Downloaded 151 times
![Rapid, Scalable Web Development with MongoDB, Ming, and Python Rick Copeland @rick446 [email_address]](https://image.slidesharecdn.com/mongodc2011-110627214336-phpapp02/75/Rapid-Scalable-Web-Development-with-MongoDB-Ming-and-Python-1-2048.jpg)















![Repository Cache Lessons Learned Using MongoDB to represent graph structures (commit graph, commit trees) requires careful query planning. Pointer-chasing is no fun! Sometimes Ming validation and ORM overhead can be prohibitively expensive – time to drop down a layer. Benchmarking and profiling are your friends, as are queries like {‘_id’: {‘$in’:[…]}} for returning multiple objects](https://image.slidesharecdn.com/mongodc2011-110627214336-phpapp02/75/Rapid-Scalable-Web-Development-with-MongoDB-Ming-and-Python-21-2048.jpg)







![Rick Copeland @rick446 [email_address]](https://image.slidesharecdn.com/mongodc2011-110627214336-phpapp02/75/Rapid-Scalable-Web-Development-with-MongoDB-Ming-and-Python-30-2048.jpg)

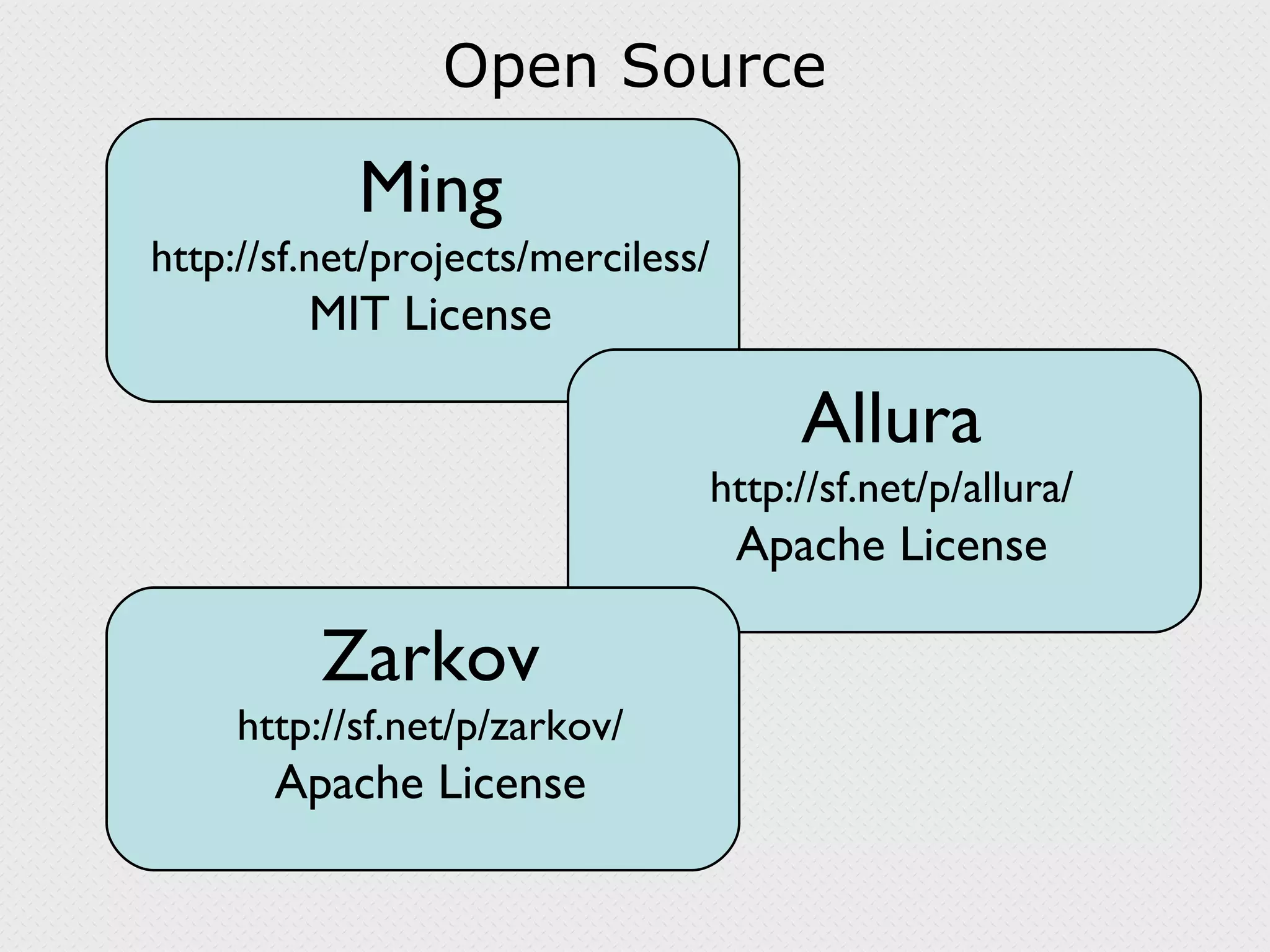
The document discusses the use of MongoDB, Ming, and Python for scalable web development, particularly in the context of SourceForge.net's project management and analytics systems. It outlines architecture changes, performance metrics, and the advantages of NoSQL databases for supporting complex data and real-time analytics. Key components include the implementation of systems for document storage, asynchronous event logging, and the benefits of flexible data schemas.