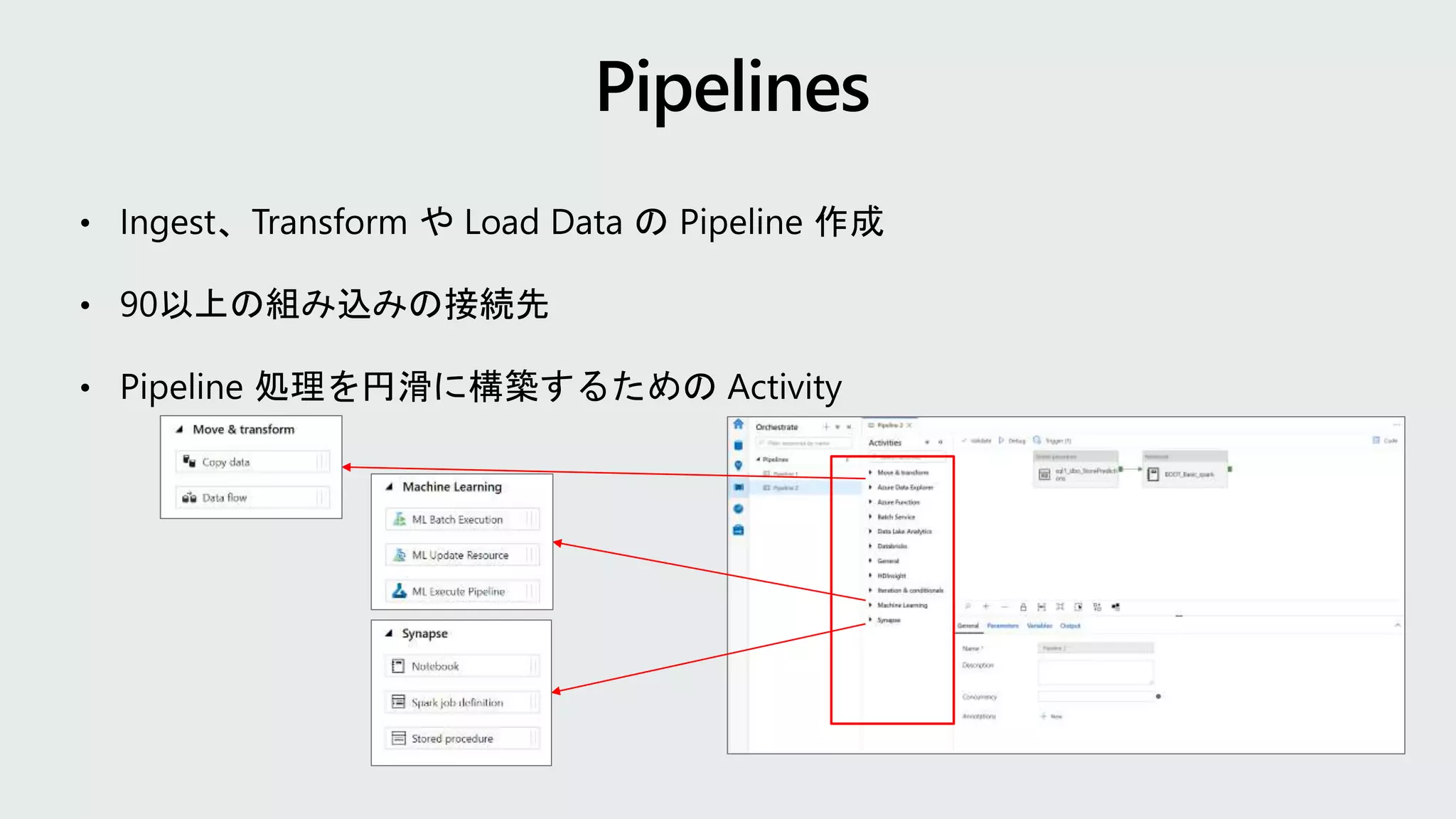
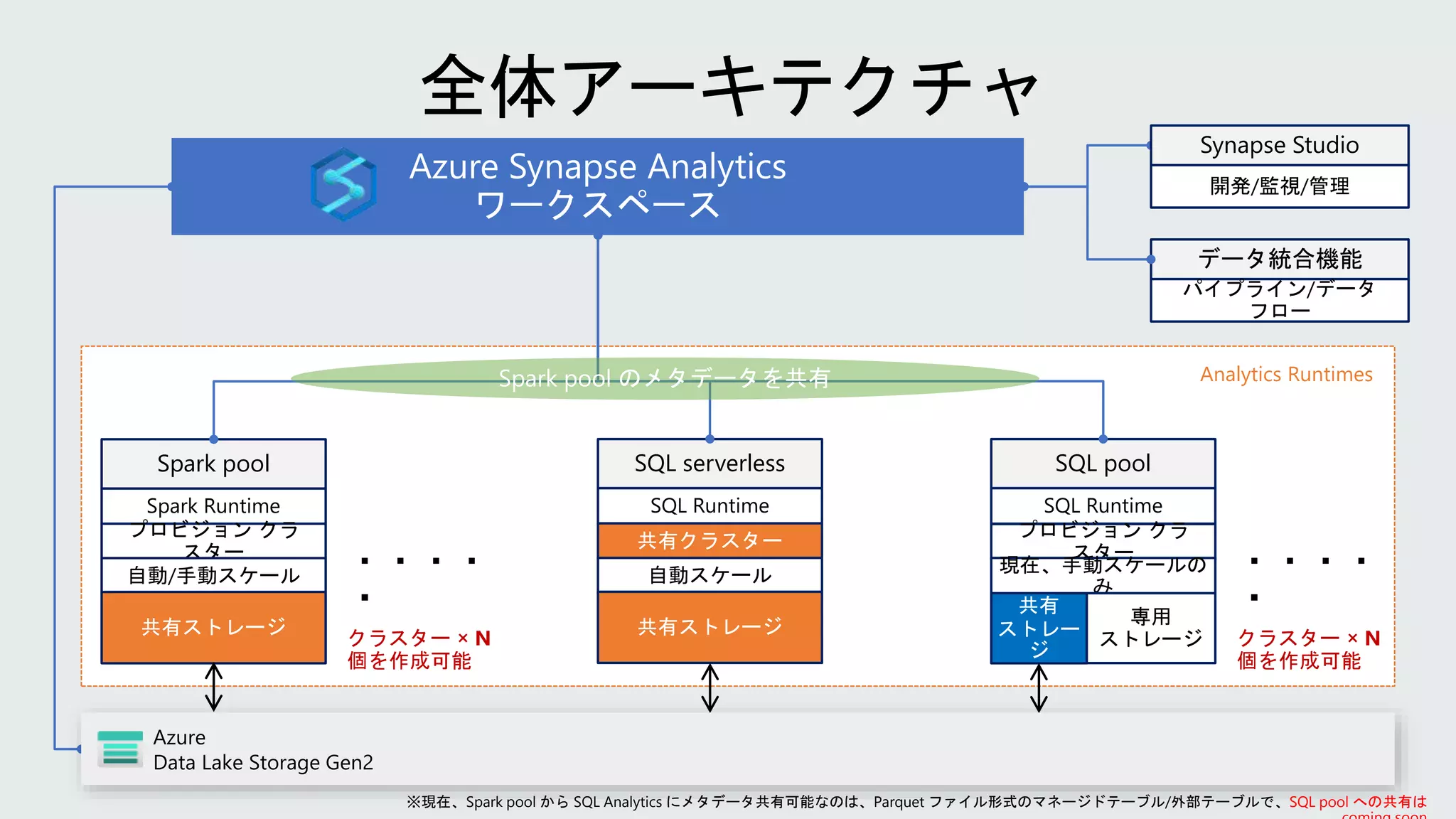
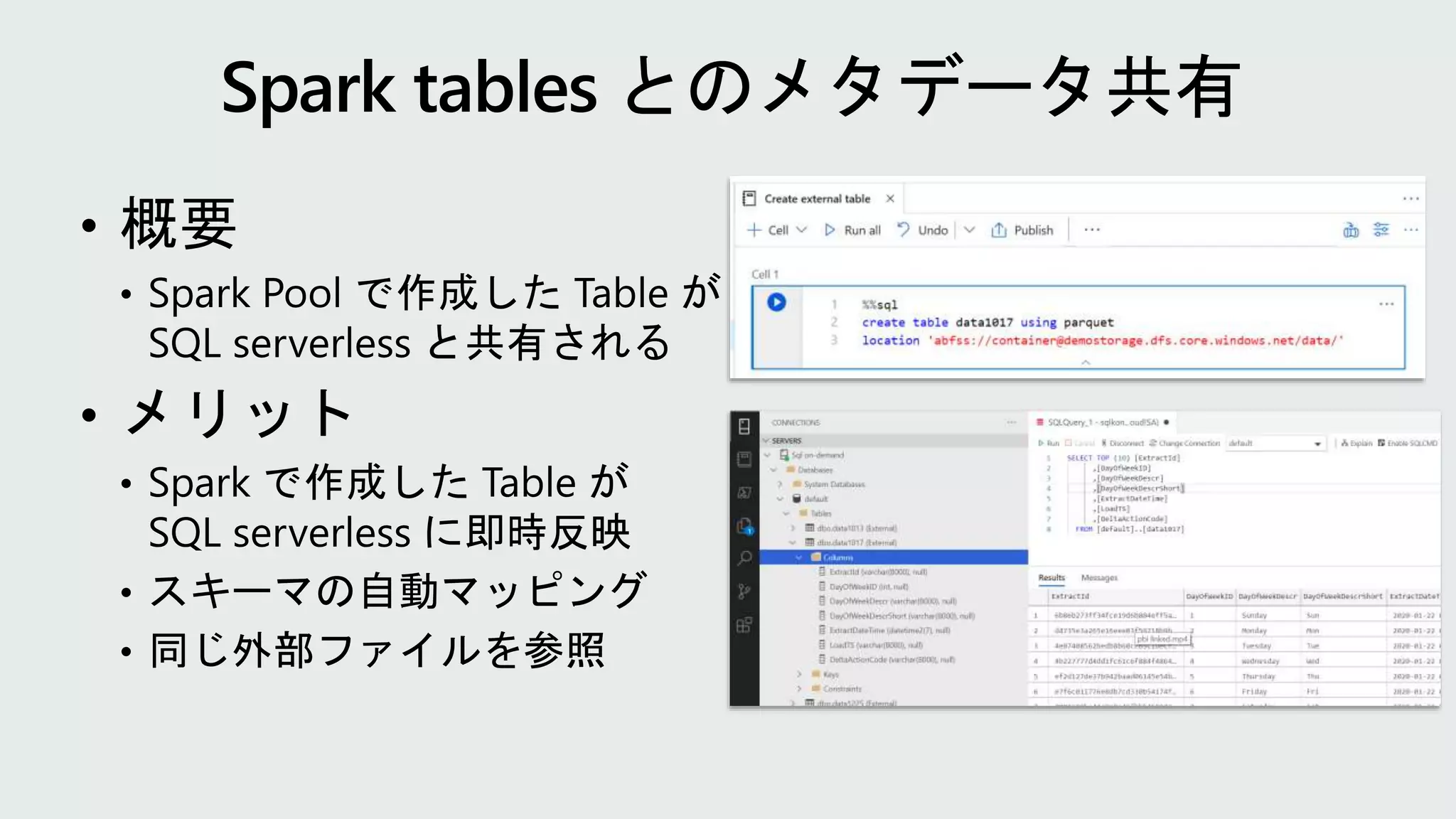
SQL Server 使いのための Azure Synapse Analytics - Spark 入門
Japan SQL Server Users Group - 第35回 SQL Server 2019勉強会 - Azure Synapese Analytics - SQL Pool 入門 のセッション資料です。 Spark の位置づけ。Synapse の中での入門編の使い方。そして、Synapse ならではの価値について触れてます。
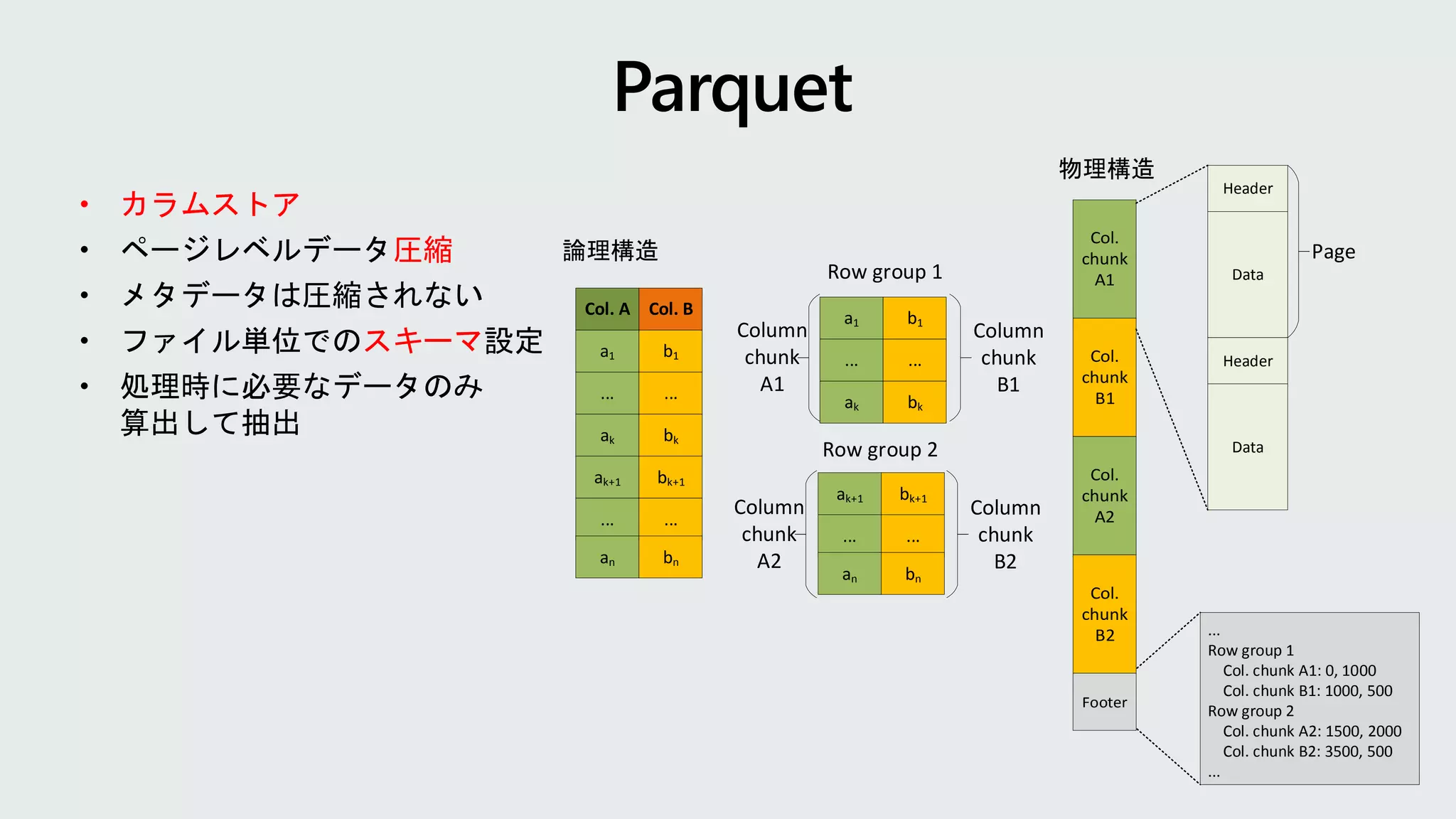
• カラムストア 圧縮 スキーマ Col. ACol. B a1 ... ak ak+1 ... an b1 ... bk bk+1 ... bn a1 ... ak b1 ... bk ak+1 ... an bk+1 ... bn Row group 1 Row group 2 Column chunk A1 Column chunk B1 Column chunk A2 Column chunk B2 Col. chunk A1 Col. chunk B1 Col. chunk A2 Col. chunk B2 Footer Header Data Header Data Page ... Row group 1 Col. chunk A1: 0, 1000 Col. chunk B1: 1000, 500 Row group 2 Col. chunk A2: 1500, 2000 Col. chunk B2: 3500, 500 ... 論理構造 物理構造
14.
Metric Result Comment Serializedsize Parquet is 20-40% smaller than Bond Columnar format -> better compression Serialization throughput Parquet is 3-6x faster than Bond Cheaper compression codec Deserialization throughput Parquet is 1.5-3x faster than Bond Cheaper string encoding (UTF-8 vs UTF-16) Query throughput: point lookup Parquet is 4x faster than Bond Most columns are not deserialized Query throughput: Scrubbing Parquet is 4x faster than Bond Most columns are not deserialized Query throughput: LogsToMetrics Parquet is 1.5x faster than Bond Better deserialization throughput Query throughput: SecurityWorkflow Parquet is as fast as Bond Data format is not a bottleneck
15.
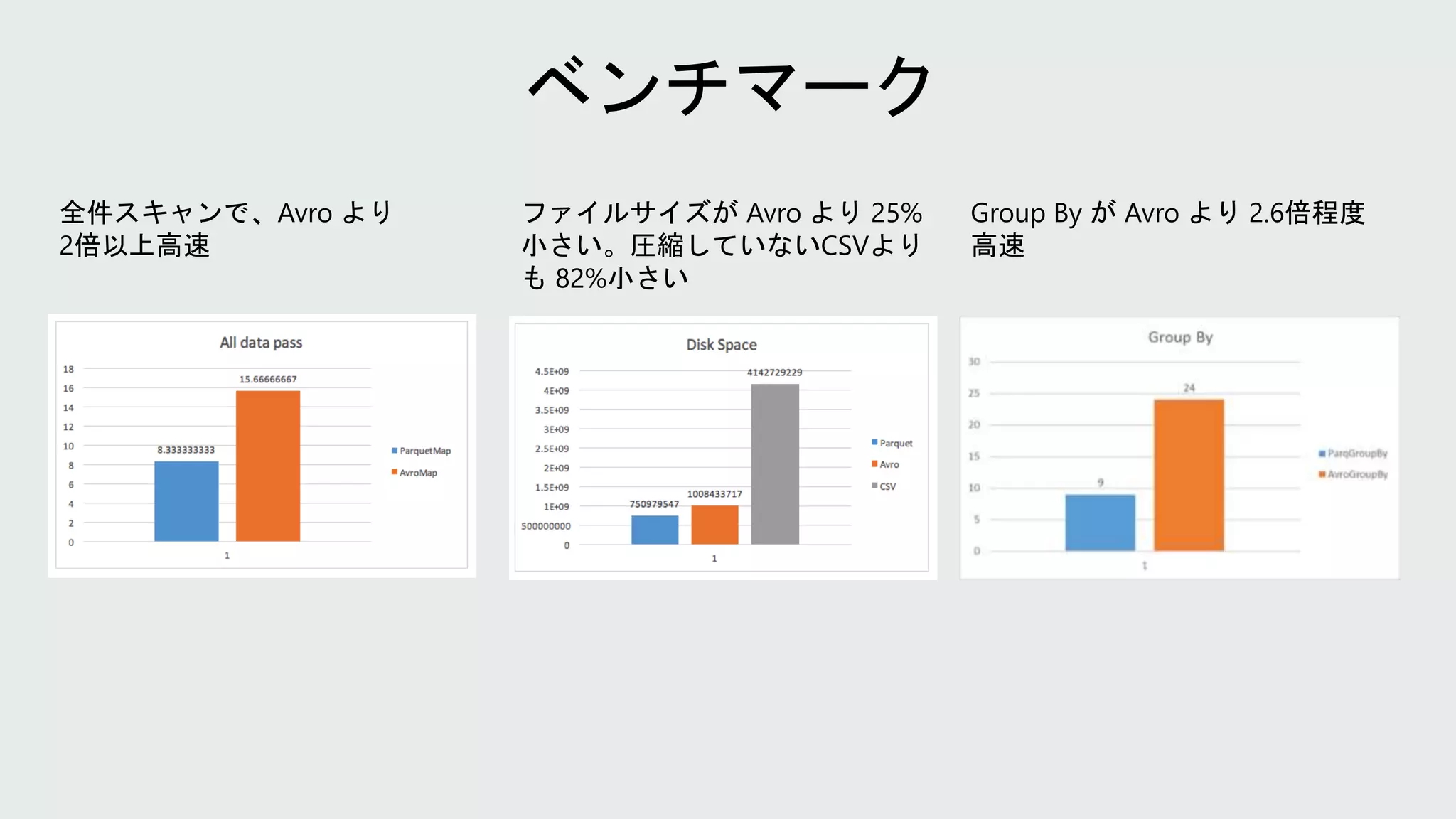
Group By がAvro より 2.6倍程度 高速 全件スキャンで、Avro より 2倍以上高速 ファイルサイズが Avro より 25% 小さい。圧縮していないCSVより も 82%小さい
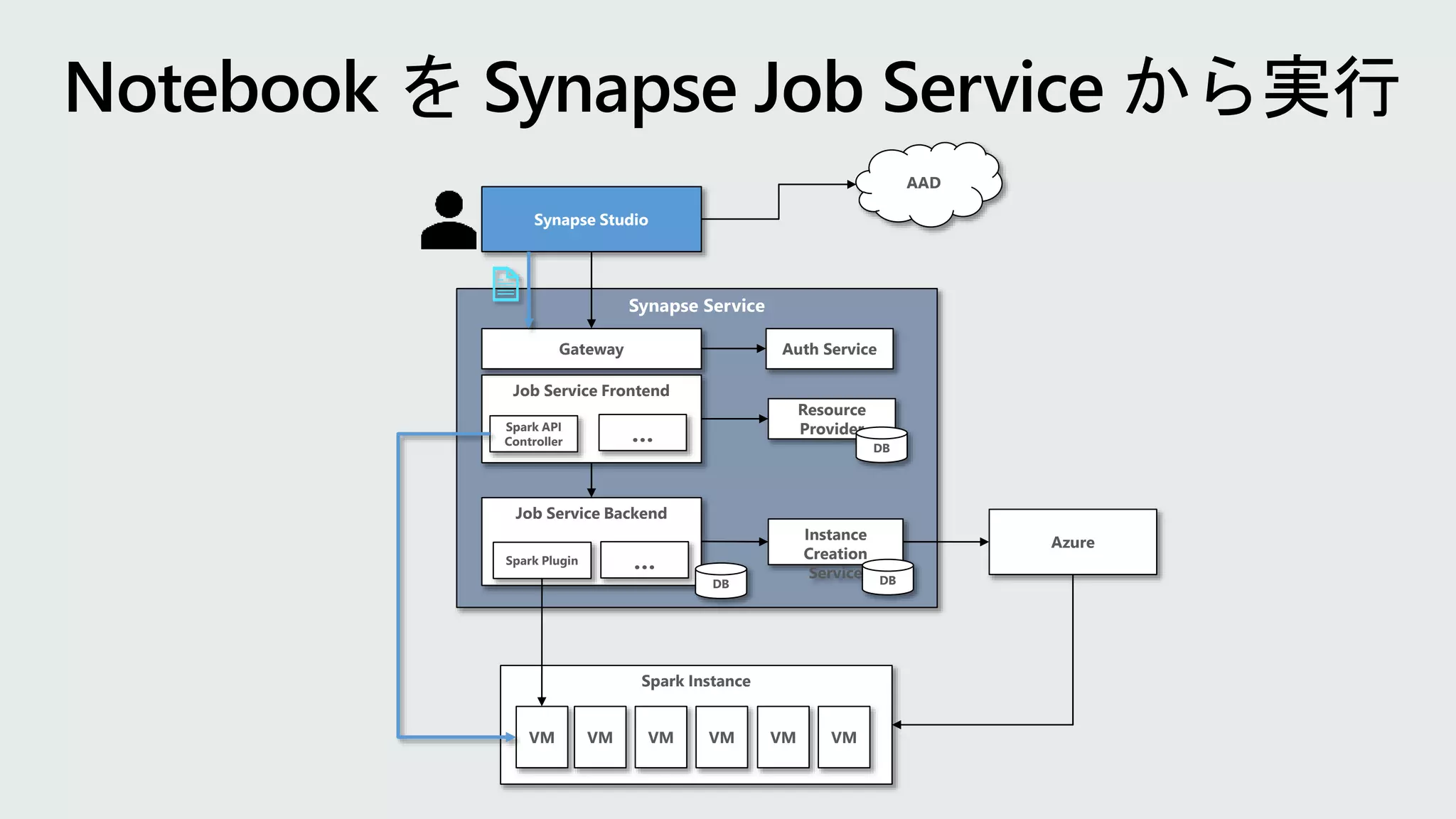
Synapse Service Job ServiceFrontend Spark API Controller … Gateway Resource Provider DB Synapse Studio AAD Auth Service Instance Creation Service DB Azure Job Service Backend Spark Plugin DB … Spark Instance VM VM VM VM VM VM
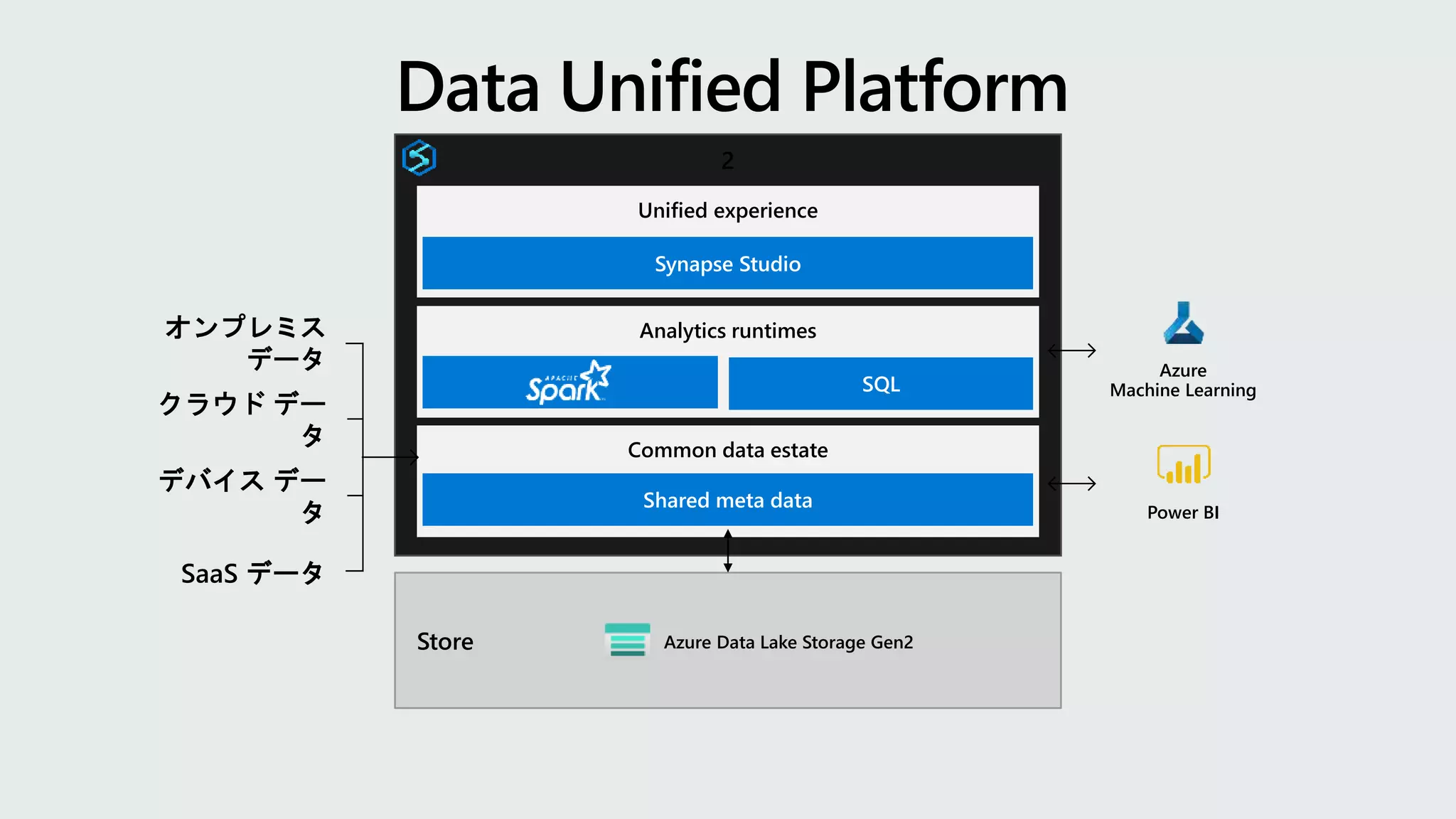
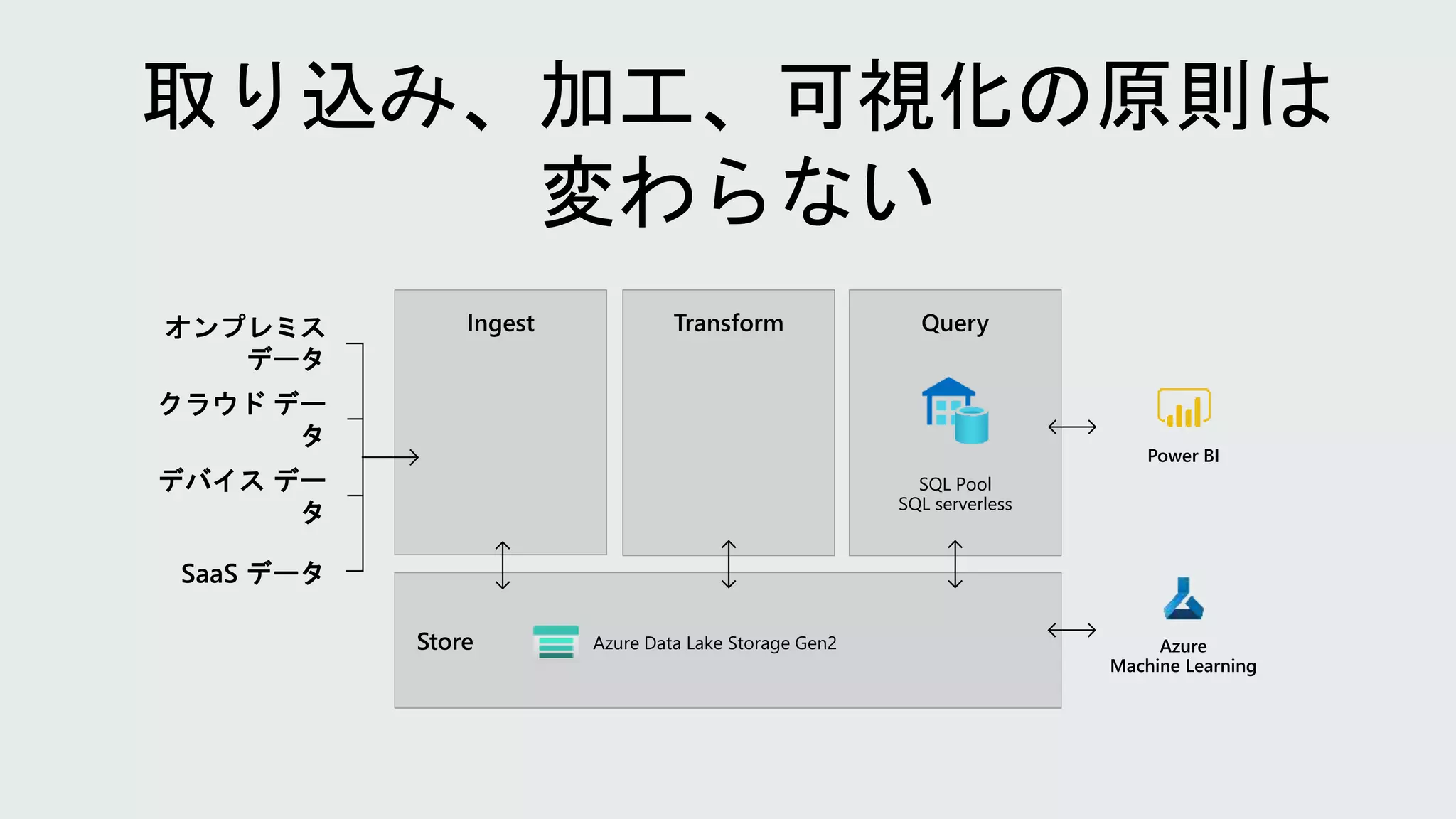
2 Analytics runtimes SQL Common dataestate Shared meta data Unified experience Synapse Studio Store Azure Data Lake Storage Gen2 Power BI Azure Machine Learning クラウド デー タ SaaS データ オンプレミス データ デバイス デー タ
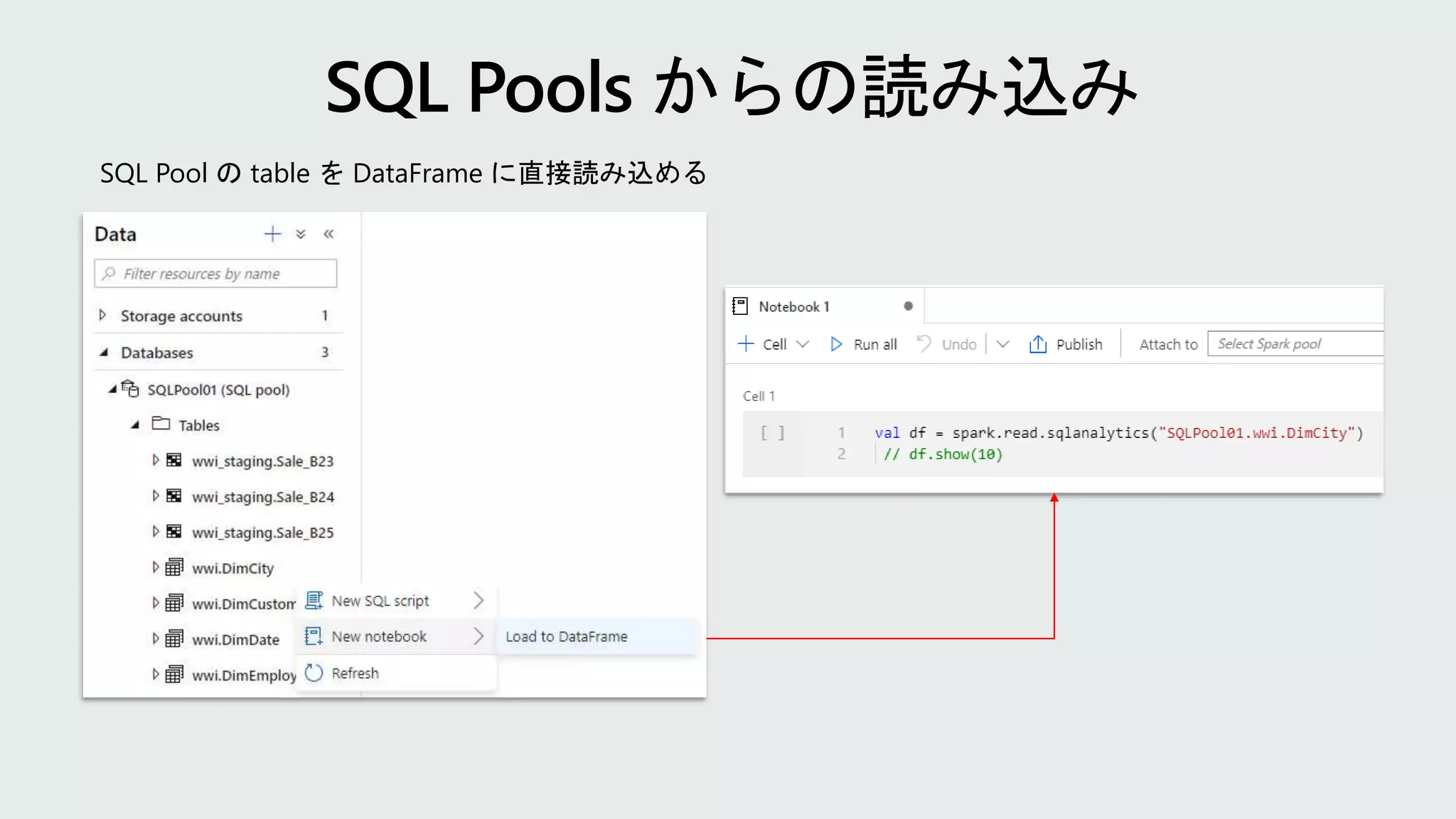
val jdbcUsername ="<SQL DB ADMIN USER>" val jdbcPwd = "<SQL DB ADMIN PWD>" val jdbcHostname = "servername.database.windows.net” val jdbcPort = 1433 val jdbcDatabase ="<AZURE SQL DB NAME>“ val jdbc_url = s"jdbc:sqlserver://${jdbcHostname}:${jdbcPort};database =${jdbcDatabase};encrypt=true;trustServerCertificate=fa lse;hostNameInCertificate=*.database.windows.net;loginT imeout=60;“ val connectionProperties = new Properties() connectionProperties.put("user", s"${jdbcUsername}") connectionProperties.put("password", s"${jdbcPwd}") val sqlTableDf = spark.read.jdbc(jdbc_url, “dbo.Tbl1", connectionProperties) // Construct a Spark DataFrame from SQL Pool table var df = spark.read.sqlanalytics("sql1.dbo.Tbl1") // Write the Spark DataFrame into SQL Pool table df.write.sqlanalytics(“sql1.dbo.Tbl2”) 従来型 Synapse での Scala %%spark val df = spark.read.sqlanalytics("sql1.dbo.Tbl1") df.createOrReplaceTempView("tbl1") %%pyspark sample = spark.sql("SELECT * FROM tbl1") sample.createOrReplaceTempView("tblnew") %%spark val df = spark.sql("SELECT * FROM tblnew") df.write.sqlanalytics(“sql1.dbo.tbl2", Constants.INTERNAL) Synapse での Python