Downloaded 11 times



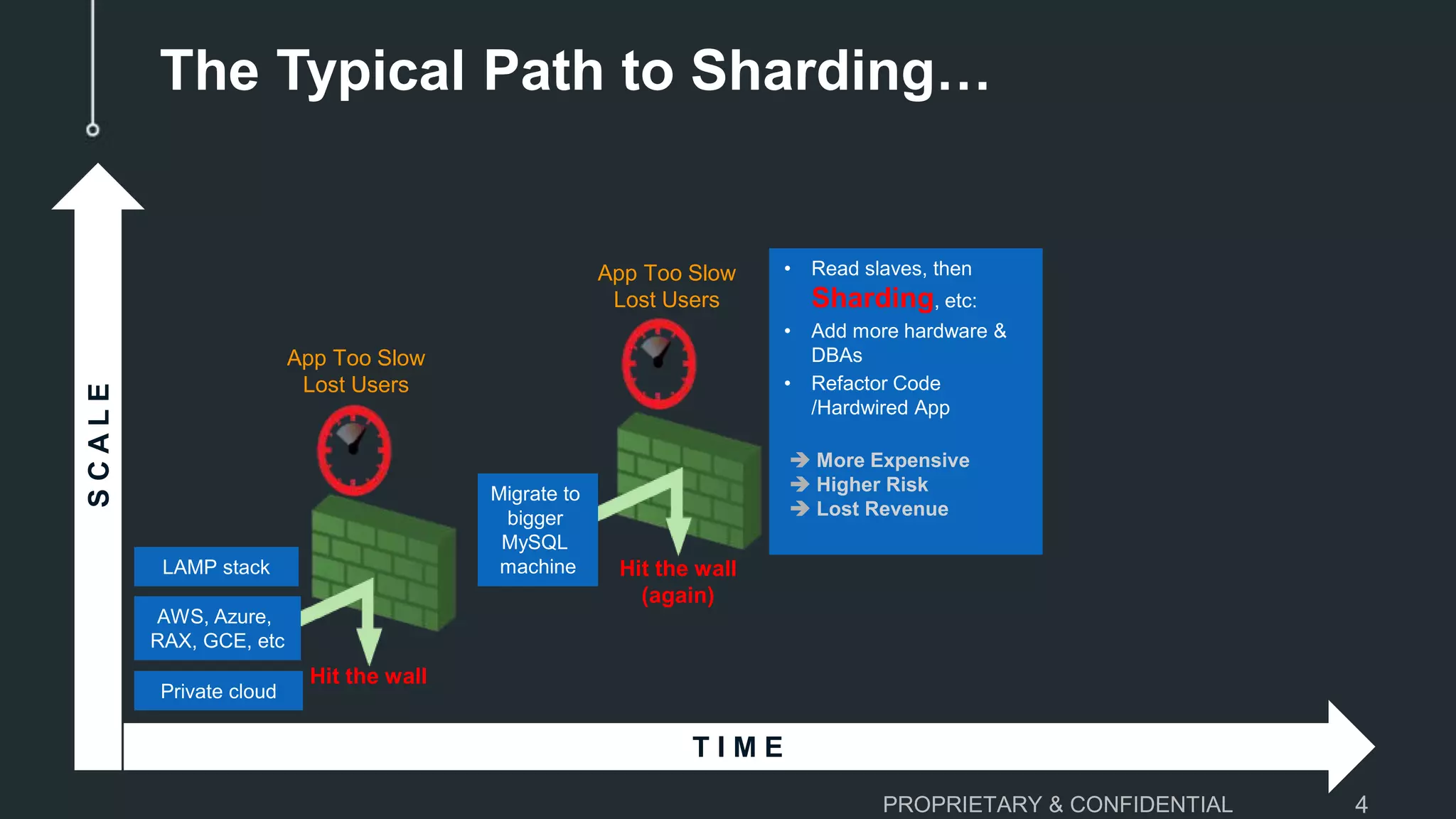
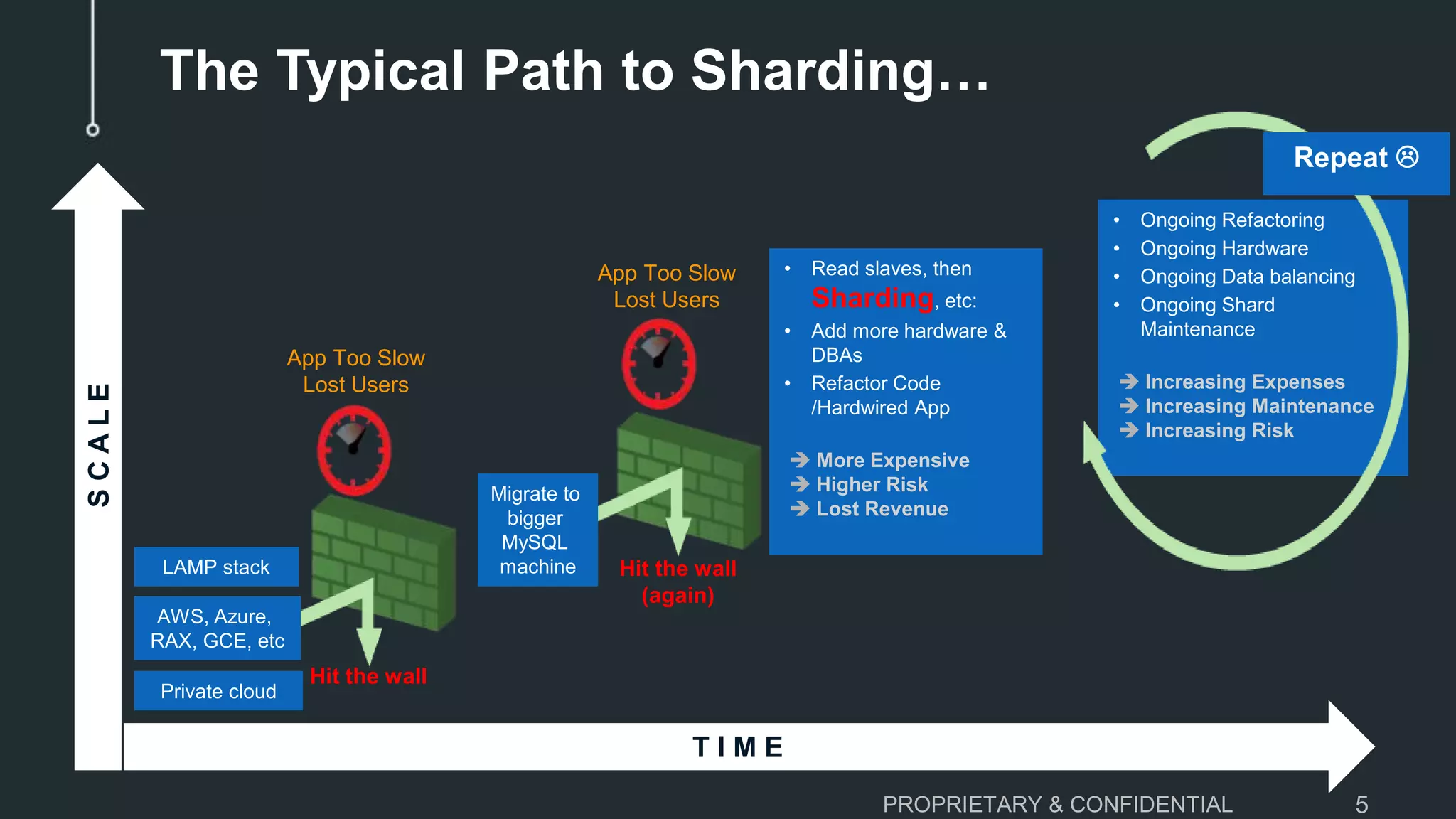


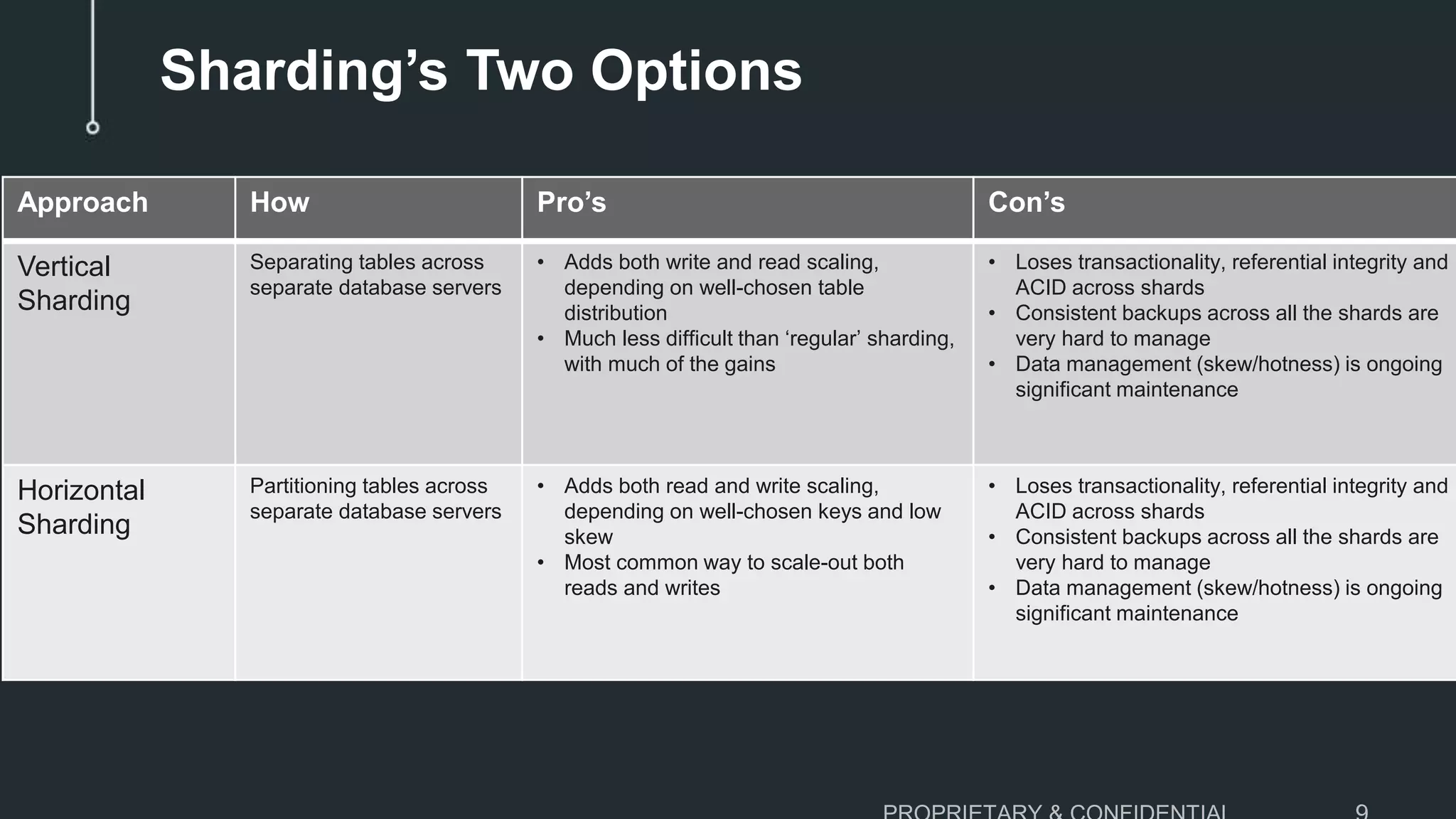

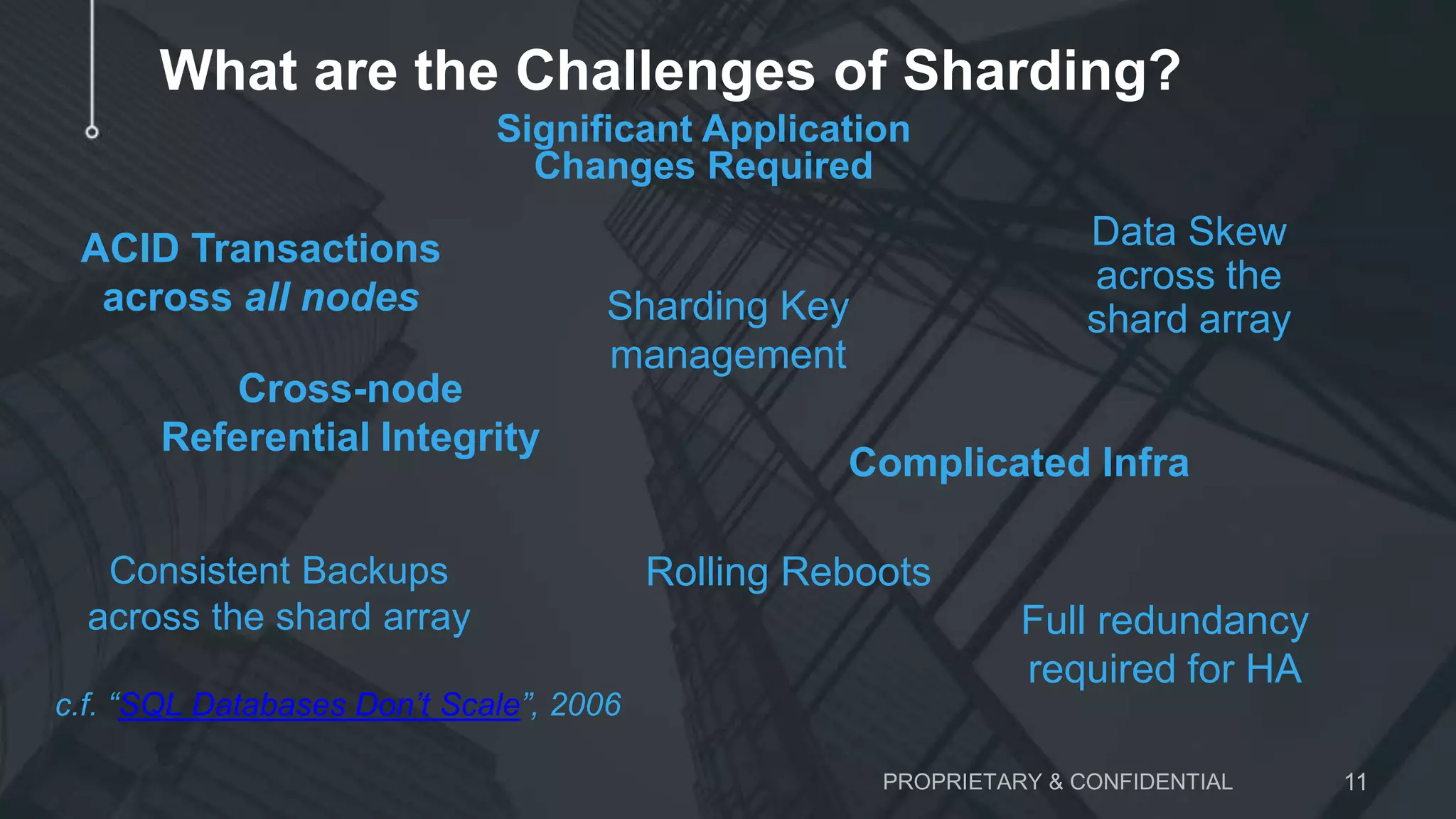







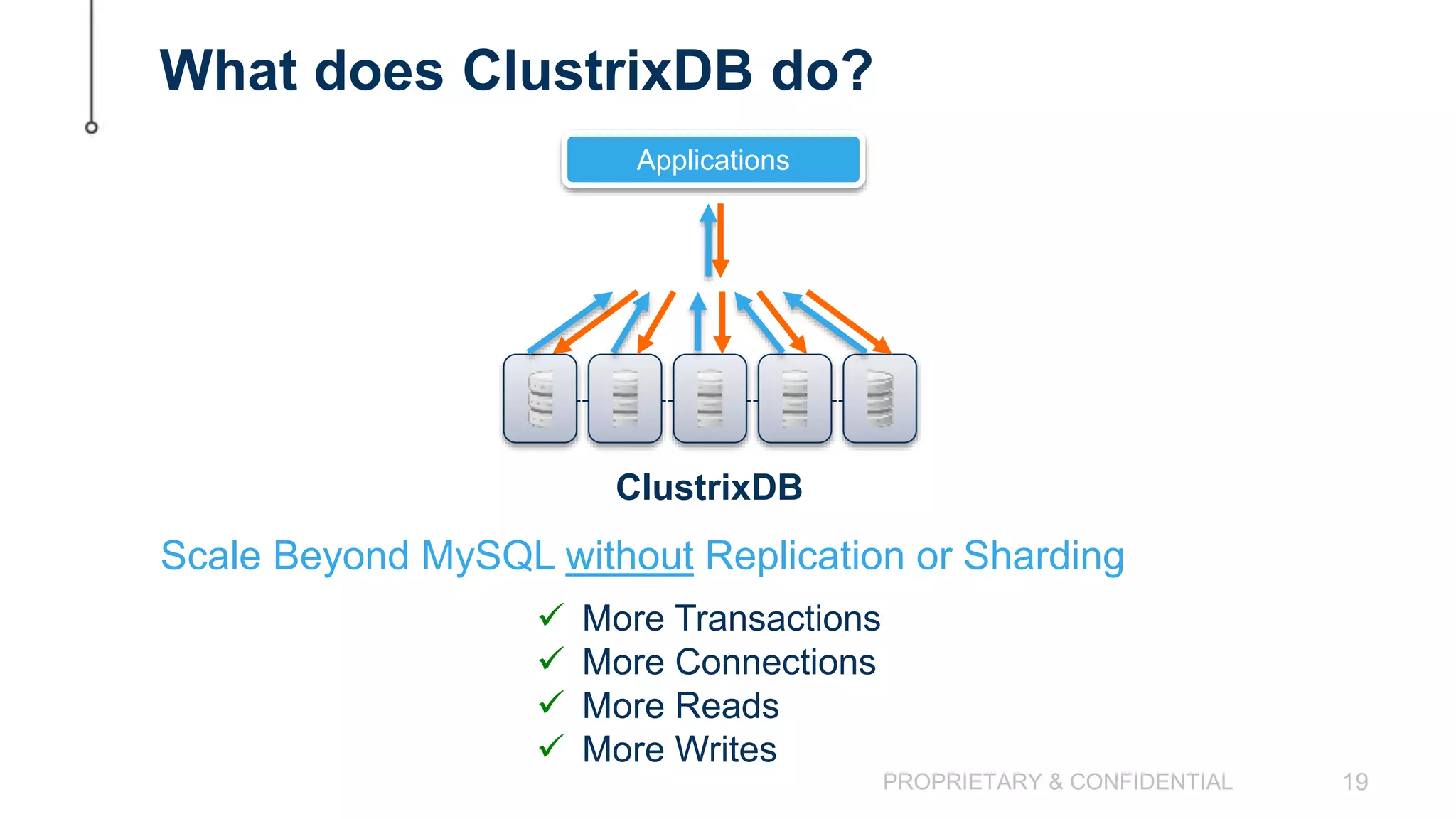
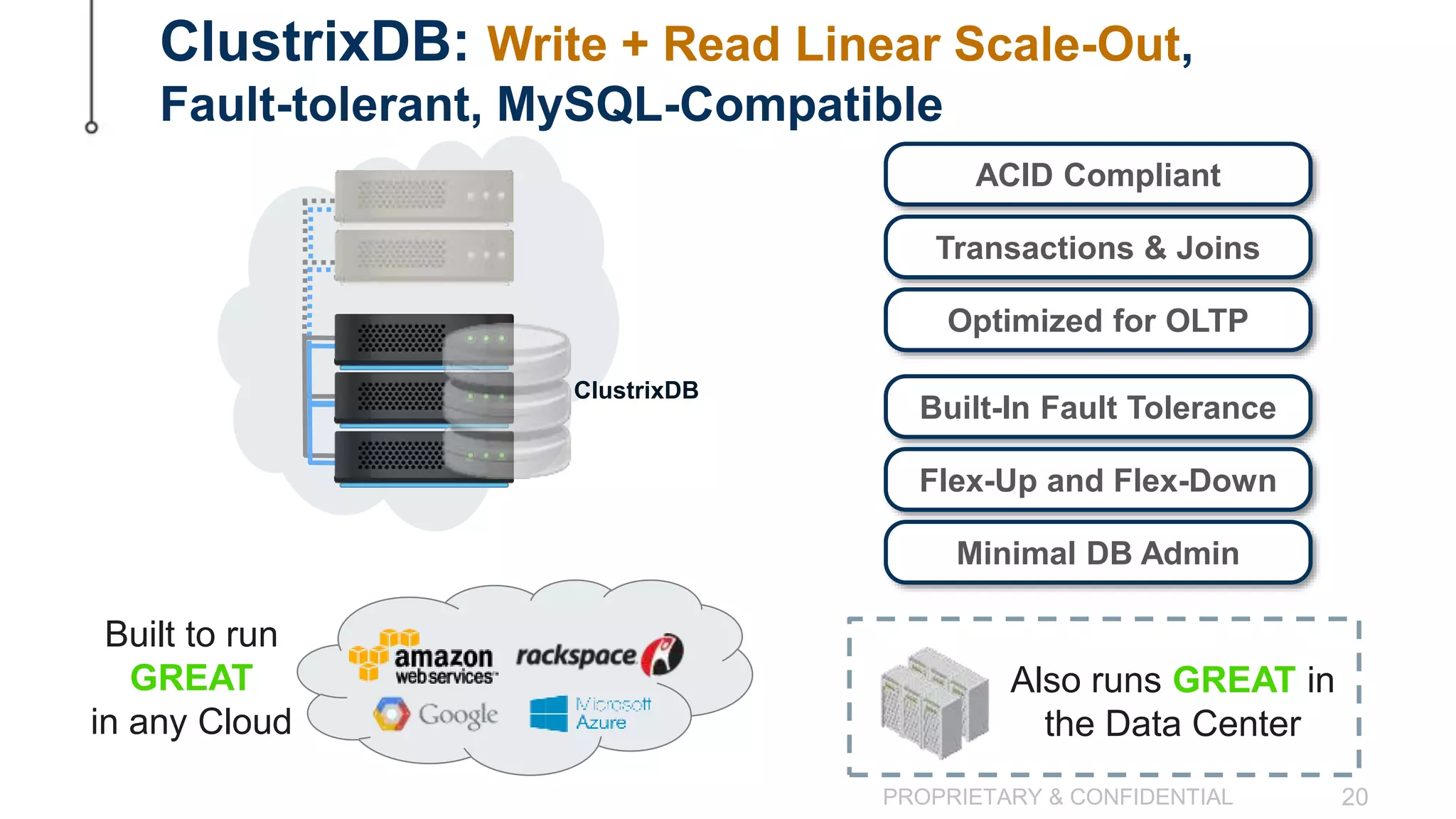
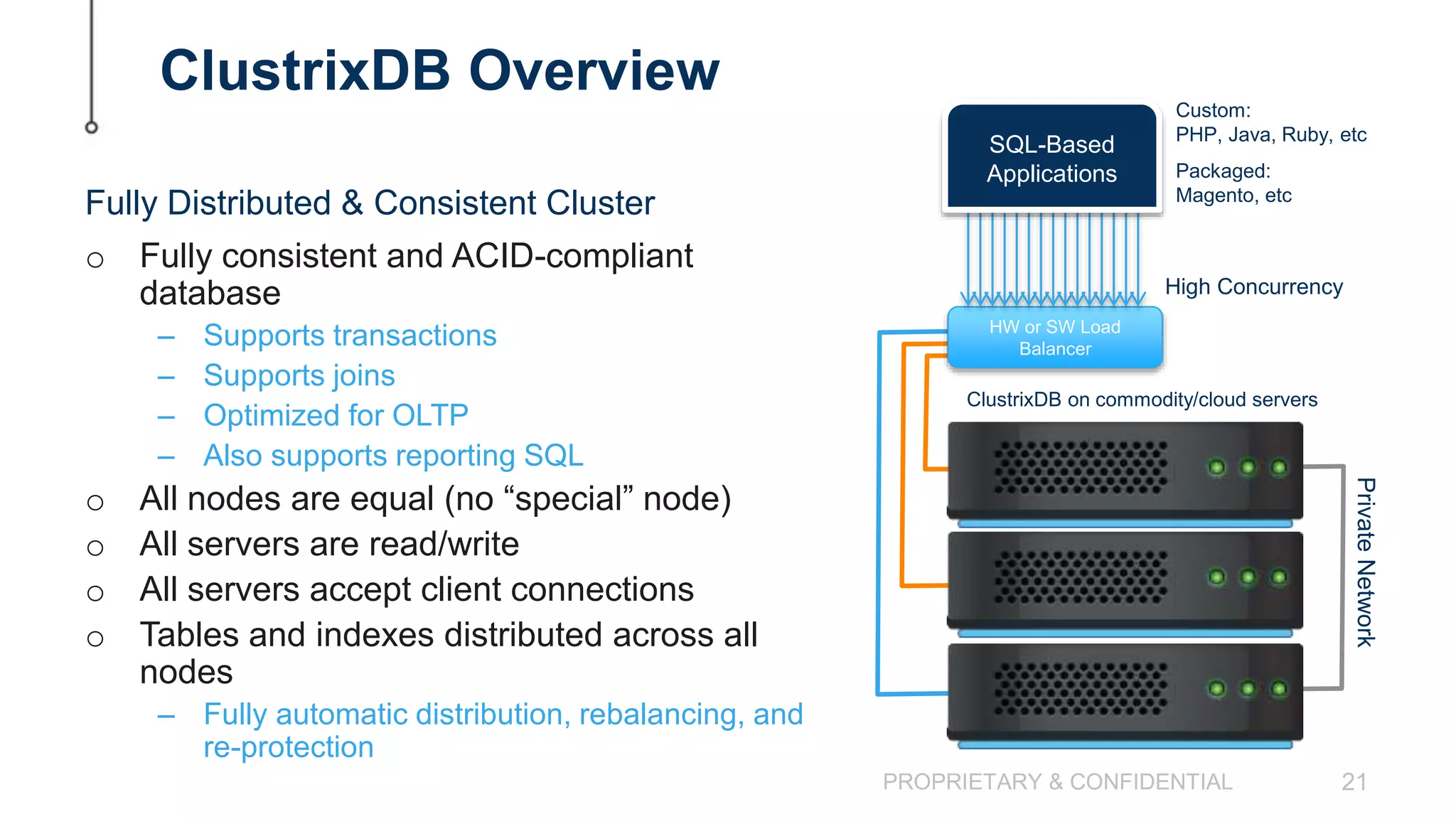
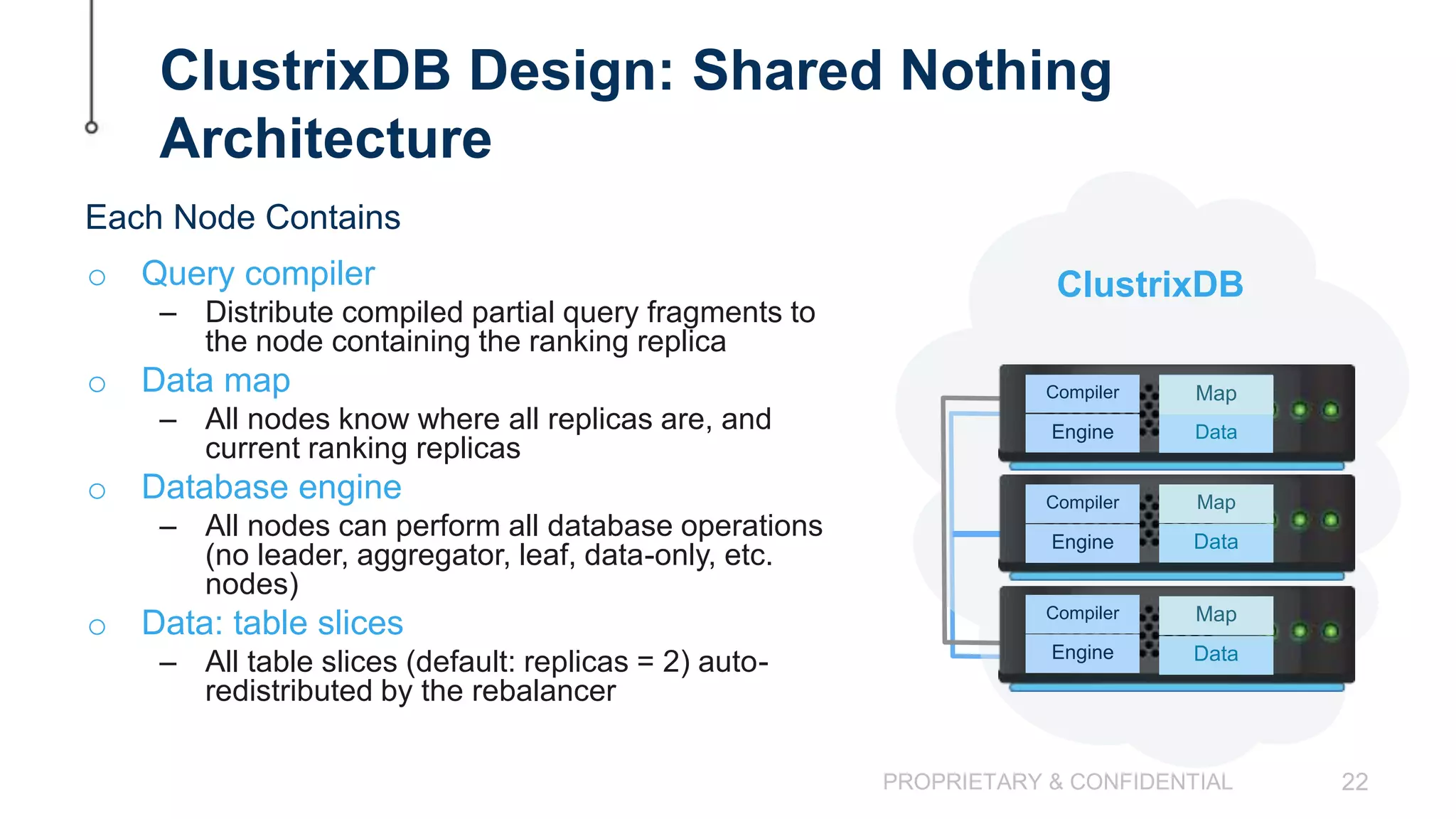

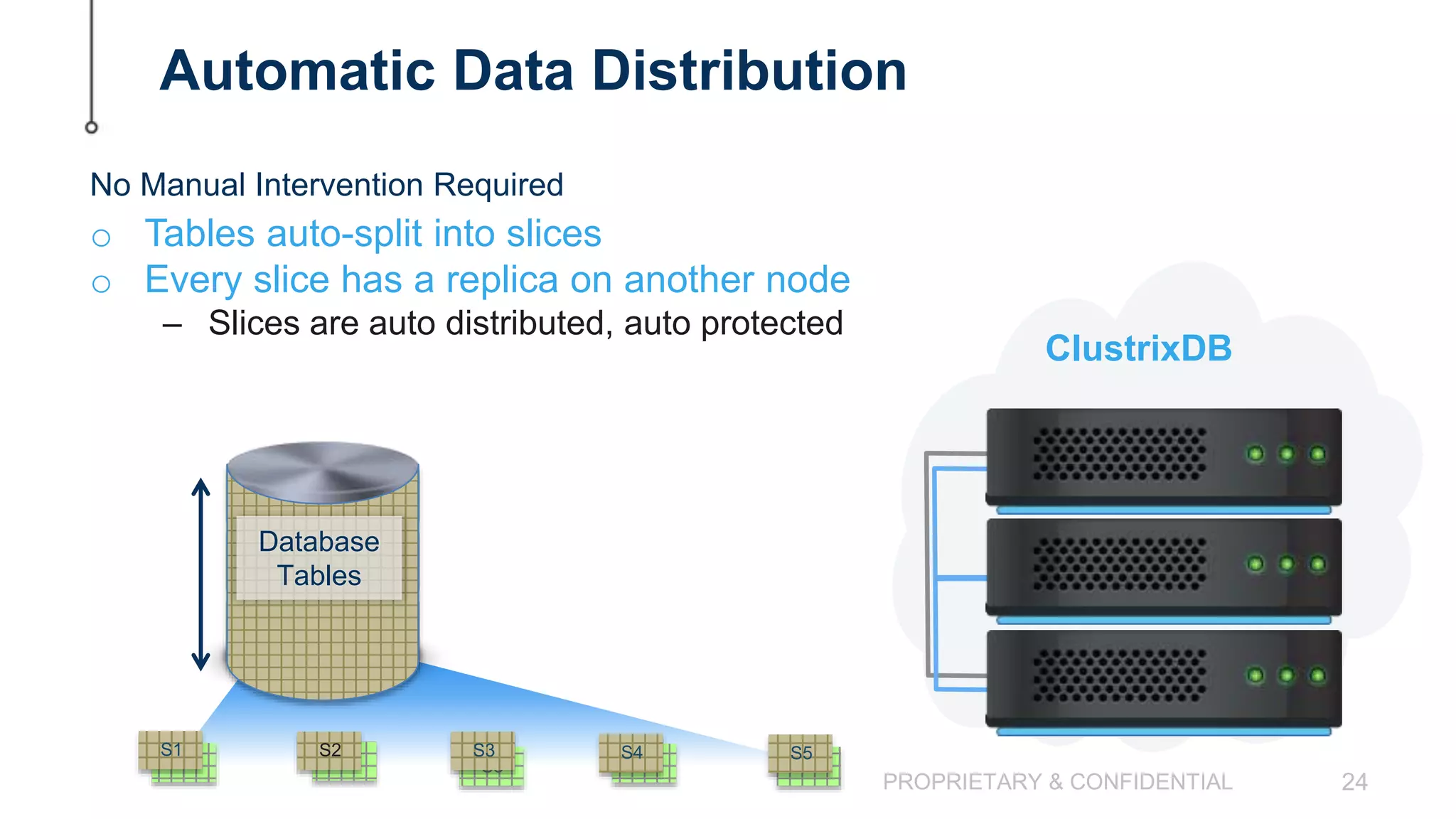
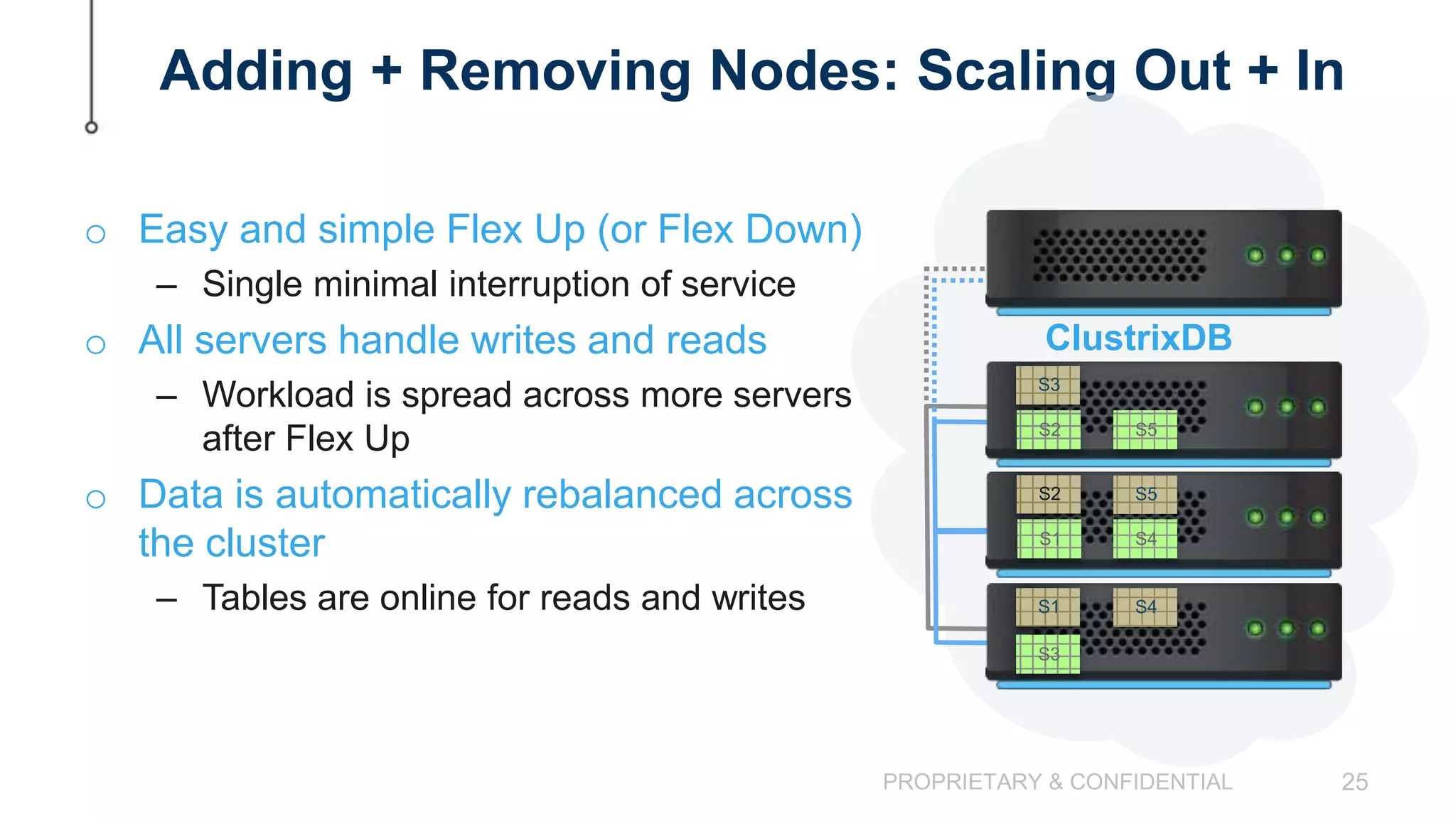
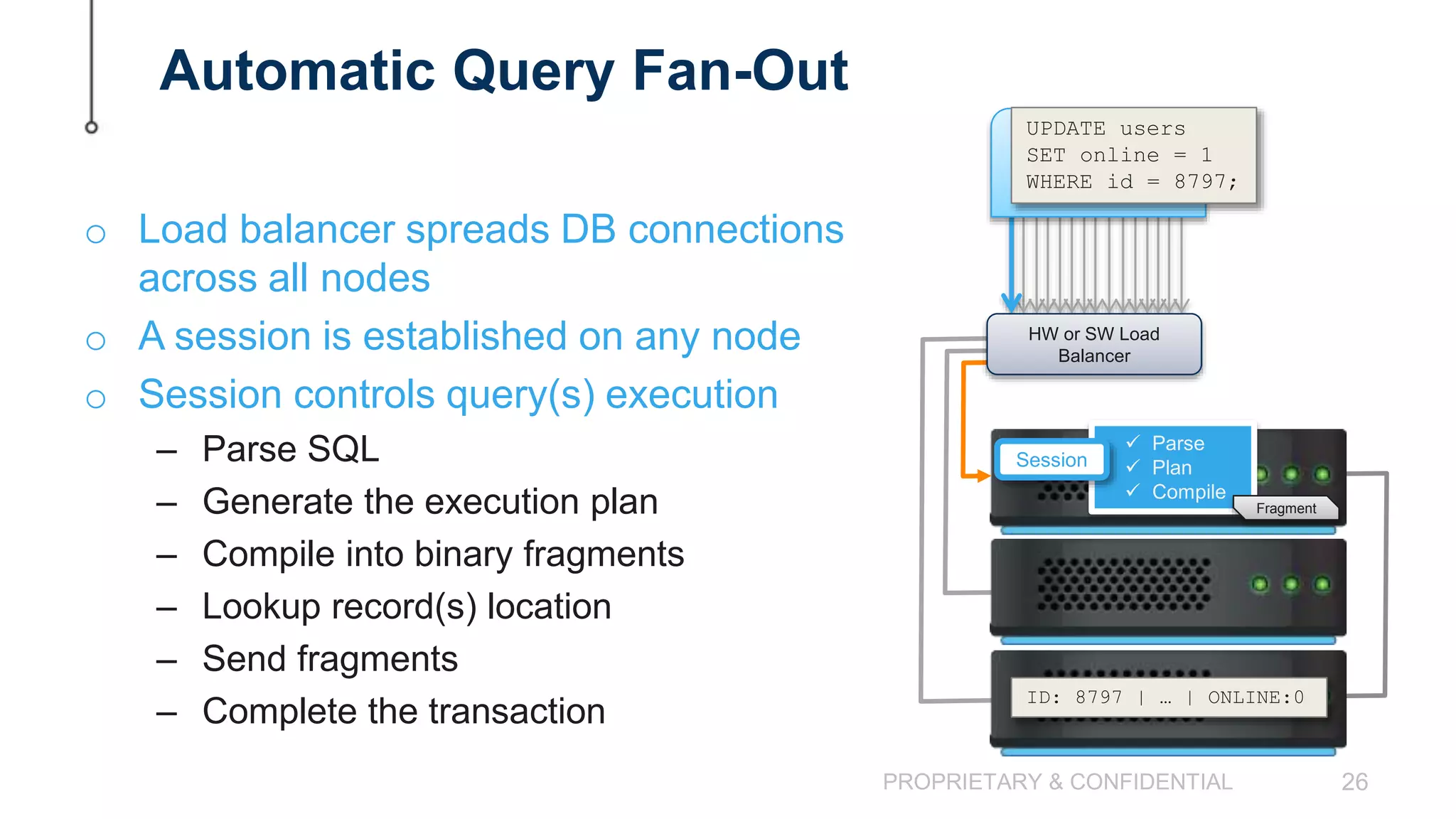
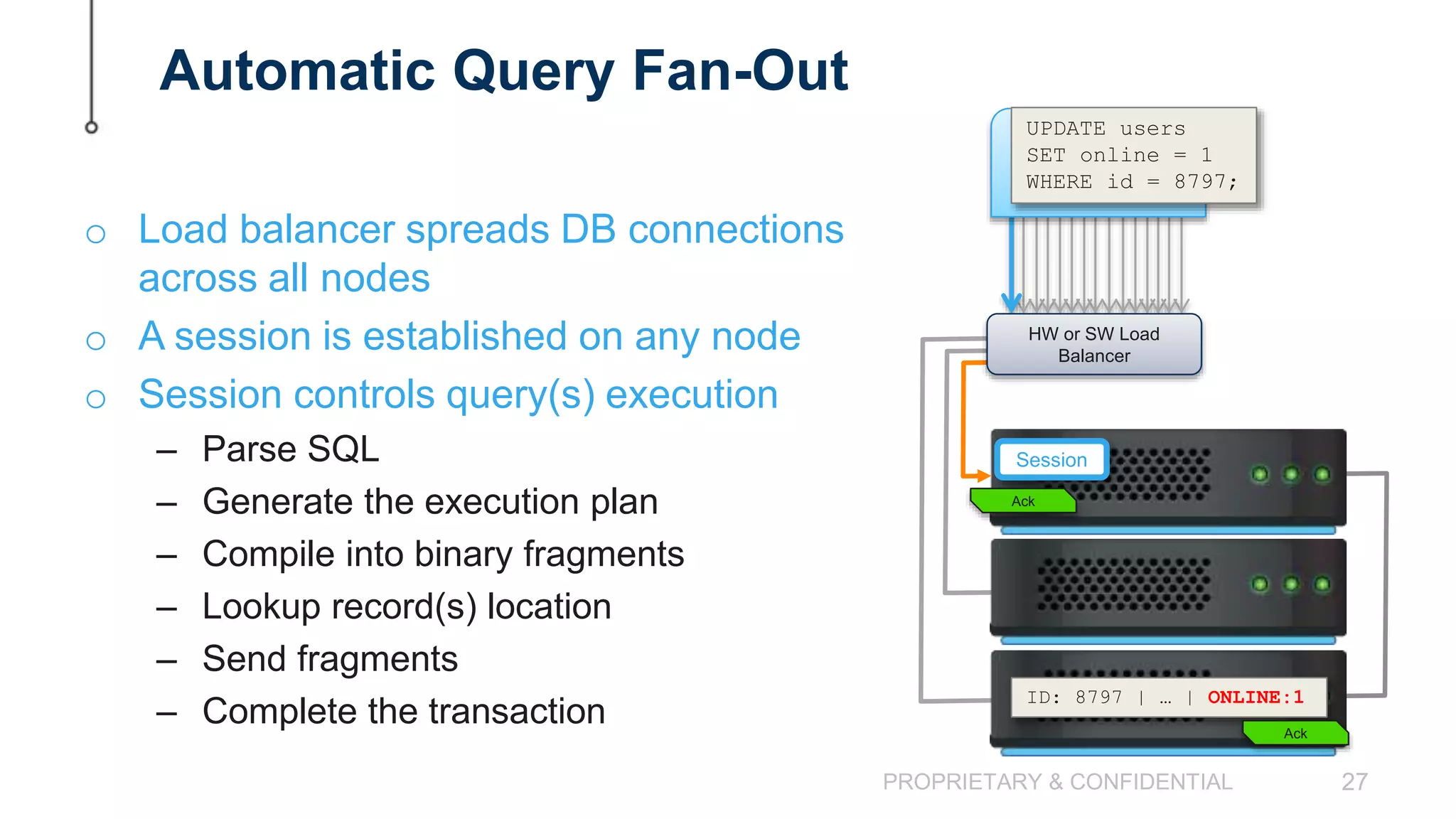




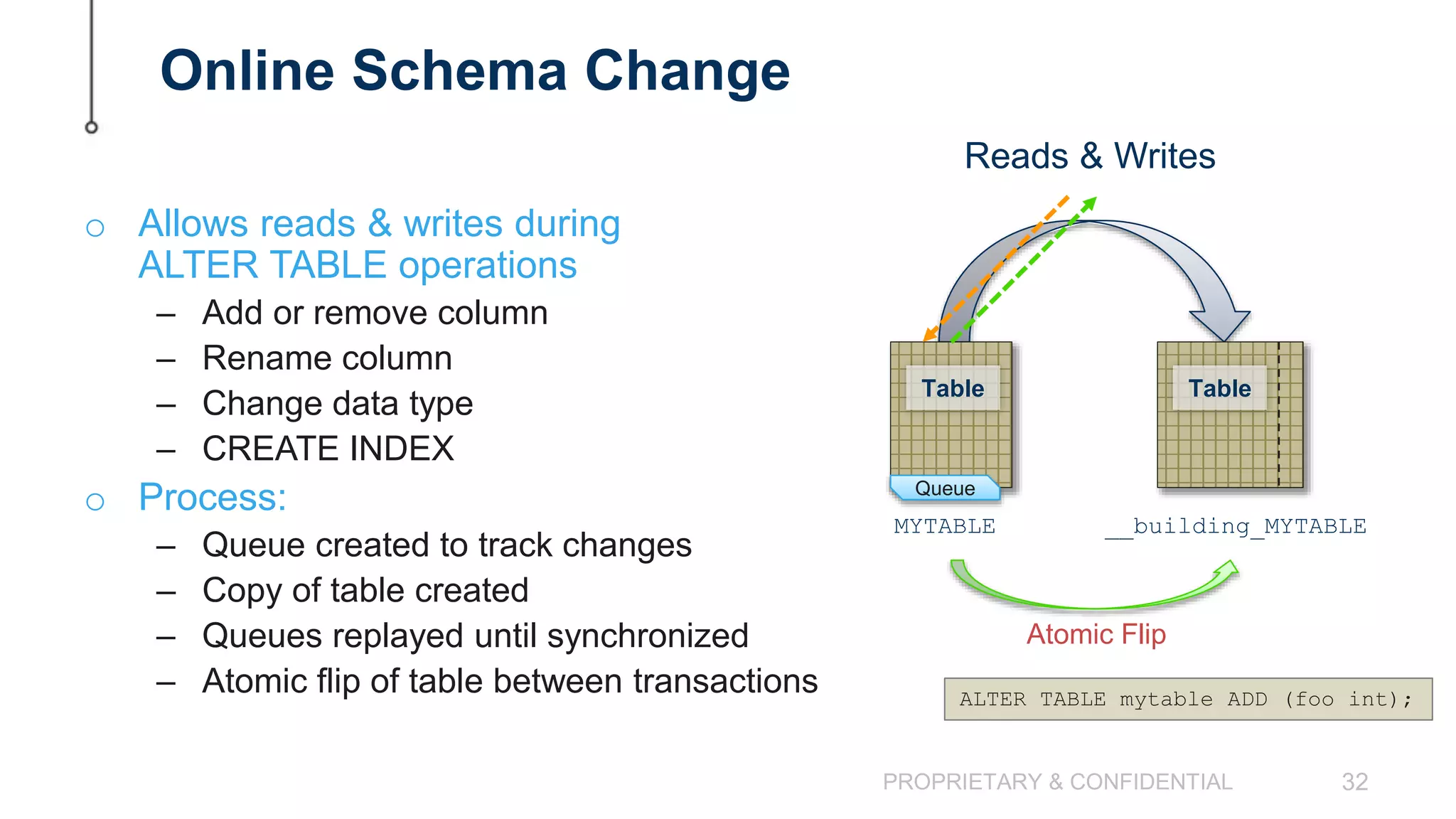
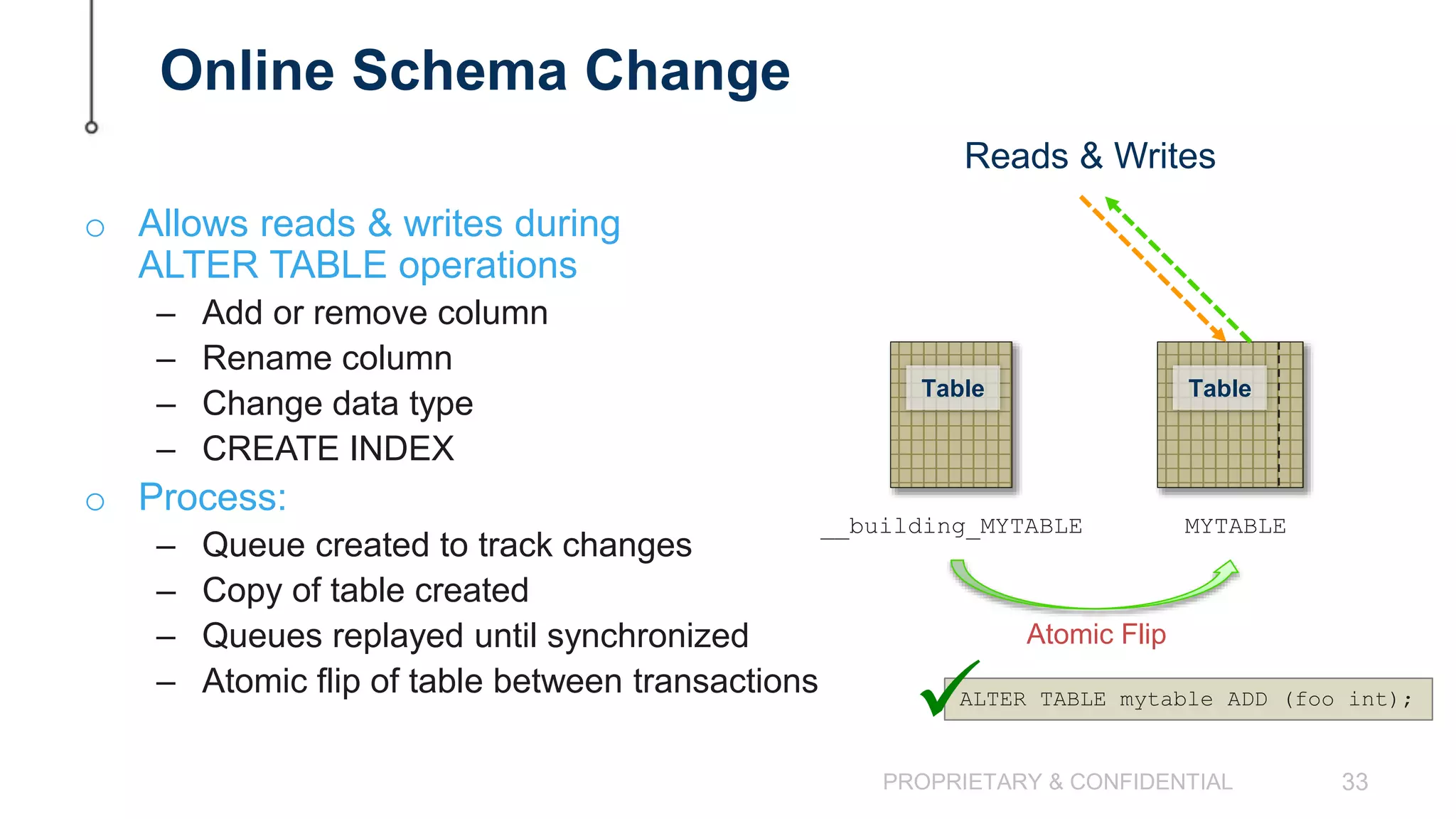

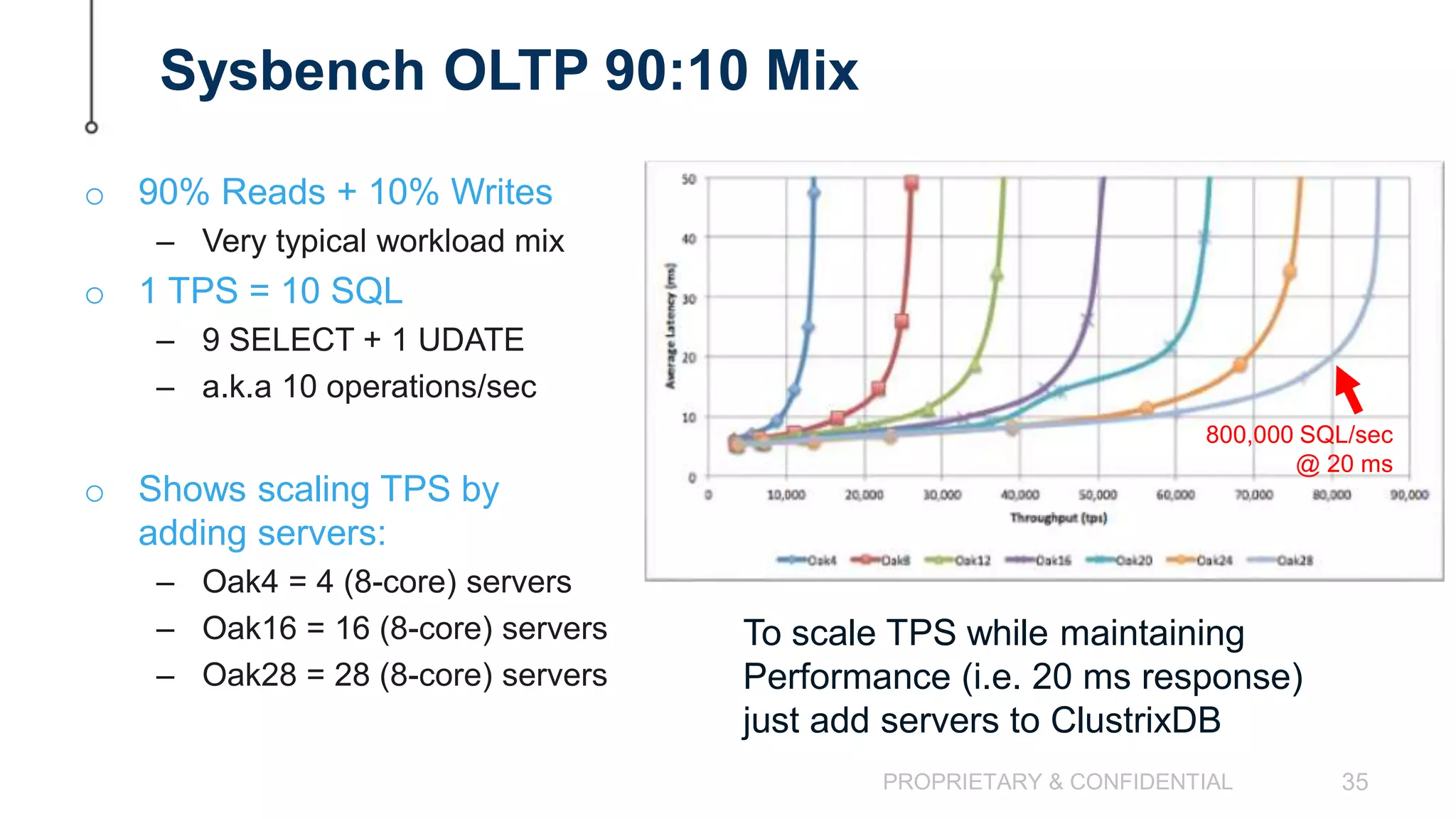
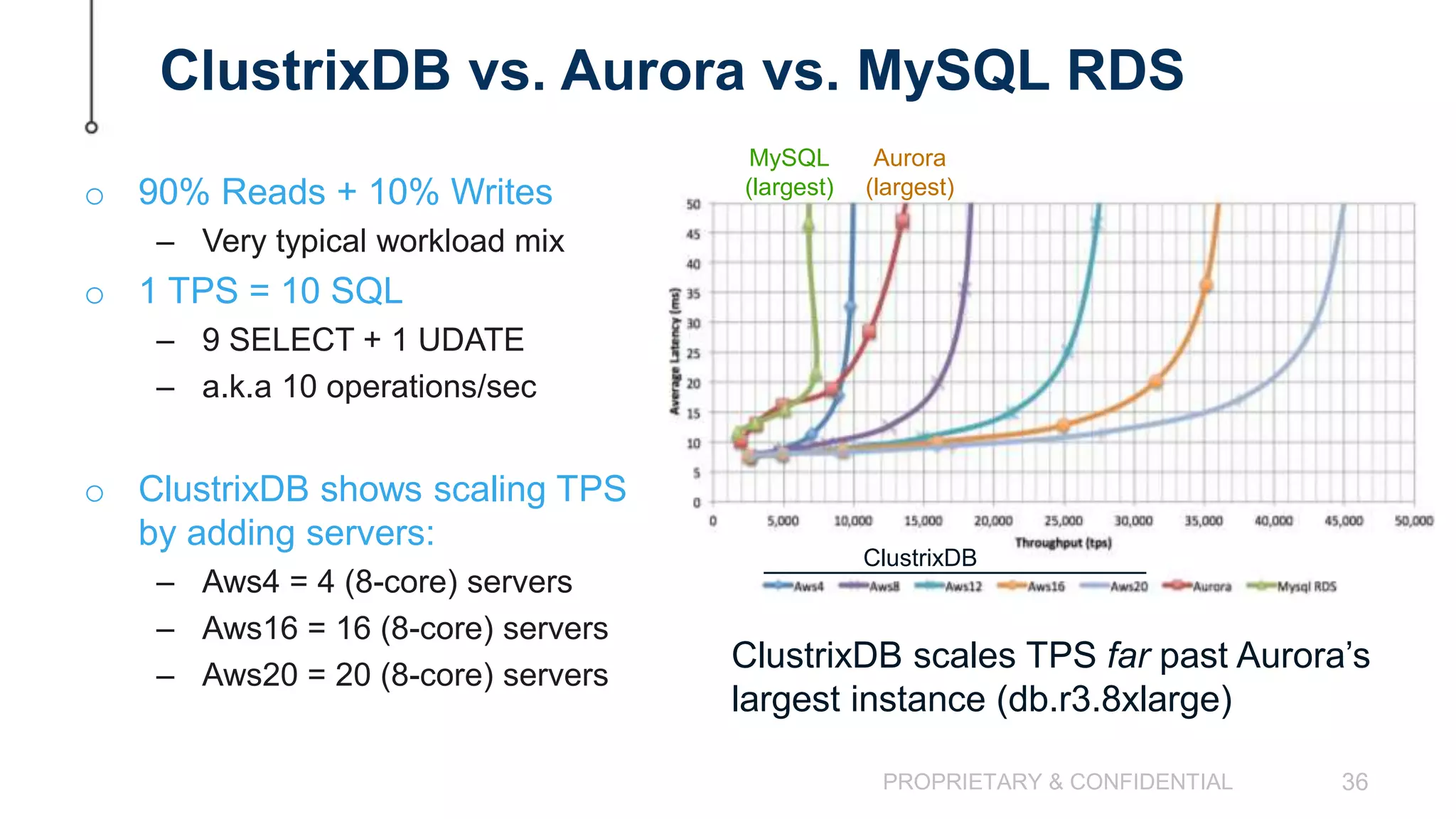
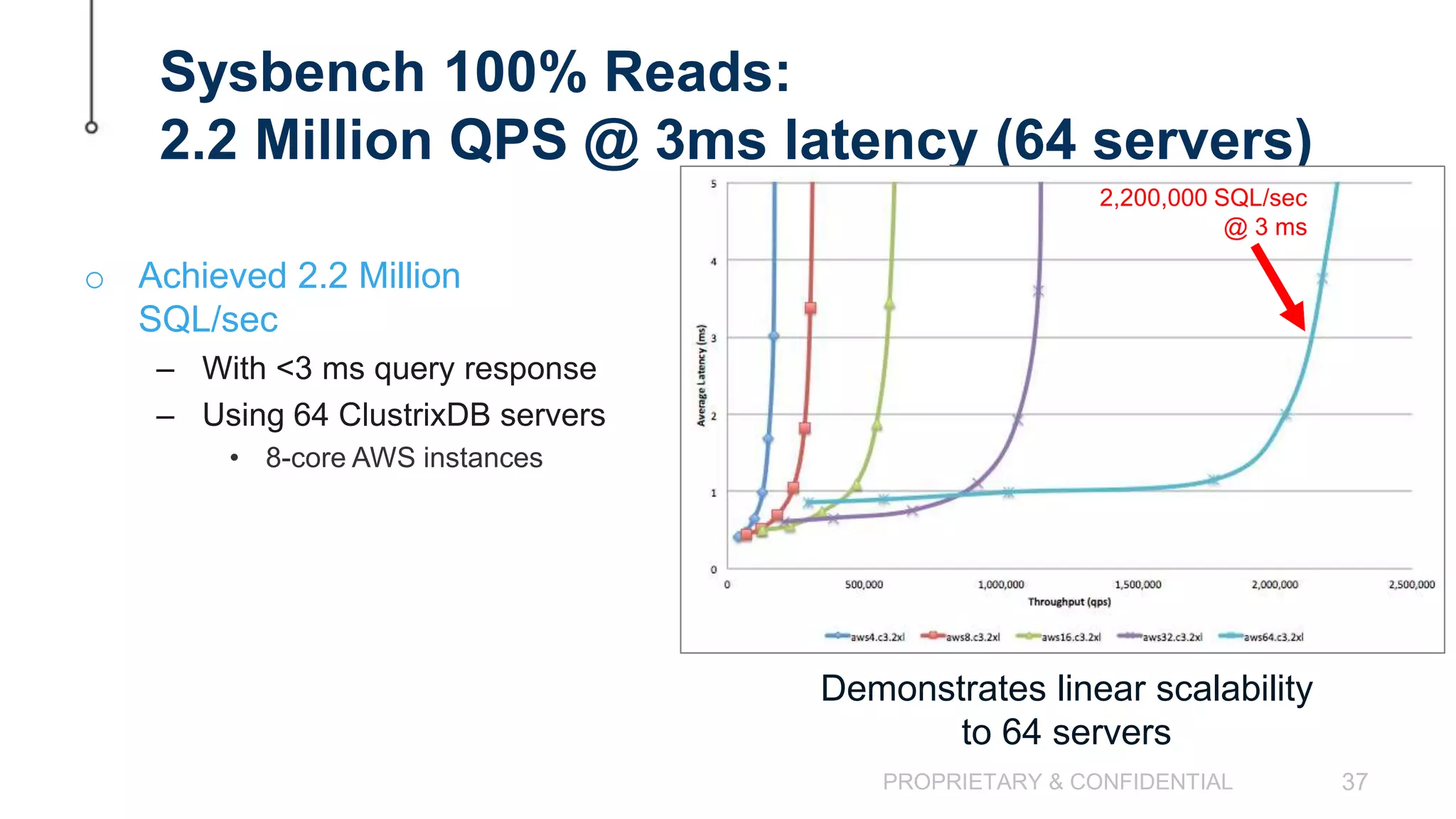
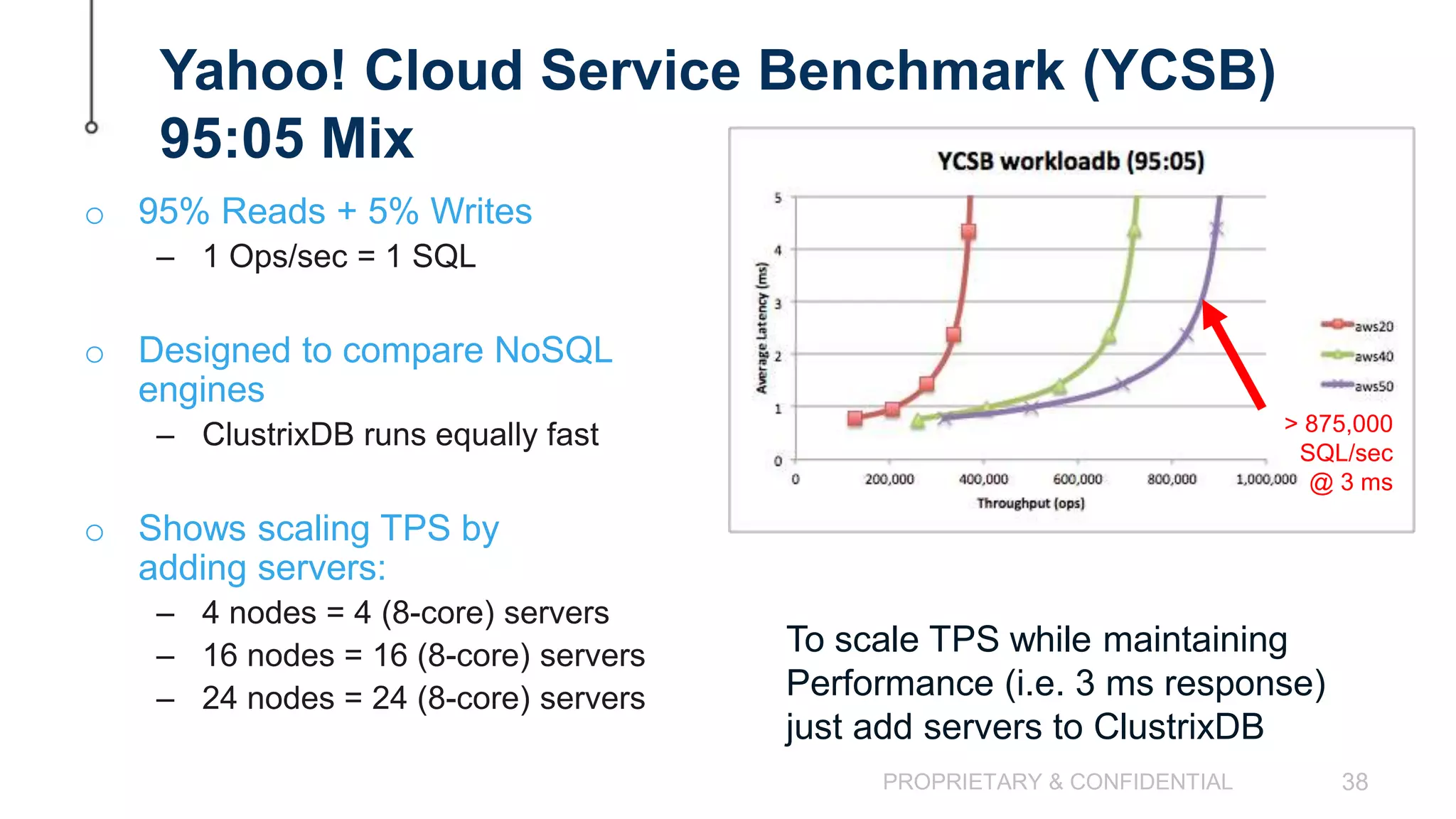

The document discusses scaling MySQL databases and alternatives to sharding. It begins by outlining the typical path organizations take to sharding MySQL as their data and usage grows over time. This involves continually upgrading hardware, adding read replicas, and eventually implementing sharding. The document then covers the challenges of sharding, such as data skew across shards, lack of ACID transactions, application changes required, and complex infrastructure needs. As an alternative, the document introduces ClustrixDB, a database that can scale write and read performance linearly just by adding more servers without sharding. It achieves this through automatic data distribution, query fan-out, and data rebalancing. Performance benchmarks show ClustrixDB vastly outscaling alternatives on Amazon