Download as PDF, PPTX

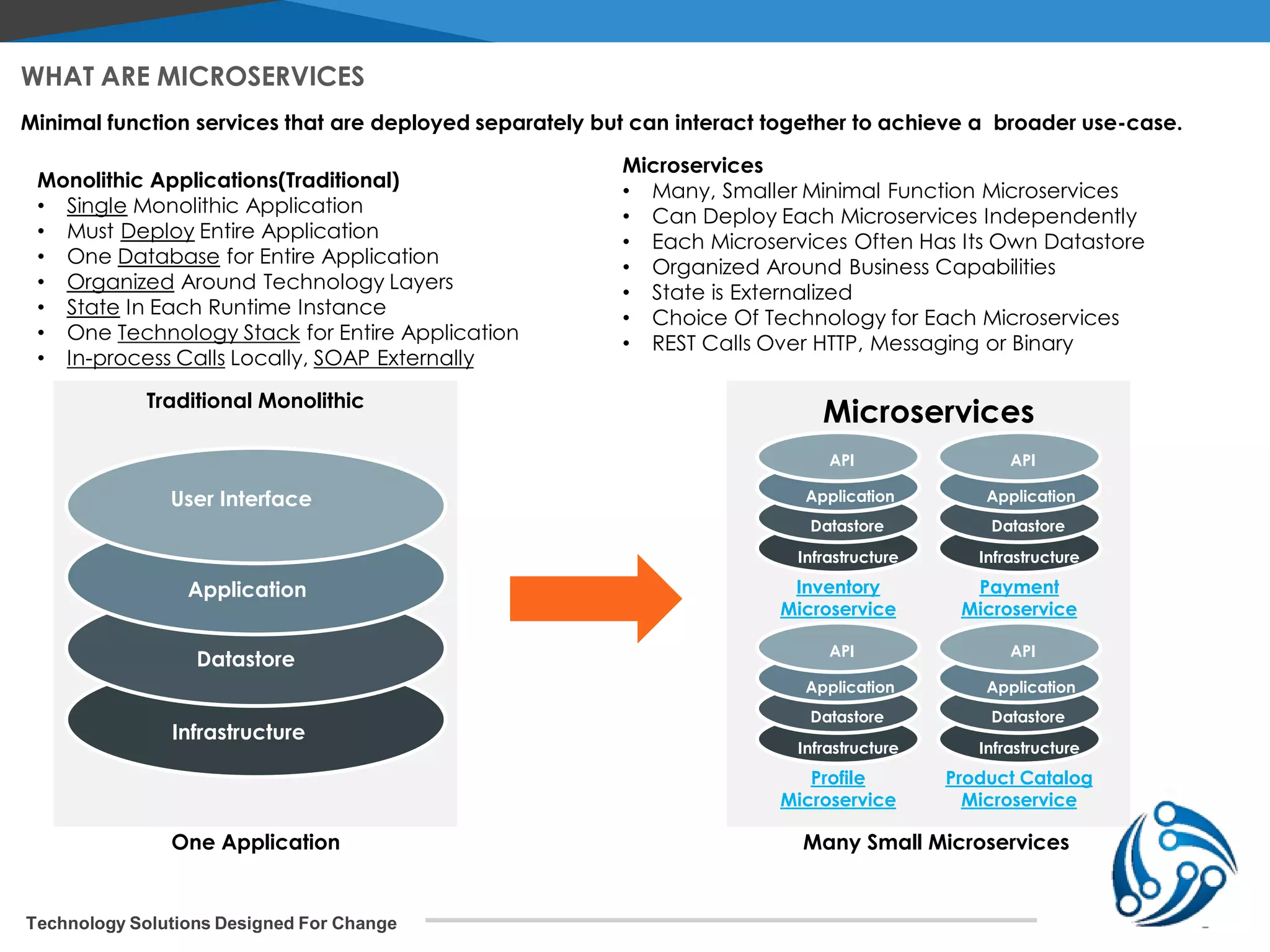
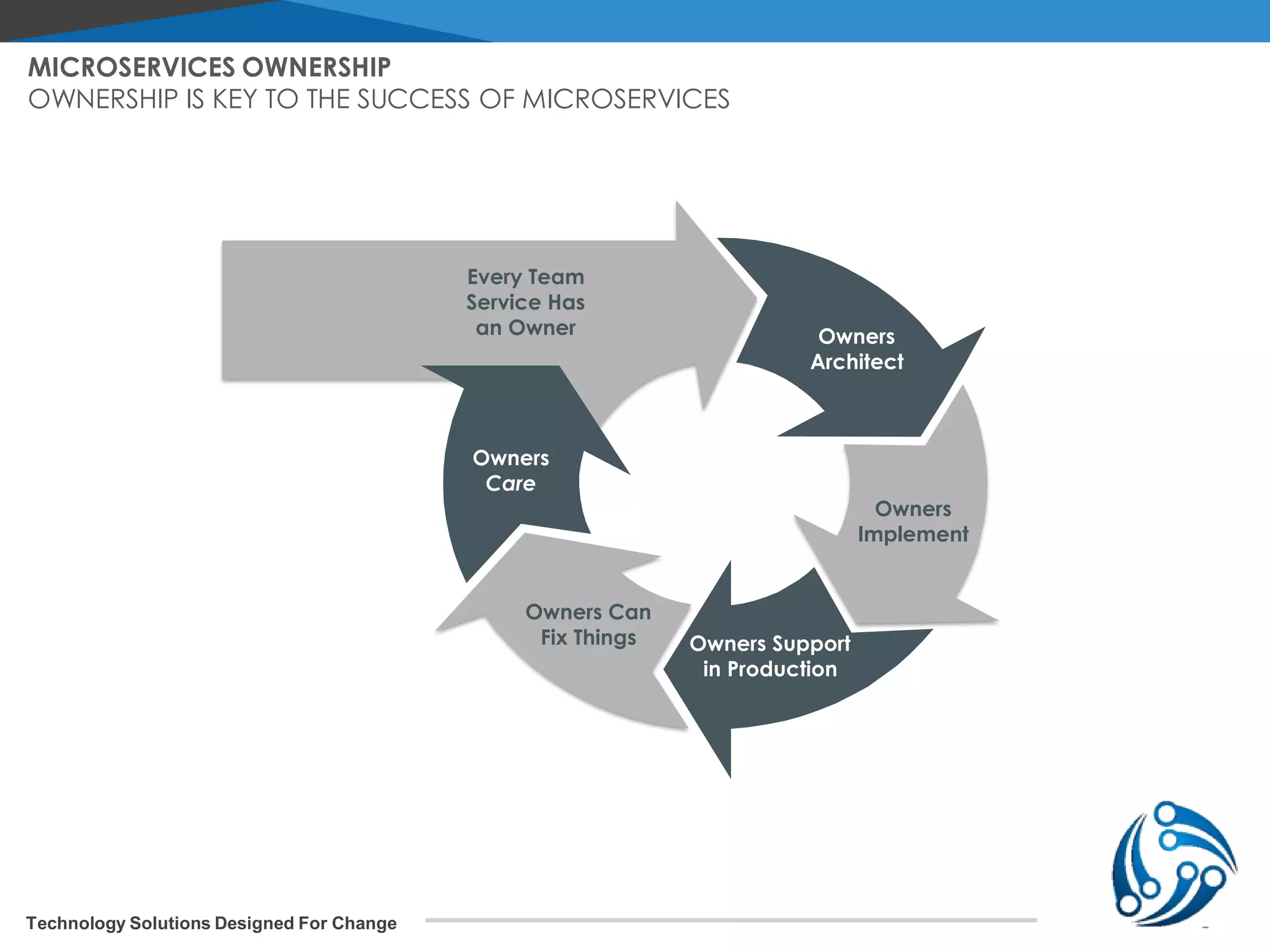
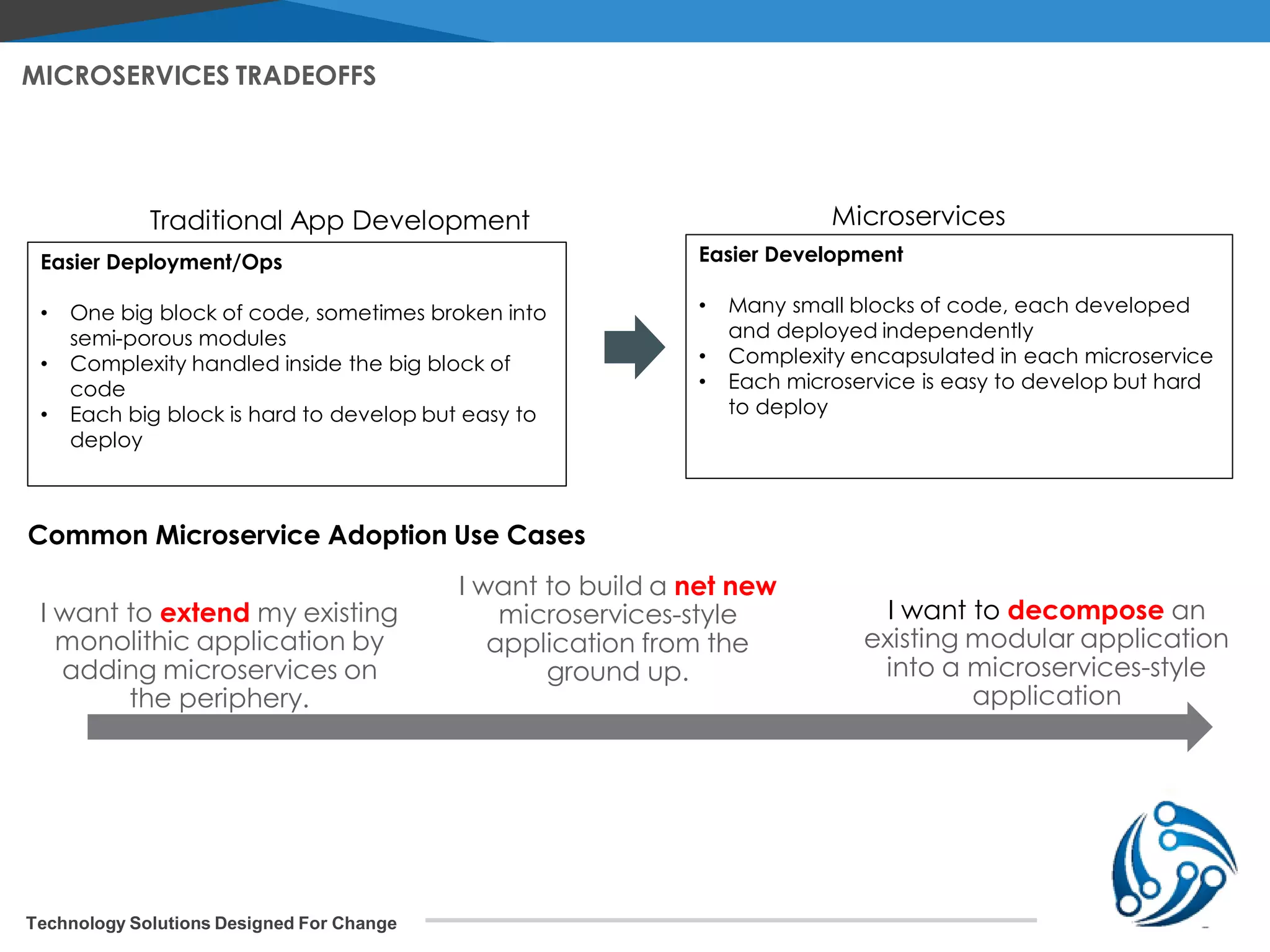
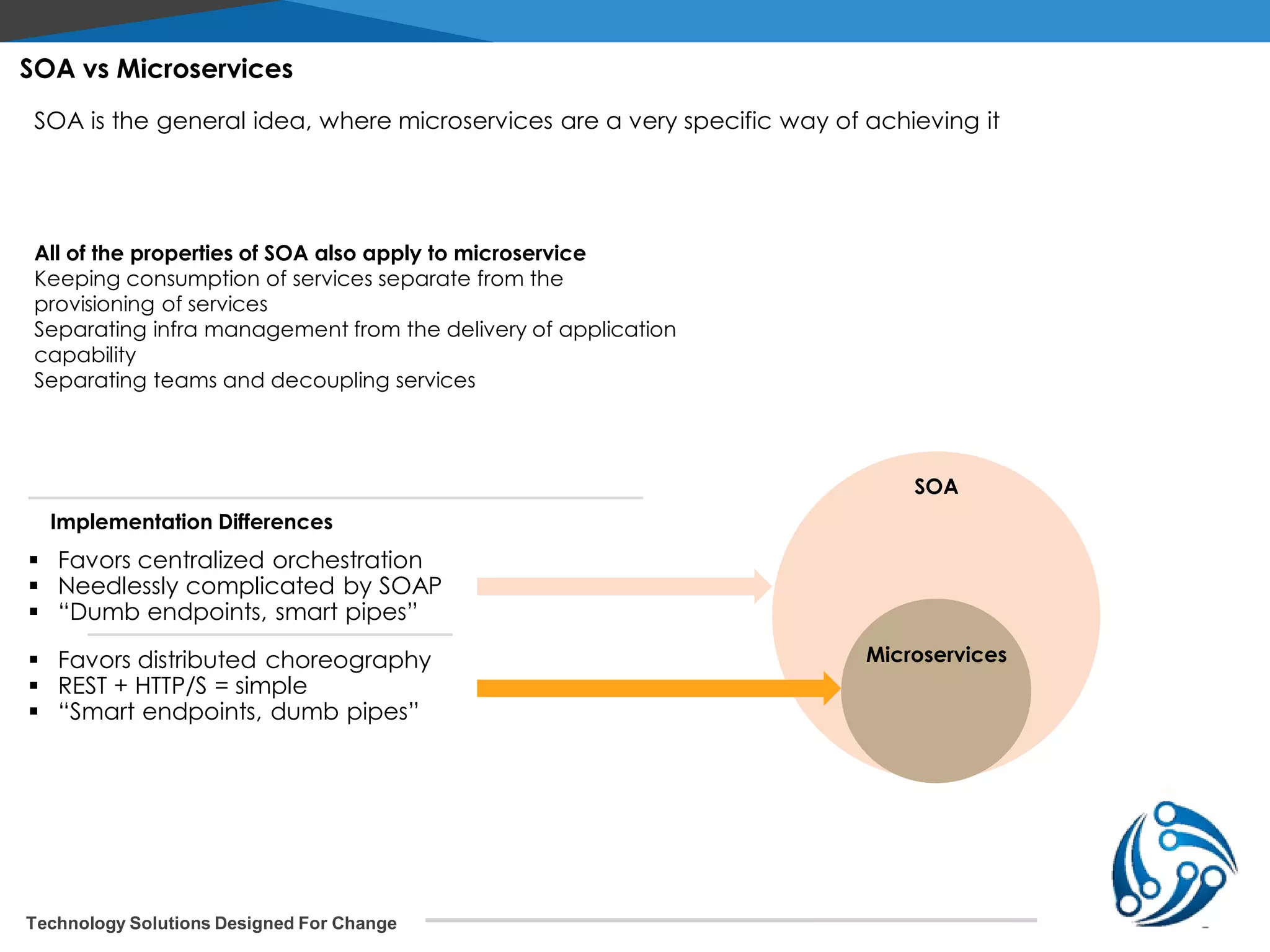
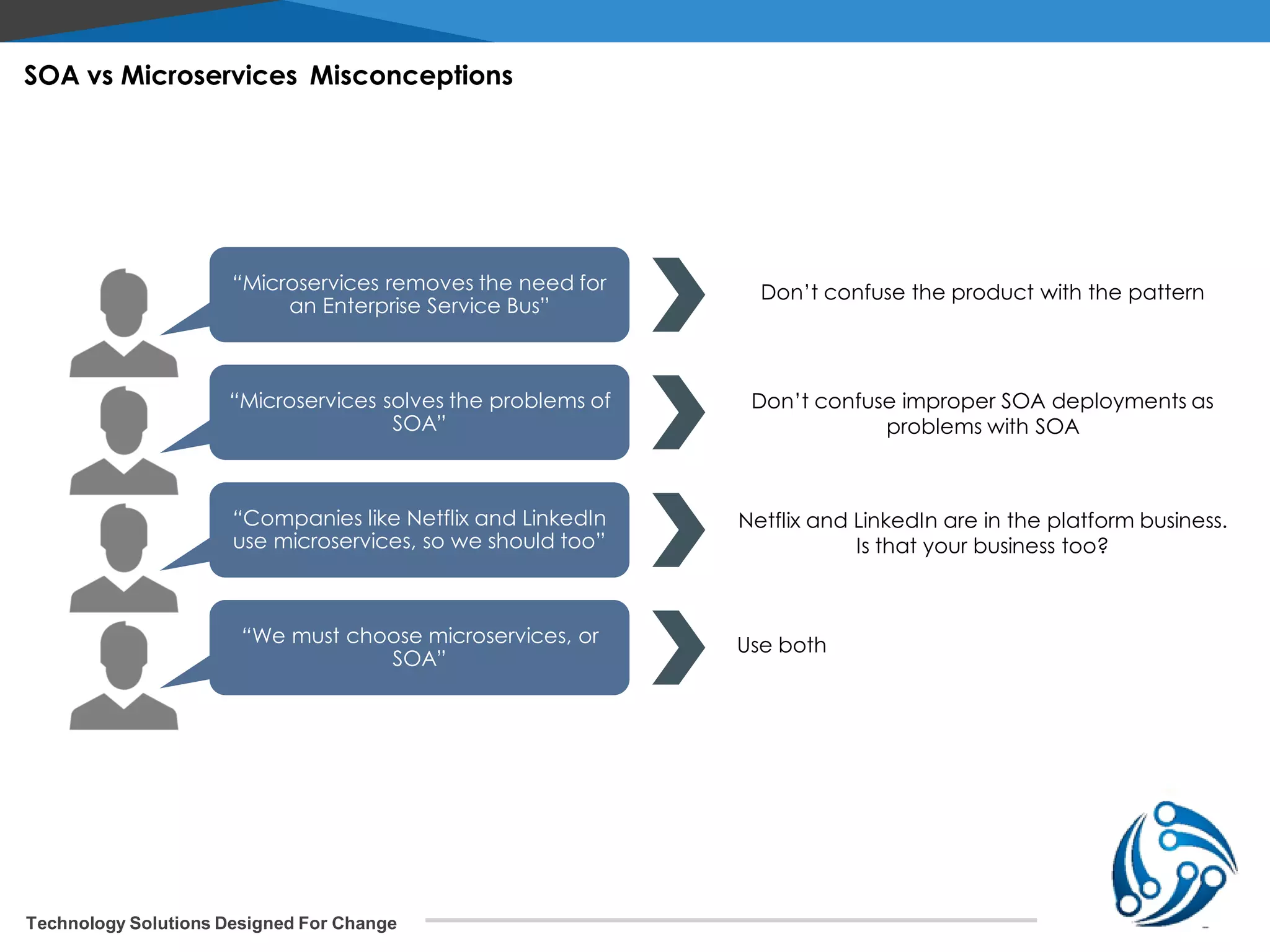
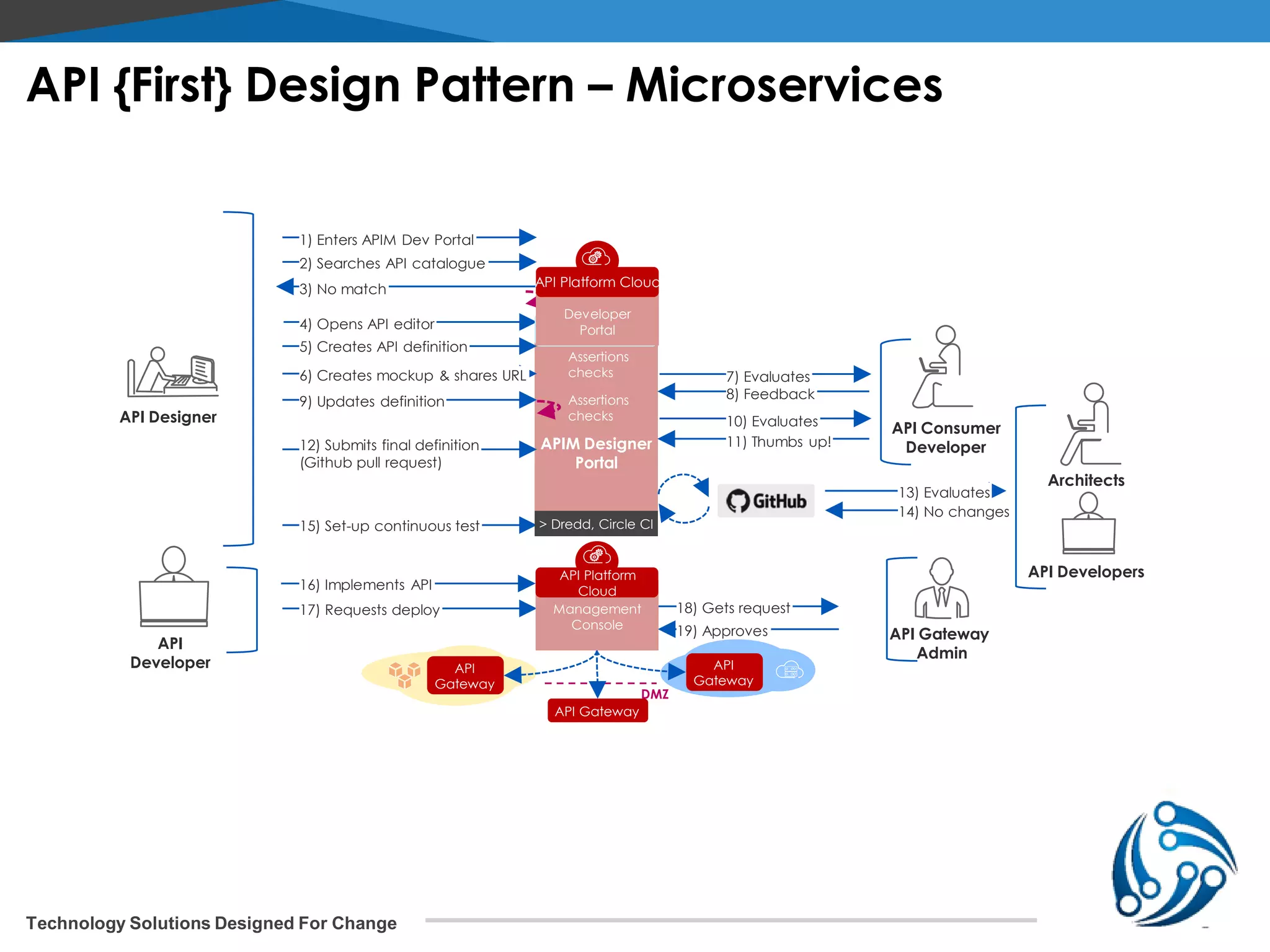
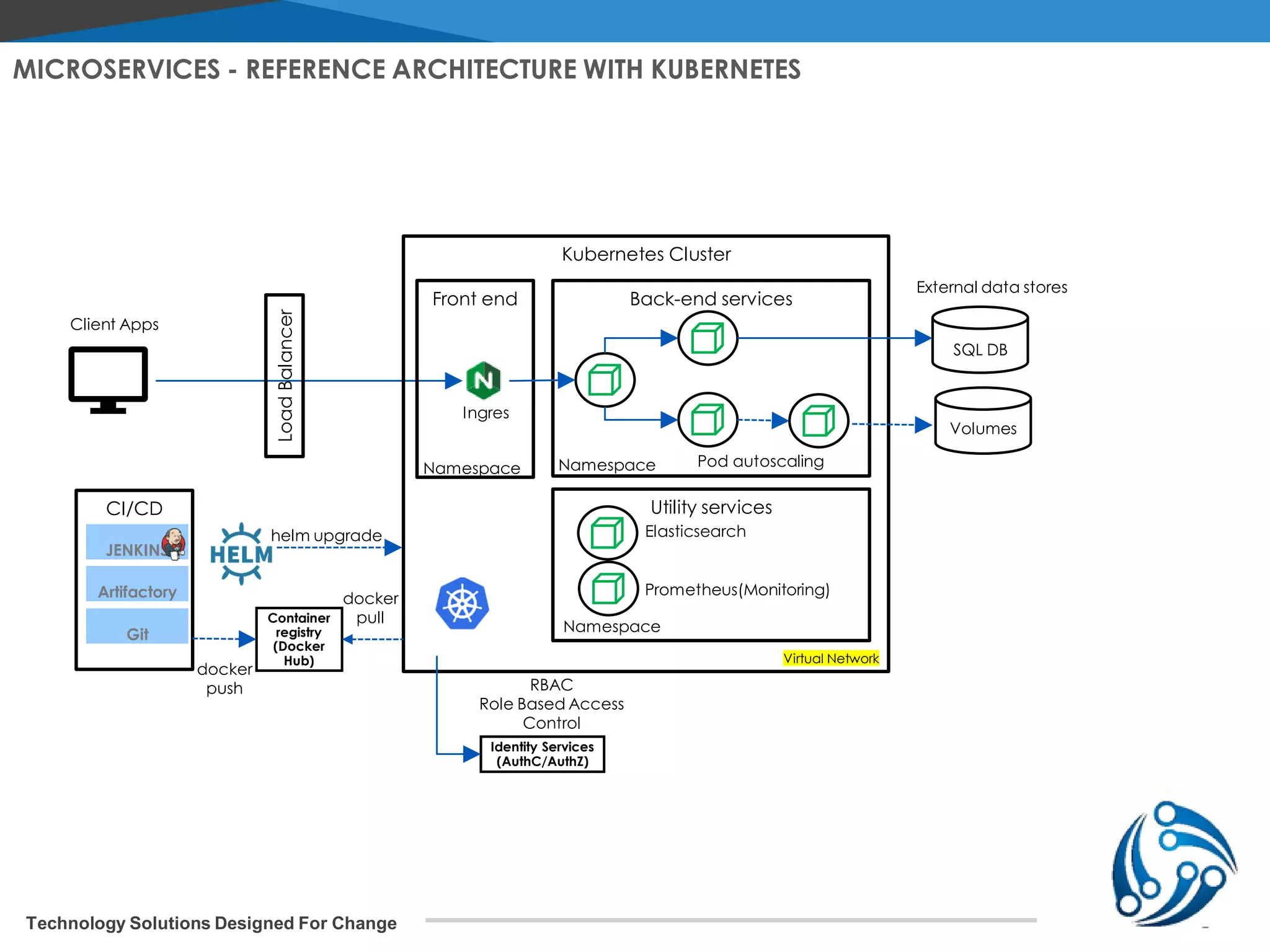

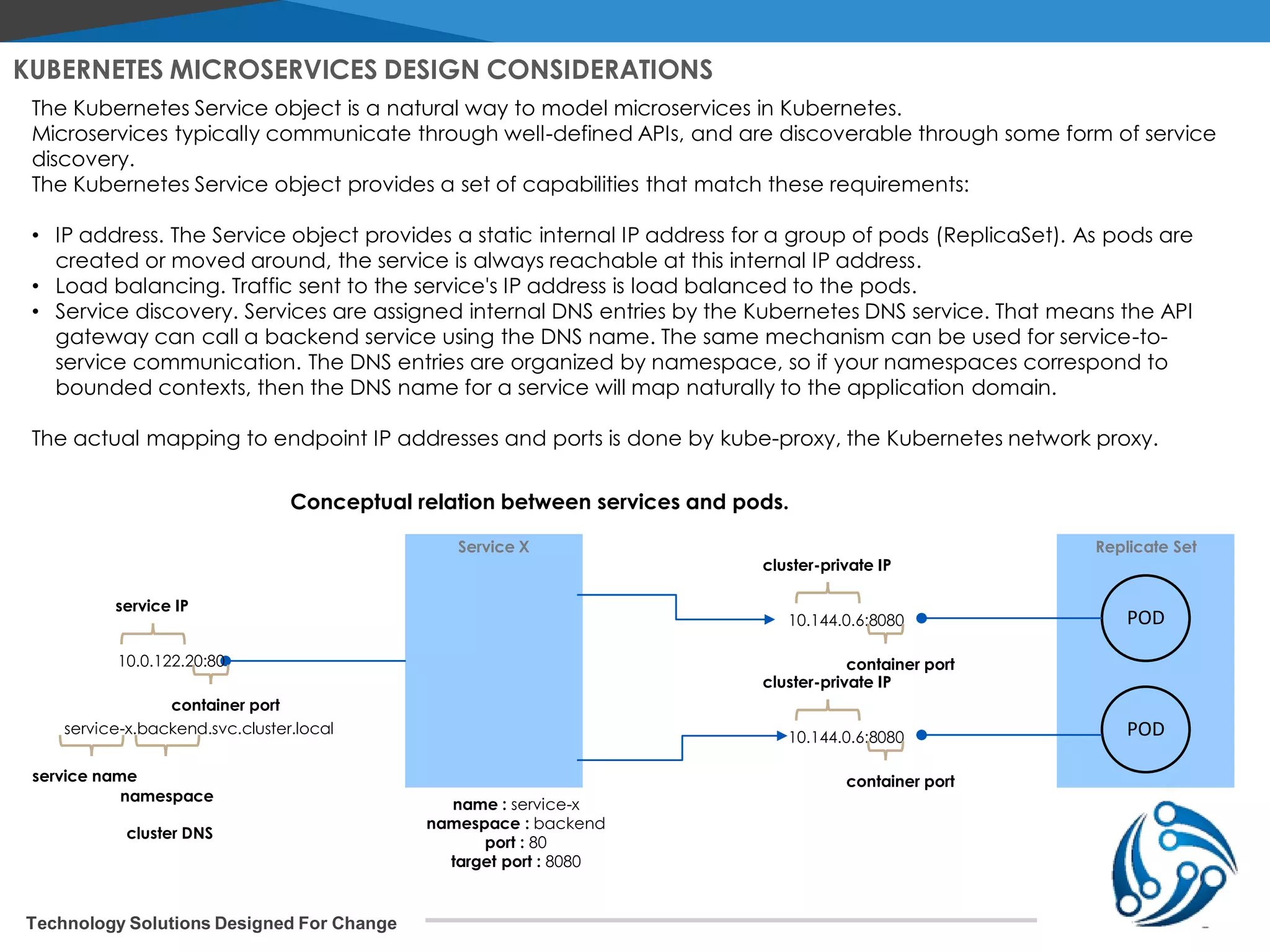









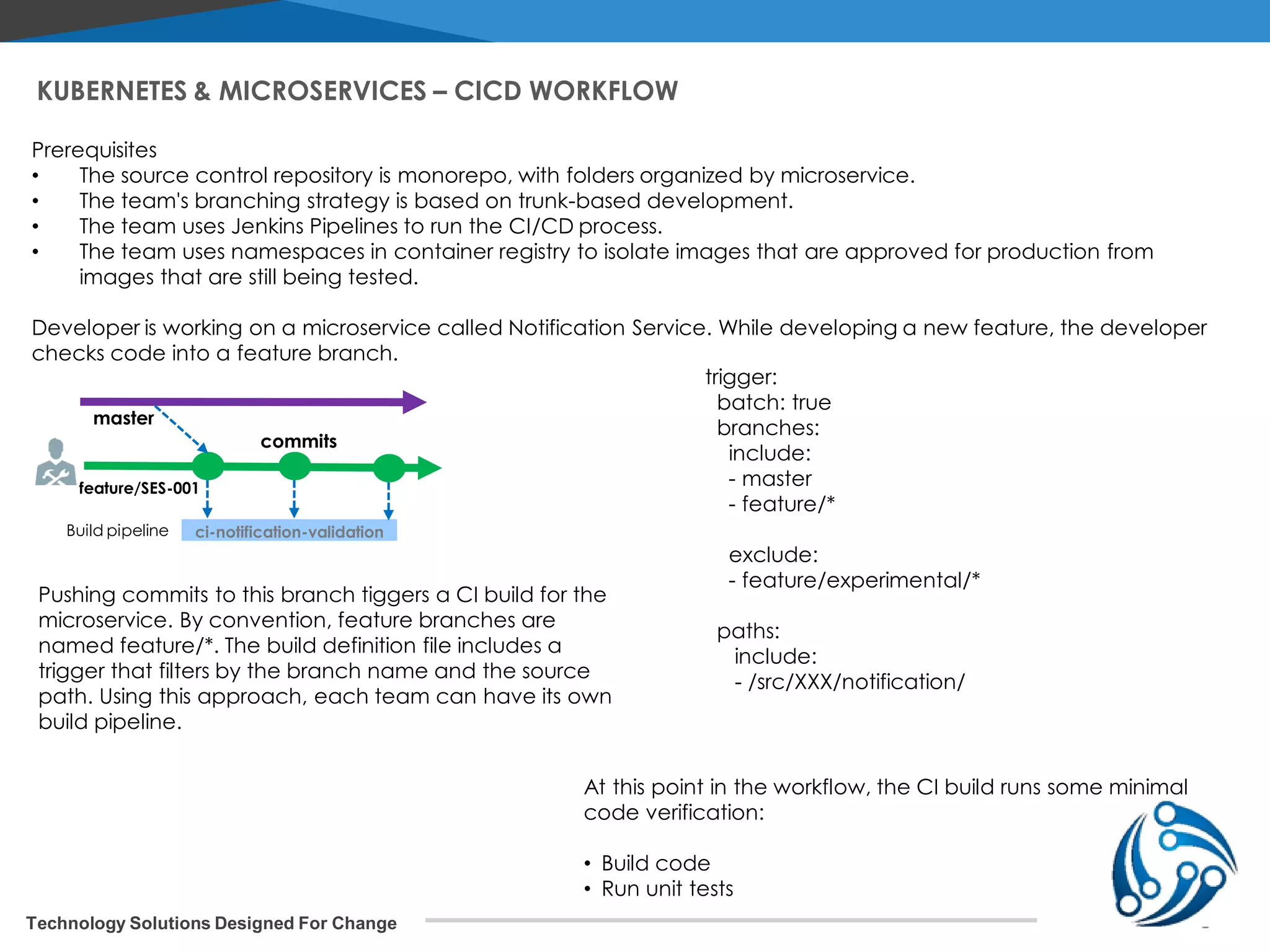
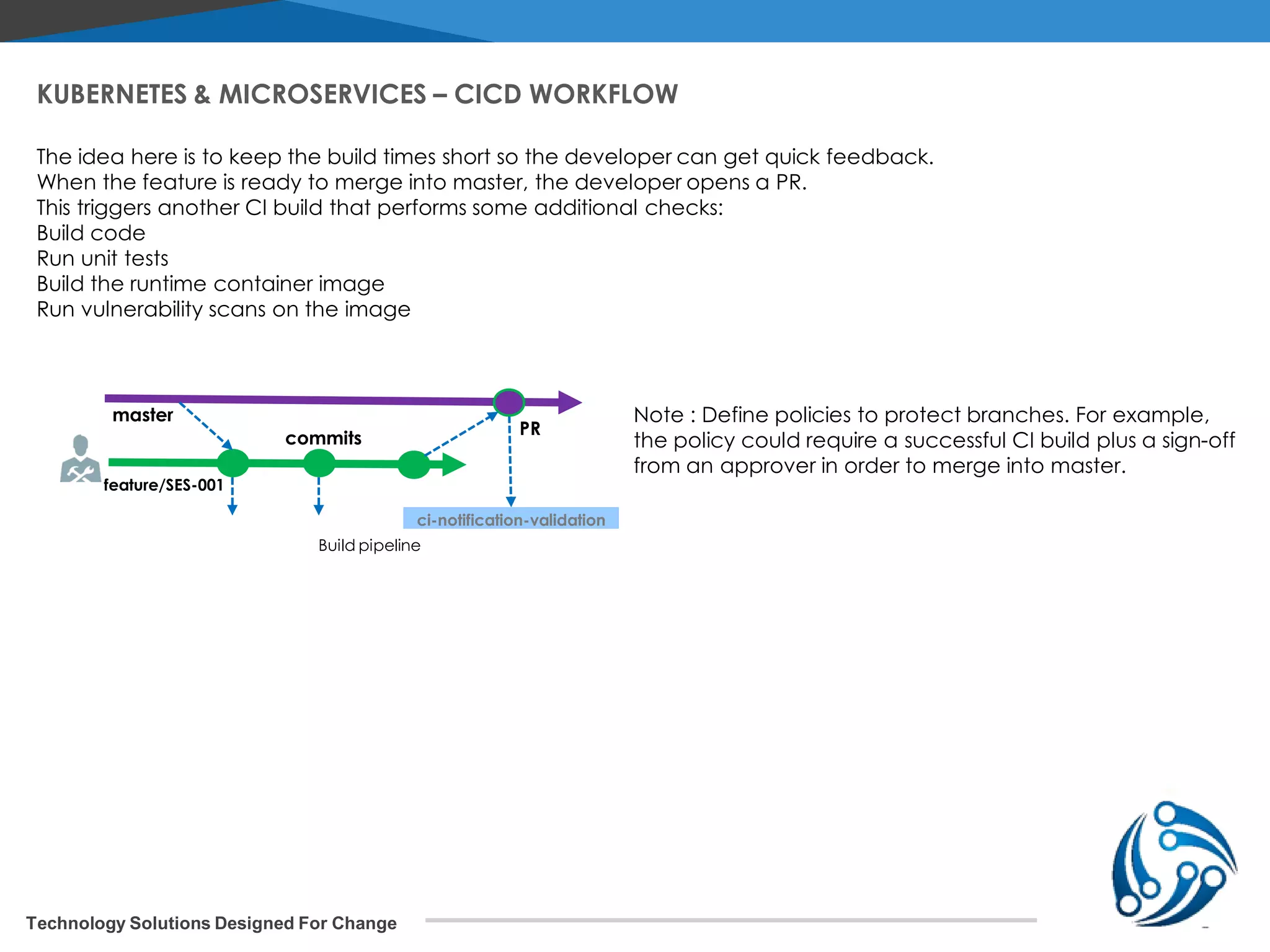
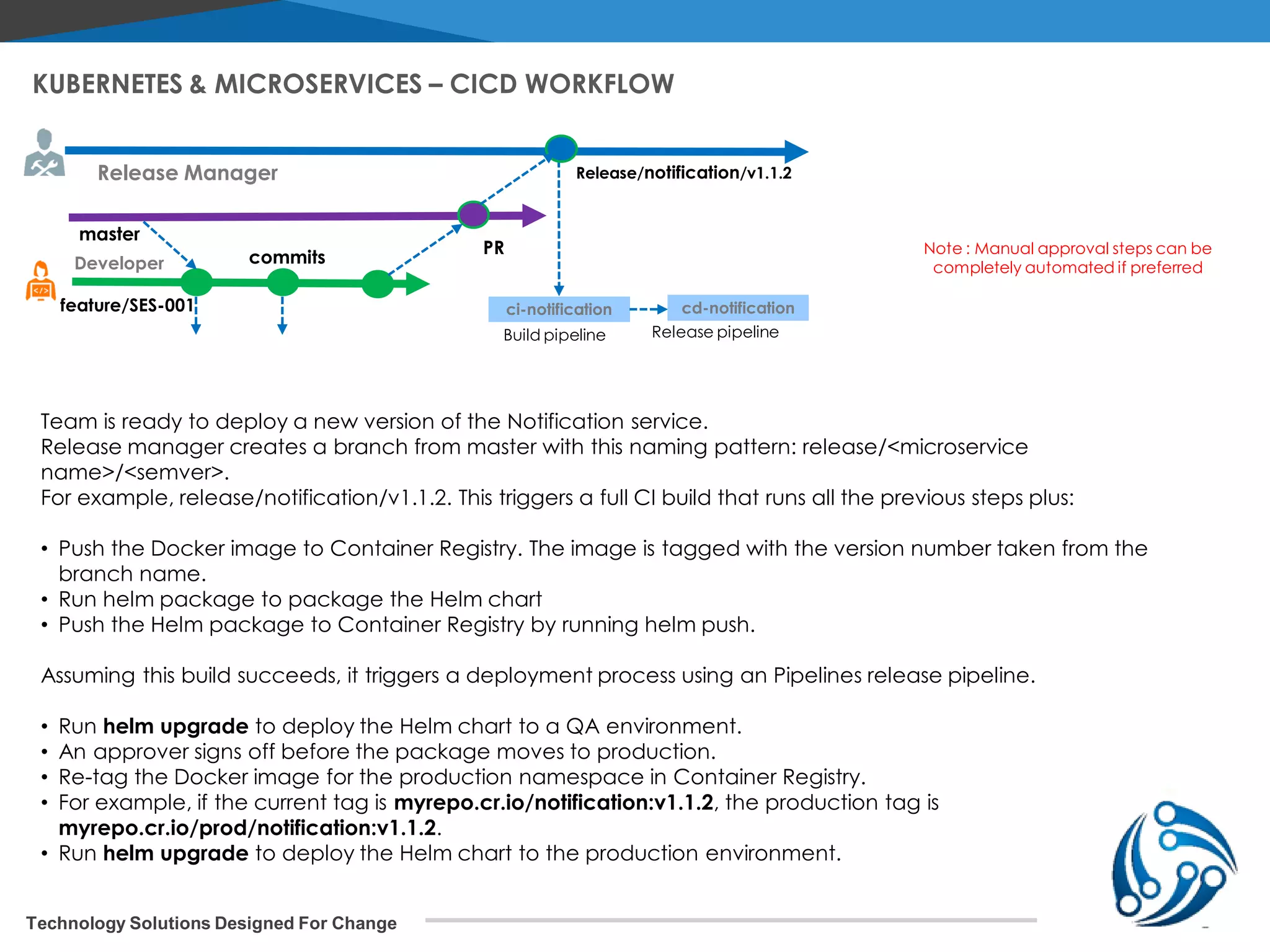

The document discusses microservices architecture on Kubernetes. It describes microservices as minimal, independently deployable services that interact to provide broader functionality. It contrasts this with monolithic applications. It then covers key aspects of microservices like ownership, tradeoffs compared to traditional applications, common adoption cases, and differences from SOA. It provides a reference architecture diagram for microservices on Kubernetes including components like ingress, services, CI/CD pipelines, container registry, and data stores. It also discusses design considerations for Kubernetes microservices including using Kubernetes services for service discovery and load balancing, and using an API gateway for routing between clients and services.