Kronos: Ein Grundmodell für die Sprache der Finanzmärkte




![]()
Kronos ist das erste Open-Source-Grundmodell für Finanzkerzen (K-Linien), trainiert mit Daten von über 45 globalen Börsen.
📰 Neuigkeiten
- 🚩 [2025.08.17] Wir haben die Skripte für das Fine-Tuning veröffentlicht! Nutzen Sie sie, um Kronos an Ihre eigenen Aufgaben anzupassen.
- 🚩 [2025.08.02] Unser Paper ist jetzt auf arXiv verfügbar!
📜 Einführung
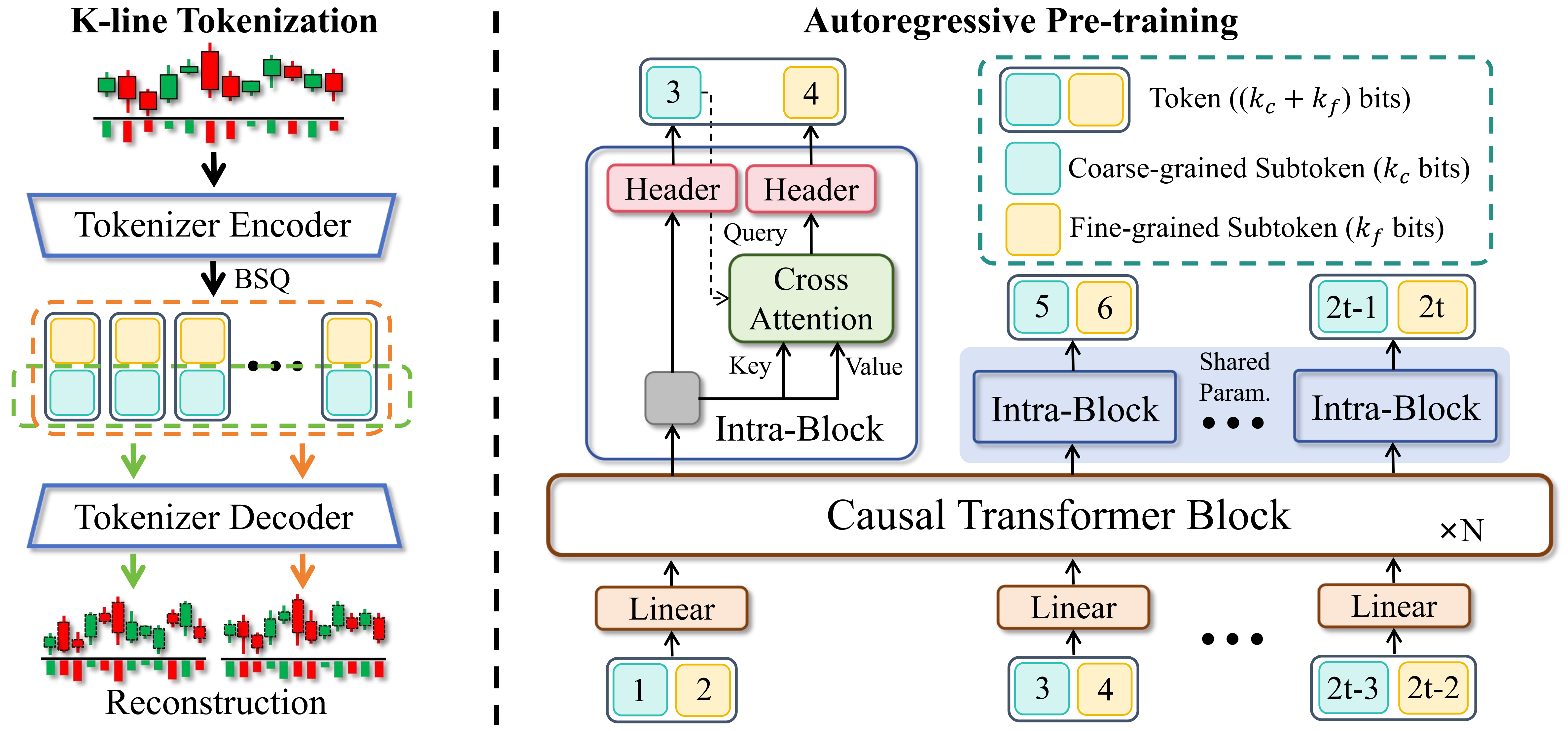
Kronos ist eine Familie von ausschließlich dekodierenden Grundmodellen, die speziell für die "Sprache" der Finanzmärkte – K-Linien-Sequenzen – vortrainiert wurden. Im Gegensatz zu allgemeinen TSFMs ist Kronos dafür ausgelegt, die einzigartigen, hochgradig verrauschten Eigenschaften von Finanzdaten zu verarbeiten. Es nutzt einen neuartigen Zwei-Stufen-Ansatz:
- Ein spezialisierter Tokenizer quantisiert zunächst kontinuierliche, mehrdimensionale K-Linien-Daten (OHLCV) in hierarchische diskrete Tokens.
- Ein großer, autoregressiver Transformer wird dann auf diesen Tokens vortrainiert, was ihn zu einem einheitlichen Modell für verschiedene quantitative Aufgaben macht.
✨ Live-Demo
Wir haben eine Live-Demo eingerichtet, um die Prognoseergebnisse von Kronos zu visualisieren. Die Webseite zeigt eine Prognose für das BTC/USDT-Handelspaar für die nächsten 24 Stunden.
📦 Modell-Zoo
Wir veröffentlichen eine Familie von vortrainierten Modellen mit unterschiedlichen Kapazitäten, um verschiedenen Rechen- und Anwendungsanforderungen gerecht zu werden. Alle Modelle sind direkt über den Hugging Face Hub zugänglich.
| Modell | Tokenizer | Kontextlänge | Parameter | Open-source |
|---|---|---|---|---|
| Kronos-mini | Kronos-Tokenizer-2k | 2048 | 4,1M | ✅ NeoQuasar/Kronos-mini |
| Kronos-small | Kronos-Tokenizer-base | 512 | 24,7M | ✅ NeoQuasar/Kronos-small |
| Kronos-base | Kronos-Tokenizer-base | 512 | 102,3M | ✅ NeoQuasar/Kronos-base |
| Kronos-large | Kronos-Tokenizer-base | 512 | 499,2M | ❌ |
🚀 Erste Schritte
Installation
- Installieren Sie Python 3.10+ und dann die Abhängigkeiten:
pip install -r requirements.txt 📈 Prognosen erstellen
Das Erstellen von Prognosen mit Kronos ist unkompliziert mit der Klasse KronosPredictor. Sie übernimmt die Datenvorverarbeitung, Normalisierung, Vorhersage und inverse Normalisierung, sodass Sie mit nur wenigen Codezeilen von Rohdaten zu Prognosen gelangen.
Wichtiger Hinweis: Der max_context für Kronos-small und Kronos-base beträgt 512. Dies ist die maximale Sequenzlänge, die das Modell verarbeiten kann. Für eine optimale Leistung wird empfohlen, dass die Länge Ihrer Eingabedaten (d.h. lookback) diese Grenze nicht überschreitet. Der KronosPredictor behandelt automatisch die Kürzung für längere Kontexte.
Hier ist eine Schritt-für-Schritt-Anleitung für Ihre erste Prognose.
1. Tokenizer und Modell laden
Laden Sie zunächst ein vortrainiertes Kronos-Modell und den entsprechenden Tokenizer vom Hugging Face Hub.
from model import Kronos, KronosTokenizer, KronosPredictor # Load from Hugging Face Hub tokenizer = KronosTokenizer.from_pretrained("NeoQuasar/Kronos-Tokenizer-base") model = Kronos.from_pretrained("NeoQuasar/Kronos-small") 2. Predictor instanziieren
Erstellen Sie eine Instanz von KronosPredictor, indem Sie das Modell, den Tokenizer und das gewünschte Device übergeben.
# Initialize the predictor predictor = KronosPredictor(model, tokenizer, device="cuda:0", max_context=512) 3. Eingabedaten vorbereiten
Die predict-Methode erfordert drei Haupteingaben:
df: Ein pandas DataFrame, der die historischen K-Linien-Daten enthält. Er muss die Spalten['open', 'high', 'low', 'close']enthalten.volumeundamountsind optional.x_timestamp: Eine pandas Series von Zeitstempeln, die den historischen Daten indfentsprechen.y_timestamp: Eine pandas Series von Zeitstempeln für die zukünftigen Zeiträume, die Sie vorhersagen möchten.
import pandas as pd # Load your data df = pd.read_csv("./data/XSHG_5min_600977.csv") df['timestamps'] = pd.to_datetime(df['timestamps']) # Define context window and prediction length lookback = 400 pred_len = 120 # Prepare inputs for the predictor x_df = df.loc[:lookback-1, ['open', 'high', 'low', 'close', 'volume', 'amount']] x_timestamp = df.loc[:lookback-1, 'timestamps'] y_timestamp = df.loc[lookback:lookback+pred_len-1, 'timestamps'] 4. Prognosen generieren
Rufen Sie die predict-Methode auf, um Prognosen zu generieren. Sie können den Sampling-Prozess mit Parametern wie T, top_p und sample_count für probabilistische Prognosen steuern.
# Generate predictions pred_df = predictor.predict( df=x_df, x_timestamp=x_timestamp, y_timestamp=y_timestamp, pred_len=pred_len, T=1.0, # Temperature for sampling top_p=0.9, # Nucleus sampling probability sample_count=1 # Number of forecast paths to generate and average ) print("Forecasted Data Head:") print(pred_df.head()) Die predict-Methode gibt einen pandas DataFrame zurück, der die prognostizierten Werte für open, high, low, close, volume und amount enthält, indiziert nach dem von Ihnen bereitgestellten y_timestamp.
Für die effiziente Verarbeitung mehrerer Zeitreihen bietet Kronos eine predict_batch-Methode, die parallele Vorhersagen auf mehreren Datensätzen gleichzeitig ermöglicht. Dies ist besonders nützlich, wenn Sie mehrere Assets oder Zeitperioden auf einmal prognostizieren müssen.
# Prepare multiple datasets for batch prediction df_list = [df1, df2, df3] # List of DataFrames x_timestamp_list = [x_ts1, x_ts2, x_ts3] # List of historical timestamps y_timestamp_list = [y_ts1, y_ts2, y_ts3] # List of future timestamps # Generate batch predictions pred_df_list = predictor.predict_batch( df_list=df_list, x_timestamp_list=x_timestamp_list, y_timestamp_list=y_timestamp_list, pred_len=pred_len, T=1.0, top_p=0.9, sample_count=1, verbose=True ) # pred_df_list contains prediction results in the same order as input for i, pred_df in enumerate(pred_df_list): print(f"Predictions for series {i}:") print(pred_df.head()) Wichtige Anforderungen für Batch-Vorhersagen:
- Alle Reihen müssen die gleiche historische Länge (Lookback-Fenster) haben
- Alle Reihen müssen die gleiche Vorhersagelänge (
pred_len) haben - Jeder DataFrame muss die erforderlichen Spalten enthalten:
['open', 'high', 'low', 'close'] volume- undamount-Spalten sind optional und werden bei Fehlen mit Nullen gefüllt
Die predict_batch-Methode nutzt GPU-Parallelität für effiziente Verarbeitung und behandelt automatisch Normalisierung und Denormalisierung für jede Reihe unabhängig.
5. Beispiel und Visualisierung
Für ein vollständiges, ausführbares Skript, das Datenladen, Vorhersage und Plotting enthält, siehe examples/prediction_example.py.
Das Ausführen dieses Skripts erzeugt eine Grafik, die die Ground-Truth-Daten mit der Prognose des Modells vergleicht, ähnlich der unten gezeigten:
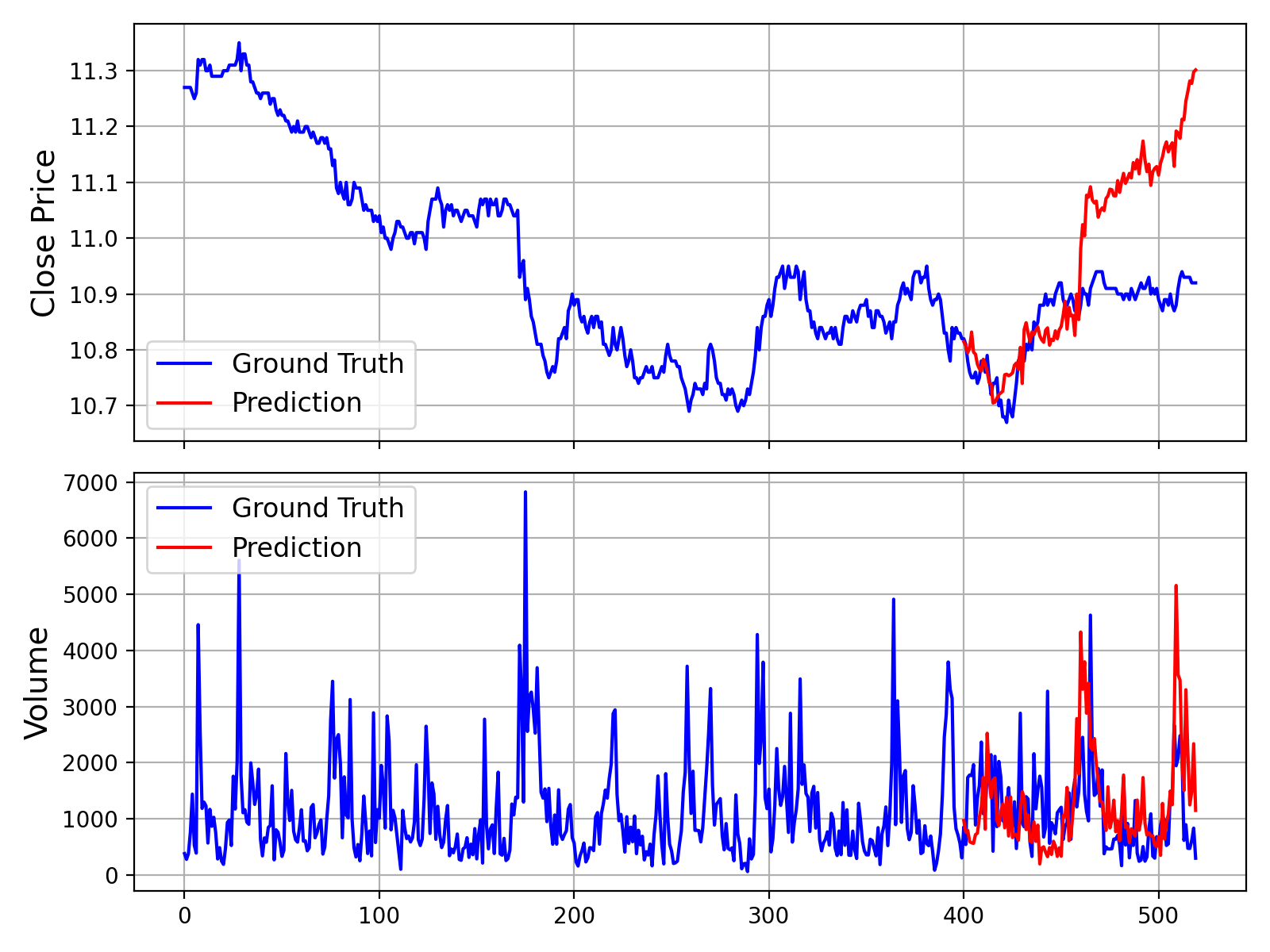
Zusätzlich stellen wir auch ein Skript zur Verfügung, das Vorhersagen ohne Volumen- und Betragsdaten trifft, welches in examples/prediction_wo_vol_example.py zu finden ist.
🔧 Feinabstimmung mit eigenen Daten (Aktienmarkt-Beispiel)
Wir bieten eine komplette Pipeline zur Feinabstimmung von Kronos mit Ihren eigenen Datensätzen. Als Beispiel zeigen wir, wie Sie Qlib verwenden können, um Daten vom chinesischen A-Aktienmarkt aufzubereiten und einen einfachen Backtest durchzuführen.
Haftungsausschluss: Diese Pipeline dient als Demonstration zur Veranschaulichung des Feinabstimmungsprozesses. Es handelt sich um ein vereinfachtes Beispiel und kein produktionsreifes quantitatives Handelssystem. Eine robuste quantitative Strategie erfordert anspruchsvollere Techniken, wie Portfolio-Optimierung und Risikofaktor-Neutralisierung, um stabiles Alpha zu erreichen.
Der Feinabstimmungsprozess ist in vier Hauptschritte unterteilt:
- Konfiguration: Einrichten von Pfaden und Hyperparametern.
- Datenaufbereitung: Verarbeitung und Aufteilung Ihrer Daten mit Qlib.
- Modell-Feinabstimmung: Feinabstimmung des Tokenizers und der Predictor-Modelle.
- Backtesting: Bewertung der Leistung des feinabgestimmten Modells.
Voraussetzungen
- Stellen Sie zunächst sicher, dass alle Abhängigkeiten aus
requirements.txtinstalliert sind. - Diese Pipeline basiert auf
qlib. Bitte installieren Sie es:pip install pyqlib - Sie müssen Ihre Qlib-Daten vorbereiten. Befolgen Sie die offizielle Qlib-Anleitung, um Ihre Daten lokal herunterzuladen und einzurichten. Die Beispielskripte gehen davon aus, dass Sie Tagesdaten verwenden.
Schritt 1: Konfigurieren Sie Ihr Experiment
Alle Einstellungen für Daten, Training und Modellpfade sind in finetune/config.py zentralisiert. Bevor Sie Skripte ausführen, ändern Sie bitte die folgenden Pfade entsprechend Ihrer Umgebung:
qlib_data_path: Pfad zu Ihrem lokalen Qlib-Datenverzeichnis.dataset_path: Verzeichnis, in dem die verarbeiteten Trainings-/Validierungs-/Test-Pickle-Dateien gespeichert werden.save_path: Basisverzeichnis zum Speichern von Modell-Checkpoints.backtest_result_path: Verzeichnis zum Speichern von Backtesting-Ergebnissen.pretrained_tokenizer_pathundpretrained_predictor_path: Pfade zu den vortrainierten Modellen, von denen Sie starten möchten (können lokale Pfade oder Hugging Face-Modellnamen sein).
Sie können auch andere Parameter wie instrument, train_time_range, epochs und batch_size an Ihre spezifische Aufgabe anpassen. Wenn Sie Comet.ml nicht verwenden, setzen Sie use_comet = False.
Schritt 2: Bereiten Sie den Datensatz vor
Führen Sie das Datenvorverarbeitungsskript aus. Dieses Skript lädt Rohmarkt-Daten aus Ihrem Qlib-Verzeichnis, verarbeitet sie, teilt sie in Trainings-, Validierungs- und Testdatensätze auf und speichert sie als Pickle-Dateien.
python finetune/qlib_data_preprocess.py Nach der Ausführung finden Sie train_data.pkl, val_data.pkl und test_data.pkl in dem durch dataset_path in Ihrer Konfiguration angegebenen Verzeichnis.
Schritt 3: Finetuning durchführen
Der Finetuning-Prozess besteht aus zwei Stufen: Finetuning des Tokenizers und anschließend des Predictors. Beide Trainingsskripte sind für Multi-GPU-Training mit torchrun ausgelegt.
3.1 Tokenizer finetunen
Dieser Schritt passt den Tokenizer an die Datenverteilung Ihrer spezifischen Domäne an.
# Replace NUM_GPUS with the number of GPUs you want to use (e.g., 2) torchrun --standalone --nproc_per_node=NUM_GPUS finetune/train_tokenizer.py Der beste Tokenizer-Checkpoint wird unter dem in config.py konfigurierten Pfad gespeichert (abgeleitet von save_path und tokenizer_save_folder_name).
3.2 Predictor finetunen
Dieser Schritt trainiert das Haupt-Kronos-Modell für die Prognoseaufgabe mittels Finetuning.
# Replace NUM_GPUS with the number of GPUs you want to use (e.g., 2) torchrun --standalone --nproc_per_node=NUM_GPUS finetune/train_predictor.py Der beste Predictor-Checkpoint wird unter dem in config.py konfigurierten Pfad gespeichert.
Schritt 4: Evaluation mit Backtesting
Führen Sie abschließend das Backtesting-Skript aus, um Ihr finetuned Modell zu evaluieren. Dieses Skript lädt die Modelle, führt Inferenz auf dem Testdatensatz durch, generiert Prognosesignale (z.B. vorhergesagte Preisänderung) und führt einen einfachen Top-K-Strategie-Backtest durch.
# Specify the GPU for inference python finetune/qlib_test.py --device cuda:0 Das Skript gibt eine detaillierte Leistungsanalyse in Ihrer Konsole aus und erzeugt eine Grafik, die die kumulativen Renditekurven Ihrer Strategie im Vergleich zur Benchmark zeigt, ähnlich der folgenden:
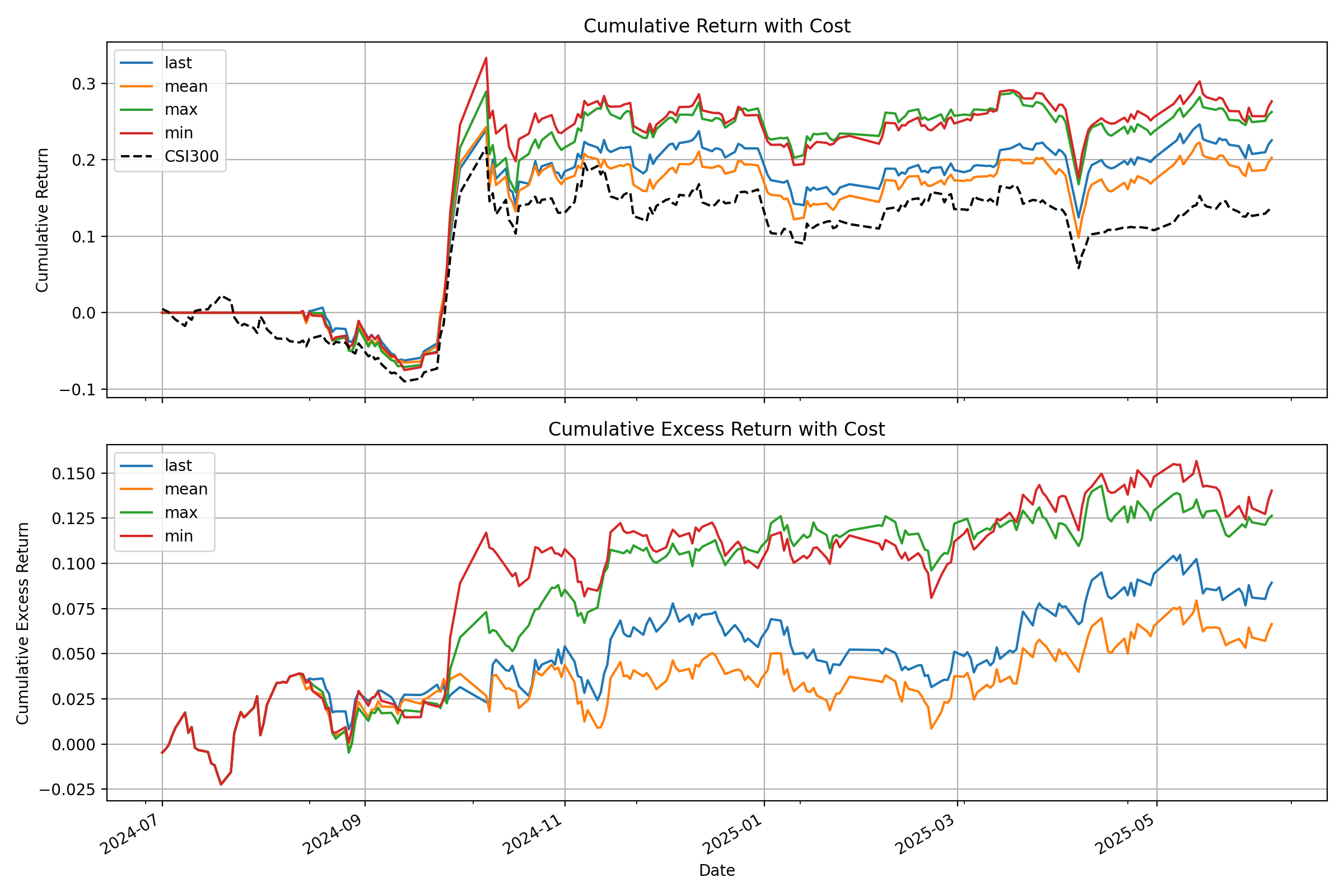
💡 Von der Demo zur Produktion: Wichtige Überlegungen
- Rohsignale vs. reine Alpha-Signale: Die in dieser Demo vom Modell erzeugten Signale sind Rohvorhersagen. In einem realen quantitativen Workflow würden diese Signale typischerweise in ein Portfolio-Optimierungsmodell eingespeist. Dieses Modell würde Beschränkungen anwenden, um die Exposition gegenüber gemeinsamen Risikofaktoren (z.B. Markt-Beta, Stilfaktoren wie Größe und Wert) zu neutralisieren, wodurch das "reine Alpha" isoliert und die Robustheit der Strategie verbessert würde.
- Datenverwaltung: Der bereitgestellte
QlibDatasetist ein Beispiel. Für verschiedene Datenquellen oder Formate müssen Sie die Datenlade- und Vorverarbeitungslogik anpassen. - Strategie- und Backtesting-Komplexität: Die hier verwendete einfache Top-K-Strategie ist ein grundlegender Ausgangspunkt. Produktionsreife Strategien beinhalten oft komplexere Logik für den Portfoliobau, dynamische Positionsgrößenanpassung und Risikomanagement (z.B. Stop-Loss/Take-Profit-Regeln). Darüber hinaus sollte ein hochpräzises Backtestmodell Transaktionskosten, Slippage und Marktauswirkungen sorgfältig modellieren, um eine genauere Schätzung der realen Performance zu liefern.
📝 KI-generierte Kommentare: Bitte beachten Sie, dass viele der Code-Kommentare im Verzeichnis
finetune/von einem KI-Assistenten (Gemini 2.5 Pro) zu Erklärungszwecken generiert wurden. Obwohl sie hilfreich sein sollen, können sie Ungenauigkeiten enthalten. Wir empfehlen, den Code selbst als maßgebliche Quelle der Logik zu behandeln.
📖 Zitierung
Wenn Sie Kronos in Ihrer Forschung verwenden, würden wir uns über eine Zitierung unserer Arbeit freuen:
@misc{shi2025kronos, title={Kronos: A Foundation Model for the Language of Financial Markets}, author={Yu Shi and Zongliang Fu and Shuo Chen and Bohan Zhao and Wei Xu and Changshui Zhang and Jian Li}, year={2025}, eprint={2508.02739}, archivePrefix={arXiv}, primaryClass={q-fin.ST}, url={https://arxiv.org/abs/2508.02739}, } 📜 Lizenz
Dieses Projekt ist unter der MIT-Lizenz lizenziert.