Download as PDF, PPTX


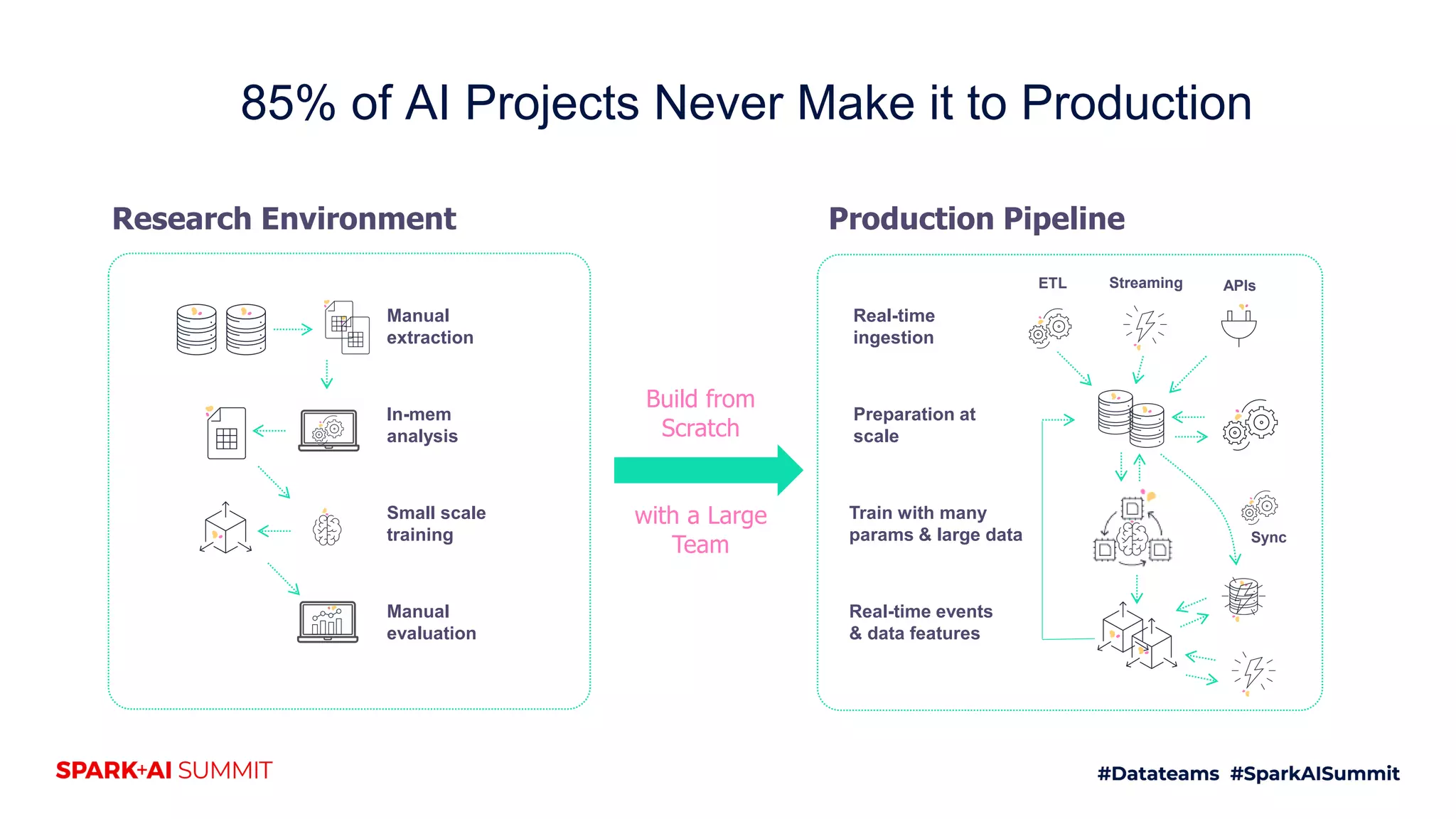
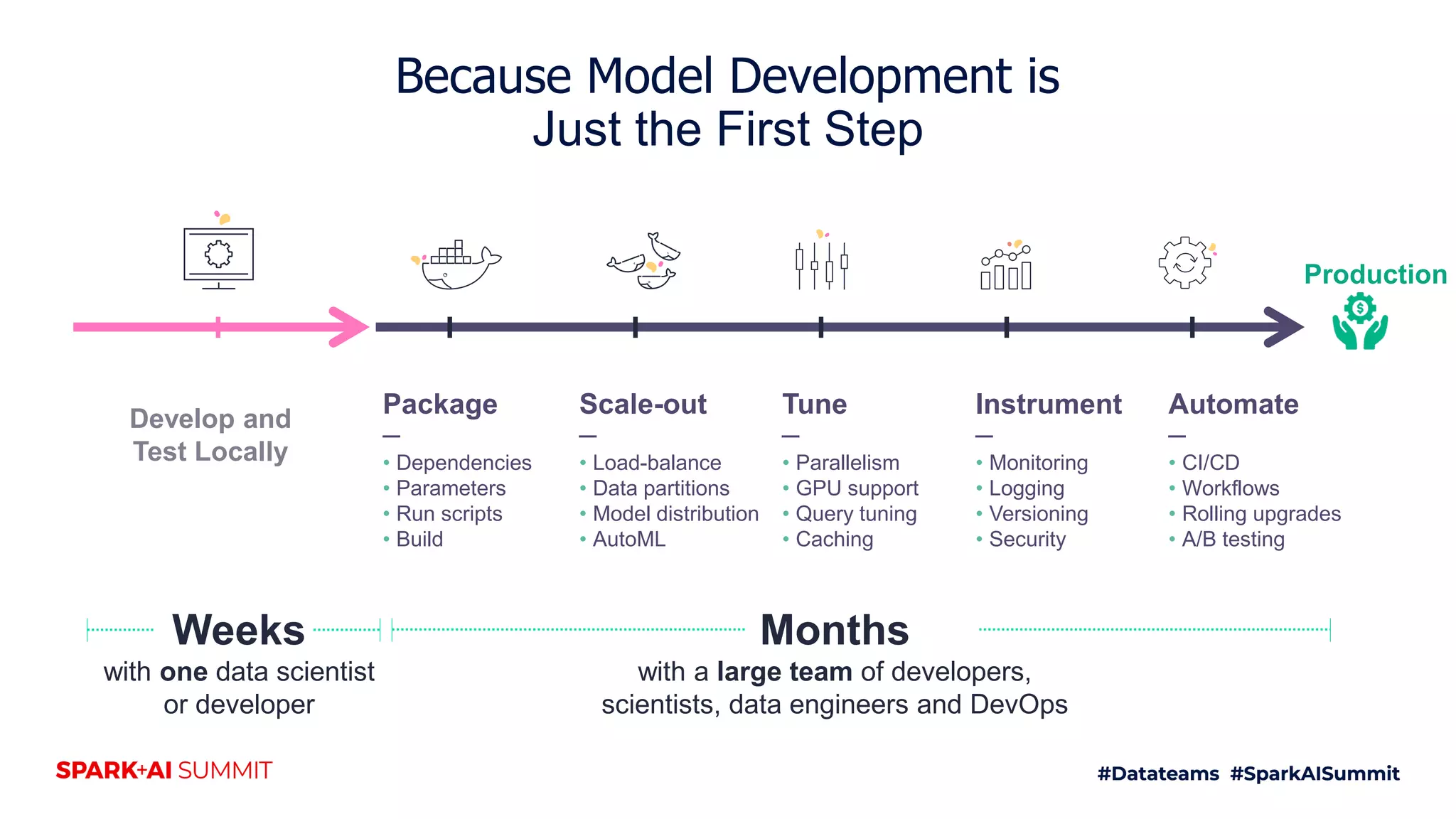
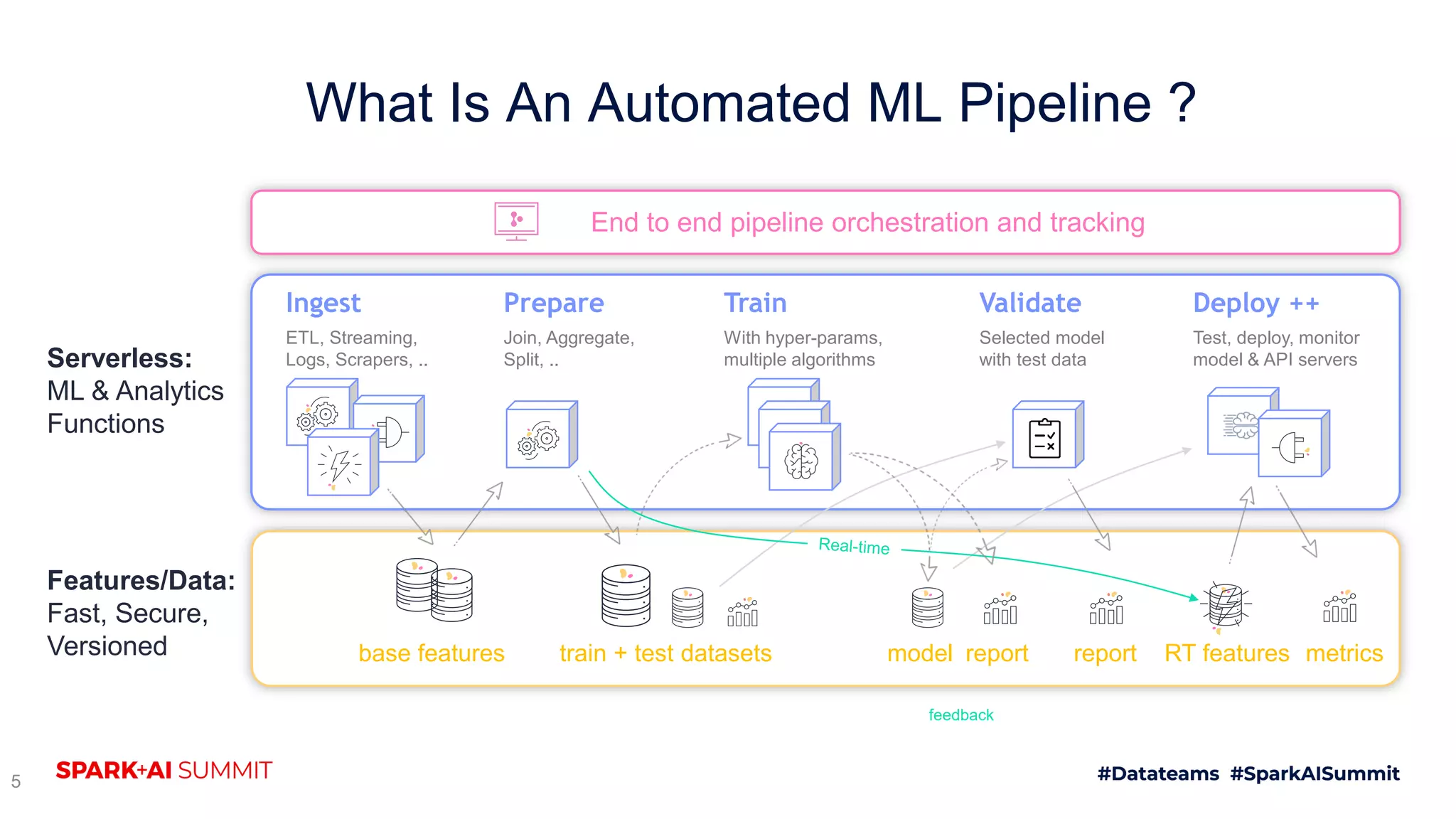
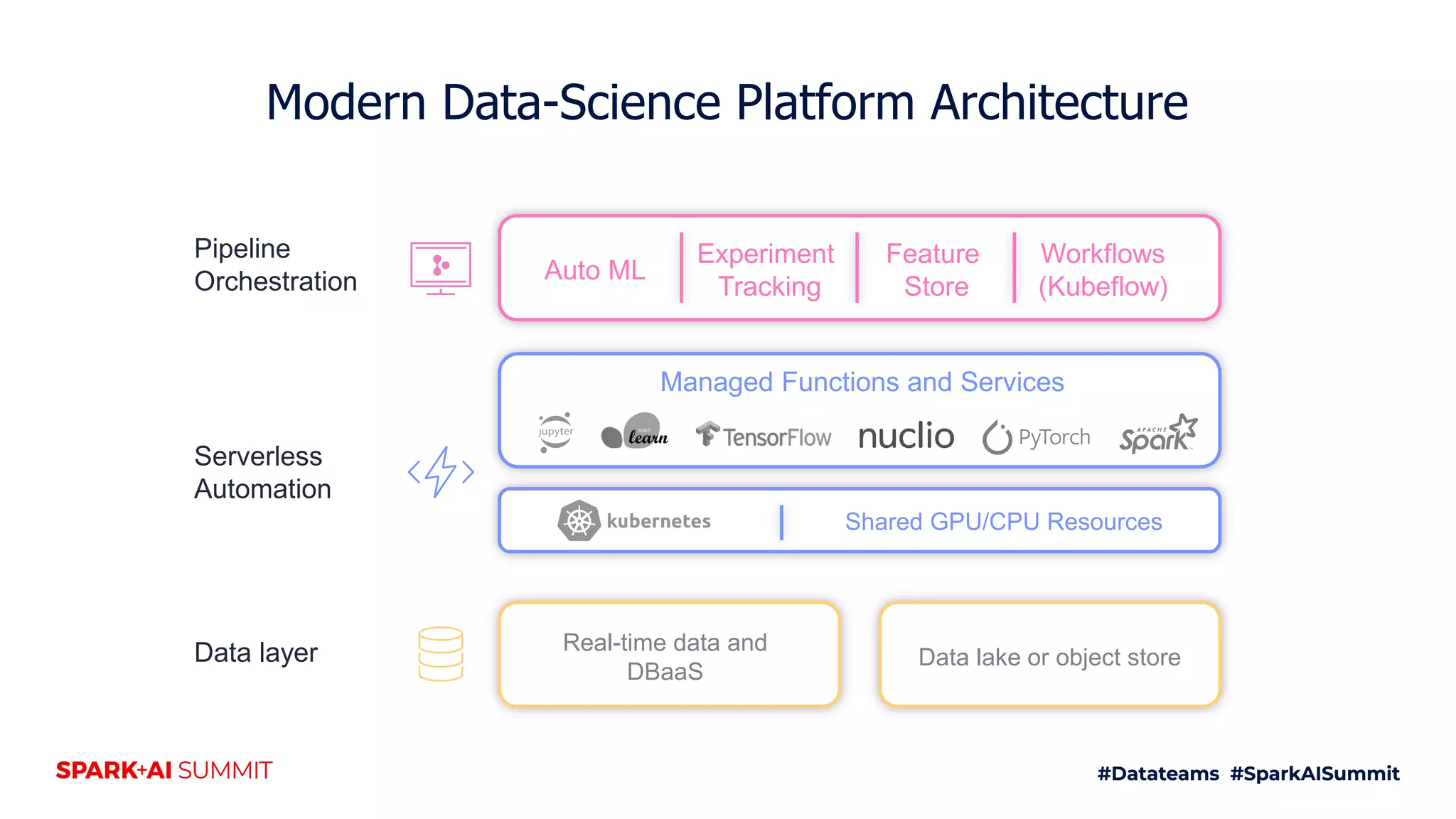

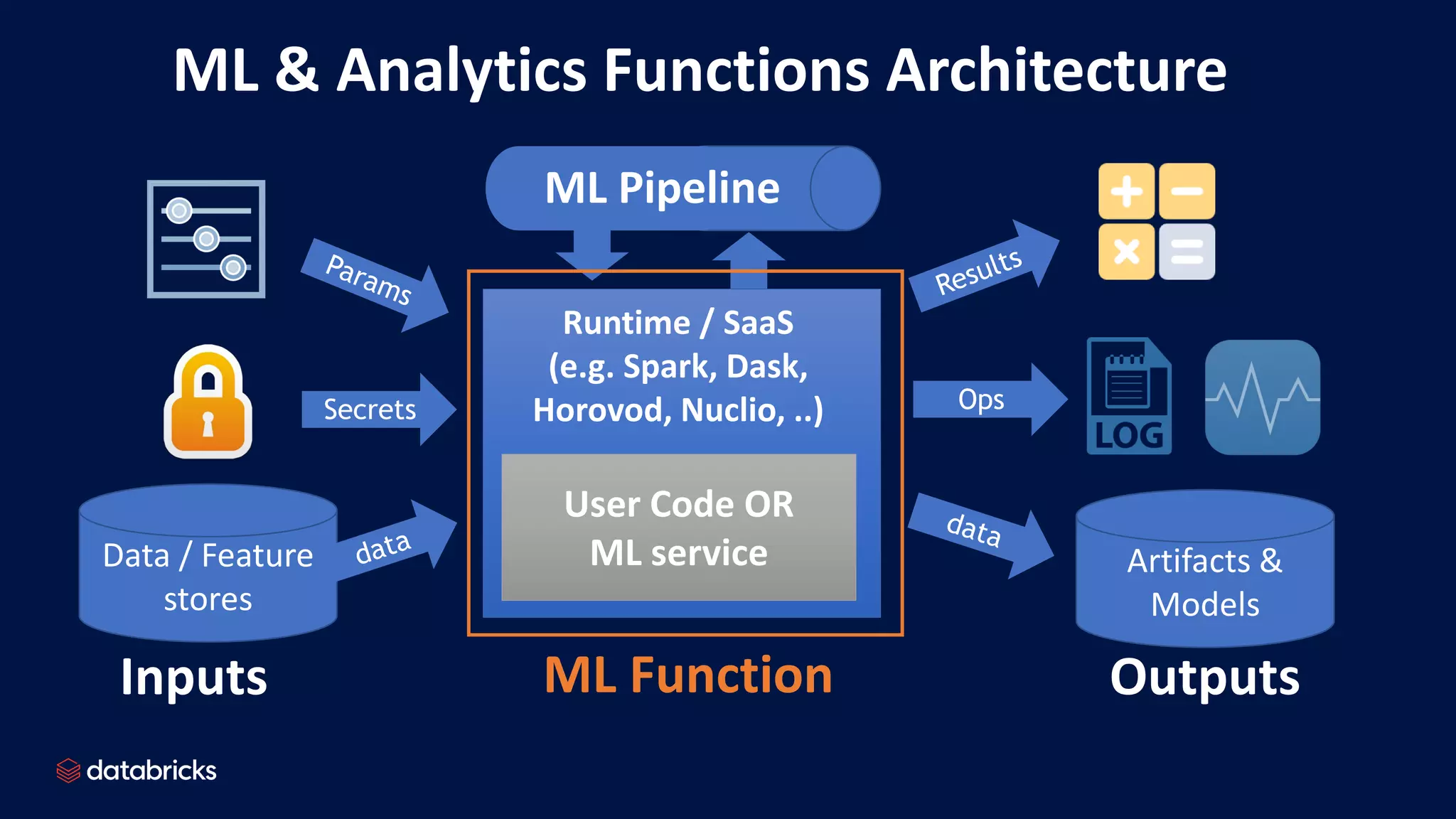

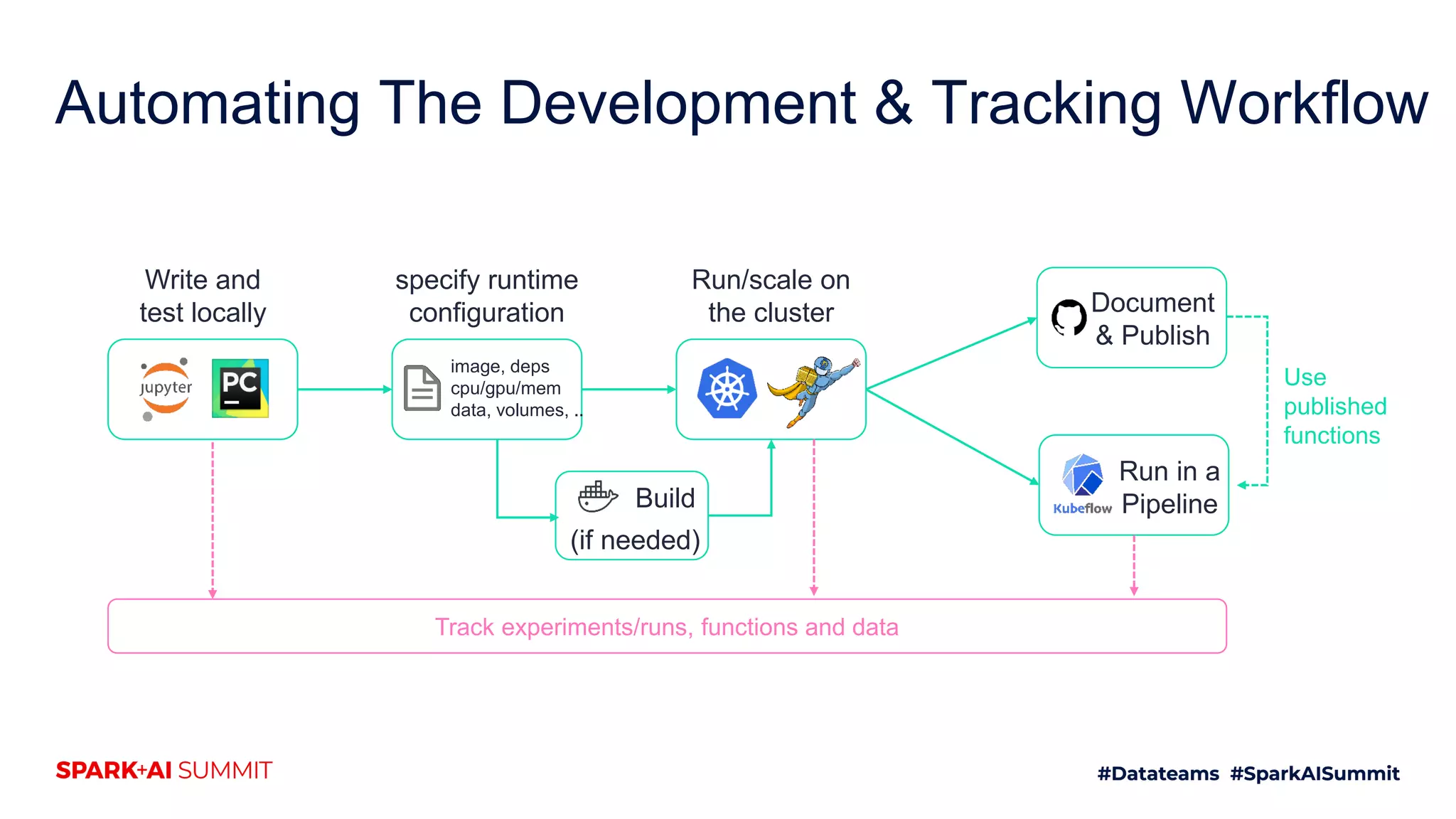
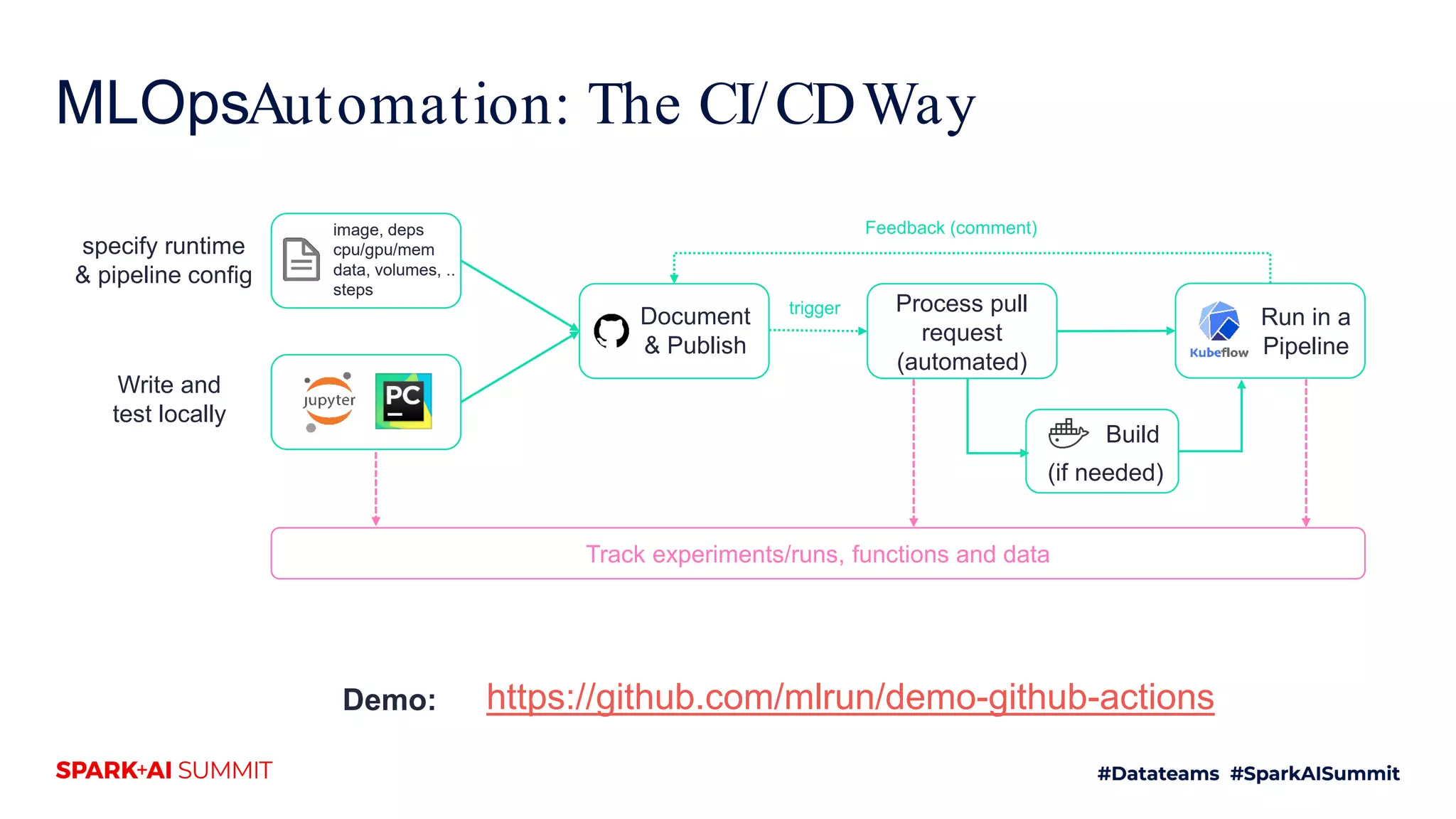

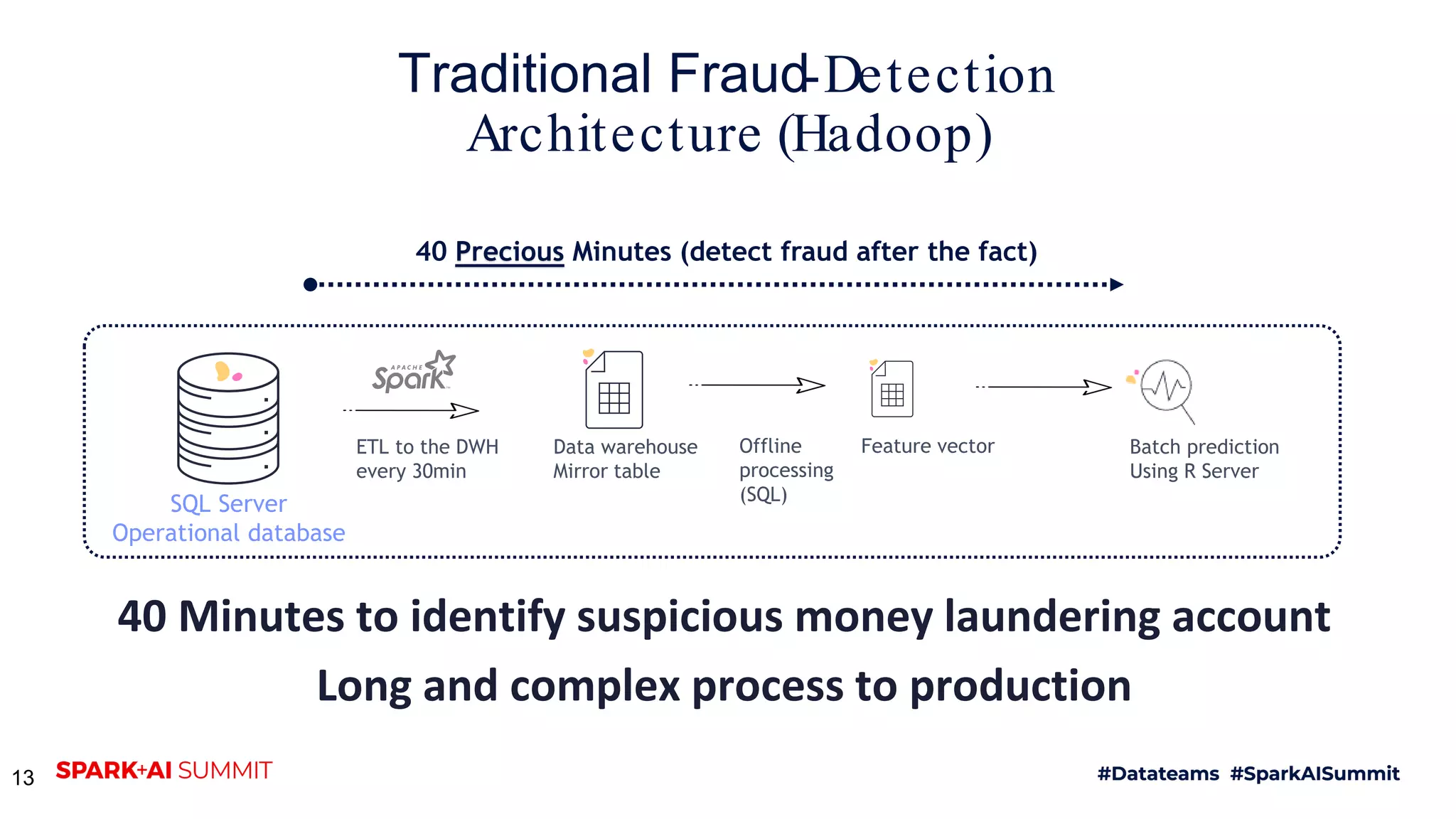
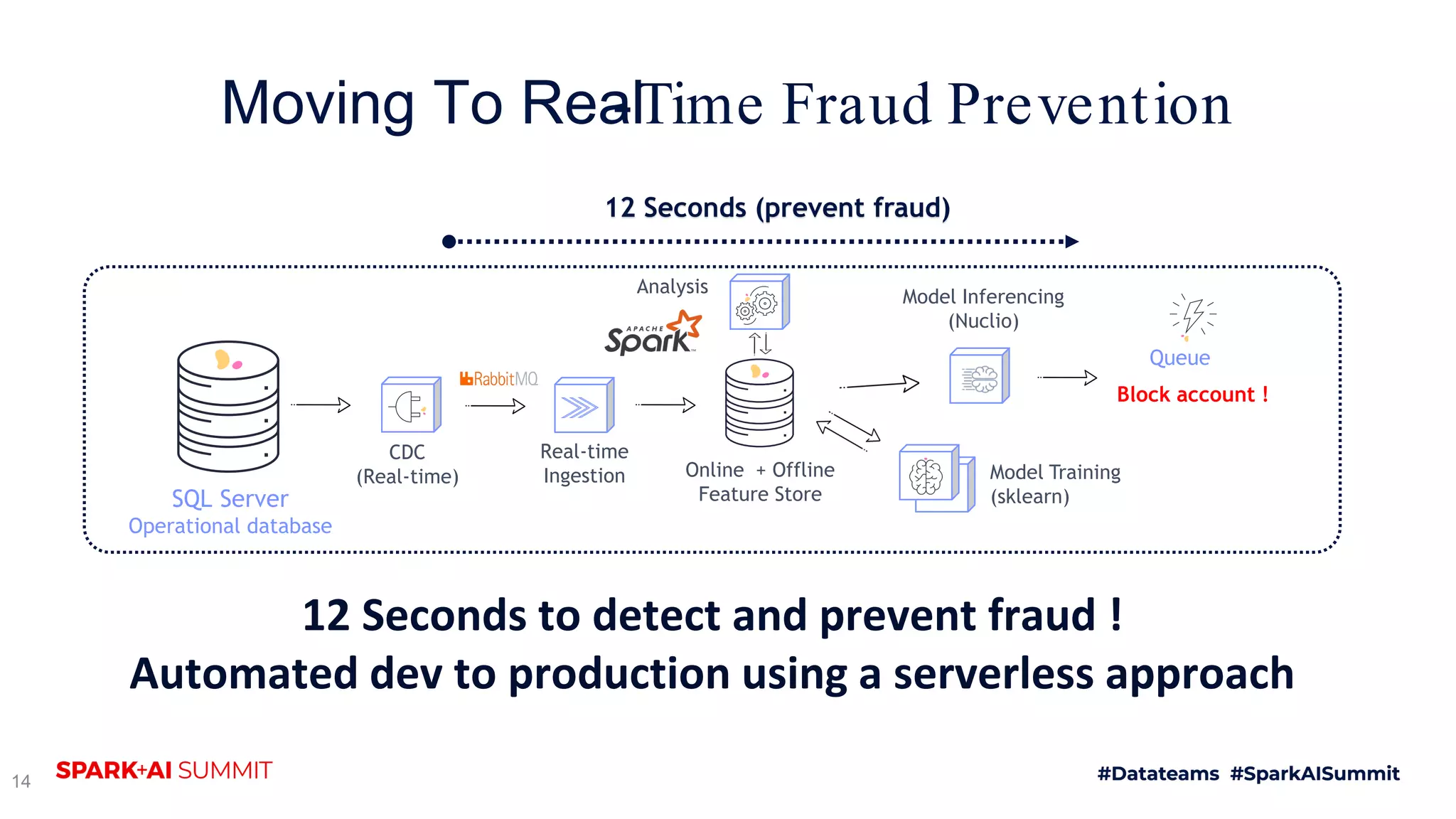
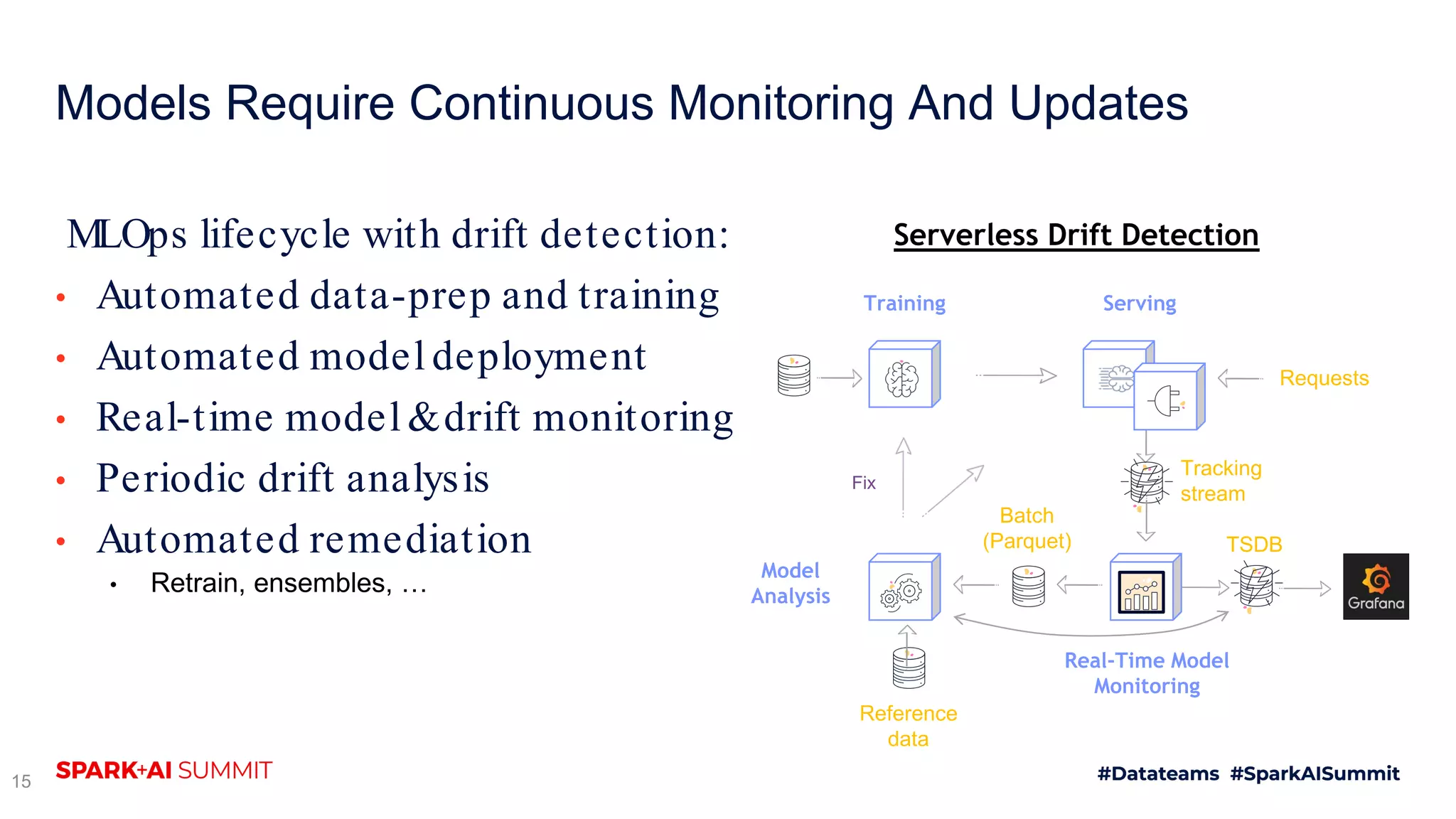




The document discusses the challenges of productionizing machine learning projects and highlights the importance of a microservices architecture in automating workflows. It emphasizes the benefits of using serverless functions for machine learning, including automated deployment, scaling, and monitoring. A case study on real-time fraud prevention illustrates how these methods can significantly reduce the time to detect and prevent fraudulent activities.