



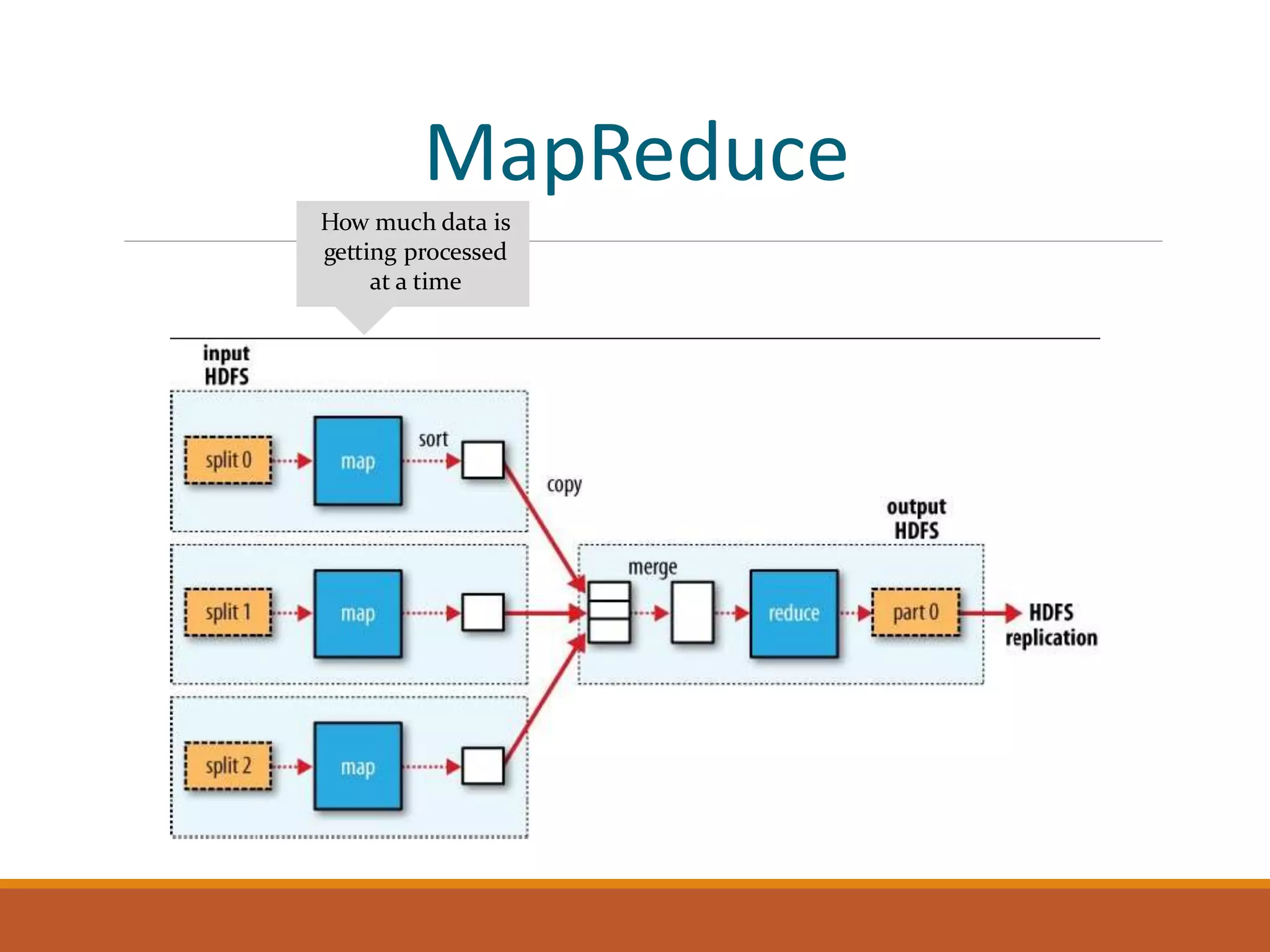
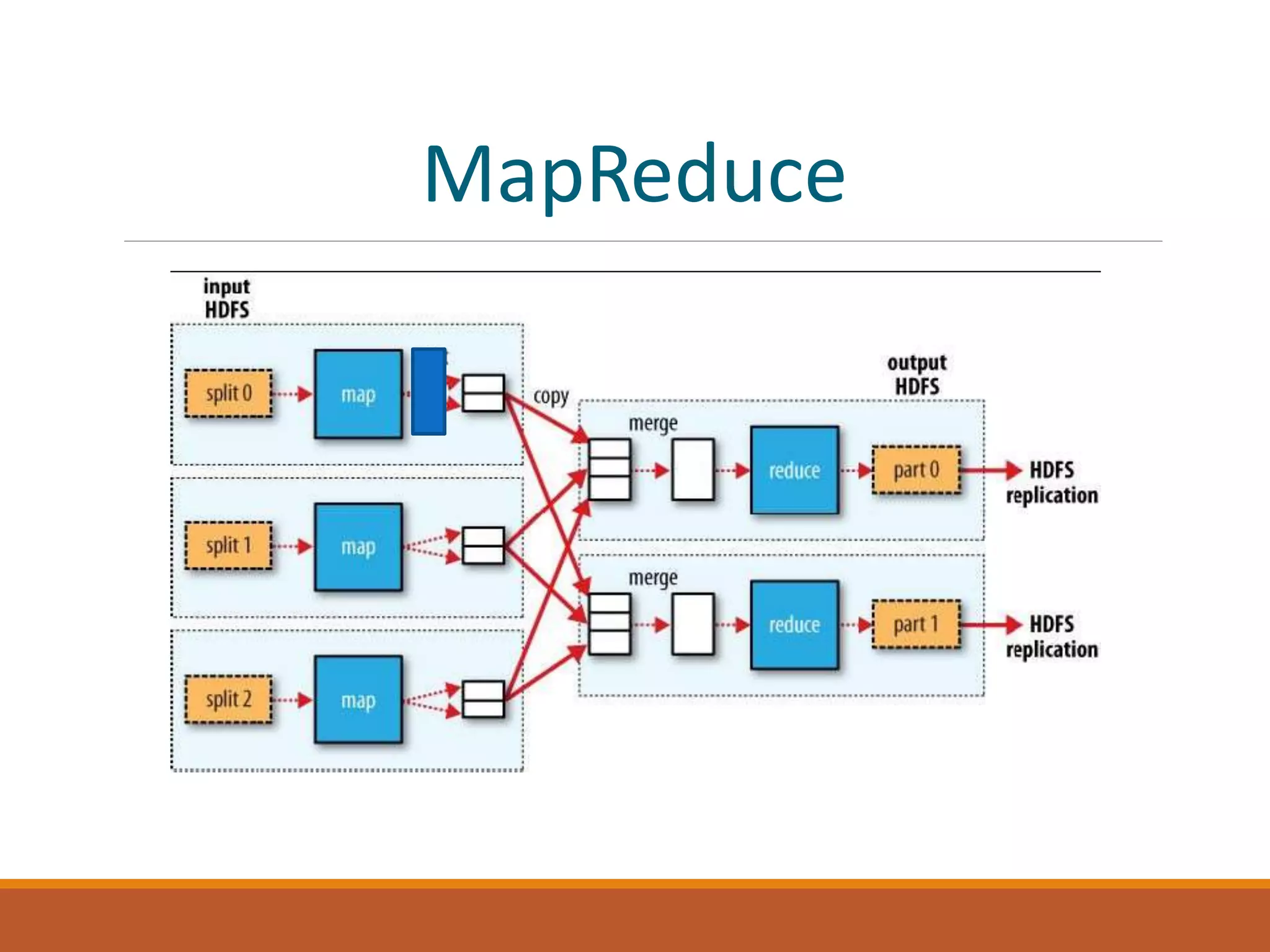
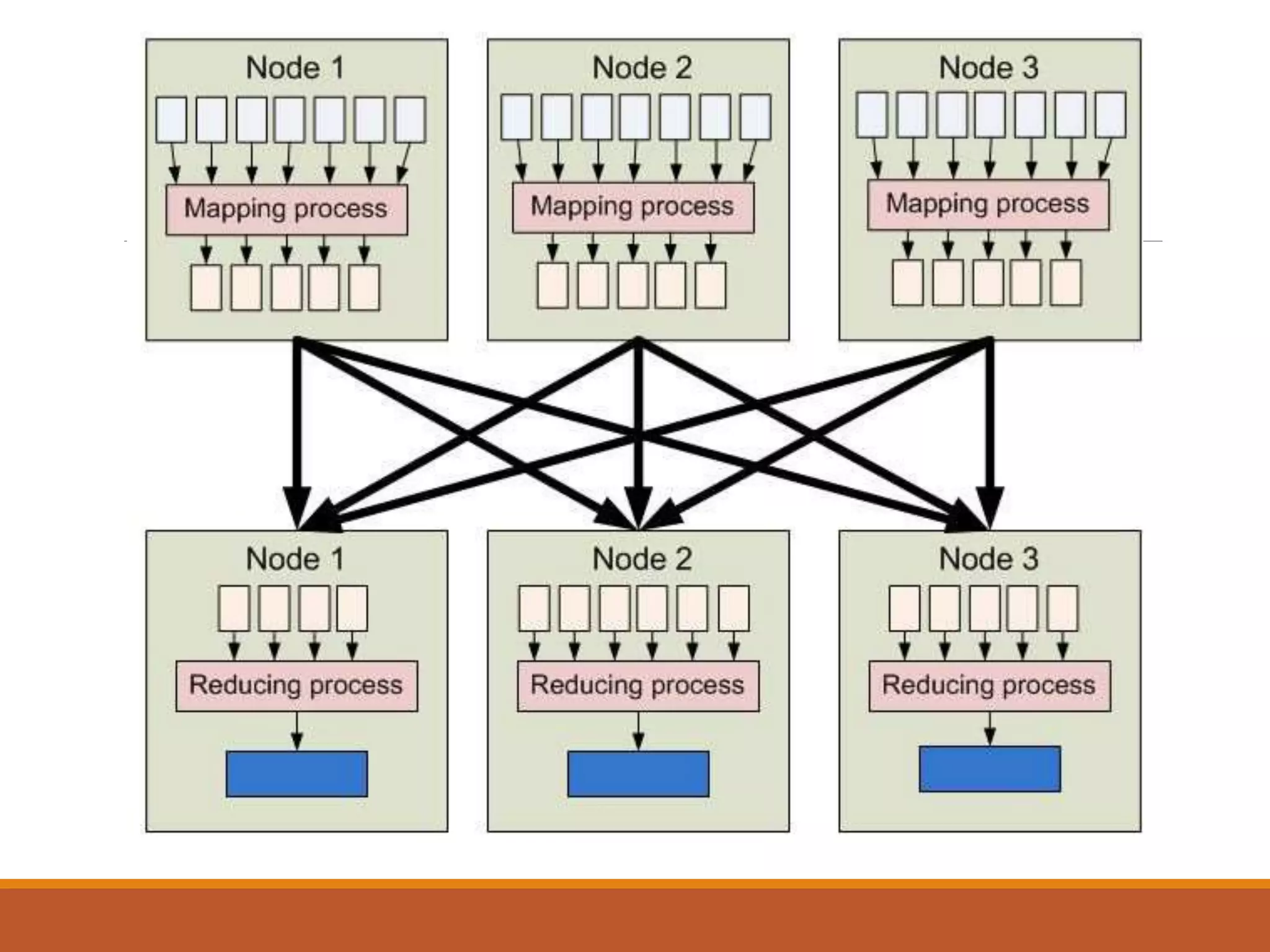
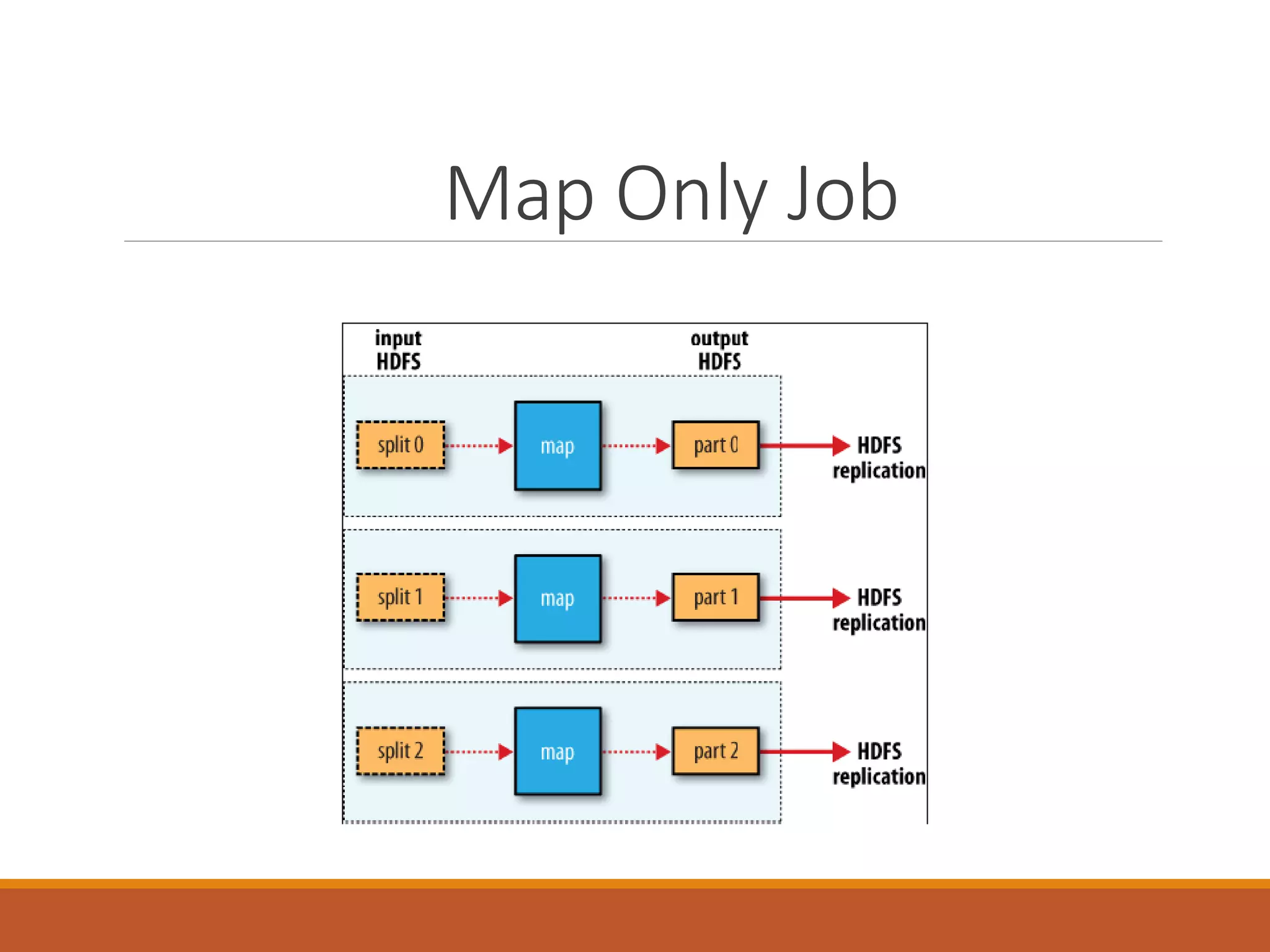





MapReduce is a programming model for processing large datasets in parallel. It works by breaking the dataset into independent chunks which are processed by the map function, and then grouping the output of the maps into partitions to be processed by the reduce function. Hadoop uses MapReduce to provide fault tolerance by restarting failed tasks and monitoring the JobTracker and TaskTrackers. MapReduce programs can be written in languages other than Java using Hadoop Streaming.