















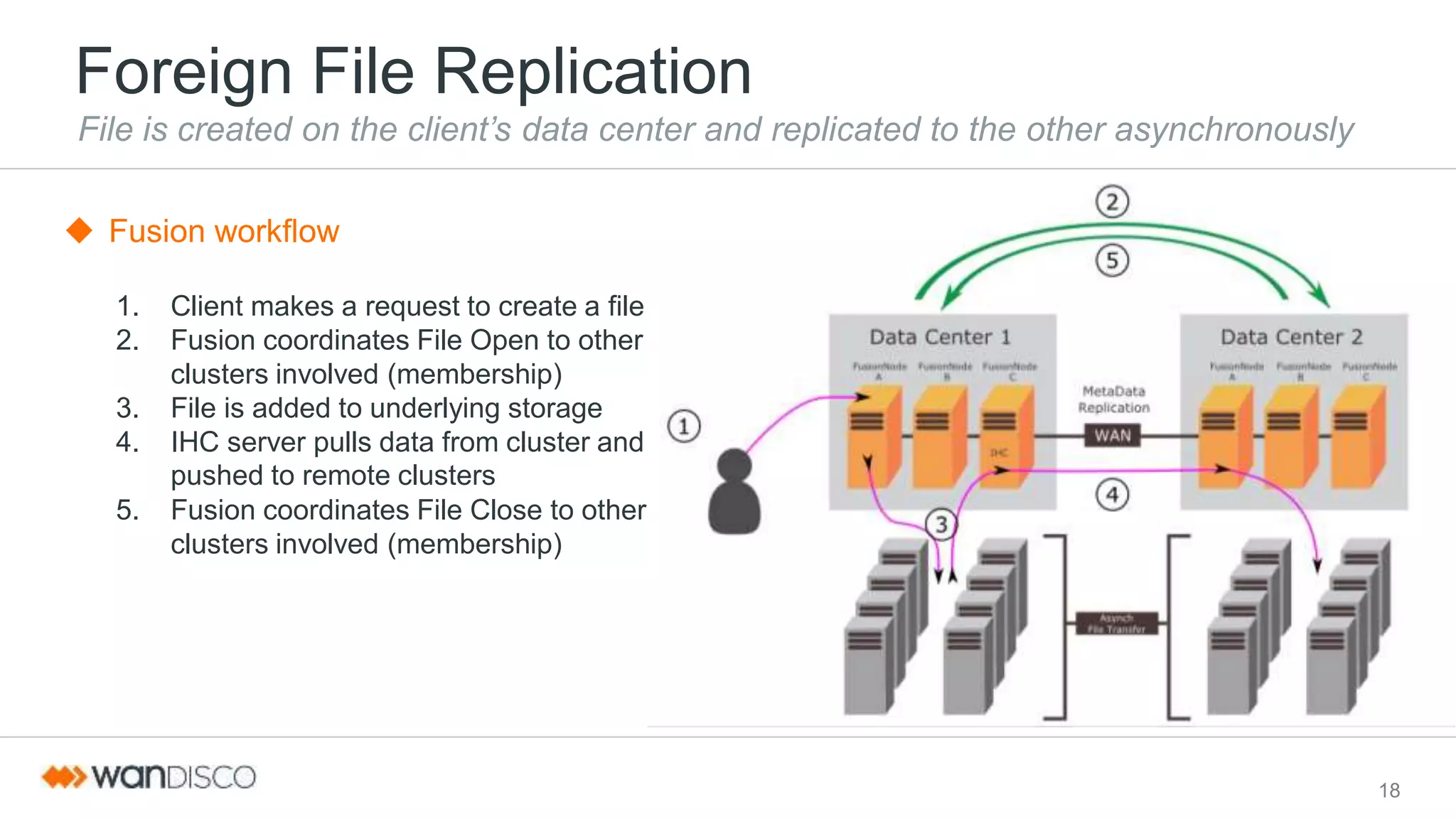

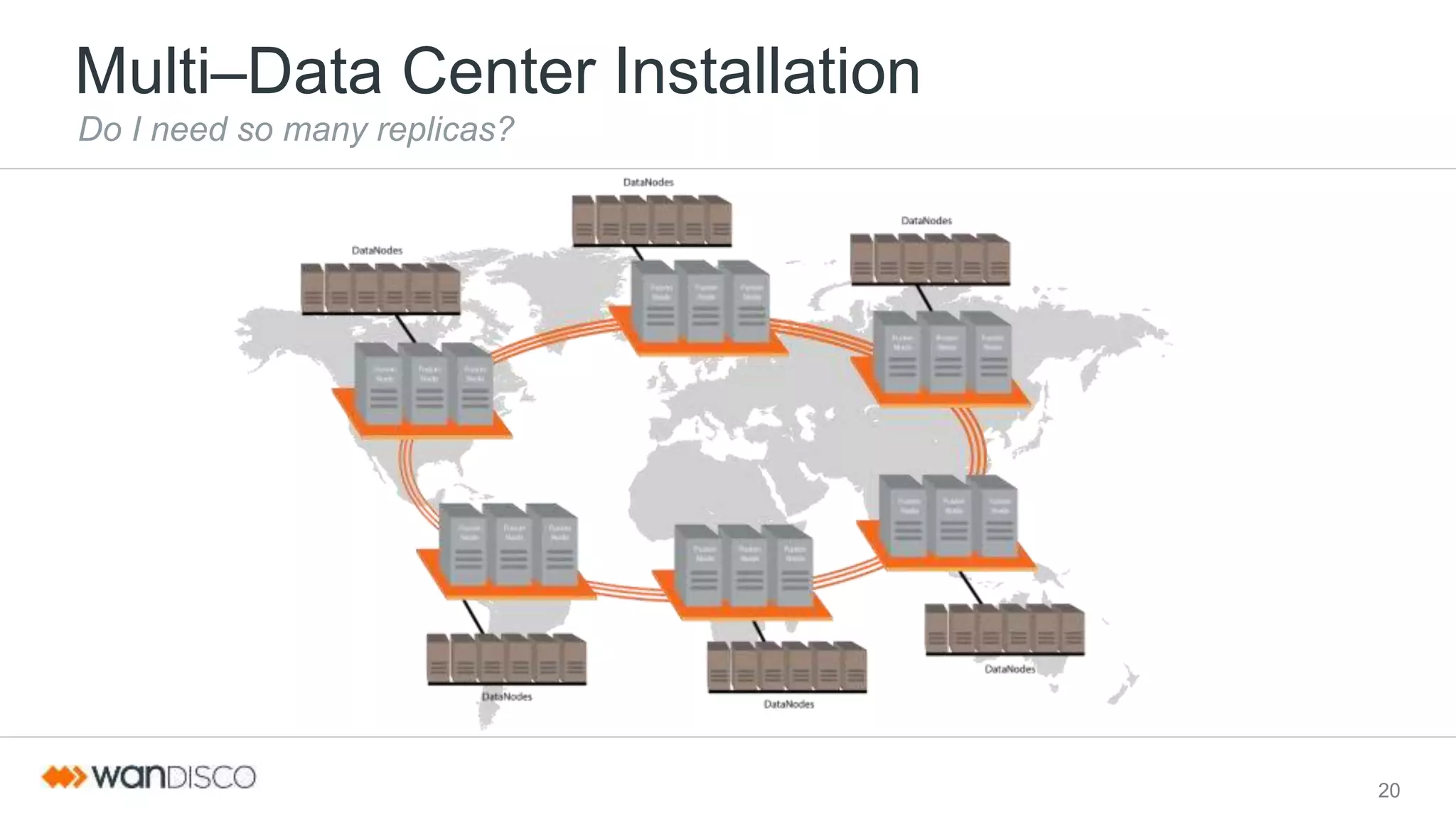


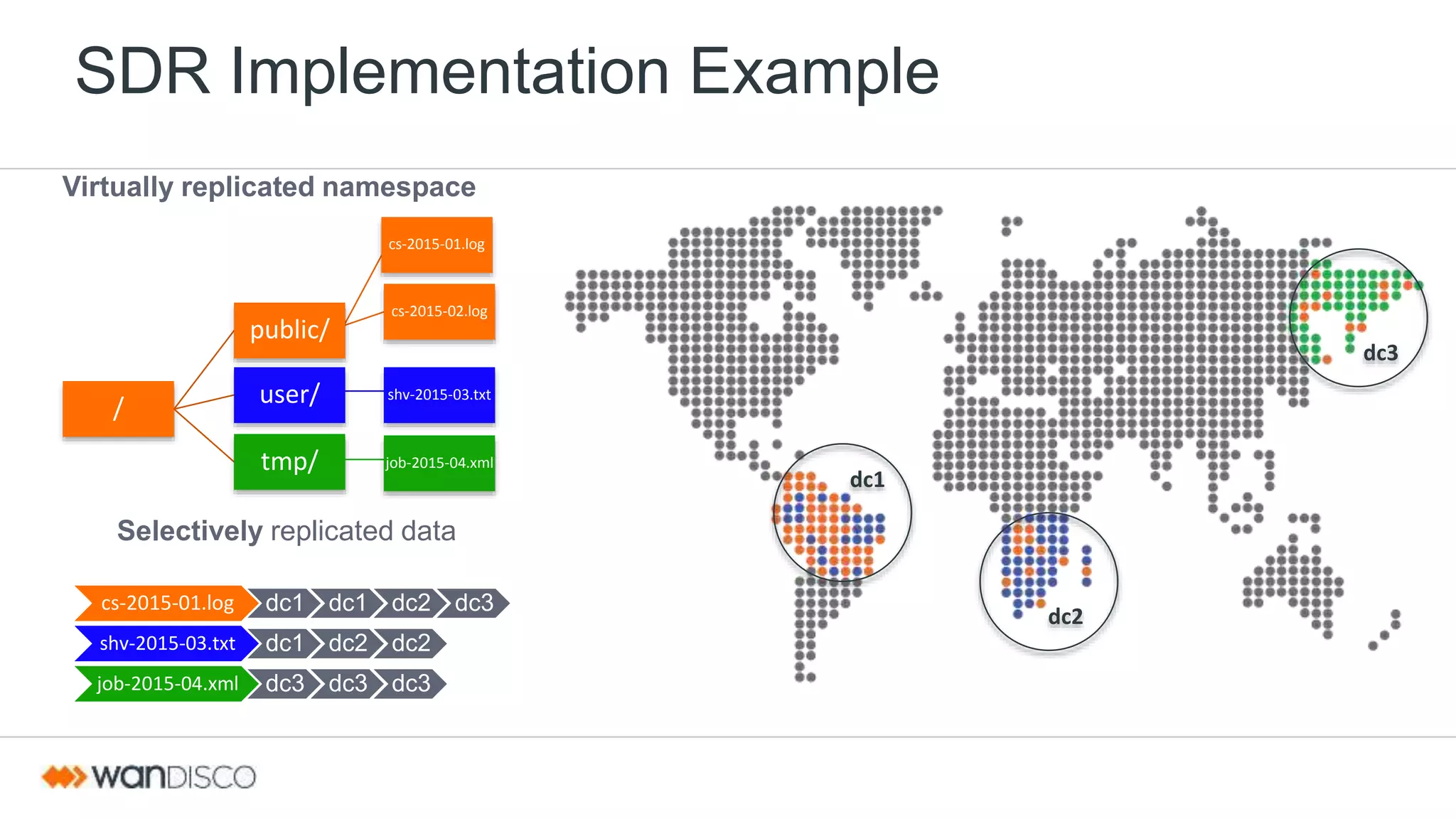




This document discusses selective data replication with geographically distributed Hadoop. It describes running Hadoop across multiple data centers as a single cluster. A coordination engine ensures consistent metadata replication and a global sequence of updates. Data is replicated asynchronously over the WAN for fast ingestion. Selective data replication allows restricting replication of some data to specific locations for regulations, temporary data, or ingest-only use cases. Heterogeneous storage zones with different performance profiles can also be used for selective placement. This architecture aims to provide a single unified file system view, strict consistency, continuous availability, and geographic scalability across data centers.