Downloaded 13 times







![map and flatMap • map takes a function that transforms each element of a collection: map(f: T => U) • RDD[T] => RDD[U] • flatMap takes a function that transforms a single element of a collection into a sequence of elements: flatMap(f: T => Seq[U]) • Flattens out the output into a single sequence • RDD[T] => RDD[U]](https://image.slidesharecdn.com/scalameetup-introtospark-150925132147-lva1-app6892/75/Scala-meetup-Intro-to-spark-12-2048.jpg)
![filter, distinct • filter takes a (predicate) function that returns true if an element should be in the output collection: map(f: T => Bool) • distinct removes duplicates from the RDD • Both filter and distinct transform from RDD[T] => RDD[T]](https://image.slidesharecdn.com/scalameetup-introtospark-150925132147-lva1-app6892/75/Scala-meetup-Intro-to-spark-13-2048.jpg)

![reduce, fold & aggregate • reduce takes a function that combines pairwise element of a collection: reduce(f: (T, T) => T) • fold is like reduce except it takes a zero value i.e. fold(zero: T) (f: (T, T) => T) • reduce and fold: RDD[T] => T • aggregate is the most general form • aggregate(zero: U)(seqOp: (U, T) => U, combOp: (U, U) => U) • aggregate: RDD[T] => U](https://image.slidesharecdn.com/scalameetup-introtospark-150925132147-lva1-app6892/75/Scala-meetup-Intro-to-spark-15-2048.jpg)

![keyBy, reduceByKey • keyBy creates tuples of the elements in an RDD by applying a function: keyBy(f: T => K) • RDD[ T ] => RDD[ (K, T) ] • reduceByKey takes a function that takes a two values and returns a single value: reduceByKey(f: (V,V) => V) • RDD[ (K, V) ] => RDD[ (K, V) ]](https://image.slidesharecdn.com/scalameetup-introtospark-150925132147-lva1-app6892/75/Scala-meetup-Intro-to-spark-17-2048.jpg)
![groupByKey • Takes a collection of key-value pairs and no parameters • Returns a sequence of values associated with each key • RDD[ ( K, V ) ] => RDD[ ( K, Iterable[V] ) ] • Results must fit in memory • Can be slow – use aggregateByKey or reduceByKey where possible • Ordering of values not guaranteed and can vary on every evaluation](https://image.slidesharecdn.com/scalameetup-introtospark-150925132147-lva1-app6892/75/Scala-meetup-Intro-to-spark-18-2048.jpg)
 => C, mergeCombiners: (C, C) => C, partitioner: Partitioner, mapSideCombine: Boolean = true, serializer: Serializer = null) • RDD [ (K, V) ] => RDD[ (K, C) ] • createCombiner called per partition when a new key is found • mergeValue combines a new value to an existing accumulator • mergeCombiners with results from different partitions • Sometimes map-size combine not useful e.g. groupByKey • groupByKey, aggregateByKey and reduceByKey all implemented using combineByKey](https://image.slidesharecdn.com/scalameetup-introtospark-150925132147-lva1-app6892/75/Scala-meetup-Intro-to-spark-19-2048.jpg)
![map vs mapValues • map takes a function that transforms each element of a collection: map(f: T => U) • RDD[T] => RDD[U] • When T is a tuple we may want to only act on the values – not the keys • mapValues takes a function that maps the values in the inputs to the values in the output: mapValues(f: V => W) • Where RDD[ (K, V) ] => RDD[ (K, W) ] • NB: use mapValues when you can: avoids reshuffle when data is partitioned by key](https://image.slidesharecdn.com/scalameetup-introtospark-150925132147-lva1-app6892/75/Scala-meetup-Intro-to-spark-20-2048.jpg)

![Pseudo-set: union, intersection, subtract, cartesian • rdd.union(otherRdd): RRD containing elements from both • rdd.intersection(otherRdd): RDD containing only elements found in both • rdd.subtract(otherRdd): remove content of one from the other e.g. removing training data • rdd.cartesian(otherRdd): Cartesian product of two RDDs e.g. similarity of pairs: RDD[T] RDD[U] => RDD[ (T, U) ]](https://image.slidesharecdn.com/scalameetup-introtospark-150925132147-lva1-app6892/75/Scala-meetup-Intro-to-spark-22-2048.jpg)

![join, rightOuterJoin, leftOuterJoin, cogroup • Join: RDD[ ( K, V) ] and RDD[ (K, W) ] => RDD[ ( K, (V,W) ) ] • Cogroup: RDD[ ( K, V) ] and RDD[ (K, W) ] => RDD[ ( K, ( Seq[V], Seq[W] ) ) ] • rightOuterJoin and leftRightJoin when keys must be present in left / right RDD](https://image.slidesharecdn.com/scalameetup-introtospark-150925132147-lva1-app6892/75/Scala-meetup-Intro-to-spark-24-2048.jpg)






![Code val metaStream = stream.map { case (k, v) => (k, DocumentMetadata.fromMutable(recordDecoder.decode(v).asInstanceOf[GenericRecord])) } private val pdfFiles = metaStream.filter(_._2.contentType == "application/pdf") .map { case (k, meta) => (meta, fetchFileFromMessage(k, meta)) } val pdfDocs = pdfFiles.map { case (meta, file) => (meta, TextExtractor.parseFile(file)) } val texts = pdfDocs.map { case (meta, doc) => (meta, TextExtractor.extractText(doc)) }.cache() val wordStream = texts.map { case (meta, text) => (meta, text.split("""[ nrtu00a0]+""").toList.map(_.replaceAll("""[,;.]$""", "").trim.toLowerCase()).filter(_.length > 1)) } texts.foreachRDD( rdd => rdd.foreach { case (meta,text) => indexText(meta.id, text) } ) val wordCountStream = wordStream.flatMap(_._2).map(word => (word, 1)).reduceByKey(_ + _) val totalWordCountStream = wordStream.map(_._2.size) val totalWords = totalWordCountStream.reduce(_+_) val sortedWordCount = wordCountStream.transform(rdd => rdd.sortBy(_._2, ascending = false)) sortedWordCount.foreachRDD(rdd => println(rdd.toDebugString)) sortedWordCount.print(30) totalWords.print()](https://image.slidesharecdn.com/scalameetup-introtospark-150925132147-lva1-app6892/75/Scala-meetup-Intro-to-spark-36-2048.jpg)


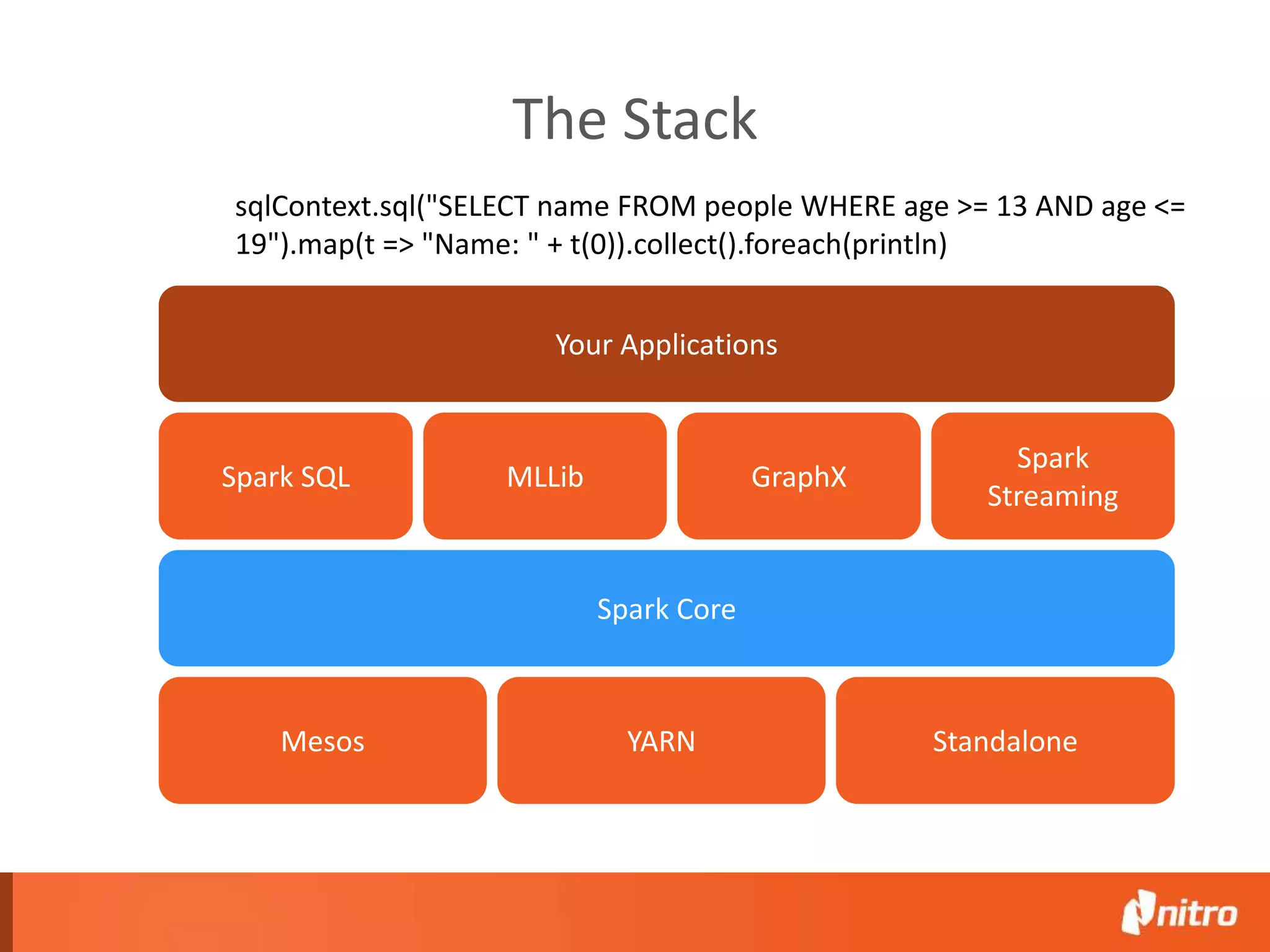
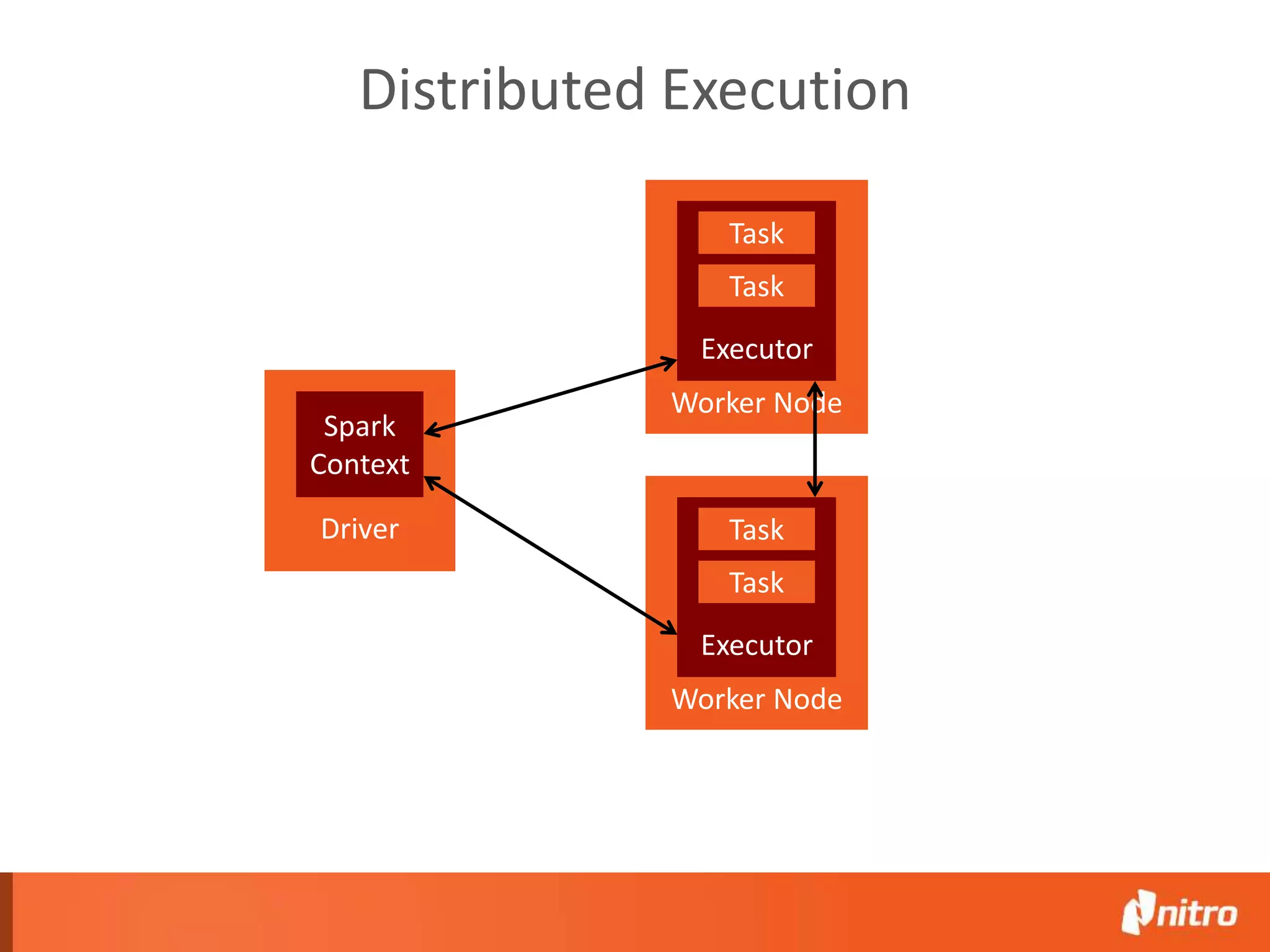
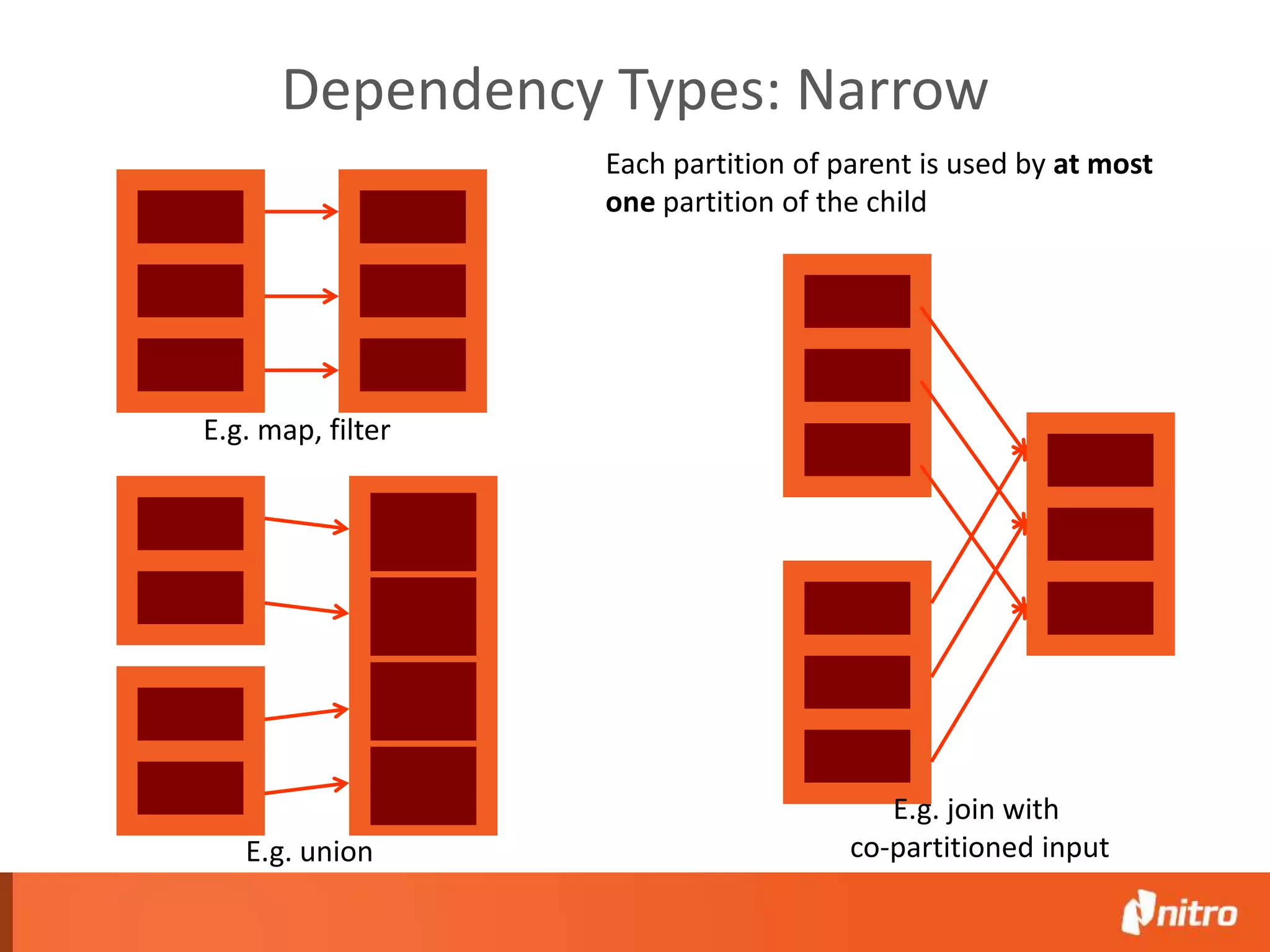
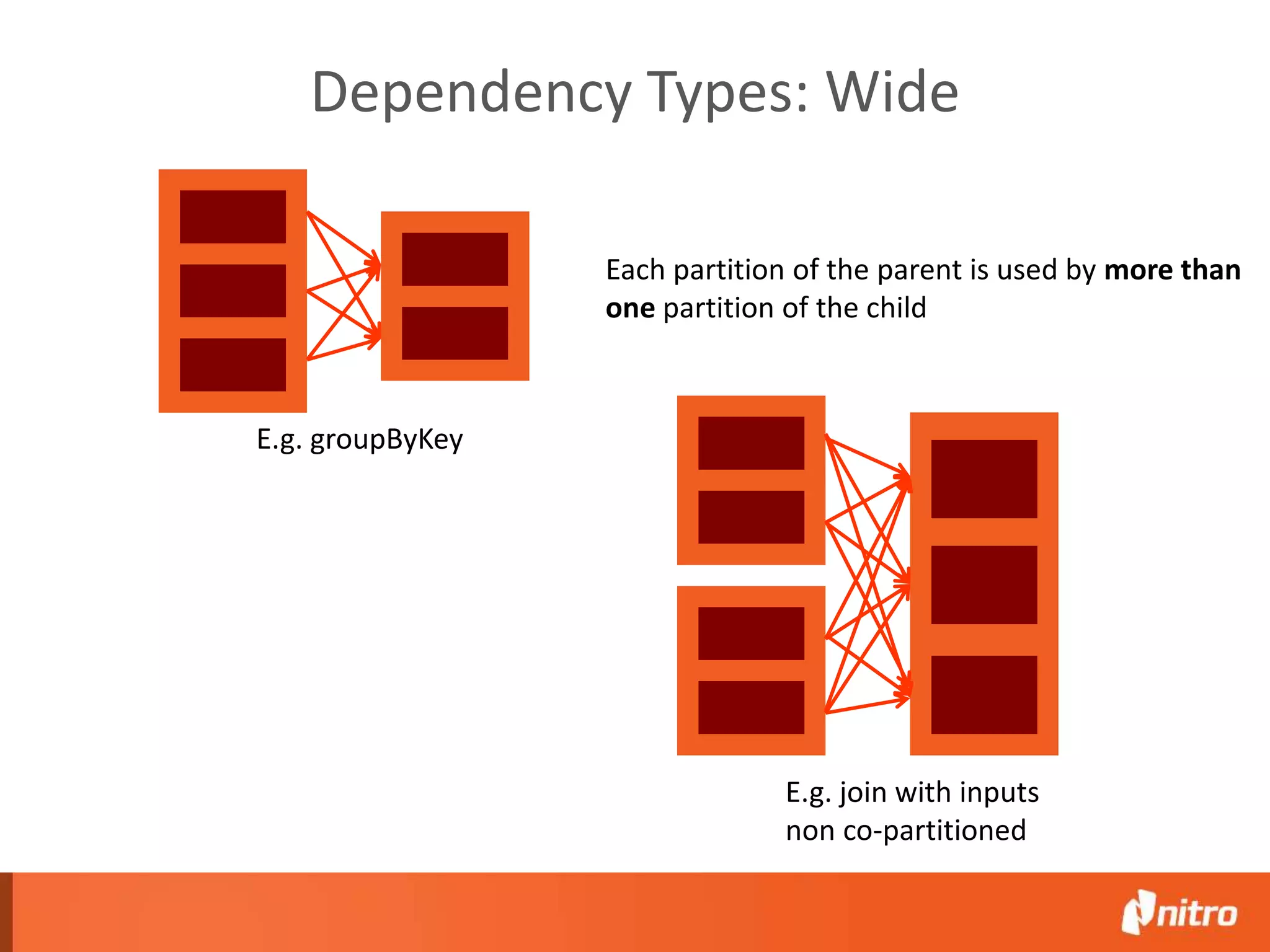
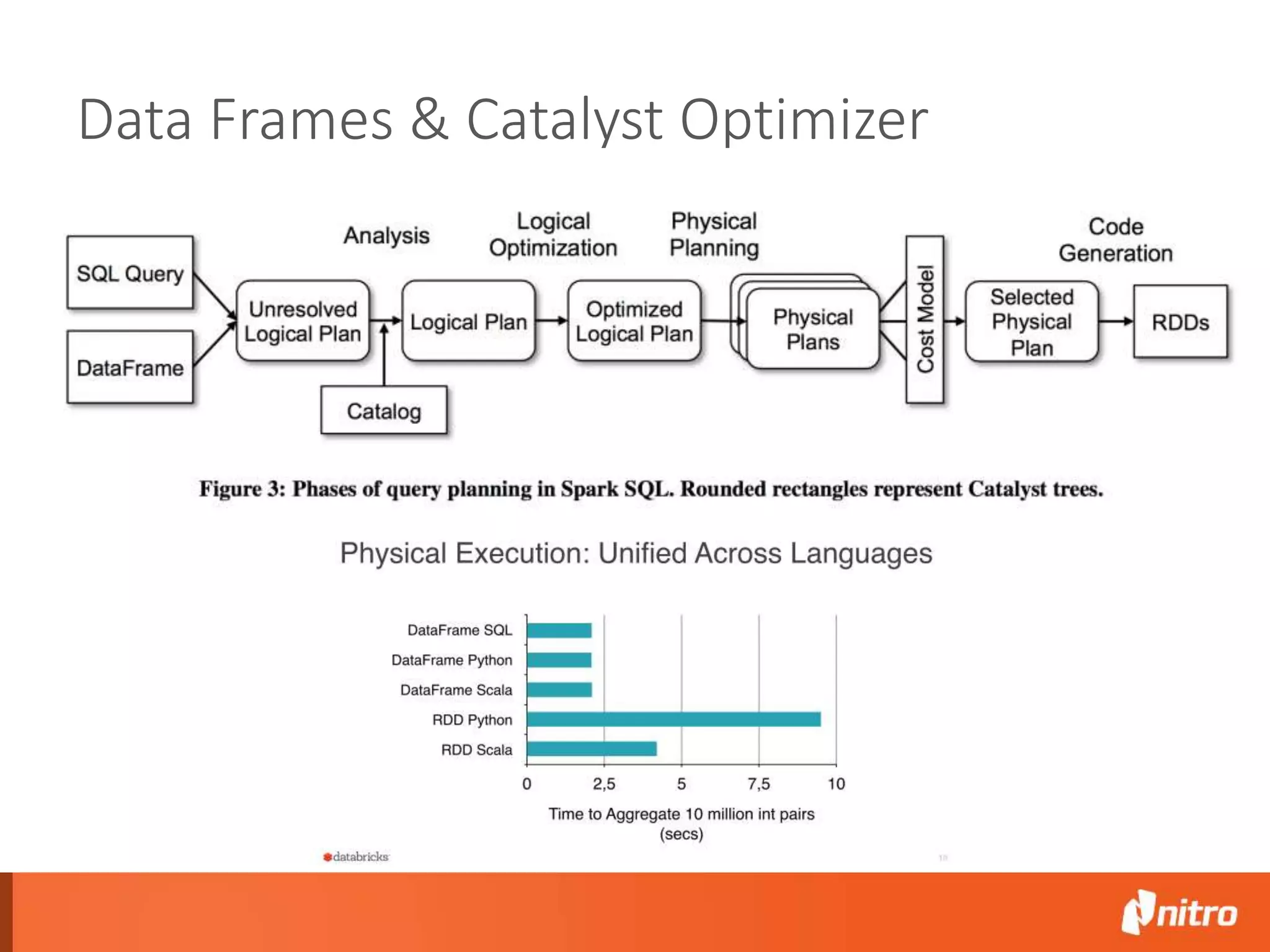
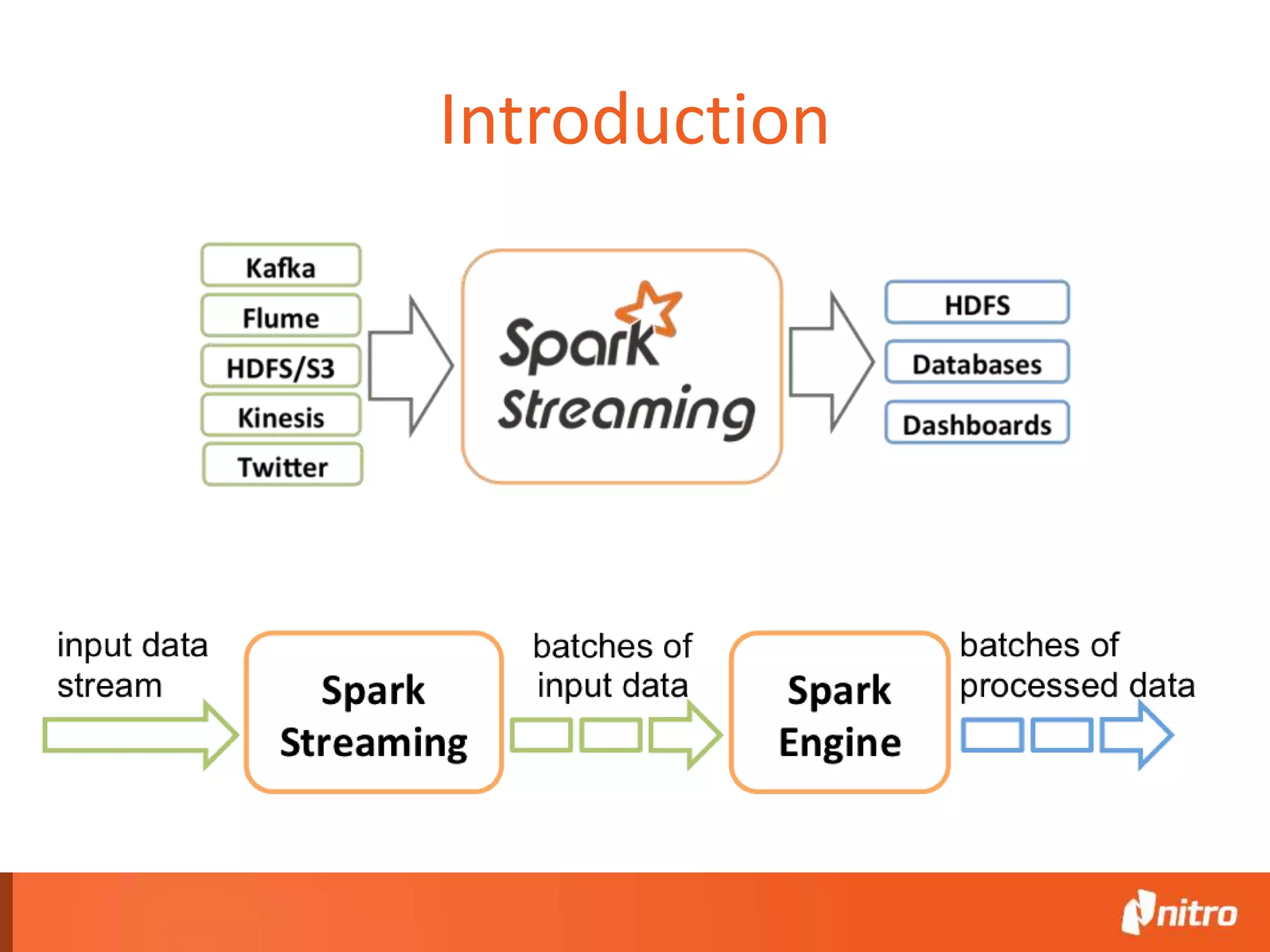
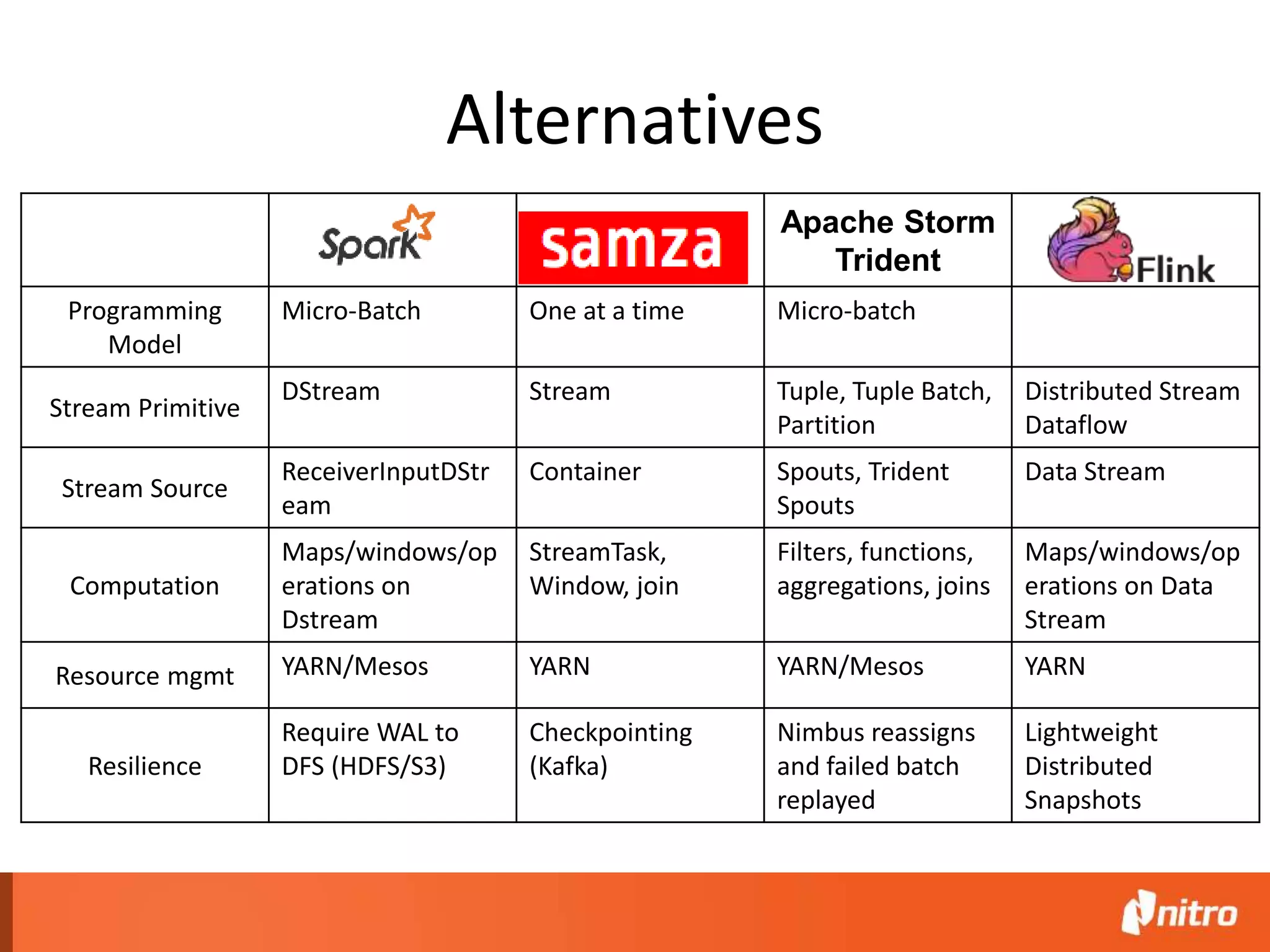
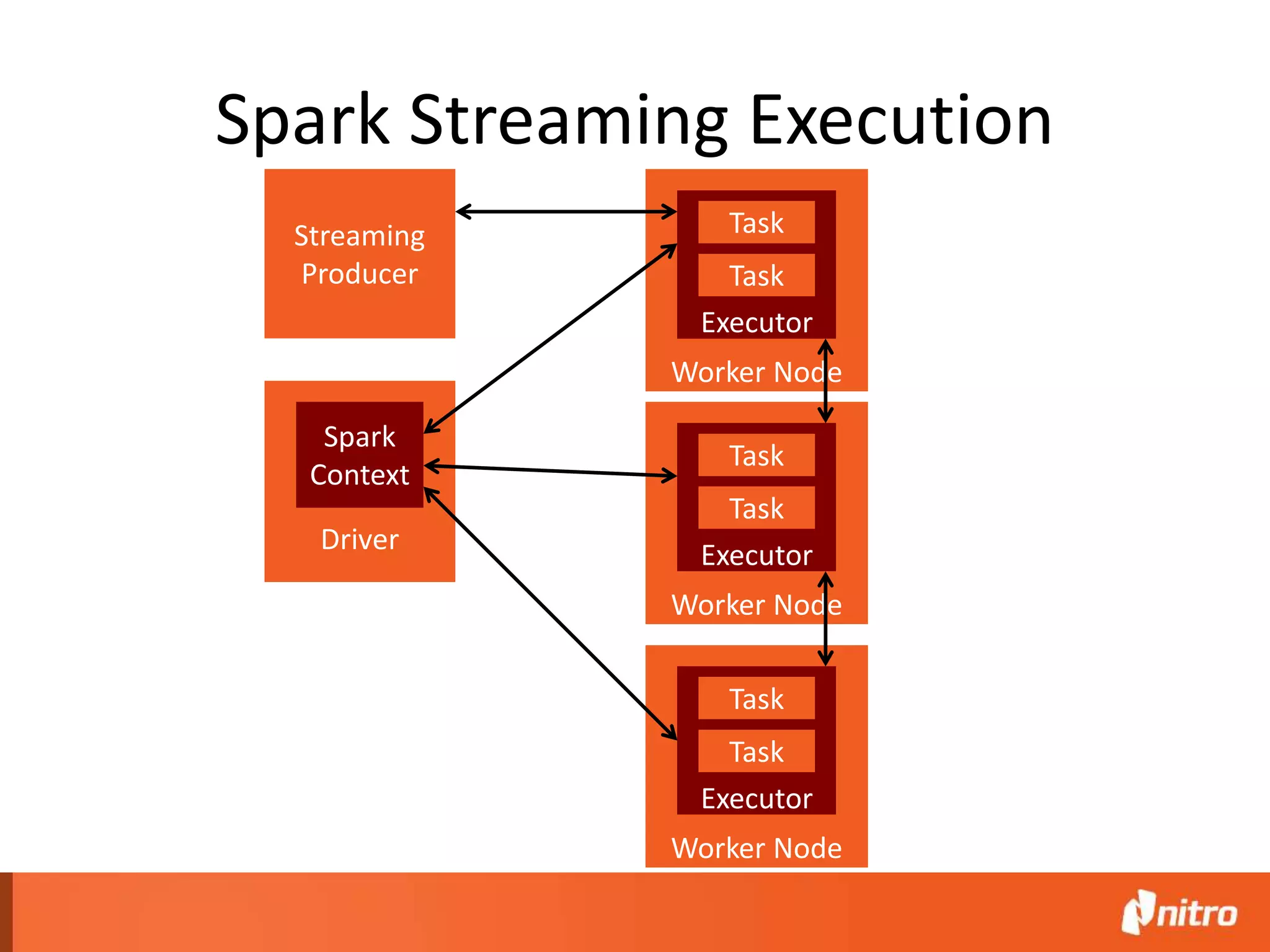
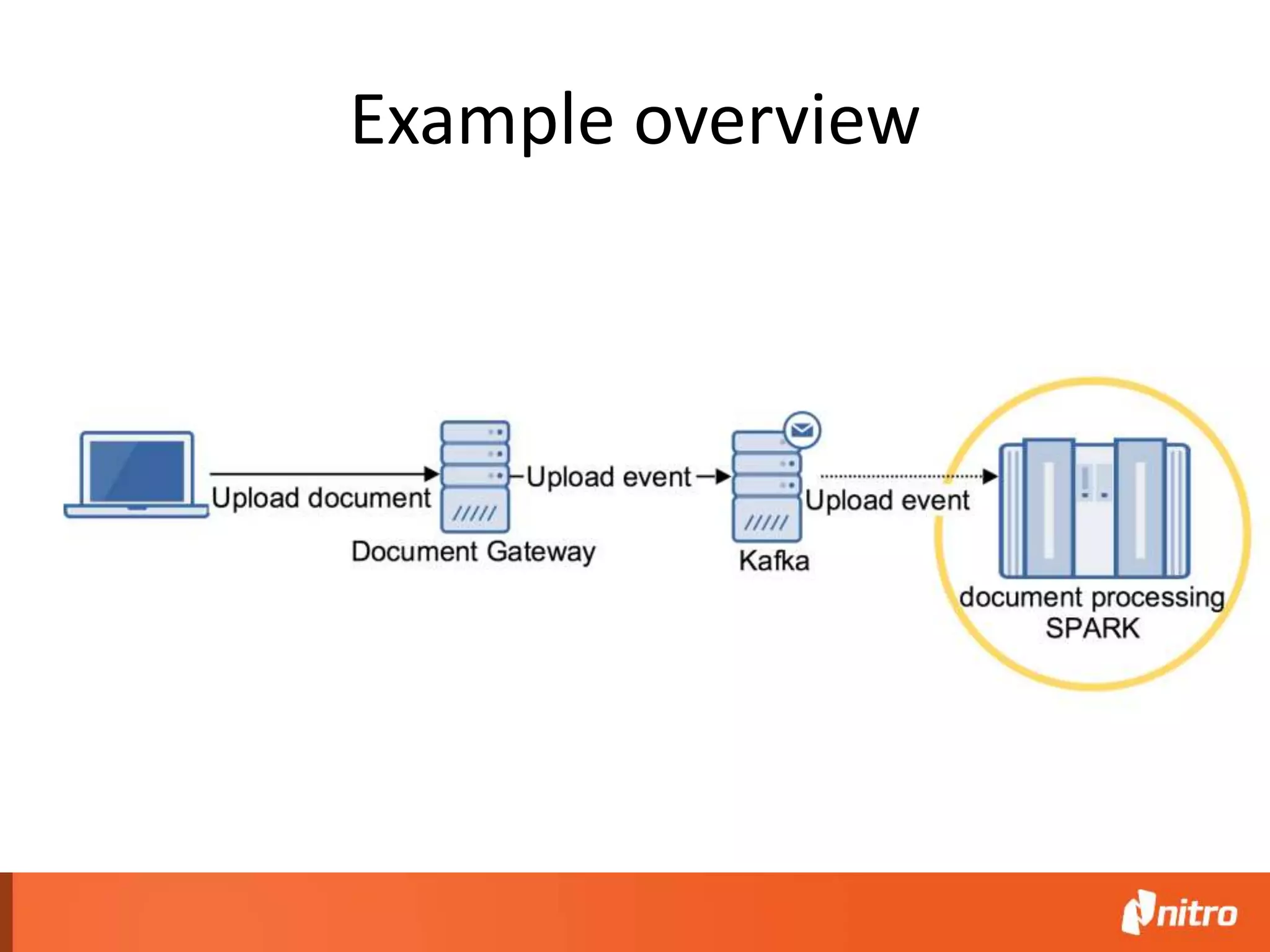
This document provides an introduction to Apache Spark, including its core components, architecture, and programming model. Some key points: - Spark uses Resilient Distributed Datasets (RDDs) as its fundamental data structure, which are immutable distributed collections that allow in-memory computing across a cluster. - RDDs support transformations like map, filter, reduce, and actions like collect that return results. Transformations are lazy while actions trigger computation. - Spark's execution model involves a driver program that coordinates tasks on worker nodes using an optimized scheduler. - Spark SQL, MLlib, GraphX, and Spark Streaming extend the core Spark API for structured data, machine learning, graph processing, and stream processing