Downloaded 129 times




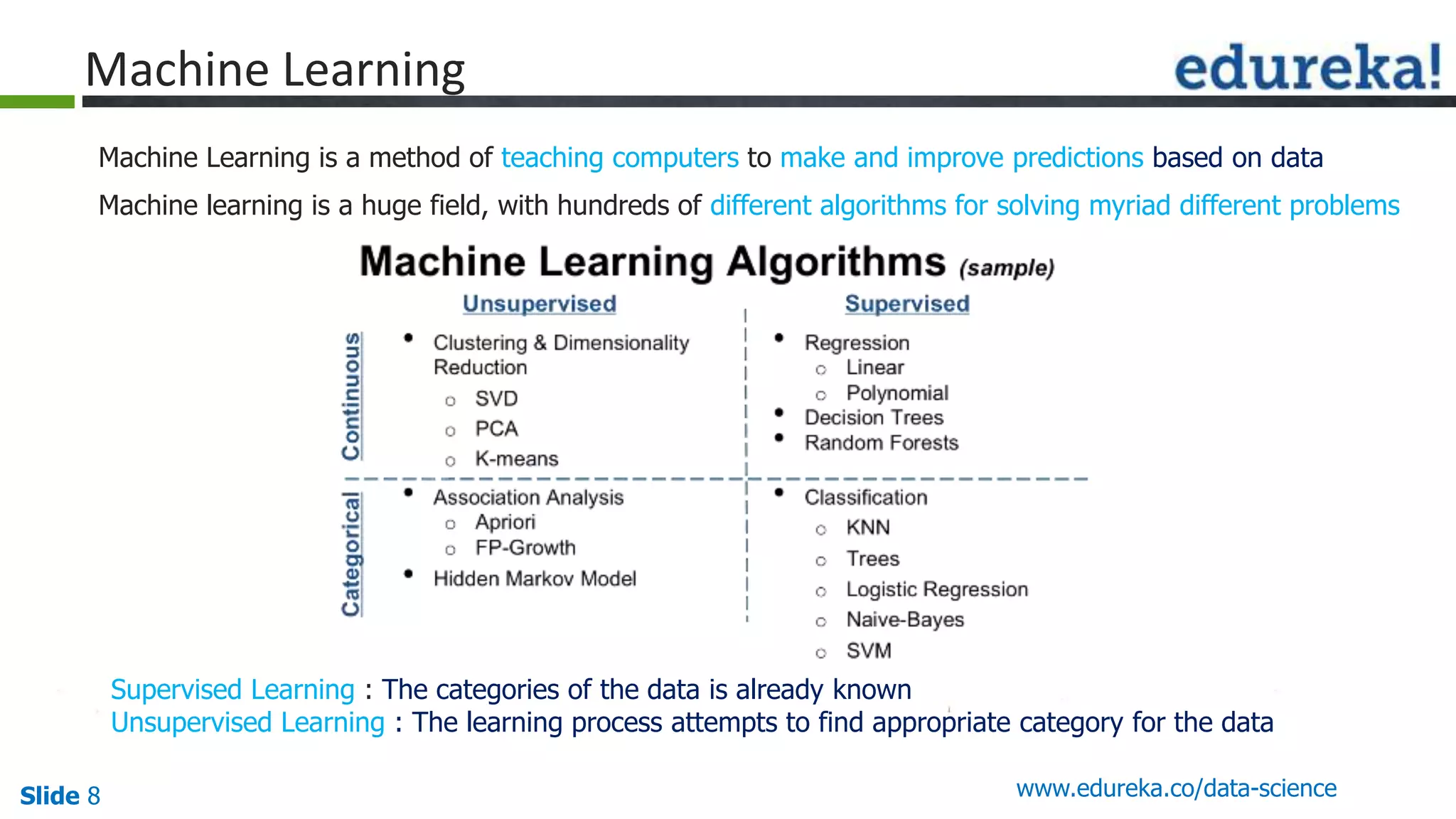

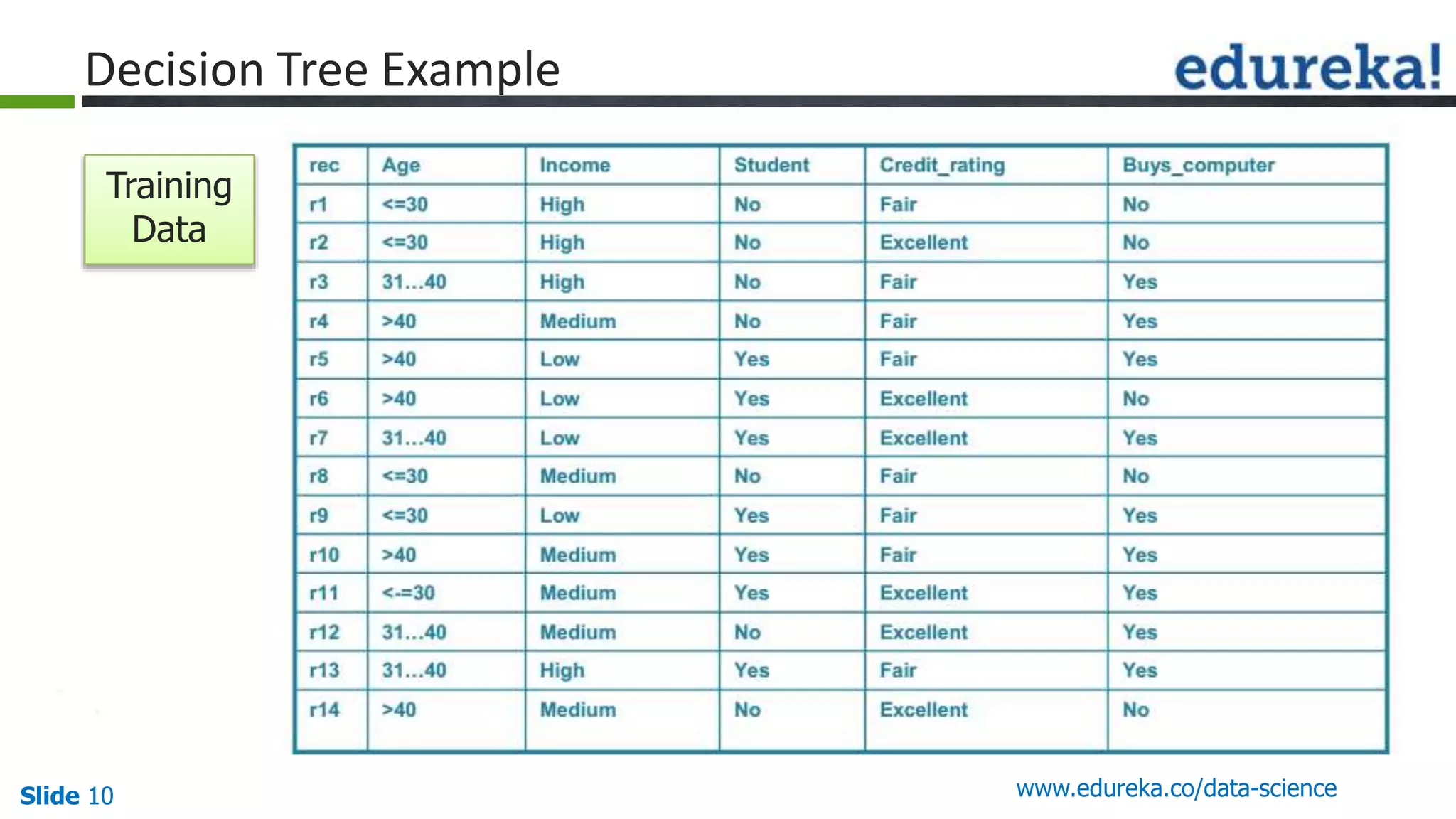
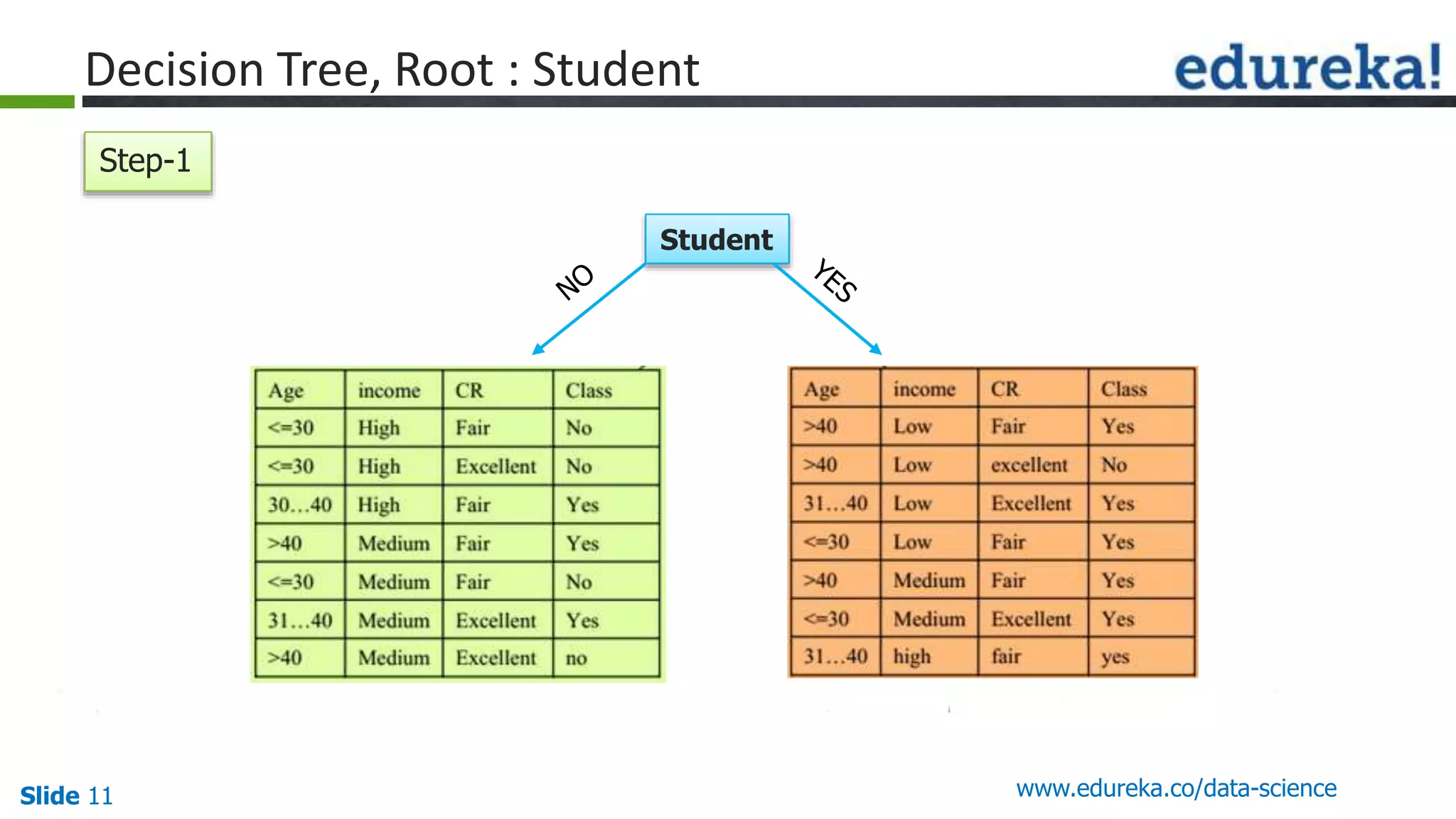
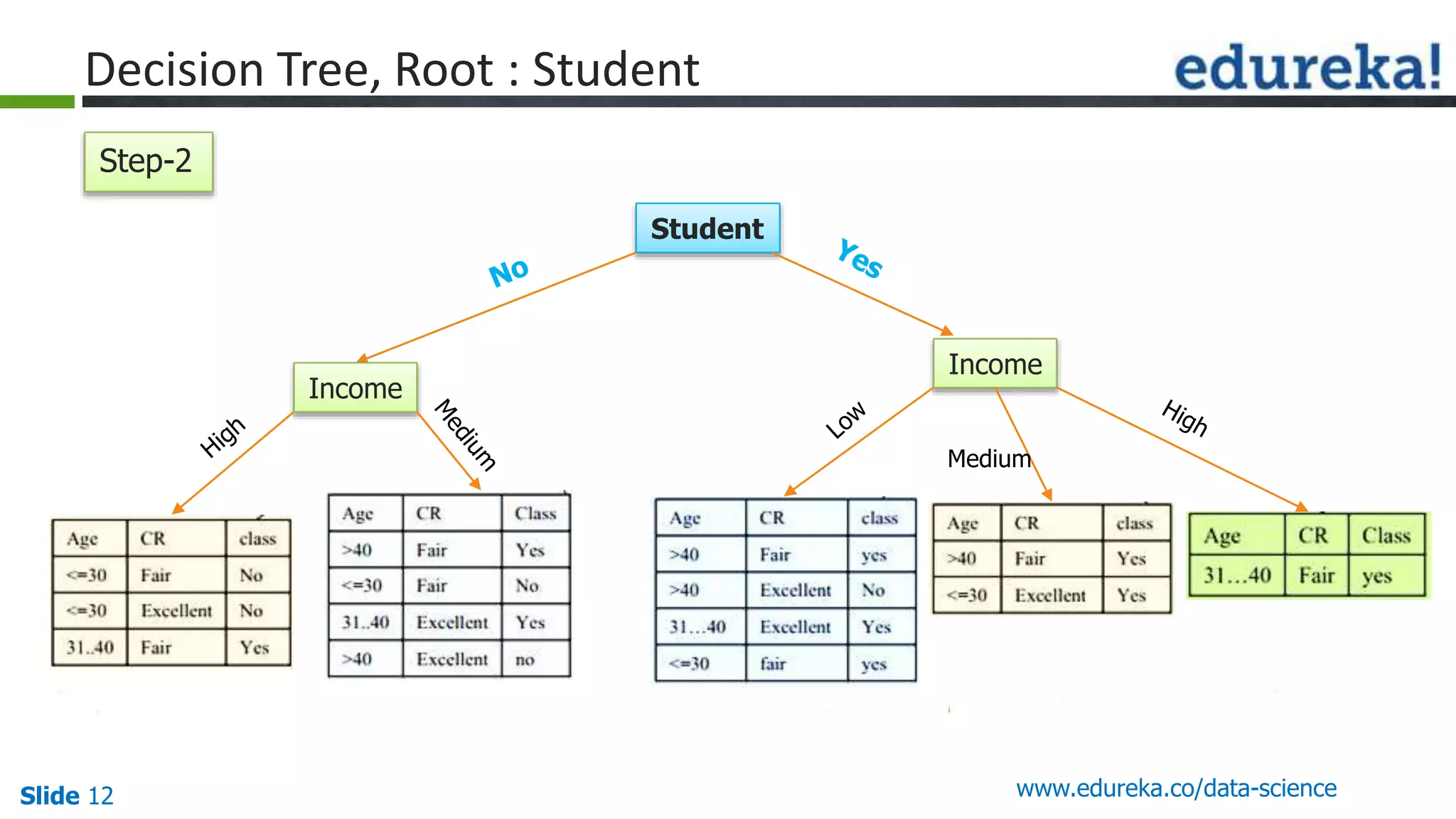
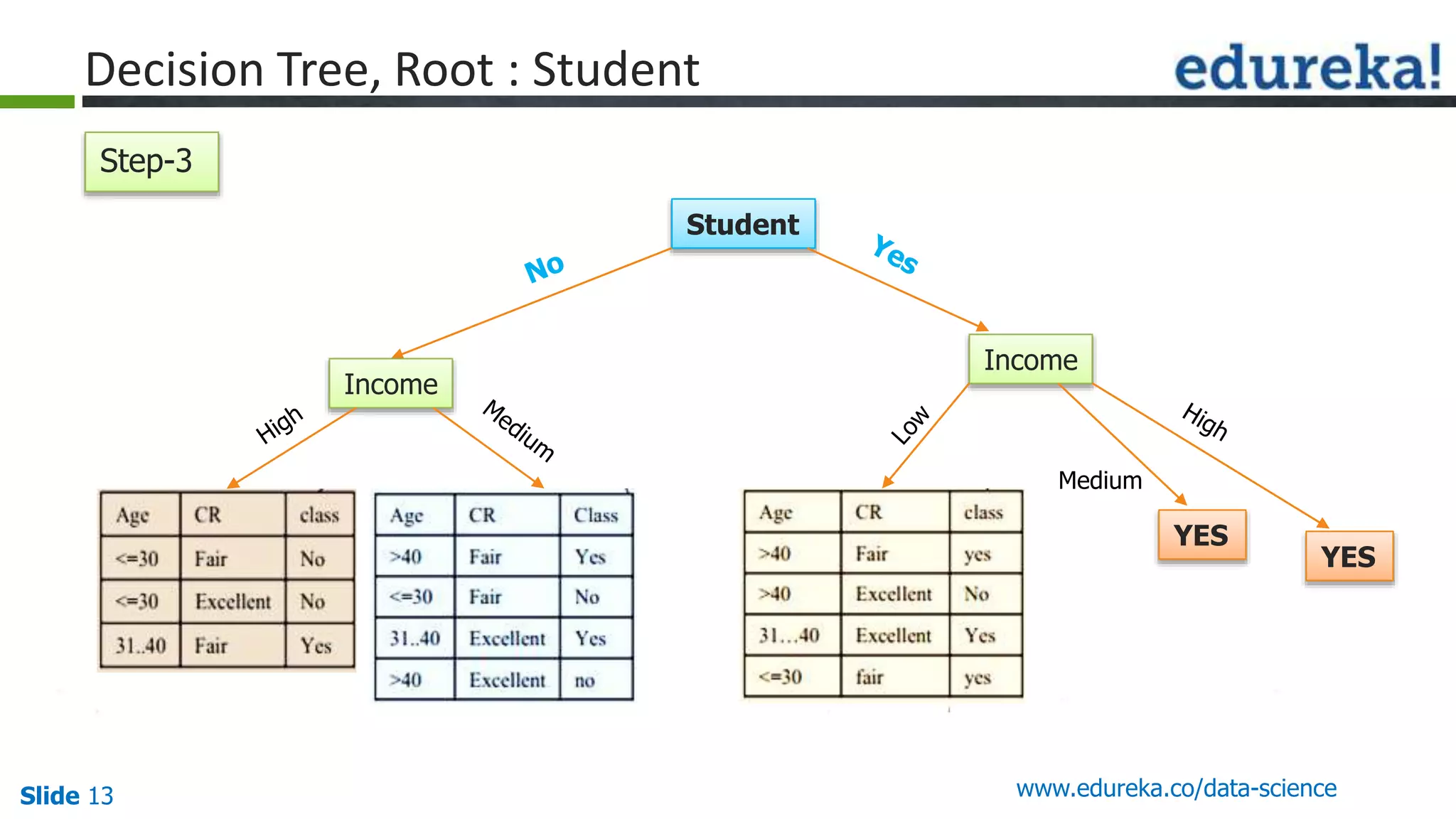
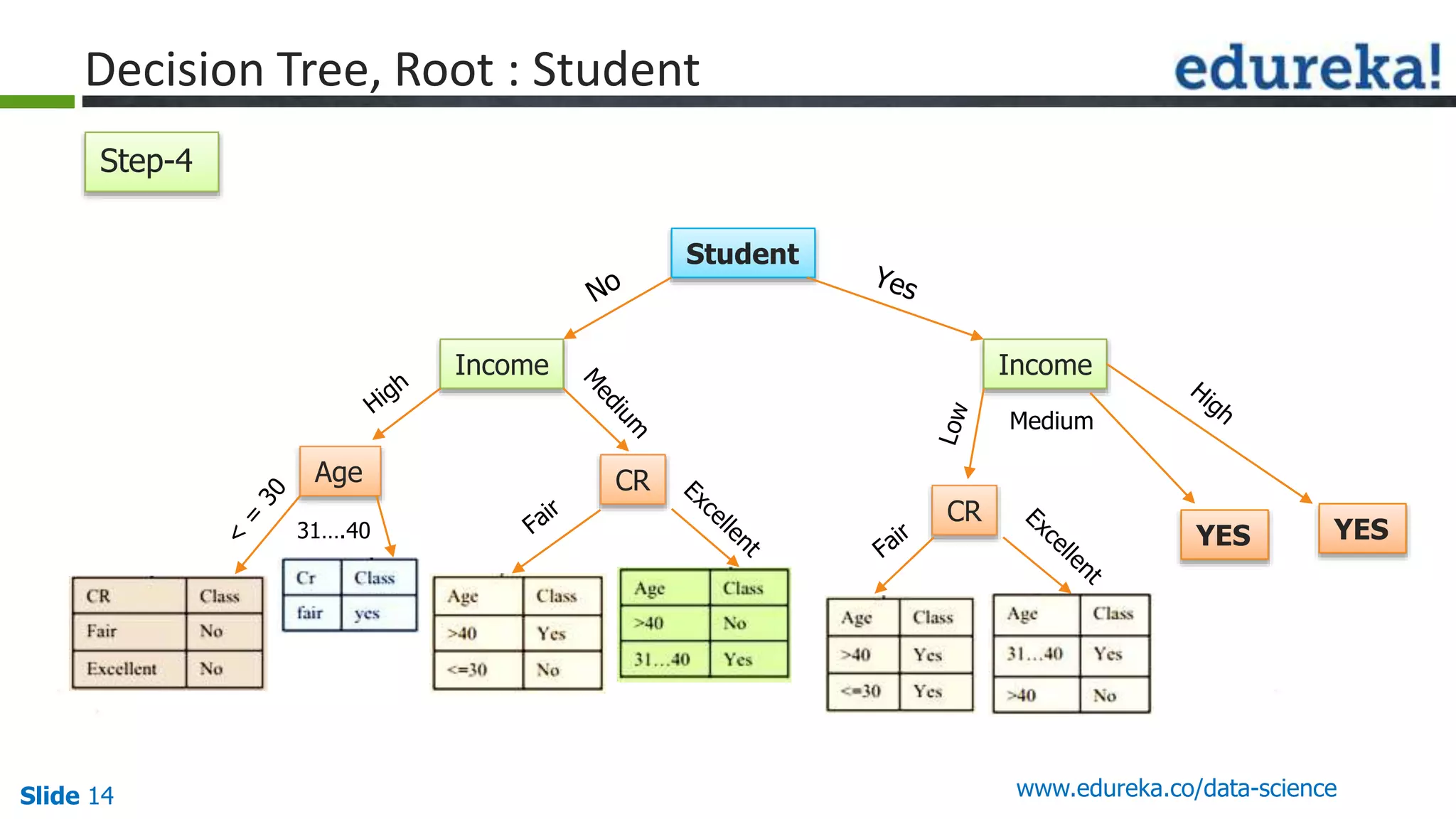
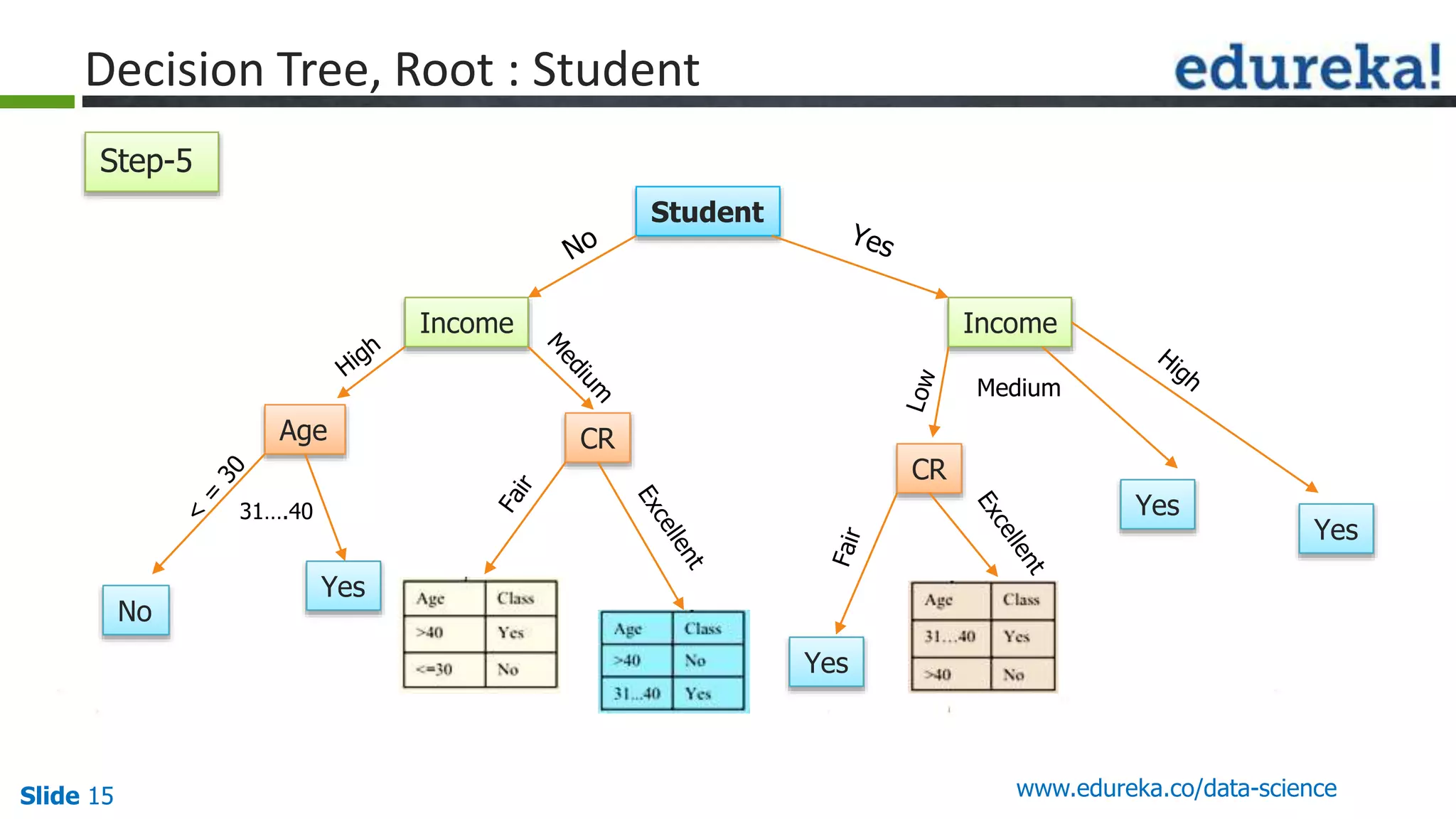
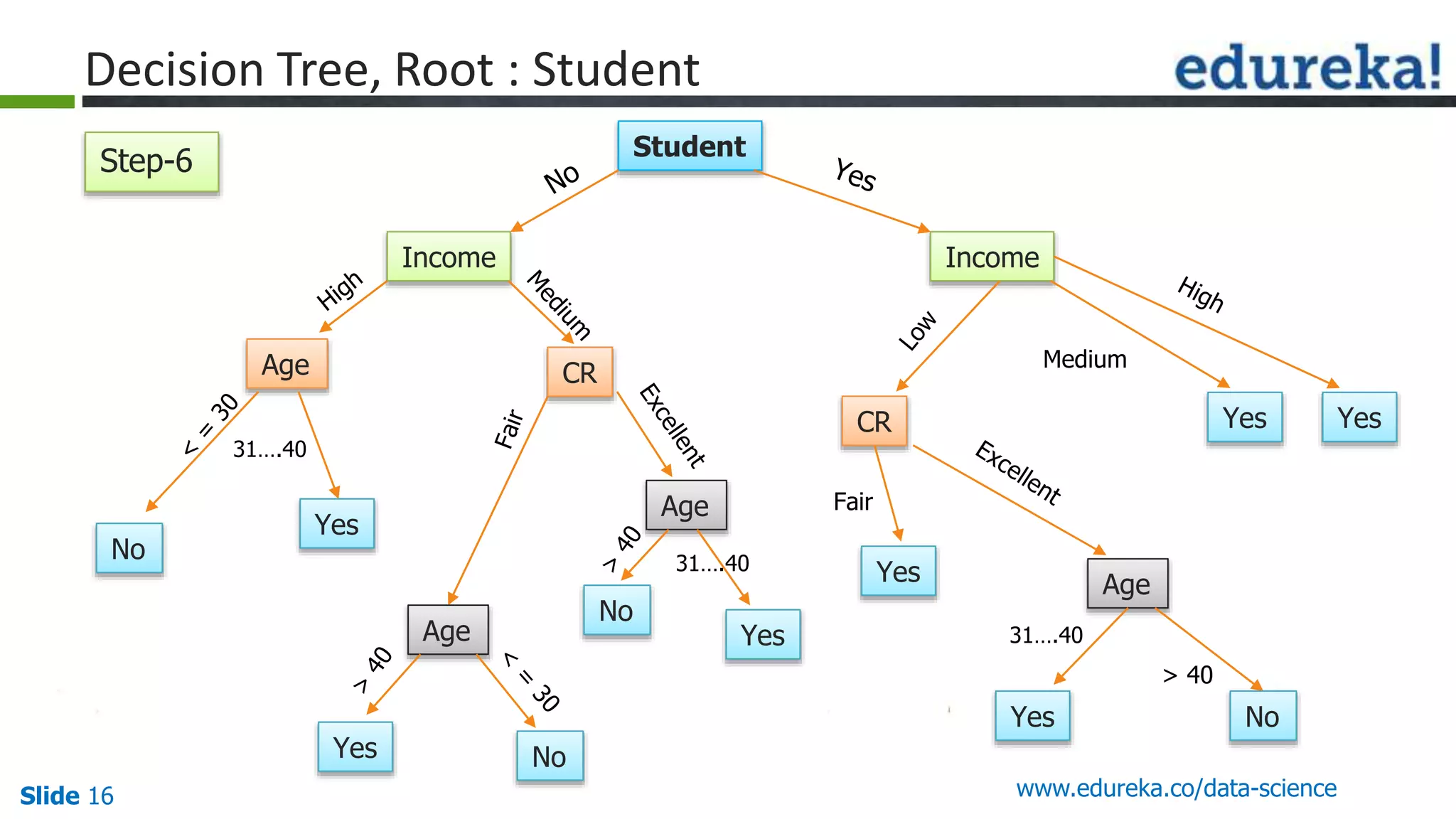



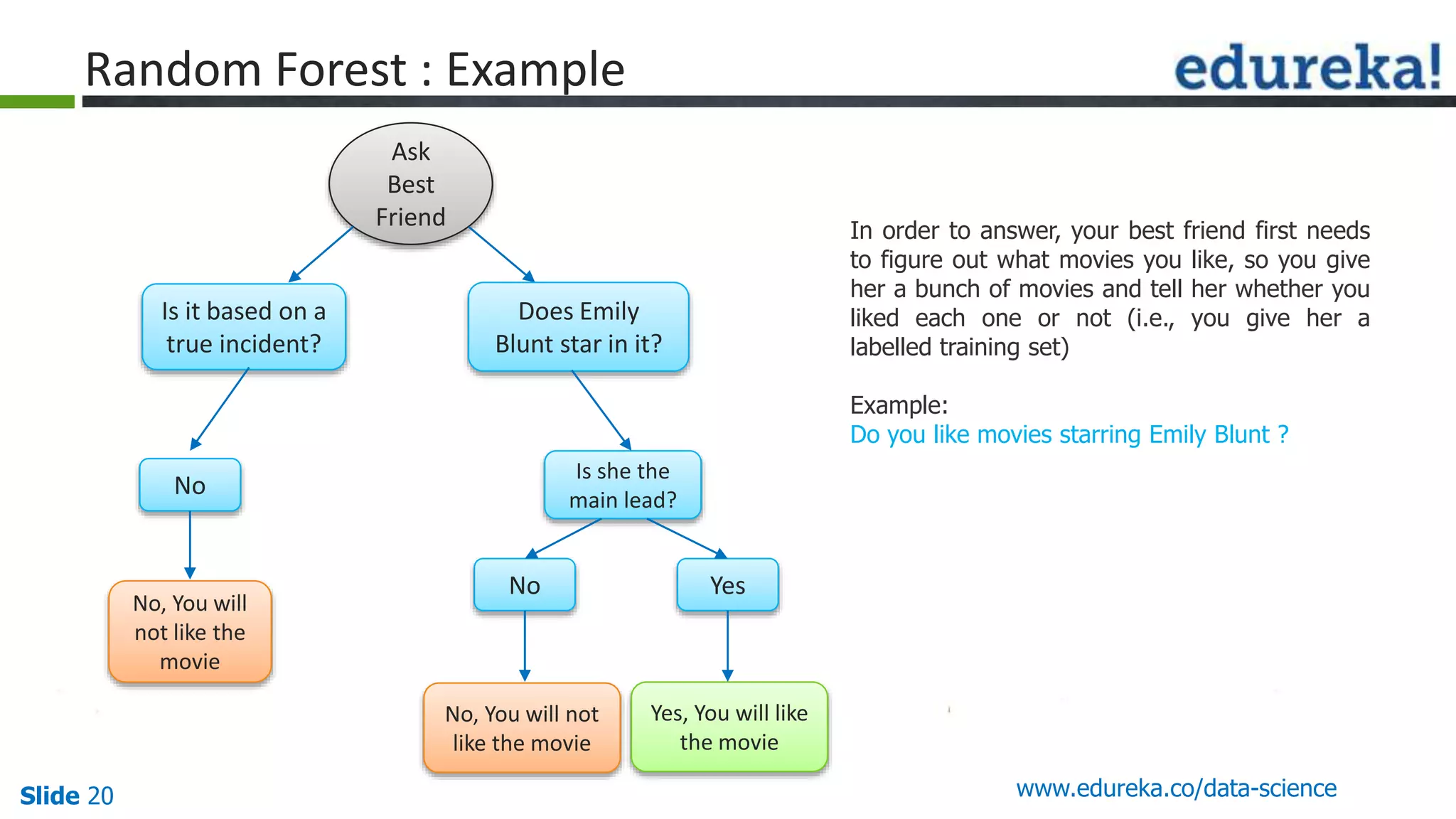

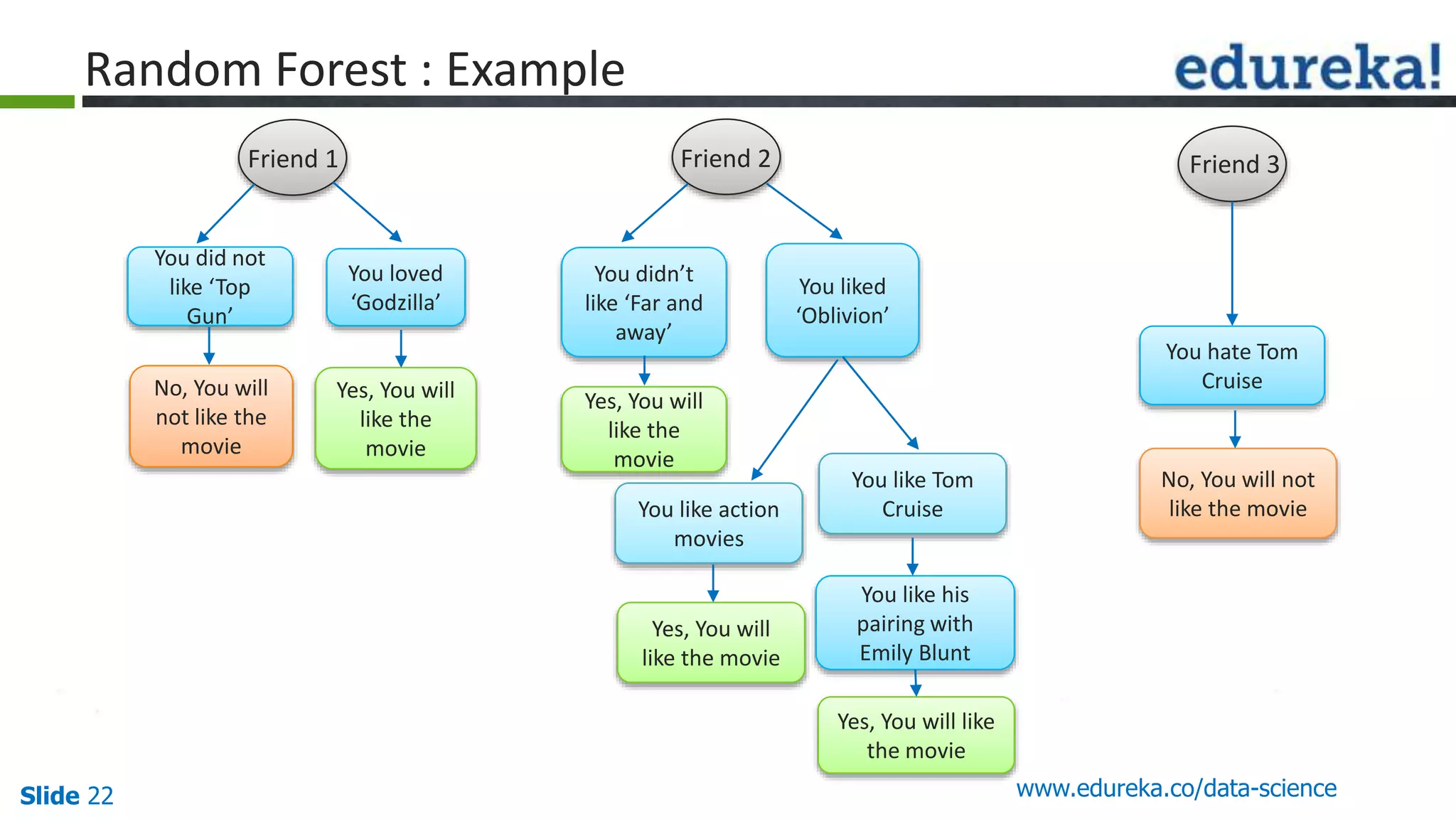


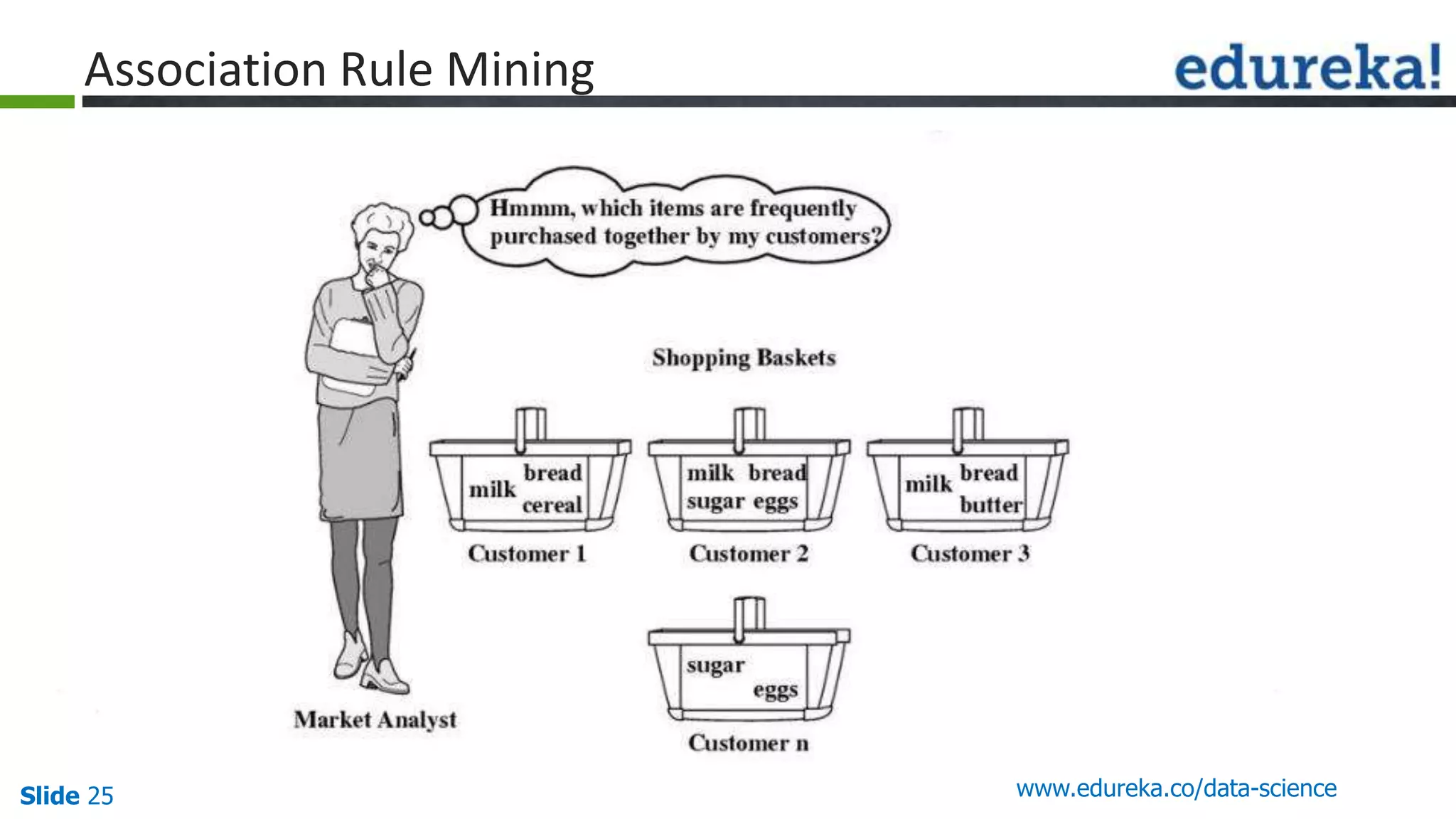


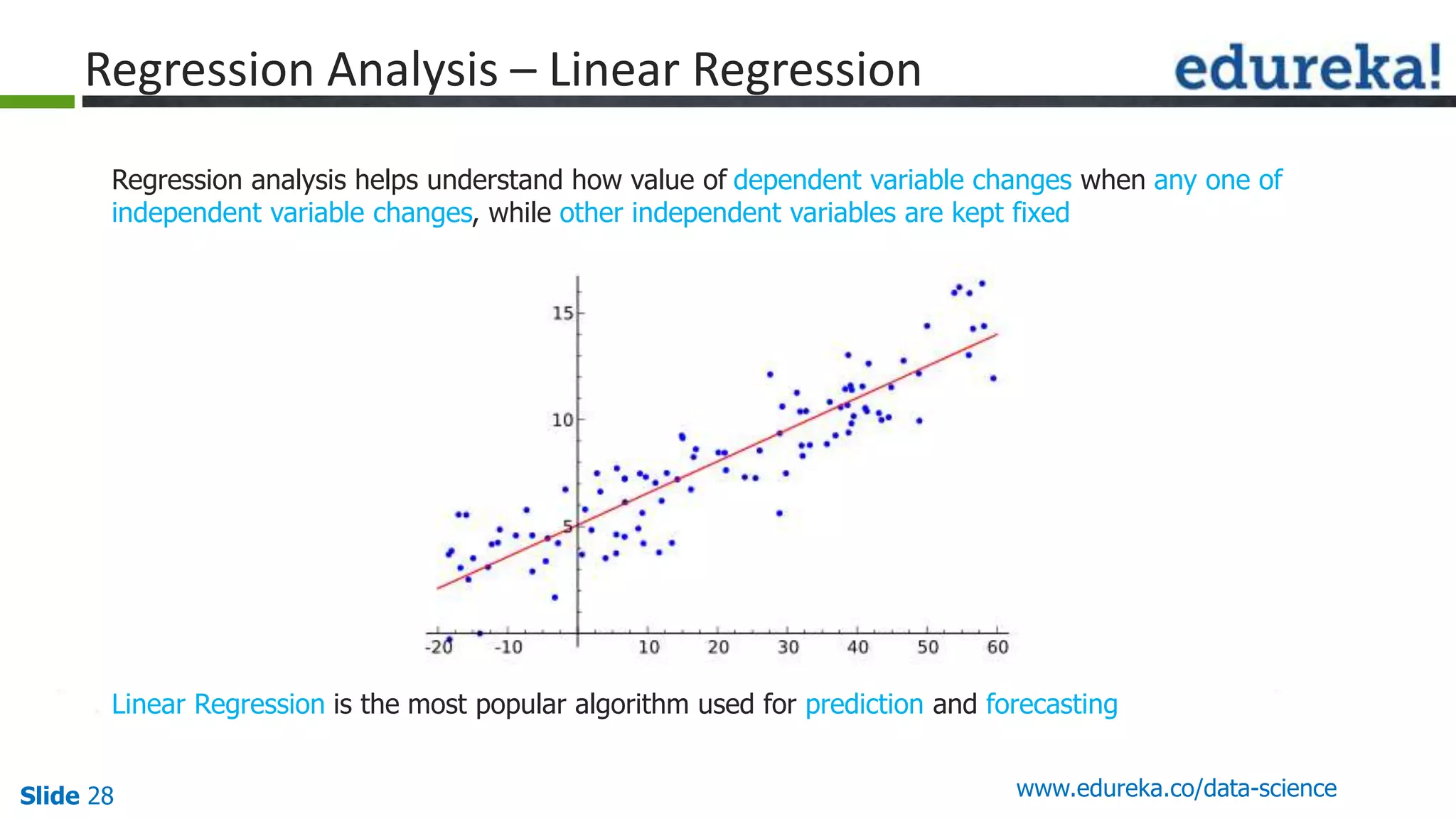

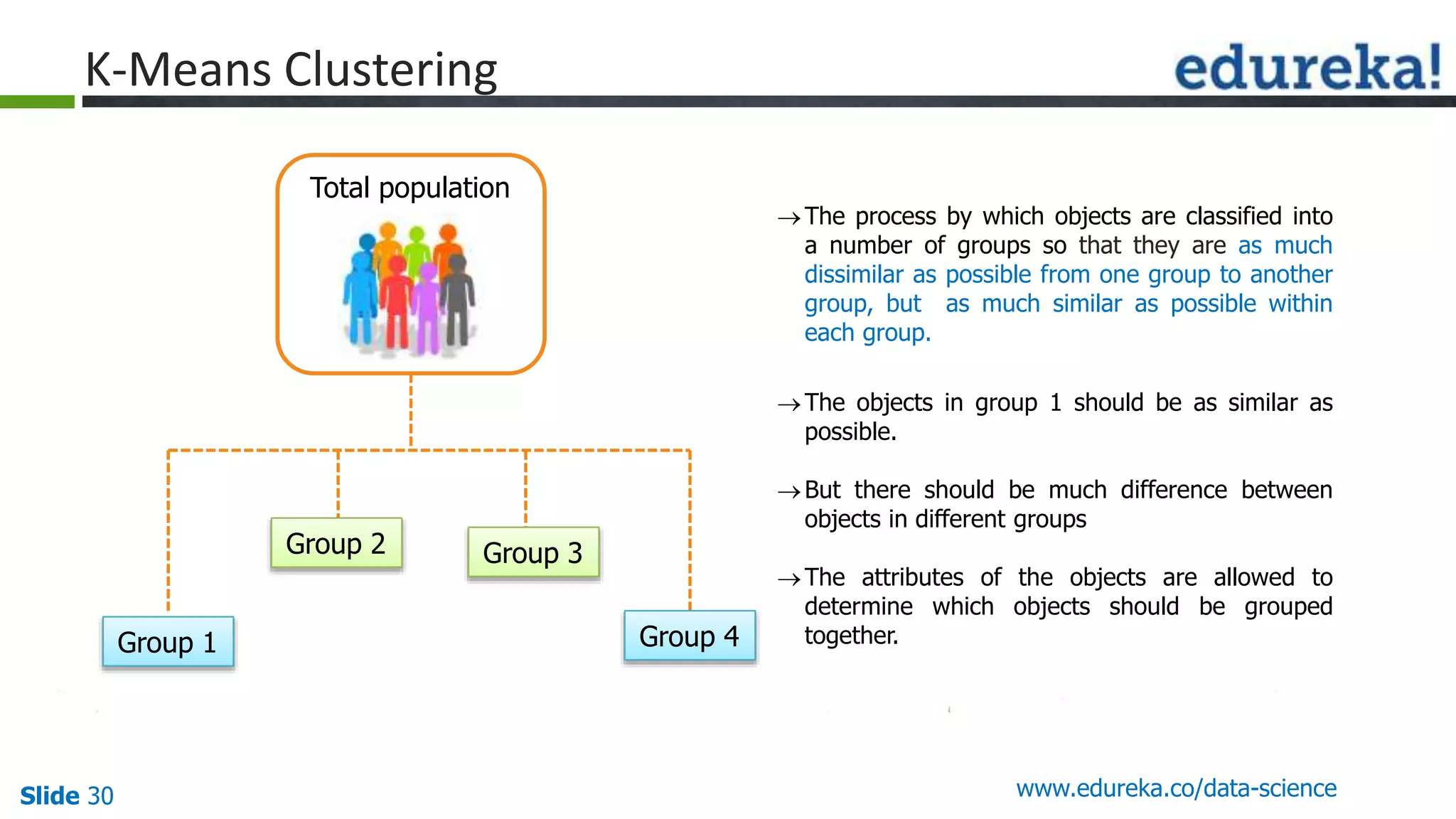


This document provides an overview of the top 5 algorithms used in data science: decision trees, random forests, association rule mining, linear regression, and K-means clustering. It explains what each algorithm is and provides an example of how it works. It also includes a demo of the K-means clustering algorithm. The document is presented as a slide deck that was likely used for a training or educational session on data science algorithms.