



![Vectors in R 5 • create a vector (list) of elements, use the "c" operator v = c("hello","world","welcome","to","the class.") v = seq(1,100) v[1] v[1:10] • Subscripting in R square brackets operators allow you to extract values: • insert logical expressions in the square brackets to retrieve subsets of data from a vector or list. For example:](https://image.slidesharecdn.com/module2introductiontor-160425221924/75/SQLBits-Module-2-RStats-Introduction-to-R-and-Statistics-5-2048.jpg)
![Vectors in R Microsoft Confidential 6 v = seq(1,100) logi = v>95 logi v[logi] v[v<6] v[105]=105 v[is.na(v)]](https://image.slidesharecdn.com/module2introductiontor-160425221924/75/SQLBits-Module-2-RStats-Introduction-to-R-and-Statistics-6-2048.jpg)





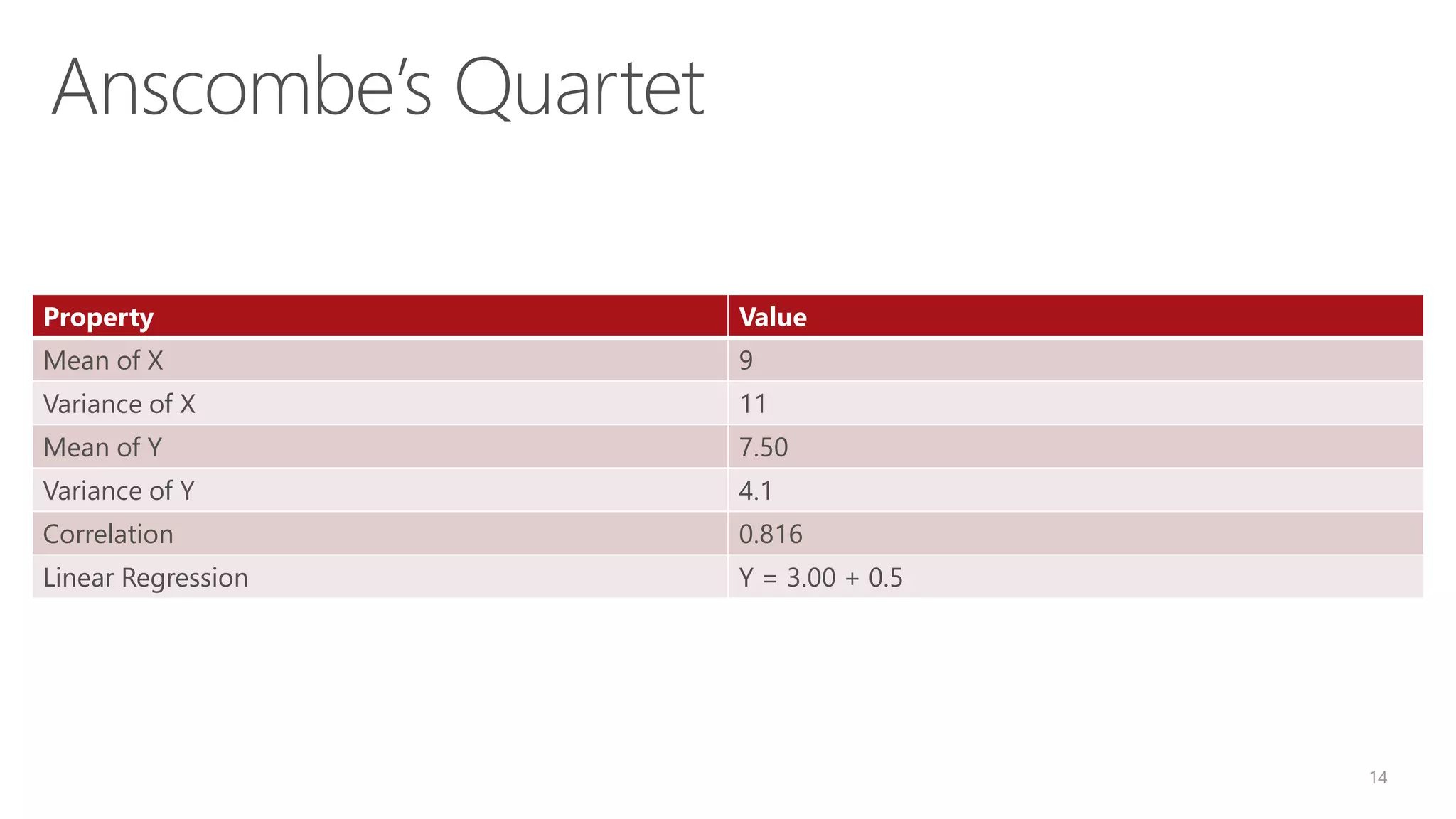
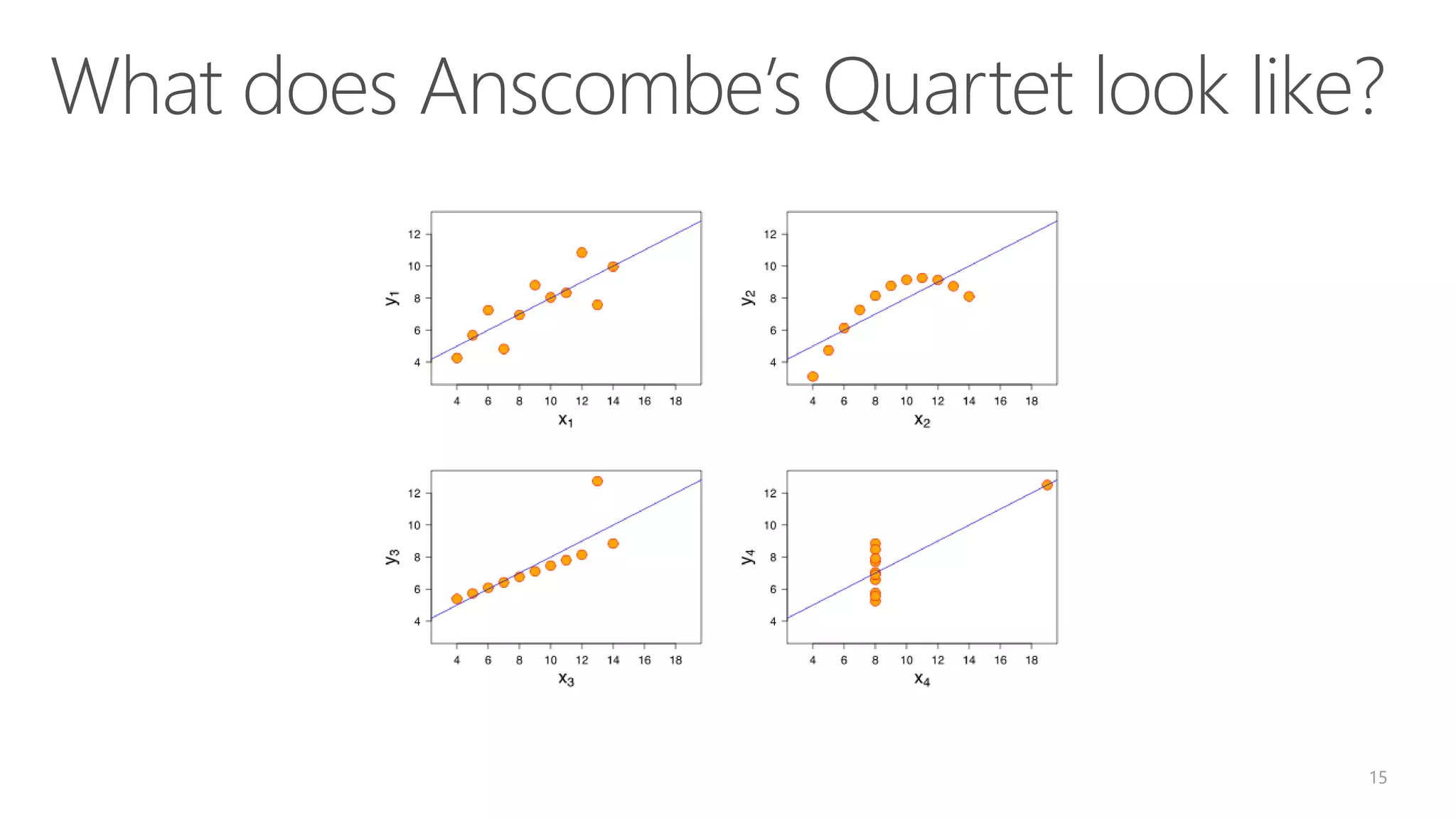














![Examples of Data Mining in R cpi2011 <- fit$coefficients[[1]] + fit$coefficients[[2]]*2011 + fit$coefficients[[3]]*(1:4) attributes(fit) fit$coefficients Residuals(fit) – difference between observed and fitted values Summary(fit) Plot(fit)](https://image.slidesharecdn.com/module2introductiontor-160425221924/75/SQLBits-Module-2-RStats-Introduction-to-R-and-Statistics-34-2048.jpg)










![Remove Missing Data • dim(ds) ## [1] 366 24 sum(is.na(ds[vars])) • ## [1] 47 ds <- ds[-attr(na.omit(ds[vars]), "na.action"),] • dim(ds) ## [1] 328 24 sum(is.na(ds[vars])) • ## [1] 0](https://image.slidesharecdn.com/module2introductiontor-160425221924/75/SQLBits-Module-2-RStats-Introduction-to-R-and-Statistics-45-2048.jpg)
![Clean Data Target as Categorical Data • summary(ds[target]) • ## RainTomorrow ## Min. :0.000 ## 1st Qu.:0.000 • ## Median :0.000 ## Mean :0.183 ## 3rd Qu.:0.000 ## Max. :1.000 • .... • ds[target] <- as.factor(ds[[target]]) levels(ds[target]) <- c("No", "Yes") • summary(ds[target])](https://image.slidesharecdn.com/module2introductiontor-160425221924/75/SQLBits-Module-2-RStats-Introduction-to-R-and-Statistics-46-2048.jpg)
![Model Preparation • (form <- formula(paste(target, "~ ."))) ## RainTomorrow ~ . • (nobs <- nrow(ds)) ## [1] 328 • train <- sample(nobs, 0.70*nobs) length(train) ## [1] 229 • test <- setdiff(1:nobs, train) length(test) • ## [1] 99](https://image.slidesharecdn.com/module2introductiontor-160425221924/75/SQLBits-Module-2-RStats-Introduction-to-R-and-Statistics-47-2048.jpg)
![Random Forest • library(randomForest) model <- randomForest(form, ds[train, vars], na.action=na.omit) model • ## • ## Call: • ## randomForest(formula=form, data=ds[train, vars], ... • ## Type of random forest: classification • ## Number of trees: 500 • ## No. of variables tried at each split: 4 ....](https://image.slidesharecdn.com/module2introductiontor-160425221924/75/SQLBits-Module-2-RStats-Introduction-to-R-and-Statistics-48-2048.jpg)
![Evaluate the Model – Risk Chart • pr <- predict(model, ds[test,], type="prob")[,2] riskchart(pr, ds[test, target], ds[test, risk], • title="Random Forest - Risk Chart", risk=risk, recall=target, thresholds=c(0.35, 0.15))](https://image.slidesharecdn.com/module2introductiontor-160425221924/75/SQLBits-Module-2-RStats-Introduction-to-R-and-Statistics-49-2048.jpg)


















This document is a guide for data analysts on using R in combination with Power BI, covering topics such as data setup, importing data, statistical analysis, and creating visualizations. It outlines the structure of a workshop by Jen Stirrup, including various modules focused on R programming basics, data manipulation, and several statistical tests. The presentation highlights the growing demand for R skills in data science and offers insights on practical applications in business intelligence.