
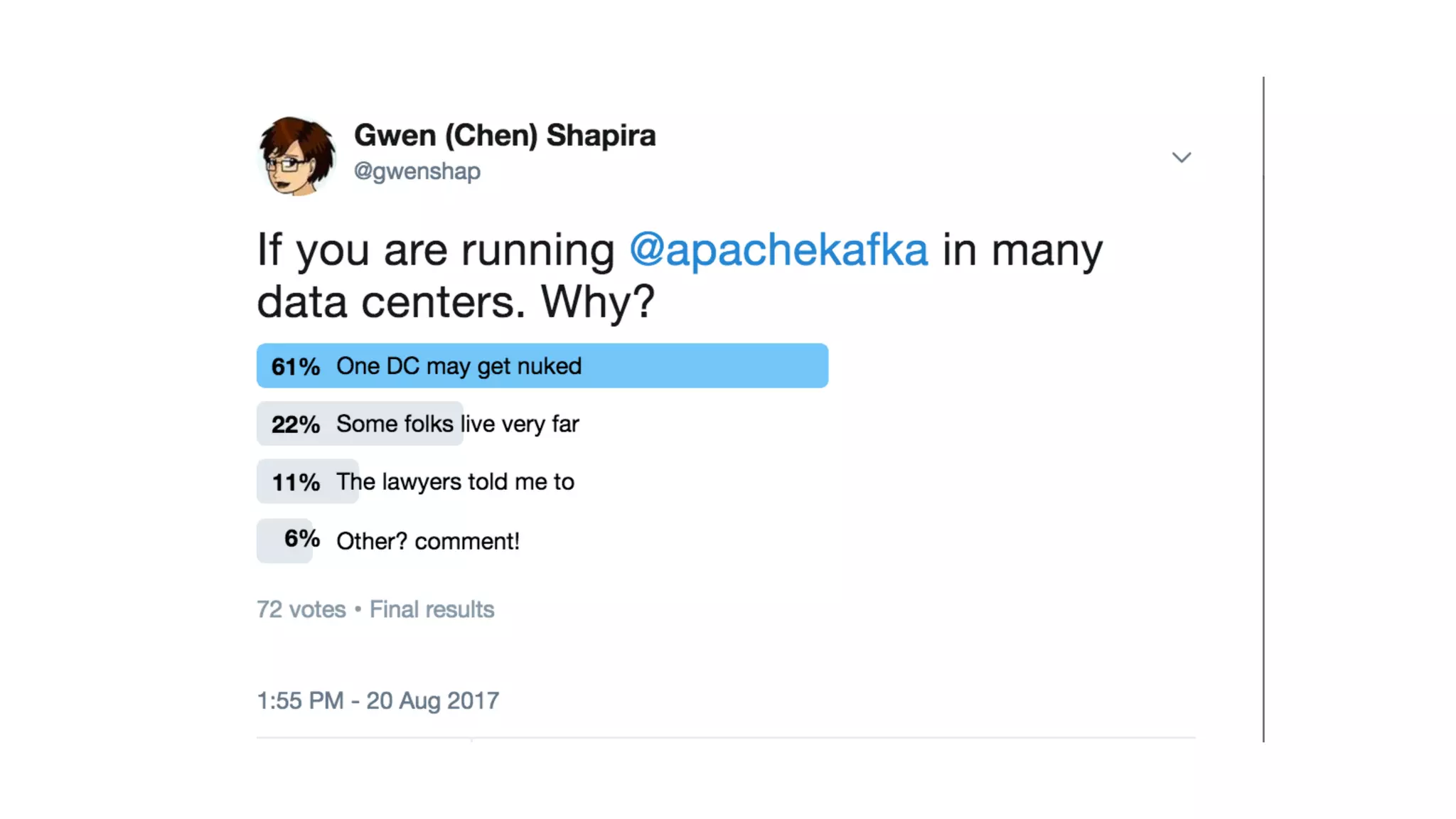


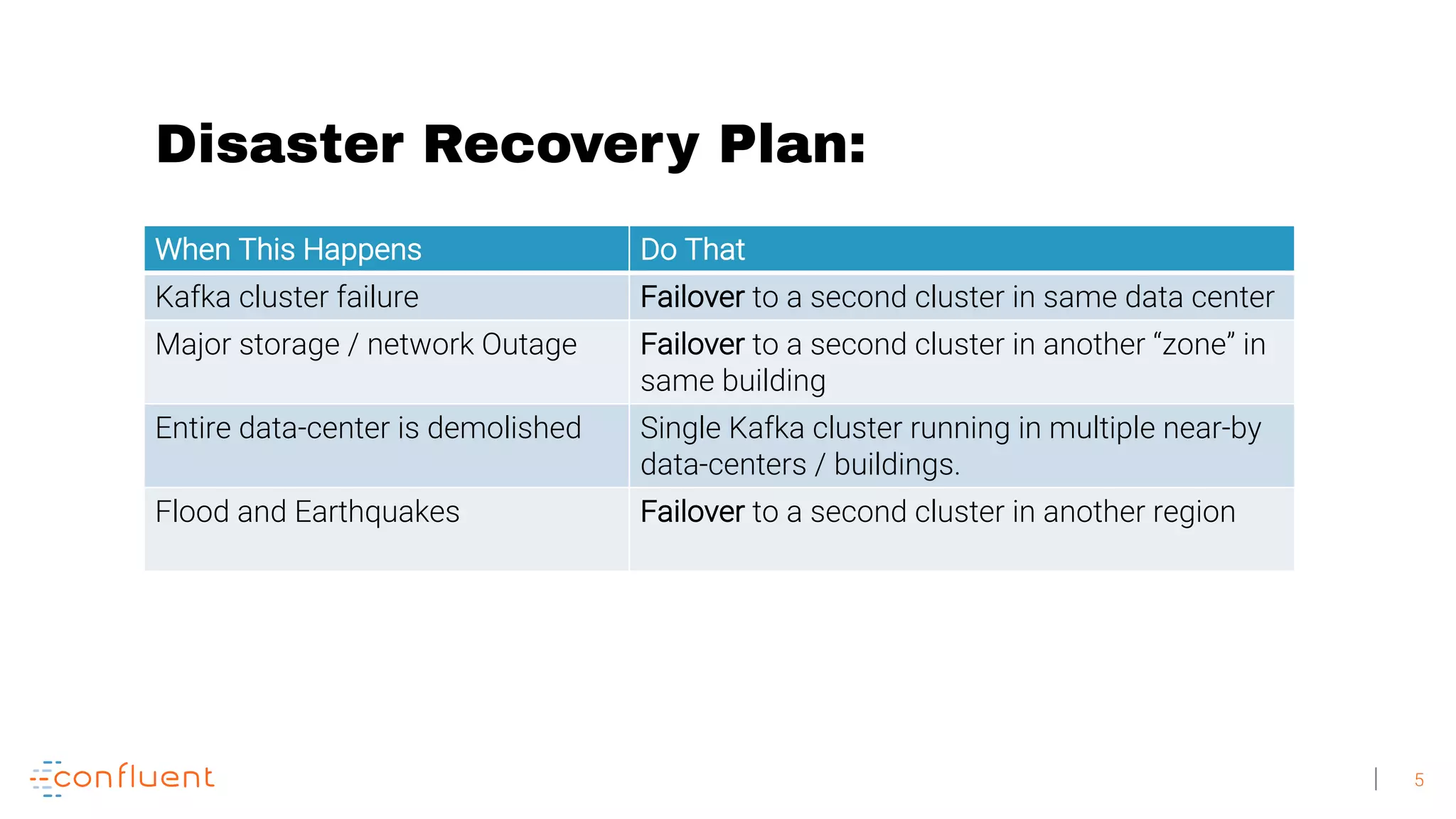










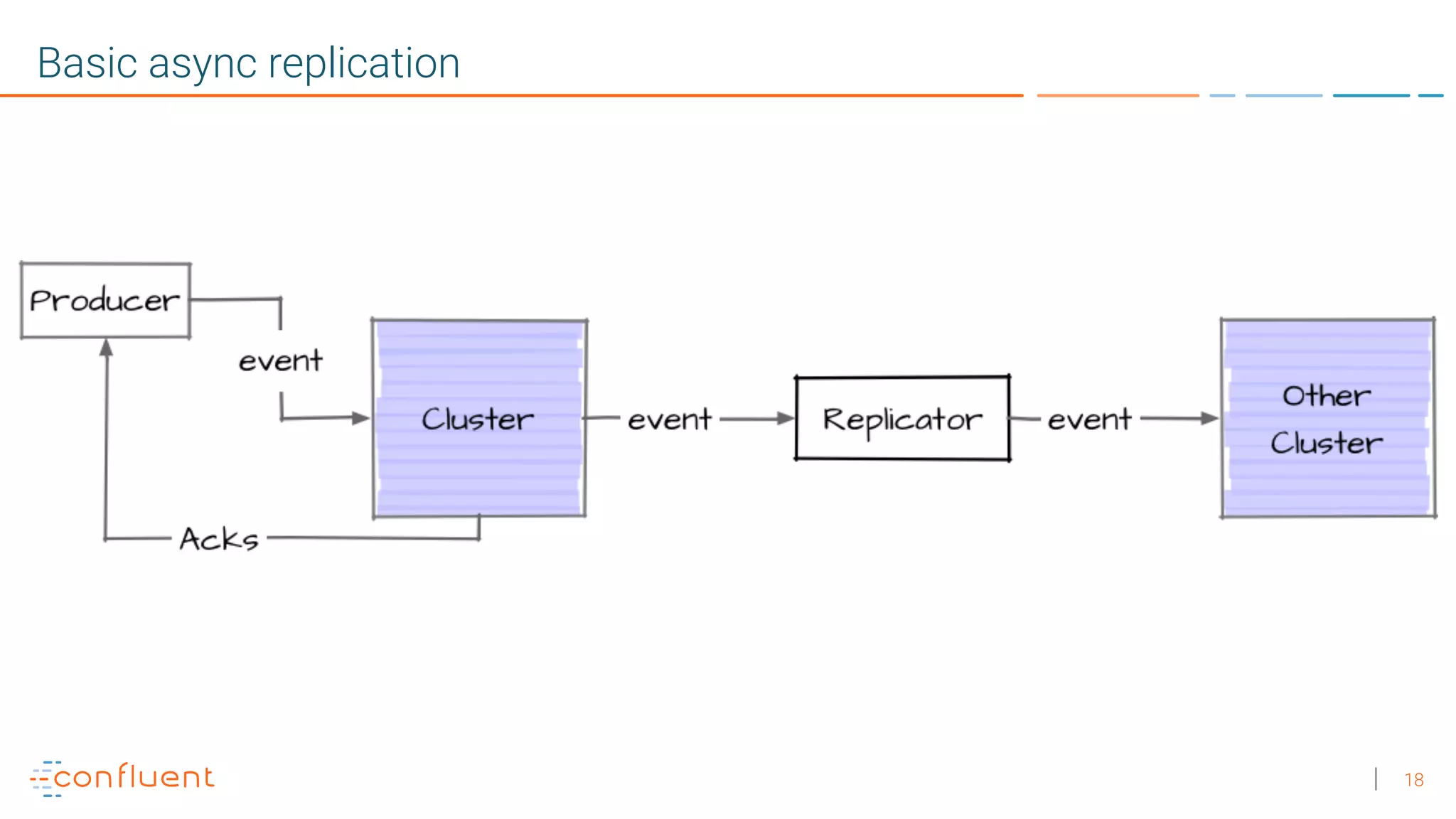
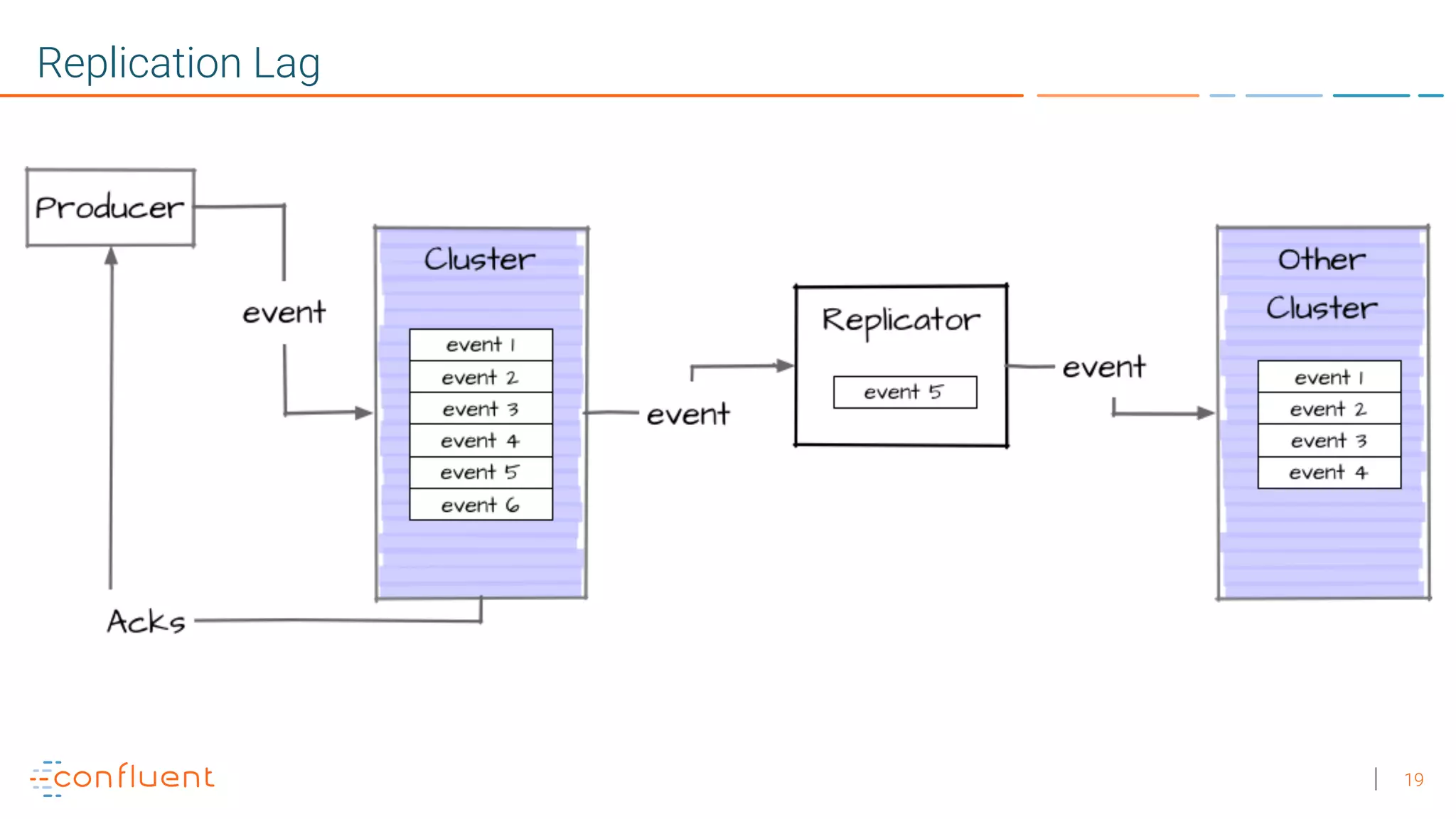

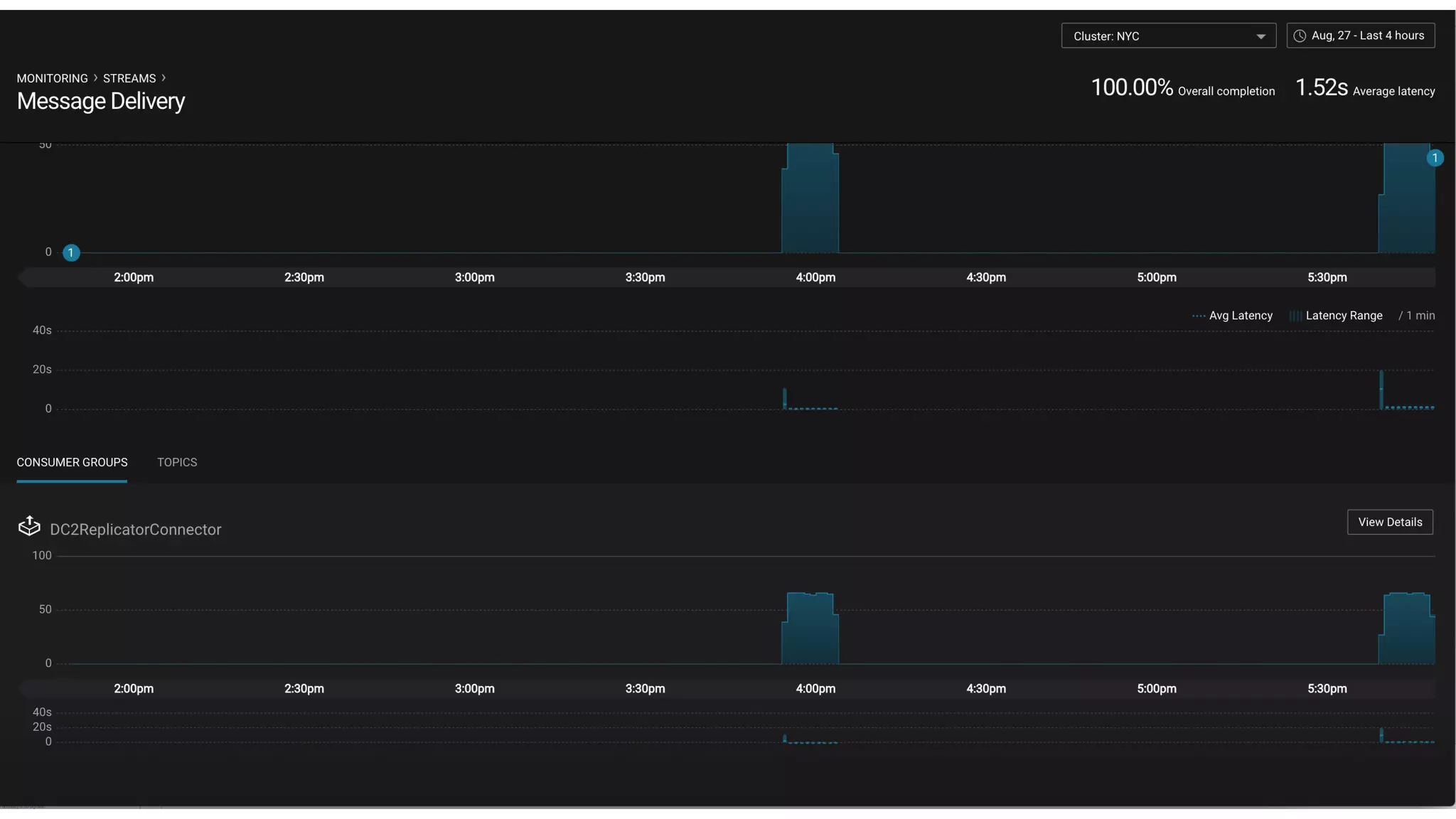

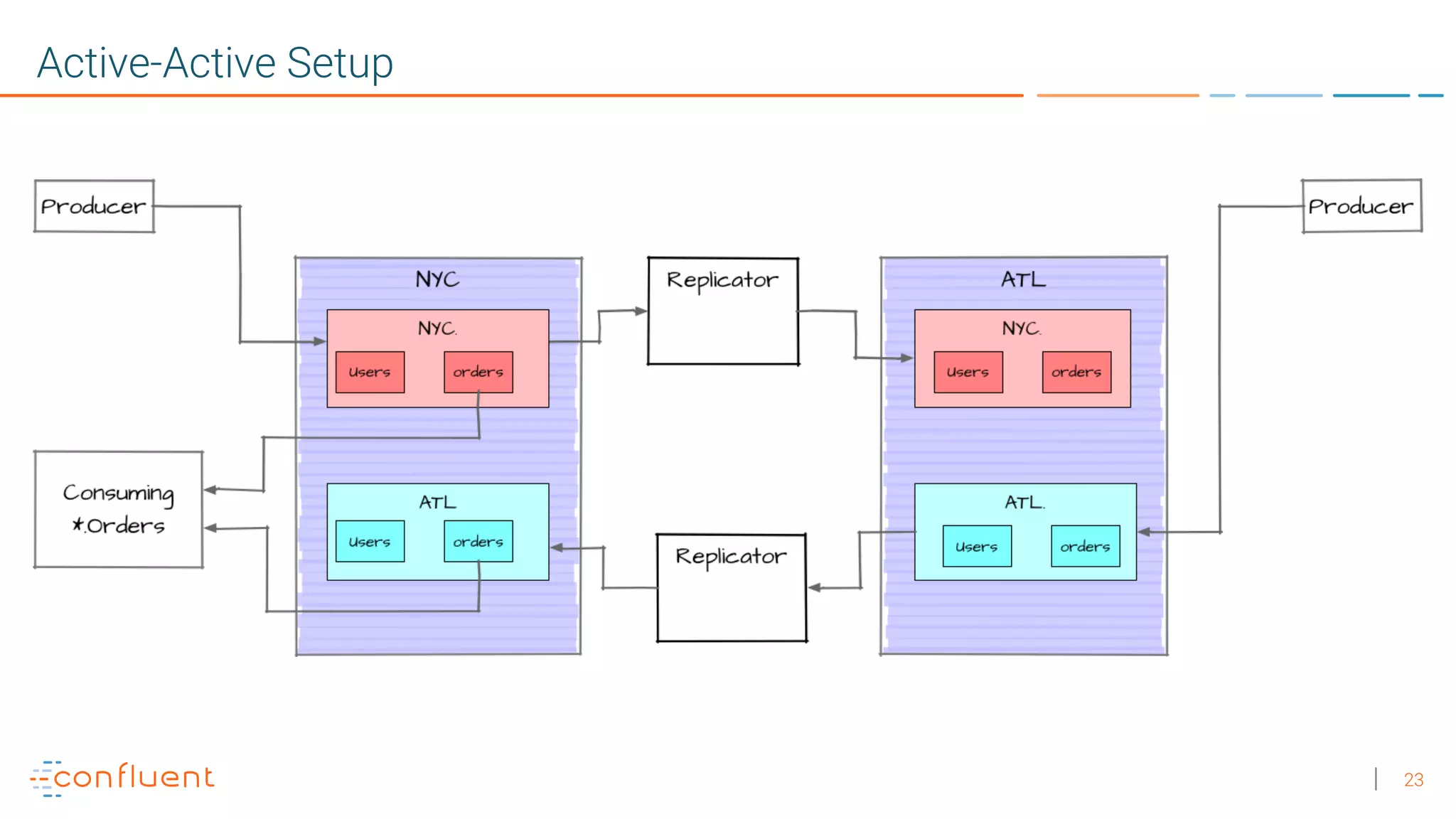

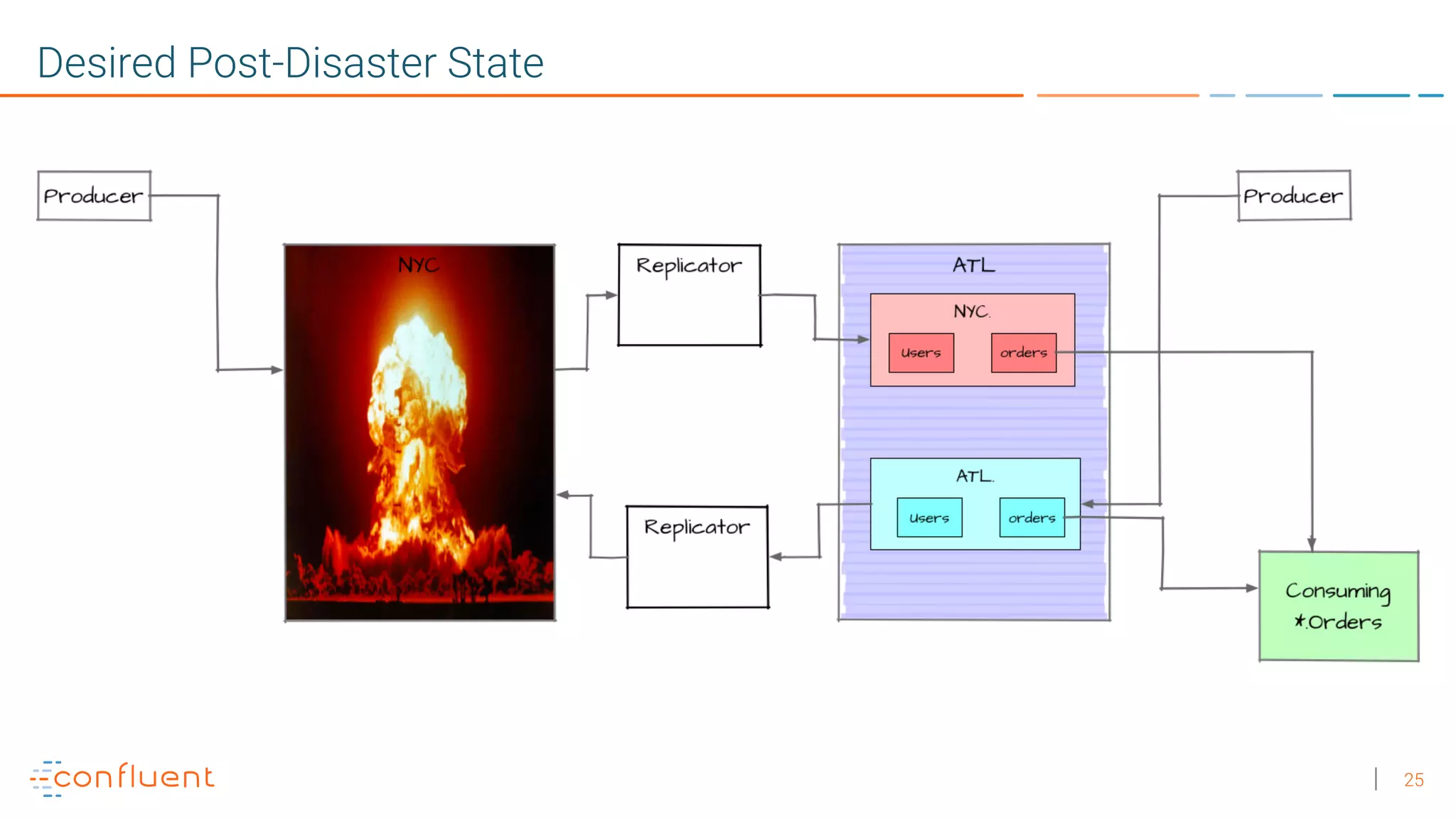

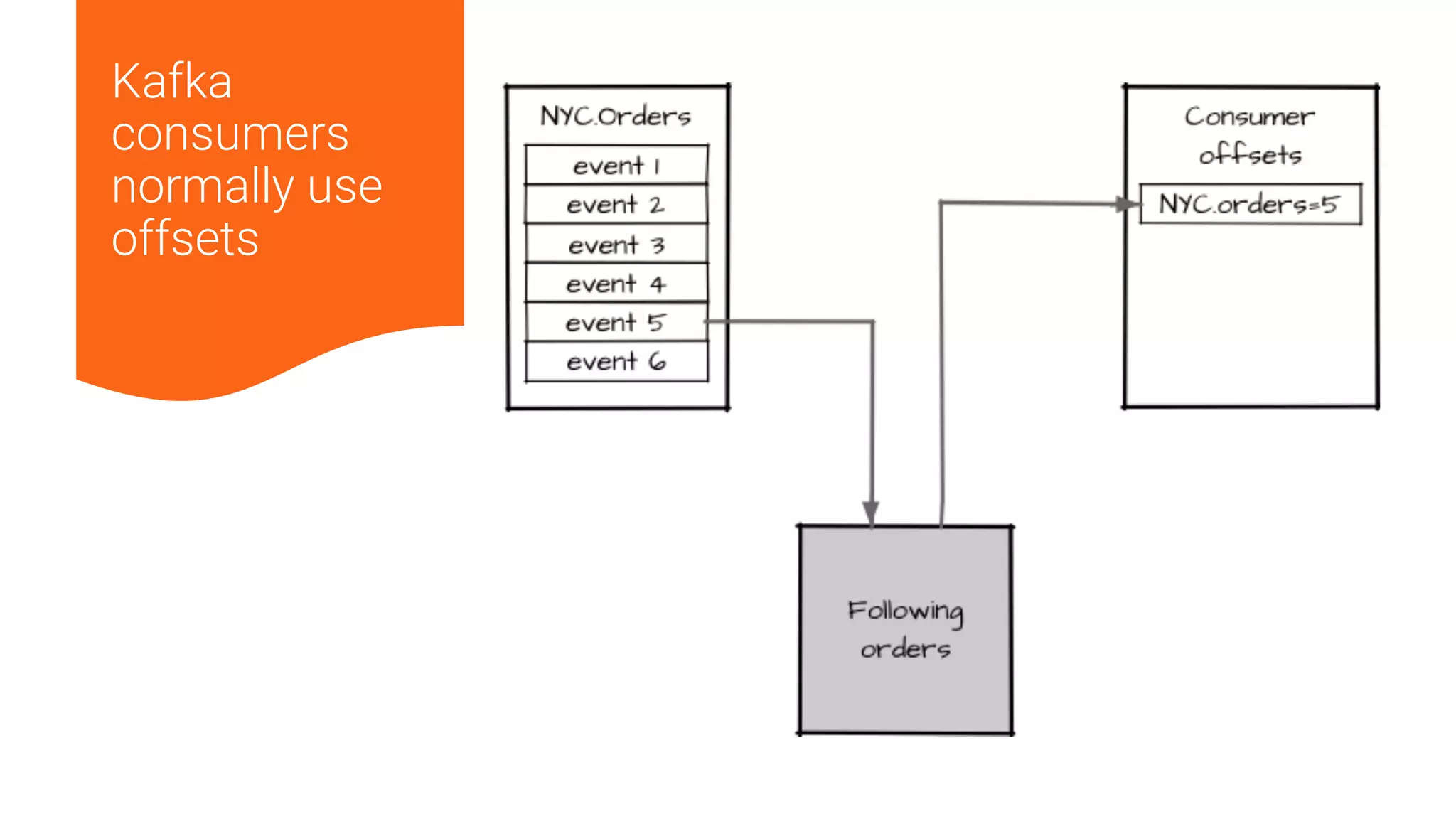
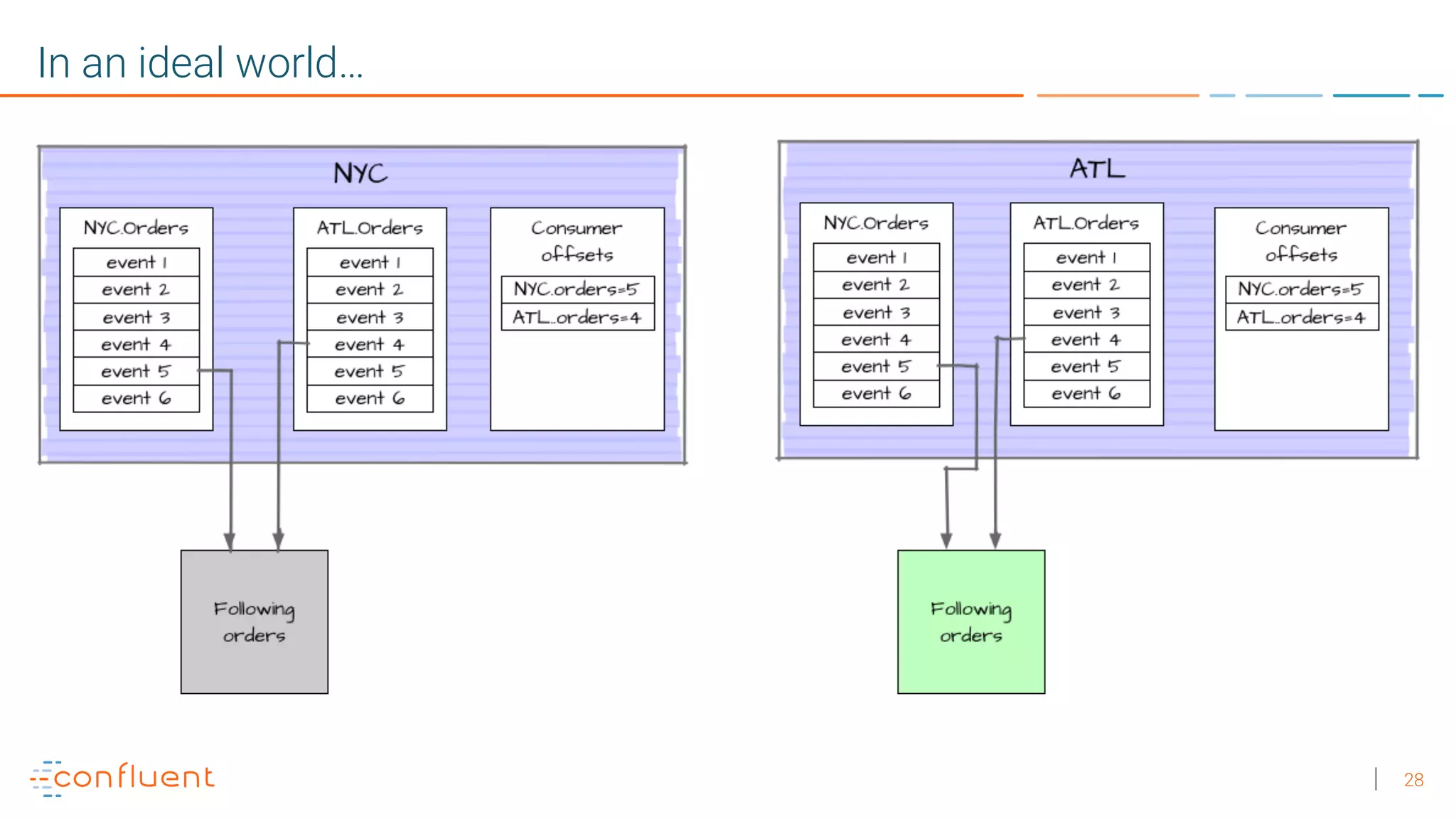








1. Running a single Kafka cluster is not sufficient for high availability and disaster recovery. Having multiple clusters across different data centers is necessary to handle failures like an entire data center being demolished. 2. There are different approaches to setting up Kafka clusters across multiple data centers, including a "stretch cluster" with at least one broker and Zookeeper in each data center, or running two independent clusters and replicating data between them asynchronously or actively. 3. With multiple data center replication, there are tradeoffs around latency, throughput, infrastructure costs, and the difficulty of handling consumer offsets during failover. The optimal solution depends on an organization's specific availability, data consistency, and disaster recovery requirements.