Downloaded 232 times














![@doanduyhai Remember token ranges ?! A: ]0, X/8] B: ] X/8, 2X/8] C: ] 2X/8, 3X/8] D: ] 3X/8, 4X/8] E: ] 4X/8, 5X/8] F: ] 5X/8, 6X/8] G: ] 6X/8, 7X/8] H: ] 7X/8, X] n1 n2 n3 n4 n5 n6 n7 n8 A B C D E F G H 16](https://image.slidesharecdn.com/sparkcassandraconnector-apibestpracticesanduse-cases-150421071716-conversion-gate01/75/Spark-cassandra-connector-API-Best-Practices-and-Use-Cases-16-2048.jpg)
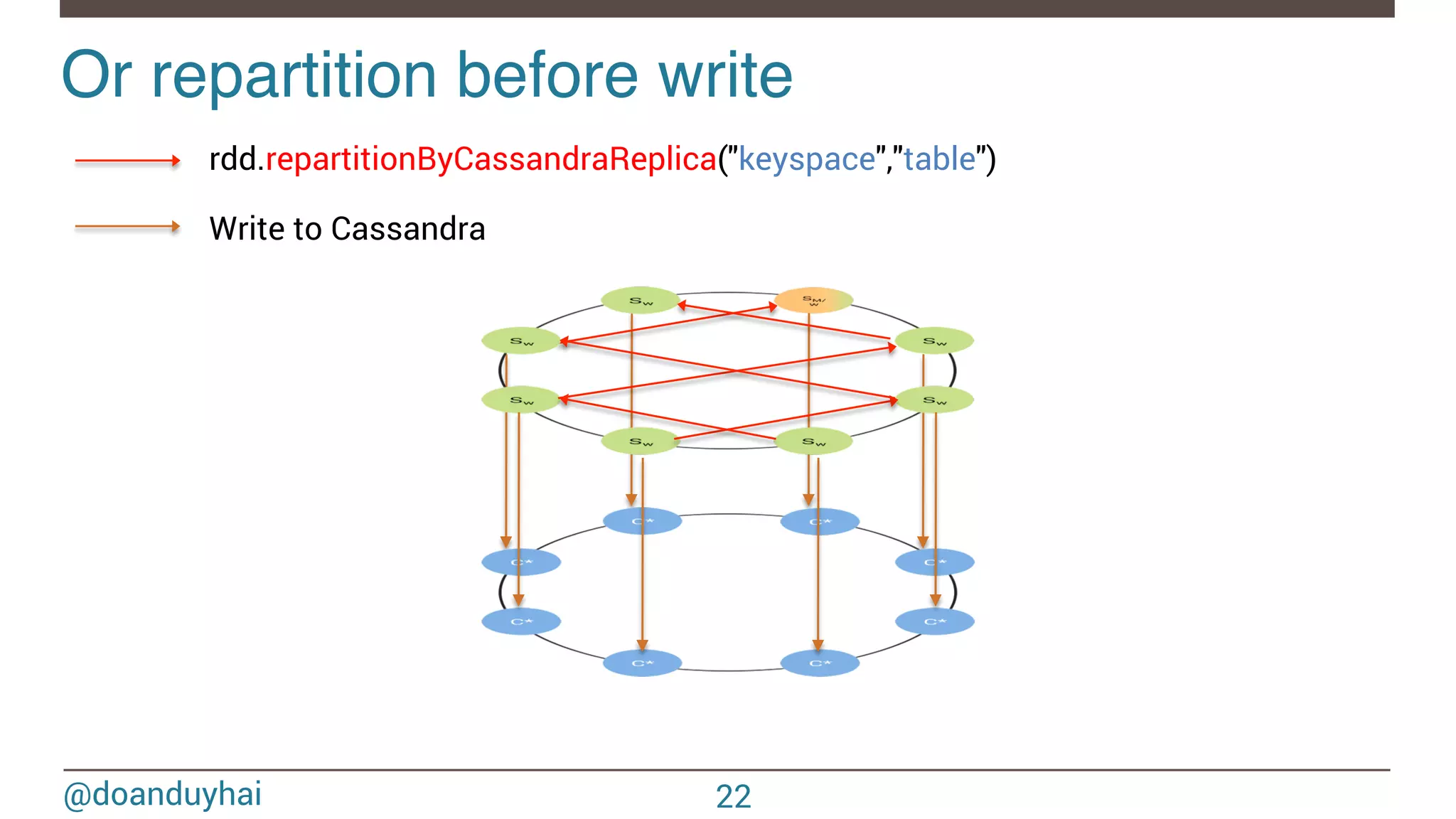
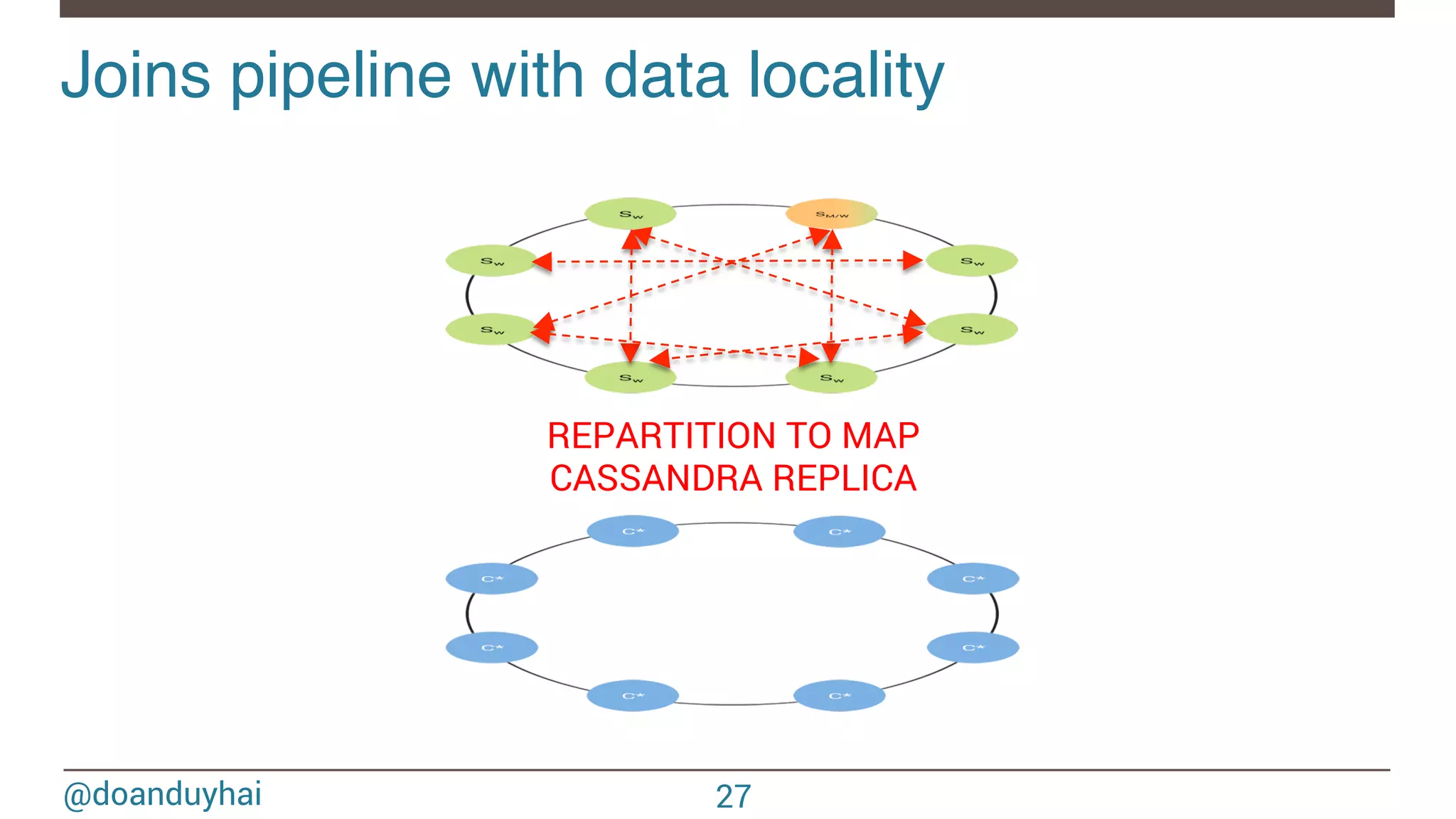
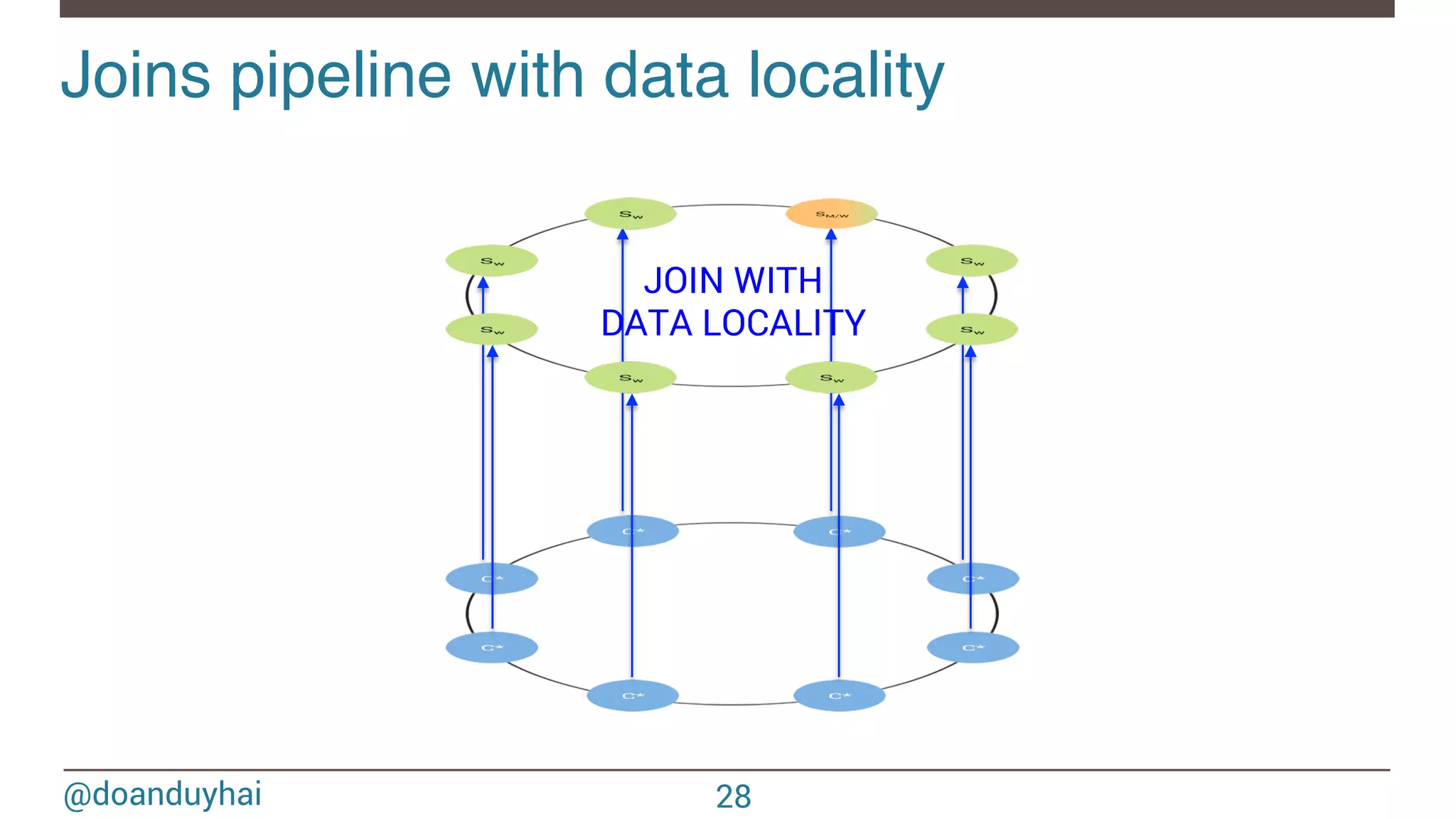
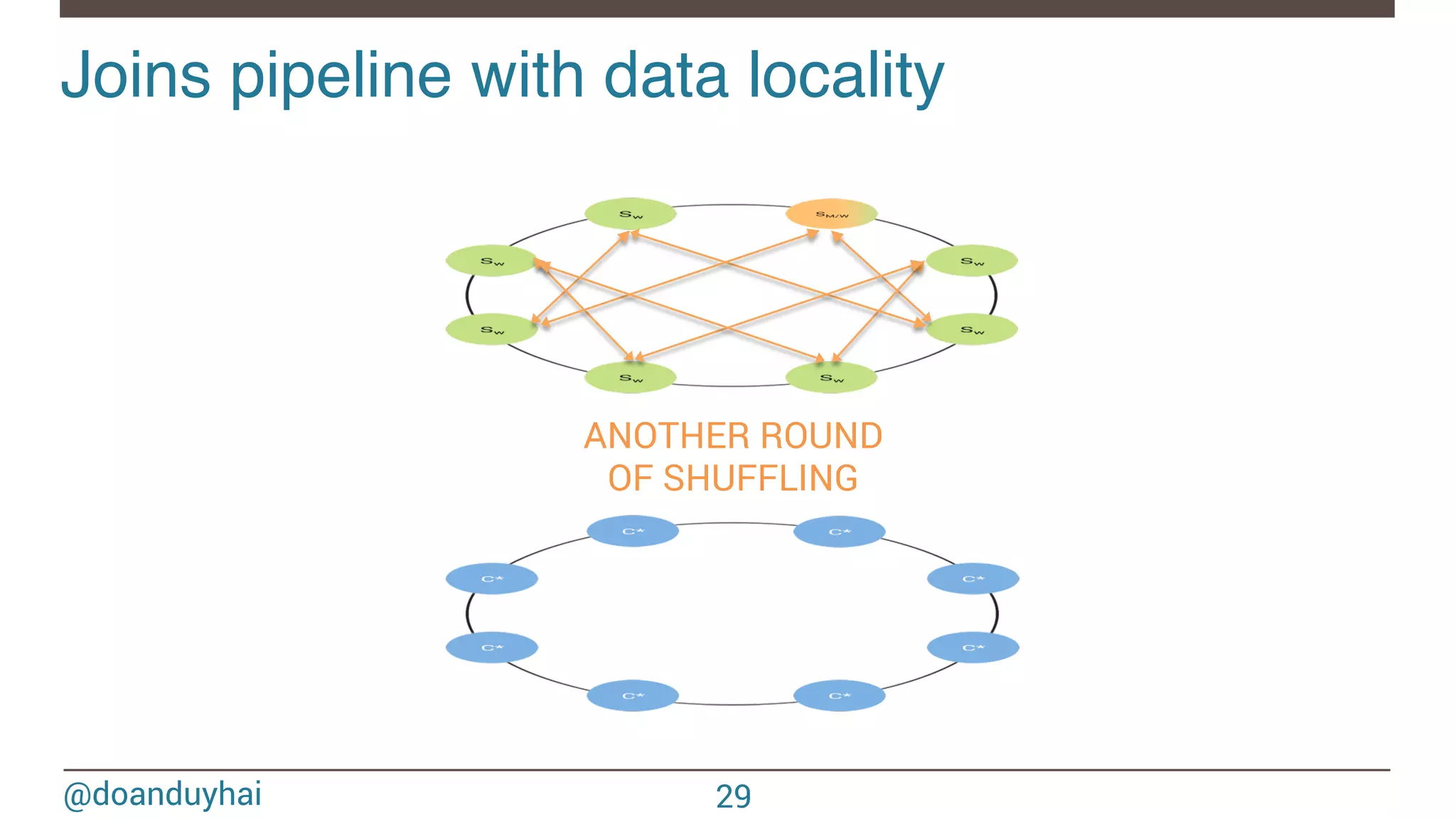
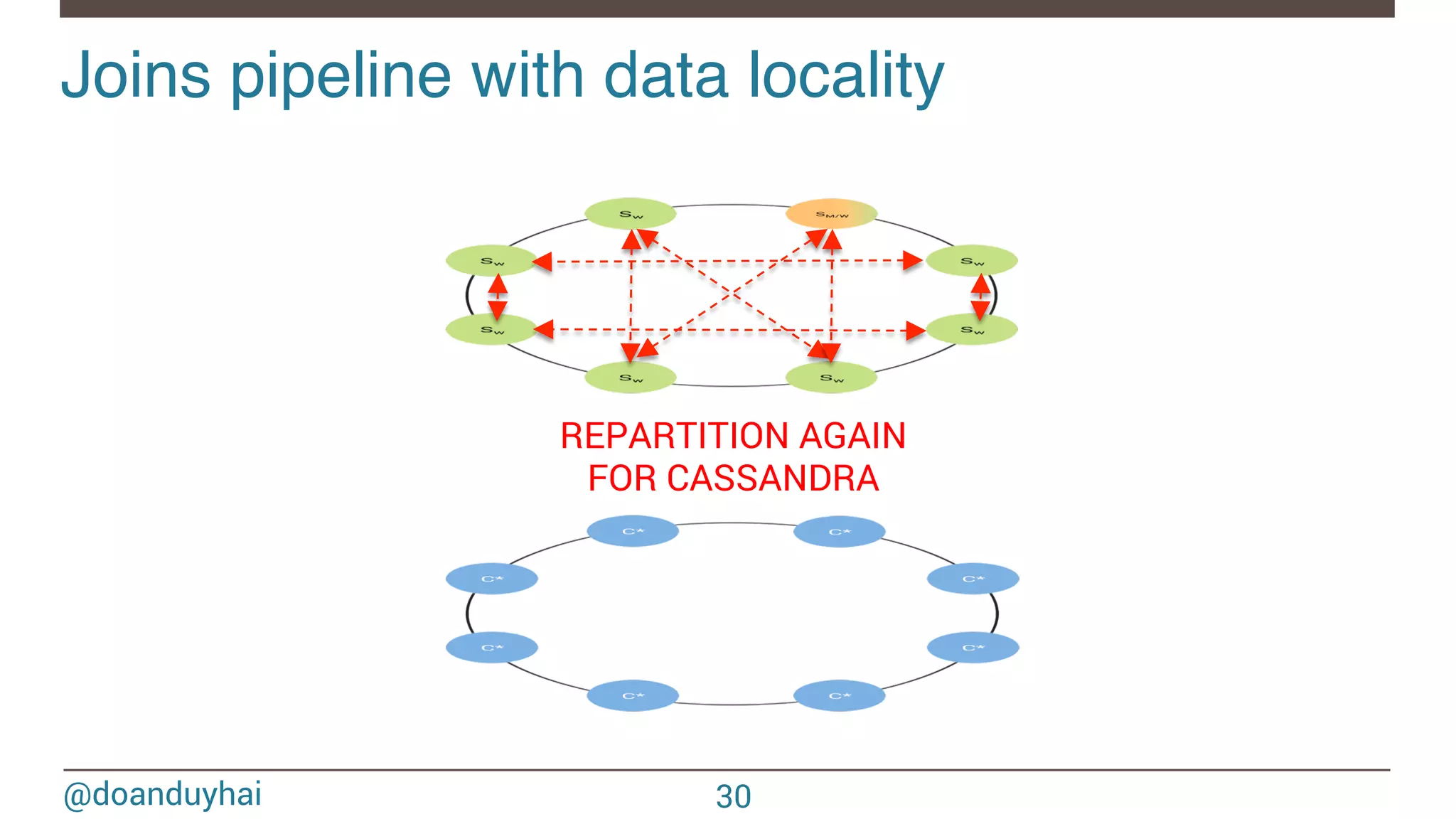
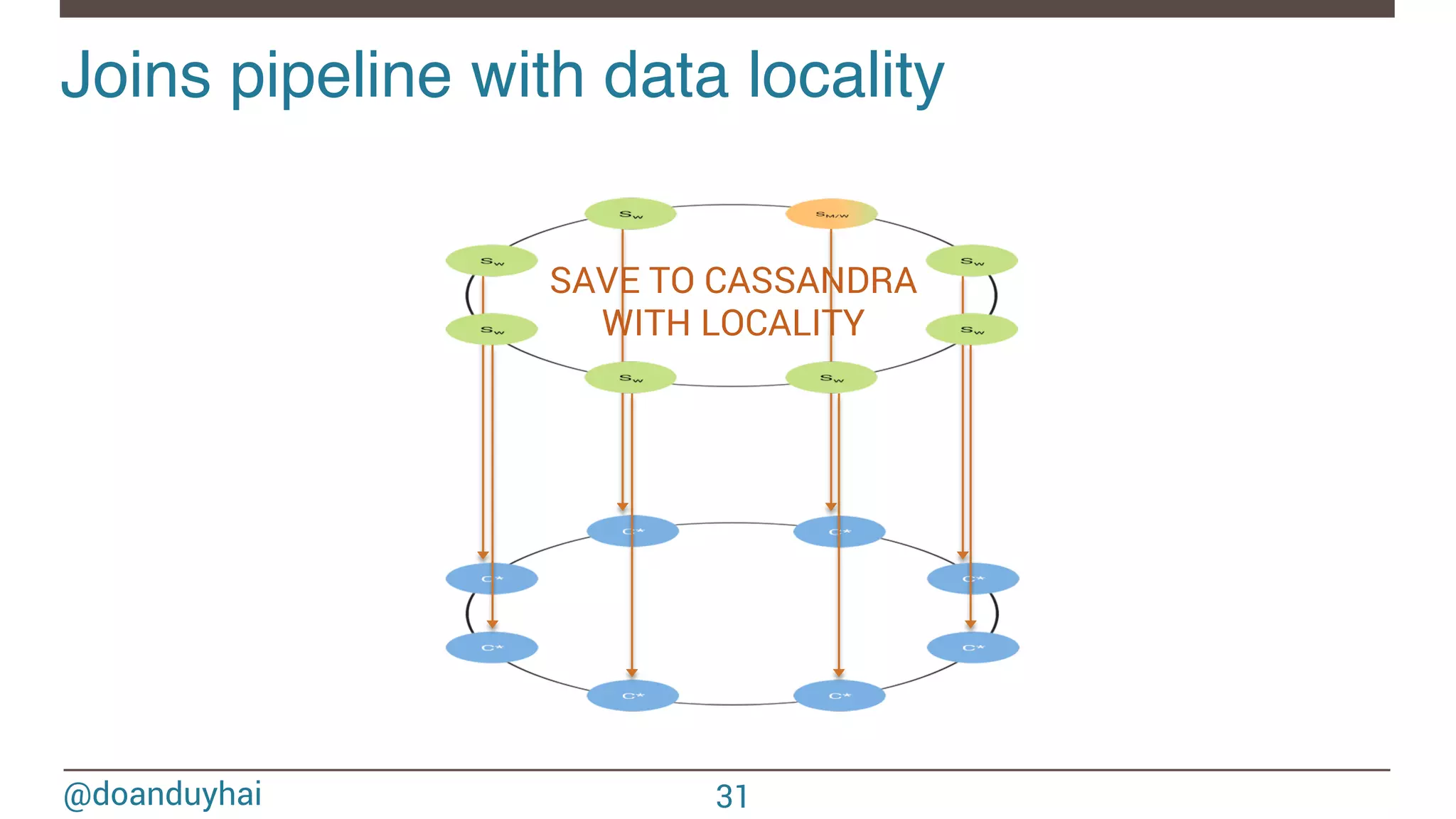
![@doanduyhai Joins with data locality! 24 CREATE TABLE artists(name text, style text, … PRIMARY KEY(name)); CREATE TABLE albums(title text, artist text, year int,… PRIMARY KEY(title)); val join: CassandraJoinRDD[(String,Int), (String,String)] = sc.cassandraTable[(String,Int)](KEYSPACE, ALBUMS) // Select only useful columns for join and processing .select("artist","year") .as((_:String, _:Int)) // Repartition RDDs by "artists" PK, which is "name" .repartitionByCassandraReplica(KEYSPACE, ARTISTS) // Join with "artists" table, selecting only "name" and "country" columns .joinWithCassandraTable[(String,String)](KEYSPACE, ARTISTS, SomeColumns("name","country")) .on(SomeColumns("name"))](https://image.slidesharecdn.com/sparkcassandraconnector-apibestpracticesanduse-cases-150421071716-conversion-gate01/75/Spark-cassandra-connector-API-Best-Practices-and-Use-Cases-24-2048.jpg)



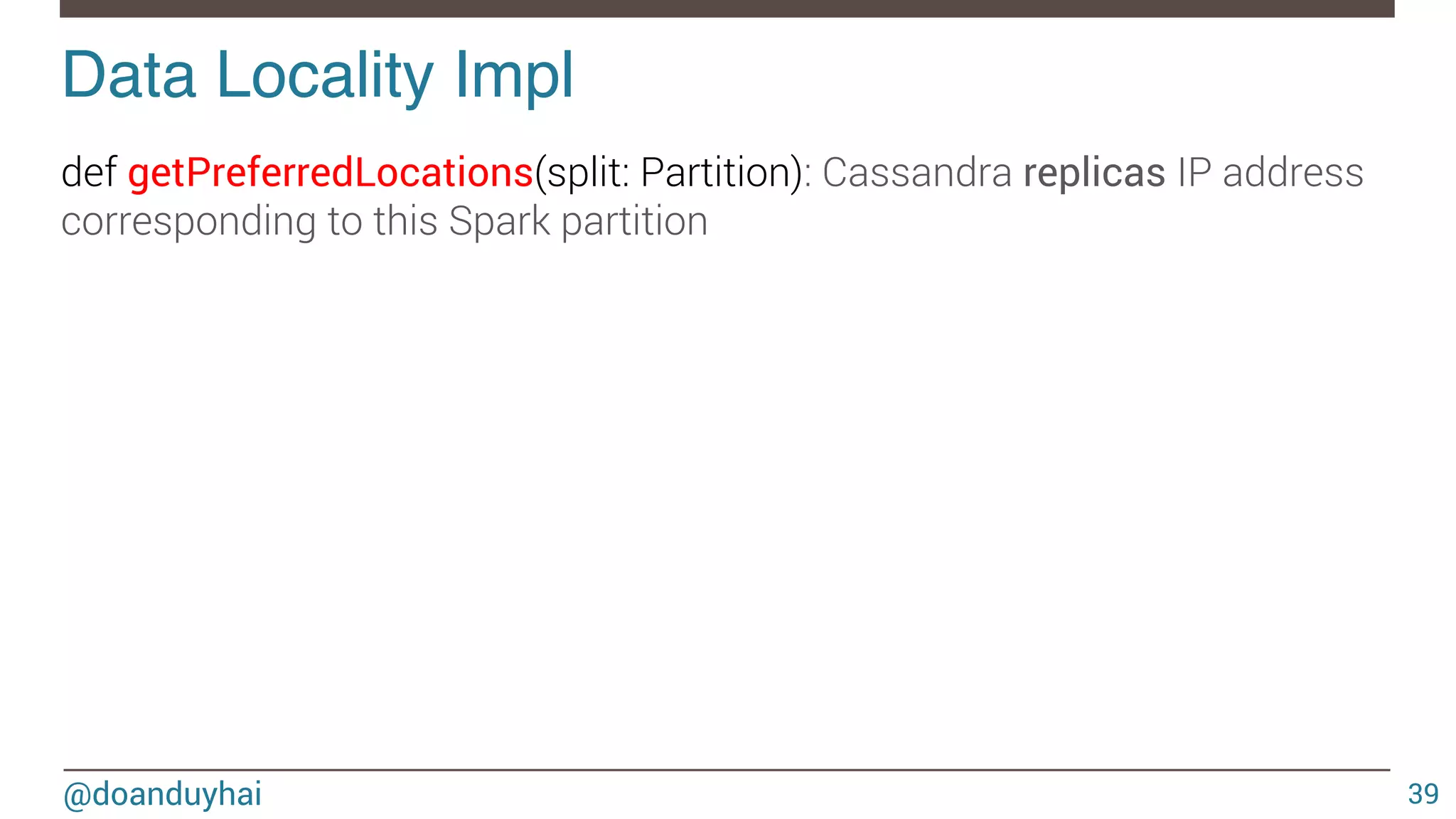
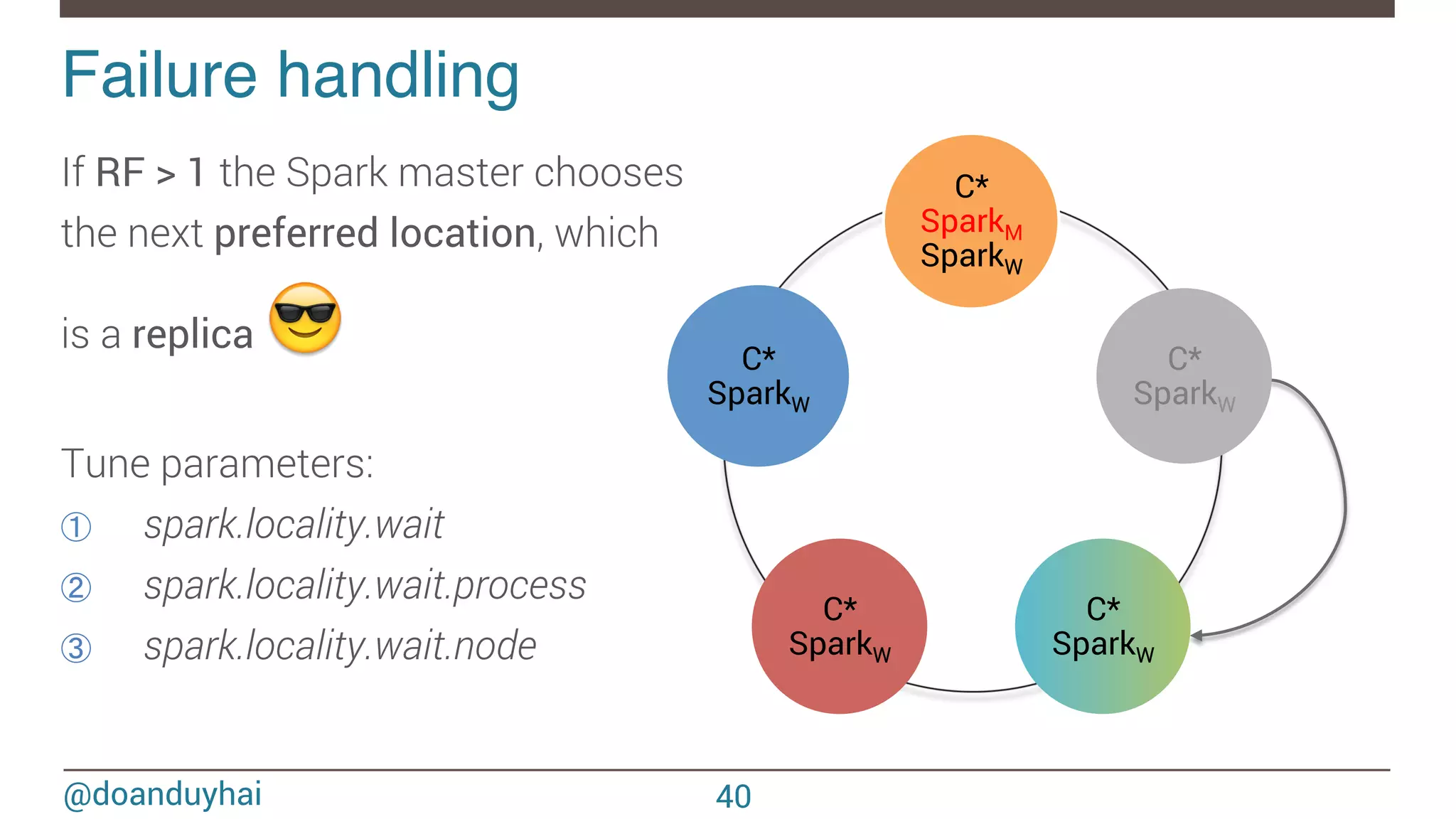
'{' ' @DeveloperApi' ' def'compute(split:'Partition,'context:'TaskContext):'Iterator[T]' ' ' protected'def'getPartitions:'Array[Partition]' ' ' ' protected'def'getPreferredLocations(split:'Partition):'Seq[String]'='Nil'''''''' }'](https://image.slidesharecdn.com/sparkcassandraconnector-apibestpracticesanduse-cases-150421071716-conversion-gate01/75/Spark-cassandra-connector-API-Best-Practices-and-Use-Cases-38-2048.jpg)
 .map[Performer](???) .saveToCassandra(KEYSPACE,PERFORMERS) (CassandraConnector(confDC2),implicitly[RowWriterFactory[Performer]]) Cross-DC operations! 41](https://image.slidesharecdn.com/sparkcassandraconnector-apibestpracticesanduse-cases-150421071716-conversion-gate01/75/Spark-cassandra-connector-API-Best-Practices-and-Use-Cases-41-2048.jpg)
 .map[Performer](???) .saveToCassandra(KEYSPACE,PERFORMERS) (CassandraConnector(confCluster2),implicitly[RowWriterFactory[Performer]]) Cross-cluster operations! 42](https://image.slidesharecdn.com/sparkcassandraconnector-apibestpracticesanduse-cases-150421071716-conversion-gate01/75/Spark-cassandra-connector-API-Best-Practices-and-Use-Cases-42-2048.jpg)












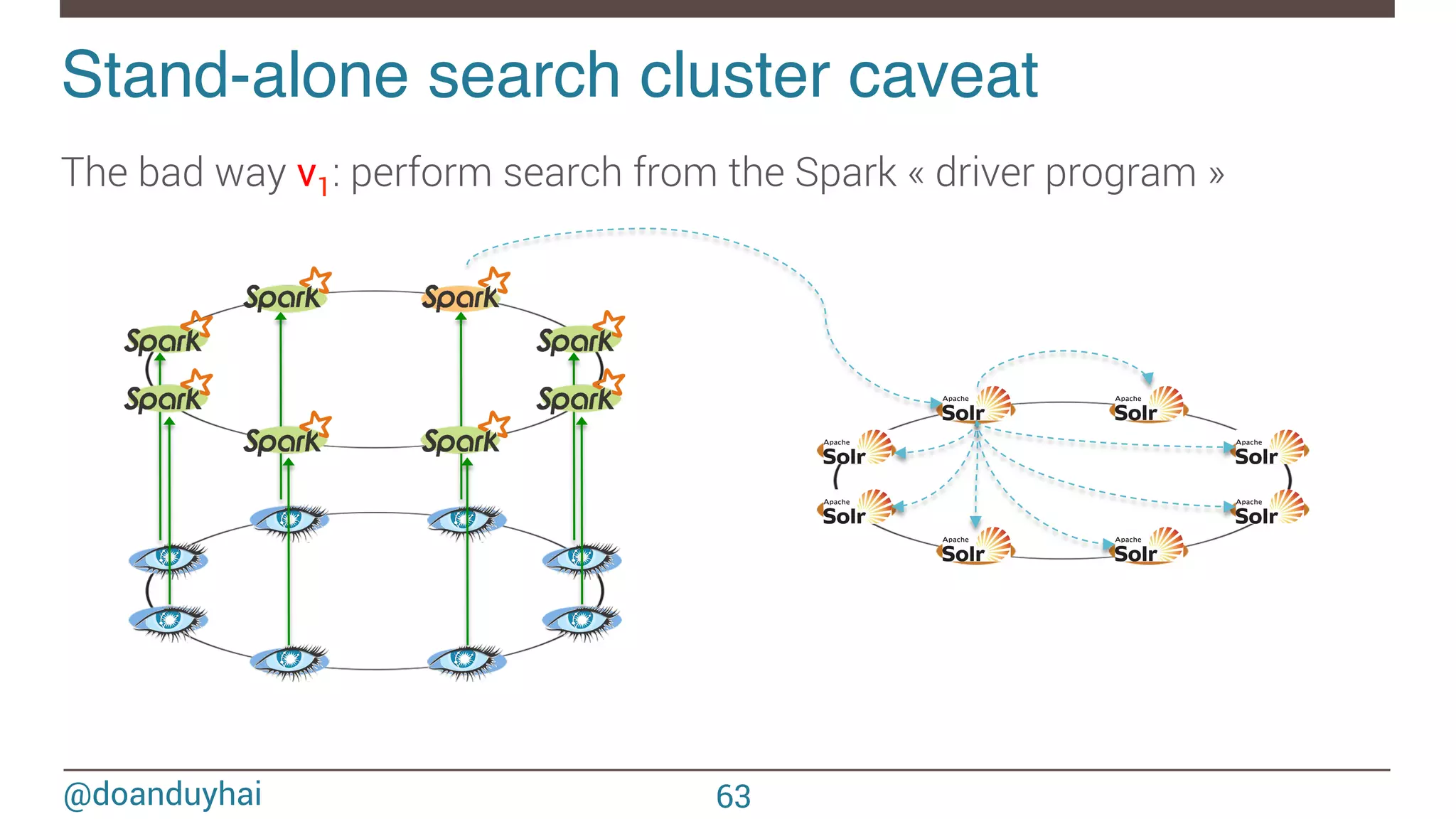
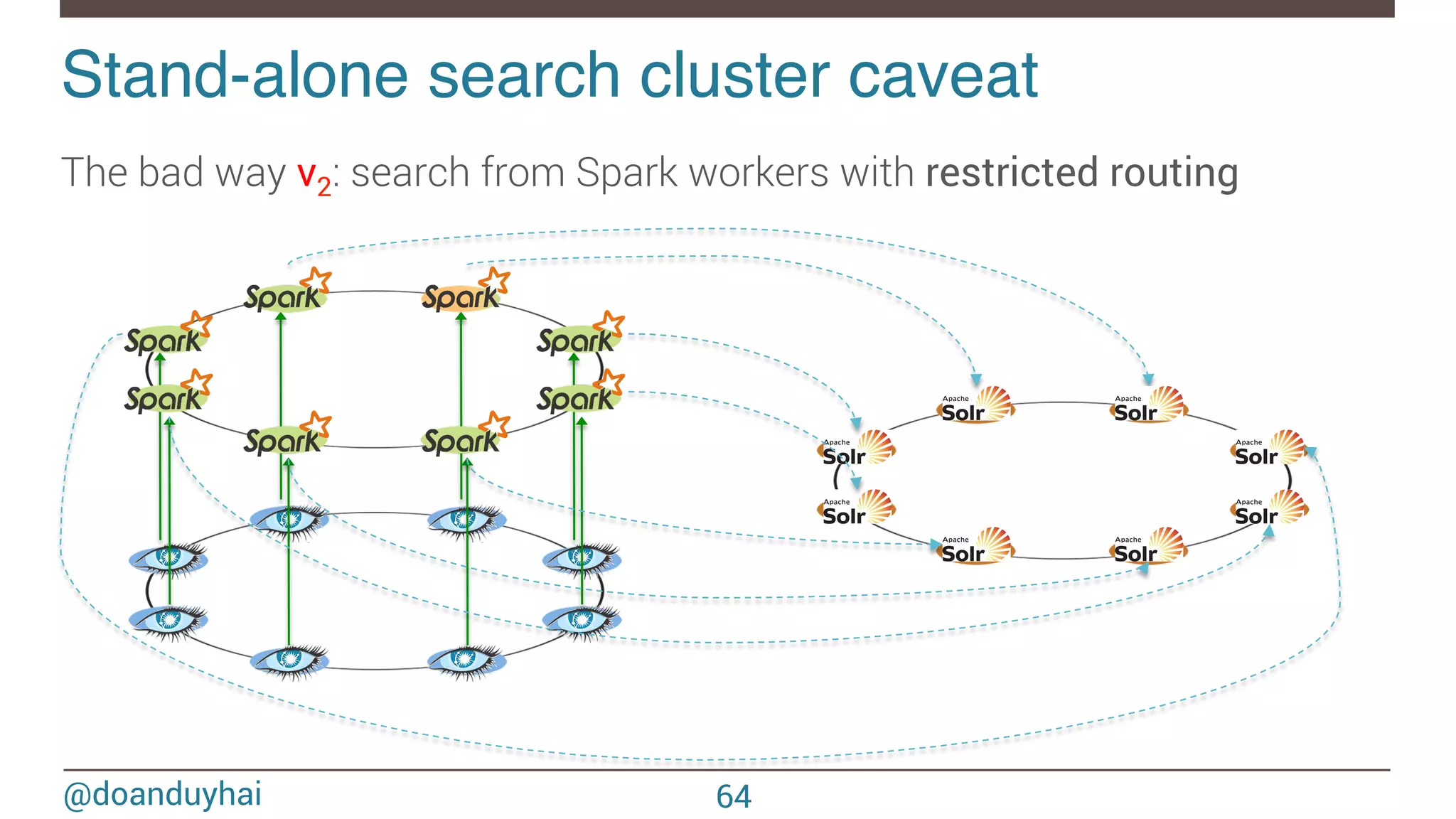
![@doanduyhai Until now in Datastax Enterprise! Cassandra + Solr in same JVM Unlock full text search power for Cassandra CQL syntax extension 56 SELECT * FROM users WHERE solr_query = ‘age:[33 TO *] AND gender:male’; SELECT * FROM users WHERE solr_query = ‘lastname:*schwei?er’;](https://image.slidesharecdn.com/sparkcassandraconnector-apibestpracticesanduse-cases-150421071716-conversion-gate01/75/Spark-cassandra-connector-API-Best-Practices-and-Use-Cases-56-2048.jpg)






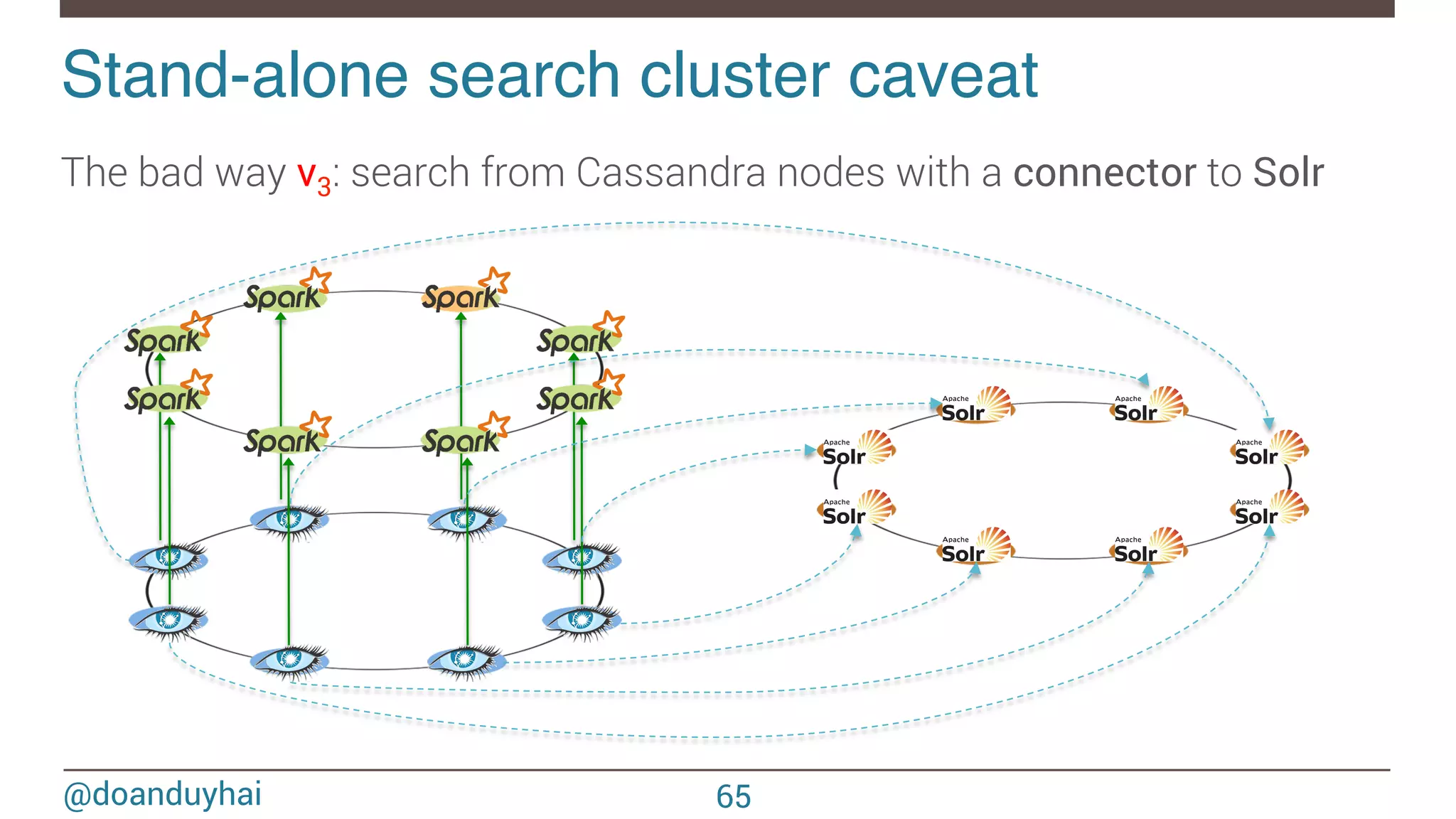

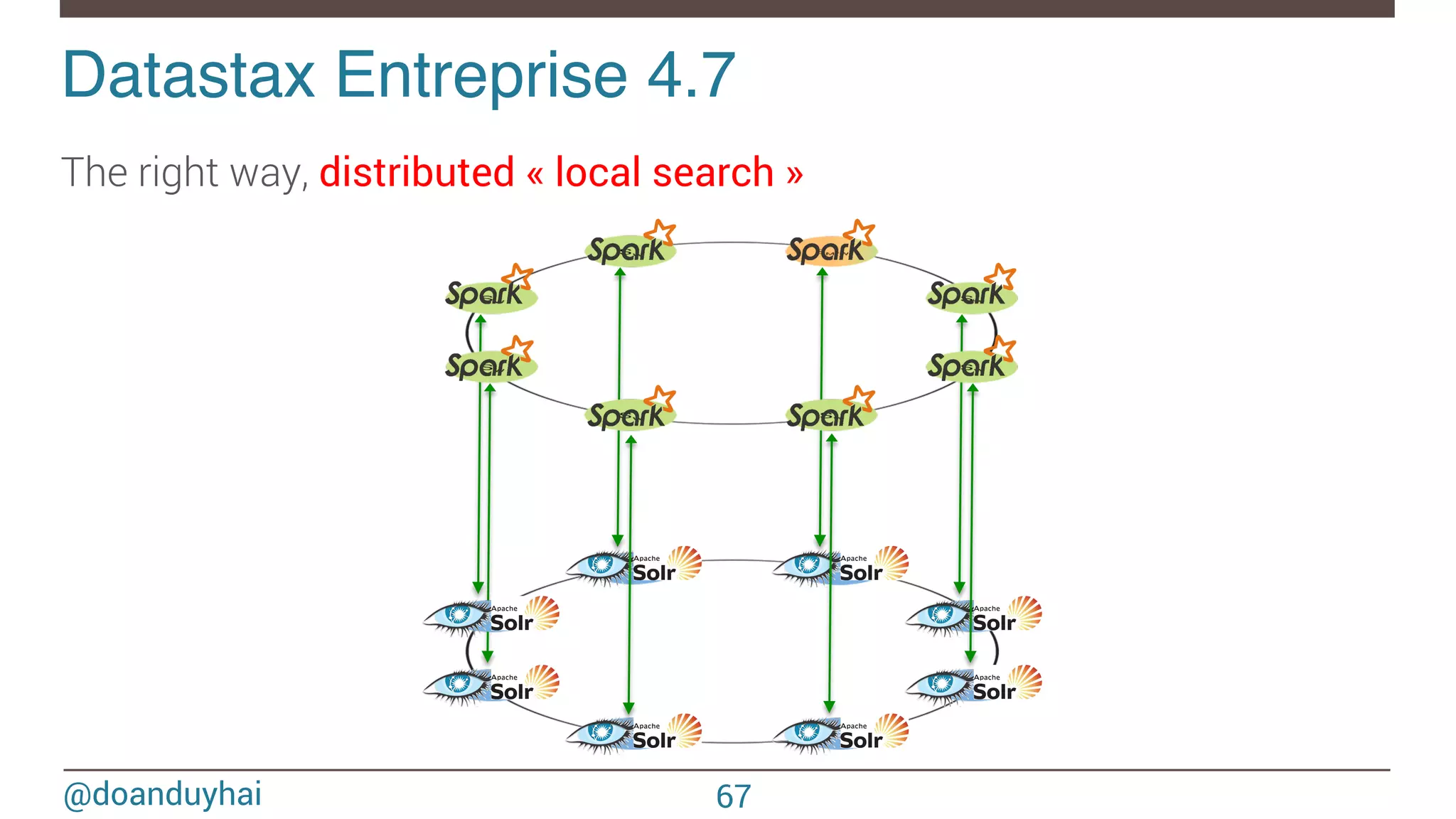
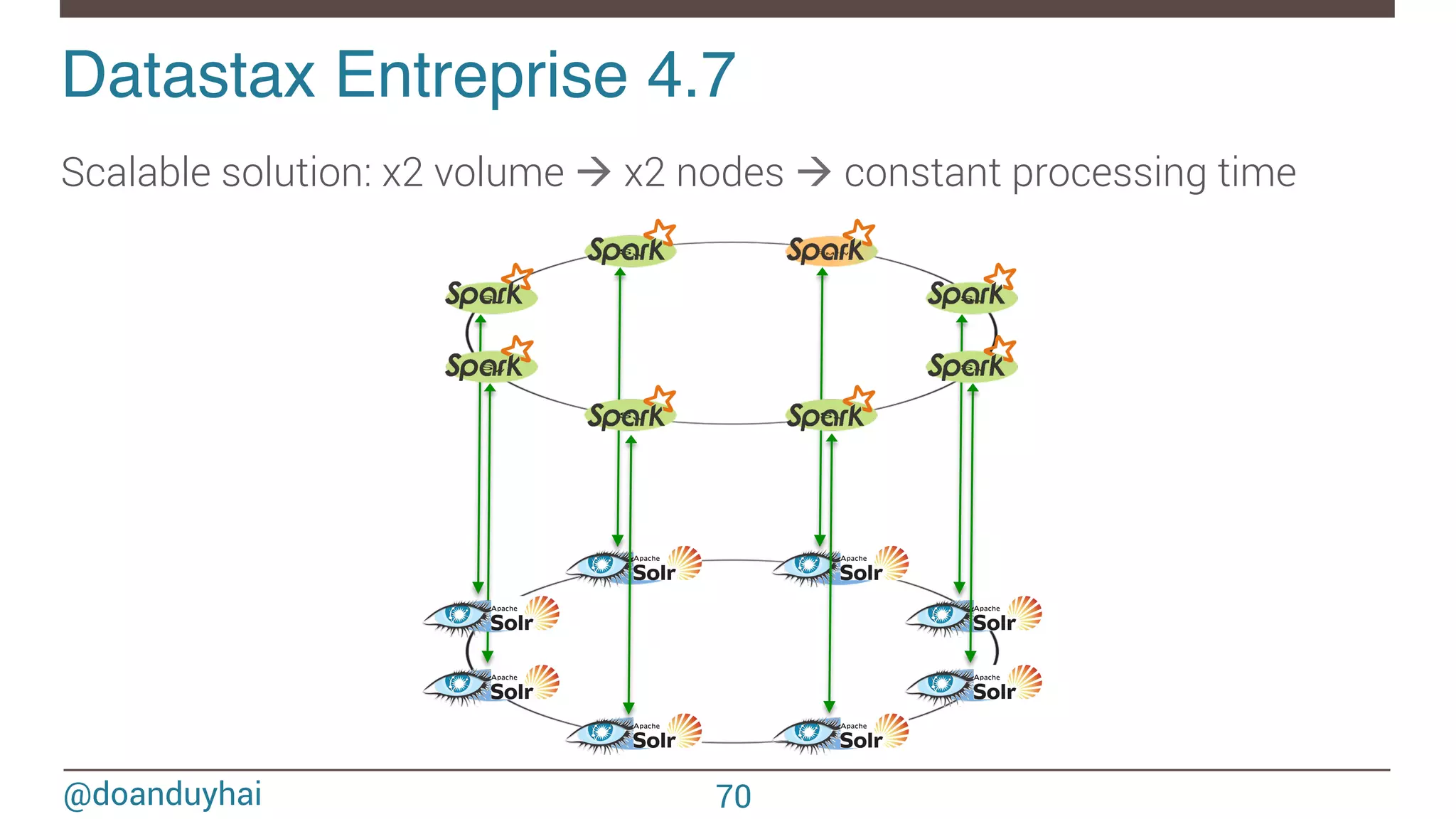
![@doanduyhai val join: CassandraJoinRDD[(String,Int), (String,String)] = sc.cassandraTable[(String,Int)](KEYSPACE, ALBUMS) // Select only useful columns for join and processing .select("artist","year").where("solr_query = 'style:*rock* AND ratings:[3 TO *]' ") .as((_:String, _:Int)) .repartitionByCassandraReplica(KEYSPACE, ARTISTS) .joinWithCassandraTable[(String,String)](KEYSPACE, ARTISTS, SomeColumns("name","country")) .on(SomeColumns("name")).where("solr_query = 'age:[20 TO 30]' ") Datastax Entreprise 4.7! ① compute Spark partitions using Cassandra token ranges ② on each partition, use Solr for local data filtering (no distributed query!) ③ fetch data back into Spark for aggregations 68](https://image.slidesharecdn.com/sparkcassandraconnector-apibestpracticesanduse-cases-150421071716-conversion-gate01/75/Spark-cassandra-connector-API-Best-Practices-and-Use-Cases-68-2048.jpg)
![@doanduyhai Datastax Entreprise 4.7! 69 SELECT … FROM … WHERE token(#partition)> 3X/8 AND token(#partition)<= 4X/8 AND solr_query='full text search expression'; 1 2 3 Advantages of same JVM Cassandra + Solr integration 1 Single-pass local full text search (no fan out) 2 Data retrieval Token Range : ] 3X/8, 4X/8]](https://image.slidesharecdn.com/sparkcassandraconnector-apibestpracticesanduse-cases-150421071716-conversion-gate01/75/Spark-cassandra-connector-API-Best-Practices-and-Use-Cases-69-2048.jpg)




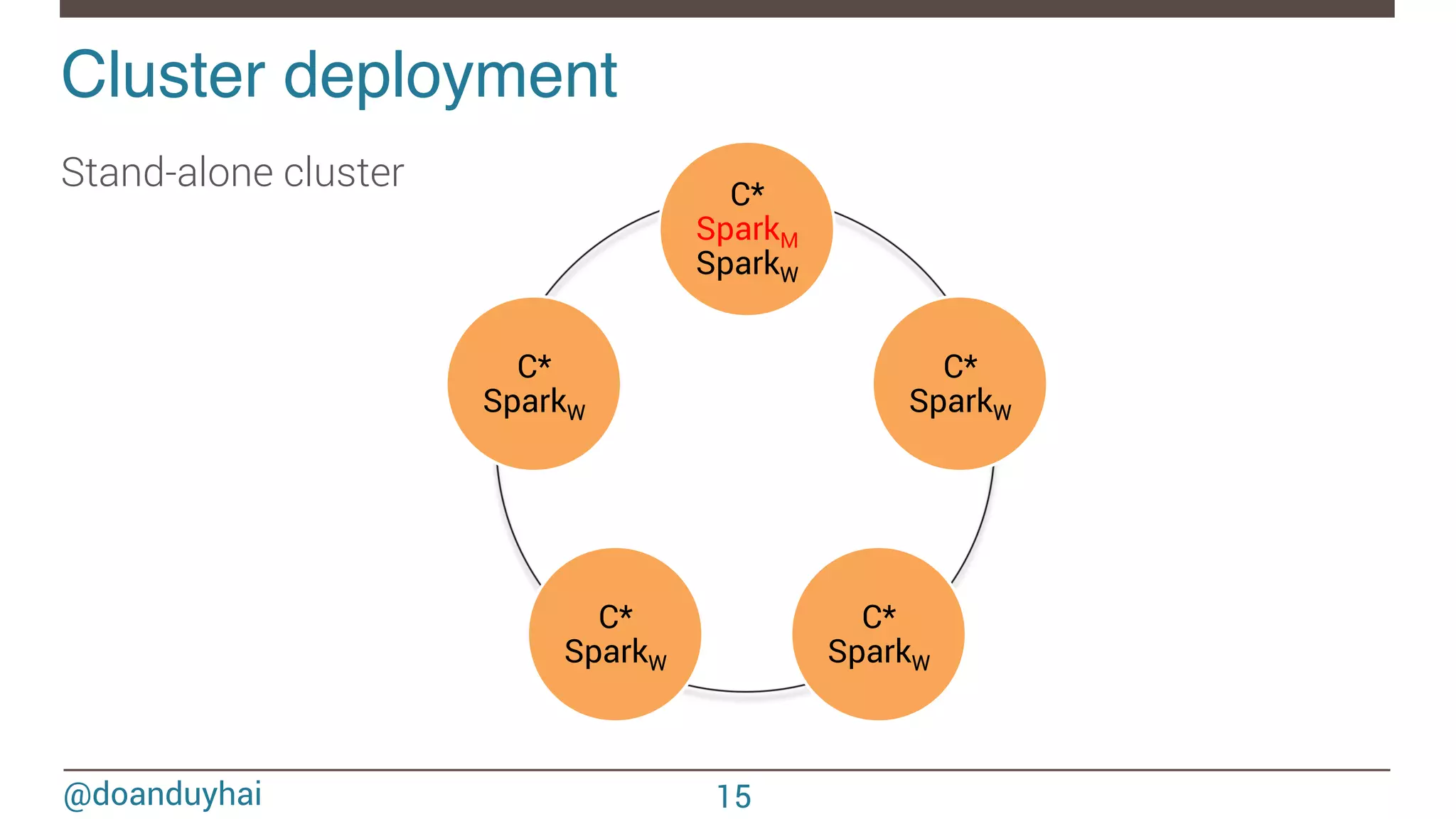
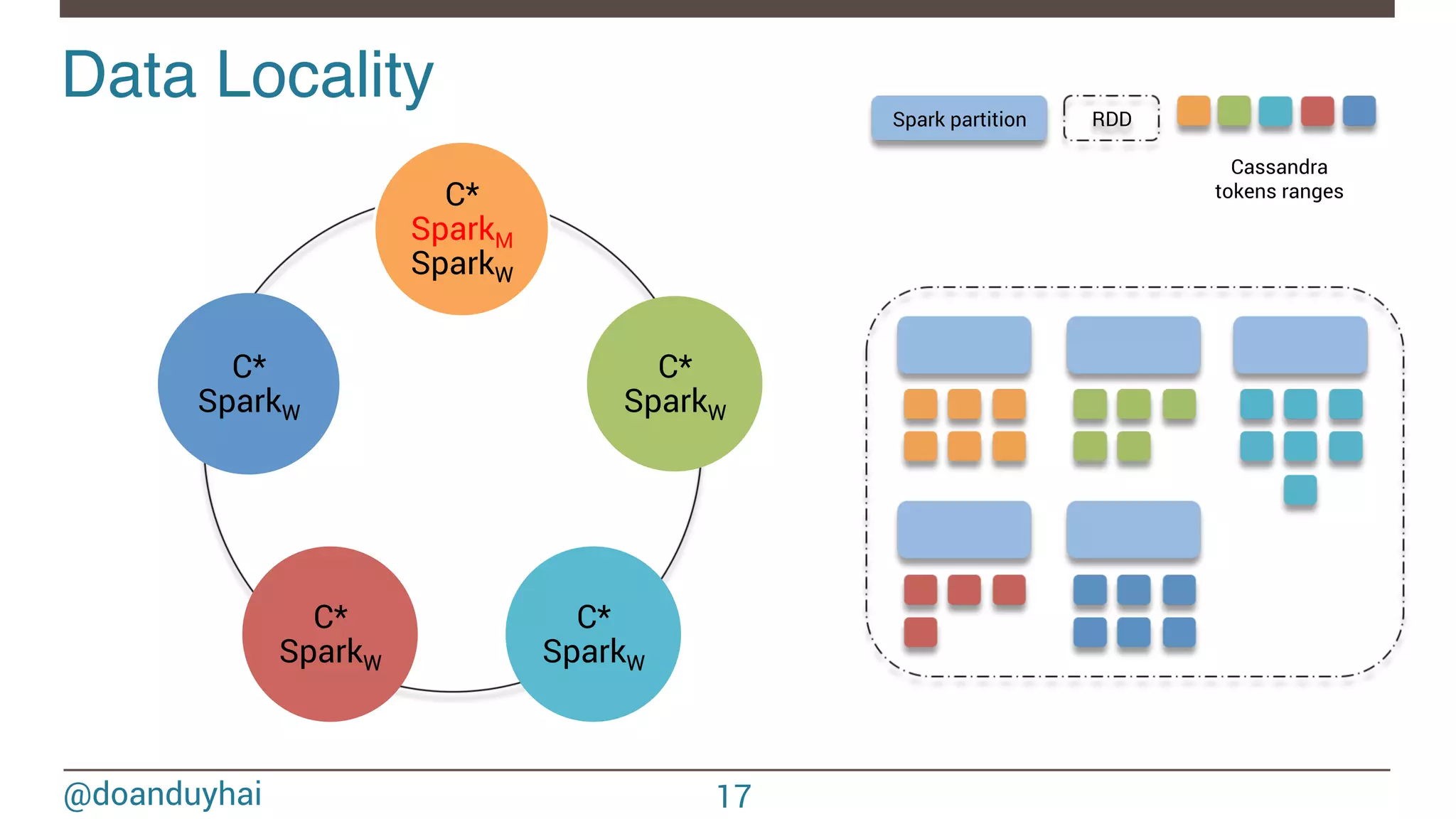
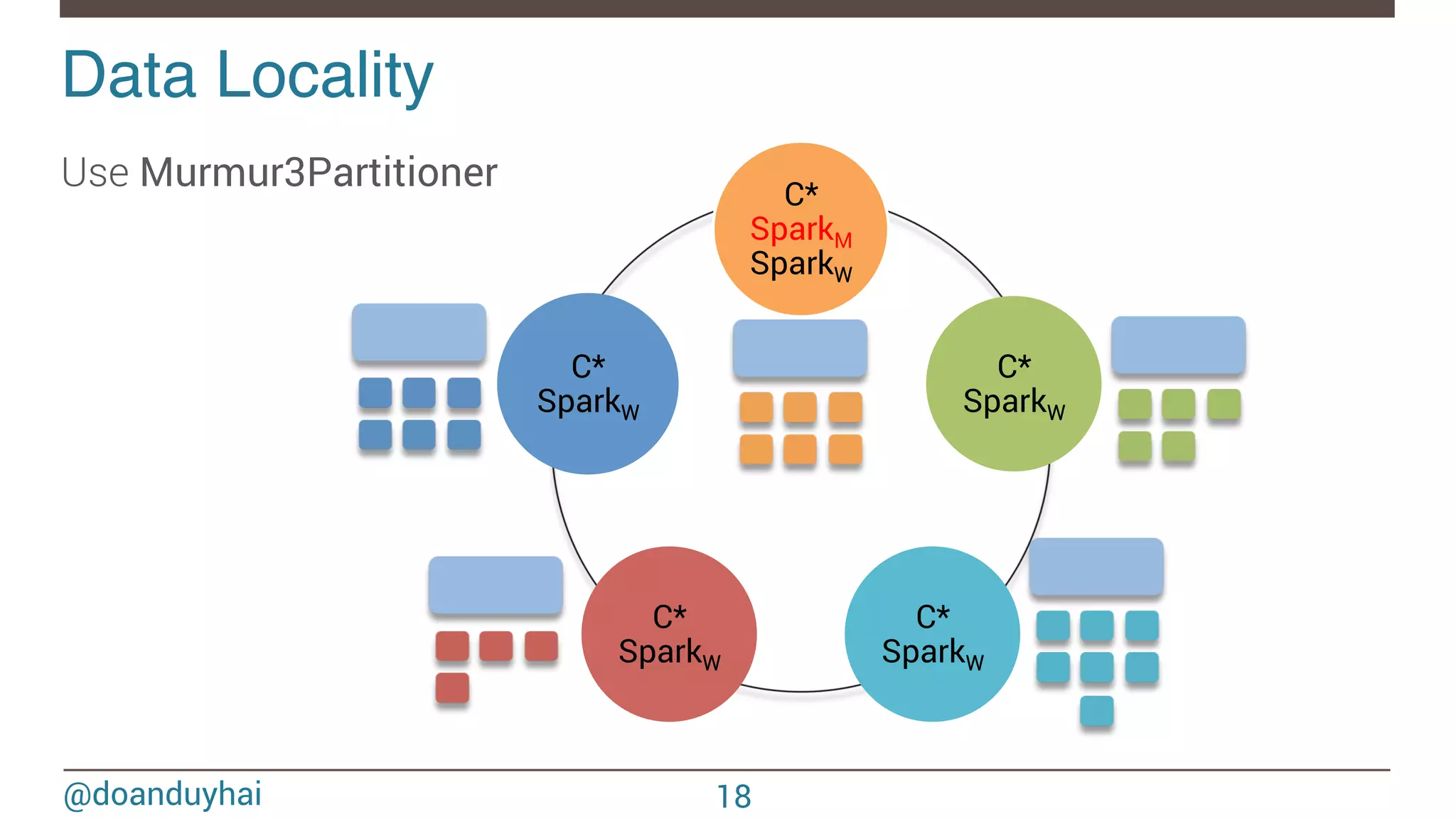
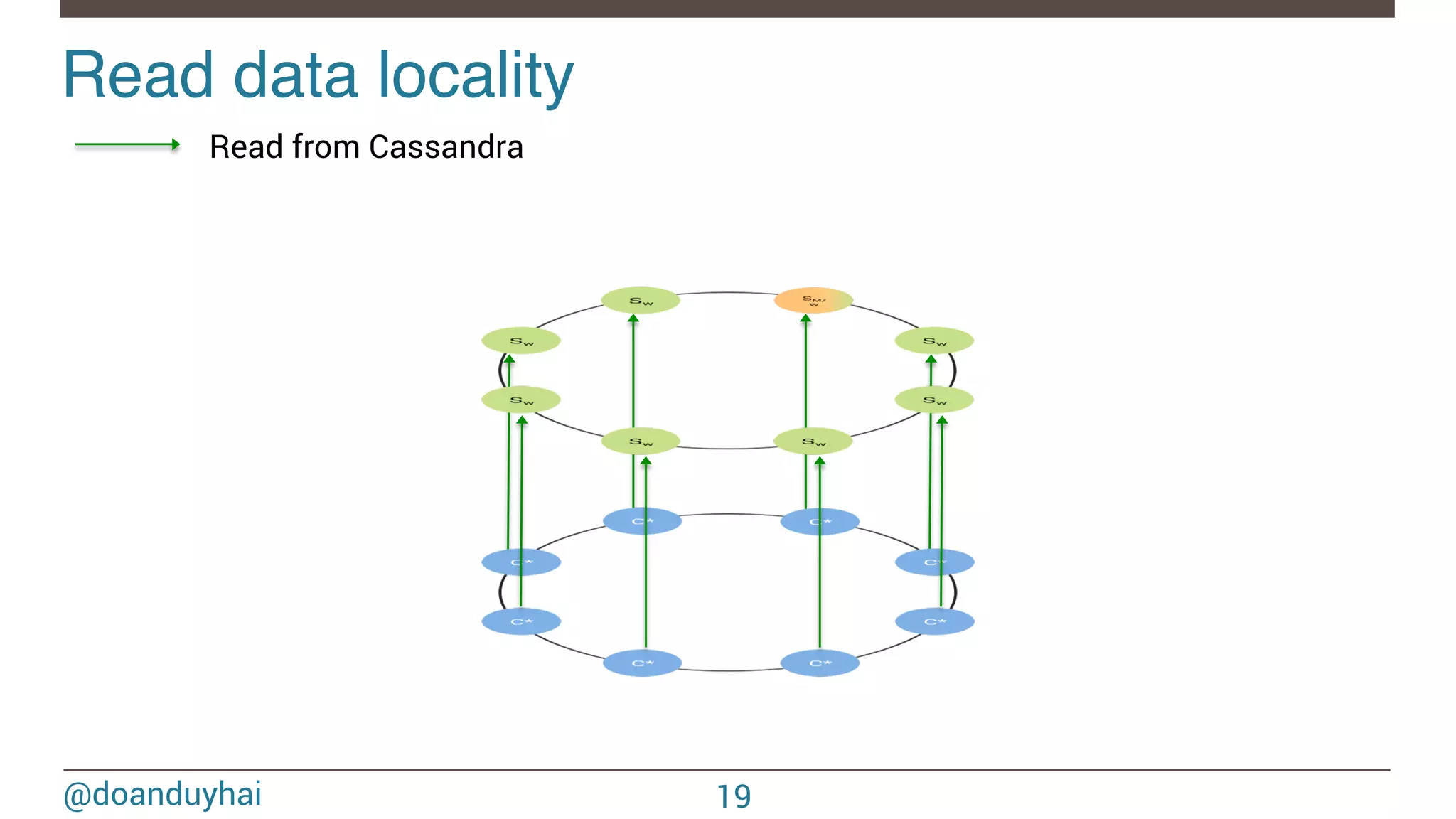
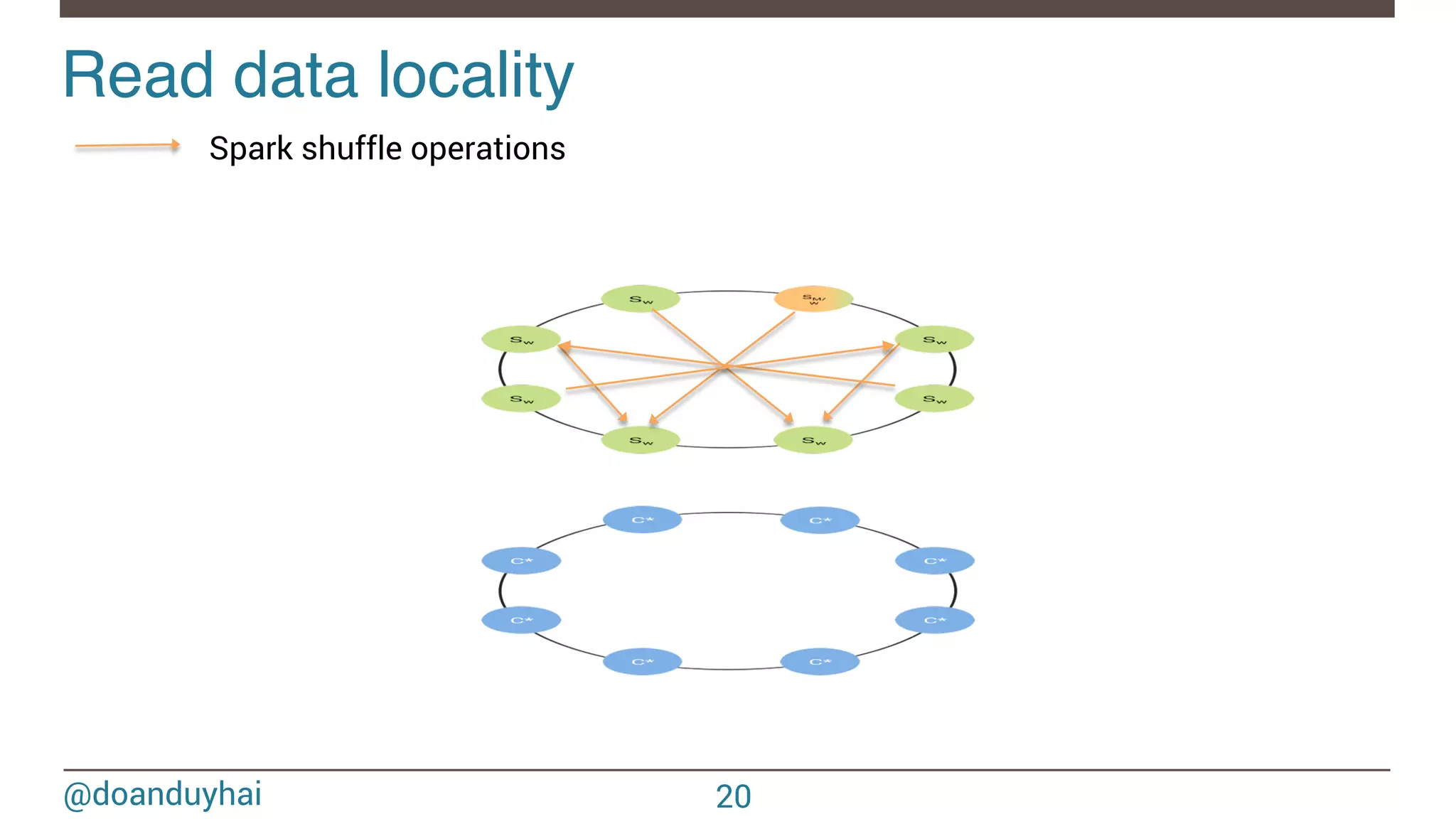
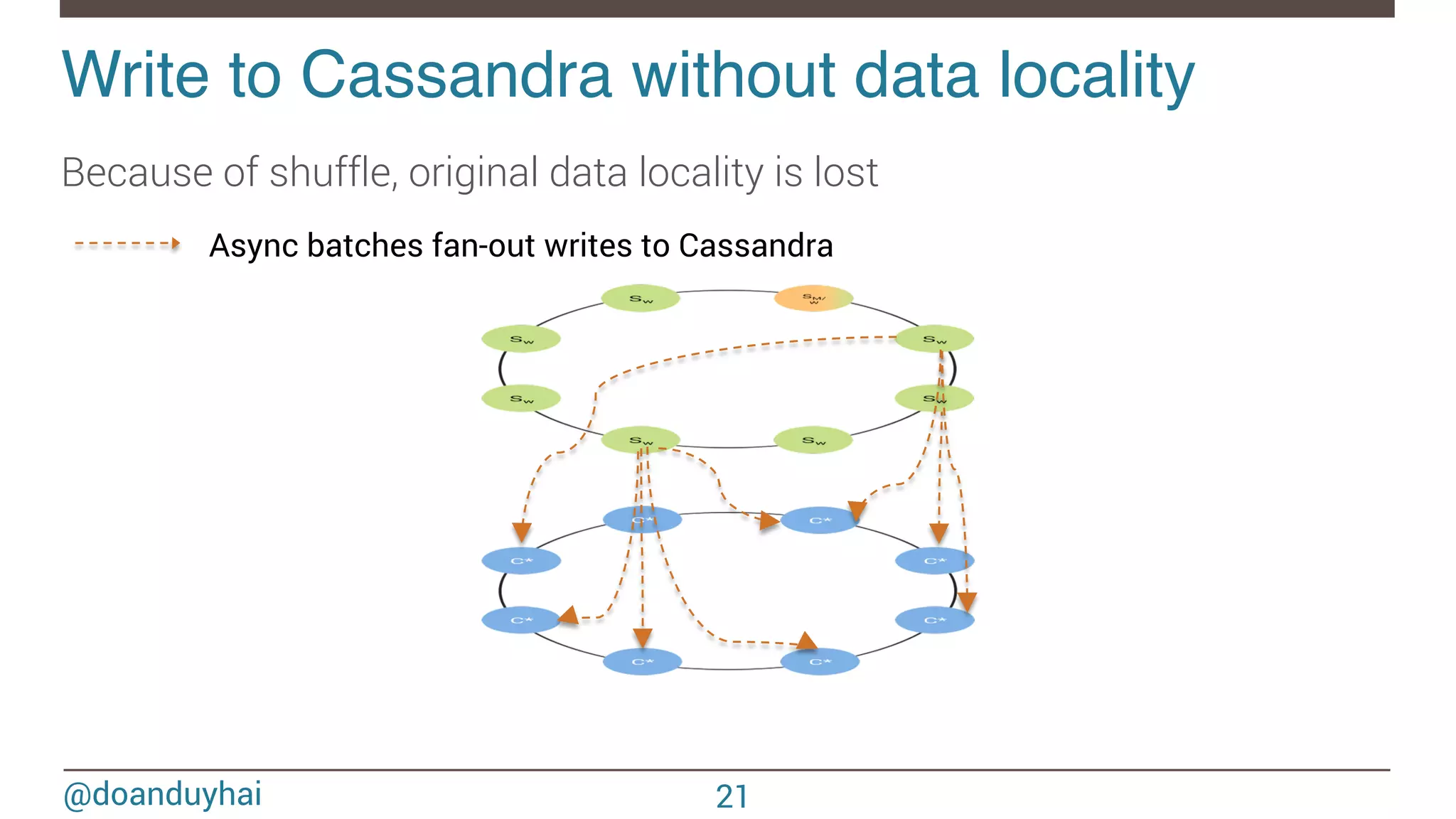
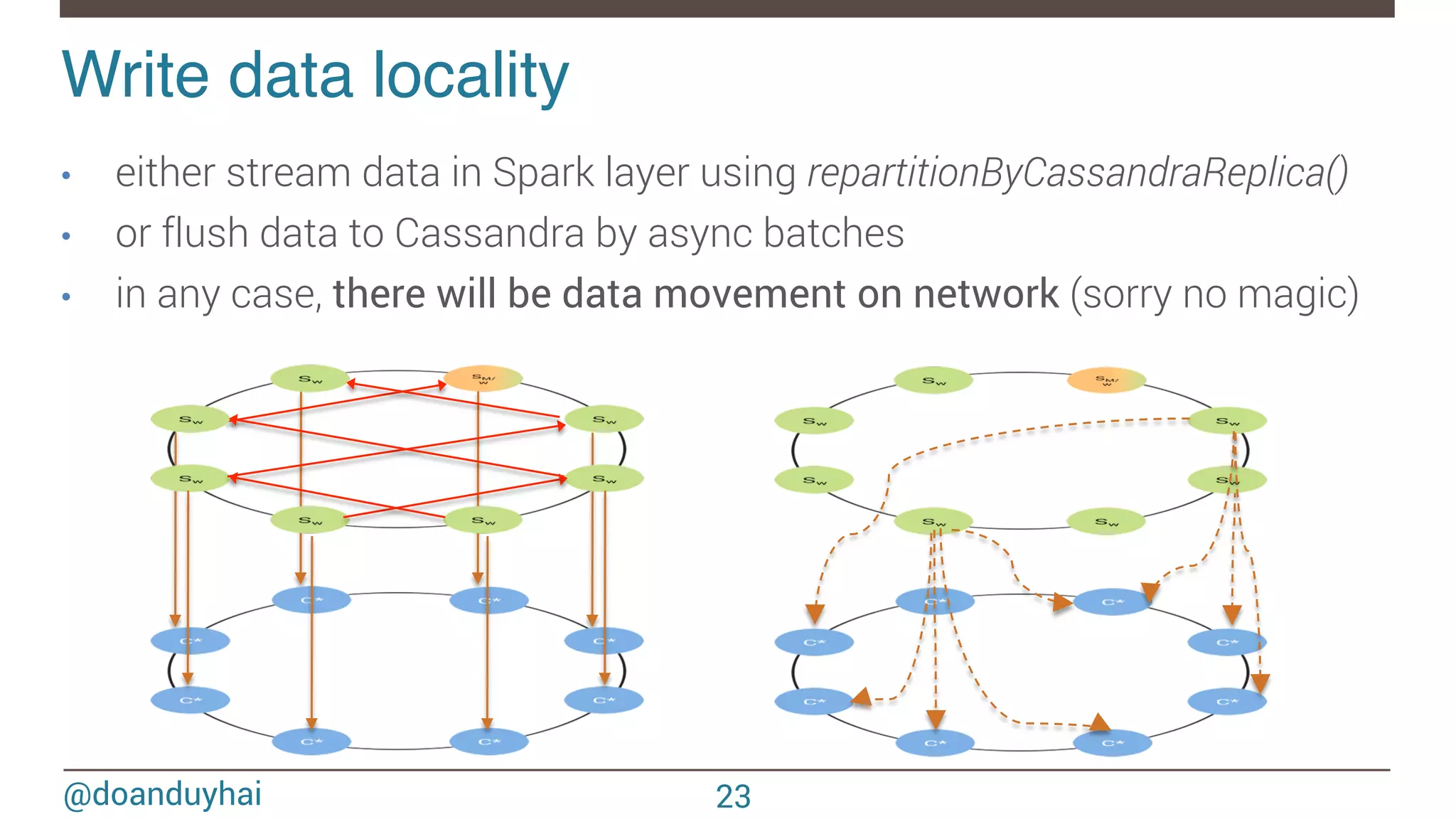
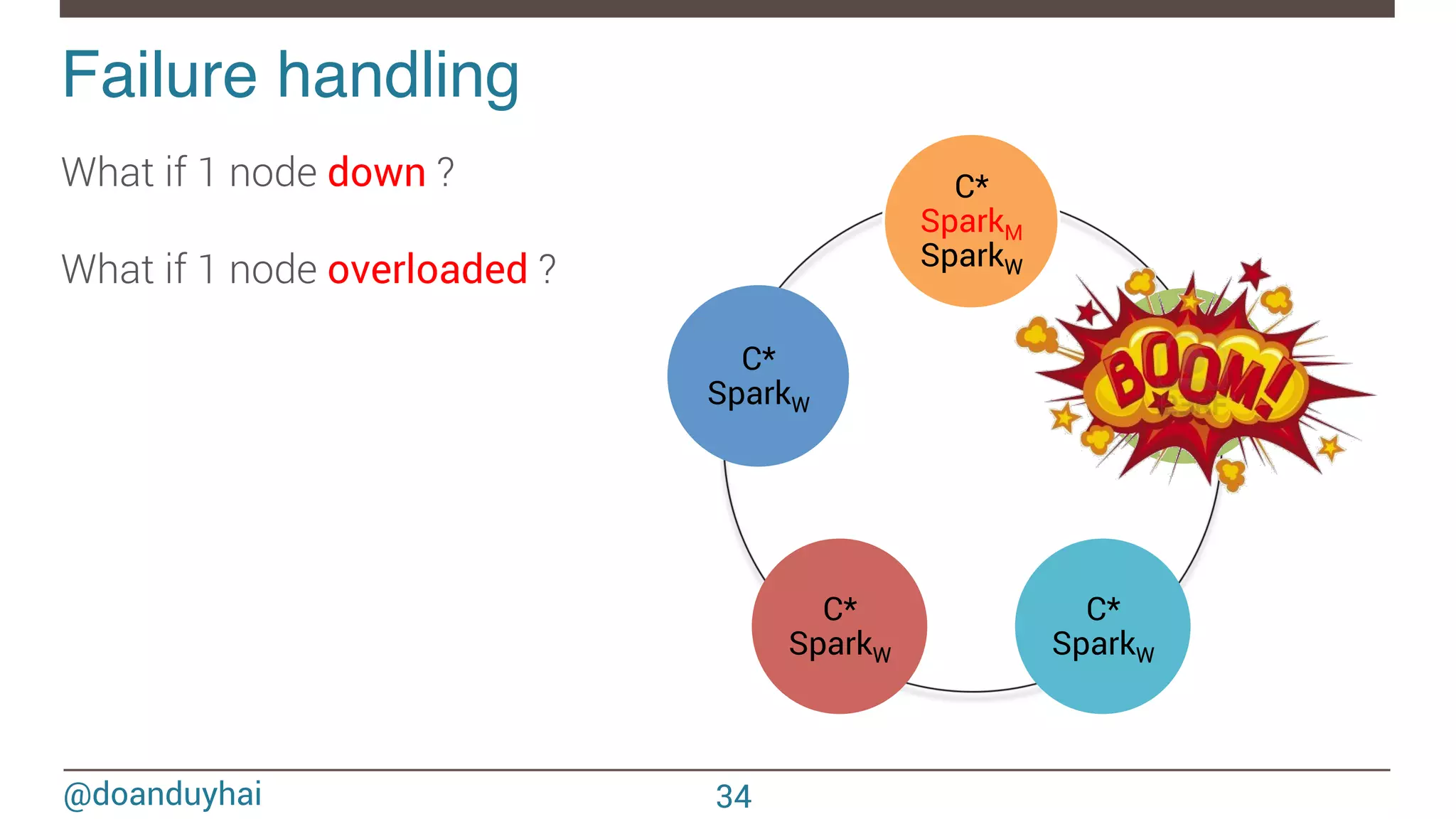
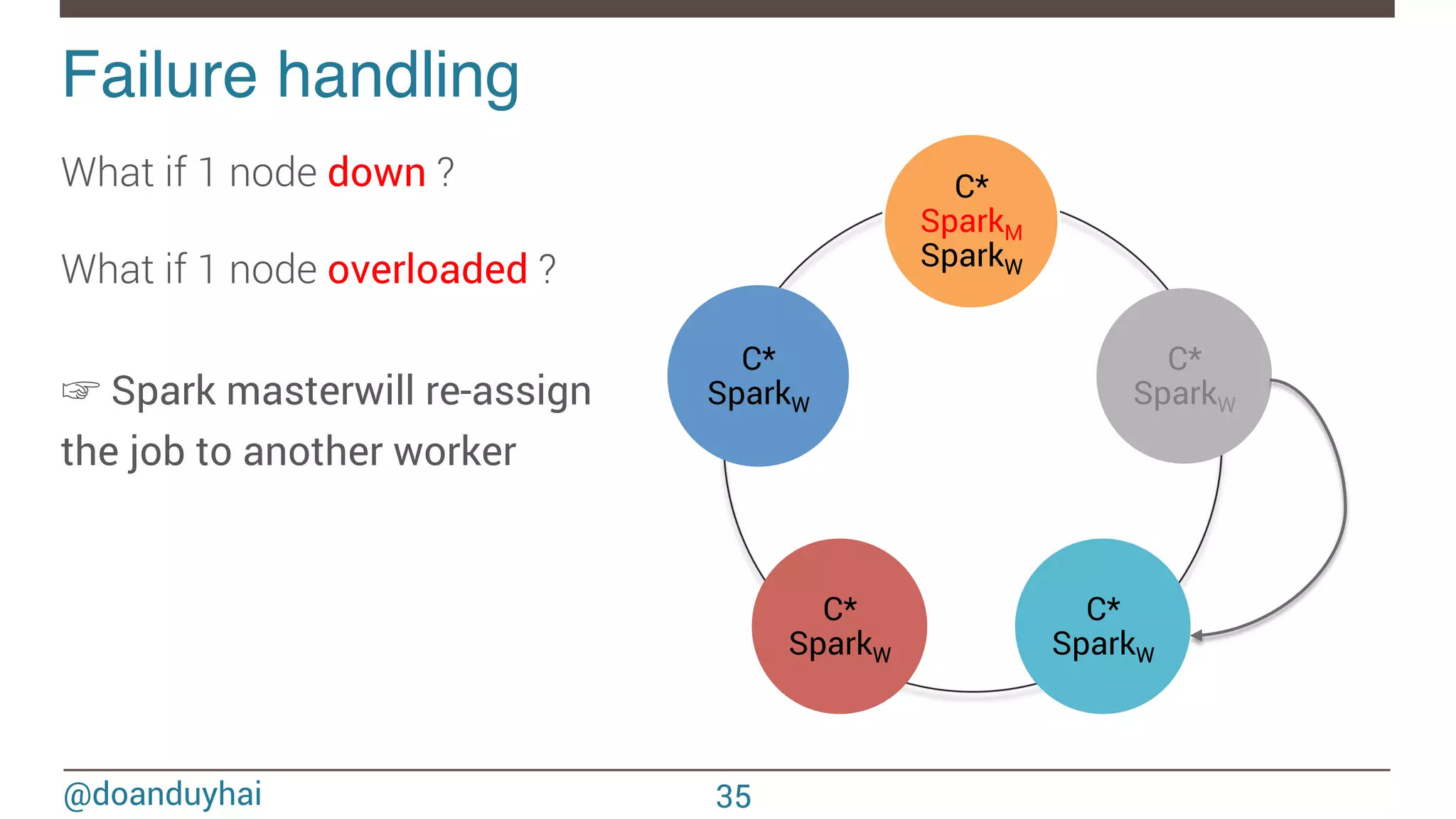
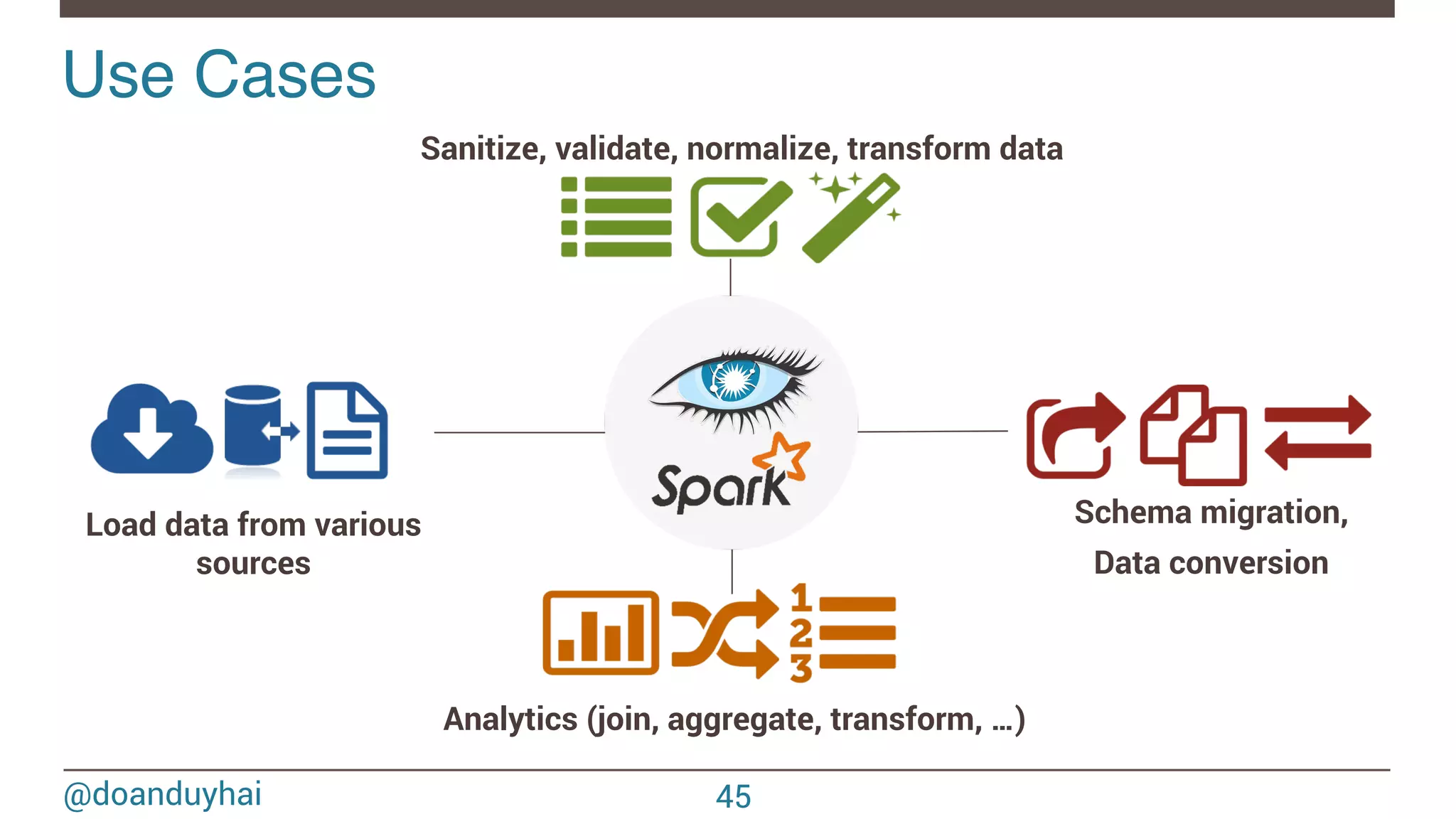
- The document discusses Spark/Cassandra connector API, best practices, and use cases. - It describes the connector architecture including support for Spark Core, SQL, and Streaming APIs. Data is read from and written to Cassandra tables mapped as RDDs. - Best practices around data locality, failure handling, and cross-region/cluster operations are covered. Locality is important for performance. - Use cases include data cleaning, schema migration, and analytics like joins and aggregation. The connector allows processing and analytics on Cassandra data with Spark.