Download as PDF, PPTX





























![Our contributions Based on Delta Lake 0.7 + Spark 3.0.0 ▪ Migrate all changes and improvements to latest version ▪ Support Subquery in Where ▪ Reduce memory consumption in Driver ▪ [SPARK-32994][CORE] Update external heavy accumulators before they entering into listener event loop ▪ Skip schema infer and merge when table schema can be read from catalog ▪ Fallback to simple update if all SET statements are foldable and no join](https://image.slidesharecdn.com/104lantaojin-201129182511/75/Using-Delta-Lake-to-Transform-a-Legacy-Apache-Spark-to-Support-Complex-Update-Delete-SQL-Operation-48-2048.jpg)
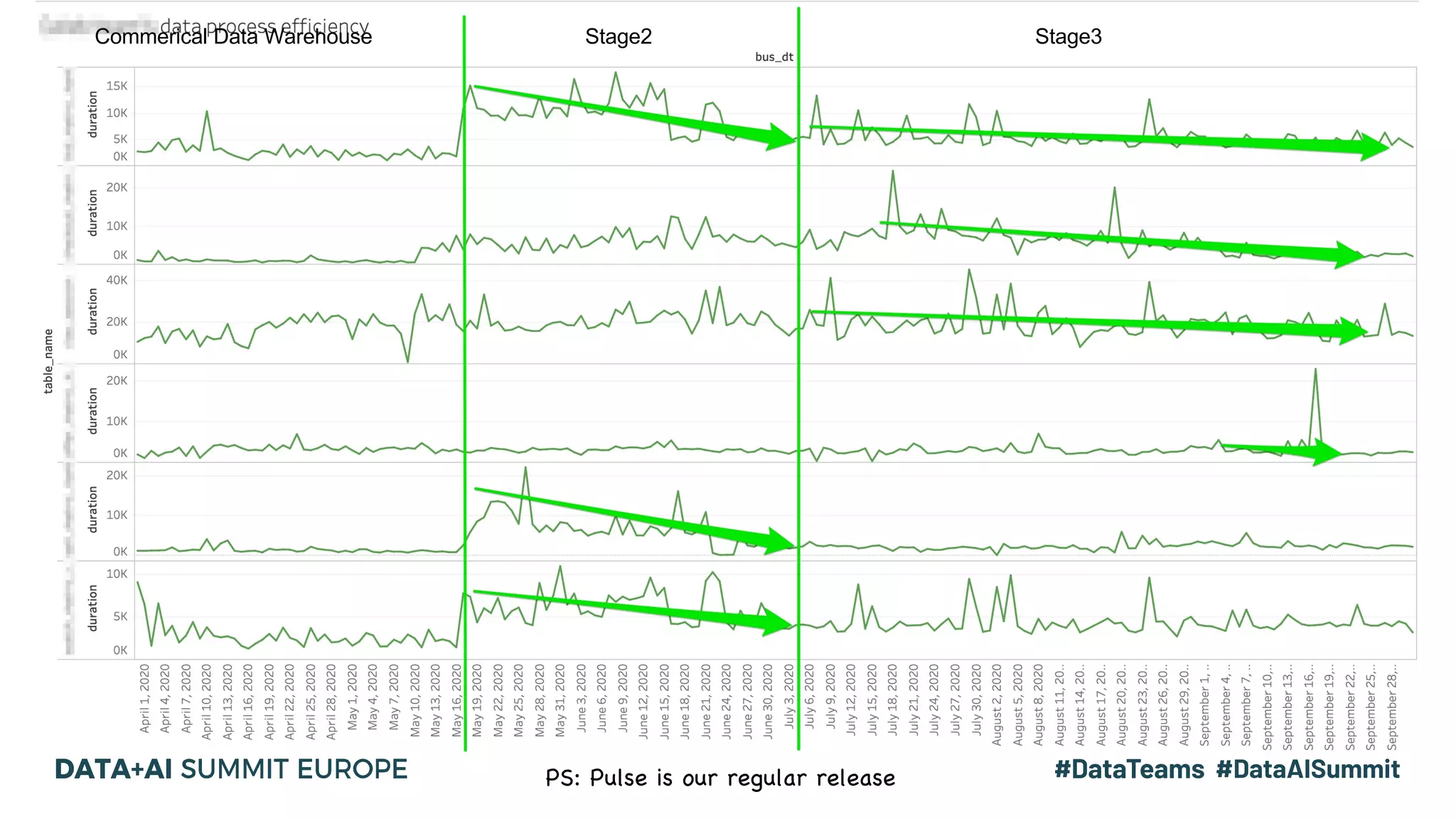




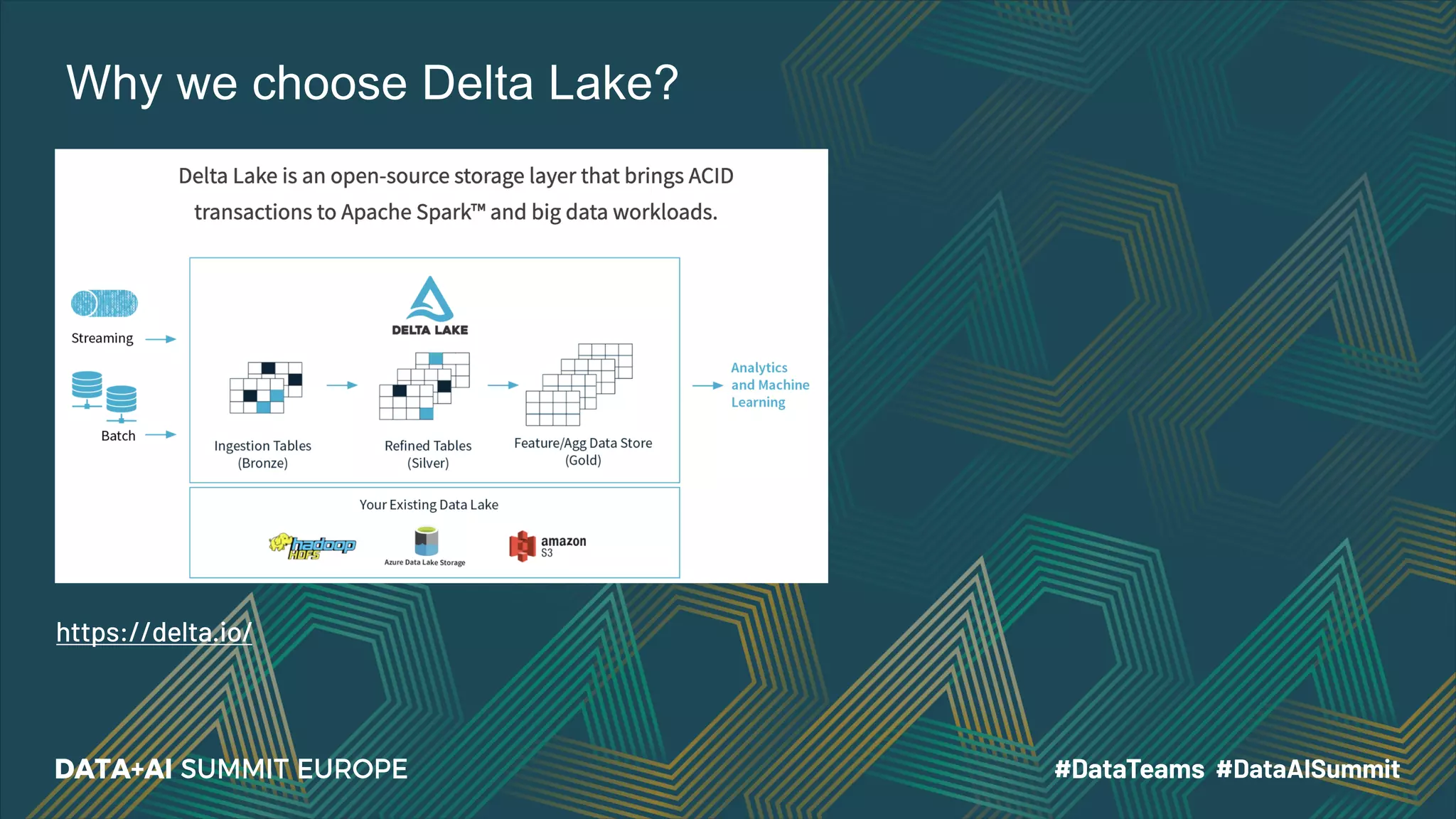
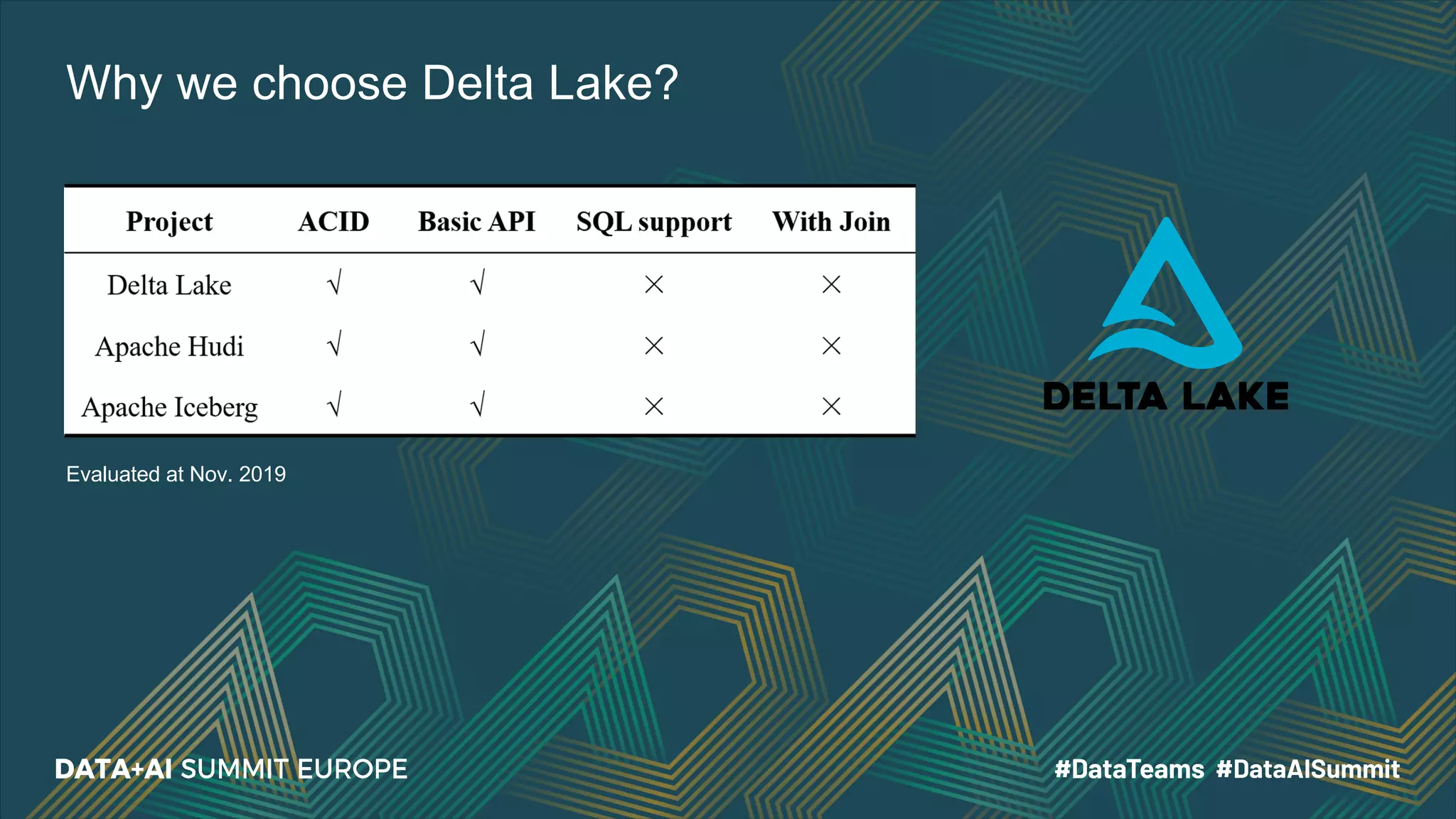
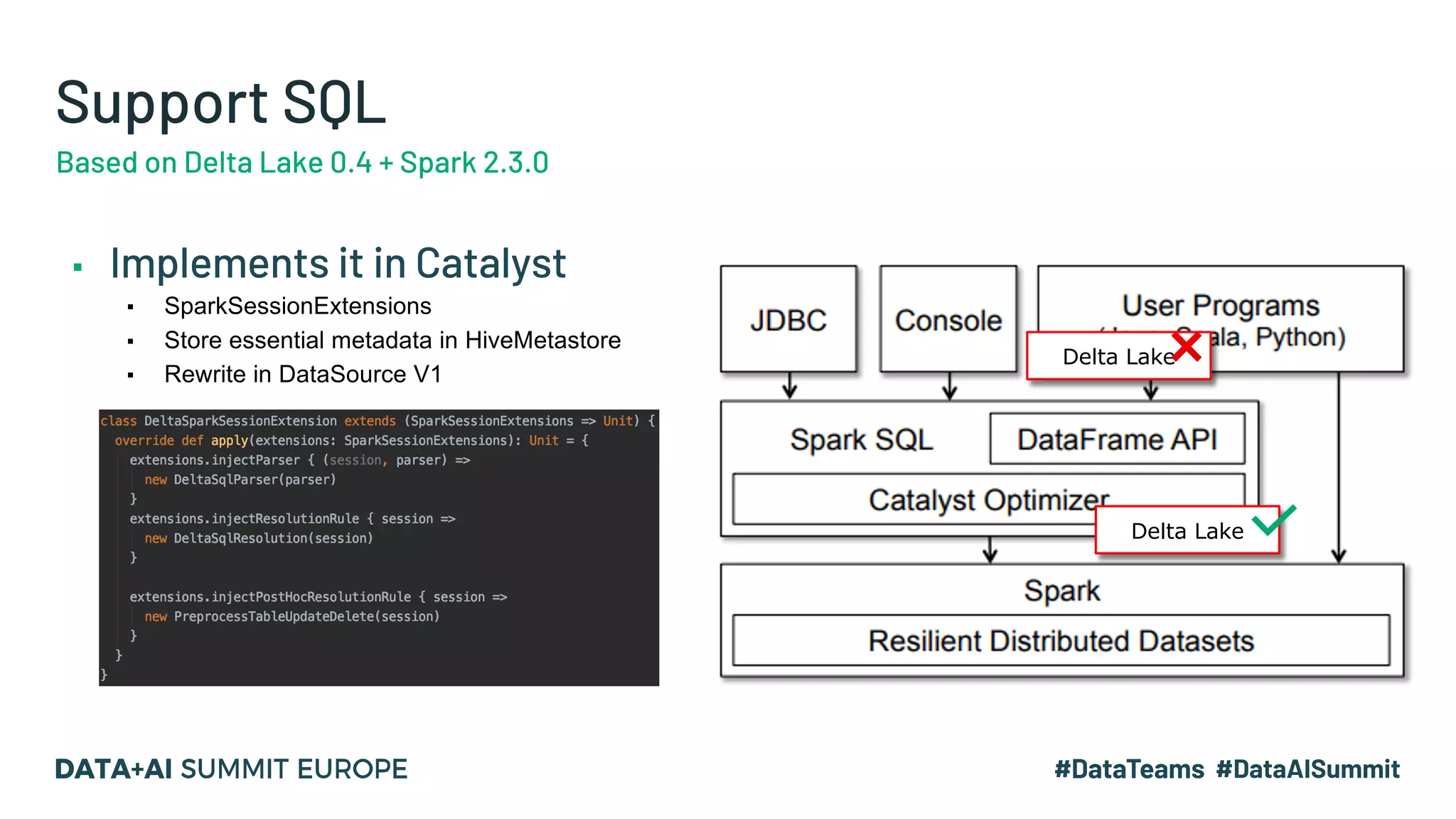
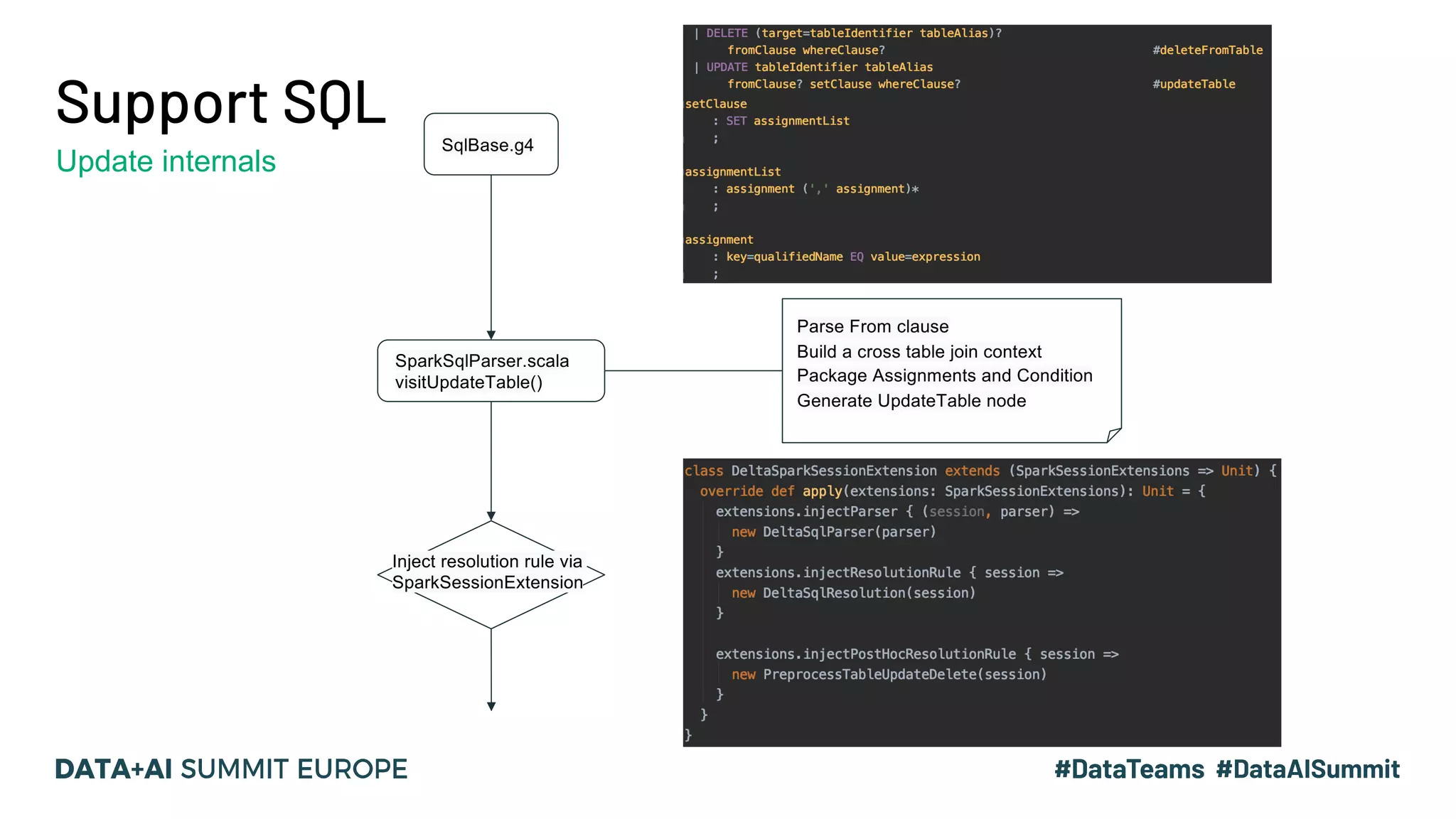
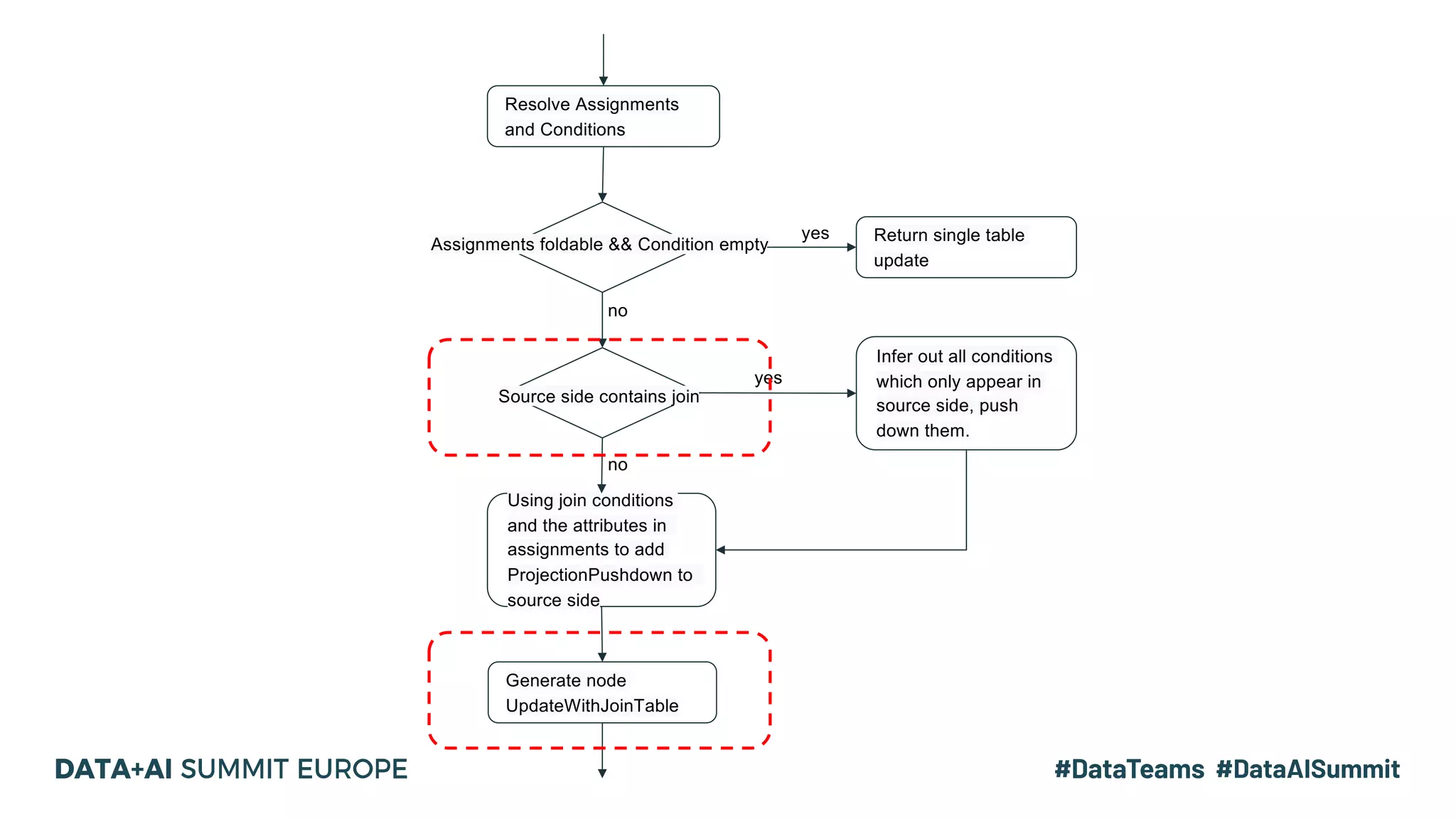
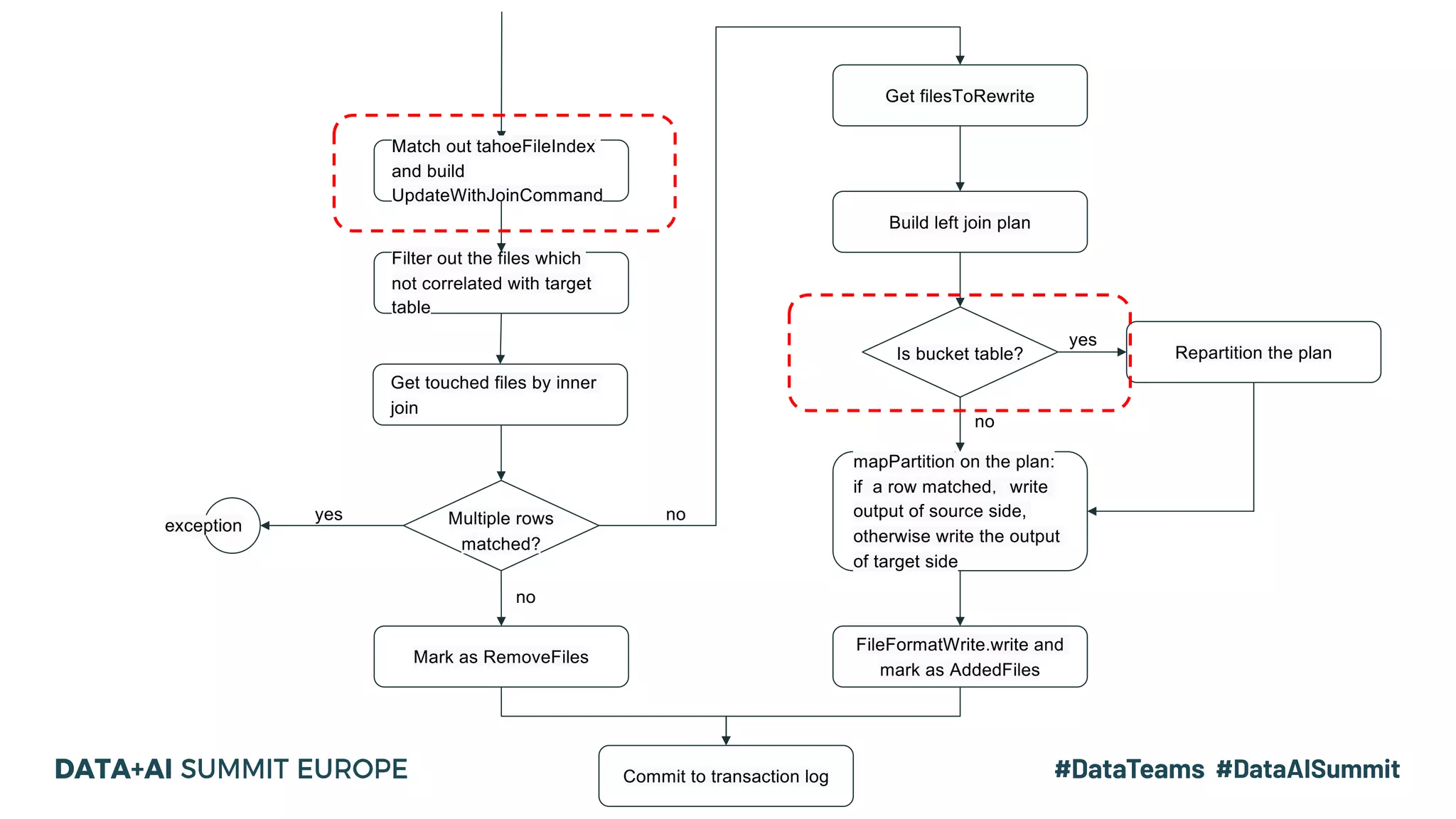
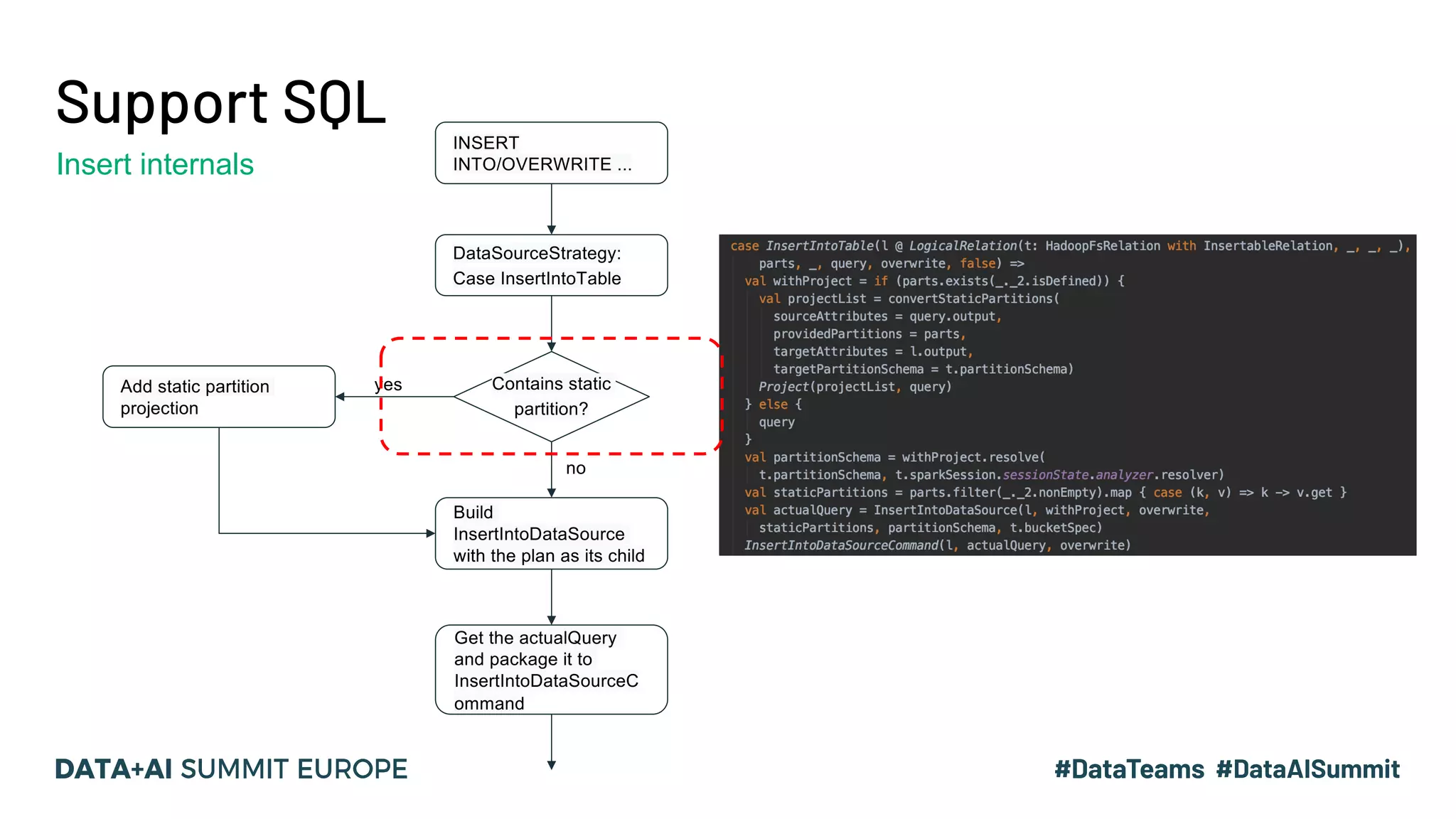
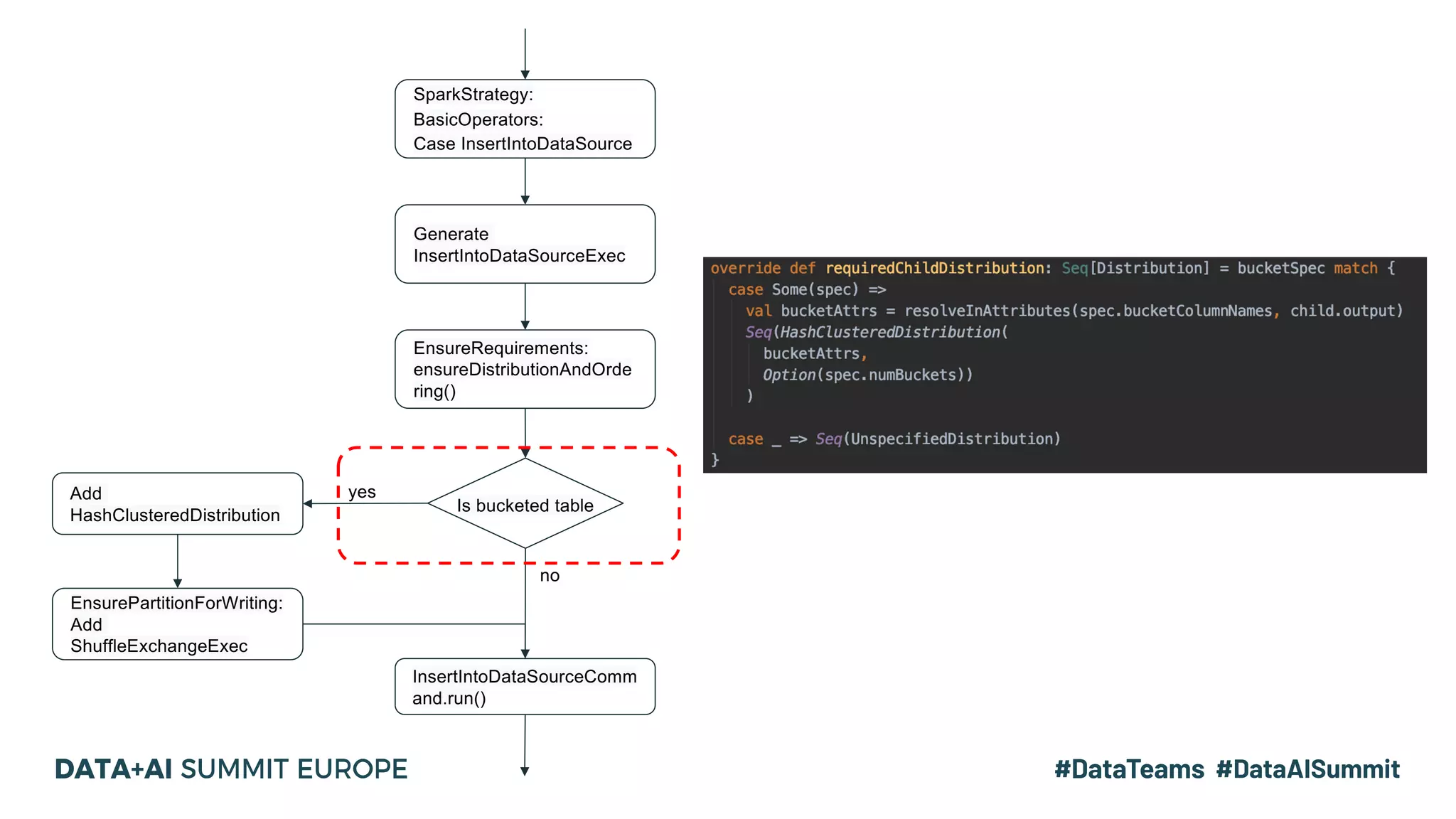
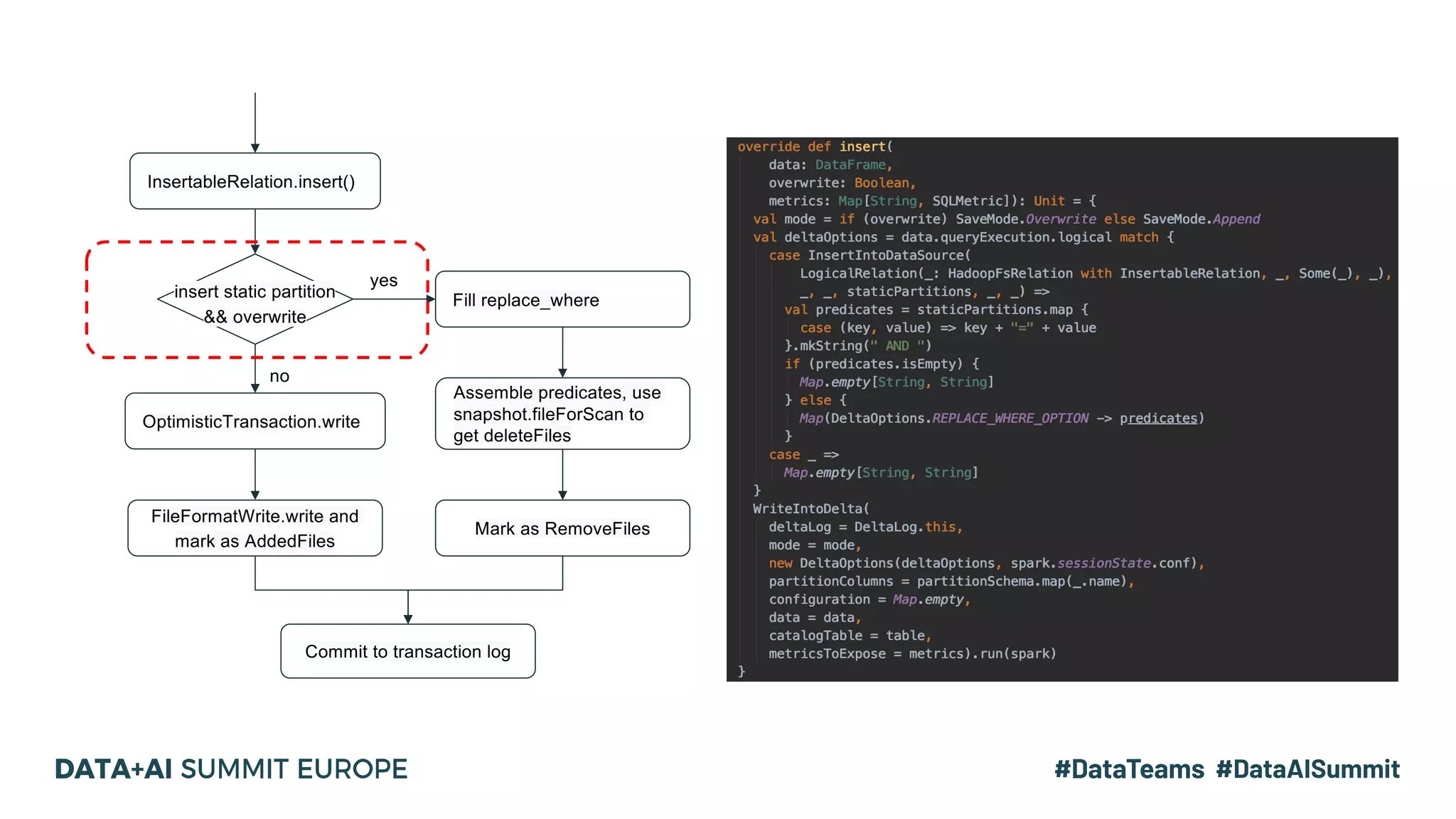
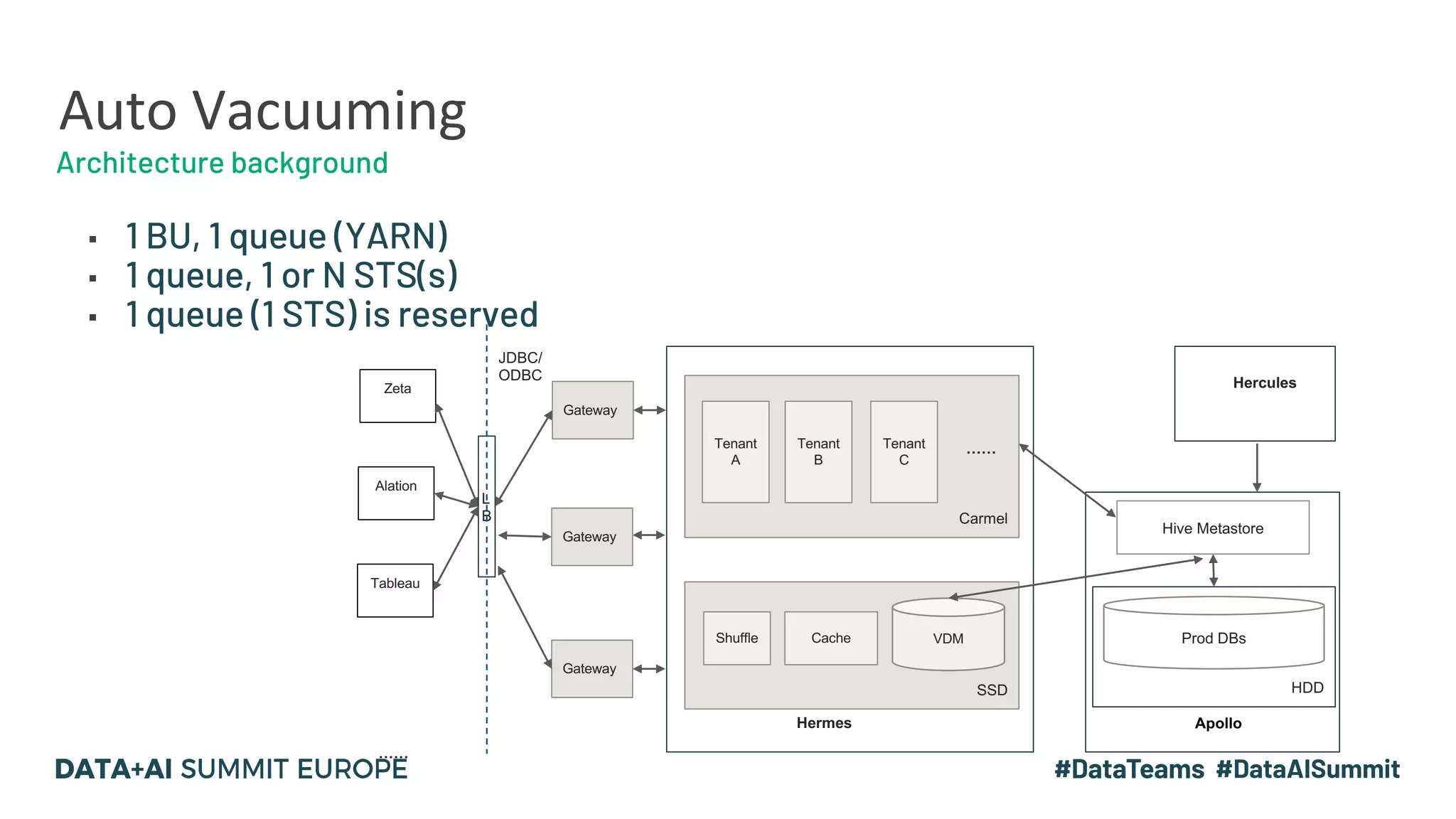
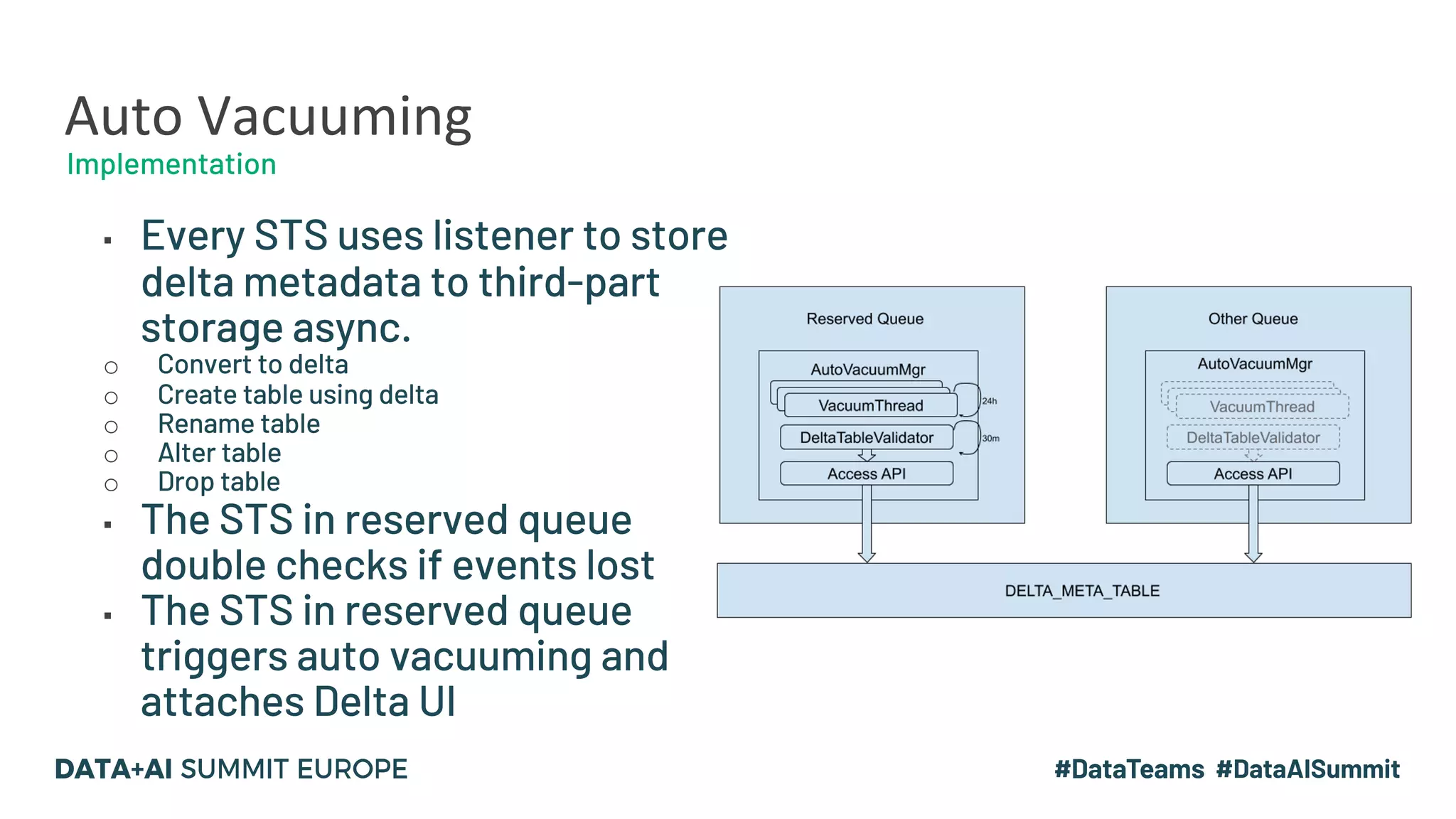
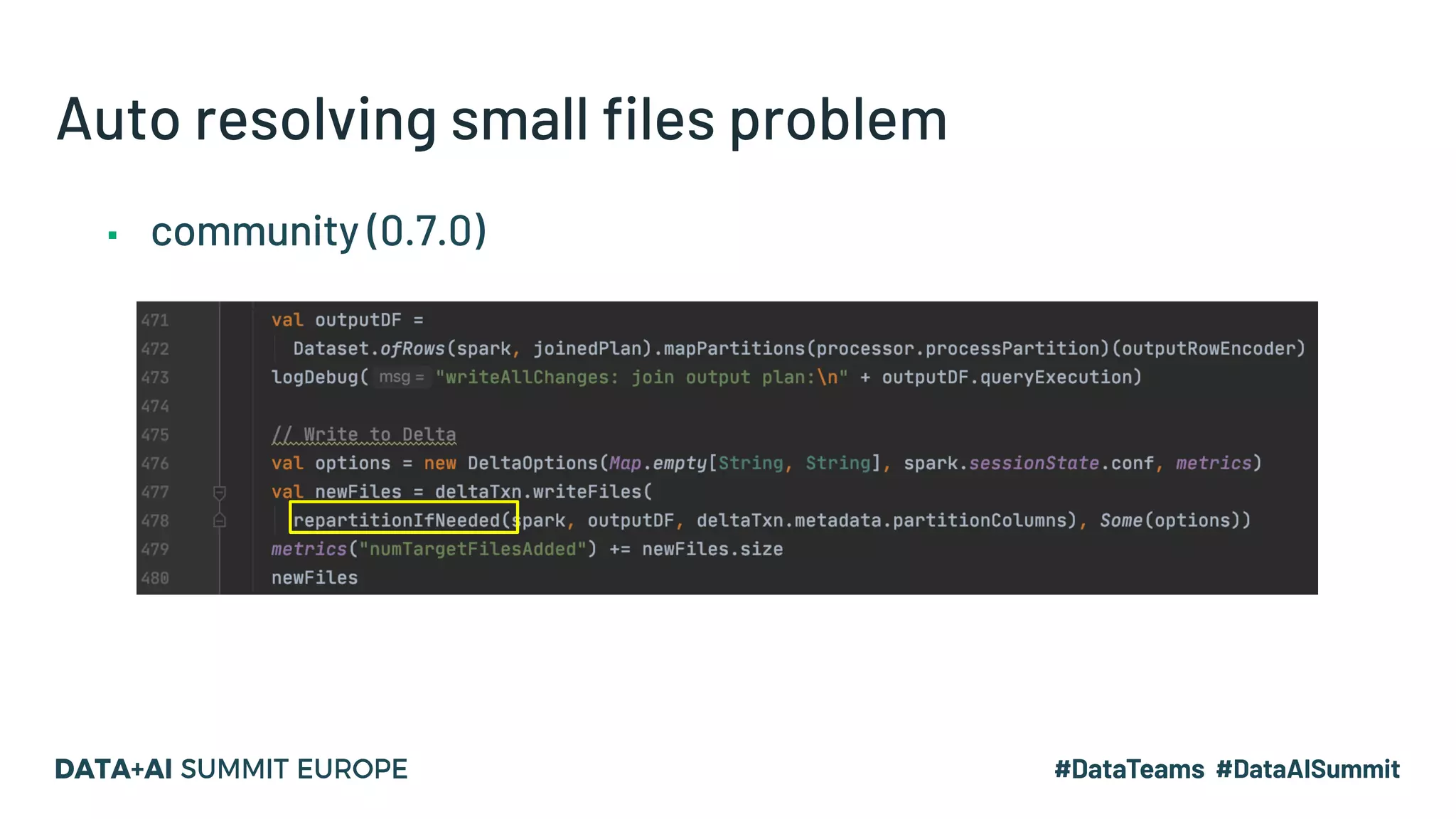
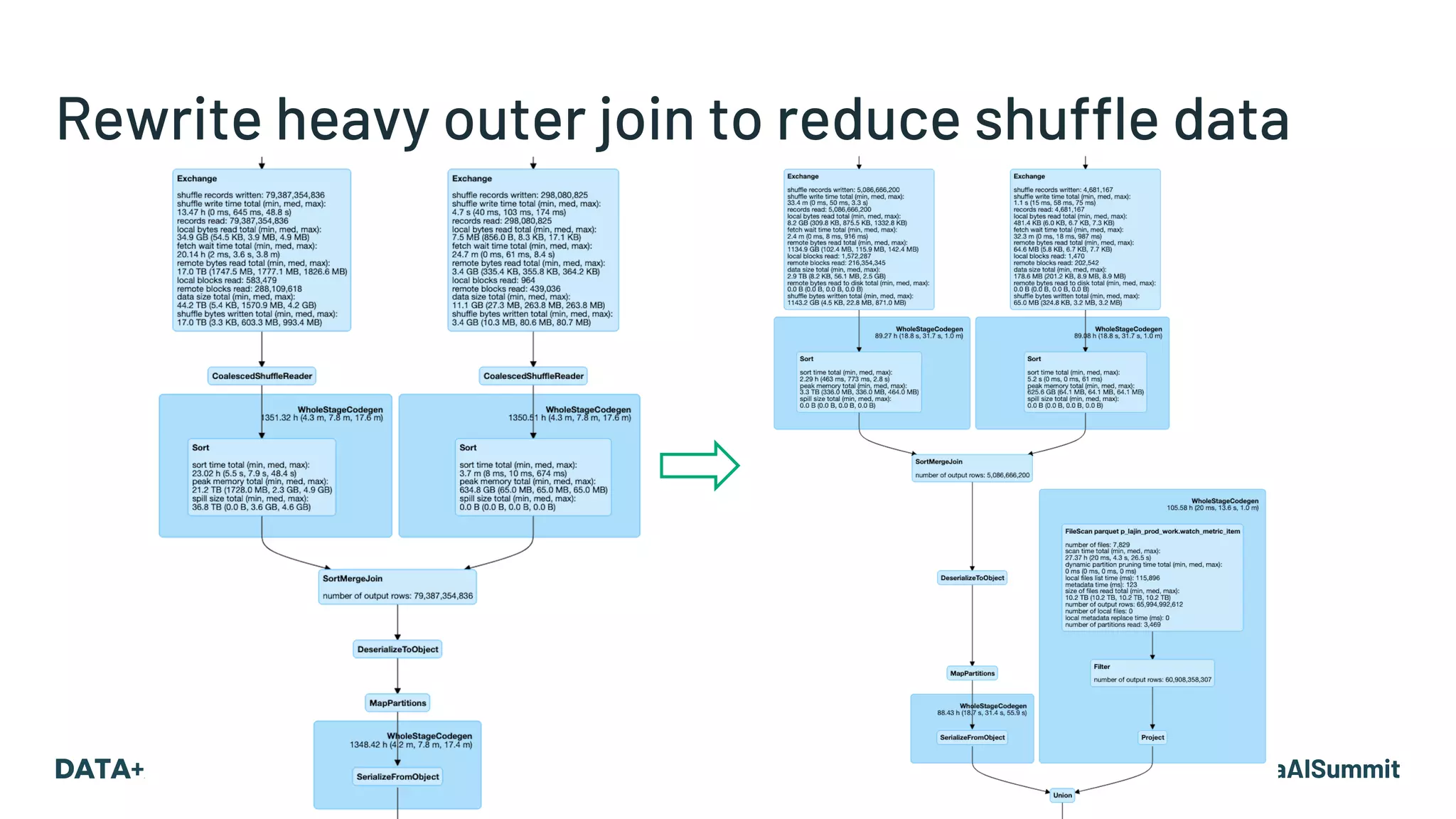
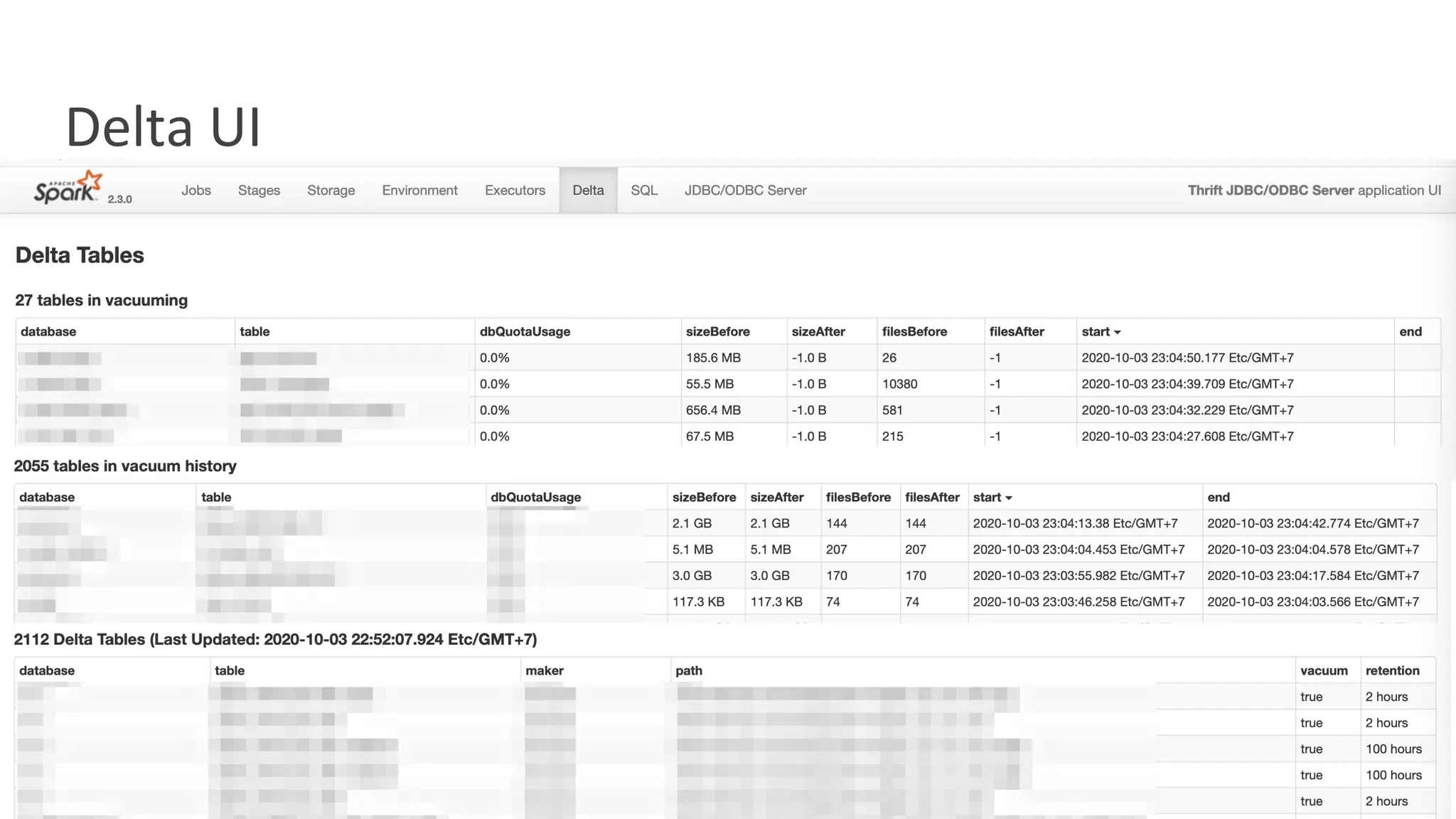
The document details the use of Delta Lake to enhance legacy SparkSQL for complex CRUD operations at eBay, led by Lantao Jin. It outlines the project's stages from technical selection to implementation, including performance improvements achieving 5x to 10x faster operations, and highlights challenges faced with SQL syntax and memory management. Future work includes supporting range partitioning, file indexing, and further optimizations.