Download as PDF, PPTX




![Pipeline p = Pipeline.create(options); p.apply(TextIO.Read.from("gs://dataflow-samples/shakespeare/*")) .apply(FlatMapElements.via( word → Arrays.asList(word.split("[^a-zA-Z']+")))) .apply(Filter.byPredicate(word → !word.isEmpty())) .apply(Count.perElement()) .apply(MapElements.via( count → count.getKey() + ": " + count.getValue()) .apply(TextIO.Write.to("gs://.../...")); p.run();](https://image.slidesharecdn.com/efficientandportabledataprocessingwithapachebeamandhbase1-170620190351/75/HBaseCon2017-Efficient-and-portable-data-processing-with-Apache-Beam-and-HBase-8-2048.jpg)




![HBaseIO PCollection<Result> data = p.apply( HBaseIO.read() .withConfiguration(conf) .withTableId(table) … withScan, withFilter …) PCollection<KV<byte[], Iterable<Mutation>>> mutations = …; mutations.apply( HBaseIO.write() .withConfiguration(conf)) .withTableId(table)](https://image.slidesharecdn.com/efficientandportabledataprocessingwithapachebeamandhbase1-170620190351/75/HBaseCon2017-Efficient-and-portable-data-processing-with-Apache-Beam-and-HBase-21-2048.jpg)




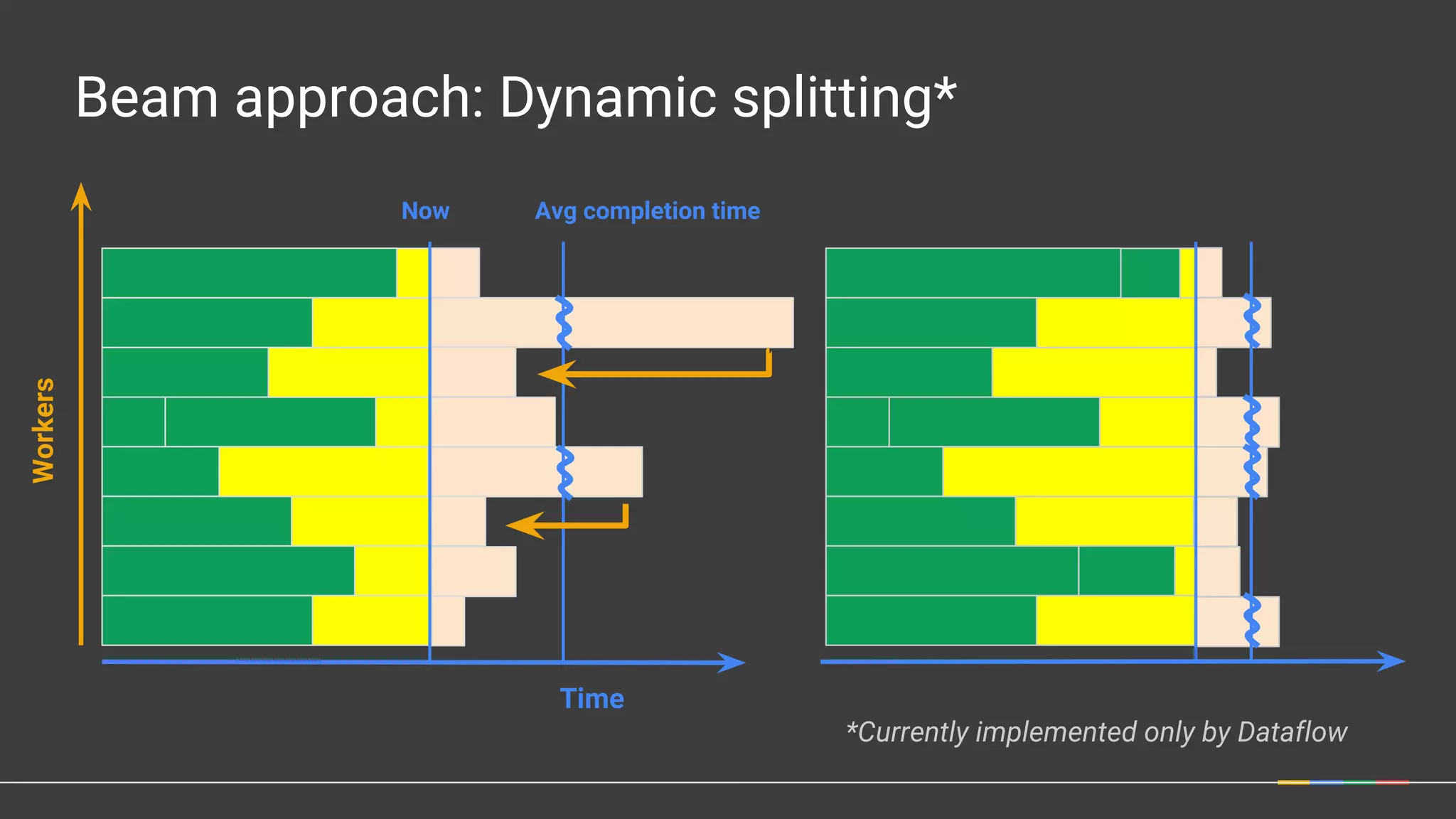


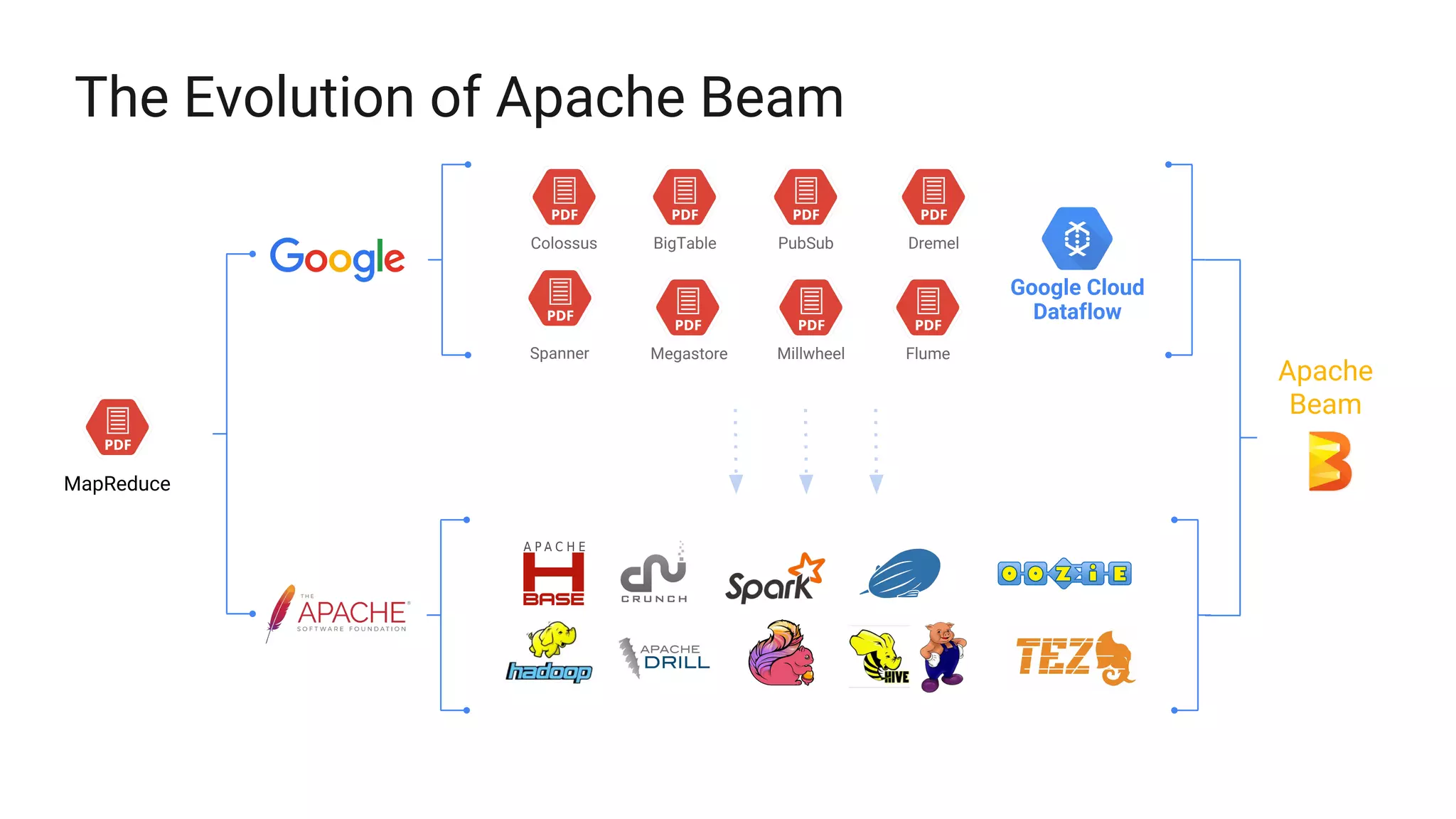
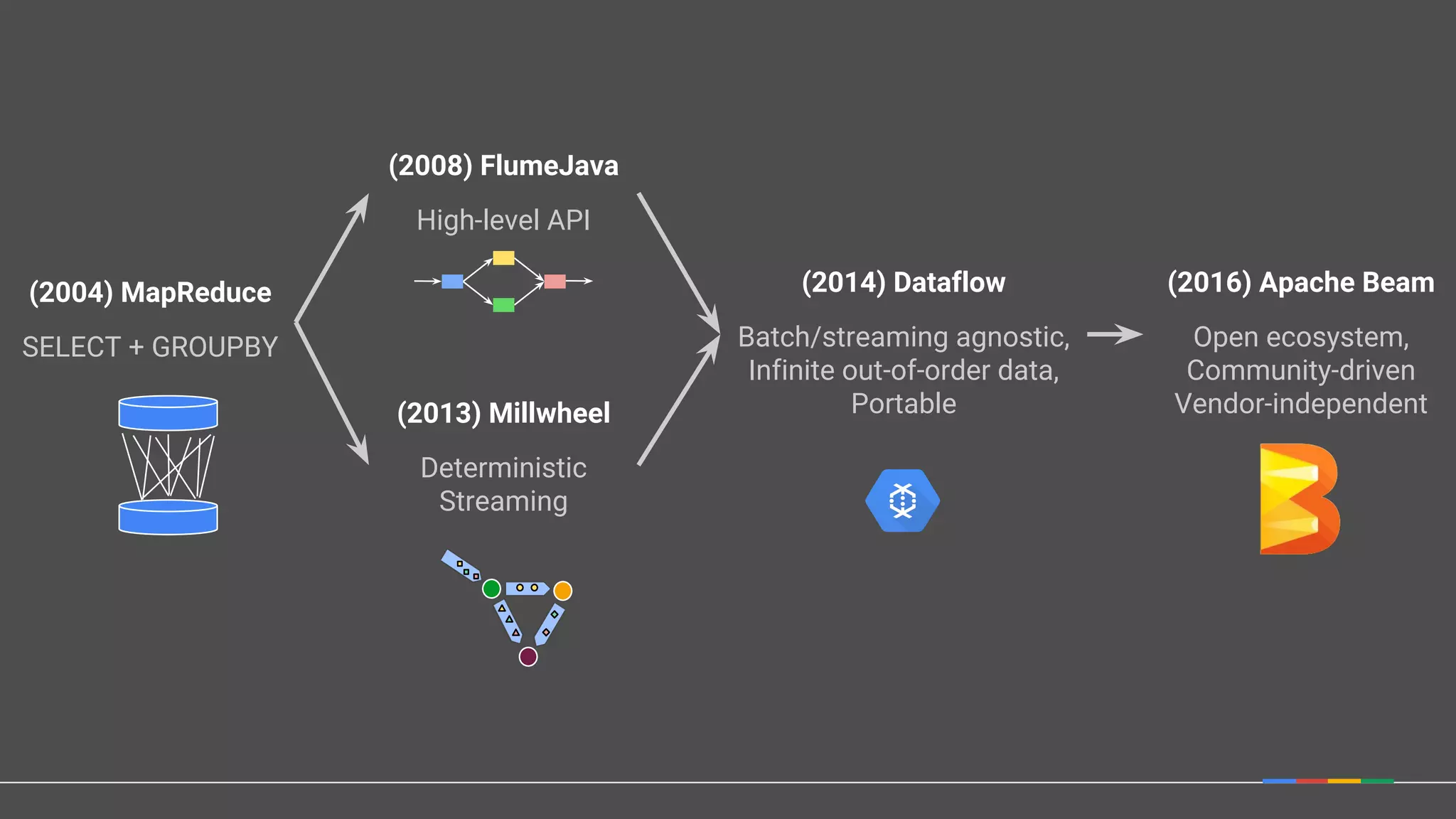
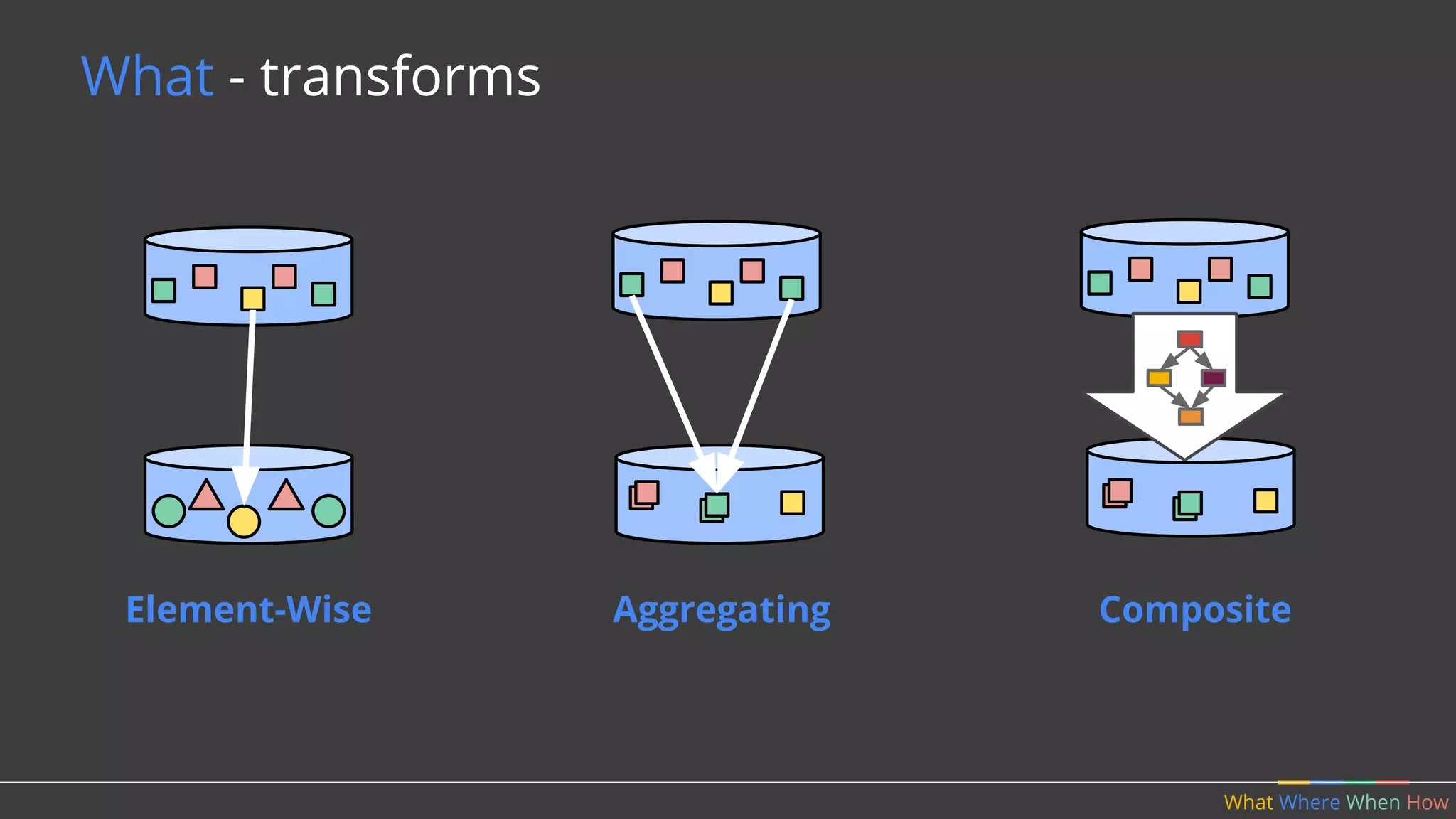
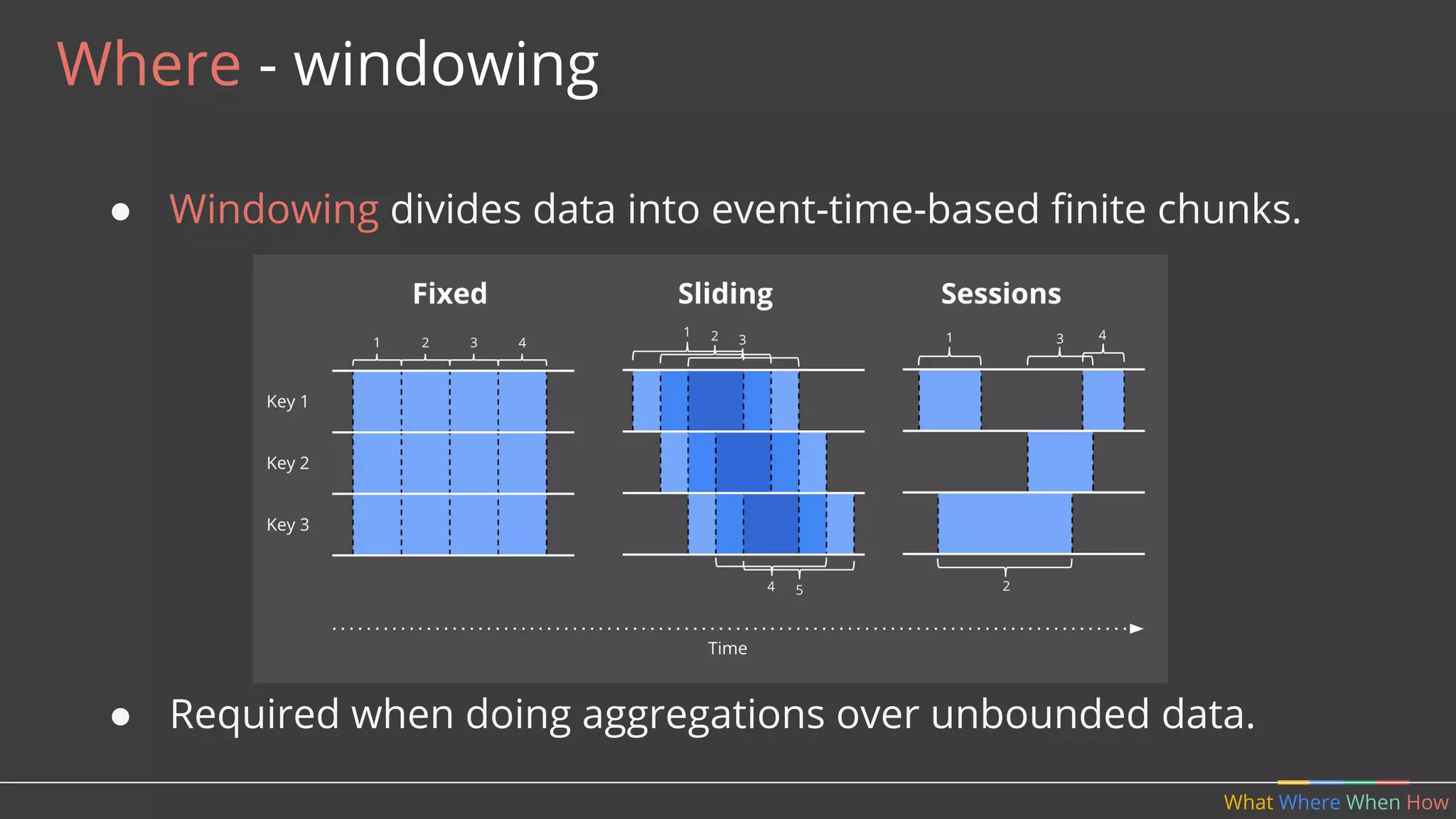
The document discusses Apache Beam, a unified programming model for batch and streaming data processing, highlighting its evolution and features such as windowing, triggering, and portability across various execution environments. It details the integration of Beam with data storage and processing systems like HBase, providing examples of pipeline constructions. Furthermore, it mentions the community and ecosystem surrounding Apache Beam, including contributions, SDKs, and IO connectors.