Downloaded 59 times






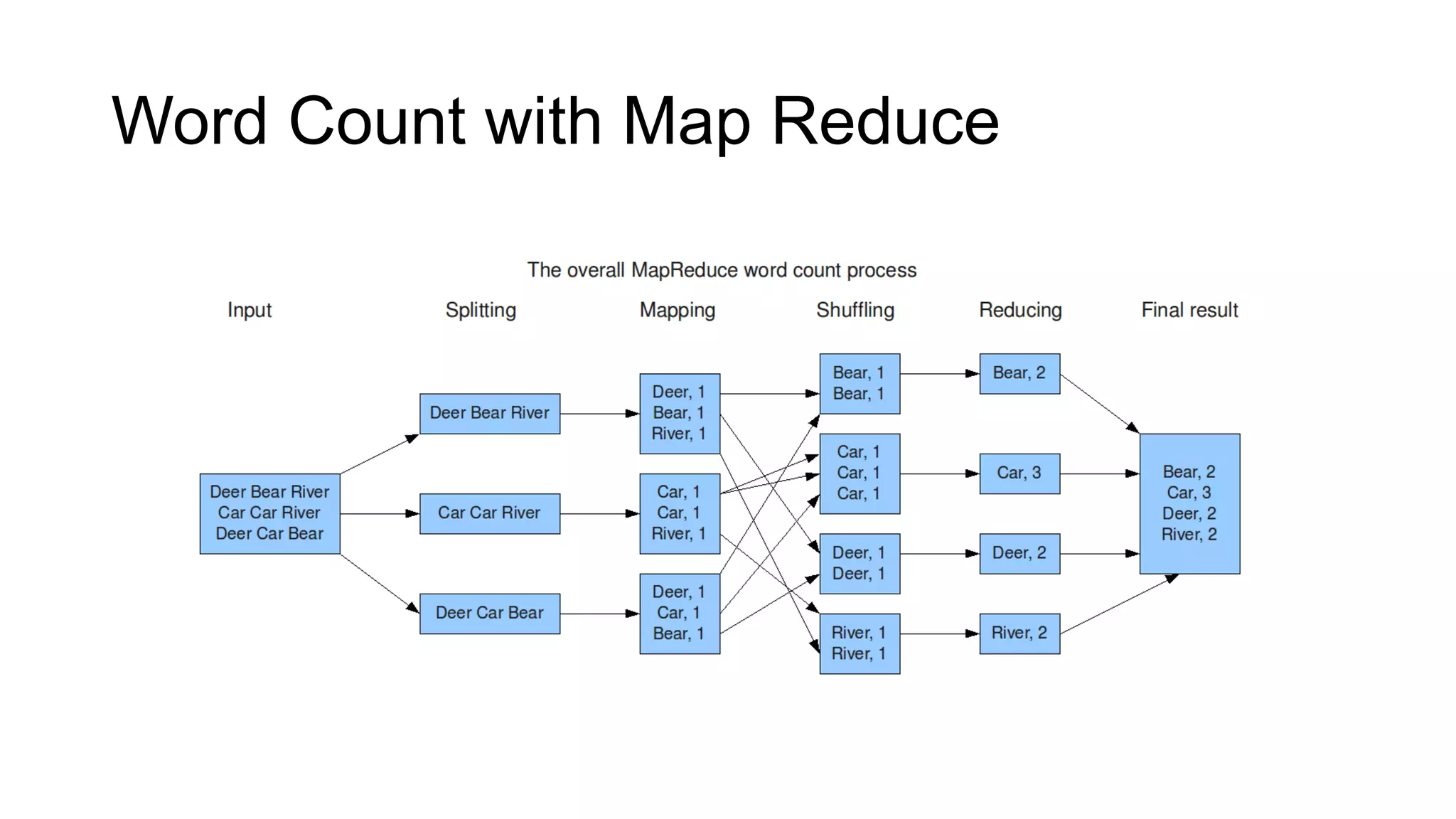



![WordCount MapReduce with Hadoop public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = new Job(conf, "wordcount"); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); job.setMapperClass(Map.class); job.setReducerClass(Reduce.class); job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.waitForCompletion(true); }](https://image.slidesharecdn.com/bigdata-analysis-130418120801-phpapp02/75/Big-data-just-an-introduction-to-Hadoop-and-Scripting-Languages-13-2048.jpg)





![Apache Pig – Log Flow analysis • A common scenario is collect logs and analyse it as post processing • We will cover Apache2 (web server) log analysis • Read AWS Elastic Map Reduce Apache Pig example • http://aws.amazon.com/articles/2729 • Apache Log: • 122.161.184.193 - - [21/Jul/2009:13:14:17 -0700] "GET /rss.pl HTTP/1.1" 200 35942 "-" "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Trident/4.0; SLCC1; .NET CLR 2.0.50727; .NET CLR 3.5.21022; InfoPath.2; .NET CLR 3.5.30729; .NET CLR 3.0.30618; OfficeLiveConnector.1.3; OfficeLivePatch.1.3; MSOffice 12)"](https://image.slidesharecdn.com/bigdata-analysis-130418120801-phpapp02/75/Big-data-just-an-introduction-to-Hadoop-and-Scripting-Languages-19-2048.jpg)
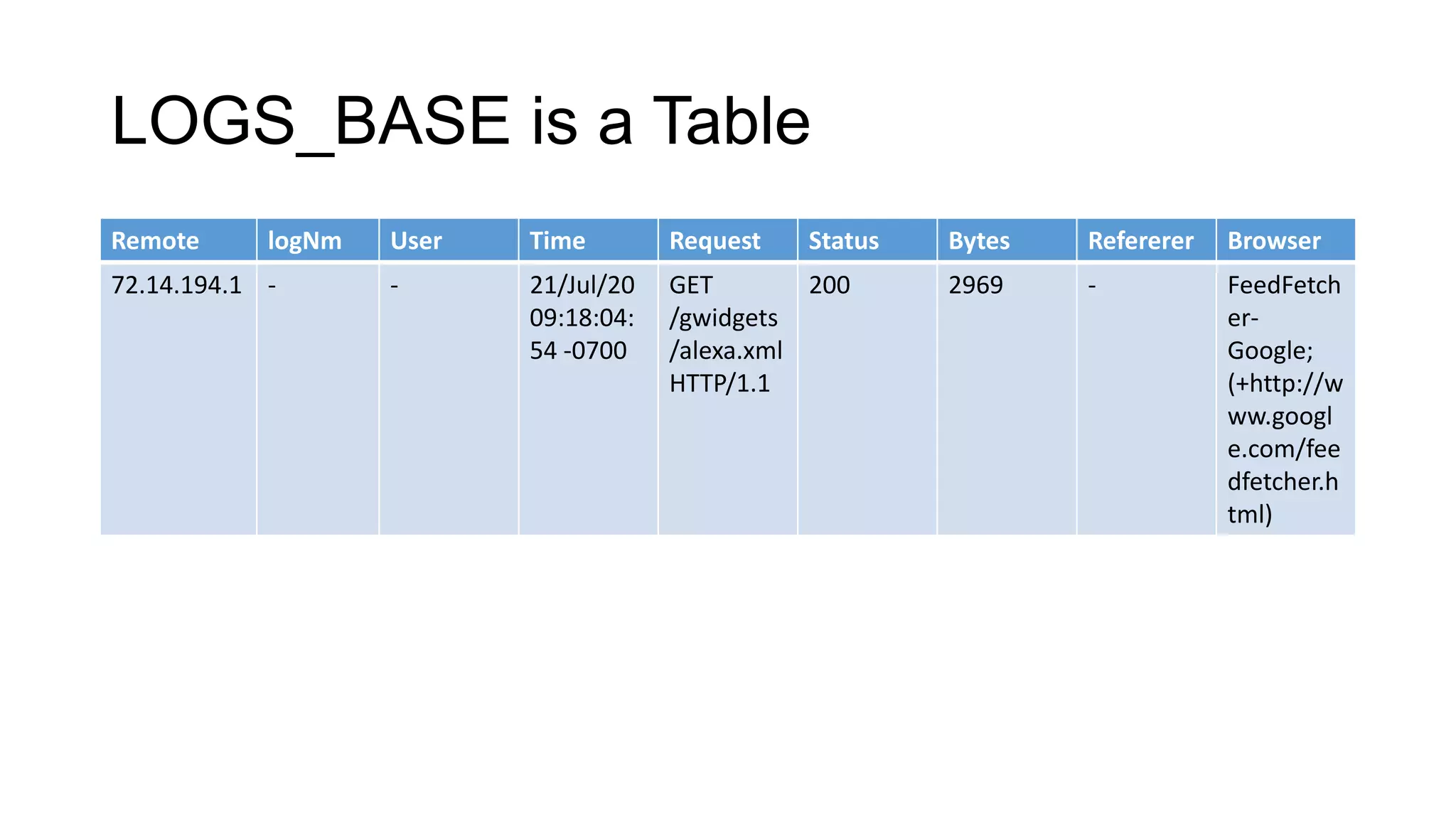
![Log Analysis [Common Log Format (CLF)] • More information about CLF: • http://httpd.apache.org/docs/2.2/logs.html • Log interesting fields: • Remote Address (IP) • Remote Log Name • User • Time • Request • Status • Bytes • Refererer • Browser](https://image.slidesharecdn.com/bigdata-analysis-130418120801-phpapp02/75/Big-data-just-an-introduction-to-Hadoop-and-Scripting-Languages-20-2048.jpg)

![Load logs from S3 and create a table RAW_LOGS = LOAD ‘s3://bucket/path’ USING TextLoader as (line:chararray); LOGS_BASE = FOREACH RAW_LOGS GENERATE FLATTEN( EXTRACT(line, '^(S+) (S+) (S+) [([w:/]+s[+-]d{4})] "(.+?)" (S+) (S+) "([^"]*)" "([^"]*)"') ) as ( remoteAddr: chararray, remoteLogname: chararray, user: chararray, time: chararray, request: chararray, status: int, bytes_string: chararray, referrer: chararray, browser: chararray );](https://image.slidesharecdn.com/bigdata-analysis-130418120801-phpapp02/75/Big-data-just-an-introduction-to-Hadoop-and-Scripting-Languages-22-2048.jpg)
![Data Analysis REFERRER_ONLY = FOREACH LOGS_BASE GENERATE referrer; FILTERED = FILTER REFERRER_ONLY BY referrer matches '.*bing.*' OR referrer matches '.*google.*'; SEARCH_TERMS = FOREACH FILTERED GENERATE FLATTEN(EXTRACT(referrer, '.*[&?]q=([^&]+).*')) as terms:chararray; SEARCH_TERMS_FILTERED = FILTER SEARCH_TERMS BY NOT $0 IS NULL; SEARCH_TERMS_COUNT = FOREACH (GROUP SEARCH_TERMS_FILTERED BY $0) GENERATE $0, COUNT($1) as num; SEARCH_TERMS_COUNT_SORTED = ORDER SEARCH_TERMS_COUNT BY num DESC;](https://image.slidesharecdn.com/bigdata-analysis-130418120801-phpapp02/75/Big-data-just-an-introduction-to-Hadoop-and-Scripting-Languages-24-2048.jpg)


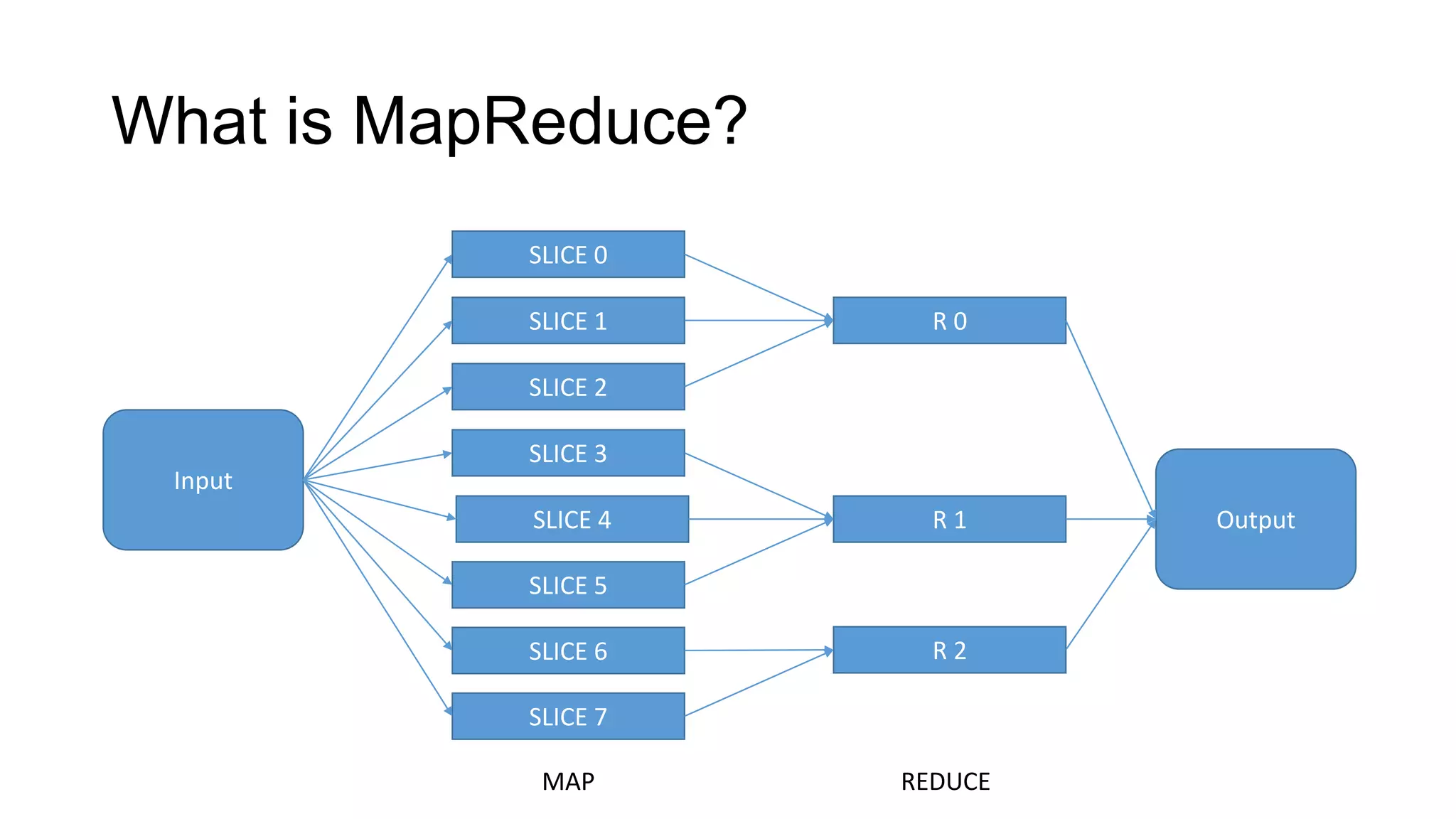
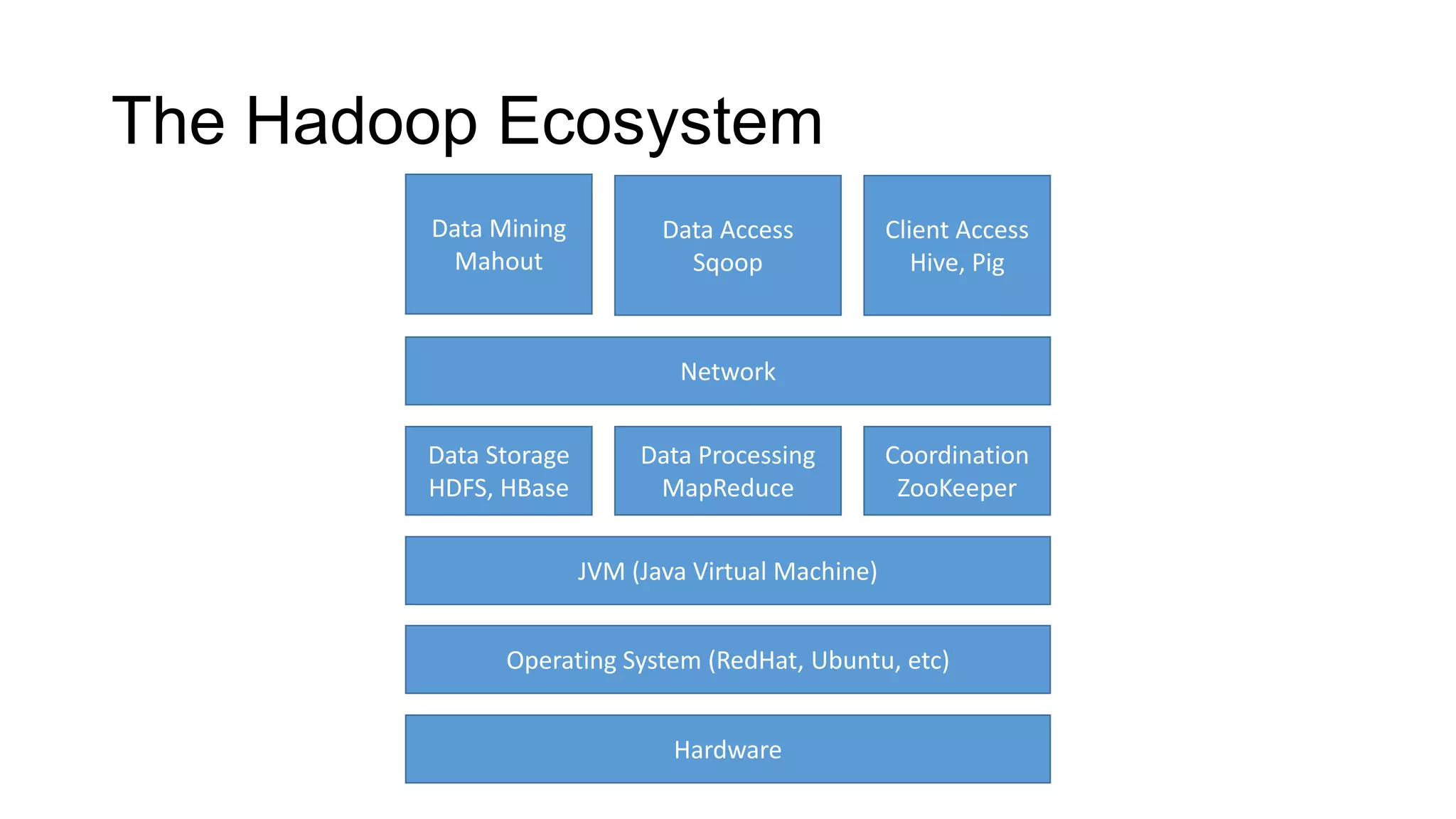
This document provides an introduction to Big Data and Apache Hadoop. It defines Big Data as large and complex datasets that are difficult to process using traditional database tools. It describes how Hadoop uses MapReduce and HDFS to provide scalable storage and parallel processing of Big Data. It provides examples of companies using Hadoop to analyze exabytes of data and common Hadoop use cases like log analysis. Finally, it summarizes some popular Hadoop ecosystem projects like Hive, Pig, and Zookeeper that provide SQL-like querying, data flows, and coordination.