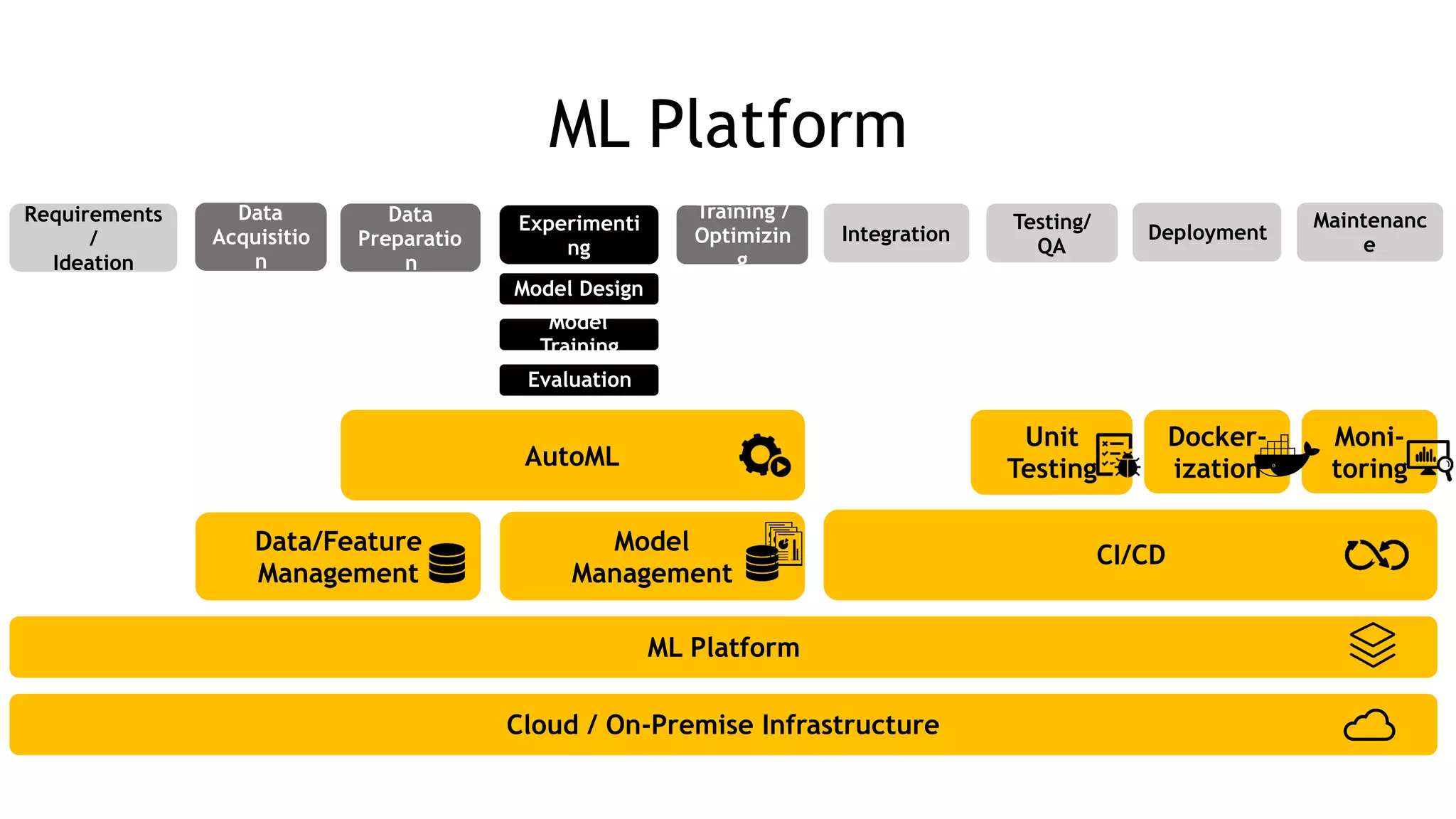
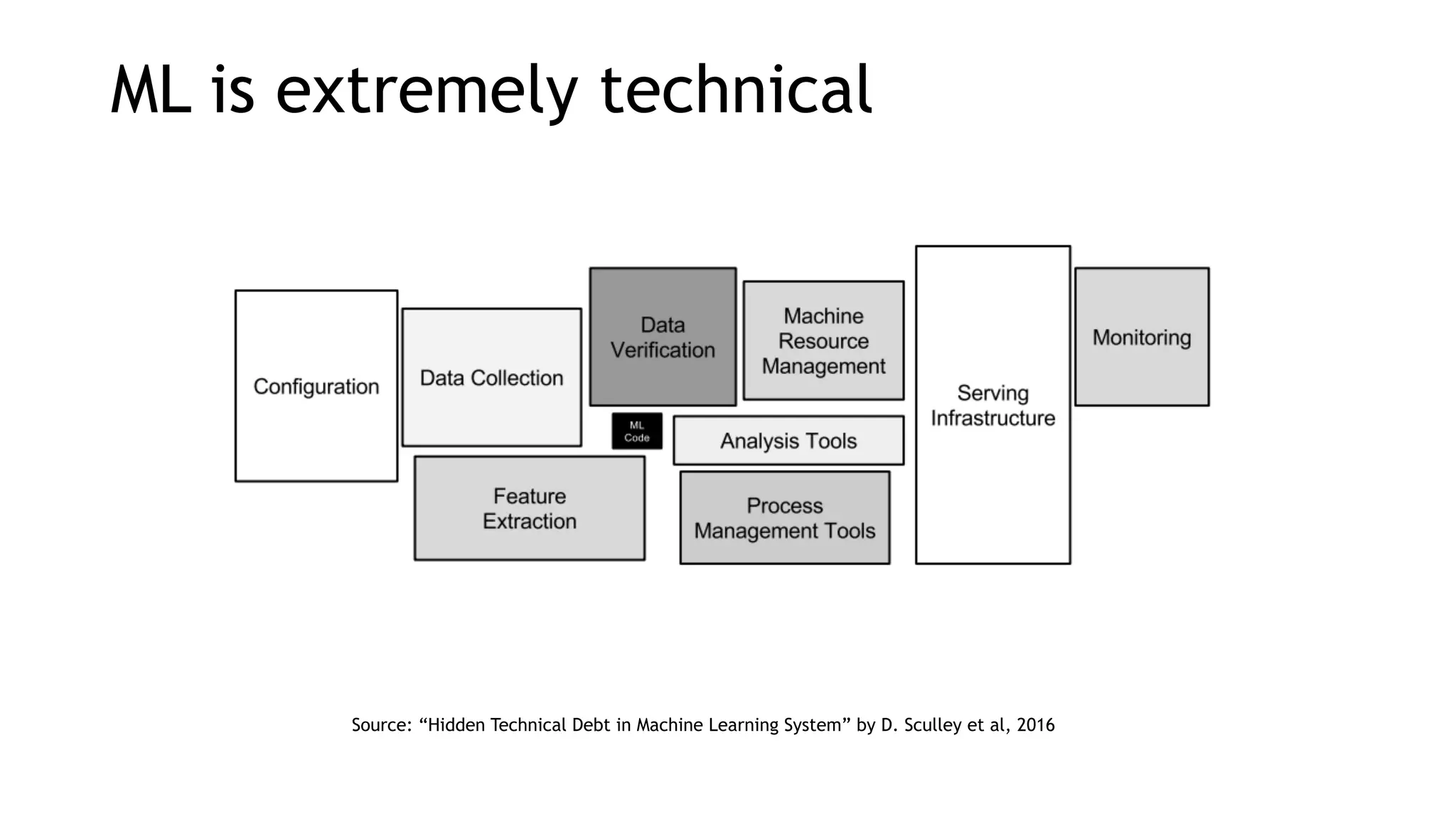
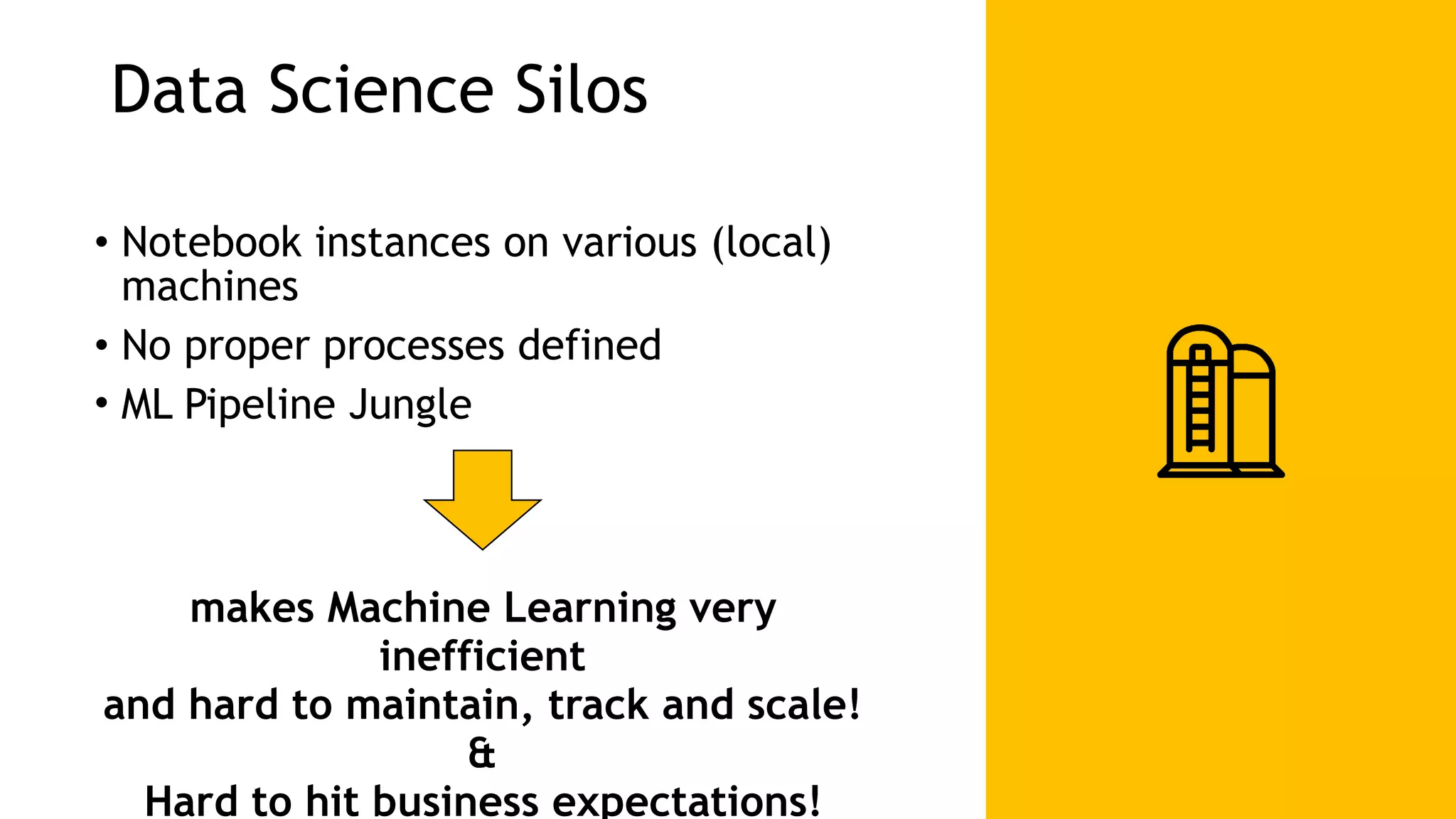
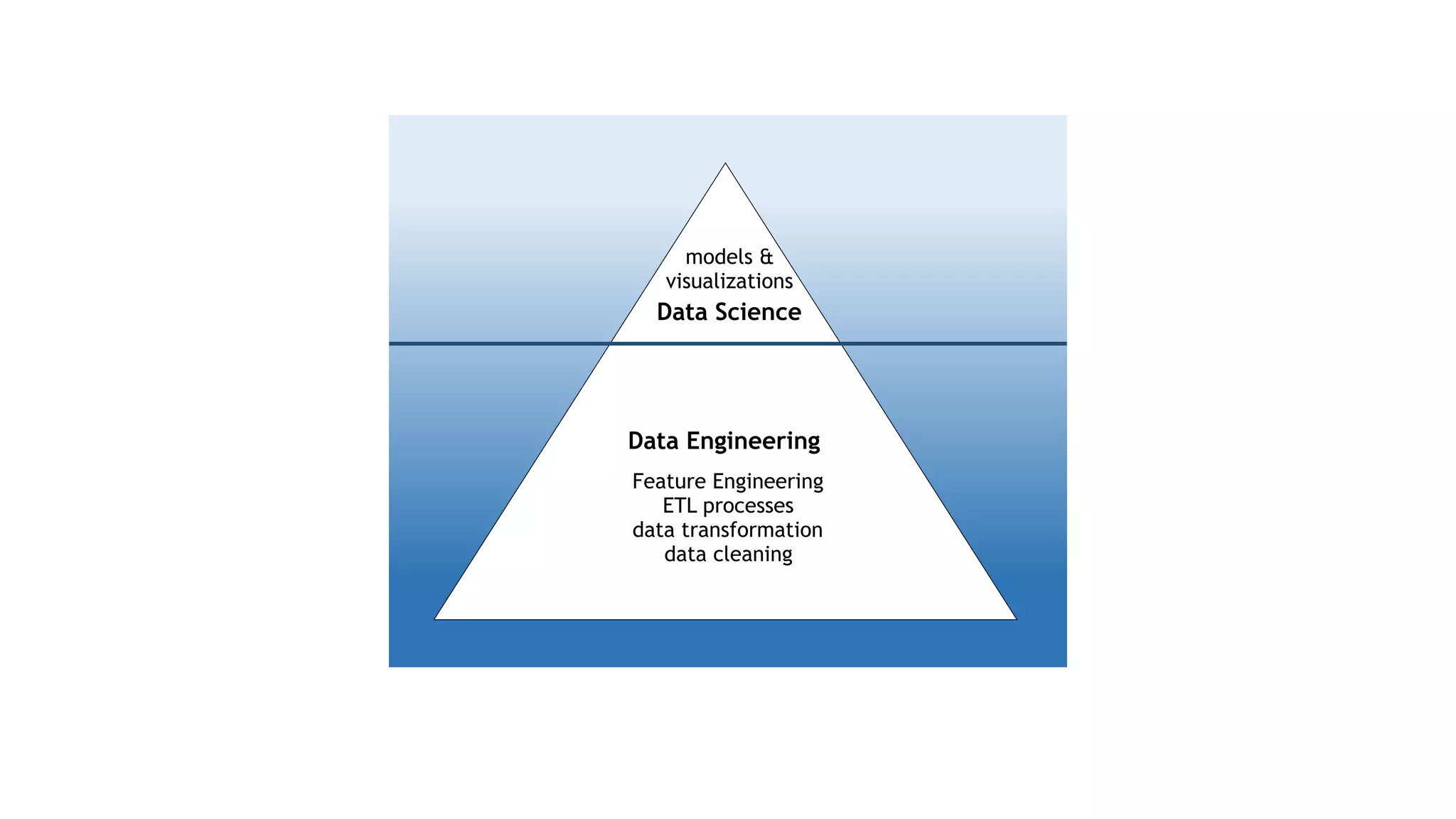
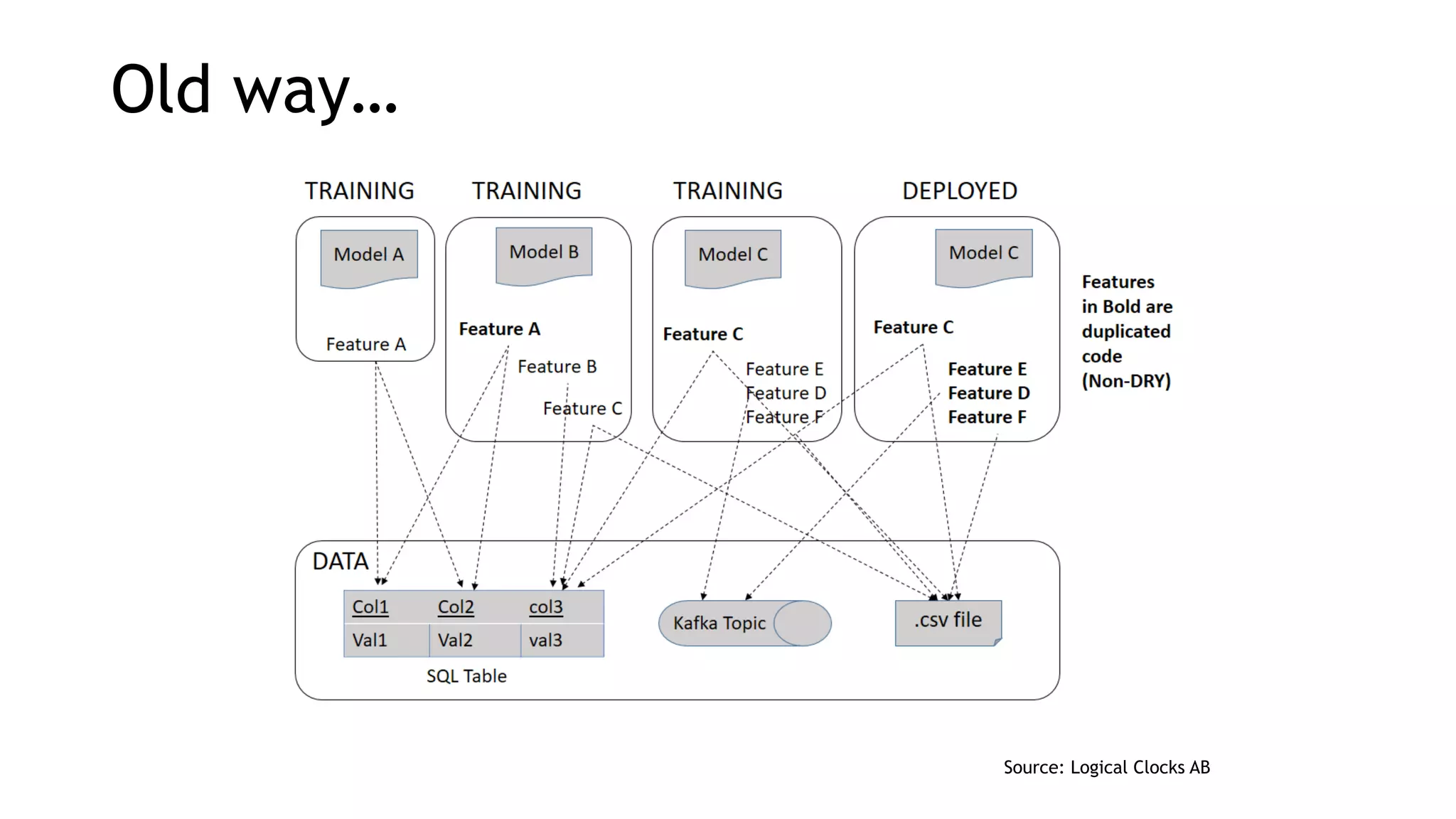
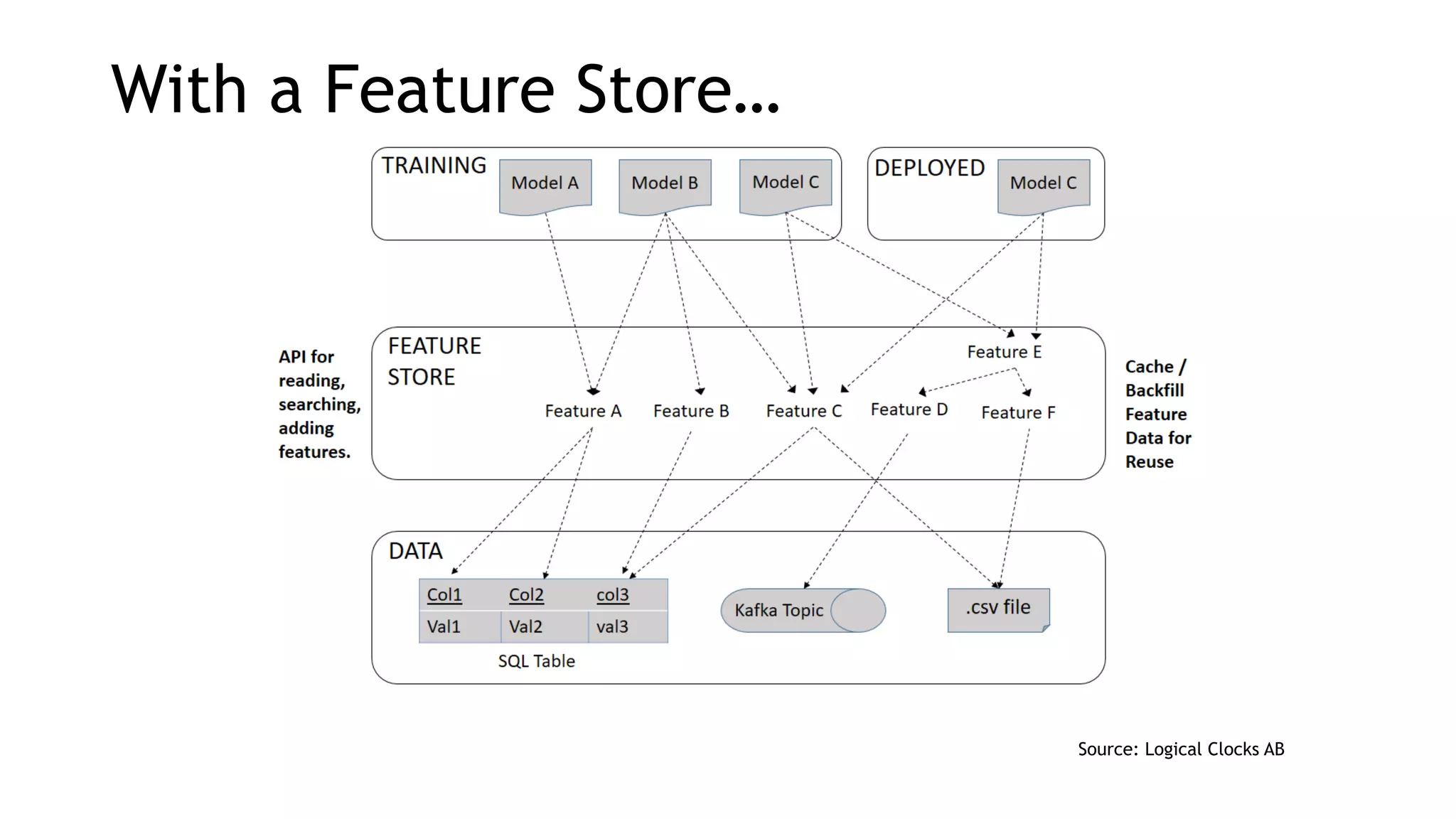
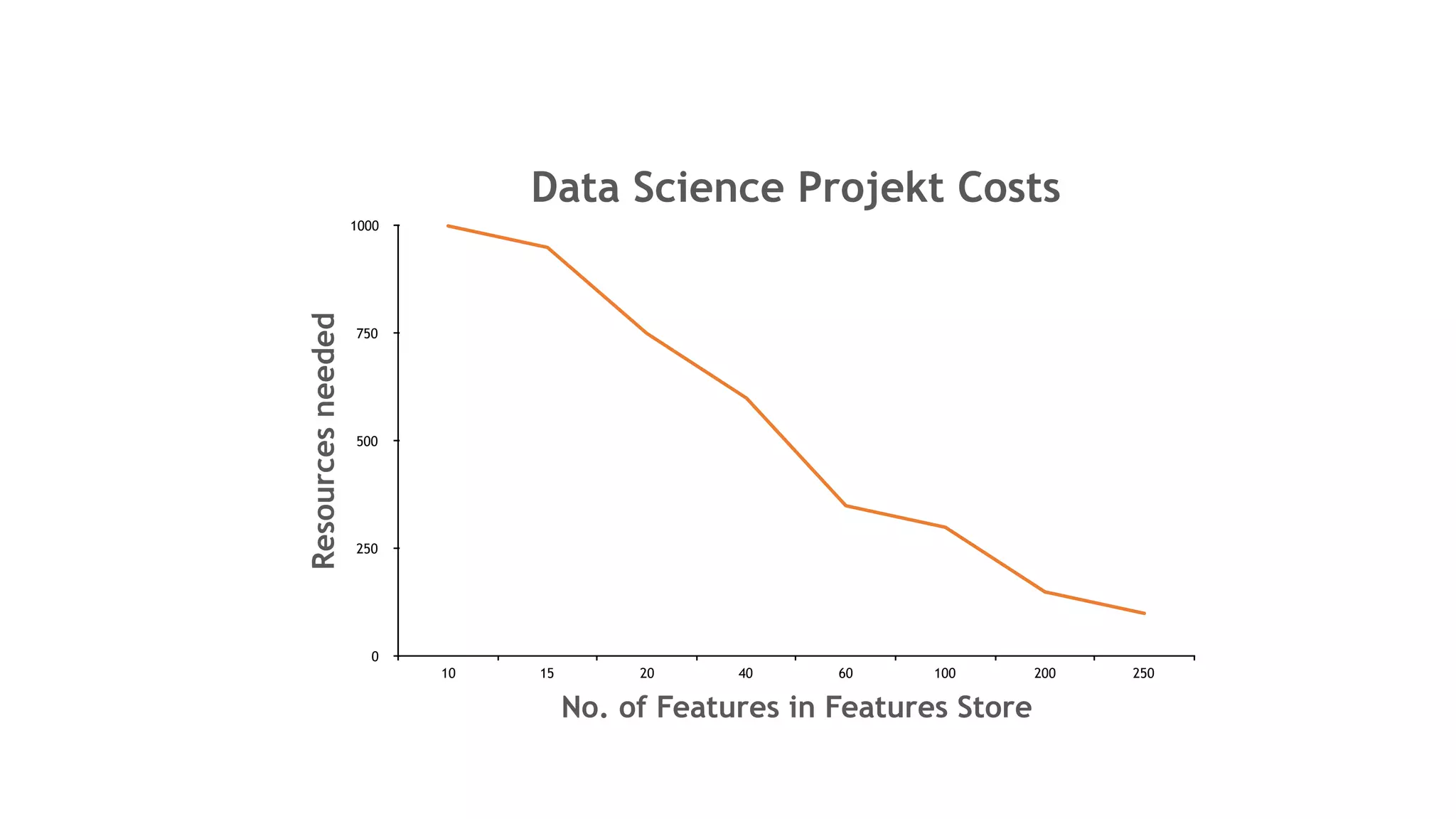
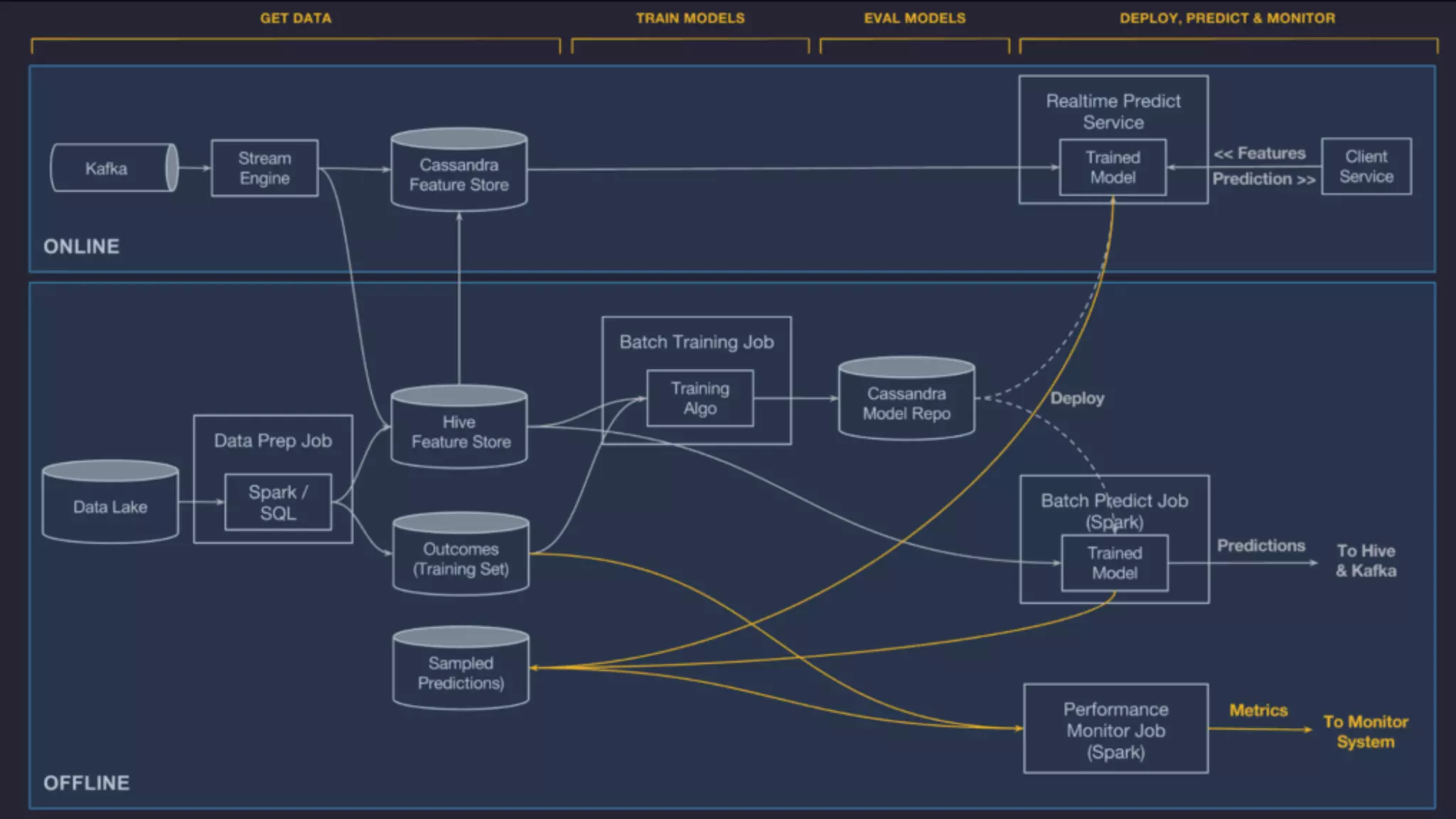
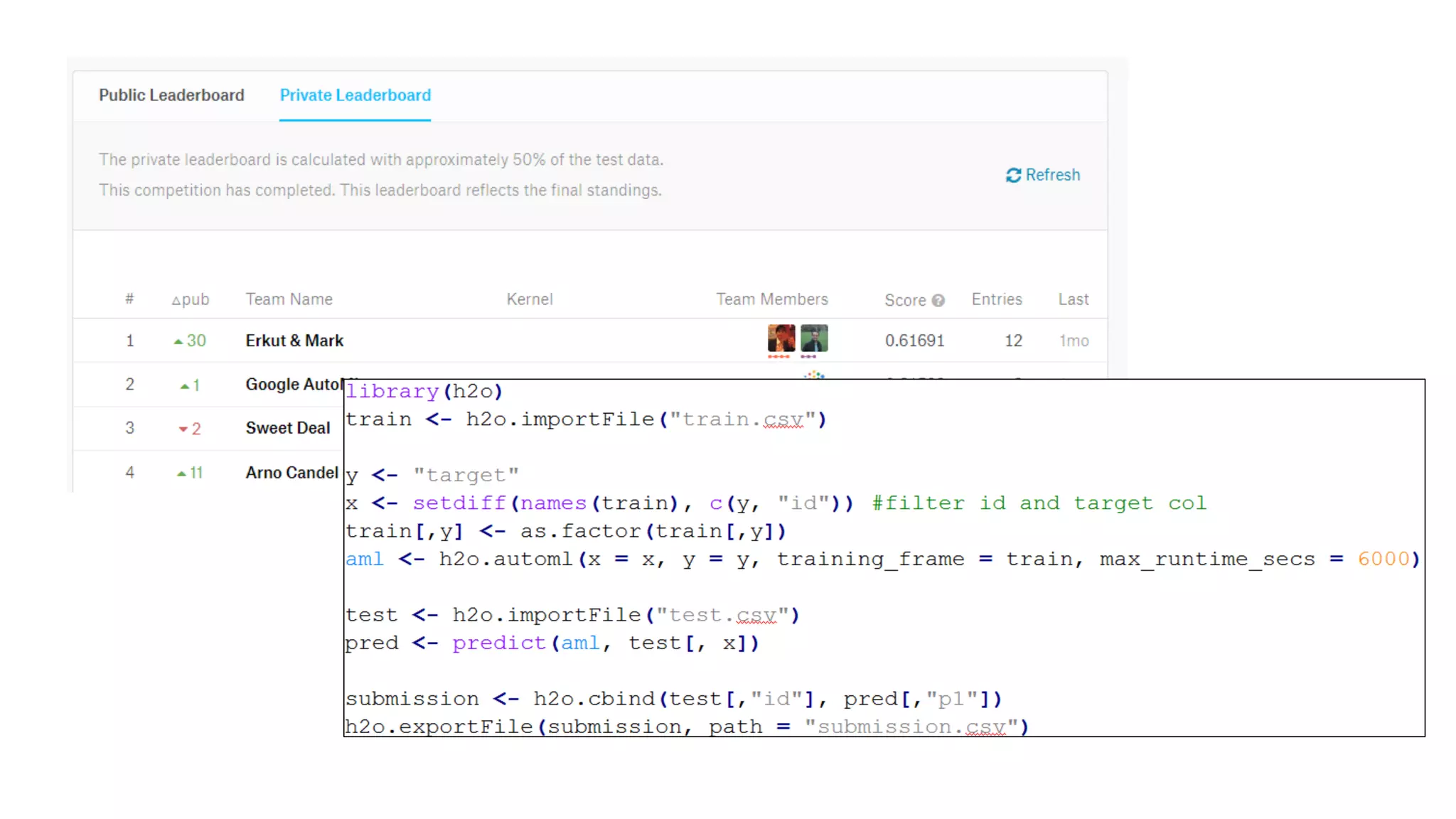
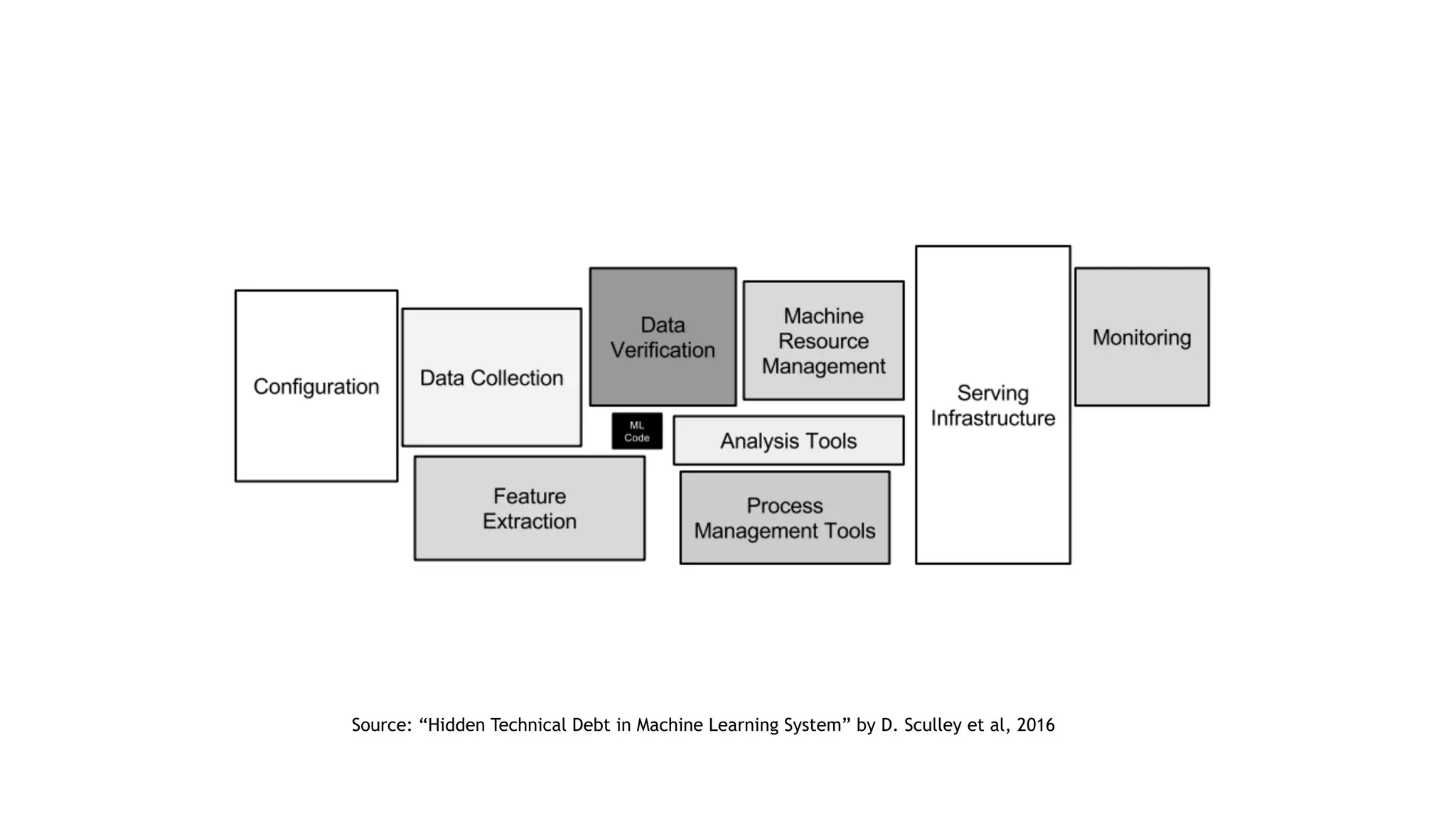
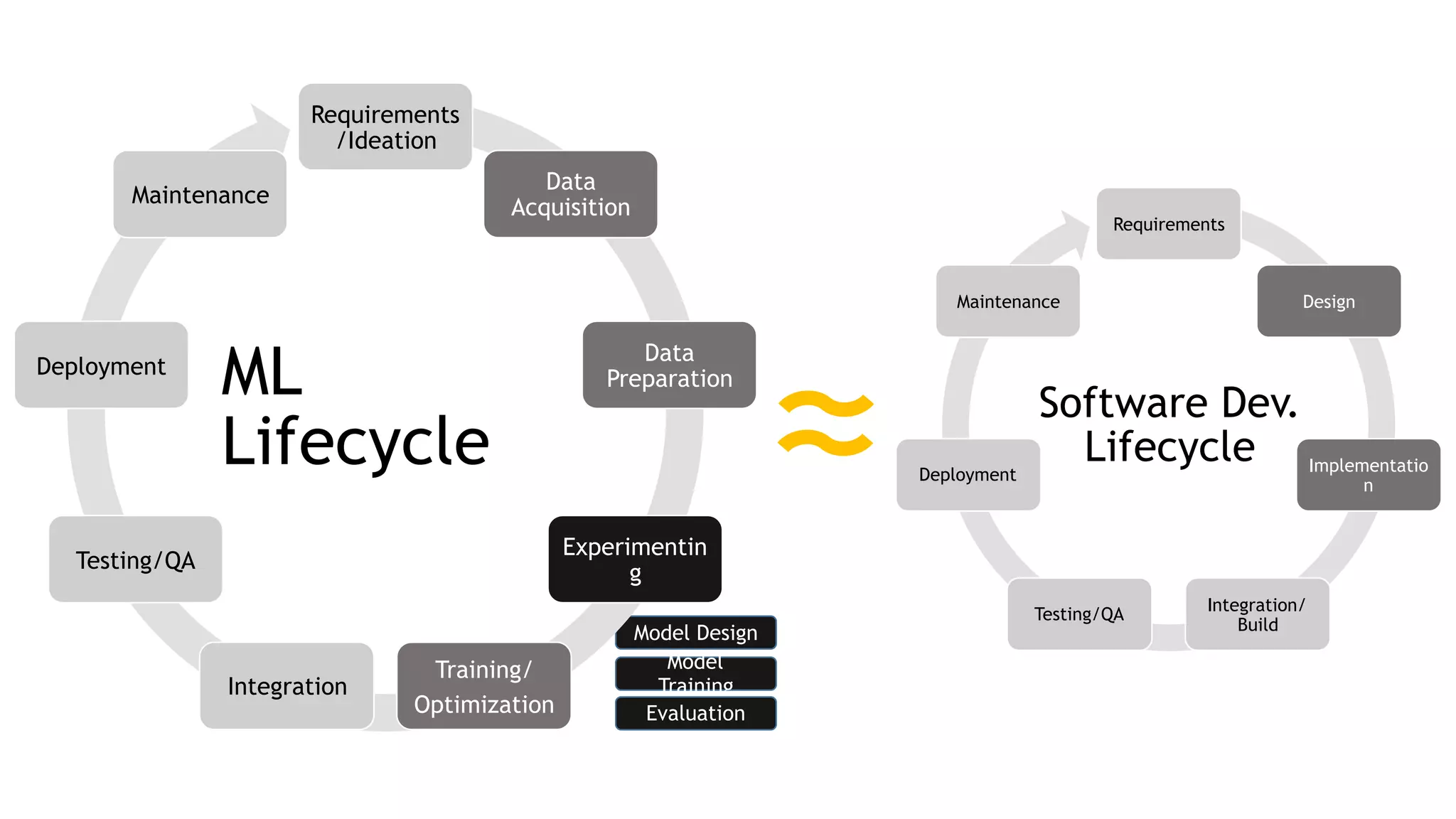
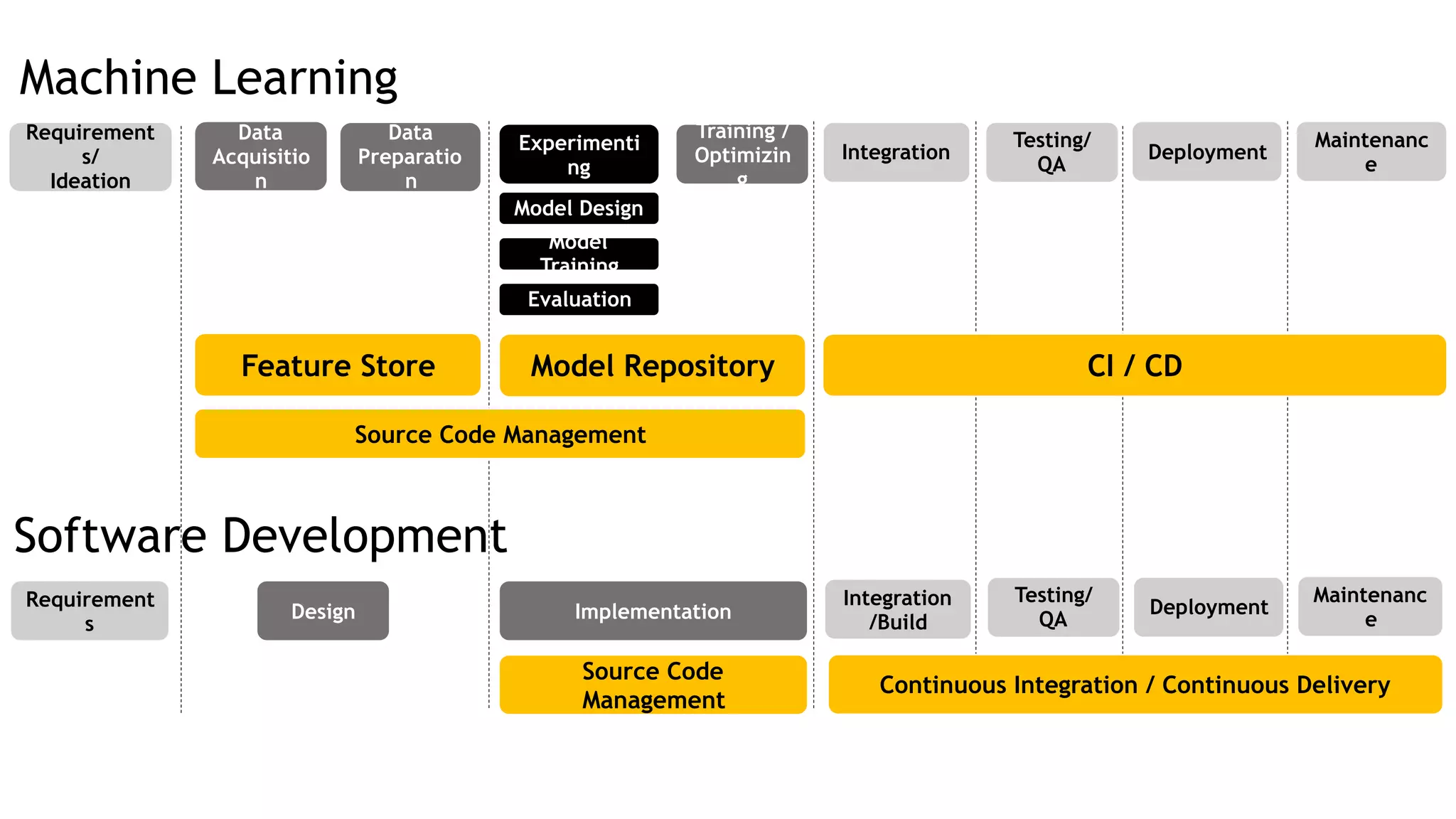
The document discusses the importance of scalability in building machine learning platforms, highlighting key lessons learned from industry practices. It emphasizes the need for integrated systems, such as feature stores, and recommends treating data science projects similarly to software development to enhance efficiency and tracking. Additionally, it advocates for the use of cloud infrastructure and automl to streamline processes and improve model management.

















![Monitoring Score distributions (may) change over time [0 ,0.1] (0.2 ,0.3] (0.4 ,0.5] (0.6 ,0.7] (0.8 ,0.9] Week 1 Week 4 • Validate & track your model performance constantly • Retrain (automatically) on new data if needed](https://image.slidesharecdn.com/makingdatasciencescalable-191007205247/75/Making-Data-Science-Scalable-5-Lessons-Learned-29-2048.jpg)