Downloaded 154 times








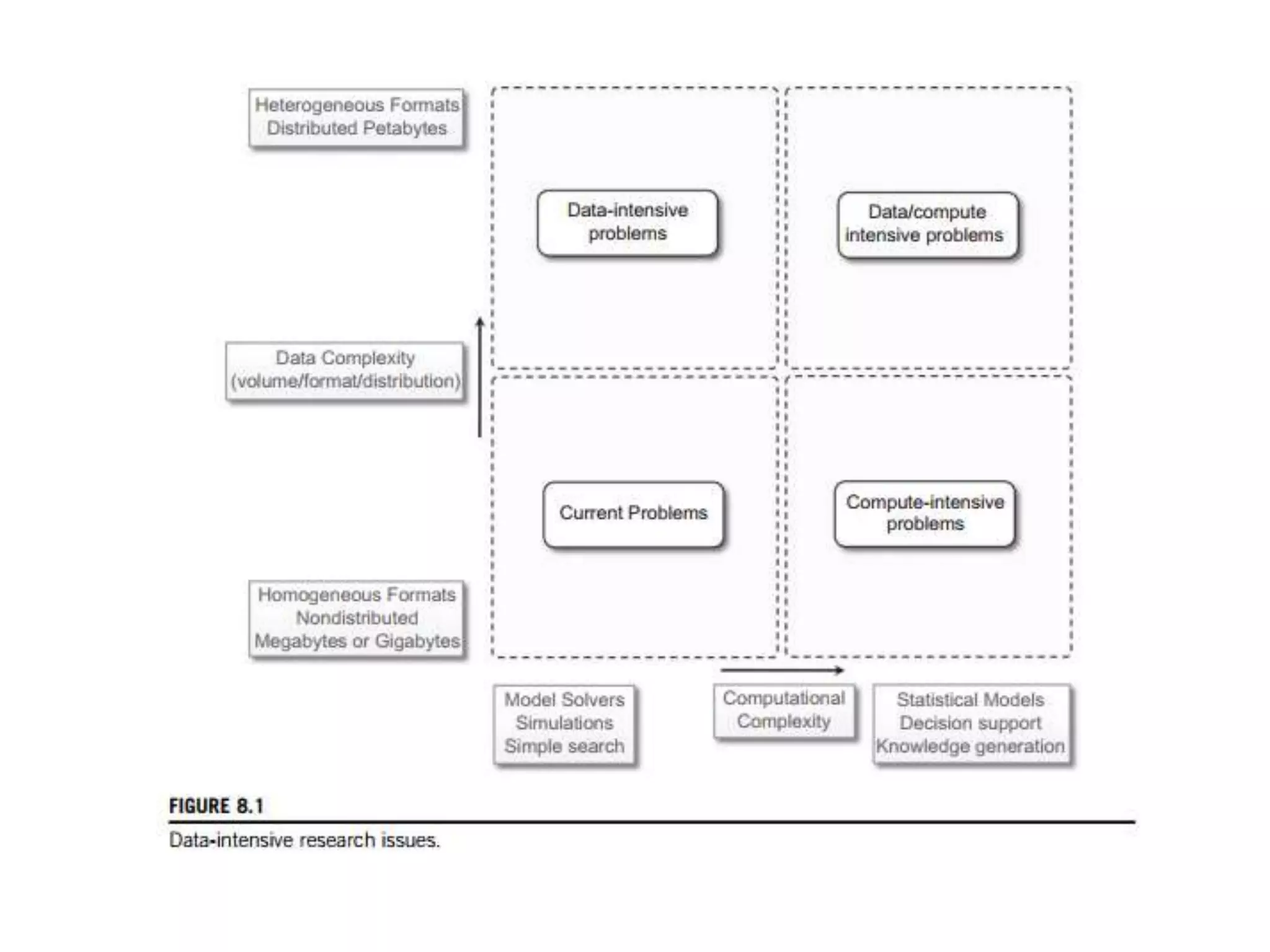





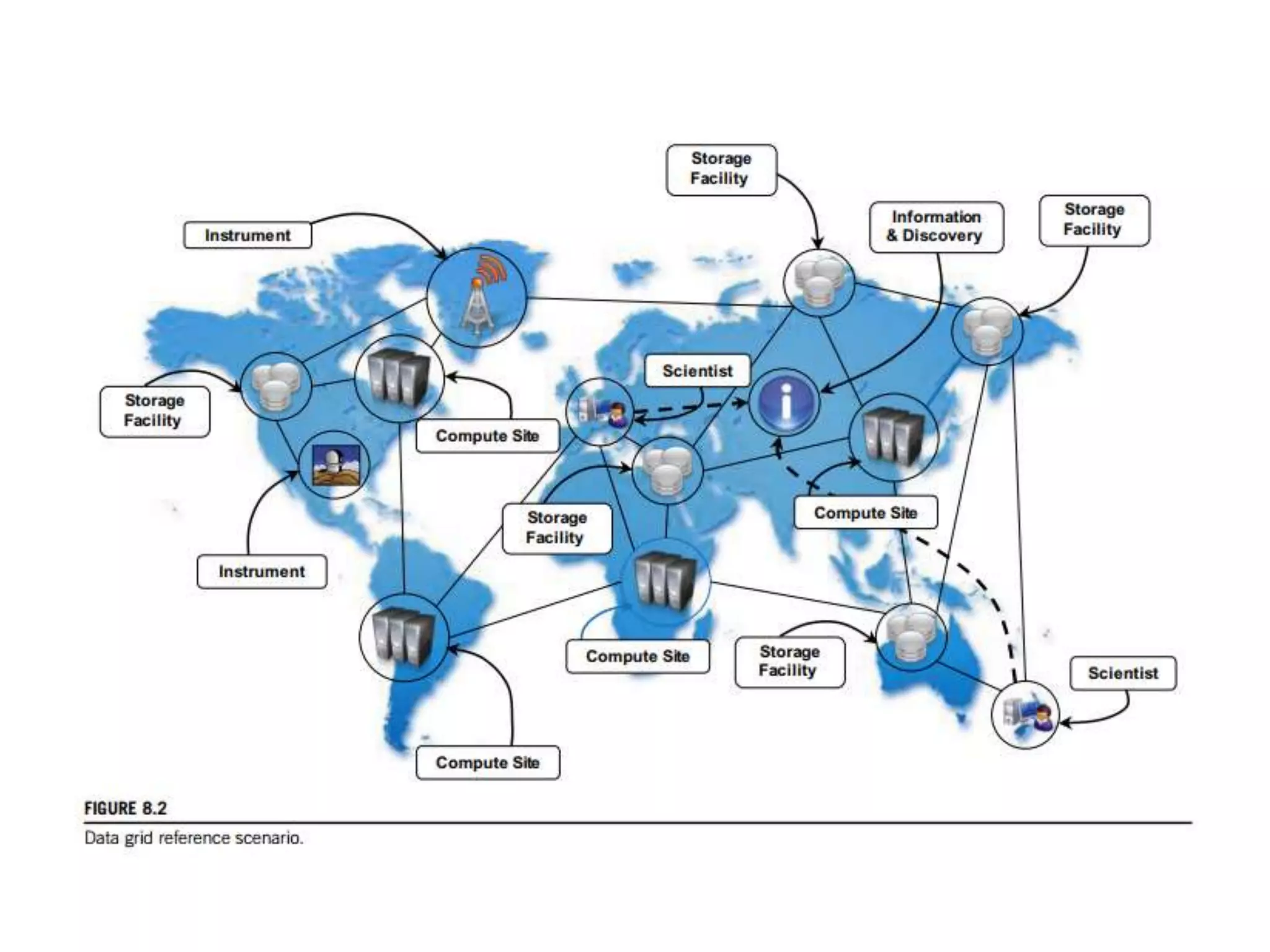
















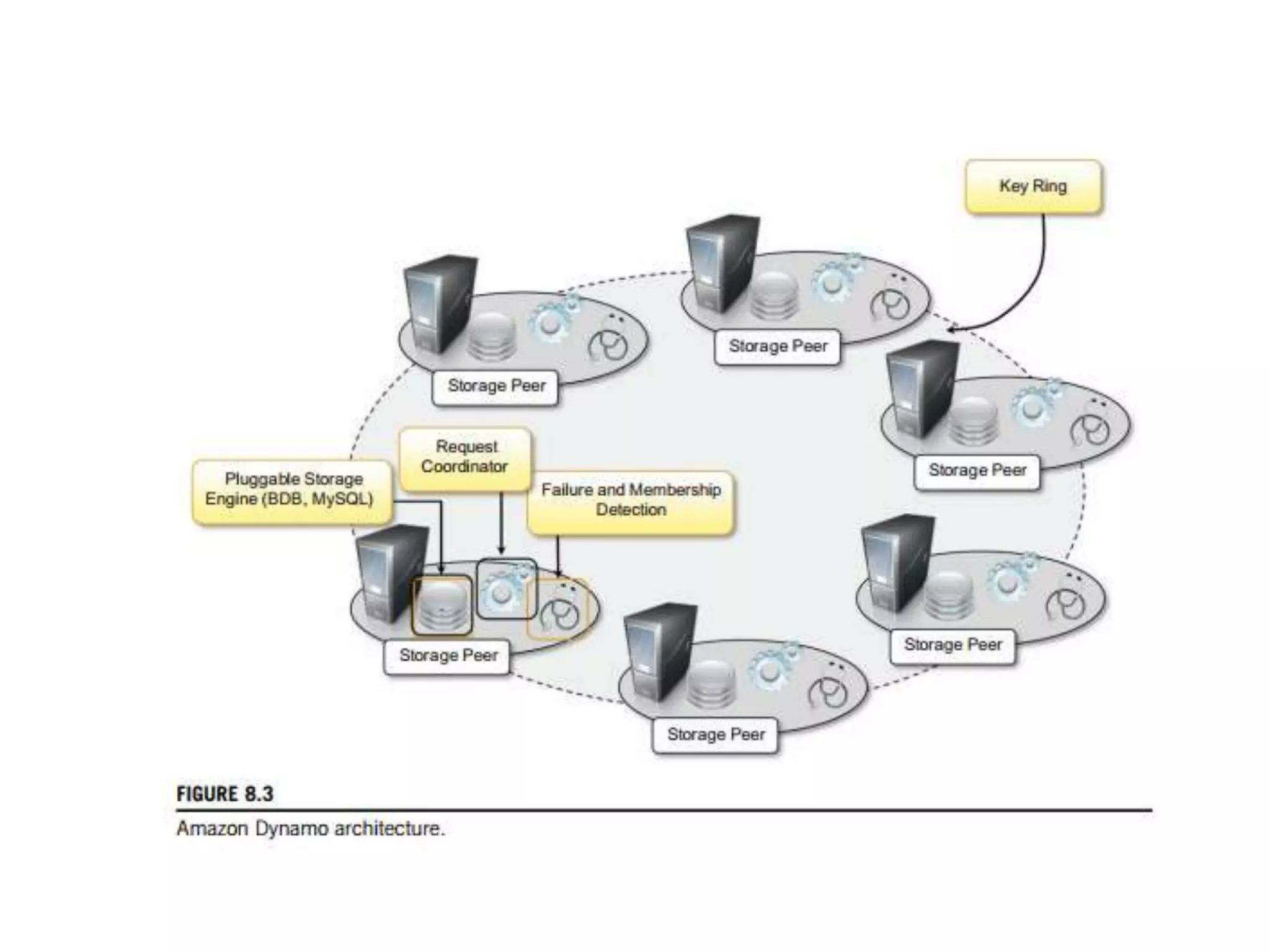

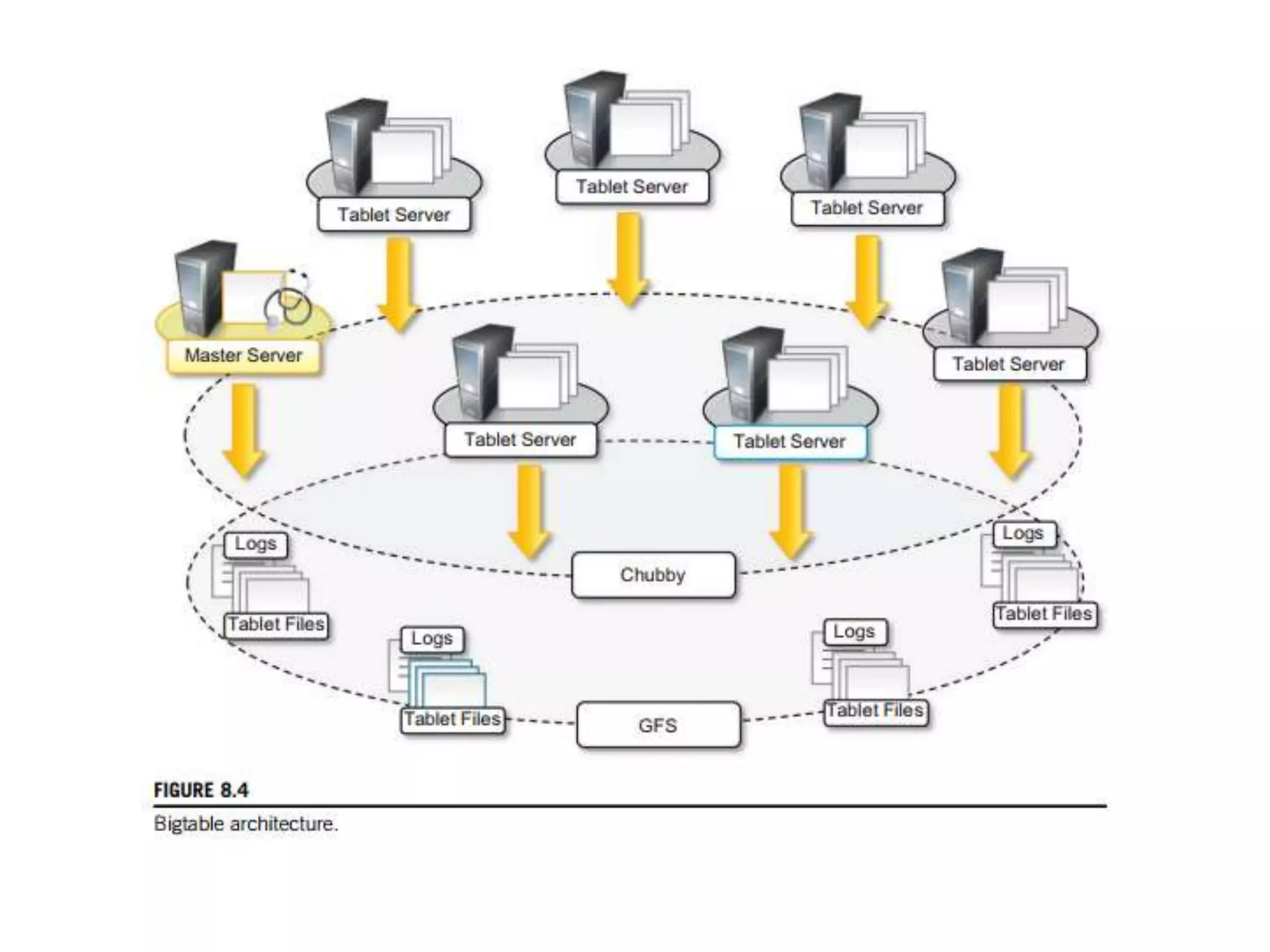




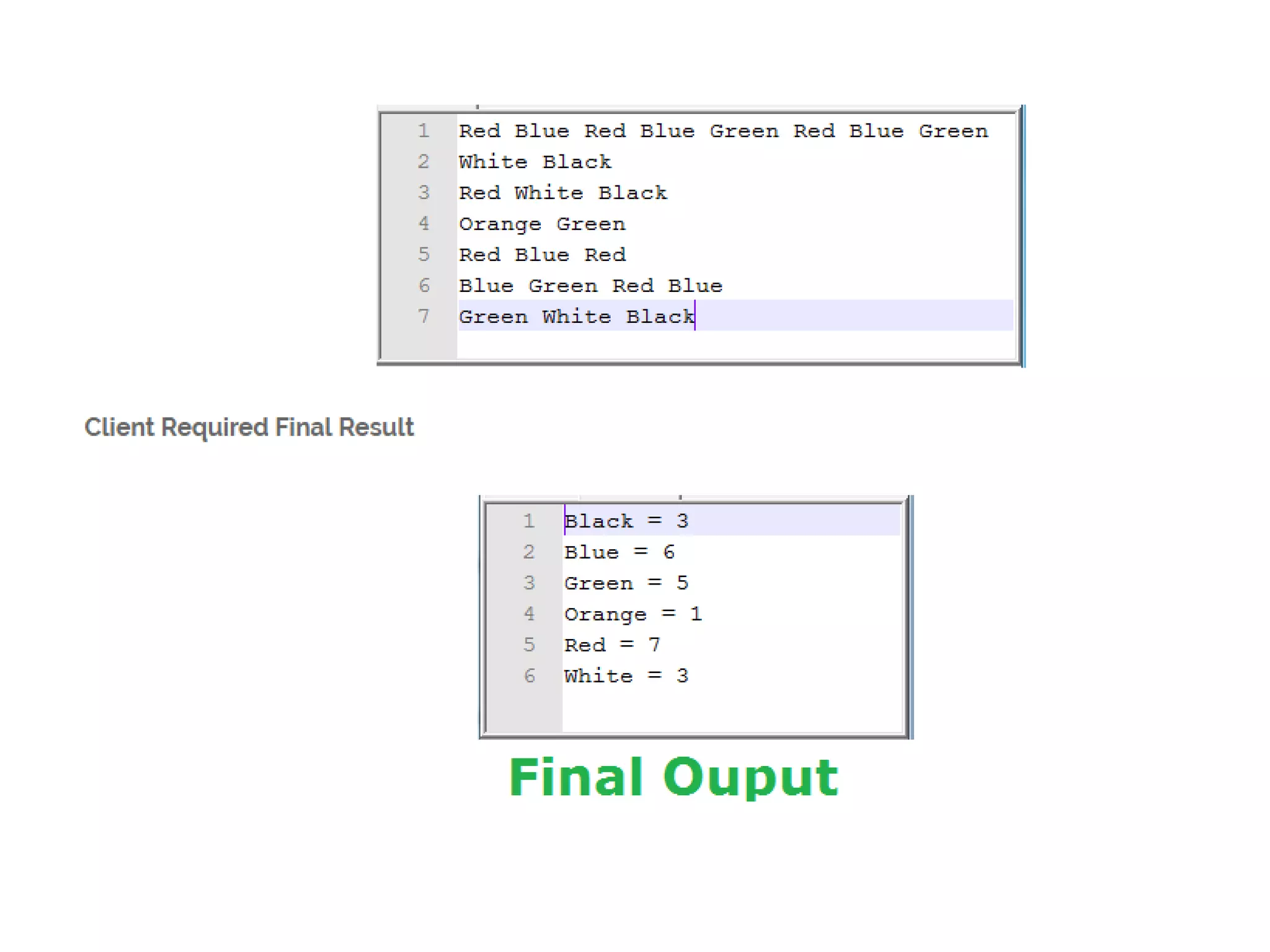
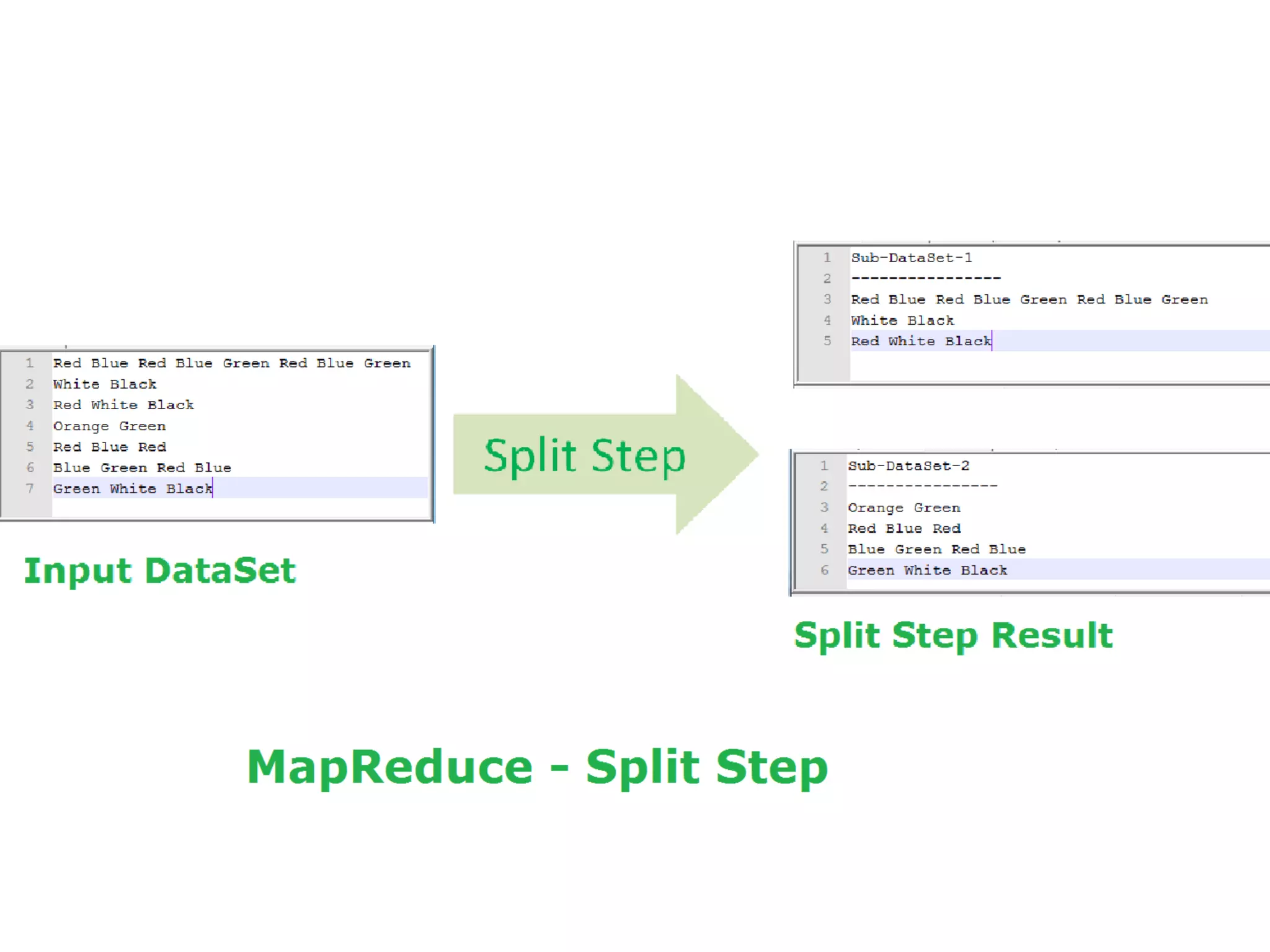
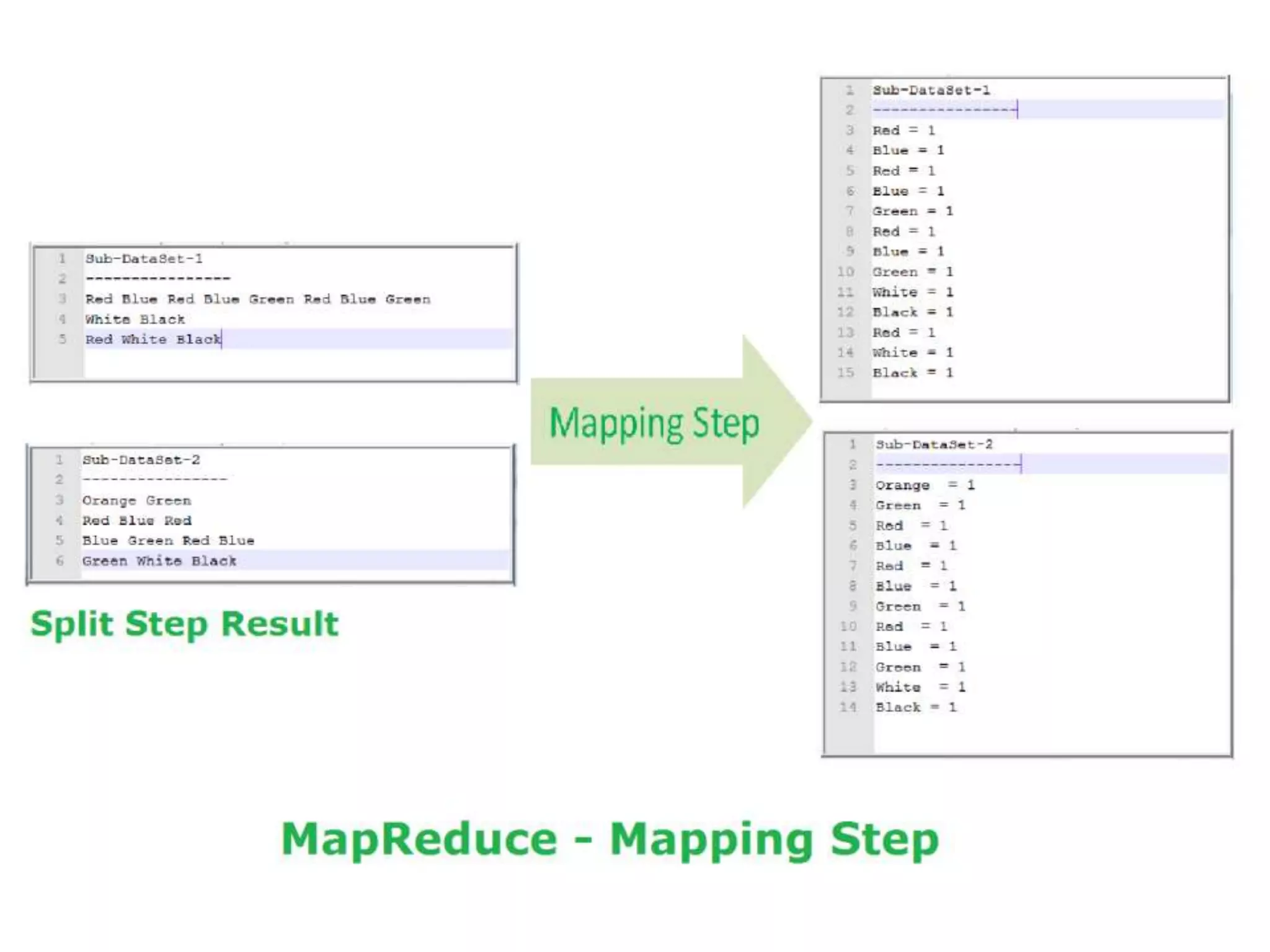
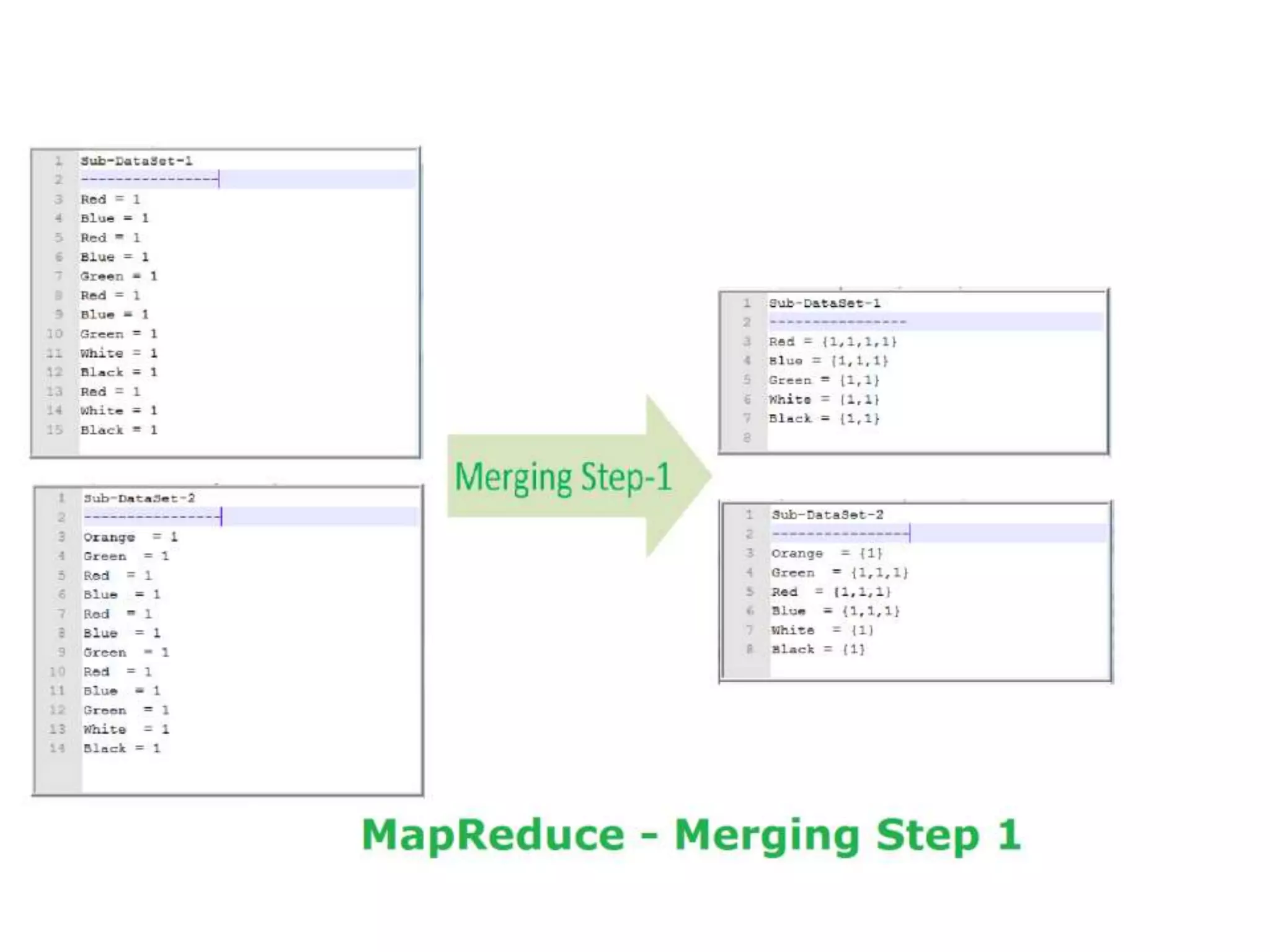
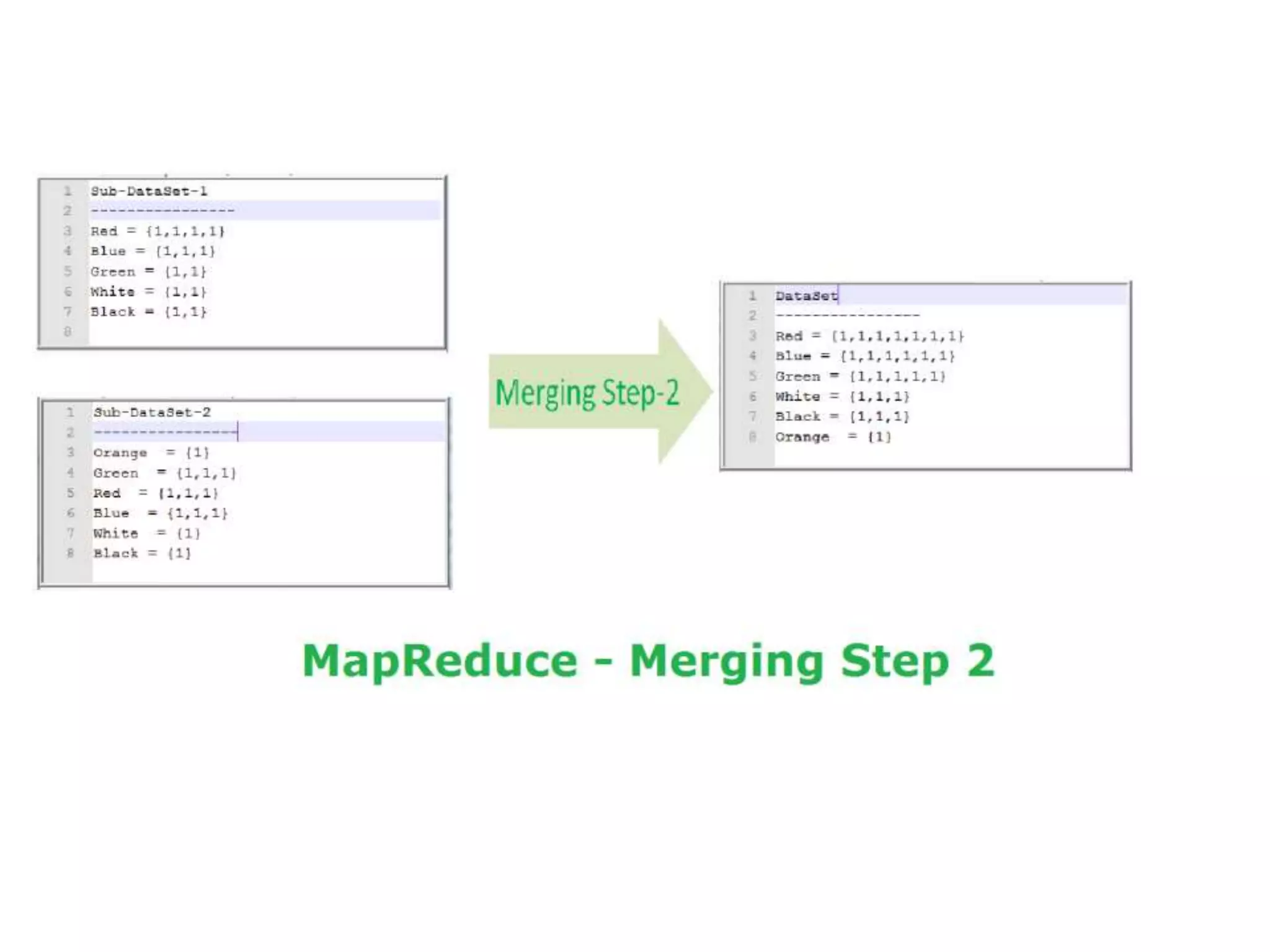
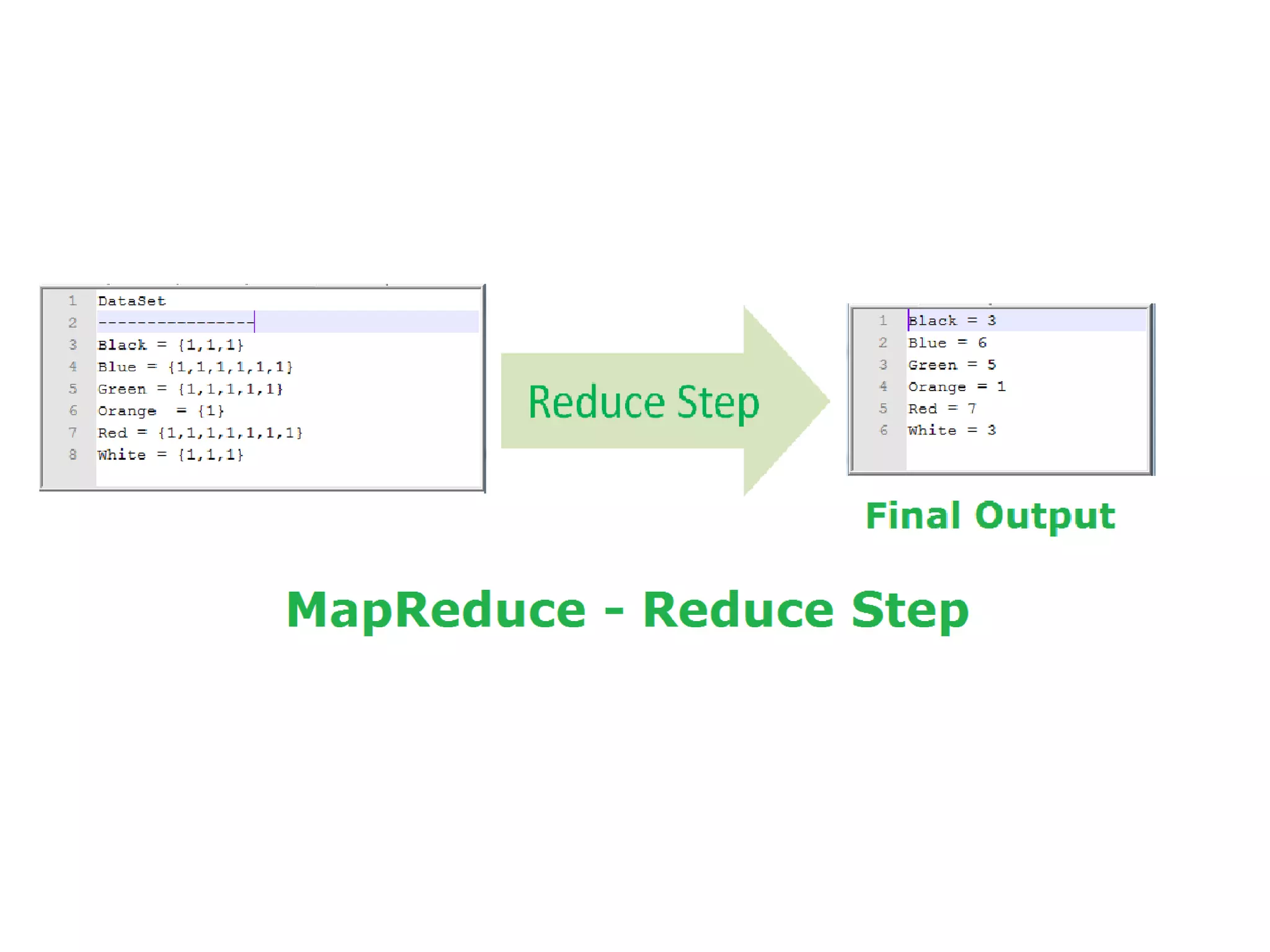
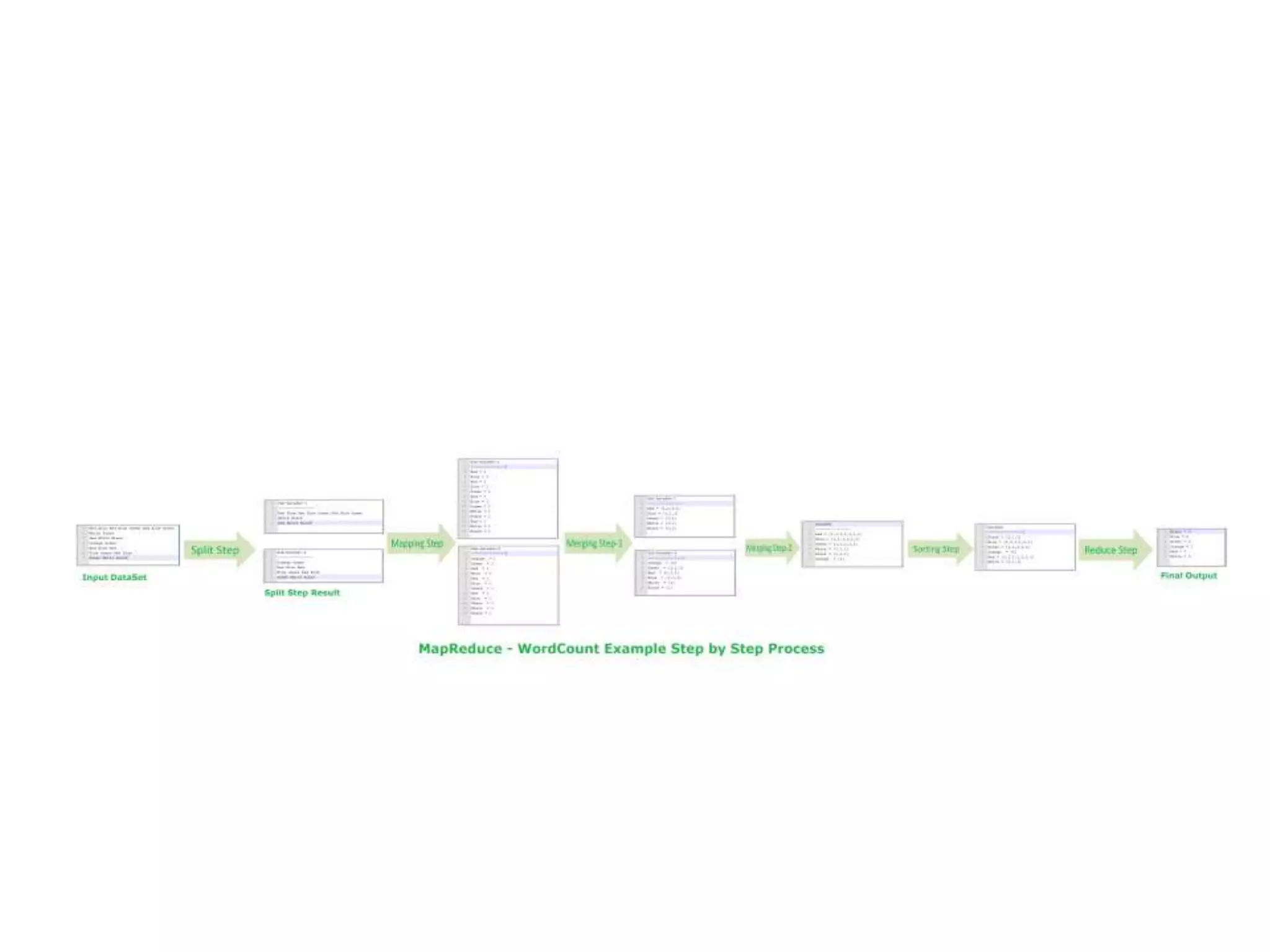
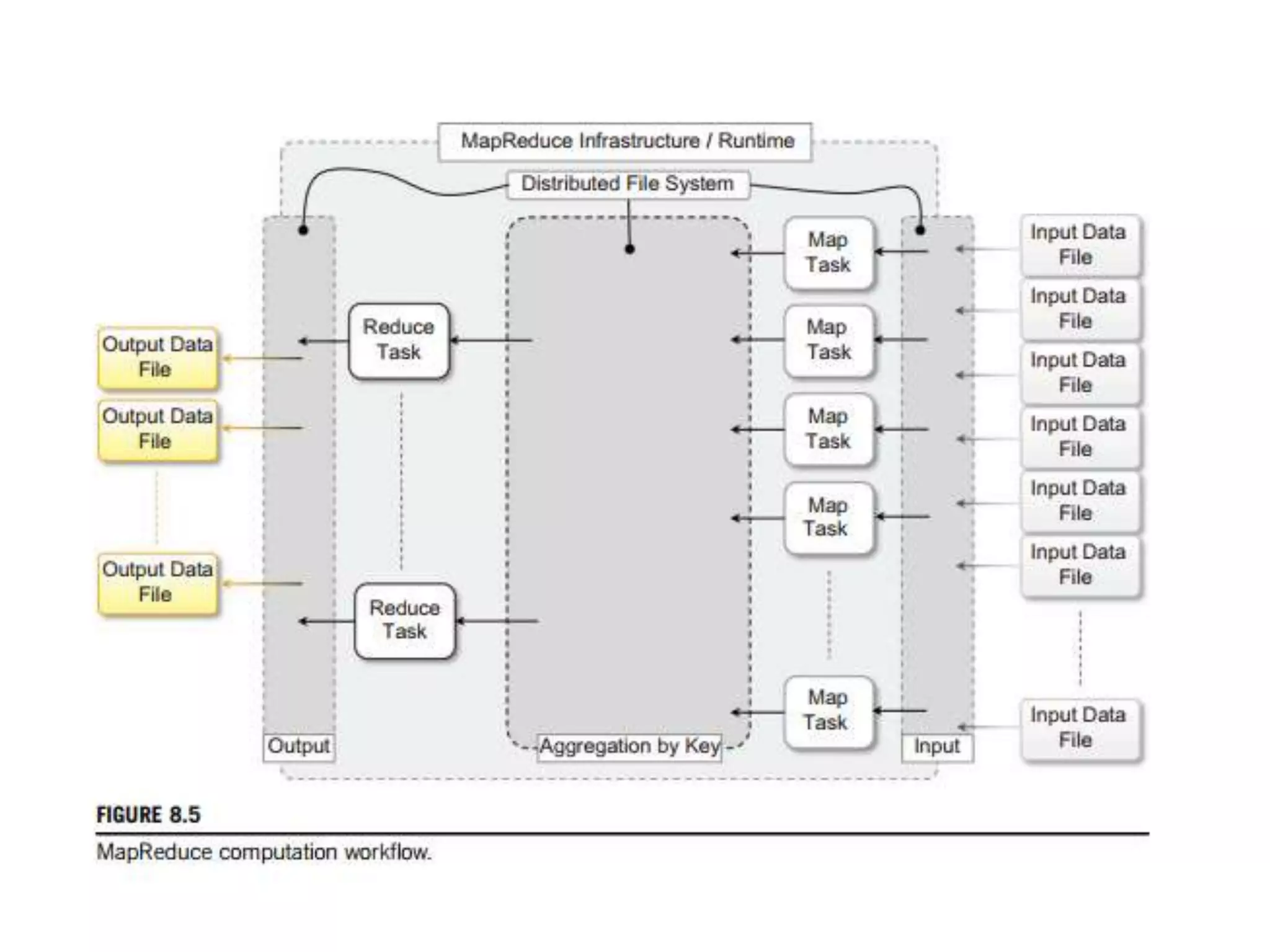



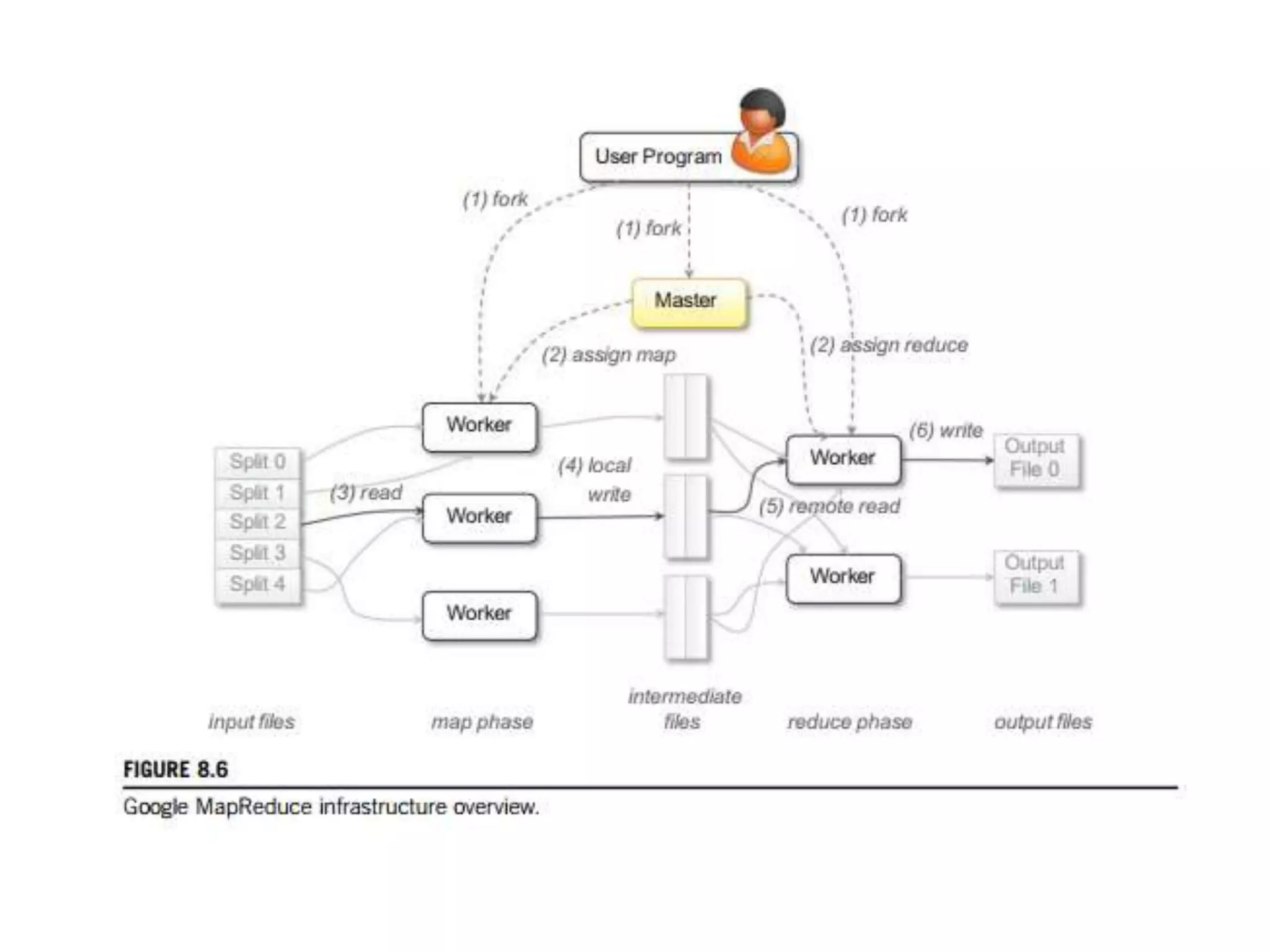












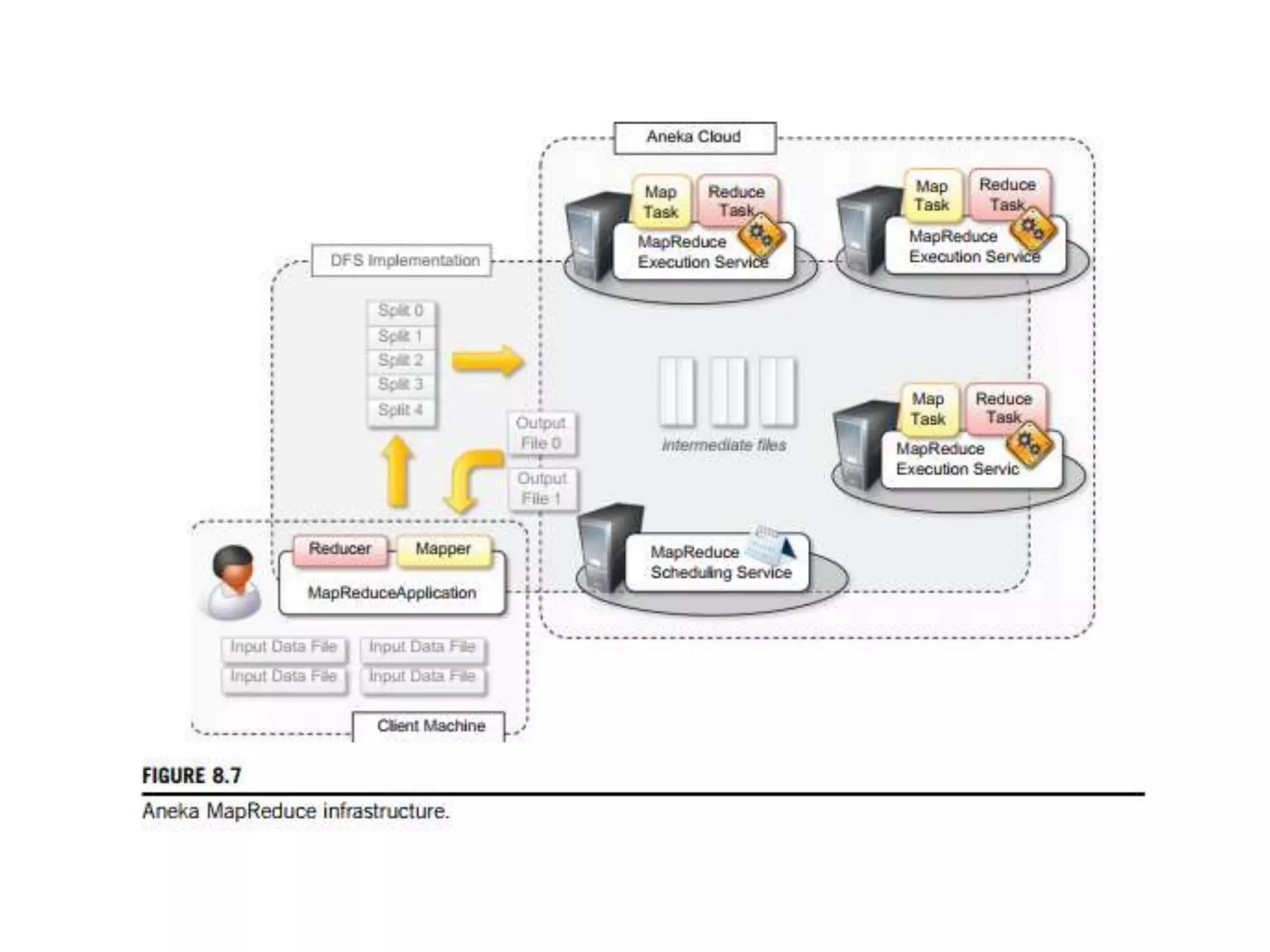


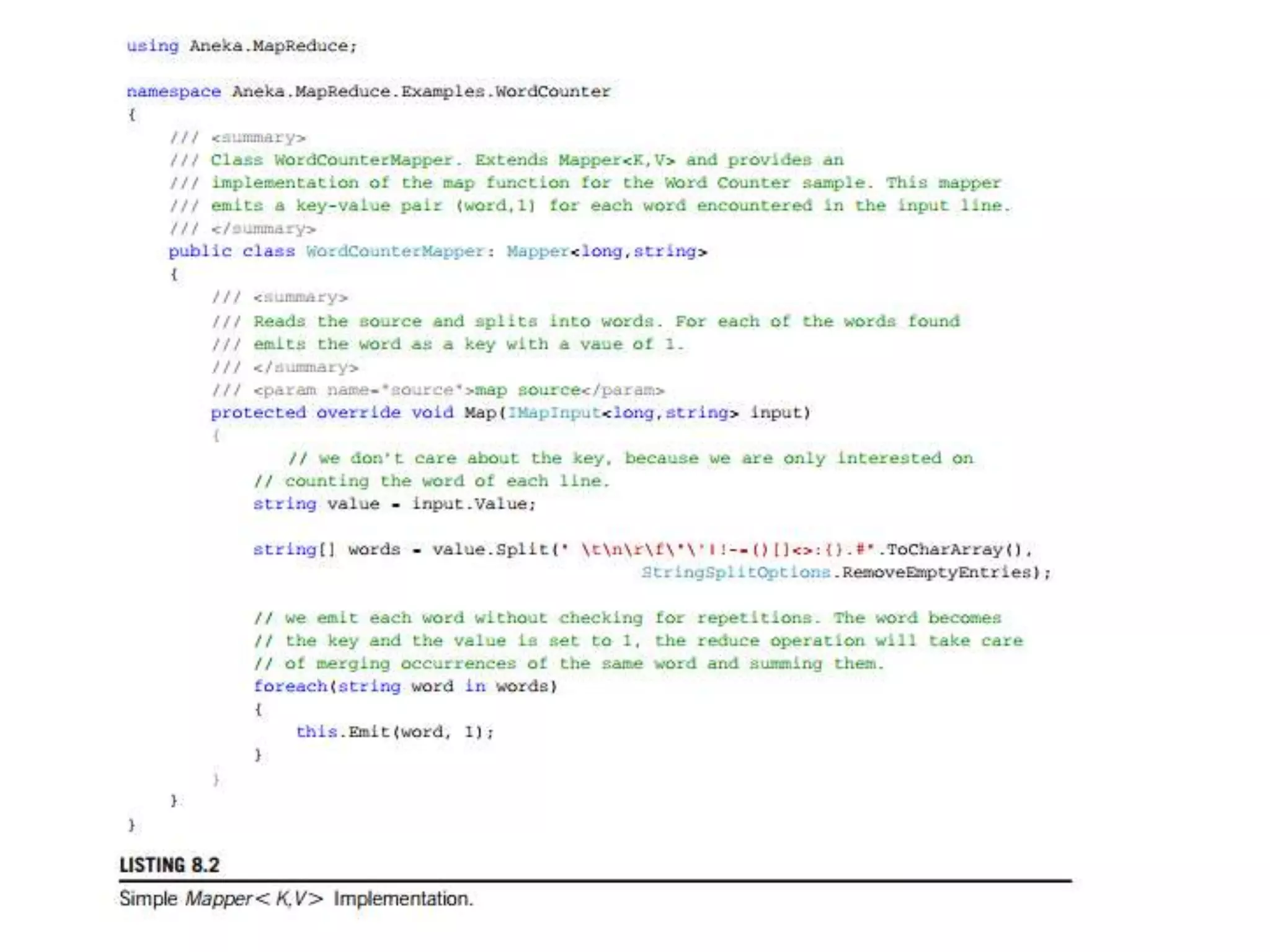

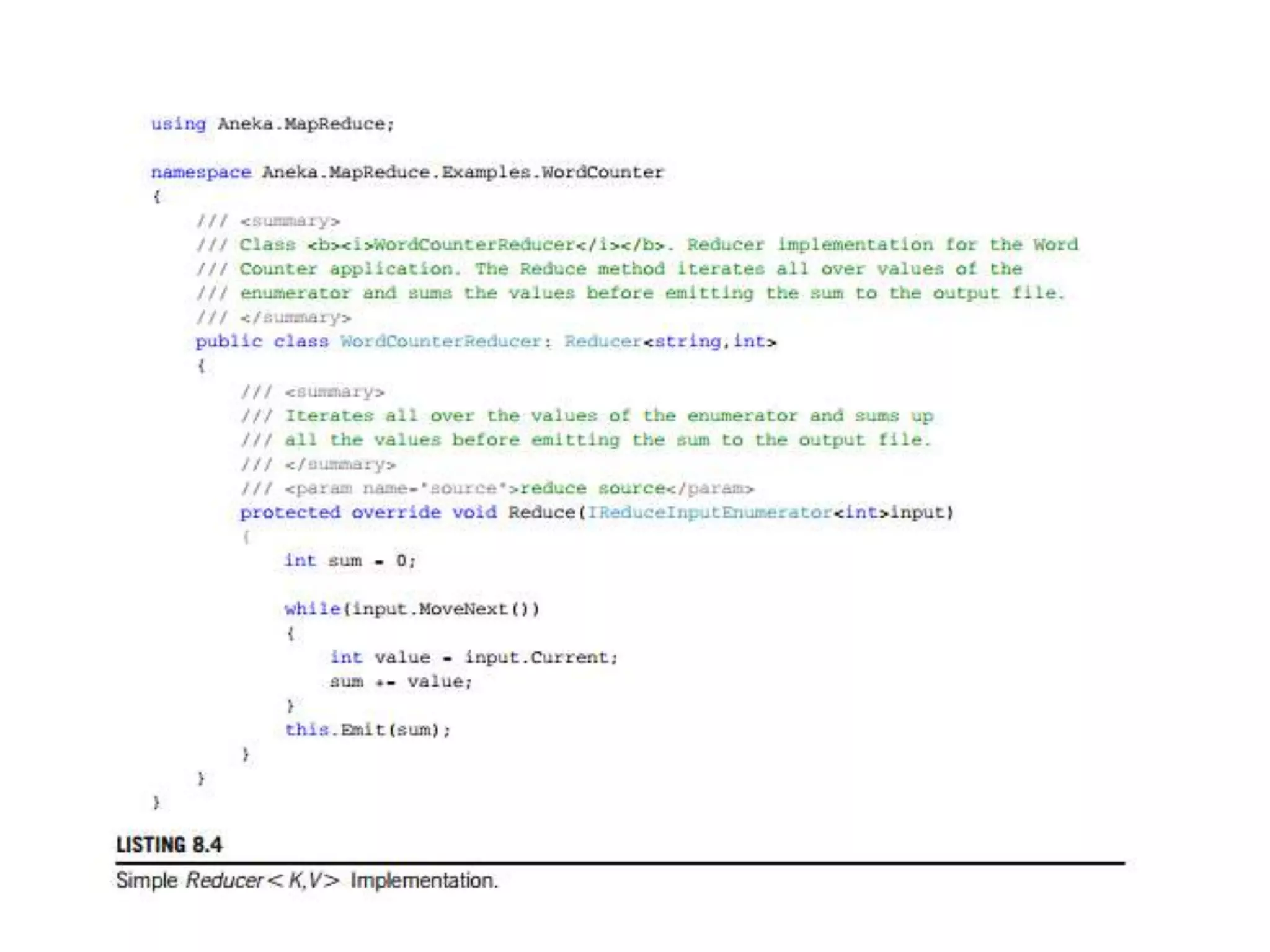




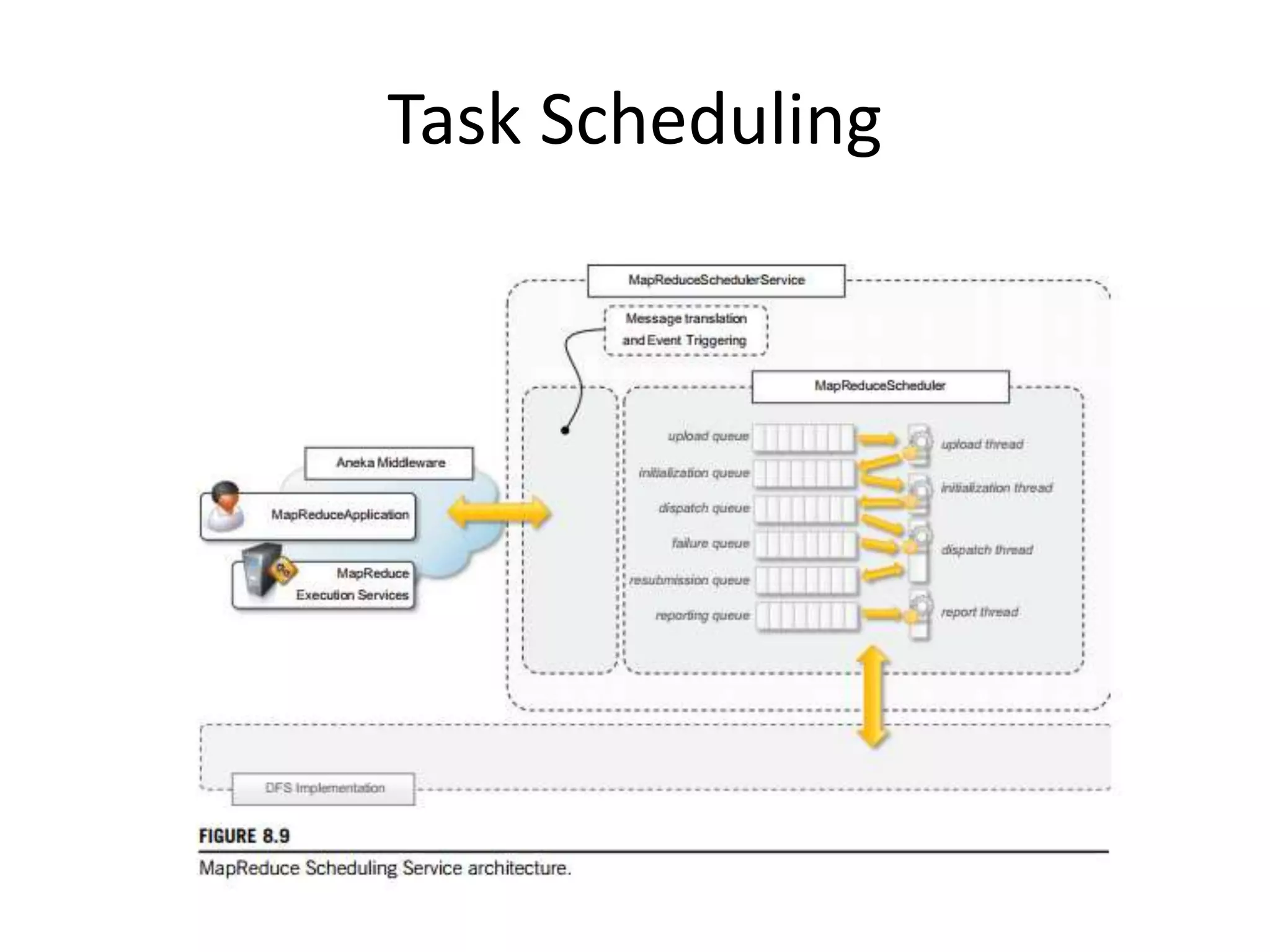
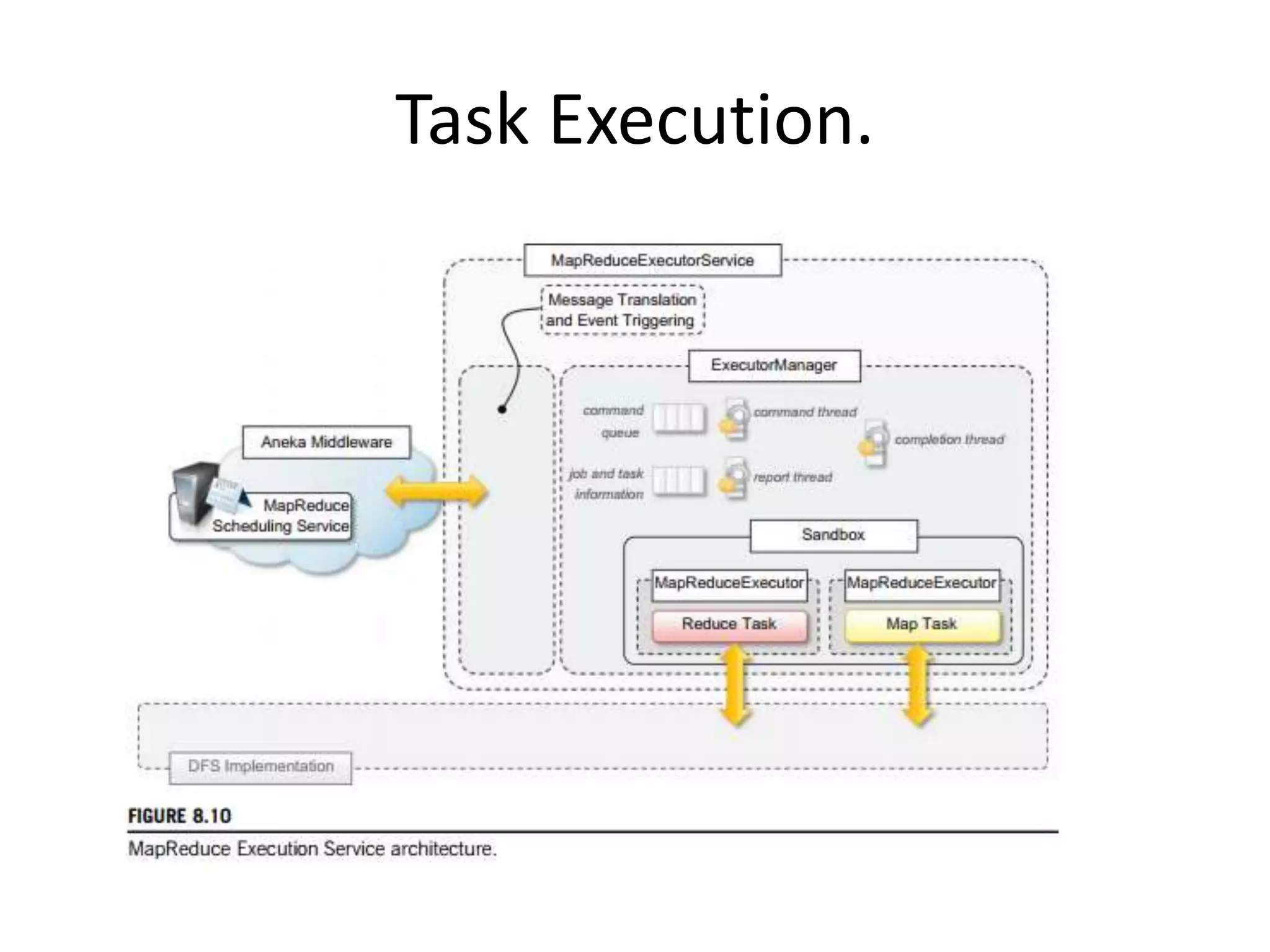


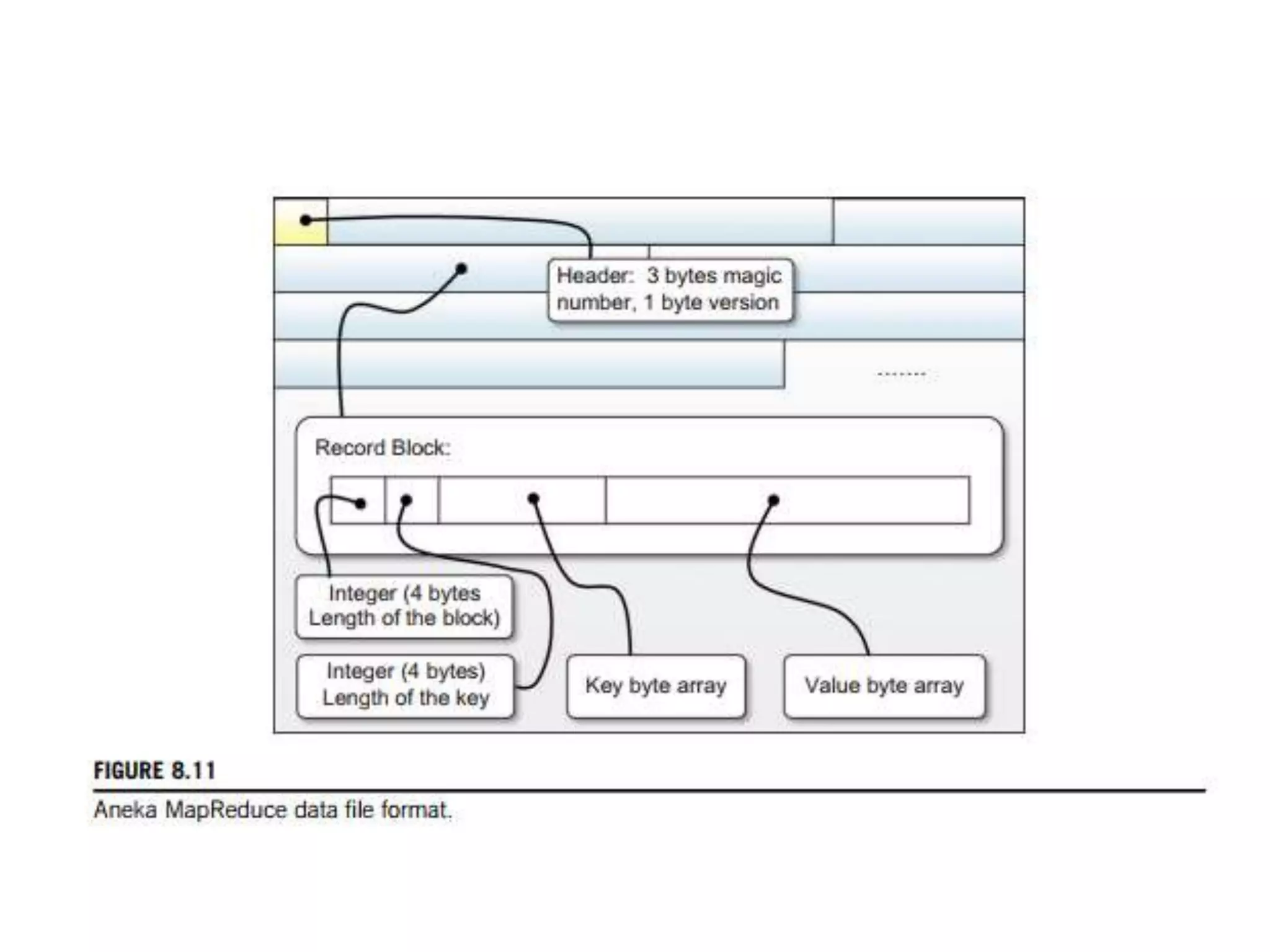



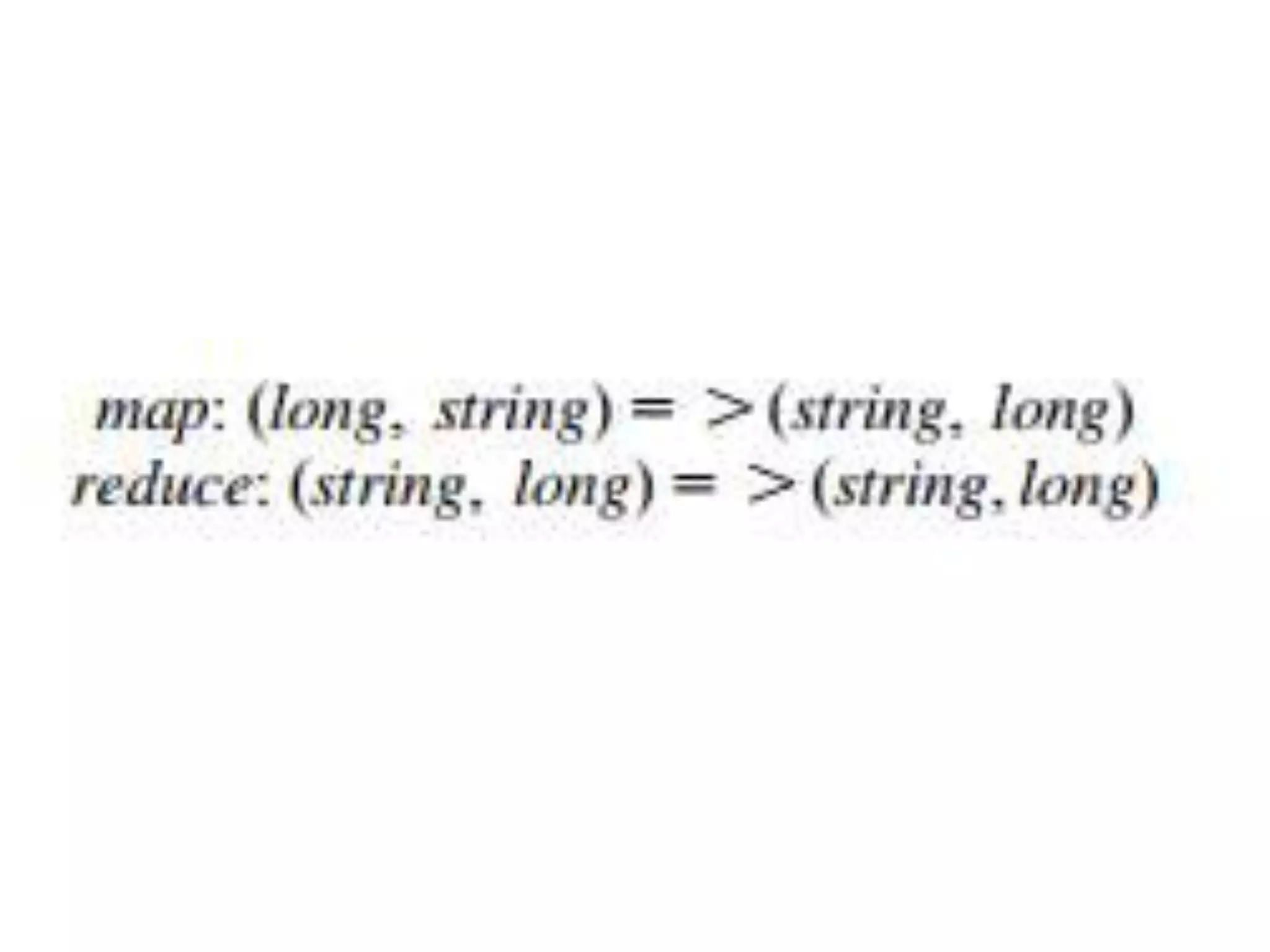



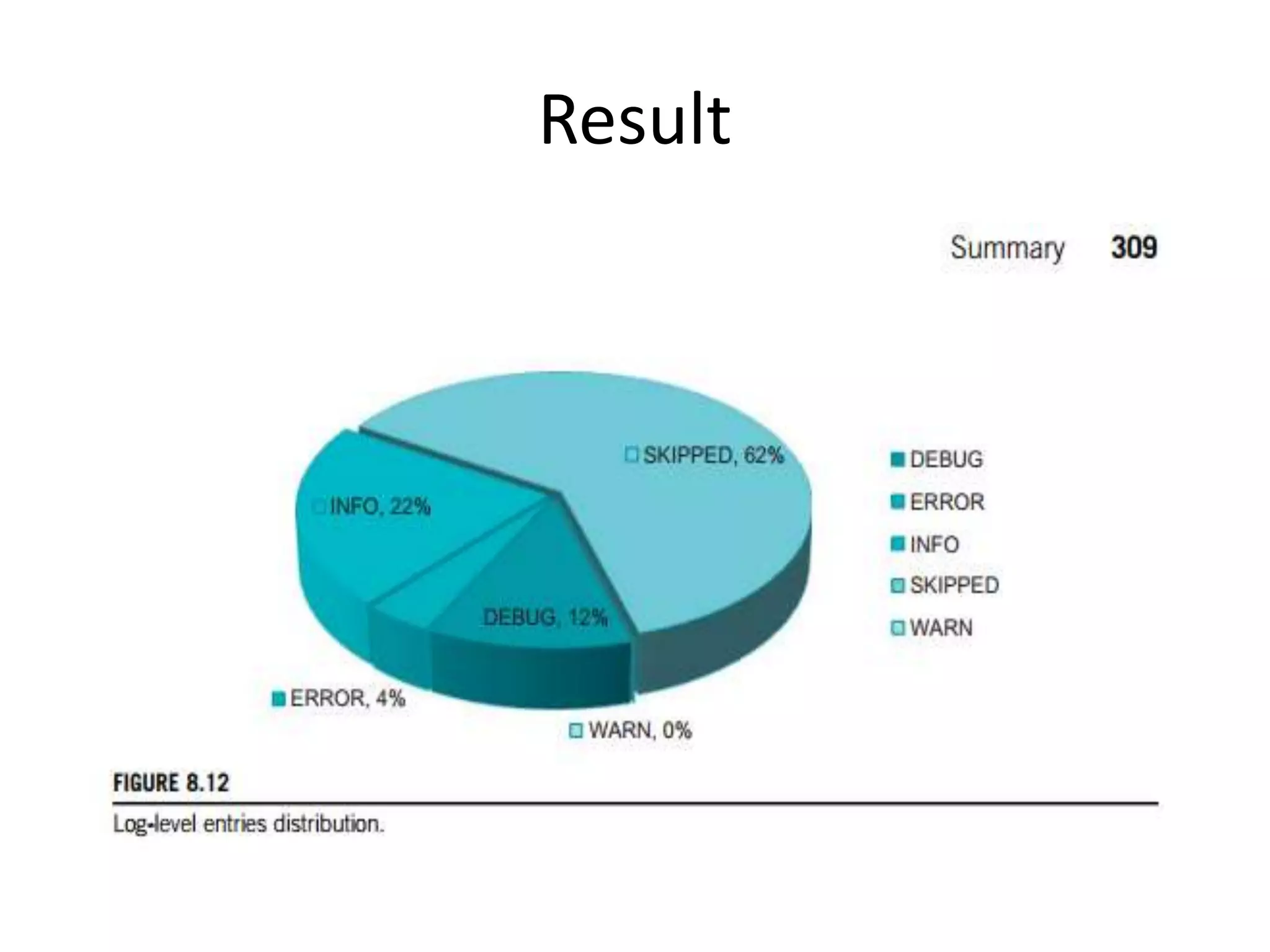

The document discusses data-intensive computing and provides details about related technologies. It defines data-intensive computing as concerned with large-scale data in the hundreds of megabytes to petabytes range. Key challenges include scalable algorithms, metadata management, high-performance computing platforms, and distributed file systems. Technologies discussed include MapReduce frameworks like Hadoop, Pig, and Hive; NoSQL databases like MongoDB, Cassandra, and HBase; and distributed file systems like Lustre, GPFS, and HDFS. The document also covers programming models, scheduling, and an example application to parse Aneka logs using MapReduce.