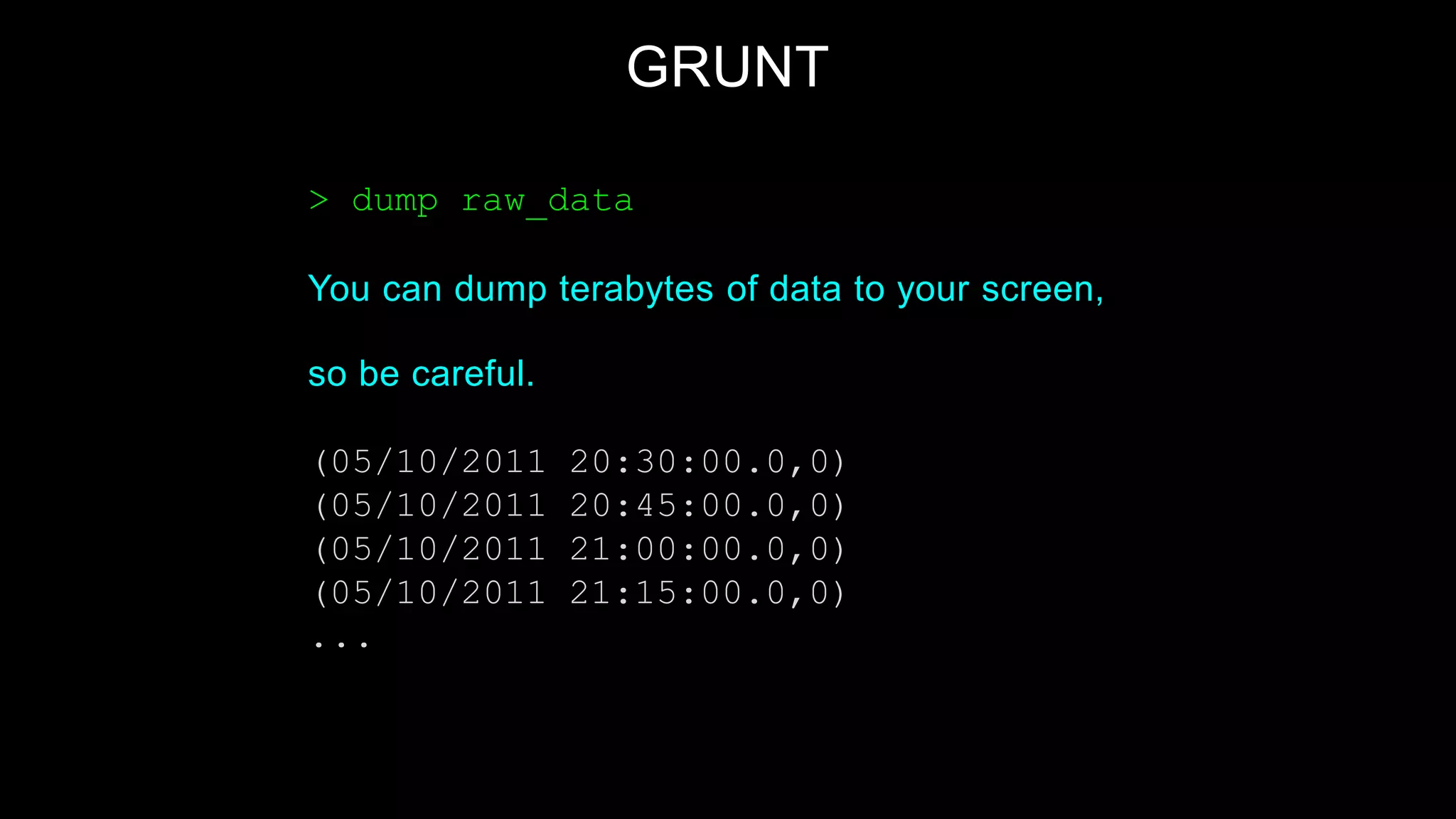
Downloaded 331 times












































![The SET command Used to set a hadoop job variable. Like the name of your pig job. SET job.name 'Day over Day - [$input]’;](https://image.slidesharecdn.com/practicalhadoop-111013232651-phpapp02/75/Practical-Hadoop-using-Pig-66-2048.jpg)
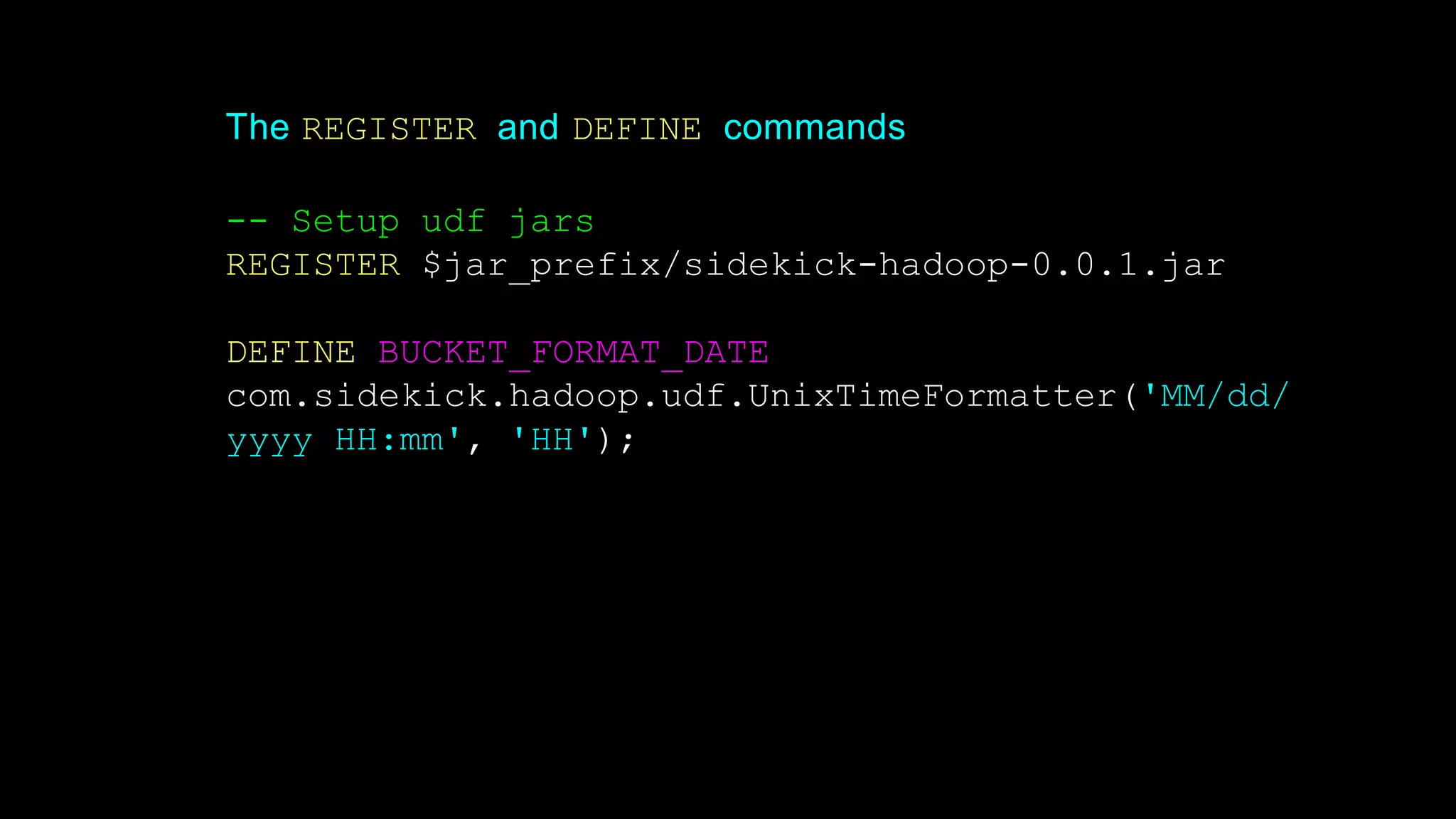
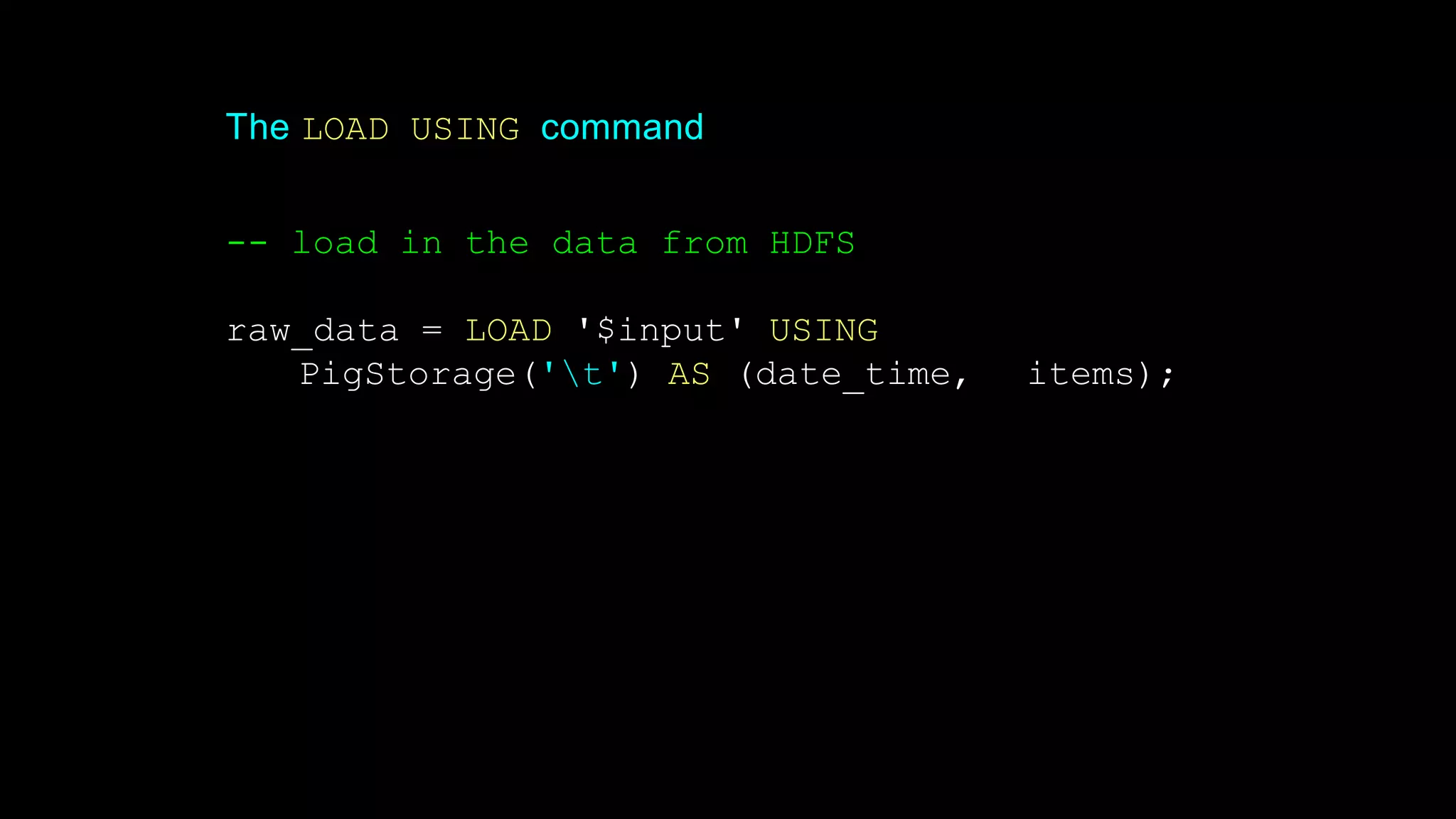

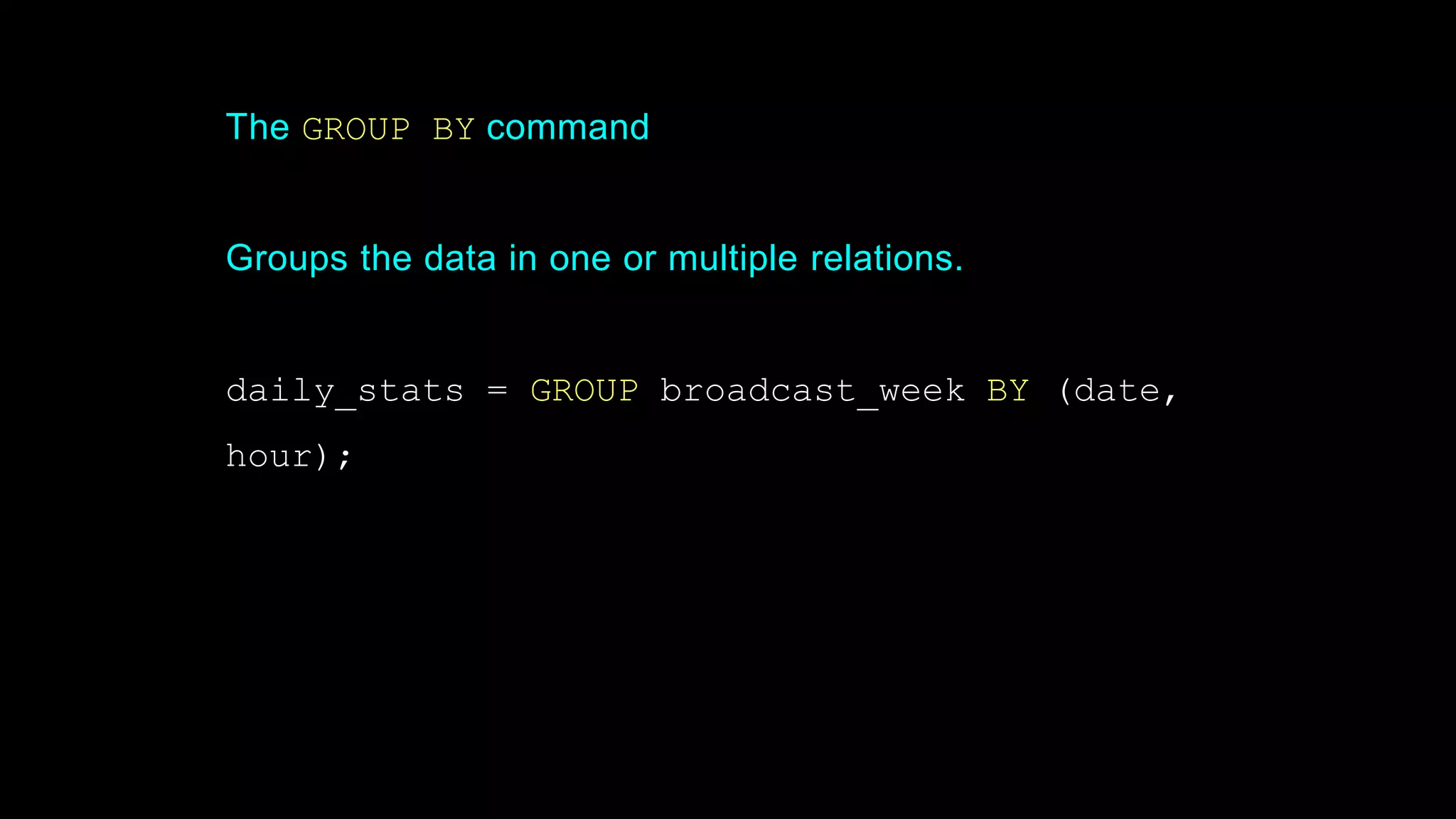



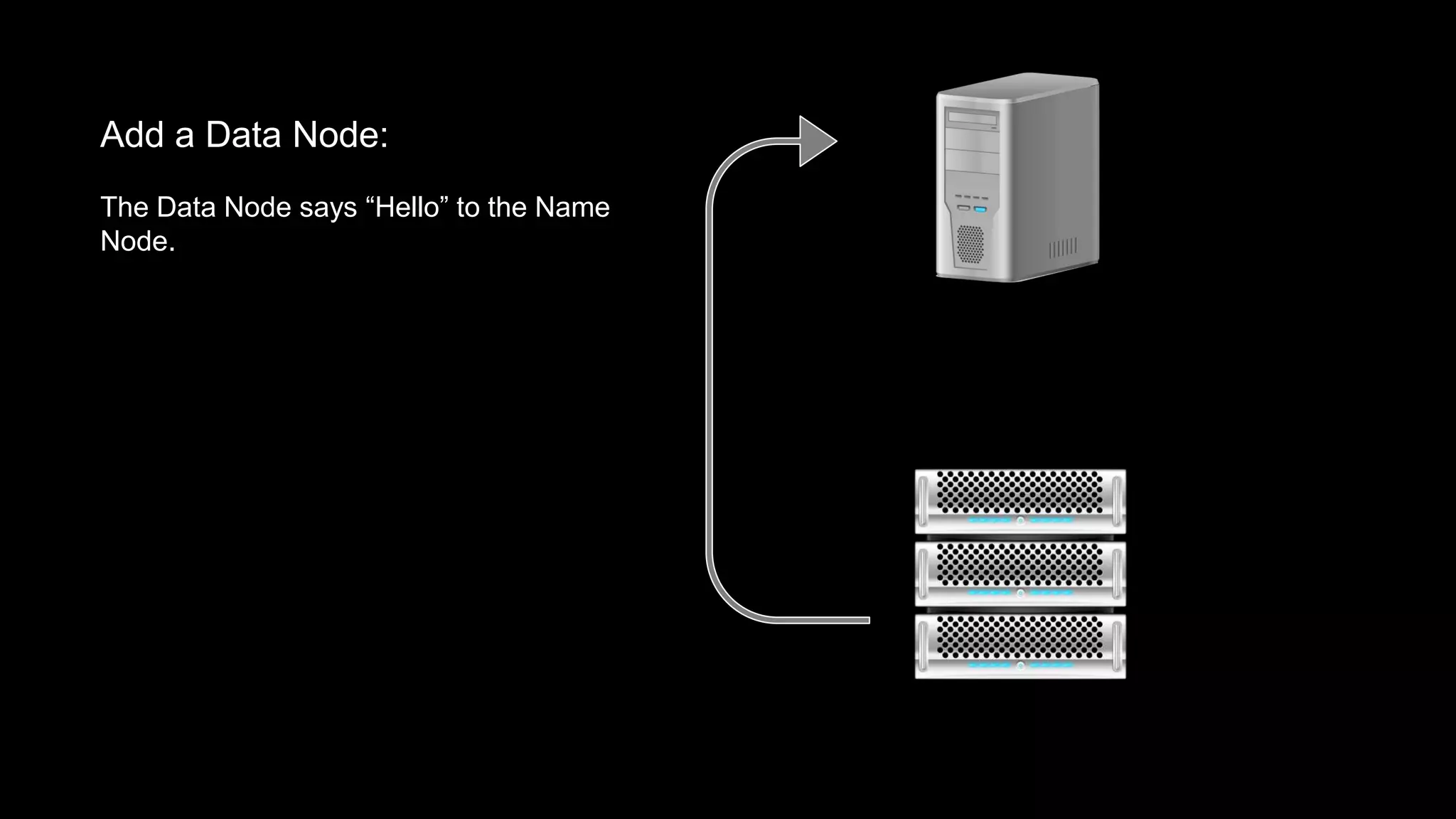
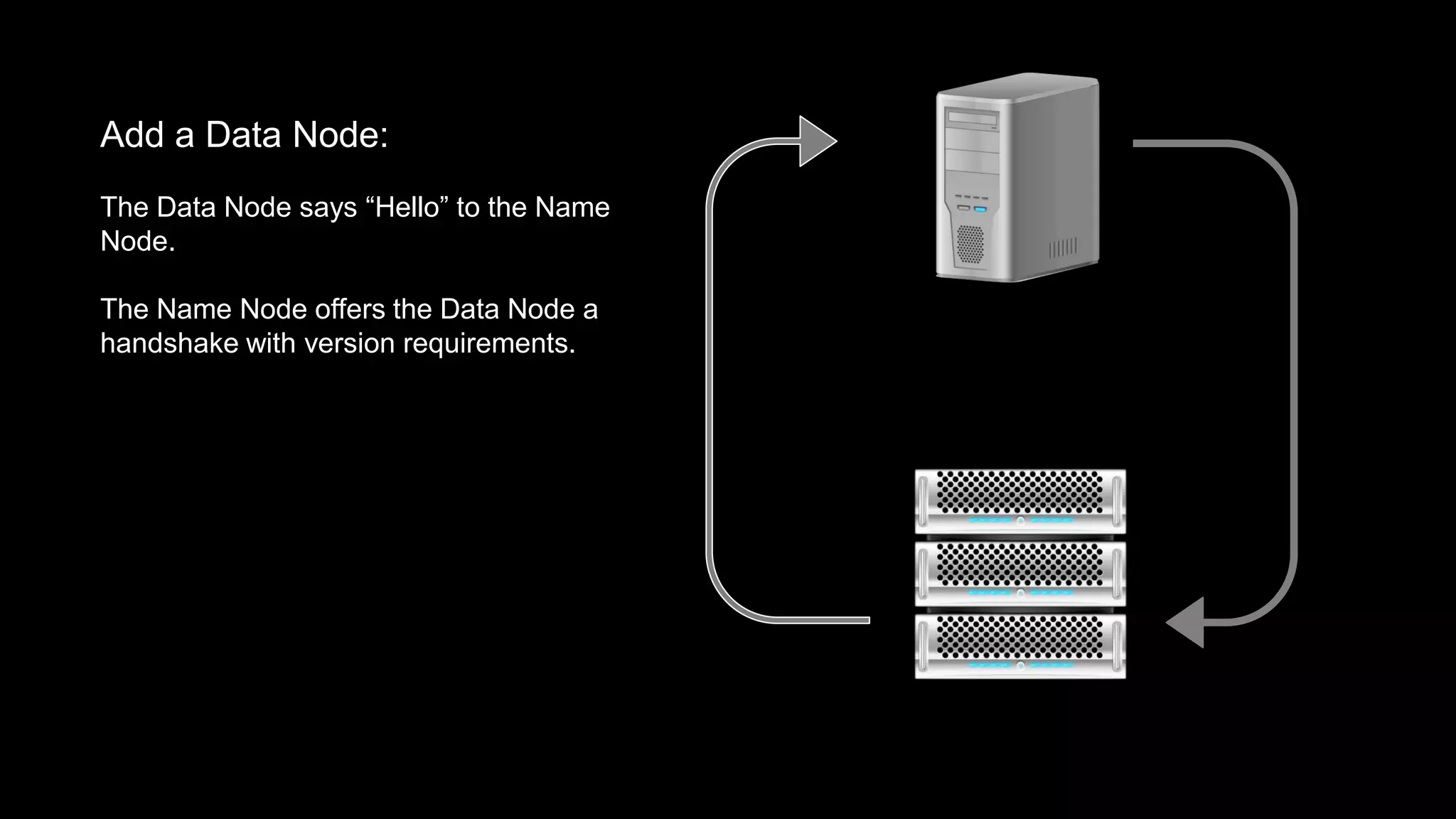
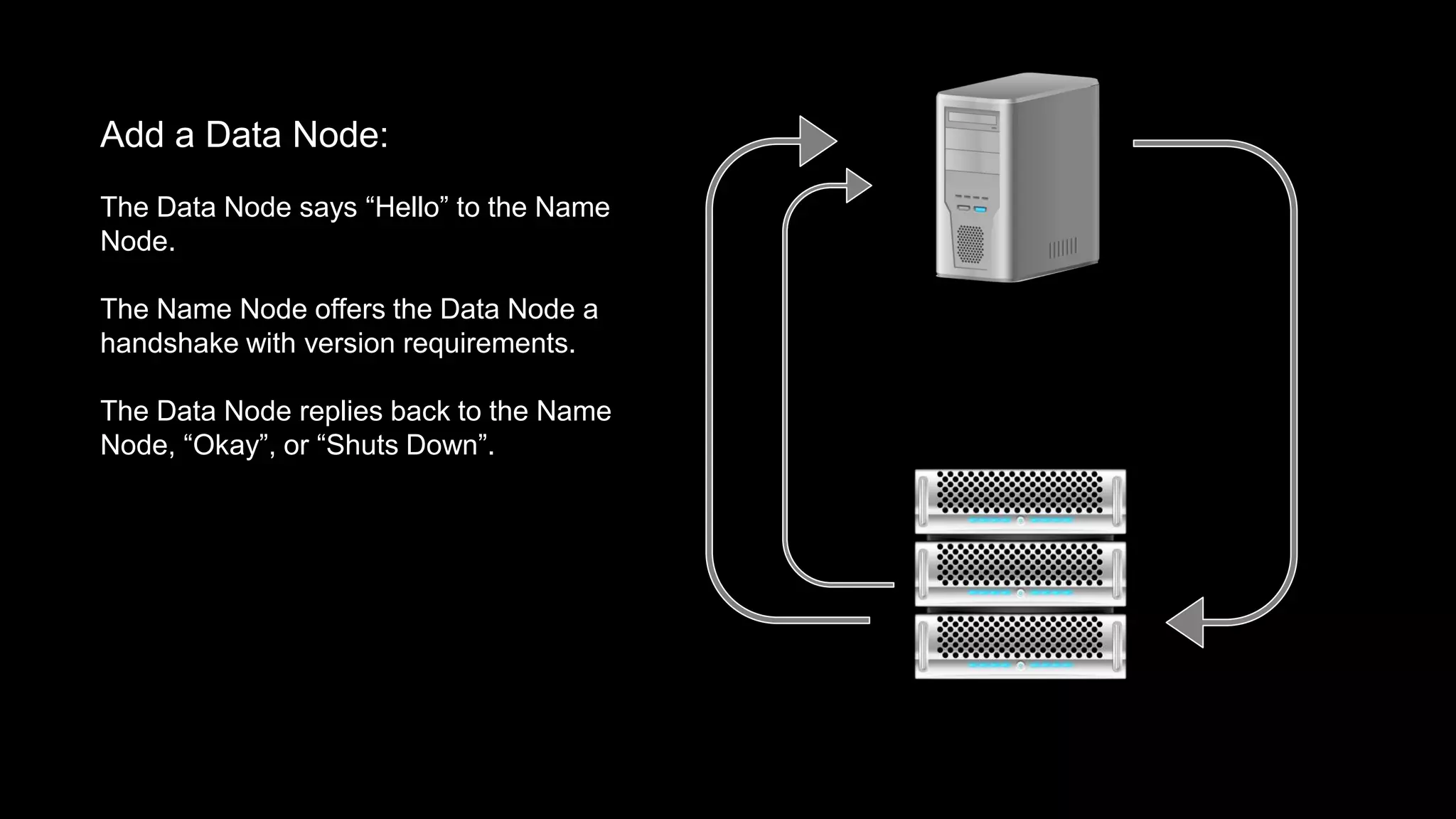
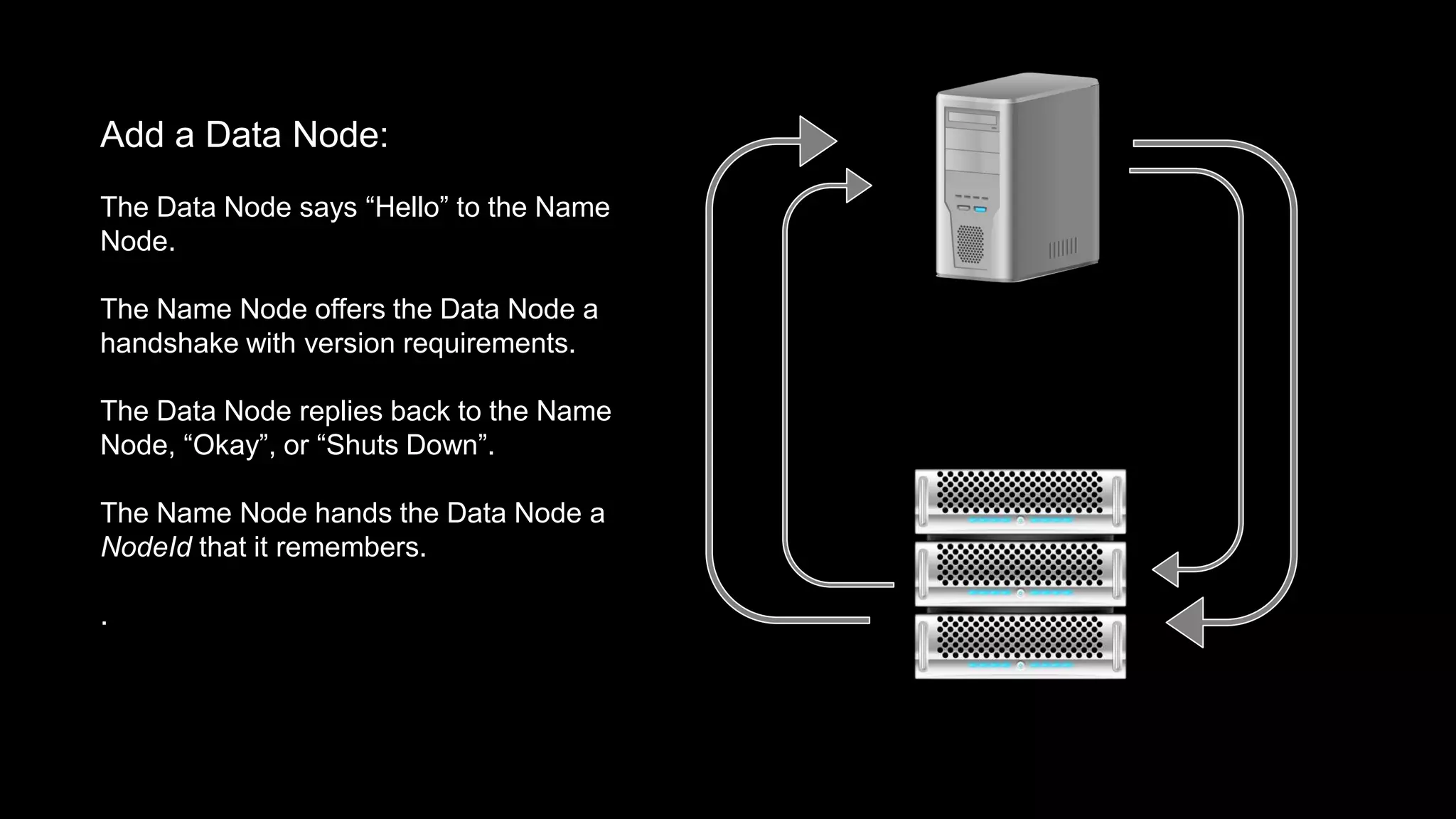
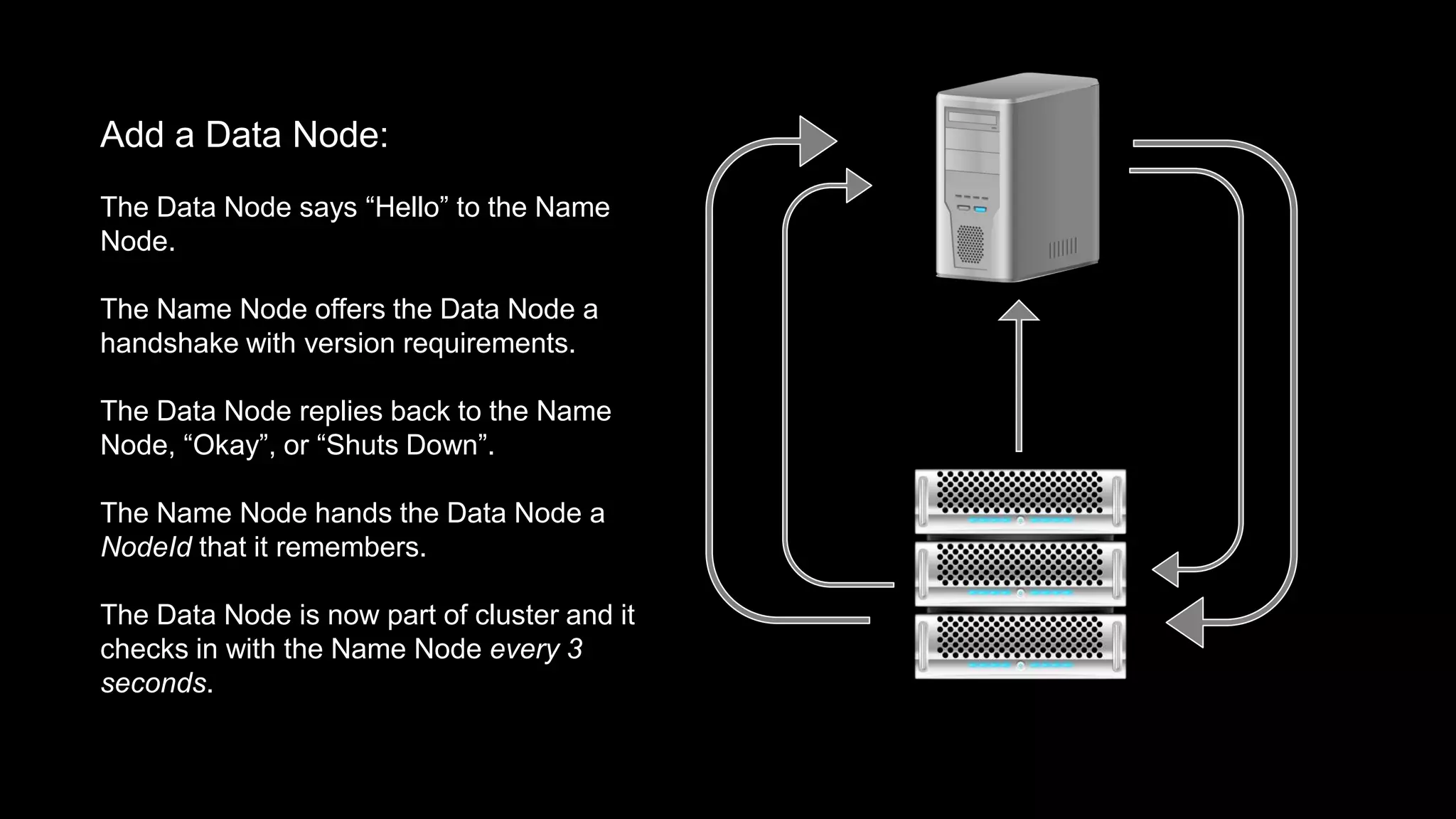
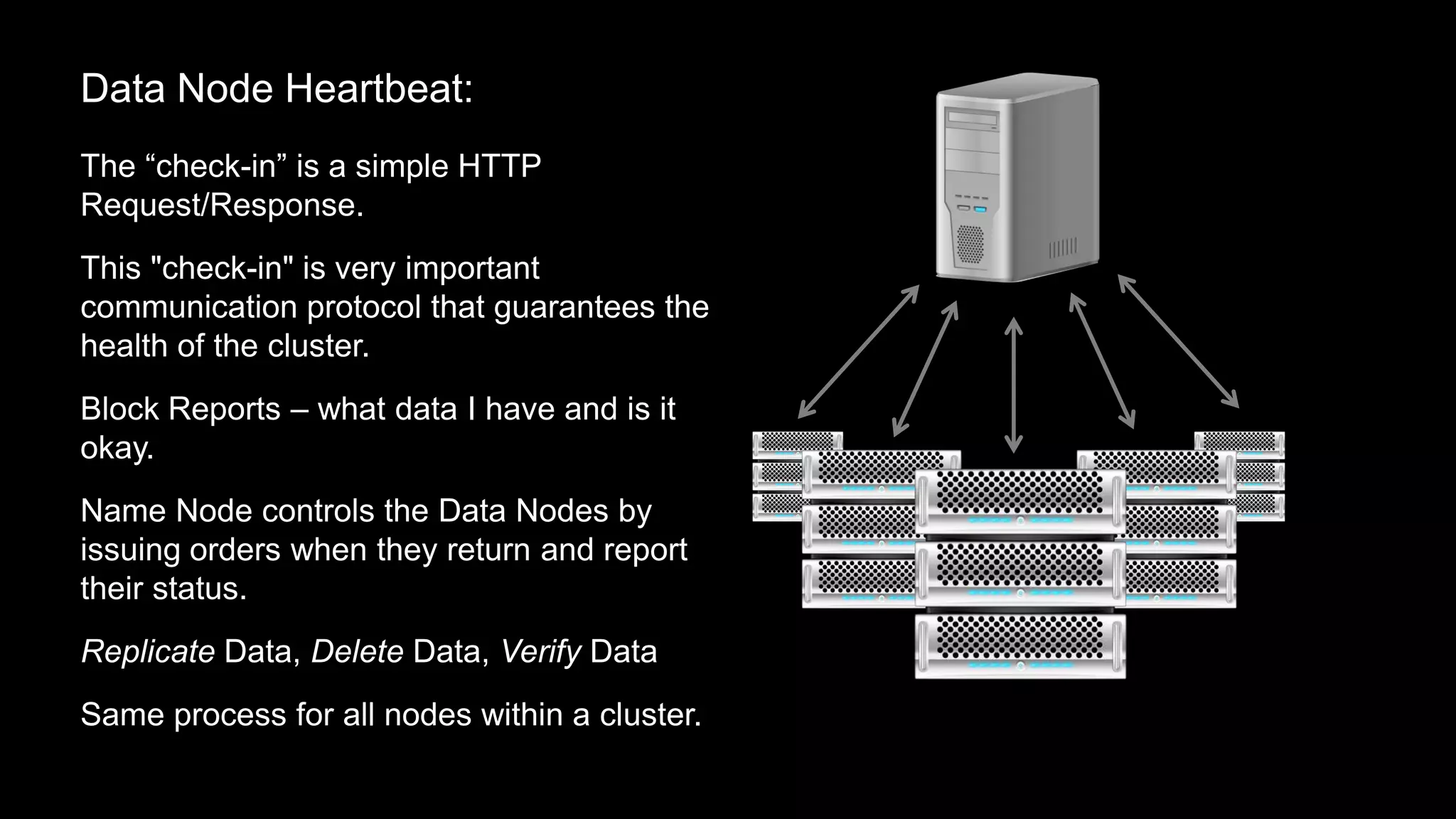
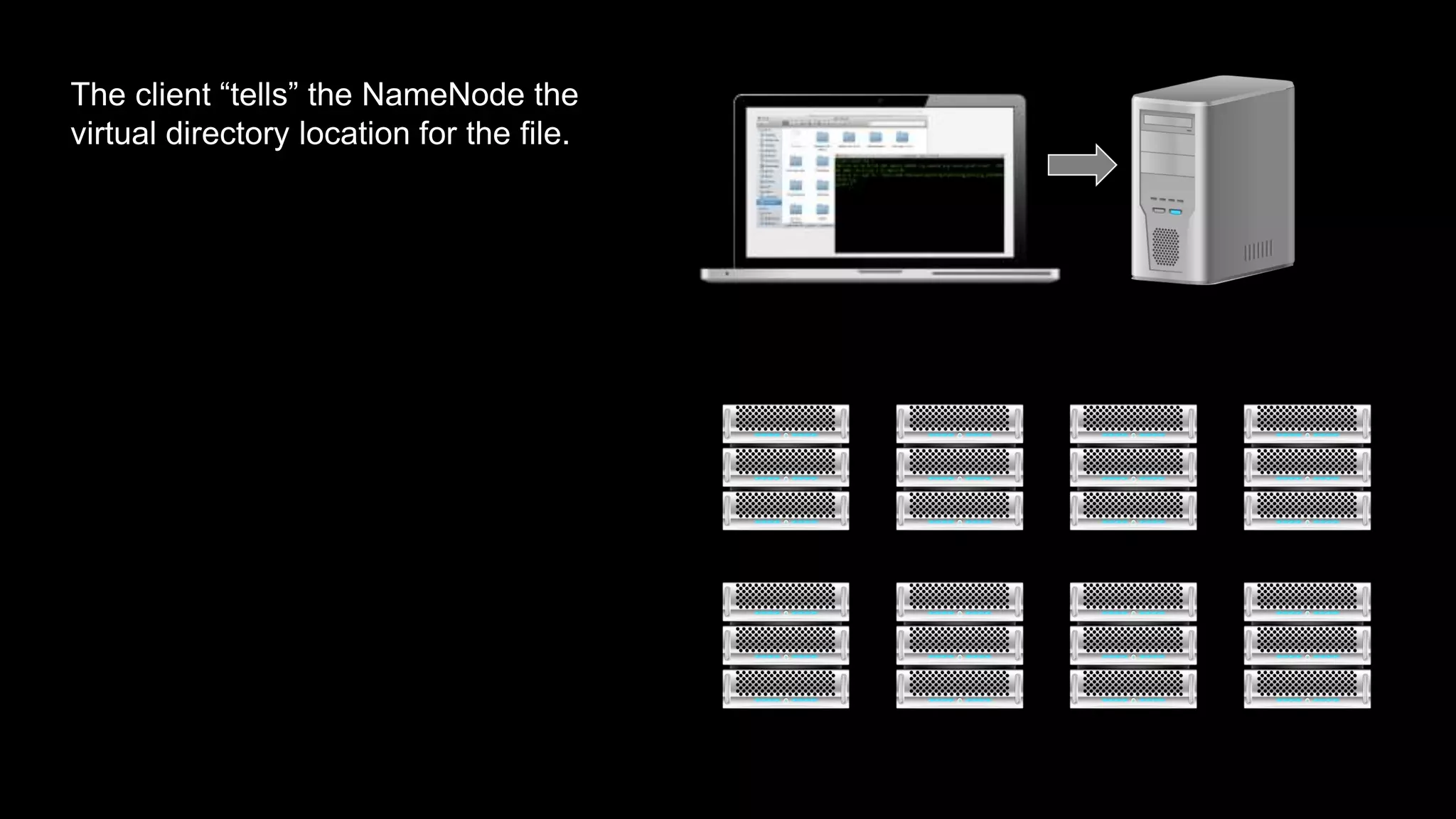
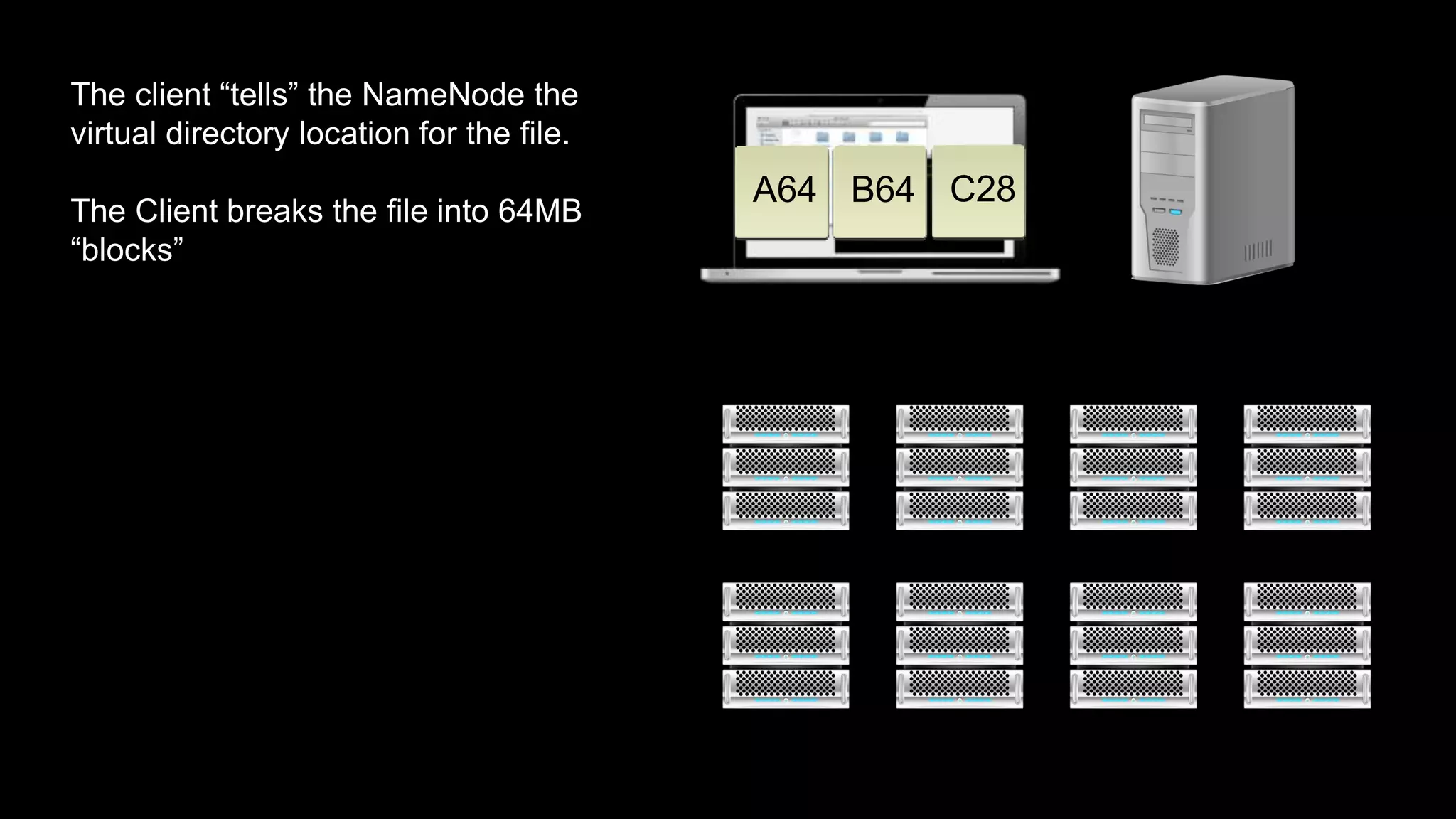
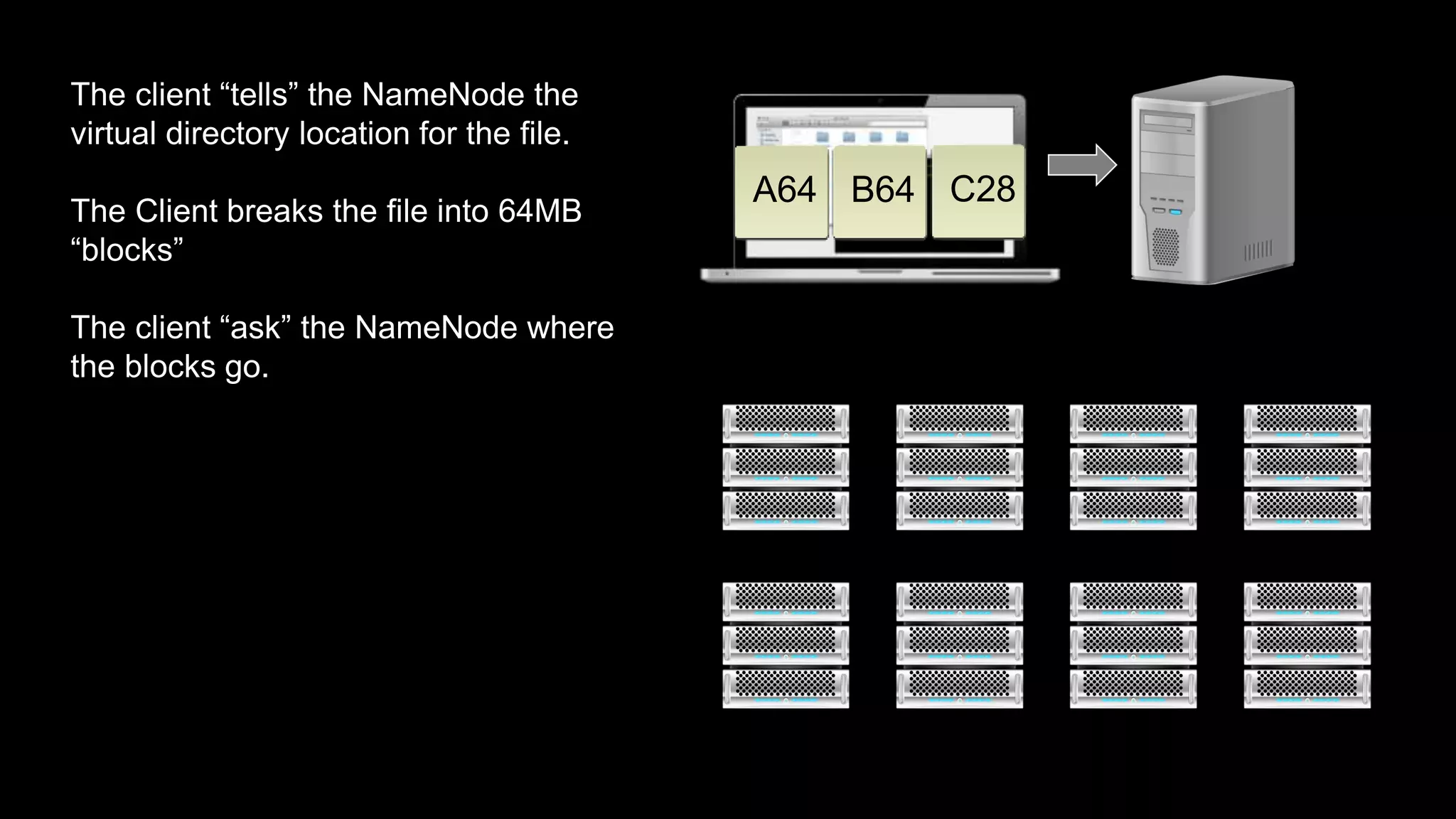
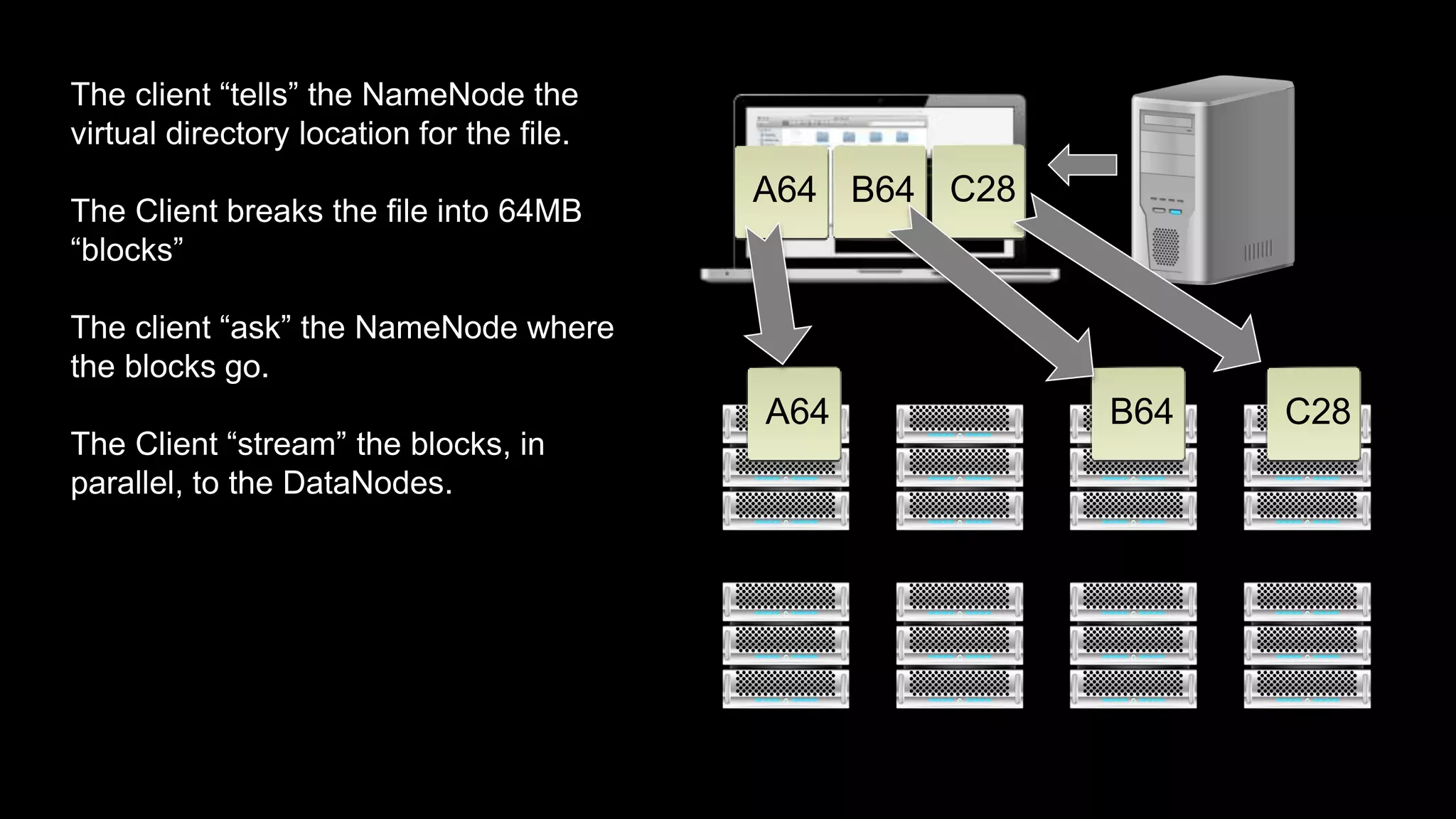
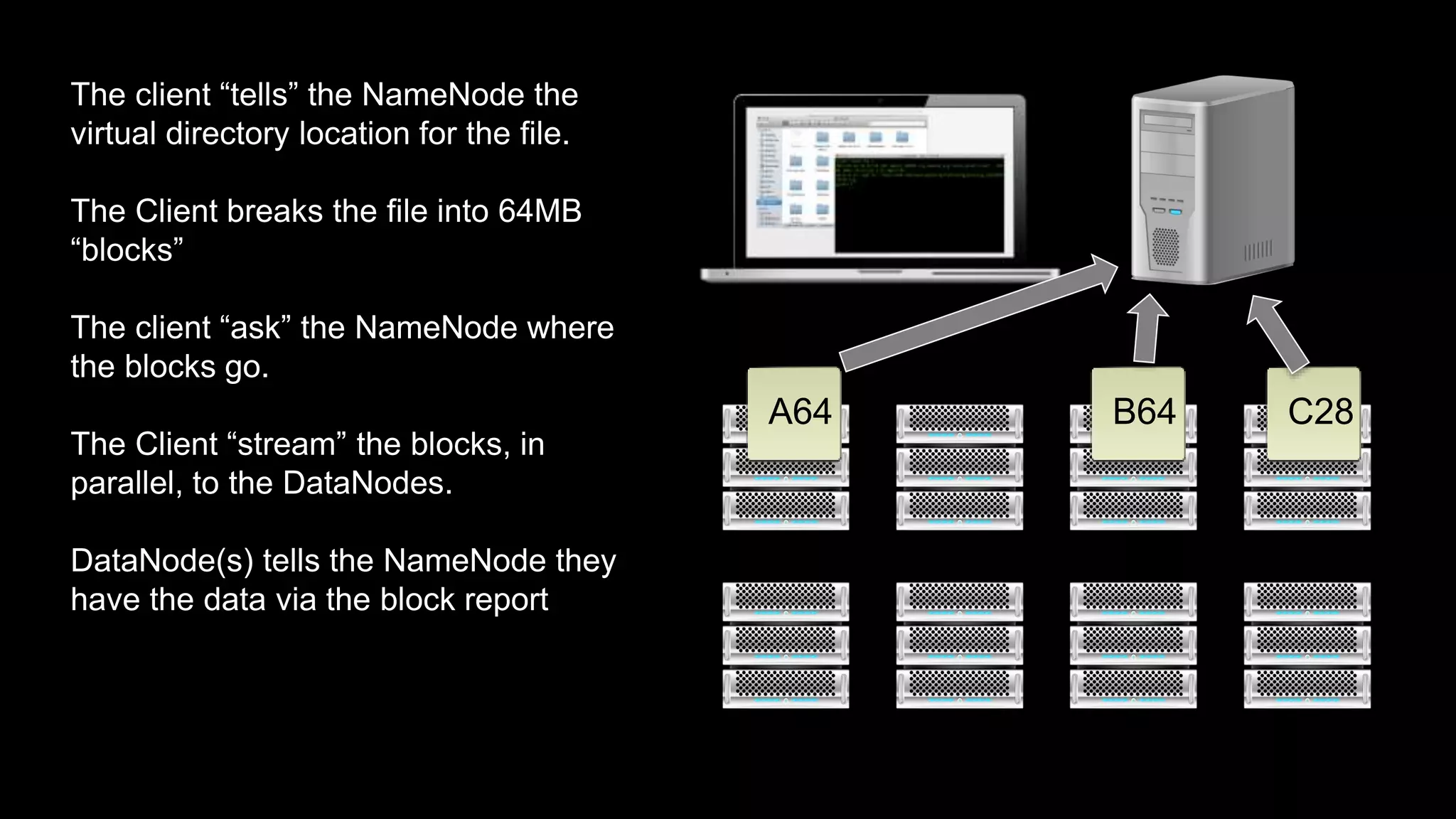
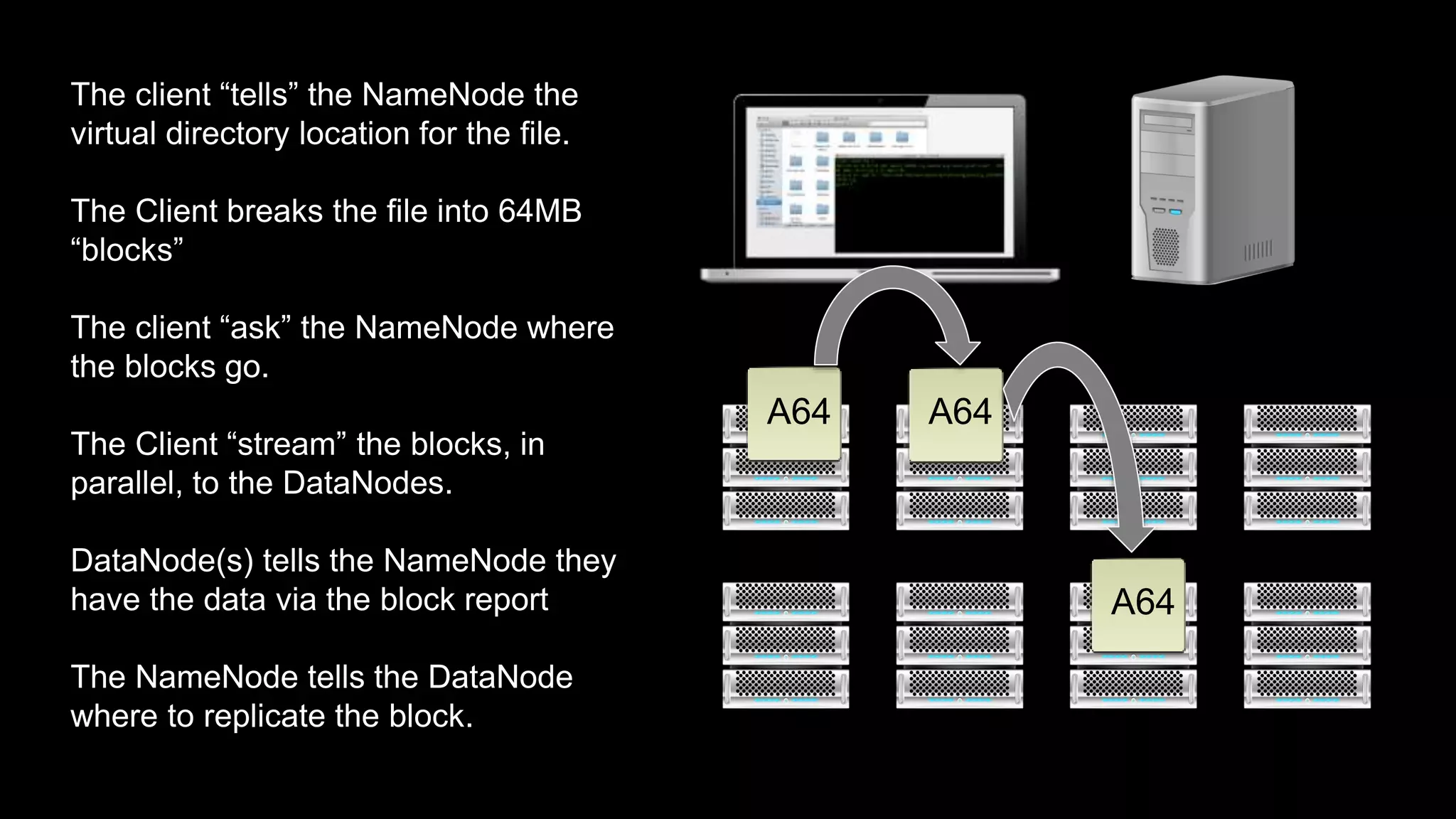
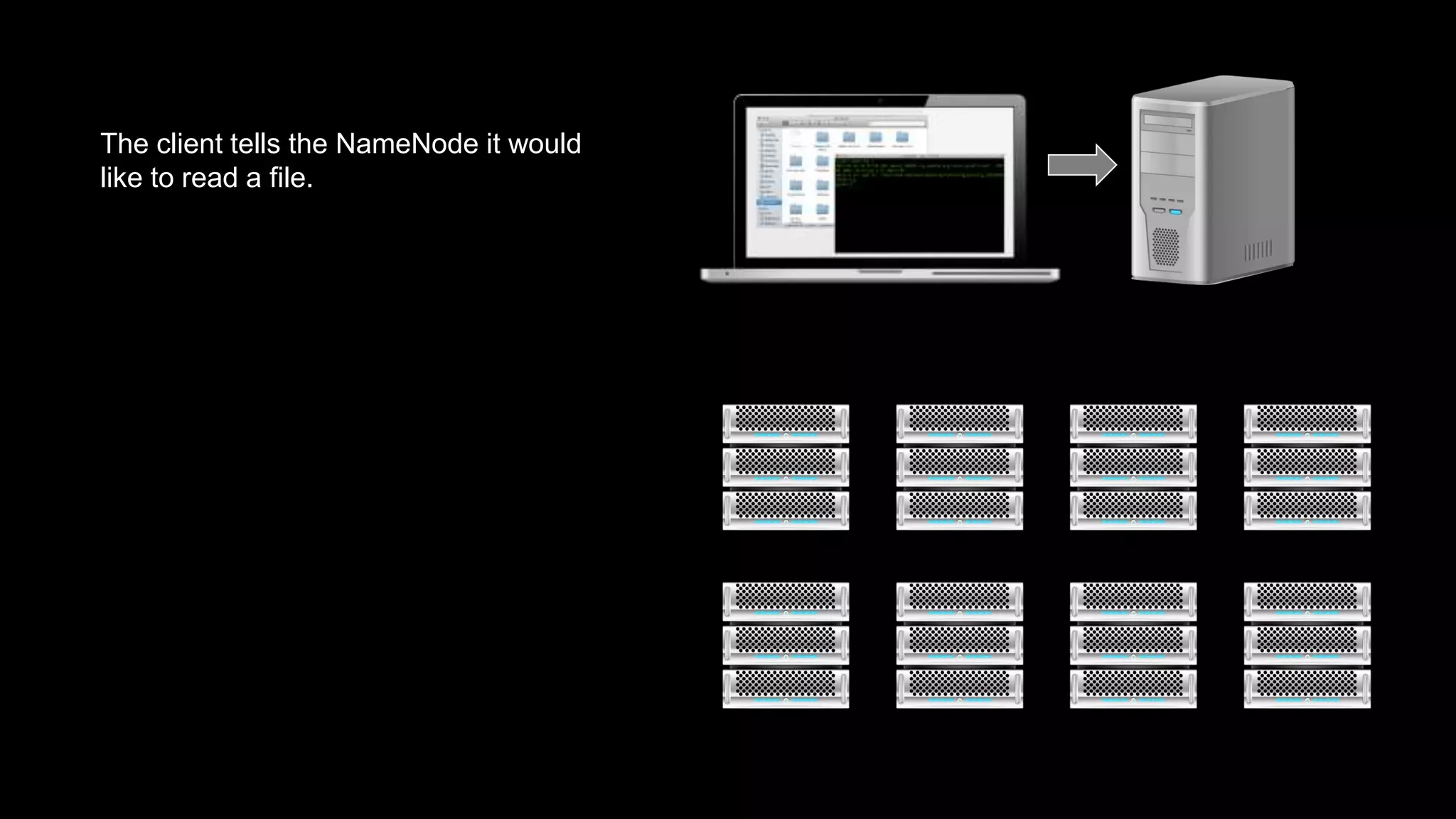
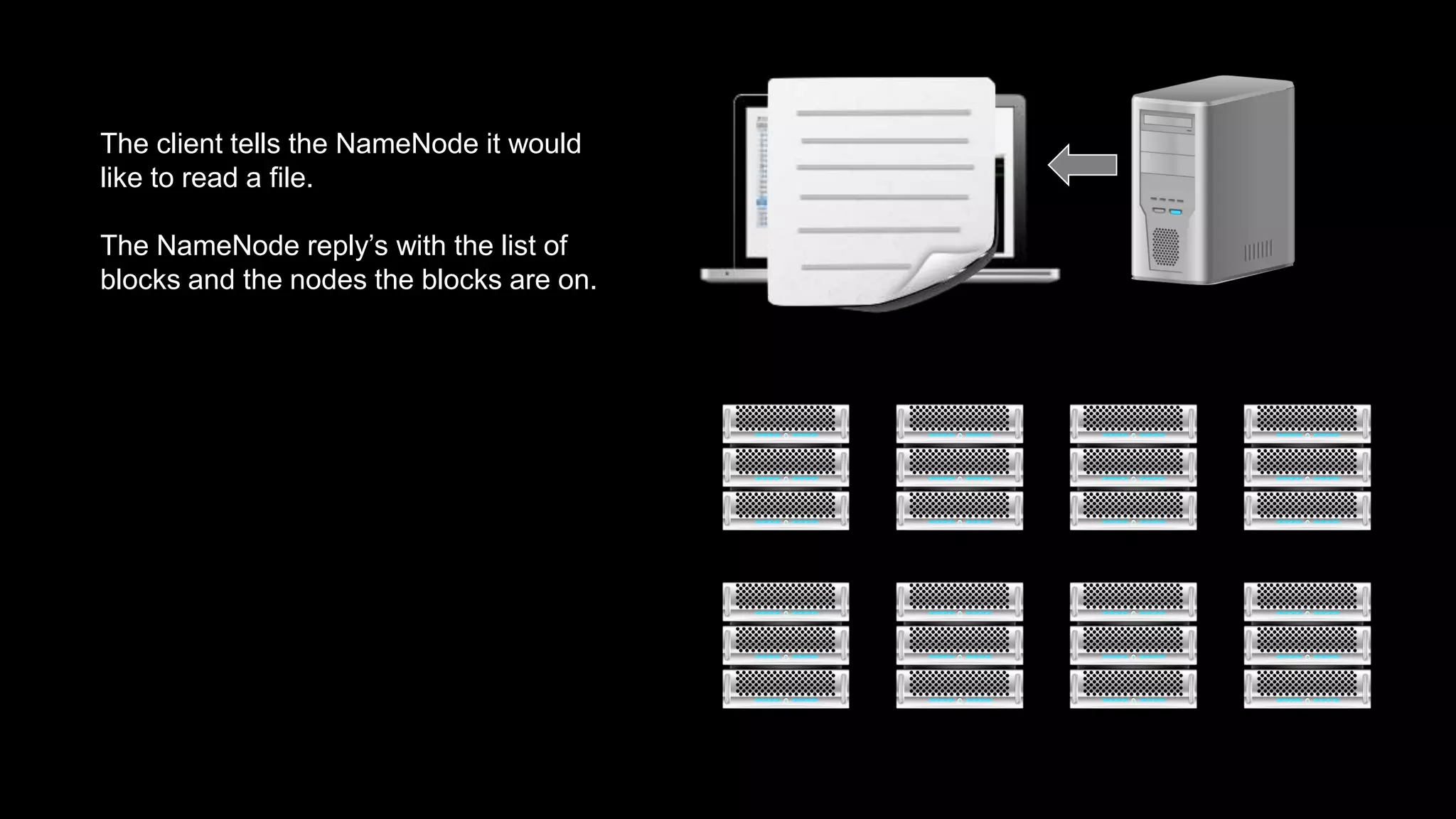
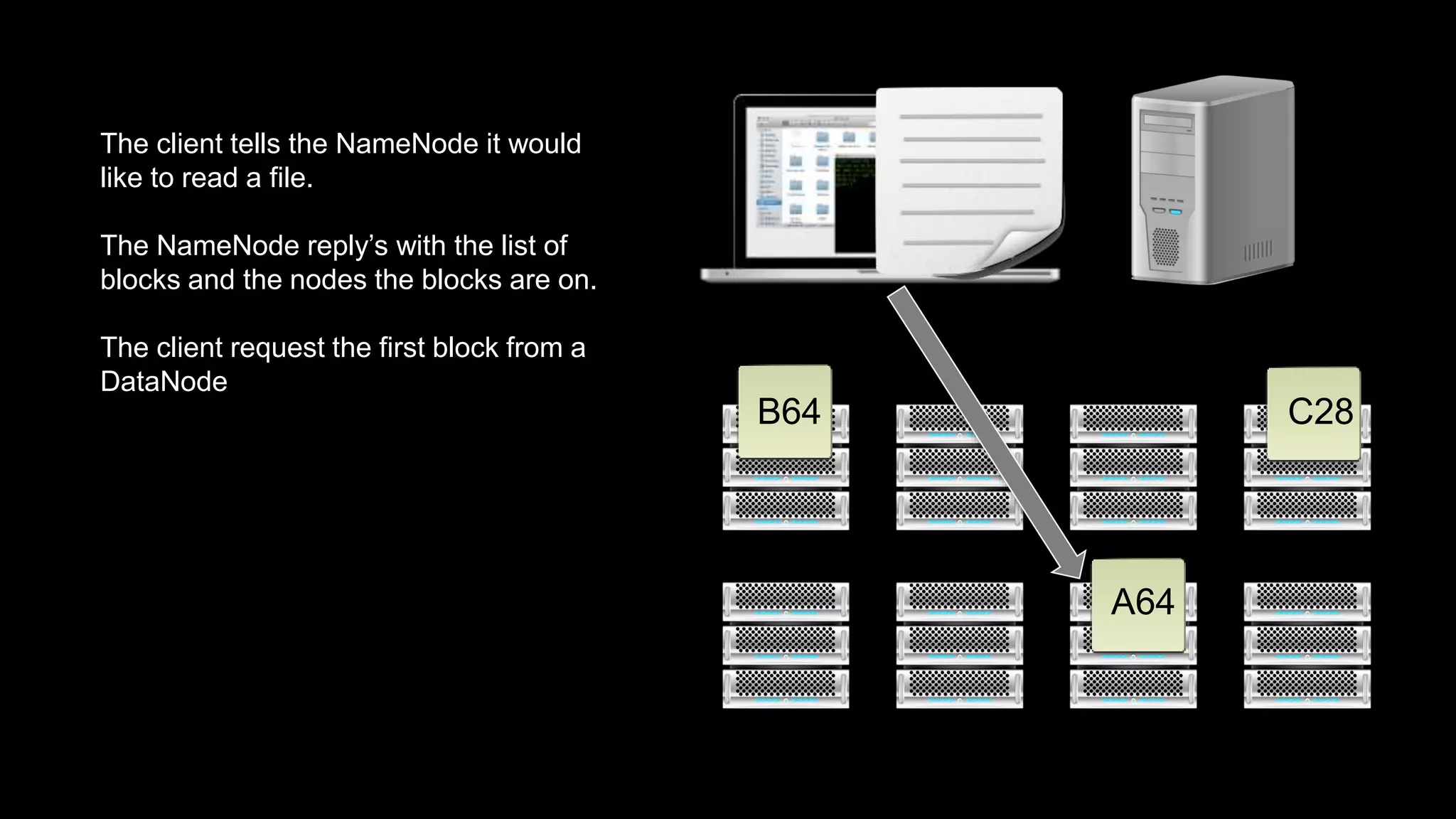
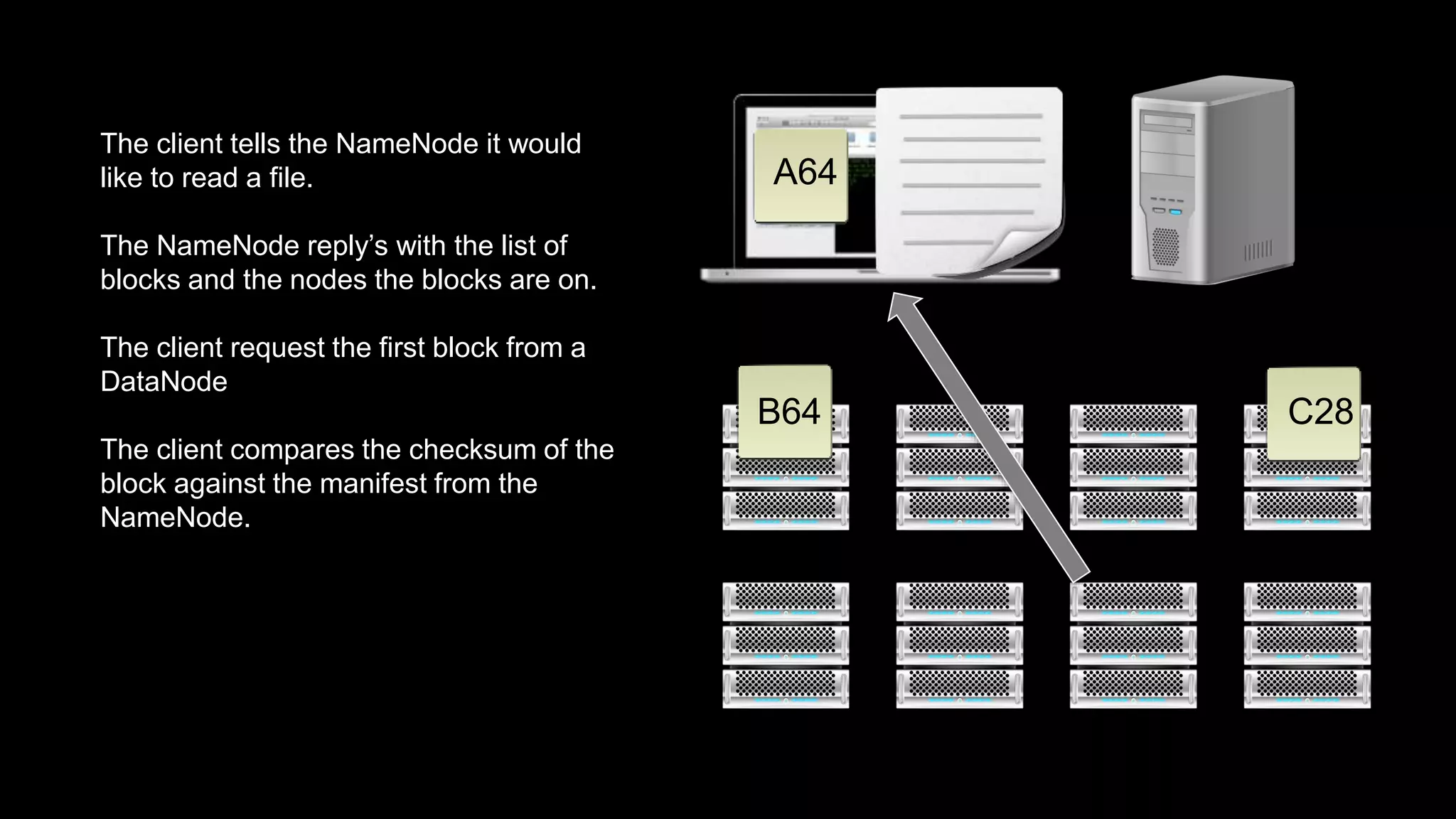
The document provides an overview of Hadoop's architecture and functionalities, focusing on HDFS and Pig. It explains the roles of the name node and data nodes in managing data storage, including processes for writing, reading, and recovering data. Additionally, it introduces command-line interface commands for interacting with HDFS and summarizes key Pig commands for processing data in Hadoop.