Download to read offline
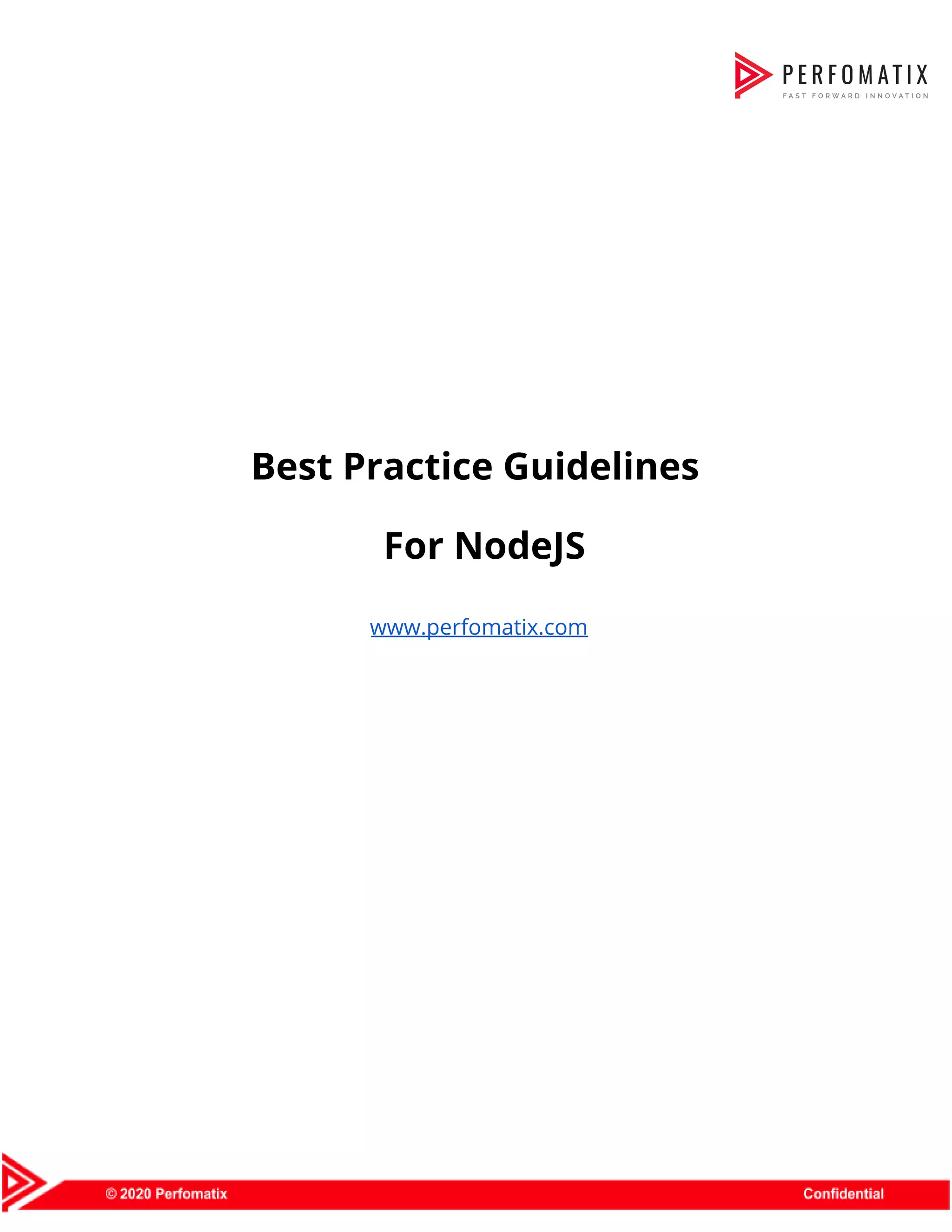









![3.4 Separate your statements properly Use ESLint to gain awareness about separation concerns. Prettier or Standardjs can automatically resolve these issues. Code example // Do function doThing() { // ... } doThing() // Do const items = [1, 2, 3] items.forEach(console.log) // Avoid — throws exception const m = new Map() const a = [1,2,3] [...m.values()].forEach(console.log) > [...m.values()].forEach(console.log) > ^^^ > SyntaxError: Unexpected token ... // Avoid — throws exception const count = 2 // it tries to run 2(), but 2 is not a function (function doSomething() { // do something amazing }()) // put a semicolon before the immediately invoked function, after the const definition, save the return value of the anonymous function to a variable or avoid IIFEs altogether 3.5 Name your functions Name all functions, including closures and callbacks. Avoid anonymous functions. This is especially useful when profiling a node app. Naming all functions will allow you to easily understand what you're looking at when checking a memory snapshot.](https://image.slidesharecdn.com/perfomatix-nodejscodingstandards-200109062944/75/Perfomatix-NodeJS-Coding-Standards-11-2048.jpg)

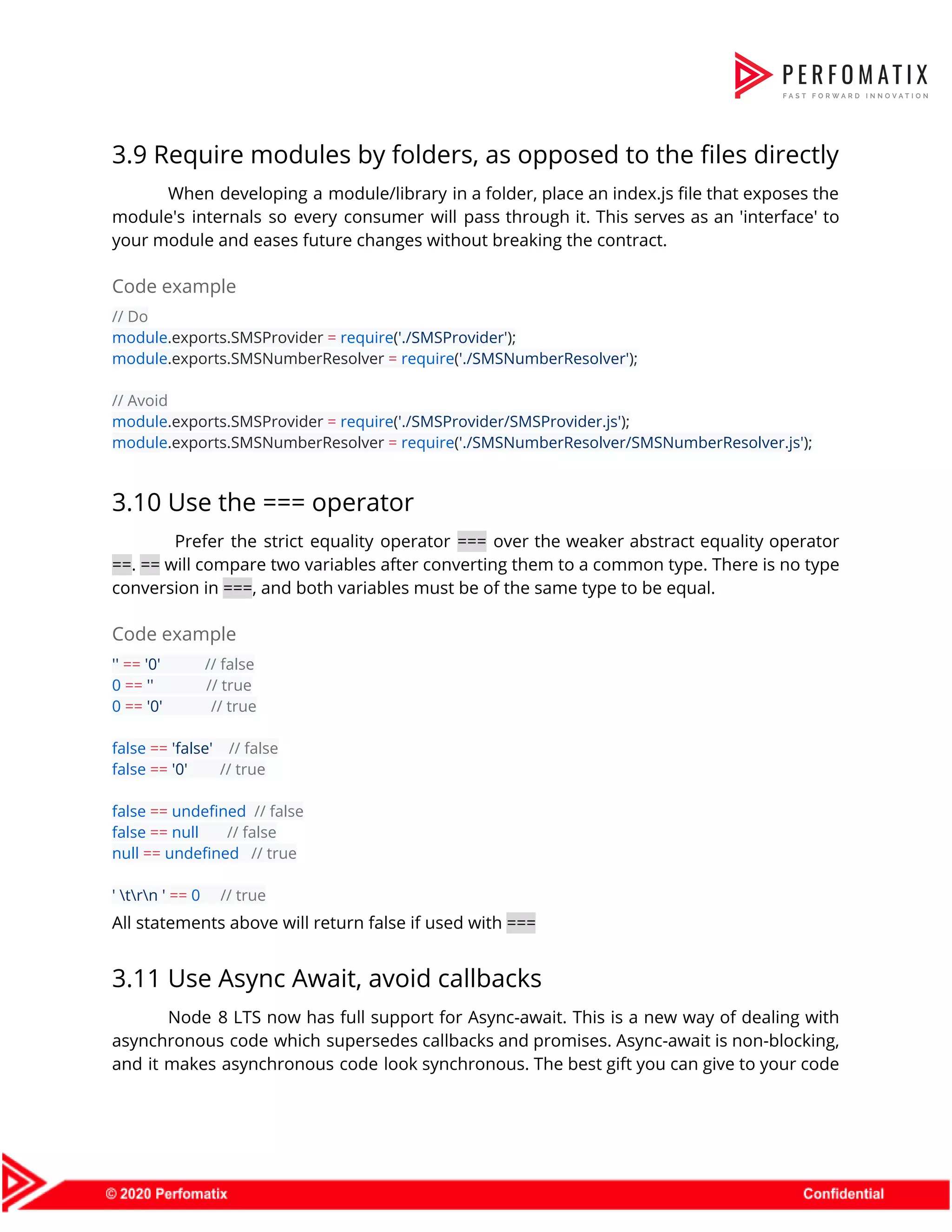








![Developers should write logs to stdout using a logger utility and then let the execution environment (container, server, etc.) pipe the stdout stream to the appropriate destination (i.e. Splunk, Graylog, ElasticSearch, etc.). Code Example – Anti-pattern: Log routing tightly coupled to the application const { createLogger, transports, winston } = require('winston'); const winston-mongodb = require('winston-mongodb'); // log to two different files, which the application now must be concerned with const logger = createLogger({ transports: [ new transports.File({ filename: 'combined.log' }), ], exceptionHandlers: [ new transports.File({ filename: 'exceptions.log' }) ] }); // log to MongoDB, which the application now must be concerned with winston.add(winston.transports.MongoDB, options); Doing it this way, the application now handles both application/business logic AND log routing logic! Code Example – Better log handling + Docker example In the application: const logger = new winston.Logger({ level: 'info', transports: [ new (winston.transports.Console)() ] }); logger.log('info', 'Test Log Message with some parameter %s', 'some parameter', { anything: 'This is metadata' }); Then, in the docker container daemon.json: { "log-driver": "splunk", /* just using Splunk as an example, it could be another storage type*/ "log-opts": { "splunk-token": "", "splunk-url": "", ... }](https://image.slidesharecdn.com/perfomatix-nodejscodingstandards-200109062944/75/Perfomatix-NodeJS-Coding-Standards-23-2048.jpg)




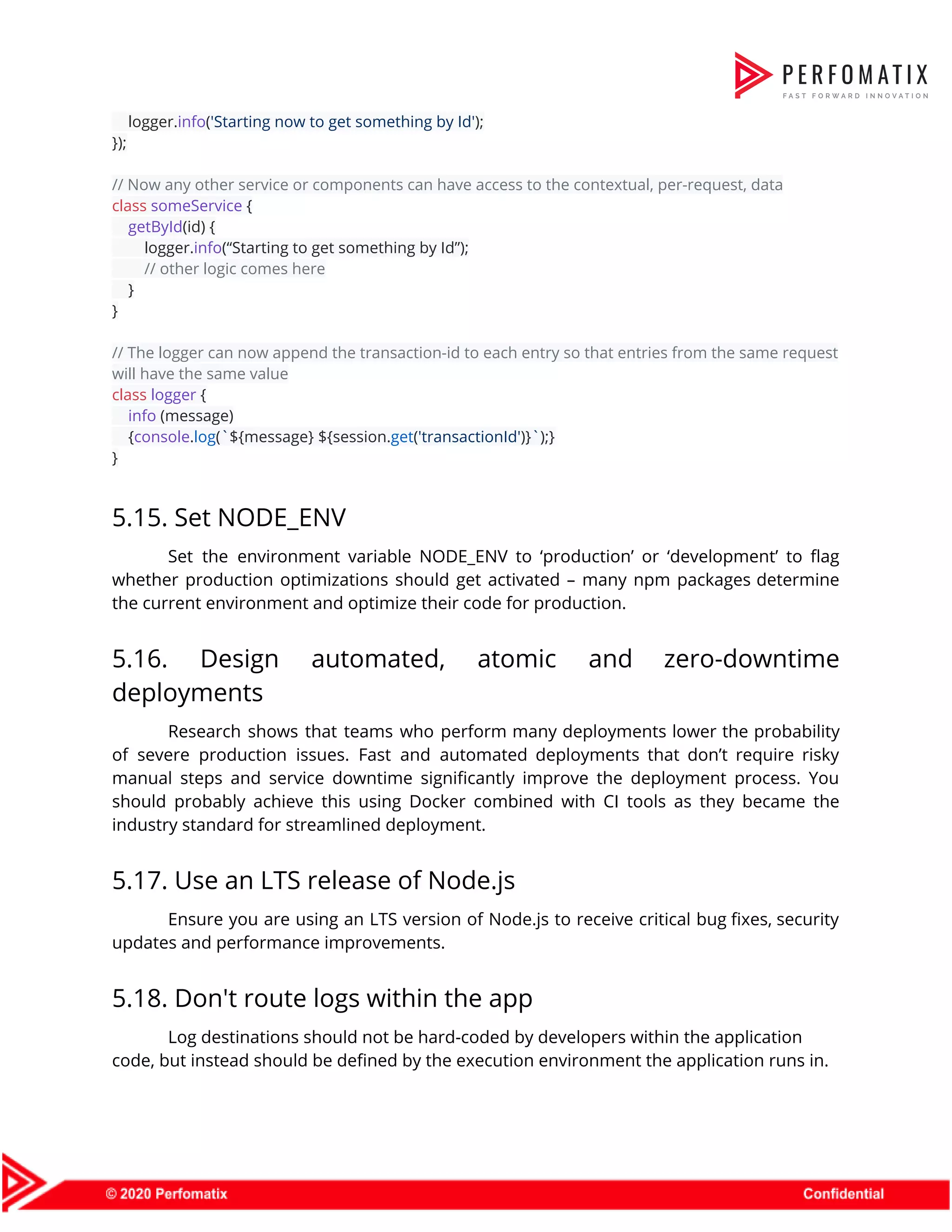
![6.12. Run Node.js as non-root user There is a common scenario where Node.js runs as a root user with unlimited permissions. For example, this is the default behavior in Docker containers. It's recommended to create a non-root user and either bake it into the Docker image (examples given below) or run the process on this user's behalf by invoking the container with the flag "-u username". Code example - Building a Docker image as non-root FROM node:latest COPY package.json . RUN npm install COPY . . EXPOSE 3000 USER node CMD ["node", "server.js"] 6.13. Limit payload size using a reverse-proxy or a middleware The bigger the body payload is, the harder your single thread works in processing it. This is an opportunity for attackers to bring servers to their knees without tremendous amount of requests (DOS/DDOS attacks). Mitigate this limiting the body size of incoming requests on the edge (e.g. firewall, ELB) or by configuring express body parser to accept only small-size payloads. 6.14. Avoid JavaScript eval statements eval is evil as it allows executing custom JavaScript code during run time. This is not just a performance concern but also an important security concern due to malicious JavaScript code that may be sourced from user input. Another language feature that should be avoided is new Function constructor. setTimeout and setInterval should never be passed dynamic JavaScript code either. Code example // example of malicious code which an attacker was able to input userInput = "require('child_process').spawn('rm', ['-rf', '/'])"; // malicious code executed eval(userInput);](https://image.slidesharecdn.com/perfomatix-nodejscodingstandards-200109062944/75/Perfomatix-NodeJS-Coding-Standards-28-2048.jpg)





The document outlines best practices for Node.js development across various aspects such as project structure, error handling, code style, testing, deployment, and security. Key recommendations include using a layered component architecture, adopting centralized error handling, maintaining consistent code style with tools like ESLint, implementing thorough testing, and ensuring production readiness with secure configurations. Additionally, it emphasizes the importance of proper logging, validating inputs, and avoiding common security pitfalls.