Download as PDF, PPTX





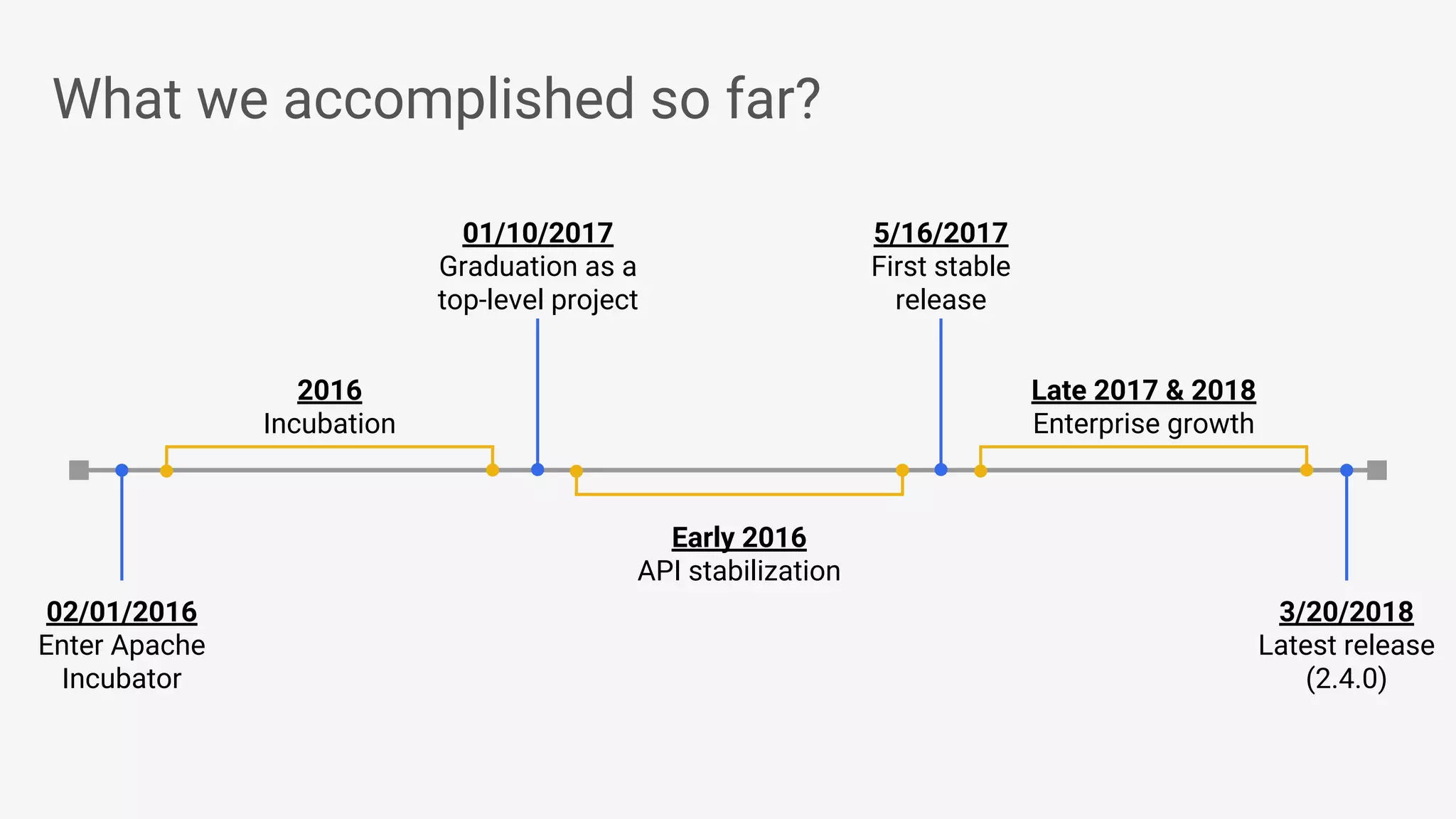

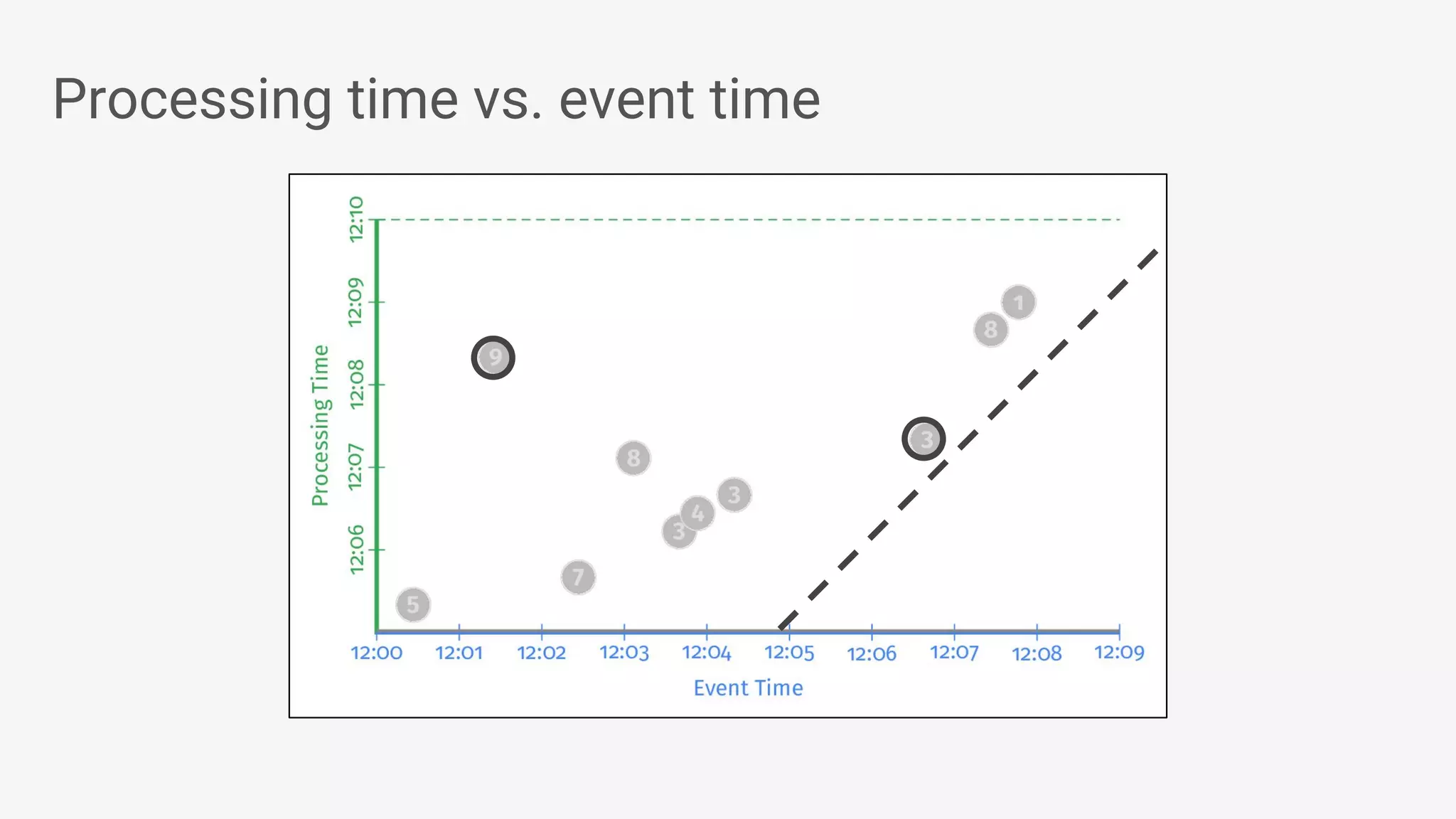

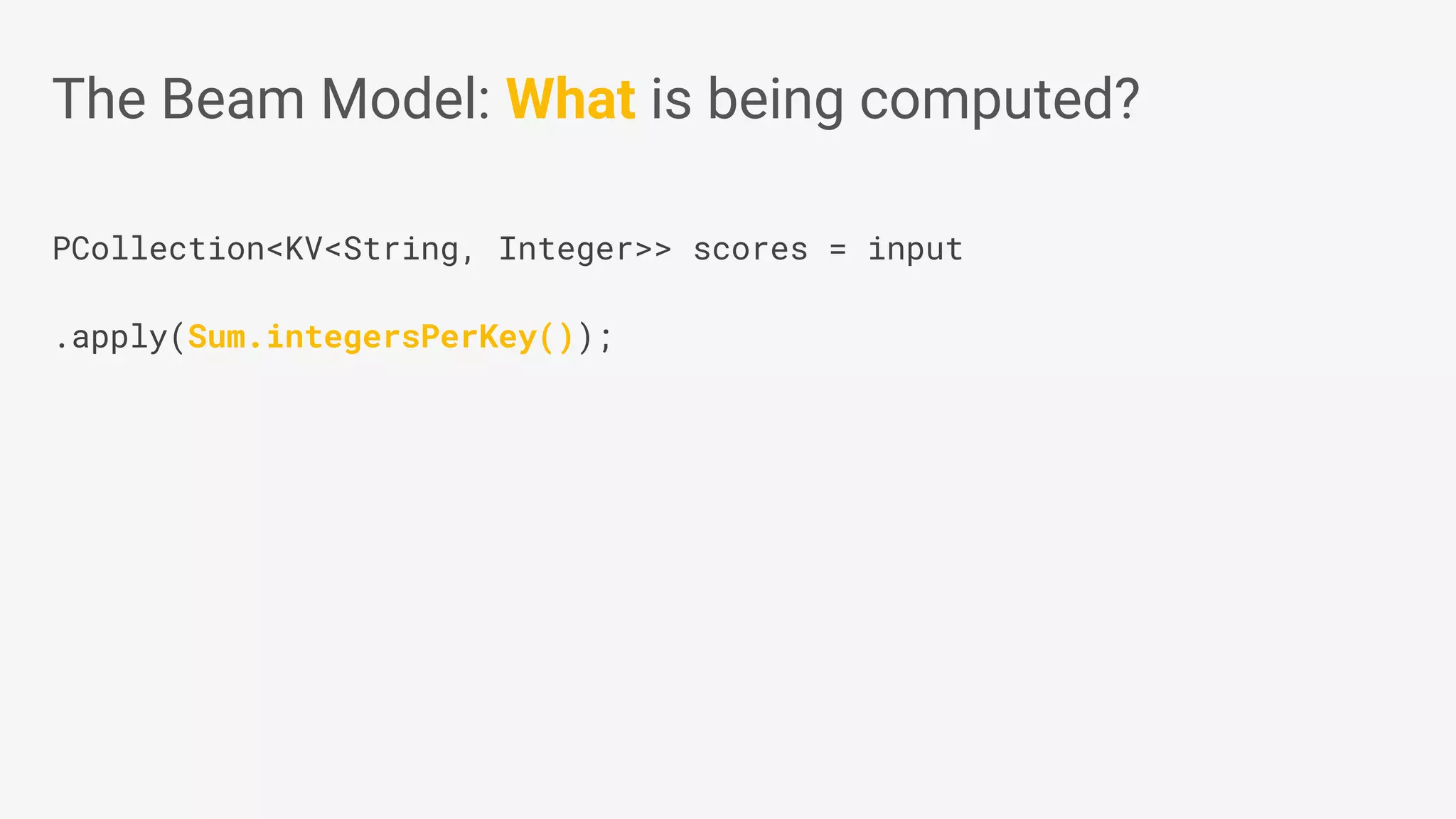
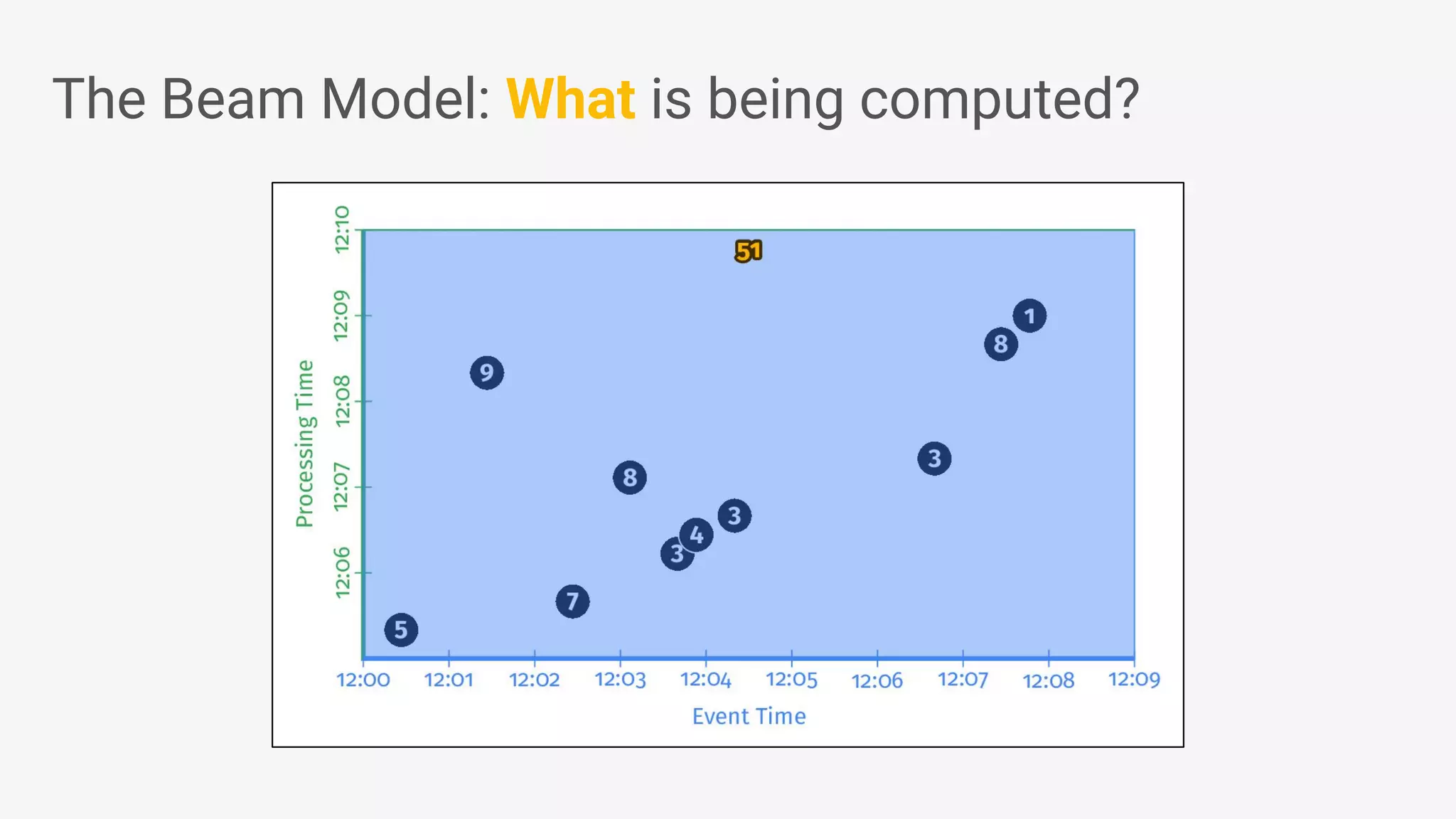

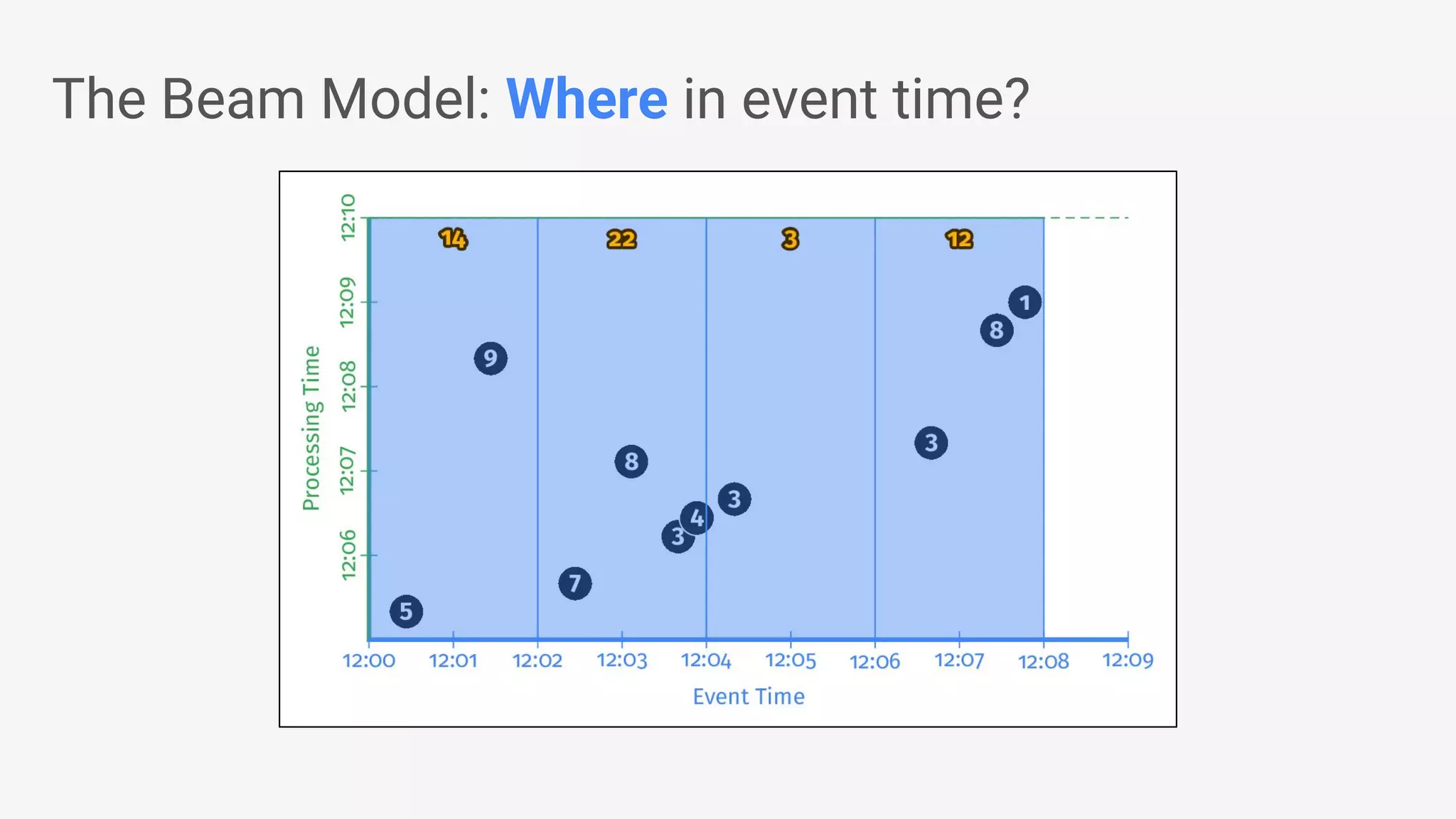

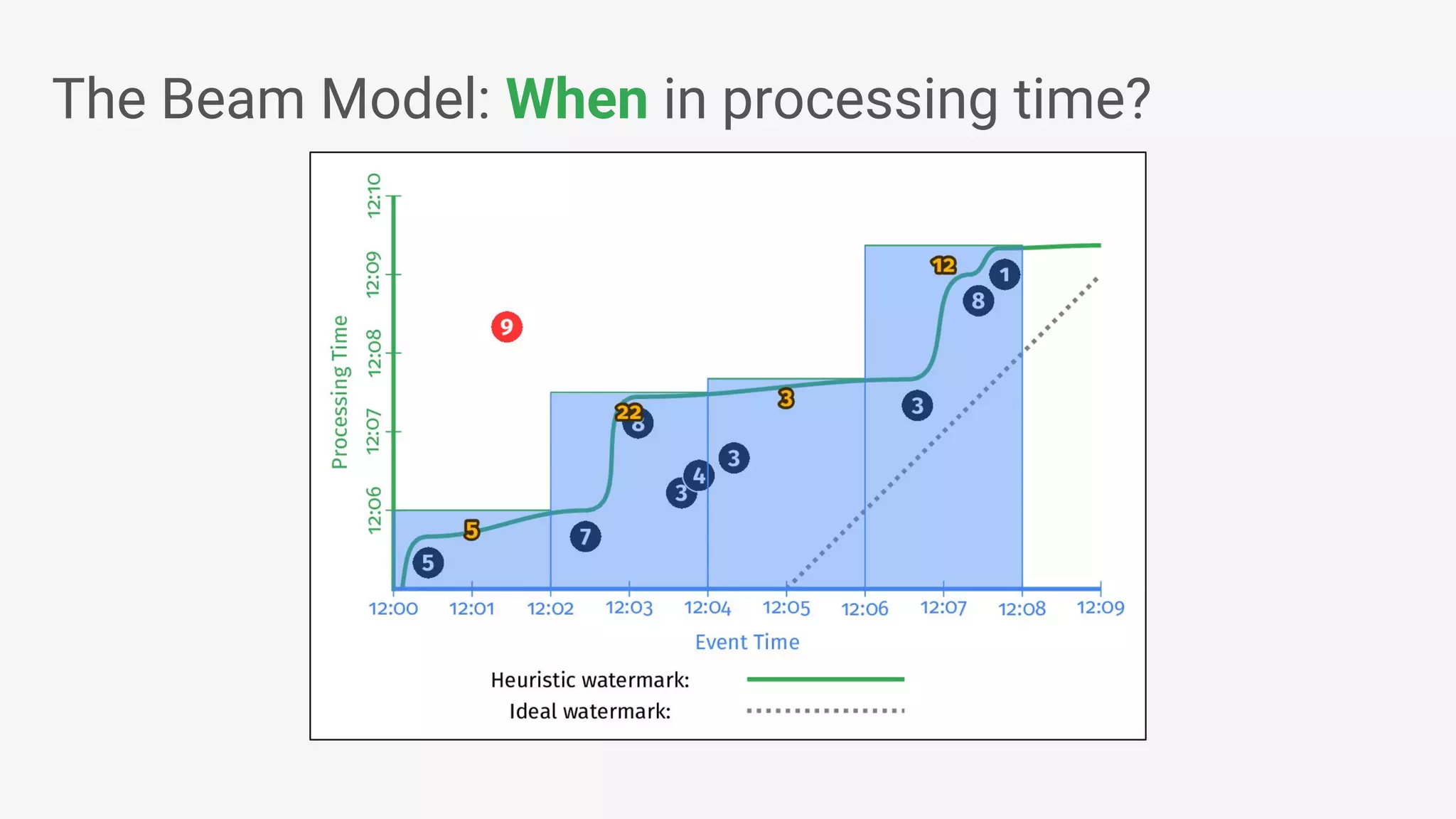

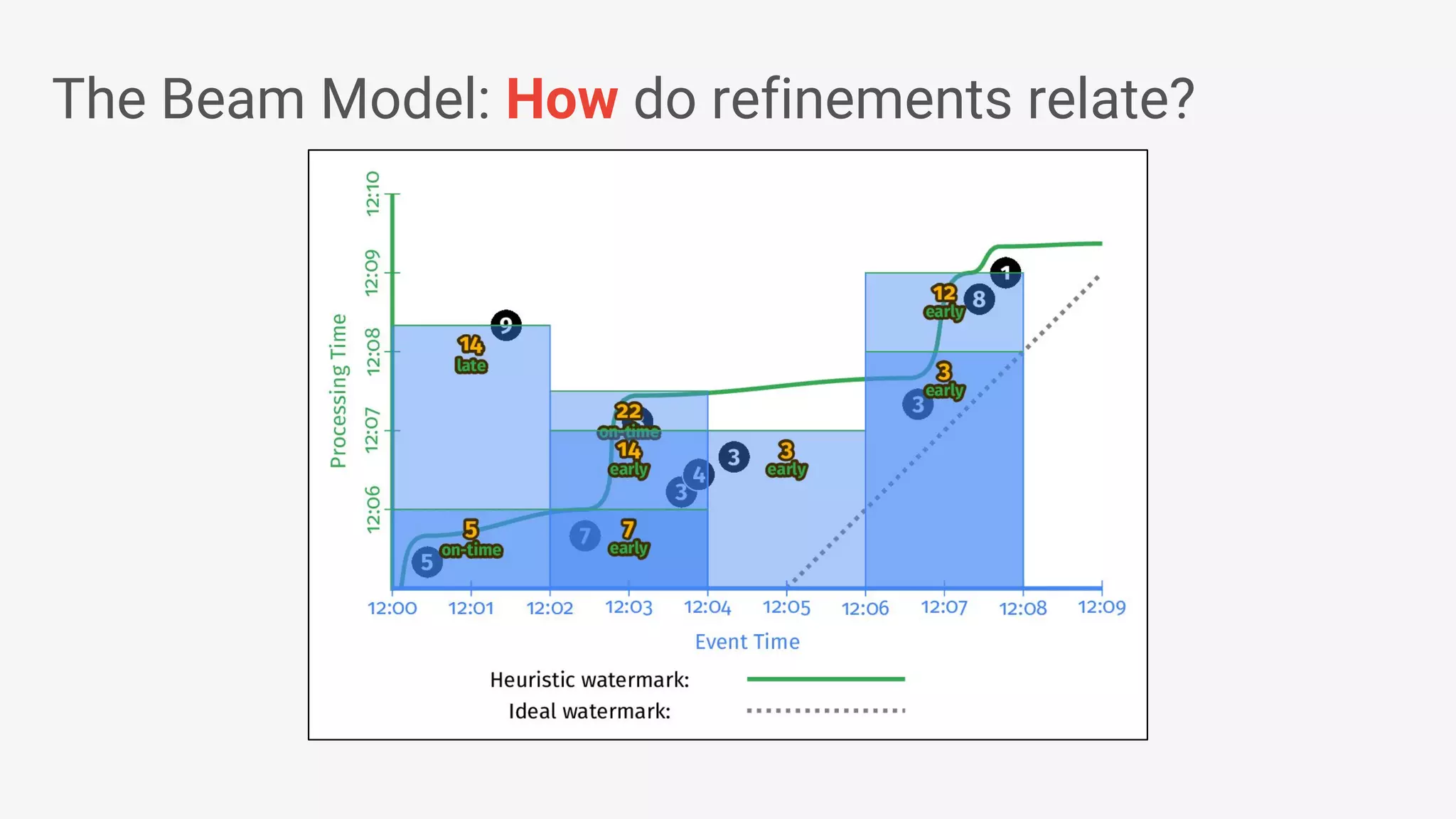
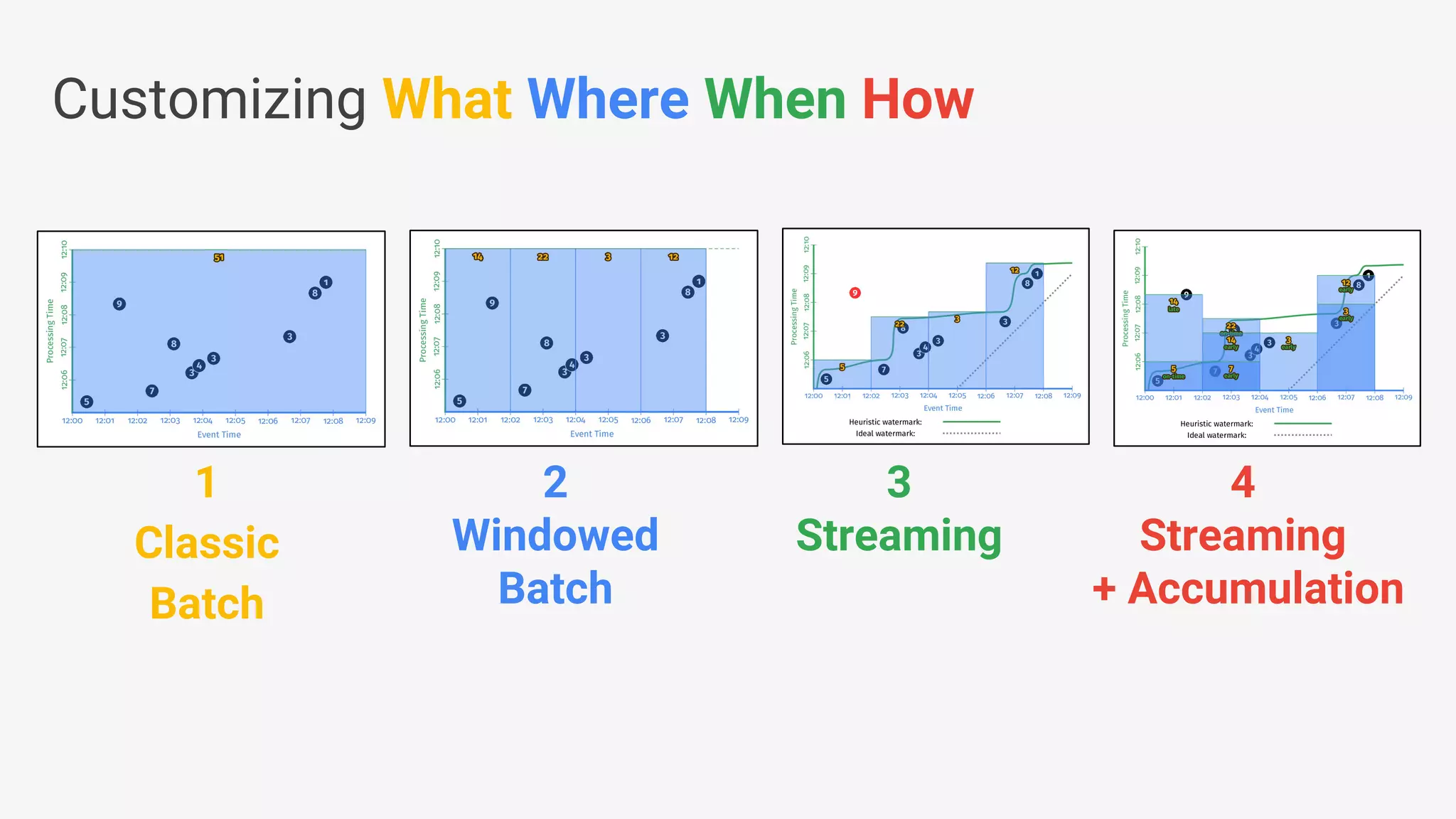

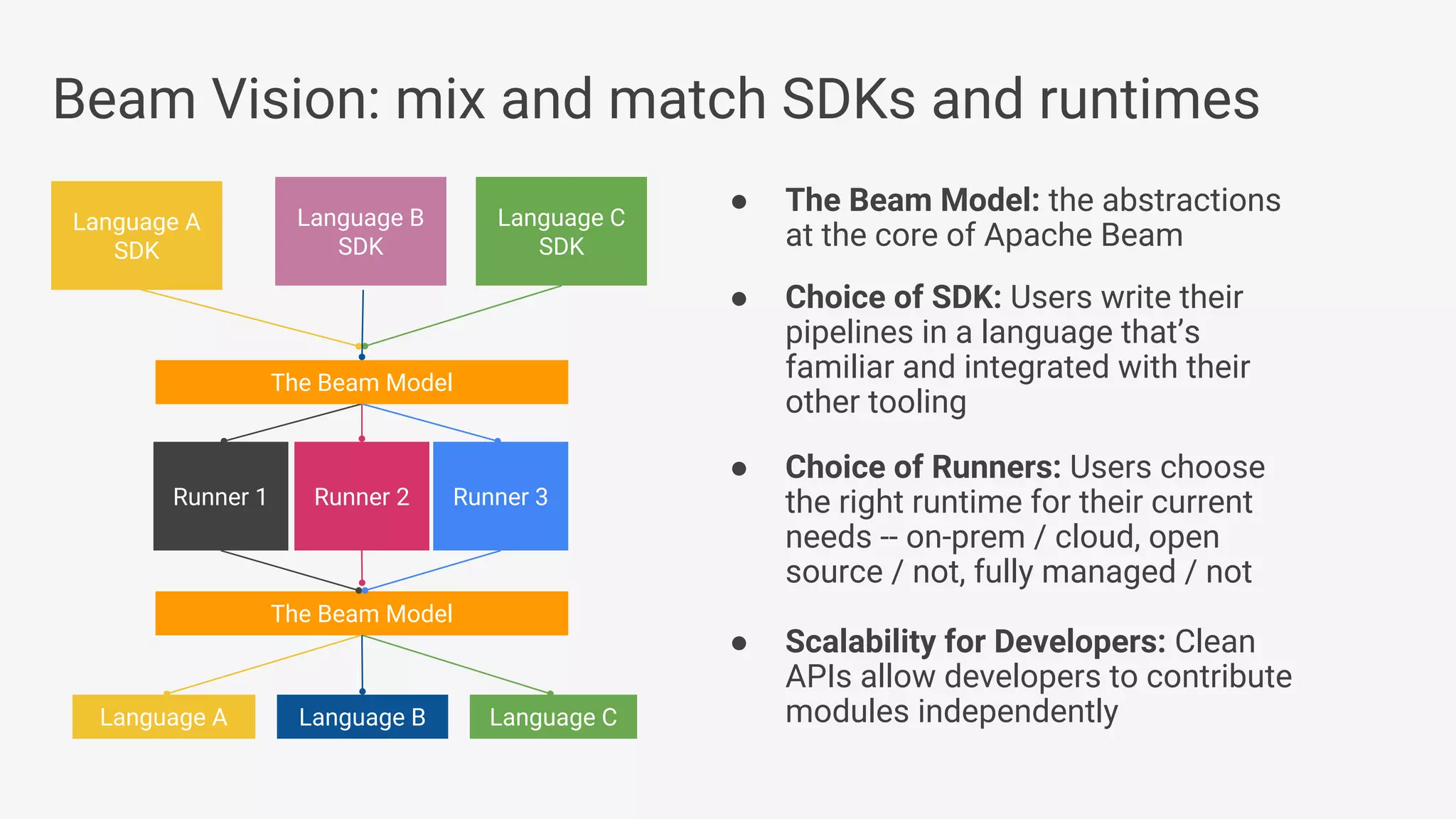



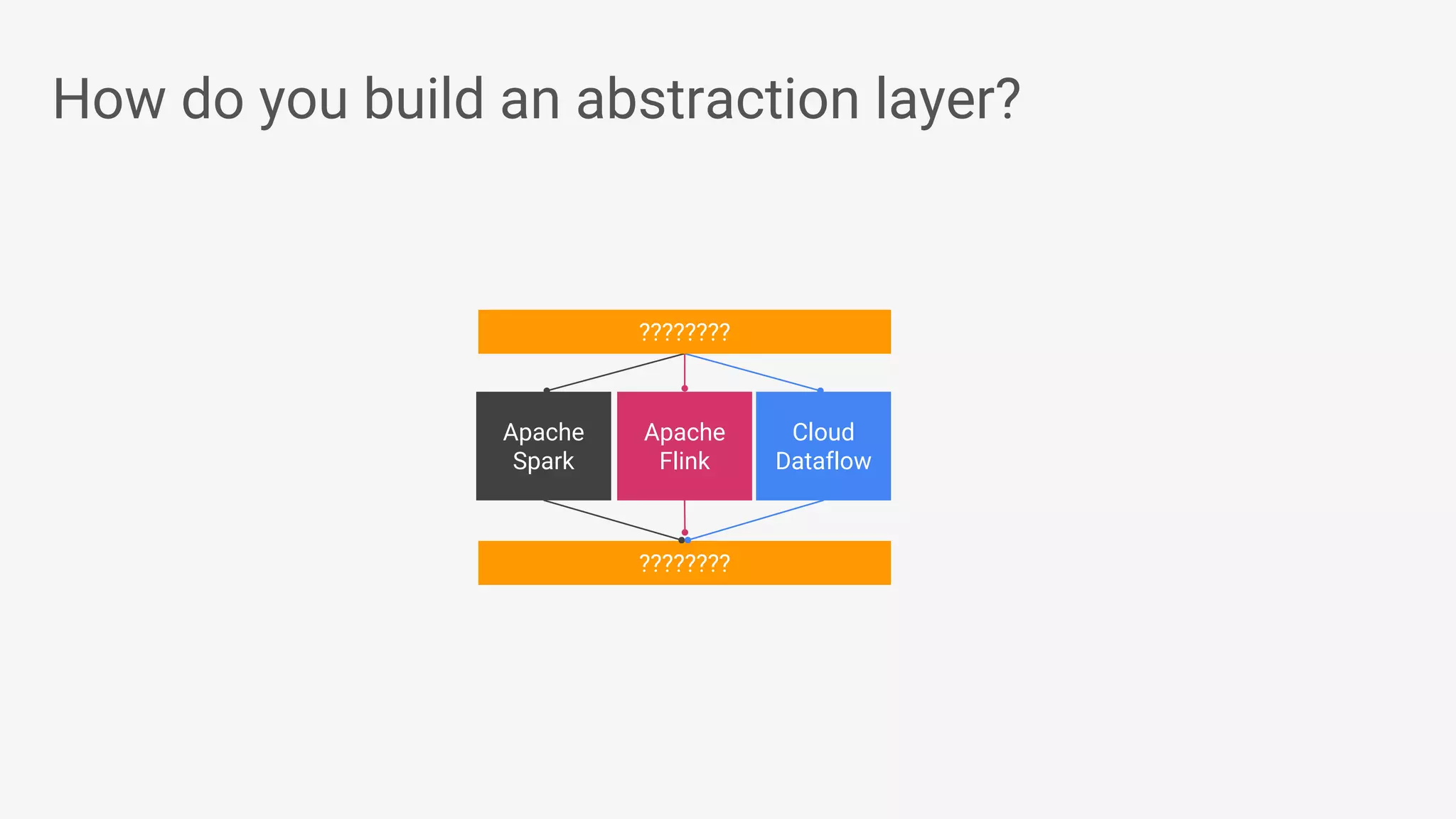
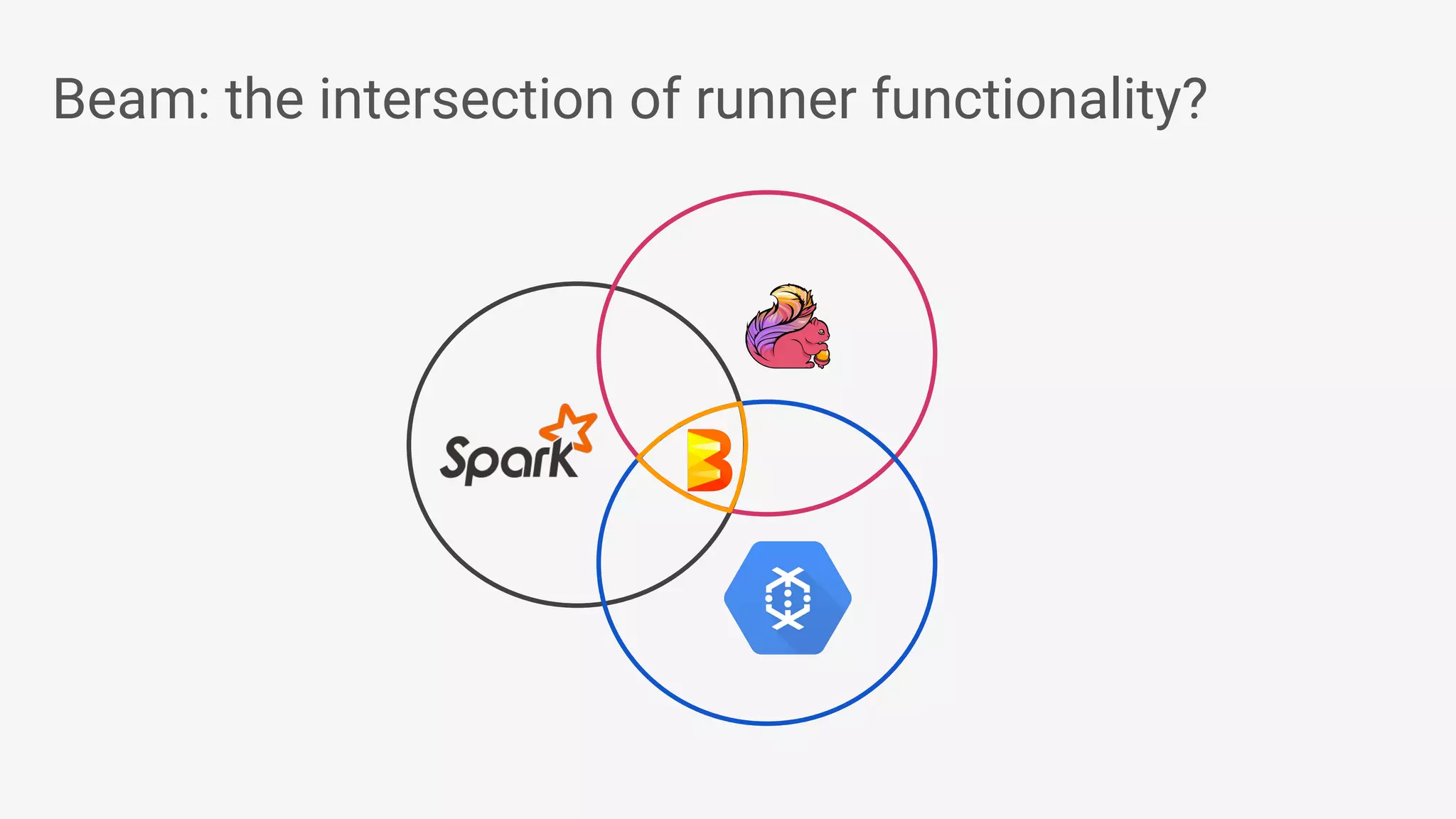




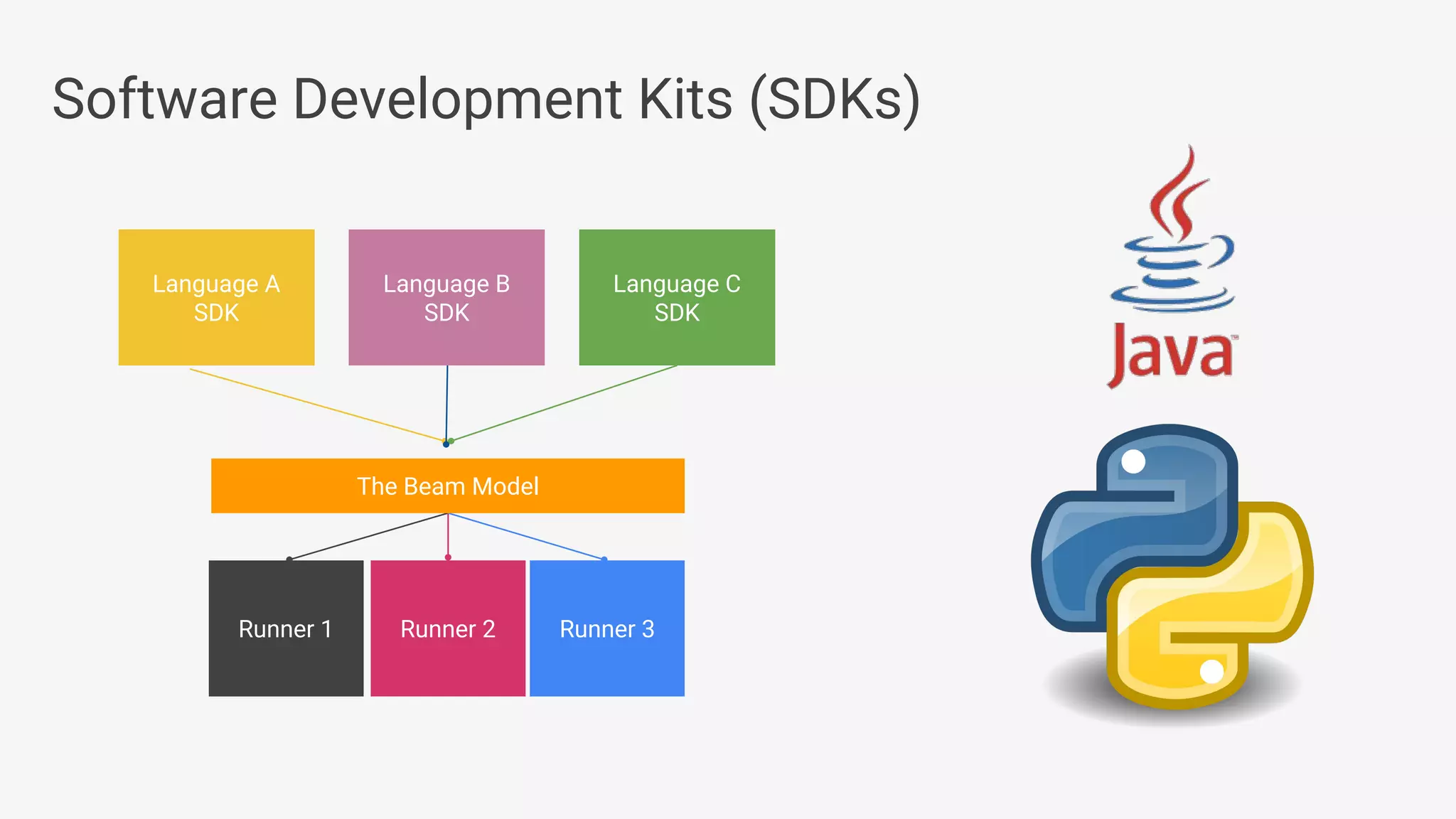
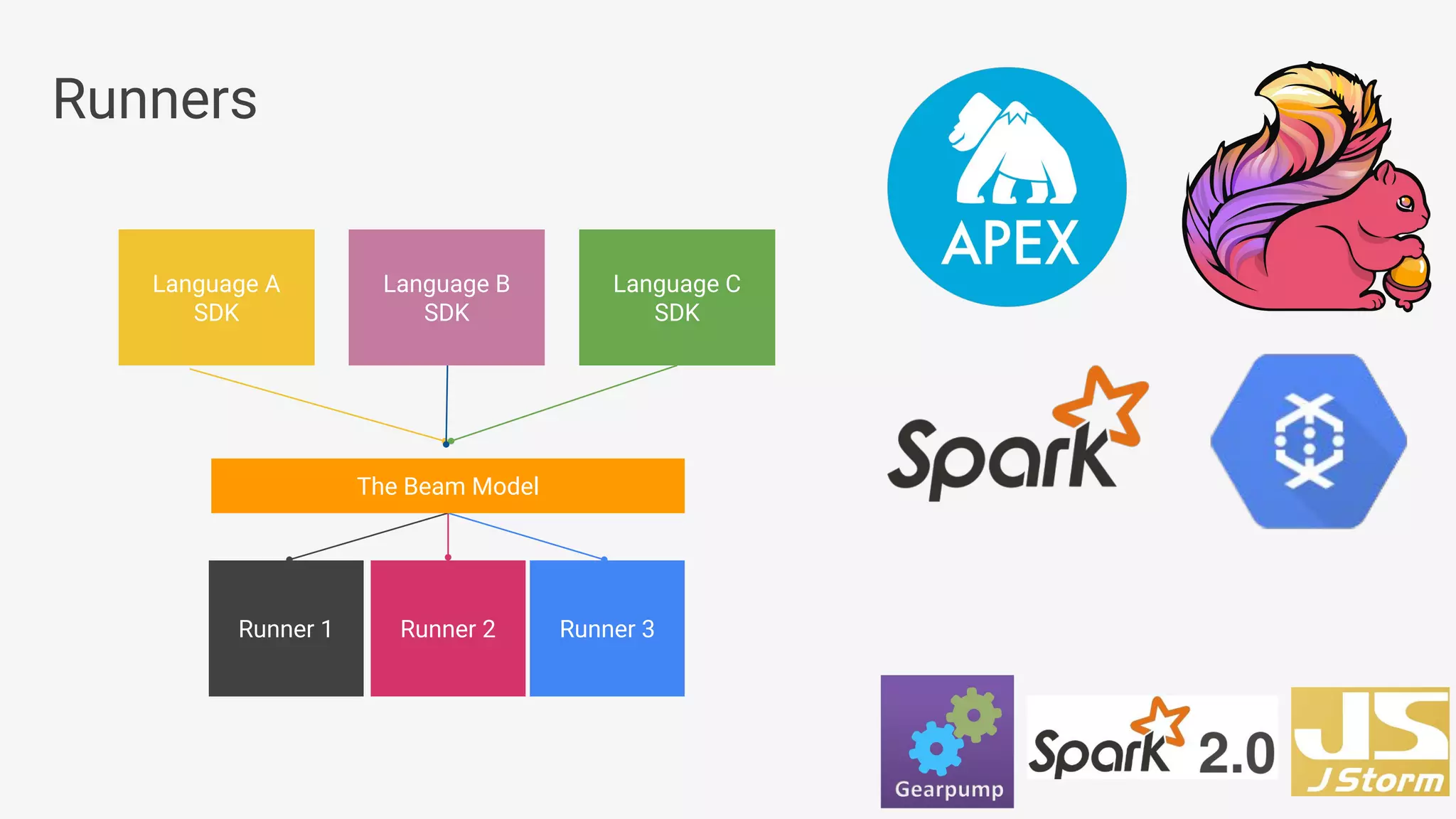
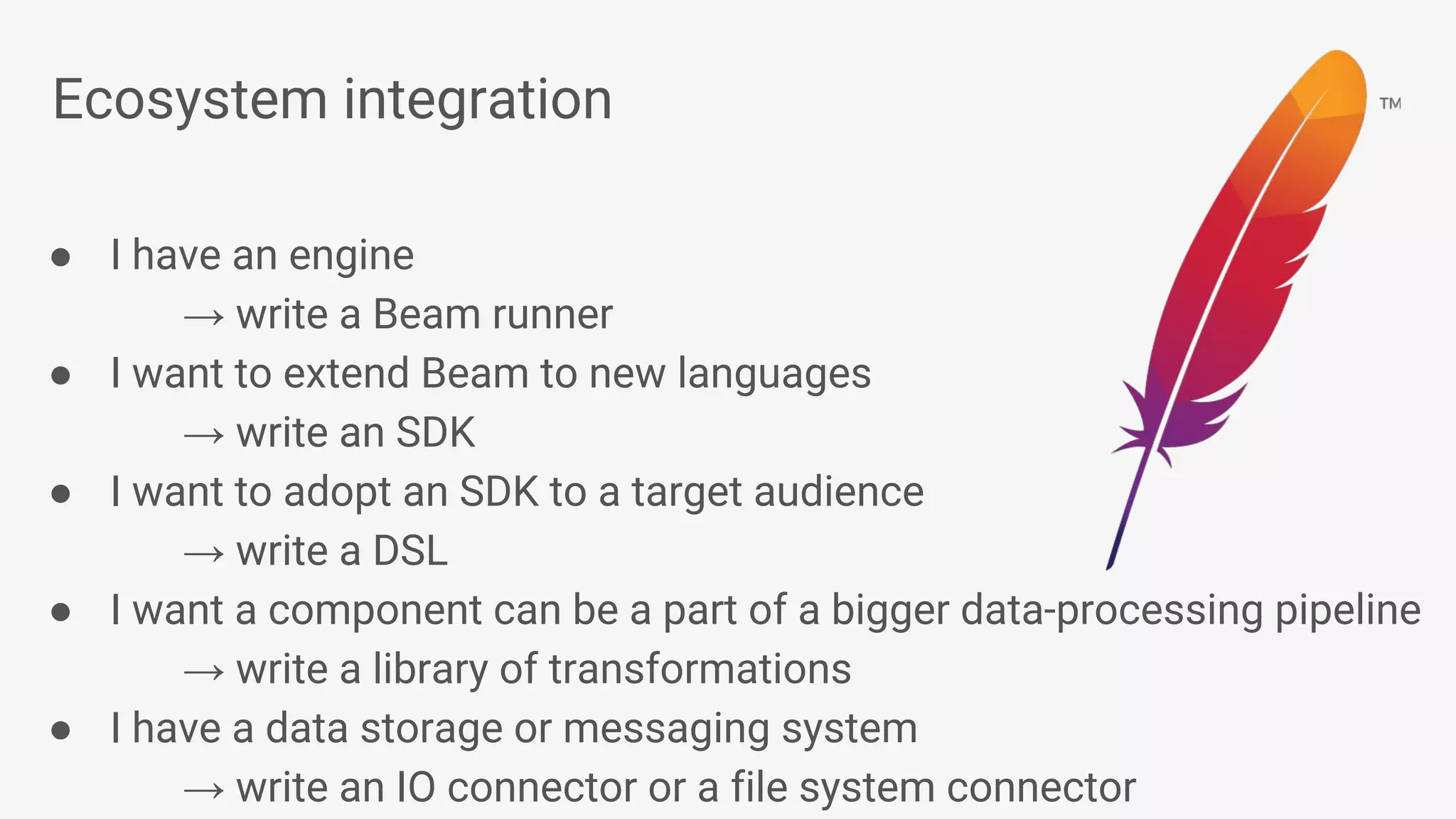


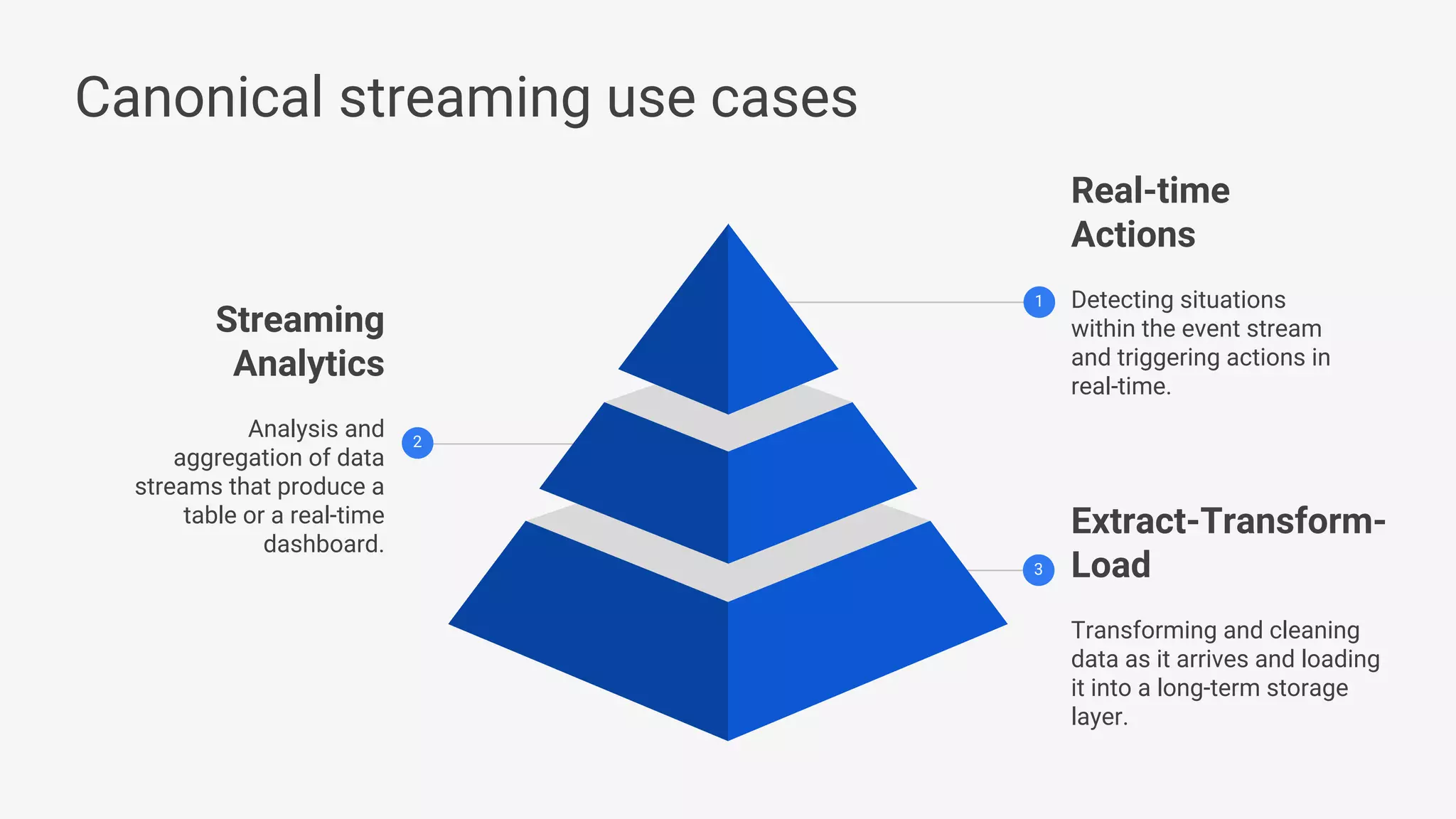

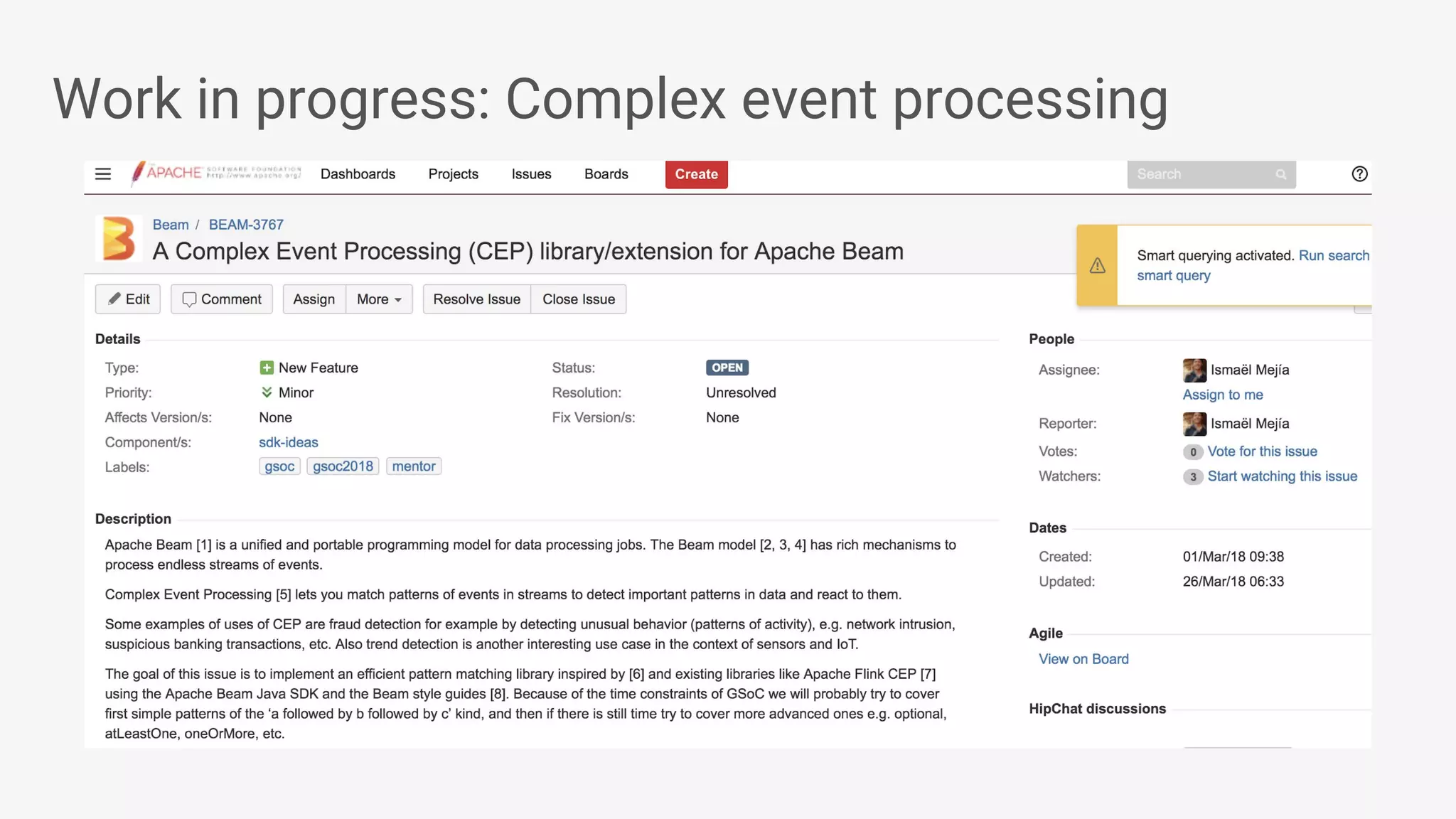




Apache Beam provides a unified programming model for efficient data processing pipelines that can run across varied platforms and languages. The architecture focuses on portability and extensibility, enabling integration with the big data ecosystem while supporting both batch and streaming processing. The document outlines project accomplishments, future roadmaps, and the benefits of using Apache Beam in various data processing scenarios.