Downloaded 12,800 times
























































































![Event-Driven Architecture “Four years from now,‘mere mortals’ will begin to adopt an event-driven architecture (EDA) for the sort of complex event processing that has been attempted only by software gurus [until now]” --Roy Schulte (Gartner), 2003](https://image.slidesharecdn.com/scalabilitypatterns20100510-100512004526-phpapp02/75/Scalability-Availability-Stability-Patterns-115-2048.jpg)






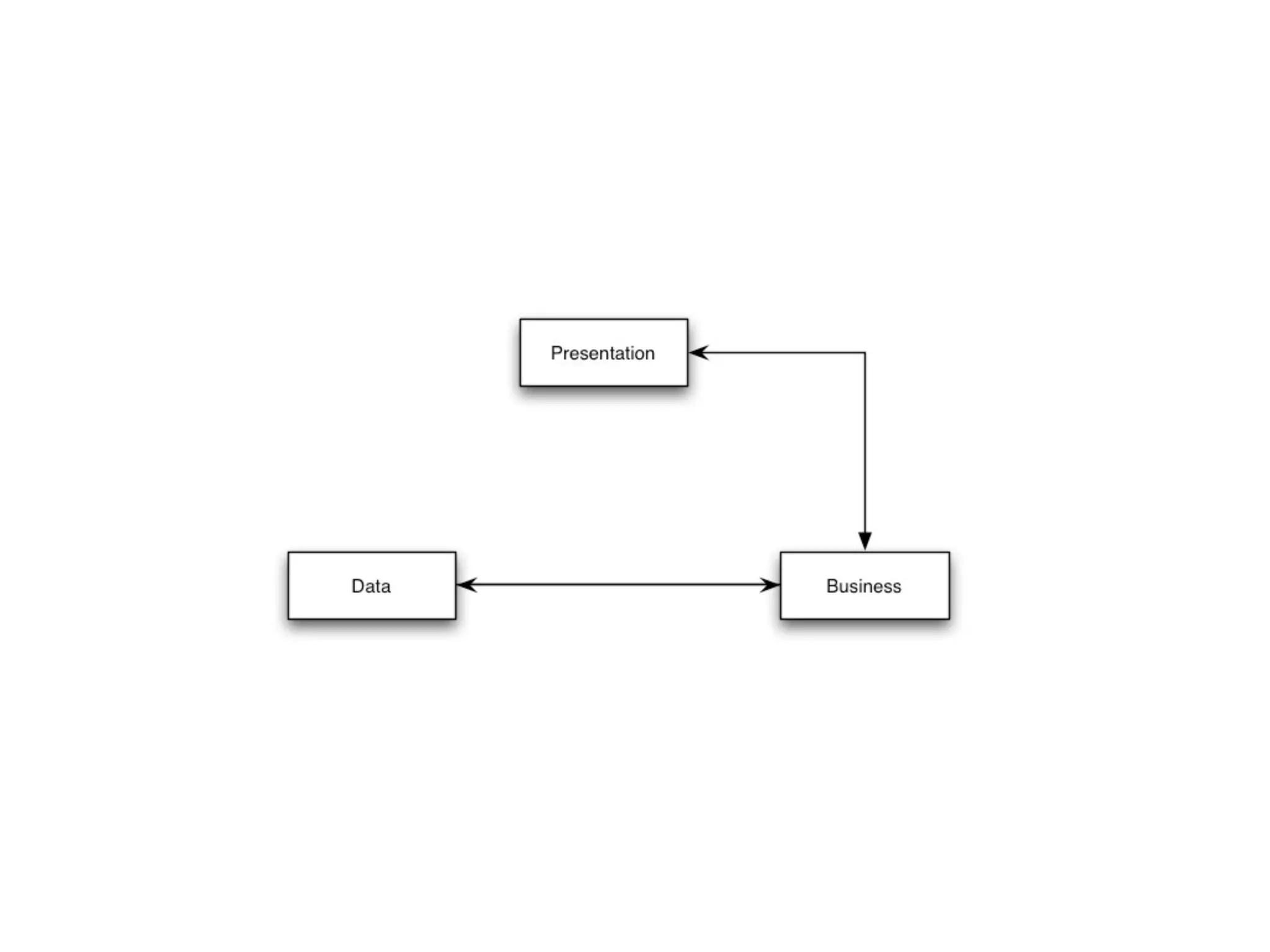
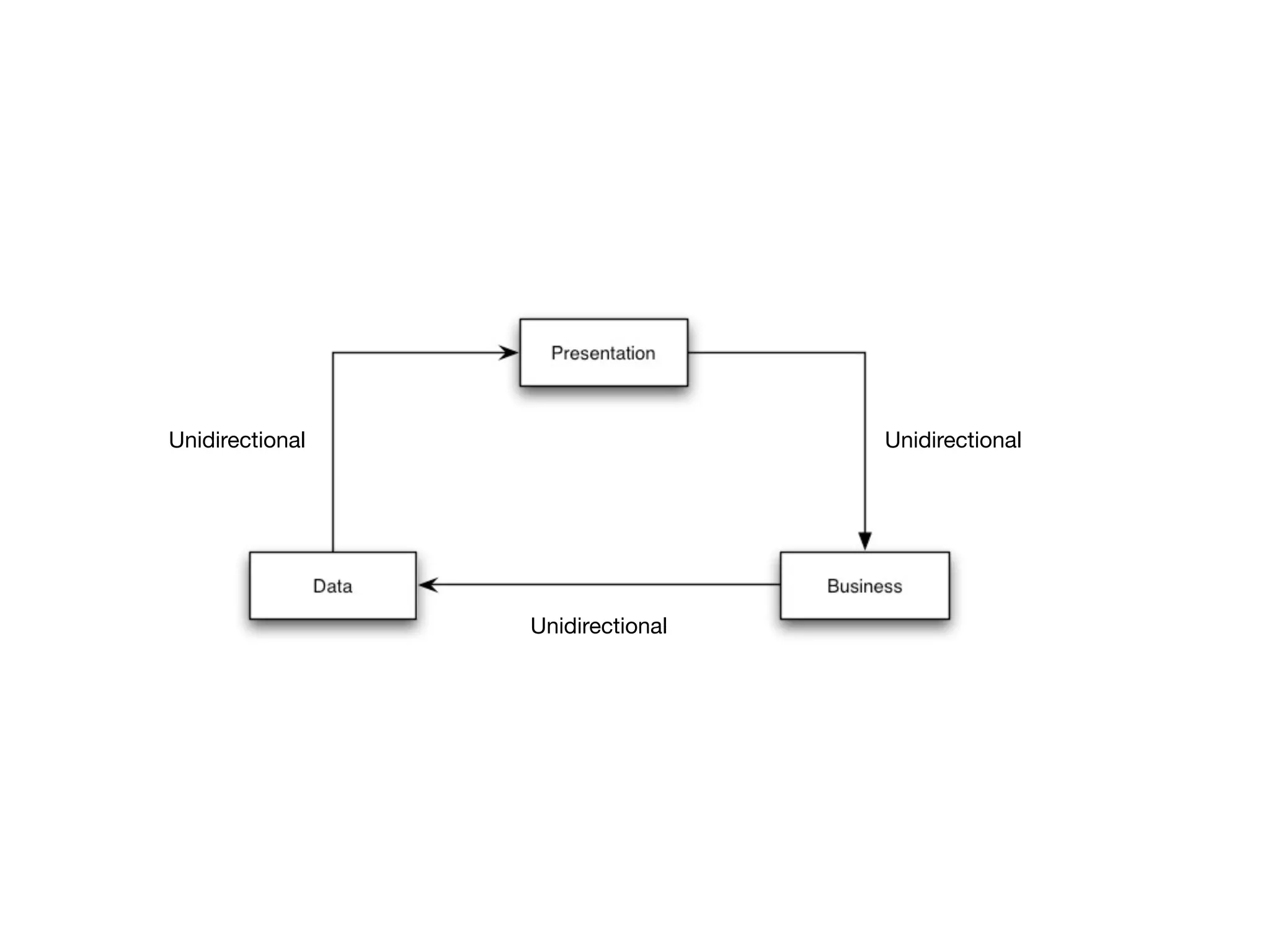
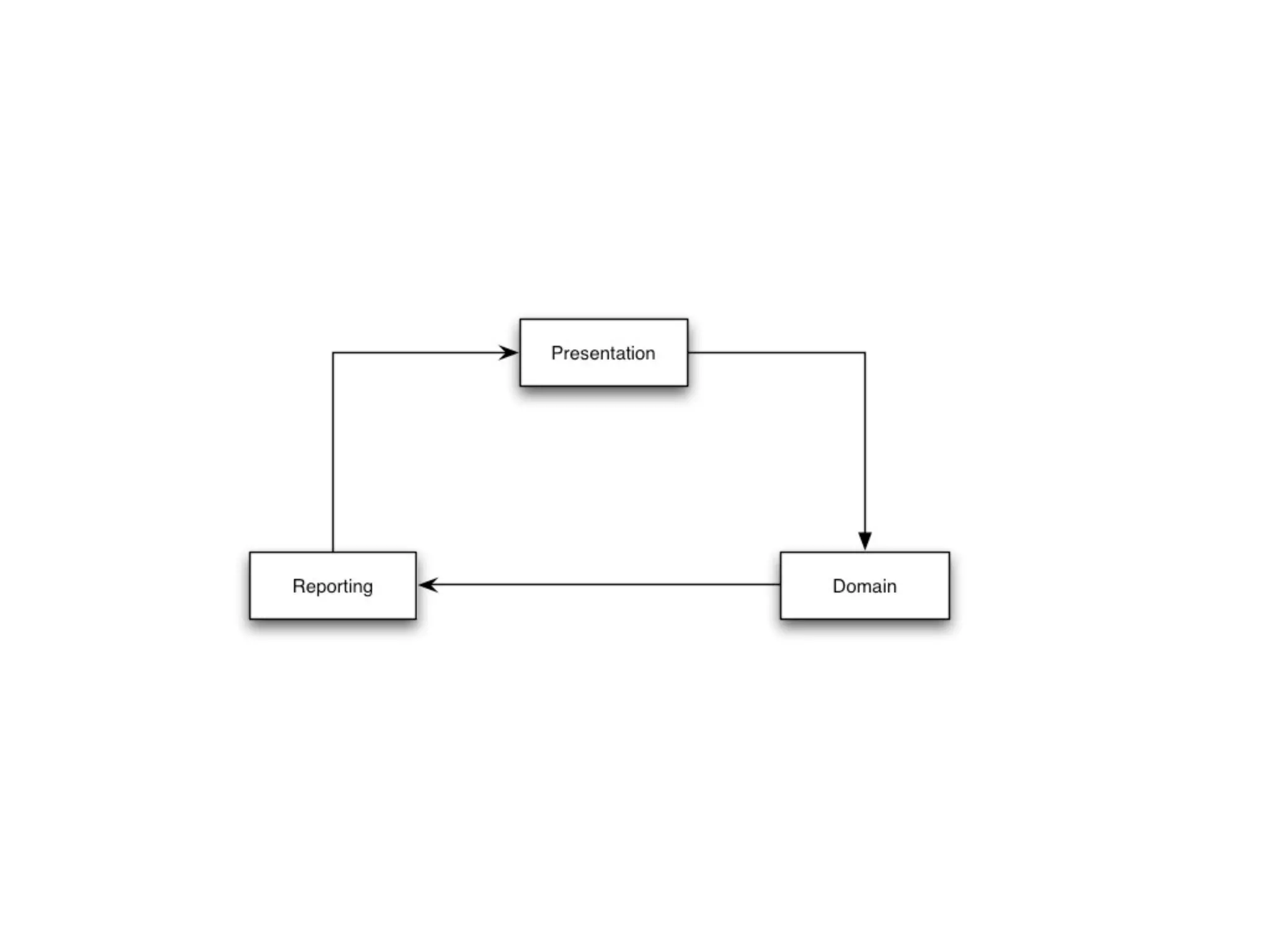
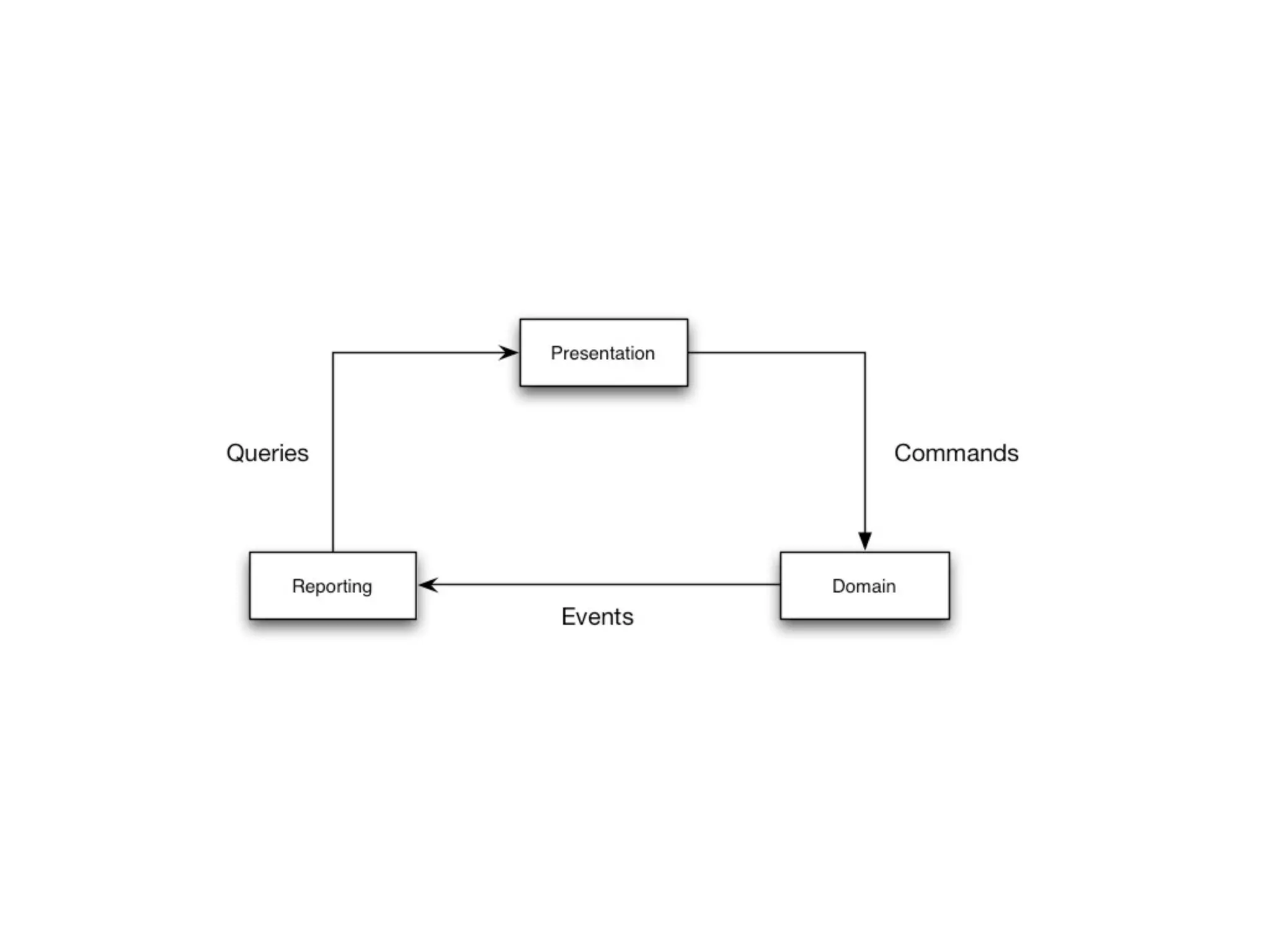
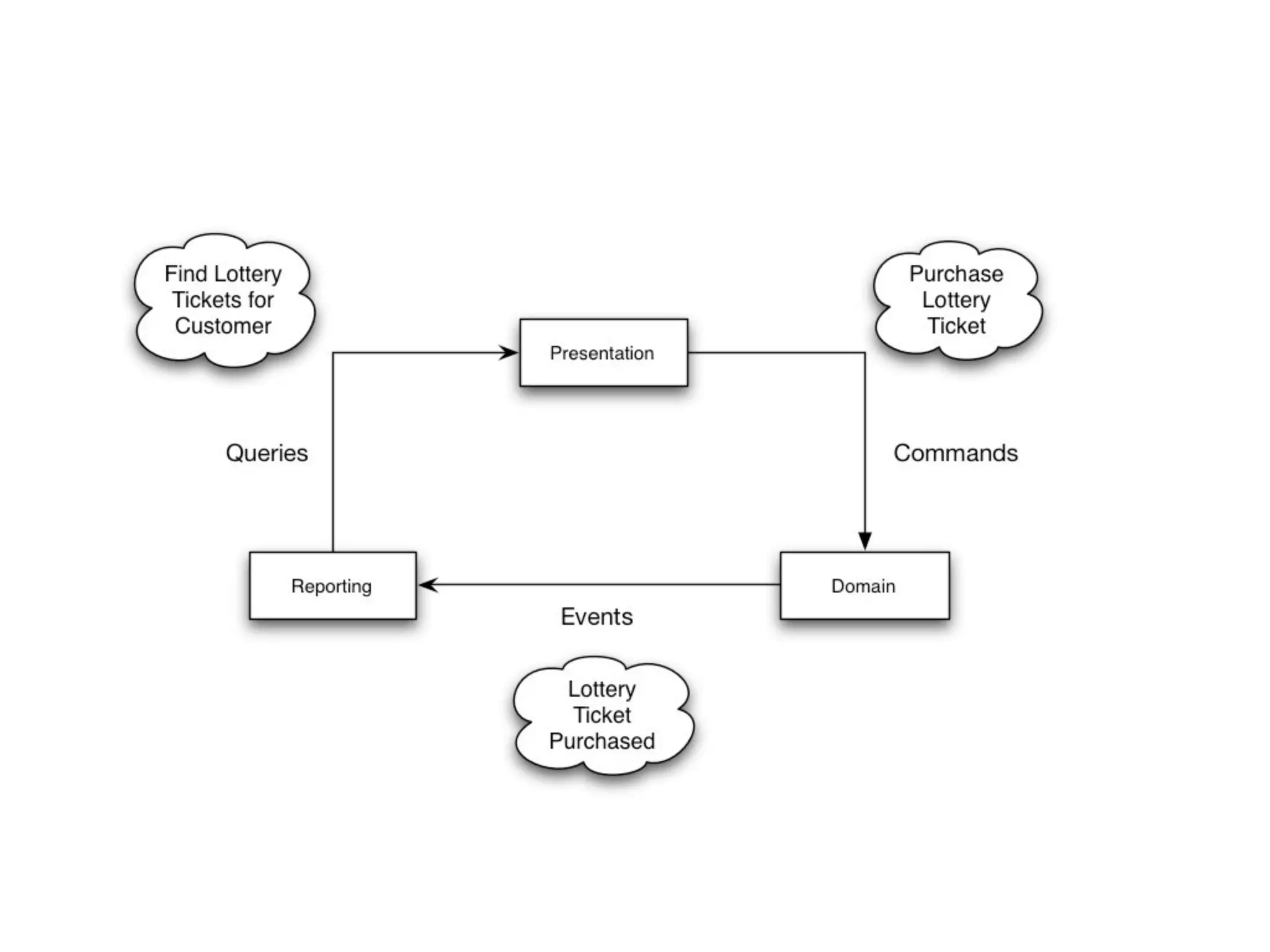

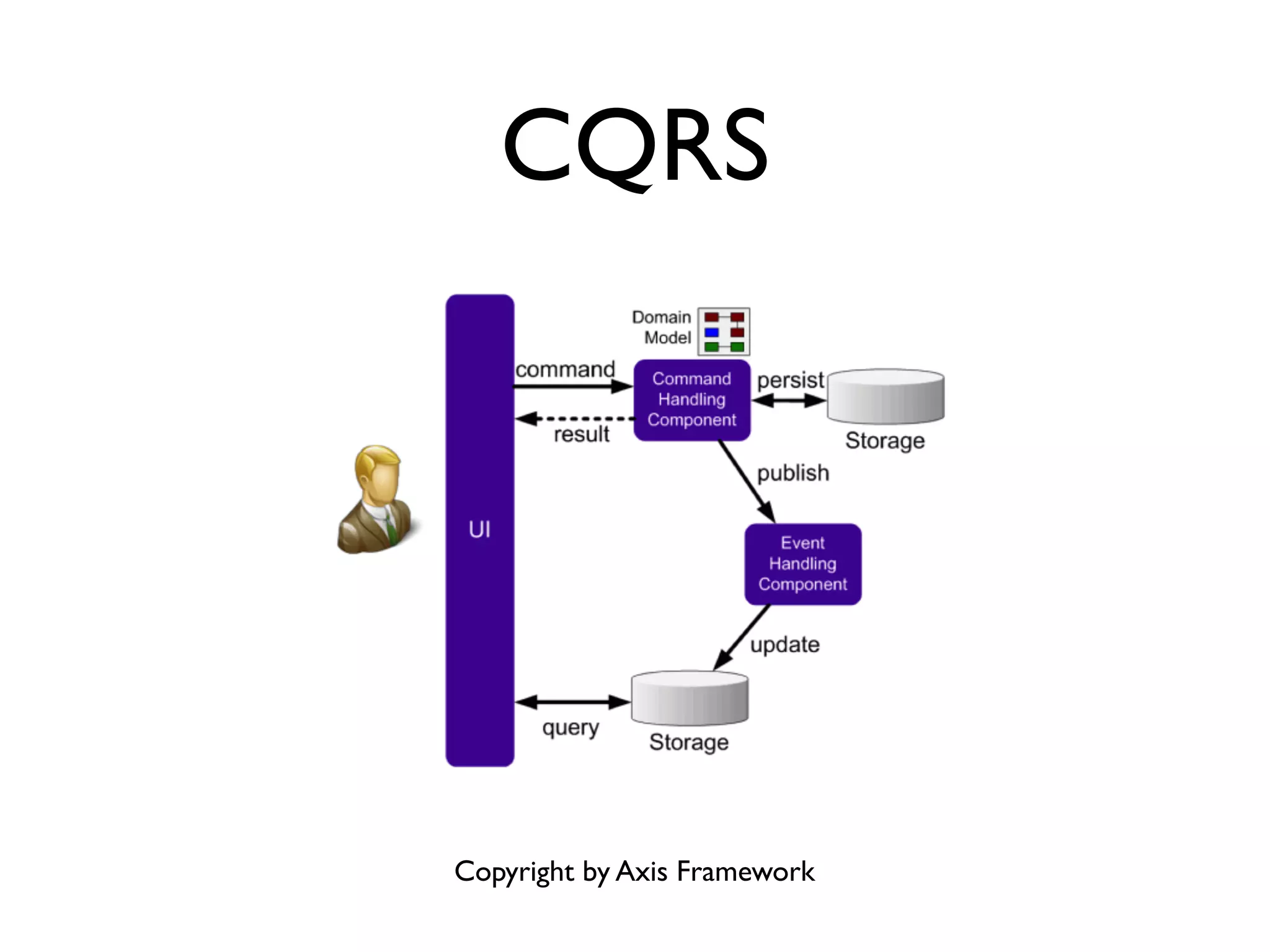

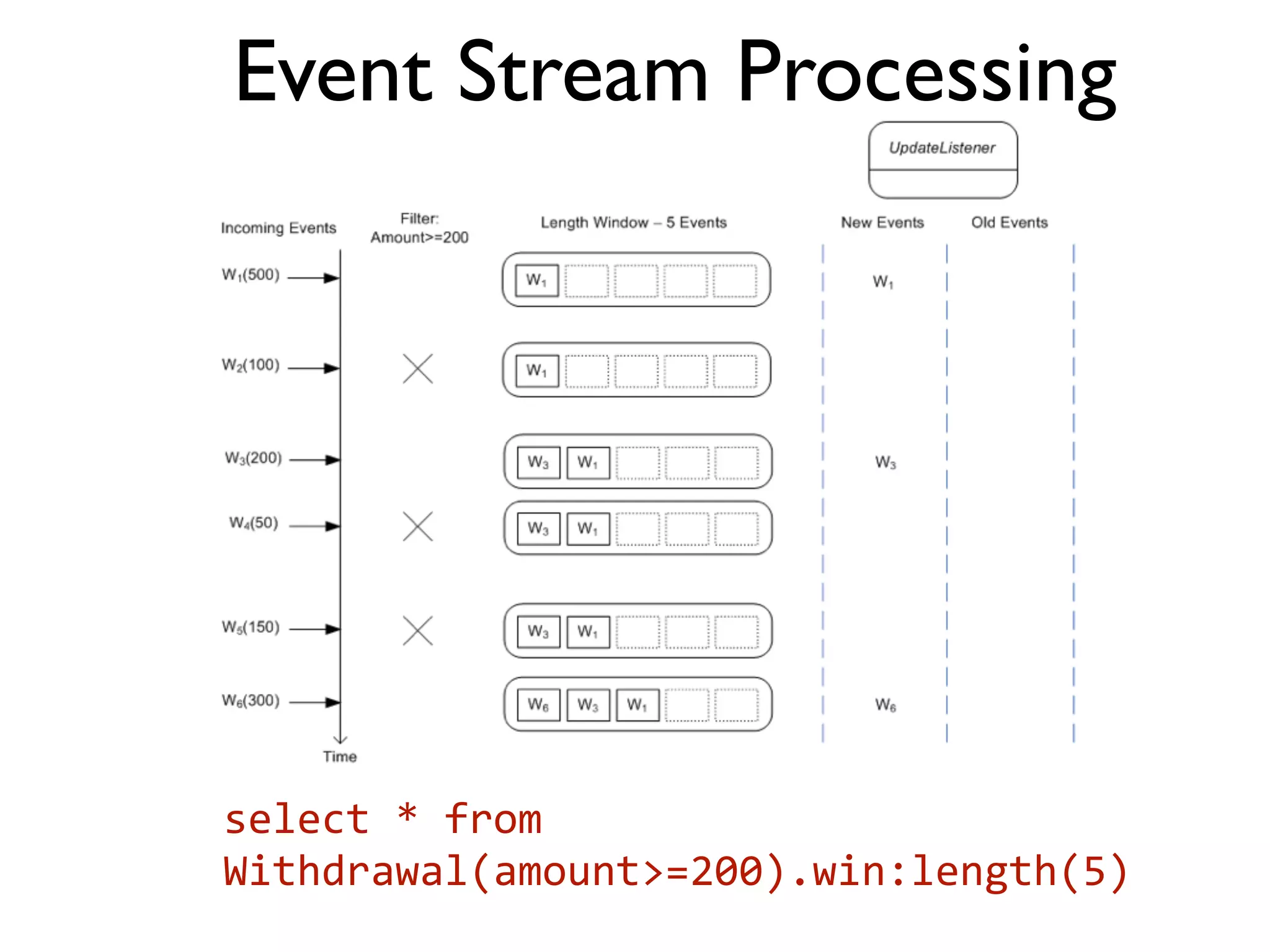


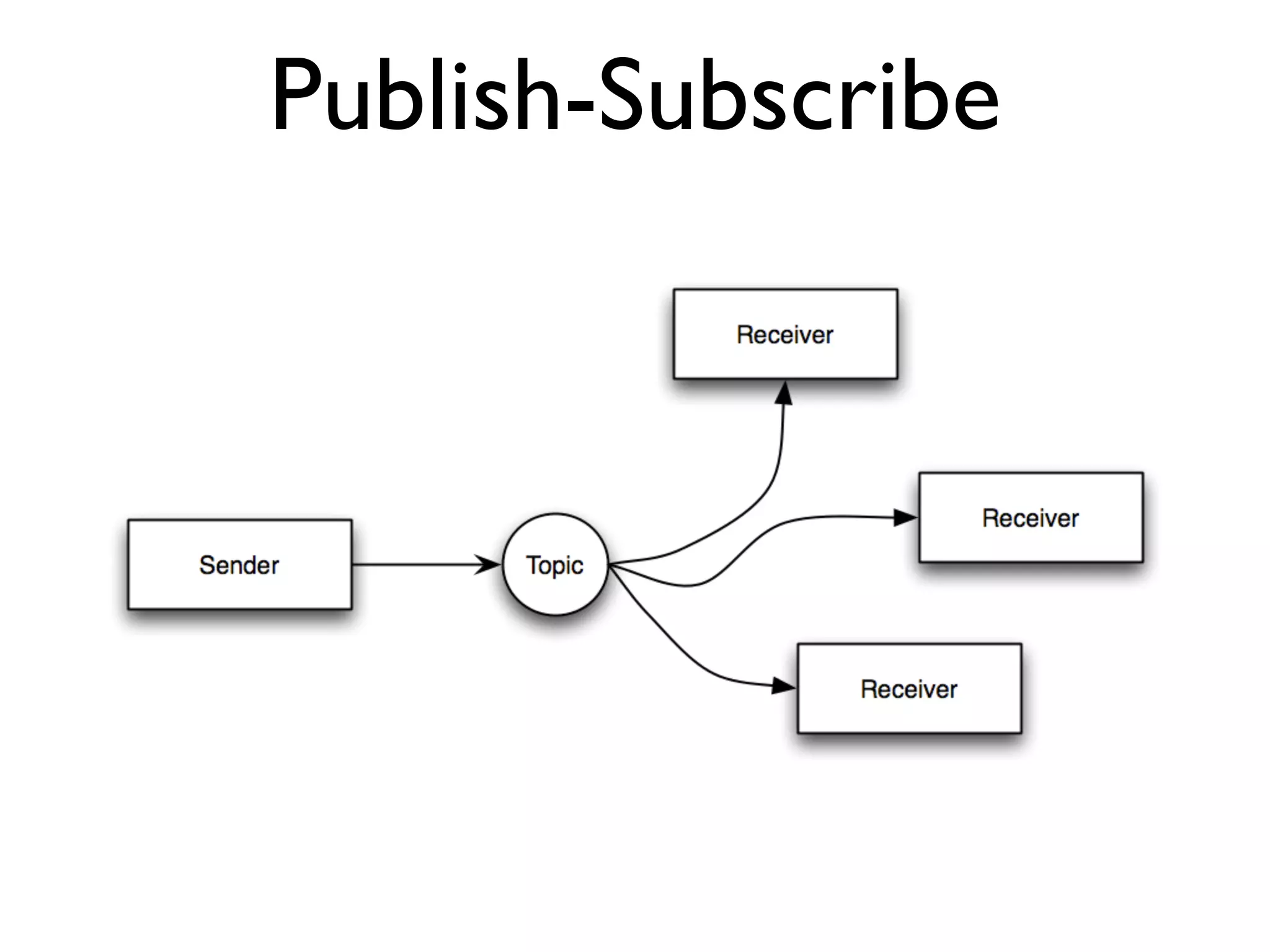
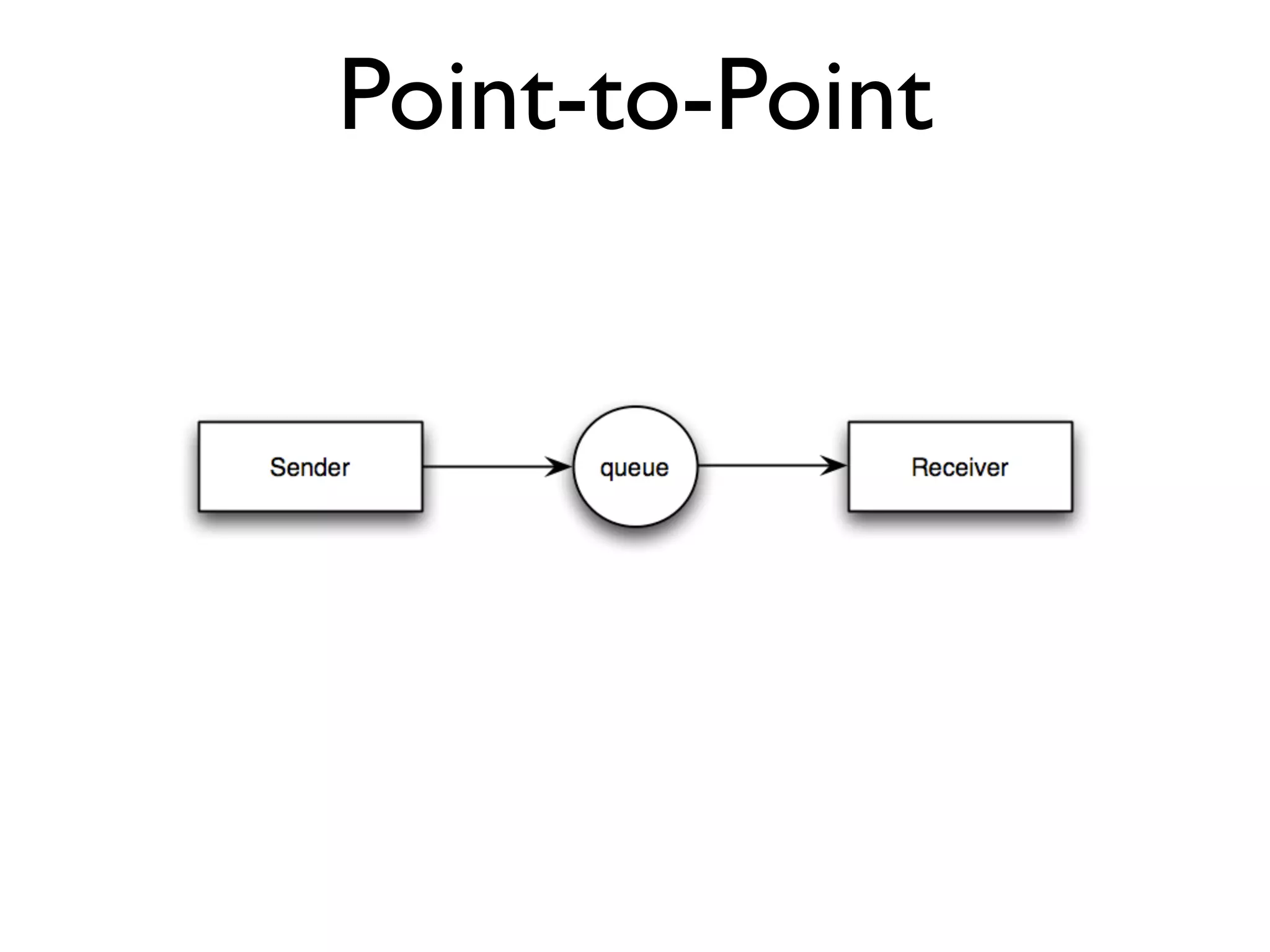
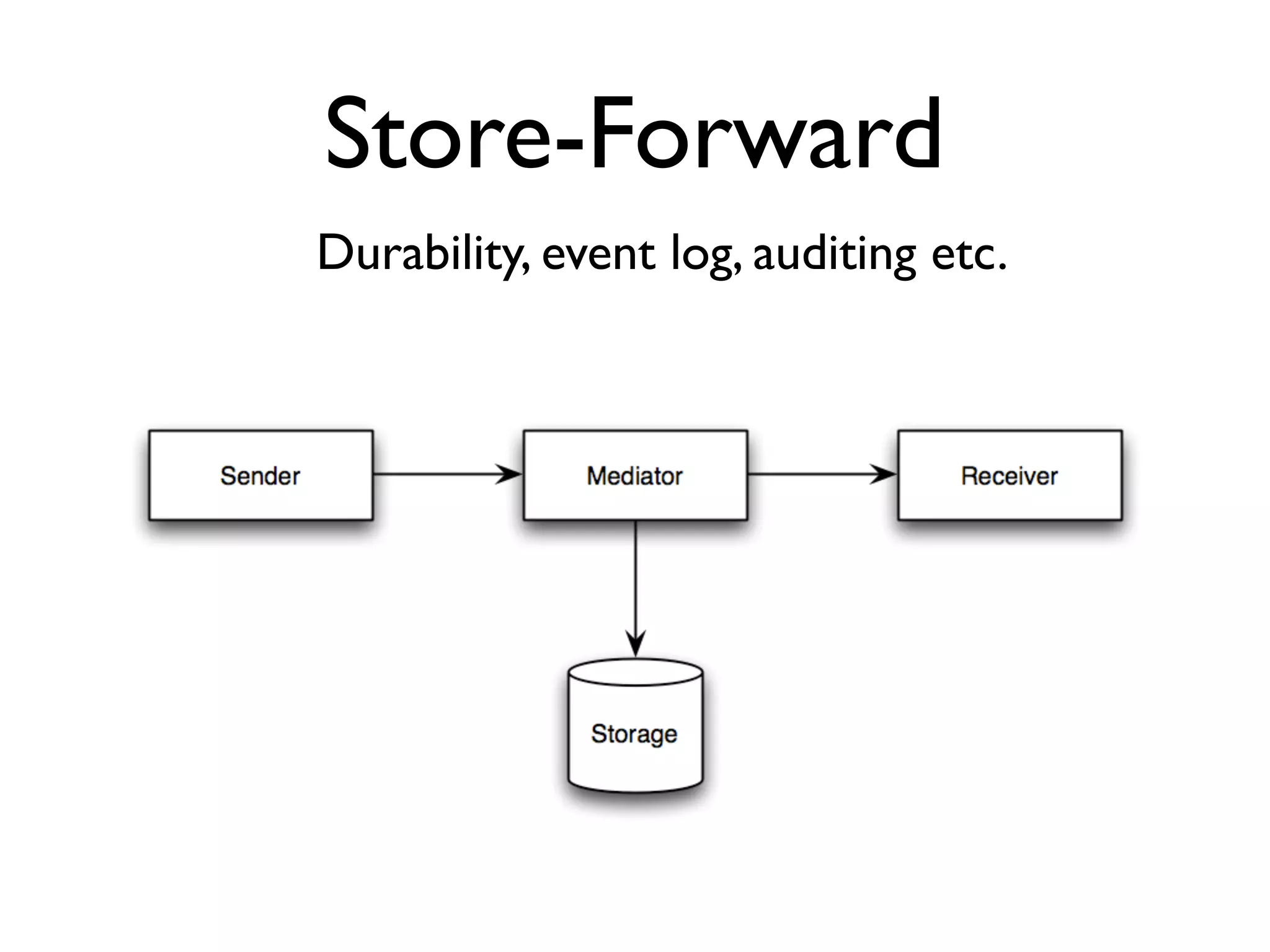
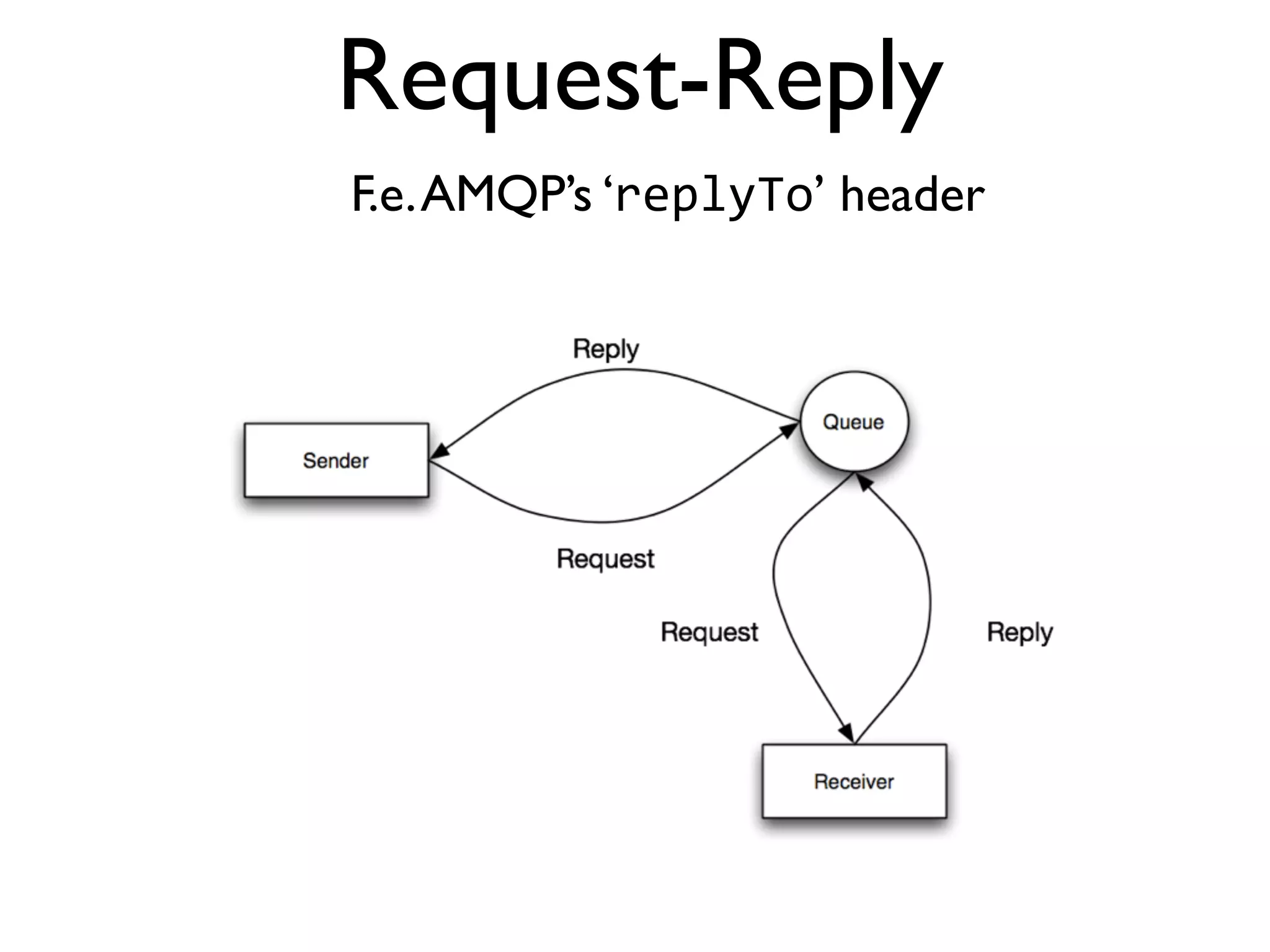

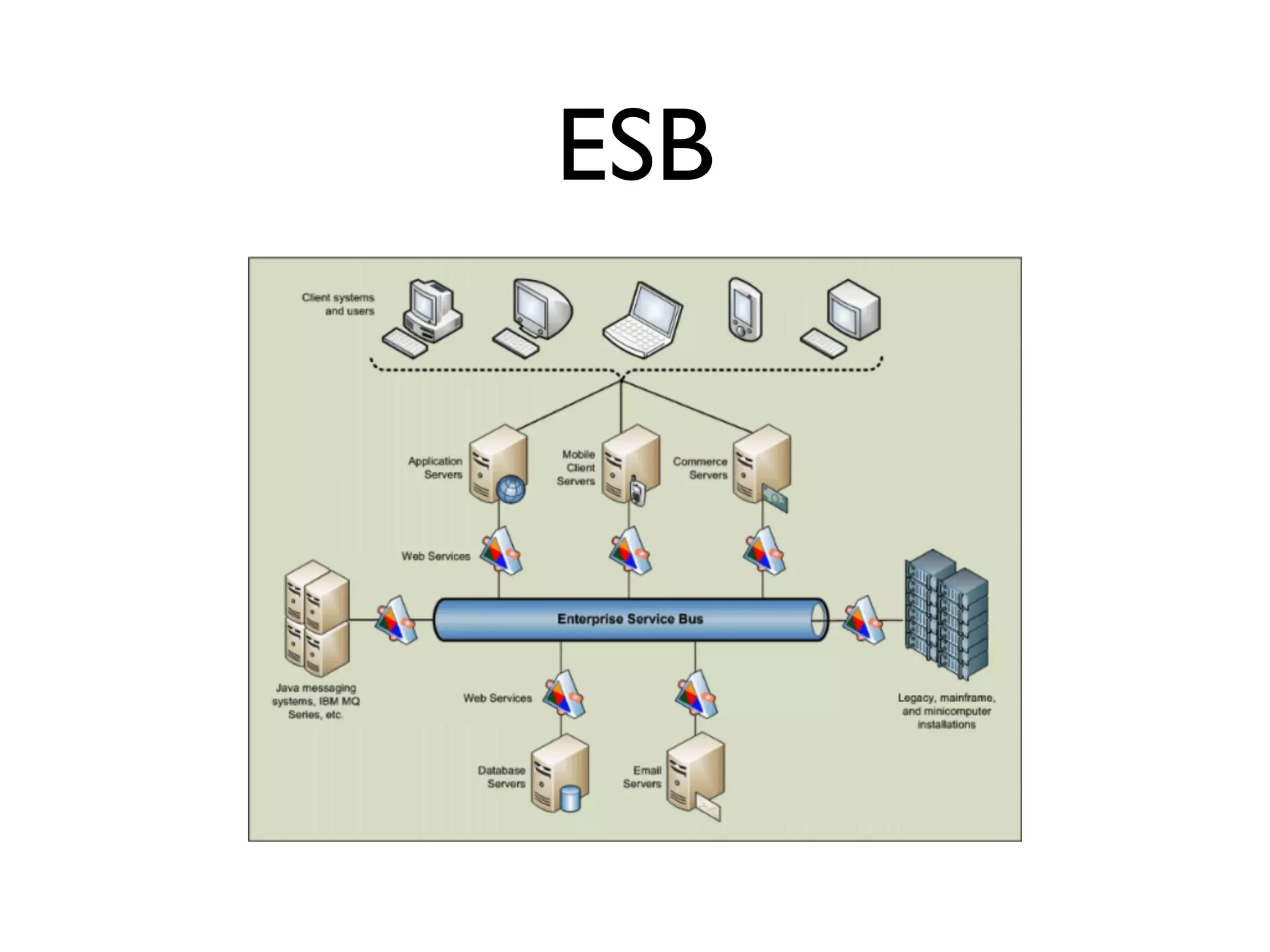

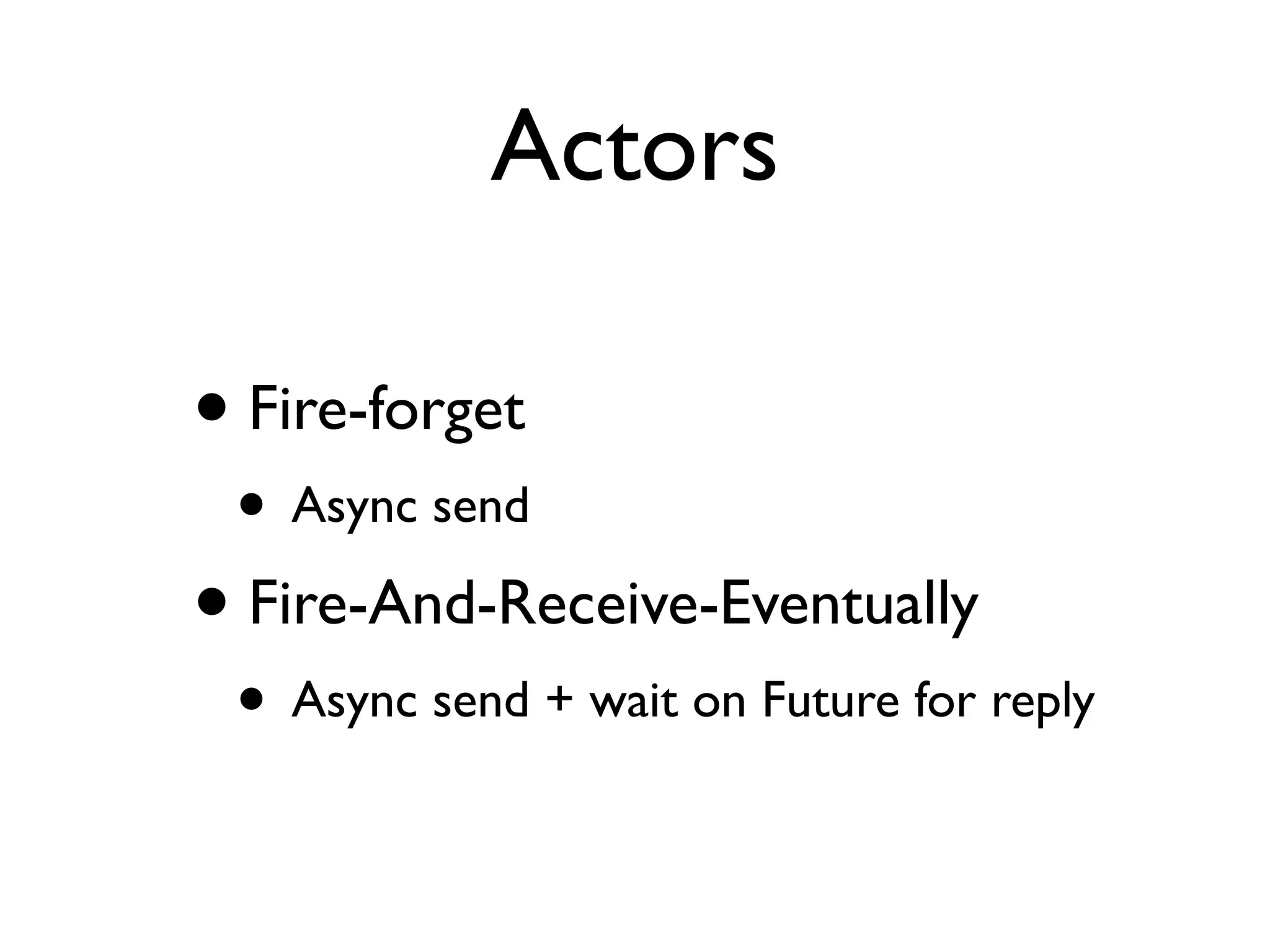













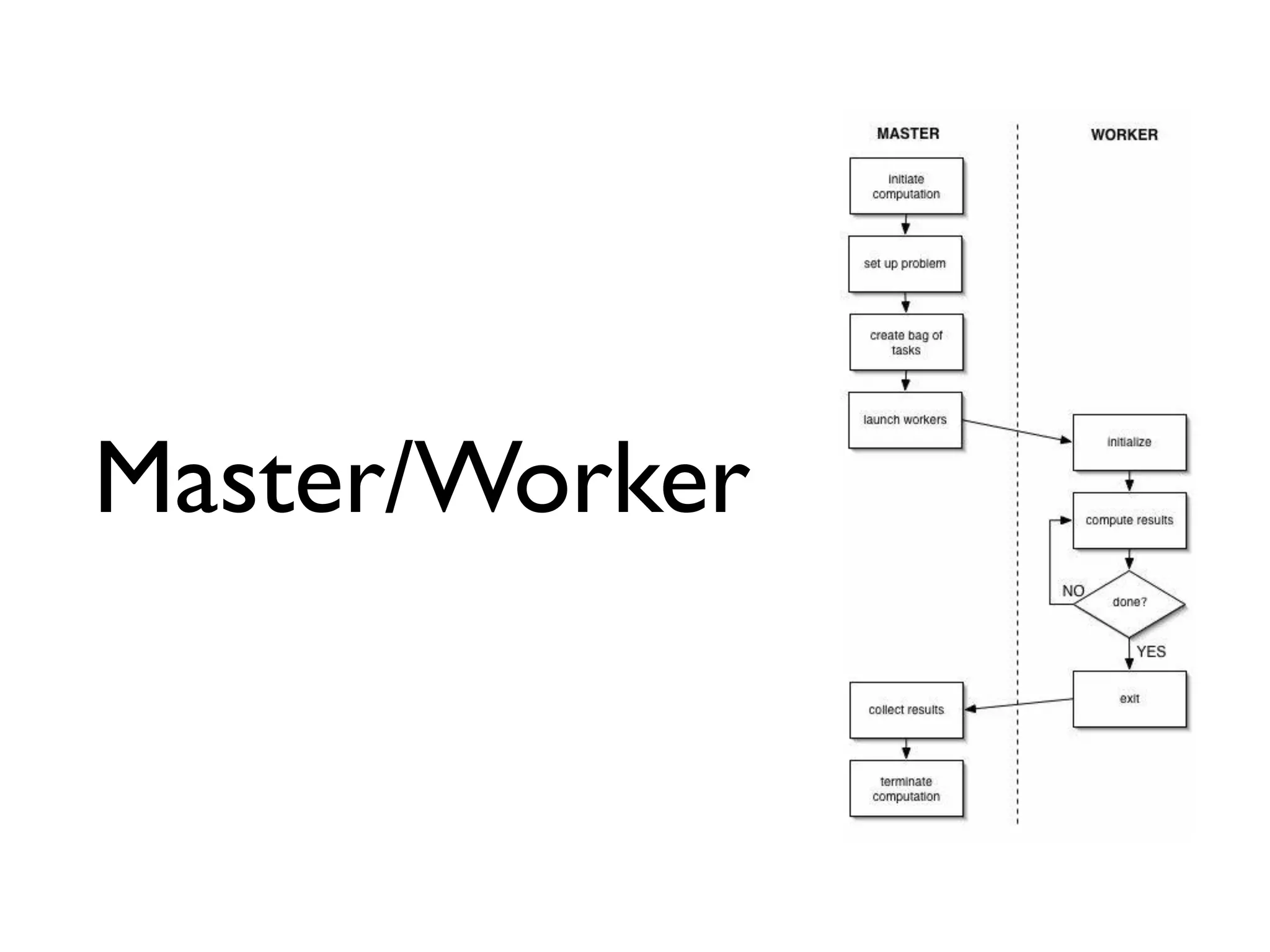





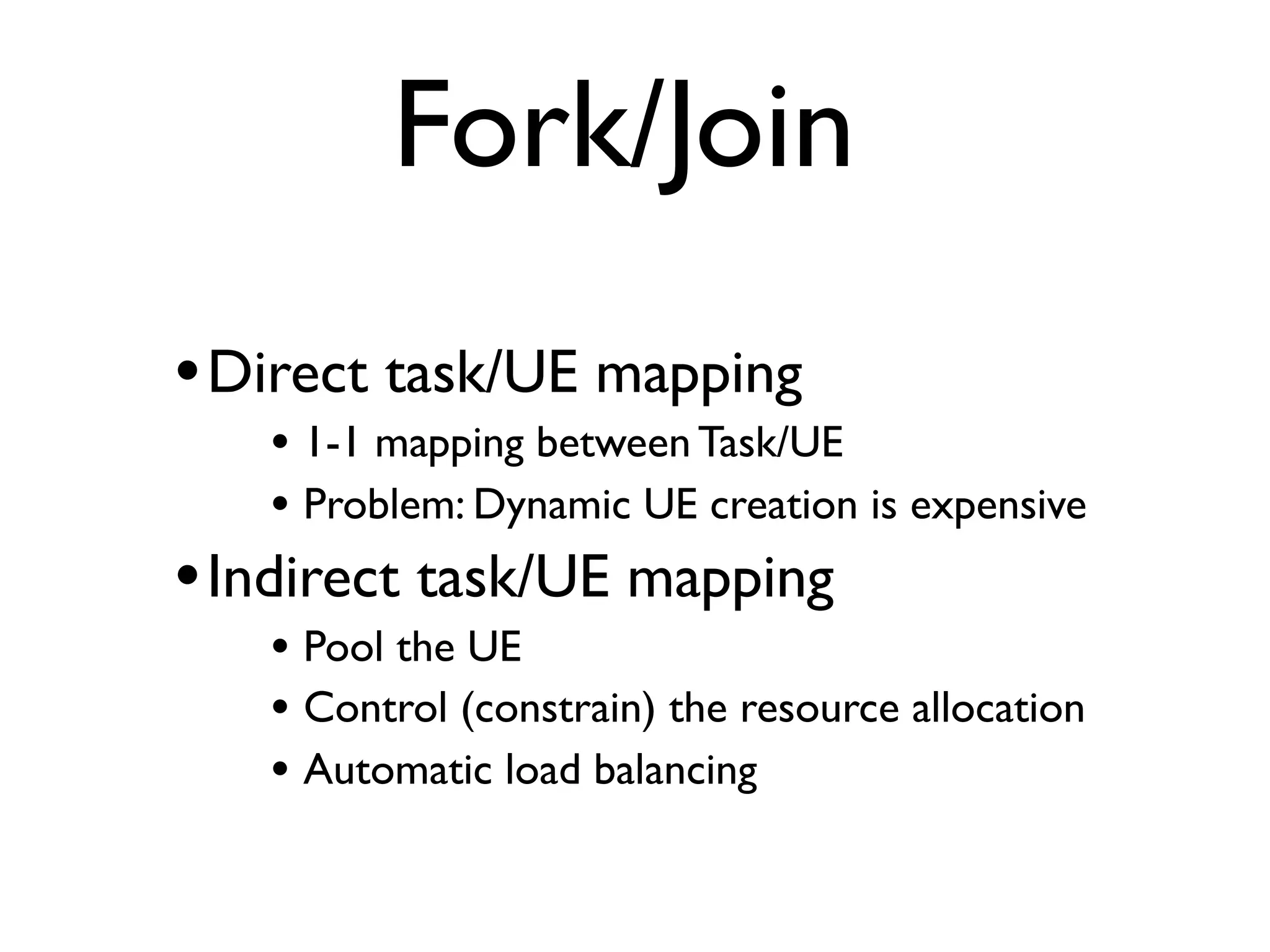




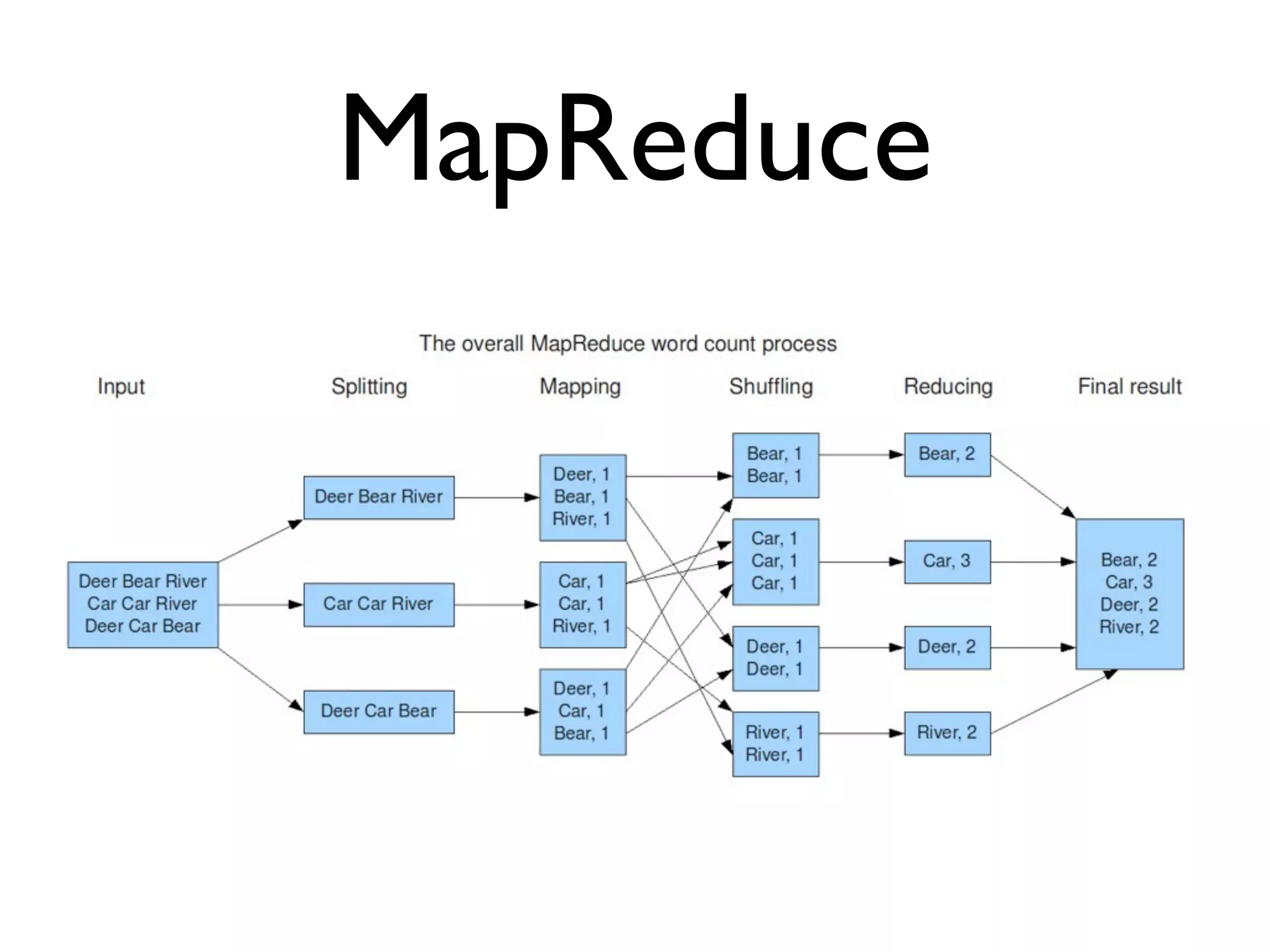




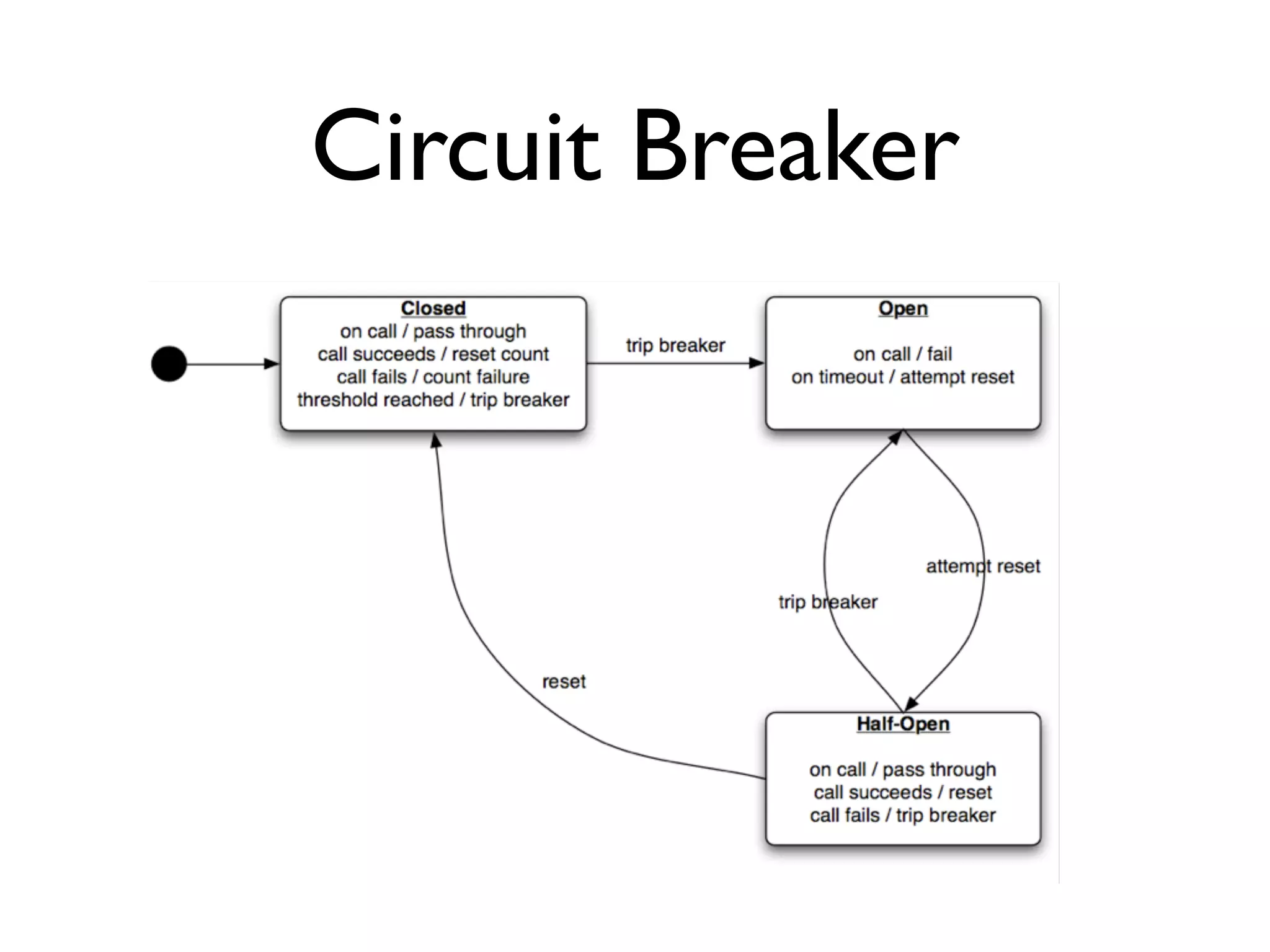

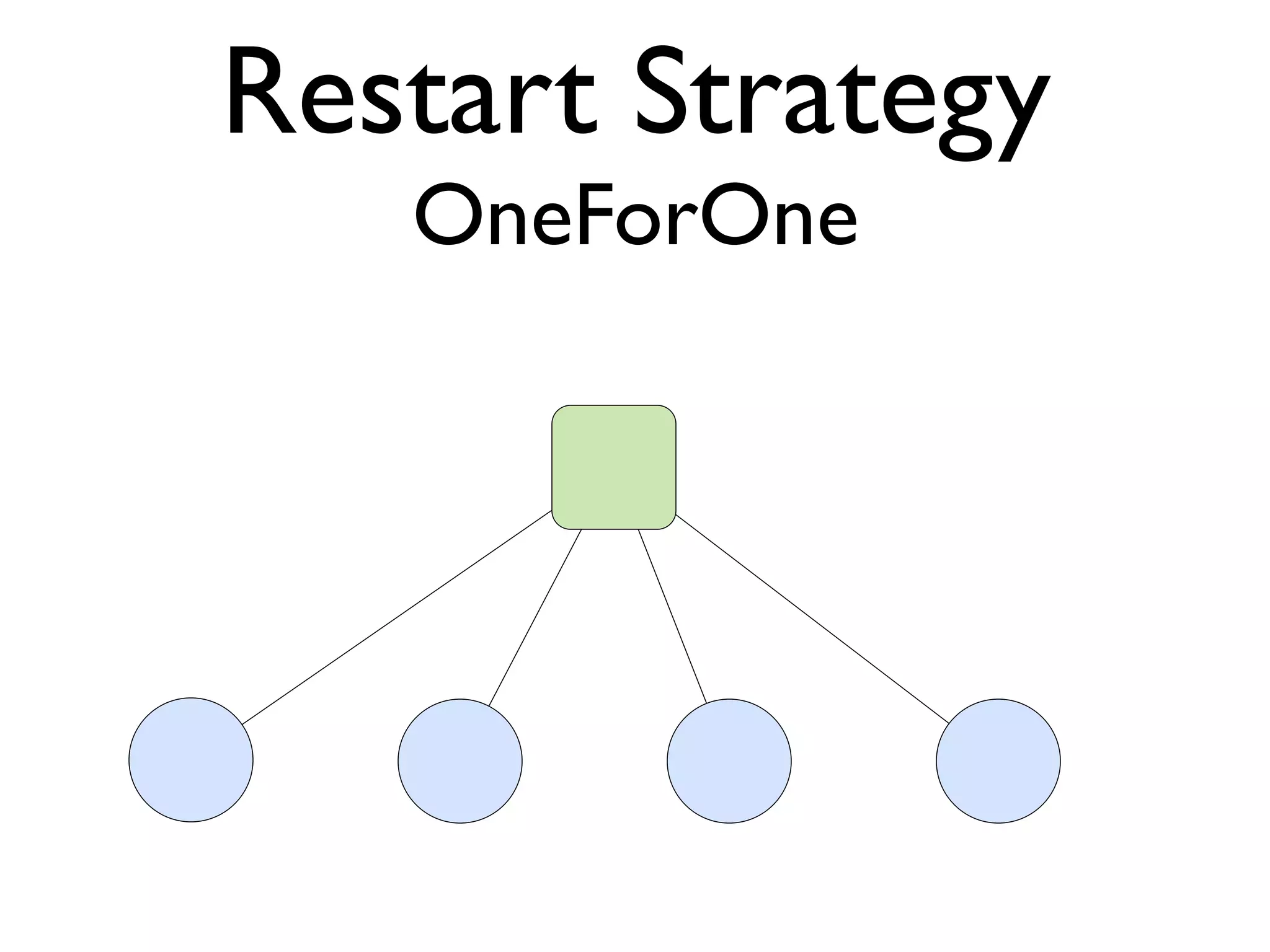










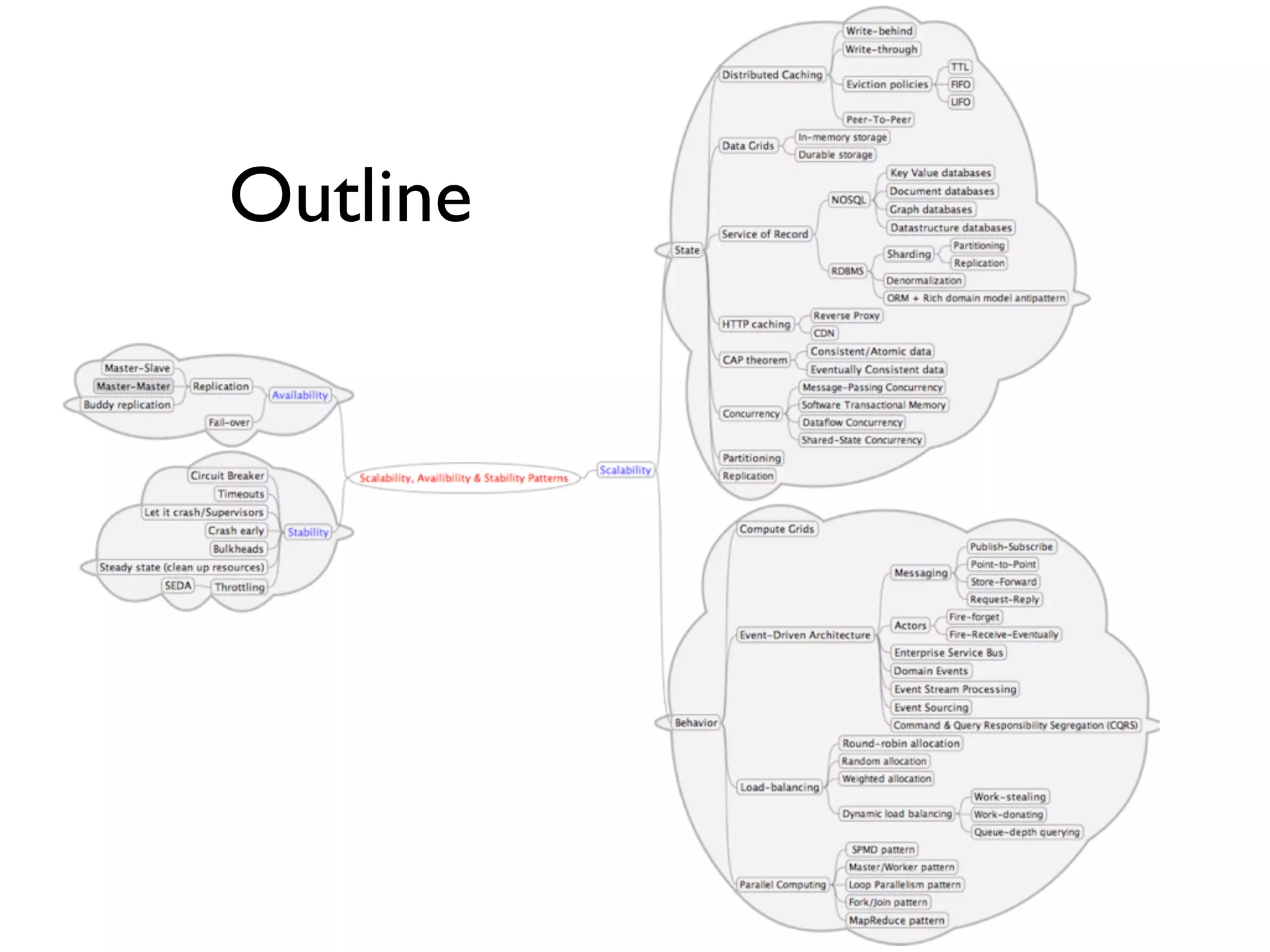
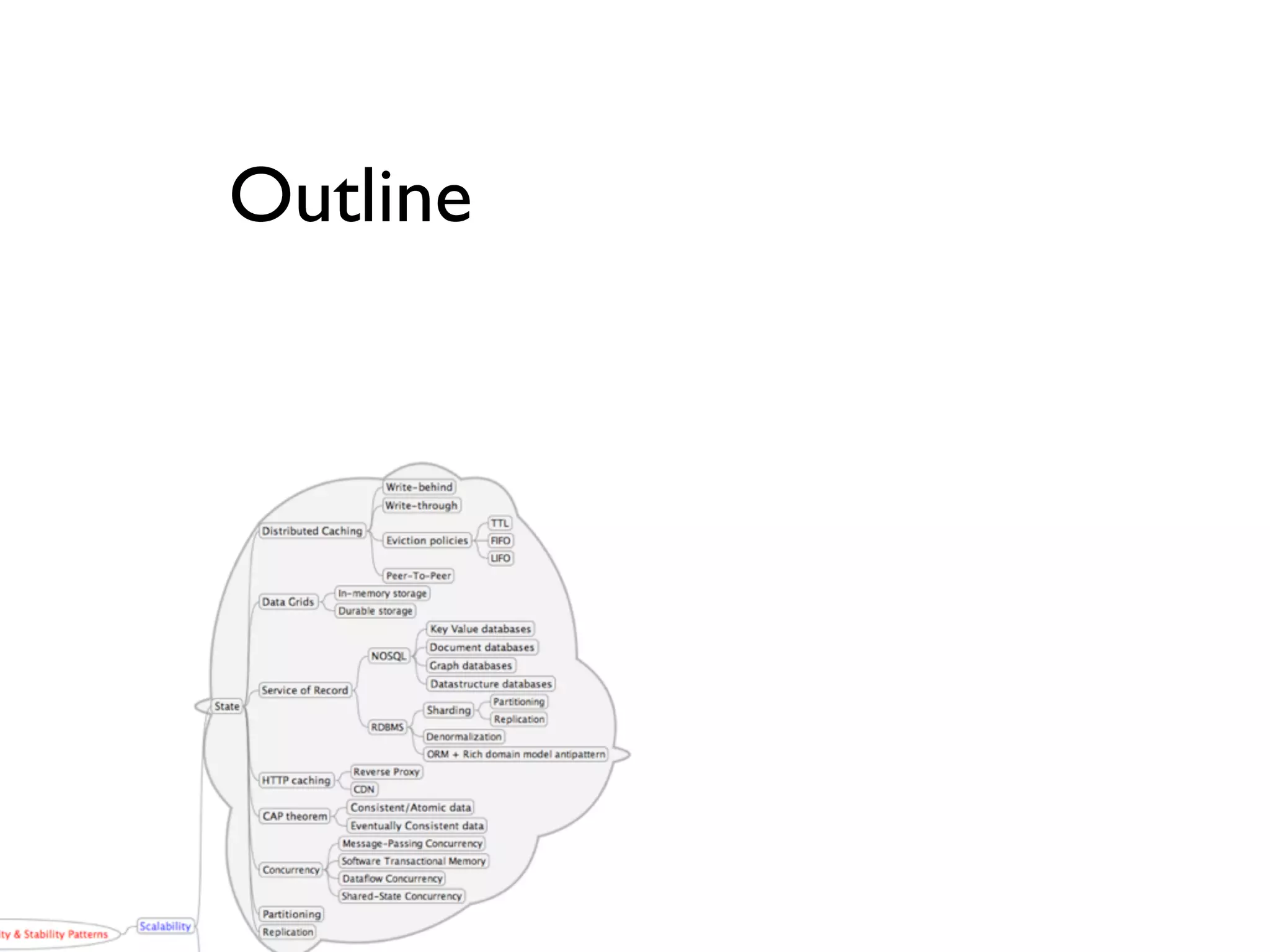
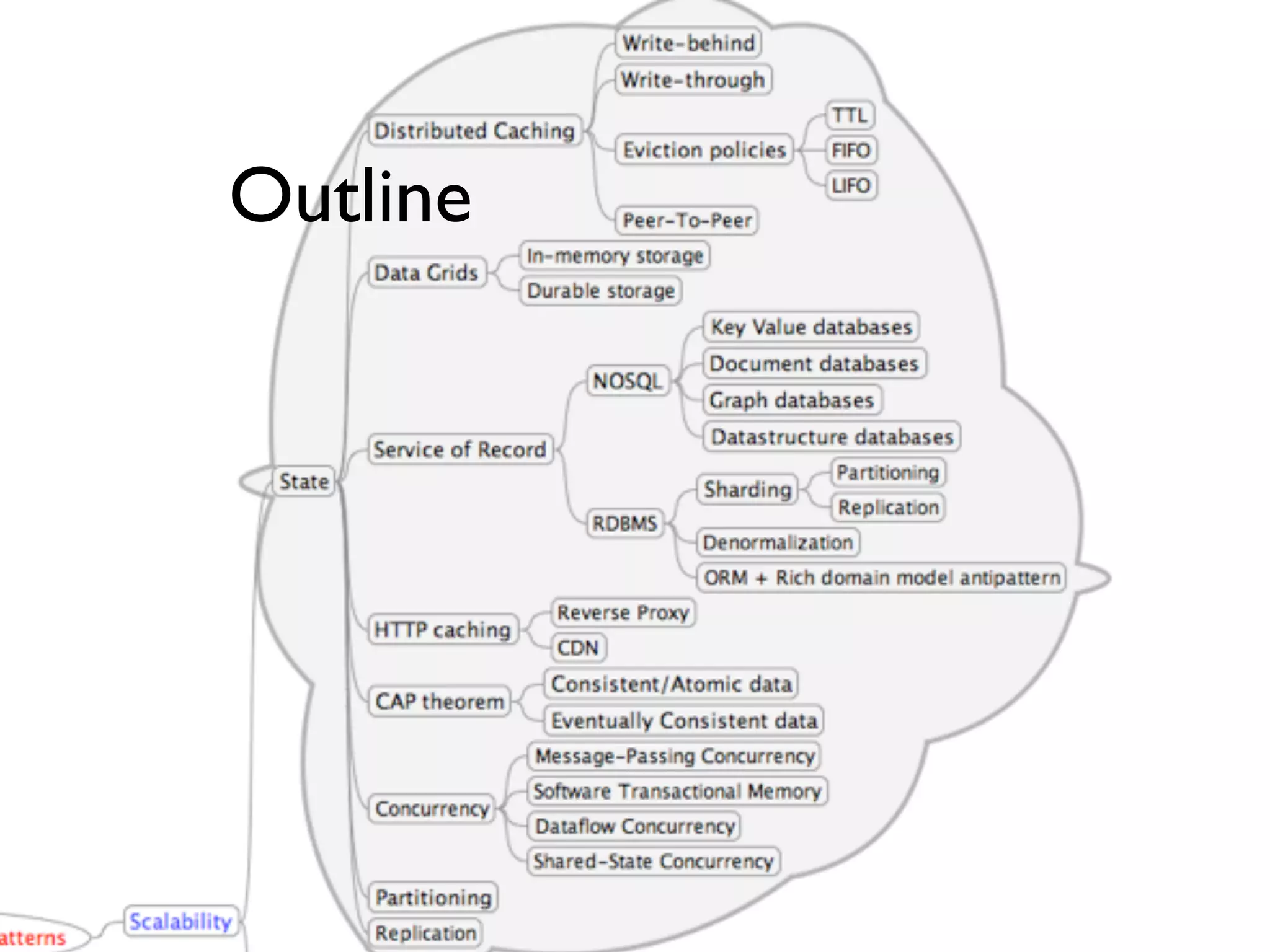
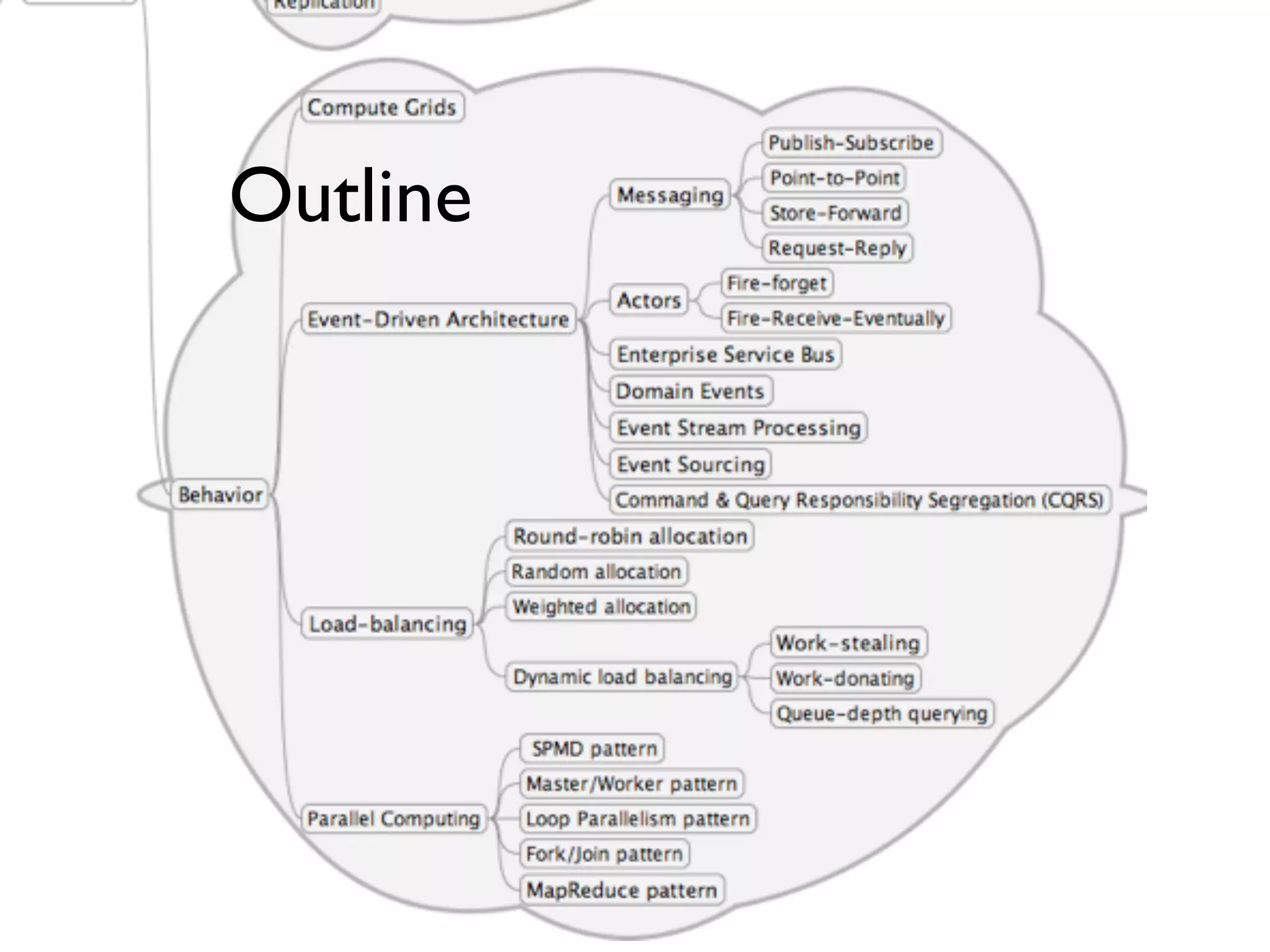
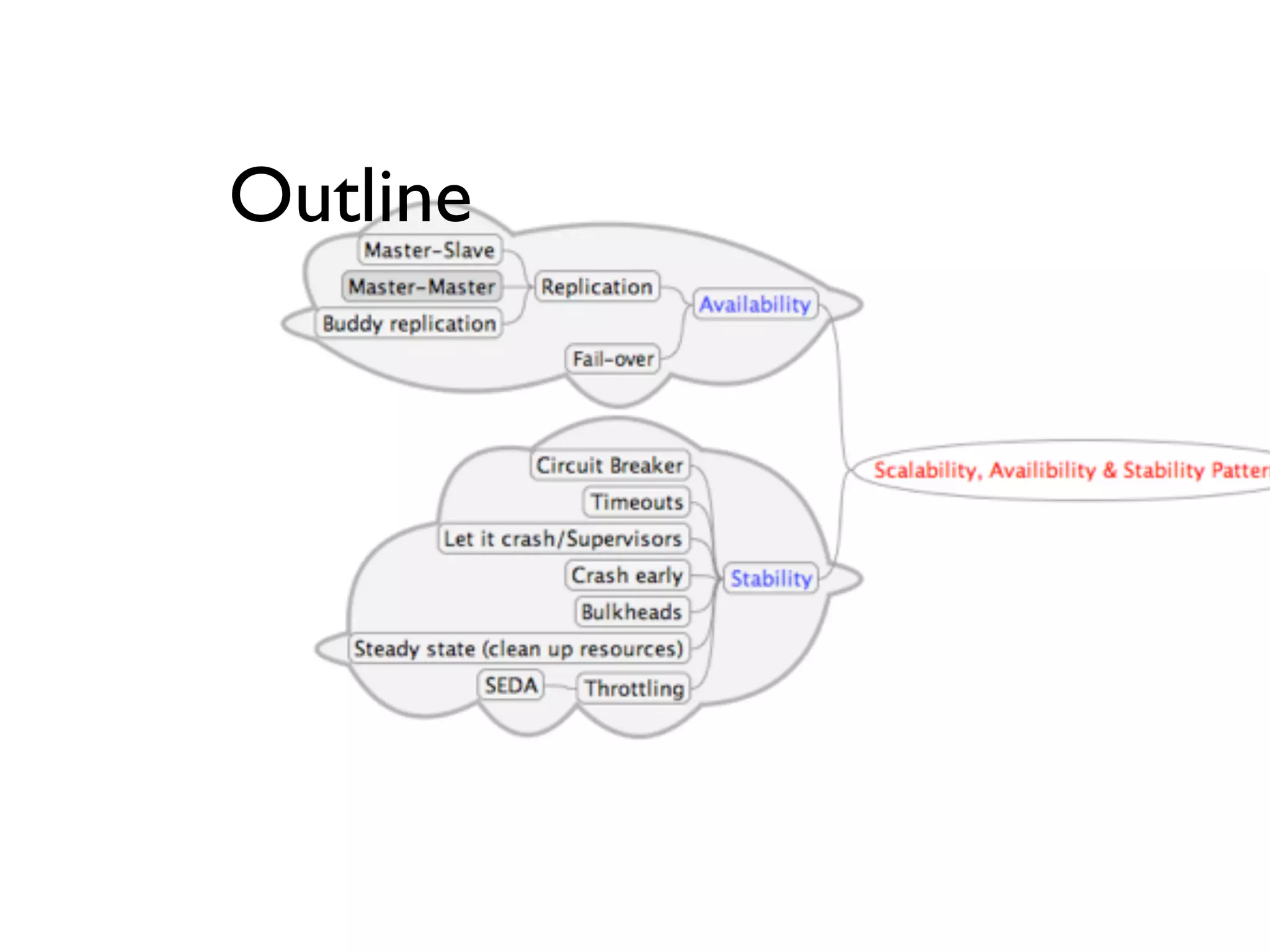
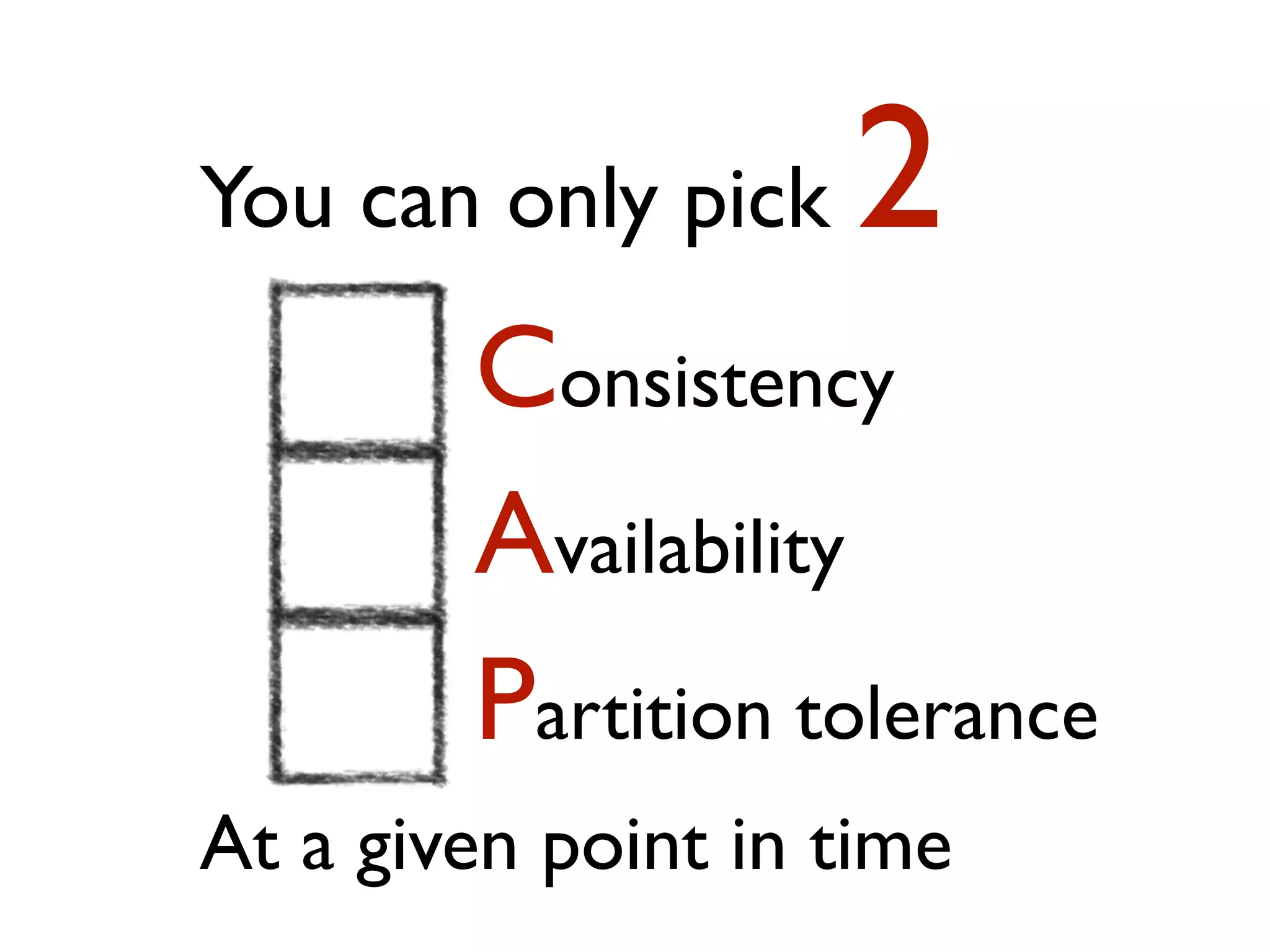
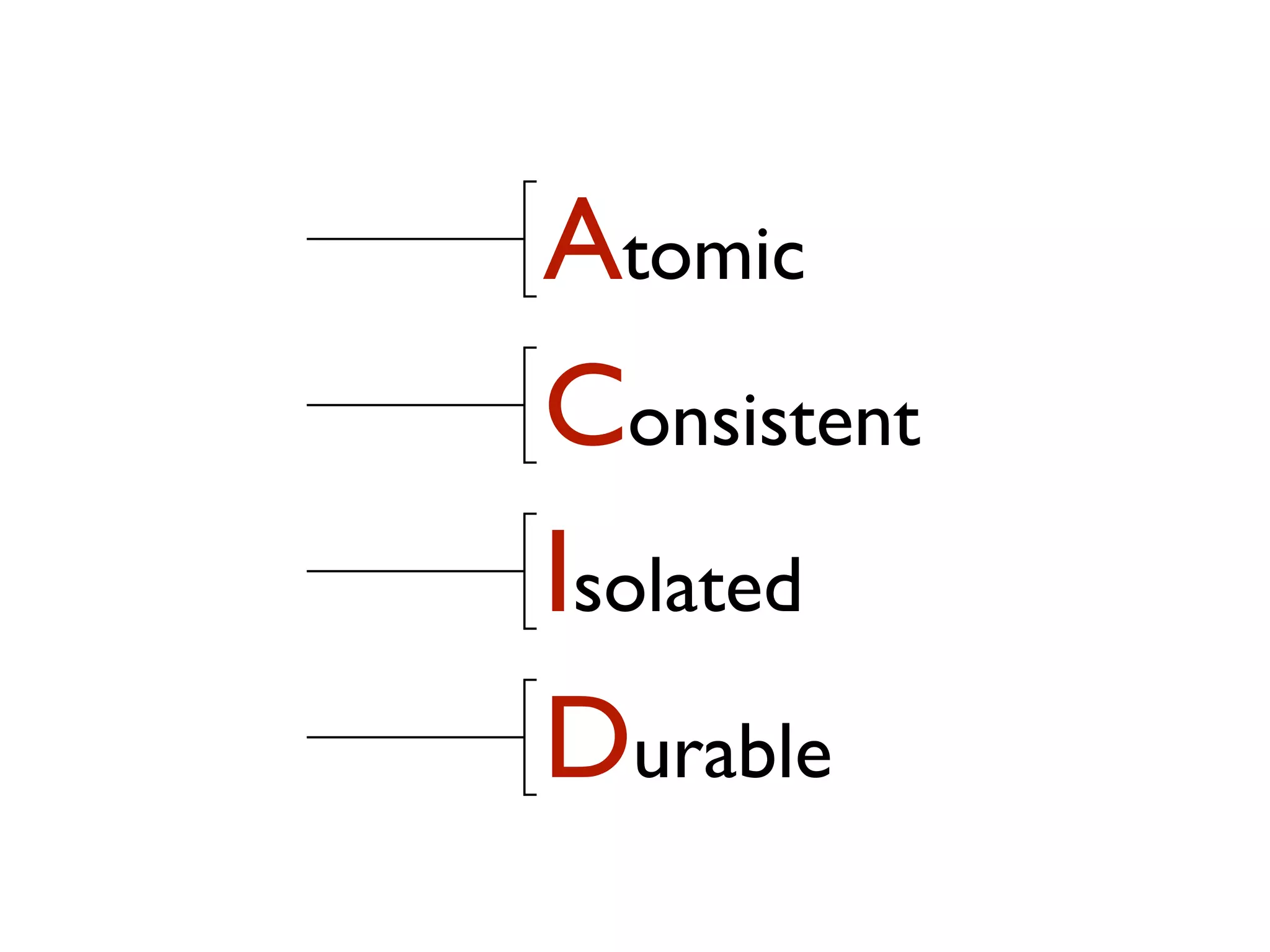
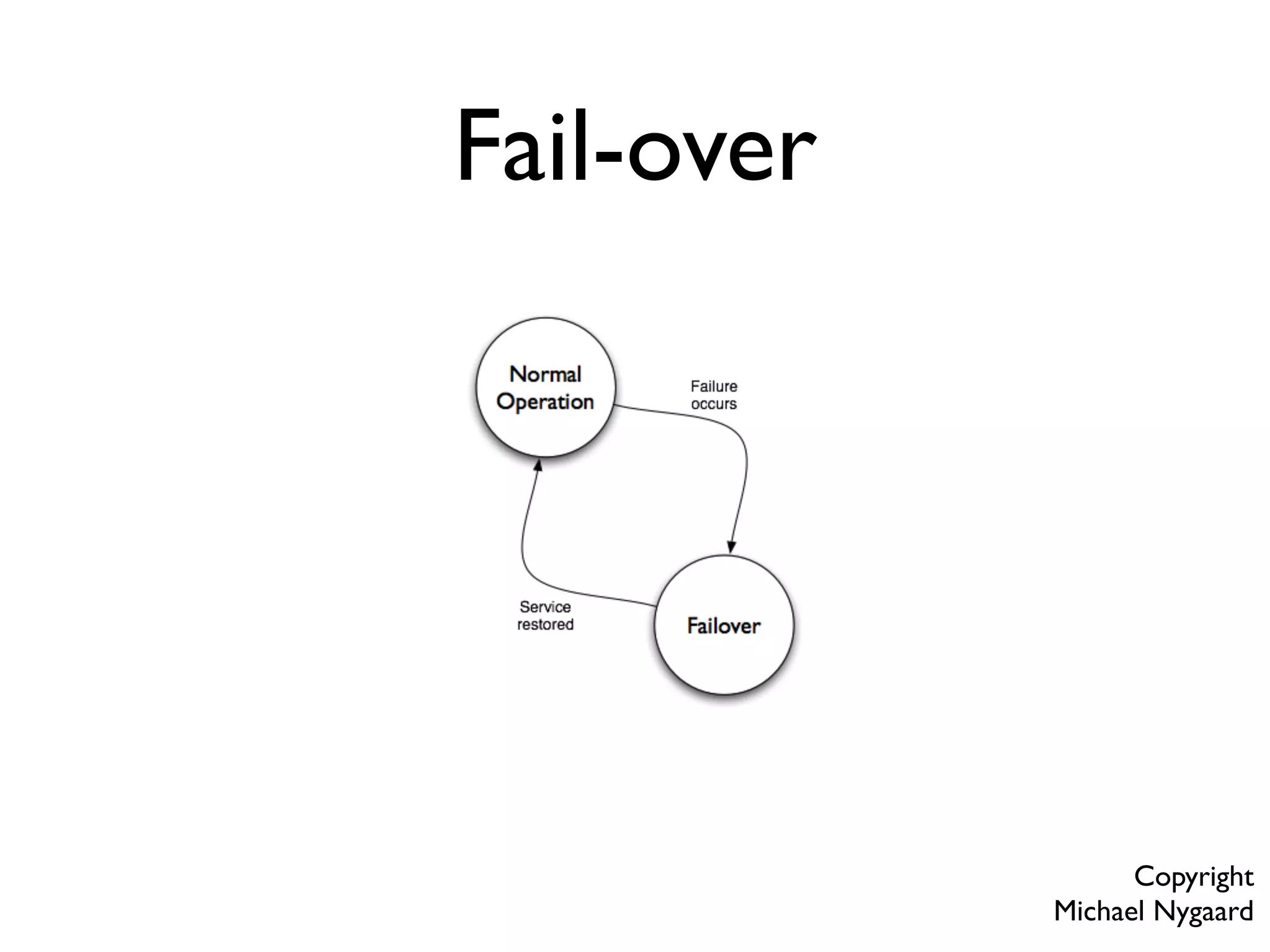
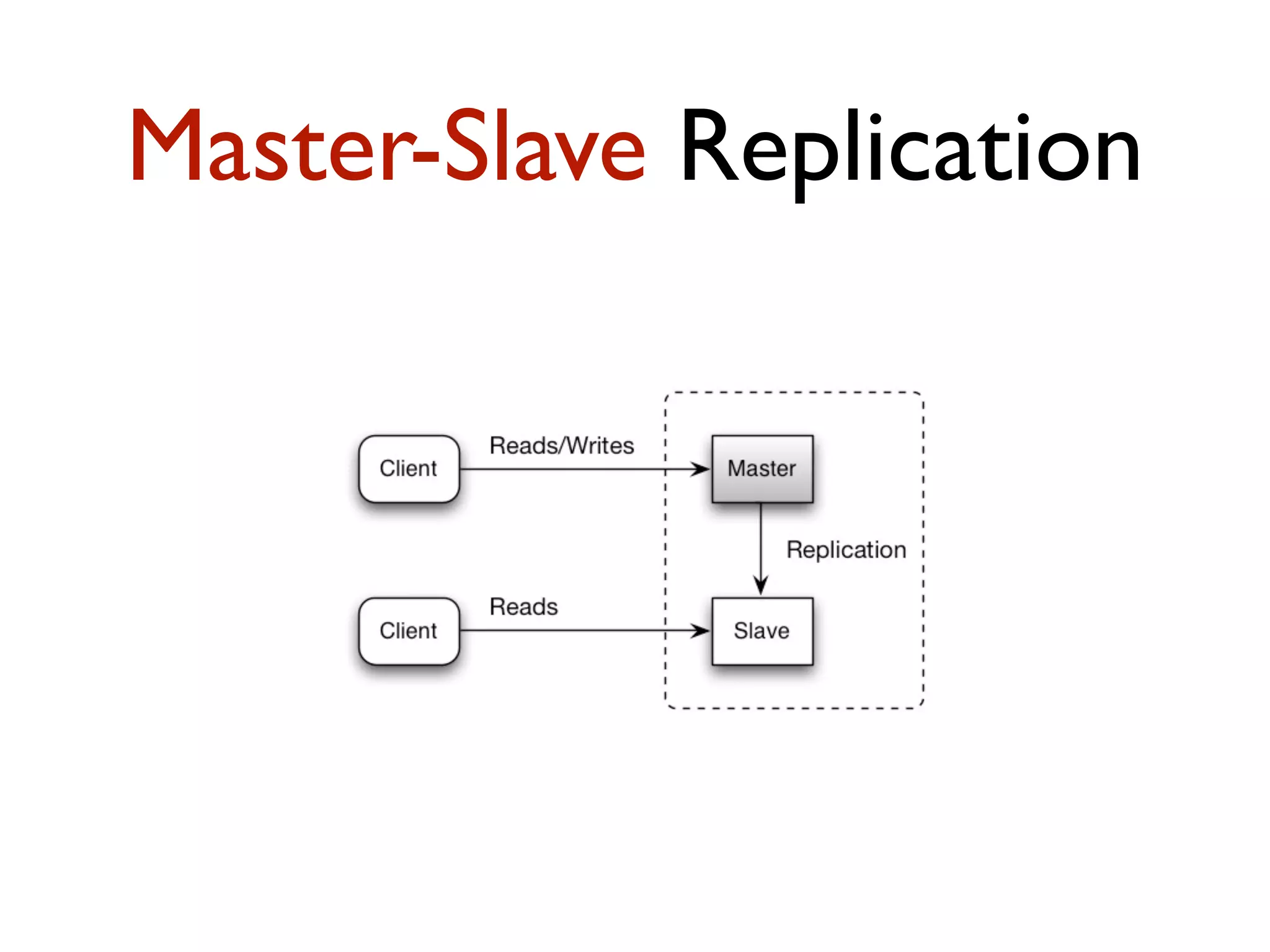
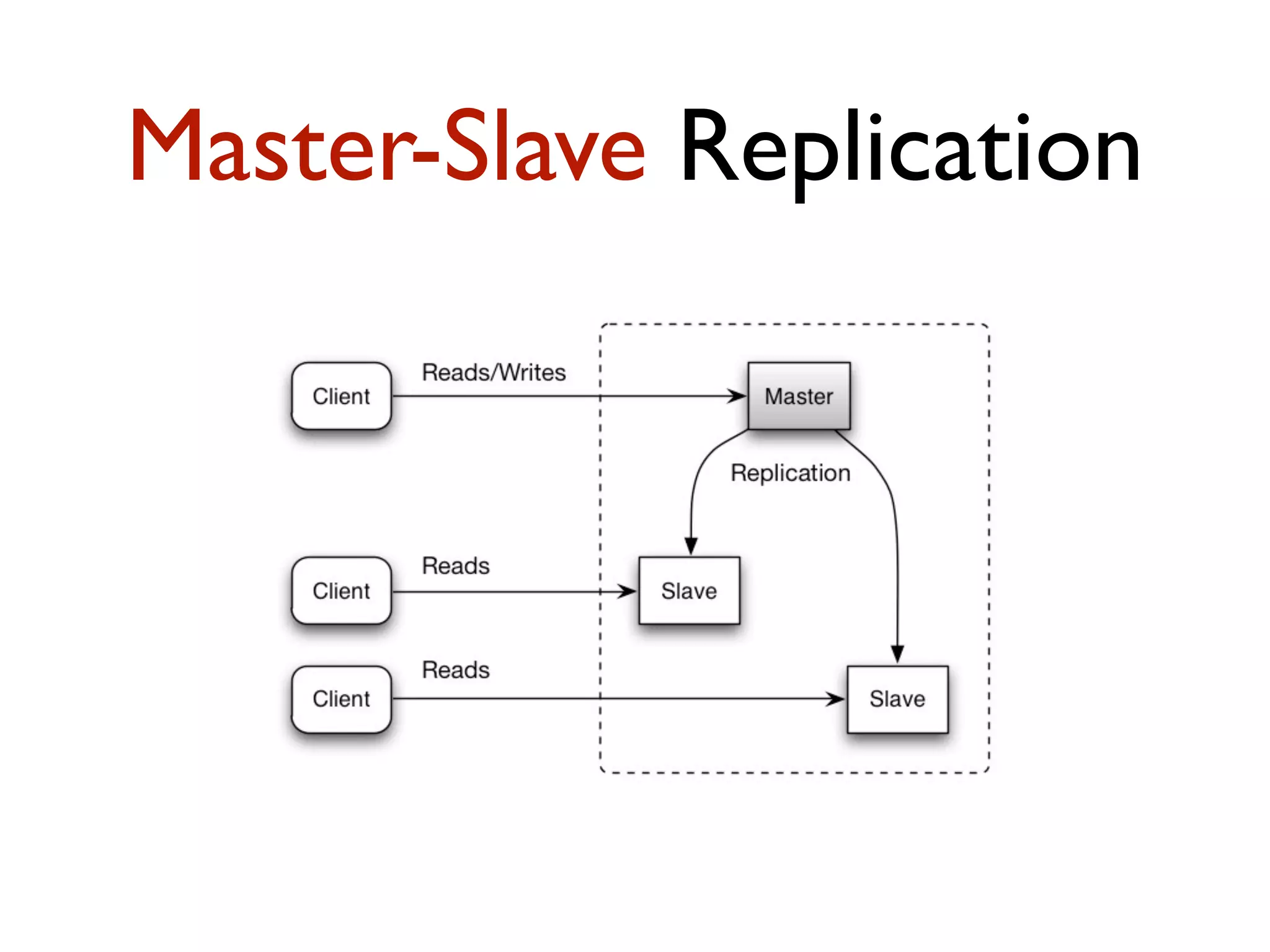
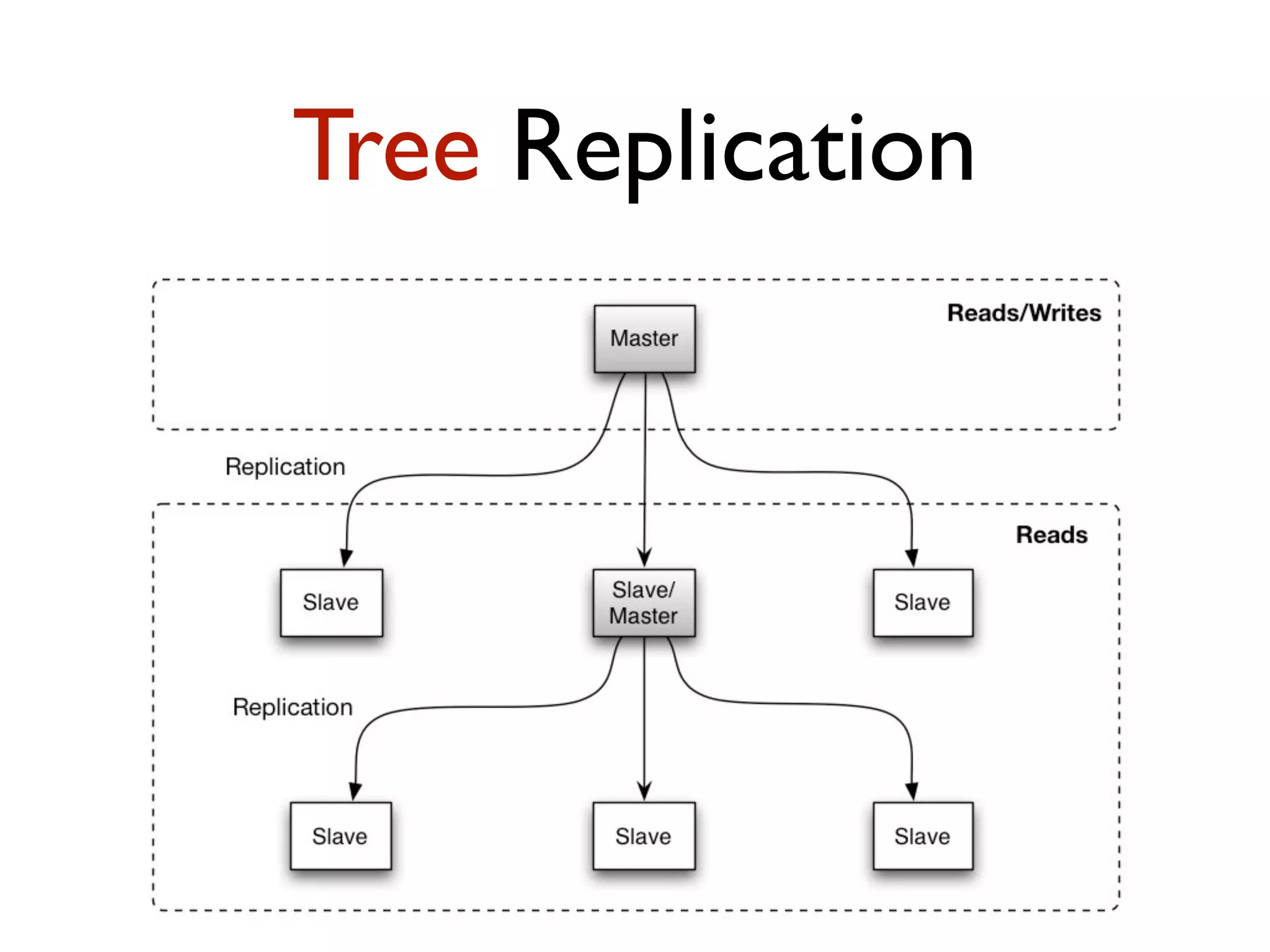
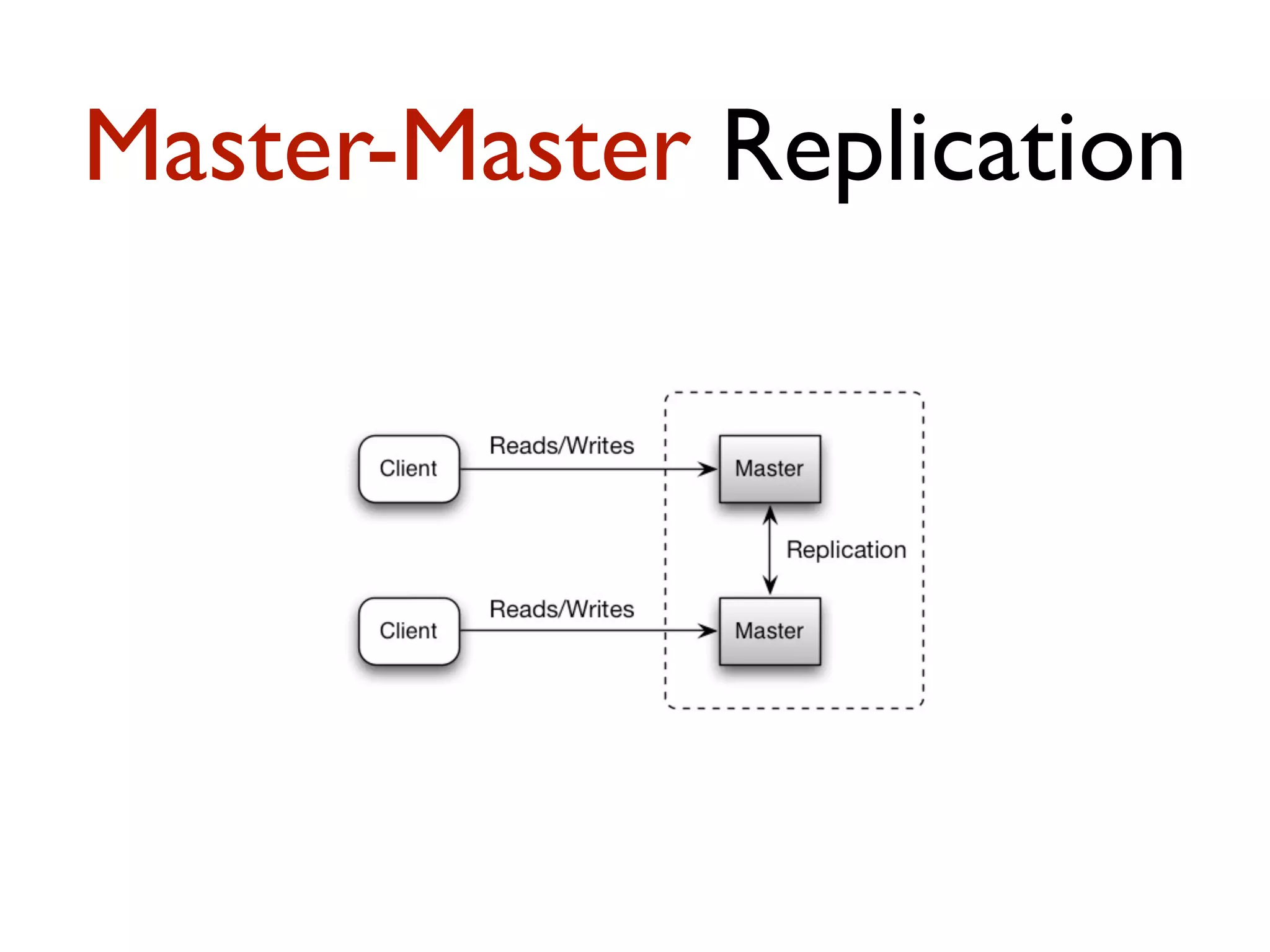
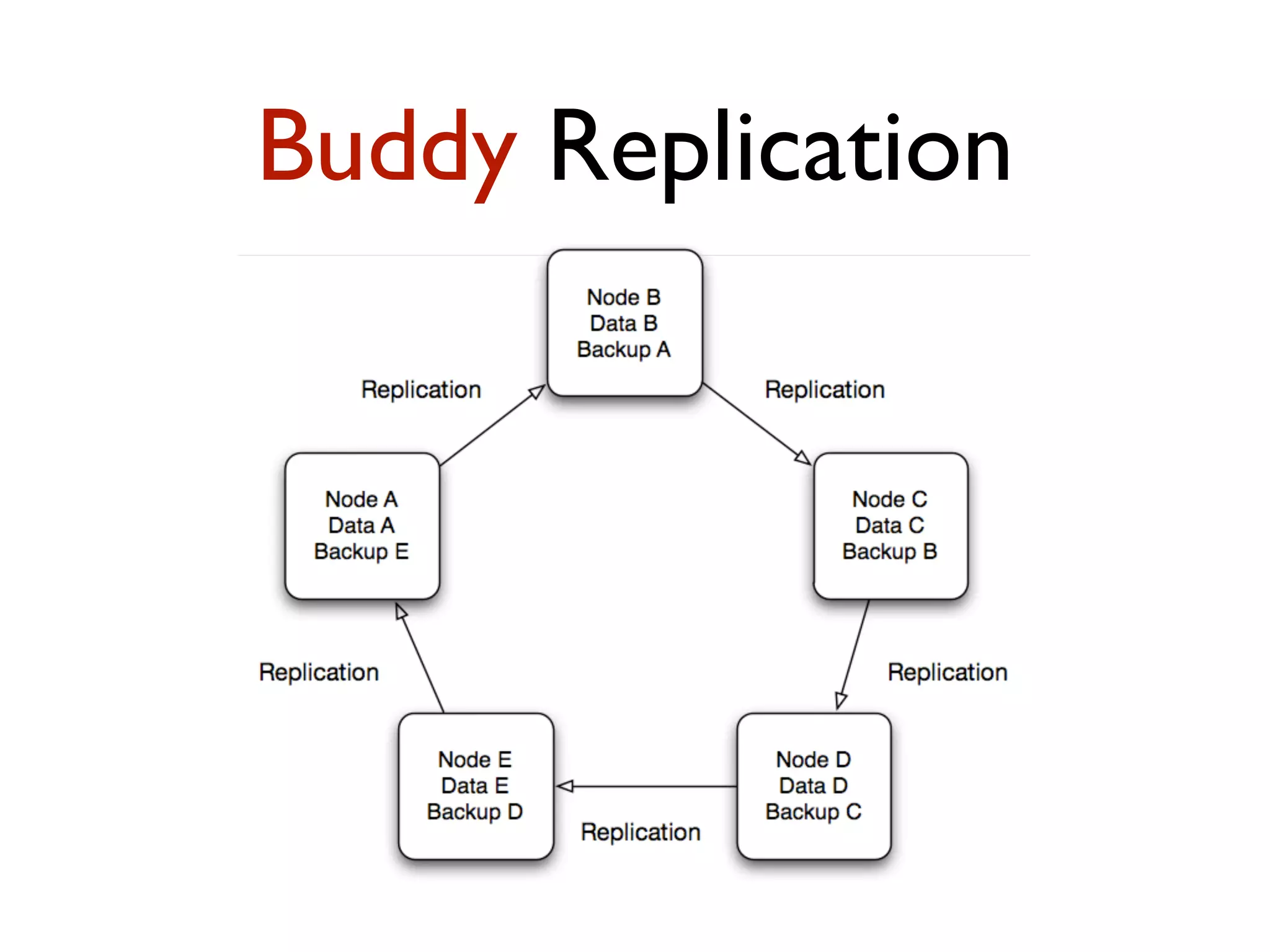
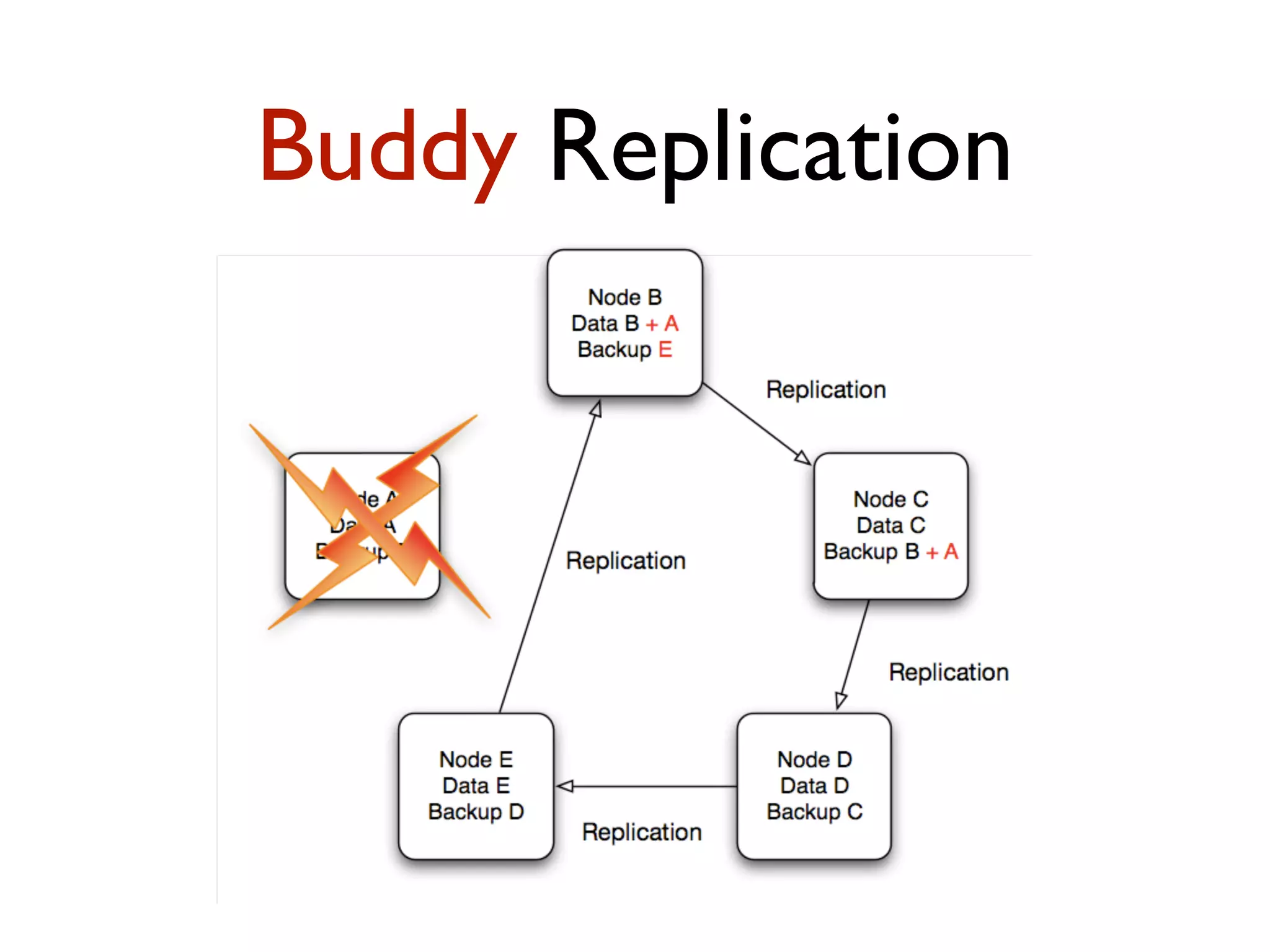
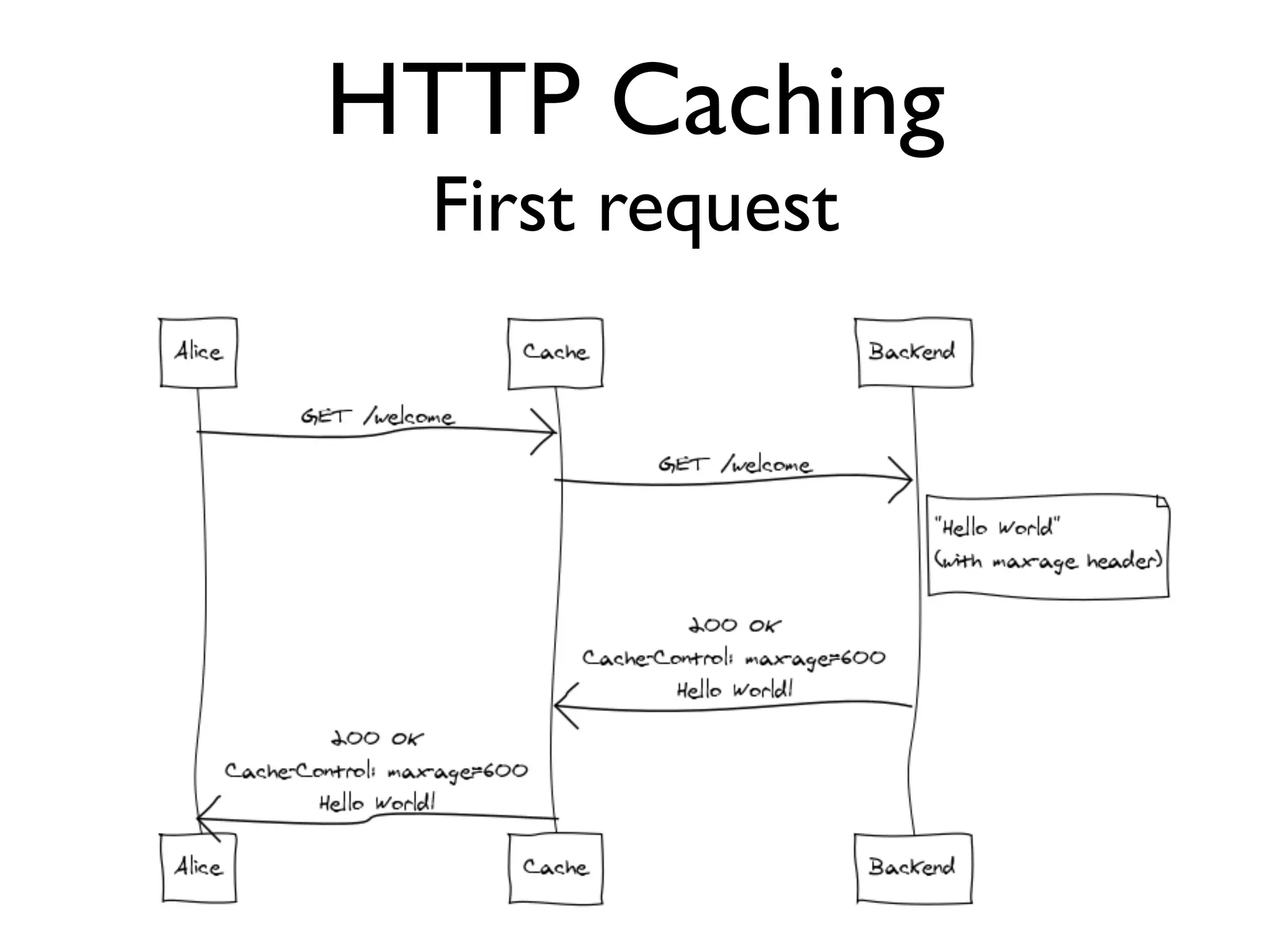
This document provides an overview of patterns for scalability, availability, and stability in distributed systems. It discusses general recommendations like immutability and referential transparency. It covers scalability trade-offs around performance vs scalability, latency vs throughput, and availability vs consistency. It then describes various patterns for scalability including managing state through partitioning, caching, sharding databases, and using distributed caching. It also covers patterns for managing behavior through event-driven architecture, compute grids, load balancing, and parallel computing. Availability patterns like fail-over, replication, and fault tolerance are discussed. The document provides examples of popular technologies that implement many of these patterns.