Downloaded 56 times

















This document discusses the integration of software engineering practices into the data science and machine learning lifecycle, emphasizing the importance of collaboration among various teams and the influence of cloud technology. It outlines challenges faced by enterprises in operationalizing data science, such as ensuring data security, explainability of models, and efficient resource utilization. The document proposes a structured approach using tools like Docker and Kubernetes, along with establishing governance and compliance measures to support the development and deployment of data science projects.
Introduction to Data Science practices; importance of quick ROI, cross-team collaboration, and critical need for compliance.
Data Scientists face hurdles such as accessing required data, model deployment, and collaboration challenges.
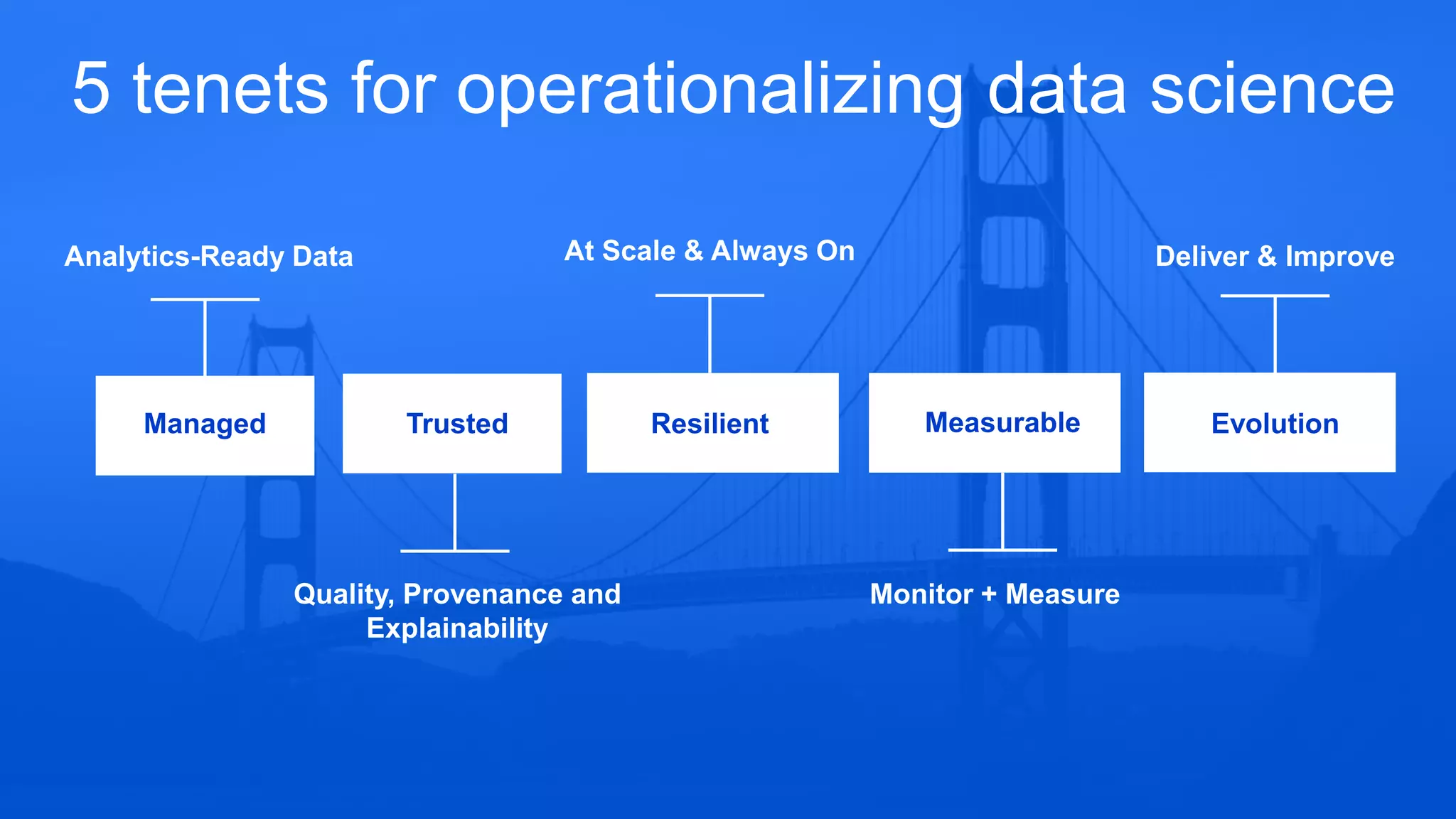
Five tenets for operationalizing Data Science include analytics-ready data, resilience, explainability, and continuous improvements.
Emphasis on analytics-ready data access, model provenance and explainability for quality outputs.
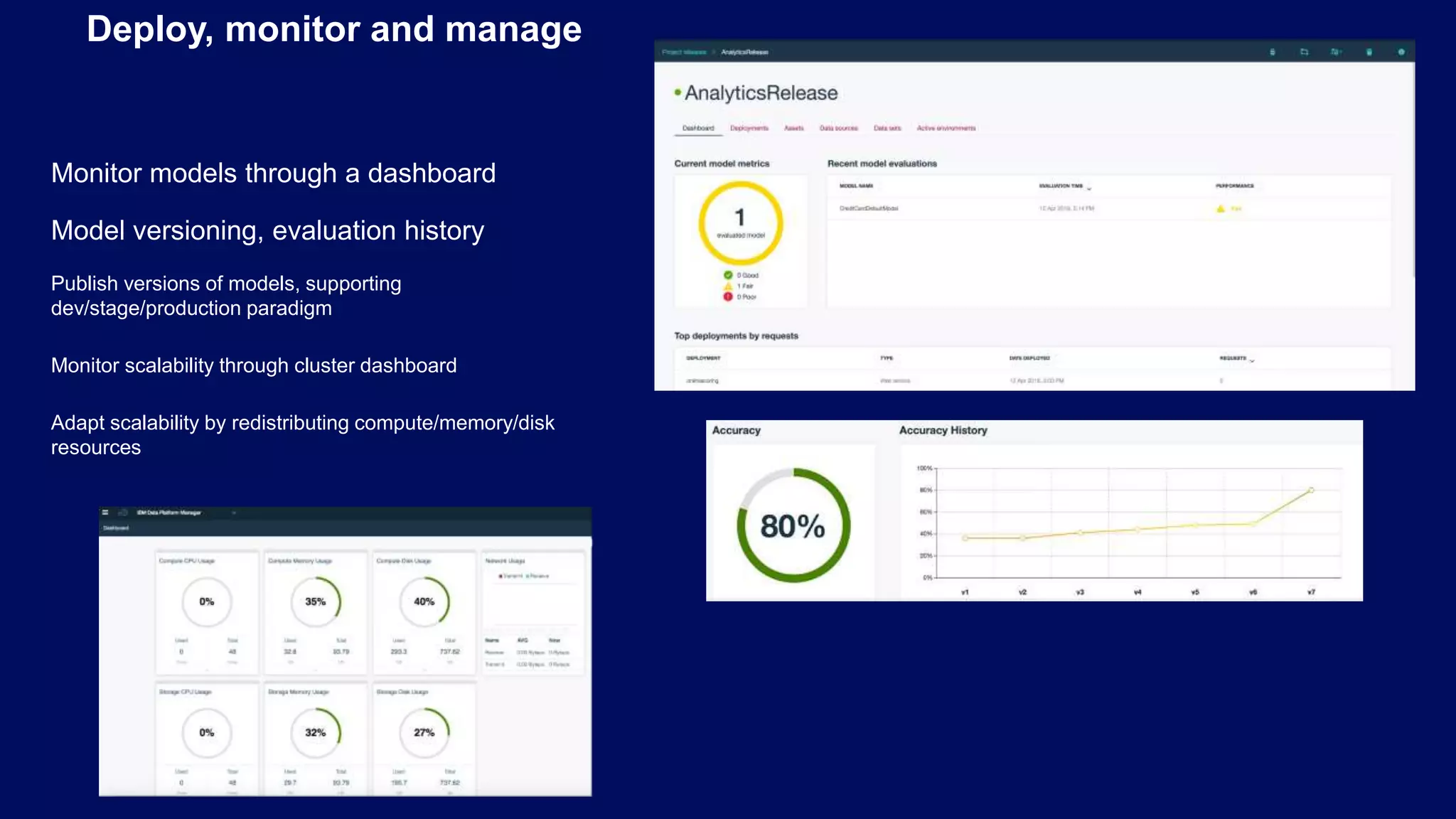
Focus on continuous model evaluations, version control, and ensuring process efficiency for improvements.
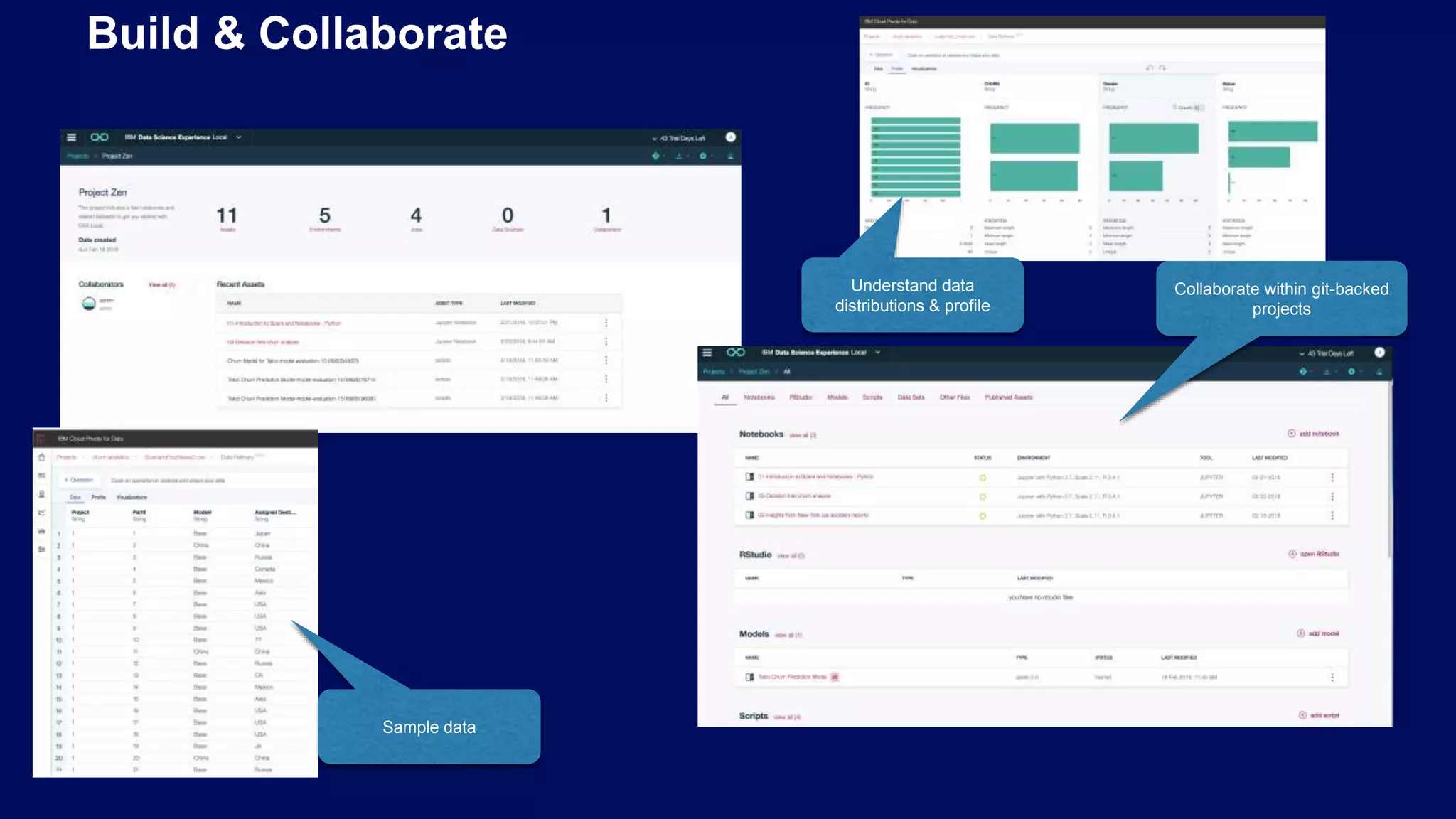
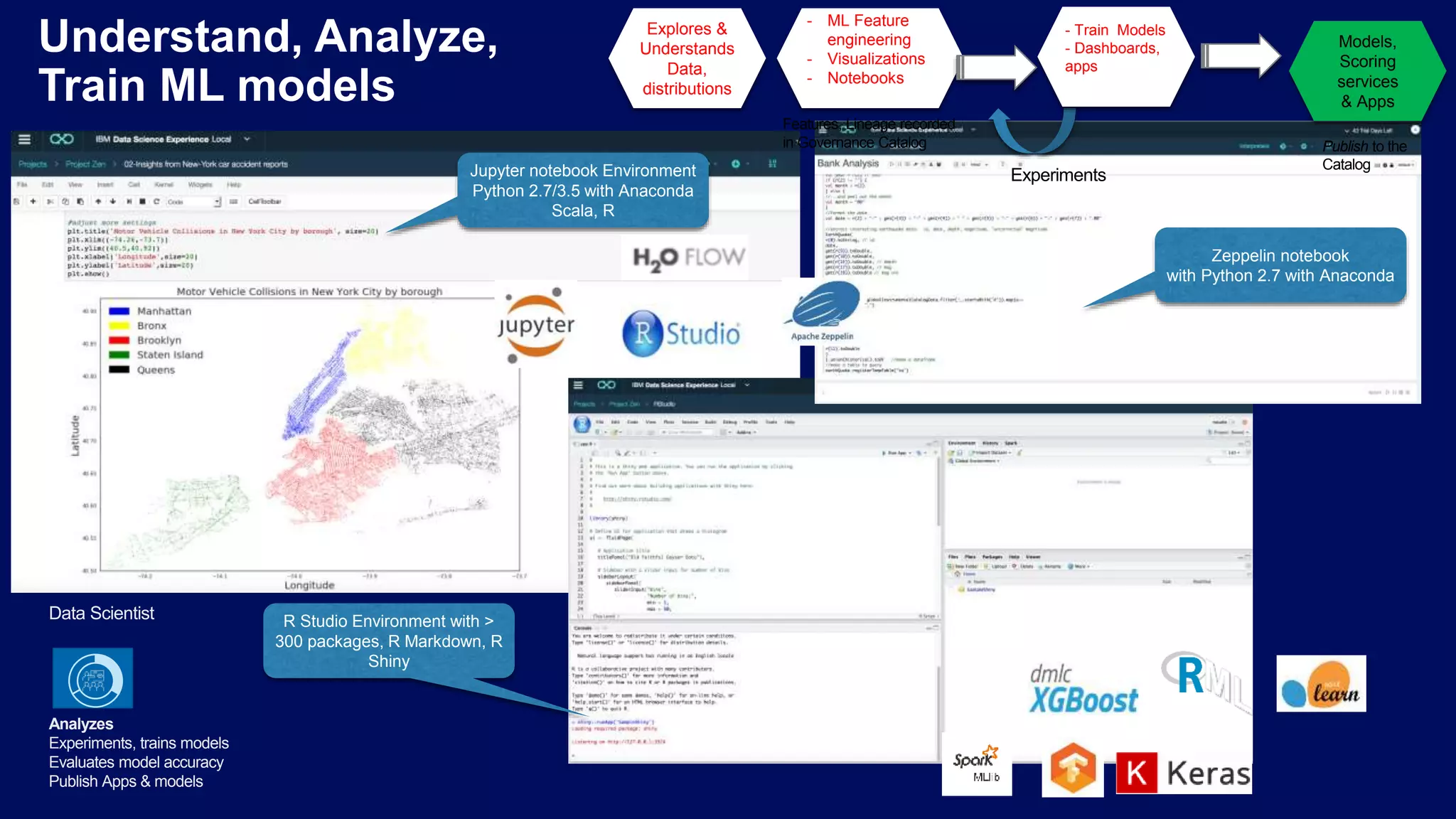
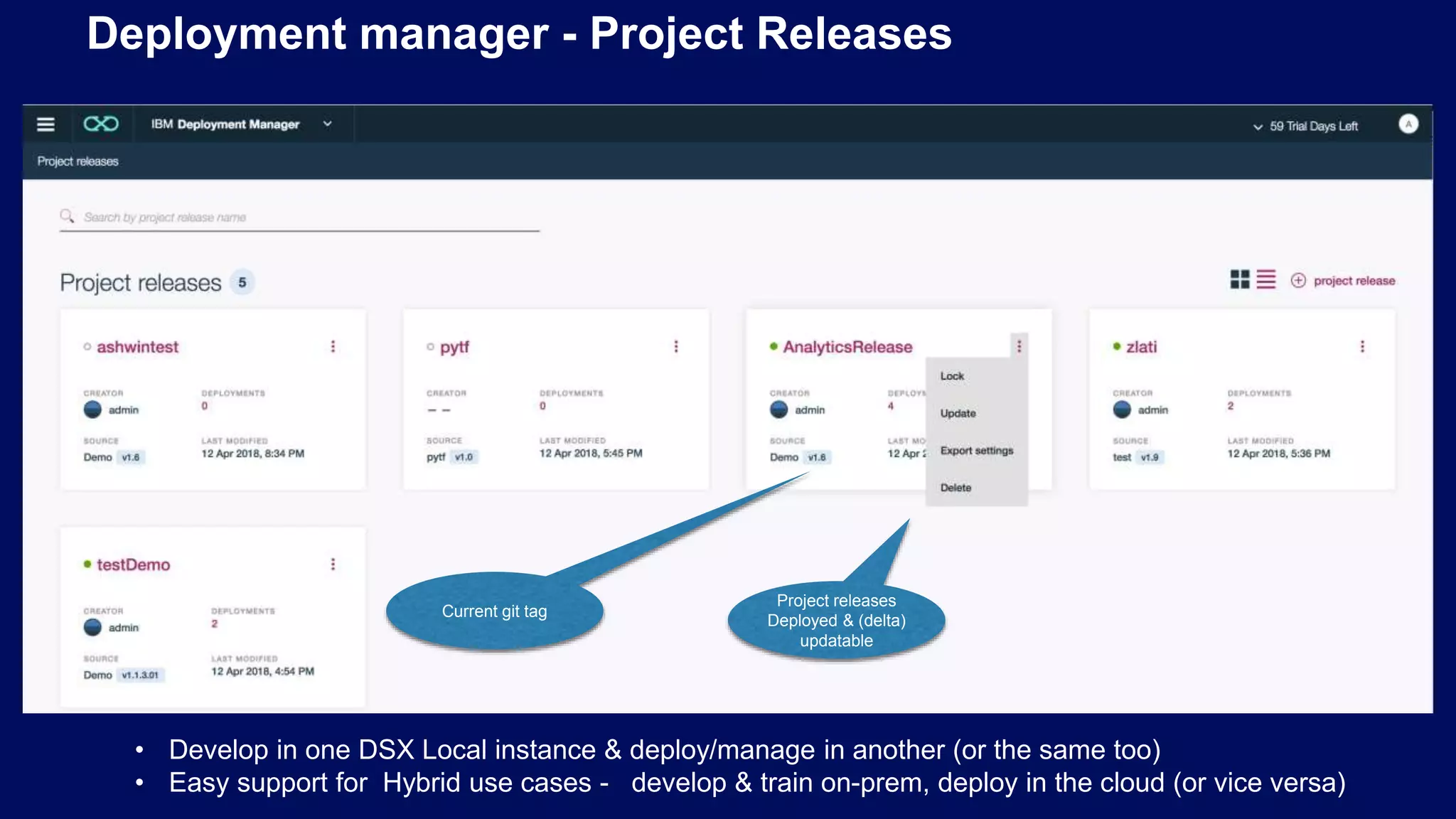
Using Git and Docker for managing projects, environments, and deploying data science models effectively.
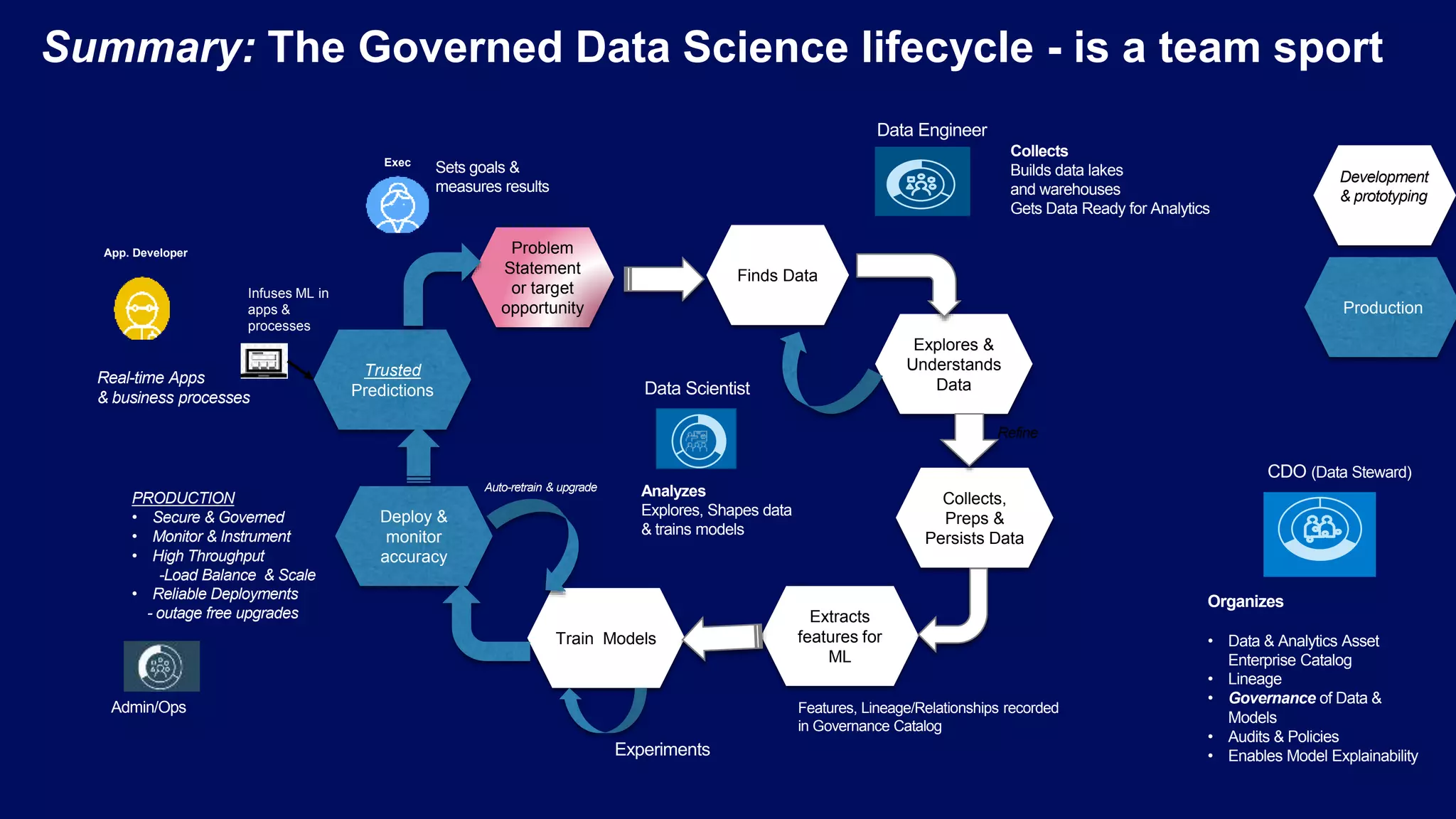
Collaborative efforts among Data Engineers, Scientists, and Analysts; building a governed lifecycle for data assets.
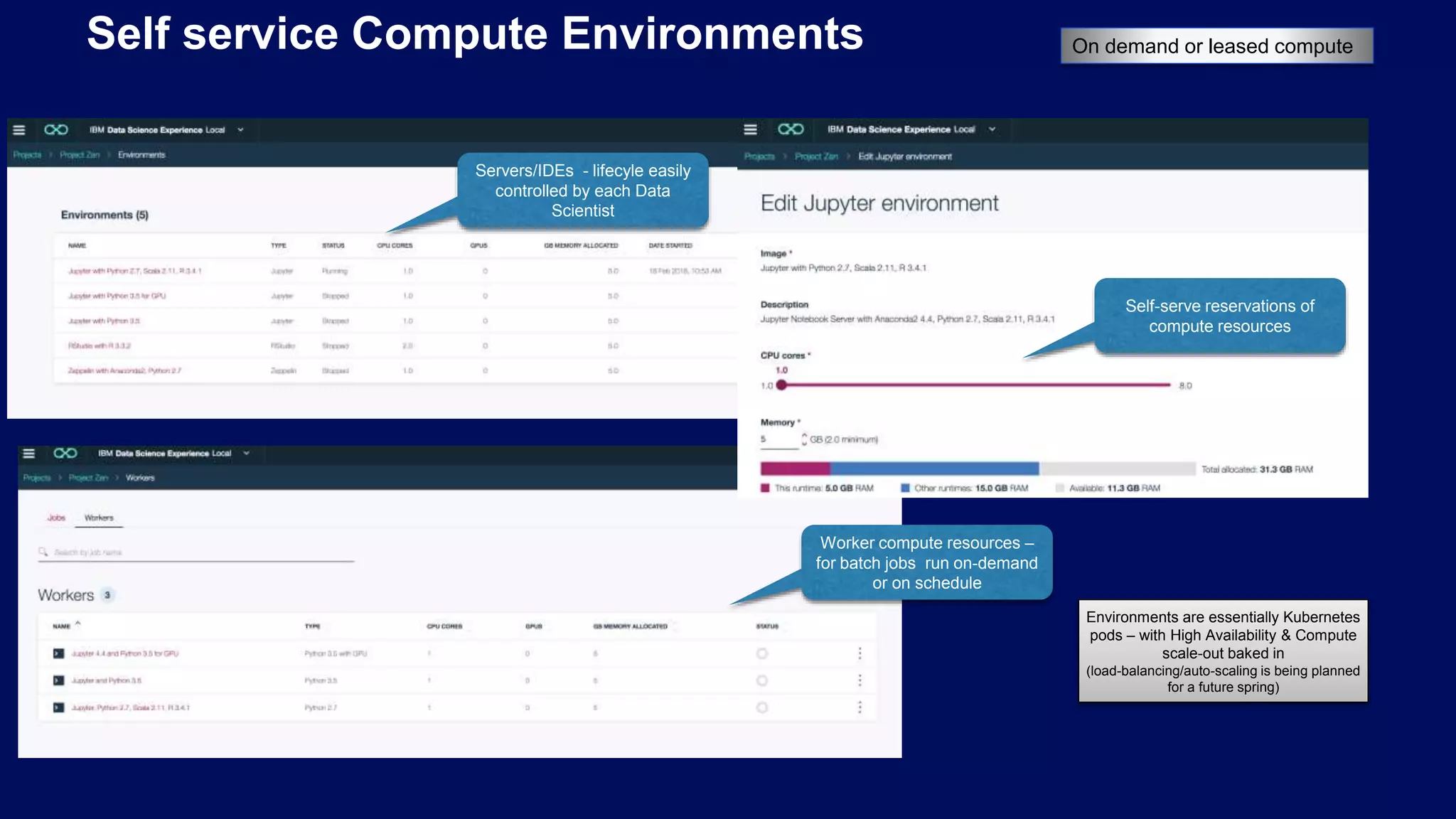
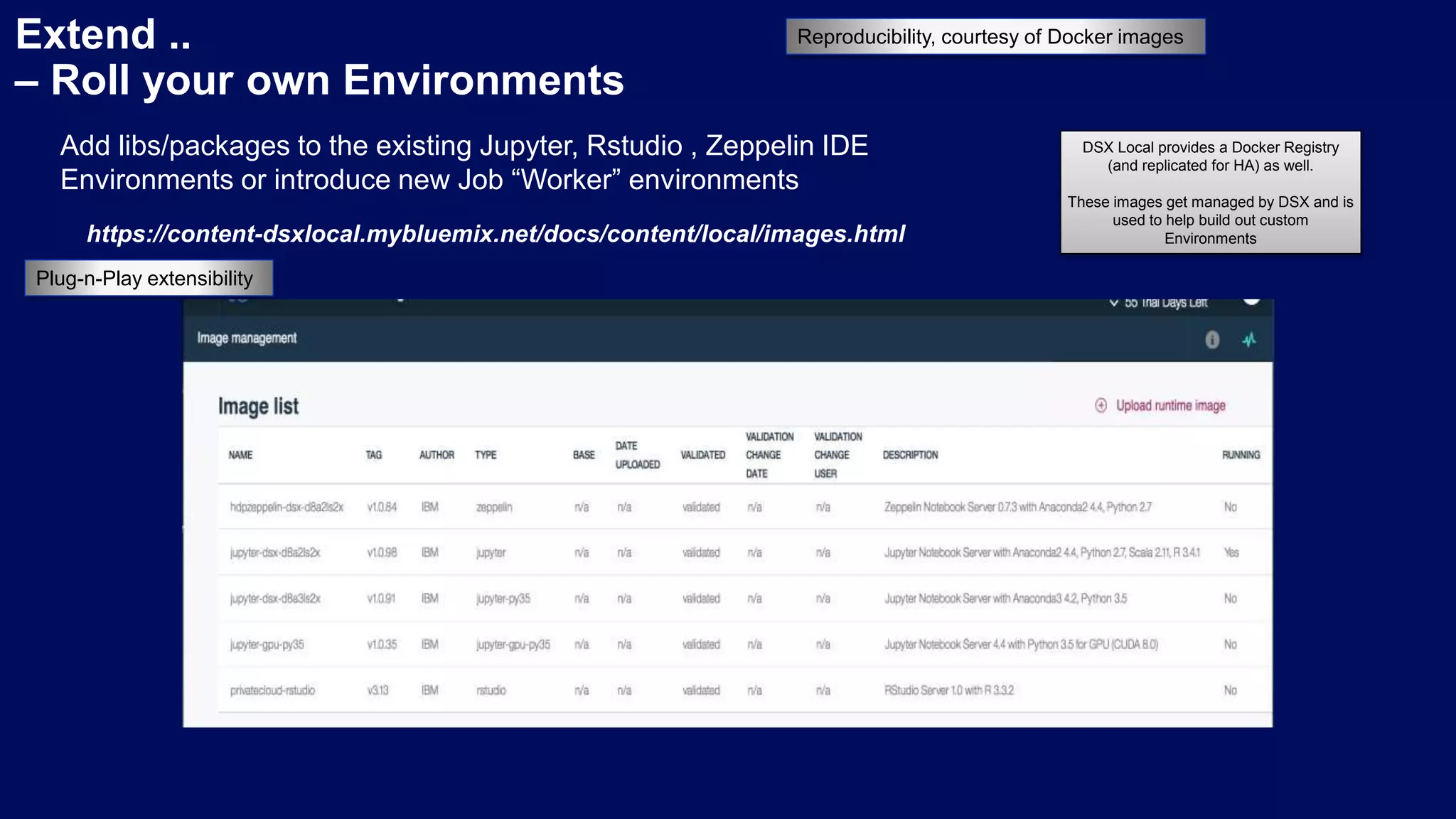
Importance of structured project organization and custom environments using Docker/Kubernetes for Data Science.
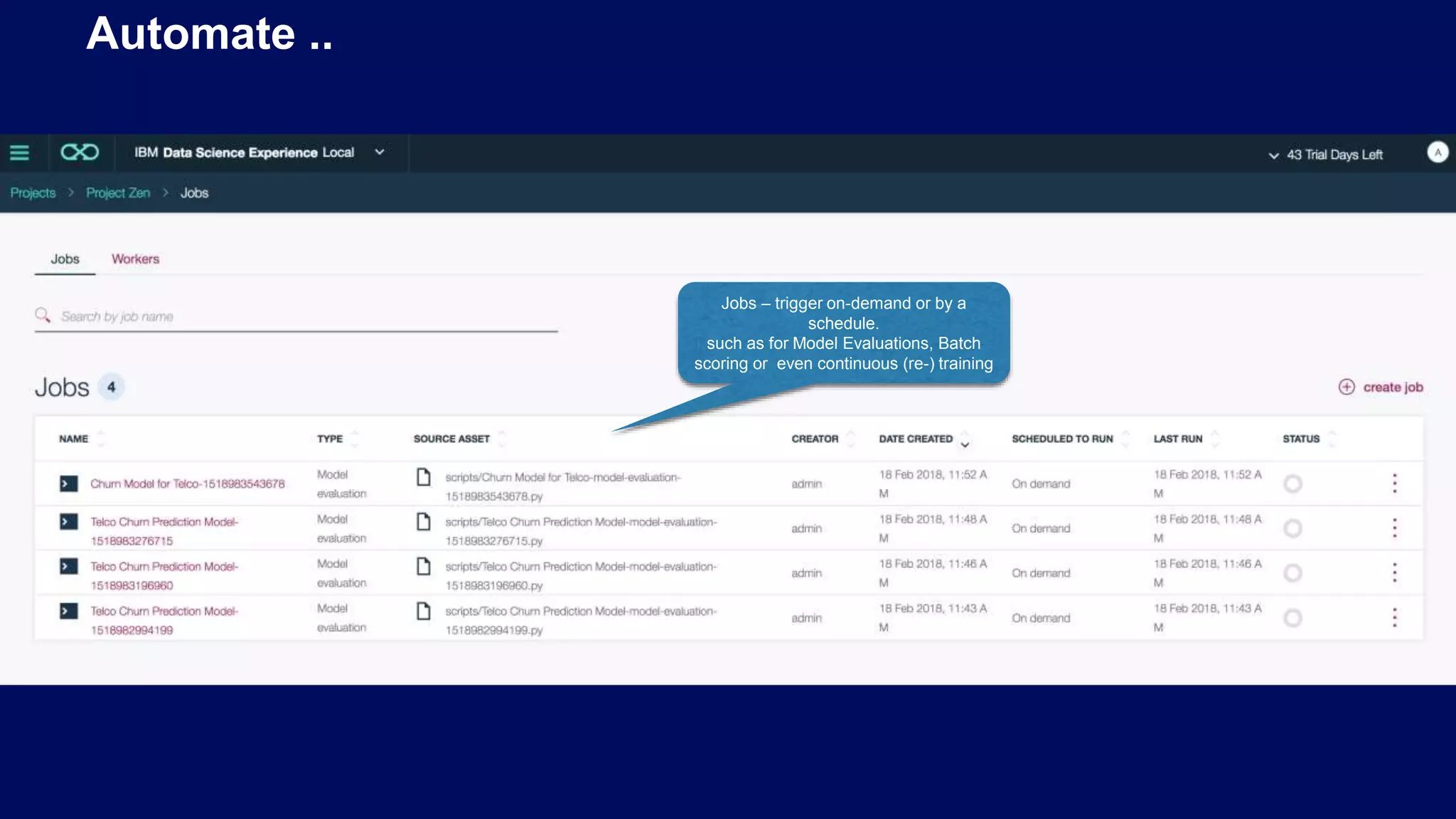
Automation of jobs and a dashboard for model monitoring to manage model versions and deployments efficiently.
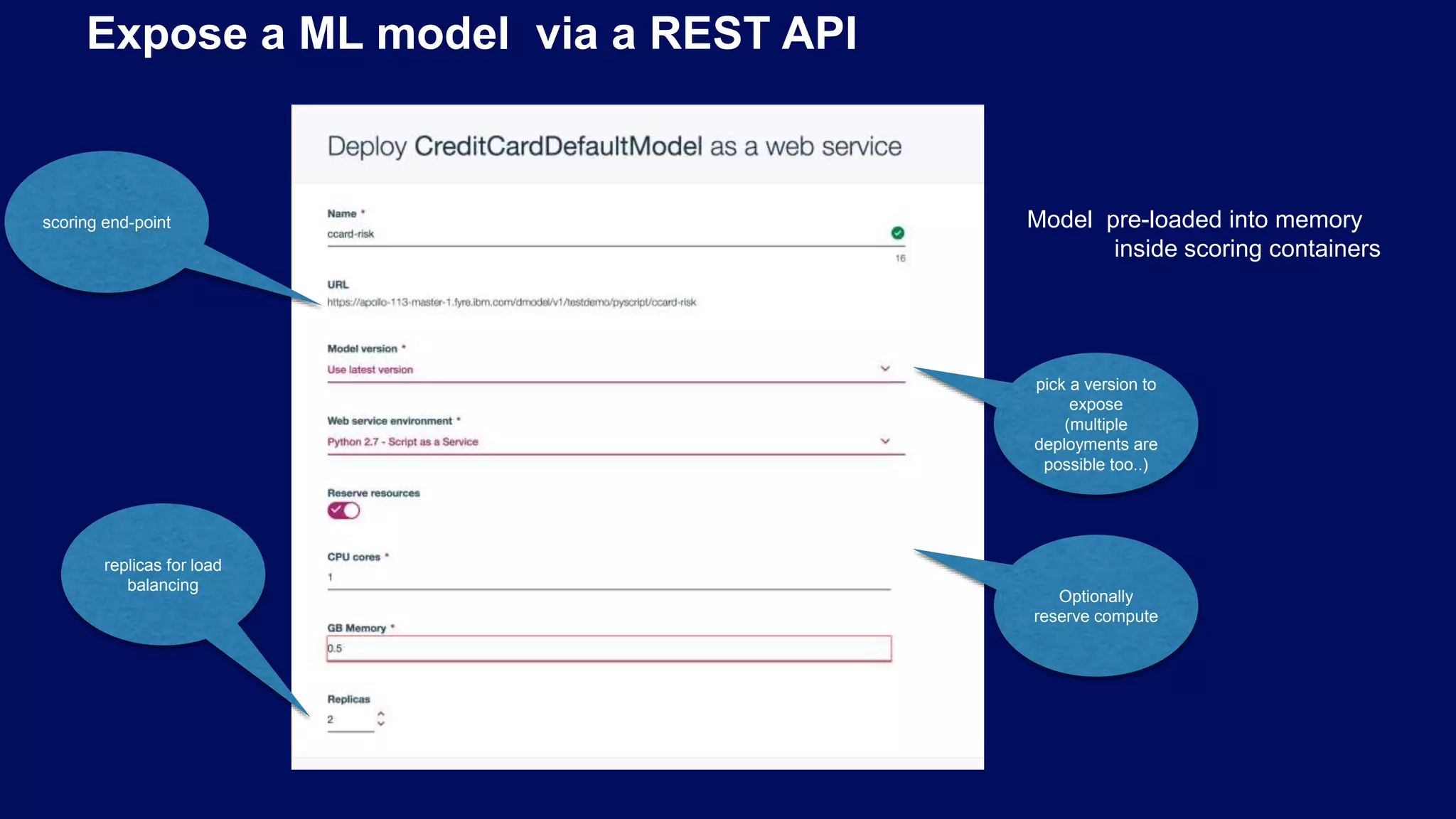
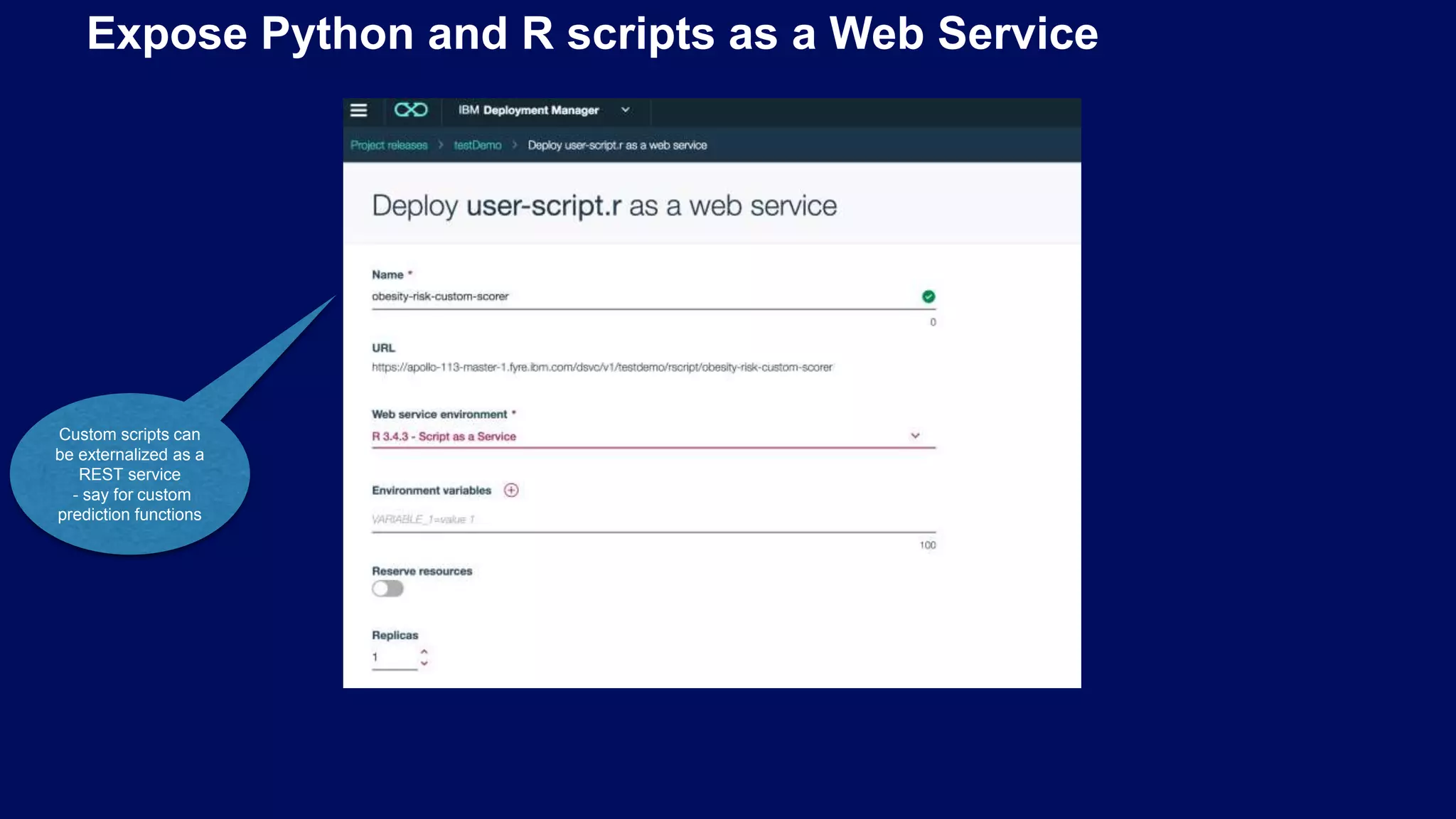
Processes to expose ML models as REST APIs; enabling efficient custom predictions and load balancing.