Download as PDF, PPTX






















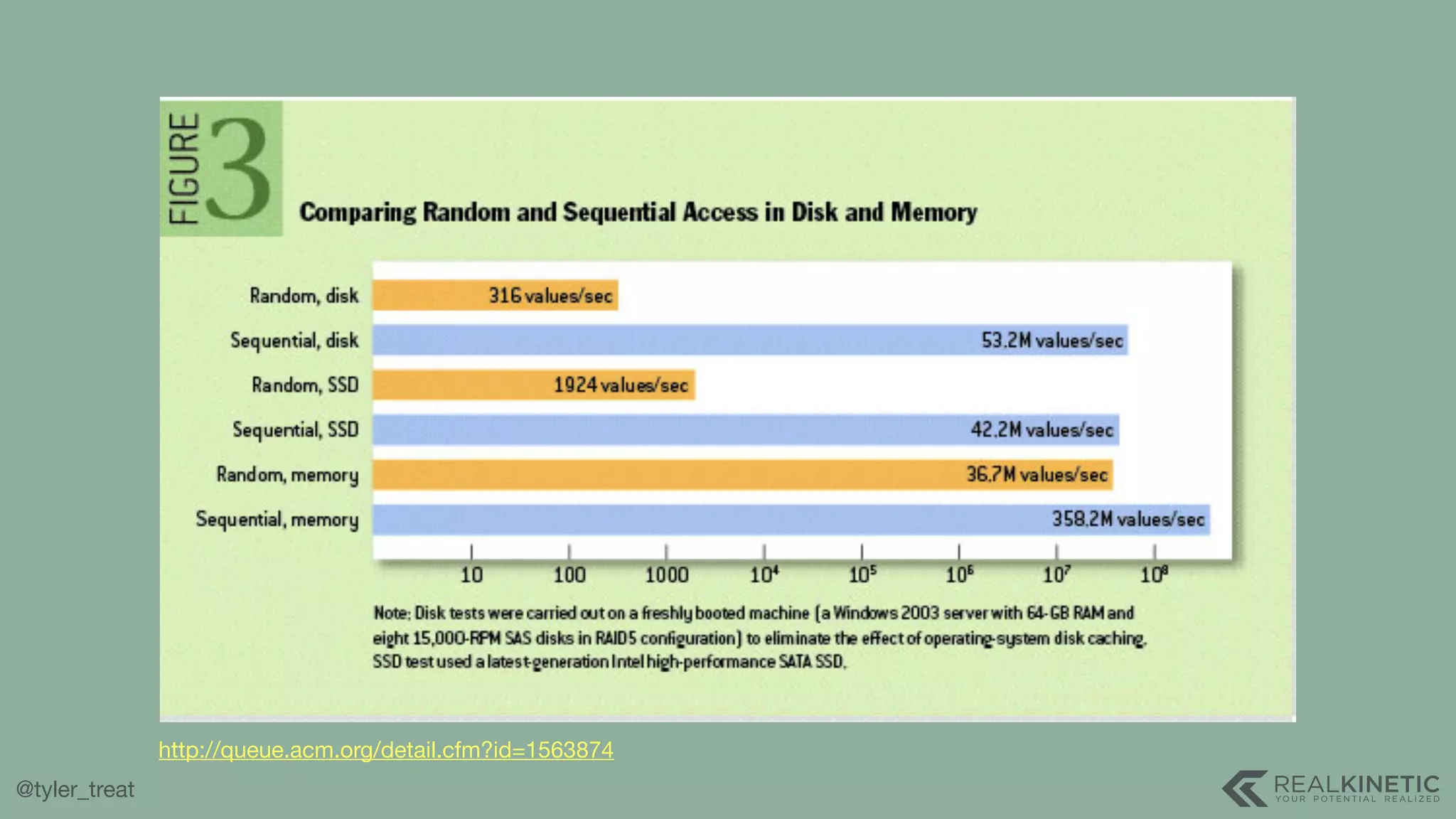




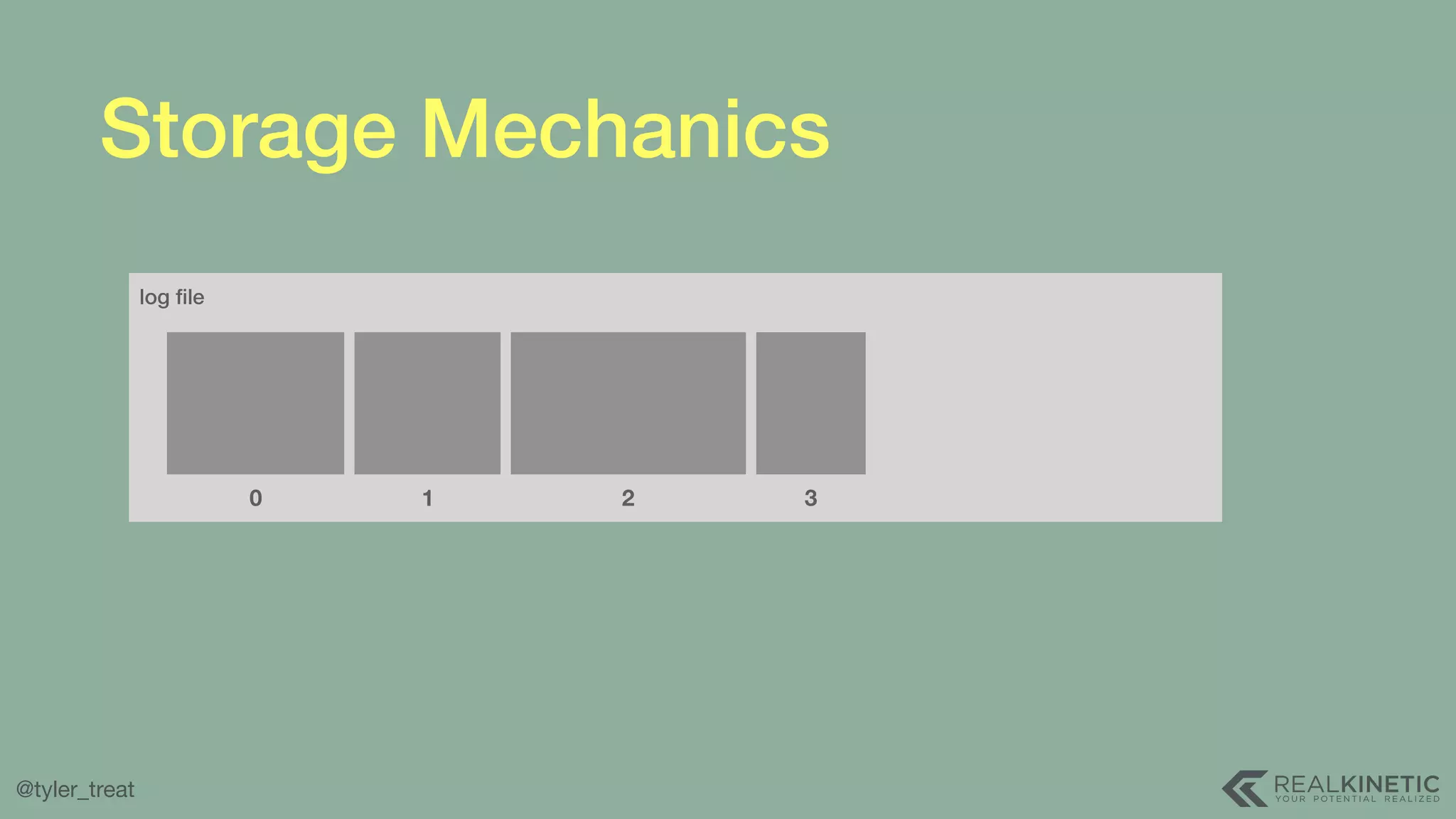
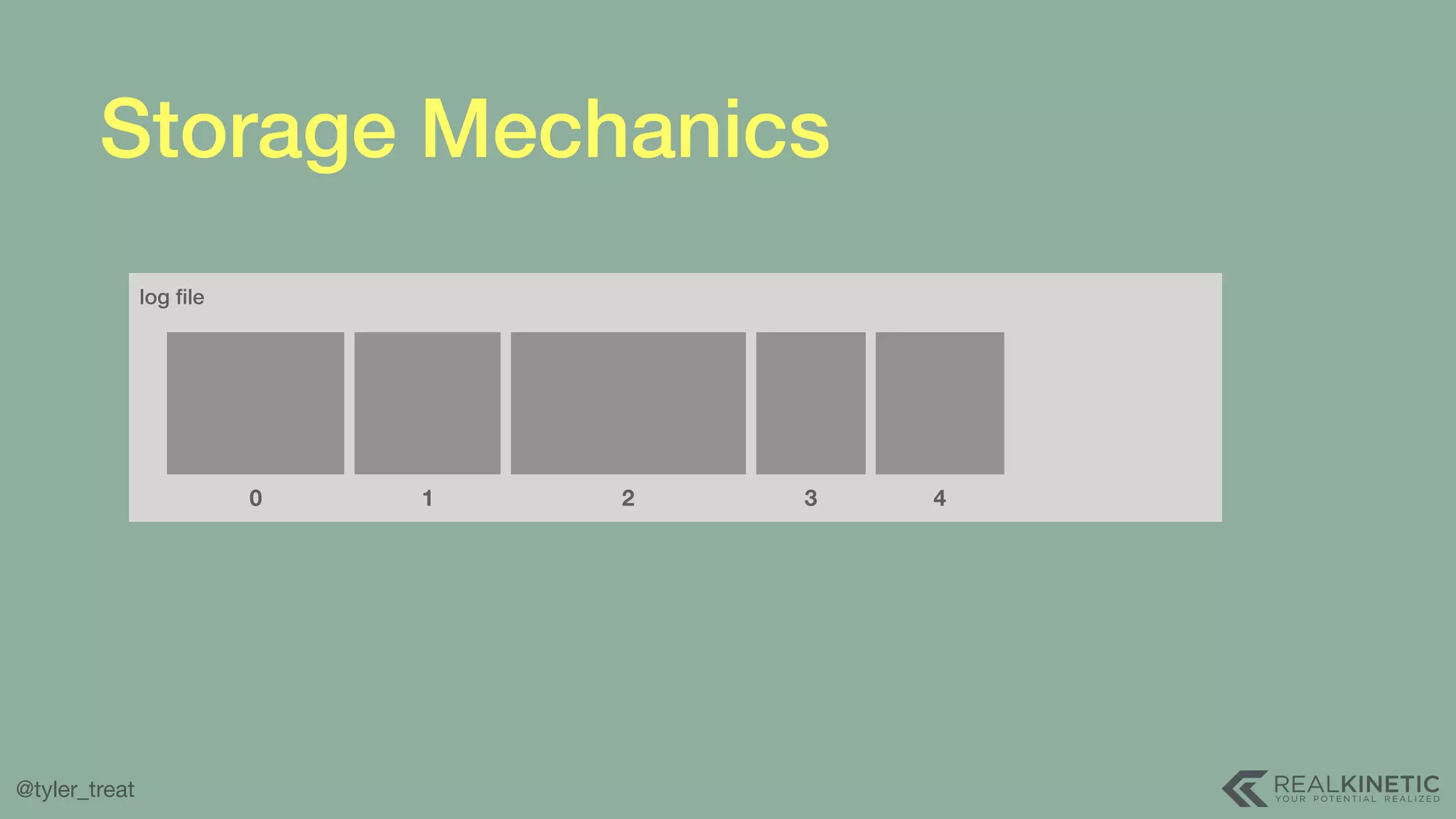


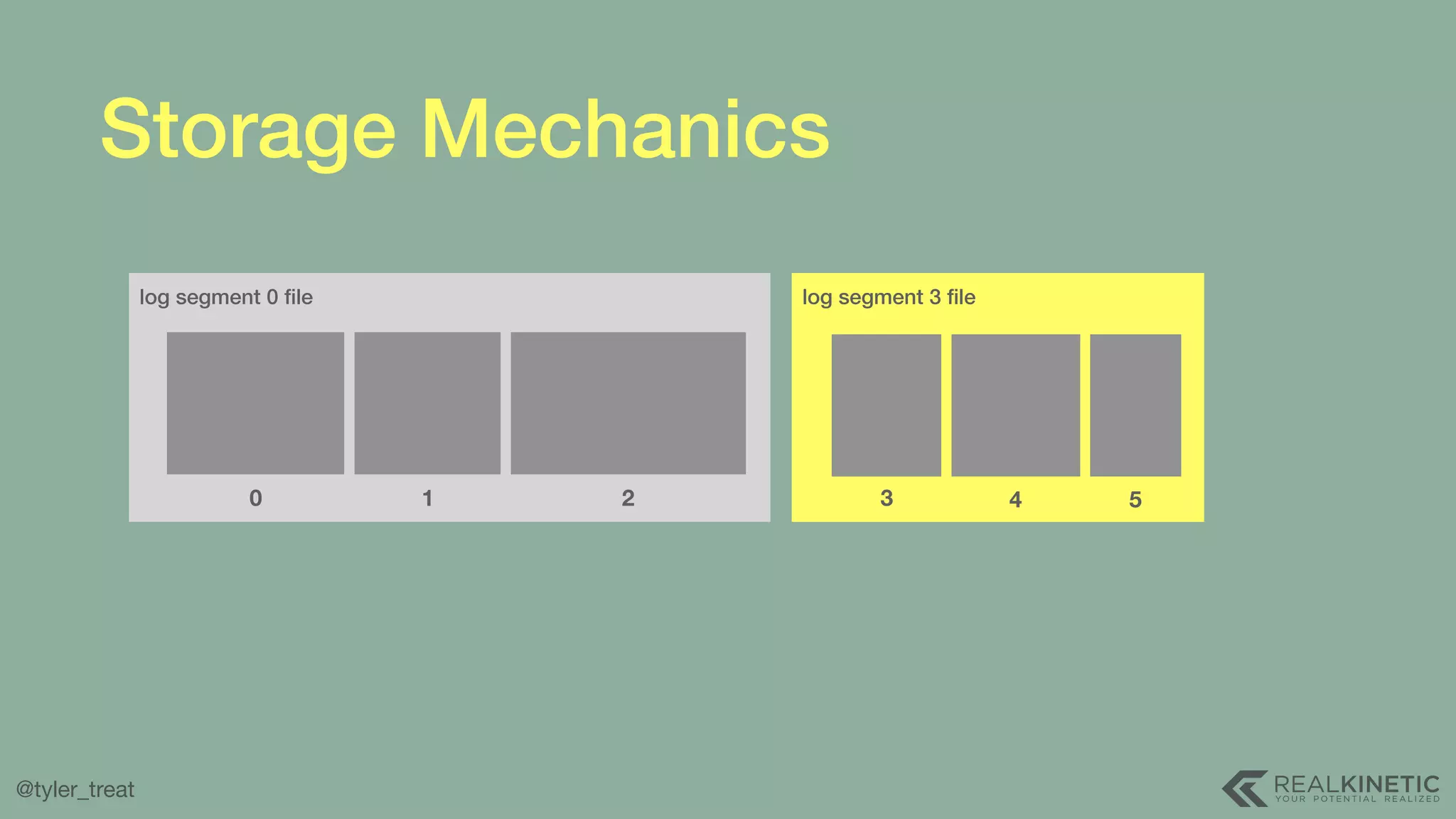
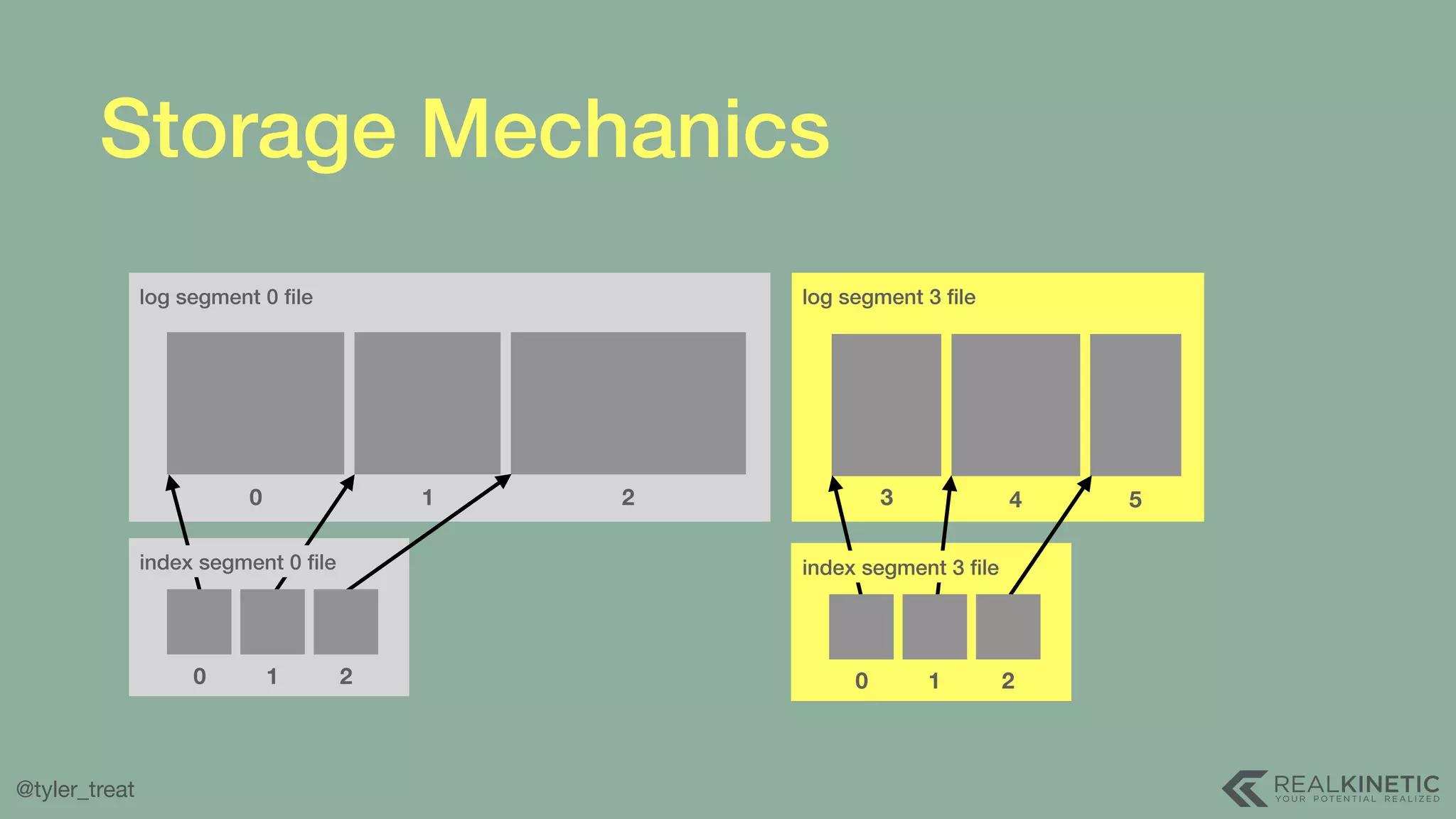
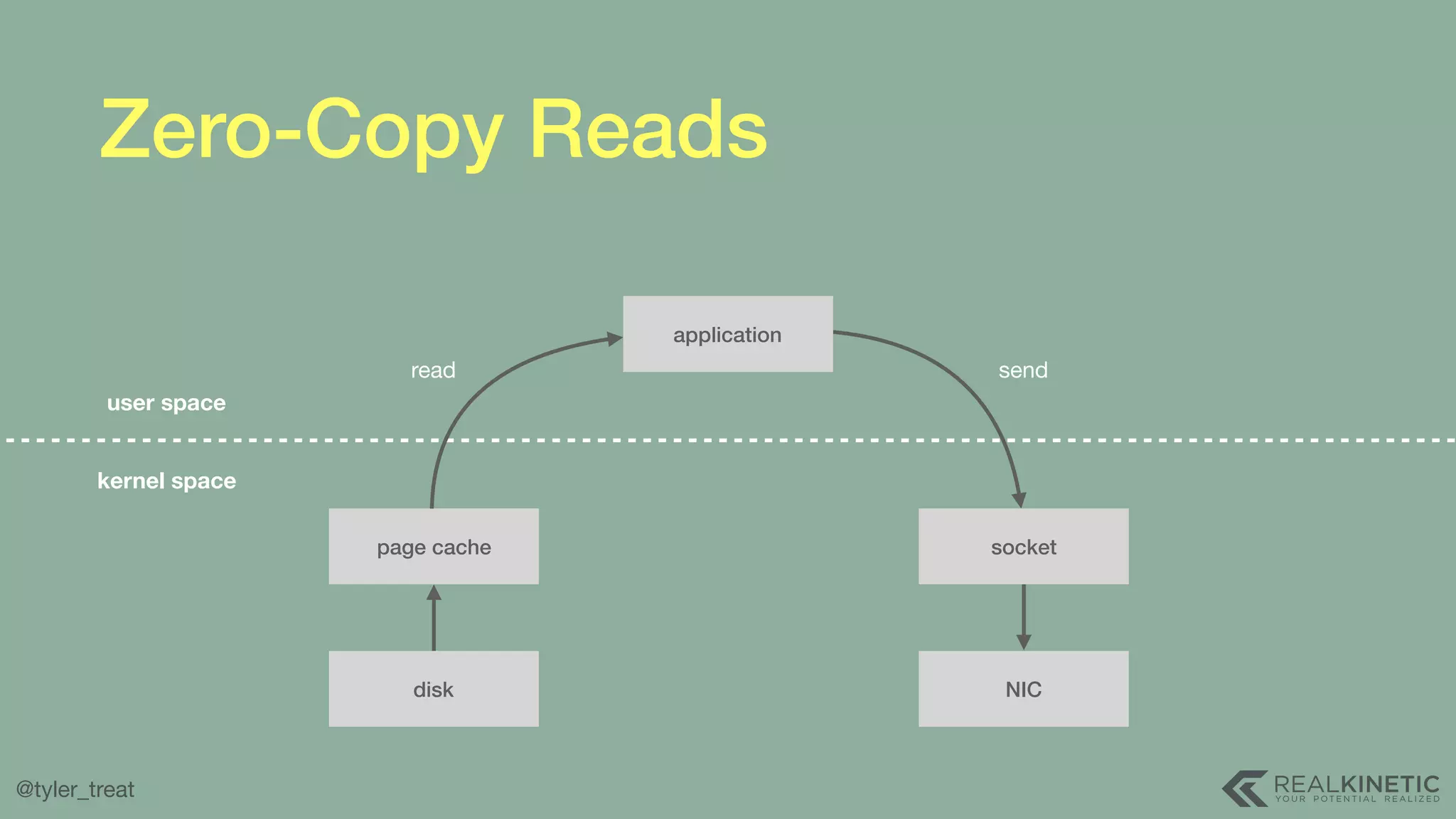
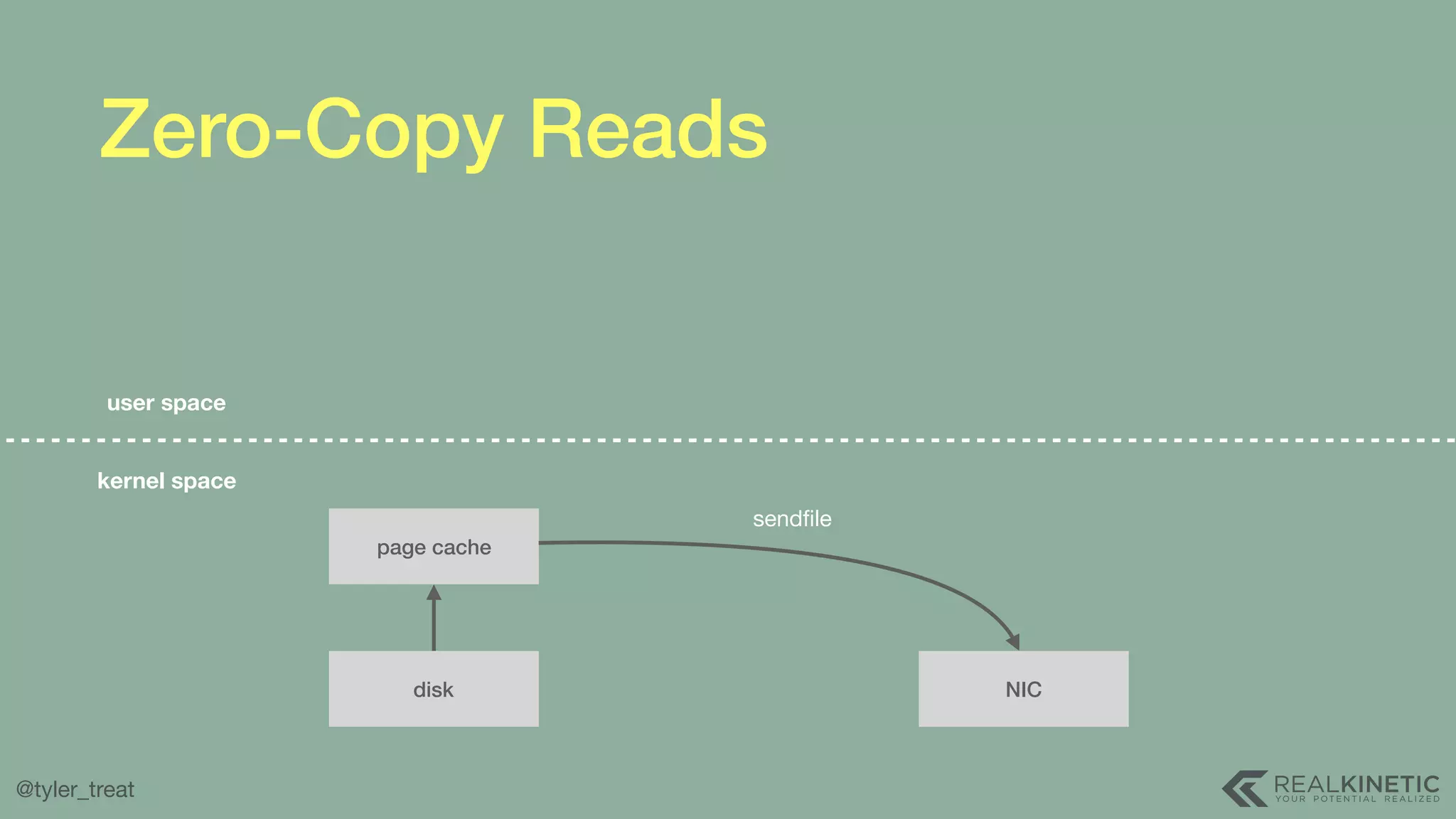


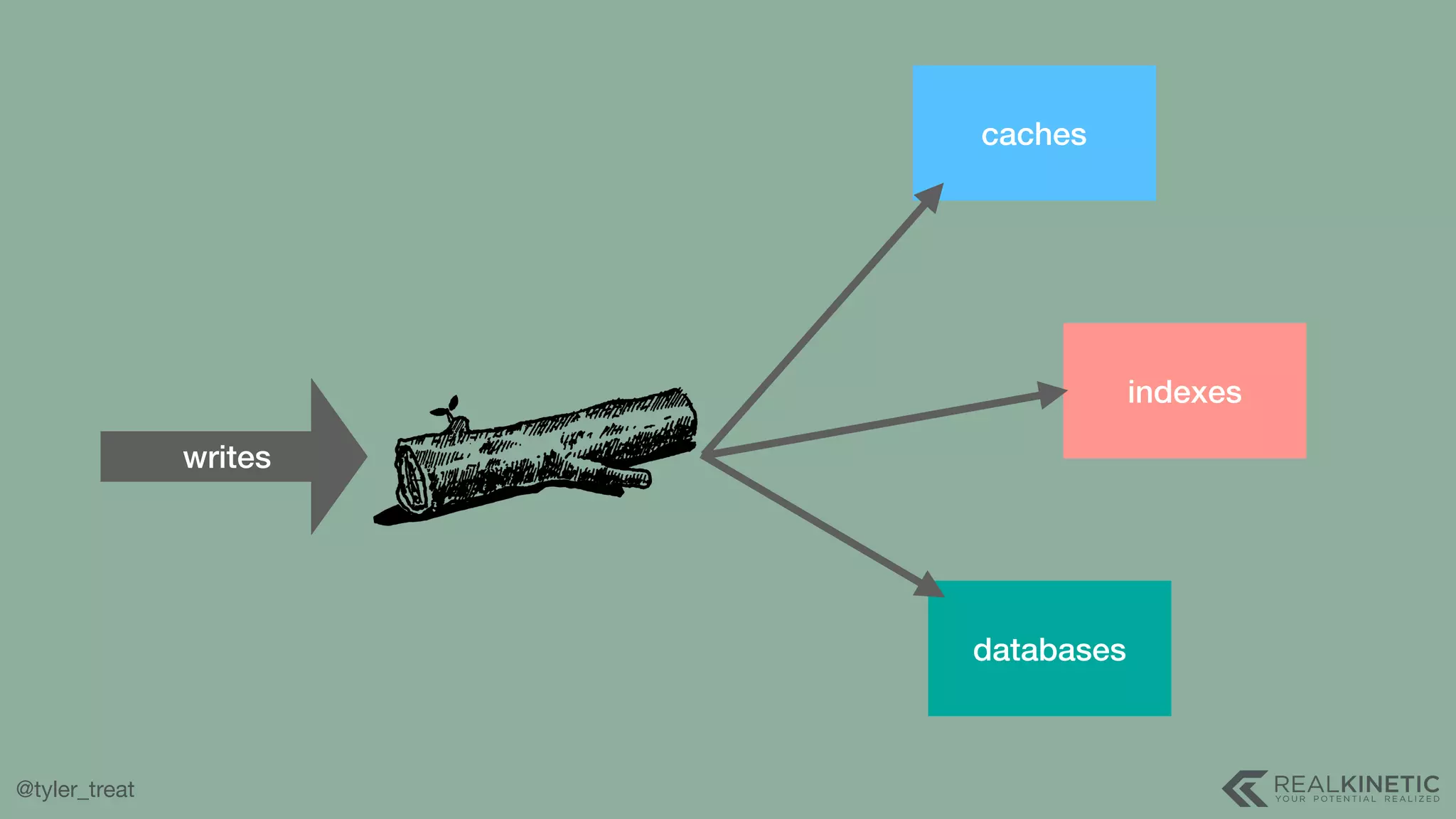
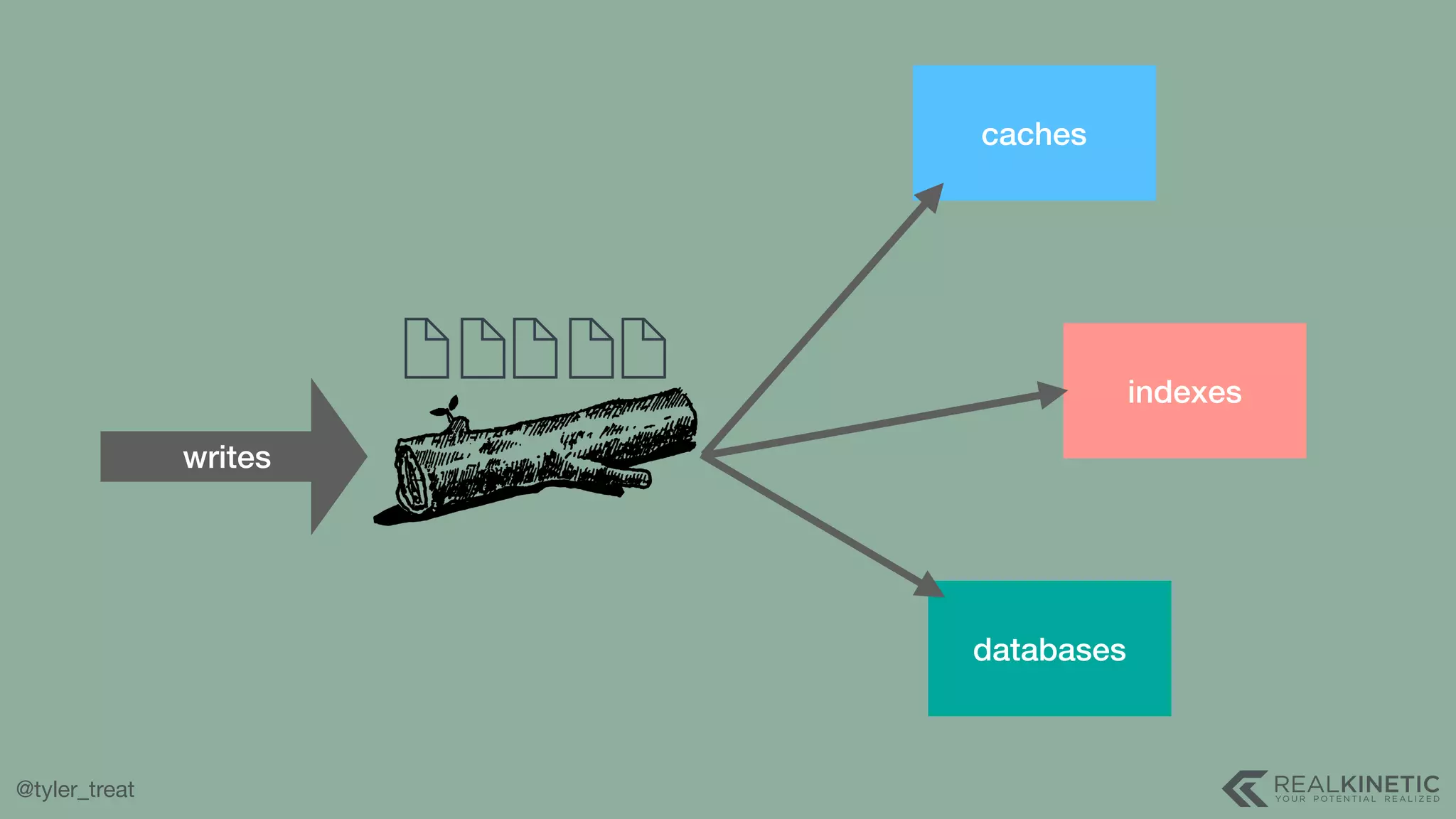




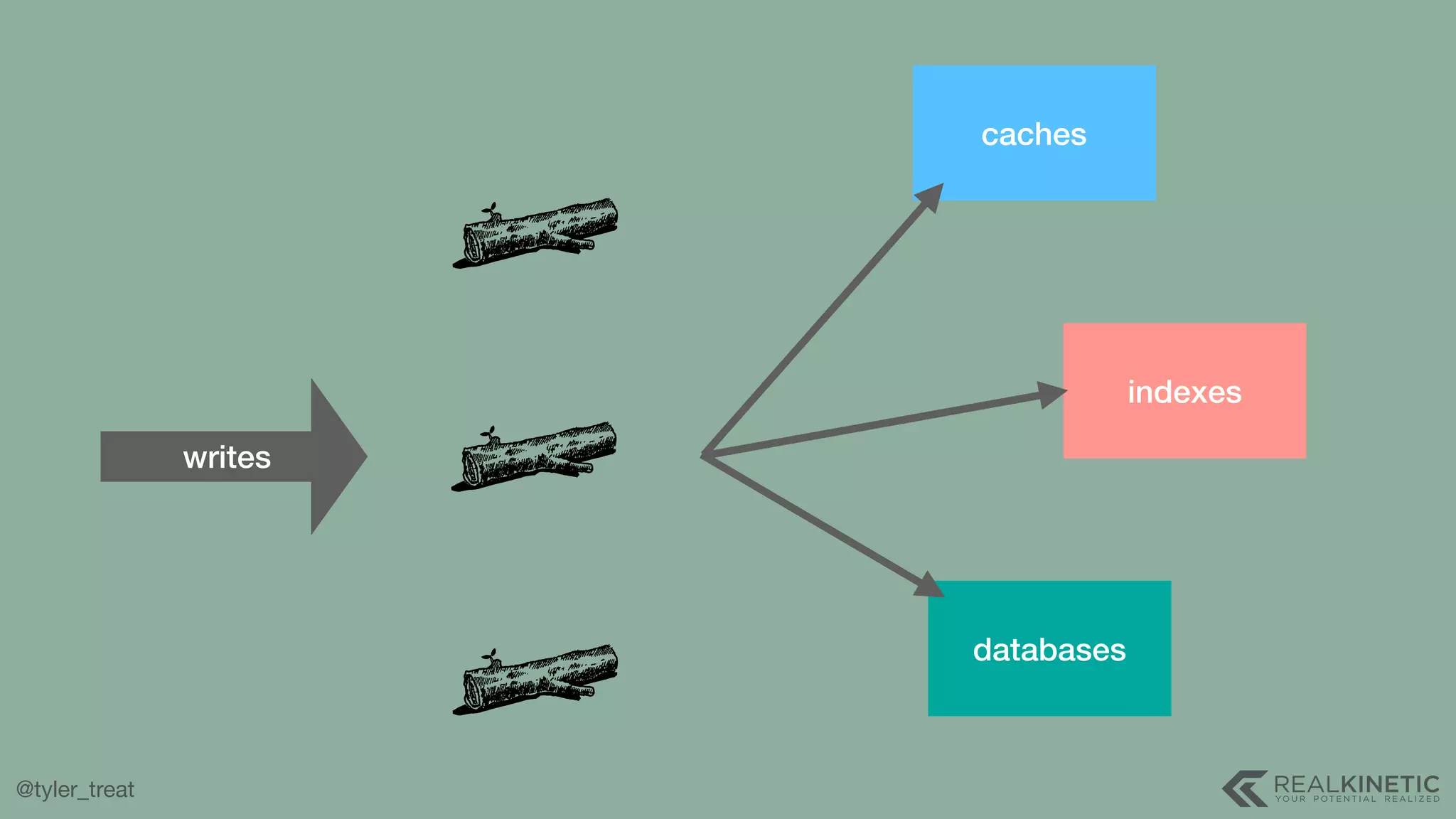





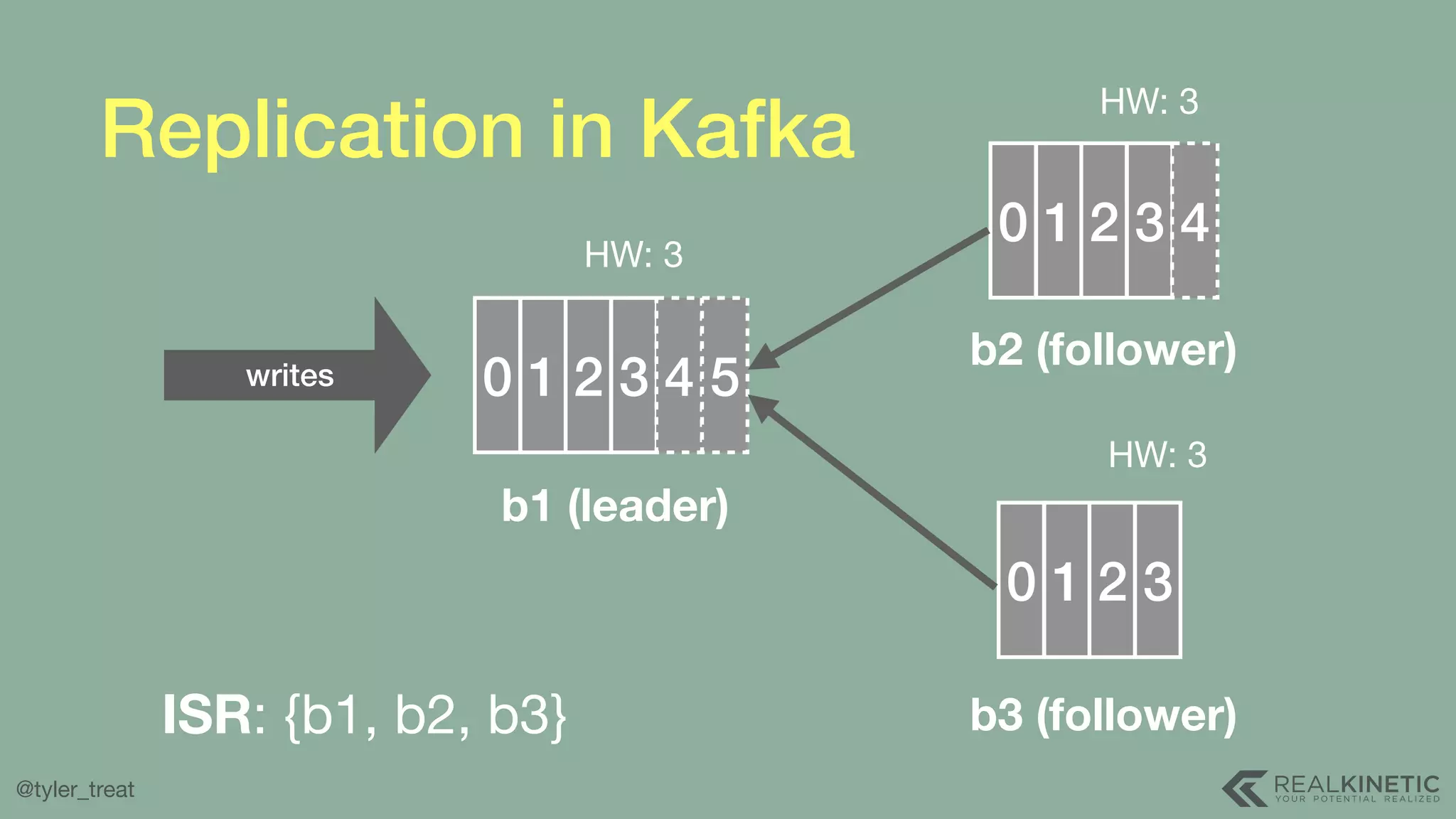

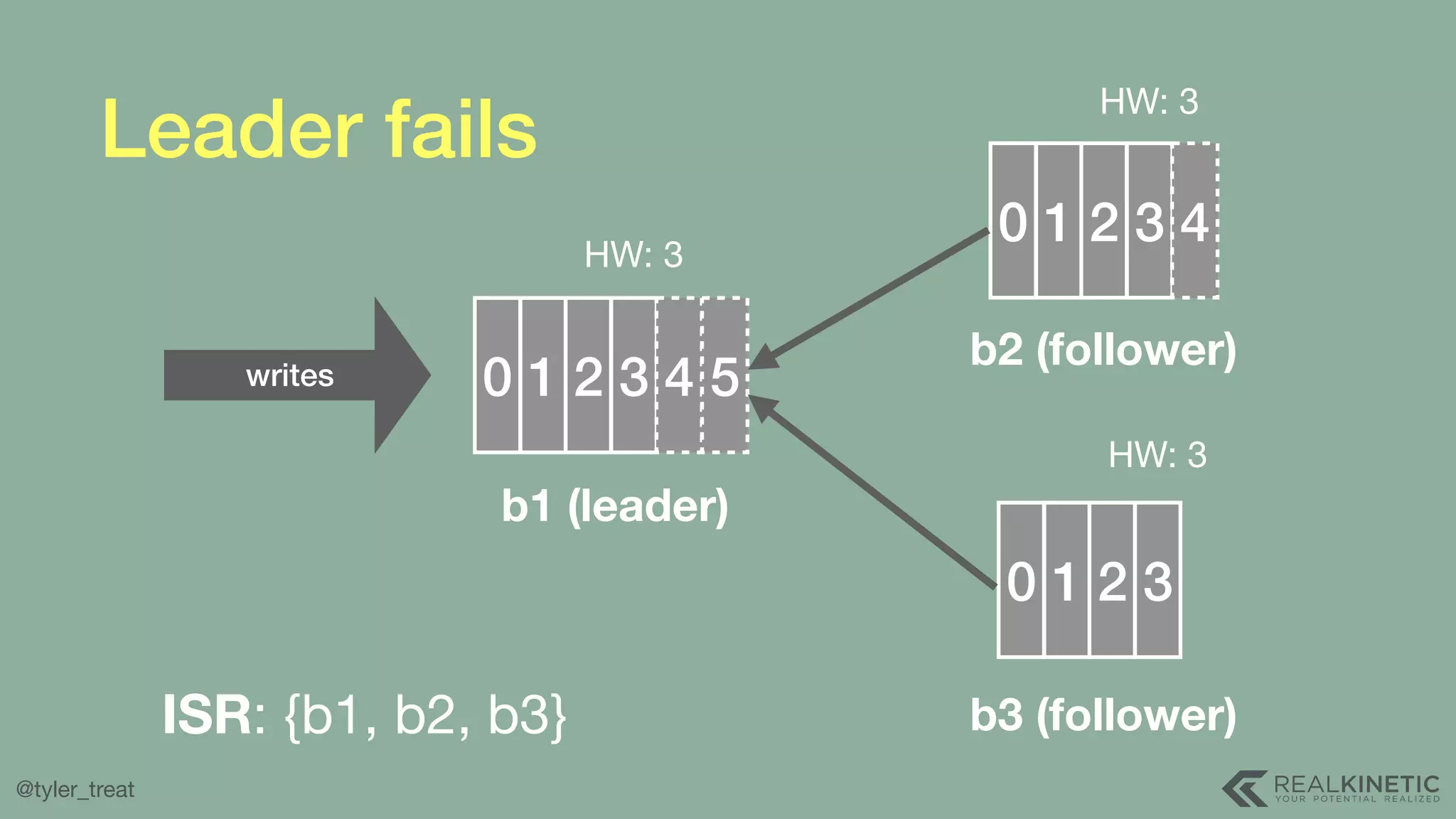
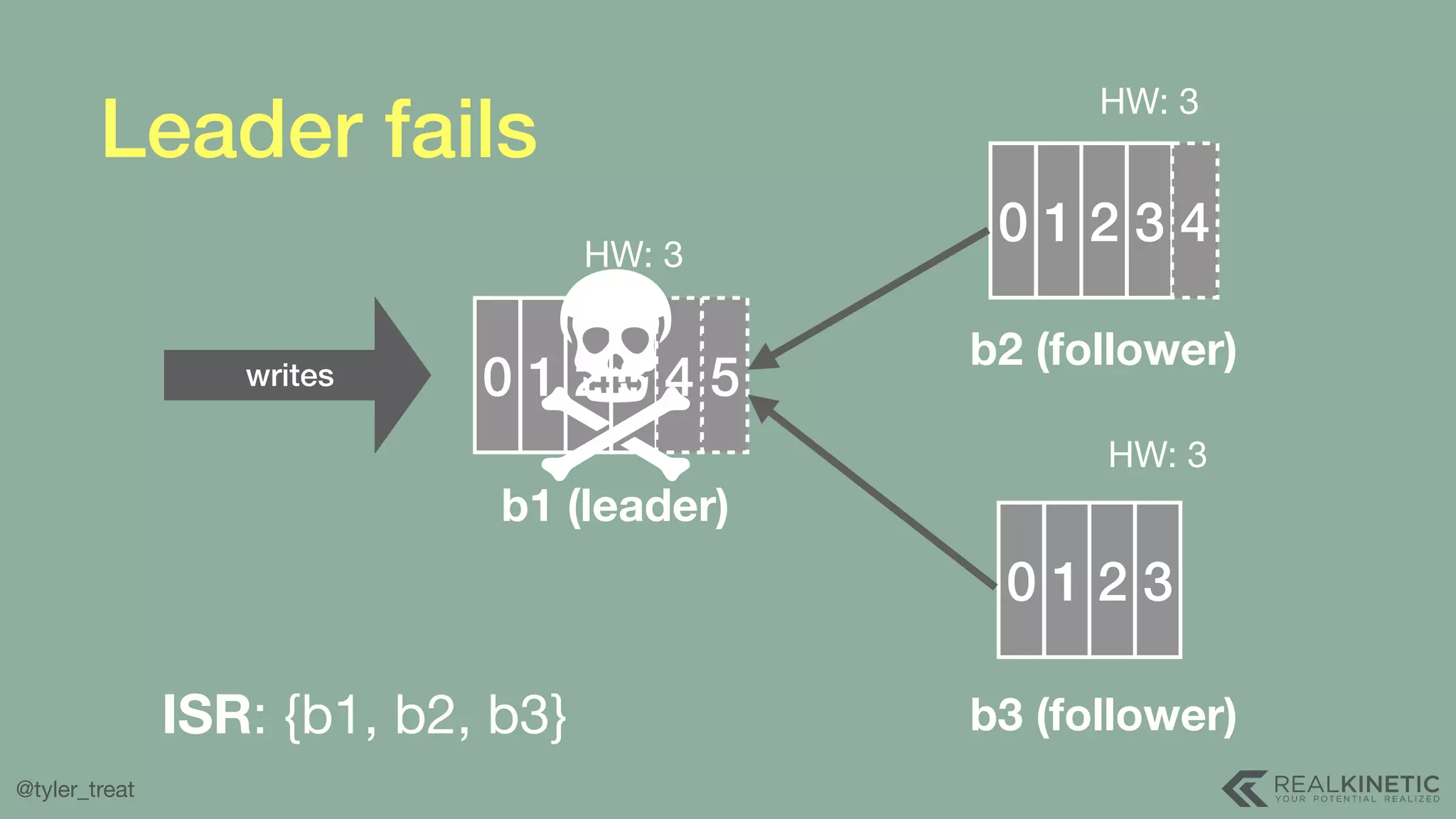
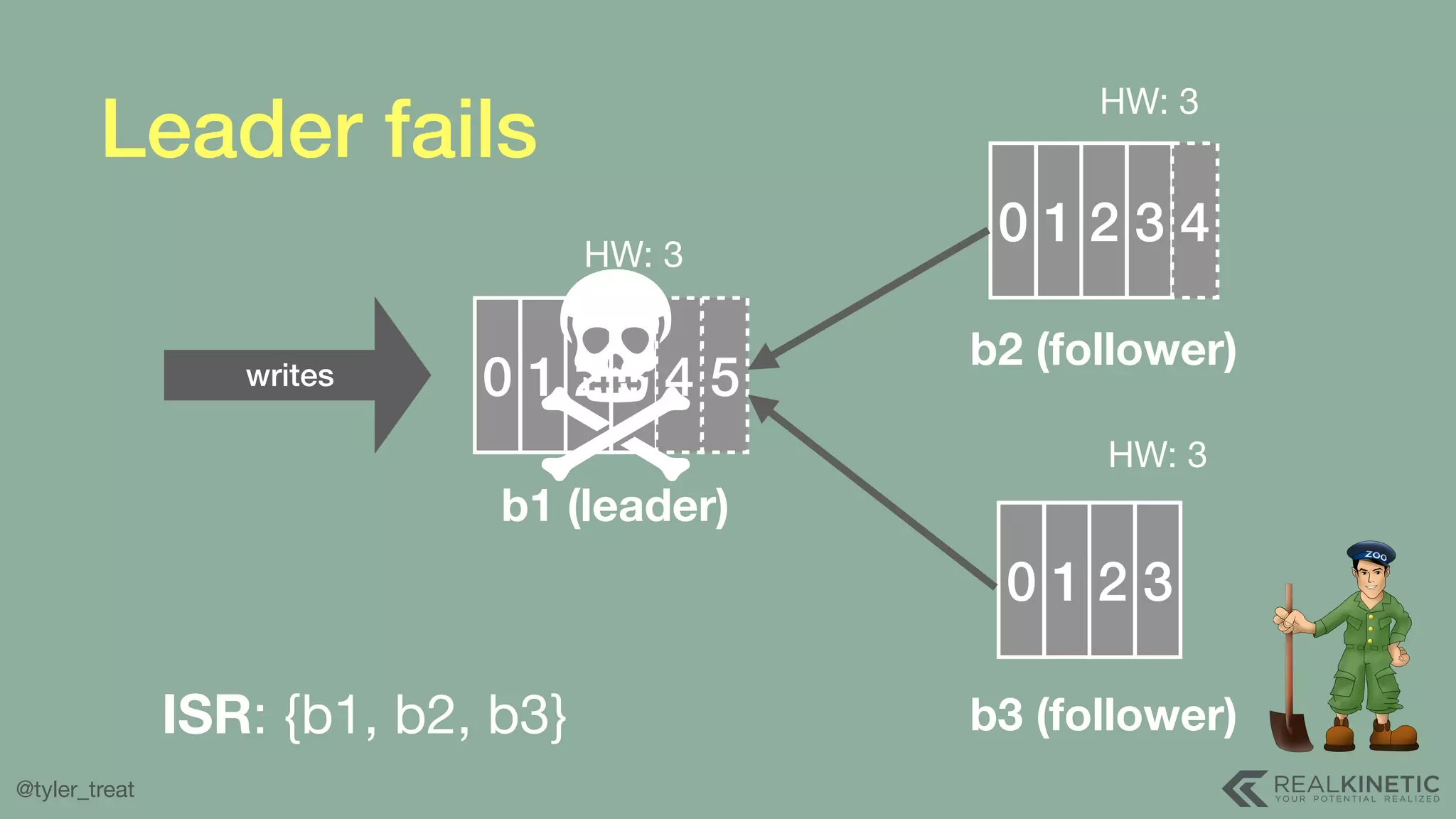
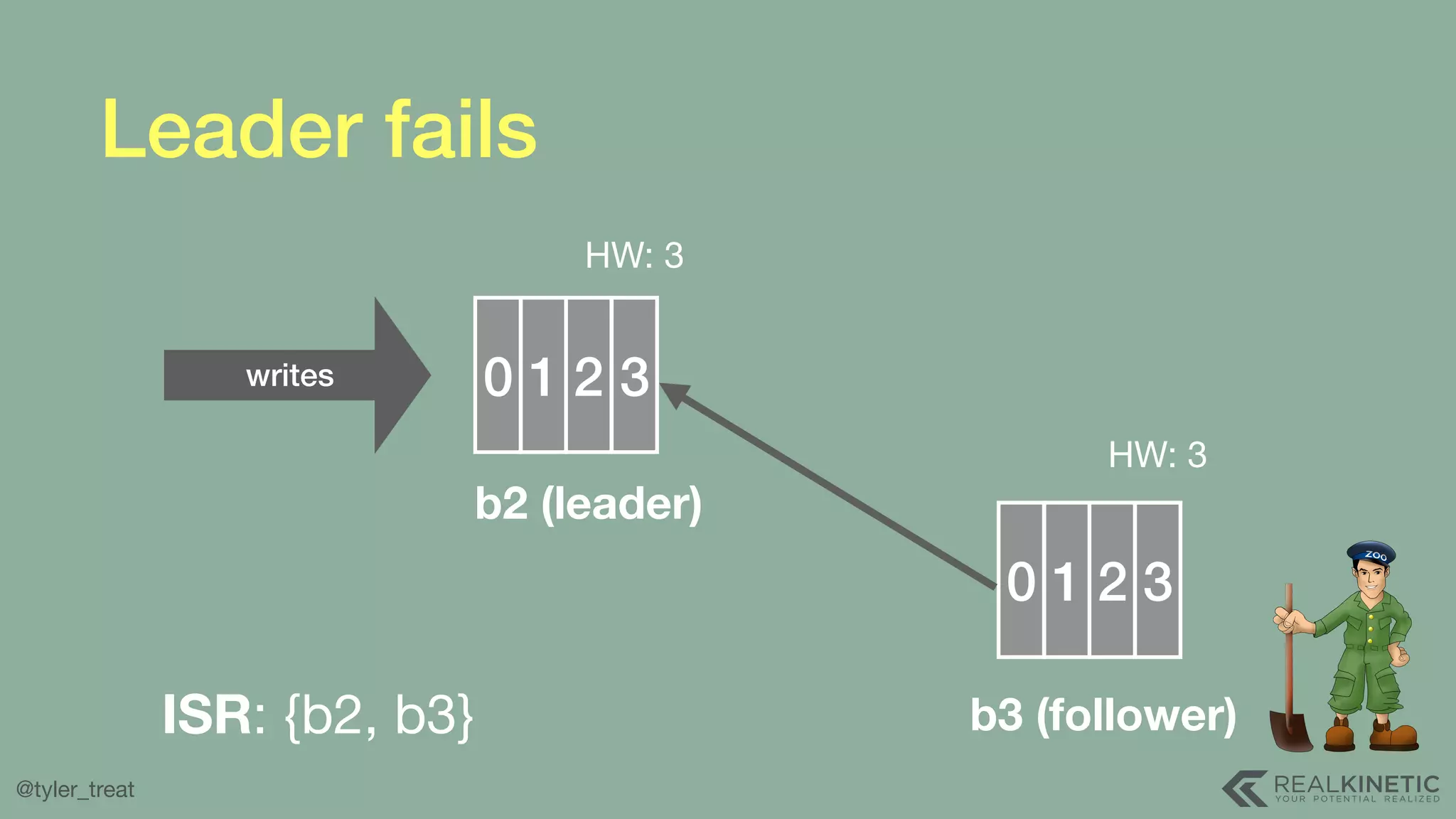

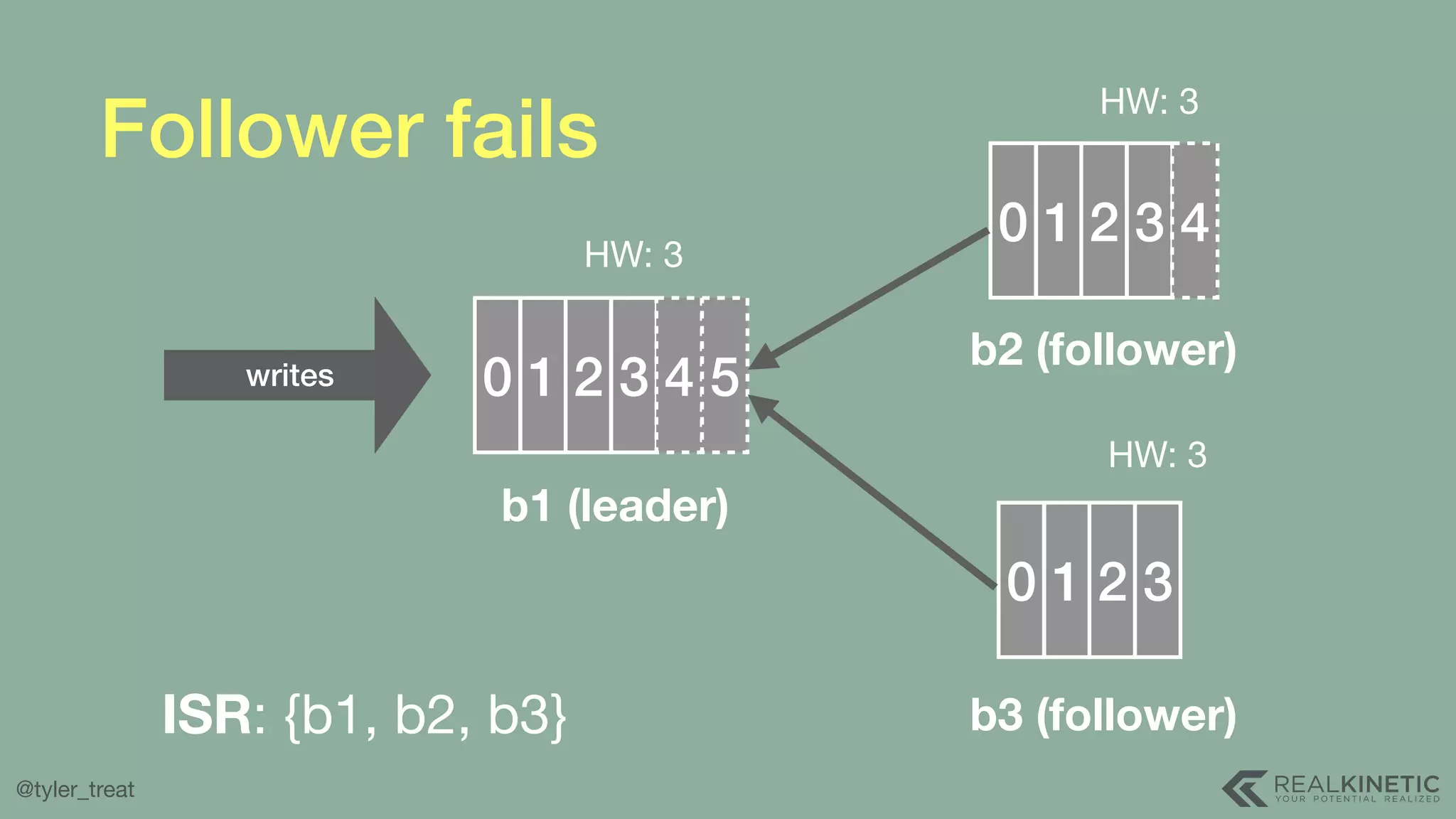
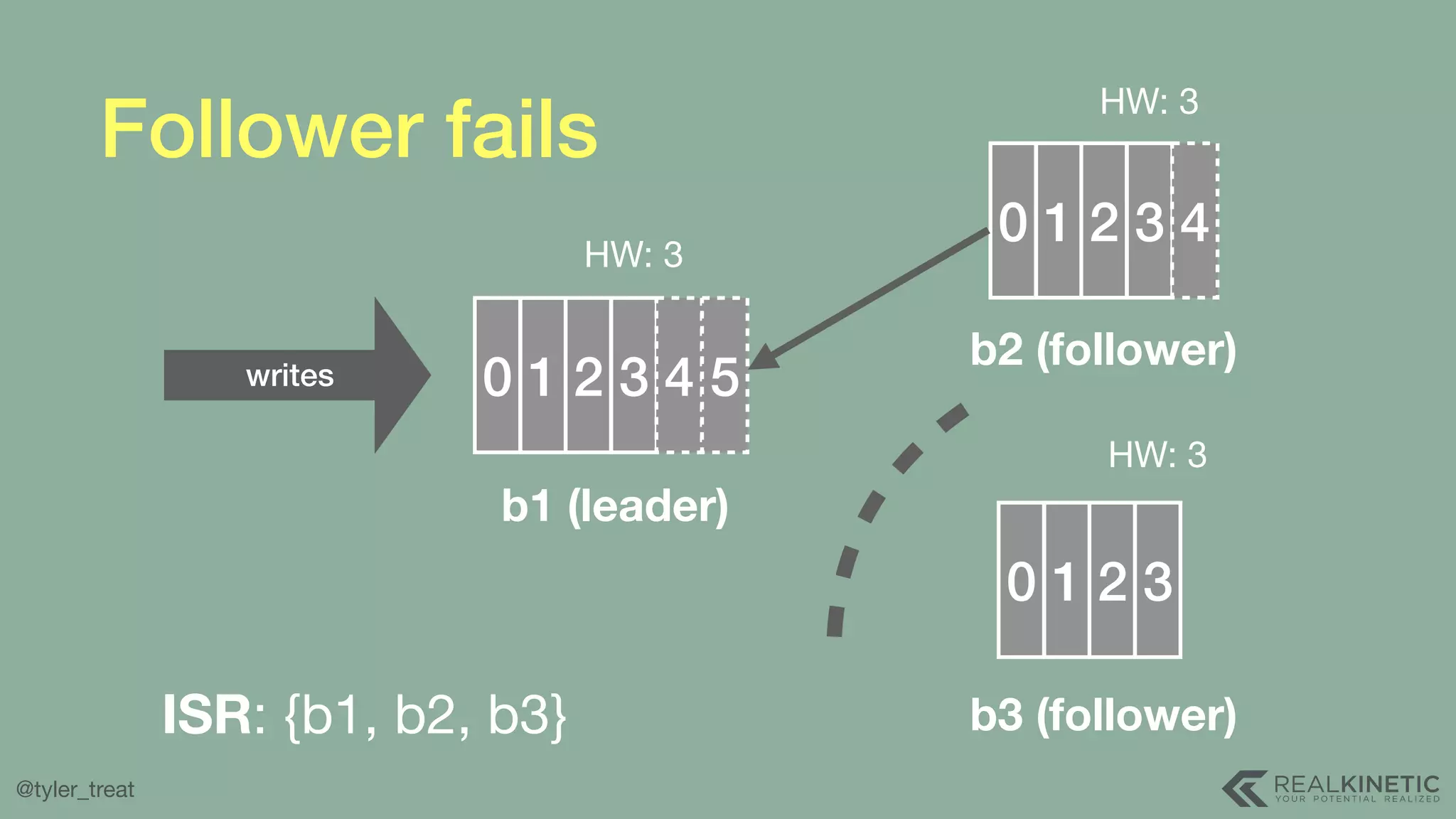
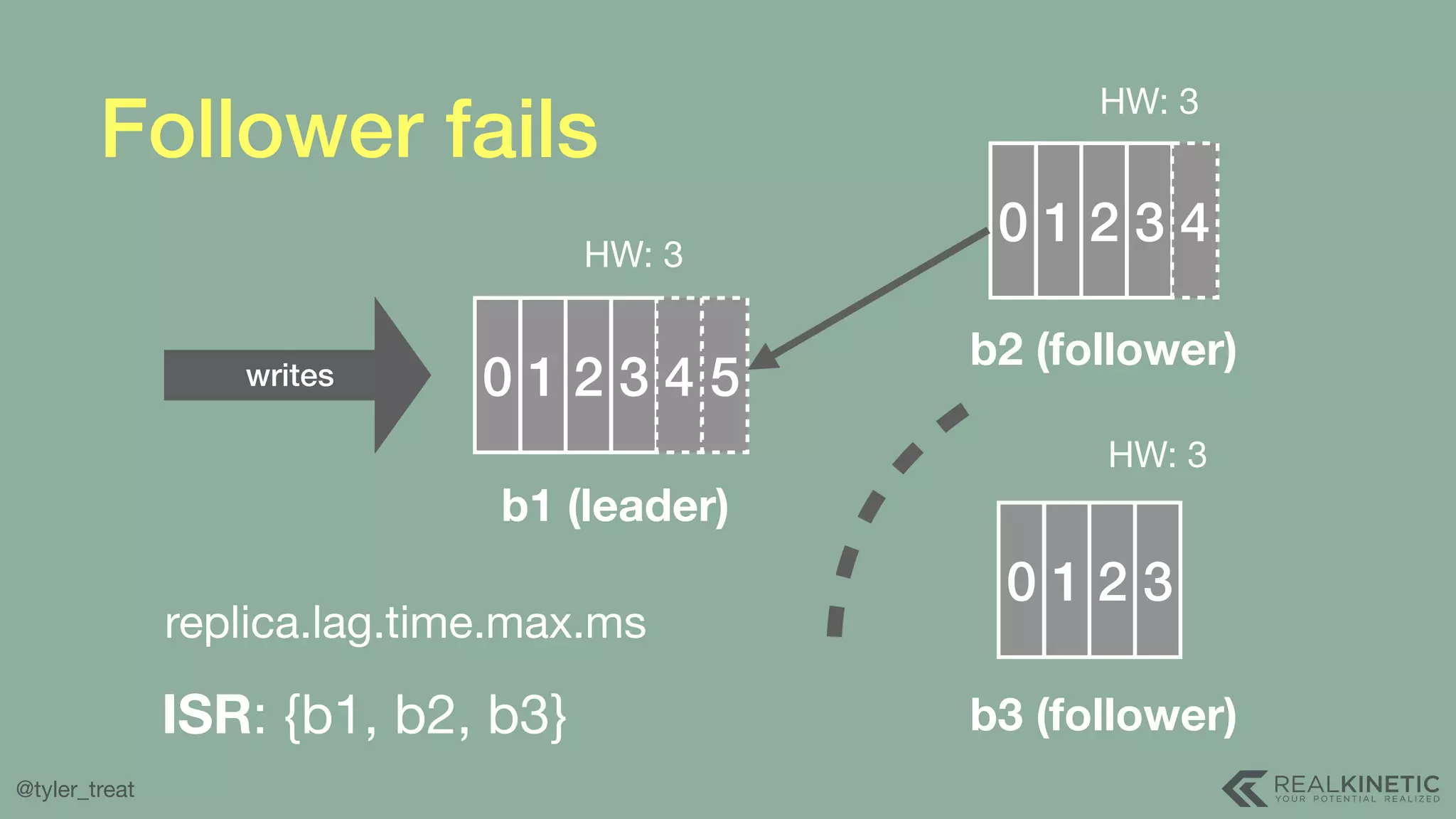
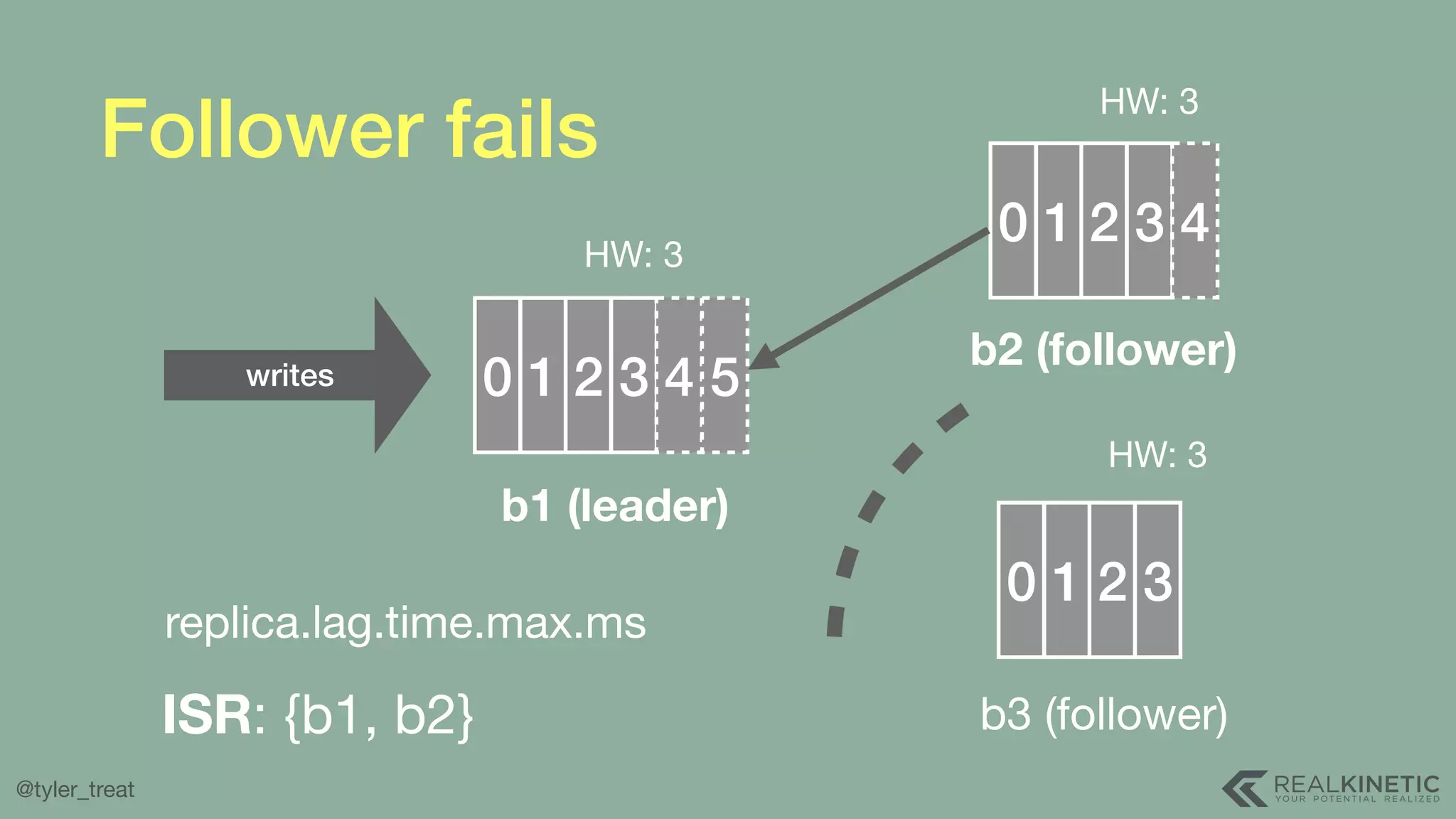
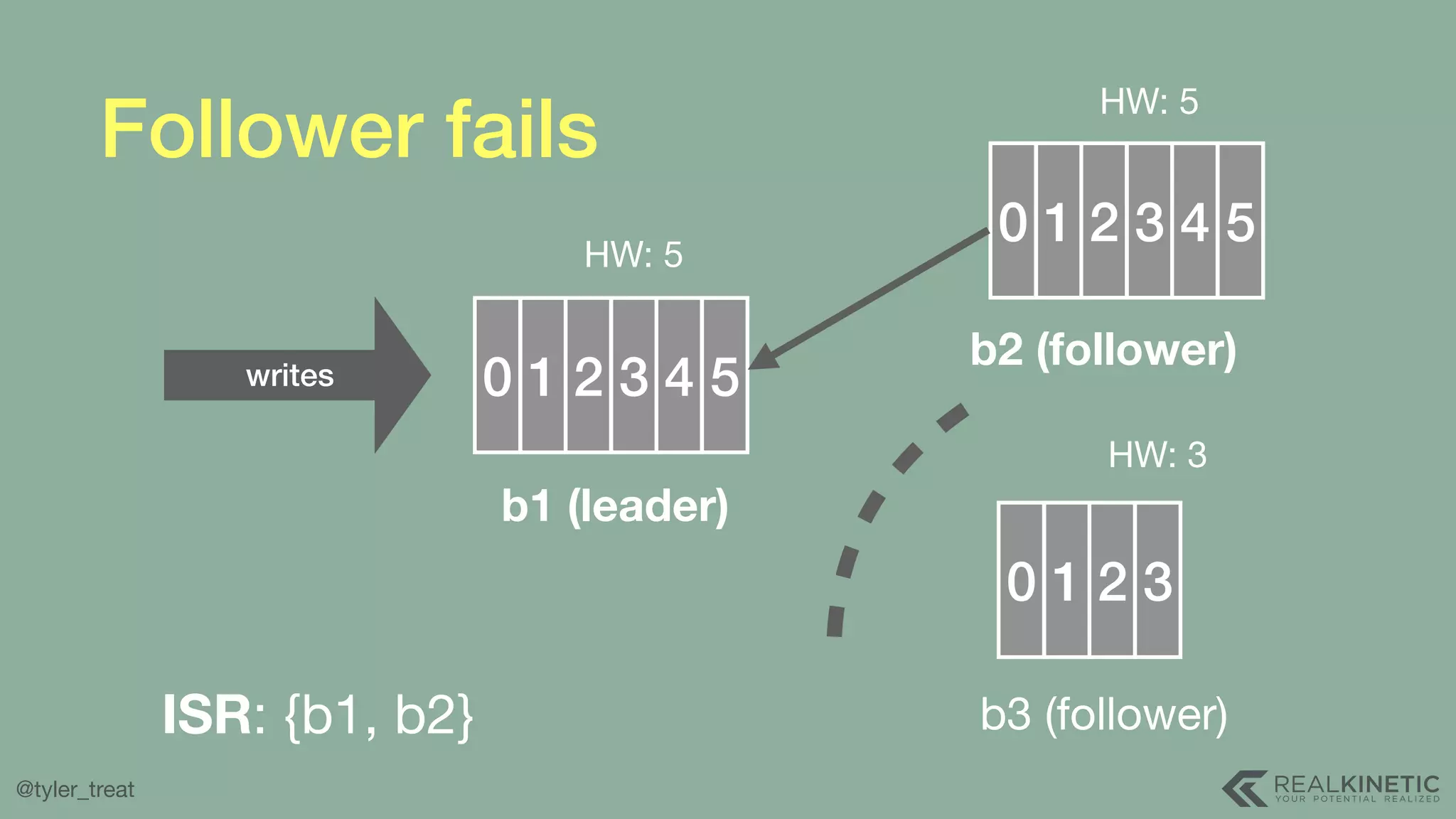
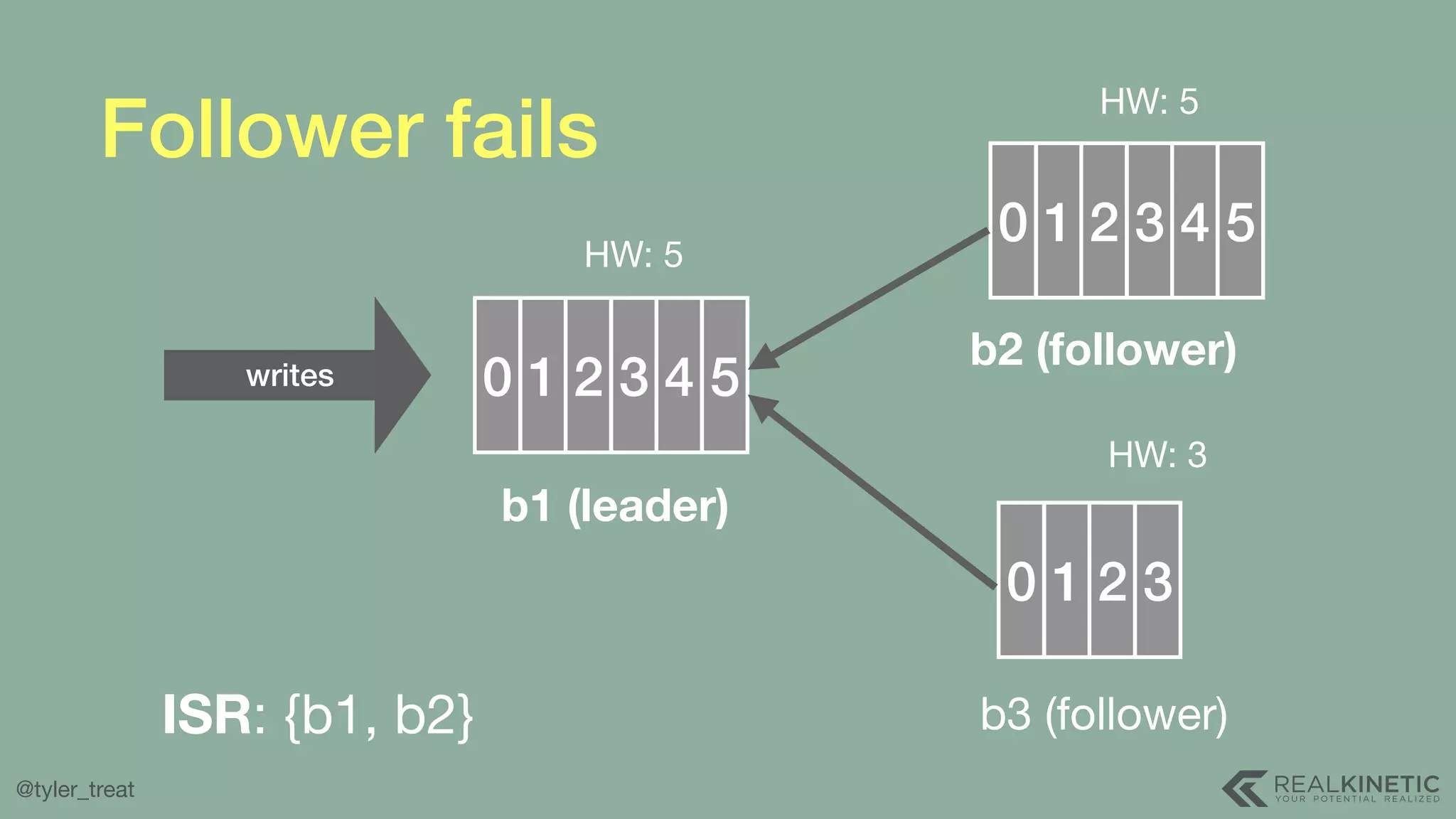
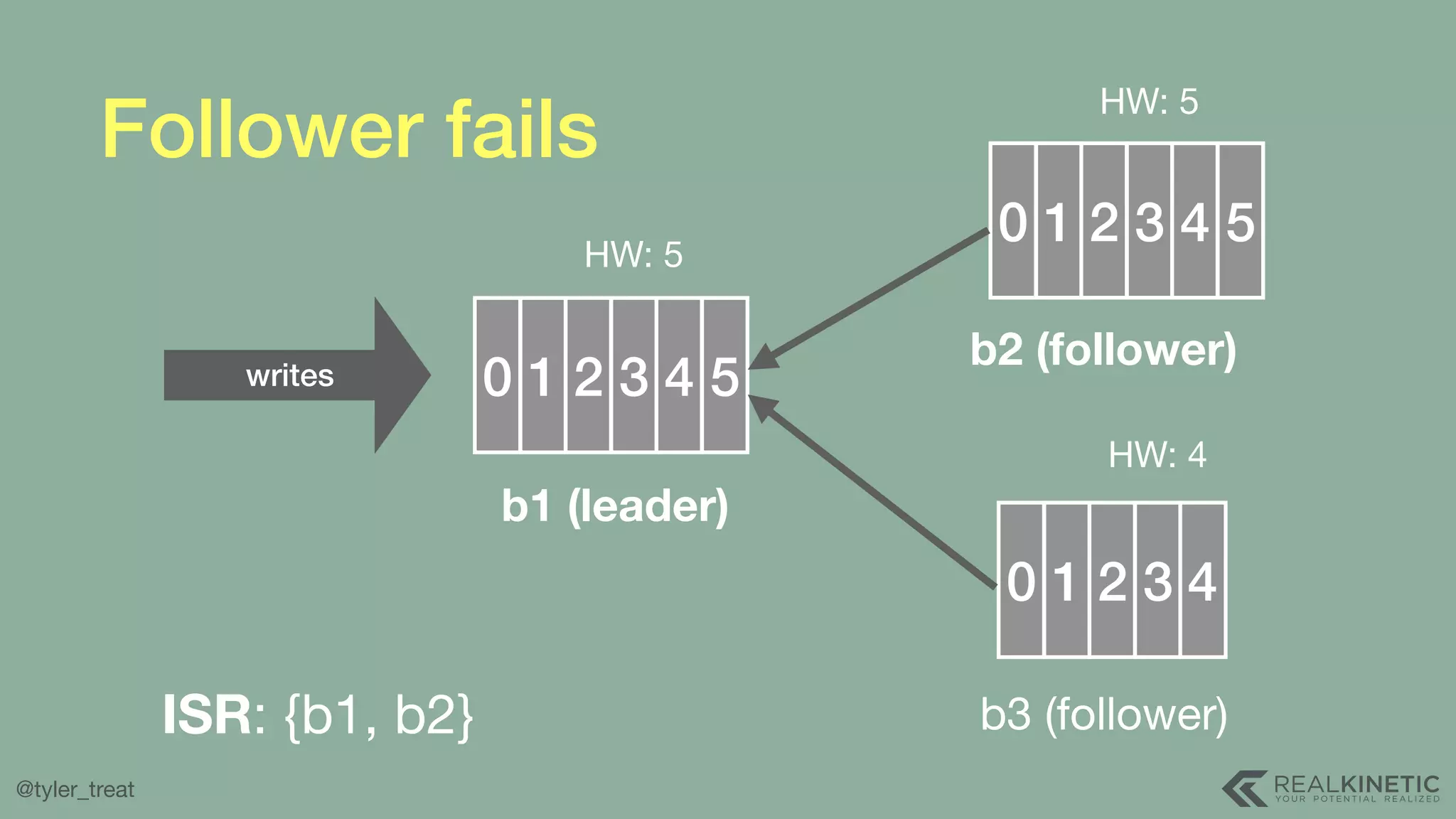
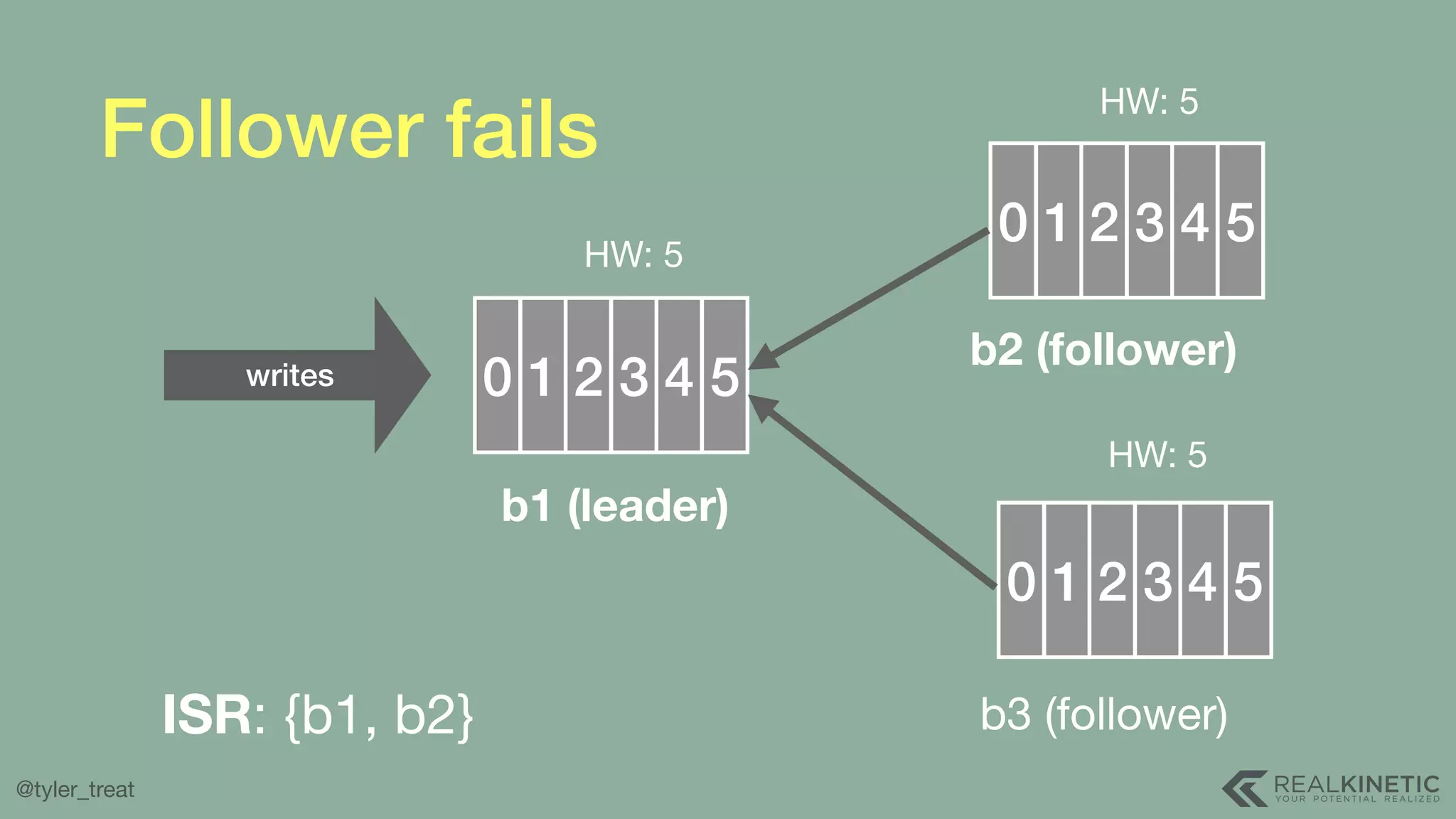
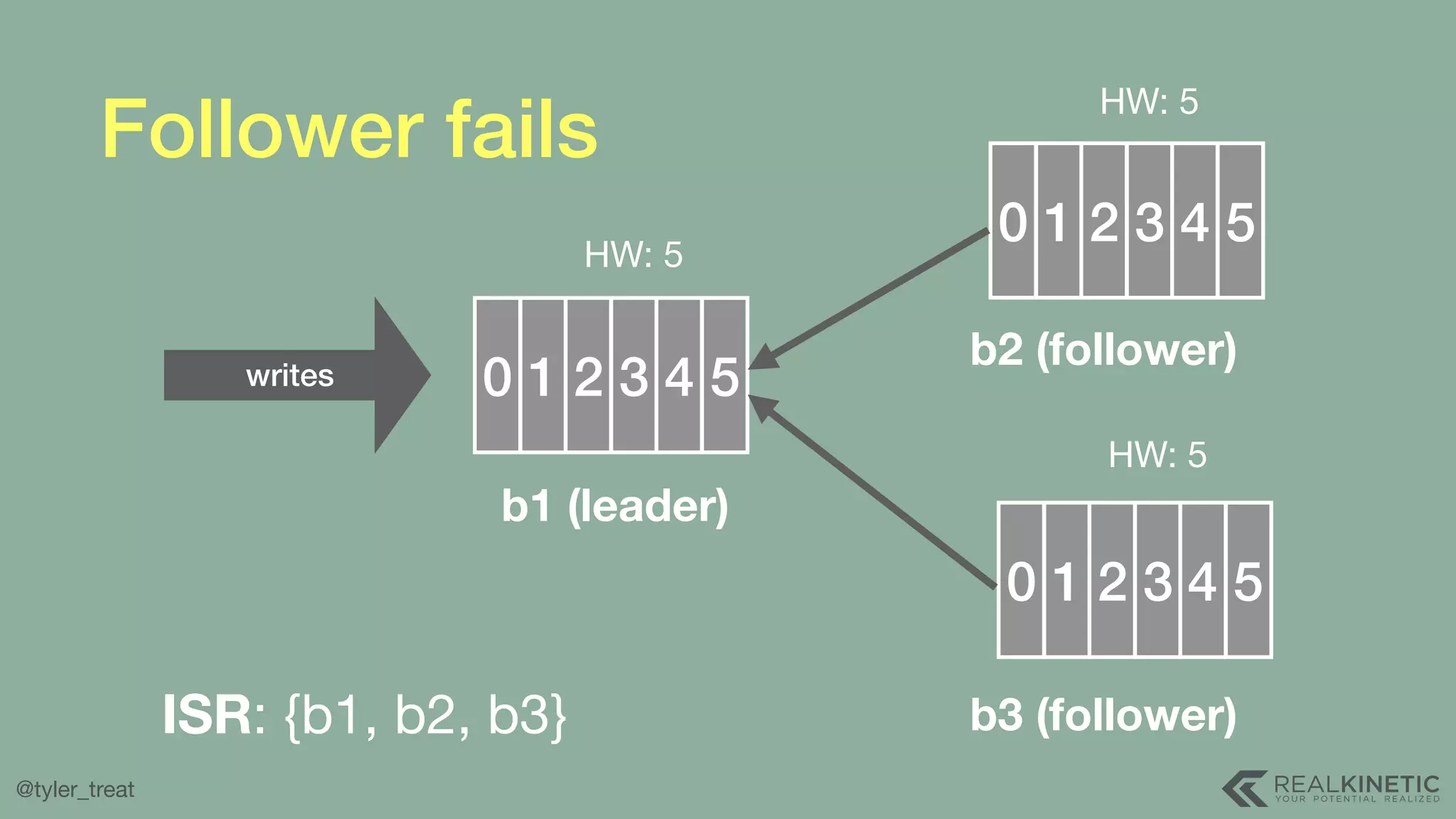




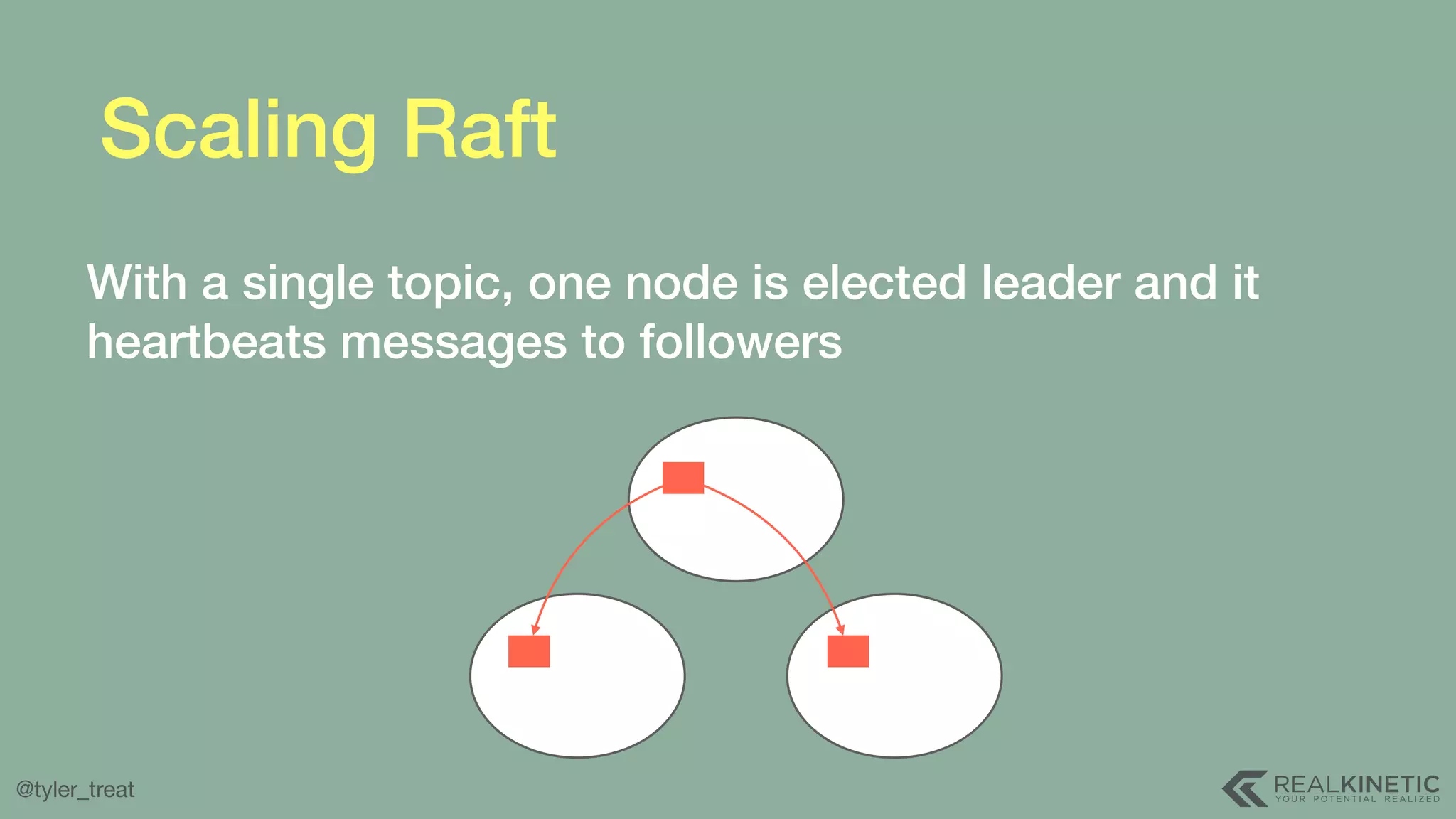
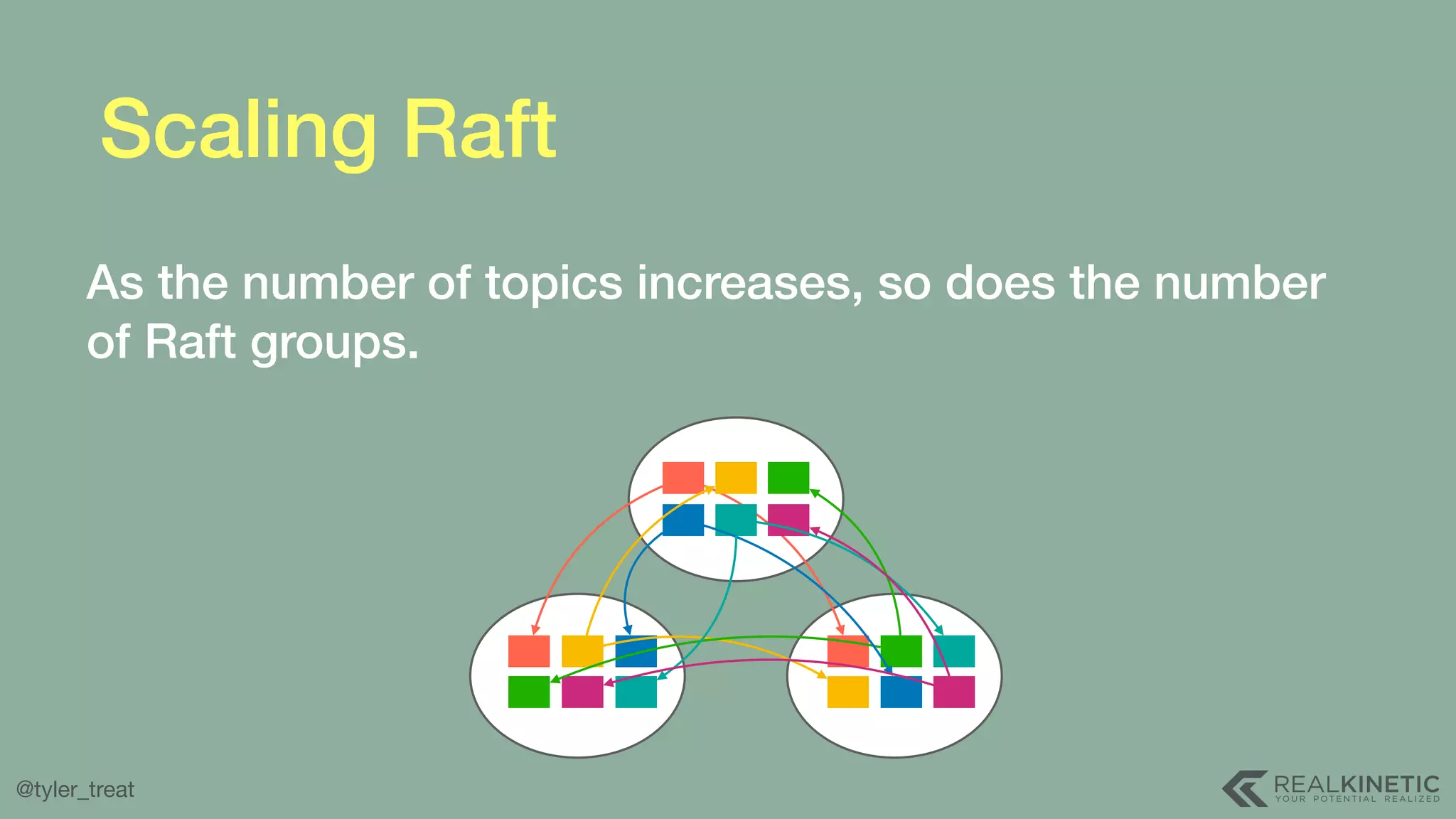
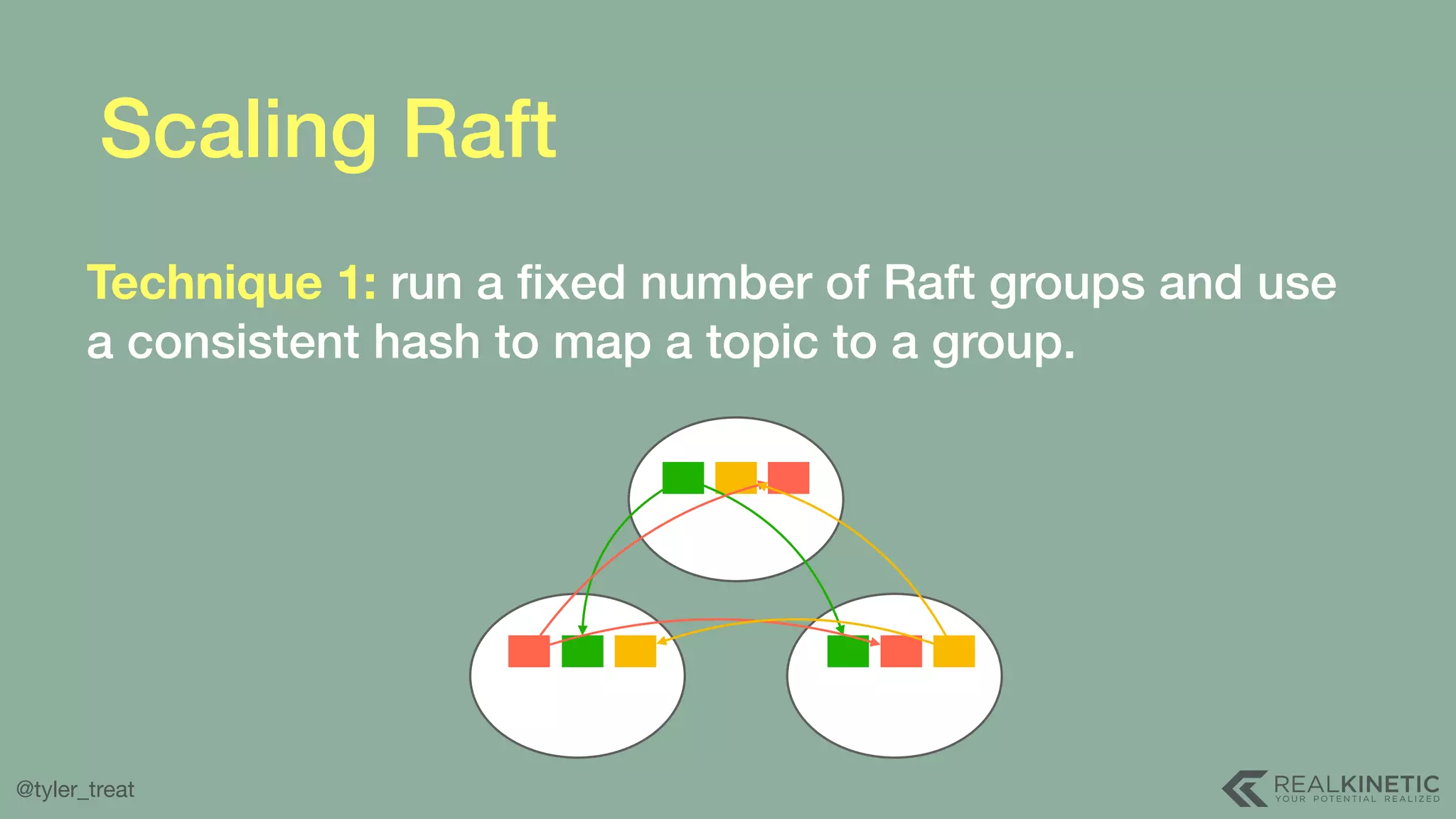
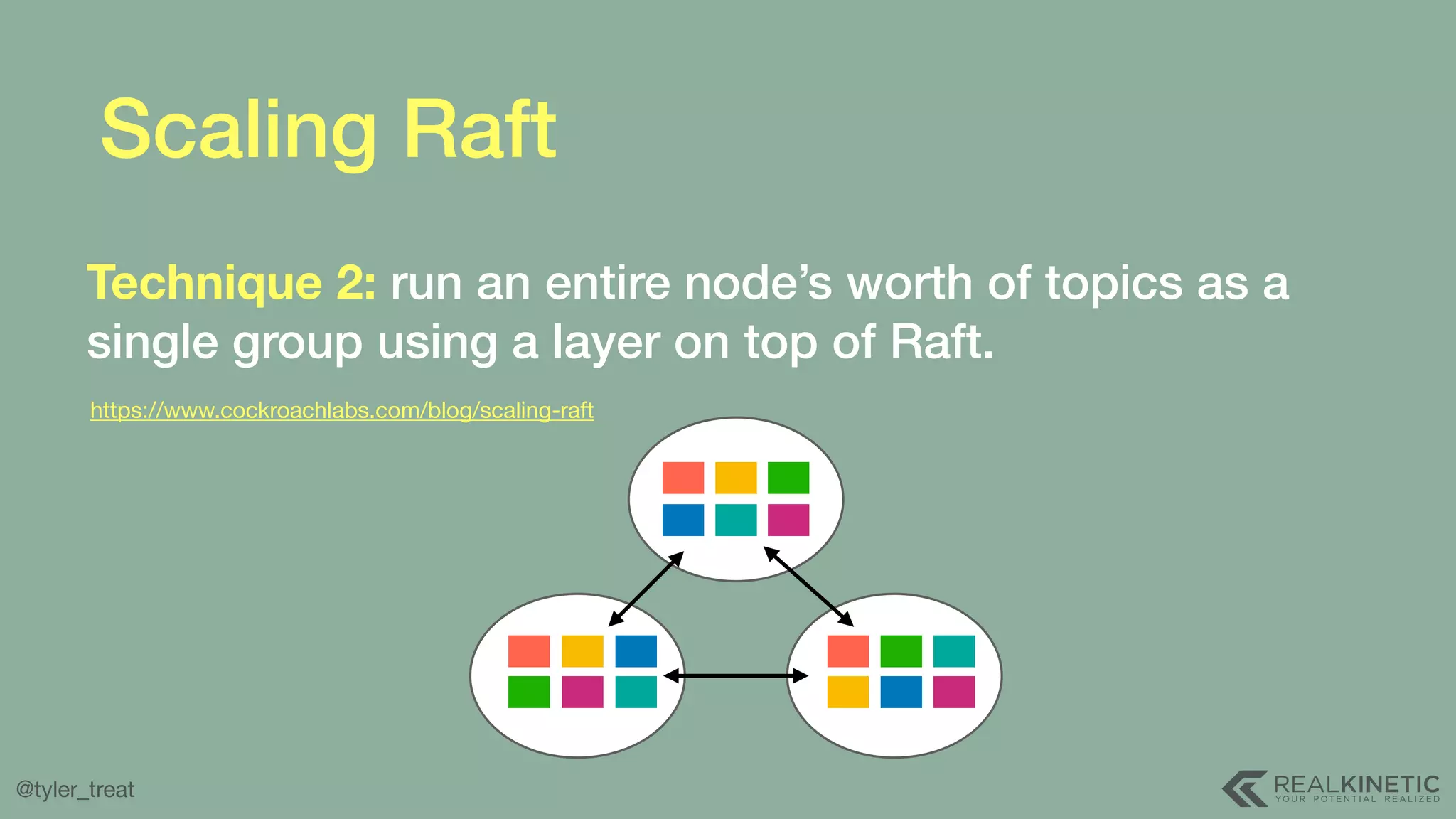
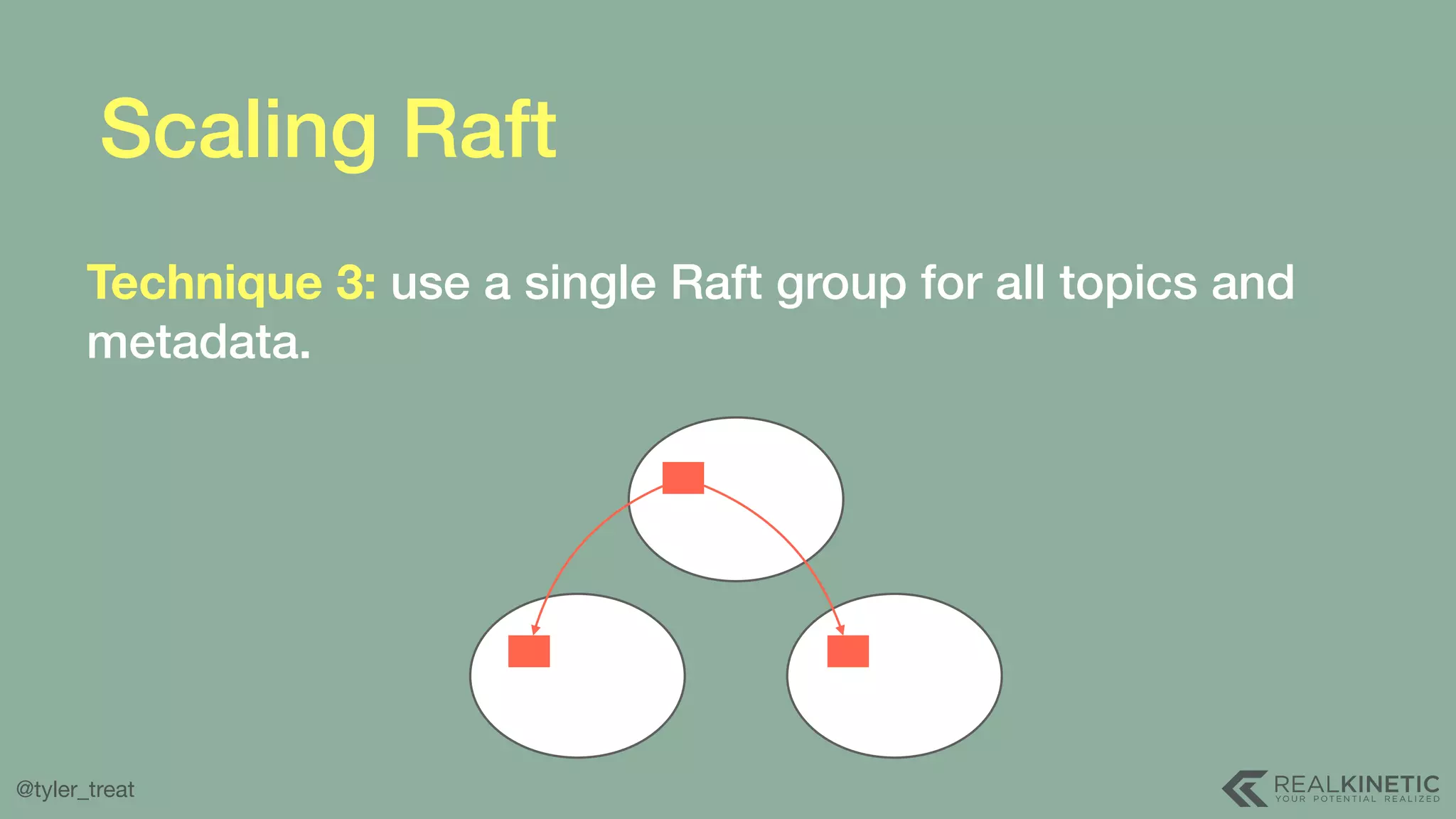




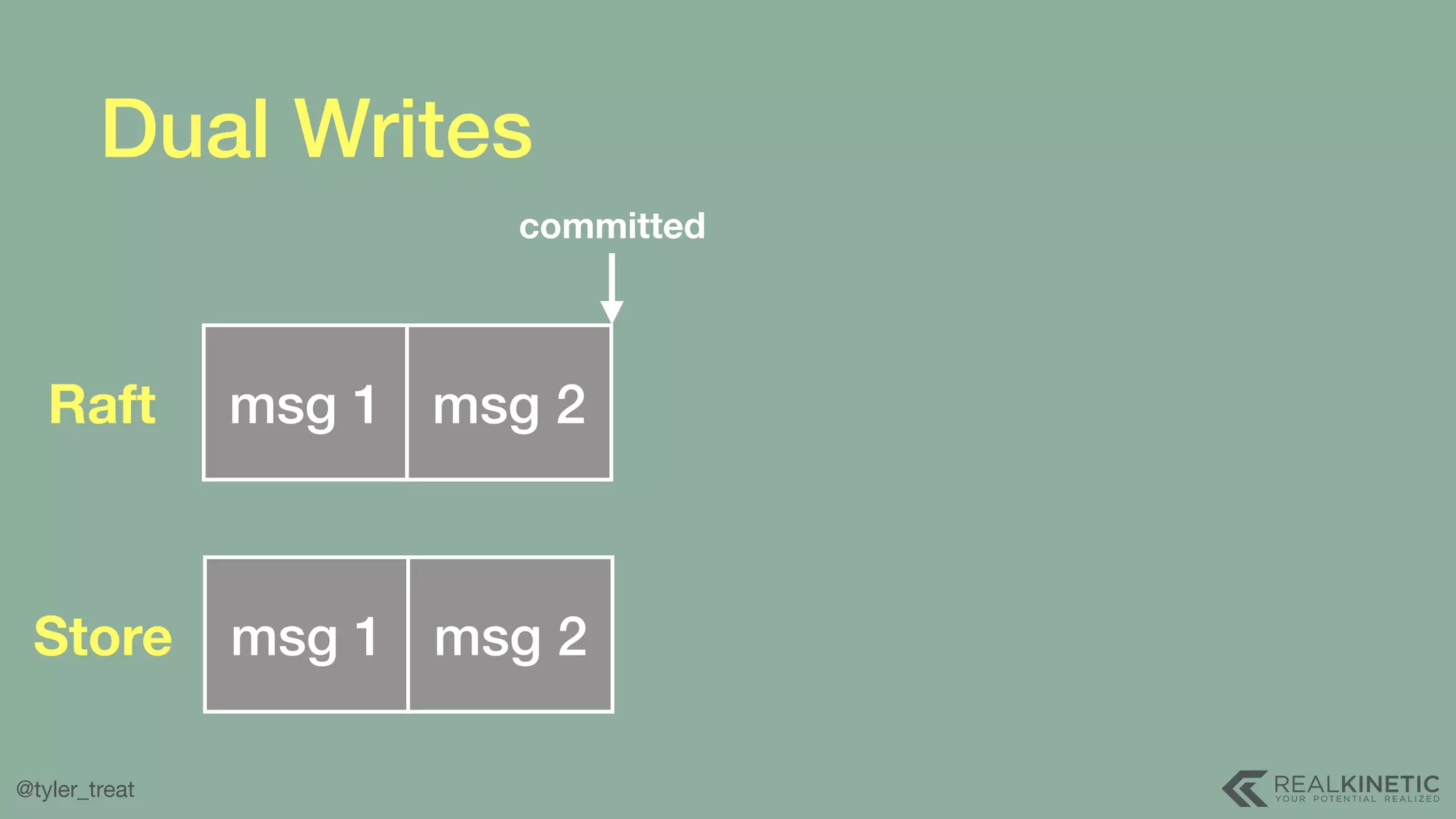
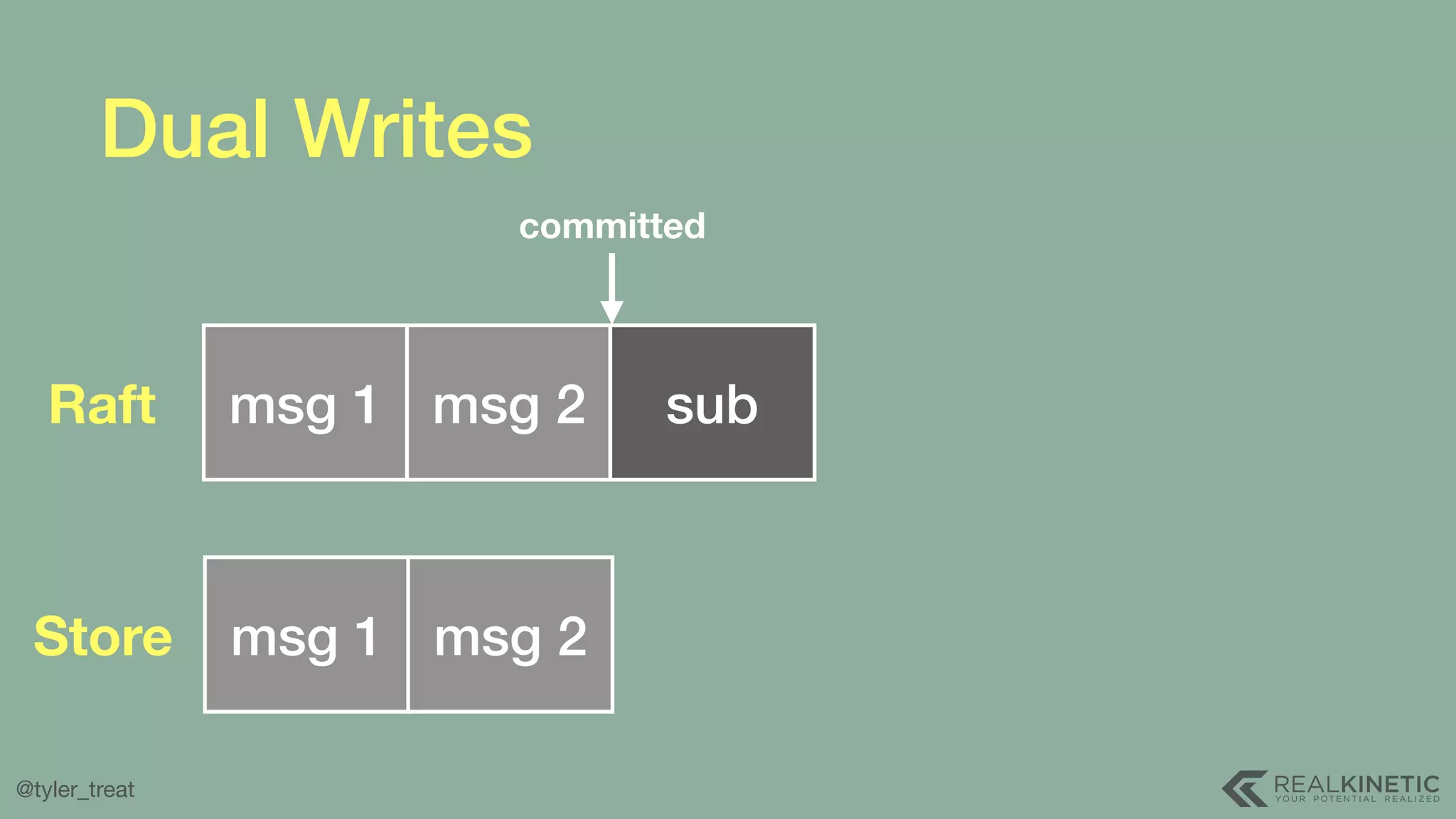
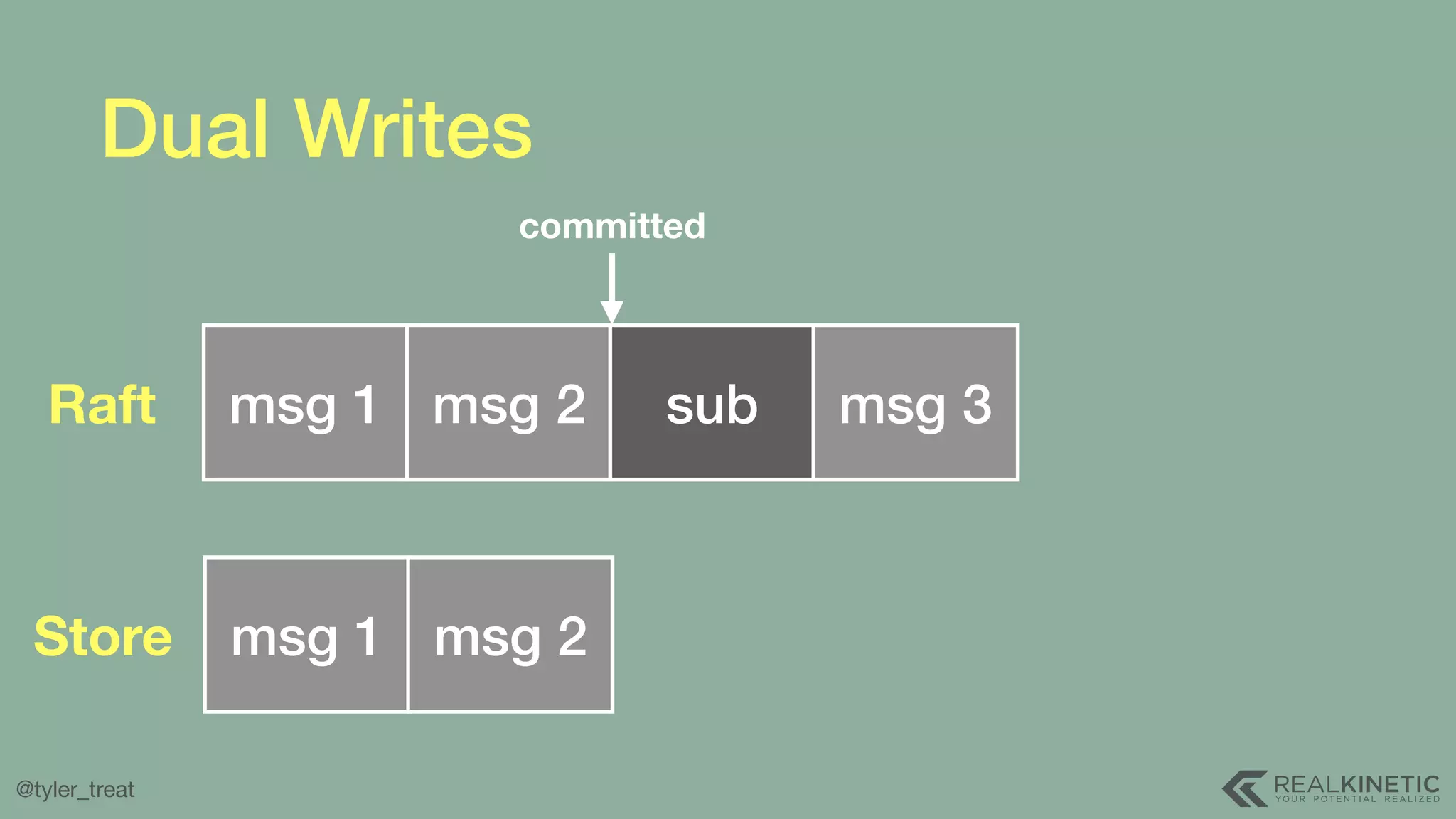




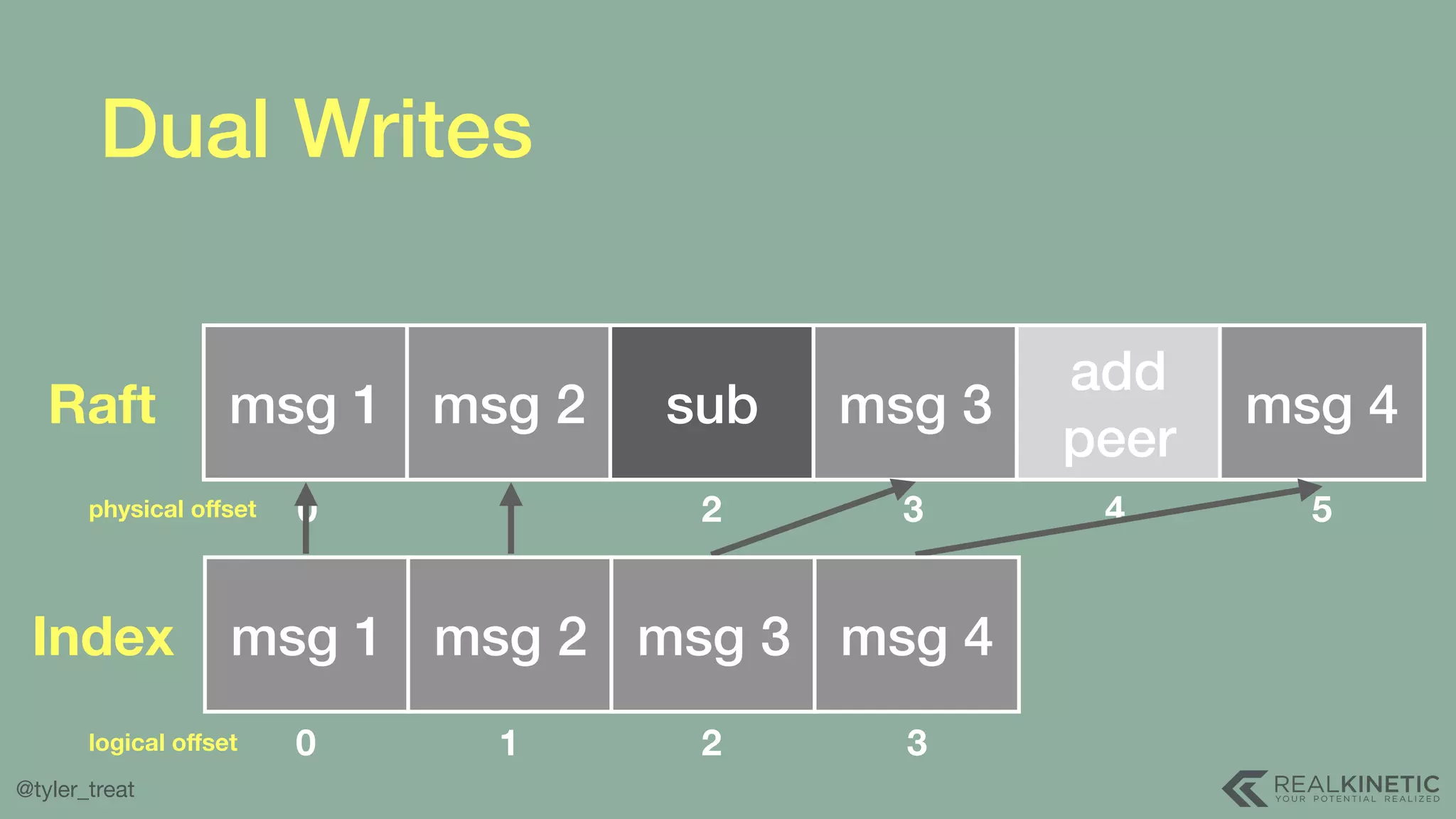








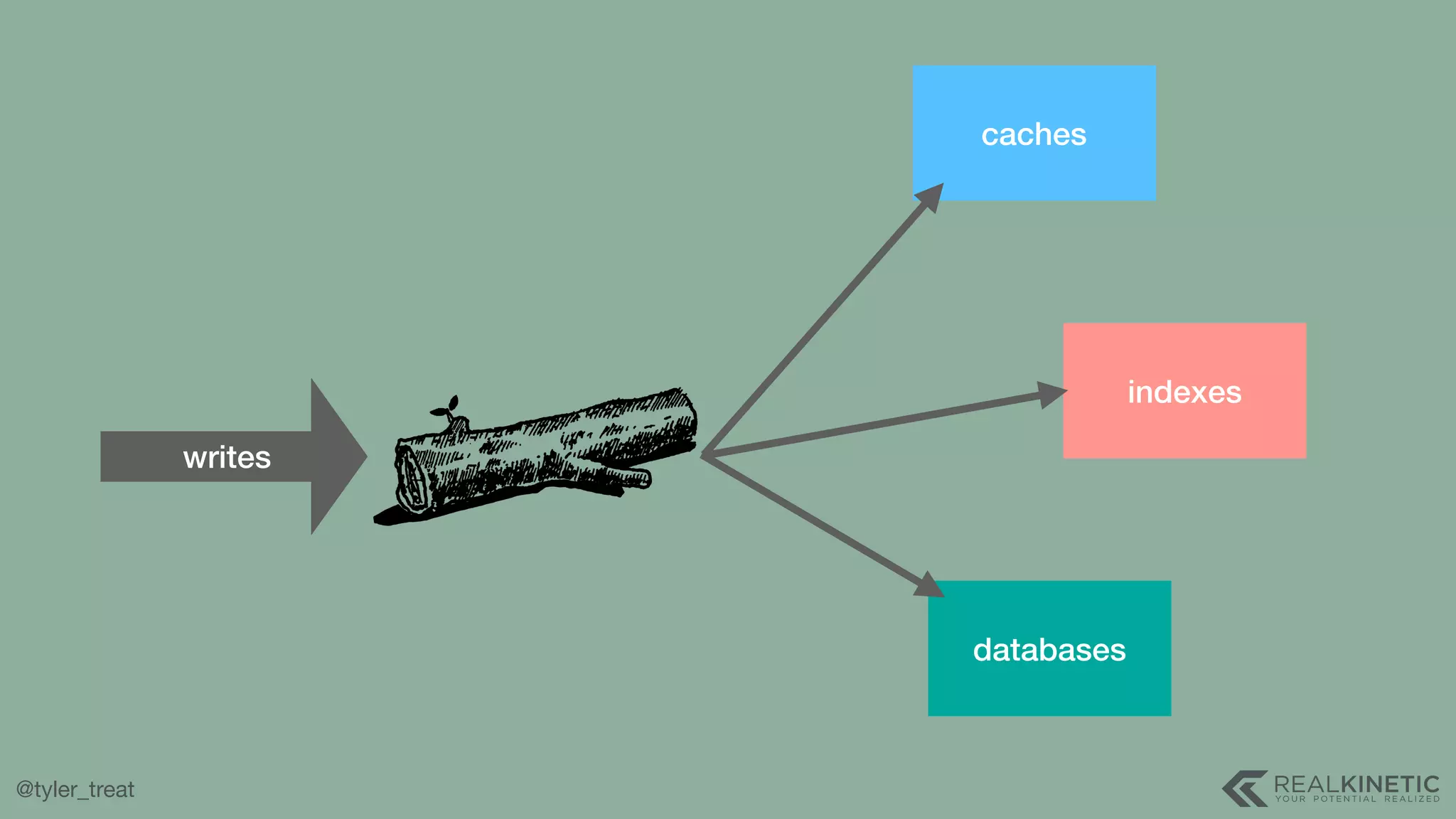
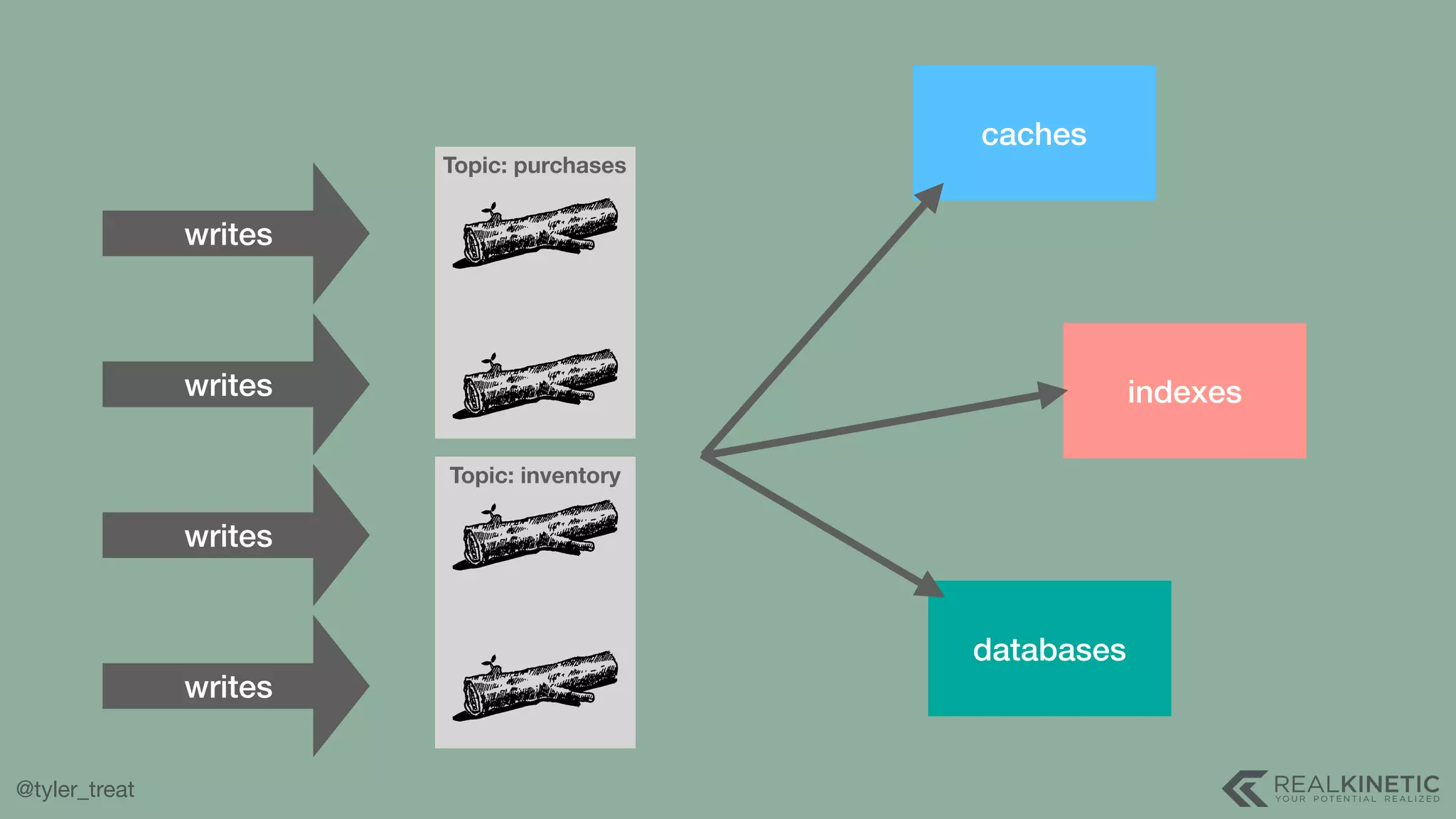
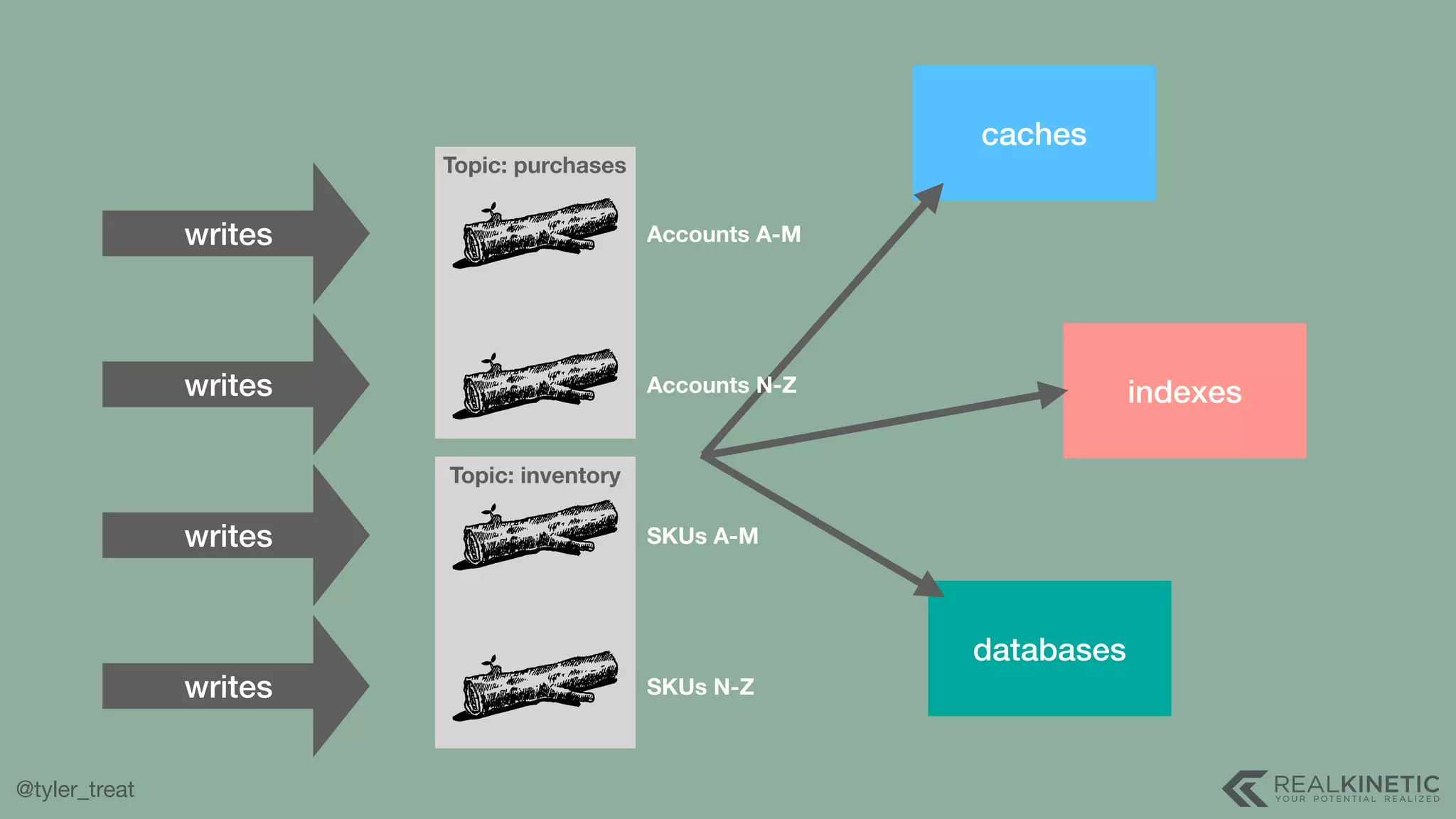

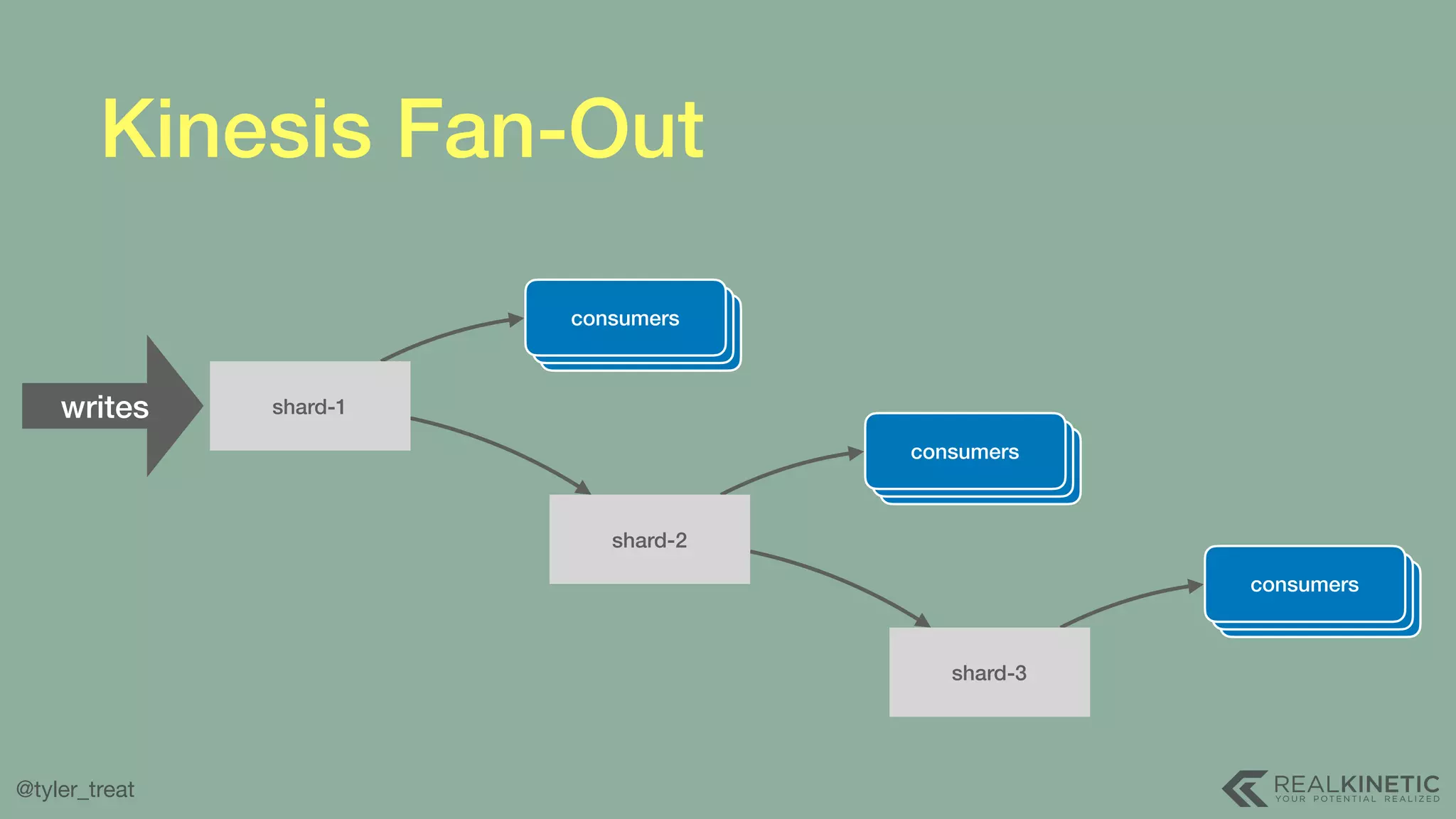





















The document presents a detailed discussion on building a distributed message log, outlining its structure, implementation considerations, and various techniques for data replication and scaling. Key concepts include the characteristics of the log, storage mechanics, and how different systems like Kafka and NATS manage message delivery and fault tolerance. It emphasizes the trade-offs between performance, durability, and availability while providing insights into the underlying principles of distributed systems.