Downloaded 29 times









![Word count - MapReduce vs Spark 13 package org.myorg; import java.io.IOException; import java.util.*; import org.apache.hadoop.fs.Path; import org.apache.hadoop.conf.*; import org.apache.hadoop.io.*; import org.apache.hadoop.mapred.*; import org.apache.hadoop.util.*; public class WordCount { public static class Map extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException { String line = value.toString(); StringTokenizer tokenizer = new StringTokenizer(line); while (tokenizer.hasMoreTokens()) { word.set(tokenizer.nextToken()); output.collect(word, one); } } } public static class Reduce extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> { public void reduce(Text key, Iterator values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException { int sum = 0; while (values.hasNext()) { sum += values.next().get(); } output.collect(key, new IntWritable(sum)); } } public static void main(String[] args) throws Exception { JobConf conf = new JobConf(WordCount.class); conf.setJobName("wordcount"); conf.setOutputKeyClass(Text.class); conf.setOutputValueClass(IntWritable.class); conf.setMapperClass(Map.class); conf.setCombinerClass(Reduce.class); conf.setReducerClass(Reduce.class); conf.setInputFormat(TextInputFormat.class); conf.setOutputFormat(TextOutputFormat.class); FileInputFormat.setInputPaths(conf, new Path(args[0])); FileOutputFormat.setOutputPath(conf, new Path(args[1])); JobClient.runJob(conf); } } val file = spark.textFile("hdfs://...") val counts = file.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_ + _) counts.saveAsTextFile("hdfs://...")](https://image.slidesharecdn.com/apachesparkthenextgenerationclustercomputing-170426000340/75/Apache-Spark-the-Next-Generation-Cluster-Computing-13-2048.jpg)










![Dataset ● Extension to DataFrame ● Type-safe ● DataFrame = Dataset[Row] 27 case class Incident(Category: String, DayOfWeek: String) val incidents = spark .read .option("header", "true") .csv("/data/SFPD_Incidents_2003.csv") .select("Category", "DayOfWeek") .as[Incident] val days = Array("Monday", "Tuesday", "Wednesday", "Thursday", "Friday", "Saturday", "Sunday") val histogram = incidents.groupByKey(_.Category).mapGroups { case (category, daysOfWeek) => { val buckets = new Array[Int](7) daysOfWeek.map(_.DayOfWeek).foreach { dow => buckets(days.indexOf(dow)) += 1 } (category, buckets) } }](https://image.slidesharecdn.com/apachesparkthenextgenerationclustercomputing-170426000340/75/Apache-Spark-the-Next-Generation-Cluster-Computing-27-2048.jpg)








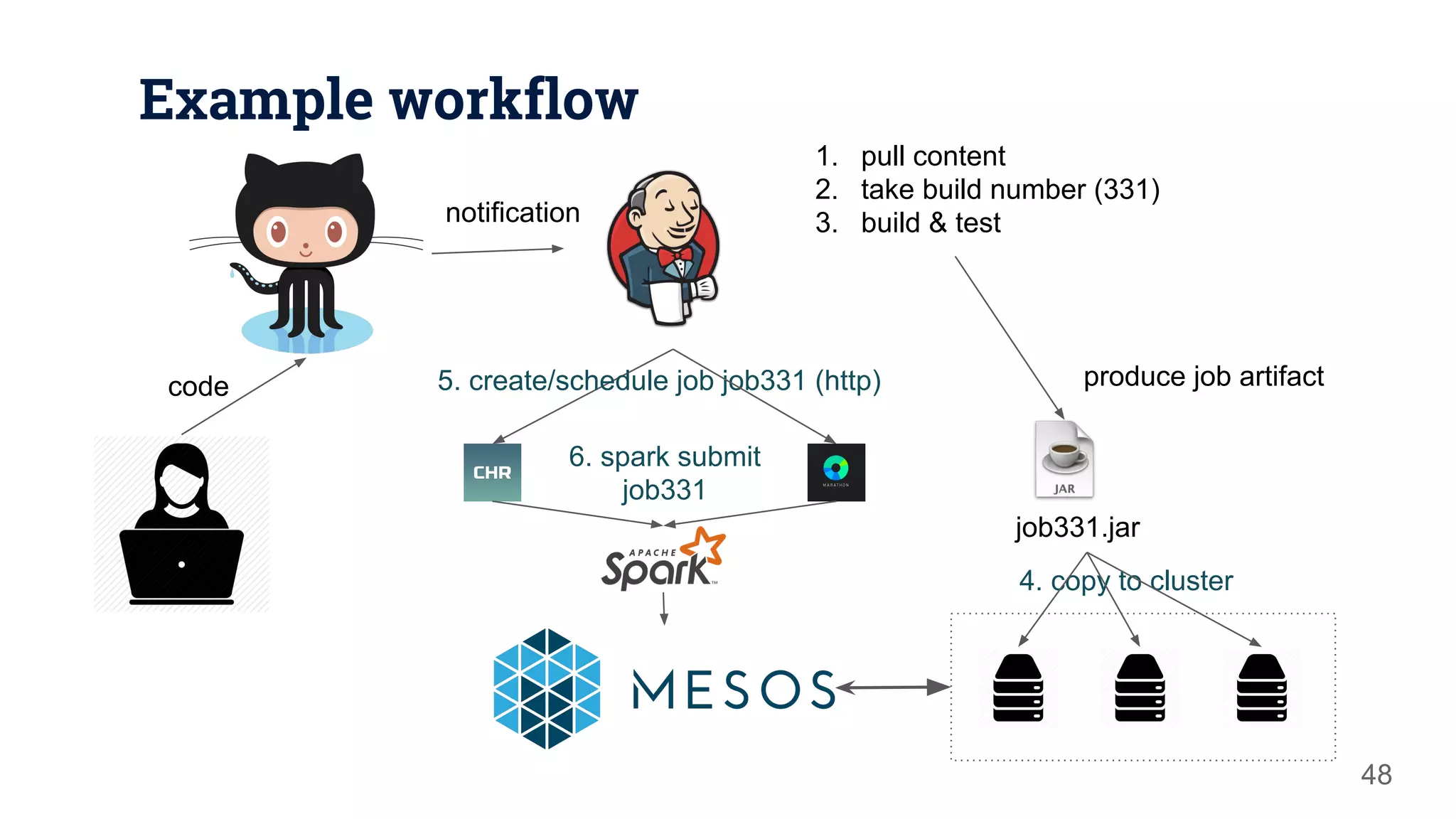
![Define Spark job entry point 44 object IncidentsJob { def main(args: Array[String]) { val spark = SparkSession.builder() .appName("Incidents processing job") .config("spark.sql.shuffle.partitions", "16") .master("local[4]") .getOrCreate() { spark transformations and actions... } System.exit(0) }](https://image.slidesharecdn.com/apachesparkthenextgenerationclustercomputing-170426000340/75/Apache-Spark-the-Next-Generation-Cluster-Computing-44-2048.jpg)


![Submit job via spark-submit command ./bin/spark-submit --class <main-class> --master <master-url> --deploy-mode <deploy-mode> --conf <key>=<value> ... # other options <application-jar> [application-arguments] 47](https://image.slidesharecdn.com/apachesparkthenextgenerationclustercomputing-170426000340/75/Apache-Spark-the-Next-Generation-Cluster-Computing-47-2048.jpg)
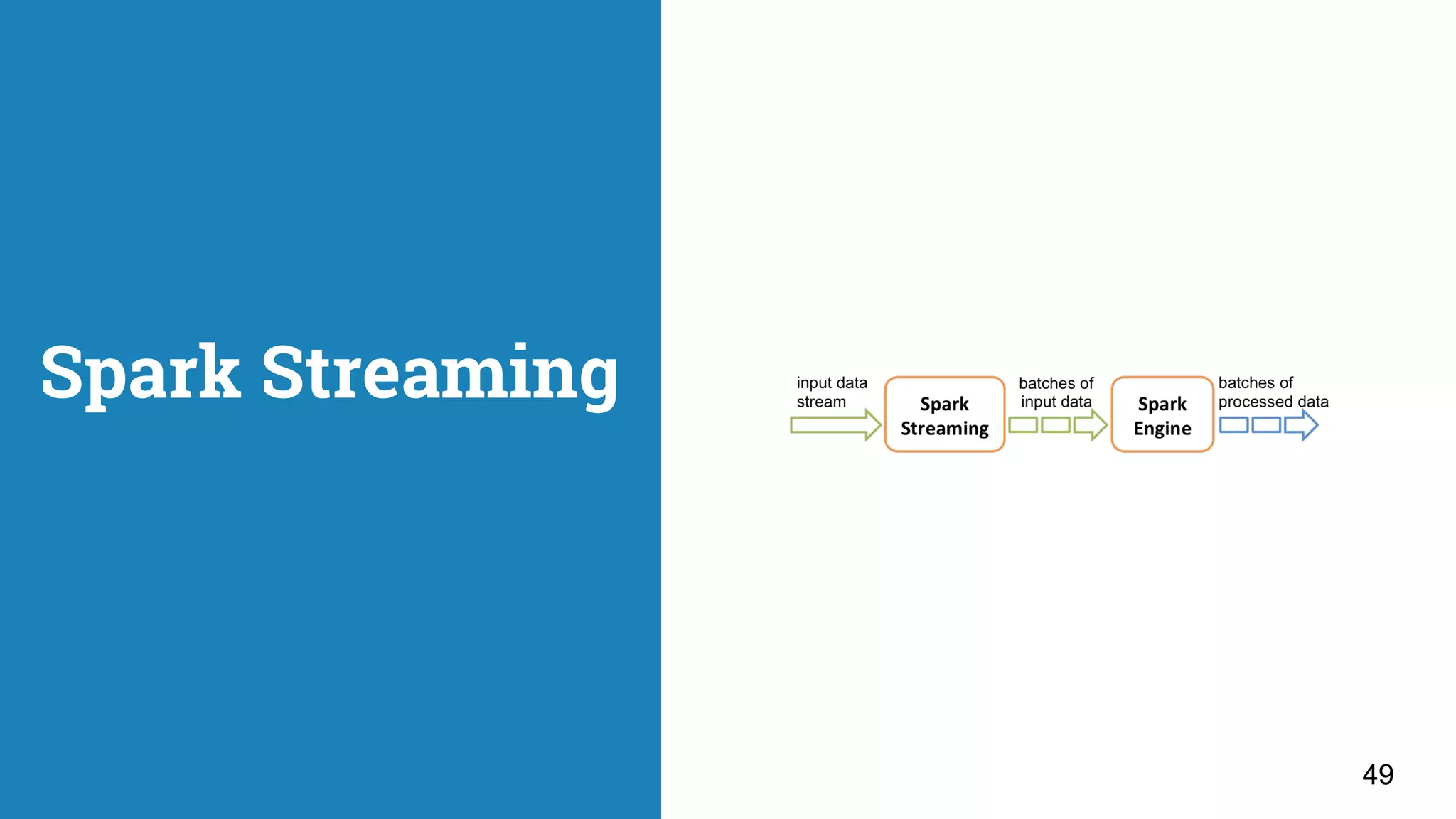
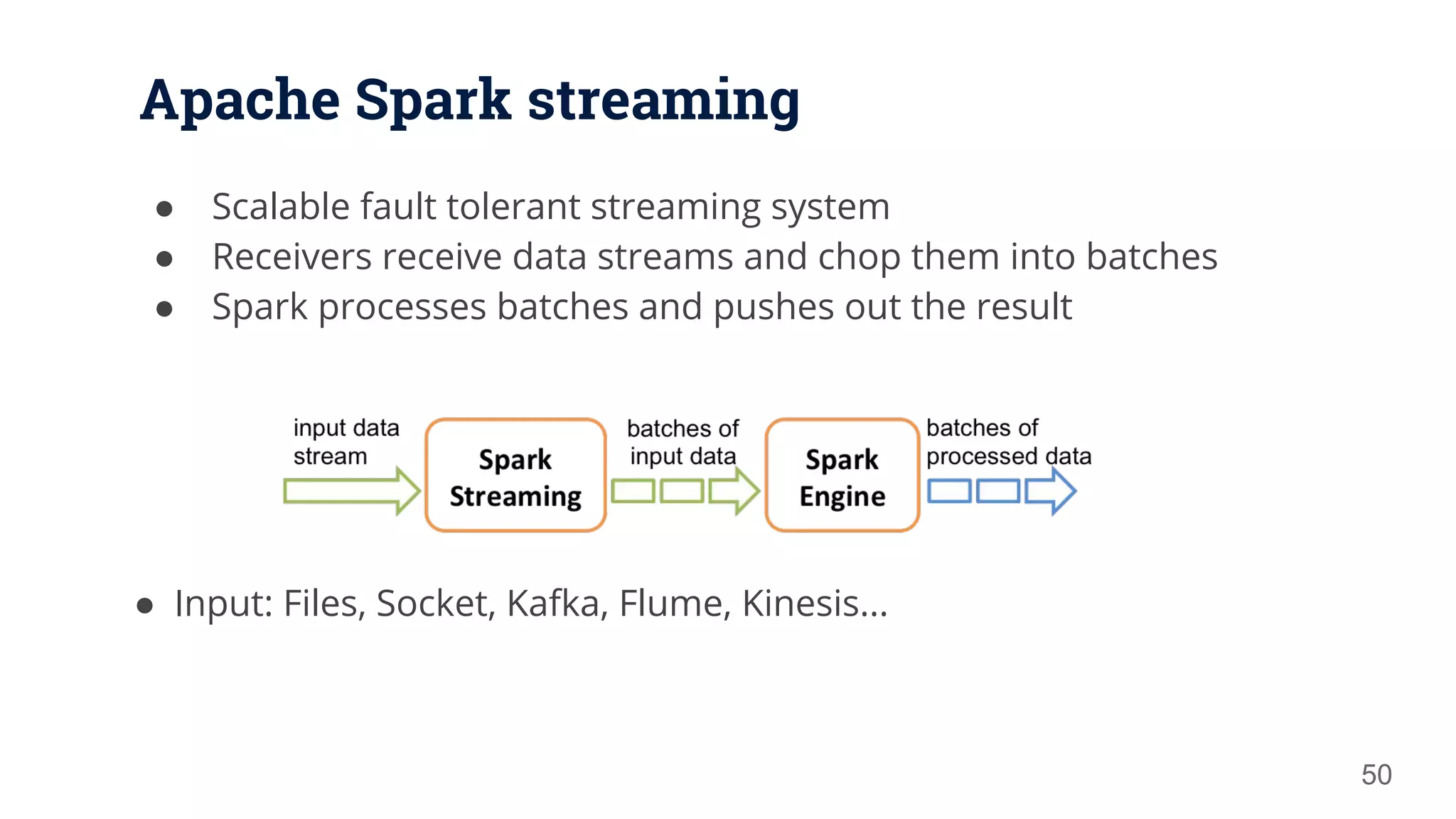
![Apache Spark streaming 51 def main(args: Array[String]) { val conf = new SparkConf() .setMaster("local[2]") .setAppName("Incidents processing job - Stream") val ssc = new StreamingContext(conf, Seconds(1)) val topics = Set( Topics.Incident, val directKafkaStream = KafkaUtils.createDirectStream[Array[Byte], Array[Byte], DefaultDecoder, DefaultDecoder]( ssc, kafkaParams, topics) // process batches directKafkaStream.map(_._2).flatMap(_.split(“ “))... // Start the computation ssc.start() ssc.awaitTermination() System.exit(0) }](https://image.slidesharecdn.com/apachesparkthenextgenerationclustercomputing-170426000340/75/Apache-Spark-the-Next-Generation-Cluster-Computing-51-2048.jpg)

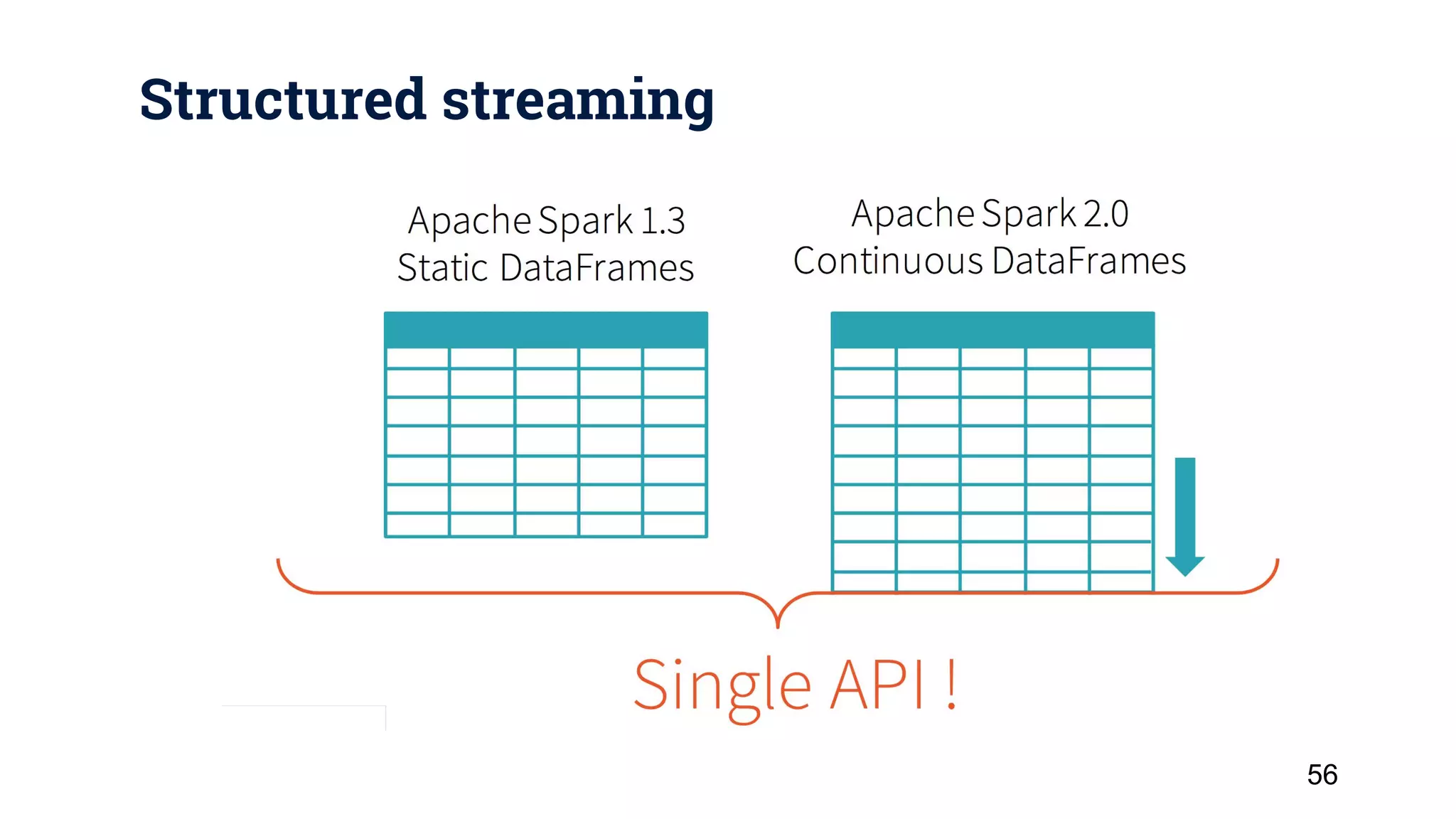
![Structured streaming 53 [Alpha version in Spark 2.1] 53](https://image.slidesharecdn.com/apachesparkthenextgenerationclustercomputing-170426000340/75/Apache-Spark-the-Next-Generation-Cluster-Computing-53-2048.jpg)








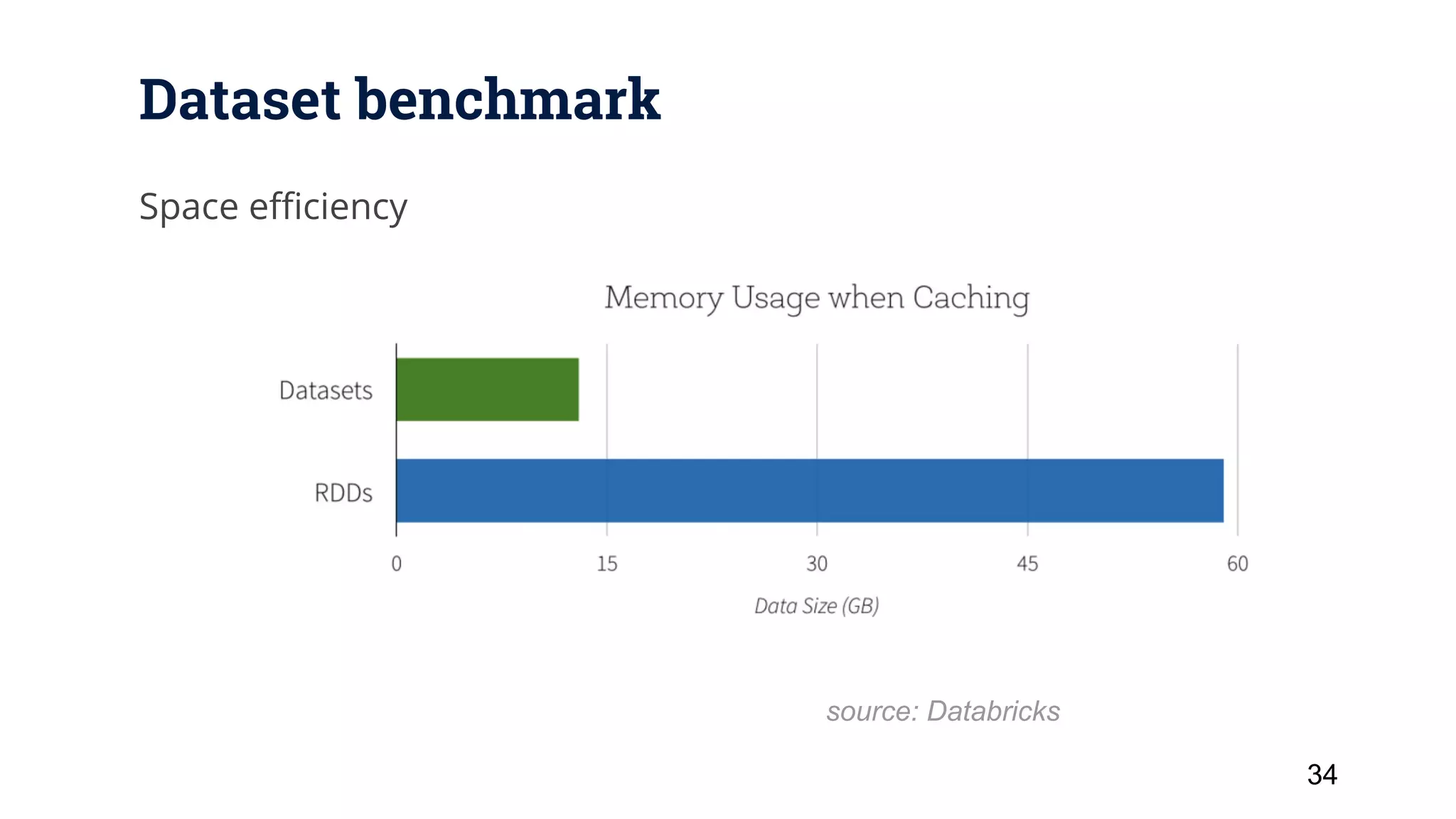
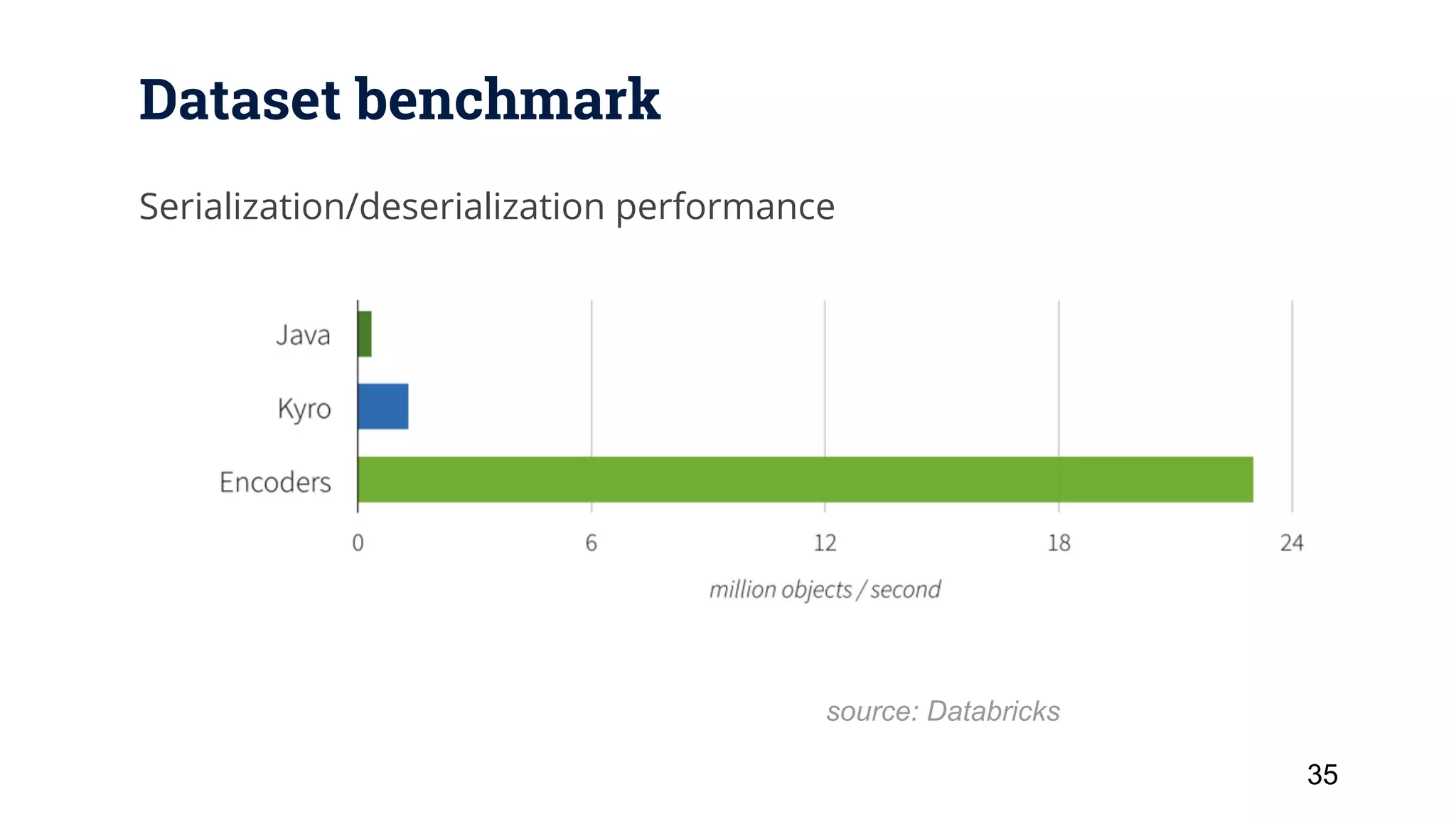
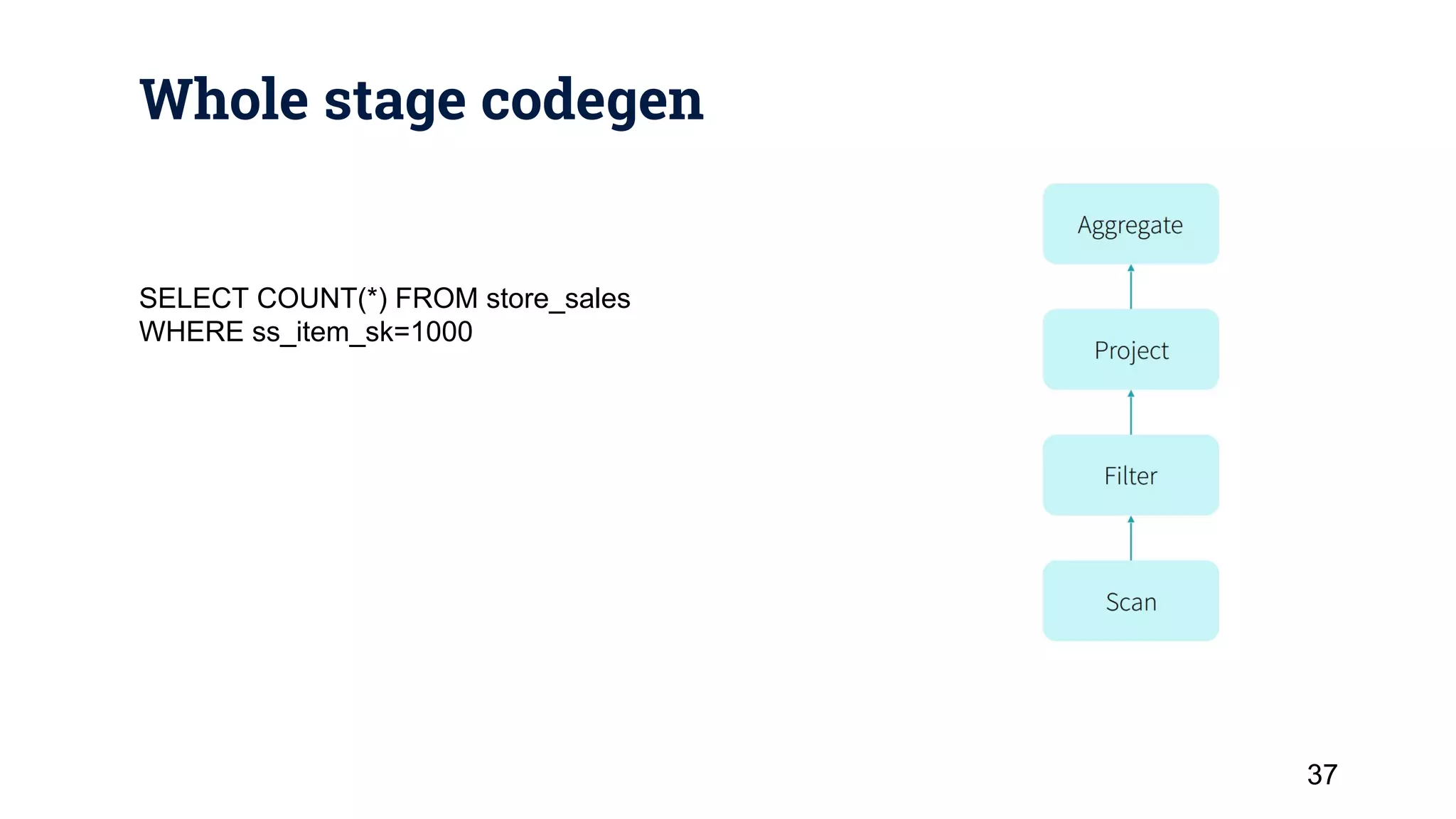
This document provides a 3 sentence summary of the key points: Apache Spark is an open source cluster computing framework that is faster than Hadoop MapReduce by running computations in memory through RDDs, DataFrames and Datasets. It provides high-level APIs for batch, streaming and interactive queries along with libraries for machine learning. Spark's performance is improved through techniques like Catalyst query optimization, Tungsten in-memory columnar formats, and whole stage code generation.