Kronos: 金融市場の言語のための基盤モデル




![]()
Kronosは、金融ローソク足(Kライン)のための初のオープンソース基盤モデルであり、 45以上のグローバル取引所からのデータでトレーニングされています。
📰 ニュース
- 🚩 [2025.08.17] ファインチューニング用のスクリプトをリリースしました!Kronosを独自のタスクに適応させるためにご確認ください。
- 🚩 [2025.08.02] 私たちの論文がarXivで公開されました!
📜 はじめに
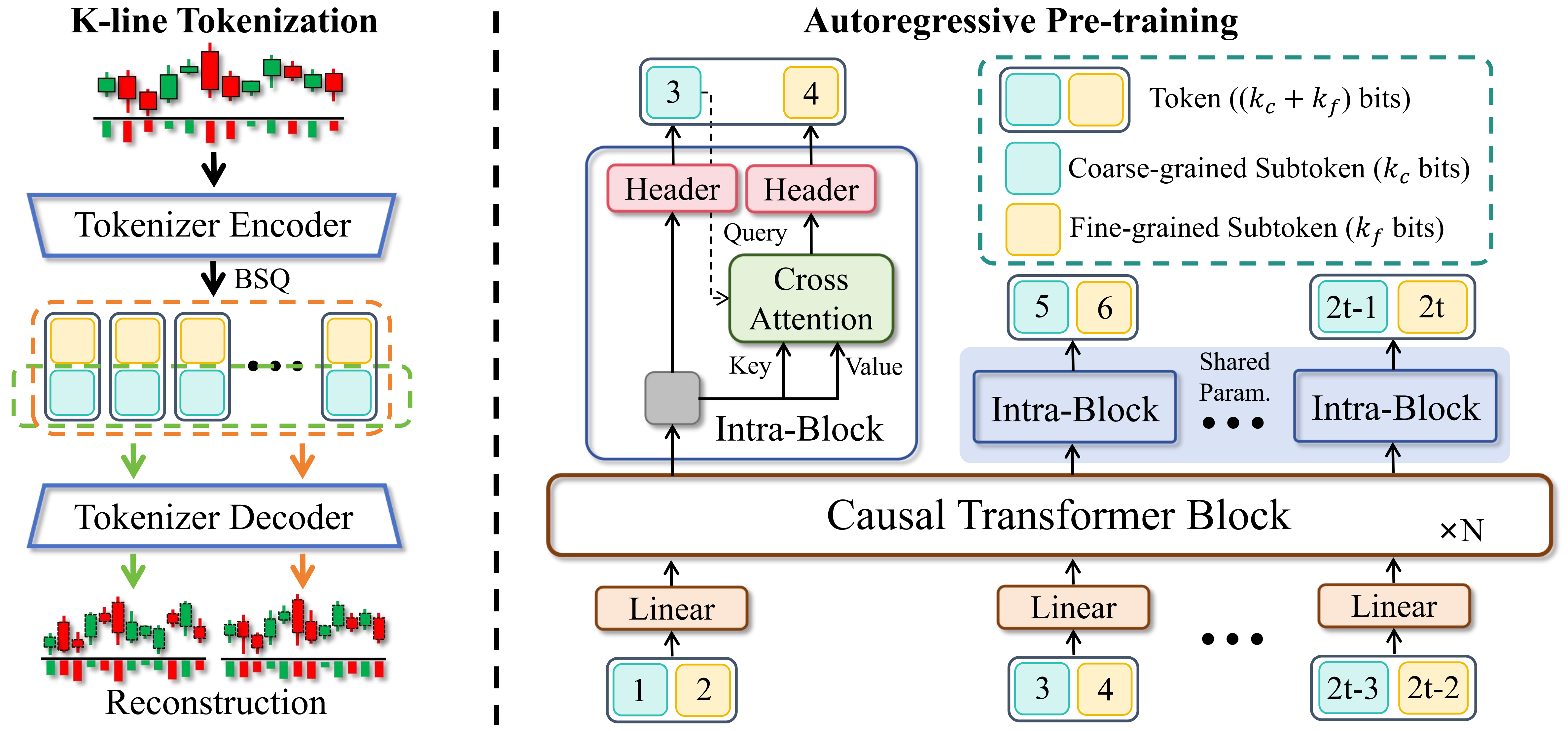
Kronosは、金融市場の「言語」であるKラインシーケンスに特化して事前学習された、デコーダのみの基盤モデルファミリーです。汎用のTSFMとは異なり、Kronosは金融データに特有の高ノイズ特性を扱うように設計されています。革新的な2段階フレームワークを活用しています:
- 専用のトークナイザーが、連続的な多次元Kラインデータ(OHLCV)を階層的な離散トークンにまず量子化します。
- その後、大規模な自己回帰型Transformerがこれらのトークンで事前学習され、多様な定量タスクのための統一モデルとして機能できるようになります。
✨ ライブデモ
Kronosの予測結果を可視化するライブデモを設置しました。このウェブページは、今後24時間におけるBTC/USDT取引ペアの予測を示しています。
📦 モデルズー
様々な計算リソースとアプリケーション要件に対応するため、多様な容量の事前学習済みモデルファミリーをリリースしました。すべてのモデルは Hugging Face Hub からすぐにアクセス可能です。
| モデル | トークナイザー | コンテキスト長 | パラメータ数 | オープンソース |
|---|---|---|---|---|
| Kronos-mini | Kronos-Tokenizer-2k | 2048 | 4.1M | ✅ NeoQuasar/Kronos-mini |
| Kronos-small | Kronos-Tokenizer-base | 512 | 24.7M | ✅ NeoQuasar/Kronos-small |
| Kronos-base | Kronos-Tokenizer-base | 512 | 102.3M | ✅ NeoQuasar/Kronos-base |
| Kronos-large | Kronos-Tokenizer-base | 512 | 499.2M | ❌ |
🚀 はじめに
インストール方法
- Python 3.10以上をインストールし、依存関係をインストールします:
pip install -r requirements.txt 📈 予測の実行
Kronosでの予測は、KronosPredictorクラスを使用することで簡単に行えます。データの前処理、正規化、予測、逆正規化を処理するため、生データから予測までわずか数行のコードで実現できます。
重要注意: Kronos-smallおよびKronos-baseのmax_contextは512です。これはモデルが処理できる最大シーケンス長です。最適なパフォーマンスを得るためには、入力データの長さ(すなわちlookback)がこの制限を超えないことを推奨します。KronosPredictorは、より長いコンテキストに対して自動的に切り詰め処理を行います。
以下に、初めての予測を行うためのステップバイステップガイドを示します。
1. トークナイザーとモデルの読み込み
まず、Hugging Face Hubから事前学習済みのKronosモデルとそれに対応するトークナイザーを読み込みます。
from model import Kronos, KronosTokenizer, KronosPredictor # Load from Hugging Face Hub tokenizer = KronosTokenizer.from_pretrained("NeoQuasar/Kronos-Tokenizer-base") model = Kronos.from_pretrained("NeoQuasar/Kronos-small") 2. 予測器のインスタンス化
モデル、トークナイザー、および希望するデバイスを渡して、KronosPredictorのインスタンスを作成します。
# Initialize the predictor predictor = KronosPredictor(model, tokenizer, device="cuda:0", max_context=512) 3. 入力データの準備
predictメソッドには、主に3つの入力が必要です:
df: 過去のKラインデータを含むpandas DataFrame。['open', 'high', 'low', 'close']の列を含む必要があります。volumeとamountはオプションです。x_timestamp:df内の過去データに対応するタイムスタンプのpandas Series。y_timestamp: 予測したい将来の期間に対応するタイムスタンプのpandas Series。
import pandas as pd # Load your data df = pd.read_csv("./data/XSHG_5min_600977.csv") df['timestamps'] = pd.to_datetime(df['timestamps']) # Define context window and prediction length lookback = 400 pred_len = 120 # Prepare inputs for the predictor x_df = df.loc[:lookback-1, ['open', 'high', 'low', 'close', 'volume', 'amount']] x_timestamp = df.loc[:lookback-1, 'timestamps'] y_timestamp = df.loc[lookback:lookback+pred_len-1, 'timestamps'] 4. 予測の生成
予測を生成するには predict メソッドを呼び出します。確率的予測のため、T、top_p、sample_count などのパラメータでサンプリングプロセスを制御できます。
# Generate predictions pred_df = predictor.predict( df=x_df, x_timestamp=x_timestamp, y_timestamp=y_timestamp, pred_len=pred_len, T=1.0, # Temperature for sampling top_p=0.9, # Nucleus sampling probability sample_count=1 # Number of forecast paths to generate and average ) print("Forecasted Data Head:") print(pred_df.head()) predict メソッドは、指定した y_timestamp でインデックス付けされた open、high、low、close、volume、amount の予測値を含む pandas DataFrame を返します。
複数の時系列データを効率的に処理するために、Kronos は predict_batch メソッドを提供しており、複数のデータセットに対して同時に並列予測を可能にします。これは、複数の資産や期間を一度に予測する必要がある場合に特に便利です。
# Prepare multiple datasets for batch prediction df_list = [df1, df2, df3] # List of DataFrames x_timestamp_list = [x_ts1, x_ts2, x_ts3] # List of historical timestamps y_timestamp_list = [y_ts1, y_ts2, y_ts3] # List of future timestamps # Generate batch predictions pred_df_list = predictor.predict_batch( df_list=df_list, x_timestamp_list=x_timestamp_list, y_timestamp_list=y_timestamp_list, pred_len=pred_len, T=1.0, top_p=0.9, sample_count=1, verbose=True ) # pred_df_list contains prediction results in the same order as input for i, pred_df in enumerate(pred_df_list): print(f"Predictions for series {i}:") print(pred_df.head()) バッチ予測の重要な要件:
- すべての系列は同じ履歴長(ルックバックウィンドウ)を持つ必要があります
- すべての系列は同じ予測長(
pred_len)を持つ必要があります - 各 DataFrame には必要な列
['open', 'high', 'low', 'close']が含まれている必要があります volumeとamount列はオプションであり、欠落している場合はゼロで埋められます
predict_batch メソッドは、効率的な処理のために GPU 並列処理を活用し、各系列の正規化と非正規化を独立して自動的に処理します。
5. 例と可視化
データ読み込み、予測、プロットを含む完全な実行可能スクリプトについては、examples/prediction_example.py を参照してください。
このスクリプトを実行すると、以下の図のように、実測データとモデルの予測を比較するプロットが生成されます:
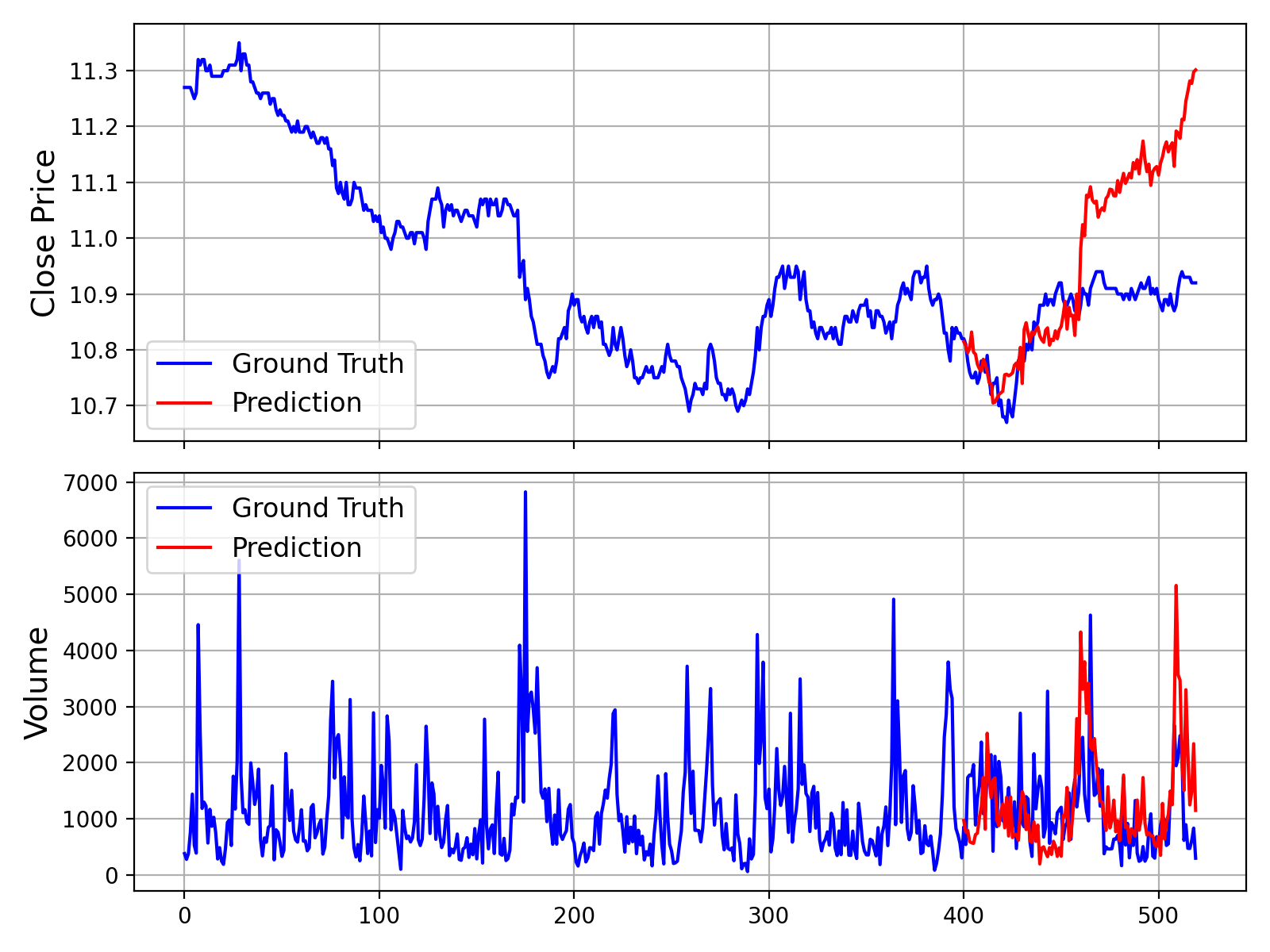
さらに、出来高(Volume)と取引金額(Amount)データを使用せずに予測を行うスクリプトも提供しています。これは examples/prediction_wo_vol_example.py で確認できます。
🔧 独自データでのファインチューニング(A株市場の例)
Kronosを独自のデータセットでファインチューニングするための完全なパイプラインを提供します。例として、Qlib を使用して中国A株市場のデータを準備し、簡単なバックテストを実施する方法を実演します。
免責事項: このパイプラインはファインチューニングプロセスを説明するためのデモンストレーションとして提供されています。これは簡略化された例であり、本番環境対応の定量取引システムではありません。堅牢な定量戦略には、安定的なアルファを達成するために、ポートフォリオ最適化やリスクファクターの中立化など、より高度な技術が必要です。
ファインチューニングプロセスは以下の4つの主要ステップに分かれています:
- 設定: パスとハイパーパラメータの設定
- データ準備: Qlibを使用したデータの処理と分割
- モデルのファインチューニング: TokenizerとPredictorモデルのファインチューニング
- バックテスト: ファインチューニング済みモデルの性能評価
前提条件
- まず、
requirements.txtからすべての依存関係がインストールされていることを確認してください。 - このパイプラインは
qlibに依存しています。以下のコマンドでインストールしてください:pip install pyqlib - Qlib データを準備する必要があります。公式 Qlib ガイド に従って、データをローカルにダウンロードしセットアップしてください。サンプルスクリプトは日次頻度データを使用することを想定しています。
ステップ 1: 実験の設定
データ、トレーニング、モデルパスに関するすべての設定は finetune/config.py に一元化されています。スクリプトを実行する前に、ご利用の環境に応じて以下のパスを変更してください:
qlib_data_path: ローカルの Qlib データディレクトリへのパス。dataset_path: 処理済みのトレーニング/検証/テスト用 pickle ファイルが保存されるディレクトリ。save_path: モデルチェックポイントを保存するベースディレクトリ。backtest_result_path: バックテスト結果を保存するディレクトリ。pretrained_tokenizer_pathおよびpretrained_predictor_path: 開始点とする事前トレーニング済みモデルへのパス(ローカルパスまたは Hugging Face のモデル名)。
また、instrument、train_time_range、epochs、batch_size などの他のパラメータを調整して、特定のタスクに適合させることもできます。Comet.ml を使用しない場合は、use_comet = False に設定してください。
ステップ 2: データセットの準備
データ前処理スクリプトを実行します。このスクリプトはQlibディレクトリから生の市場データを読み込み、処理を行い、トレーニング、検証、テストセットに分割し、それらをpickleファイルとして保存します。
python finetune/qlib_data_preprocess.py 実行後、設定ファイルのdataset_pathで指定されたディレクトリにtrain_data.pkl、val_data.pkl、test_data.pklが生成されます。
ステップ3: ファインチューニングの実行
ファインチューニングプロセスは2段階で構成されます:トークナイザーのファインチューニングと、その後に行う予測モデルのファインチューニングです。両方のトレーニングスクリプトは、torchrunを使用したマルチGPUトレーニング用に設計されています。
3.1 トークナイザーのファインチューニング
このステップでは、特定ドメインのデータ分布に合わせてトークナイザーを調整します。
# Replace NUM_GPUS with the number of GPUs you want to use (e.g., 2) torchrun --standalone --nproc_per_node=NUM_GPUS finetune/train_tokenizer.py 最良のトークナイザーチェックポイントは、config.pyで設定されたパス(save_pathとtokenizer_save_folder_nameから派生)に保存されます。
3.2 予測モデルのファインチューニング
このステップでは、予測タスクのために主要なKronosモデルをファインチューニングします。
# Replace NUM_GPUS with the number of GPUs you want to use (e.g., 2) torchrun --standalone --nproc_per_node=NUM_GPUS finetune/train_predictor.py 最良の予測モデルチェックポイントは、config.pyで設定されたパスに保存されます。
ステップ4: バックテストによる評価
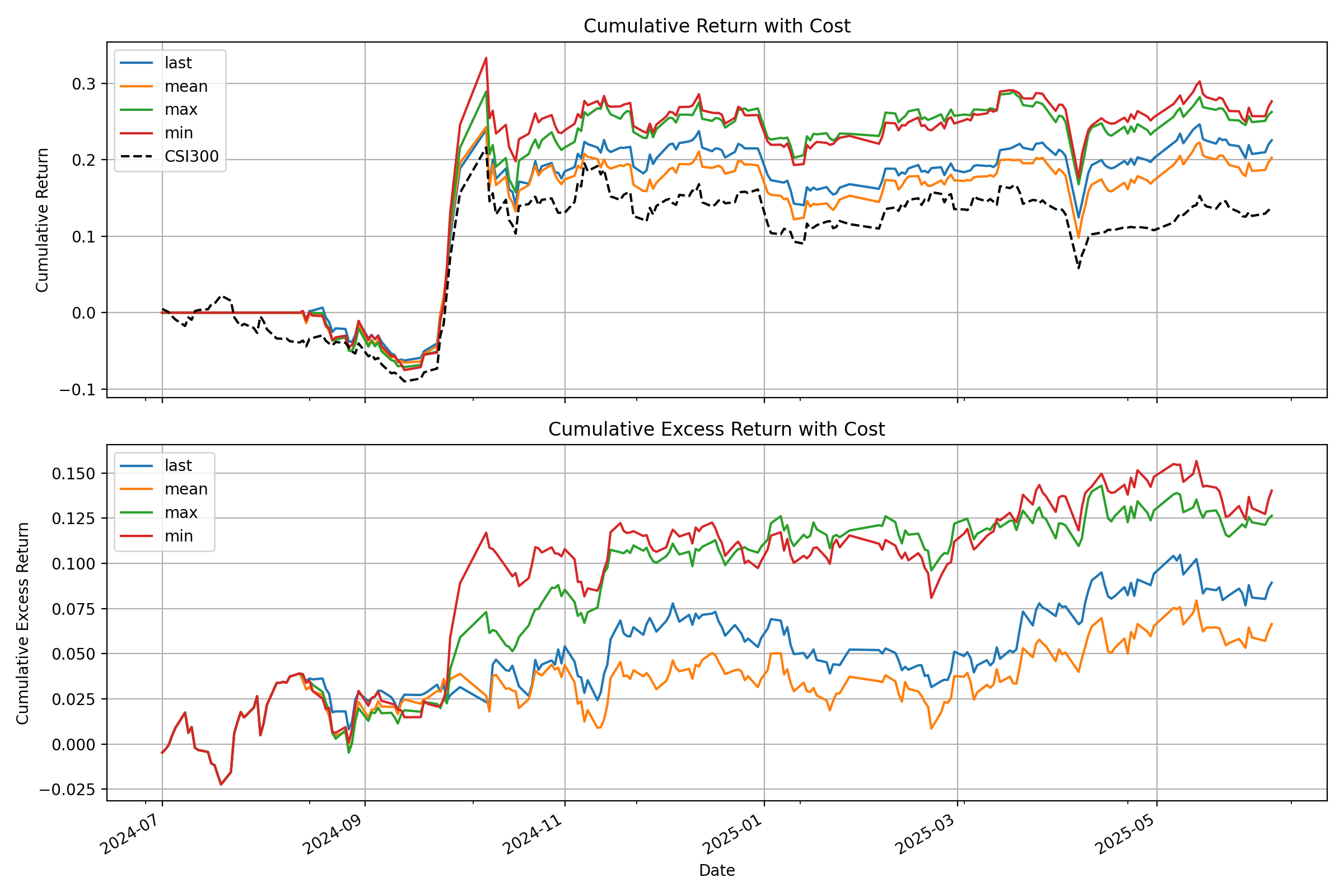
最後に、バックテストスクリプトを実行してファインチューニングされたモデルを評価します。このスクリプトはモデルを読み込み、テストセットで推論を実行し、予測信号(例:予測価格変動)を生成し、シンプルなトップK戦略のバックテストを実行します。
# Specify the GPU for inference python finetune/qlib_test.py --device cuda:0 このスクリプトは、コンソールに詳細なパフォーマンス分析を出力し、以下のようなベンチマークに対する戦略の累積リターン曲線を示すプロットを生成します:
💡 デモから本番環境へ:重要な考慮事項
- 生のシグナル vs 純粋アルファ: このデモでモデルが生成するシグナルは生の予測値です。実際の量的ワークフローでは、これらのシグナルは通常、ポートフォリオ最適化モデルに投入されます。このモデルは、一般的なリスク要因(例:市場ベータ、規模やバリューなどのスタイル要因)へのエクスポージャーを中和する制約を適用し、**「純粋アルファ」**を分離して戦略の堅牢性を向上させます。
- データ処理: 提供されている
QlibDatasetは一例です。異なるデータソースや形式の場合、データの読み込みと前処理のロジックを適応させる必要があります。 - 戦略とバックテストの複雑さ: ここで使用されている単純なトップK戦略は基本的な出発点です。本番レベルの戦略では、多くの場合、ポートフォリオ構築、動的なポジションサイジング、リスク管理(例:損切り/利確ルール)のためのより複雑なロジックが組み込まれています。さらに、高精度なバックテストでは、取引コスト、スリッページ、市場への影響を綿密にモデル化し、実世界でのパフォーマンスをより正確に推定する必要があります。
📝 AI生成のコメント:
finetune/ディレクトリ内のコードコメントの多くは、説明目的でAIアシスタント(Gemini 2.5 Pro)によって生成されたものであることにご注意ください。これらは参考になることを目的としていますが、不正確な情報が含まれている可能性があります。コード自体を論理の確定的な情報源として扱うことを推奨します。
📖 引用
研究でKronosをご利用の際は、私たちの論文を引用していただけますと幸いです:
@misc{shi2025kronos, title={Kronos: A Foundation Model for the Language of Financial Markets}, author={Yu Shi and Zongliang Fu and Shuo Chen and Bohan Zhao and Wei Xu and Changshui Zhang and Jian Li}, year={2025}, eprint={2508.02739}, archivePrefix={arXiv}, primaryClass={q-fin.ST}, url={https://arxiv.org/abs/2508.02739}, } 📜 ライセンス
このプロジェクトは MIT License の下でライセンスされています。