Downloaded 116 times


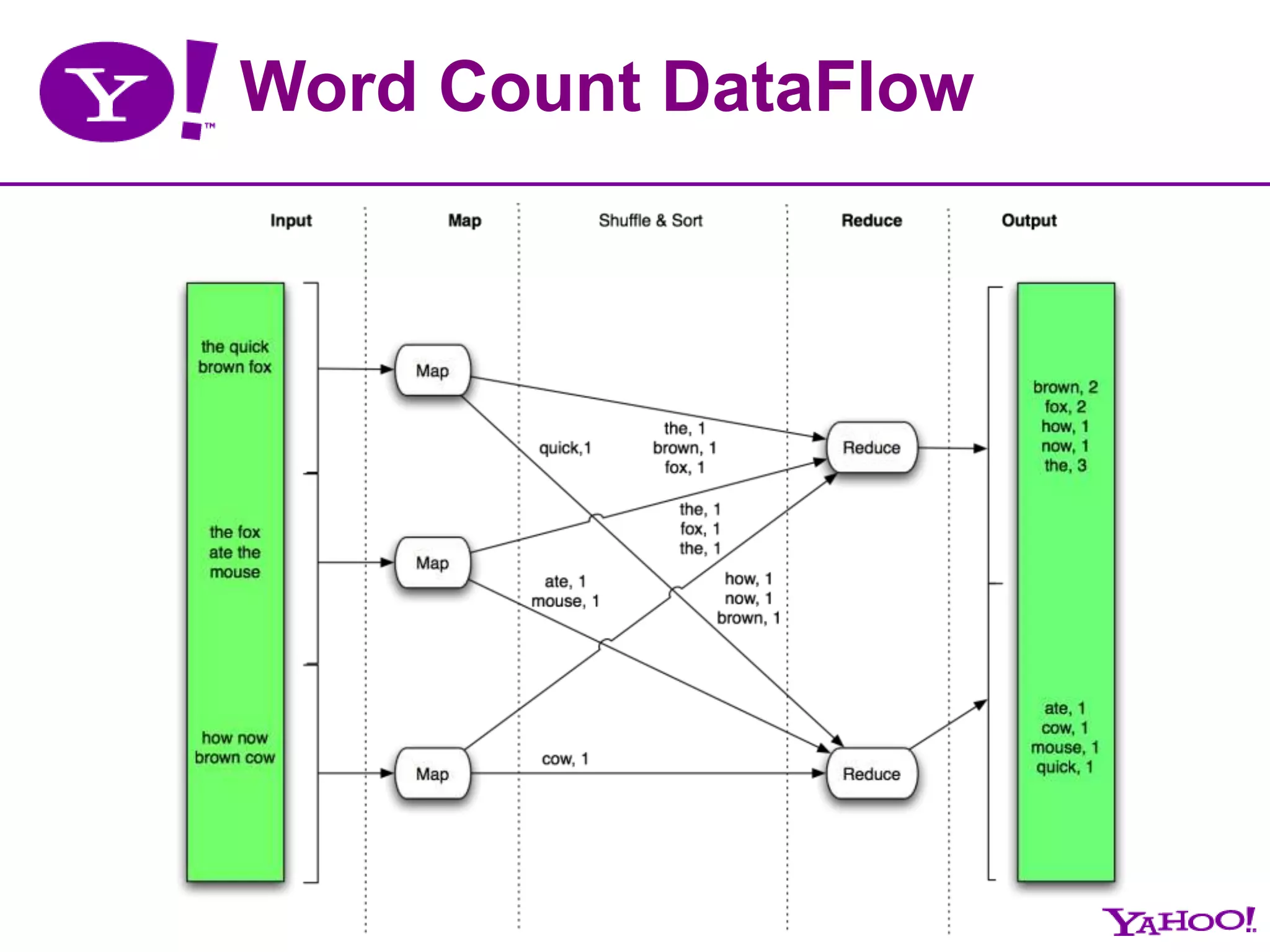

![MR for Word-Countmapper (filename, file-contents): for each word in file-contents: emit (word, 1)reducer (word, values[]): sum = 0 for each value in values: sum = sum + value emit (word, sum)5](https://image.slidesharecdn.com/ahis2011applicationmap-reduceprogrammingbestpractices-110224021311-phpapp02/75/Apache-Hadoop-India-Summit-2011-talk-Hadoop-Map-Reduce-Programming-Best-Practices-by-Basant-Verma-5-2048.jpg)
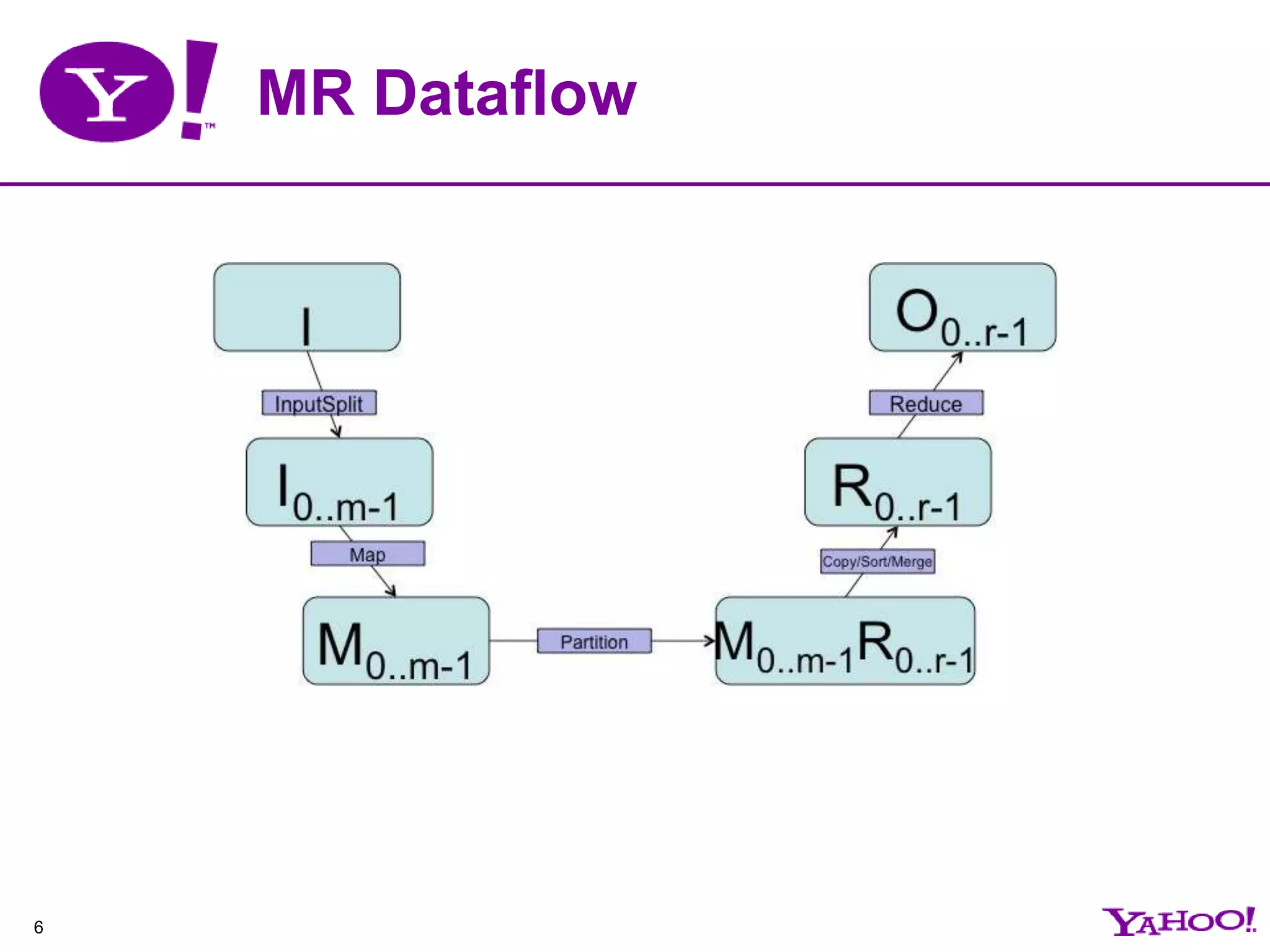
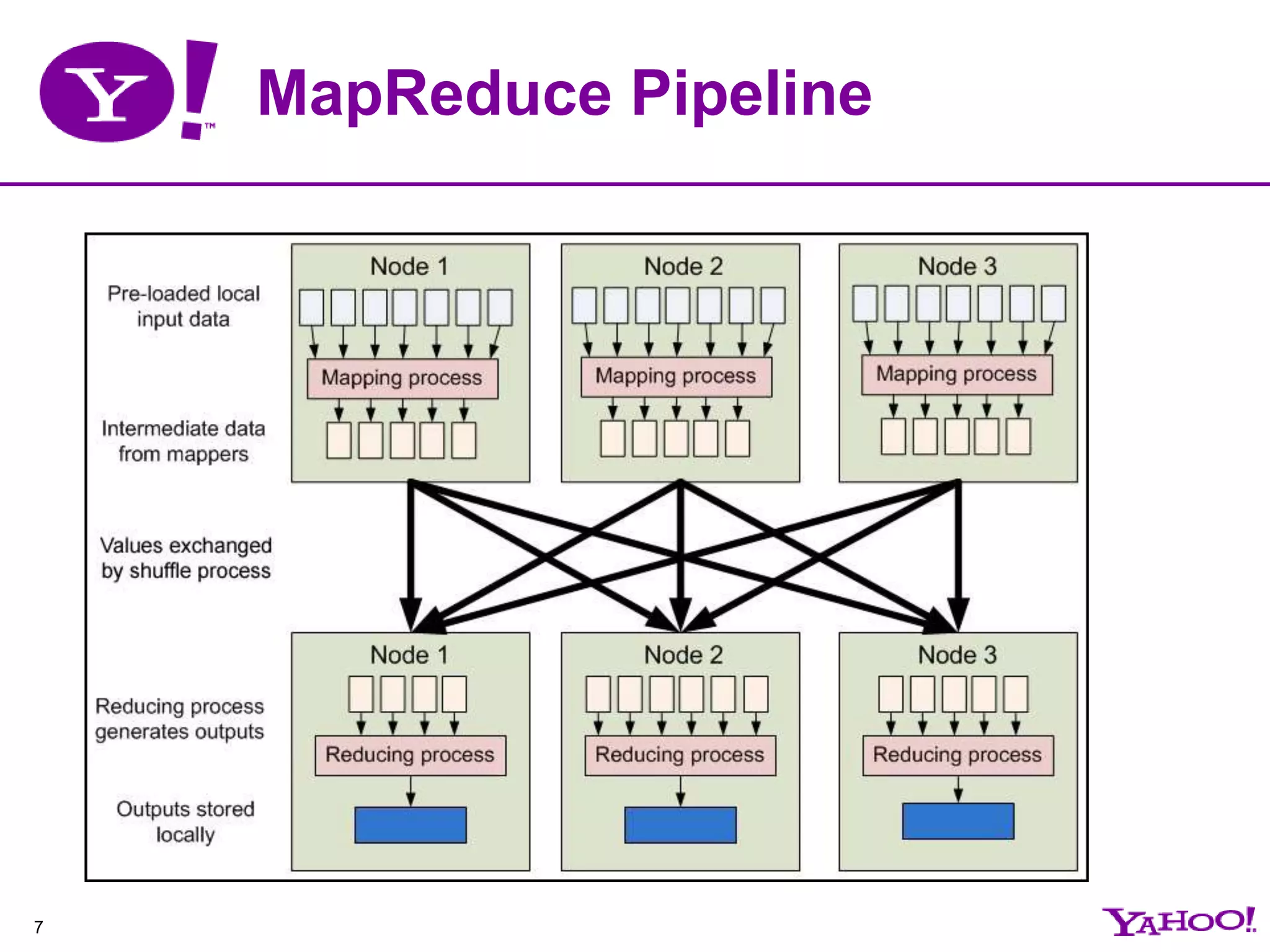
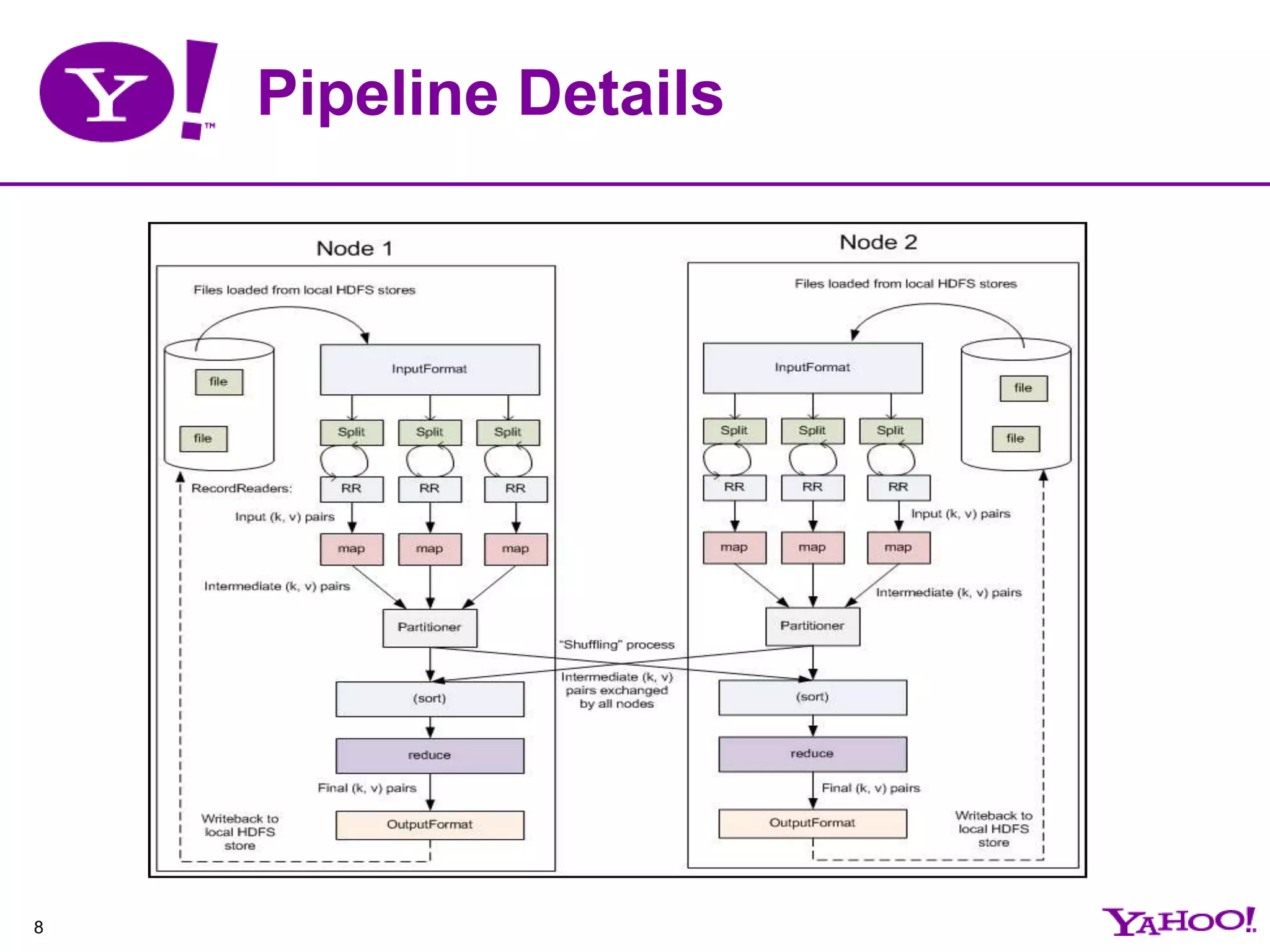




















This document provides an overview of MapReduce programming and best practices for Apache Hadoop. It describes the key components of Hadoop including HDFS, MapReduce, and the data flow. It also discusses optimizations that can be made to MapReduce jobs, such as using combiners, compression, and speculation. Finally, it outlines some anti-patterns to avoid and tips for debugging MapReduce applications.