This document discusses using Naive Bayesian methods for paragraph-level text classification in the Kannada language. It evaluates the performance of the Naive Bayesian and Naive Bayesian Multinomial models on a corpus of 1791 paragraphs from four categories (Commerce, Social Sciences, Natural Sciences, Aesthetics). Dimensionality reduction techniques like removing stop words and words with low term frequency are applied before classification. The results show that the Naive Bayesian Multinomial model outperforms the simple Naive Bayesian approach for paragraph classification in Kannada.



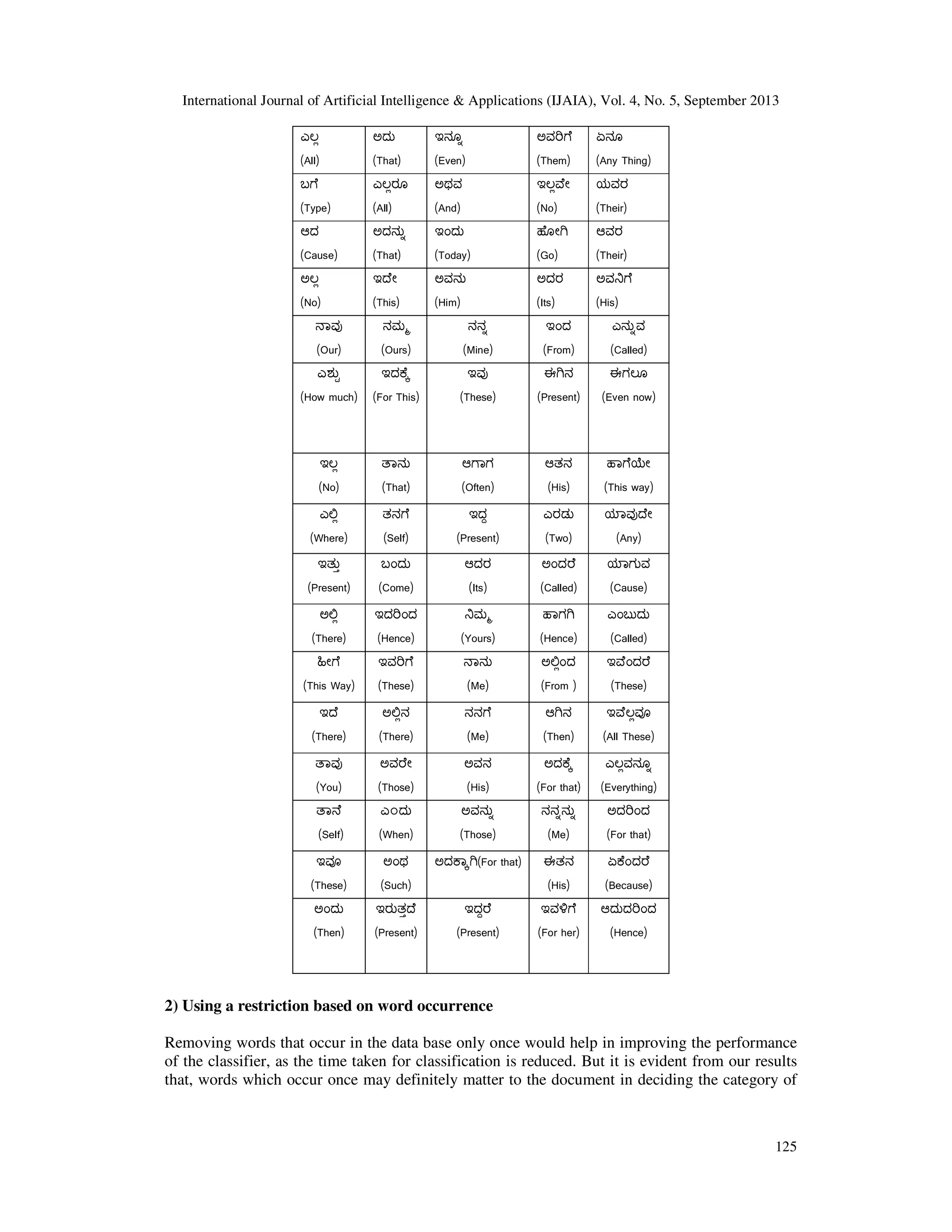
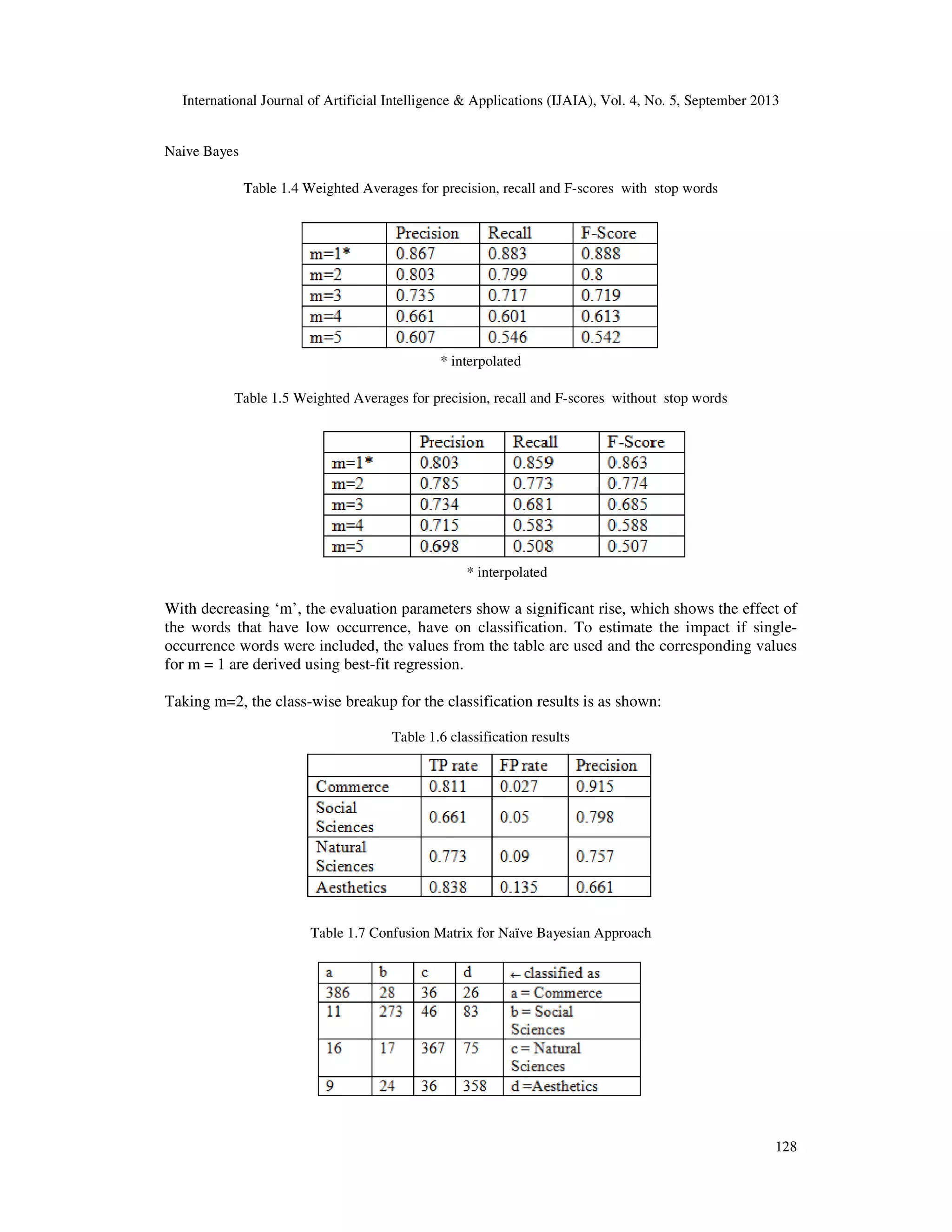
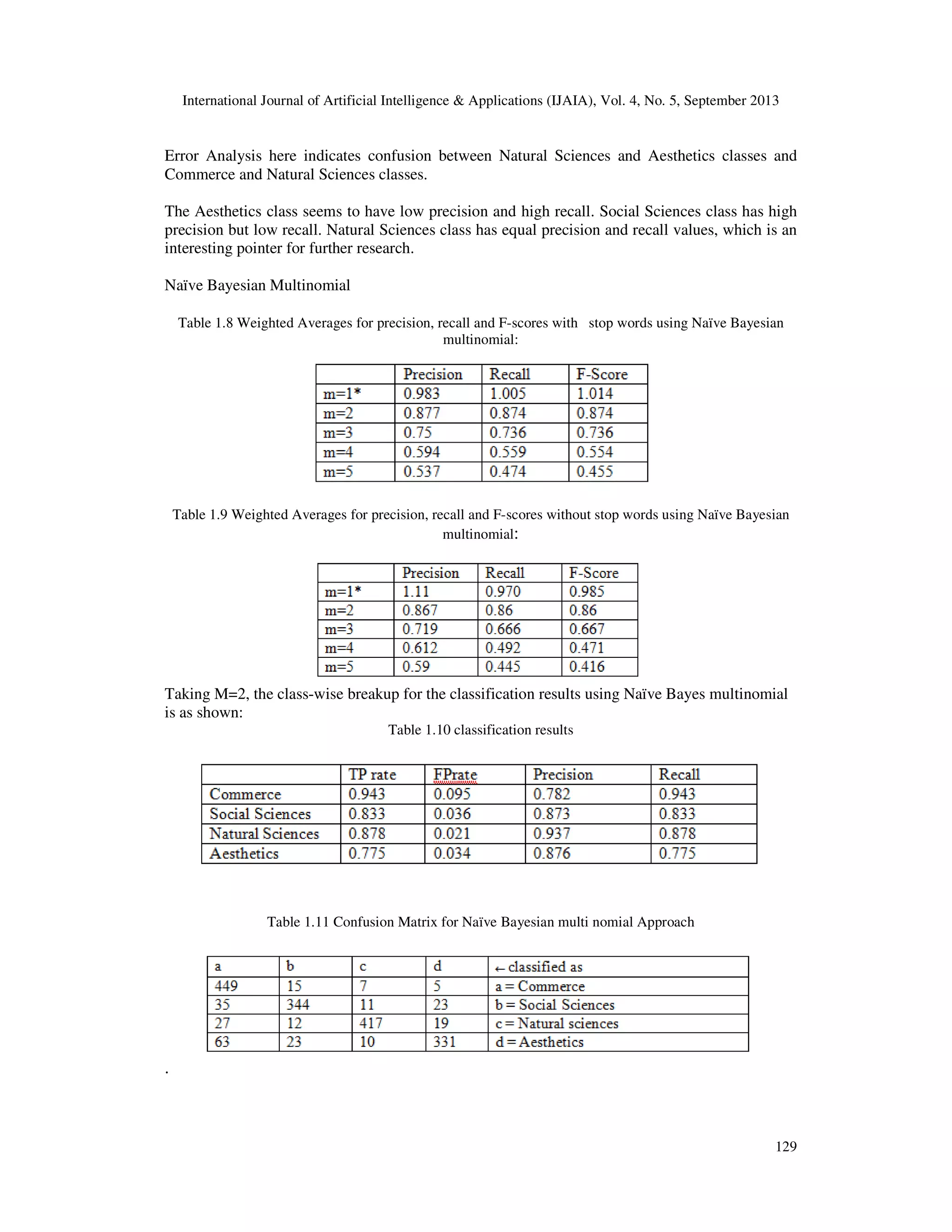
![International Journal of Artificial Intelligence & Applications (IJAIA), Vol. 4, No. 5, September 2013 124 If a document E belongs to category H , and n1,n2,n3…..nk is the number of times word ‘i’ occurs in the document and P1,P2,P3 …Pk is the probability of obtaining word ‘i’. the probability of a document E given its class H is, PR[E|H]≈N!X …………...….(1) Where N =n1+n2+n3……nk Is the number of words in the document. Dimensionality Reduction : We have tried to look at the performance of the classifier using dimensionality reduction technique. This is because the size of the feature set has a significant impact on the time required for classification. The morphological richness of the Kannada language has led to the feature dimensions to be in the order of tens of thousands. For practical classification considerations, large amounts of training samples are required to train the classifier. 1)Using stopwords The first approach for dimensionality reduction is identifying and eliminating stop words. Stop words do not hold any information about the class of the text. The function words of a language are usually identified as stop words. These words are considered as noise and are removed before the classification process. There is no standard stop word list available in the Kannada language. Hence, we sought the help of subject expert in Kannada for identifying stop words in our corpus manually. The words were manually examined and following set of stop words was created for use in the classification process. Below is the list of stop words and their meaning in English. Table 1.2 List of Stop words ಈ (This) ಮತು (And) ಾಗೂ (And) ಎ ಾ (All) ಬಂದ (Came) ಎಂಬ (Called) ಅವರ (Their) ಎಂದು (Known) ಾಗು (And) ೇ ೆ (How) ತಮ (Yours) ಇವರು (These) ಾವ (Which) ಇವರ (These) ಅ ೇ (That) ಇದು (This) ಅವರು (Those) ಅಥ ಾ (Or) ಆದ ೆ (But) ೕ ೆ (How) ಈಗ (Now) ಎ೦ಬ (Called) ಇದನು (This) ಇದರ (This) ಆಗ ೆ (Not possible)](https://image.slidesharecdn.com/suitabilityofnavebayesianmethodsforparagraphleveltextclassificationinthekannadalanguageusingdimensio-131008235937-phpapp02/75/Suitability-of-naive-bayesian-methods-for-paragraph-level-text-classification-in-the-kannada-language-using-dimensionality-reduction-technique-4-2048.jpg)



![International Journal of Artificial Intelligence & Applications (IJAIA), Vol. 4, No. 5, September 2013 131 REFERENCES [1] Alfons Juan,Hermann. Ney,'Reversing and Smoothing the Multinomial Naive Bayes Text Classifier',Work supported by the Spanish “Ministerio de Ciencia y Tecnolog´ia” under grant TIC2000-1703-CO3-01. [2] Andrew McCallumzy,Kamal Nigamy,'A Comparison of Event Models for Naive Bayes Text Classication',AAAI-98, Workshop on learning for Text Categorization.1998. [3] Maite Taboada,Julian Brooke,Manfred Stede,'Genre-Based Paragraph Classification for Sentiment Analysis',Proceedings of SIGDIAL 2009: the 10th Annual Meeting of the Special Interest Group in Discourse and Dialogue, pp 62–70,Queen Mary University of London, 2009. [4] Marti A. Hearst,'TextTiling: Segmenting Text into Multi-paragraph Subtopic Passages',) Association for Computational Linguistics, pp 33-64,1997. [5] Isaac Persing and Alan Davis and Vincent Ng,'Modeling Organization in Student Essays',Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing, pp 229–239,MIT, Massachusetts, USA, pp 9-11 ,2010. [6] Ashrof.M.Kibriya,EibeFrank,Bernard.P,Geoffrey Holm`es,'Multinomial Naive Bayes for Text’,lecture notes in Artificial Intelligence,pp 488-499,2004. [7] Jason D. Rennie,Lawrence,Shih,Jaim,Teevan,David R. Karger,'Tackling the Poor Assumptions of Naive Bayes Text Classifiers',Proceedings of the Twentieth International Conference on Machine Learning (ICML-2003), Washington DC, 2003 [8] Jayashree.R,Srikantamurthy.K,’Analysis of Sentence Level Text Cassification in the Kannada Language’,Proceedings of the 2011 International Conference on Soft Computing and Pattern Recognition’(SOCPAR_-11),pp 147-151,Dalian,China, 2011. [9] Erdong Chen, Benjamin Snyder and Regina Barzilay,'Incremental Text Structuring with Online Hierarchical Ranking',Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational linguistics, pp. 83–91, Prague, 2007. [10] Qinfeng Shi,Yasemin Altun,Alex Smola,S. V. N. Vishwanathan,'Semi-Markov Models for Sequence Segmentation',Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational linguistics, pp. 640–648, Prague, 2007. Authors Jayashree.R is an Associate Professor in the Department of Computer Science and Engineering, at PES Institute of Technology, Bangalore. She has over 18 Years of teaching experience. She has published several papers in international conferences and journals. Her research area of interest is Natural Language Processing and Pattern Recognition. Dr.K.Srikanta Murthy is a Professor and Head, Department of Computer Science and Engineering, at PES School of Engineering, Bangalore. He has put in 24 years of service in teaching and 5 years in research. He has published 8 papers in reputed International Journals; 41 papers at various International Conferences. He is currently guiding 5 PhD students .He is also a member of various Board of Studies and Board of Examiners for different universities. His research areas include Image Processing ,Document Image analysis, Pattern Recognition, Character Recognition ,Data Mining and Artificial Intelligence. Basavaraj S Anami is presently working as the Principal, K.L.E's Institute of Technology, Hubli, since August 2008. He completed his Bachelor of Engineering in Electrical Stream during November 1981. Then he completed his M.Tech in Computer Science at IIT Madras in March 1986. Later he received his Doctrine(PhD) in Computer Science at University of Mysore in January 2003.He began his academic journey as the Lecturer in Electrical department in BEC, Bagalkot from September 1983 up to December 1985. Then he was promoted as the In-charge Head of Department of Computer Science in the same college and in February 1990 2008.](https://image.slidesharecdn.com/suitabilityofnavebayesianmethodsforparagraphleveltextclassificationinthekannadalanguageusingdimensio-131008235937-phpapp02/75/Suitability-of-naive-bayesian-methods-for-paragraph-level-text-classification-in-the-kannada-language-using-dimensionality-reduction-technique-11-2048.jpg)