Download as PDF, PPTX





















The document outlines best practices for building a robust data platform using Apache Spark and Delta Lake, emphasizing effective data strategy, performance tuning, and governance. Key recommendations include optimizing cluster sizing based on workload types, improving data processing speeds through techniques like compaction and adaptive query execution, and ensuring compliance with governance policies. It also discusses the importance of managing data quality and security to drive business value.
Introduction to best practices for creating a strong data platform using Apache Spark and Delta.
Focus on optimizing costs for business value, performance tuning with Delta and Spark, and governance controls.
Emphasis on the importance of a clear data strategy.
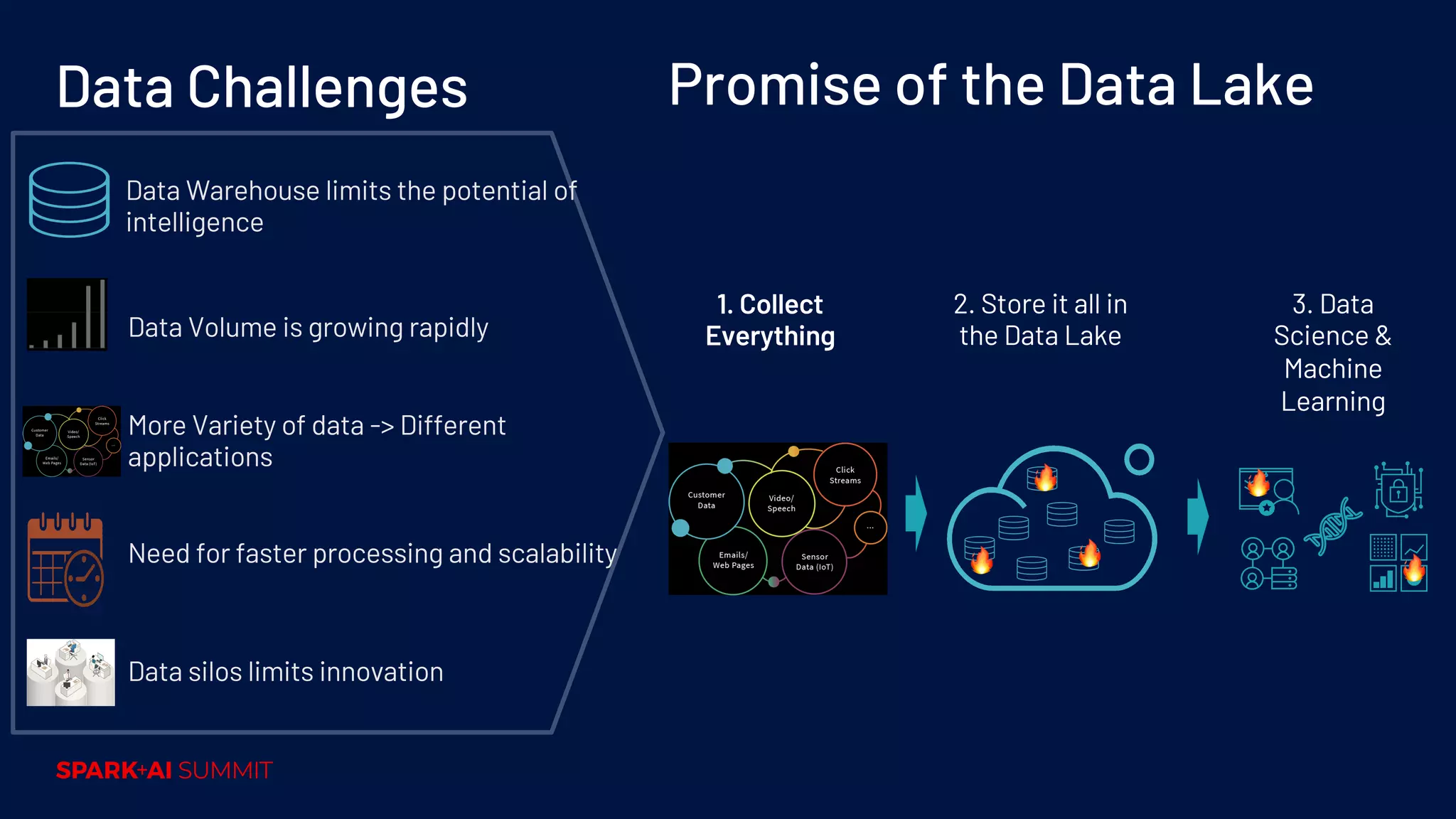
Challenges with traditional data warehouses; benefits of data lakes for scalability and innovation.
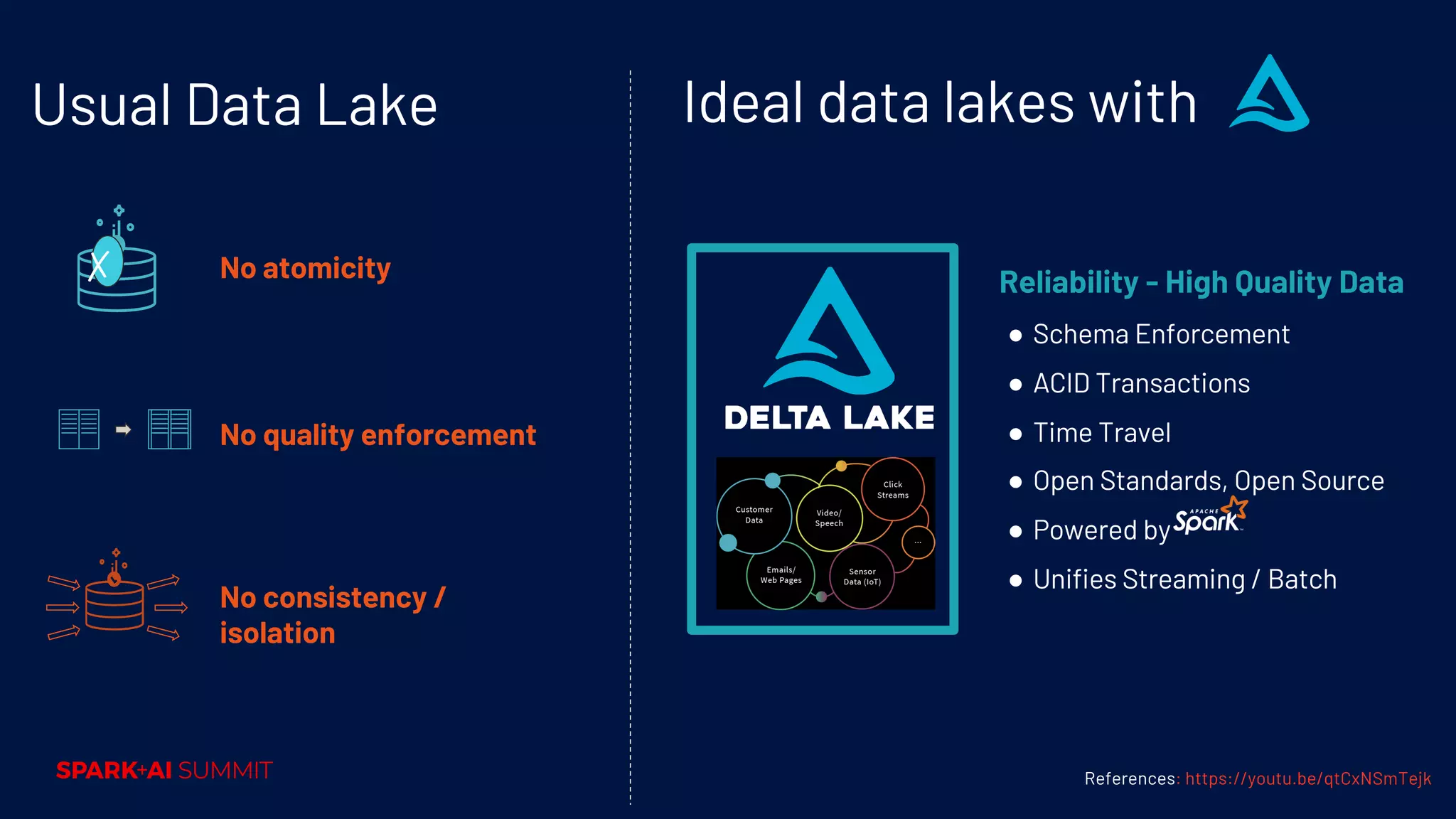
Issues with traditional data lakes; characteristics of an ideal data lake, including quality and reliability.
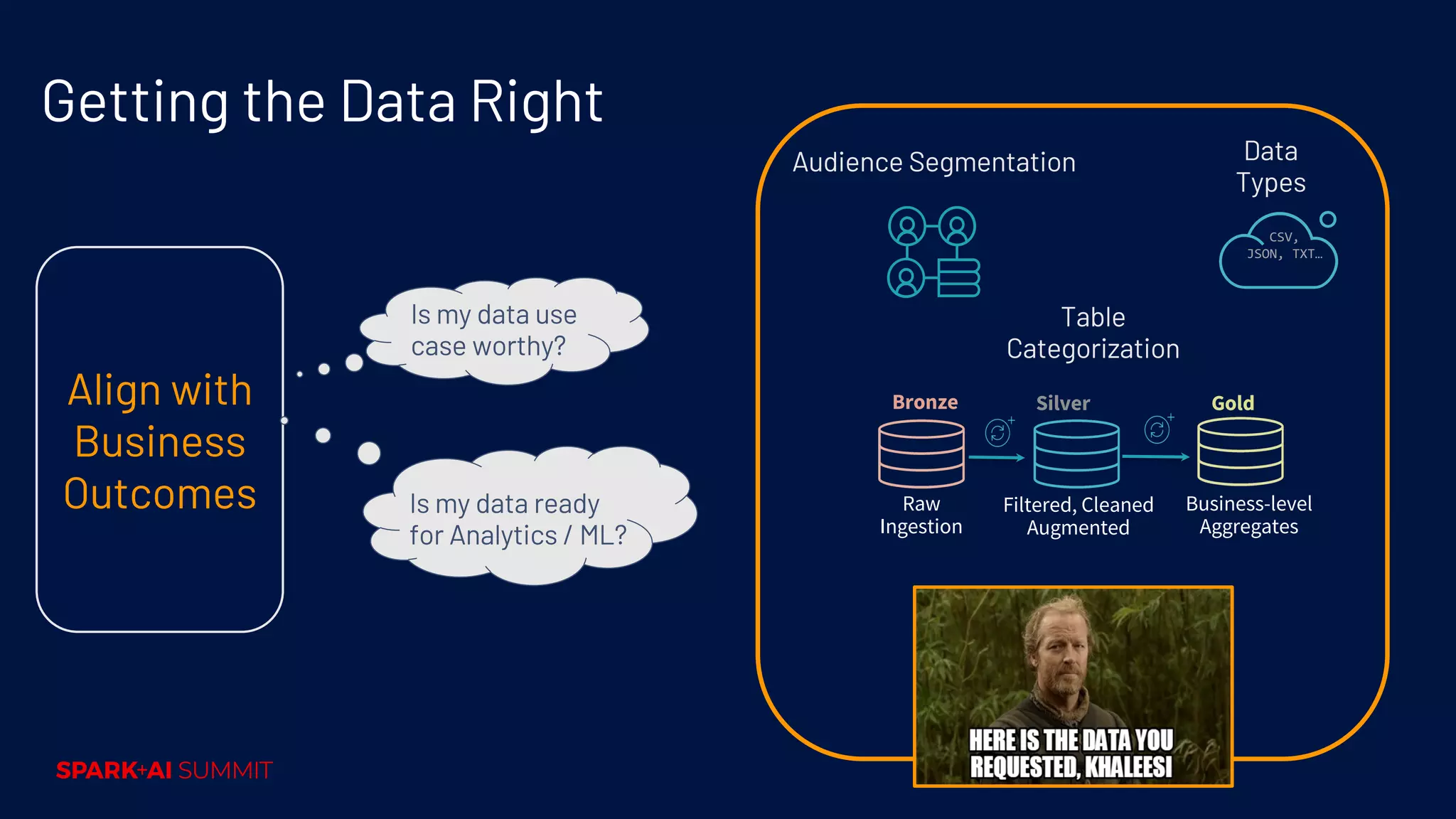
Importance of data categorization (Bronze, Silver, Gold) and ensuring data readiness for analytics.
Strategies for optimizing costs to drive business value using data platforms.
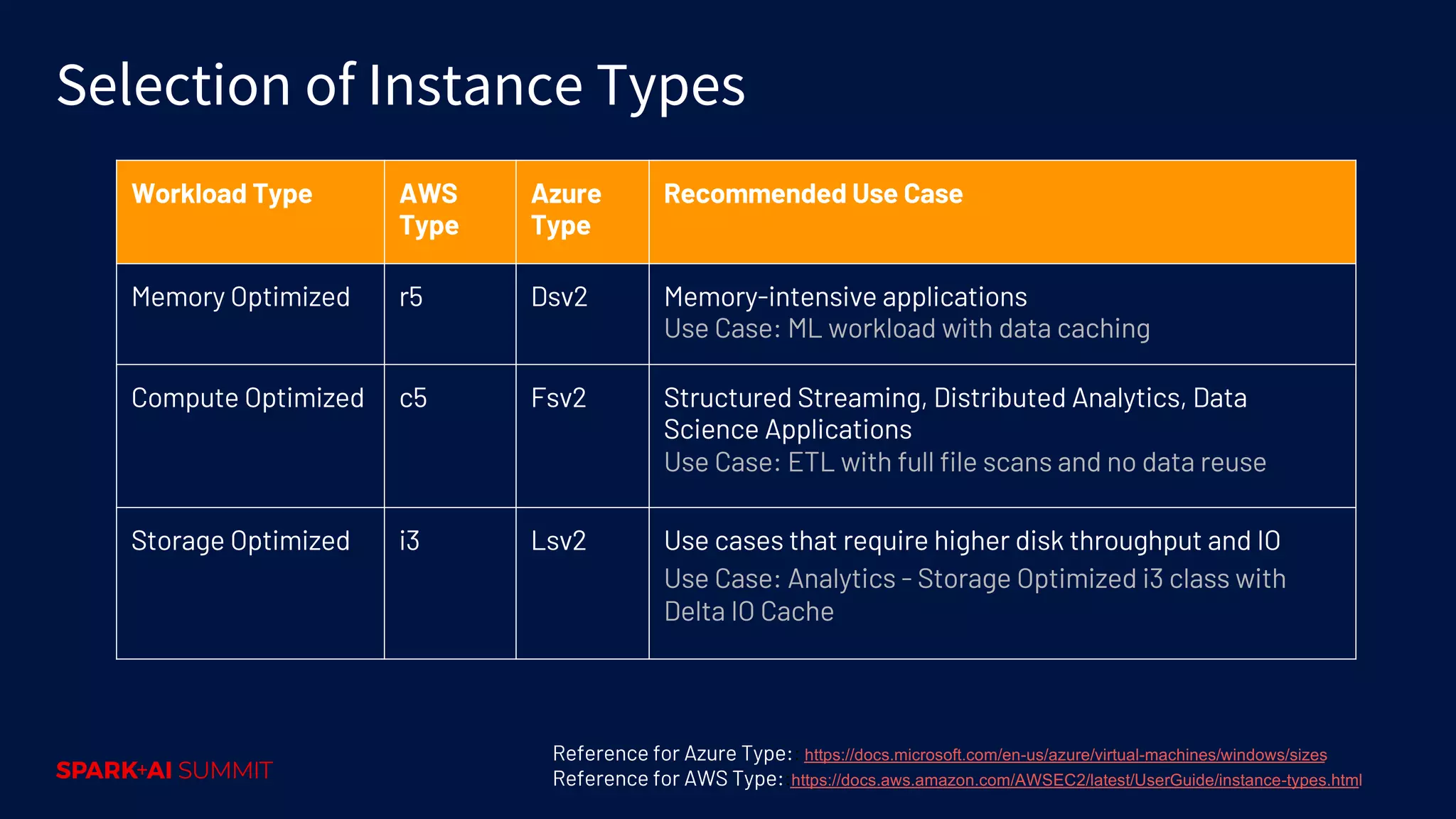
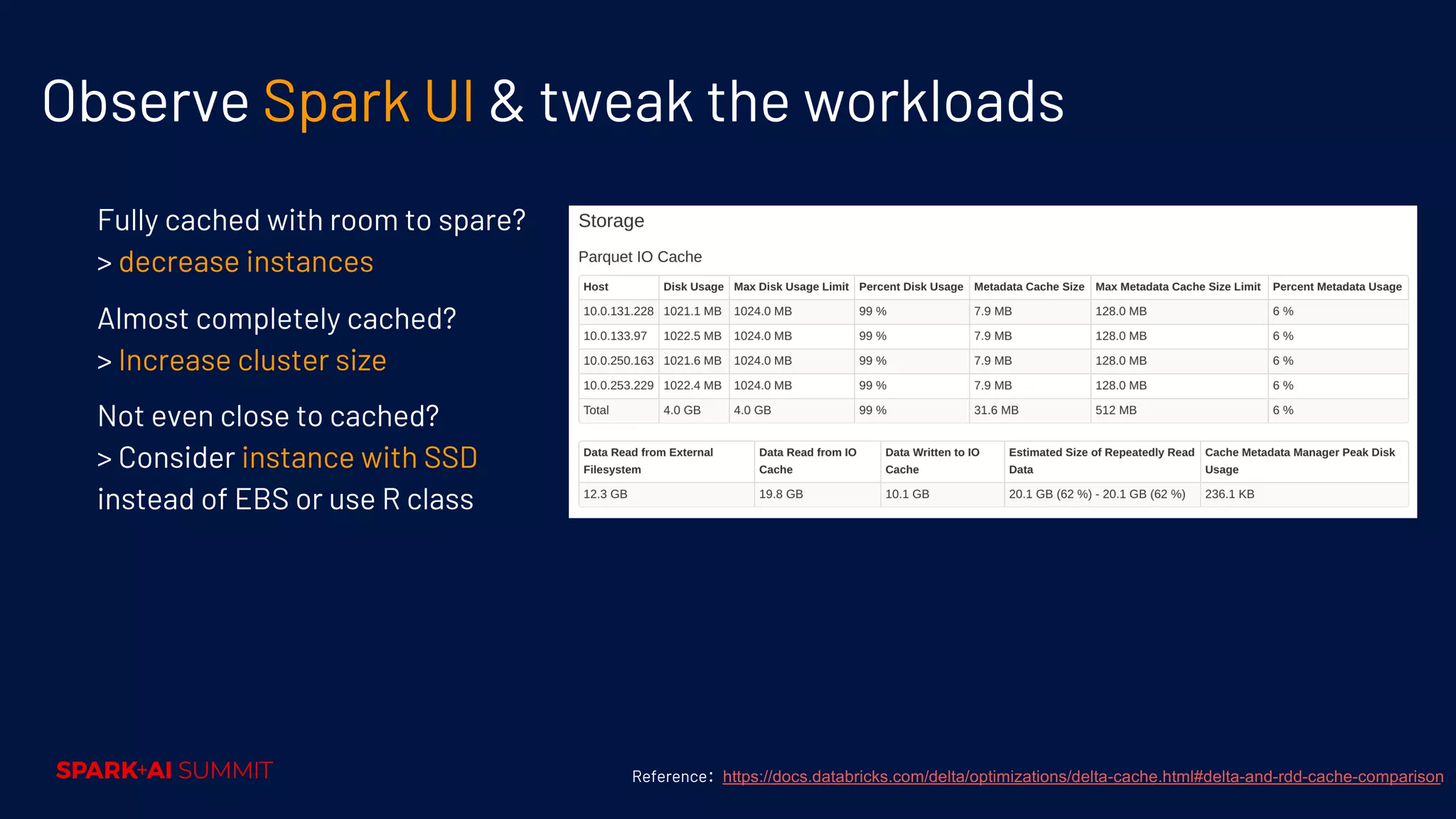
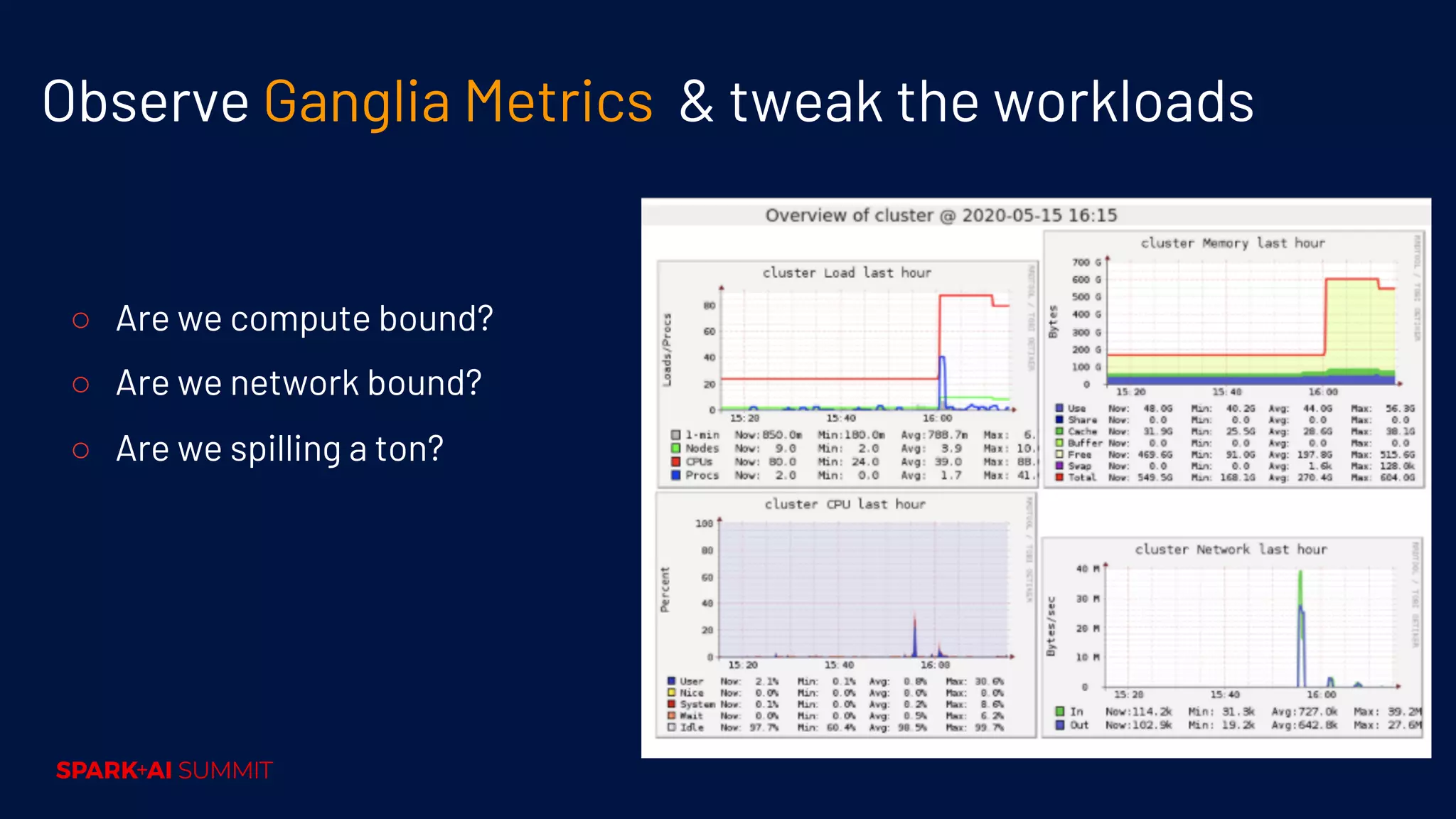
Guidelines for selecting instance types, node sizes, observing metrics, and tweaking workloads for performance.
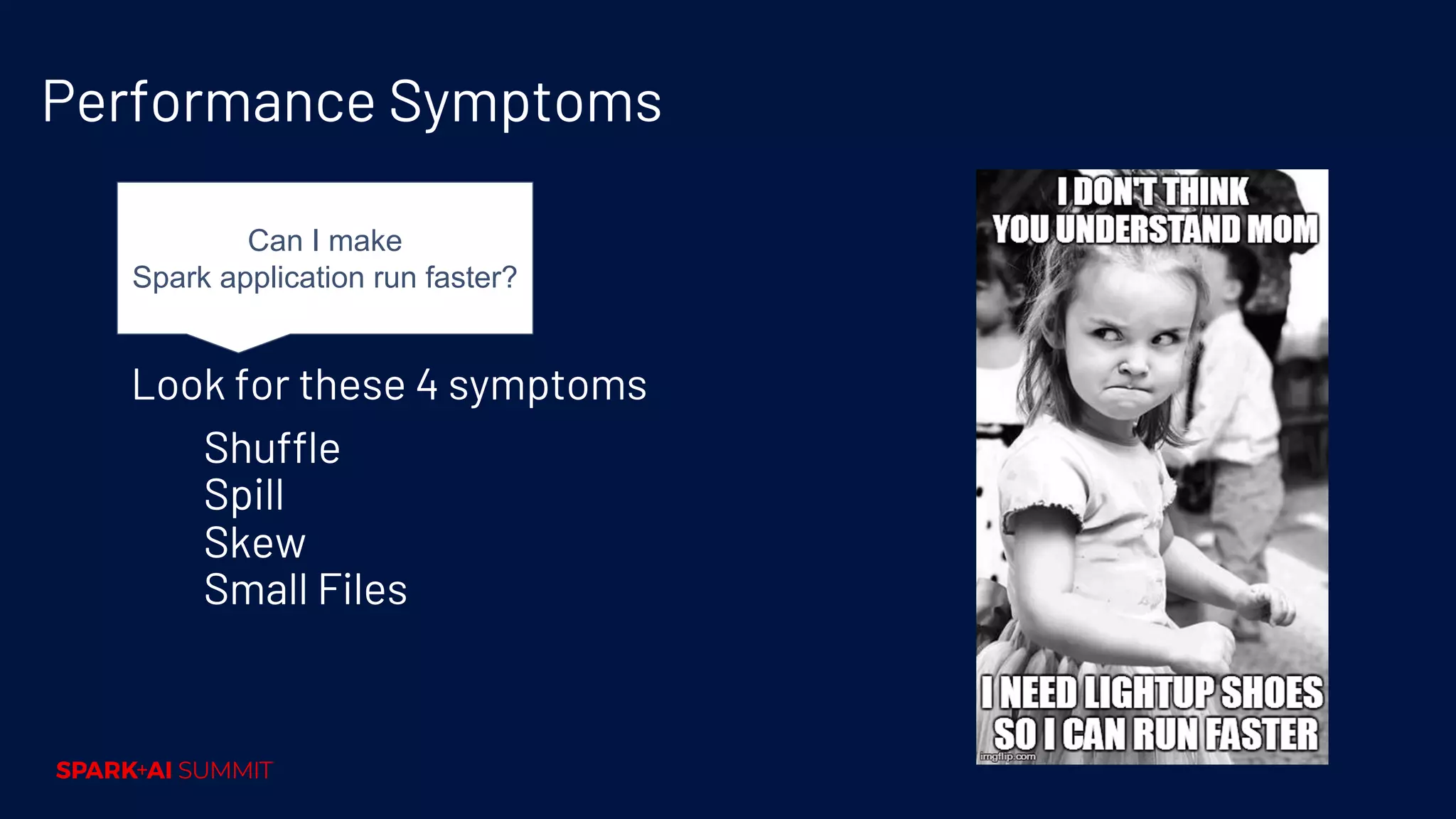
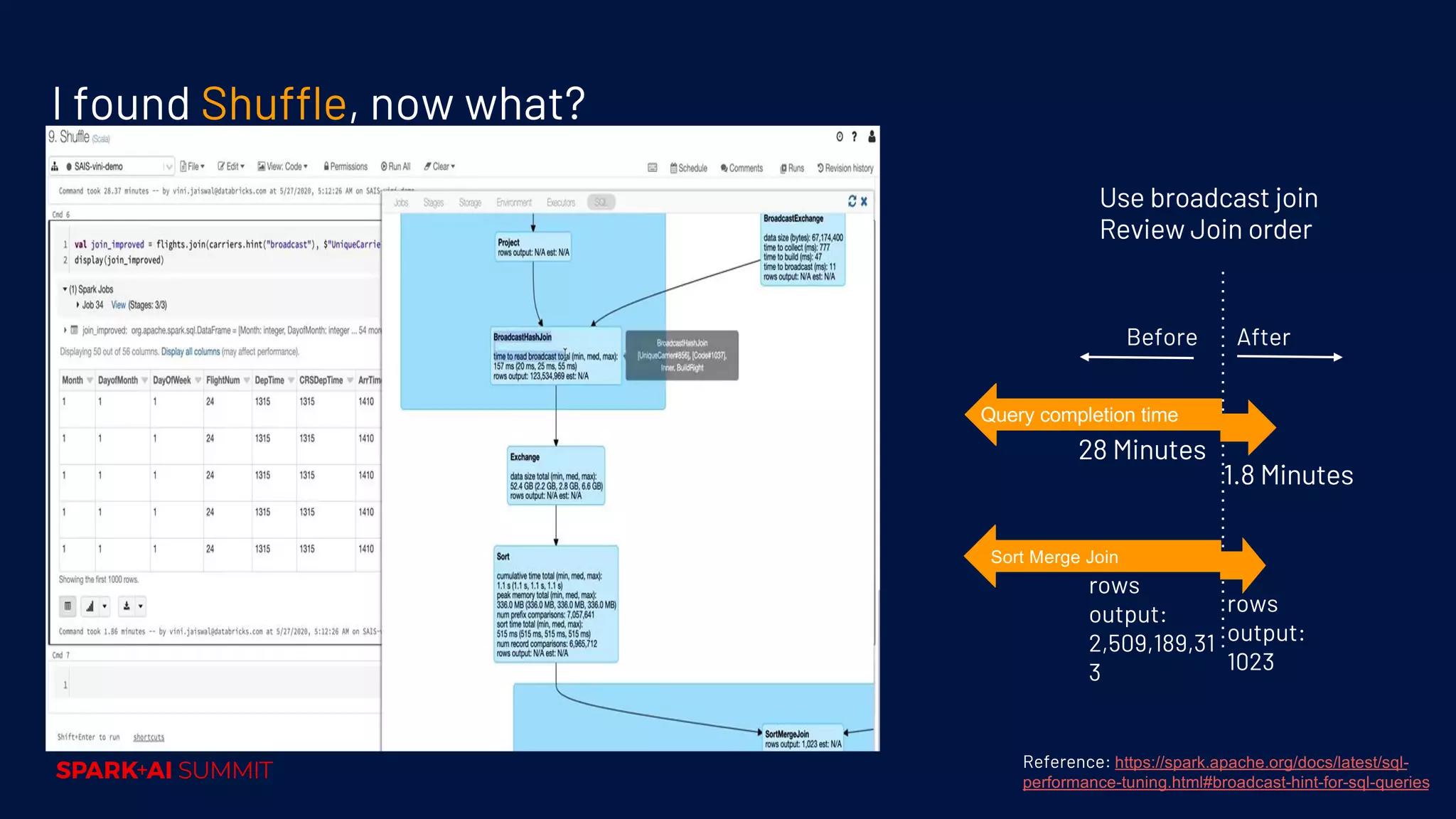
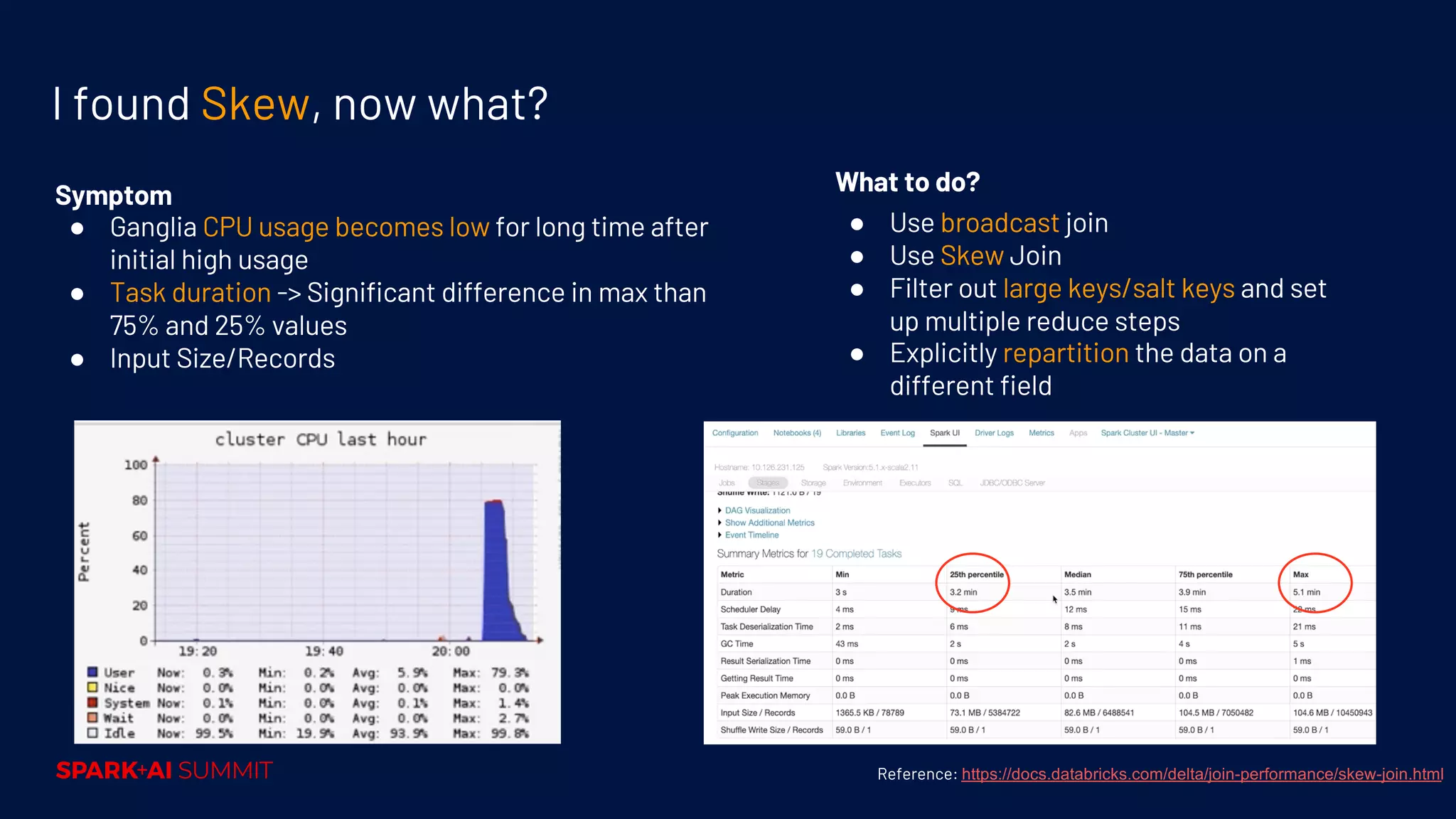
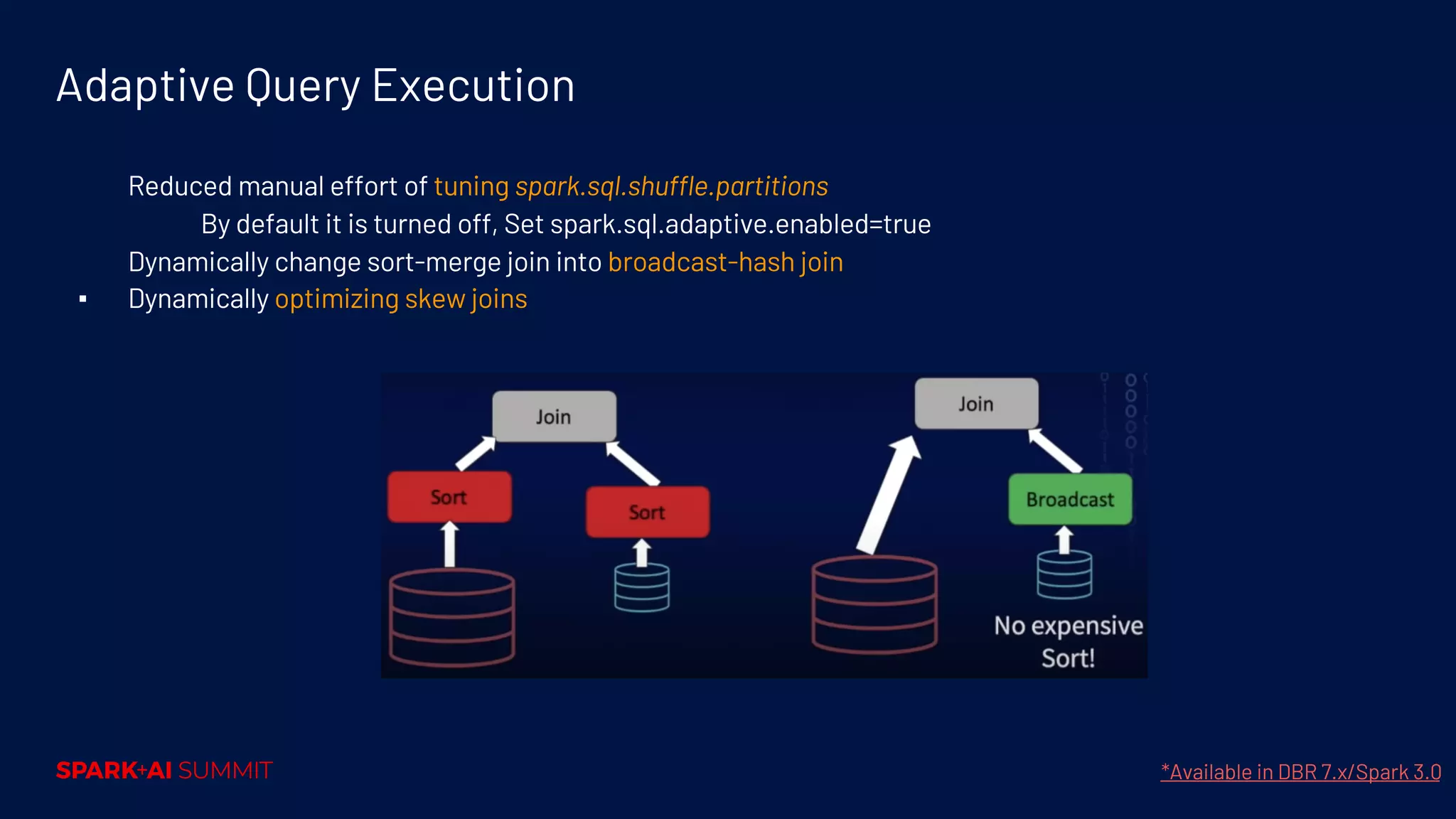
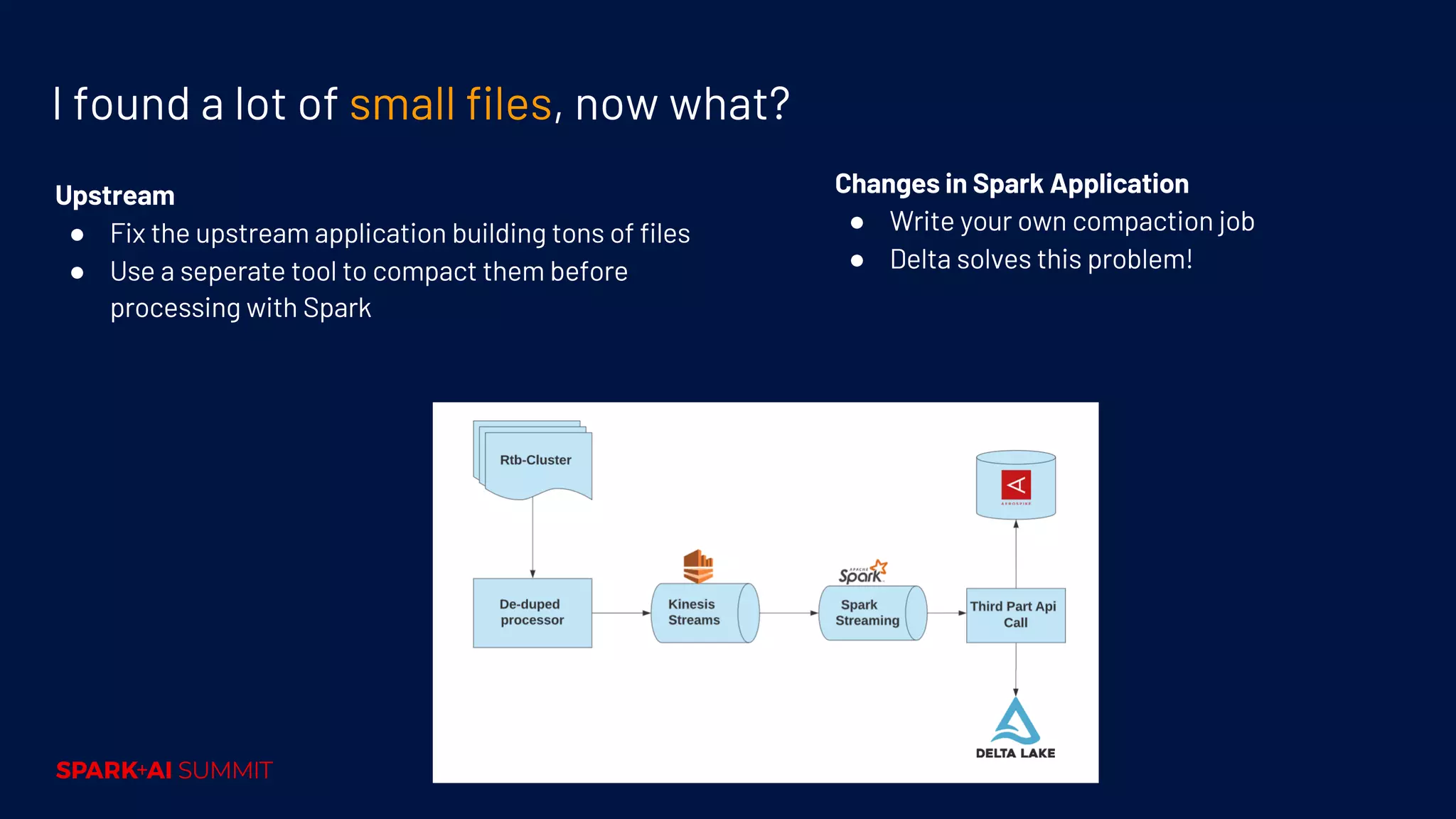
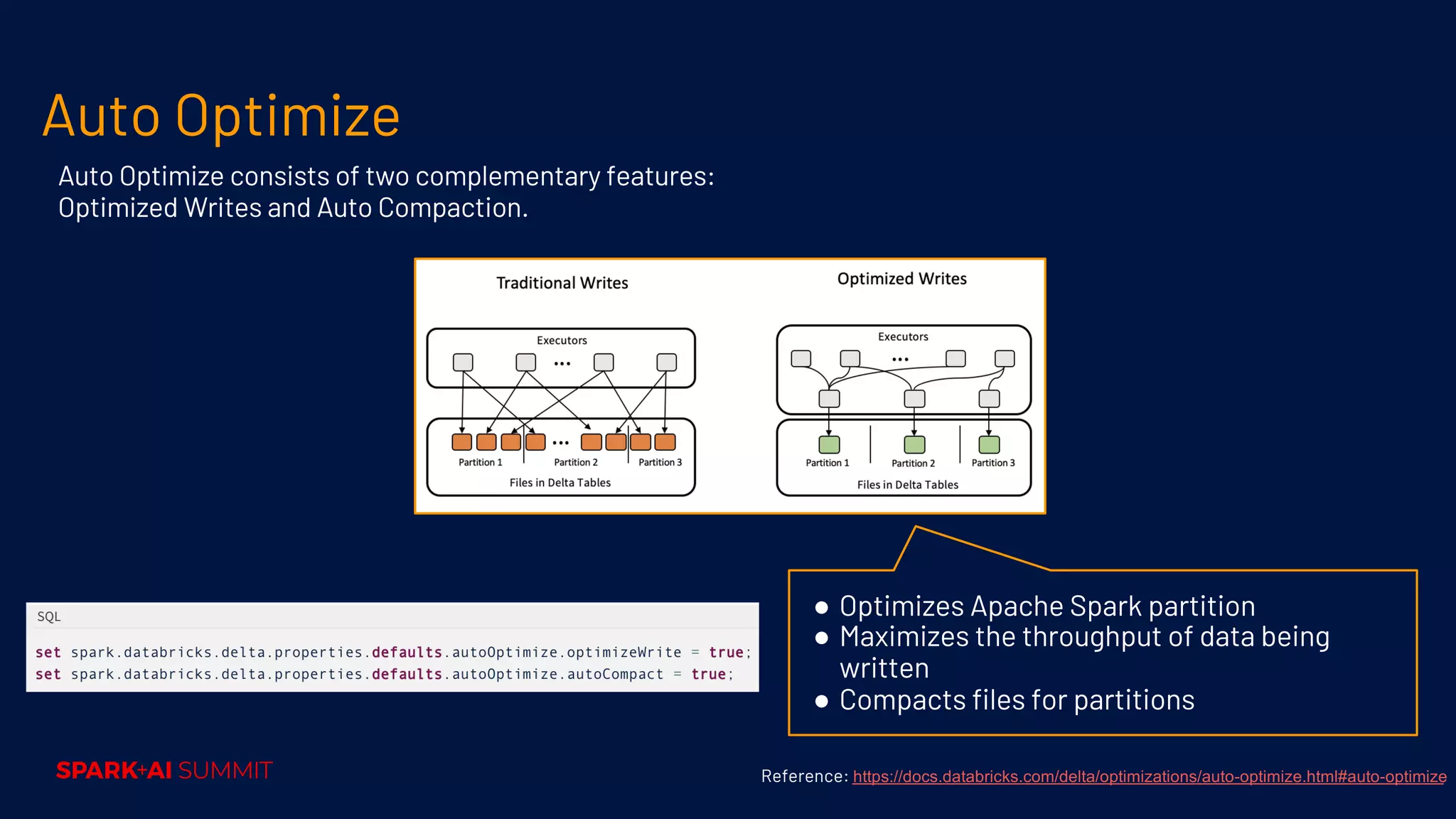
Techniques for performance tuning, addressing symptoms like shuffle and skew, and using compaction for efficiency.
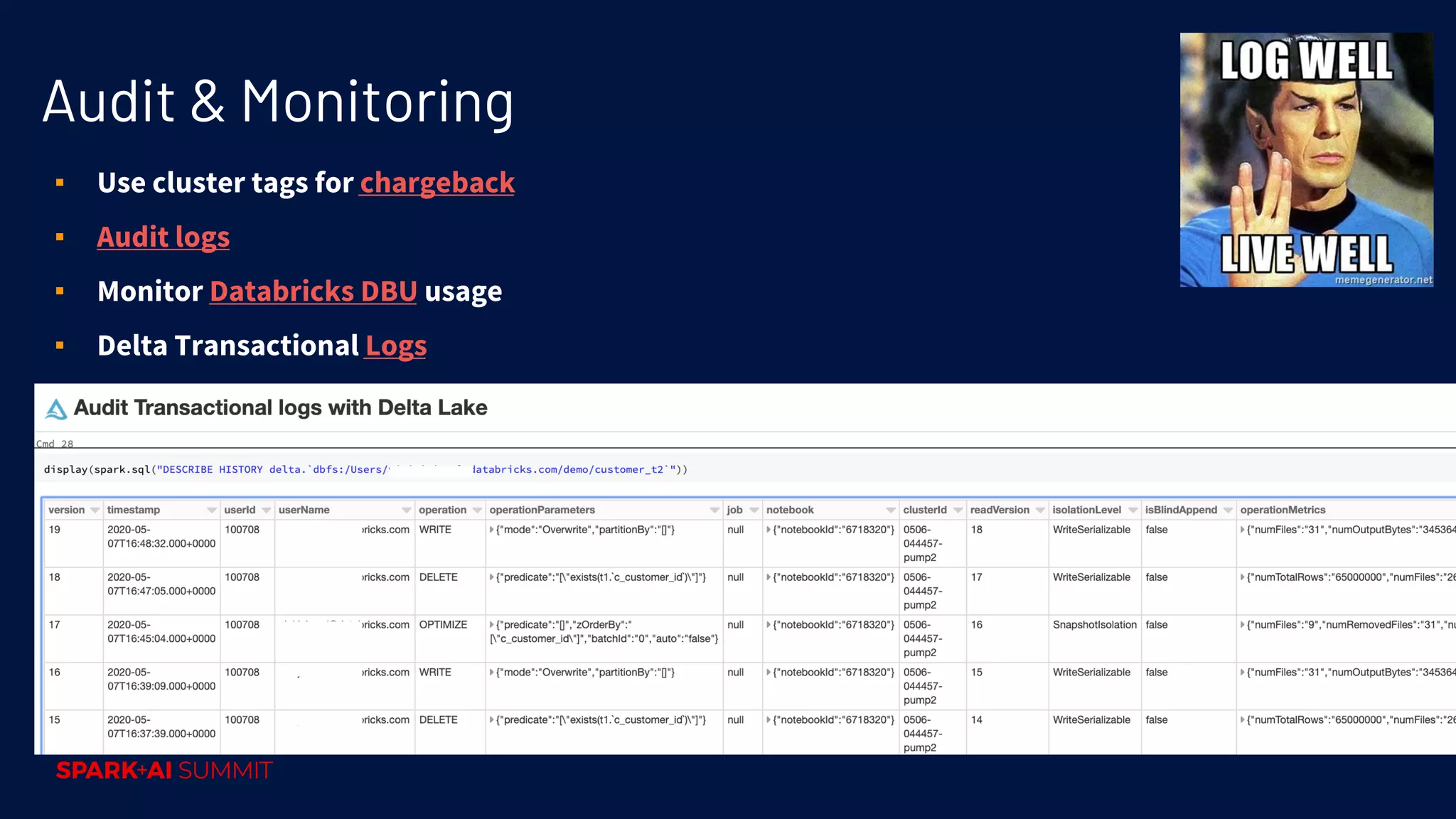
Data governance strategies, ensuring compliance, security controls, and the roles within an organization.
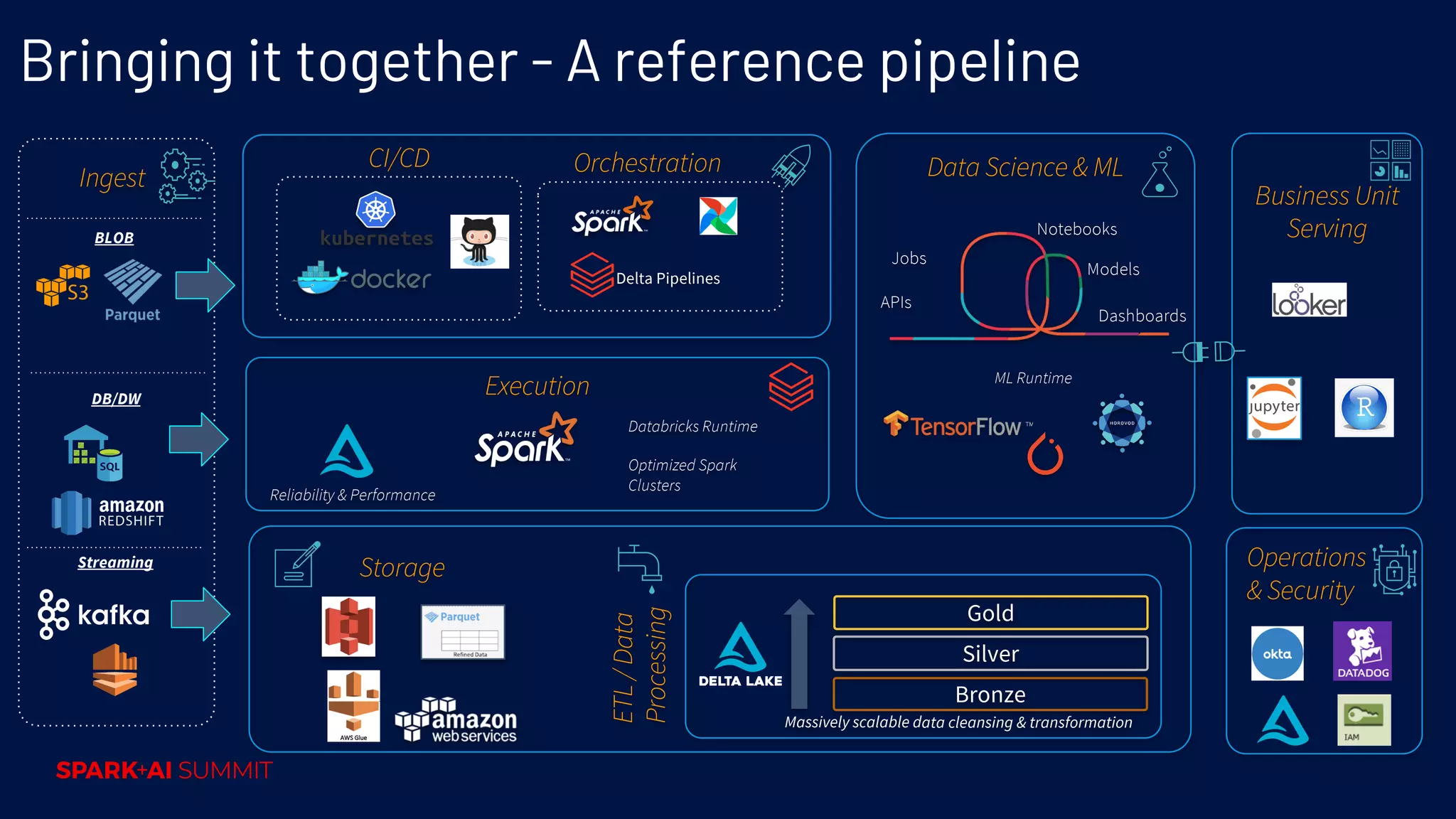
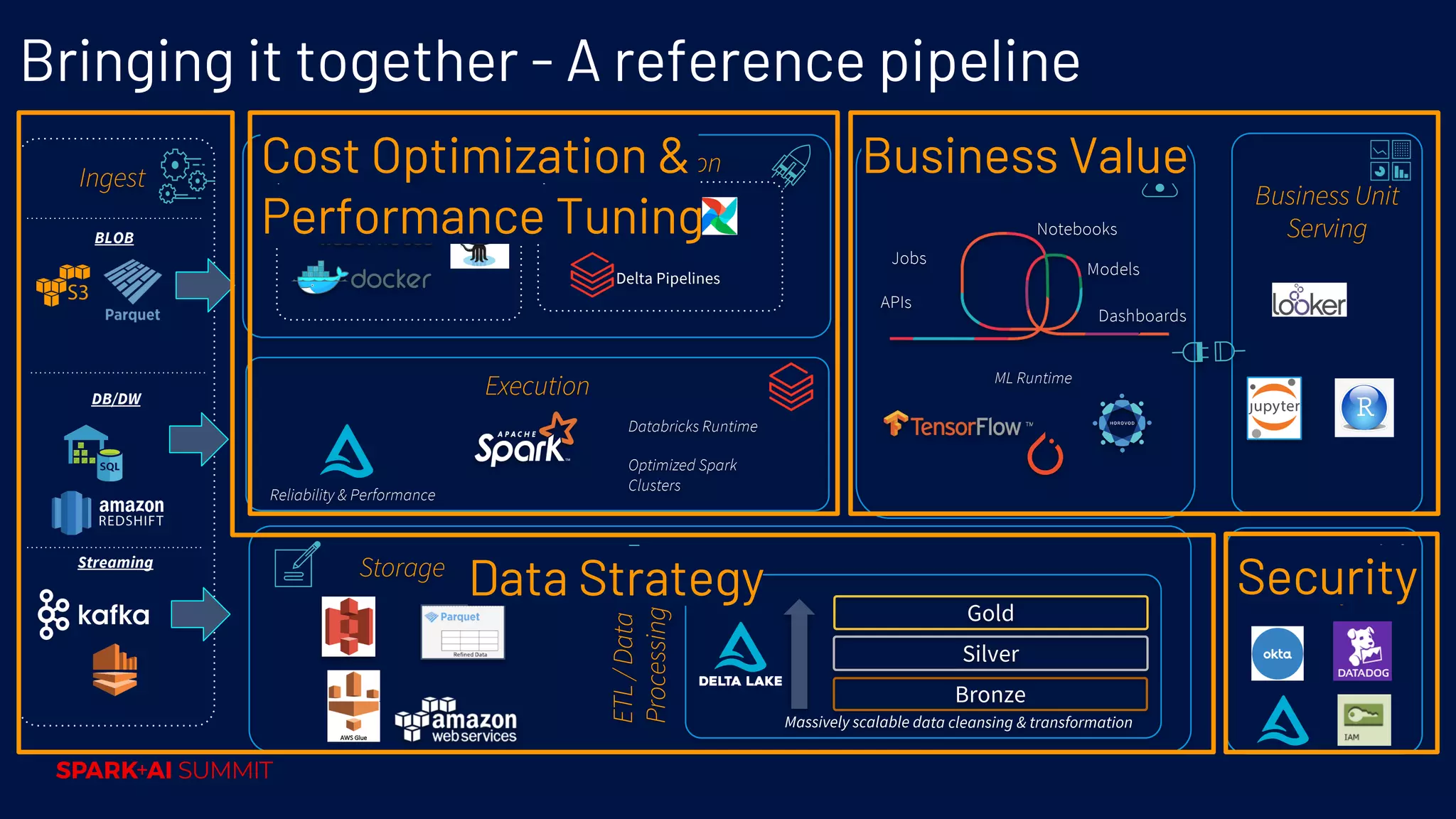
Outline of a reference pipeline that integrates various operations, supporting data processing and analytics.
Closing remarks and a request for feedback on the session.