


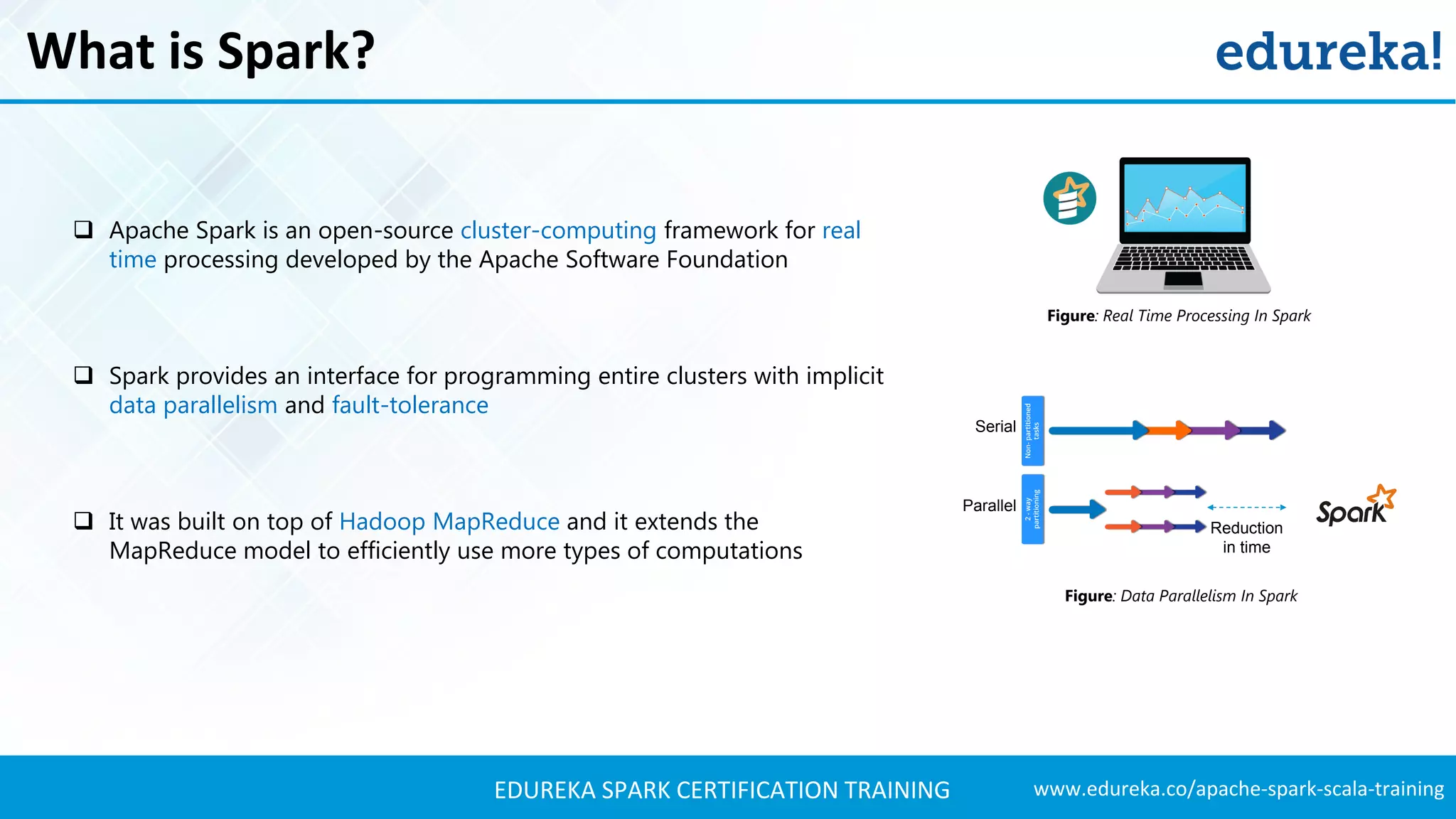









![www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Use Case – Reading Data From HDFS //Creating an object basketball containing our main() class object basketball { def main(args: Array[String]) { val sparkConf = new SparkConf().setAppName("basketball").setMaster("local[2]") val sc = new SparkContext(sparkConf) for (i <- 1980 to 2016) { println(i) val yearStats = sc.textFile(s"hdfs://localhost:9000/basketball/BasketballStats/leagues_NBA_$i*") yearStats.filter(x => x.contains(",")).map(x => (i,x)).saveAsTextFile(s"hdfs://localhost:9000/basketball/BasketballStatsWithYear/ $i/") }](https://image.slidesharecdn.com/sparkhadoop-sparktutorial-edureka-170424095515/75/Spark-Hadoop-Tutorial-Spark-Hadoop-Example-on-NBA-Apache-Spark-Training-Edureka-27-2048.jpg)
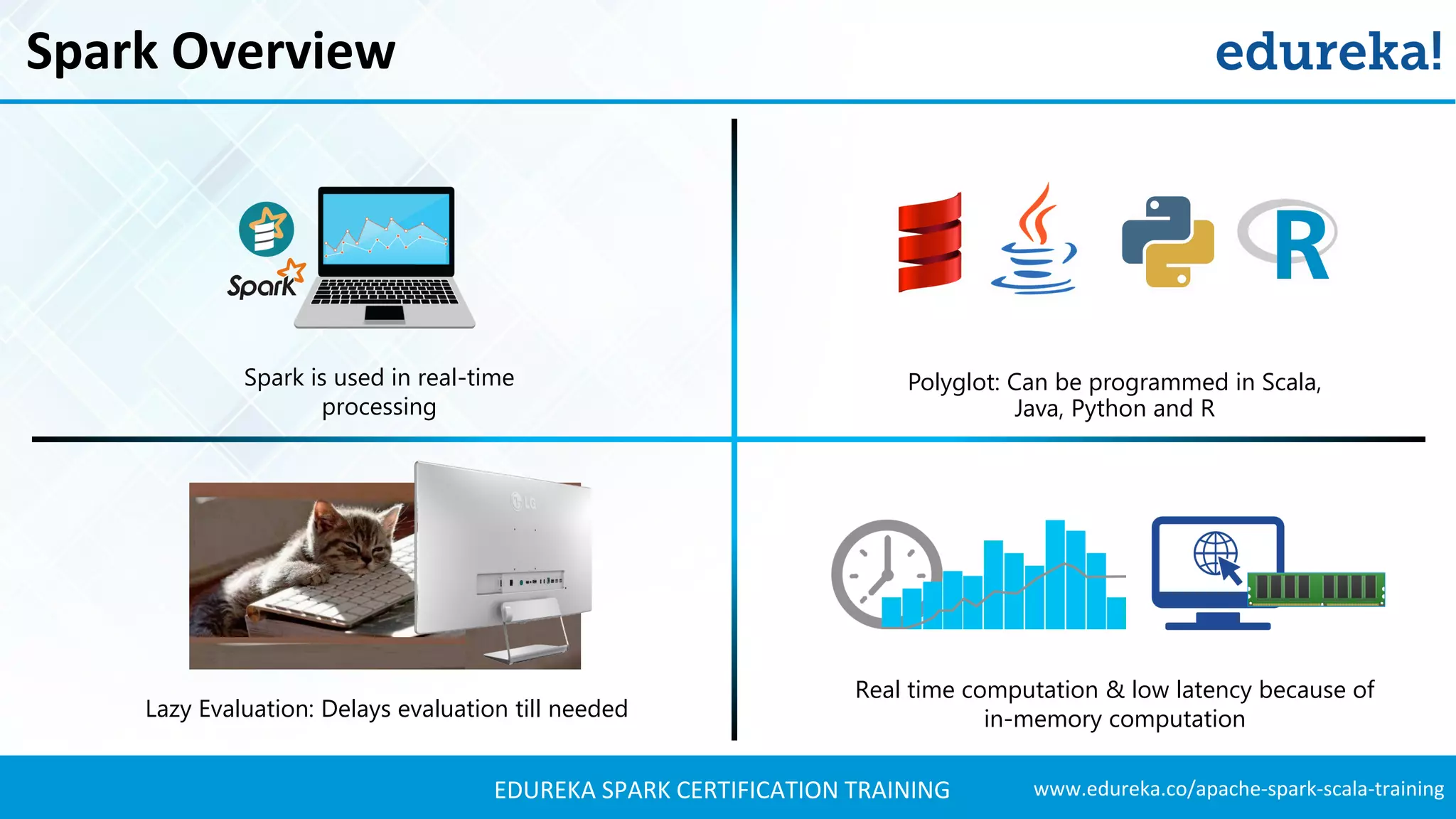
![www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Use Case – Player Statistics Transformations //Parse stats and normalize val nStats = filteredStats.map(x=>bbParse(x,broadcastStats.value,zBroadcastStats.value)) //Parse stats and track weights val txtStatZ = Array("FG","FT","3P","TRB","AST","STL","BLK","TOV","PTS") val zStats = processStats(filteredStats,txtStatZ,broadcastStats.value).collectAsMap //Collect RDD into Map and broadcast into 'zBroadcastStats' val zBroadcastStats = sc.broadcast(zStats) //Map RDD to RDD[Row] so that we can turn it into a DataFrame val nPlayer = nStats.map(x => Row.fromSeq(Array(x.name,x.year,x.age,x.position,x.team,x.gp,x.gs,x.mp) ++ x.stats ++ x.statsZ ++ Array(x.valueZ) ++ x.statsN ++ Array(x.valueN)))](https://image.slidesharecdn.com/sparkhadoop-sparktutorial-edureka-170424095515/75/Spark-Hadoop-Tutorial-Spark-Hadoop-Example-on-NBA-Apache-Spark-Training-Edureka-29-2048.jpg)



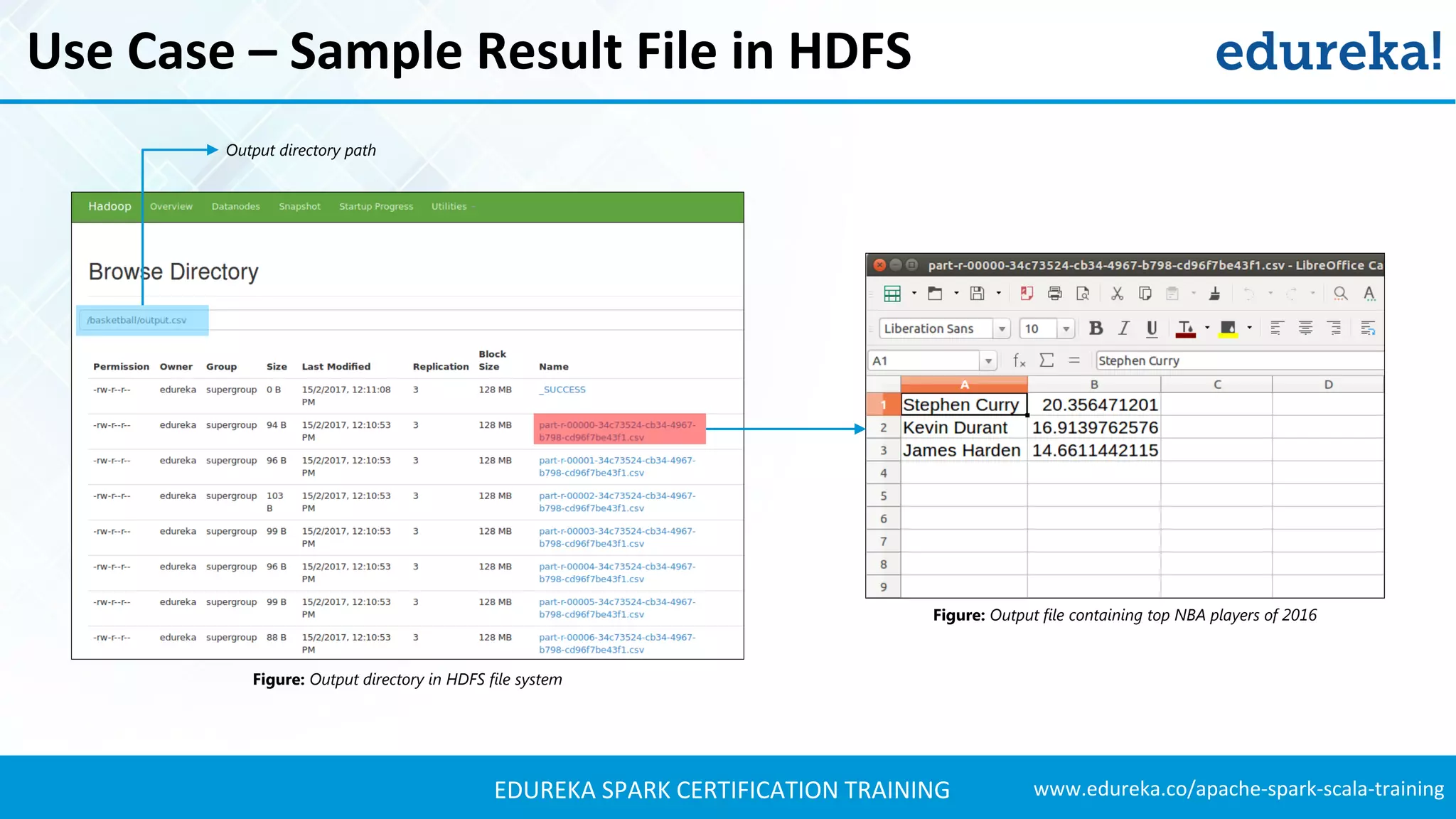

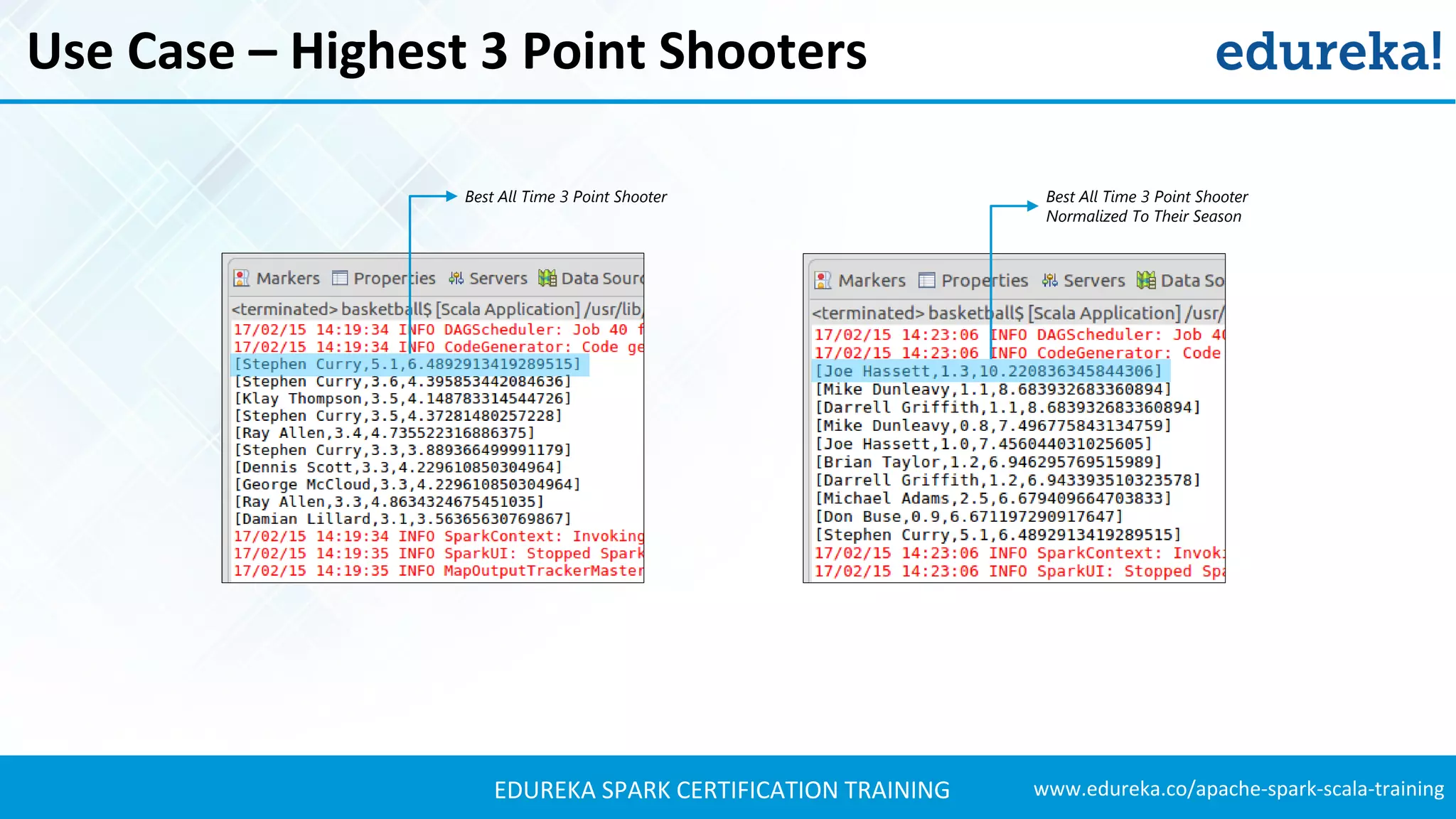








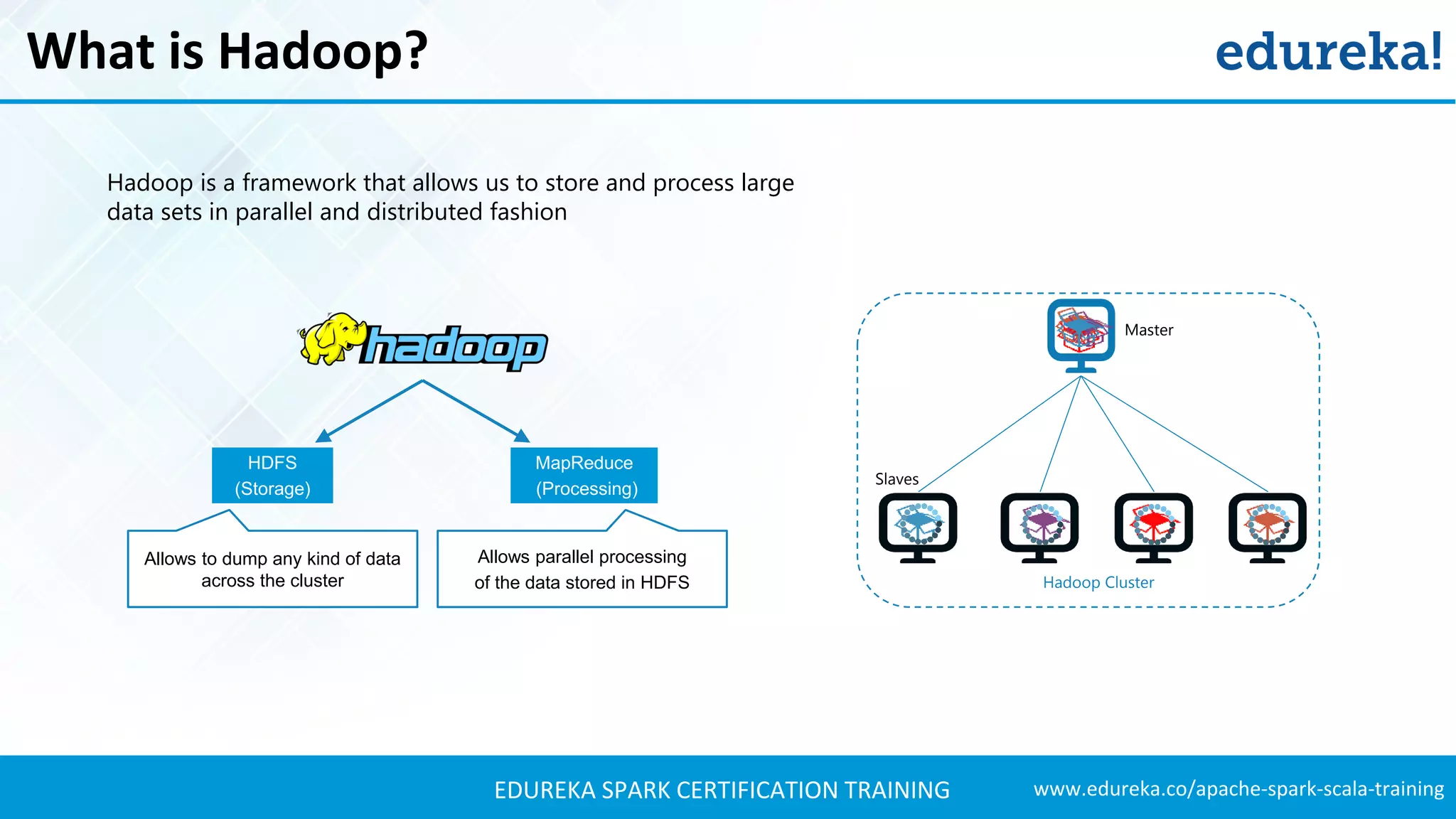
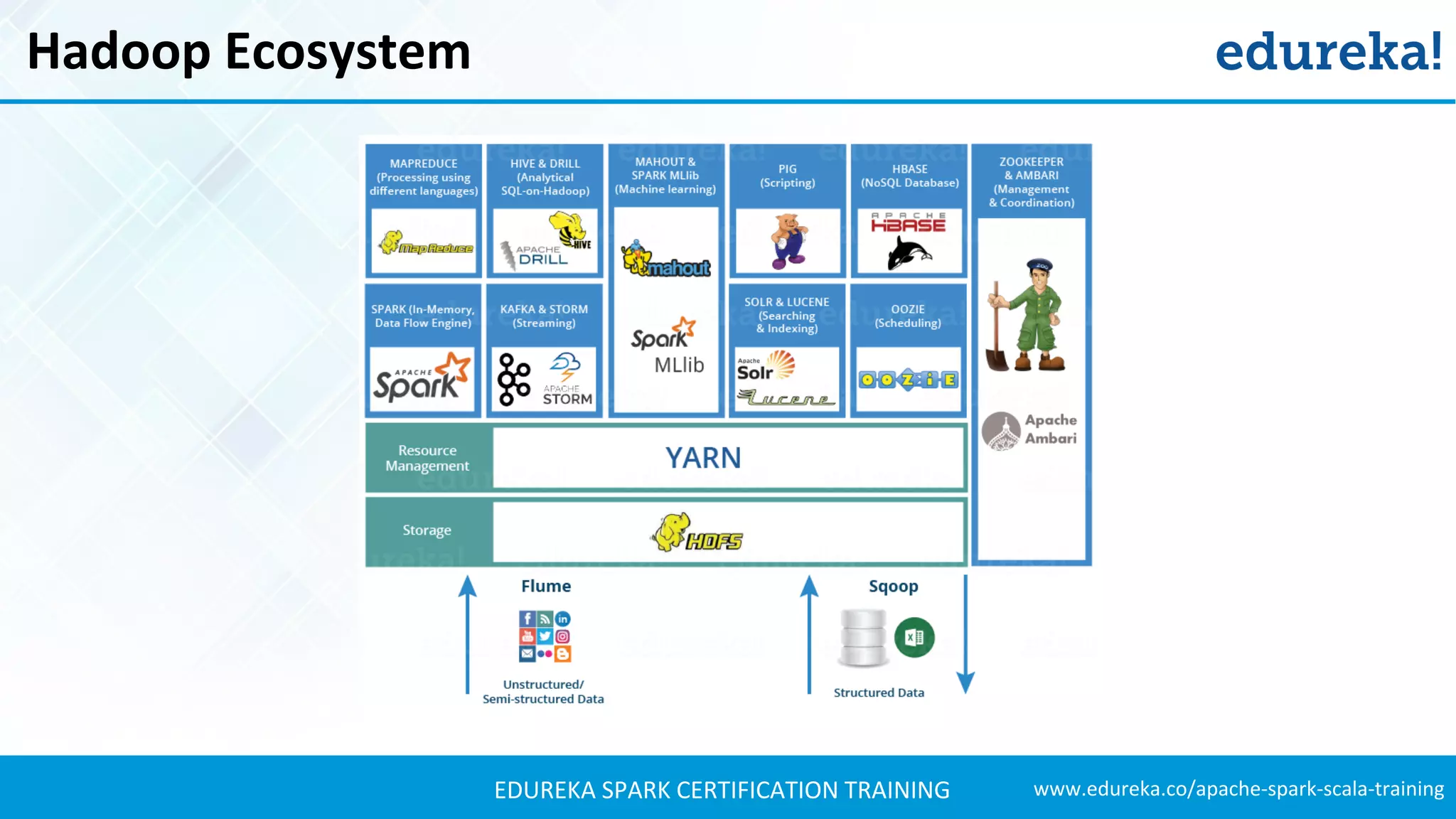
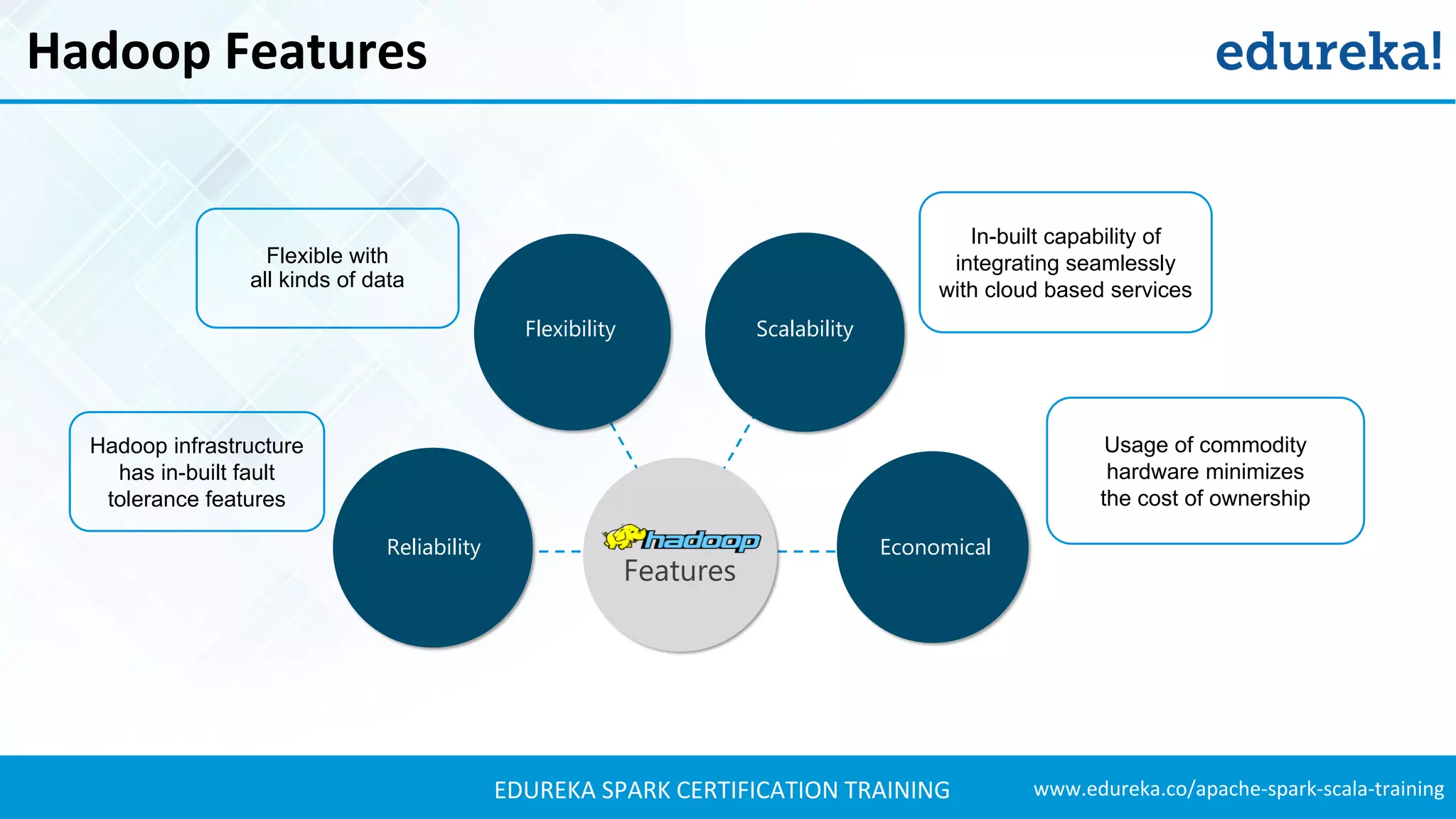
The document provides an extensive overview of Apache Spark and its integration with Hadoop for real-time data processing, detailing features, ecosystem components, and use cases such as sports analysis and banking fraud detection. It outlines the differences between Spark and Hadoop, emphasizing Spark's speed and efficiency through in-memory processing. Additionally, practical applications and sample code for using Spark in sports analytics are included to illustrate its capabilities.