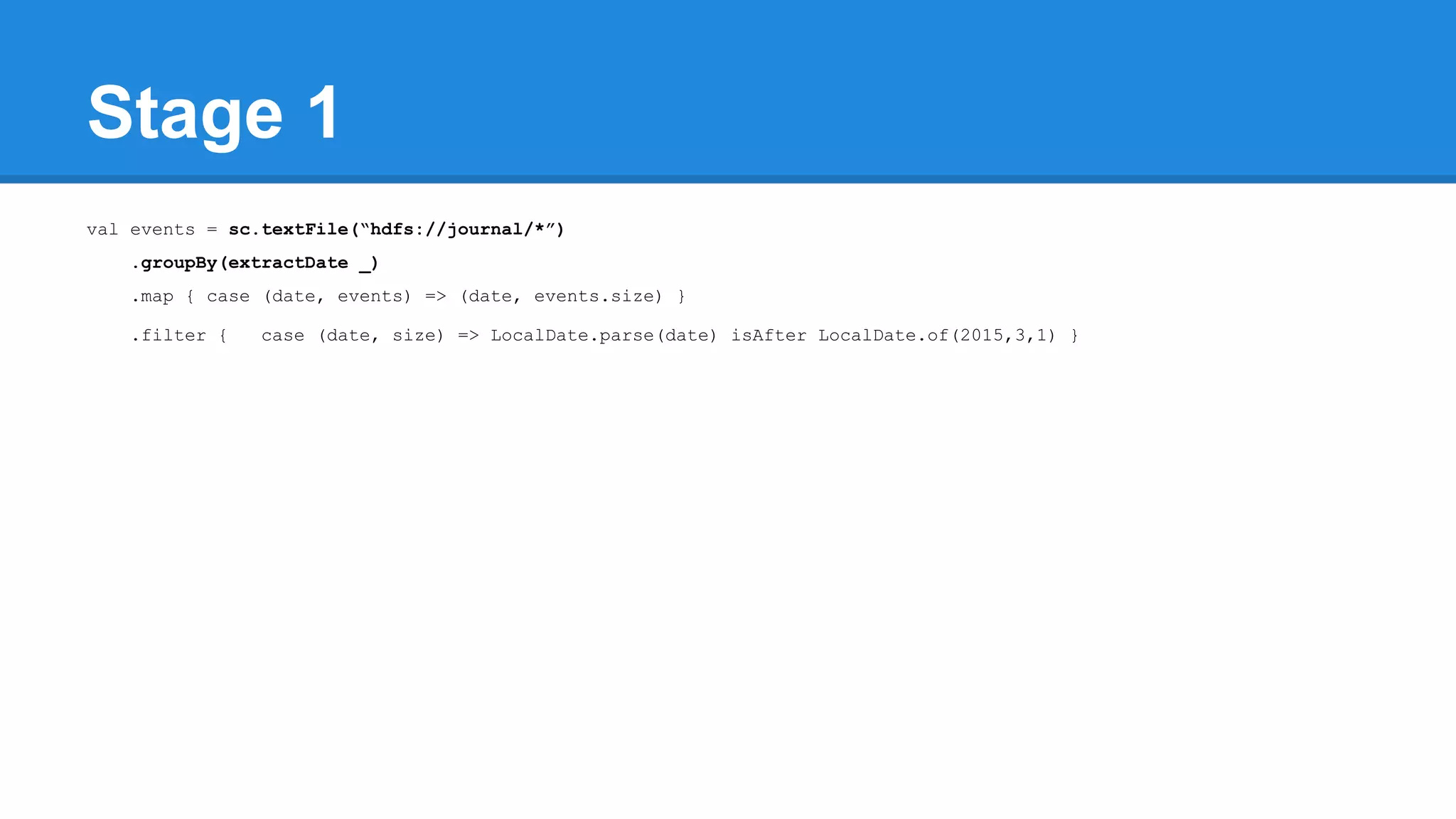
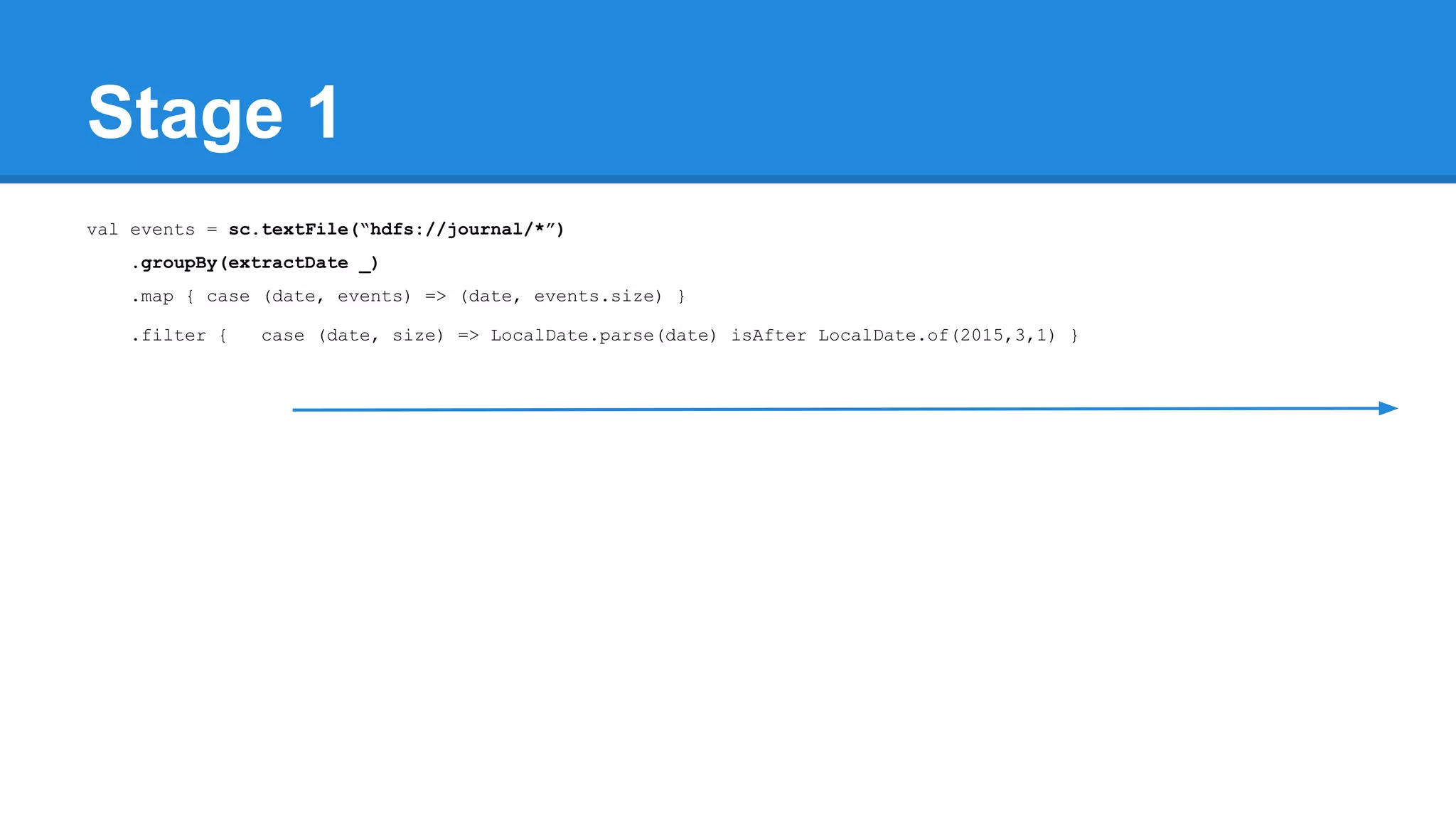
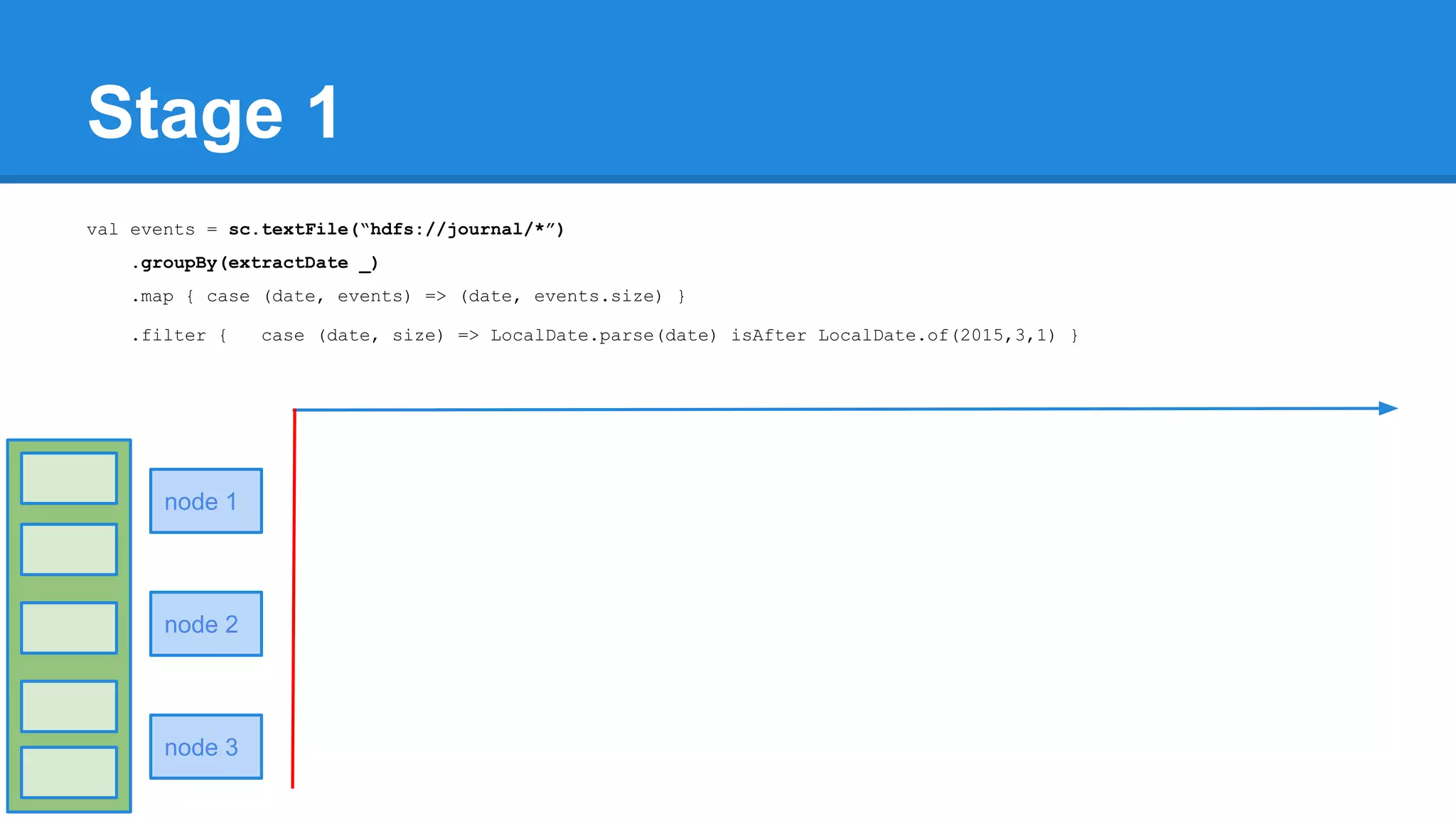
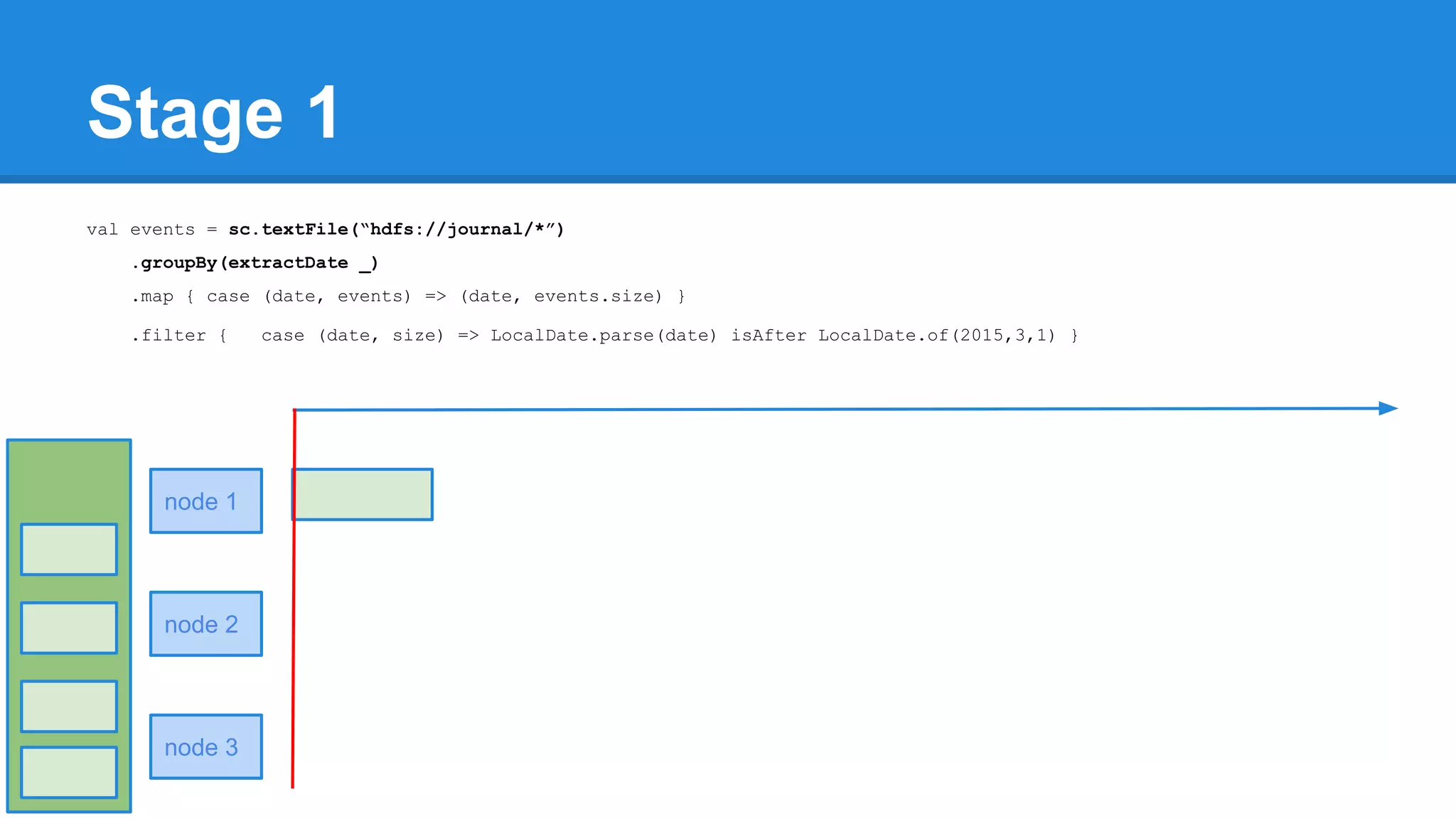
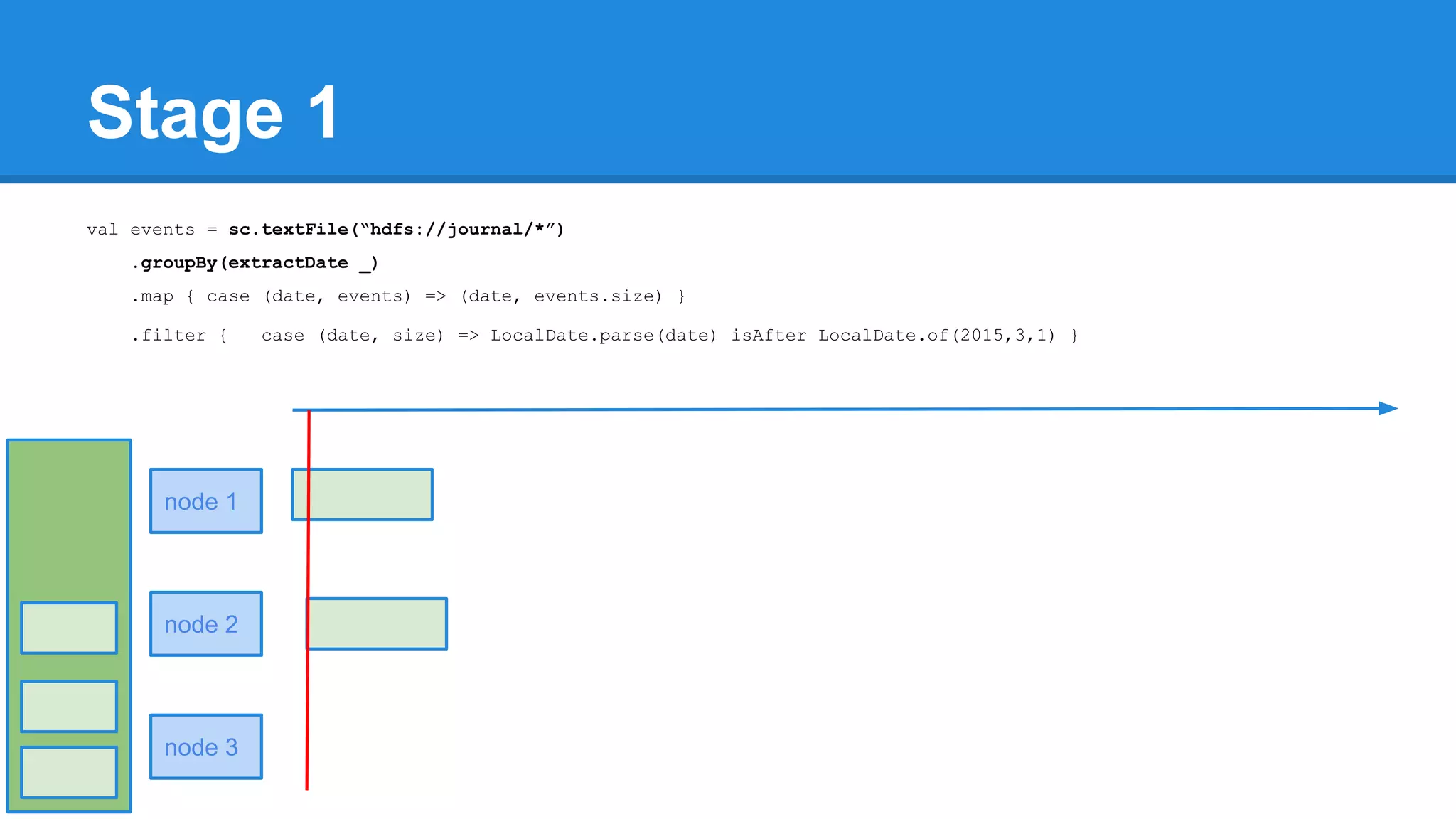
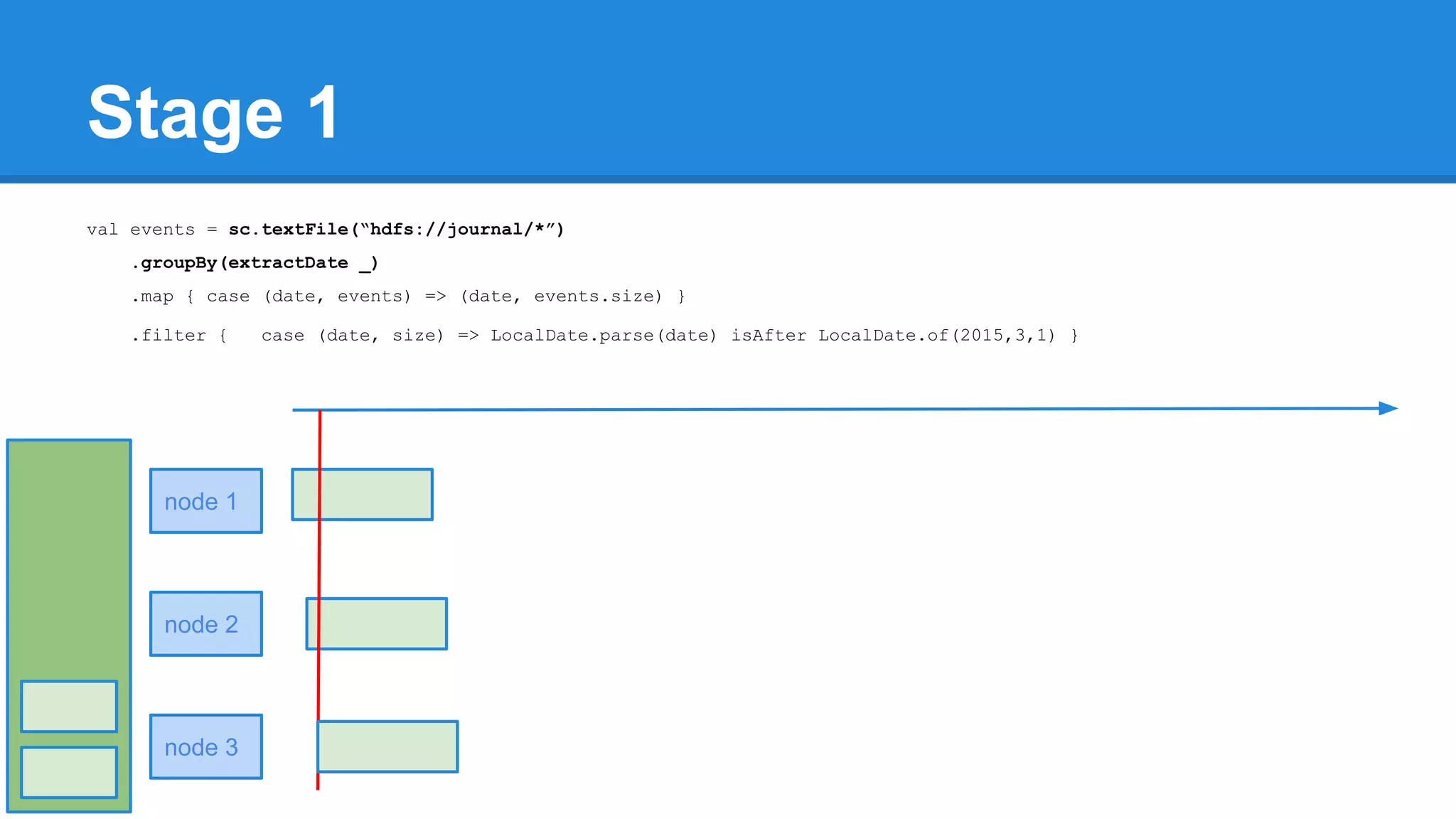
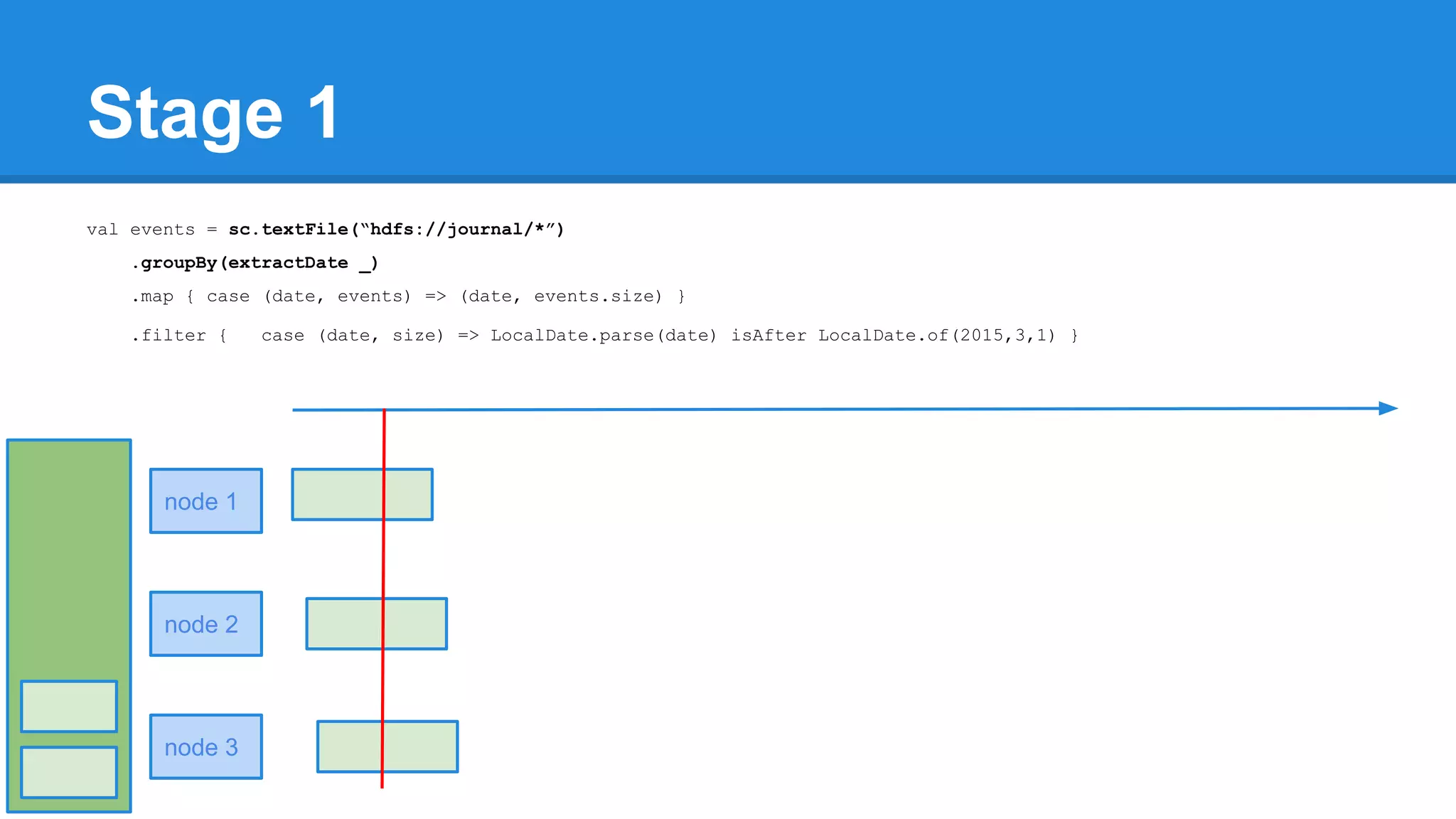
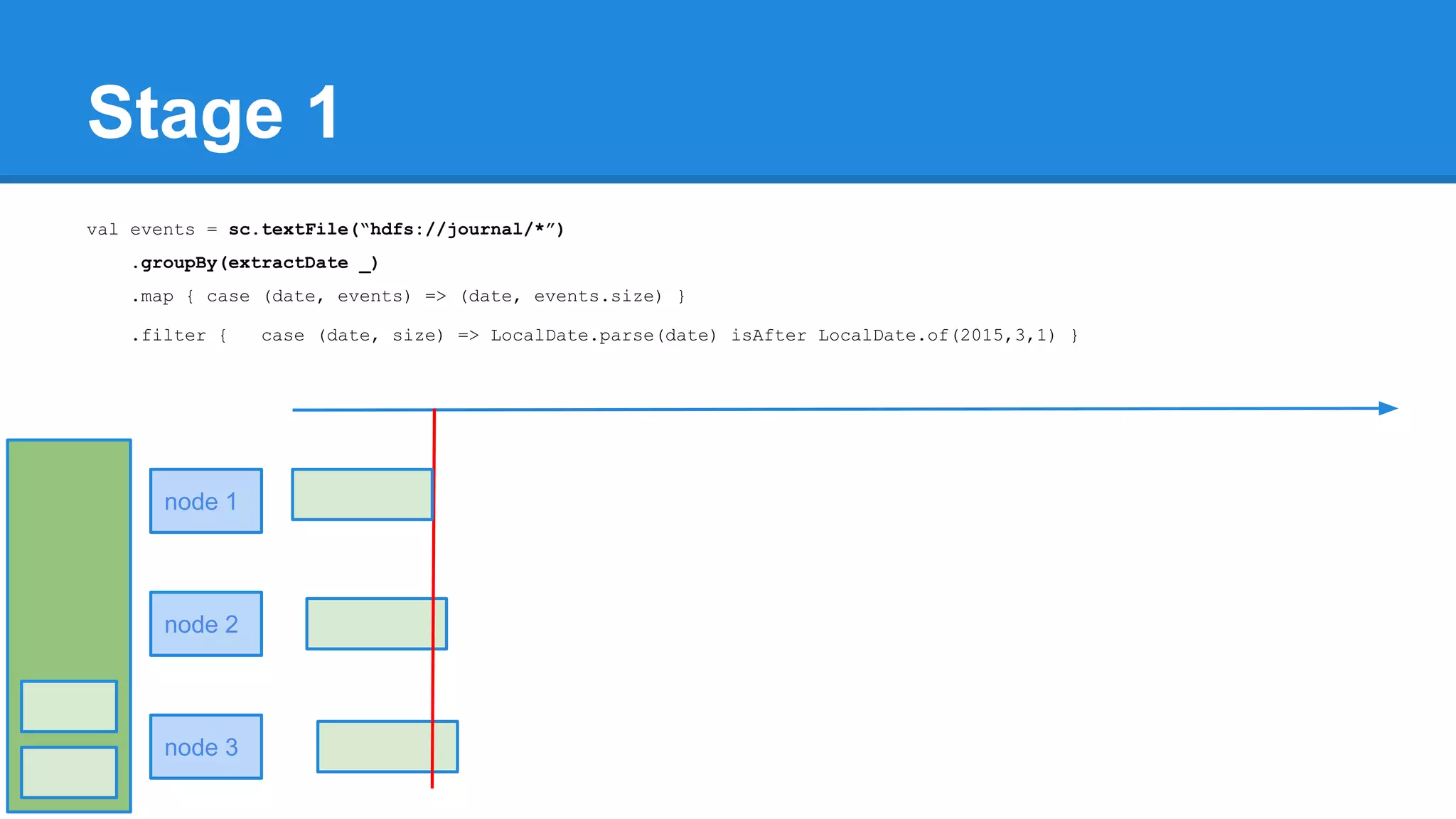
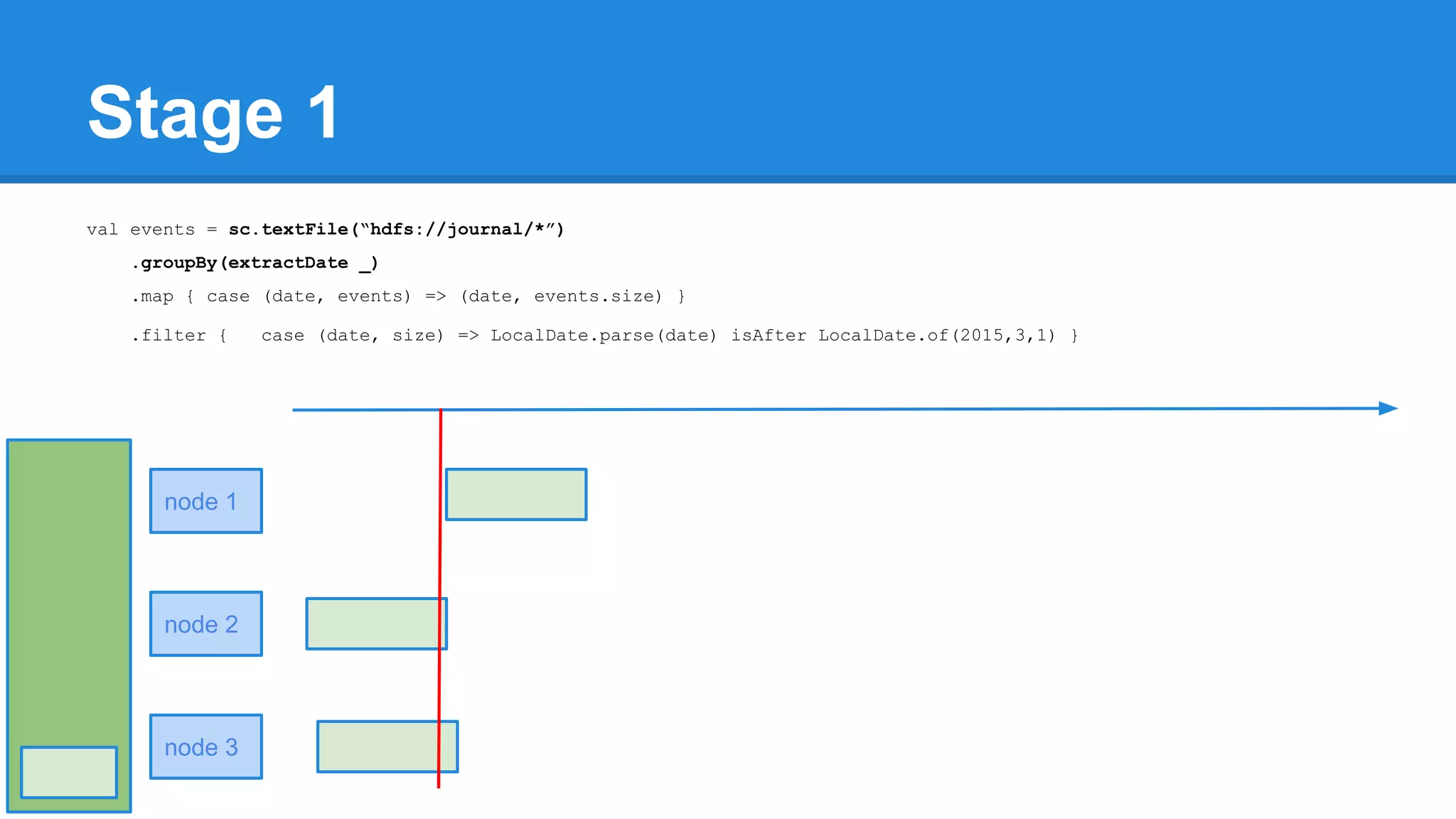
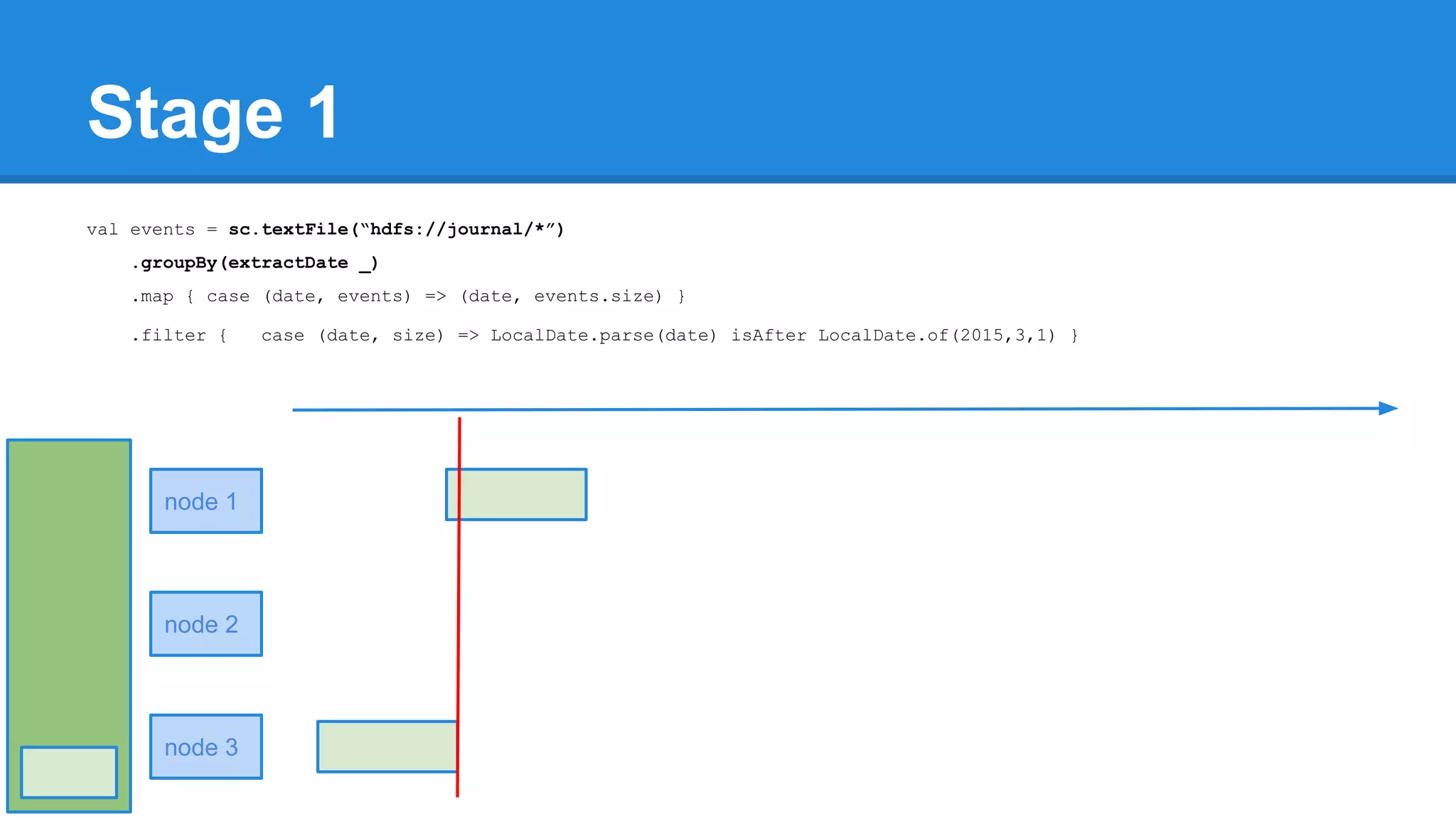
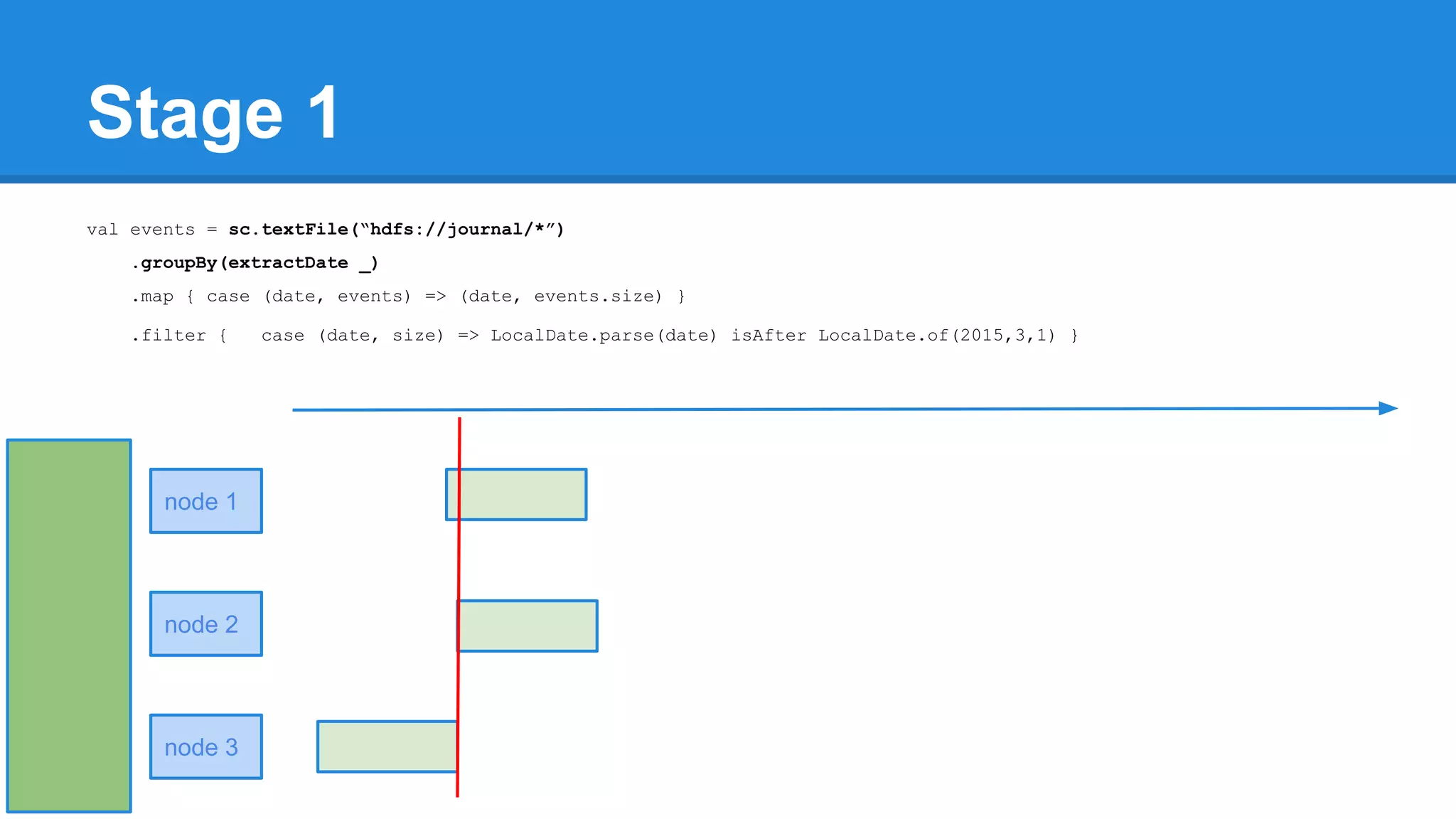
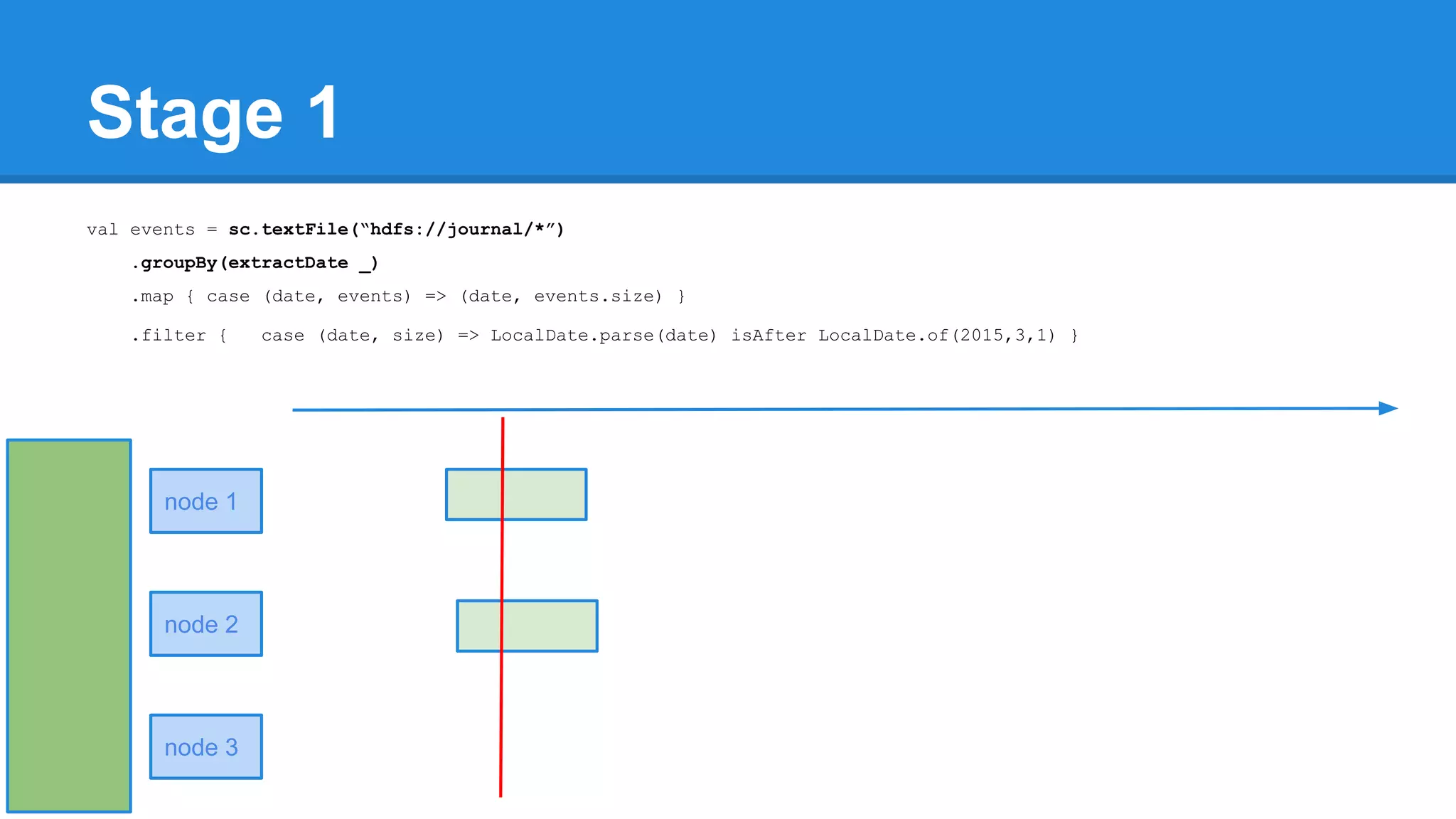
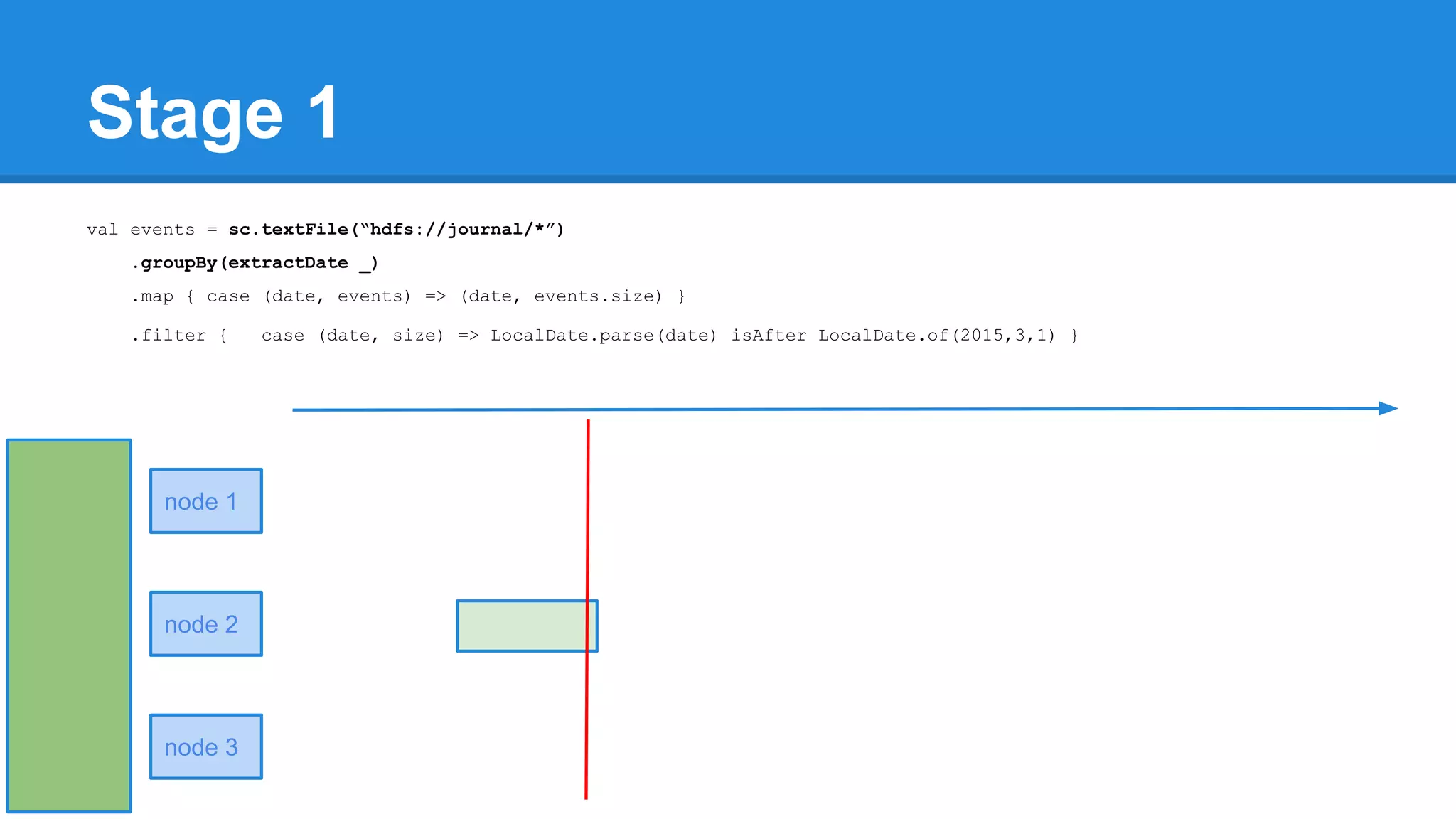
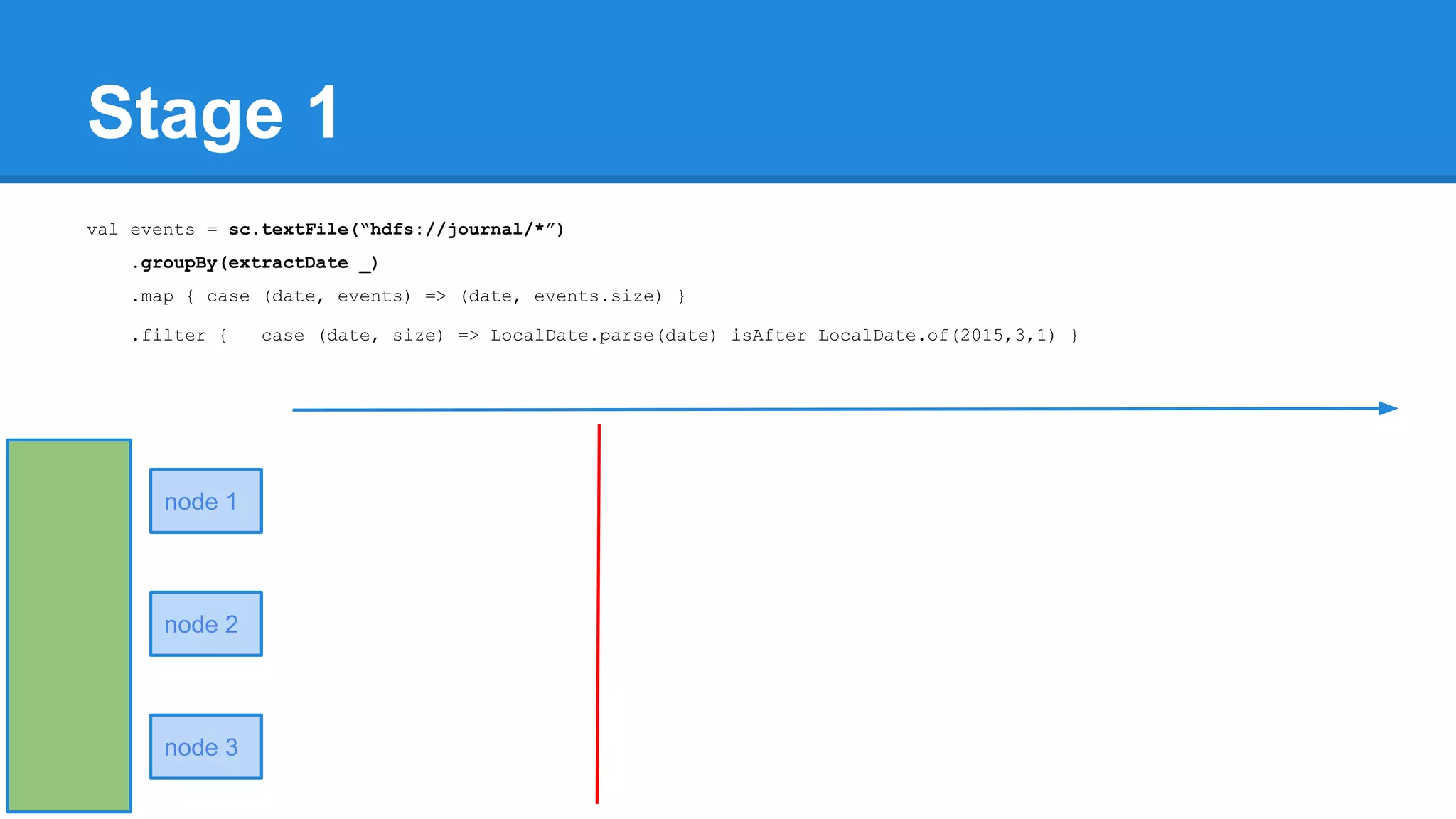
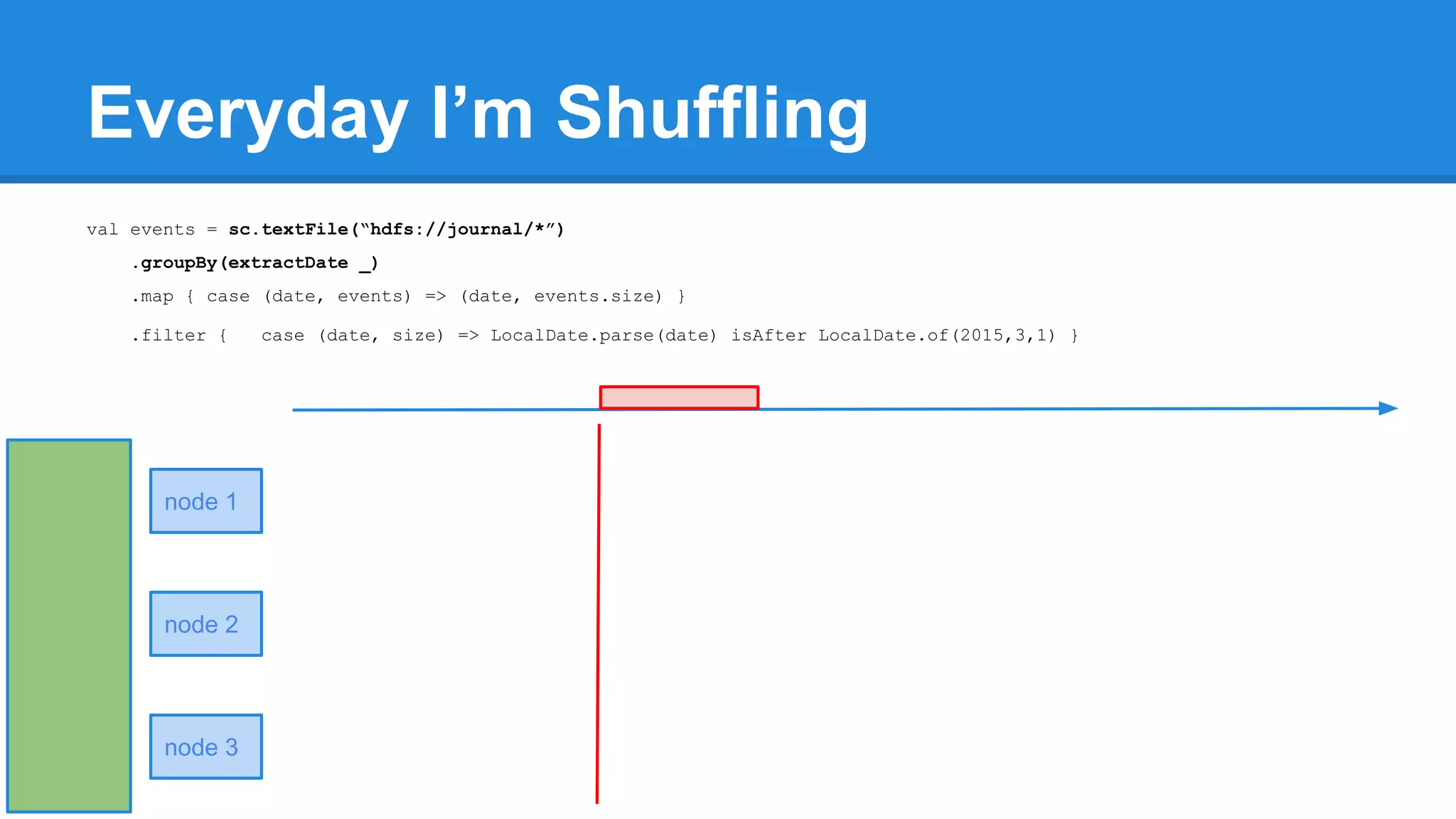
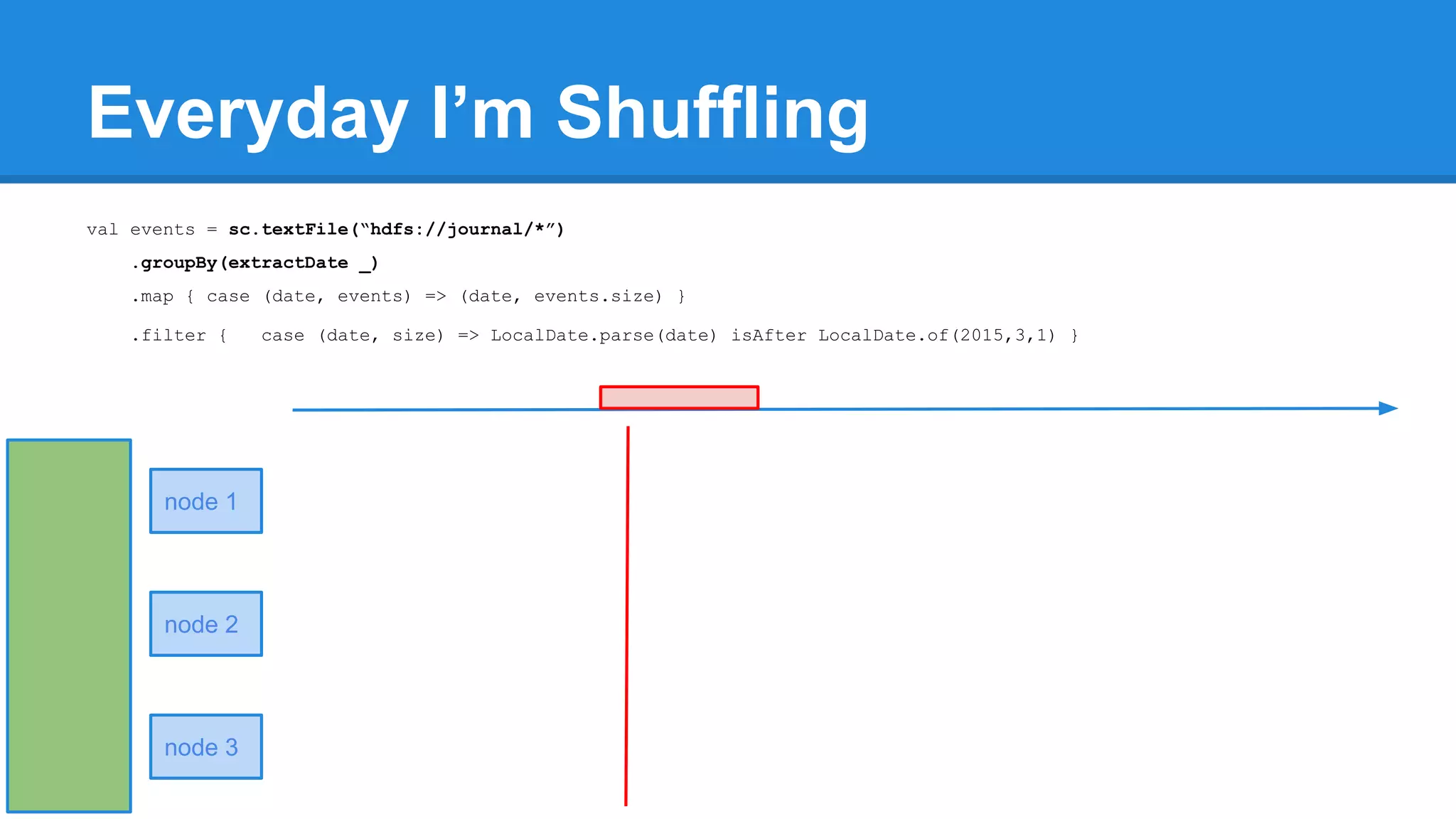
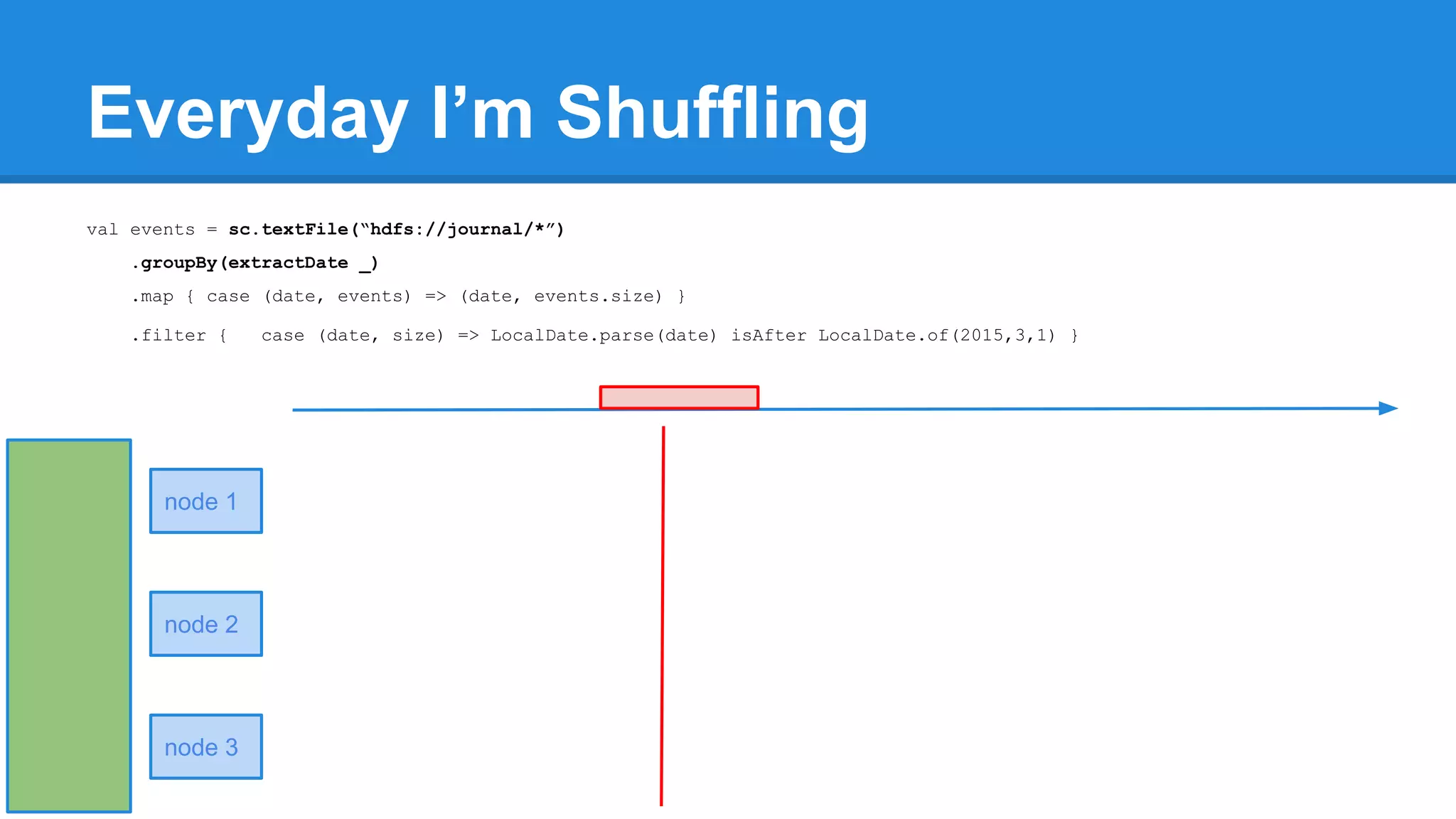
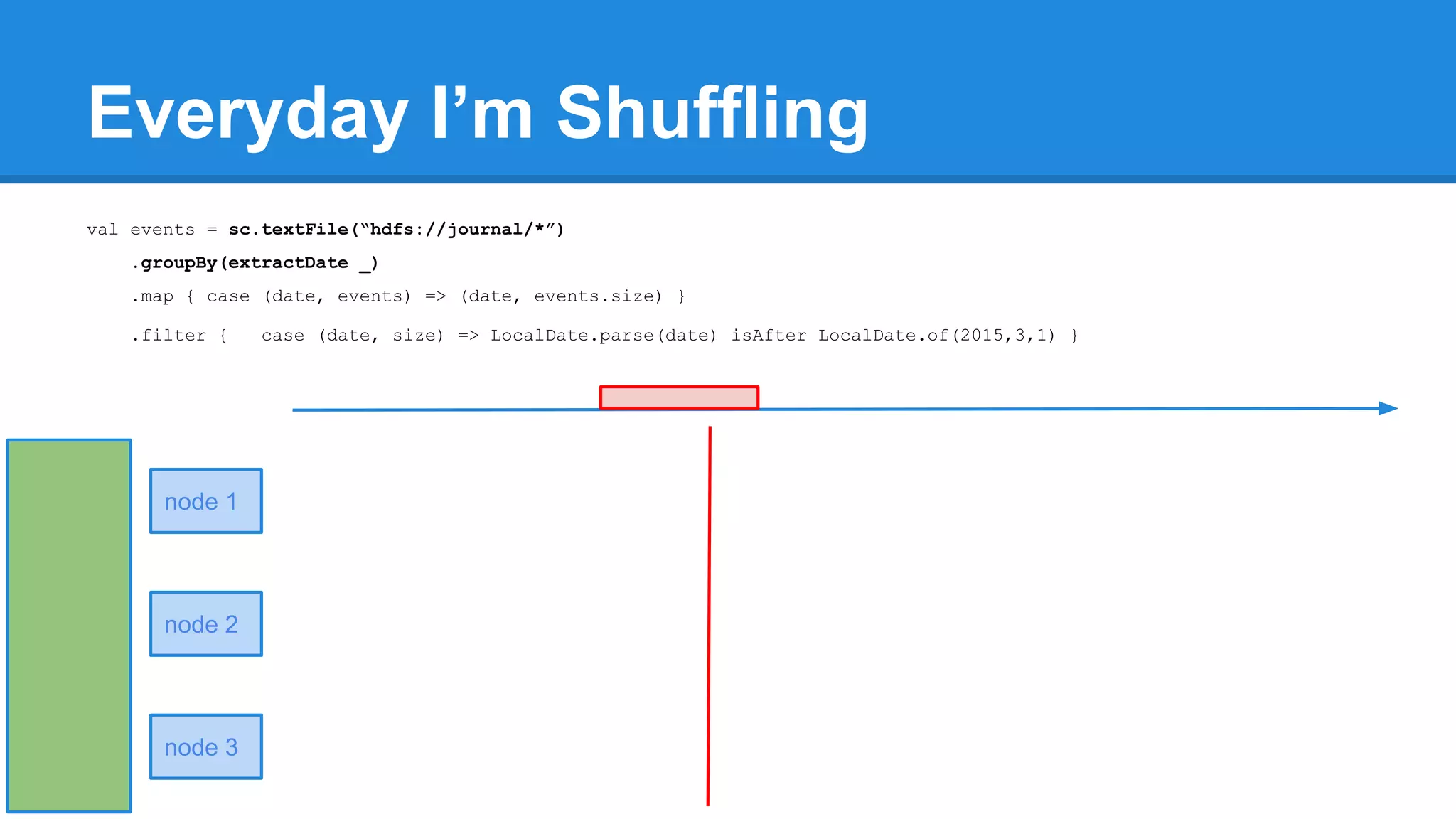
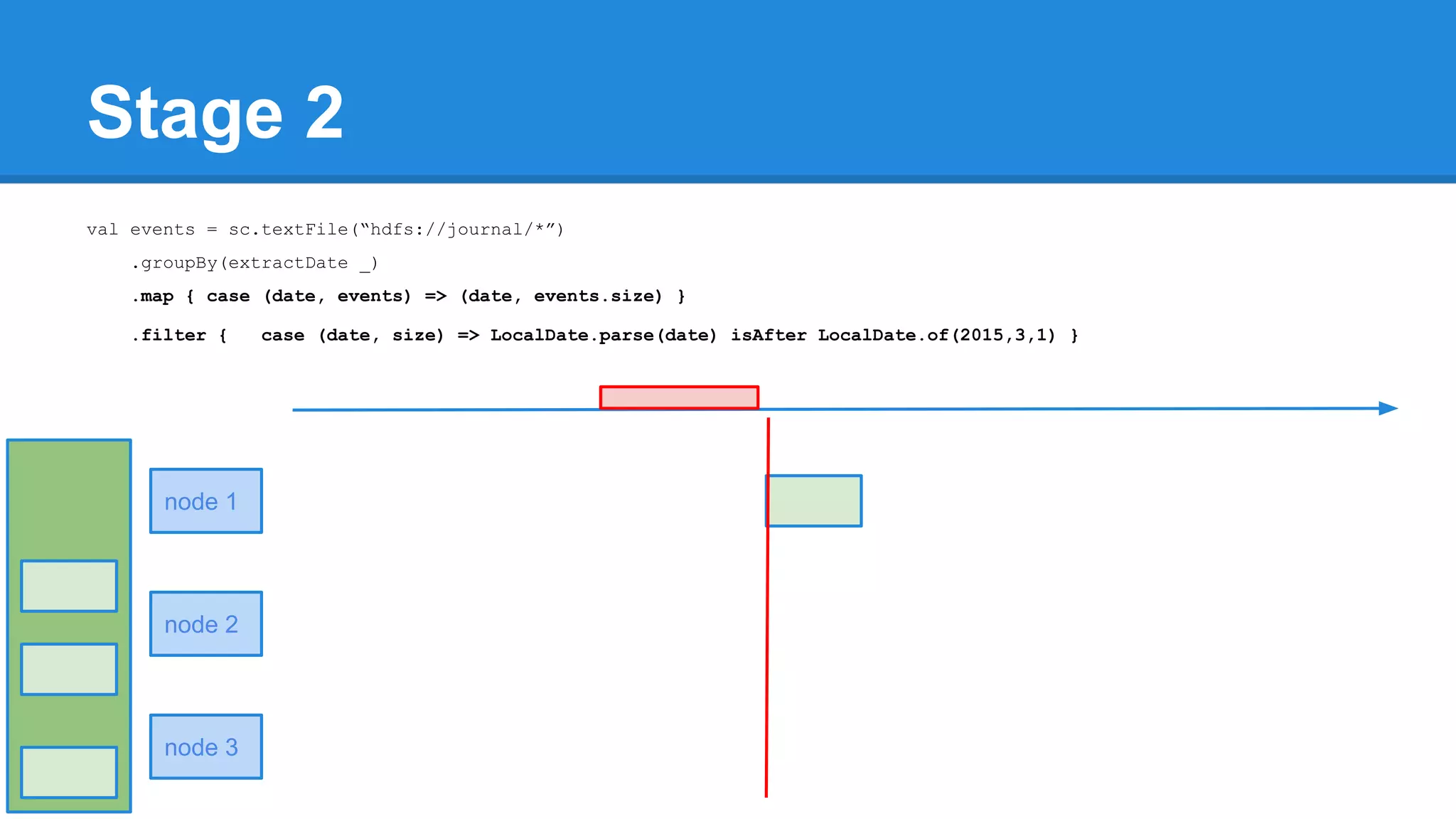
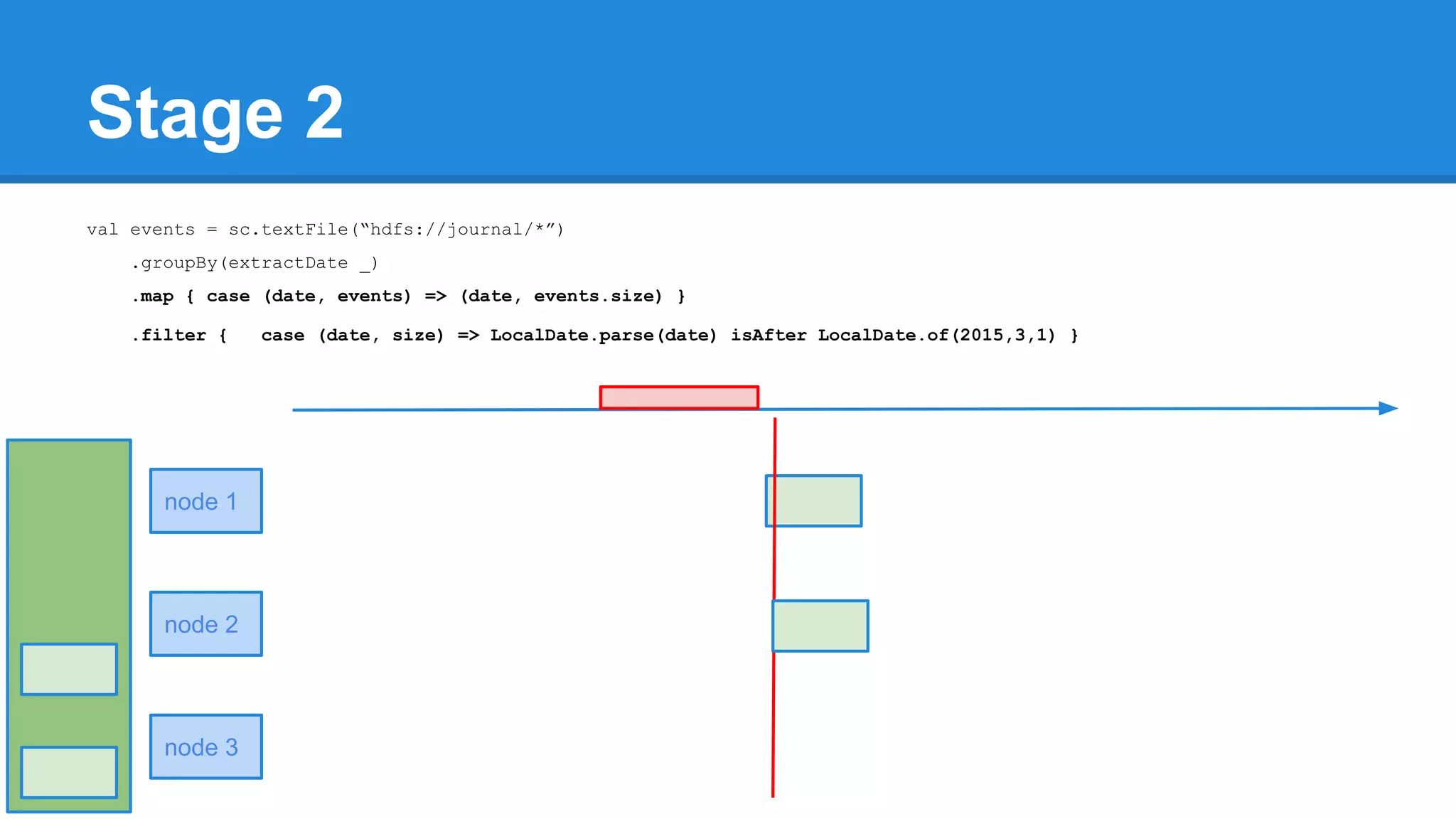
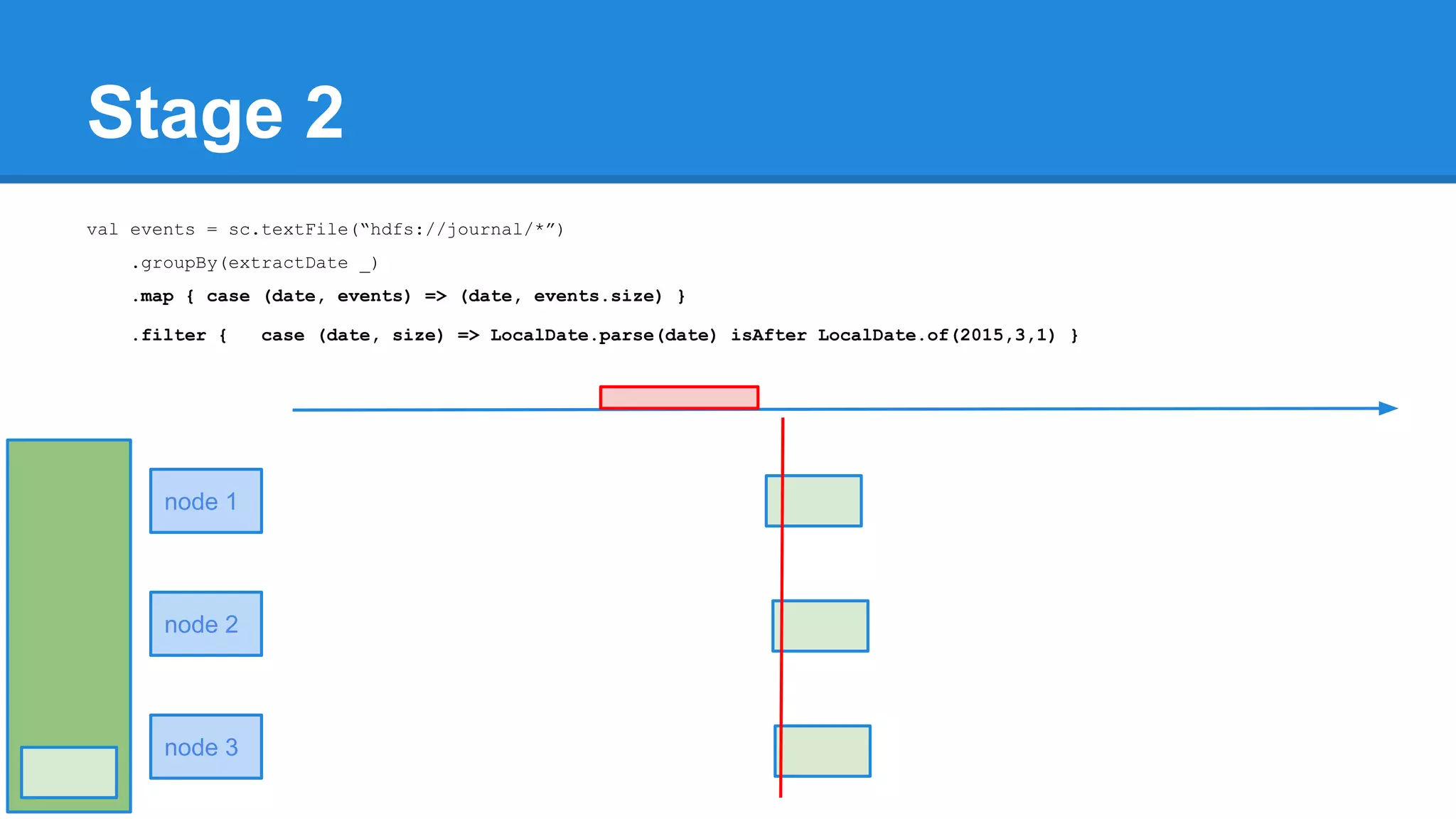
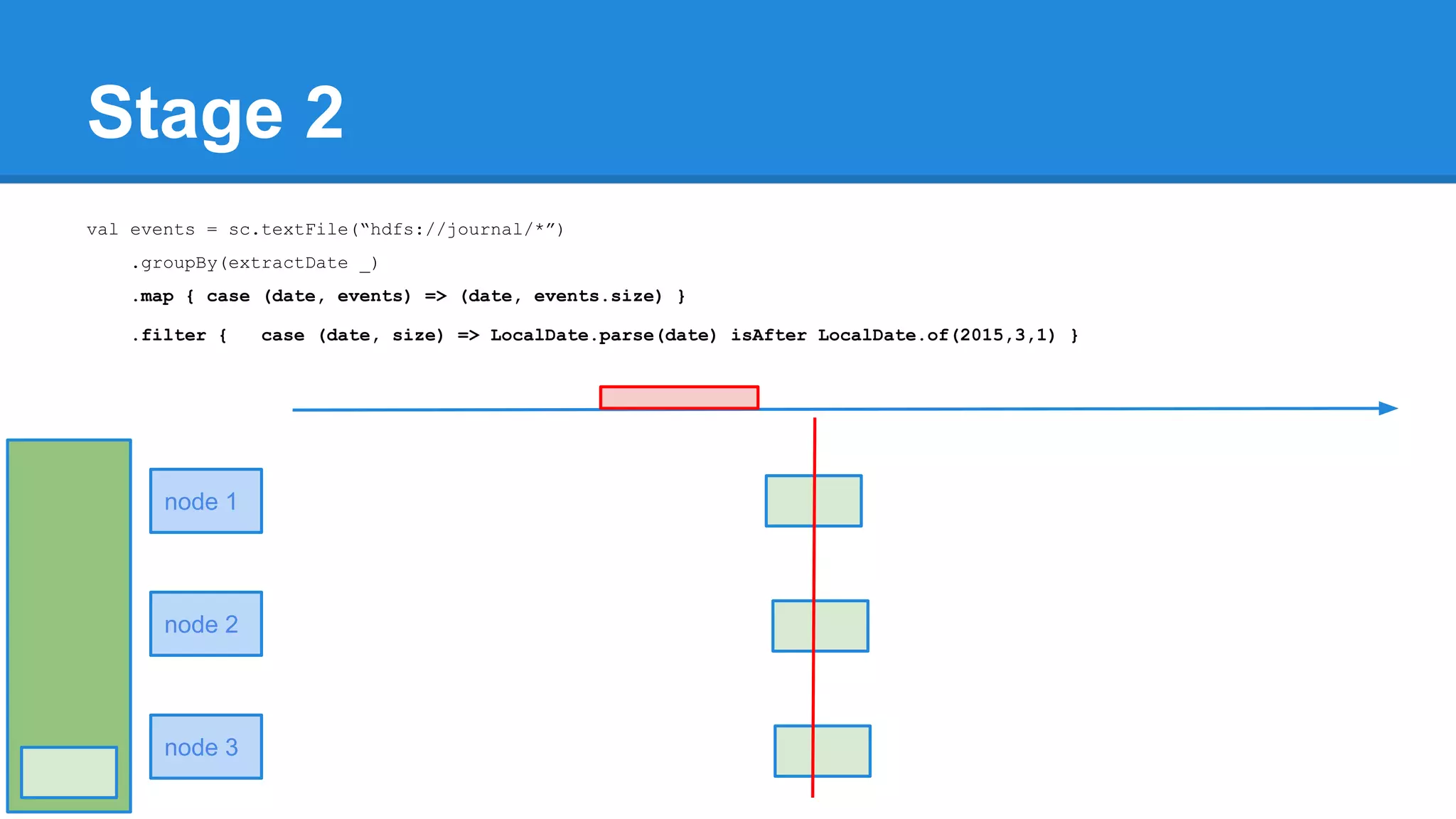
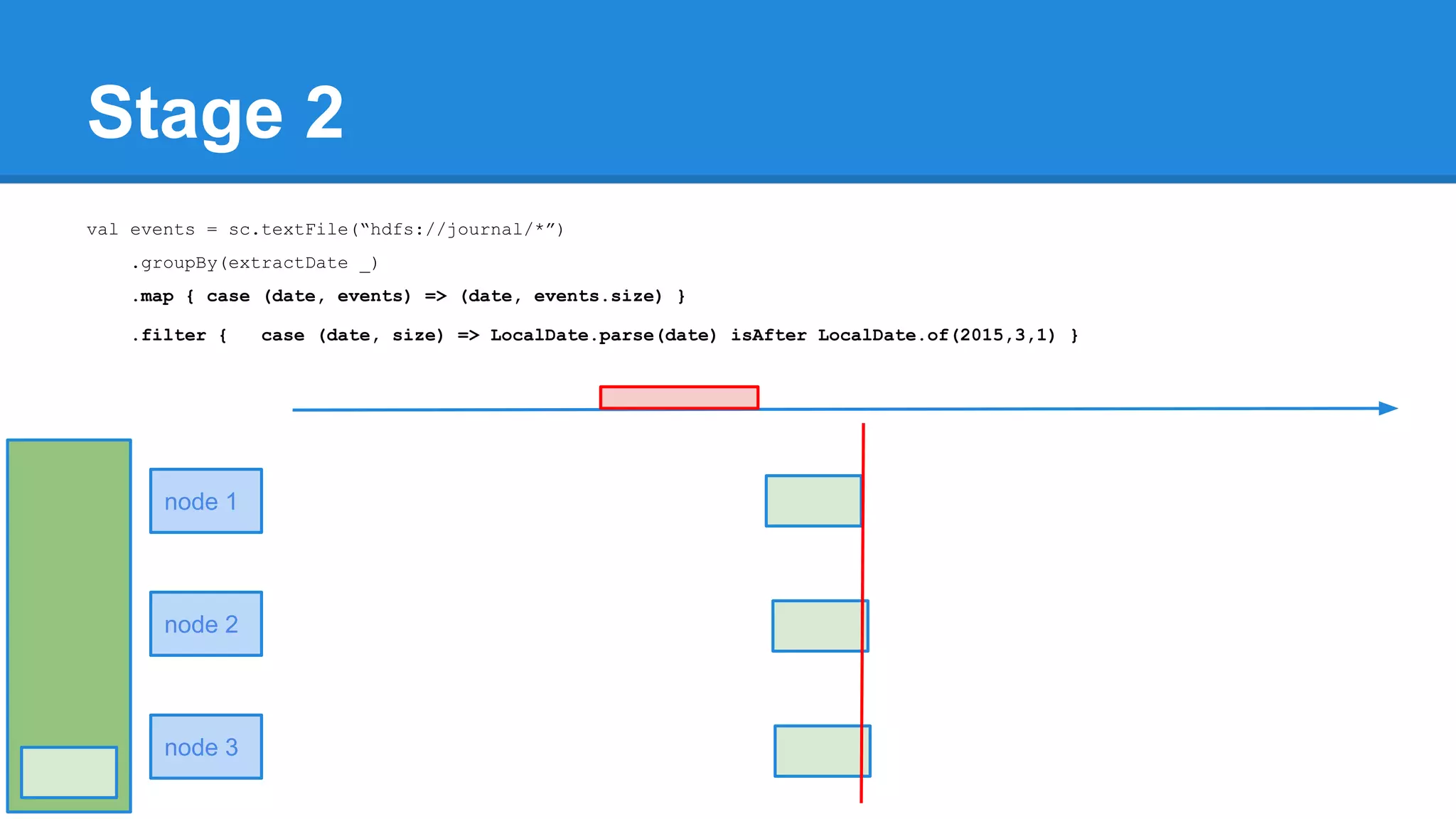
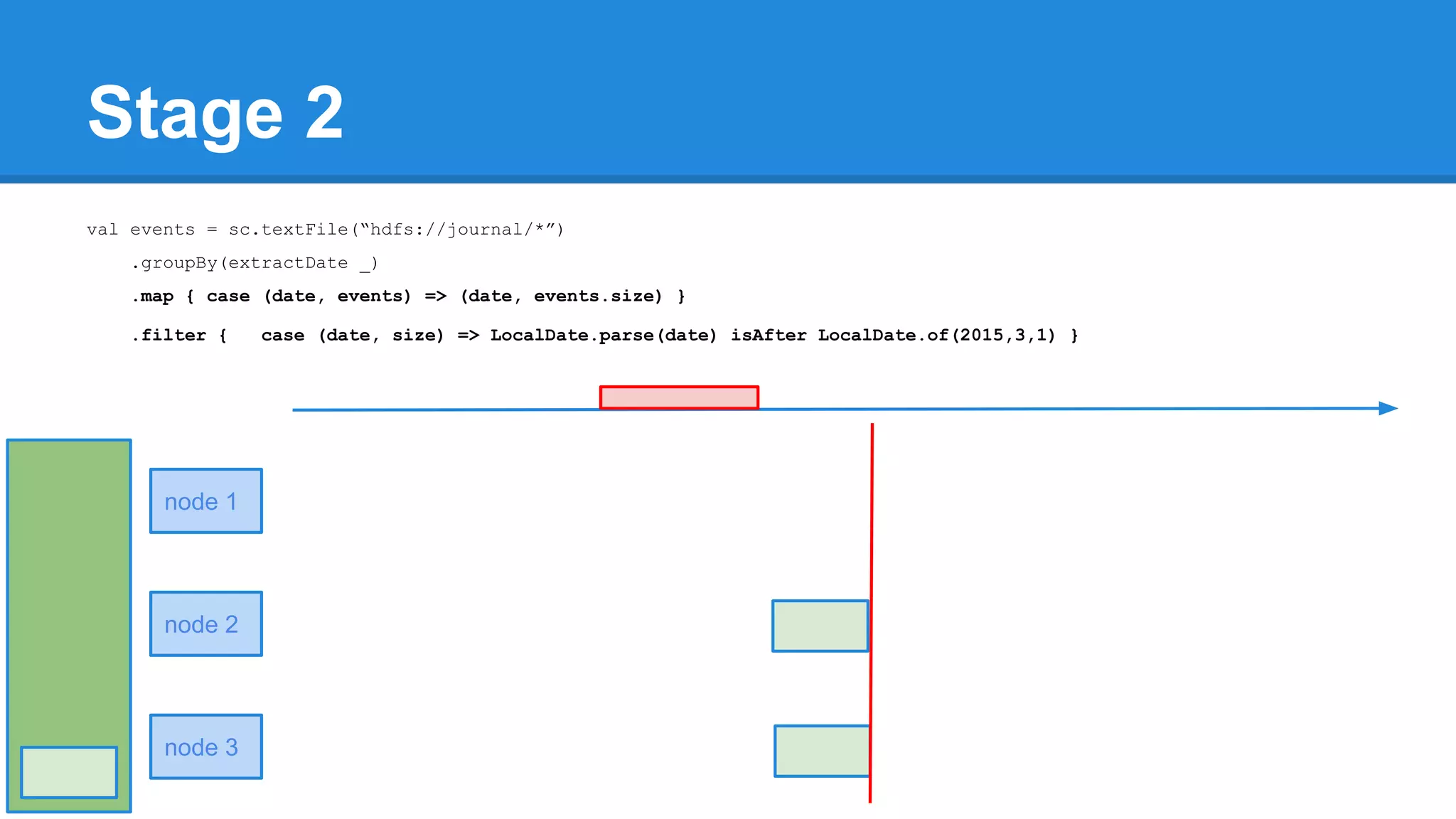
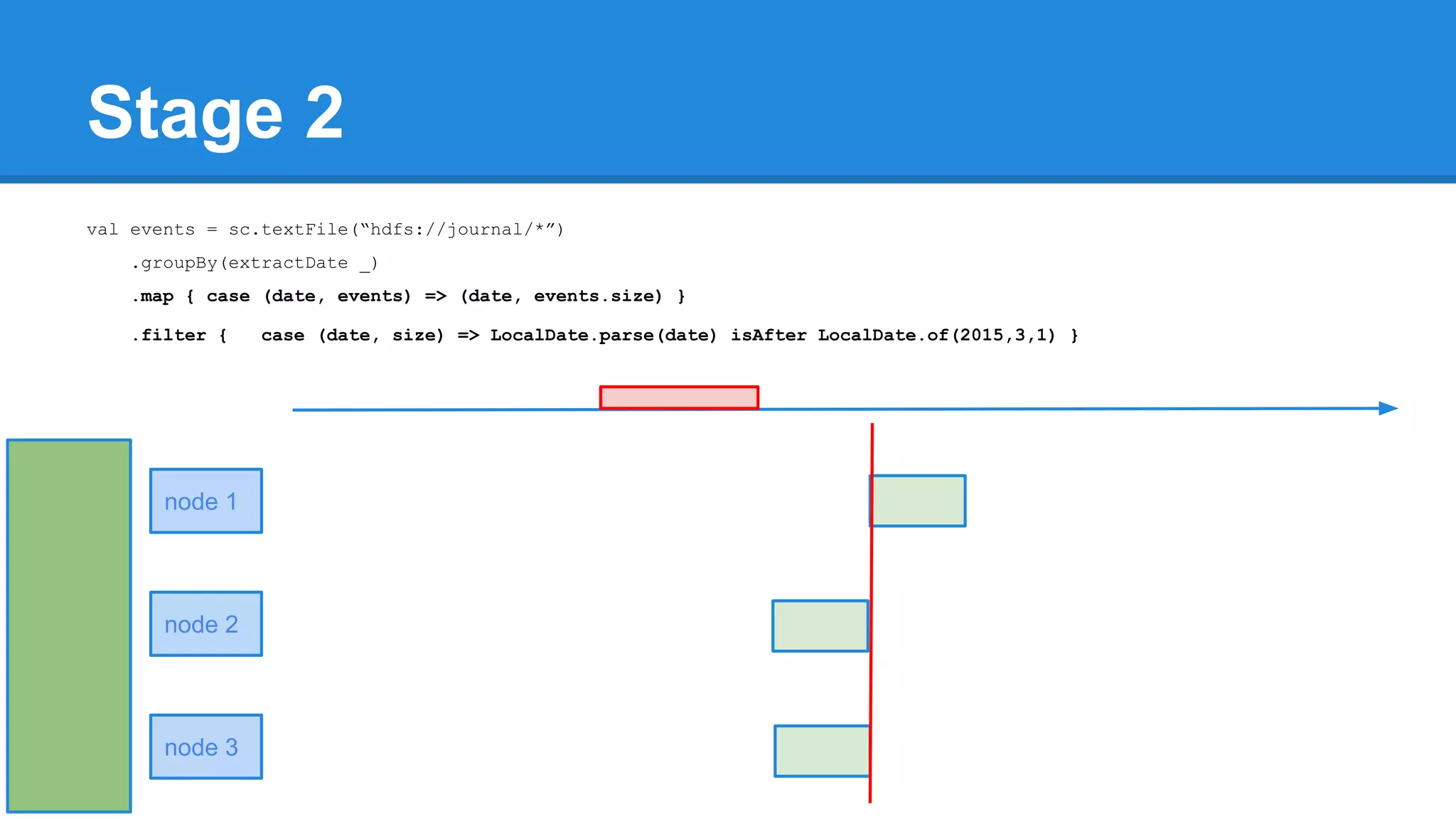
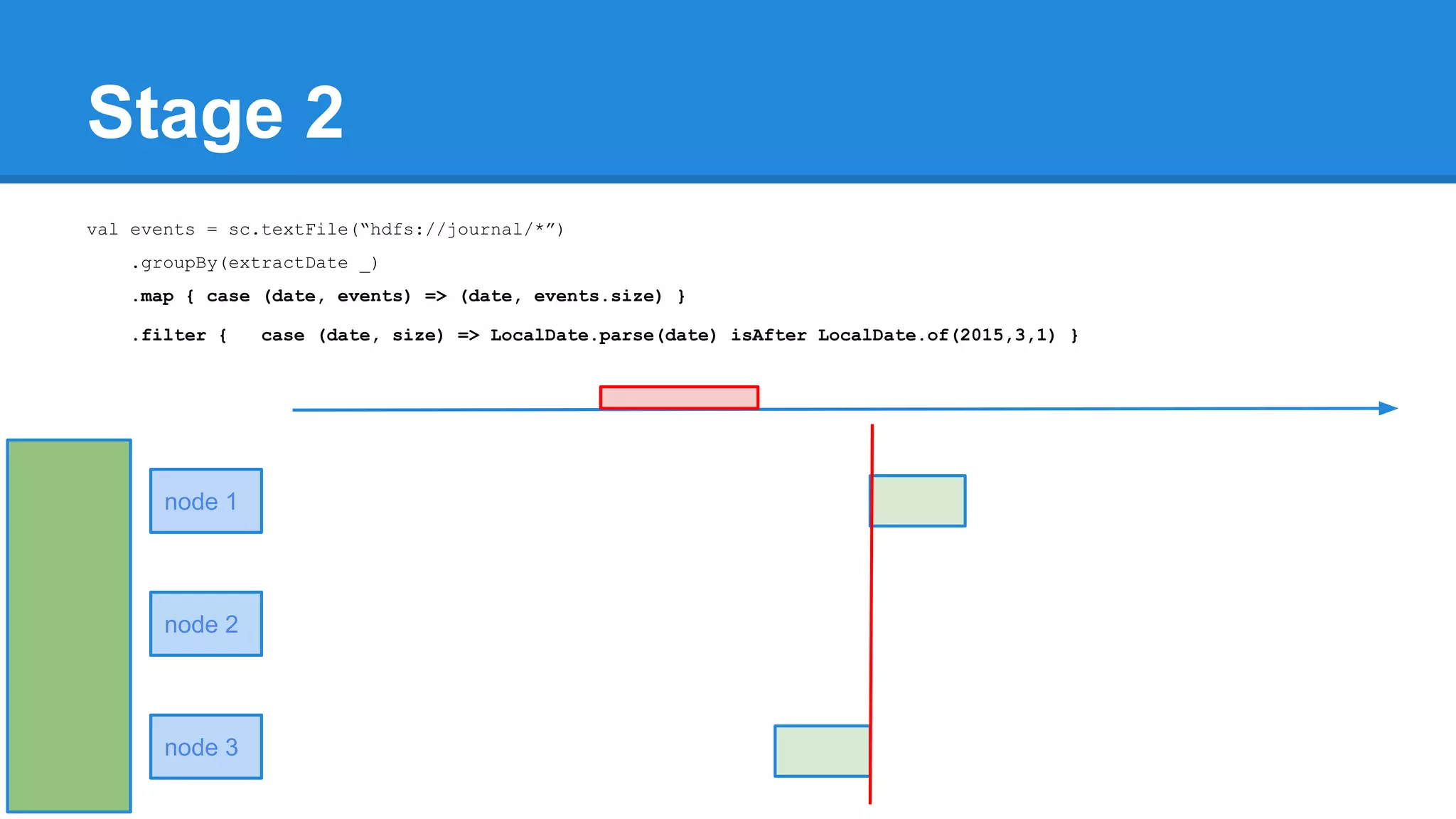
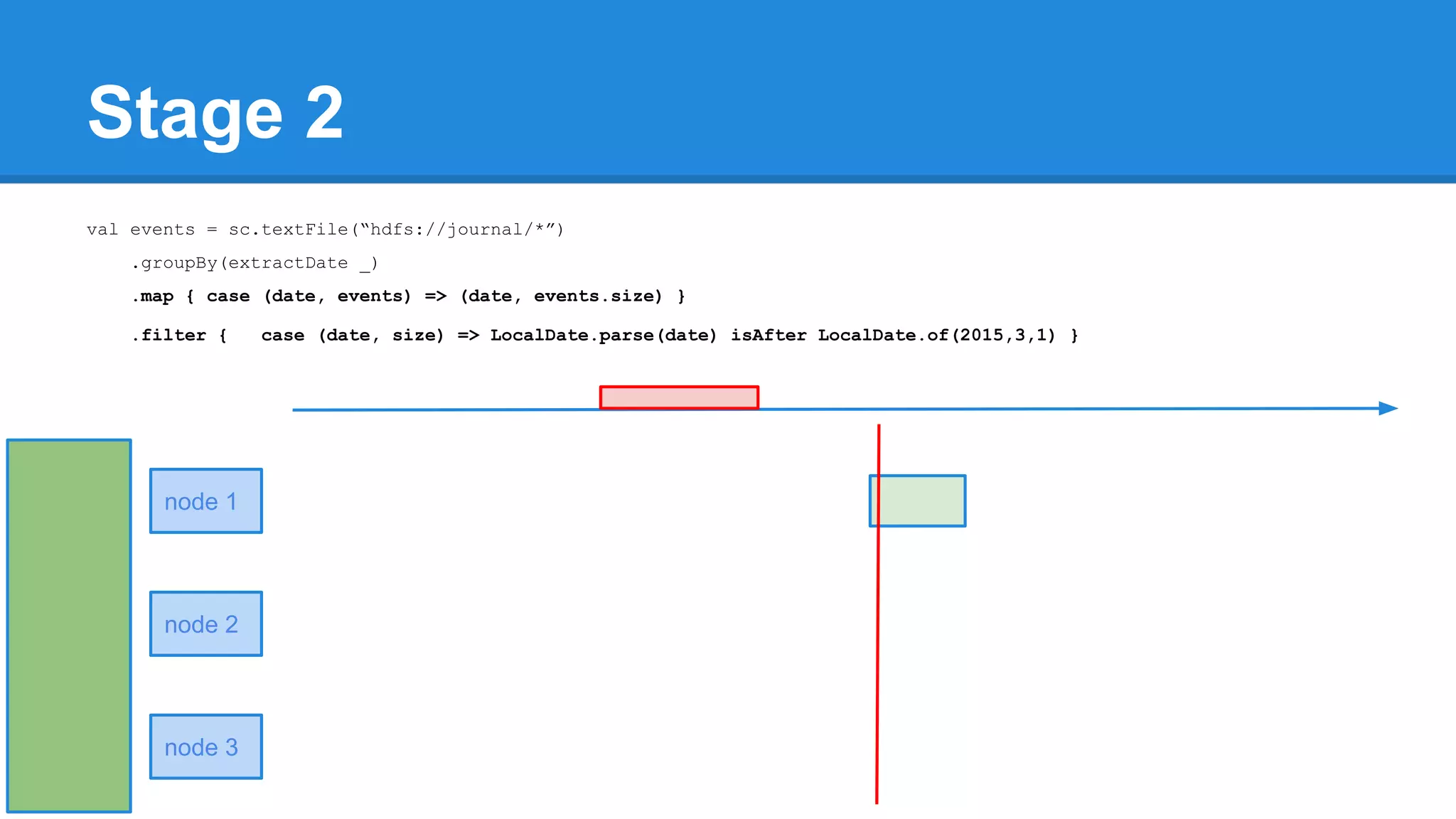
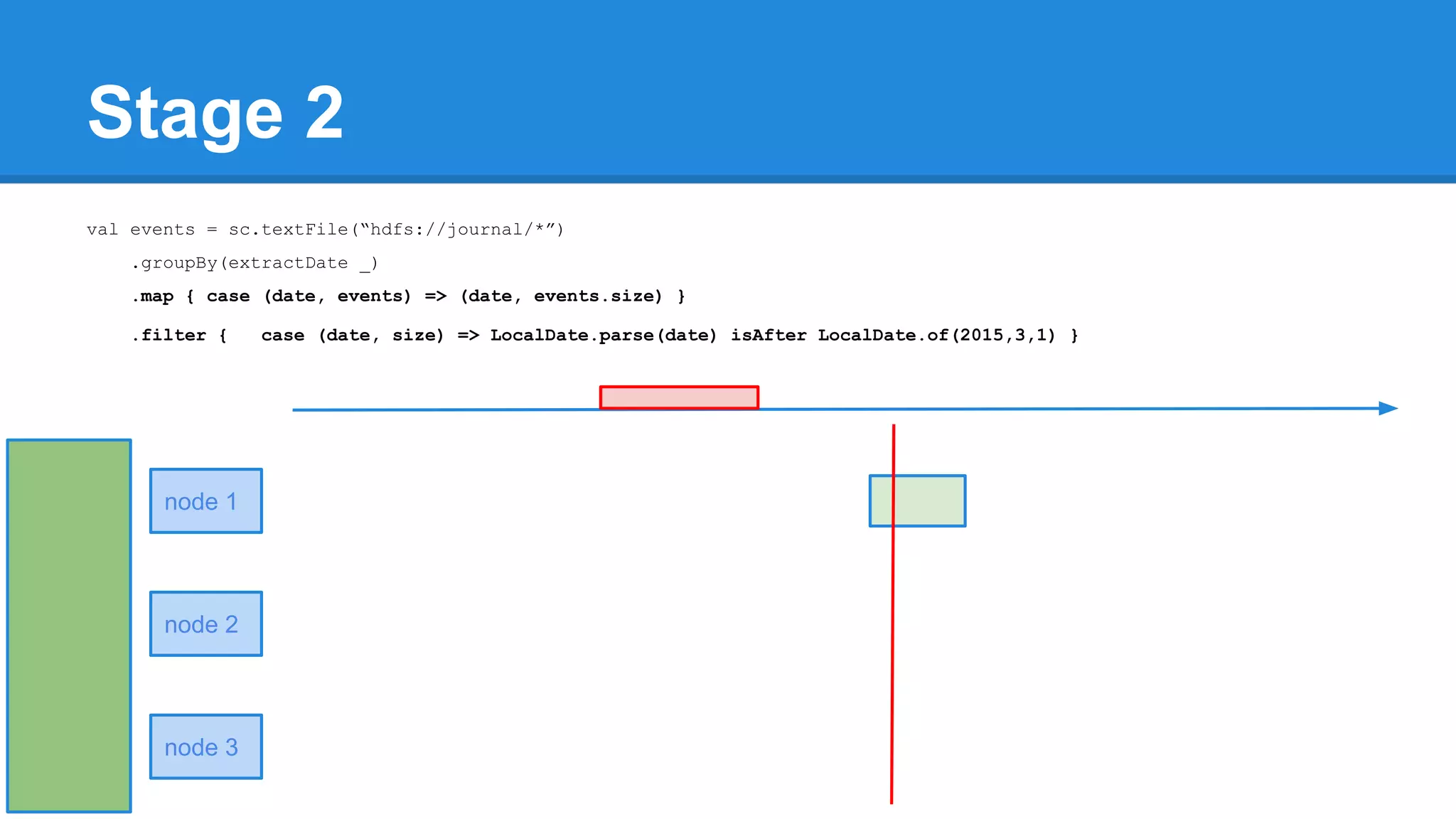
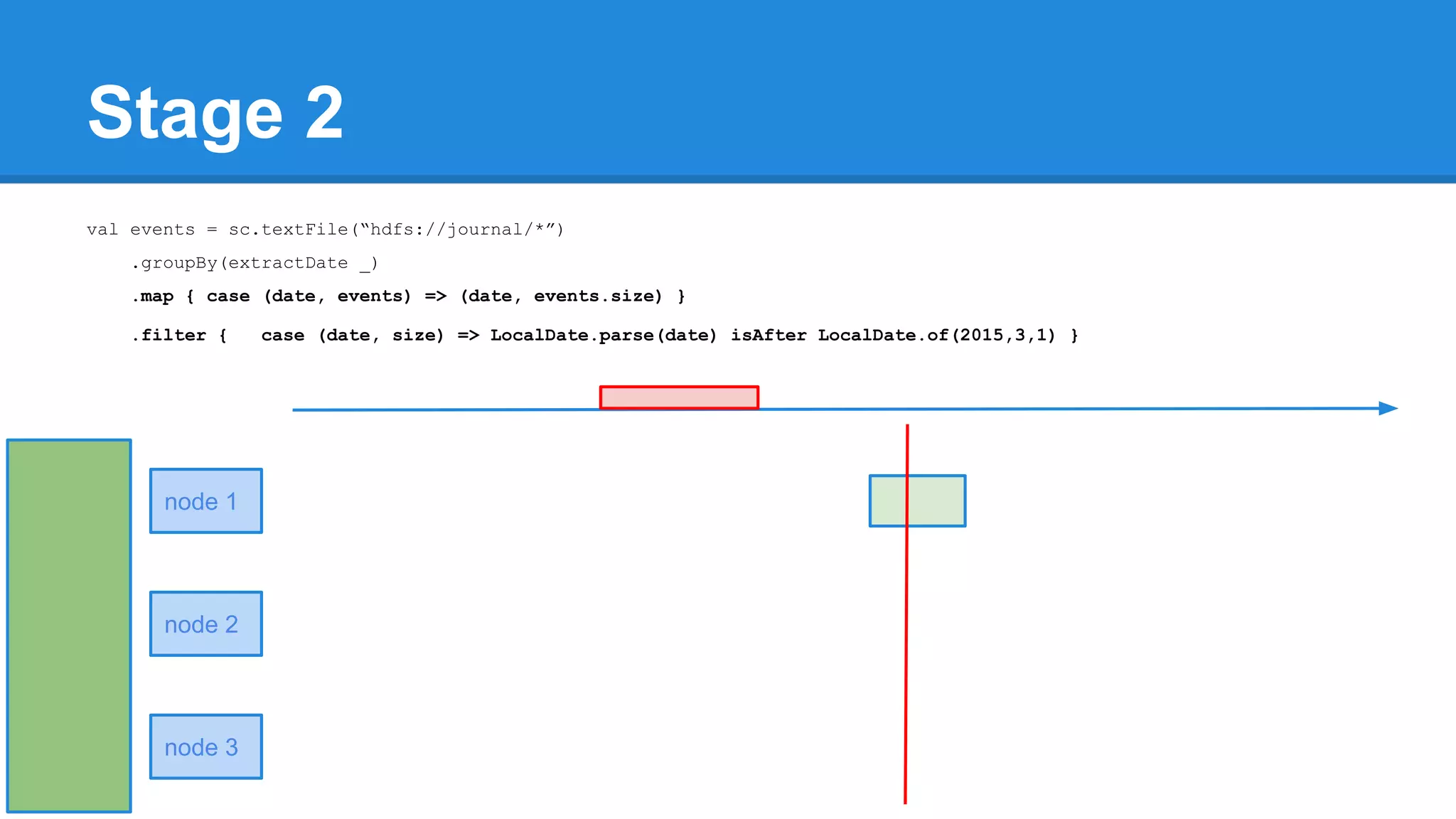
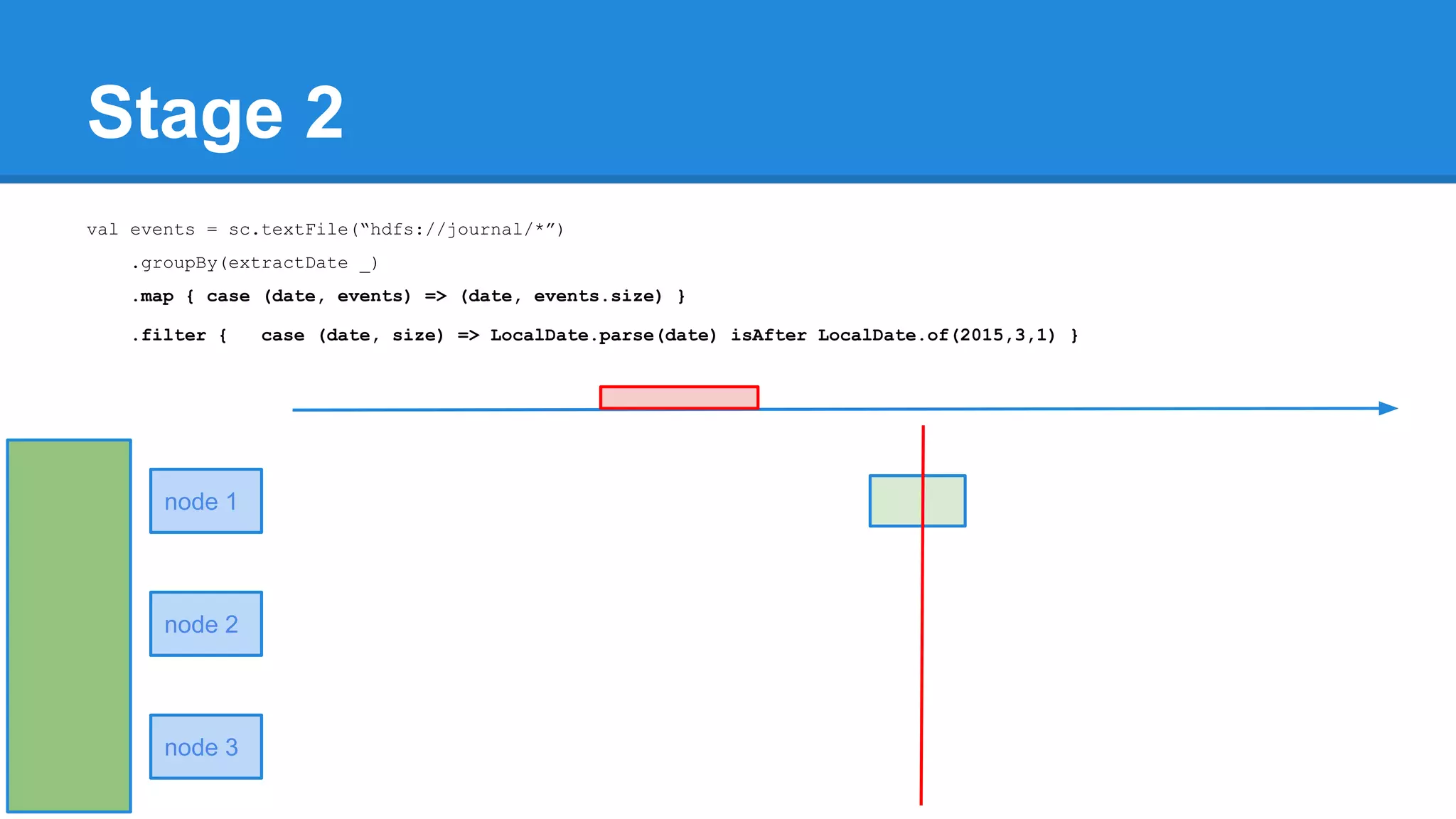
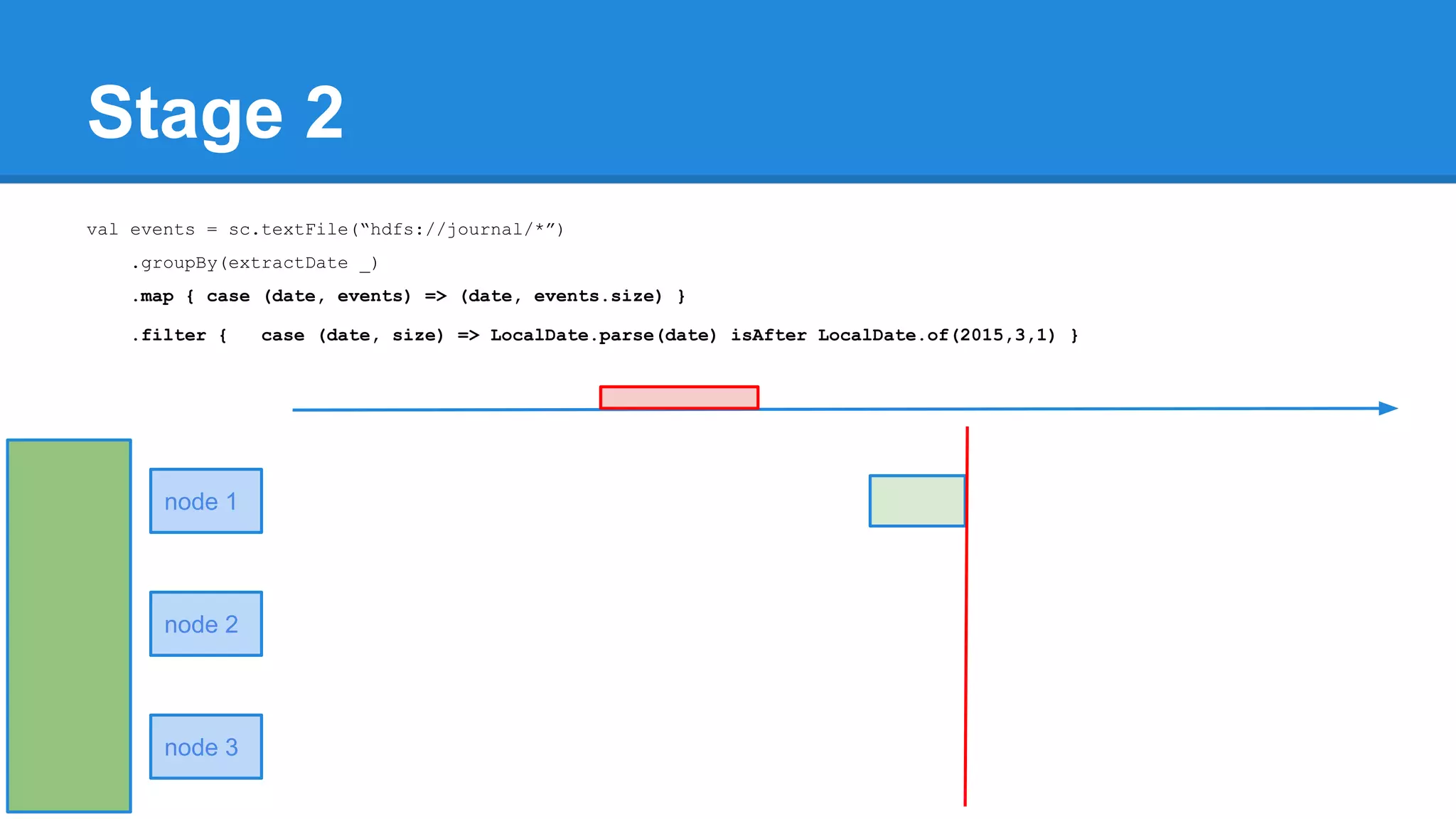
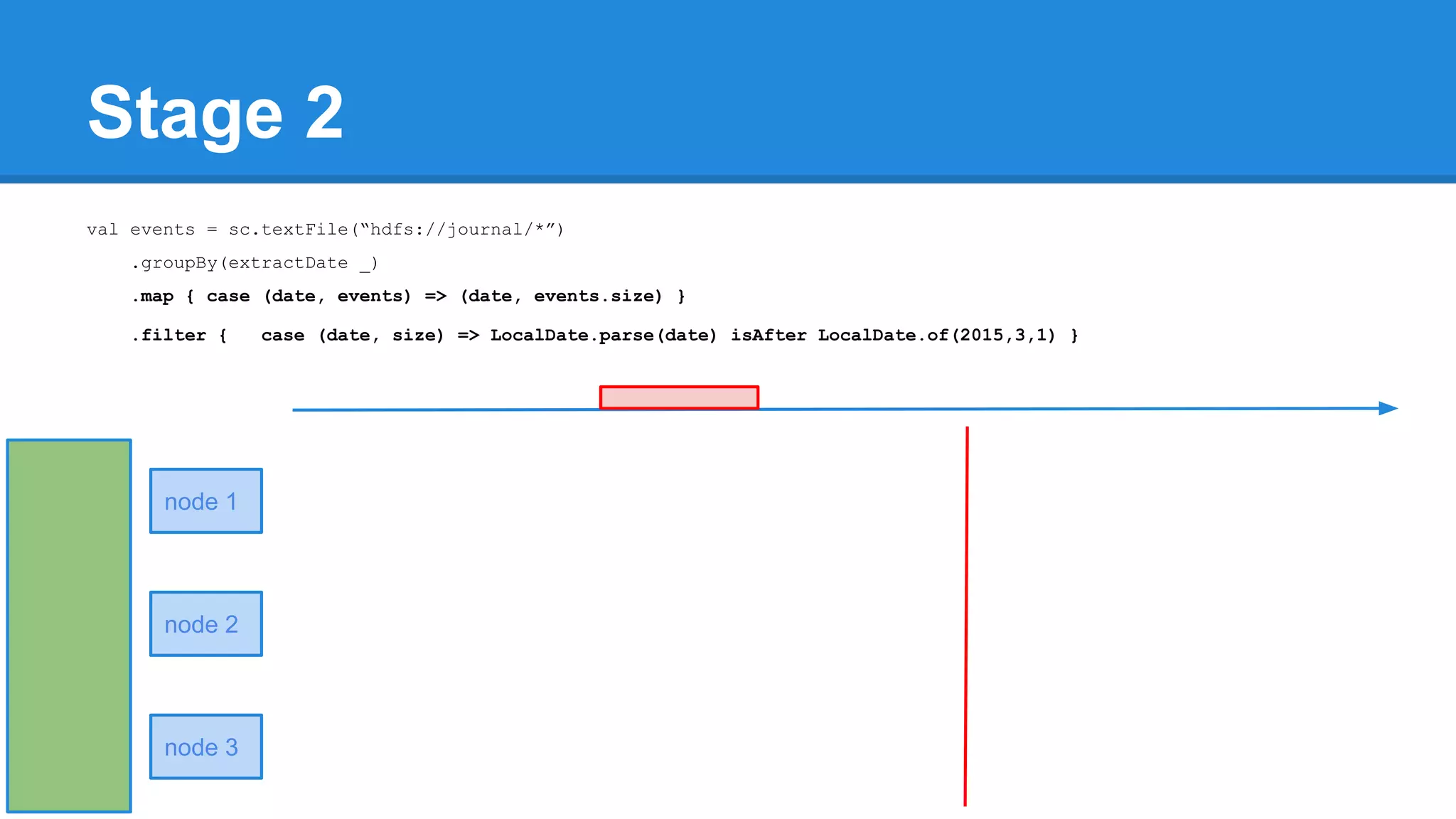
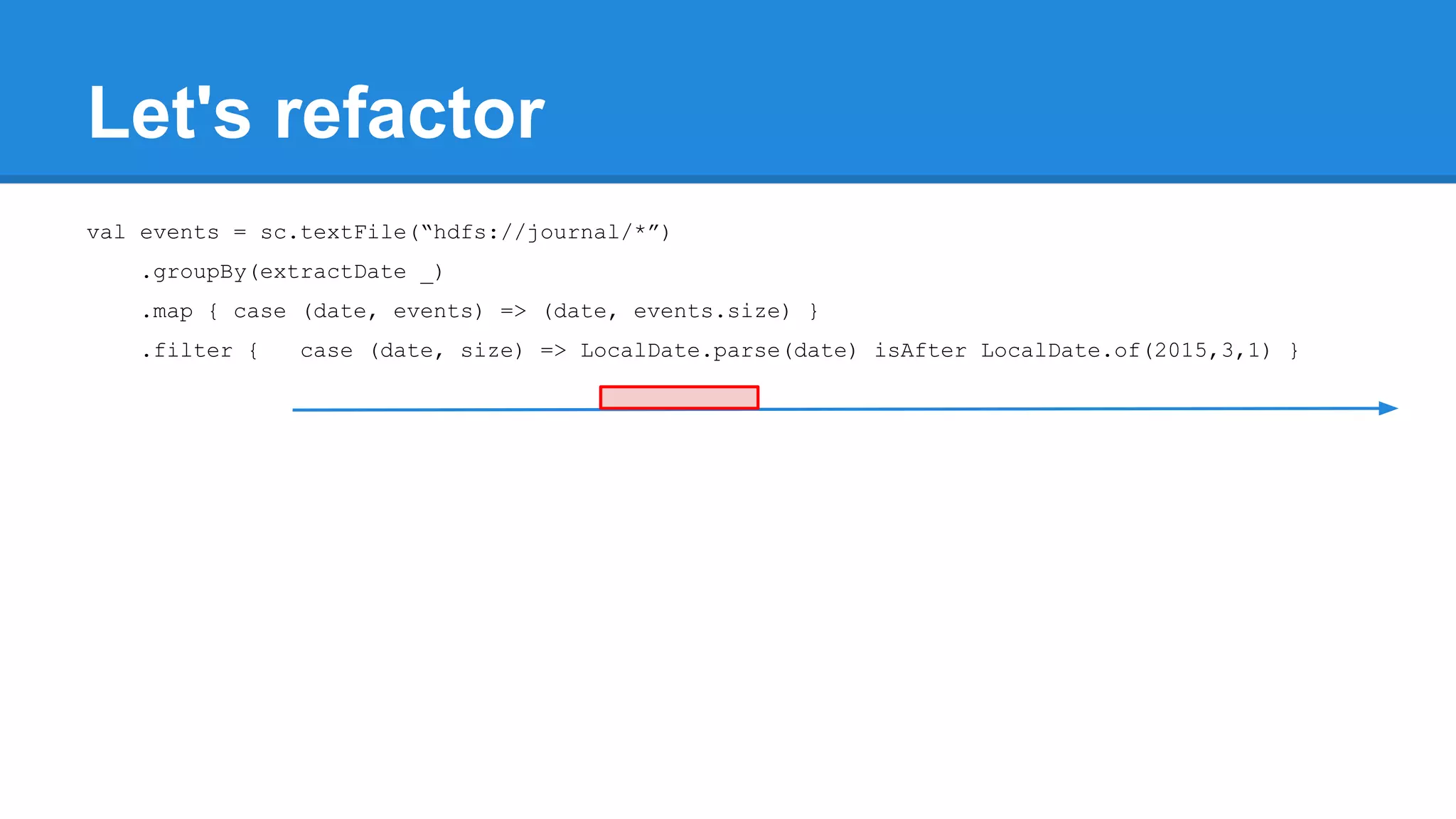
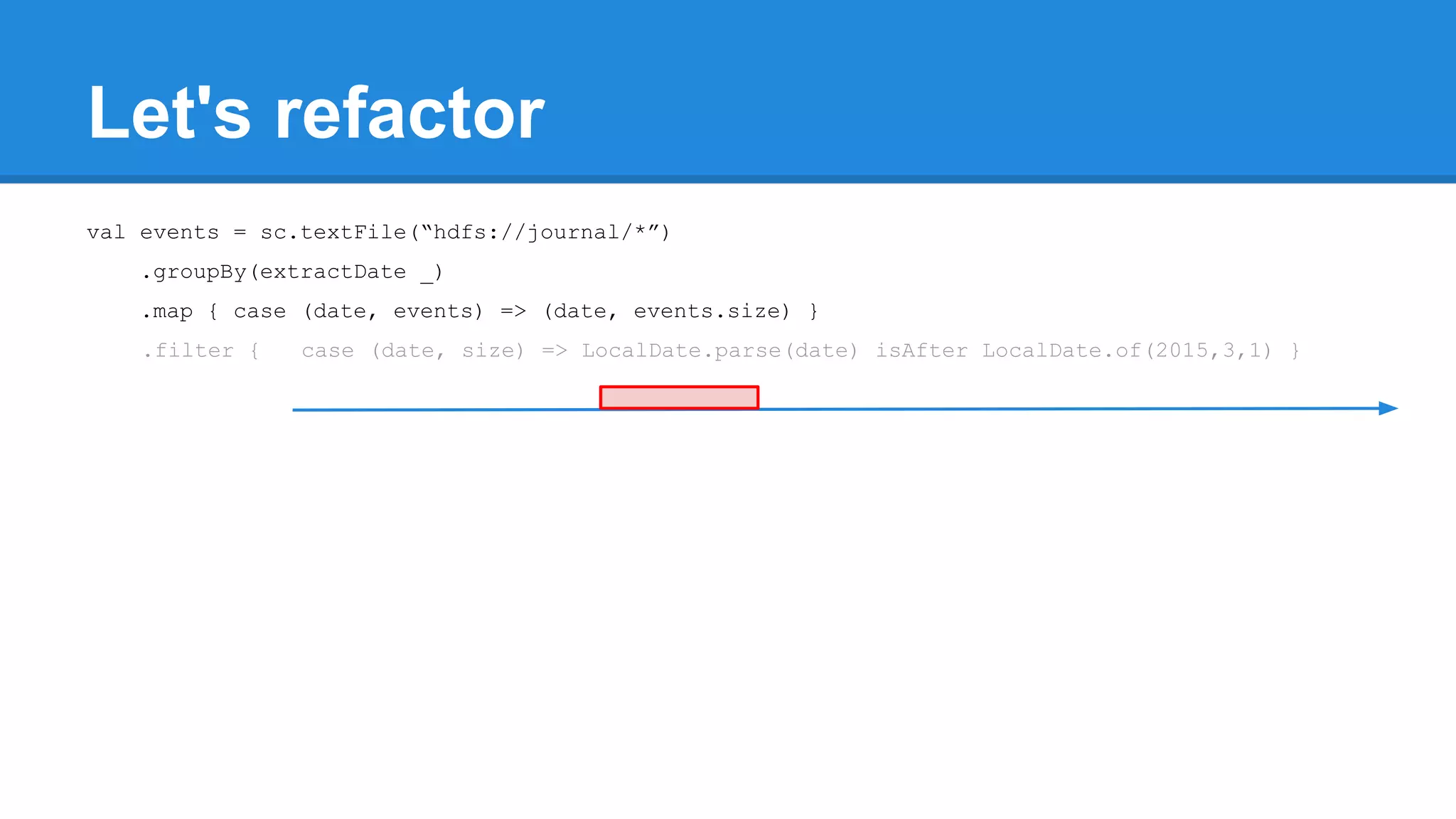
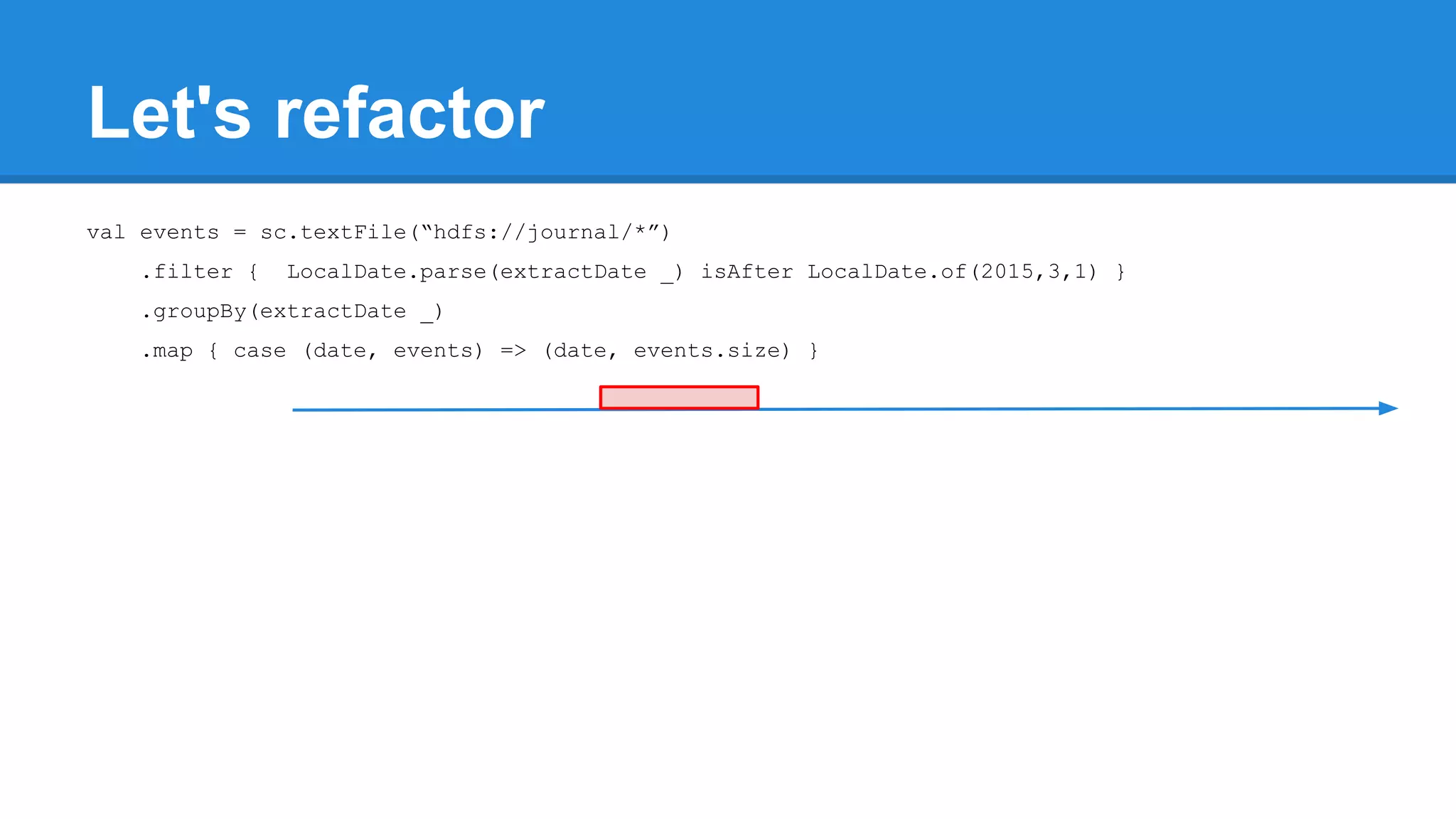
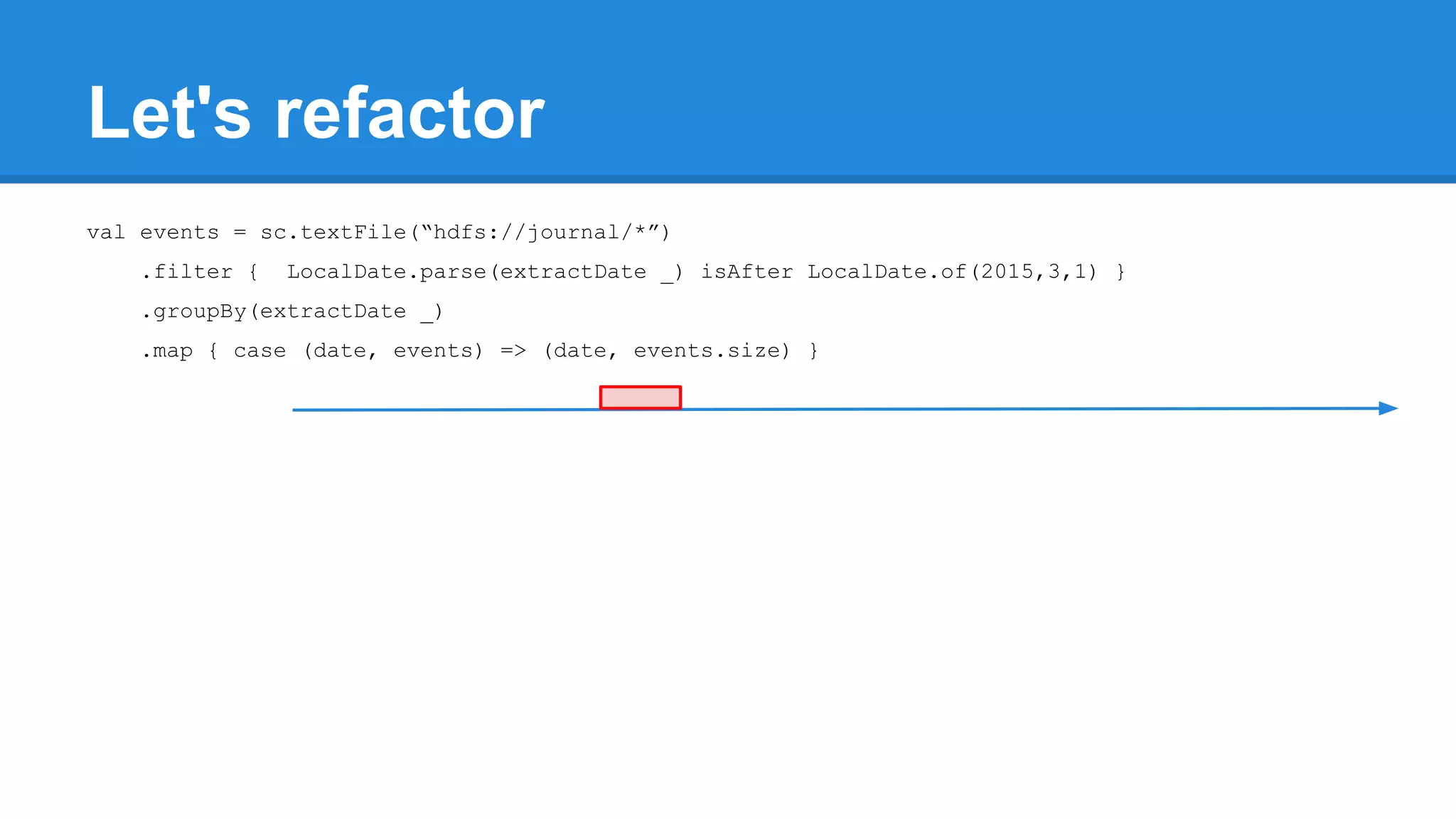
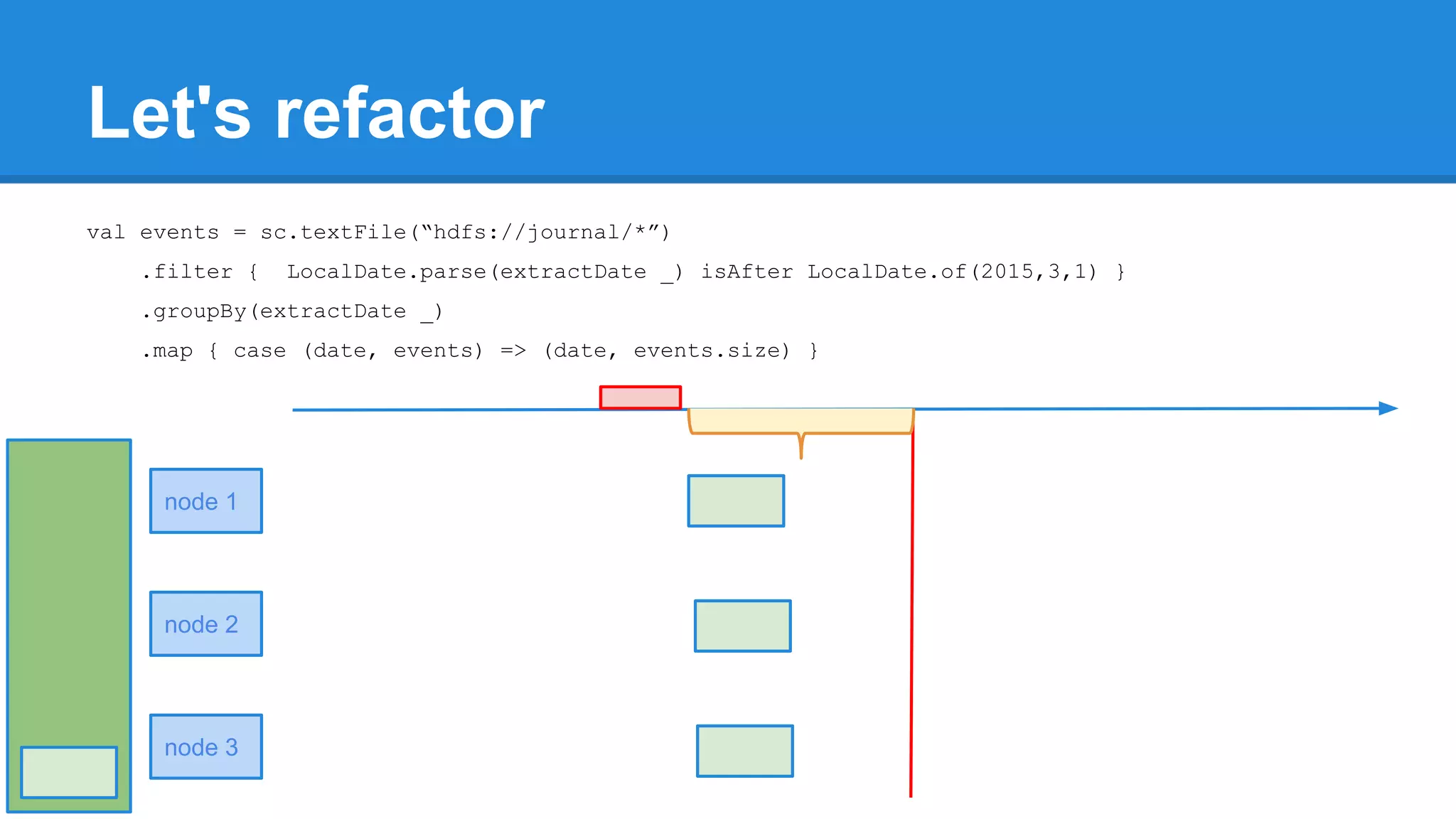
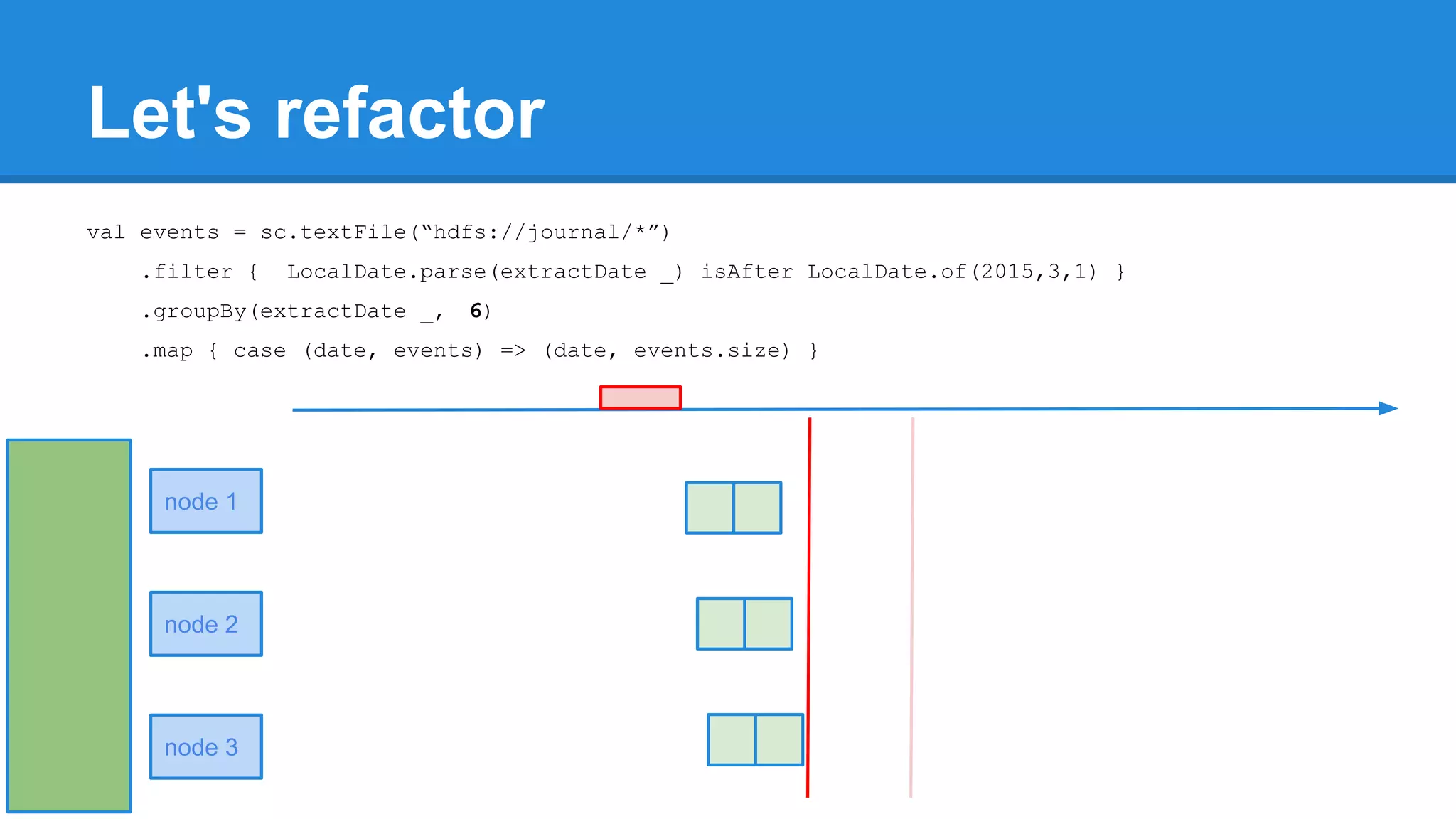
![Towards efficiency val events = sc.textFile(“hdfs://journal/*”) .groupBy(extractDate _) .map { case (date, events) => (date, events.size) } .filter { case (date, size) => LocalDate.parse(date) isAfter LocalDate.of(2015,3,1) } scala> events.toDebugString (4) MapPartitionsRDD[22] at filter at <console>:50 [] | MapPartitionsRDD[21] at map at <console>:49 [] | ShuffledRDD[20] at groupBy at <console>:48 [] +-(6) HadoopRDD[17] at textFile at <console>:47 []](https://image.slidesharecdn.com/apachesparkworkshops-160527153959/75/Apache-spark-workshop-277-2048.jpg)
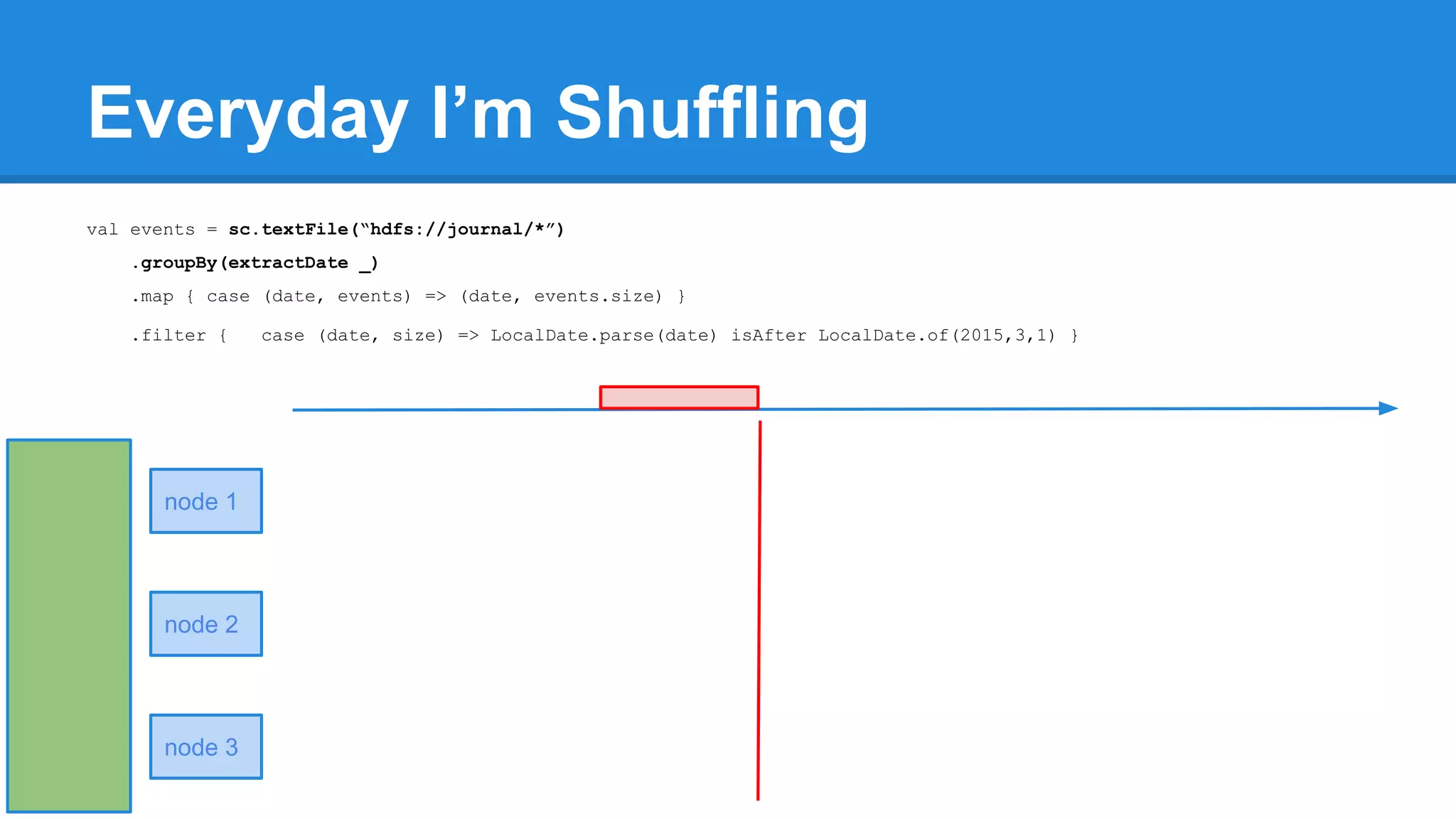
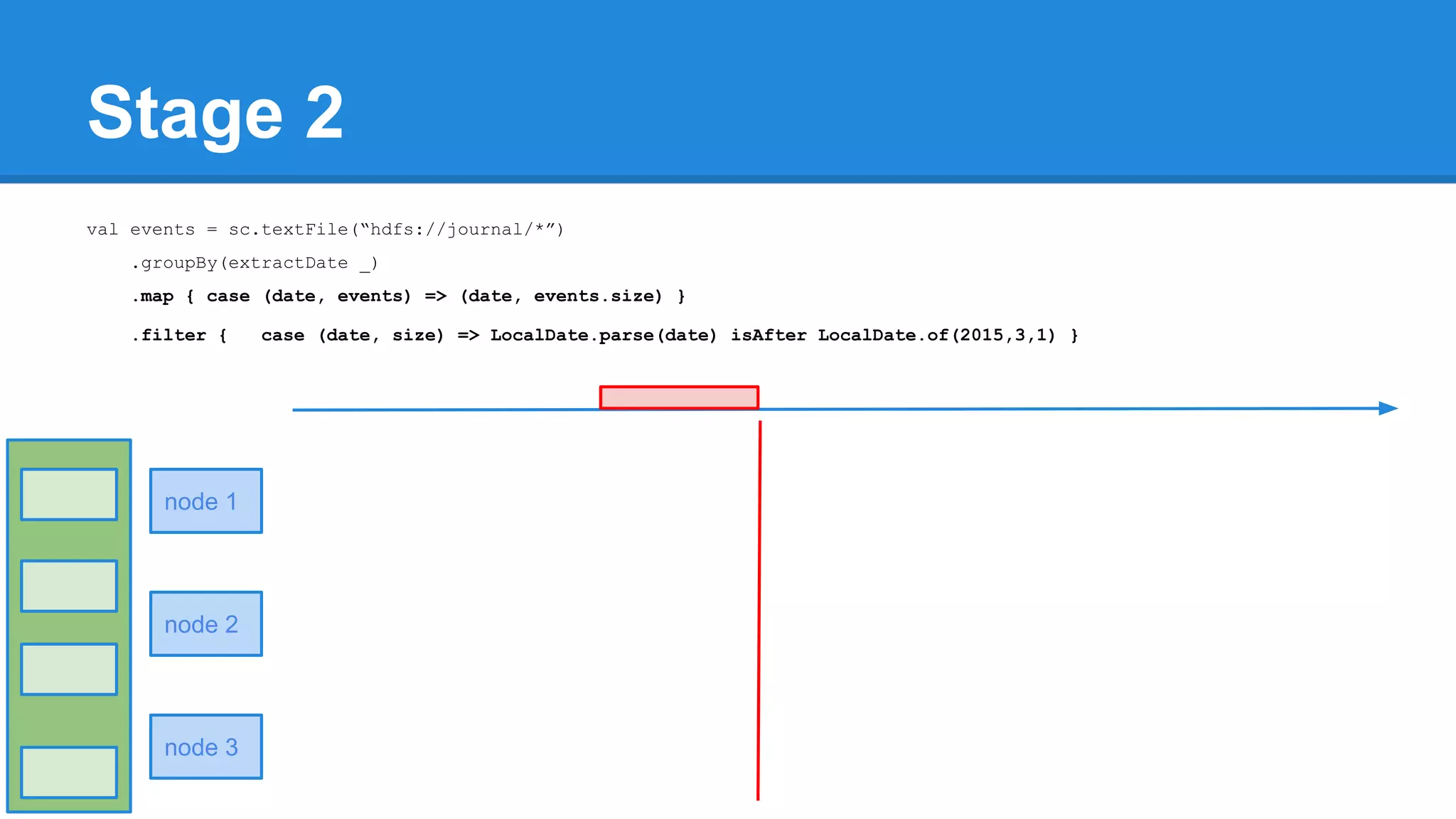
![Towards efficiency val events = sc.textFile(“hdfs://journal/*”) .groupBy(extractDate _) .map { case (date, events) => (date, events.size) } .filter { case (date, size) => LocalDate.parse(date) isAfter LocalDate.of(2015,3,1) } scala> events.toDebugString (4) MapPartitionsRDD[22] at filter at <console>:50 [] | MapPartitionsRDD[21] at map at <console>:49 [] | ShuffledRDD[20] at groupBy at <console>:48 [] +-(6) HadoopRDD[17] at textFile at <console>:47 [] events.count](https://image.slidesharecdn.com/apachesparkworkshops-160527153959/75/Apache-spark-workshop-278-2048.jpg)















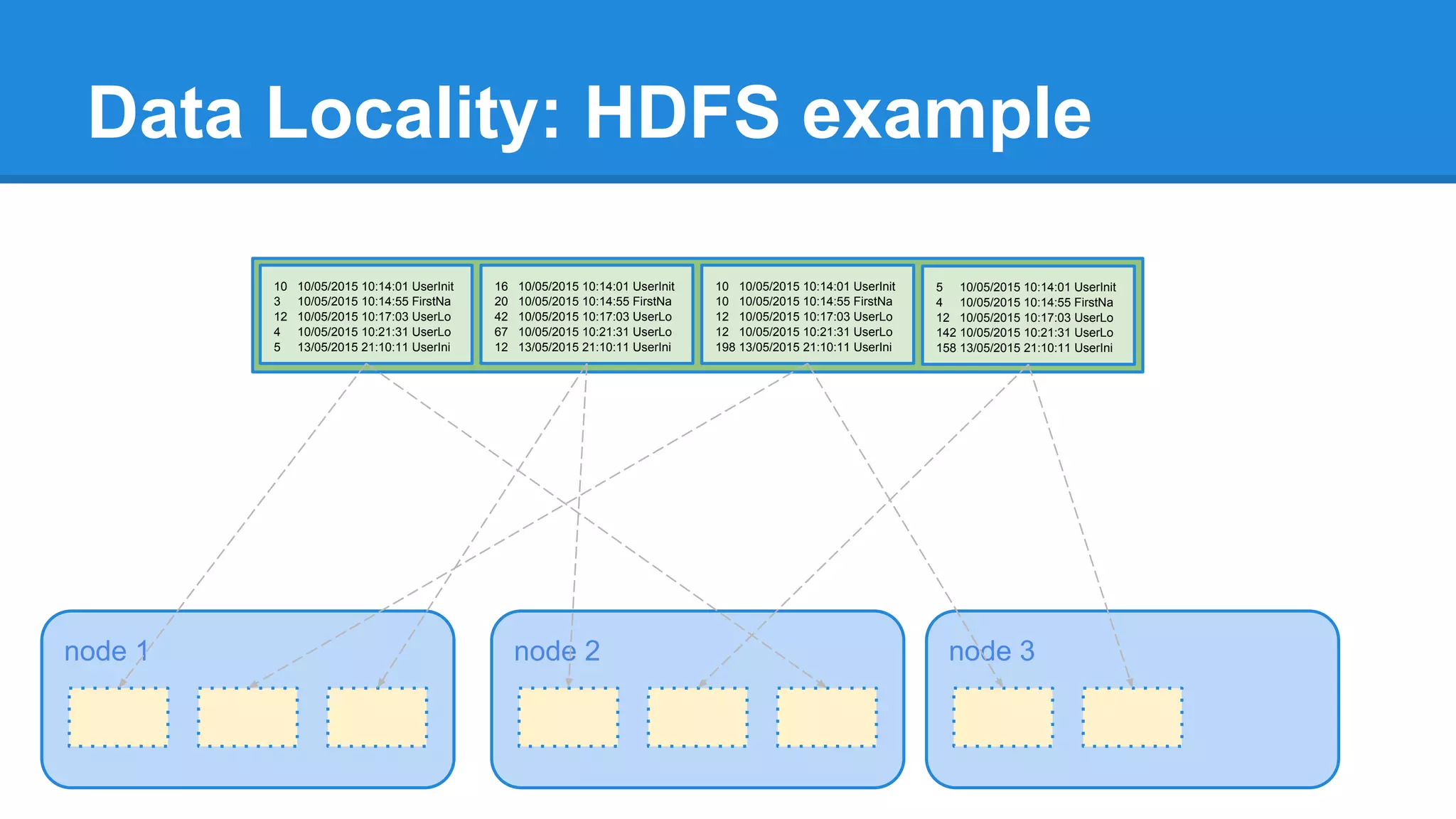


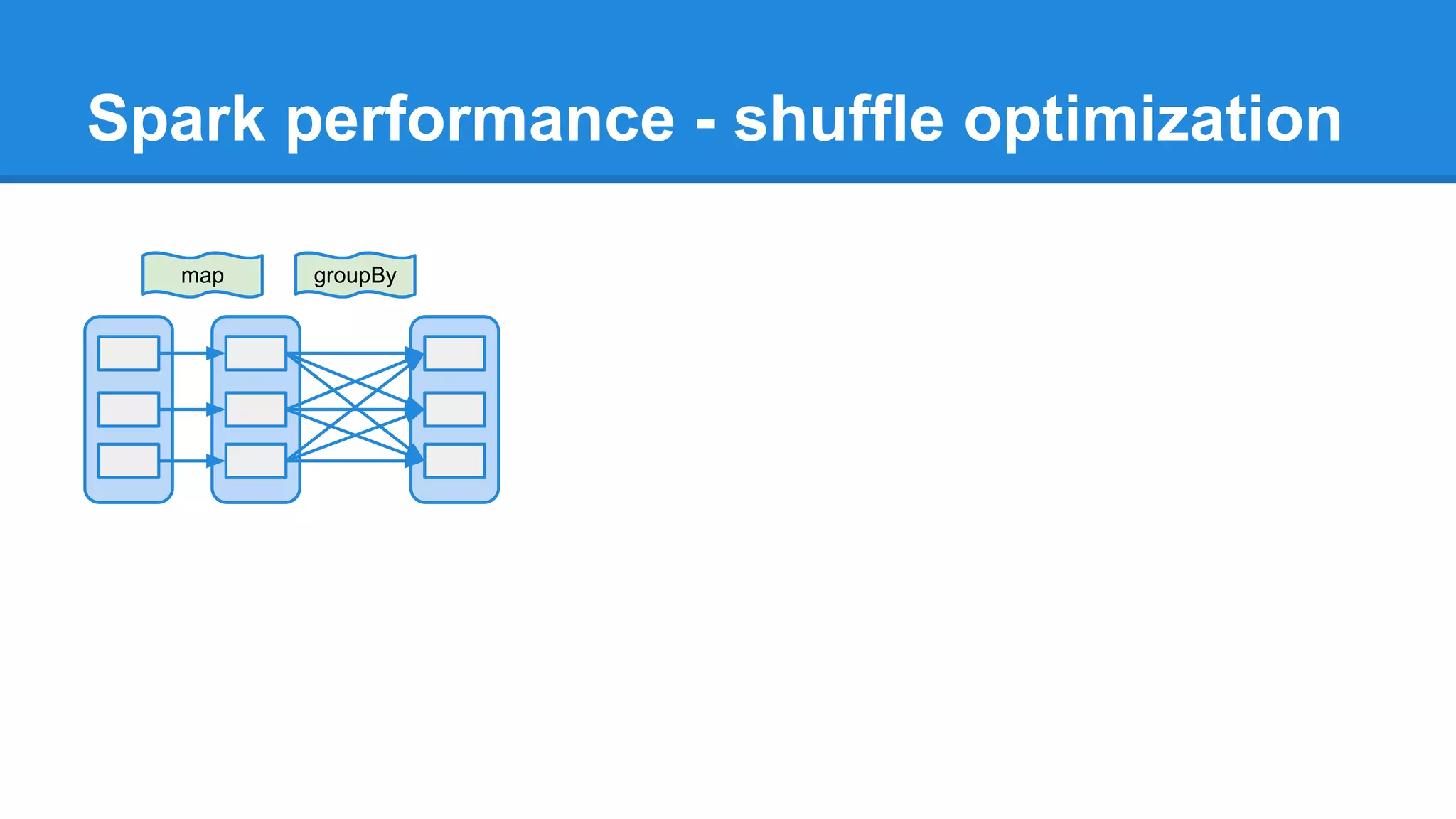
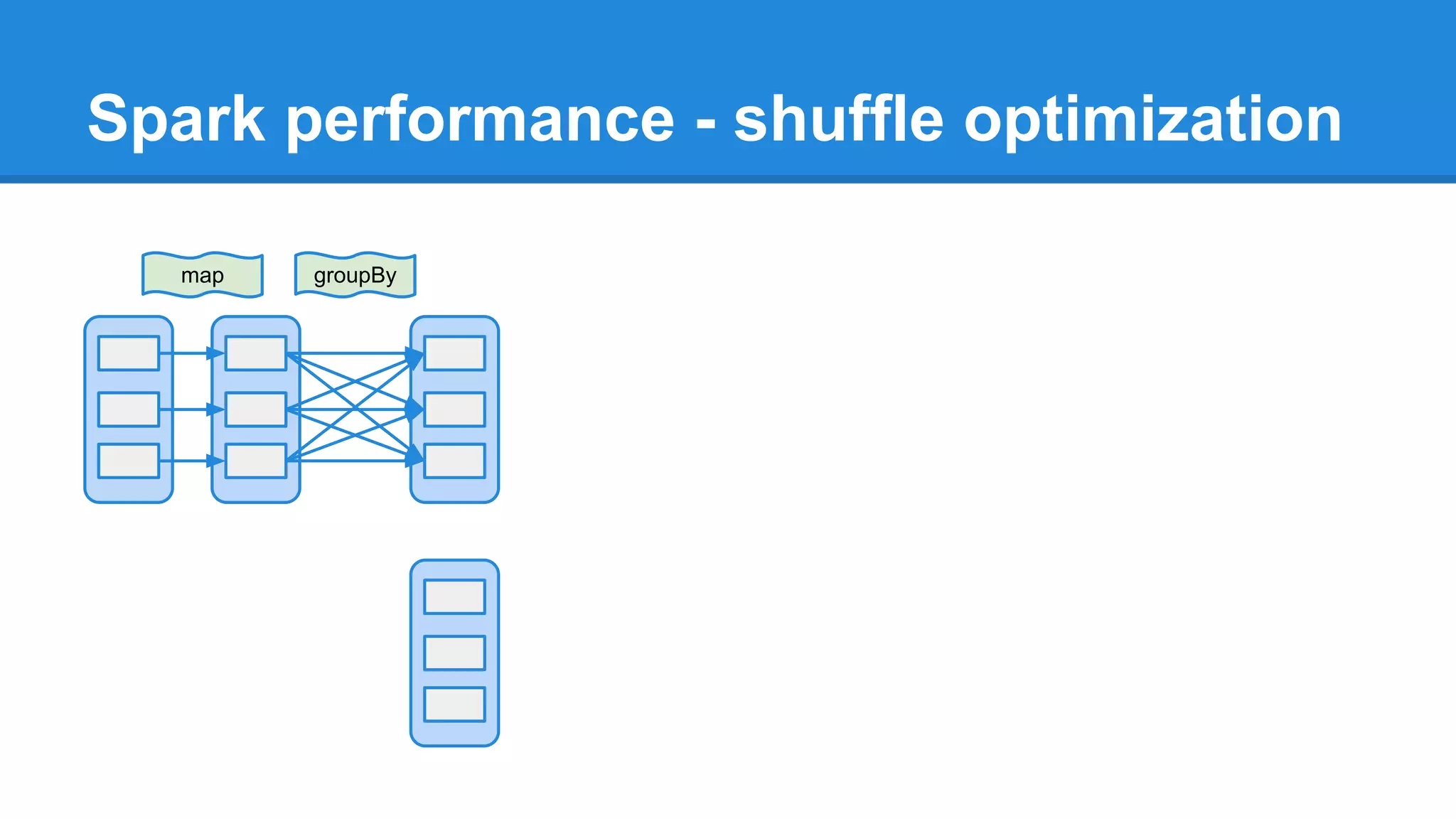
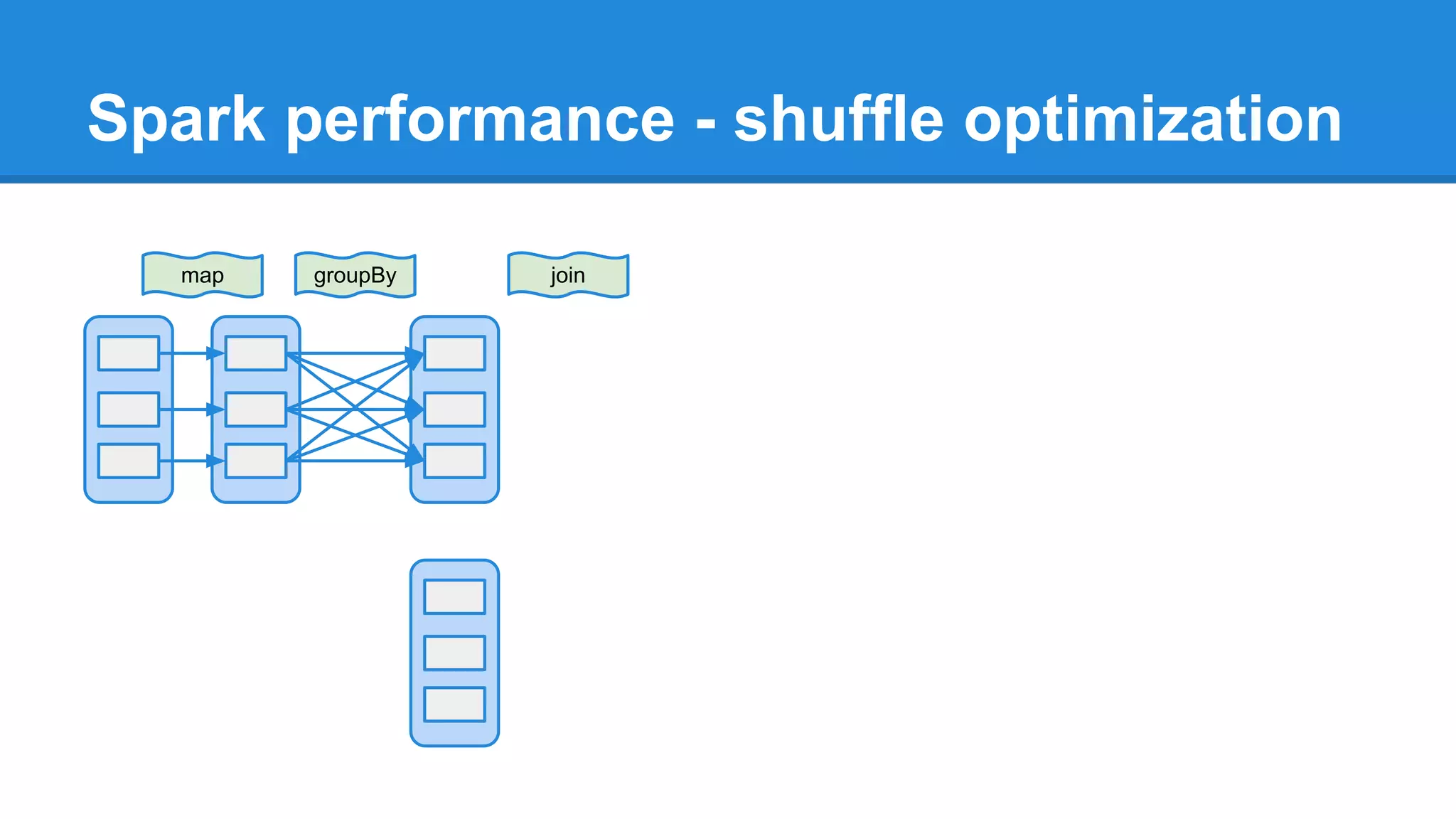
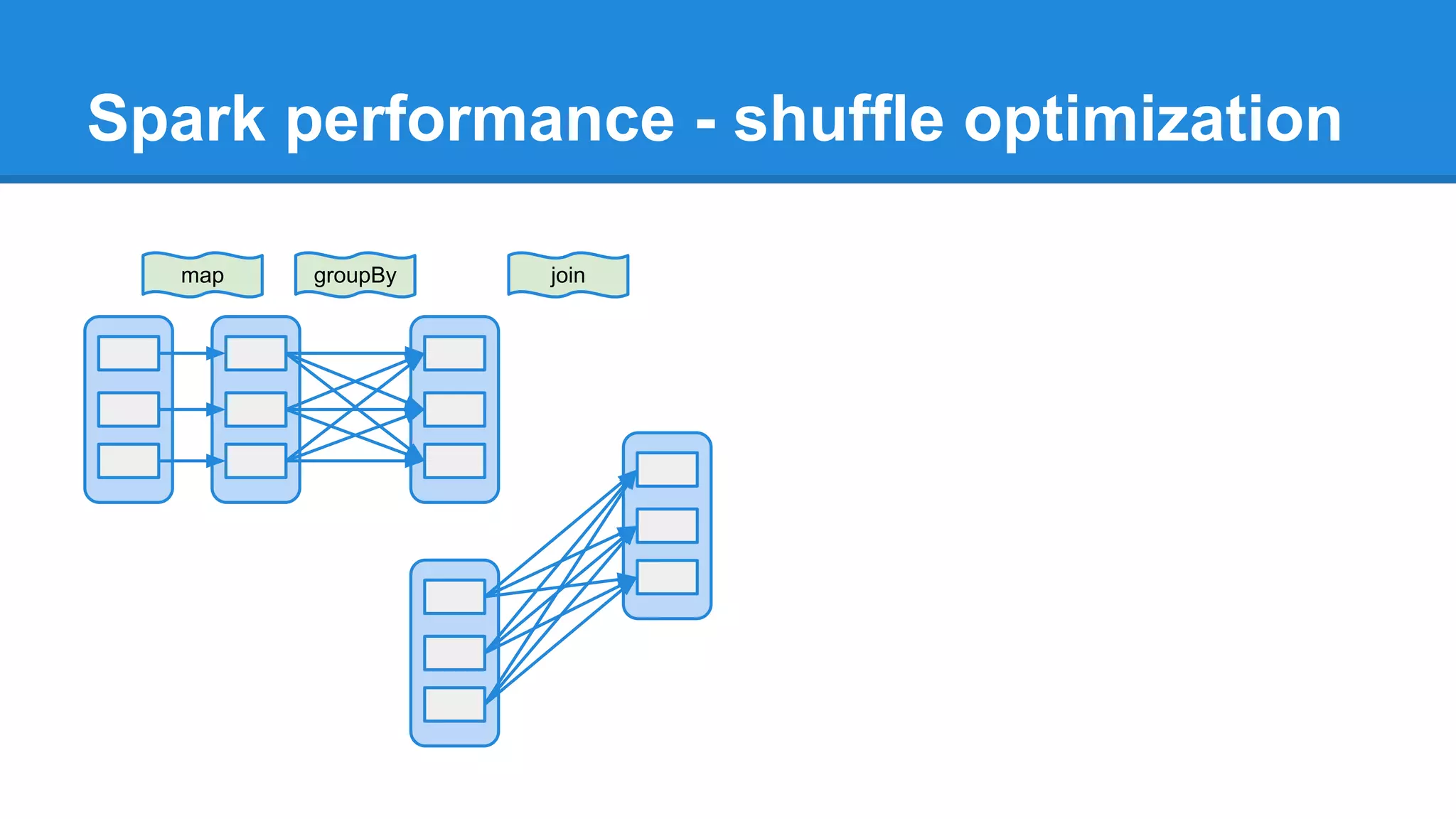
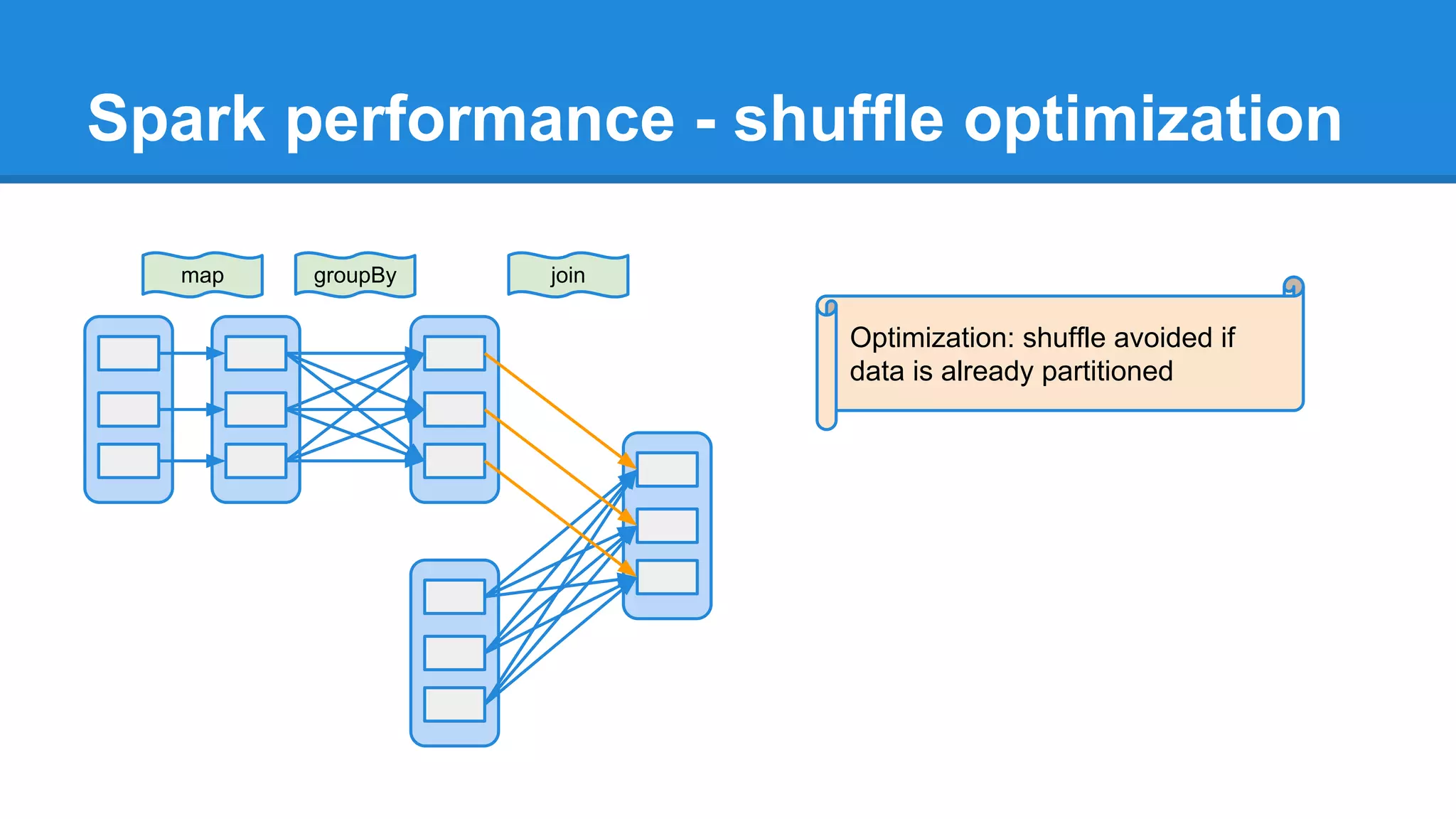

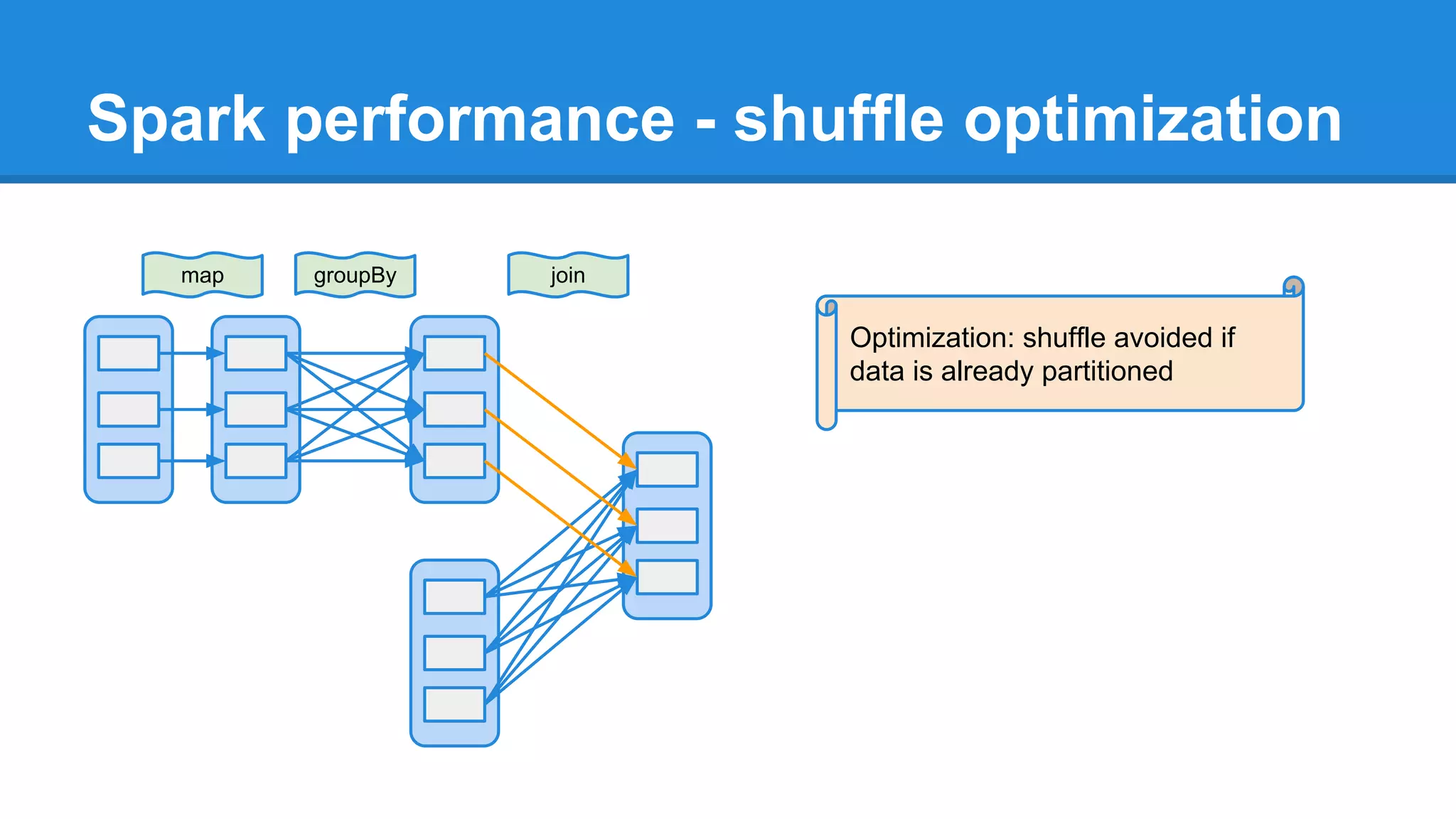
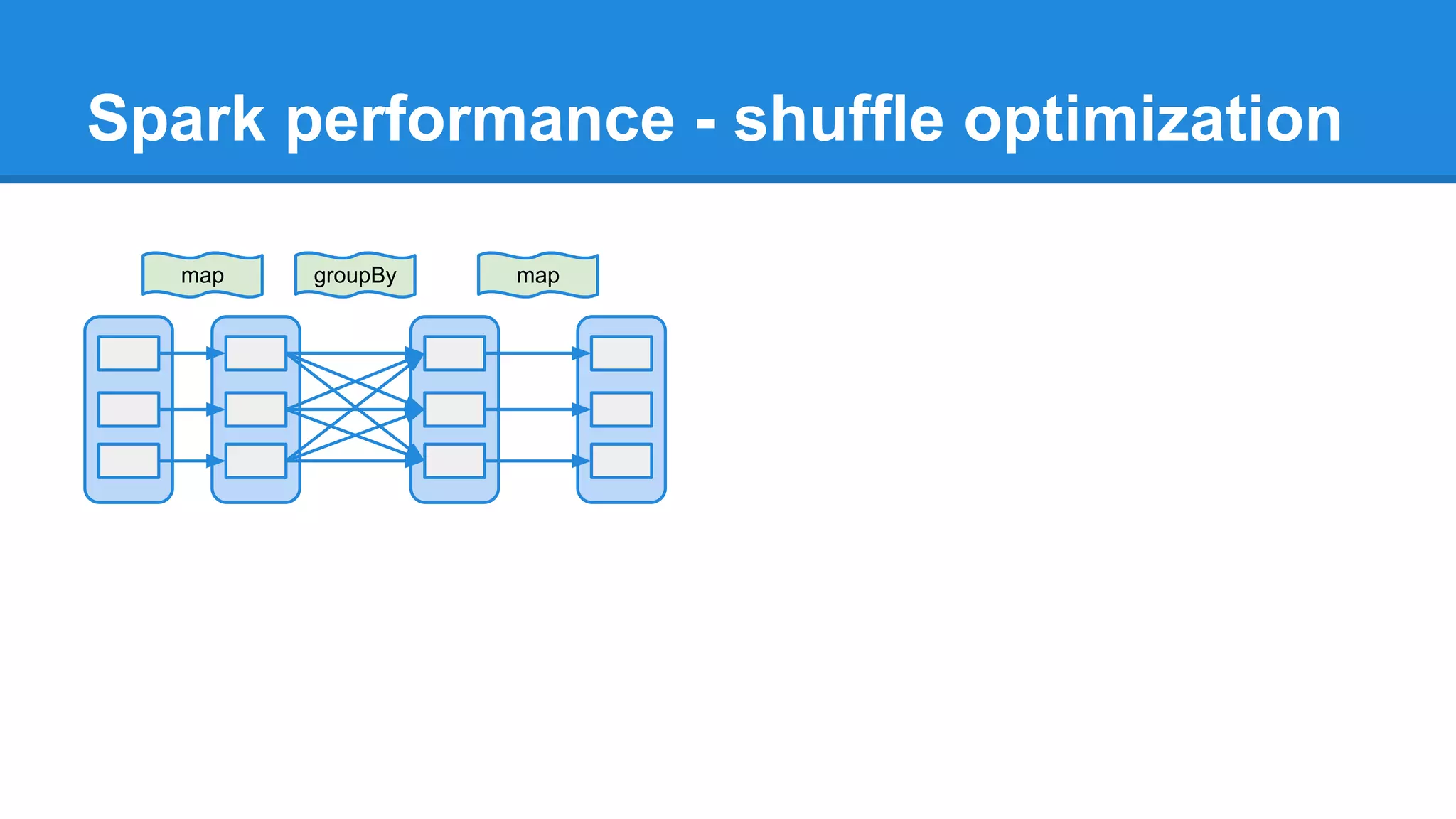
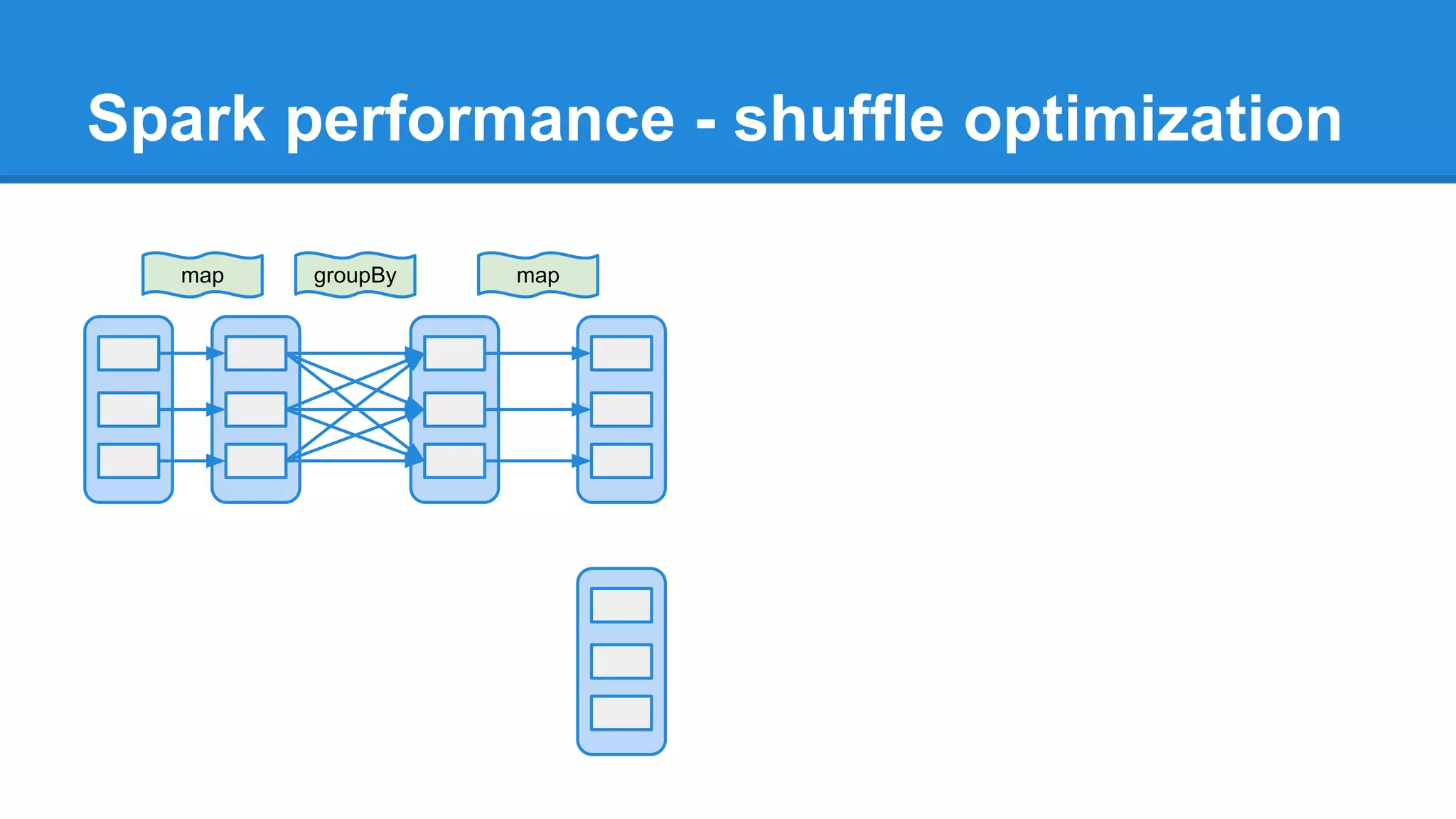
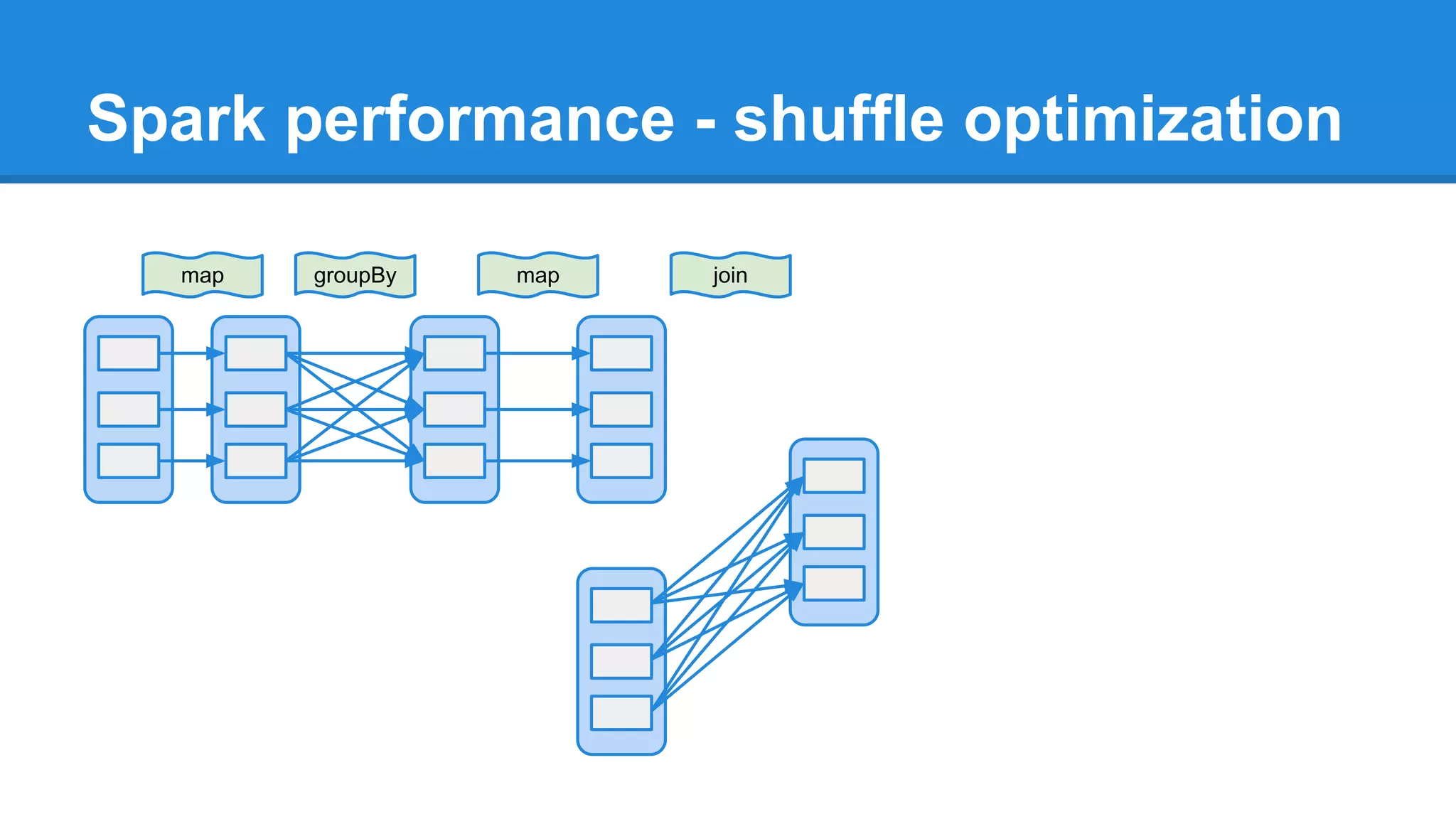
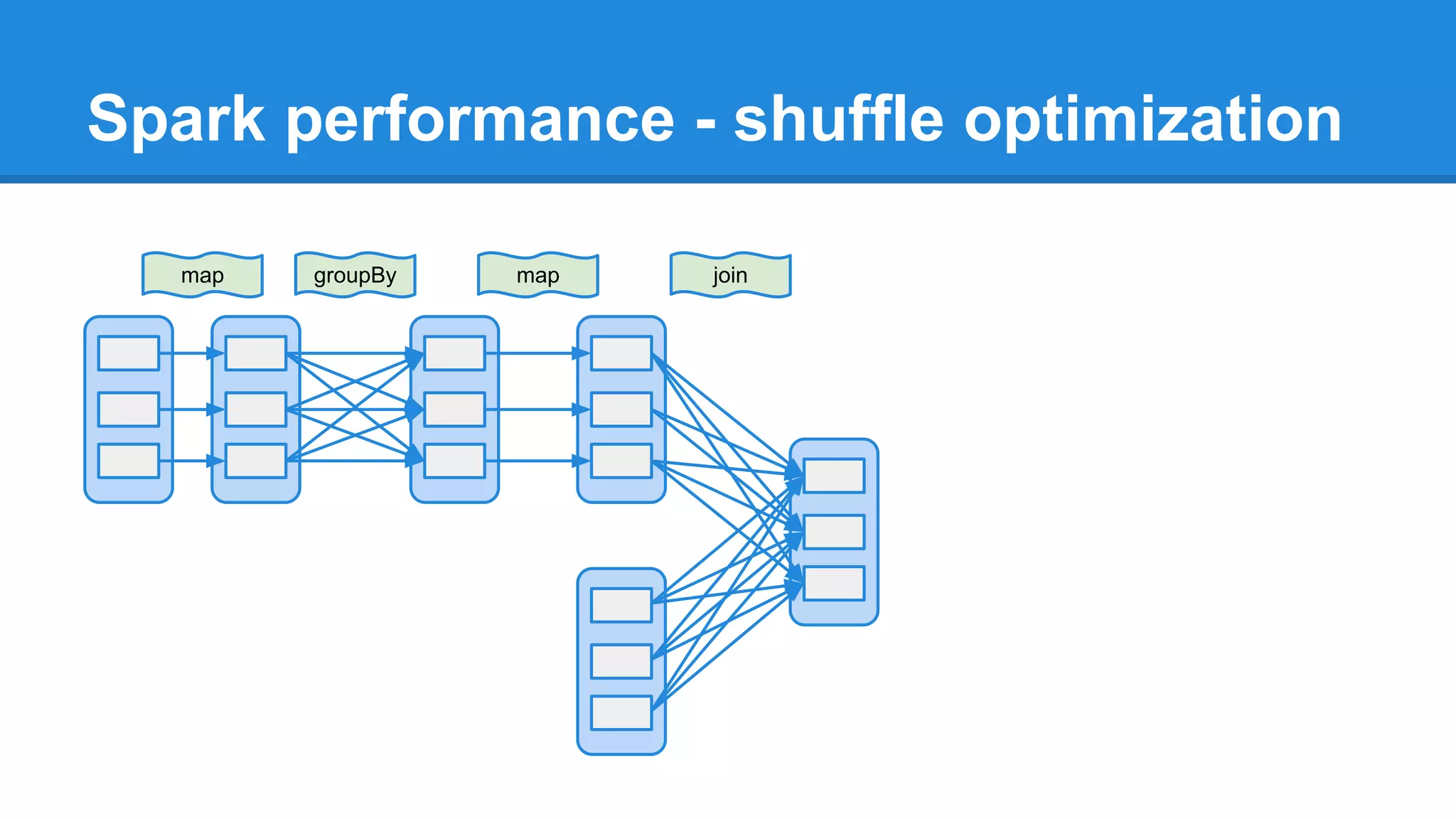
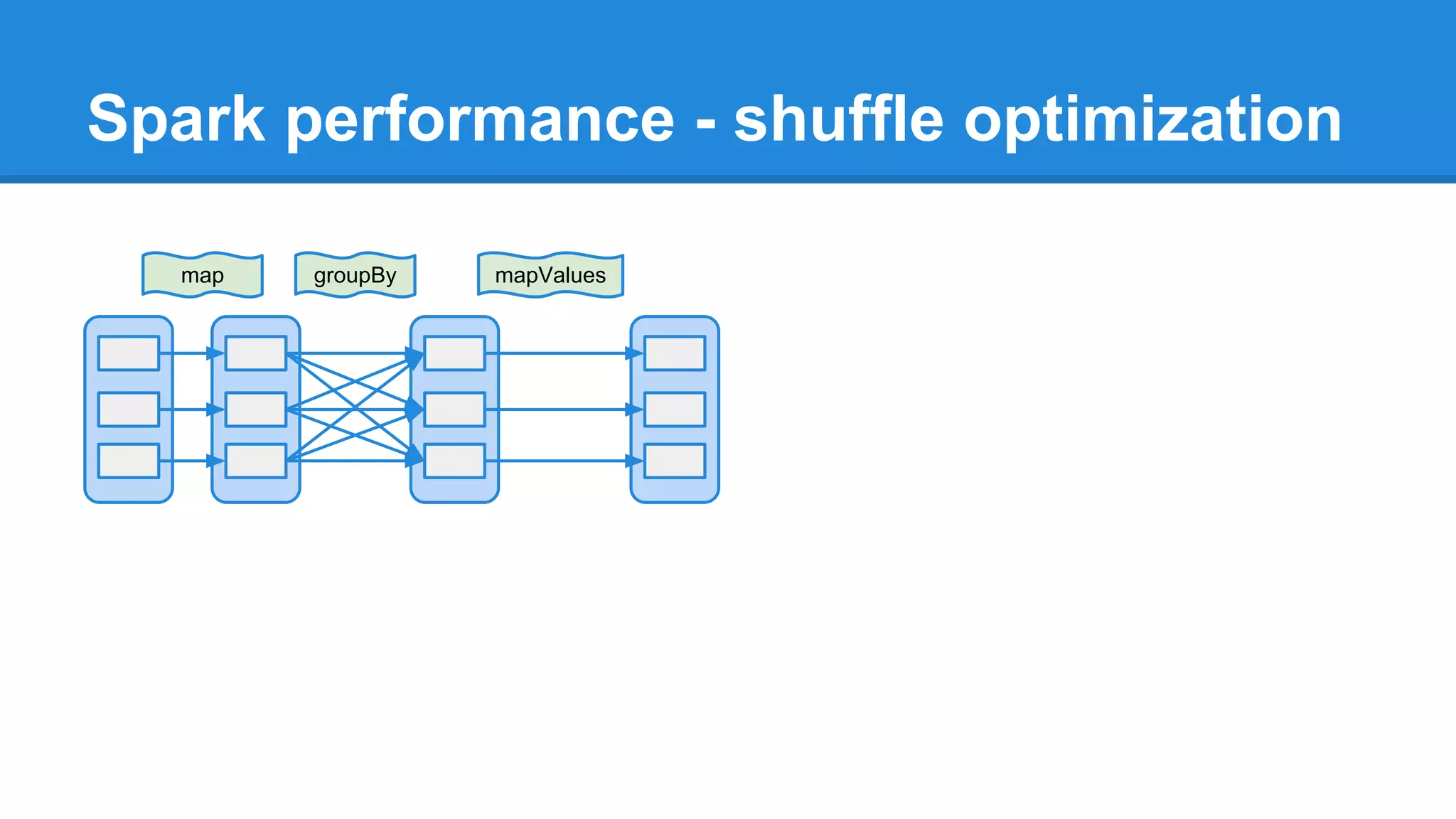
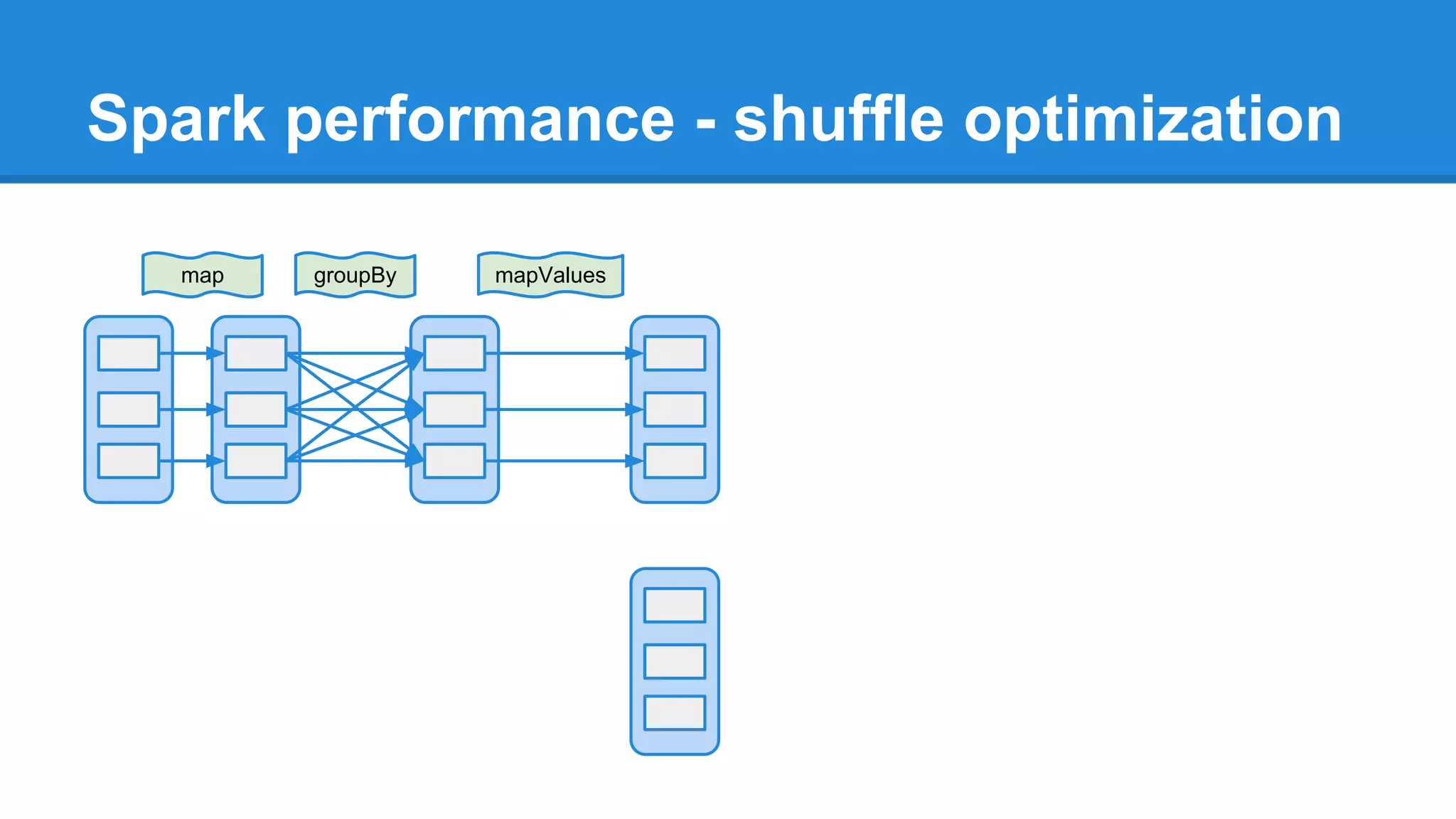
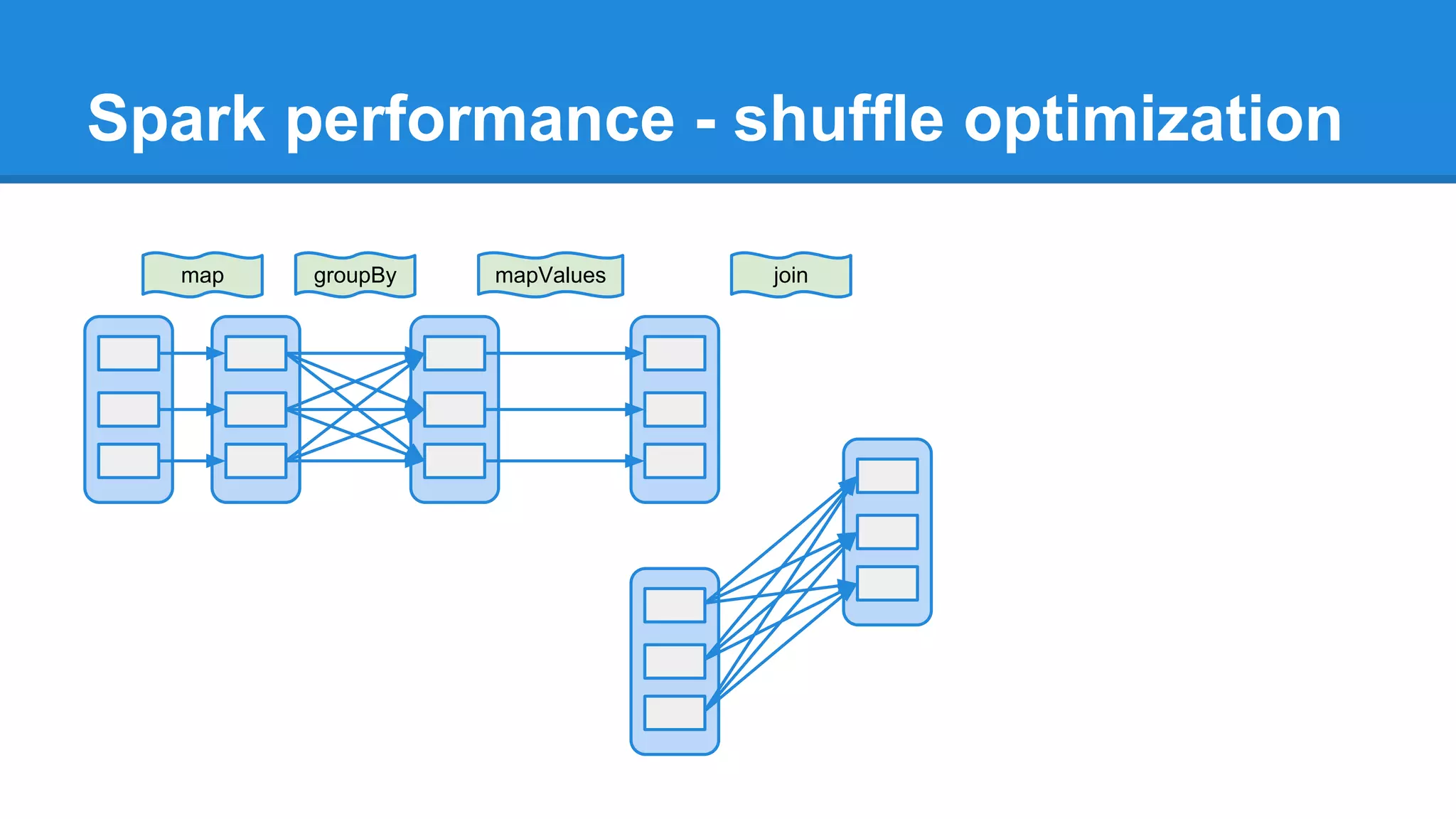
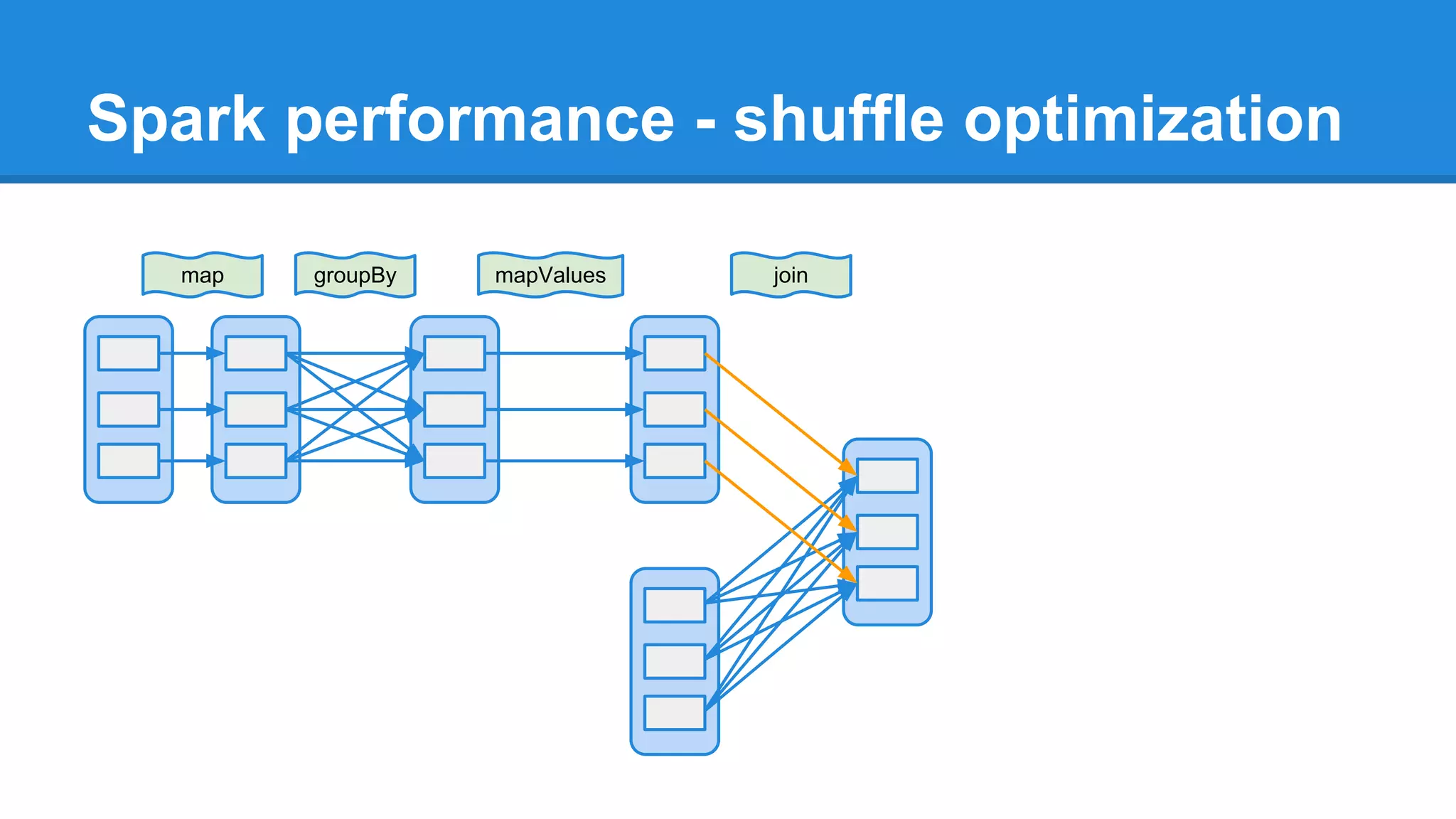





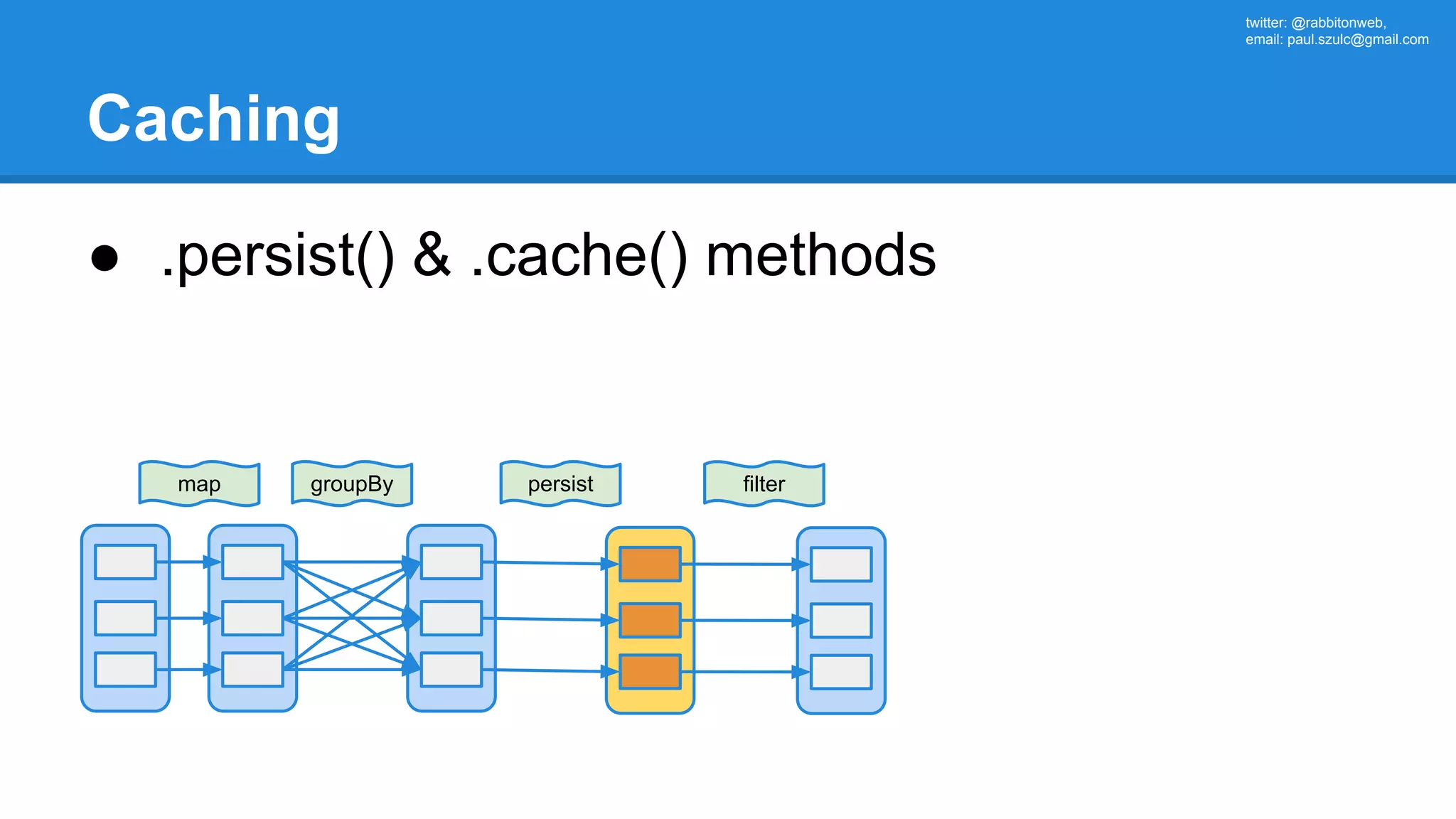
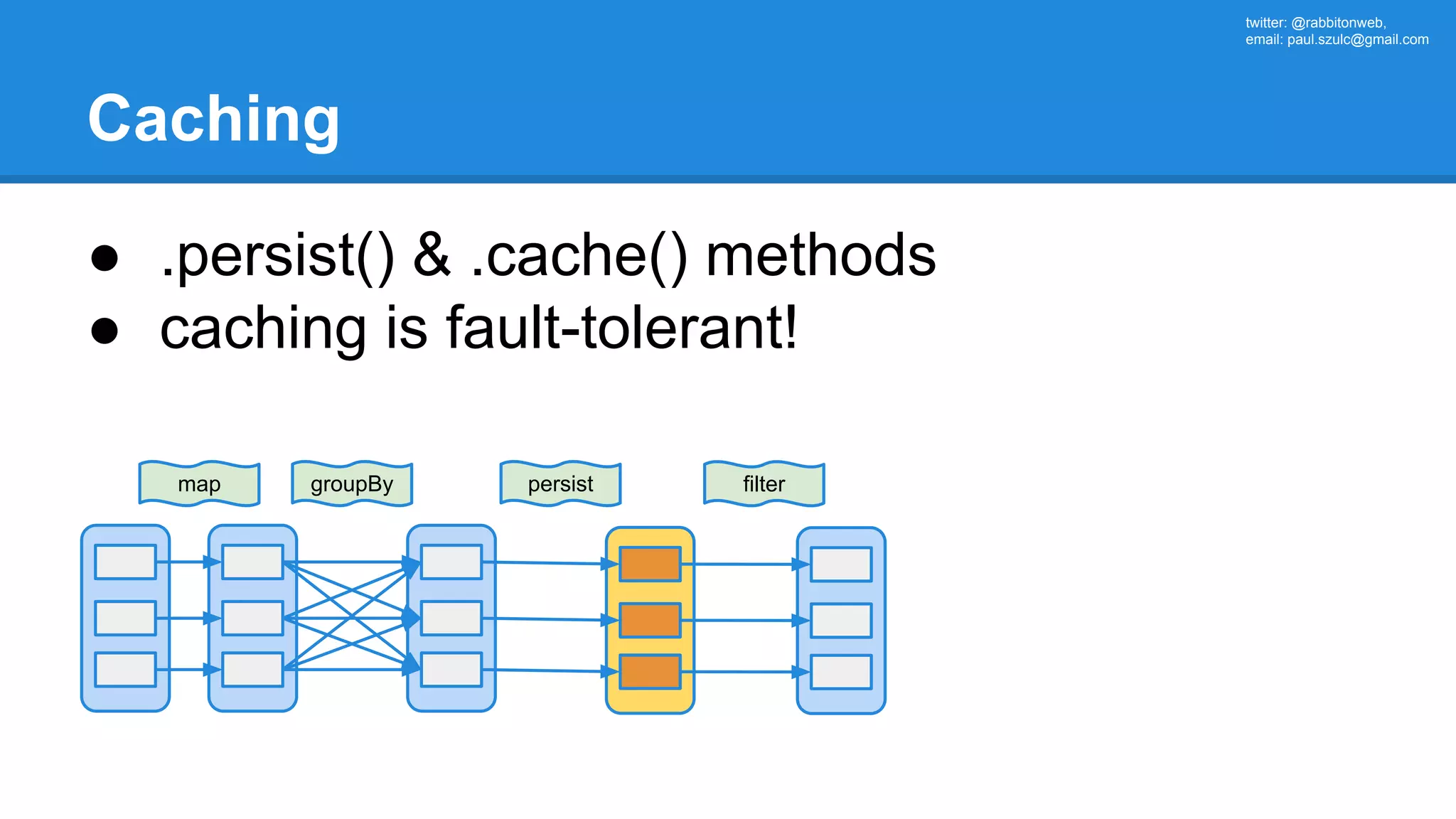
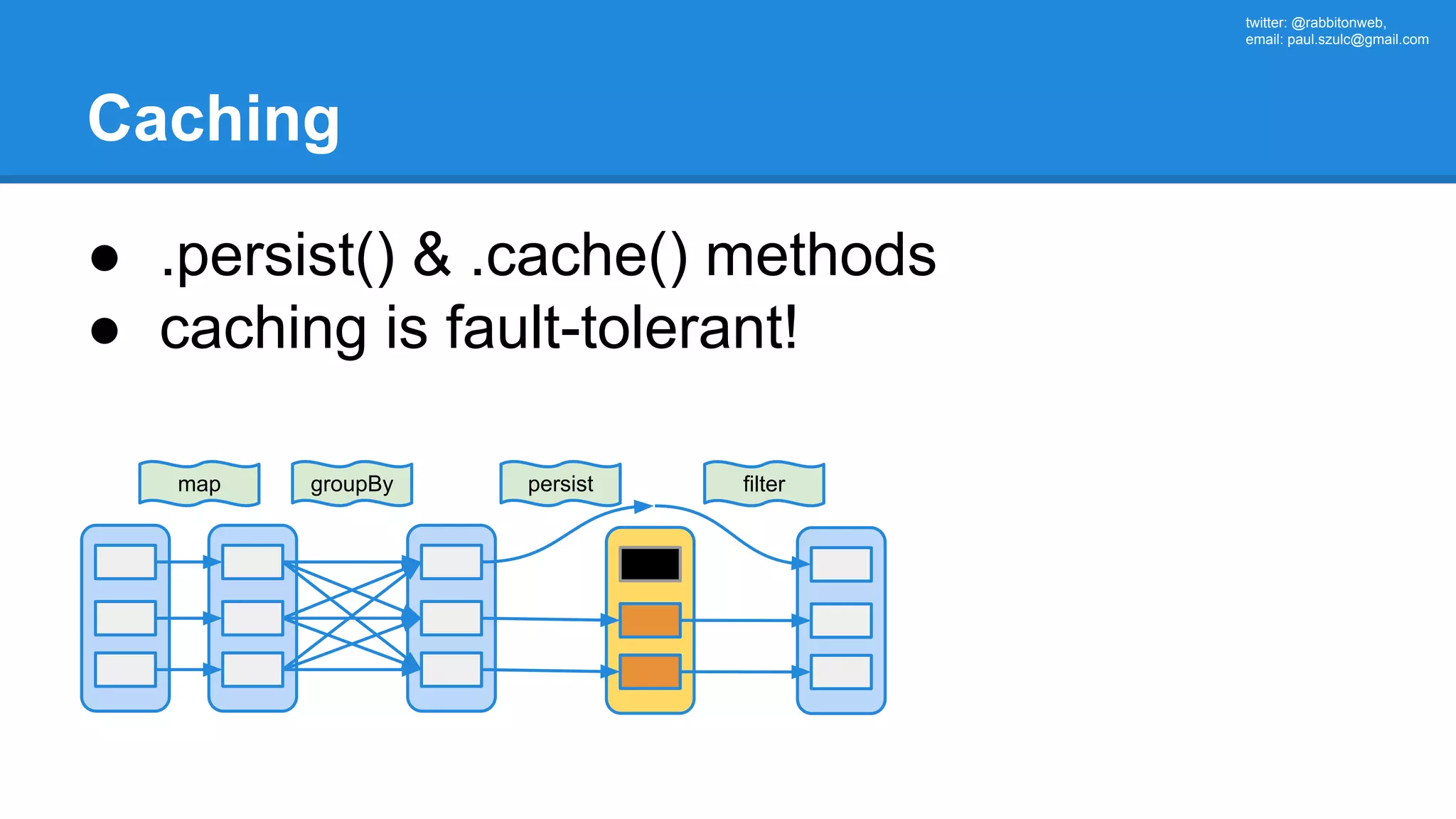








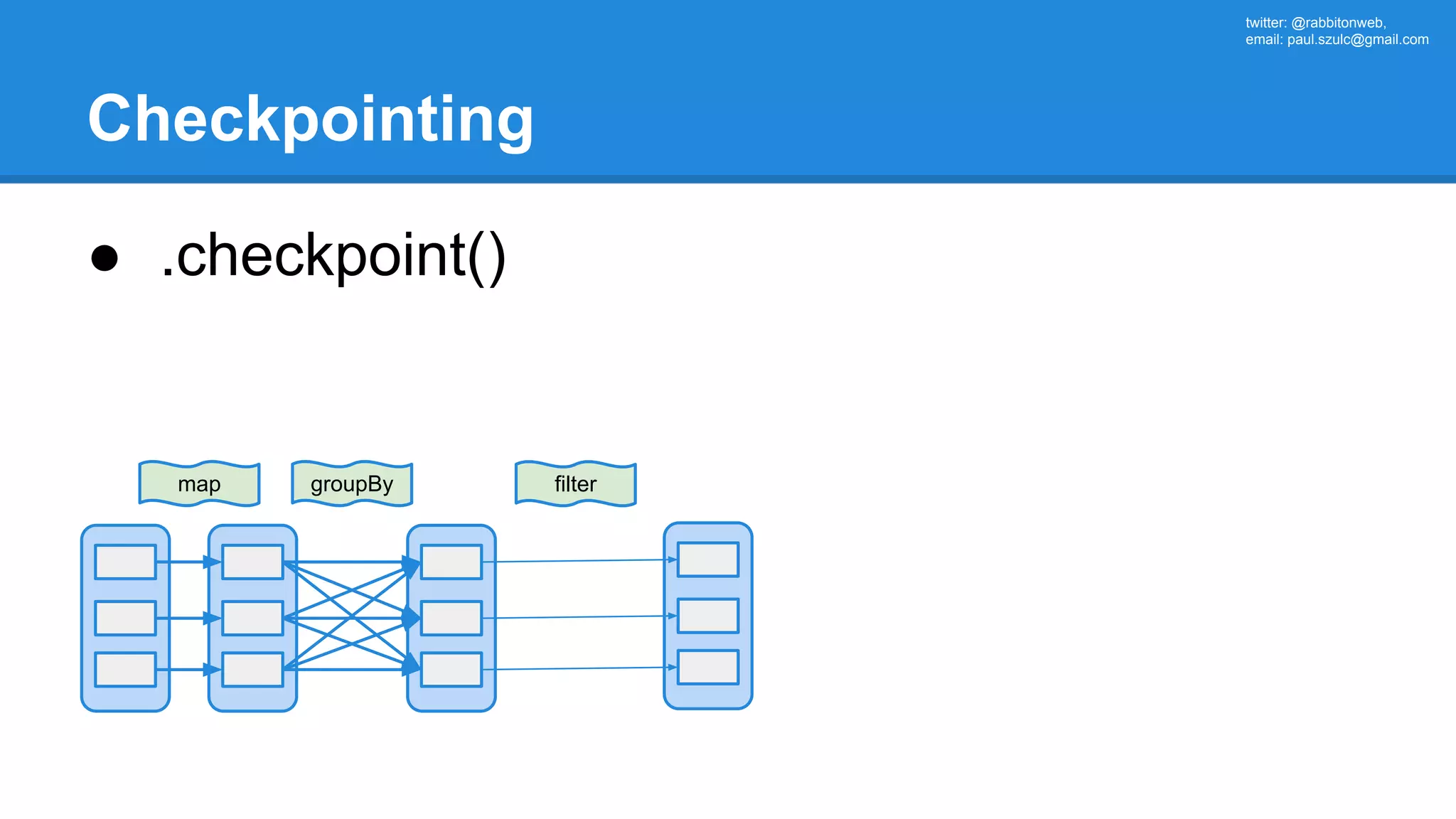
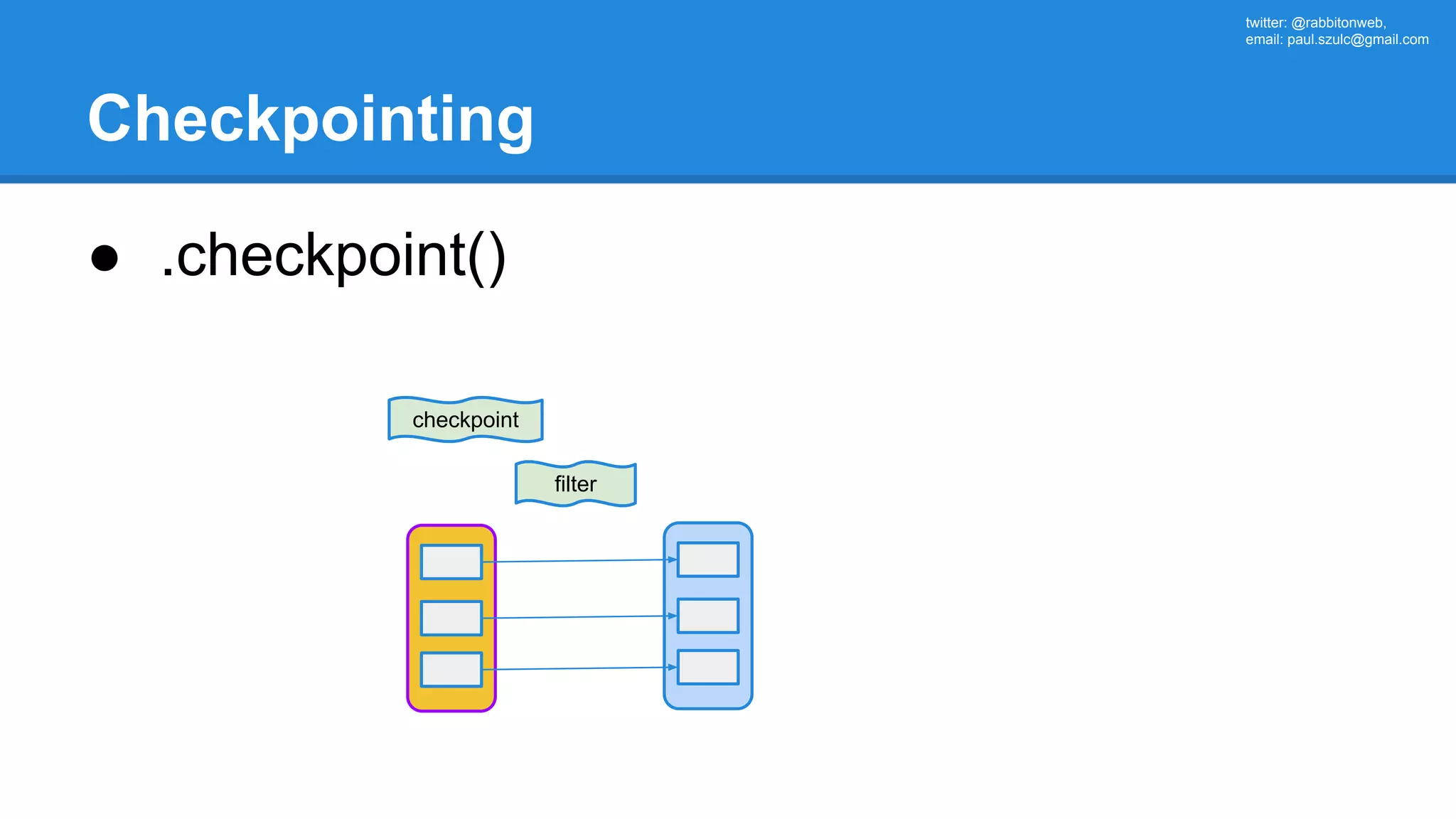

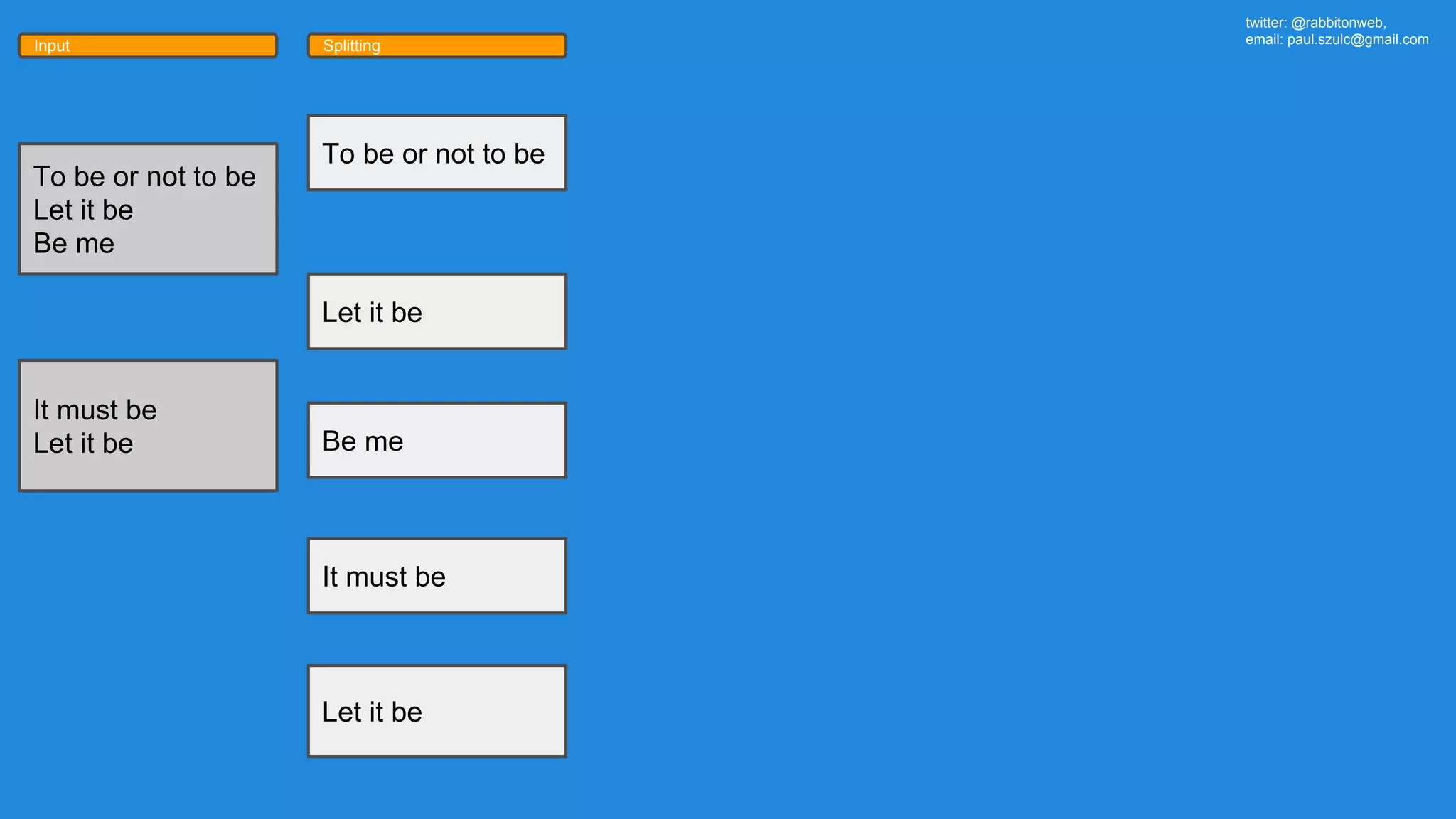
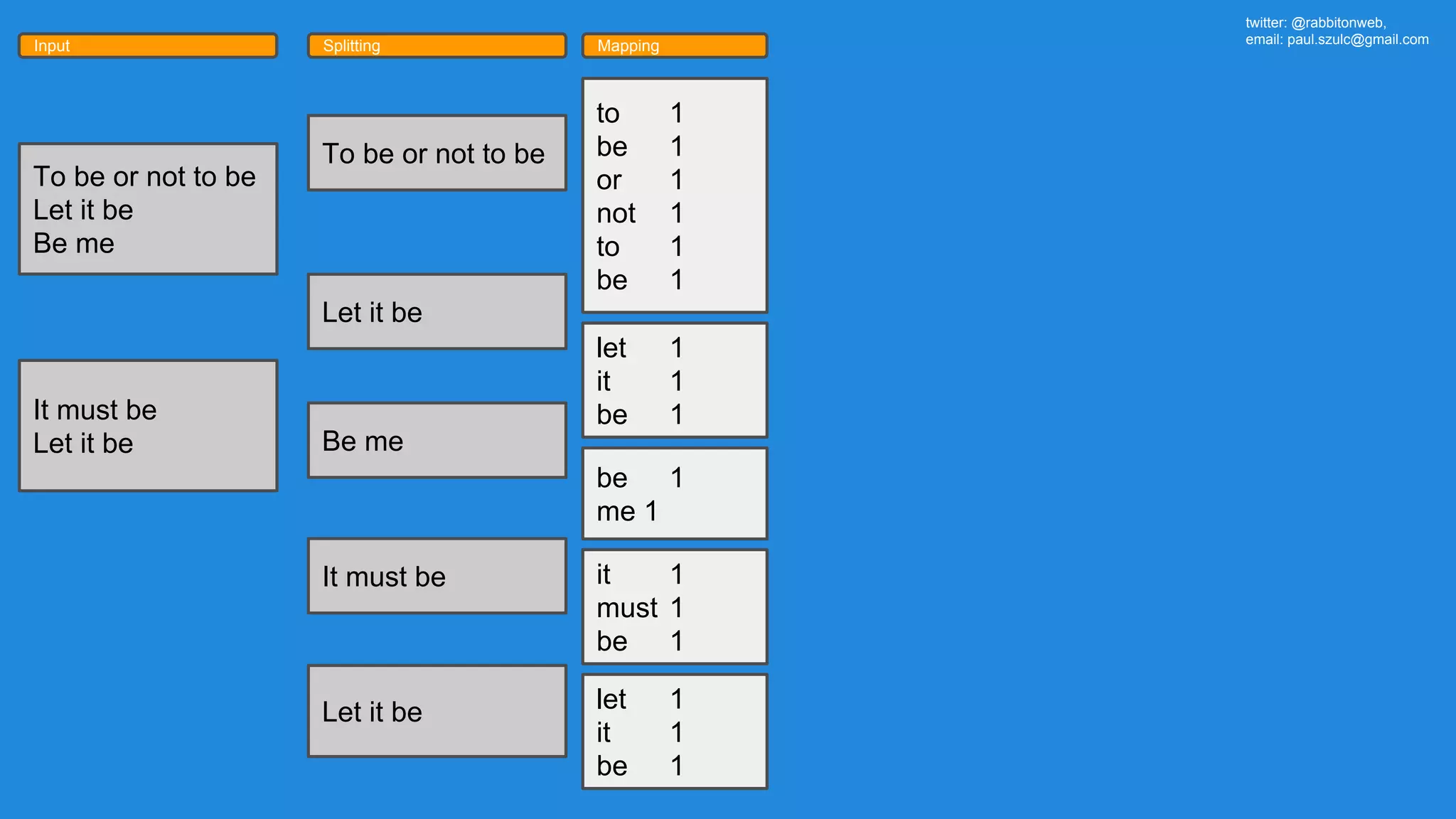
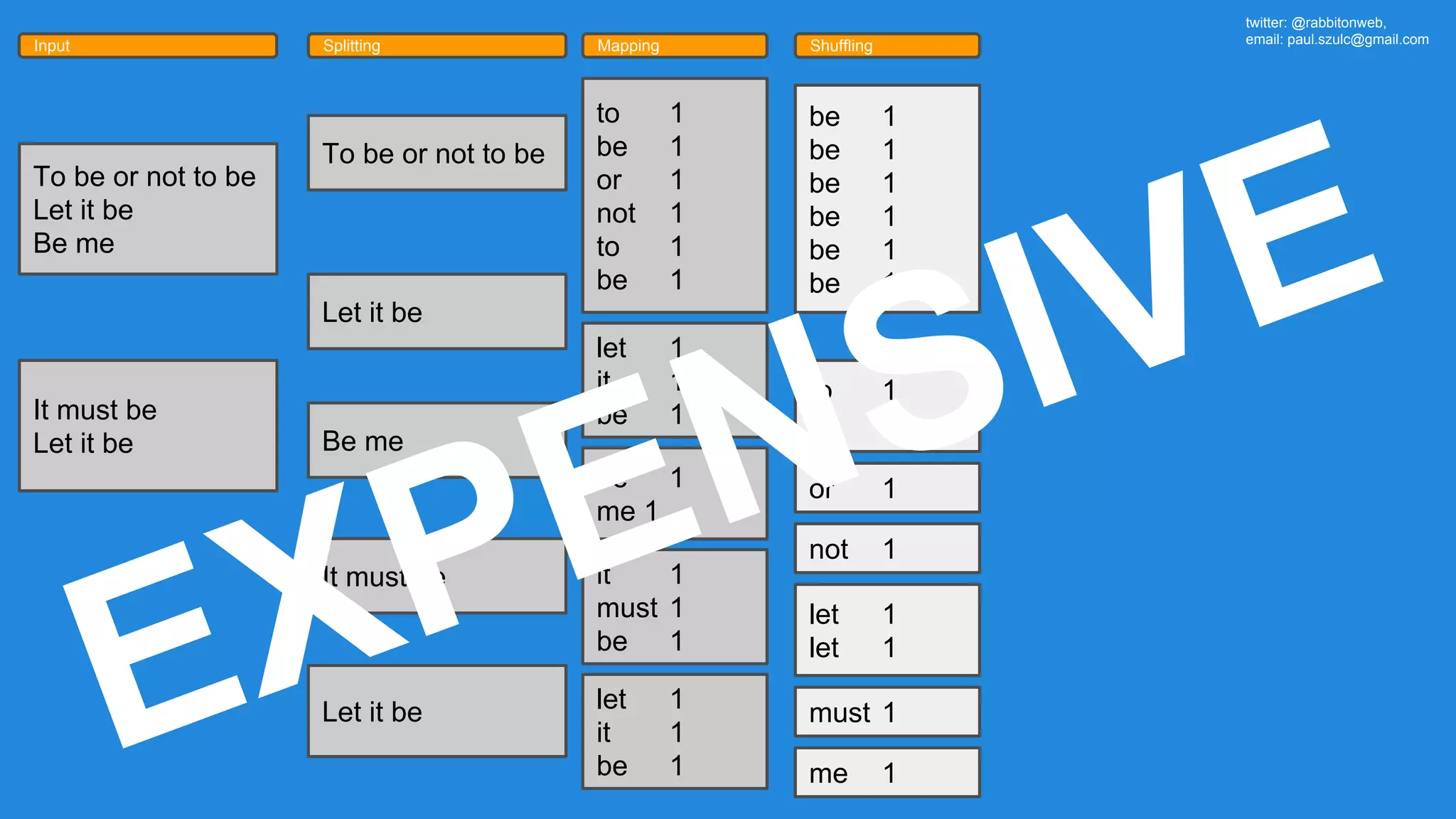
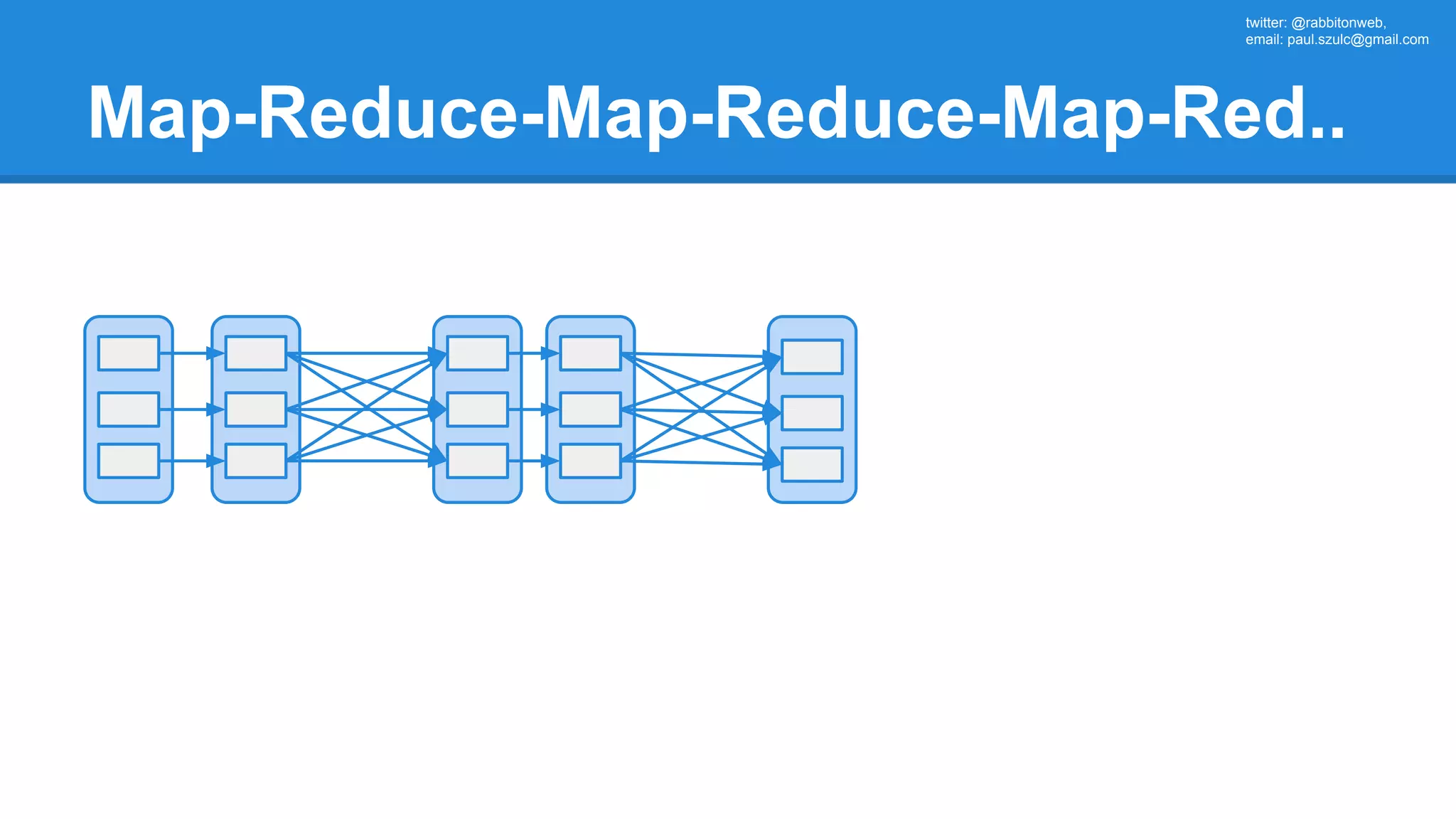
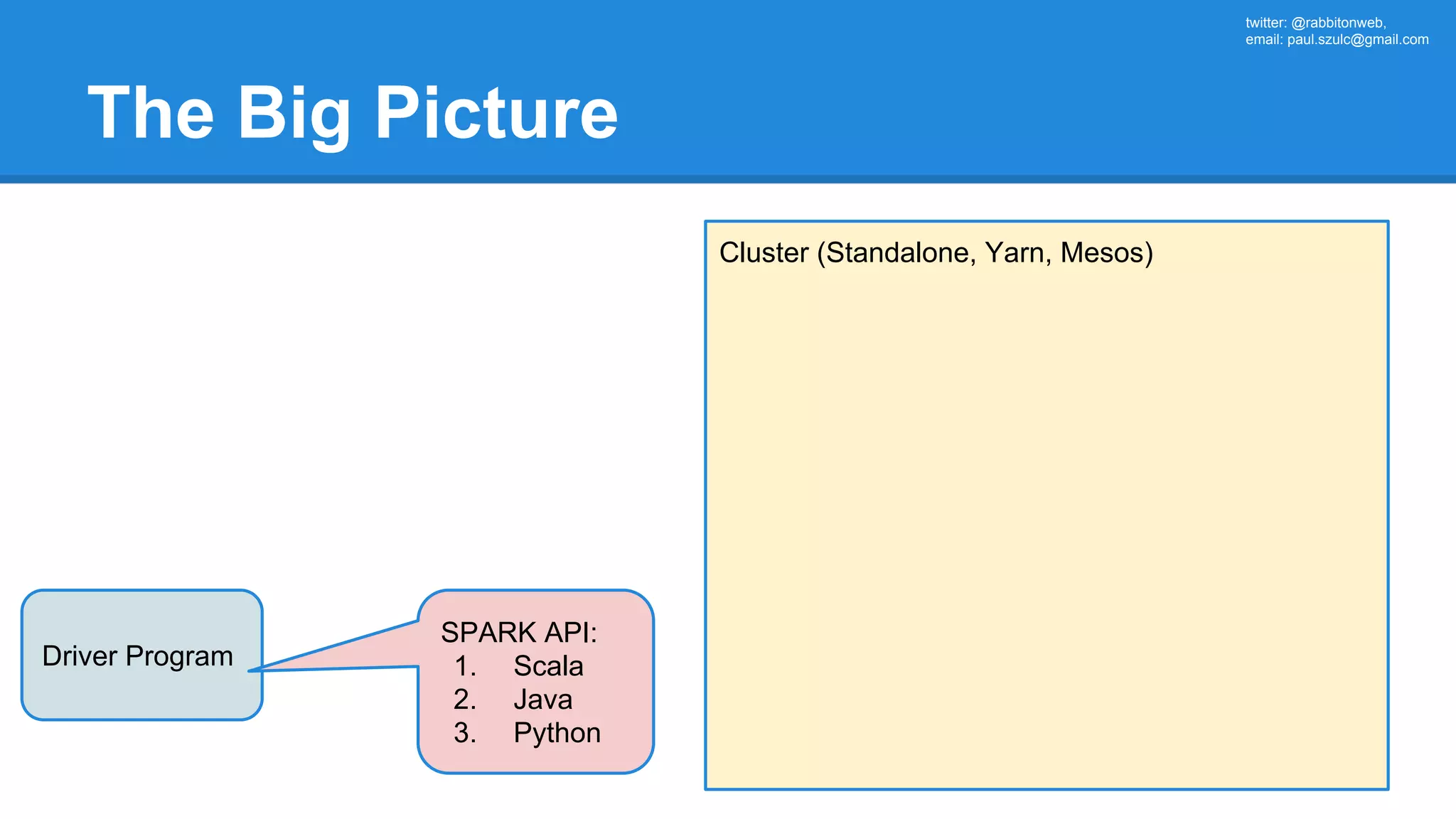
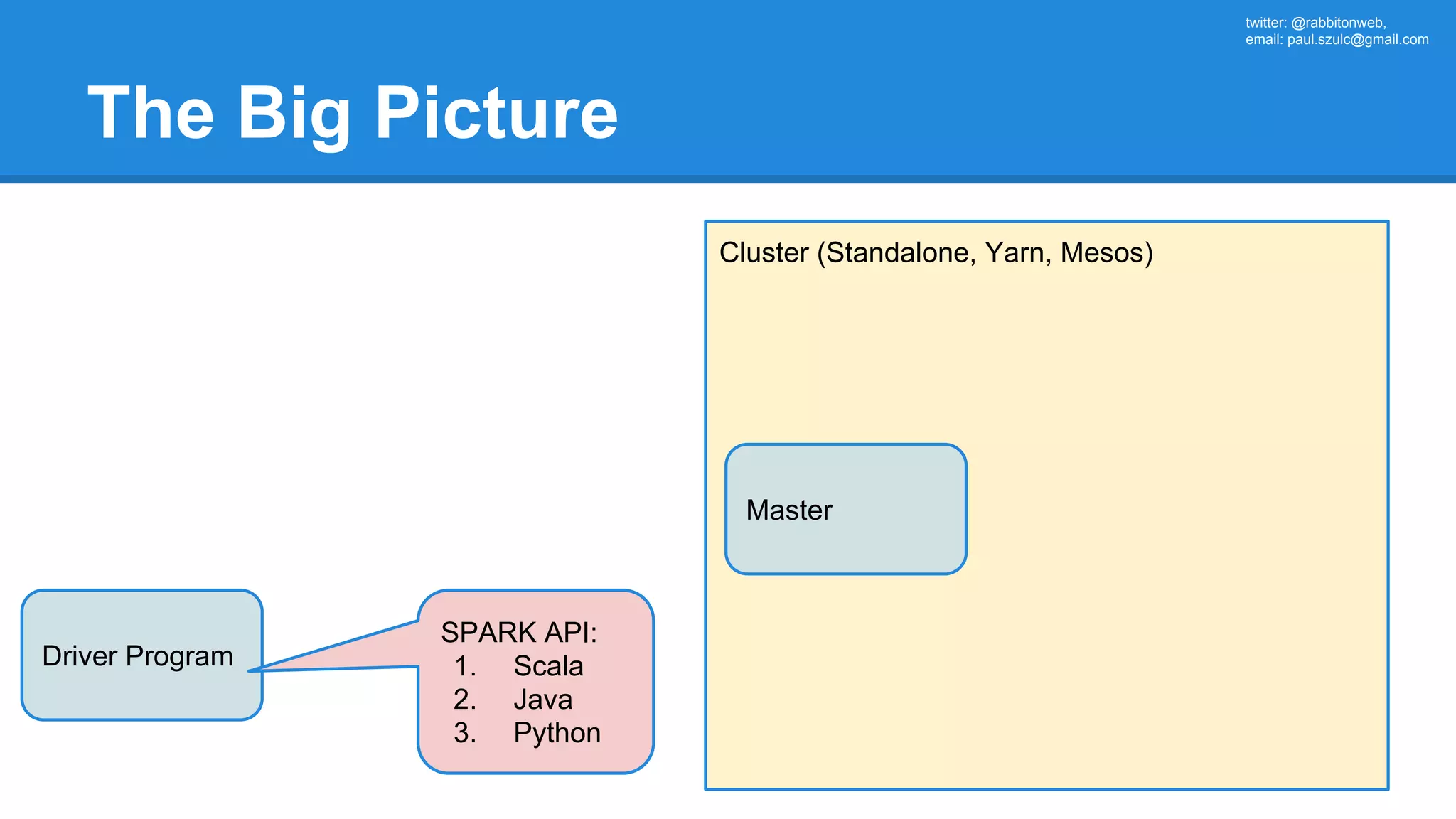
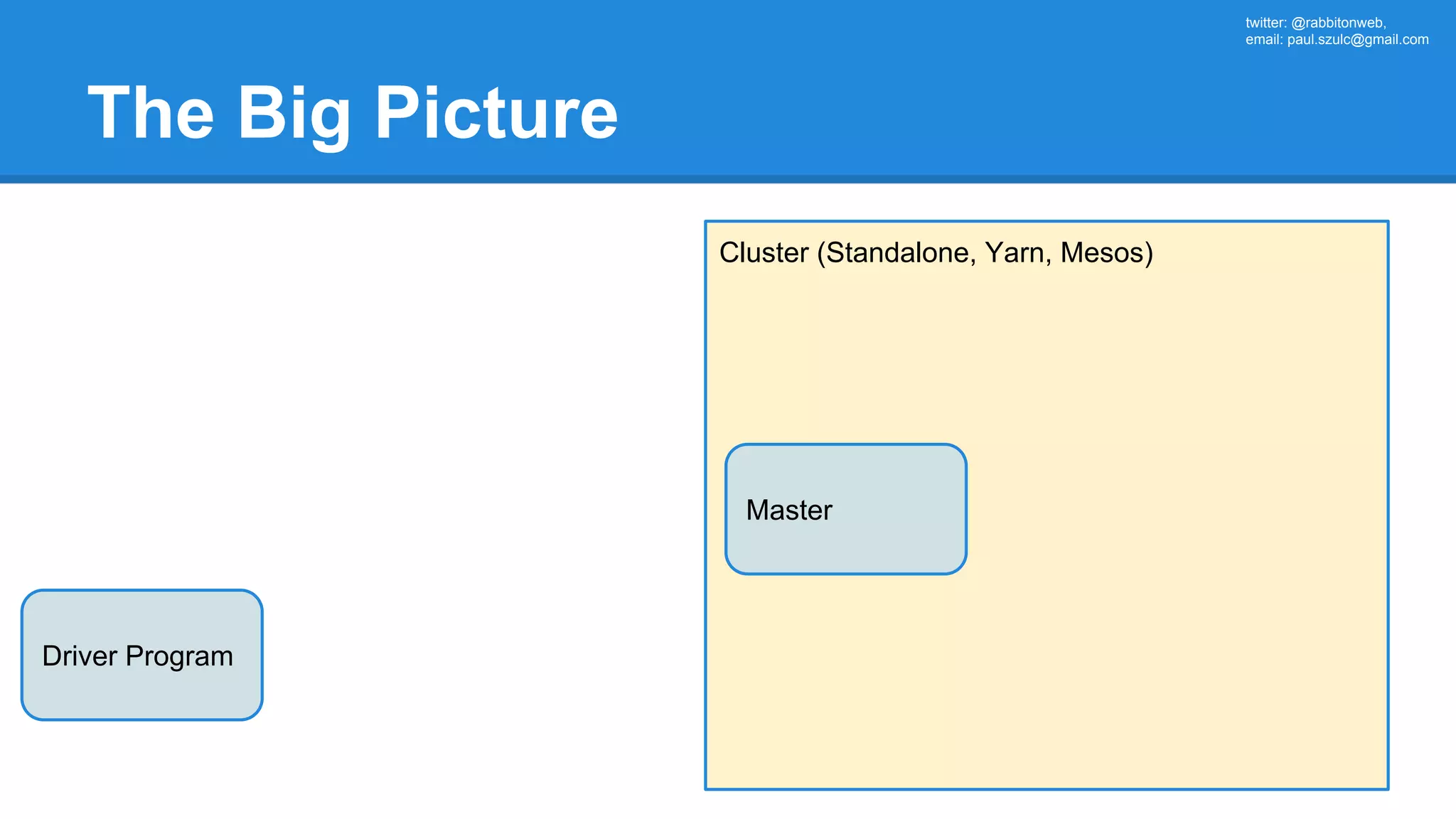
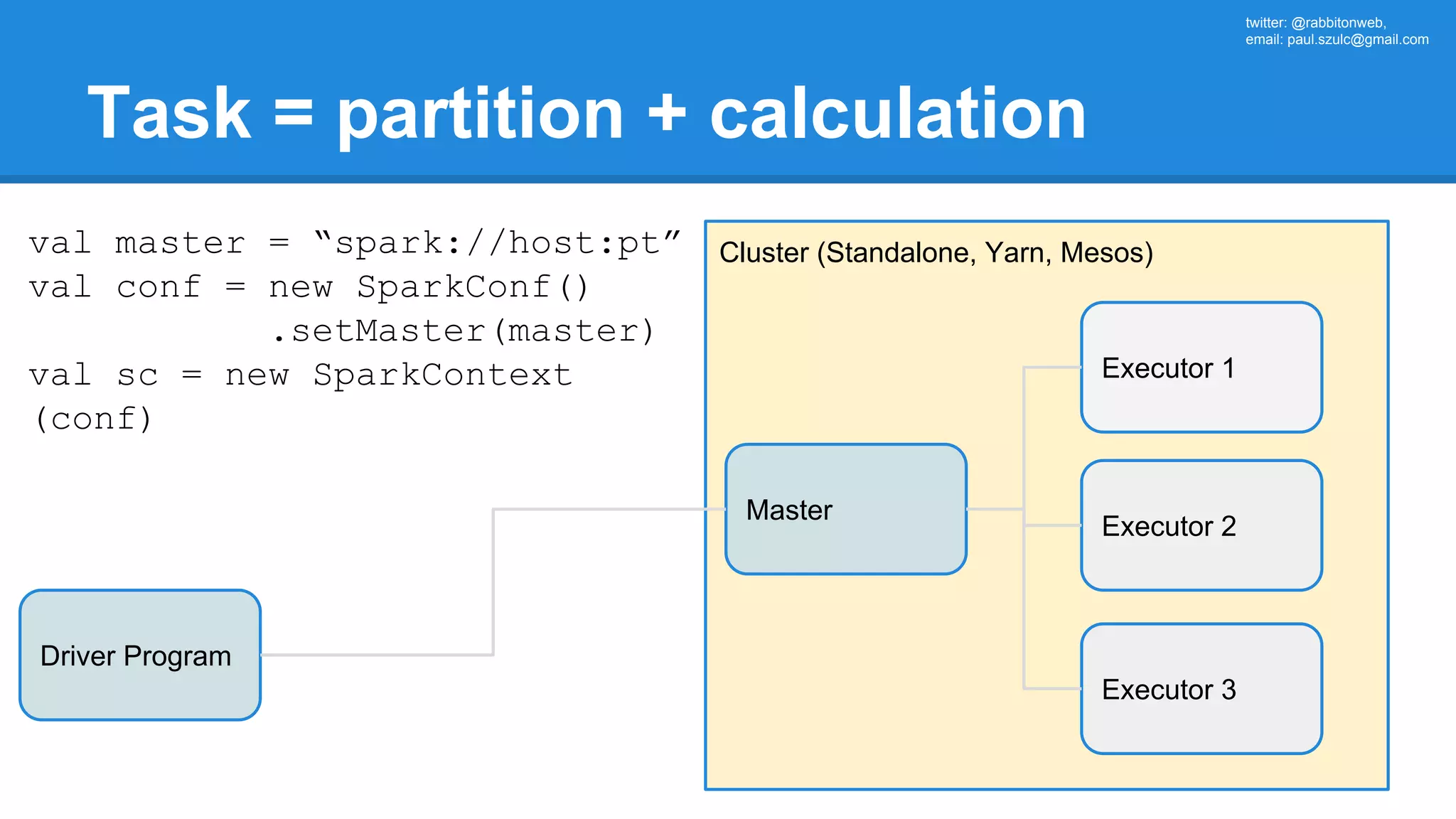
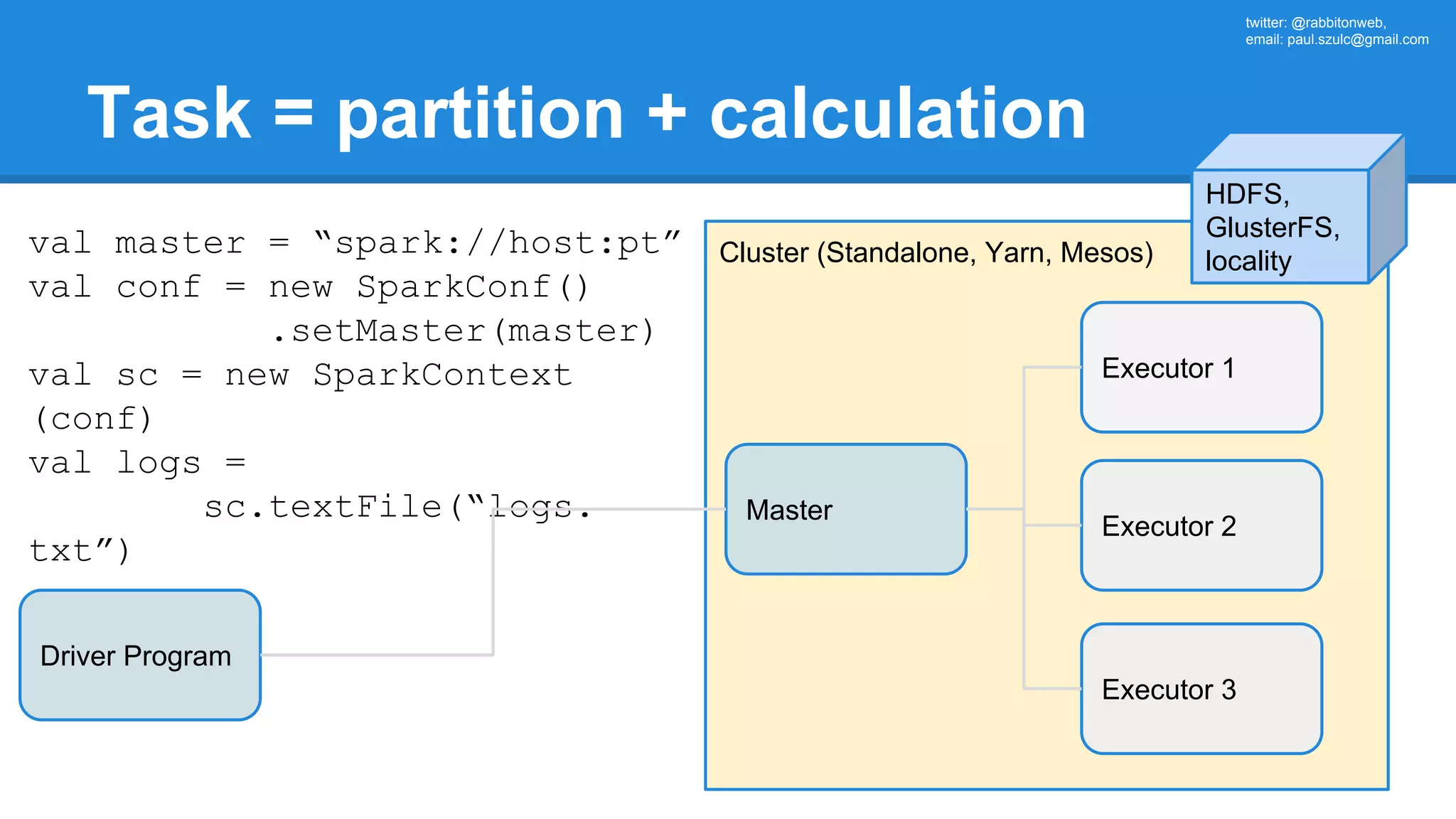
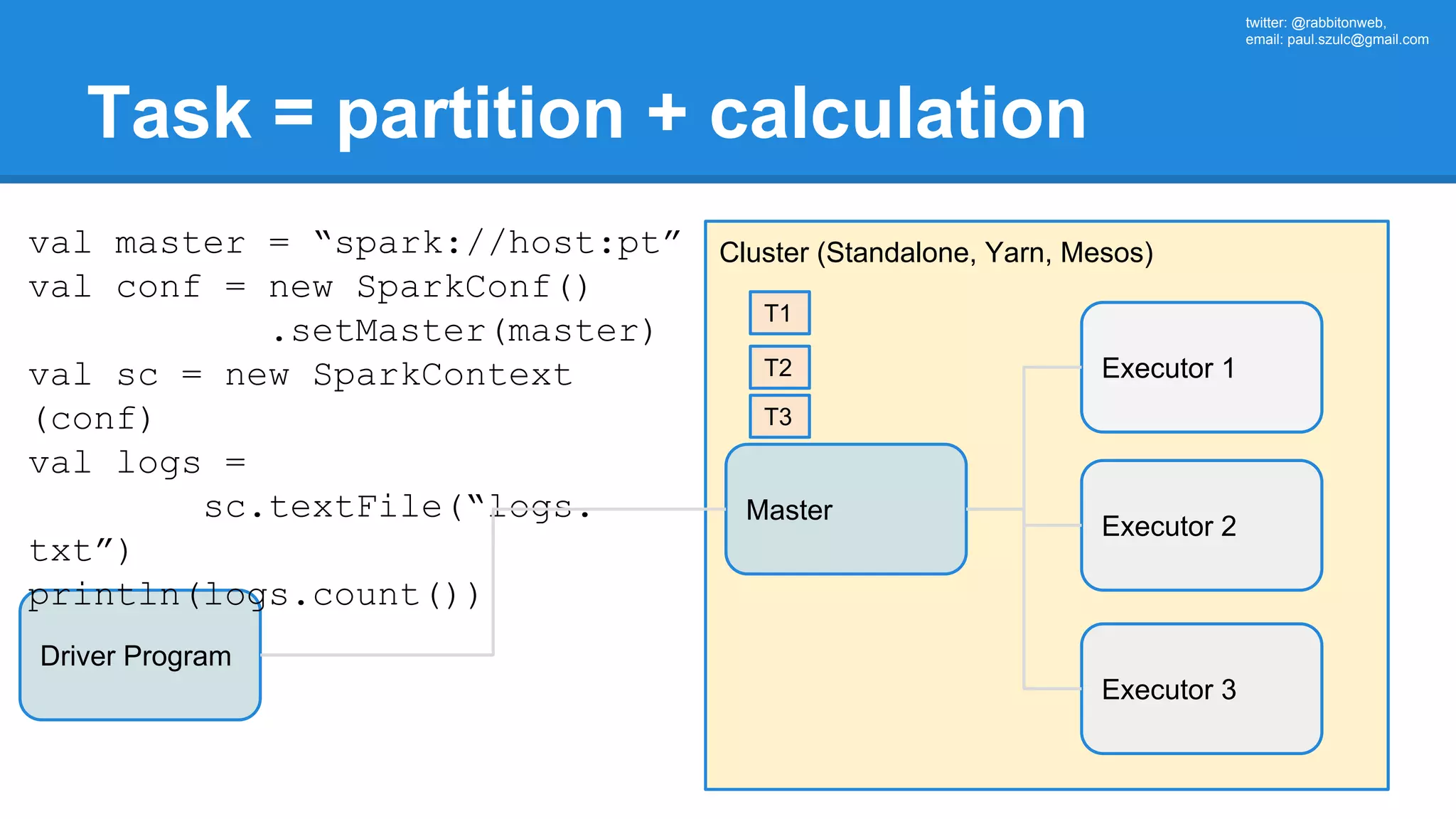
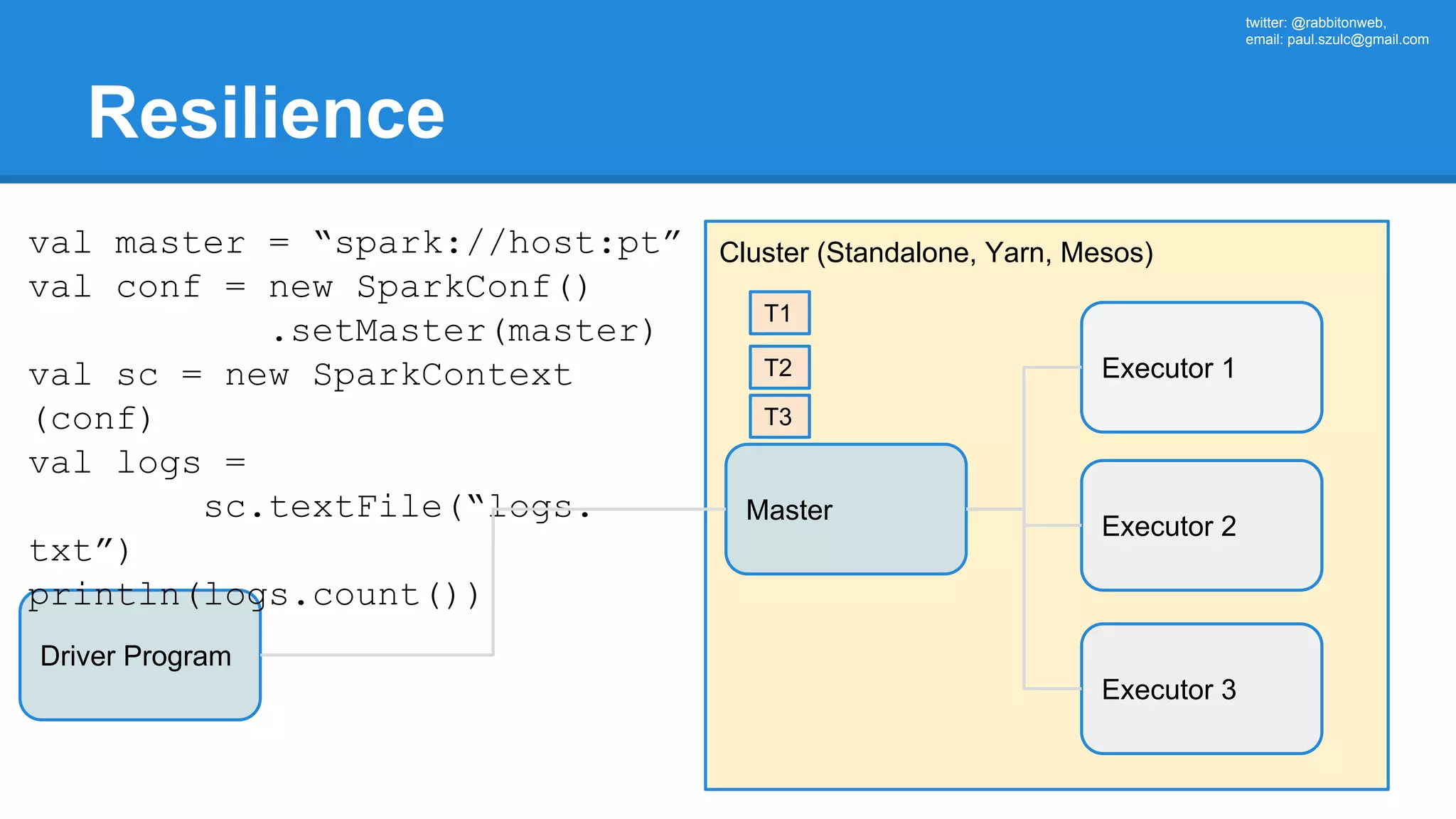
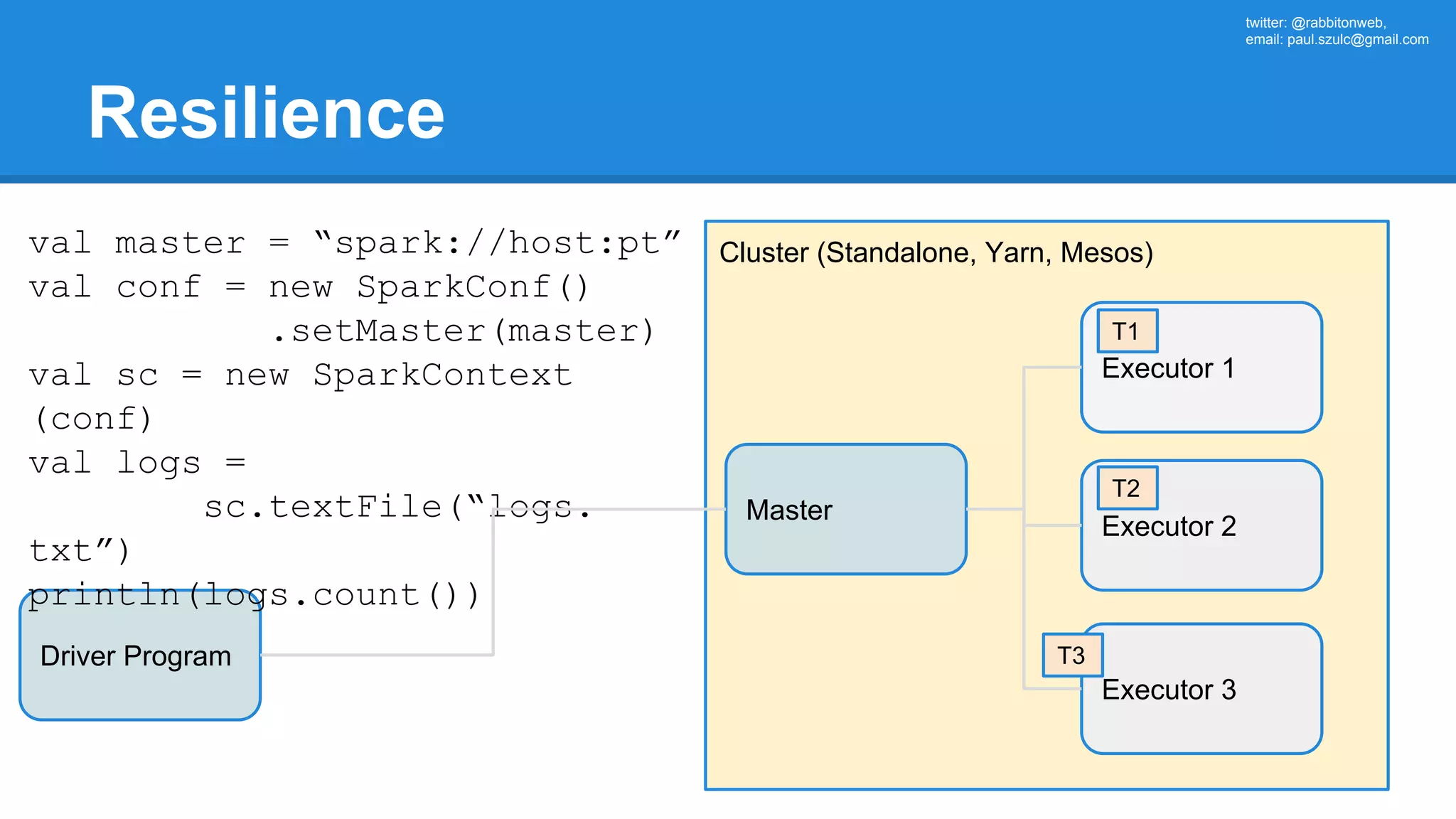
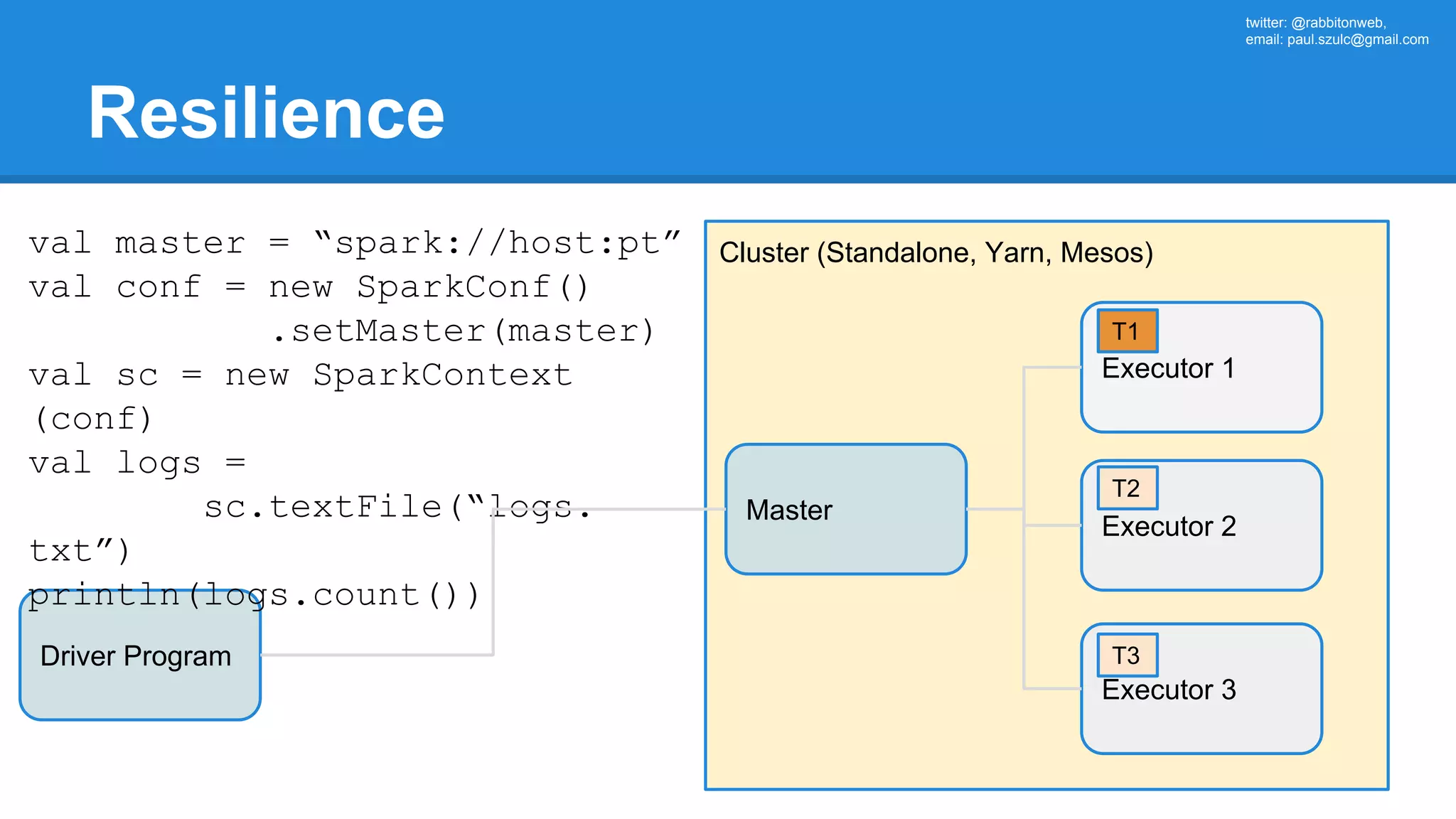
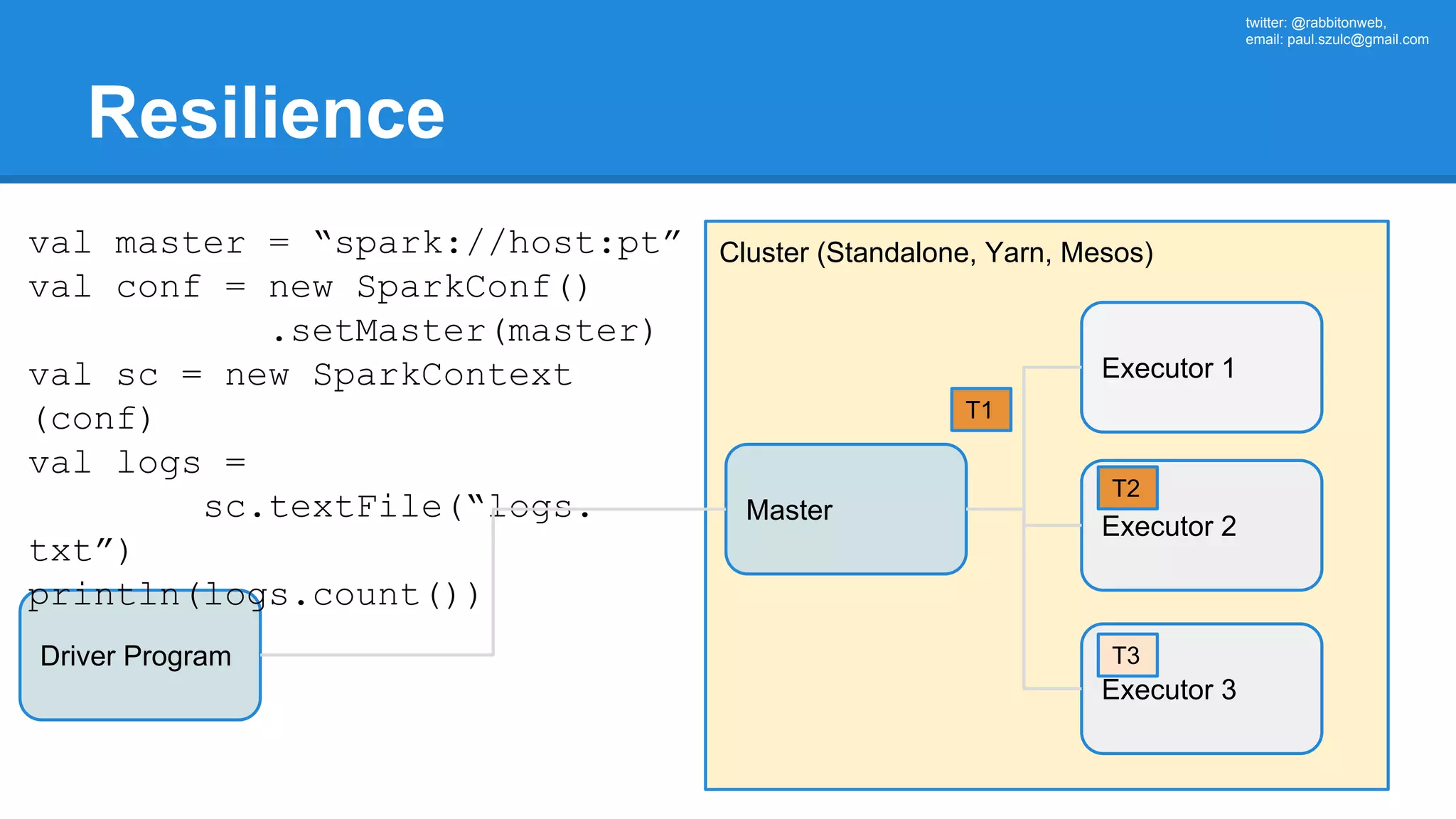
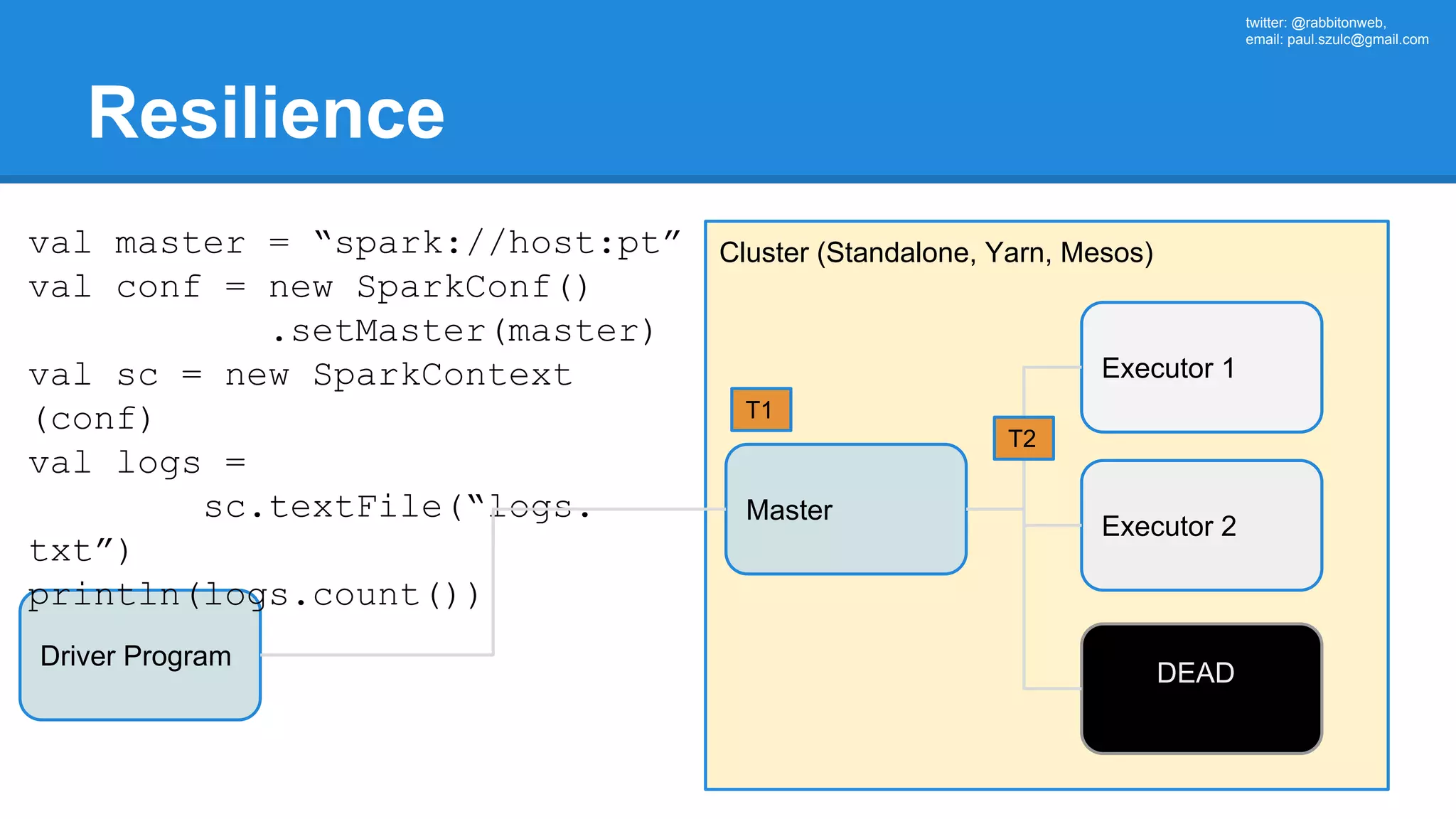
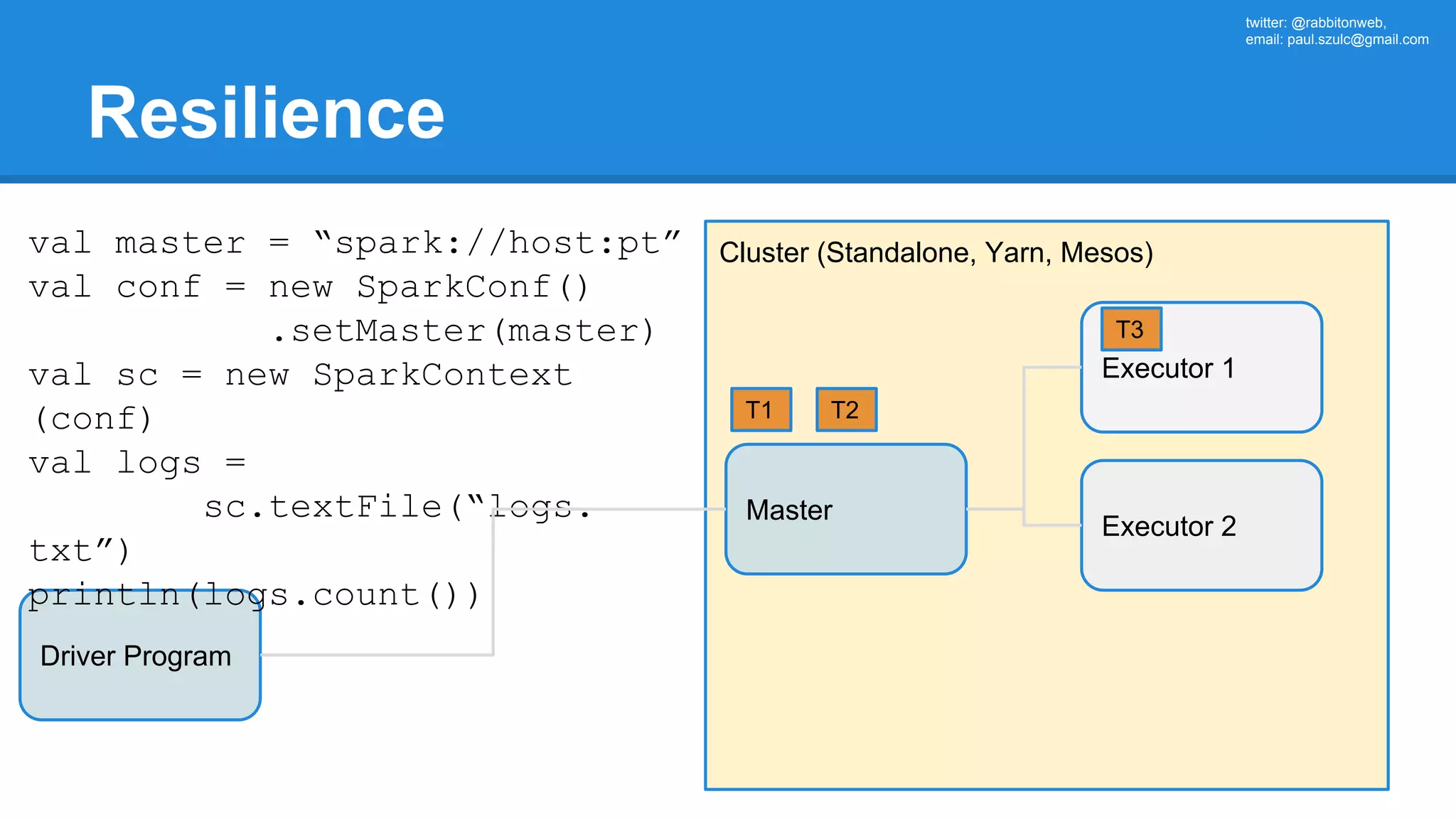
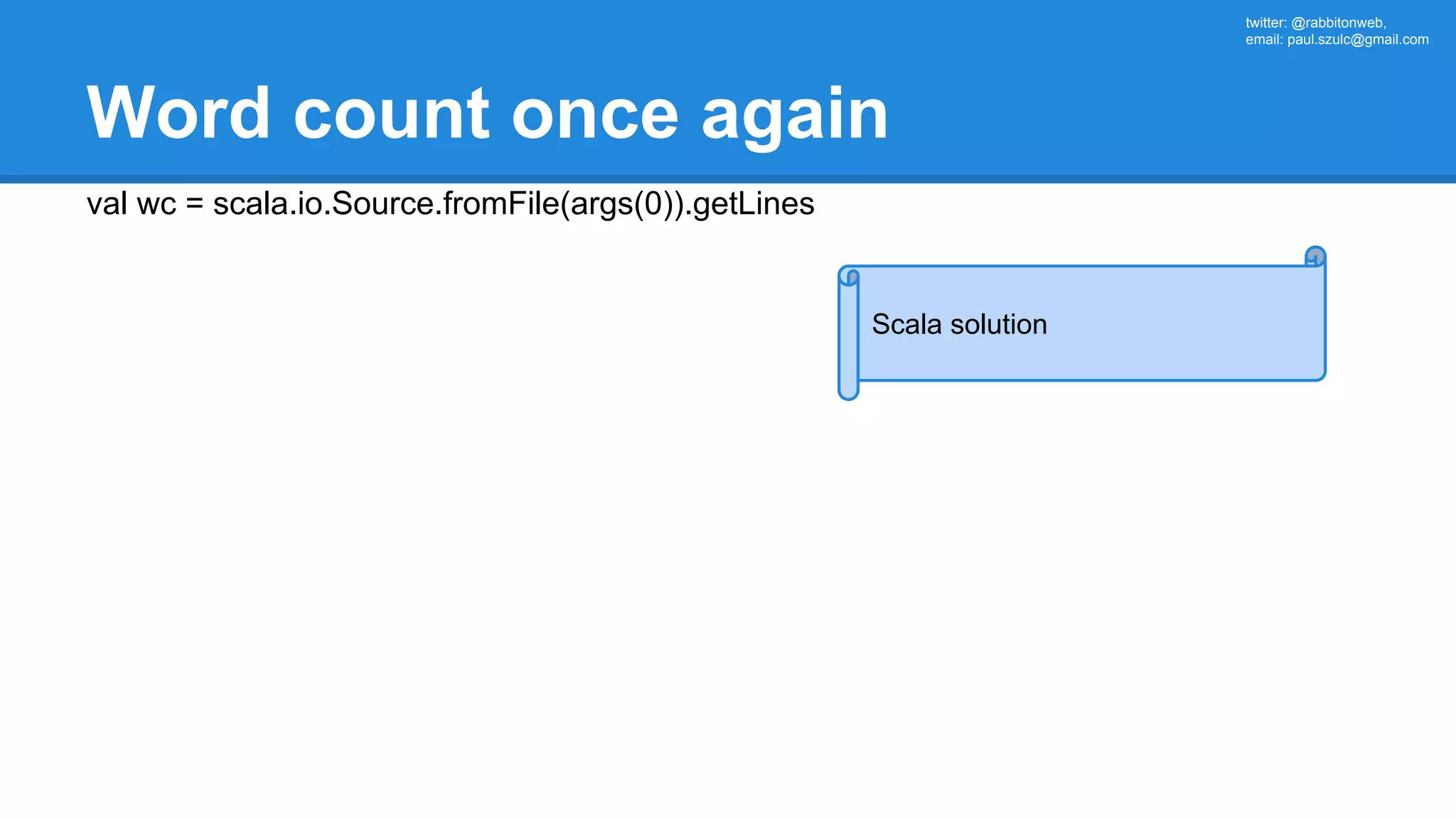
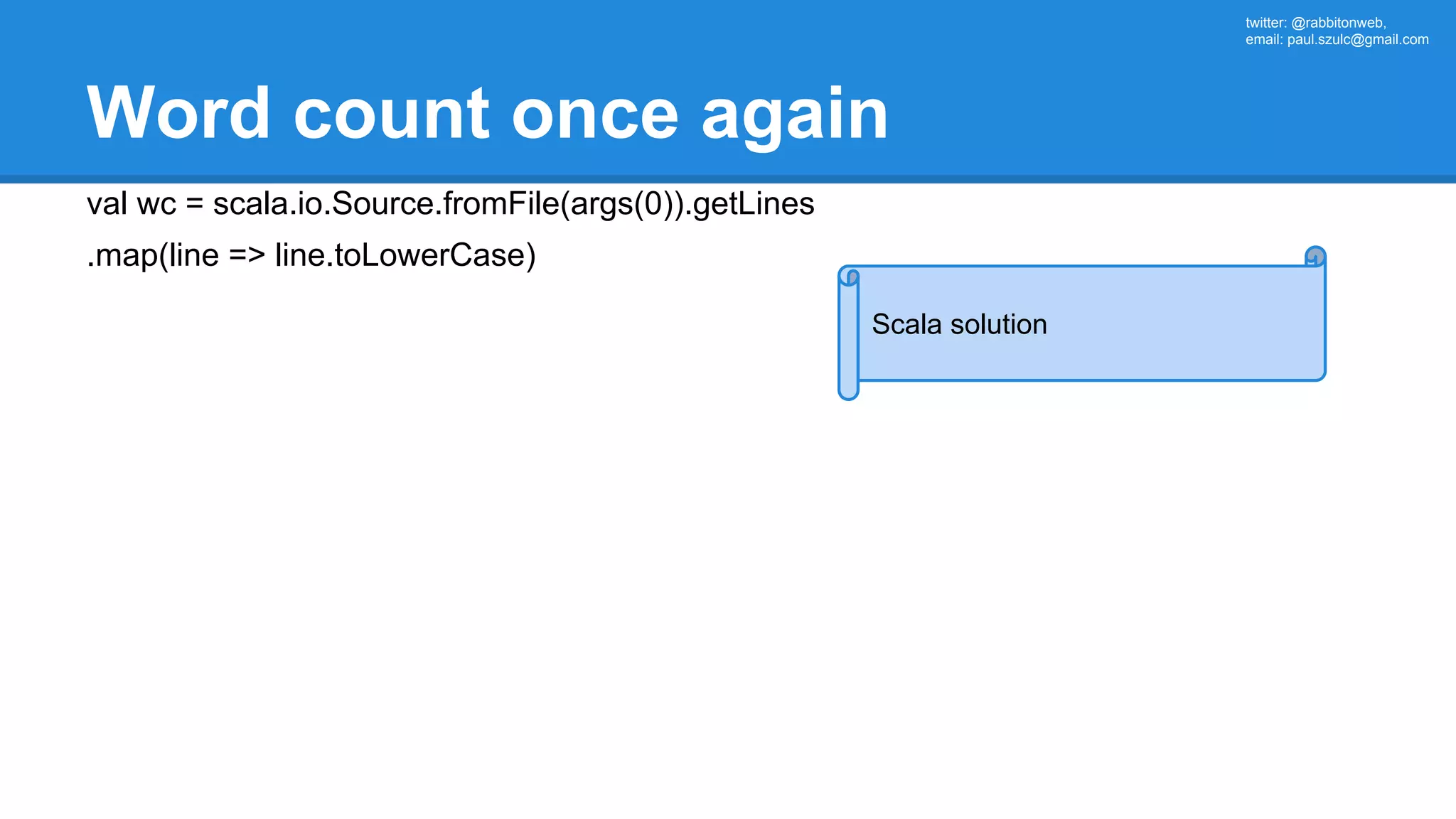
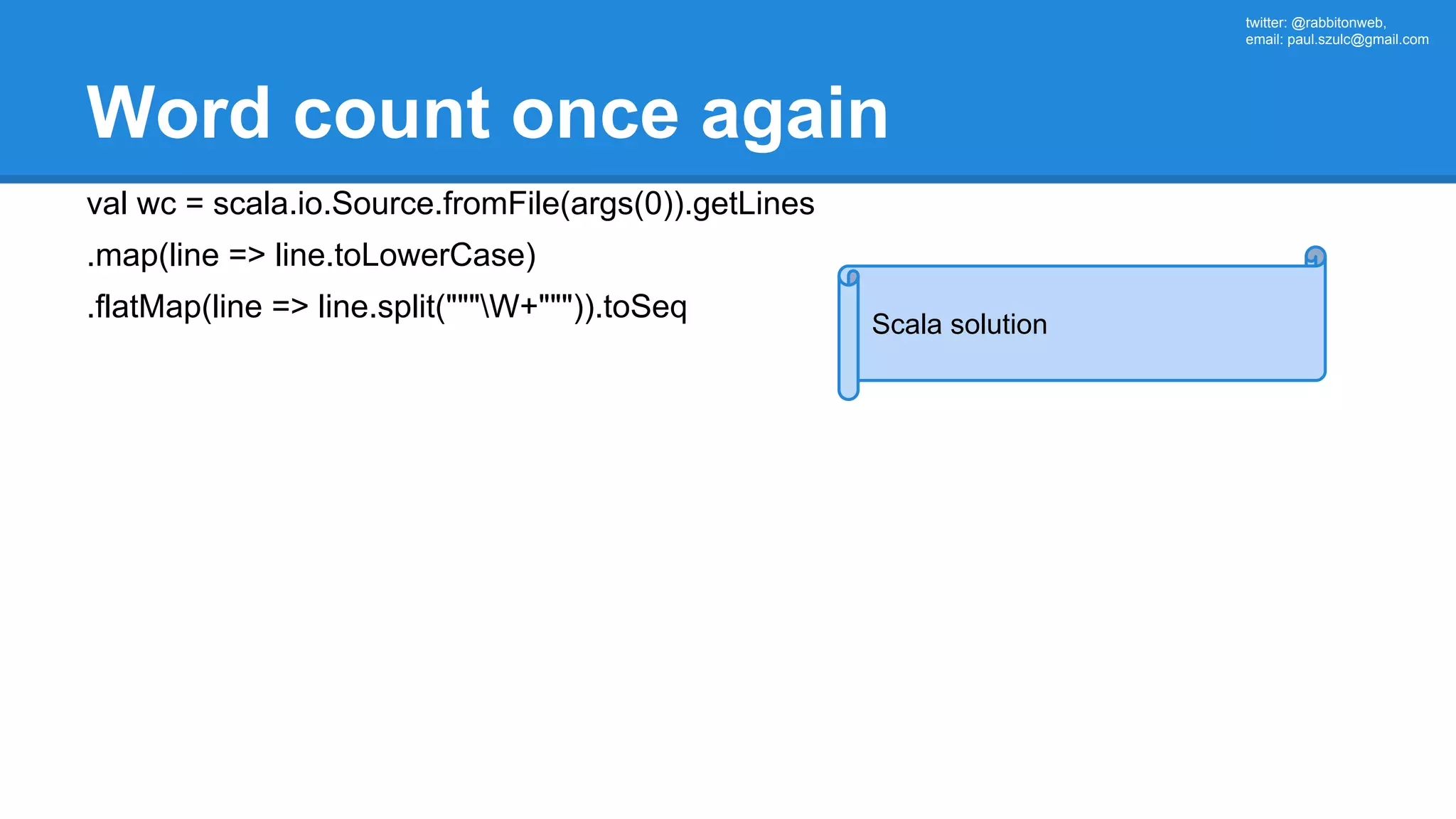
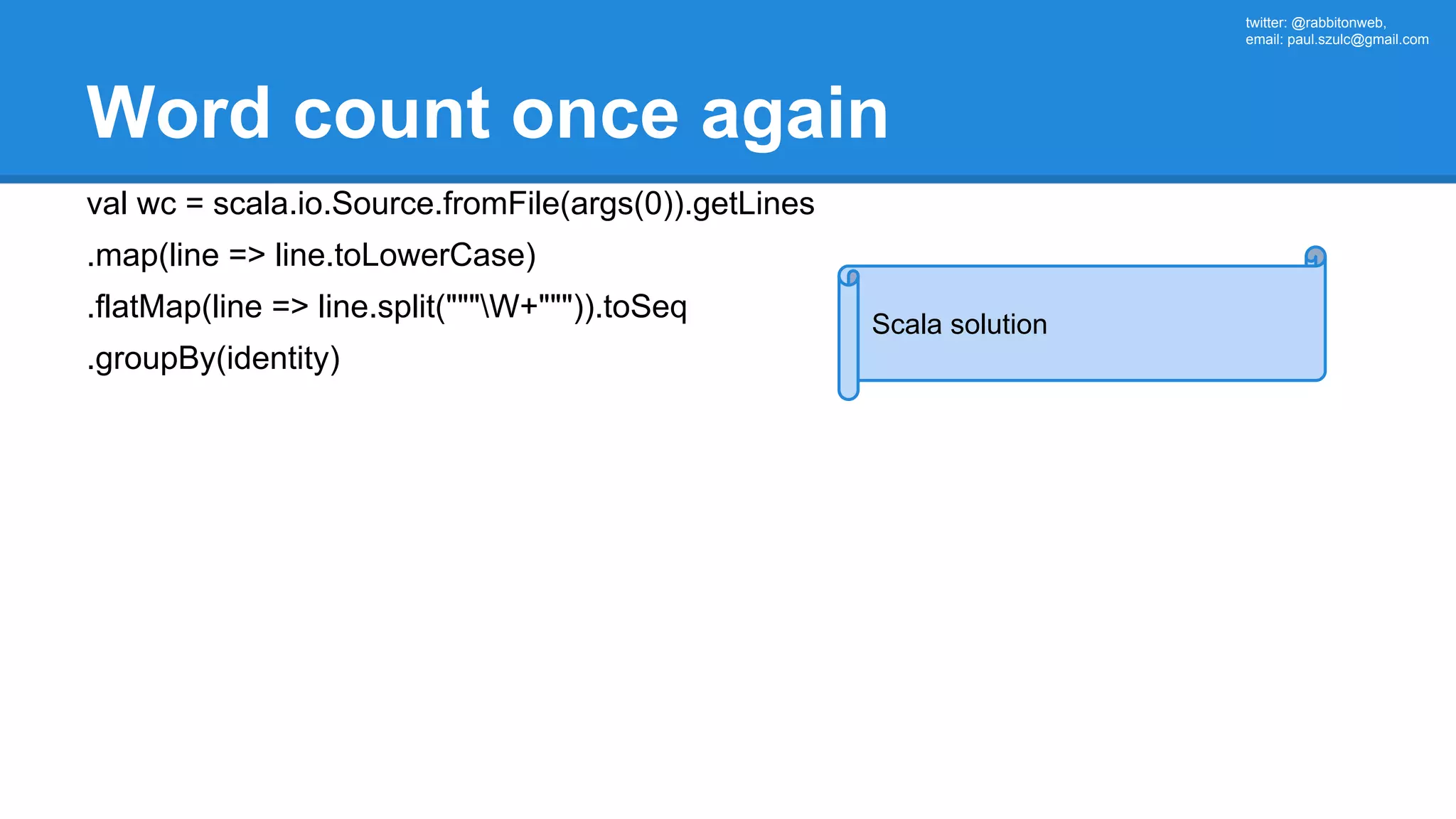
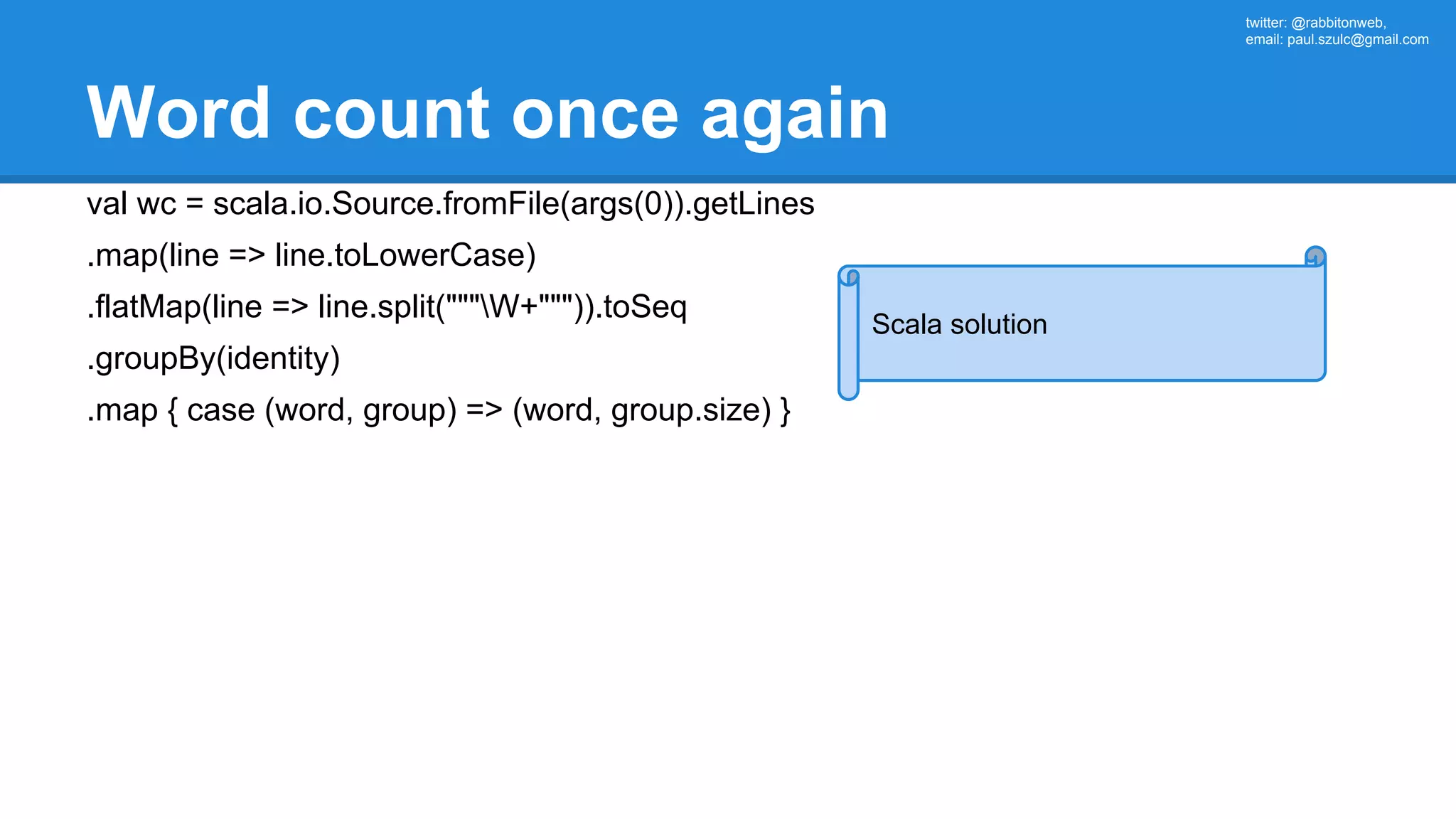
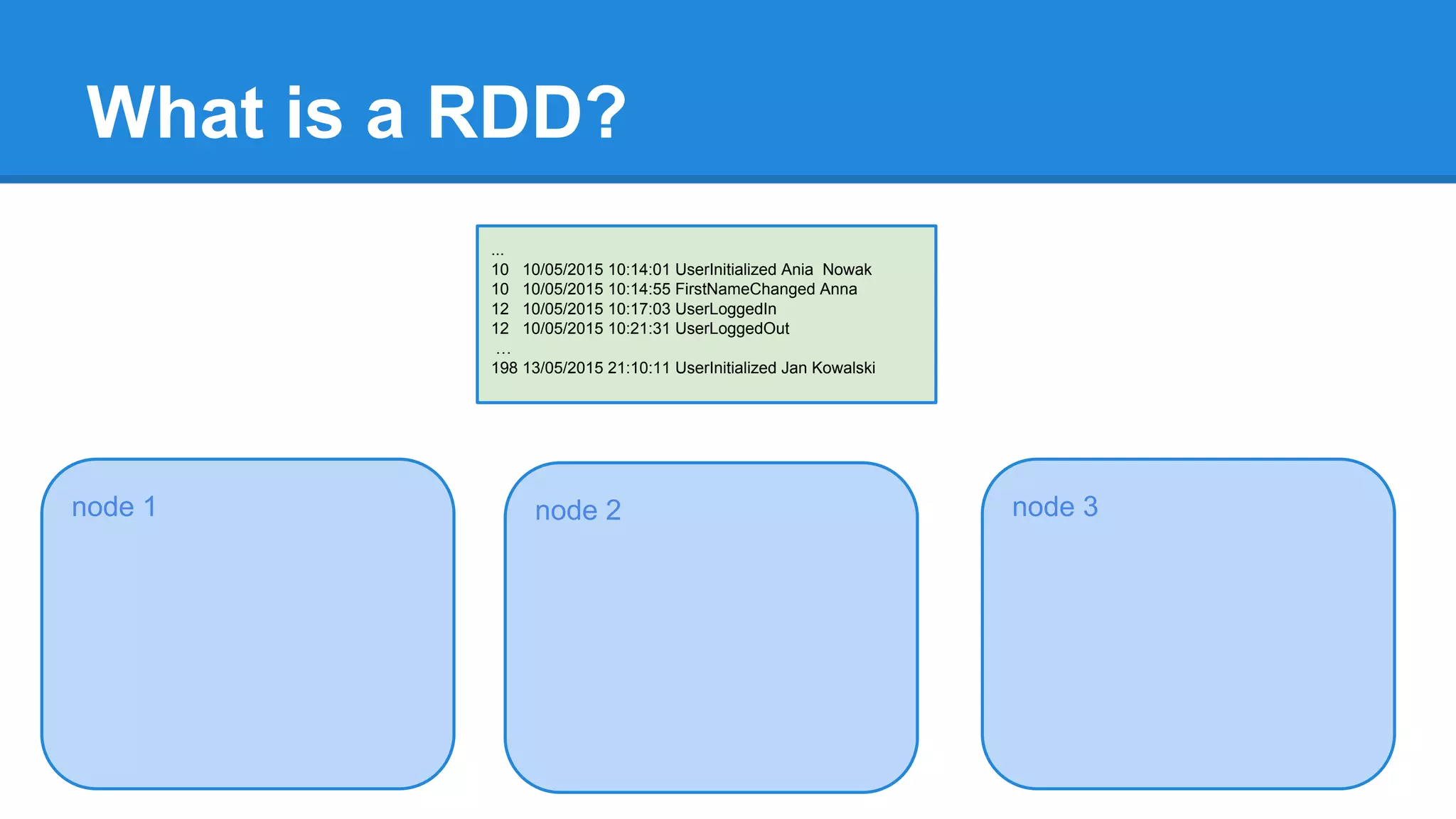
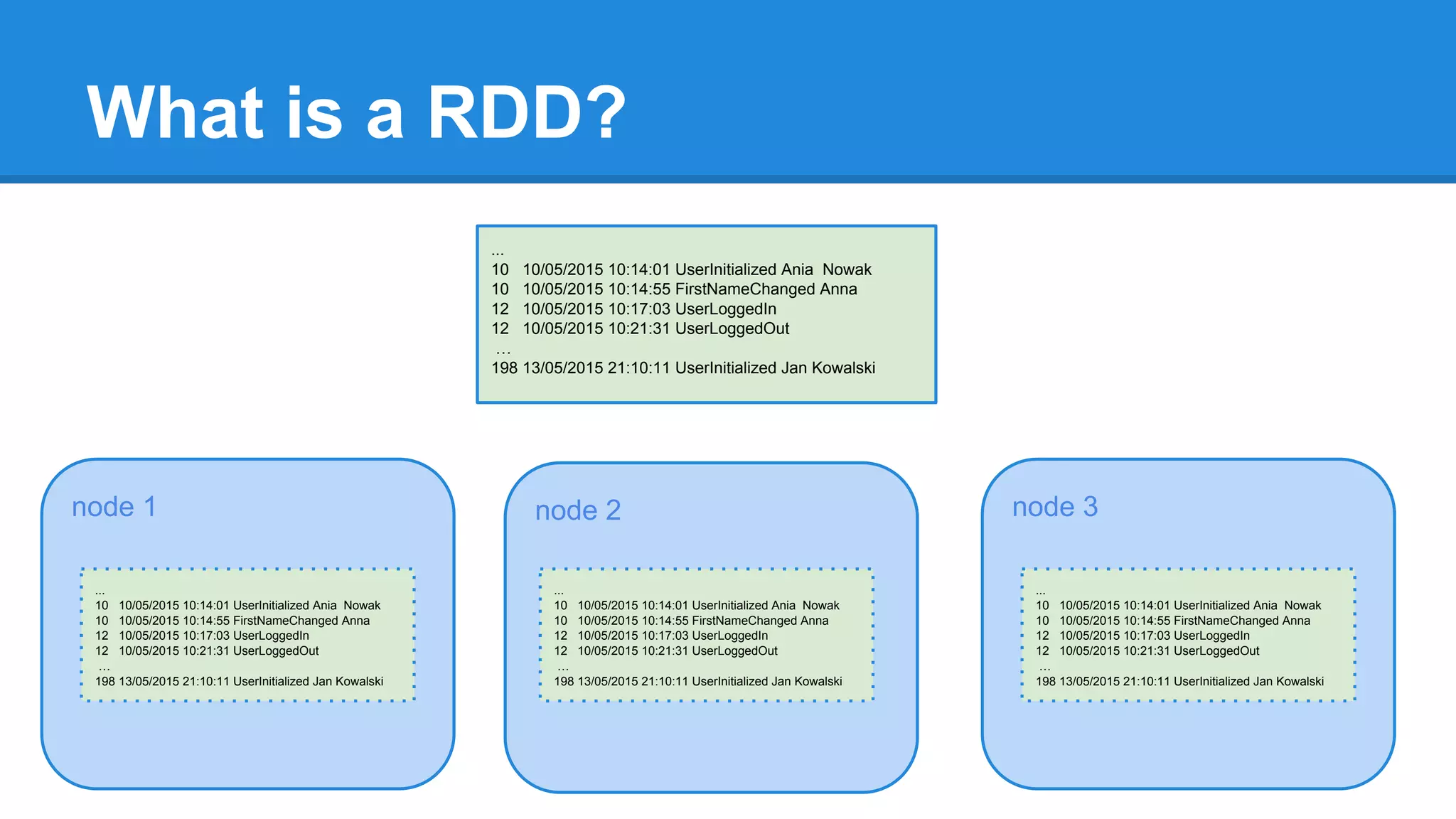
The document outlines an Apache Spark workshop presented by Paweł Szulc. It begins with installation instructions and then covers what Apache Spark is, why it was created, and how it works. Key points include that Apache Spark was created to address performance issues with MapReduce like its difficult programming model, writing outputs to disk between steps, and lack of support for iterative algorithms and real-time processing. The document uses a word count example to demonstrate how MapReduce works and how Spark improves on this pattern.