Downloaded 310 times



















This document discusses common patterns for running Apache Kafka across multiple data centers. It describes stretched clusters, active/passive, and active/active cluster configurations. For each pattern, it covers how to handle failures and recover consumer offsets when switching data centers. It also discusses considerations for using Kafka with other data stores in a multi-DC environment and future work like timestamp-based offset seeking.
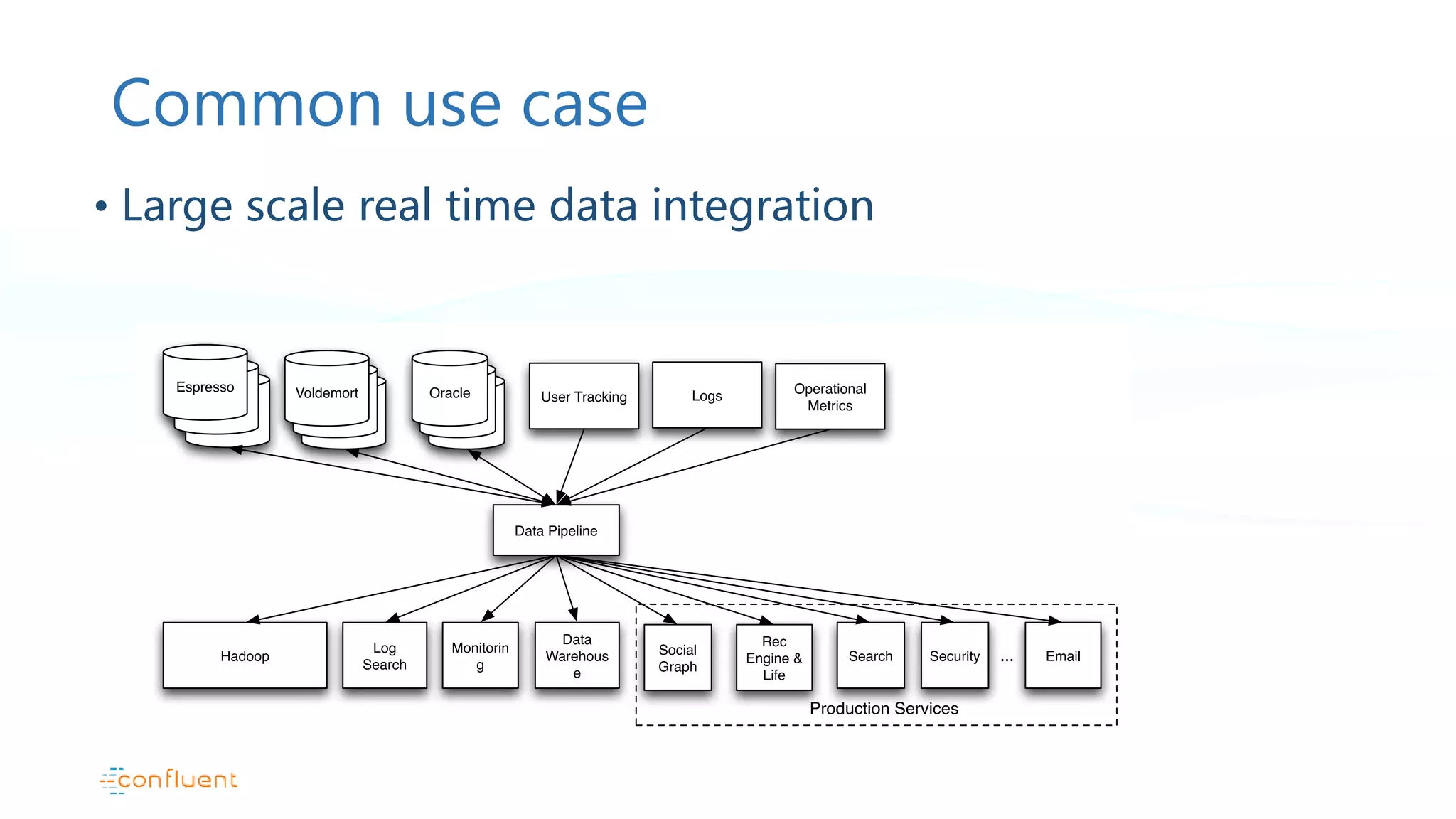
Introduction to Apache Kafka and its distributed, high-throughput capabilities with real-time data integration use cases.
Reasons for using multiple data centers: disaster recovery, geo-localization, bandwidth savings, and security.
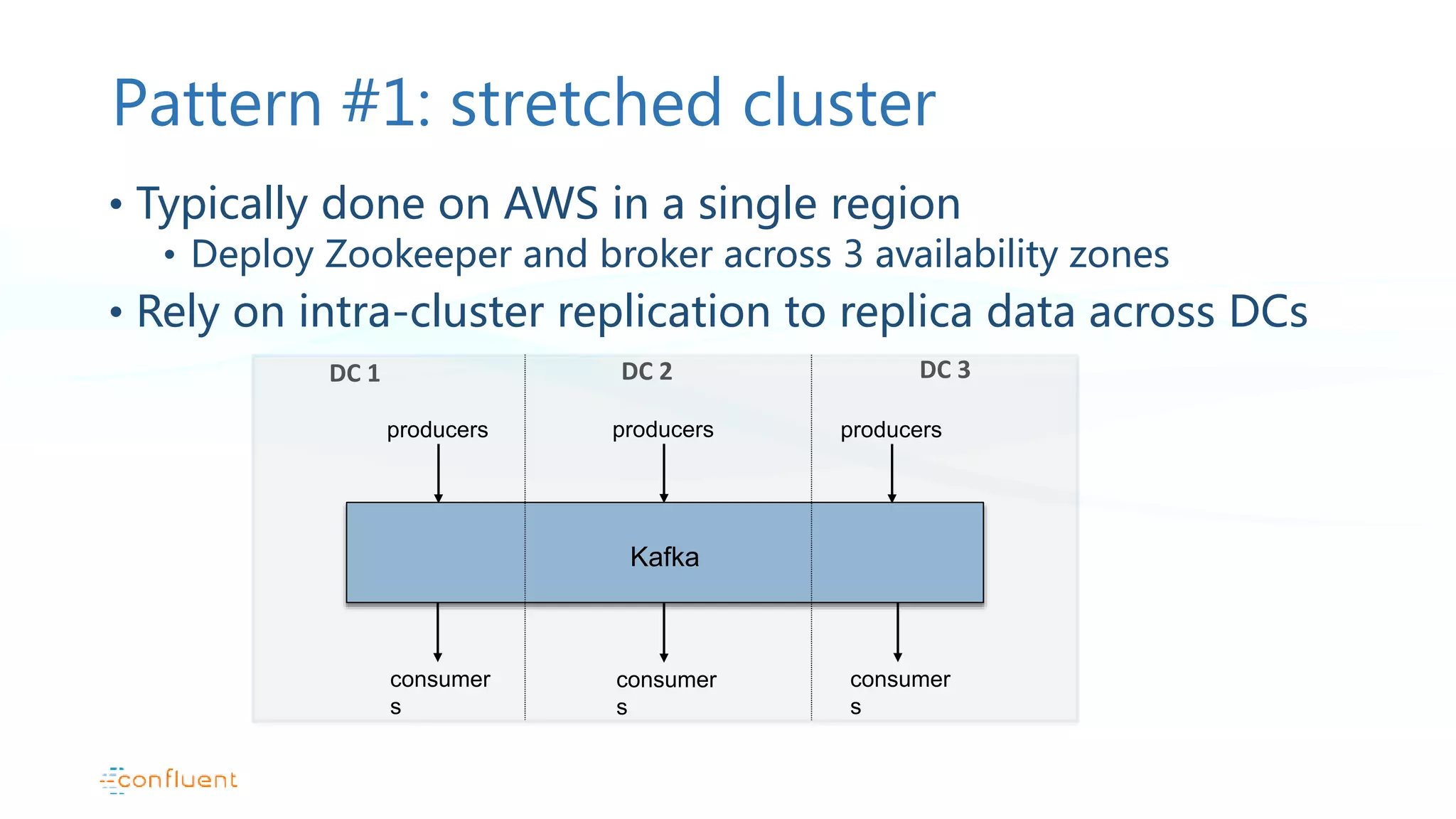
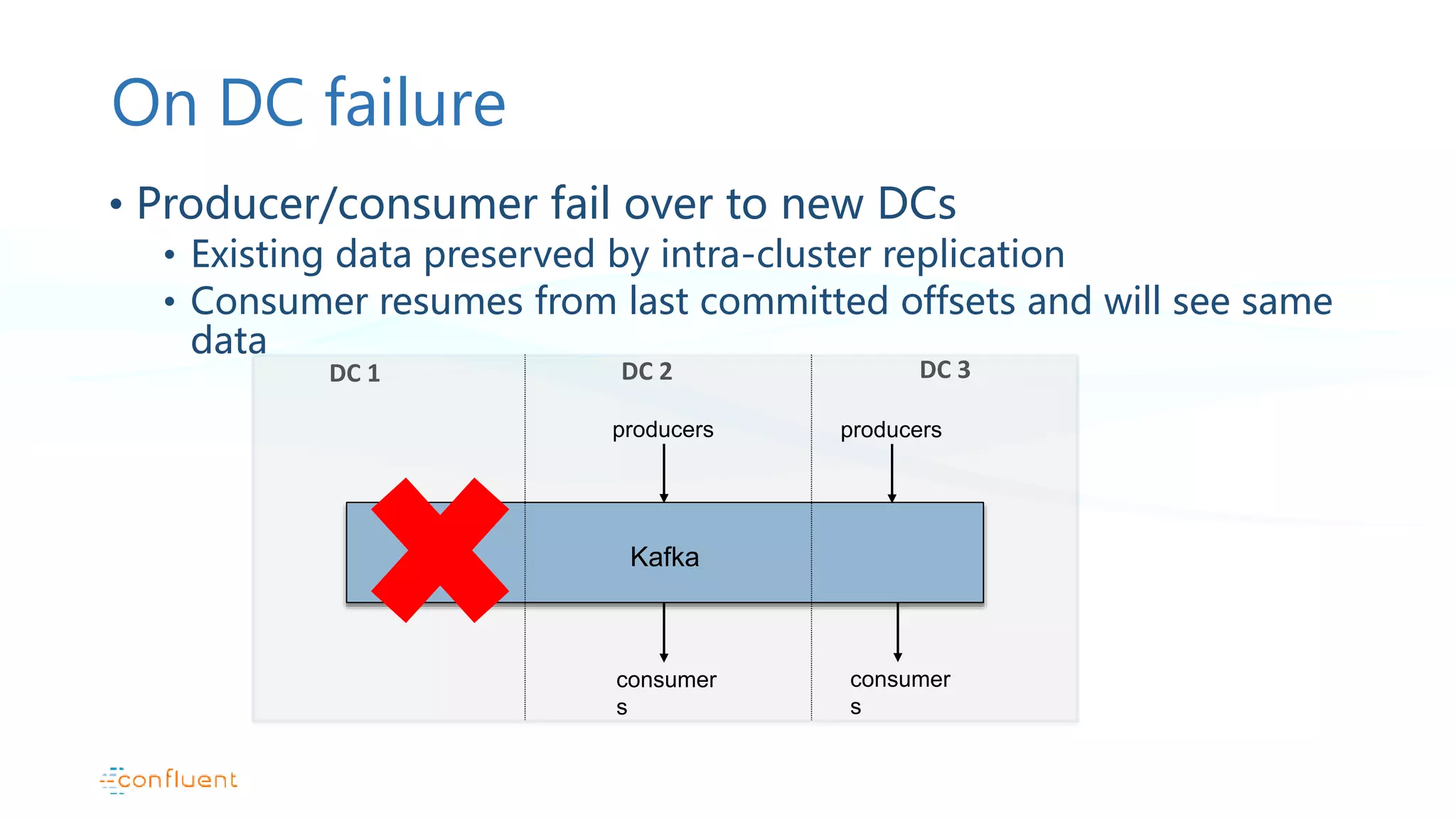
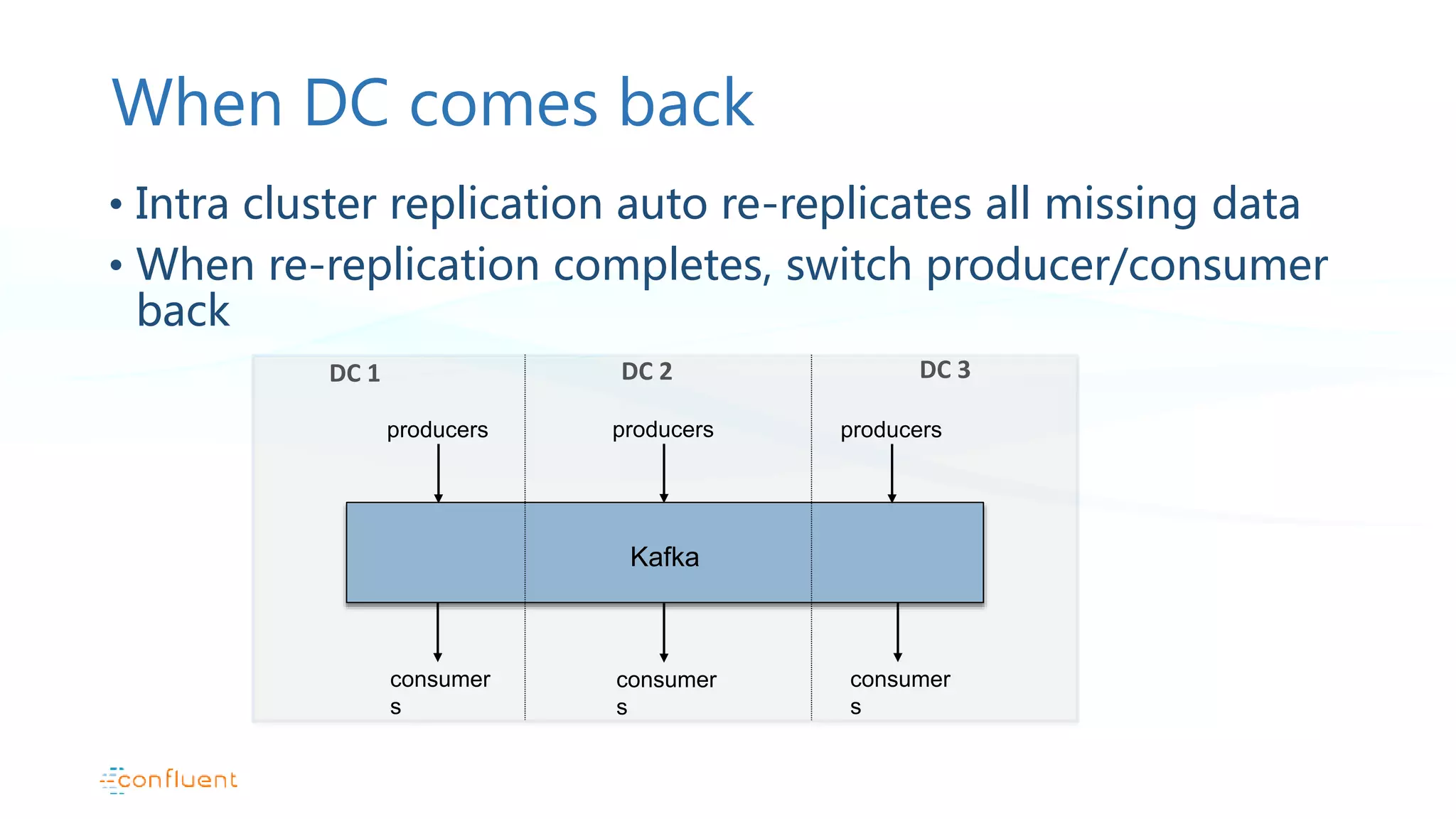
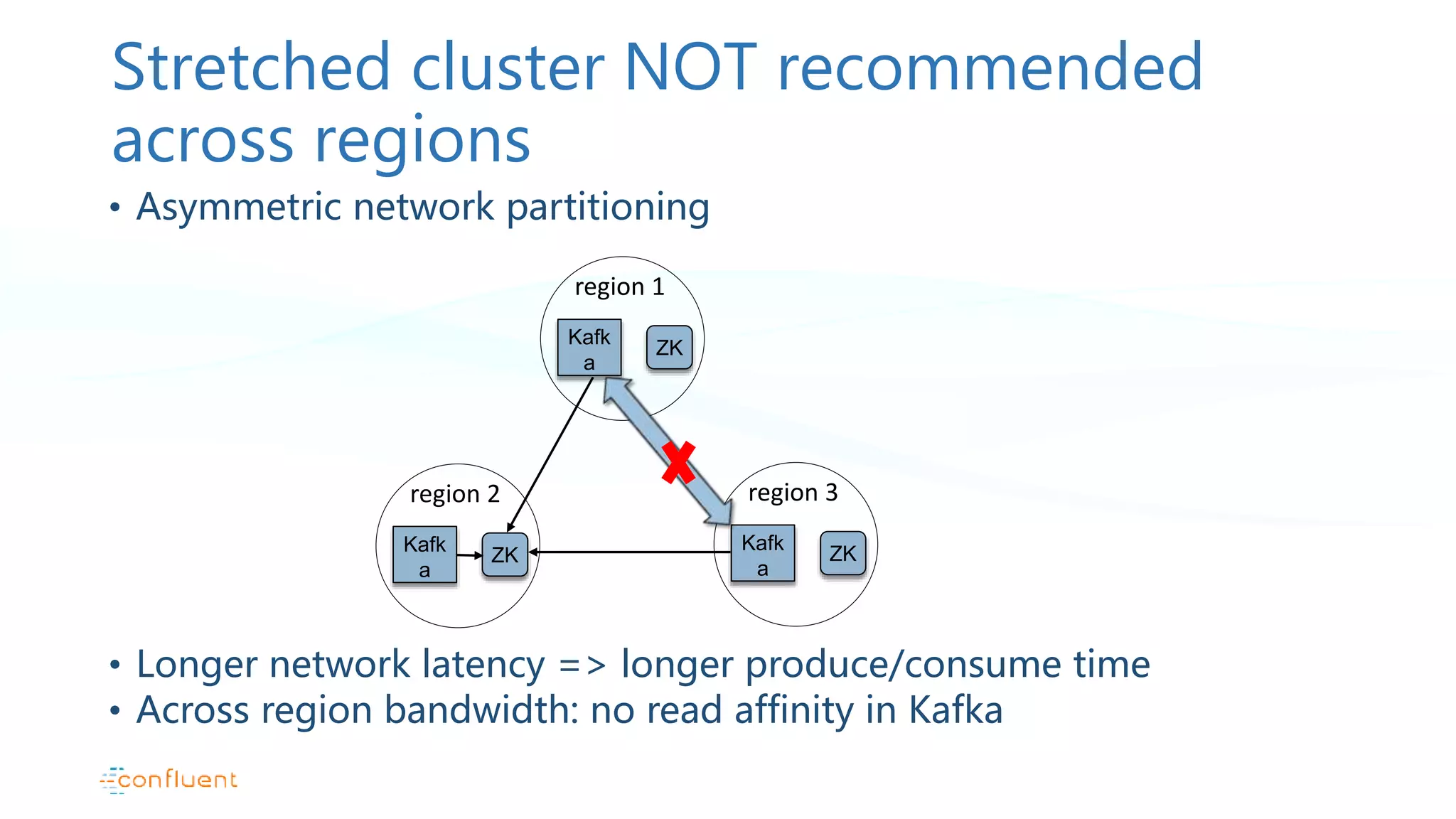
Pattern description for stretched clusters, failovers, and replication challenges within single AWS regions.
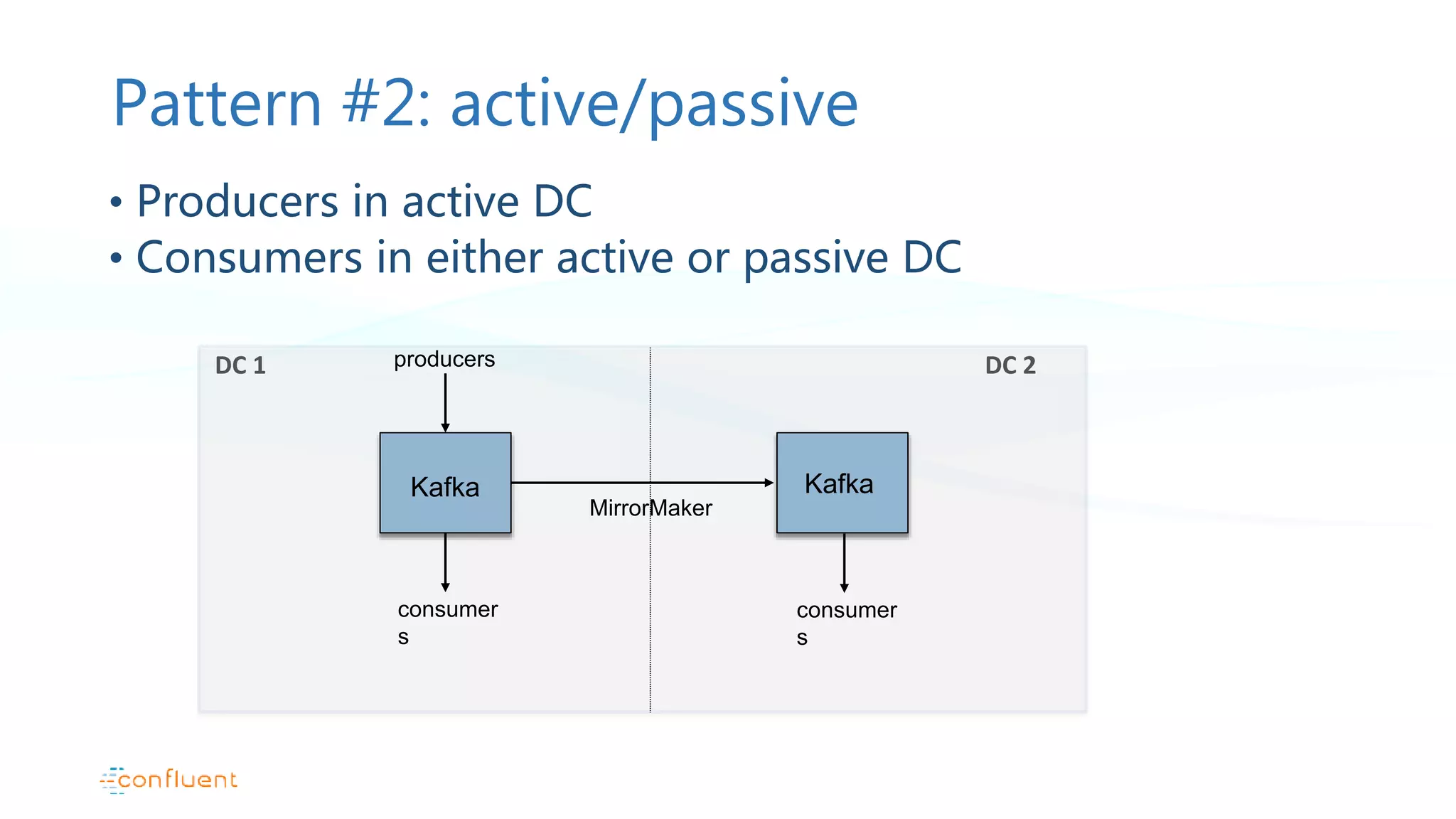
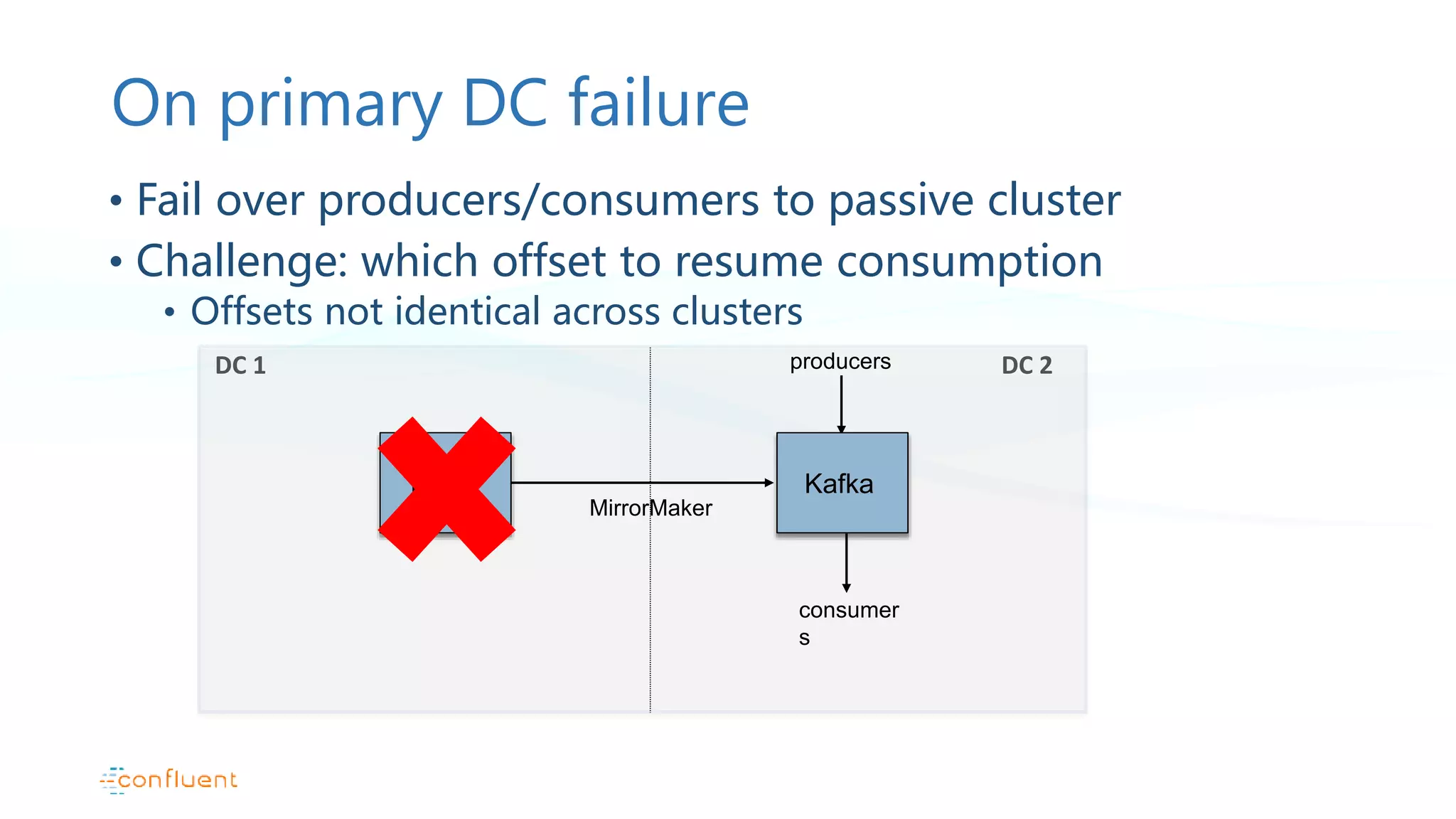
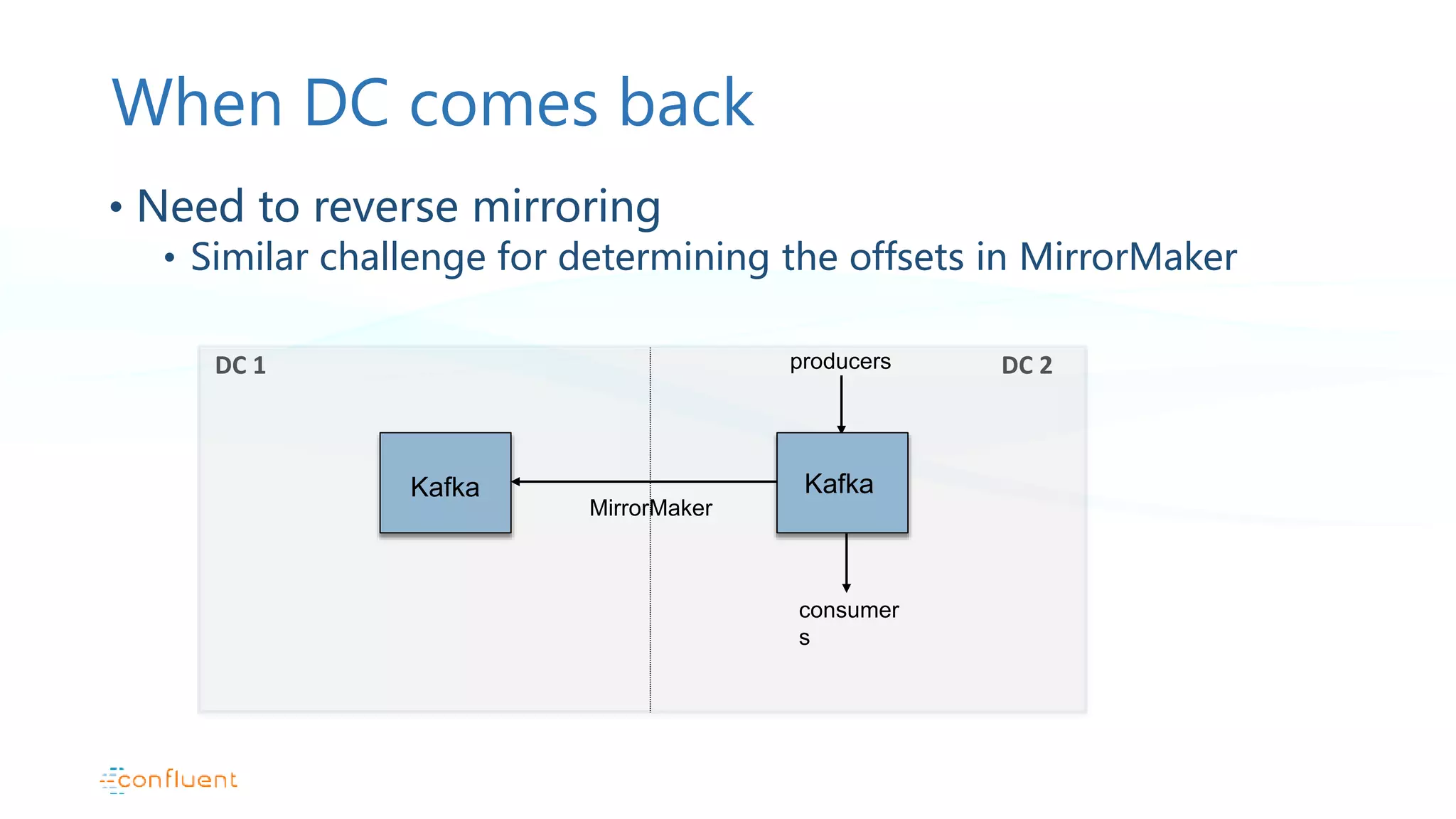
Active/passive data center configuration with MirrorMaker usage, failover strategies, and limitations.
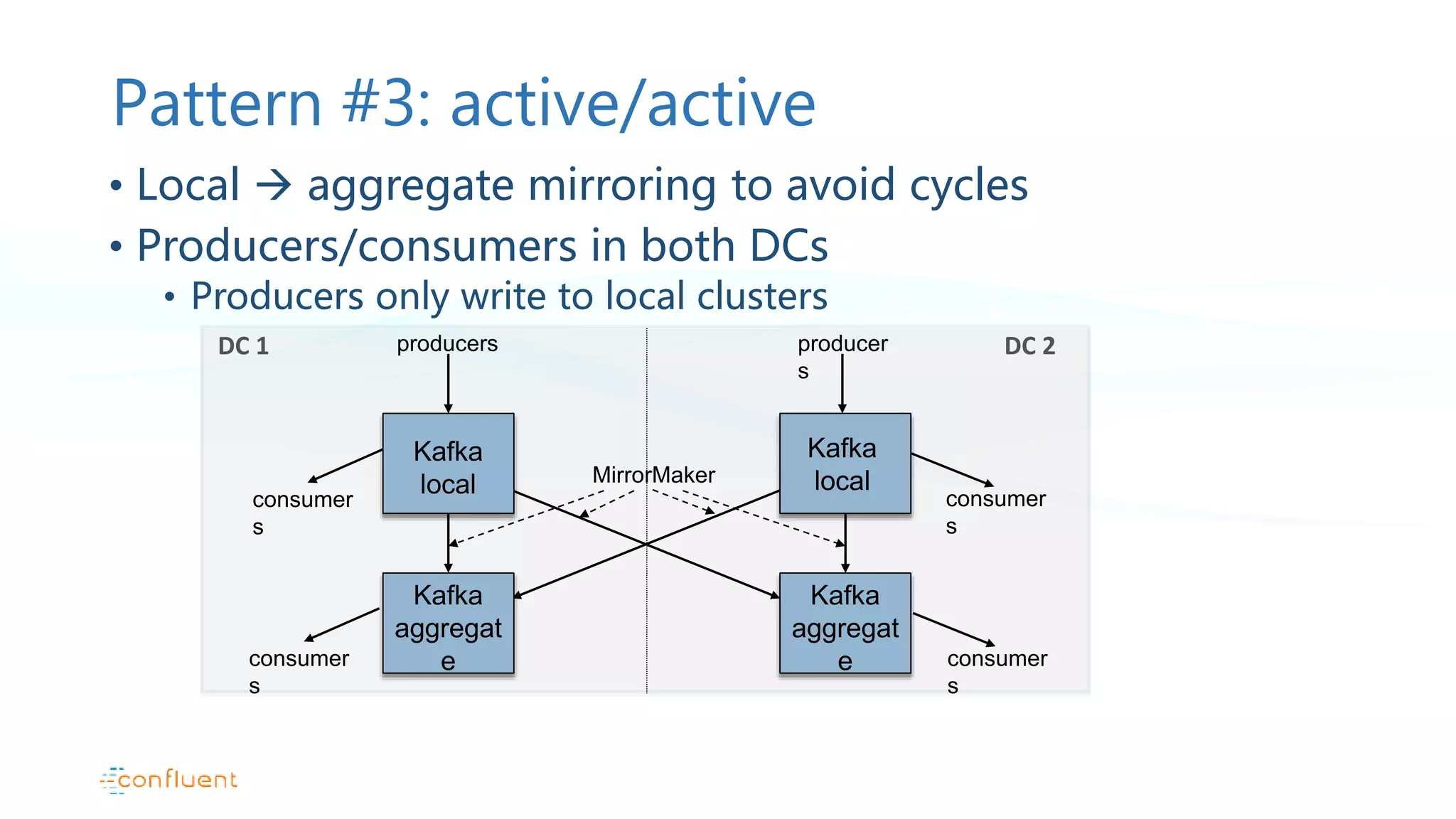
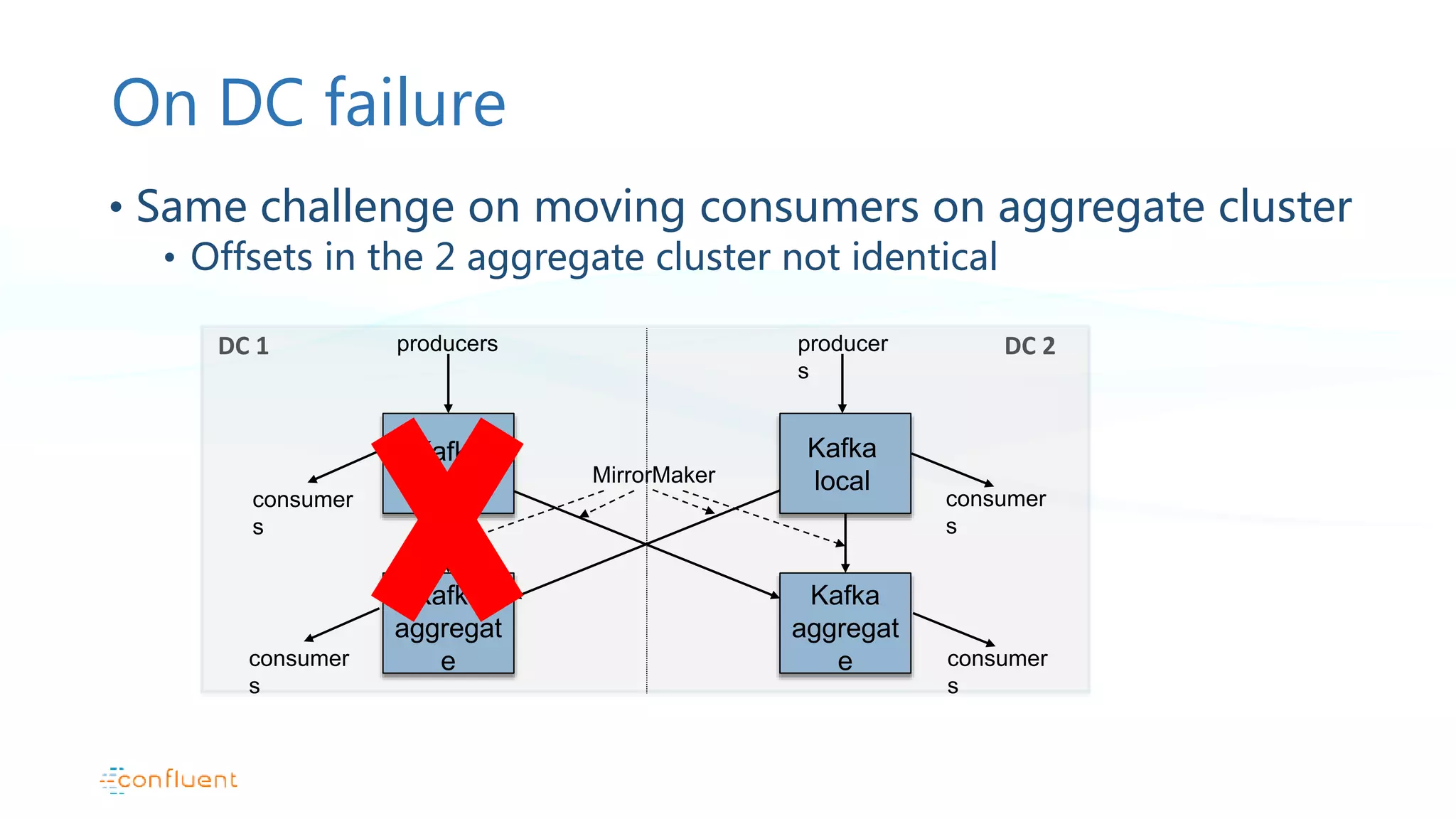
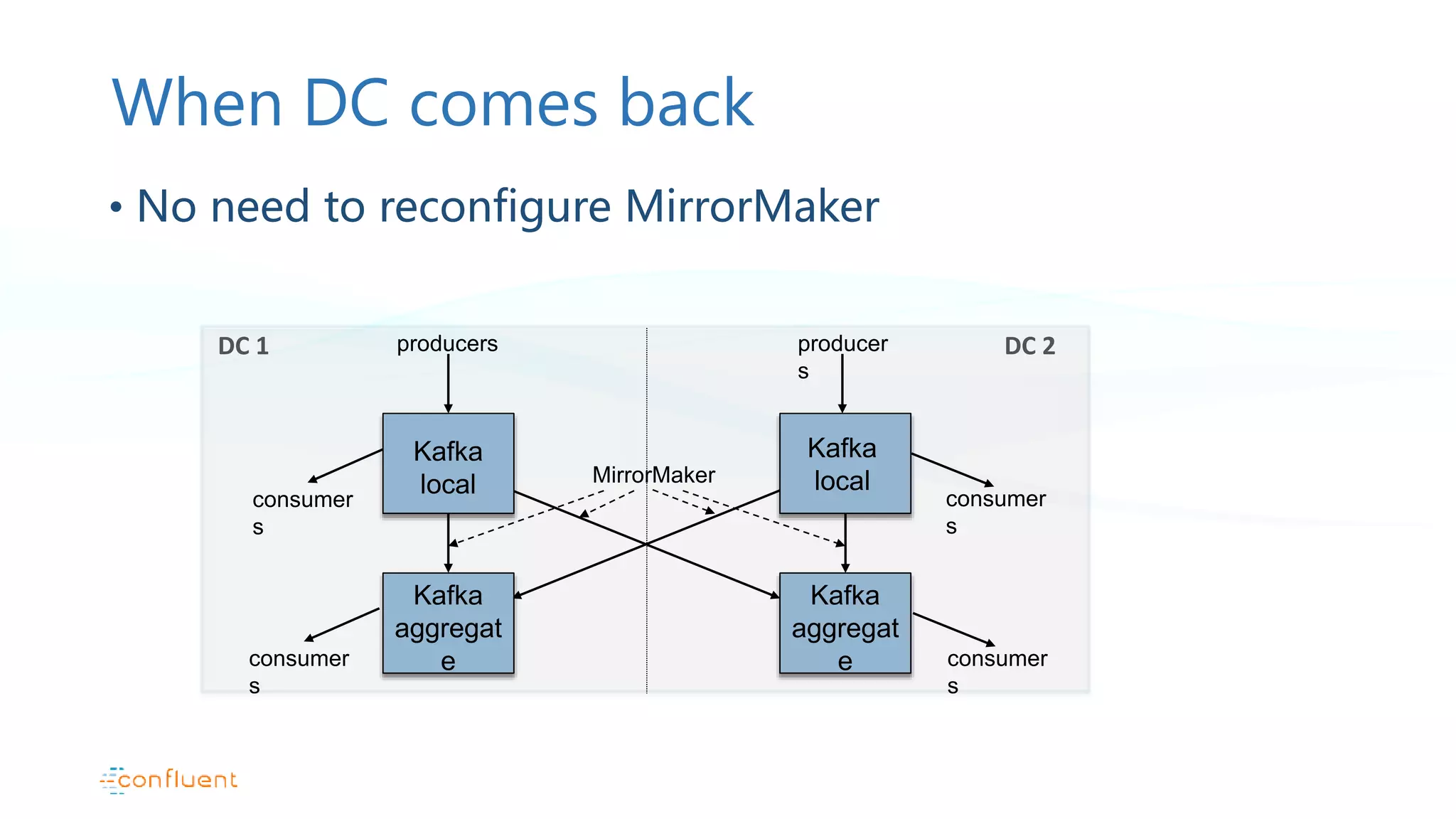
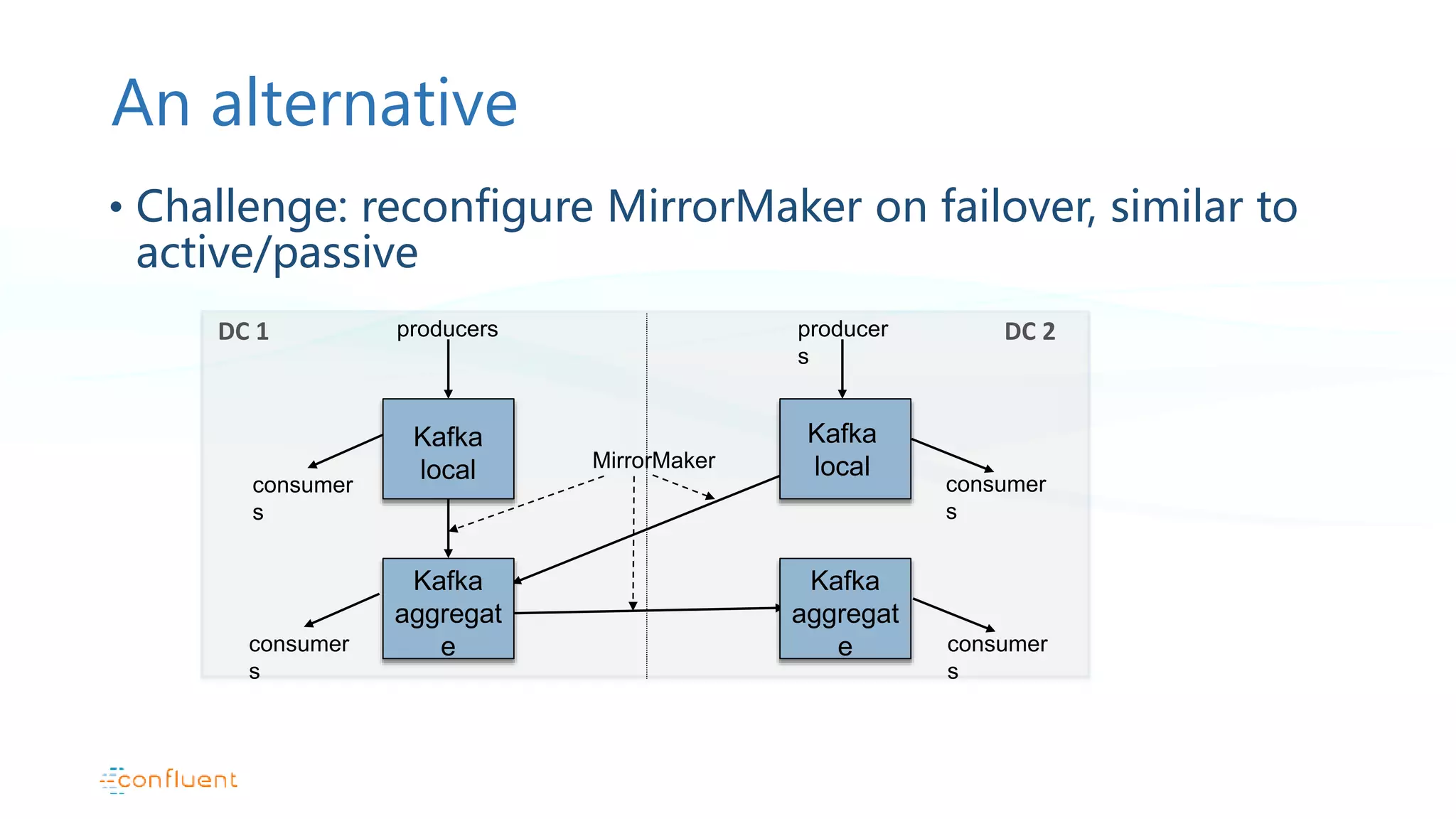
Active/active configuration pattern and addressing challenges in offset management during failures.
Strategies for managing multiple DCs, including topic mirroring and resource utilization across DCs.
Comparison of pros and cons of stretched, active/passive, and active/active data center patterns.
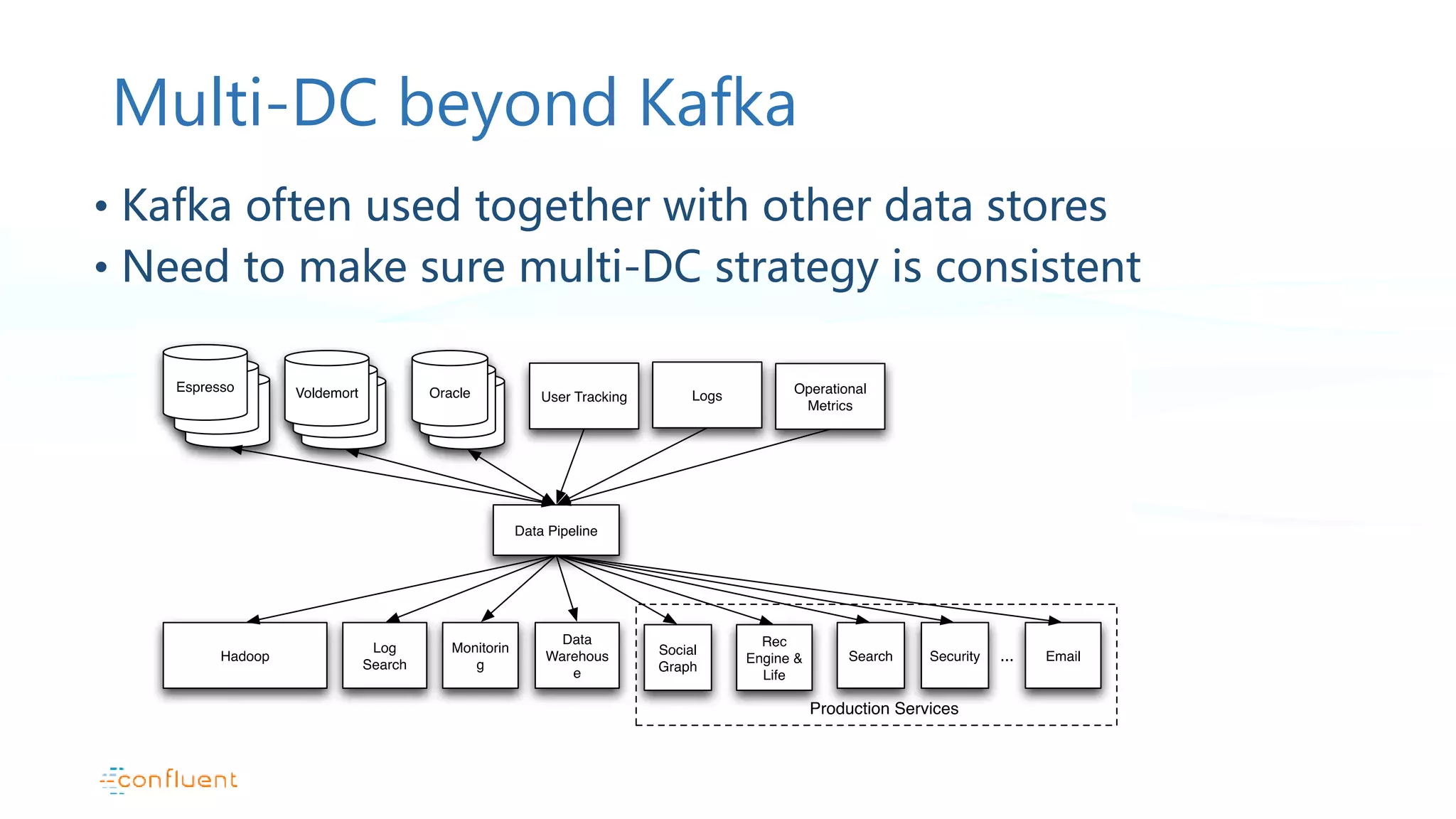
Understanding Kafka's integration with other data stores and applications for efficient data handling.
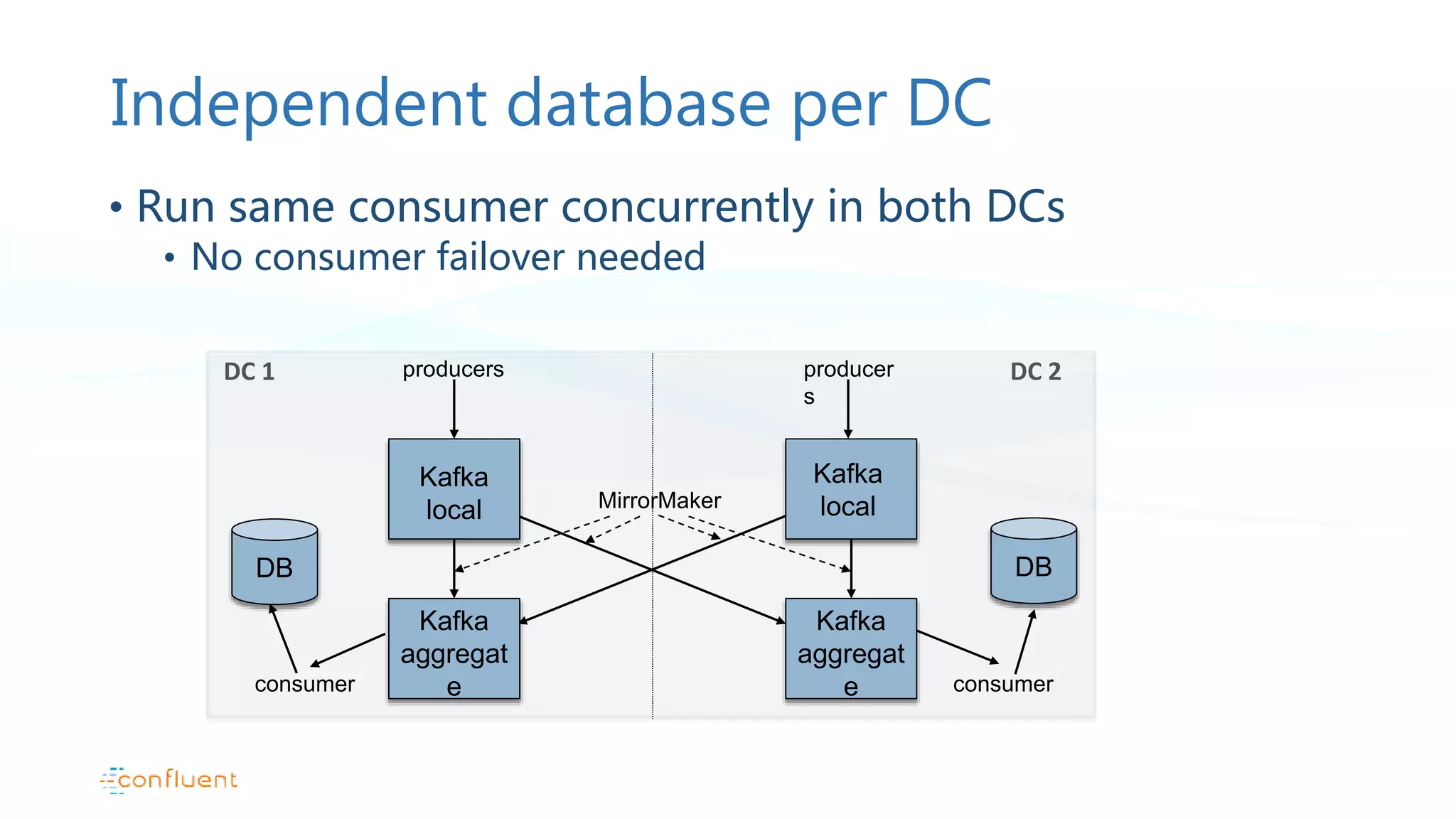
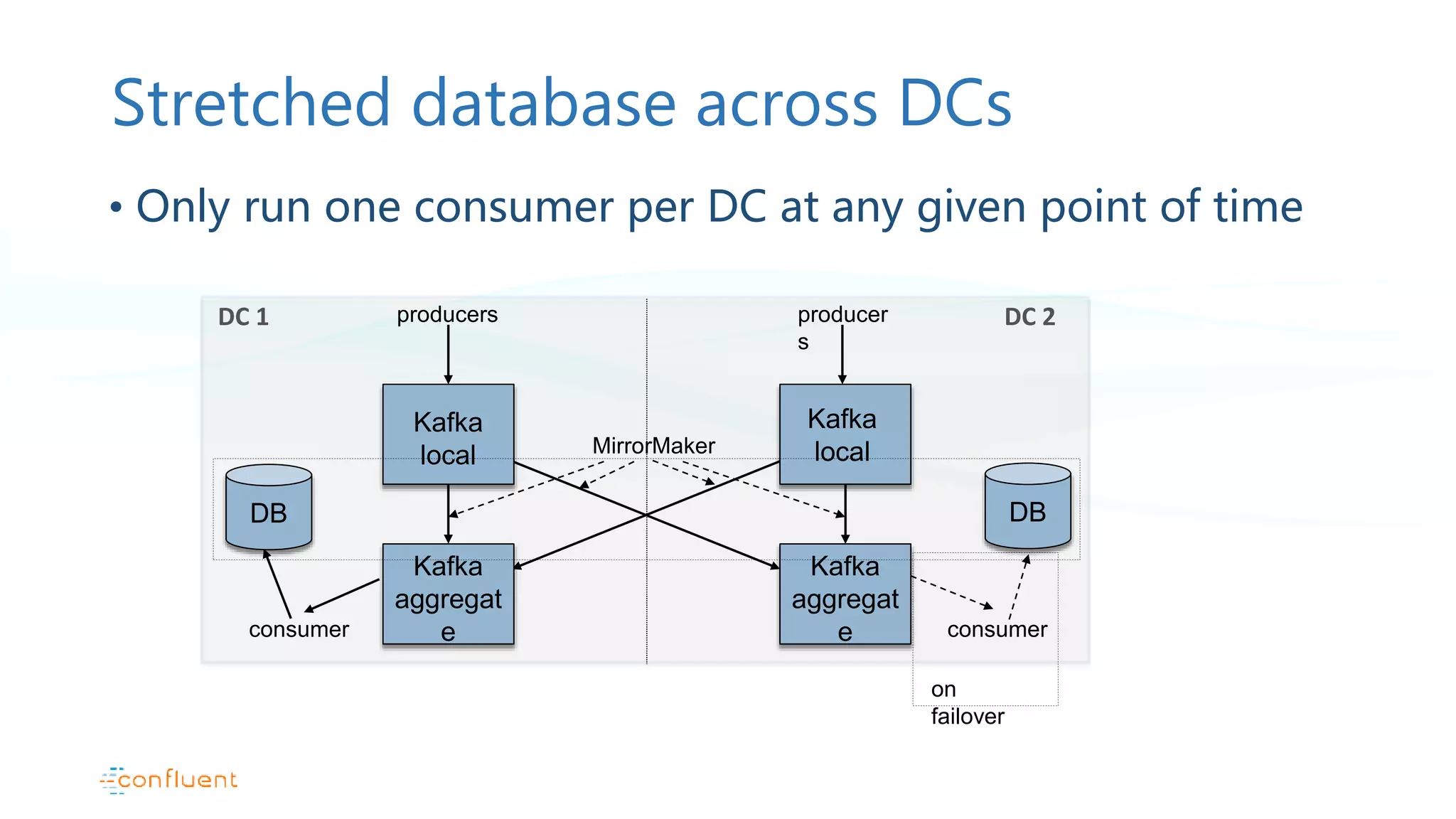
Configurations for databases in multiple data centers and considerations for failover management.
Operational aspects such as performance tuning, security, and preferred configurations for MirrorMaker.
Discussion on future work in Kafka, including timestamp indexes and integration enhancements.
Thank you note and resources for further learning and development in Kafka.