Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Takeshi Yamamuro
1,461 views
Taming Distributed/Parallel Query Execution Engine of Apache Spark
Repro Tech#9: 実践・並列分散処理基盤
Technology
◦
Read more
0
Save
Share
Embed
Download
Download to read offline
1
/ 43
2
/ 43
3
/ 43
4
/ 43
5
/ 43
6
/ 43
7
/ 43
8
/ 43
9
/ 43
10
/ 43
11
/ 43
12
/ 43
13
/ 43
14
/ 43
15
/ 43
16
/ 43
17
/ 43
18
/ 43
19
/ 43
20
/ 43
21
/ 43
22
/ 43
23
/ 43
24
/ 43
25
/ 43
26
/ 43
27
/ 43
28
/ 43
29
/ 43
30
/ 43
31
/ 43
32
/ 43
33
/ 43
34
/ 43
35
/ 43
36
/ 43
37
/ 43
38
/ 43
39
/ 43
40
/ 43
41
/ 43
42
/ 43
43
/ 43
More Related Content
PDF
perfを使ったPostgreSQLの解析(後編)
by
NTT DATA OSS Professional Services
PDF
勉強会force#4 Chatter Integration
by
Kazuki Nakajima
PDF
第16回Lucene/Solr勉強会 – ランキングチューニングと定量評価 #SolrJP
by
Yahoo!デベロッパーネットワーク
PPTX
Python for Data Analysis: Chapter 2
by
智哉 今西
PDF
pg_trgmと全文検索
by
NTT DATA OSS Professional Services
PDF
Pgunconf 20121212-postgeres fdw
by
Toshi Harada
PPTX
PostgreSQL 12は ここがスゴイ! ~性能改善やpluggable storage engineなどの新機能を徹底解説~ (NTTデータ テクノ...
by
NTT DATA Technology & Innovation
PDF
20191211_Apache_Arrow_Meetup_Tokyo
by
Kohei KaiGai
perfを使ったPostgreSQLの解析(後編)
by
NTT DATA OSS Professional Services
勉強会force#4 Chatter Integration
by
Kazuki Nakajima
第16回Lucene/Solr勉強会 – ランキングチューニングと定量評価 #SolrJP
by
Yahoo!デベロッパーネットワーク
Python for Data Analysis: Chapter 2
by
智哉 今西
pg_trgmと全文検索
by
NTT DATA OSS Professional Services
Pgunconf 20121212-postgeres fdw
by
Toshi Harada
PostgreSQL 12は ここがスゴイ! ~性能改善やpluggable storage engineなどの新機能を徹底解説~ (NTTデータ テクノ...
by
NTT DATA Technology & Innovation
20191211_Apache_Arrow_Meetup_Tokyo
by
Kohei KaiGai
What's hot
PDF
GMO プライベート DMP で ビッグデータ解析をするために アプリクラウドで Apache Spark の検証をしてみた
by
Tetsuo Yamabe
PDF
pg_bigm(ピージーバイグラム)を用いた全文検索のしくみ
by
Masahiko Sawada
PPTX
pg_bigmで全文検索するときに気を付けたい5つのポイント(第23回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
PPTX
Parquetはカラムナなのか?
by
Yohei Azekatsu
PPTX
Apache Spark 3.0新機能紹介 - 拡張機能やWebUI関連のアップデート(Spark Meetup Tokyo #3 Online)
by
NTT DATA Technology & Innovation
PDF
広告配信現場で使うSpark機械学習
by
x1 ichi
PDF
Lt ingaoho-jsonb+postgeres fdw
by
Toshi Harada
PDF
使ってみませんか?pg hint_plan
by
Masao Fujii
PDF
20171212 titech lecture_ishizaki_public
by
Kazuaki Ishizaki
PDF
2kaime
by
ymk0424
PDF
2015-11-17 きちんと知りたいApache Spark ~機械学習とさまざまな機能群
by
Yu Ishikawa
PDF
20211112_jpugcon_gpu_and_arrow
by
Kohei KaiGai
PDF
20200424_Writable_Arrow_Fdw
by
Kohei KaiGai
PPTX
Apache Hadoopに見るJavaミドルウェアのcompatibility(Open Developers Conference 2020 Onli...
by
NTT DATA Technology & Innovation
PDF
pg_bigm(ピージー・バイグラム)を用いた全文検索のしくみ(後編)
by
Masahiko Sawada
PPTX
Apache Bigtopによるオープンなビッグデータ処理基盤の構築(オープンデベロッパーズカンファレンス 2021 Online 発表資料)
by
NTT DATA Technology & Innovation
PPTX
押さえておきたい、PostgreSQL 13 の新機能!! (PostgreSQL Conference Japan 2020講演資料)
by
NTT DATA Technology & Innovation
PPTX
2014 11-20 Machine Learning with Apache Spark 勉強会資料
by
Recruit Technologies
PPTX
Hadoop Compatible File Systems (Azure編) (セミナー「Big Data Developerに贈る第二弾 ‐ Azur...
by
NTT DATA Technology & Innovation
GMO プライベート DMP で ビッグデータ解析をするために アプリクラウドで Apache Spark の検証をしてみた
by
Tetsuo Yamabe
pg_bigm(ピージーバイグラム)を用いた全文検索のしくみ
by
Masahiko Sawada
pg_bigmで全文検索するときに気を付けたい5つのポイント(第23回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
Parquetはカラムナなのか?
by
Yohei Azekatsu
Apache Spark 3.0新機能紹介 - 拡張機能やWebUI関連のアップデート(Spark Meetup Tokyo #3 Online)
by
NTT DATA Technology & Innovation
広告配信現場で使うSpark機械学習
by
x1 ichi
Lt ingaoho-jsonb+postgeres fdw
by
Toshi Harada
使ってみませんか?pg hint_plan
by
Masao Fujii
20171212 titech lecture_ishizaki_public
by
Kazuaki Ishizaki
2kaime
by
ymk0424
2015-11-17 きちんと知りたいApache Spark ~機械学習とさまざまな機能群
by
Yu Ishikawa
20211112_jpugcon_gpu_and_arrow
by
Kohei KaiGai
20200424_Writable_Arrow_Fdw
by
Kohei KaiGai
Apache Hadoopに見るJavaミドルウェアのcompatibility(Open Developers Conference 2020 Onli...
by
NTT DATA Technology & Innovation
pg_bigm(ピージー・バイグラム)を用いた全文検索のしくみ(後編)
by
Masahiko Sawada
Apache Bigtopによるオープンなビッグデータ処理基盤の構築(オープンデベロッパーズカンファレンス 2021 Online 発表資料)
by
NTT DATA Technology & Innovation
押さえておきたい、PostgreSQL 13 の新機能!! (PostgreSQL Conference Japan 2020講演資料)
by
NTT DATA Technology & Innovation
2014 11-20 Machine Learning with Apache Spark 勉強会資料
by
Recruit Technologies
Hadoop Compatible File Systems (Azure編) (セミナー「Big Data Developerに贈る第二弾 ‐ Azur...
by
NTT DATA Technology & Innovation
Similar to Taming Distributed/Parallel Query Execution Engine of Apache Spark
PPTX
PySparkによるジョブを、より速く、よりスケーラブルに実行するための最善の方法 ※講演は翻訳資料にて行います。 - Getting the Best...
by
Holden Karau
PDF
Apache spark 2.3 and beyond
by
NTT DATA Technology & Innovation
PPTX
2015 03-12 道玄坂LT祭り第2回 Spark DataFrame Introduction
by
Yu Ishikawa
PDF
Apache Spark + Arrow
by
Takeshi Yamamuro
PPTX
Apache Sparkの基本と最新バージョン3.2のアップデート(Open Source Conference 2021 Online/Fukuoka ...
by
NTT DATA Technology & Innovation
PPTX
JP version - Beyond Shuffling - Apache Spark のスケールアップのためのヒントとコツ
by
Holden Karau
PPTX
SQL Server 使いのための Azure Synapse Analytics - Spark 入門
by
Daiyu Hatakeyama
PDF
Deep Dive into Spark SQL with Advanced Performance Tuning
by
Takuya UESHIN
PDF
Spark Analytics - スケーラブルな分散処理
by
Tusyoshi Matsuzaki
PDF
hscj2019_ishizaki_public
by
Kazuaki Ishizaki
PDF
Apache Spark超入門 (Hadoop / Spark Conference Japan 2016 講演資料)
by
NTT DATA OSS Professional Services
PPT
Quick Overview of Upcoming Spark 3.0 + α
by
Takeshi Yamamuro
PDF
Big Data University Tokyo Meetup #6 (mlwith_spark) 配布資料
by
Atsushi Tsuchiya
PDF
2019.03.19 Deep Dive into Spark SQL with Advanced Performance Tuning
by
Takuya UESHIN
PPTX
大量のデータ処理や分析に使えるOSS Apache Sparkのご紹介(Open Source Conference 2020 Online/Kyoto ...
by
NTT DATA Technology & Innovation
PDF
開発中の新機能 Spark Declarative Pipeline に飛びついてみたが難しかった(JEDAI DAIS Recap#2 講演資料)
by
NTT DATA Technology & Innovation
PPTX
大量のデータ処理や分析に使えるOSS Apache Spark入門 - Open Source Conference2020 Online/Fukuoka...
by
NTT DATA Technology & Innovation
PDF
Yifeng spark-final-public
by
Yifeng Jiang
PDF
[db tech showcase Tokyo 2016] B31: Spark Summit 2016@SFに参加してきたので最新事例などを紹介しつつデ...
by
Insight Technology, Inc.
PDF
Sparkのクエリ処理系と周辺の話題
by
Takeshi Yamamuro
PySparkによるジョブを、より速く、よりスケーラブルに実行するための最善の方法 ※講演は翻訳資料にて行います。 - Getting the Best...
by
Holden Karau
Apache spark 2.3 and beyond
by
NTT DATA Technology & Innovation
2015 03-12 道玄坂LT祭り第2回 Spark DataFrame Introduction
by
Yu Ishikawa
Apache Spark + Arrow
by
Takeshi Yamamuro
Apache Sparkの基本と最新バージョン3.2のアップデート(Open Source Conference 2021 Online/Fukuoka ...
by
NTT DATA Technology & Innovation
JP version - Beyond Shuffling - Apache Spark のスケールアップのためのヒントとコツ
by
Holden Karau
SQL Server 使いのための Azure Synapse Analytics - Spark 入門
by
Daiyu Hatakeyama
Deep Dive into Spark SQL with Advanced Performance Tuning
by
Takuya UESHIN
Spark Analytics - スケーラブルな分散処理
by
Tusyoshi Matsuzaki
hscj2019_ishizaki_public
by
Kazuaki Ishizaki
Apache Spark超入門 (Hadoop / Spark Conference Japan 2016 講演資料)
by
NTT DATA OSS Professional Services
Quick Overview of Upcoming Spark 3.0 + α
by
Takeshi Yamamuro
Big Data University Tokyo Meetup #6 (mlwith_spark) 配布資料
by
Atsushi Tsuchiya
2019.03.19 Deep Dive into Spark SQL with Advanced Performance Tuning
by
Takuya UESHIN
大量のデータ処理や分析に使えるOSS Apache Sparkのご紹介(Open Source Conference 2020 Online/Kyoto ...
by
NTT DATA Technology & Innovation
開発中の新機能 Spark Declarative Pipeline に飛びついてみたが難しかった(JEDAI DAIS Recap#2 講演資料)
by
NTT DATA Technology & Innovation
大量のデータ処理や分析に使えるOSS Apache Spark入門 - Open Source Conference2020 Online/Fukuoka...
by
NTT DATA Technology & Innovation
Yifeng spark-final-public
by
Yifeng Jiang
[db tech showcase Tokyo 2016] B31: Spark Summit 2016@SFに参加してきたので最新事例などを紹介しつつデ...
by
Insight Technology, Inc.
Sparkのクエリ処理系と周辺の話題
by
Takeshi Yamamuro
More from Takeshi Yamamuro
PDF
LT: Spark 3.1 Feature Expectation
by
Takeshi Yamamuro
PDF
MLflowによる機械学習モデルのライフサイクルの管理
by
Takeshi Yamamuro
PPTX
LLJVM: LLVM bitcode to JVM bytecode
by
Takeshi Yamamuro
PDF
20180417 hivemall meetup#4
by
Takeshi Yamamuro
PDF
An Experimental Study of Bitmap Compression vs. Inverted List Compression
by
Takeshi Yamamuro
PDF
20160908 hivemall meetup
by
Takeshi Yamamuro
PDF
20150513 legobease
by
Takeshi Yamamuro
PDF
20150516 icde2015 r19-4
by
Takeshi Yamamuro
PDF
VLDB2013 R1 Emerging Hardware
by
Takeshi Yamamuro
PDF
浮動小数点(IEEE754)を圧縮したい@dsirnlp#4
by
Takeshi Yamamuro
PDF
LLVMで遊ぶ(整数圧縮とか、x86向けの自動ベクトル化とか)
by
Takeshi Yamamuro
PDF
Introduction to Modern Analytical DB
by
Takeshi Yamamuro
PDF
SIGMOD’12勉強会 -Session 7-
by
Takeshi Yamamuro
PDF
A x86-optimized rank&select dictionary for bit sequences
by
Takeshi Yamamuro
PDF
VAST-Tree, EDBT'12
by
Takeshi Yamamuro
PDF
VLDB’11勉強会 -Session 9-
by
Takeshi Yamamuro
PDF
研究動向から考えるx86/x64最適化手法
by
Takeshi Yamamuro
PDF
VLDB'10勉強会 -Session 20-
by
Takeshi Yamamuro
PDF
VLDB'10勉強会 -Session 2-
by
Takeshi Yamamuro
PDF
SIGMOD'10勉強会 -Session 8-
by
Takeshi Yamamuro
LT: Spark 3.1 Feature Expectation
by
Takeshi Yamamuro
MLflowによる機械学習モデルのライフサイクルの管理
by
Takeshi Yamamuro
LLJVM: LLVM bitcode to JVM bytecode
by
Takeshi Yamamuro
20180417 hivemall meetup#4
by
Takeshi Yamamuro
An Experimental Study of Bitmap Compression vs. Inverted List Compression
by
Takeshi Yamamuro
20160908 hivemall meetup
by
Takeshi Yamamuro
20150513 legobease
by
Takeshi Yamamuro
20150516 icde2015 r19-4
by
Takeshi Yamamuro
VLDB2013 R1 Emerging Hardware
by
Takeshi Yamamuro
浮動小数点(IEEE754)を圧縮したい@dsirnlp#4
by
Takeshi Yamamuro
LLVMで遊ぶ(整数圧縮とか、x86向けの自動ベクトル化とか)
by
Takeshi Yamamuro
Introduction to Modern Analytical DB
by
Takeshi Yamamuro
SIGMOD’12勉強会 -Session 7-
by
Takeshi Yamamuro
A x86-optimized rank&select dictionary for bit sequences
by
Takeshi Yamamuro
VAST-Tree, EDBT'12
by
Takeshi Yamamuro
VLDB’11勉強会 -Session 9-
by
Takeshi Yamamuro
研究動向から考えるx86/x64最適化手法
by
Takeshi Yamamuro
VLDB'10勉強会 -Session 20-
by
Takeshi Yamamuro
VLDB'10勉強会 -Session 2-
by
Takeshi Yamamuro
SIGMOD'10勉強会 -Session 8-
by
Takeshi Yamamuro
Recently uploaded
PDF
FOSS4G Japan 2024 ハザードマップゲームの作り方 Hazard Map Game QGIS Plugin
by
Raymond Lay
PPTX
Implementing an IoT System on a Smartphone
by
Atomu Hidaka
PDF
DX人材育成 サービスデザインで実現する「巻き込み力」の育て方 by Graat
by
Graat(グラーツ)
PPTX
FOSS4G Japan 2025 - QGISでスムーズに地図を比較 - QMapCompareプラグインの紹介
by
Raymond Lay
PPTX
「Drupal SDCについて紹介」2025/10/17の勉強会で発表されたものです。
by
iPride Co., Ltd.
PPTX
How to buy a used computer and use it with Windows 11
by
Atomu Hidaka
PDF
技育祭2025秋 サボろうとする生成AIの傾向と対策 登壇資料(フューチャー渋川)
by
Yoshiki Shibukawa
PDF
FOSS4G Hokkaido - QFieldをランナーのために活用した - QField for runners
by
Raymond Lay
PDF
「似ているようで微妙に違う言葉」2025/10/17の勉強会で発表されたものです。
by
iPride Co., Ltd.
FOSS4G Japan 2024 ハザードマップゲームの作り方 Hazard Map Game QGIS Plugin
by
Raymond Lay
Implementing an IoT System on a Smartphone
by
Atomu Hidaka
DX人材育成 サービスデザインで実現する「巻き込み力」の育て方 by Graat
by
Graat(グラーツ)
FOSS4G Japan 2025 - QGISでスムーズに地図を比較 - QMapCompareプラグインの紹介
by
Raymond Lay
「Drupal SDCについて紹介」2025/10/17の勉強会で発表されたものです。
by
iPride Co., Ltd.
How to buy a used computer and use it with Windows 11
by
Atomu Hidaka
技育祭2025秋 サボろうとする生成AIの傾向と対策 登壇資料(フューチャー渋川)
by
Yoshiki Shibukawa
FOSS4G Hokkaido - QFieldをランナーのために活用した - QField for runners
by
Raymond Lay
「似ているようで微妙に違う言葉」2025/10/17の勉強会で発表されたものです。
by
iPride Co., Ltd.
Taming Distributed/Parallel Query Execution Engine of Apache Spark
1.
Copyright©2019 NTT corp.
All Rights Reserved. Taming Distributed/Parallel Query Execution Engine of Apache Spark Takeshi Yamamuro, NTT
2.
2Copyright©2019 NTT corp.
All Rights Reserved. Who am I?
3.
3Copyright©2019 NTT corp.
All Rights Reserved. Notice - https://bit.ly/30Sh4MU
4.
4Copyright©2019 NTT corp.
All Rights Reserved. Notice - https://bit.ly/2I7Ymsj
5.
5Copyright©2019 NTT corp.
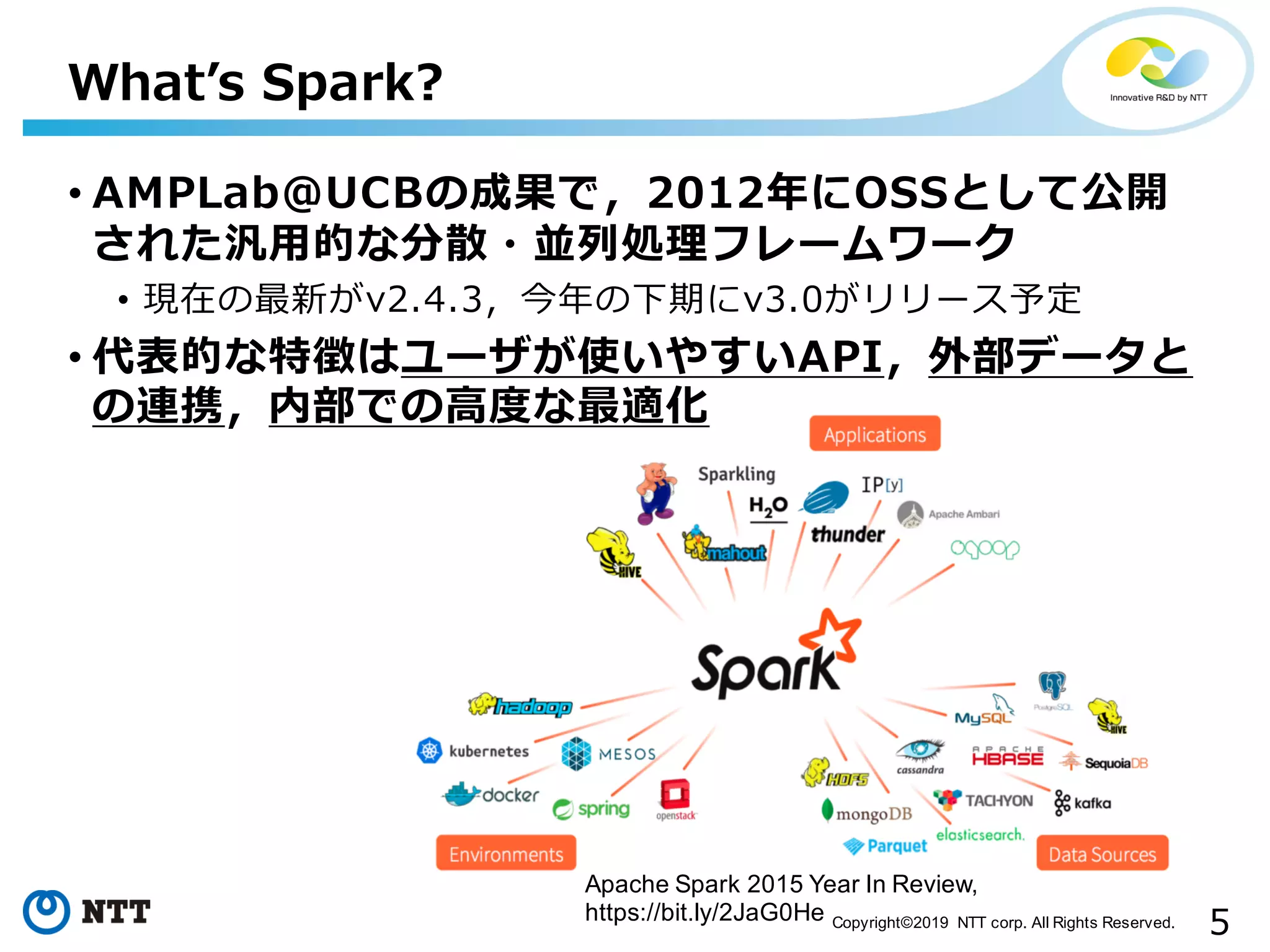
All Rights Reserved. Apache Spark 2015 Year In Review, https://bit.ly/2JaG0He • AMPLab@UCBの成果で,2012年にOSSとして公開 された汎⽤的な分散・並列処理フレームワーク • 現在の最新がv2.4.3,今年の下期にv3.0がリリース予定 • 代表的な特徴はユーザが使いやすいAPI,外部データと の連携,内部での⾼度な最適化 Whatʼs Spark?
6.
6Copyright©2019 NTT corp.
All Rights Reserved. • conda経由でSpark v2.4.3のインストール • テスト実⾏ Quick Start Guide of Spark aa$ conda install –c conda-forge pyspark aa $ cat test.csv 1,a,0.3 2,b,1.7 $ pyspark >>> df = spark.read.csv(‘test.csv’) >>> df.show()
7.
7Copyright©2019 NTT corp.
All Rights Reserved. • 本⽇はSparkにおいて主要な以下の3つの要素に関する 概要と個⼈的に興味のある性能の話をします • 1. 遅延評価と関係代数ベースのクエリ最適化 • 2. コード⽣成による実⾏時のための最適化 • 3. RDDベースの分散・並列処理 Todayʼs Talk
8.
8Copyright©2019 NTT corp.
All Rights Reserved. • Sparkの実⾏処理系の最新概要に関する発表 • Maryann Xue, Kris Mok, and Xingbo Jiang, A Deep Dive into Query Execution Engine of Spark SQL, https://bit.ly/2HLIbRk • Sparkの性能チューニングに関する発表 • Xiao Li, Understanding Query Plans and Spark UIs, https://bit.ly/2WiOm8x The Other Valuable References
9.
9Copyright©2019 NTT corp.
All Rights Reserved. • 個⼈的によく聞くSparkの使⽤⽤途は・・・ • ⾃社のデータがHDFS/S3などの分散ストレージやRDBMSなど のリモート環境に蓄積されており,それらを集約して分析をす る必要がある場合 • ローカル環境にデータはあるがサイズが搭載メモリのものに近 いか,もしくは超えている場合 • 例えばpandasの処理可能なデータサイズは搭載メモリの1/5〜 1/10程度*と⾔われ,⽐較的⼩さい When You Use Spark? * Apache Arrow and the "10 Things I Hate About pandas”, https://bit.ly/2WaSLX8
10.
10Copyright©2019 NTT corp.
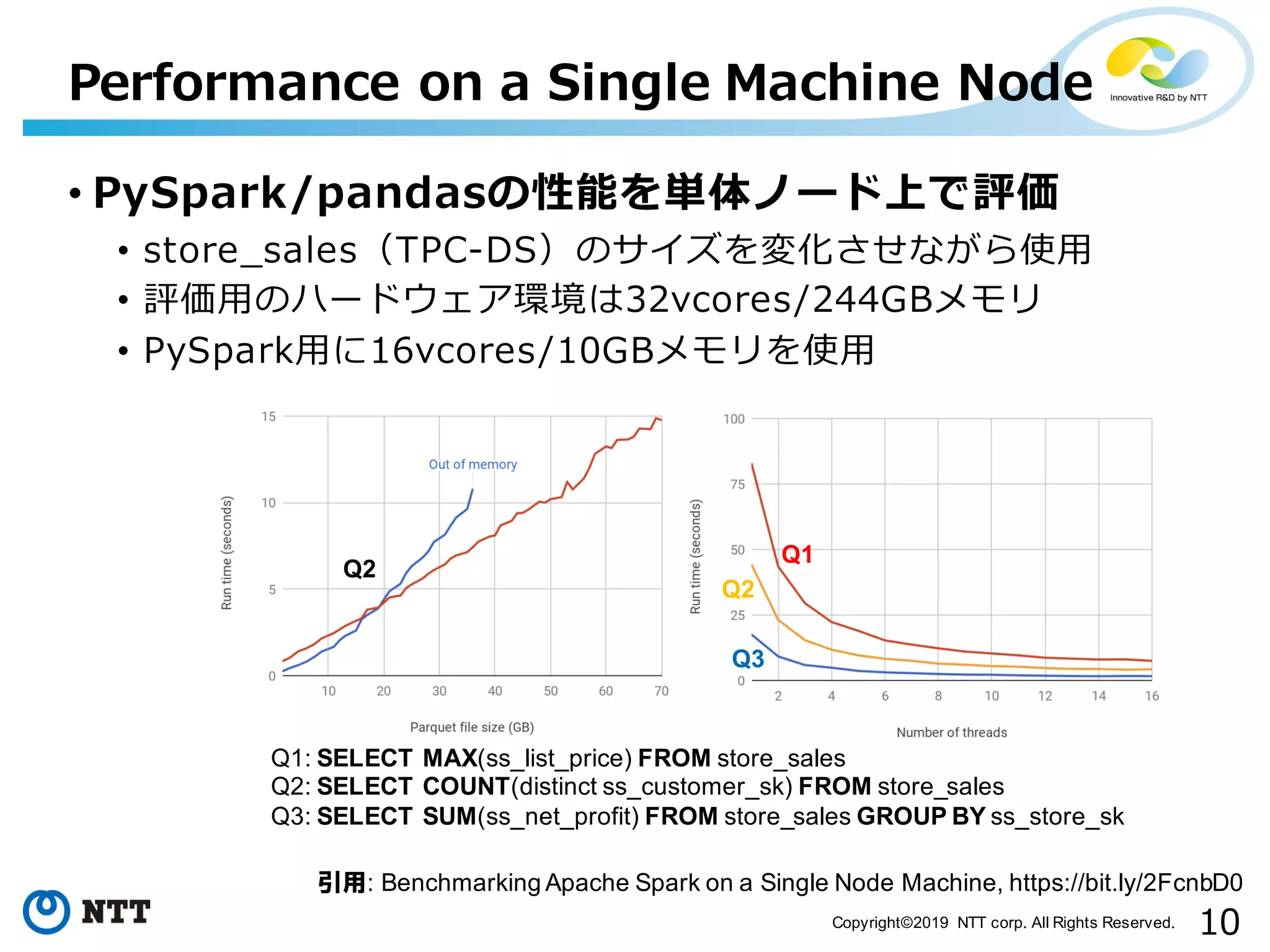
All Rights Reserved. • PySpark/pandasの性能を単体ノード上で評価 • store_sales(TPC-DS)のサイズを変化させながら使⽤ • 評価⽤のハードウェア環境は32vcores/244GBメモリ • PySpark⽤に16vcores/10GBメモリを使⽤ Performance on a Single Machine Node 引用: Benchmarking Apache Spark on a Single Node Machine, https://bit.ly/2FcnbD0 Q1: SELECT MAX(ss_list_price) FROM store_sales Q2: SELECT COUNT(distinct ss_customer_sk) FROM store_sales Q3: SELECT SUM(ss_net_profit) FROM store_sales GROUP BY ss_store_sk Q1 Q2 Q3 Q2
11.
11Copyright©2019 NTT corp.
All Rights Reserved. Spark Internal
12.
12Copyright©2019 NTT corp.
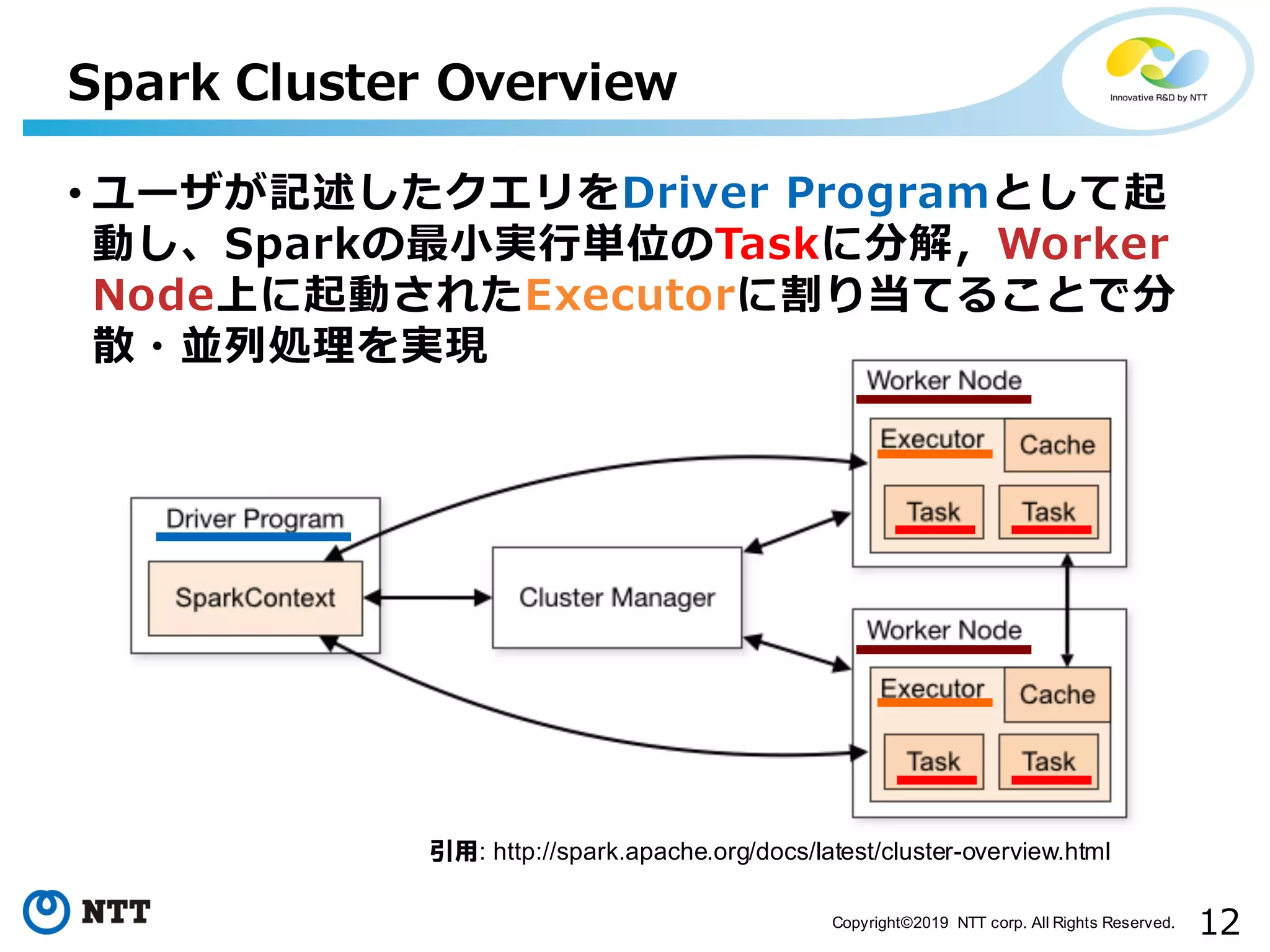
All Rights Reserved. Spark Cluster Overview • ユーザが記述したクエリをDriver Programとして起 動し、Sparkの最⼩実⾏単位のTaskに分解,Worker Node上に起動されたExecutorに割り当てることで分 散・並列処理を実現 引用: http://spark.apache.org/docs/latest/cluster-overview.html
13.
13Copyright©2019 NTT corp.
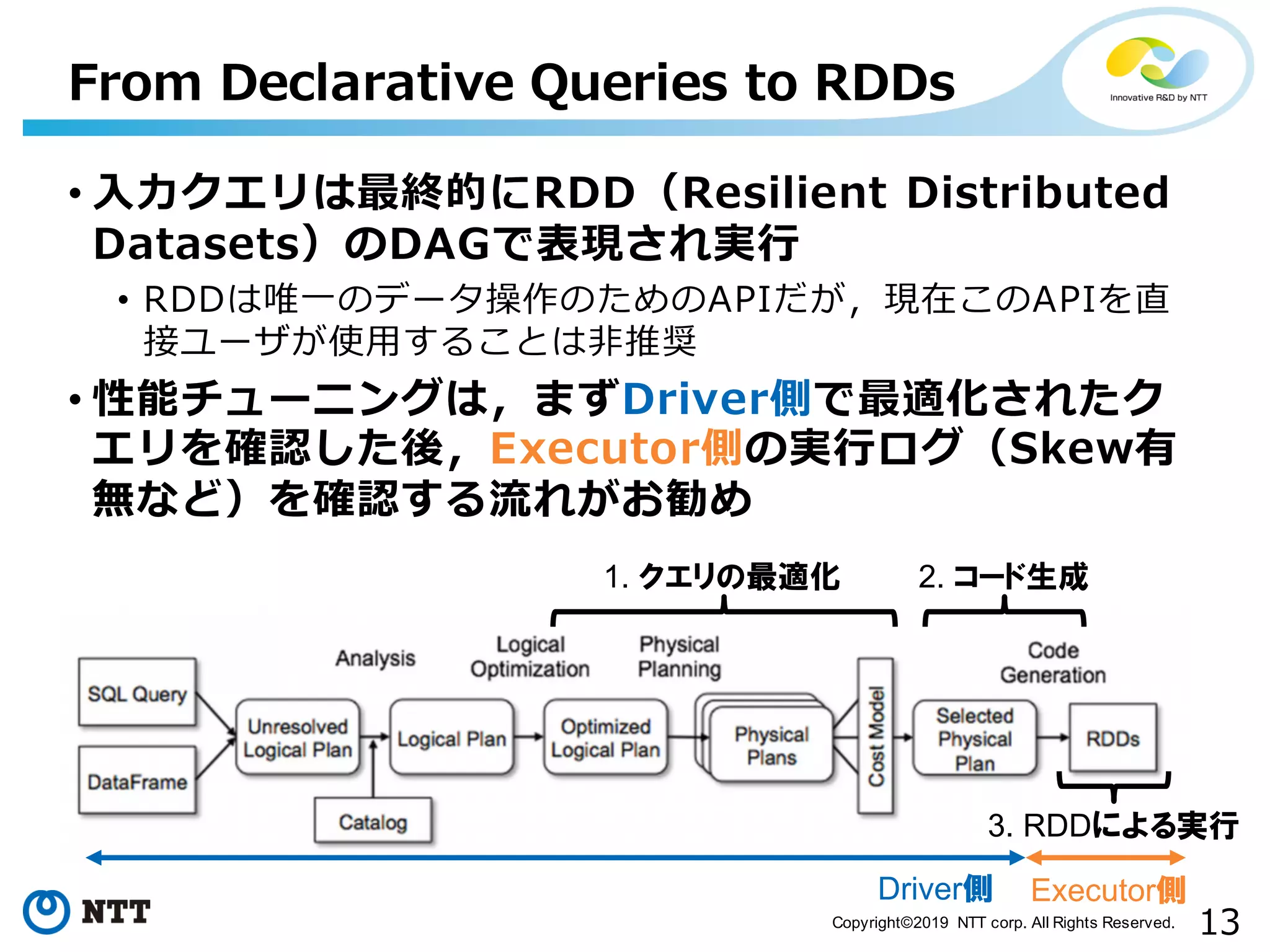
All Rights Reserved. • ⼊⼒クエリは最終的にRDD(Resilient Distributed Datasets)のDAGで表現され実⾏ • RDDは唯⼀のデータ操作のためのAPIだが,現在このAPIを直 接ユーザが使⽤することは⾮推奨 • 性能チューニングは,まずDriver側で最適化されたク エリを確認した後,Executor側の実⾏ログ(Skew有 無など)を確認する流れがお勧め From Declarative Queries to RDDs 1. クエリの最適化 2. コード生成 3. RDDによる実行 Driver側 Executor側
14.
14Copyright©2019 NTT corp.
All Rights Reserved. 1. QUERY OPTIMIZATION
15.
15Copyright©2019 NTT corp.
All Rights Reserved. • 定義したクエリはすぐに実⾏されず,結果が参照された 時にクエリを最適化して実⾏ • クエリが定義された段階で実施されるのは,論理プランの構築 とプランの正しさの検証のみ Lazy Evaluation and Query Planning aa >>> df = spark.read.load('/tmp/t') DataFrame[a: int, b: double, c: string] >>> df1 = df.groupBy(‘a’).avg(‘b’) >>> df2 = df1.where(‘a > 1’) >>> df2.count() 1 結果が参照されたため最適化され,Executor側で実行 Driver側での処理のみ
16.
16Copyright©2019 NTT corp.
All Rights Reserved. • 定義したクエリはすぐに実⾏されず,結果が参照された 時にクエリを最適化して実⾏ • クエリが定義された段階で実施されるのは,論理プランの構築 とプランの正しさの検証のみ Lazy Evaluation and Query Planning aa >>> df = spark.read.load('/tmp/t') DataFrame[a: int, b: double, c: string] >>> df1 = df.groupBy(‘a’).avg(‘b’) >>> df2 = df1.where(‘a > 1’) >>> df2.count() 1 >>> df2.explain() == Physical Plan == *(2) HashAggregate(keys=[a#0], functions=[sum(b#1)]) +- Exchange hashpartitioning(a#0, 200) +- *(1) HashAggregate(keys=[a#0], functions=[partial_sum(b#1)]) +- *(1) Project [a#0, b#1] +- *(1) Filter (isnotnull(a#0) && (a#0 > 1)) +- *(1) FileScan parquet [a#0,b#1] Batched: true, Format: Parquet, … whereでの述語処理の順序が変更され最適化
17.
17Copyright©2019 NTT corp.
All Rights Reserved. • Spark v2.4.3ではpandasと同様,遅延評価を⾏わず 定義した時に実⾏する動作に変更することも可能 • spark.sql.repl.eagerEval.enabled Eager Mode in PySpark aa >>> df = spark.read.load('/tmp/t') DataFrame[a: int, b: double, c: string] >>> df.groupBy(‘a’).avg(‘b’) DataFrame[a: int, avg(b): double] >>> sql(“SET spark.sql.repl.eagerEval.enabled=true”) >>> df.groupBy(‘a’).avg(‘b’)
18.
18Copyright©2019 NTT corp.
All Rights Reserved. • クエリプランを確認してどのように実⾏されたかを正し く理解することは⾮常に重要 • Sparkに限らず,全てのRDBMS的な処理系において • 本⽇の話は時間の関係で,特に重要な⼊⼒部分の最適化 に関連する話題に絞って紹介 • FileScan Optimization • Filter Push Down + Implicit Type Casting • Nested Schema Pruning Understanding Query Plans https://bit.ly/2QFBAMl • クエリプランの理解を深めたい⽅は,右記 の本の16章「The Query Compiler」 などがオススメ
19.
19Copyright©2019 NTT corp.
All Rights Reserved. • 物理プランのFileScanノードで重要なのは以下3項⽬ を活⽤して⼊⼒データ量を限定すること FileScan Optimization aa >>> spark.read.load('/tmp/t').explain() == Physical Plan == *(1) FileScan parquet [a#0,b#1,c#2] Batched: true, Format: Parquet, Location: InMemoryFileIndex[file:/tmp/t], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<a:int,b:double,c:string>
20.
20Copyright©2019 NTT corp.
All Rights Reserved. FileScan Optimization - PushedFilters aa >>> df2.explain() == Physical Plan == *(2) HashAggregate(keys=[a#0], functions=[sum(b#1)]) +- Exchange hashpartitioning(a#0, 200) +- *(1) HashAggregate(keys=[a#0], functions=[partial_sum(b#1)]) +- *(1) Project [a#0, b#1] +- *(1) Filter (isnotnull(a#0) && (a#0 > 1)) +- *(1) FileScan parquet [a#0,b#1] Batched: true, Format: Parquet, Location: InMemoryFileIndex[file:/tmp/t], PartitionFilters: [], PushedFilters: [IsNotNull(a), GreaterThan(a,1)], ReadSchema: struct<a:int,b:double> • Filterが隣接している場合,FileScanはその述語を使 ⽤して不要な⾏を読み込まなくても良い • 実際に読み⾶ばすかはData Sourceの実装依存で,Parquetの 場合は最適化を実施
21.
21Copyright©2019 NTT corp.
All Rights Reserved. FileScan Optimization - ReadSchema aa >>> df = spark.read.load('/tmp/t') DataFrame[a: int, b: double, c: string] … >>> df2.explain() == Physical Plan == *(2) HashAggregate(keys=[a#0], functions=[sum(b#1)]) +- Exchange hashpartitioning(a#0, 200) +- *(1) HashAggregate(keys=[a#0], functions=[partial_sum(b#1)]) +- *(1) Project [a#0, b#1] +- *(1) Filter (isnotnull(a#0) && (a#0 > 1)) +- *(1) FileScan parquet [a#0,b#1] Batched: true, Format: Parquet, Location: InMemoryFileIndex[file:/tmp/t], PartitionFilters: [], PushedFilters: [IsNotNull(a), GreaterThan(a,1)], ReadSchema: struct<a:int,b:double> • クエリ内で参照される列がReadSchemaに反映され, FileScanは不要な列を読み込まなくても良い • Parquetの場合は最適化を実施
22.
22Copyright©2019 NTT corp.
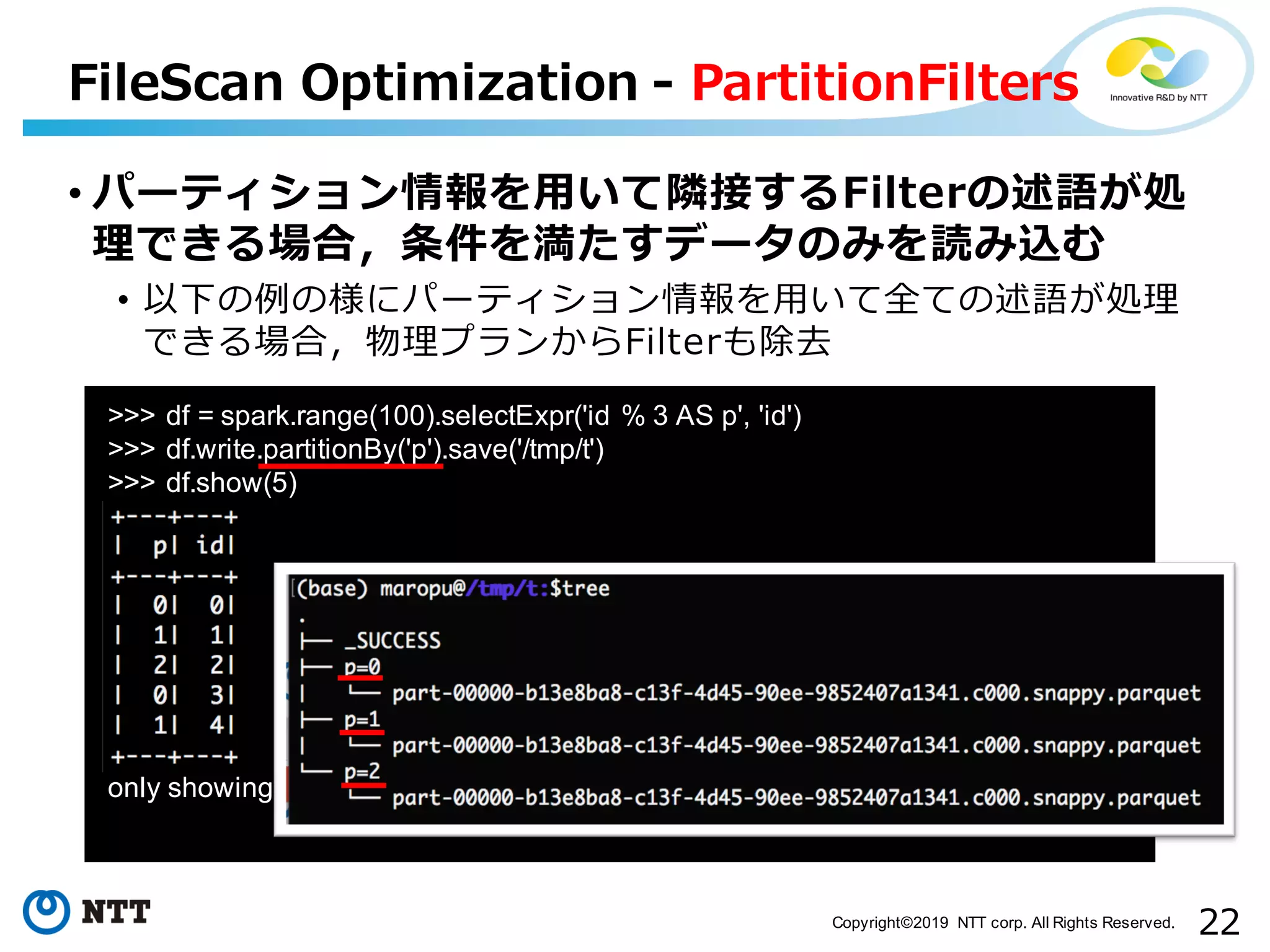
All Rights Reserved. • パーティション情報を⽤いて隣接するFilterの述語が処 理できる場合,条件を満たすデータのみを読み込む • 以下の例の様にパーティション情報を⽤いて全ての述語が処理 できる場合,物理プランからFilterも除去 FileScan Optimization - PartitionFilters >>> df = spark.range(100).selectExpr('id % 3 AS p', 'id') >>> df.write.partitionBy('p').save('/tmp/t') >>> df.show(5) only showing top 5 rows
23.
23Copyright©2019 NTT corp.
All Rights Reserved. • パーティション情報を⽤いて隣接するFilterの述語が処 理できる場合,条件を満たすデータのみを読み込む • 以下の例の様にパーティション情報を⽤いて全ての述語が処理 できる場合,物理プランからFilterも除去 FileScan Optimization - PartitionFilters >>> spark.read.load('/tmp/t').where('p = 0').explain() == Physical Plan == *(1) FileScan parquet [id#0L,p#1] Batched: true, Format: Parquet, Location: InMemoryFileIndex[file:/tmp/t], PartitionCount: 1, PartitionFilters: [isnotnull(p#1), (p#1 = 0)], PushedFilters: [], ReadSchema: struct<id:bigint> このディレクトリ以下のファイルのみを読み込み
24.
24Copyright©2019 NTT corp.
All Rights Reserved. • Filter Push Down + Implicit Type Casting • 型の不⼀致でFileScanのPushedFiltersに反映されないケース があるため注意 The Other Optimization Tips aa >>> df = spark.read.load('/tmp/t') DataFrame[a: int, b: string] >>> df.where('a > 1').explain() == Physical Plan == *(1) Project [a#0, b#1] +- *(1) Filter (isnotnull(a#0) && (a#0 > 1)) +- *(1) FileScan parquet [a#0,b#1] Batched: true, Format: Parquet, Location: InMemoryFileIndex[file:/tmp/t], PartitionFilters: [], PushedFilters: [IsNotNull(a), GreaterThan(a,1)], ReadSchema: struct<a:int,b:string> 反映されるケース
25.
25Copyright©2019 NTT corp.
All Rights Reserved. • Filter Push Down + Implicit Type Casting • 型の不⼀致でFileScanのPushedFiltersに反映されないケース があるため注意 The Other Optimization Tips aa >>> df = spark.read.load('/tmp/t') DataFrame[a: int, b: string] >>> df.where('a > 1.0').explain() == Physical Plan == *(1) Project [a#0, b#1] +- *(1) Filter (isnotnull(a#0) && (cast(a#0 as bigint) > 1)) +- *(1) FileScan parquet [a#0,b#1] Batched: true, Format: Parquet, Location: InMemoryFileIndex[file:/tmp/t], PartitionFilters: [], PushedFilters: [IsNotNull(a)], ReadSchema: struct<a:int,b:string> 反映されないケース1
26.
26Copyright©2019 NTT corp.
All Rights Reserved. • Filter Push Down + Implicit Type Casting • 型の不⼀致でFileScanのPushedFiltersに反映されないケース があるため注意 The Other Optimization Tips aa >>> df = spark.read.load('/tmp/t') DataFrame[a: int, b: string] >>> df.where('b > 0').explain() == Physical Plan == *(1) Project [a#0, b#1] +- *(1) Filter (isnotnull(b#1) && (cast(b#1 as int) > 0)) +- *(1) FileScan parquet [a#0,b#1] Batched: true, Format: Parquet, Location: InMemoryFileIndex[file:/tmp/t], PartitionFilters: [], PushedFilters: [IsNotNull(b)], ReadSchema: struct<a:int,b:string> 反映されないケース2
27.
27Copyright©2019 NTT corp.
All Rights Reserved. • Nested Schema Pruning • spark.sql.optimizer.nestedSchemaPruning.enabled • v2.4.3ではデフォルトでOFF The Other Optimization Tips aa >>> df = spark.read.load('/tmp/t’) DataFrame[id: bigint, a: struct<c:bigint,d:bigint>] >>> df.select(‘a.c’).explain() == Physical Plan == *(1) Project [a#1.c AS c#10L] +- *(1) FileScan parquet [a#1] Batched: false, Format: Parquet, ReadSchema: struct<a:struct<c:bigint,d:bigint>> # Turns on nested schema pruning >>> sql(“SET spark.sql.optimizer.nestedSchemaPruning.enabled=true”) >>> df.select(‘a.c’).explain() == Physical Plan == *(1) Project [a#1.c AS c#13L] +- *(1) FileScan parquet [a#1] Batched: false, Format: Parquet, ReadSchema: struct<a:struct<c:bigint>>
28.
28Copyright©2019 NTT corp.
All Rights Reserved. 2. CODE GENERATION
29.
29Copyright©2019 NTT corp.
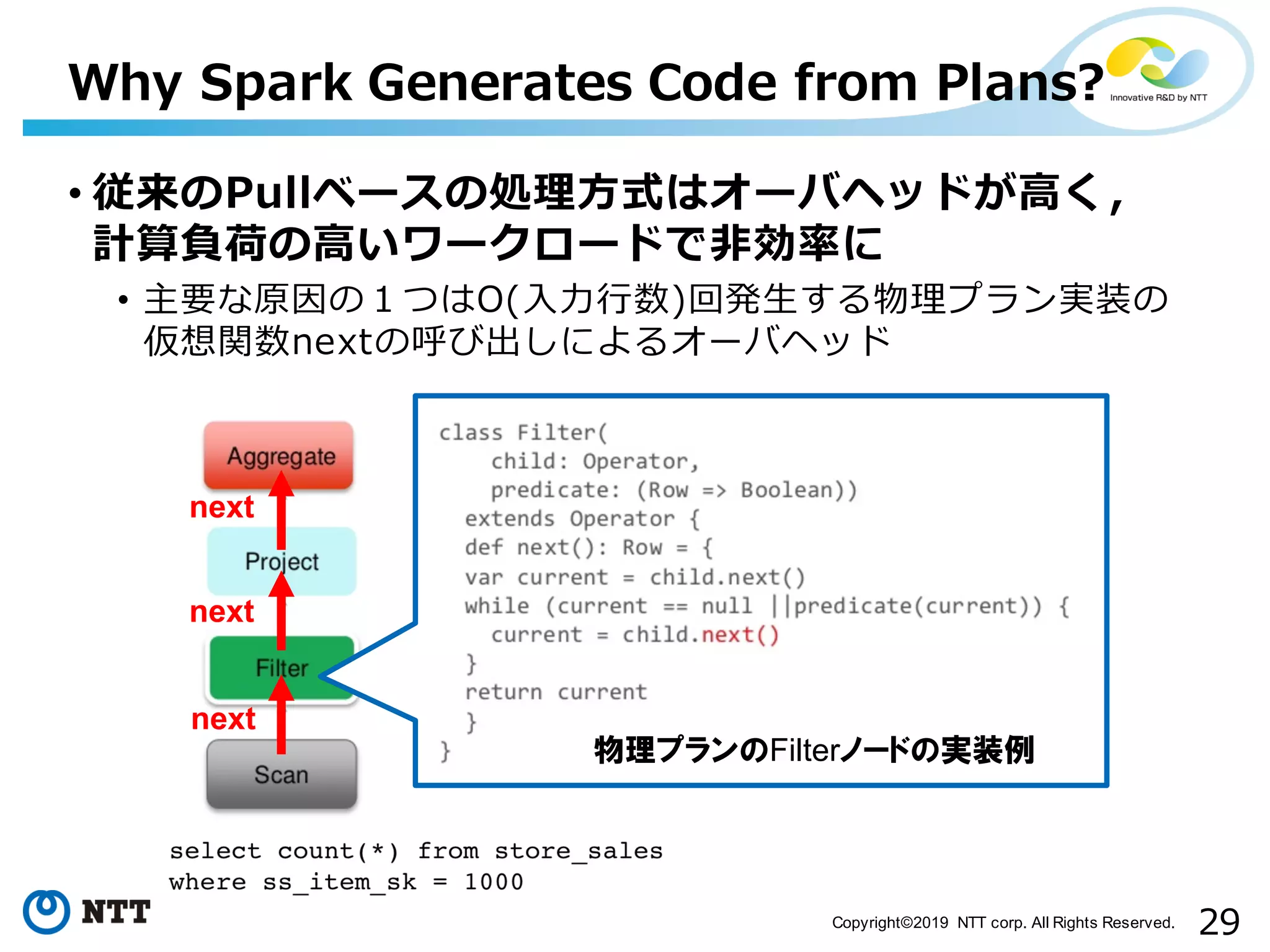
All Rights Reserved. • 従来のPullベースの処理⽅式はオーバヘッドが⾼く, 計算負荷の⾼いワークロードで⾮効率に • 主要な原因の1つはO(⼊⼒⾏数)回発⽣する物理プラン実装の 仮想関数nextの呼び出しによるオーバヘッド Why Spark Generates Code from Plans? 物理プランのFilterノードの実装例 next next next
30.
30Copyright©2019 NTT corp.
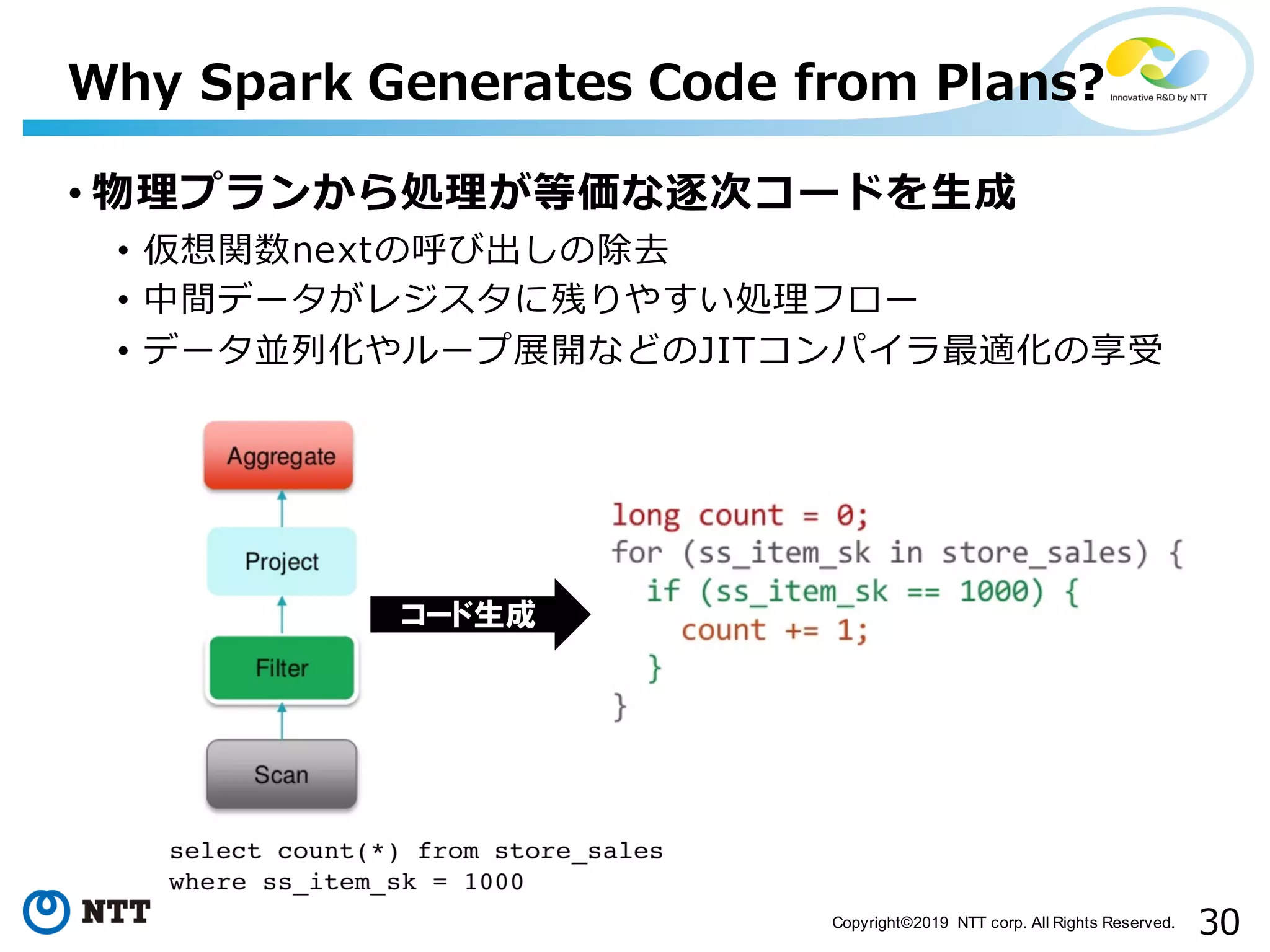
All Rights Reserved. • 物理プランから処理が等価な逐次コードを⽣成 • 仮想関数nextの呼び出しの除去 • 中間データがレジスタに残りやすい処理フロー • データ並列化やループ展開などのJITコンパイラ最適化の享受 Why Spark Generates Code from Plans? コード生成
31.
31Copyright©2019 NTT corp.
All Rights Reserved. aa Dumping Generated Code • Sparkの⽣成したコードを確認する⽅法 • EXPLAIN結果の先頭にʼ*ʼが付いているノードは内部でコード ⽣成による最適化が適⽤されていることを意味 scala> import org.apache.spark.sql.execution.debug._ scala> val df = sql("SELECT sqrt(a) FROM test WHERE b = 1”) scala> df.explain() == Physical Plan == *(1) Project [SQRT(cast(_1#2 as double)) AS SQRT(CAST(a AS DOUBLE))#18] +- *(1) Filter (_2#3 = 1) +- LocalTableScan [_1#2, _2#3] scala> df.debugCodegen
32.
32Copyright©2019 NTT corp.
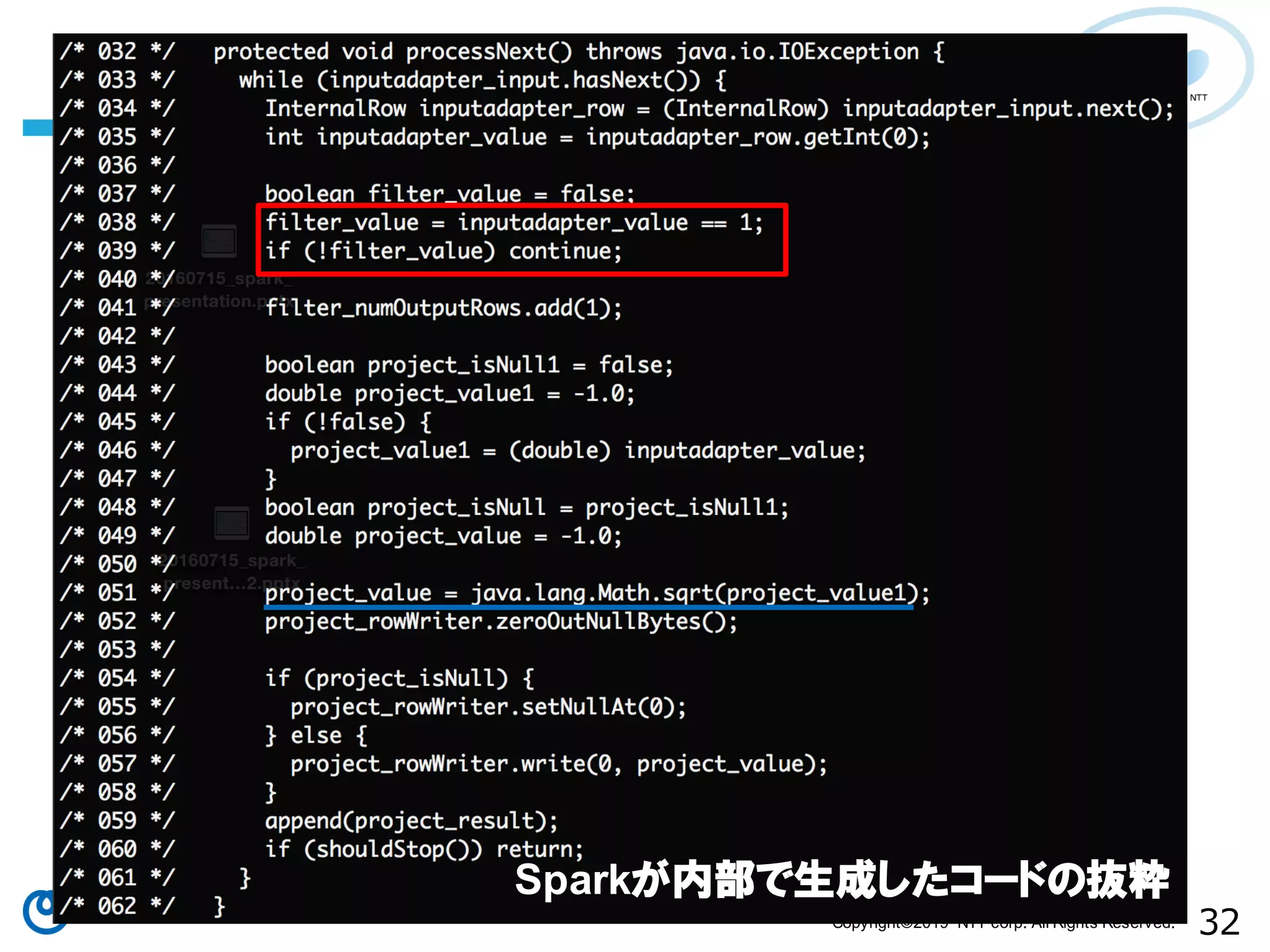
All Rights Reserved. Sparkが内部で生成したコードの抜粋
33.
33Copyright©2019 NTT corp.
All Rights Reserved. Performance Gains from Generated Code • Broadcast-Hash Joinで8.9Xの⾼速化 性能比較用のクエリ
34.
34Copyright©2019 NTT corp.
All Rights Reserved. Pitfall: Too Long Generated Code aa >>> df.groupBy().sum(‘c0’, ‘c1’, …).show() … INFO WholeStageCodegenExec: Found too long generated codes and JIT optimization might not work: the bytecode size (8094) is above the limit 8000, and the whole-stage codegen was disabled for this plan (id=2). To avoid this, you can raise the limit `spark.sql.codegen.hugeMethodLimit`: … • 出⼒ログ上で以下の⽂章を⾒かけたら要注意
35.
35Copyright©2019 NTT corp.
All Rights Reserved. Pitfall: Too Long Generated Code • OpenJDK HotSpot JVMが単⼀メソッドをJITコンパ イルするbytecodeの最⼤サイズが8000B • これを超えた場合はインタプリタモードで実⾏ • インタープリタモードに遷移した際にJVMの挙動が変 わり,性能が極端に悪化する場合があるので注意 • 特に集約関数(e.g., SUM/AVG)では,Sparkは全ての集約処 理を単⼀メソッドにinline化してコード⽣成 • KURTOSISなどの複雑な組み込み集約関数の場合,単体でこの 閾値を超えるので注意が必要 aa >>> do_agg(num_sum_functions=43) Elapsed: 14.30727505683899s >>> do_agg(44) Elapsed: 15.5922269821167s >>> do_agg(45) # bytecodeサイズが8094Bでインタープリタモードに遷移 Elapsed: 45.58869409561157s 使用したコードは https://bit.ly/2WxX0jM
36.
36Copyright©2019 NTT corp.
All Rights Reserved. Pitfall: Too Long Generated Code • 実はSparkがコード⽣成を諦めてPullベースの処理に 切り替える閾値が内部にあり,これを使うことで極端な 性能悪化を回避できる場合も • spark.sql.codegen.hugeMethodLimit aa # デフォルトでhugeMethodLimit=65536 >>> do_agg(45) Elapsed: 45.58869409561157s >>> sql('SET spark.sql.codegen.hugeMethodLimit=8000’) >>> do_agg(45) Elapsed: 16.42603611946106s SPARK-21870で集約関数が8000Bを超えにくいように メソッドを分割する修正を実施中
37.
37Copyright©2019 NTT corp.
All Rights Reserved. 3. RDD-BASED COMPUTING
38.
38Copyright©2019 NTT corp.
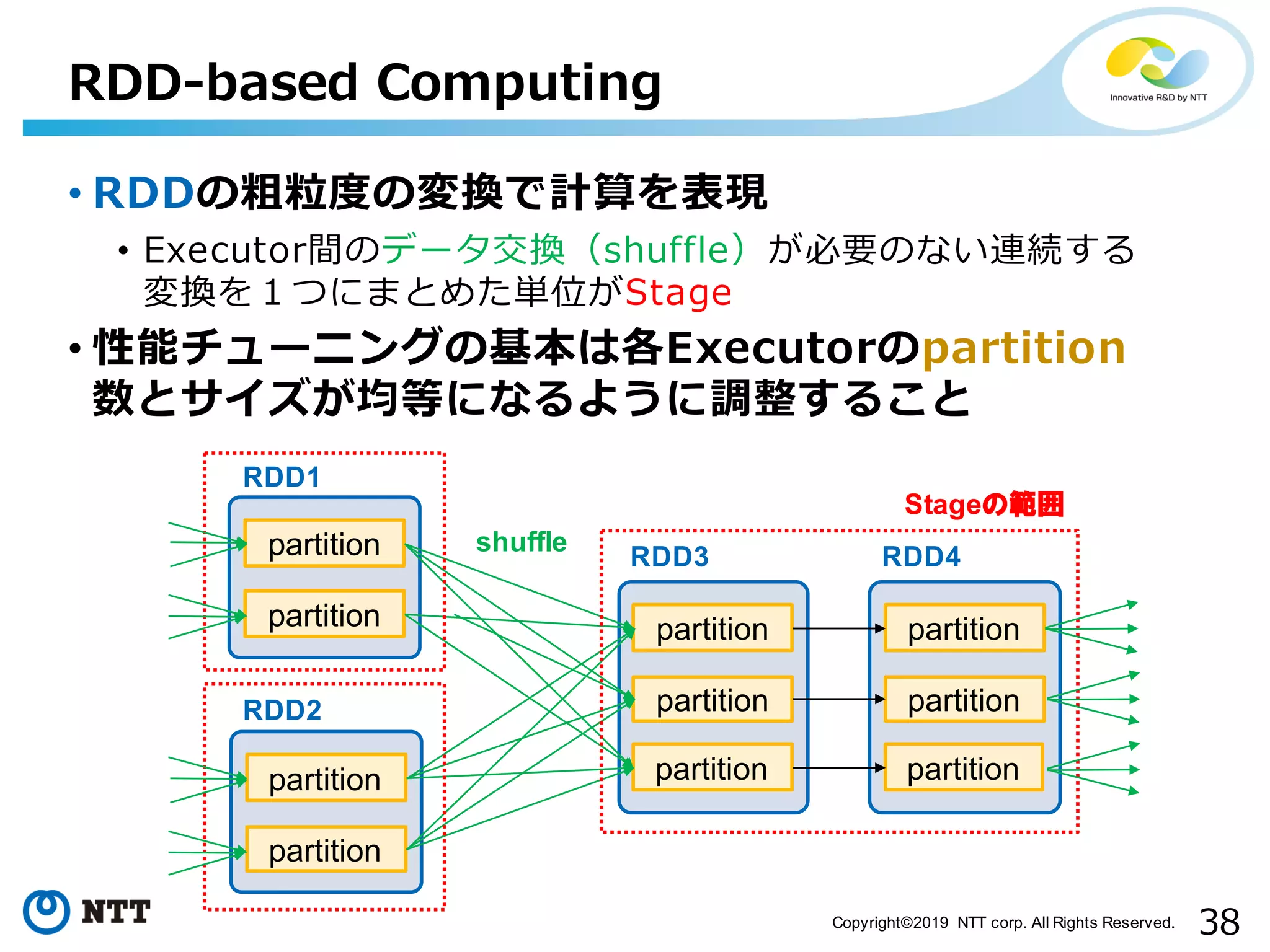
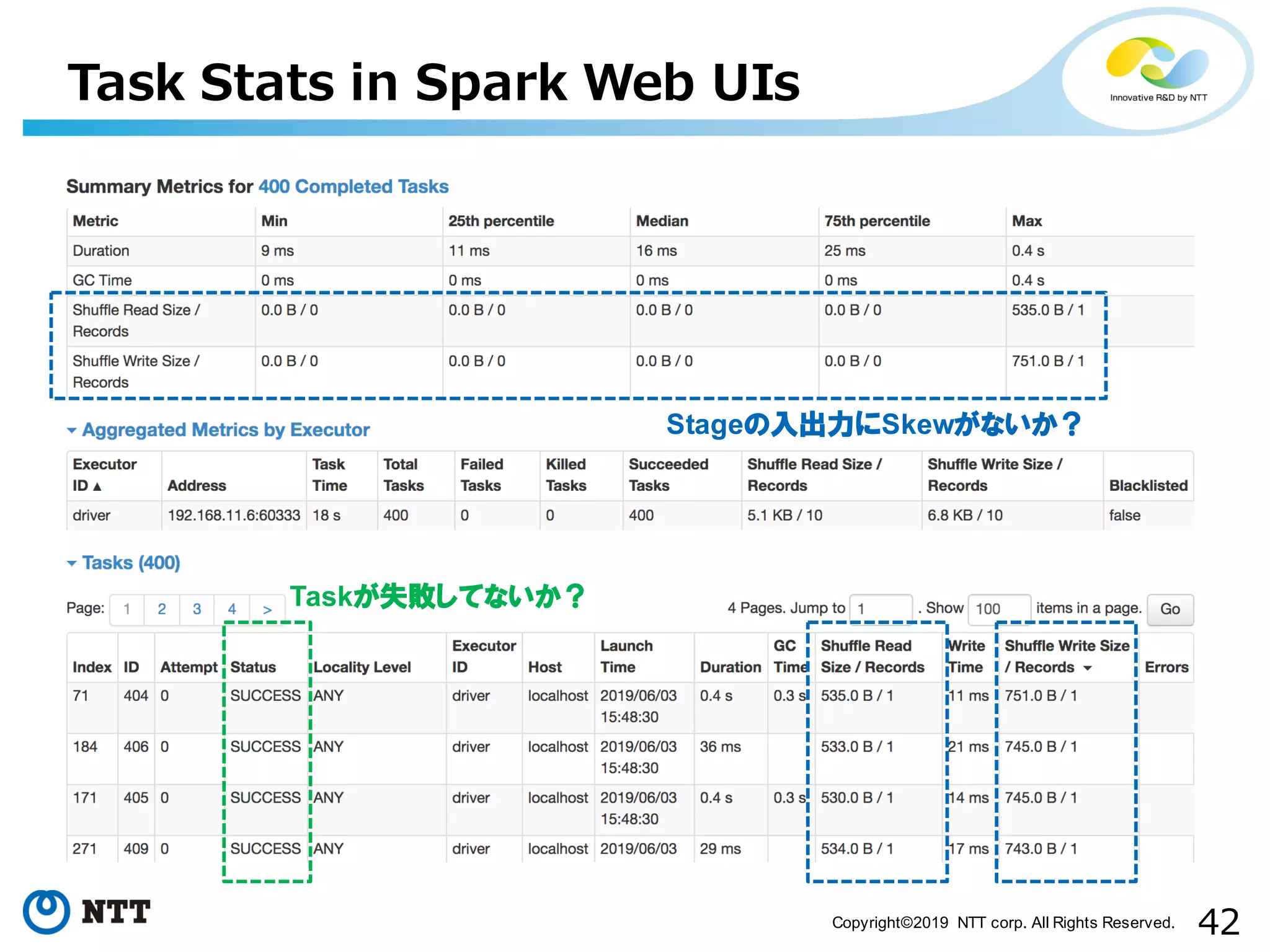
All Rights Reserved. • RDDの粗粒度の変換で計算を表現 • Executor間のデータ交換(shuffle)が必要のない連続する 変換を1つにまとめた単位がStage • 性能チューニングの基本は各Executorのpartition 数とサイズが均等になるように調整すること RDD-based Computing partition partition partition partition RDD1 RDD2 partition partition partition RDD3 partition partition partition RDD4 shuffle Stageの範囲
39.
39Copyright©2019 NTT corp.
All Rights Reserved. Spark Web UIs Sparkが起動後,ブラウザ上で http://127.0.0.1:4040 にアクセス
40.
40Copyright©2019 NTT corp.
All Rights Reserved. Spark Web UIs
41.
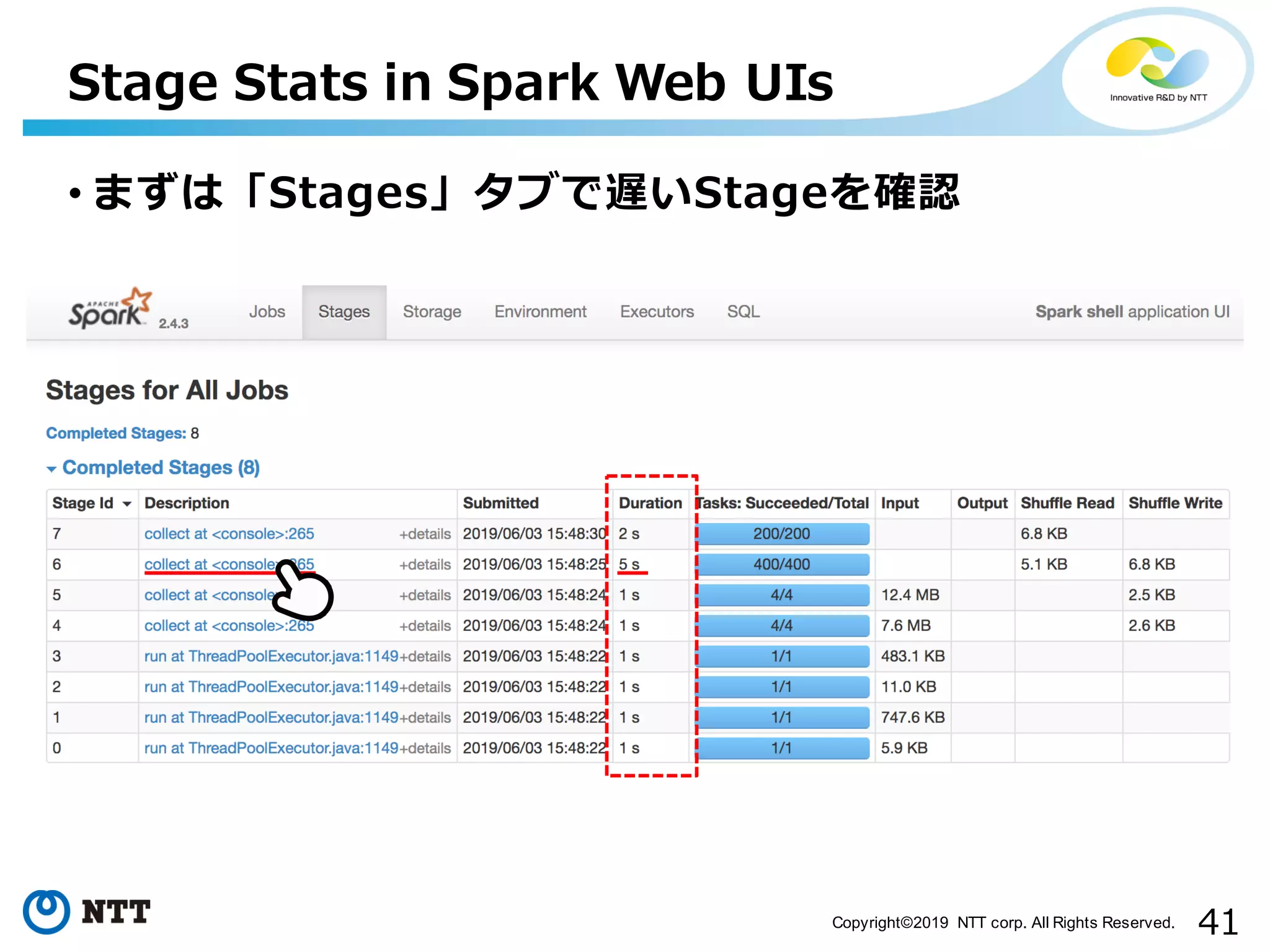
41Copyright©2019 NTT corp.
All Rights Reserved. Stage Stats in Spark Web UIs • まずは「Stages」タブで遅いStageを確認
42.
42Copyright©2019 NTT corp.
All Rights Reserved. Task Stats in Spark Web UIs Stageの入出力にSkewがないか? Taskが失敗してないか?
43.
43Copyright©2019 NTT corp.
All Rights Reserved. • 本⽇の発表概要 • 1. クエリプランとFileScanノードの最適化 • 2. コード⽣成概要と集約処理コードの肥⼤化による性能劣化 • 3. RDDの実⾏とSpark Web UIs • SparkのOSS開発は依然として活発で,性能に関する 傾向はリリース毎で変化することが多い Wrap-up アップグレードの際はクエリ結果が変わらないだけではなく, 性能が悪化していないことを確認することも大切
Download









![15Copyright©2019 NTT corp. All Rights Reserved. • 定義したクエリはすぐに実⾏されず,結果が参照された 時にクエリを最適化して実⾏ • クエリが定義された段階で実施されるのは,論理プランの構築 とプランの正しさの検証のみ Lazy Evaluation and Query Planning aa >>> df = spark.read.load('/tmp/t') DataFrame[a: int, b: double, c: string] >>> df1 = df.groupBy(‘a’).avg(‘b’) >>> df2 = df1.where(‘a > 1’) >>> df2.count() 1 結果が参照されたため最適化され,Executor側で実行 Driver側での処理のみ](https://image.slidesharecdn.com/20190529reprospark2-190604111127/75/Taming-Distributed-Parallel-Query-Execution-Engine-of-Apache-Spark-15-2048.jpg)
![16Copyright©2019 NTT corp. All Rights Reserved. • 定義したクエリはすぐに実⾏されず,結果が参照された 時にクエリを最適化して実⾏ • クエリが定義された段階で実施されるのは,論理プランの構築 とプランの正しさの検証のみ Lazy Evaluation and Query Planning aa >>> df = spark.read.load('/tmp/t') DataFrame[a: int, b: double, c: string] >>> df1 = df.groupBy(‘a’).avg(‘b’) >>> df2 = df1.where(‘a > 1’) >>> df2.count() 1 >>> df2.explain() == Physical Plan == *(2) HashAggregate(keys=[a#0], functions=[sum(b#1)]) +- Exchange hashpartitioning(a#0, 200) +- *(1) HashAggregate(keys=[a#0], functions=[partial_sum(b#1)]) +- *(1) Project [a#0, b#1] +- *(1) Filter (isnotnull(a#0) && (a#0 > 1)) +- *(1) FileScan parquet [a#0,b#1] Batched: true, Format: Parquet, … whereでの述語処理の順序が変更され最適化](https://image.slidesharecdn.com/20190529reprospark2-190604111127/75/Taming-Distributed-Parallel-Query-Execution-Engine-of-Apache-Spark-16-2048.jpg)
![17Copyright©2019 NTT corp. All Rights Reserved. • Spark v2.4.3ではpandasと同様,遅延評価を⾏わず 定義した時に実⾏する動作に変更することも可能 • spark.sql.repl.eagerEval.enabled Eager Mode in PySpark aa >>> df = spark.read.load('/tmp/t') DataFrame[a: int, b: double, c: string] >>> df.groupBy(‘a’).avg(‘b’) DataFrame[a: int, avg(b): double] >>> sql(“SET spark.sql.repl.eagerEval.enabled=true”) >>> df.groupBy(‘a’).avg(‘b’)](https://image.slidesharecdn.com/20190529reprospark2-190604111127/75/Taming-Distributed-Parallel-Query-Execution-Engine-of-Apache-Spark-17-2048.jpg)

![19Copyright©2019 NTT corp. All Rights Reserved. • 物理プランのFileScanノードで重要なのは以下3項⽬ を活⽤して⼊⼒データ量を限定すること FileScan Optimization aa >>> spark.read.load('/tmp/t').explain() == Physical Plan == *(1) FileScan parquet [a#0,b#1,c#2] Batched: true, Format: Parquet, Location: InMemoryFileIndex[file:/tmp/t], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<a:int,b:double,c:string>](https://image.slidesharecdn.com/20190529reprospark2-190604111127/75/Taming-Distributed-Parallel-Query-Execution-Engine-of-Apache-Spark-19-2048.jpg)
![20Copyright©2019 NTT corp. All Rights Reserved. FileScan Optimization - PushedFilters aa >>> df2.explain() == Physical Plan == *(2) HashAggregate(keys=[a#0], functions=[sum(b#1)]) +- Exchange hashpartitioning(a#0, 200) +- *(1) HashAggregate(keys=[a#0], functions=[partial_sum(b#1)]) +- *(1) Project [a#0, b#1] +- *(1) Filter (isnotnull(a#0) && (a#0 > 1)) +- *(1) FileScan parquet [a#0,b#1] Batched: true, Format: Parquet, Location: InMemoryFileIndex[file:/tmp/t], PartitionFilters: [], PushedFilters: [IsNotNull(a), GreaterThan(a,1)], ReadSchema: struct<a:int,b:double> • Filterが隣接している場合,FileScanはその述語を使 ⽤して不要な⾏を読み込まなくても良い • 実際に読み⾶ばすかはData Sourceの実装依存で,Parquetの 場合は最適化を実施](https://image.slidesharecdn.com/20190529reprospark2-190604111127/75/Taming-Distributed-Parallel-Query-Execution-Engine-of-Apache-Spark-20-2048.jpg)
![21Copyright©2019 NTT corp. All Rights Reserved. FileScan Optimization - ReadSchema aa >>> df = spark.read.load('/tmp/t') DataFrame[a: int, b: double, c: string] … >>> df2.explain() == Physical Plan == *(2) HashAggregate(keys=[a#0], functions=[sum(b#1)]) +- Exchange hashpartitioning(a#0, 200) +- *(1) HashAggregate(keys=[a#0], functions=[partial_sum(b#1)]) +- *(1) Project [a#0, b#1] +- *(1) Filter (isnotnull(a#0) && (a#0 > 1)) +- *(1) FileScan parquet [a#0,b#1] Batched: true, Format: Parquet, Location: InMemoryFileIndex[file:/tmp/t], PartitionFilters: [], PushedFilters: [IsNotNull(a), GreaterThan(a,1)], ReadSchema: struct<a:int,b:double> • クエリ内で参照される列がReadSchemaに反映され, FileScanは不要な列を読み込まなくても良い • Parquetの場合は最適化を実施](https://image.slidesharecdn.com/20190529reprospark2-190604111127/75/Taming-Distributed-Parallel-Query-Execution-Engine-of-Apache-Spark-21-2048.jpg)
![23Copyright©2019 NTT corp. All Rights Reserved. • パーティション情報を⽤いて隣接するFilterの述語が処 理できる場合,条件を満たすデータのみを読み込む • 以下の例の様にパーティション情報を⽤いて全ての述語が処理 できる場合,物理プランからFilterも除去 FileScan Optimization - PartitionFilters >>> spark.read.load('/tmp/t').where('p = 0').explain() == Physical Plan == *(1) FileScan parquet [id#0L,p#1] Batched: true, Format: Parquet, Location: InMemoryFileIndex[file:/tmp/t], PartitionCount: 1, PartitionFilters: [isnotnull(p#1), (p#1 = 0)], PushedFilters: [], ReadSchema: struct<id:bigint> このディレクトリ以下のファイルのみを読み込み](https://image.slidesharecdn.com/20190529reprospark2-190604111127/75/Taming-Distributed-Parallel-Query-Execution-Engine-of-Apache-Spark-23-2048.jpg)
![24Copyright©2019 NTT corp. All Rights Reserved. • Filter Push Down + Implicit Type Casting • 型の不⼀致でFileScanのPushedFiltersに反映されないケース があるため注意 The Other Optimization Tips aa >>> df = spark.read.load('/tmp/t') DataFrame[a: int, b: string] >>> df.where('a > 1').explain() == Physical Plan == *(1) Project [a#0, b#1] +- *(1) Filter (isnotnull(a#0) && (a#0 > 1)) +- *(1) FileScan parquet [a#0,b#1] Batched: true, Format: Parquet, Location: InMemoryFileIndex[file:/tmp/t], PartitionFilters: [], PushedFilters: [IsNotNull(a), GreaterThan(a,1)], ReadSchema: struct<a:int,b:string> 反映されるケース](https://image.slidesharecdn.com/20190529reprospark2-190604111127/75/Taming-Distributed-Parallel-Query-Execution-Engine-of-Apache-Spark-24-2048.jpg)
![25Copyright©2019 NTT corp. All Rights Reserved. • Filter Push Down + Implicit Type Casting • 型の不⼀致でFileScanのPushedFiltersに反映されないケース があるため注意 The Other Optimization Tips aa >>> df = spark.read.load('/tmp/t') DataFrame[a: int, b: string] >>> df.where('a > 1.0').explain() == Physical Plan == *(1) Project [a#0, b#1] +- *(1) Filter (isnotnull(a#0) && (cast(a#0 as bigint) > 1)) +- *(1) FileScan parquet [a#0,b#1] Batched: true, Format: Parquet, Location: InMemoryFileIndex[file:/tmp/t], PartitionFilters: [], PushedFilters: [IsNotNull(a)], ReadSchema: struct<a:int,b:string> 反映されないケース1](https://image.slidesharecdn.com/20190529reprospark2-190604111127/75/Taming-Distributed-Parallel-Query-Execution-Engine-of-Apache-Spark-25-2048.jpg)
![26Copyright©2019 NTT corp. All Rights Reserved. • Filter Push Down + Implicit Type Casting • 型の不⼀致でFileScanのPushedFiltersに反映されないケース があるため注意 The Other Optimization Tips aa >>> df = spark.read.load('/tmp/t') DataFrame[a: int, b: string] >>> df.where('b > 0').explain() == Physical Plan == *(1) Project [a#0, b#1] +- *(1) Filter (isnotnull(b#1) && (cast(b#1 as int) > 0)) +- *(1) FileScan parquet [a#0,b#1] Batched: true, Format: Parquet, Location: InMemoryFileIndex[file:/tmp/t], PartitionFilters: [], PushedFilters: [IsNotNull(b)], ReadSchema: struct<a:int,b:string> 反映されないケース2](https://image.slidesharecdn.com/20190529reprospark2-190604111127/75/Taming-Distributed-Parallel-Query-Execution-Engine-of-Apache-Spark-26-2048.jpg)
![27Copyright©2019 NTT corp. All Rights Reserved. • Nested Schema Pruning • spark.sql.optimizer.nestedSchemaPruning.enabled • v2.4.3ではデフォルトでOFF The Other Optimization Tips aa >>> df = spark.read.load('/tmp/t’) DataFrame[id: bigint, a: struct<c:bigint,d:bigint>] >>> df.select(‘a.c’).explain() == Physical Plan == *(1) Project [a#1.c AS c#10L] +- *(1) FileScan parquet [a#1] Batched: false, Format: Parquet, ReadSchema: struct<a:struct<c:bigint,d:bigint>> # Turns on nested schema pruning >>> sql(“SET spark.sql.optimizer.nestedSchemaPruning.enabled=true”) >>> df.select(‘a.c’).explain() == Physical Plan == *(1) Project [a#1.c AS c#13L] +- *(1) FileScan parquet [a#1] Batched: false, Format: Parquet, ReadSchema: struct<a:struct<c:bigint>>](https://image.slidesharecdn.com/20190529reprospark2-190604111127/75/Taming-Distributed-Parallel-Query-Execution-Engine-of-Apache-Spark-27-2048.jpg)

![31Copyright©2019 NTT corp. All Rights Reserved. aa Dumping Generated Code • Sparkの⽣成したコードを確認する⽅法 • EXPLAIN結果の先頭にʼ*ʼが付いているノードは内部でコード ⽣成による最適化が適⽤されていることを意味 scala> import org.apache.spark.sql.execution.debug._ scala> val df = sql("SELECT sqrt(a) FROM test WHERE b = 1”) scala> df.explain() == Physical Plan == *(1) Project [SQRT(cast(_1#2 as double)) AS SQRT(CAST(a AS DOUBLE))#18] +- *(1) Filter (_2#3 = 1) +- LocalTableScan [_1#2, _2#3] scala> df.debugCodegen](https://image.slidesharecdn.com/20190529reprospark2-190604111127/75/Taming-Distributed-Parallel-Query-Execution-Engine-of-Apache-Spark-31-2048.jpg)