Downloaded 64 times





















![simply squaring the elements of an array __global__ void square(float * d_out, float * d_in){ // Todo: Fill in this function int idx = threadIdx.x; float f = d_in[idx]; d_out[idx] = f*f } theadIdx.x =gives the current thread number GPU/CUDA programming](https://image.slidesharecdn.com/parallelcomputinggpu-130729221325-phpapp02/75/Parallel-computing-with-Gpu-27-2048.jpg)
![Main program int main(int argc, char **argv){ …………………… ……………………. float h_out[ARRAY_SIZE]; //declare GPU pointer float * d_in; float * d_out; // allocate GPU memory cudaMalloc( (void*) &d_in, ARRAY_BYTES); cudaMalloc( (void*) &d_out, ARRAY_BYTES);](https://image.slidesharecdn.com/parallelcomputinggpu-130729221325-phpapp02/75/Parallel-computing-with-Gpu-28-2048.jpg)
![Main program(cont.) // transfer the array to the GPU cudaMemcpy(d_in, h_in, ARRAY_BYTES, cudaMemcpyHostToDevice); // launch the kernel square<<<1, ARRAY_SIZE>>>(d_out, d_in); // copy back the result array to the CPU cudaMemcpy(h_out, d_out, ARRAY_BYTES, cudaMemcpyDeviceToHost); // print out the resulting array for (int i =0; i < ARRAY_SIZE; i++) { printf("%f", h_out[i]); }](https://image.slidesharecdn.com/parallelcomputinggpu-130729221325-phpapp02/75/Parallel-computing-with-Gpu-29-2048.jpg)


![References • 1.[‘IEEE’] Accelerating image processing capability using graphics processors Jason. Dalea, Gordon. Caina, Brad. ZellbaVision4ce Ltd. Crowthorne Enterprise Center, Crowthorne, Berkshire, UK, RG45 6AWbVision4ce LLC Severna Park, USA, MD2114 • • 2.Udacity cs344,Intro to parallel Programming with GPU • 3.Wikipedia • 4.Nividia docs](https://image.slidesharecdn.com/parallelcomputinggpu-130729221325-phpapp02/75/Parallel-computing-with-Gpu-33-2048.jpg)

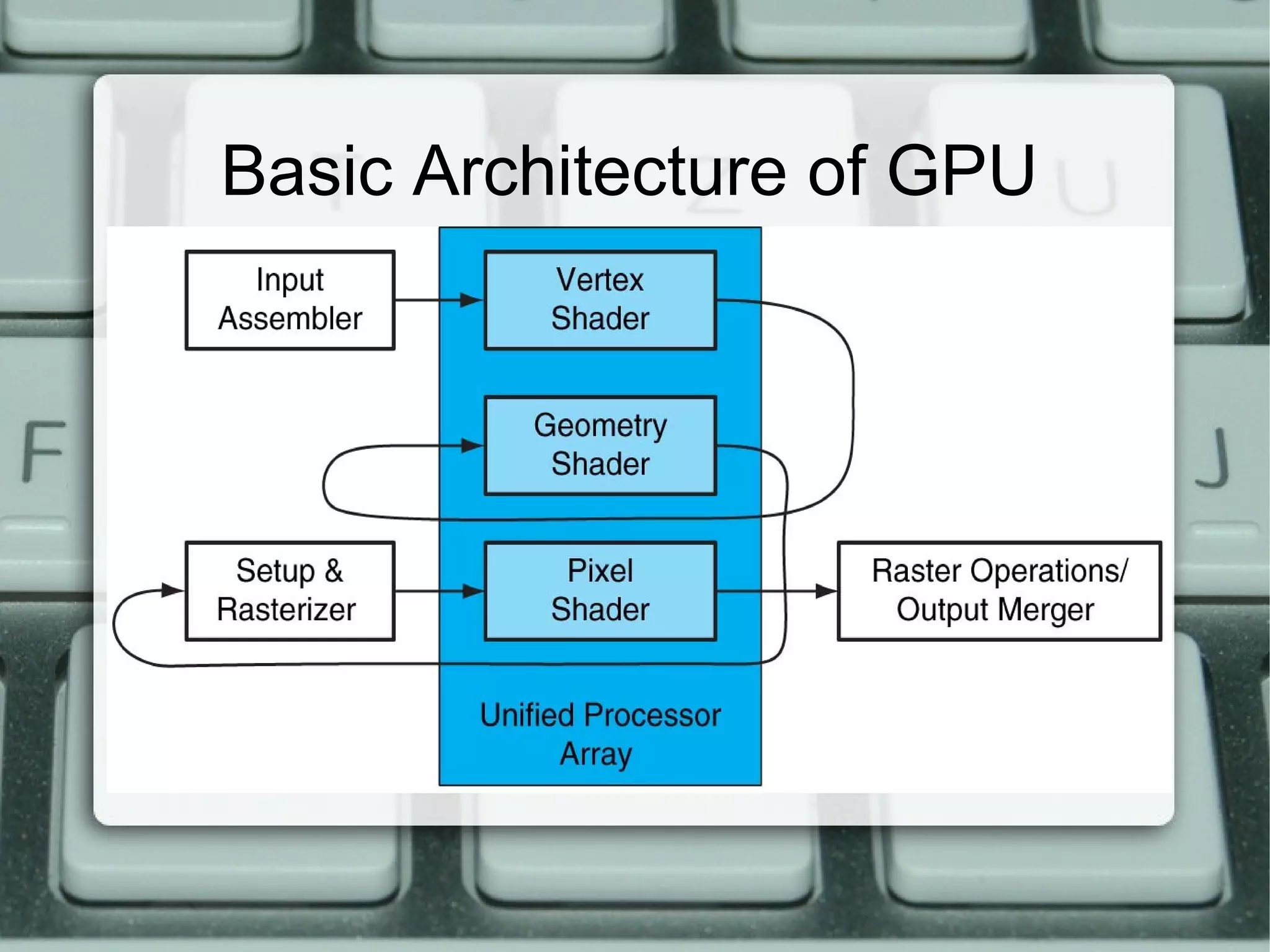
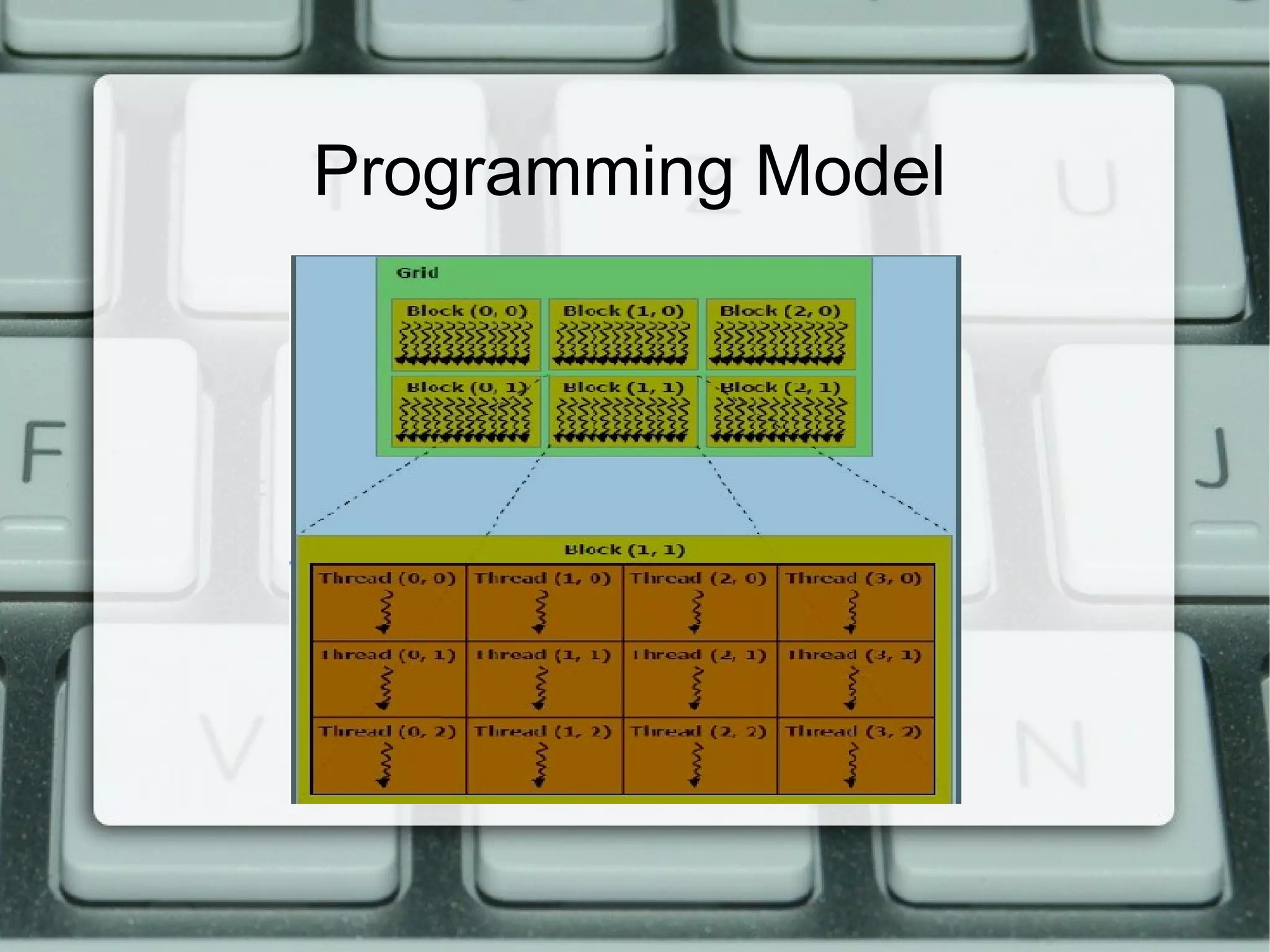
This document discusses parallel computing with GPUs. It introduces parallel computing, GPUs, and CUDA. It describes how GPUs are well-suited for data-parallel applications due to their large number of cores and throughput-oriented design. The CUDA programming model is also summarized, including how kernels are launched on the GPU from the CPU. Examples are provided of simple CUDA programs to perform operations like squaring elements in parallel on the GPU.