






















The document details a data science certification training course focusing on machine learning, specifically classification algorithms and the Naive Bayes classifier. It explains concepts such as supervised vs. unsupervised learning, provides examples of classification problems, and demonstrates how the Naive Bayes algorithm can be used to predict outcomes, such as employee salary based on various attributes. Additionally, it highlights the implementation process, model optimization, and validation for accurate predictions.
Introduction to Edureka's Data Science Certification Training, covering Machine Learning, classification, Naive Bayes, and a demo.
An overview of Machine Learning, its relationship with statistics, and applications in predictive analytics.
Comparison between supervised learning (classification) and unsupervised learning (clustering) with examples.
Introduction to classification, defining its purpose to categorize observations based on training data.
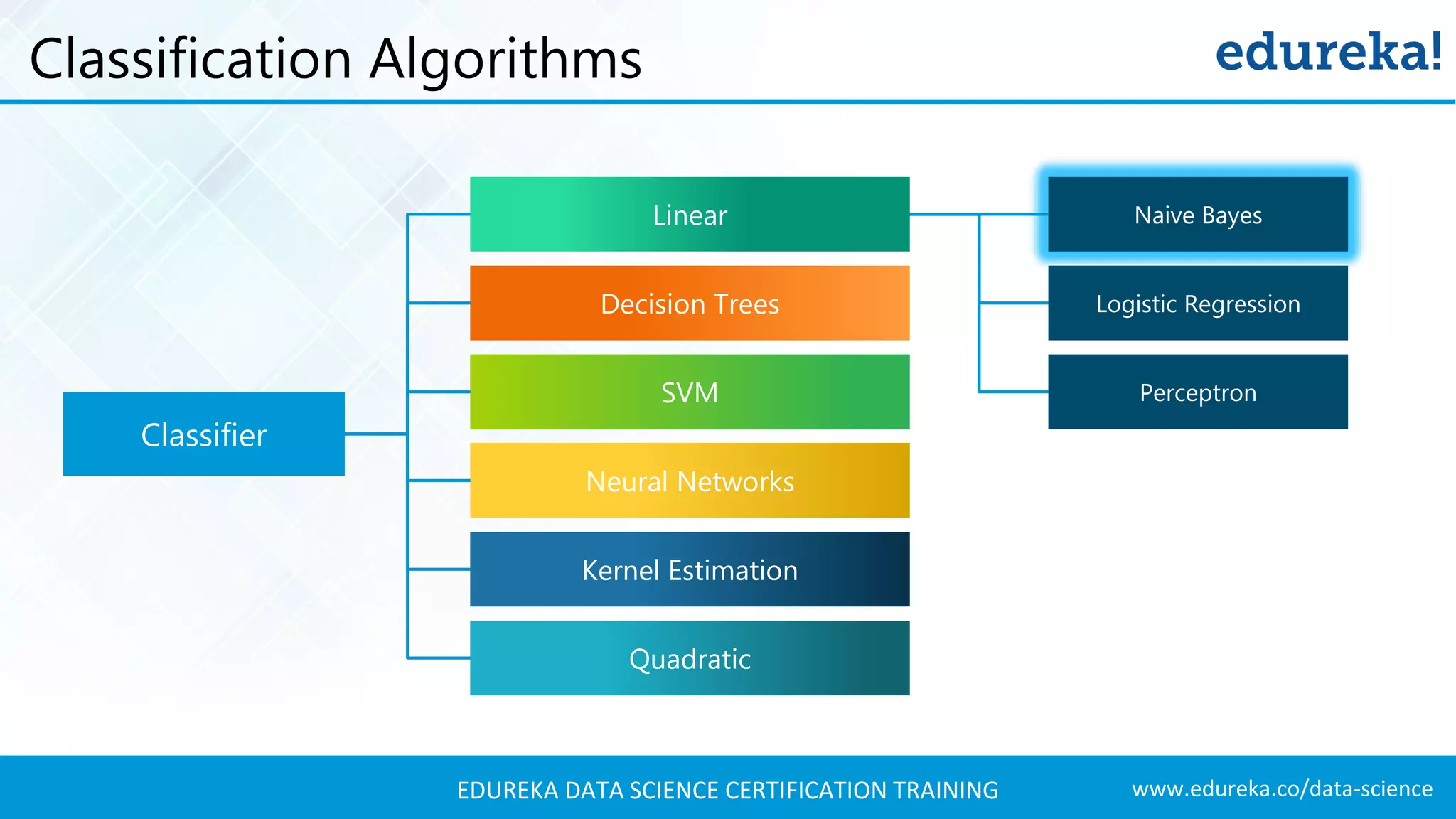
List of various classification algorithms including Naive Bayes, SVM, and Neural Networks.
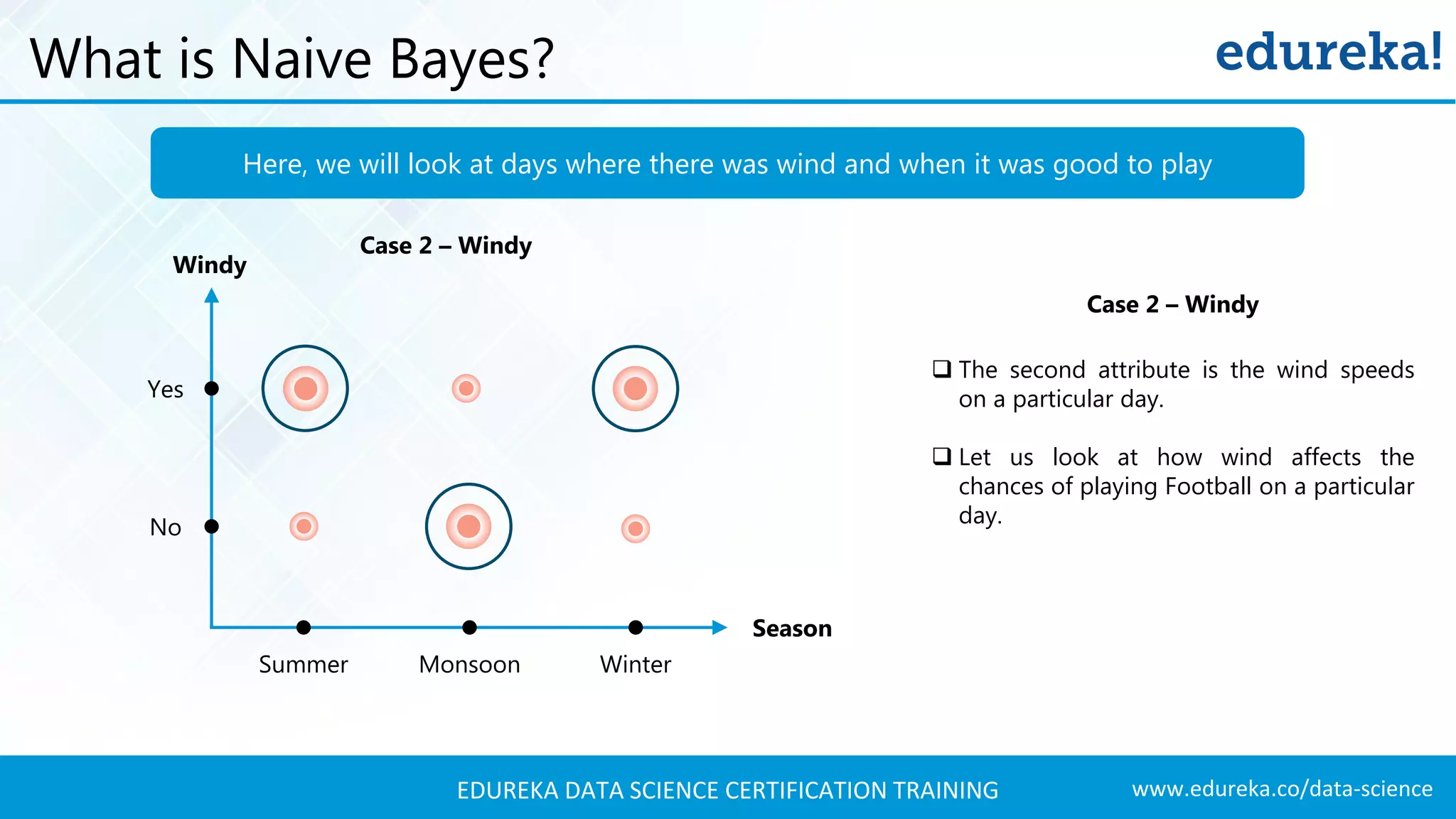
Explanation of the Naive Bayes algorithm, its practical application using weather conditions for football game prediction.
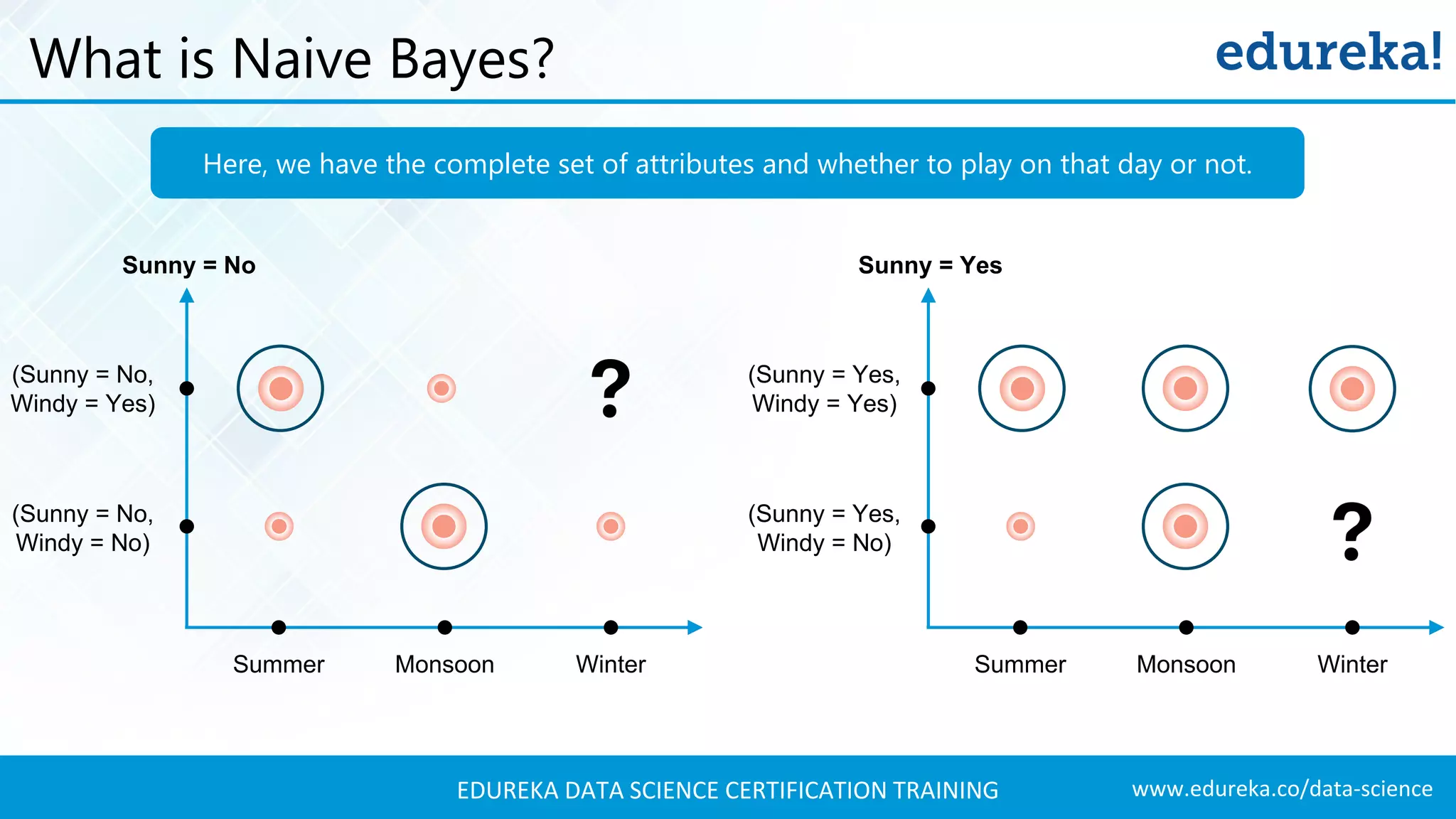
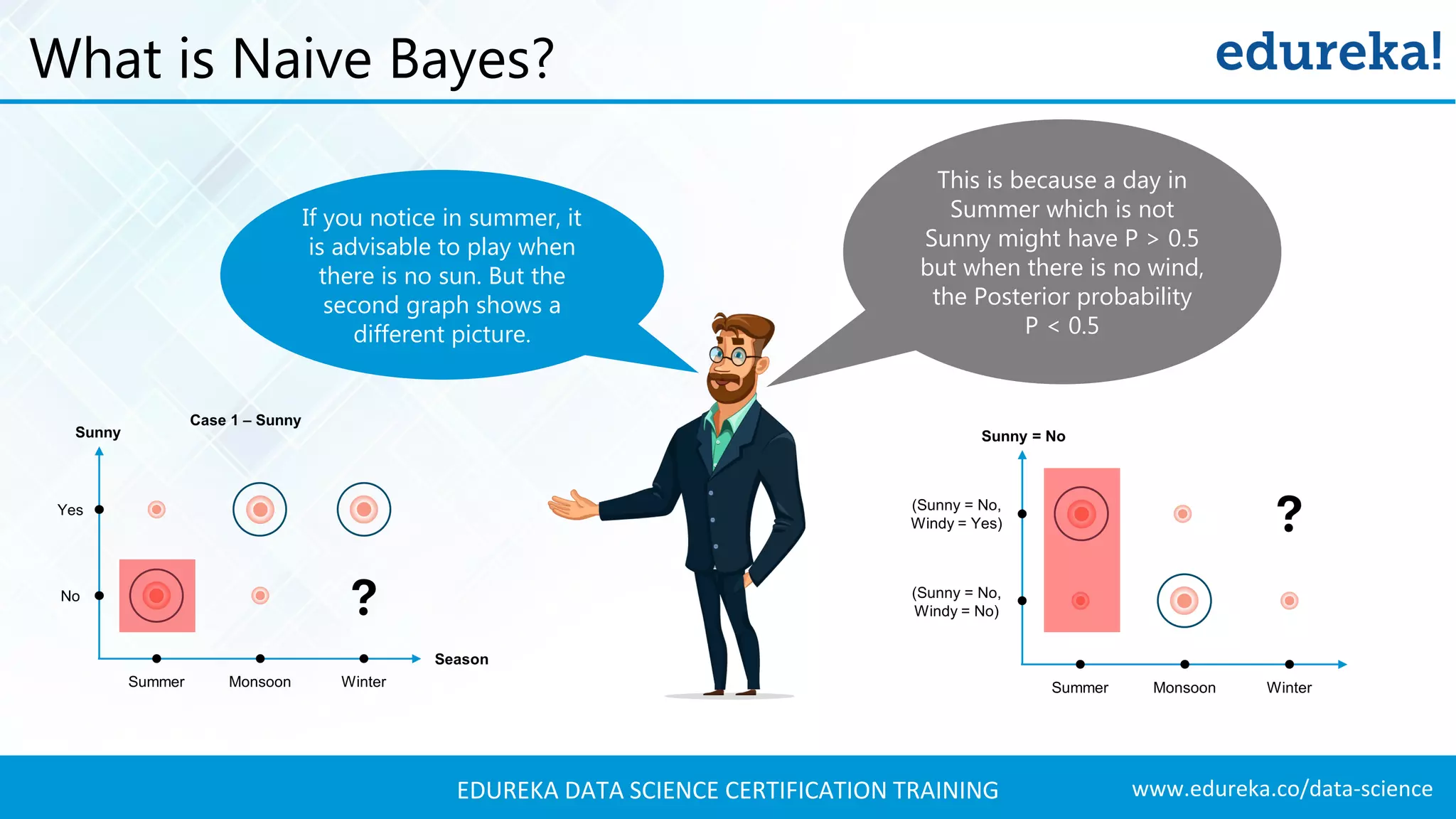
Probabilistic modeling using Naive Bayes, categorizing days based on weather attributes for decision-making.
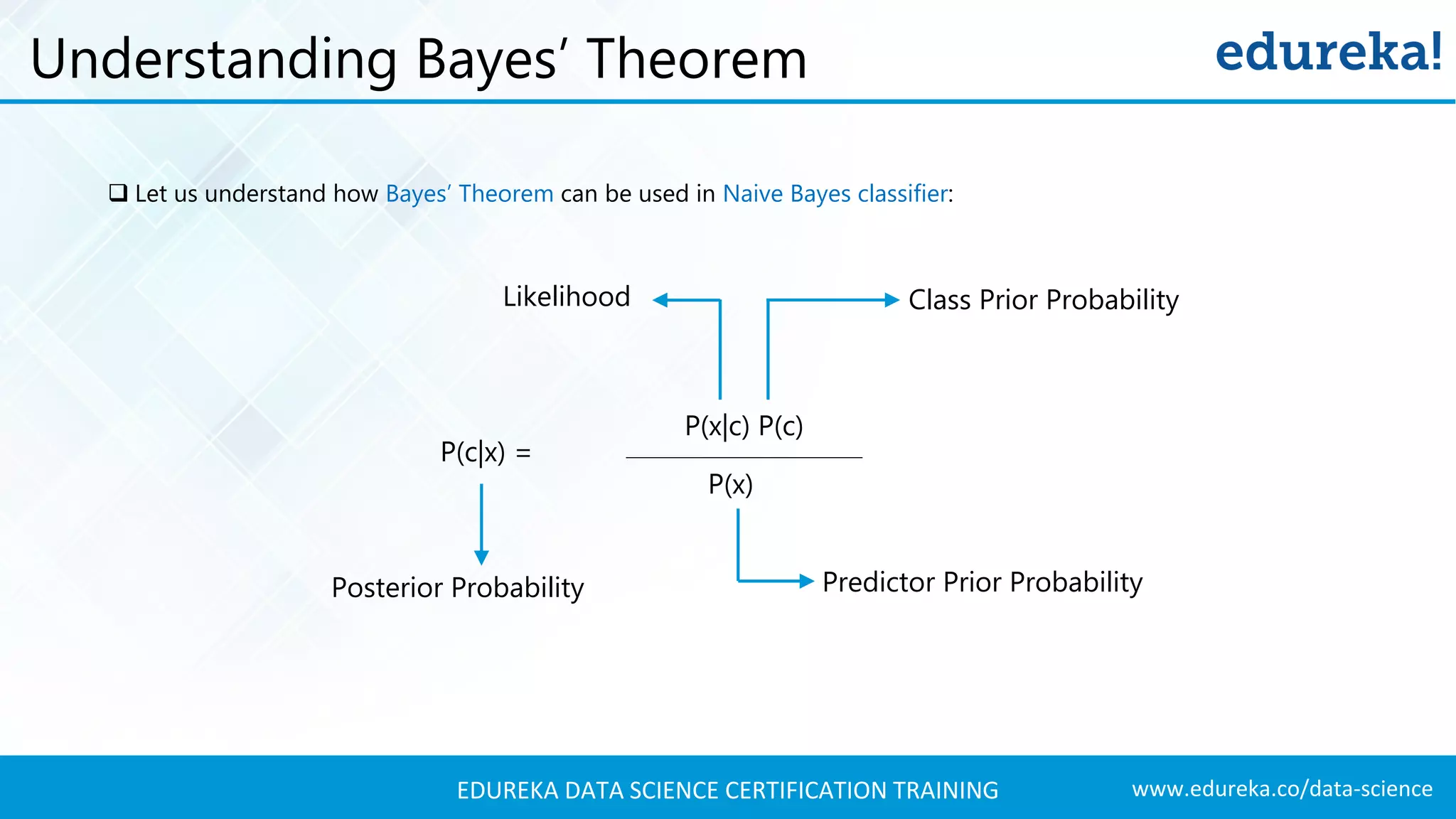
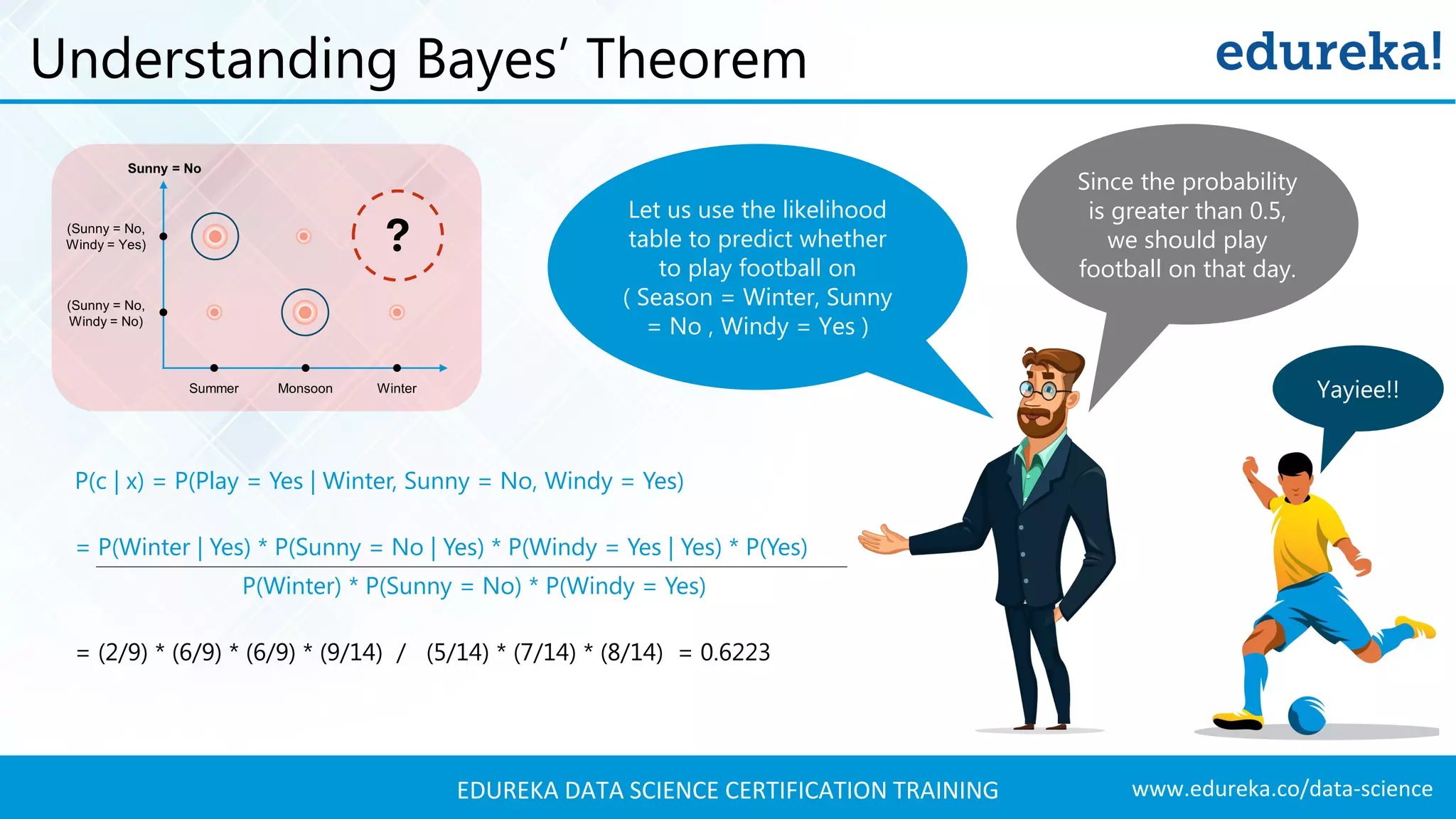
Introduction to Bayes’ theorem and its application in Naive Bayes classification with mathematical representation.
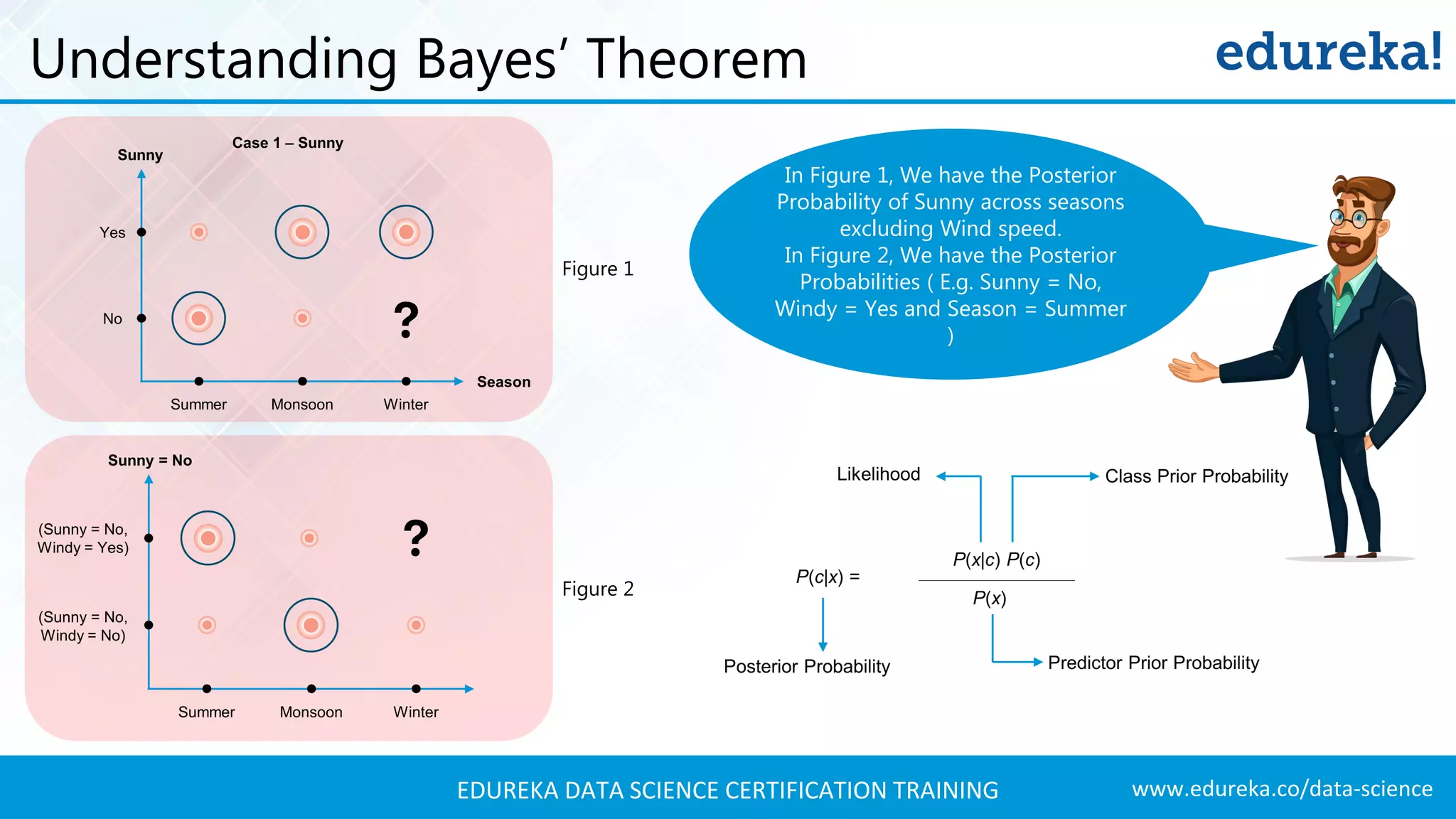
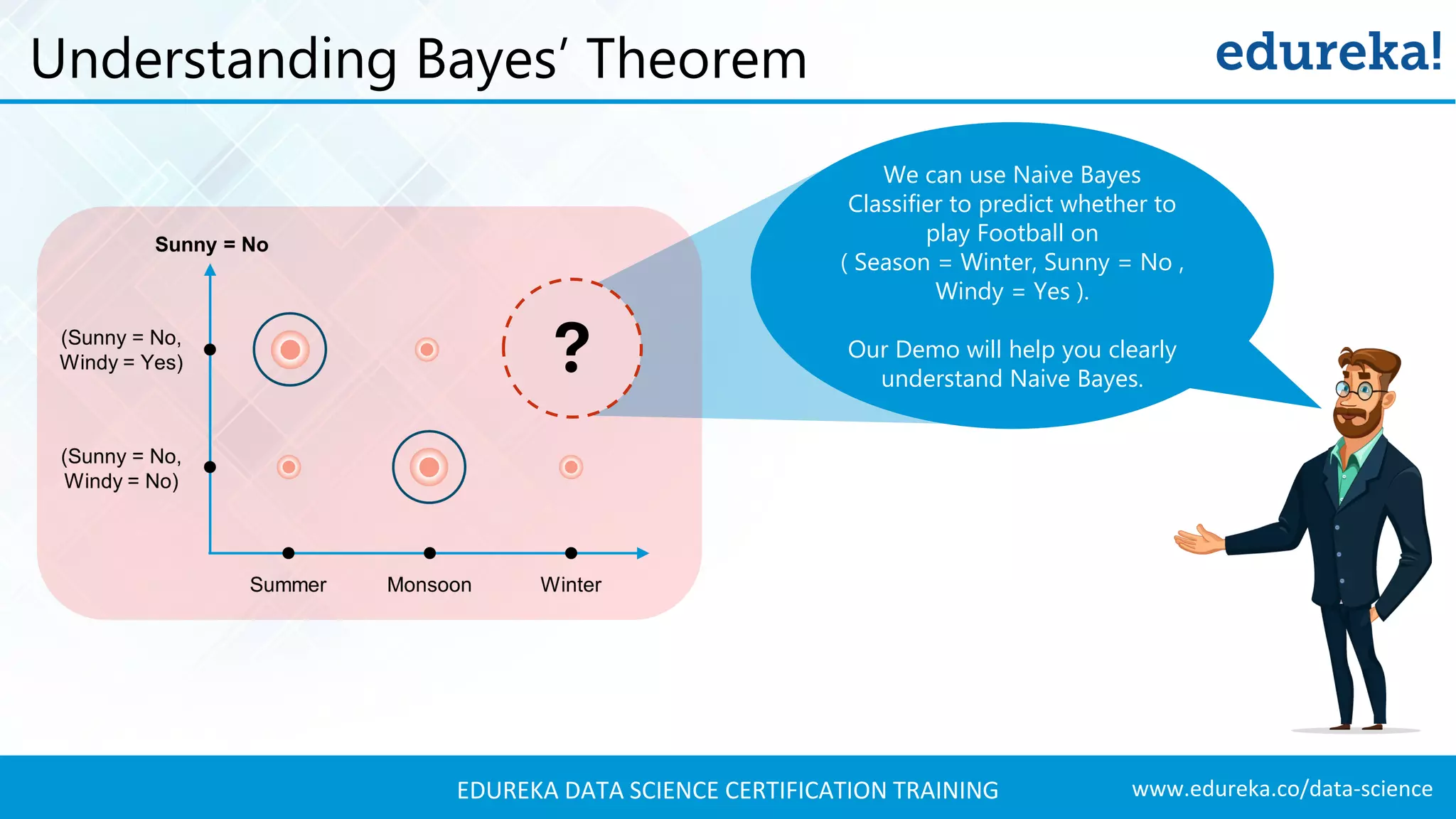
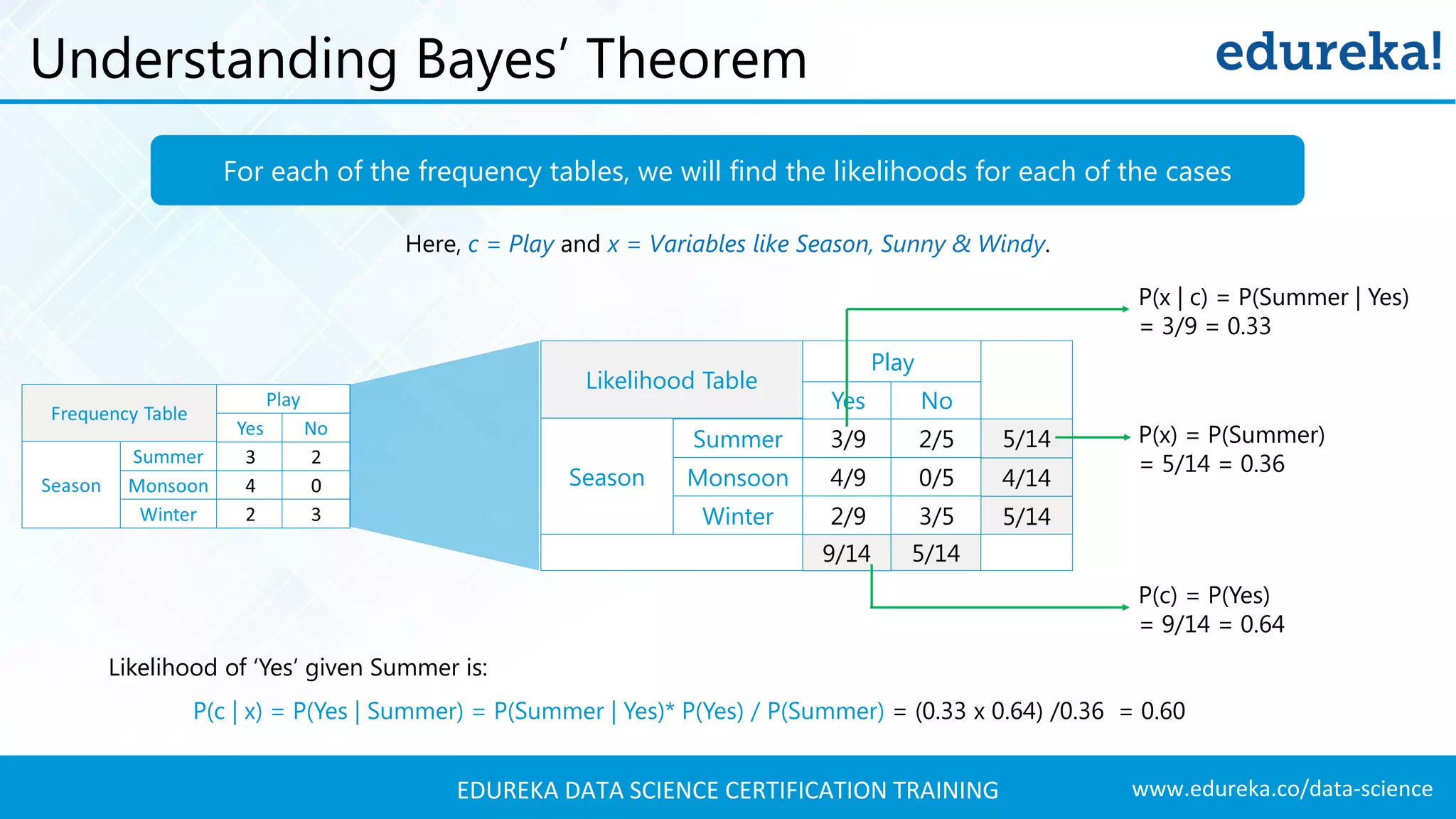
Using Bayes' theorem to calculate posterior probabilities for predicting whether to play football on specific days.
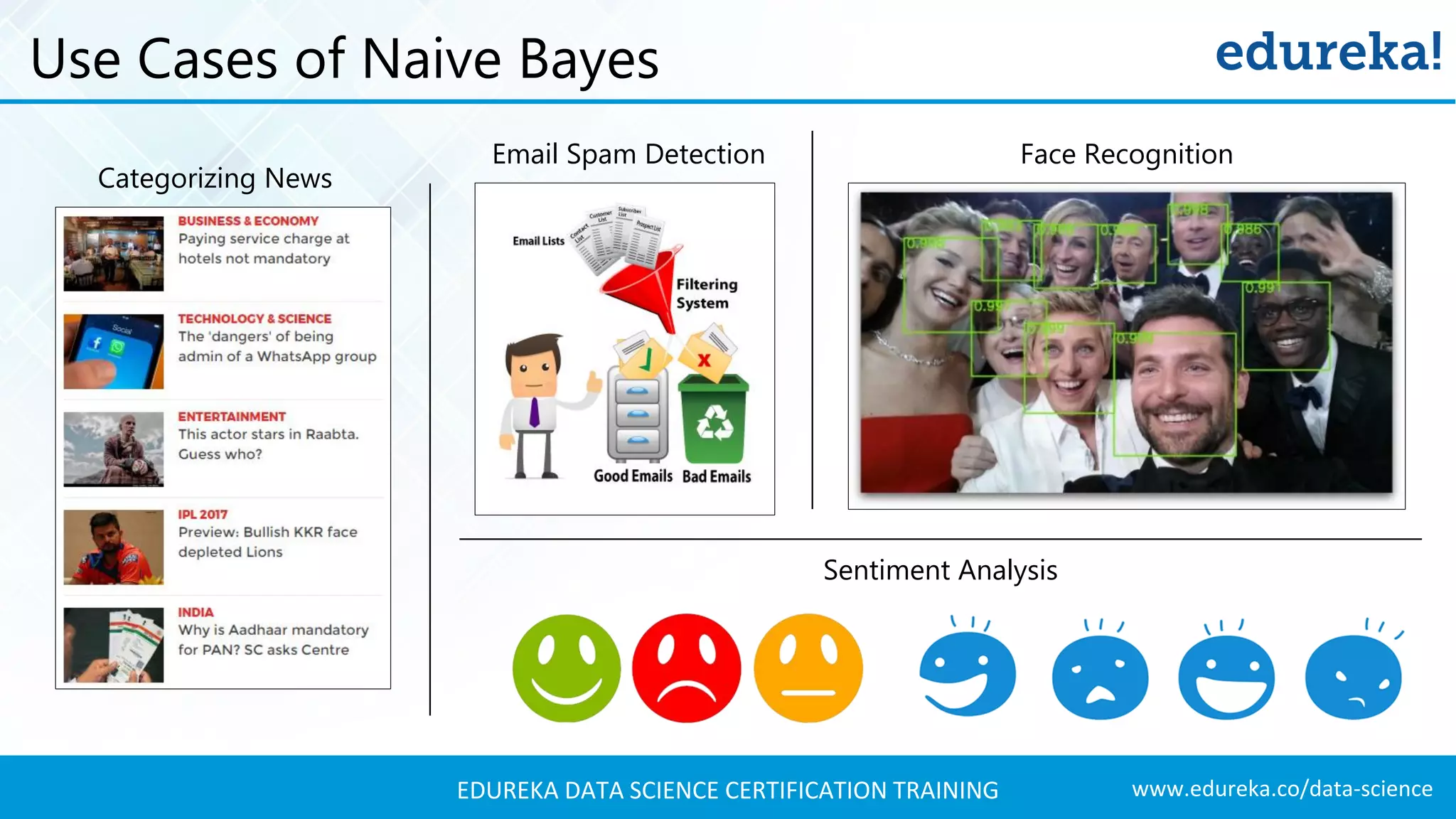
Application of Naive Bayes in various domains including email spam detection, sentiment analysis, and medical diagnosis.
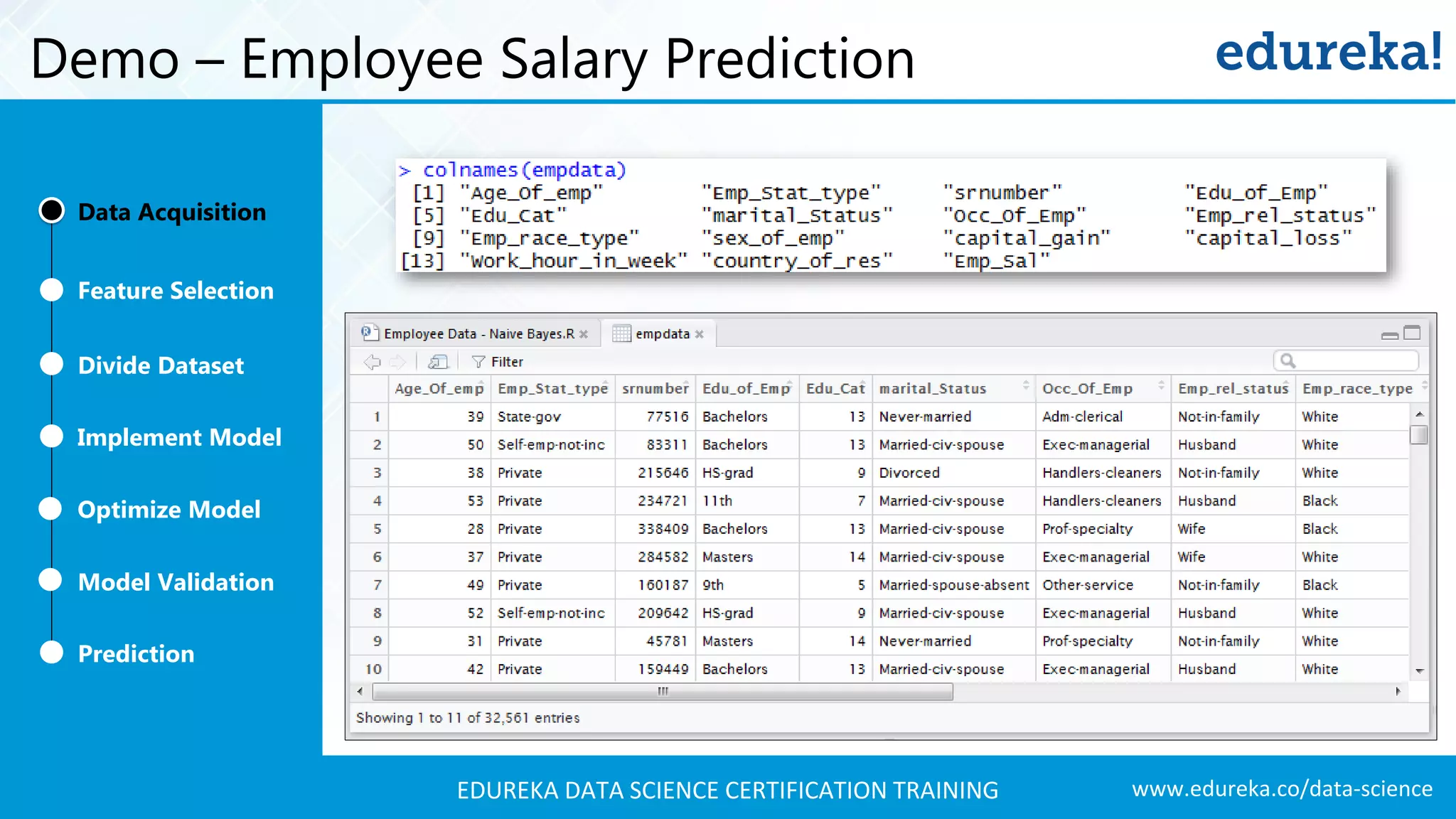
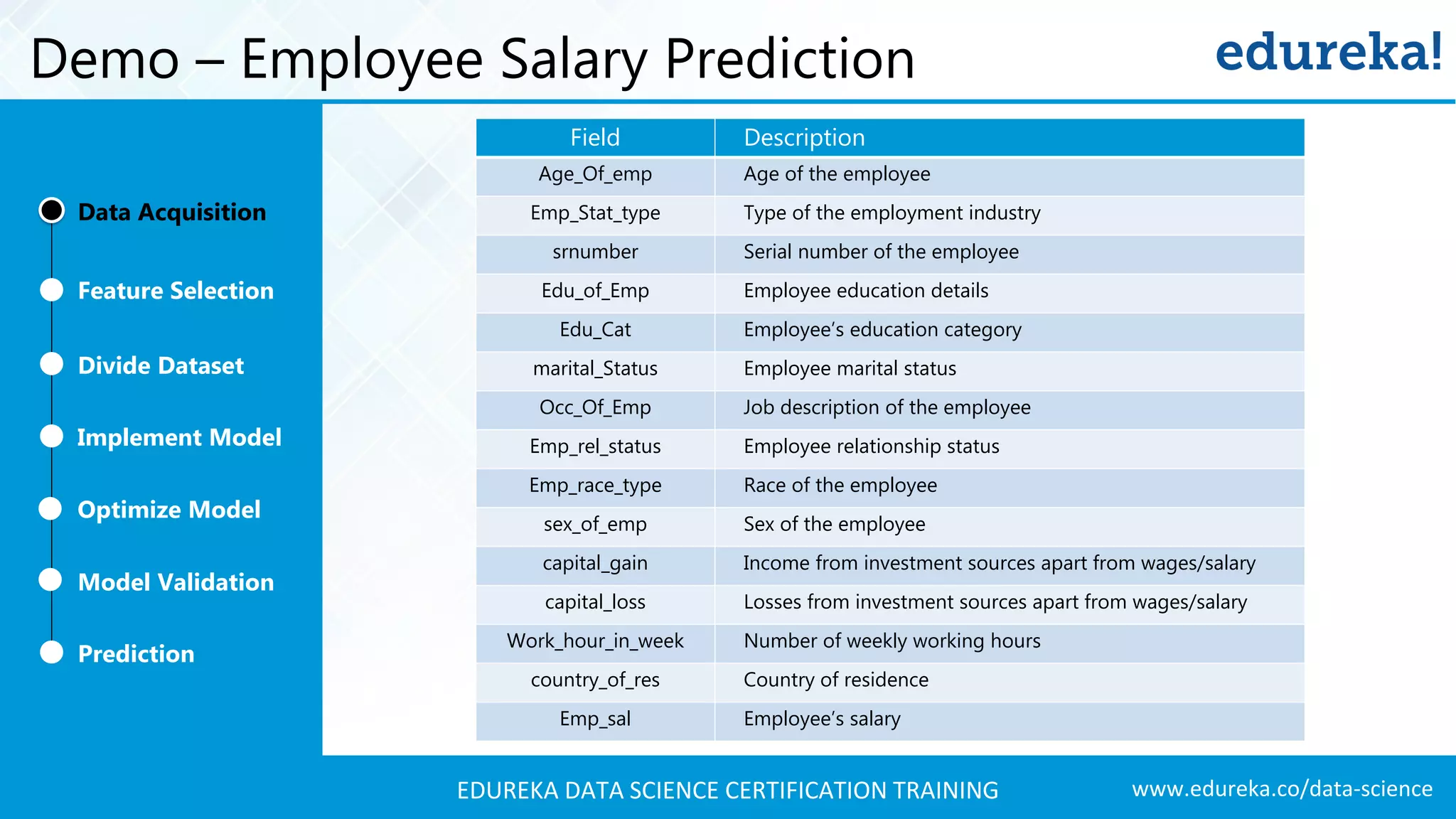
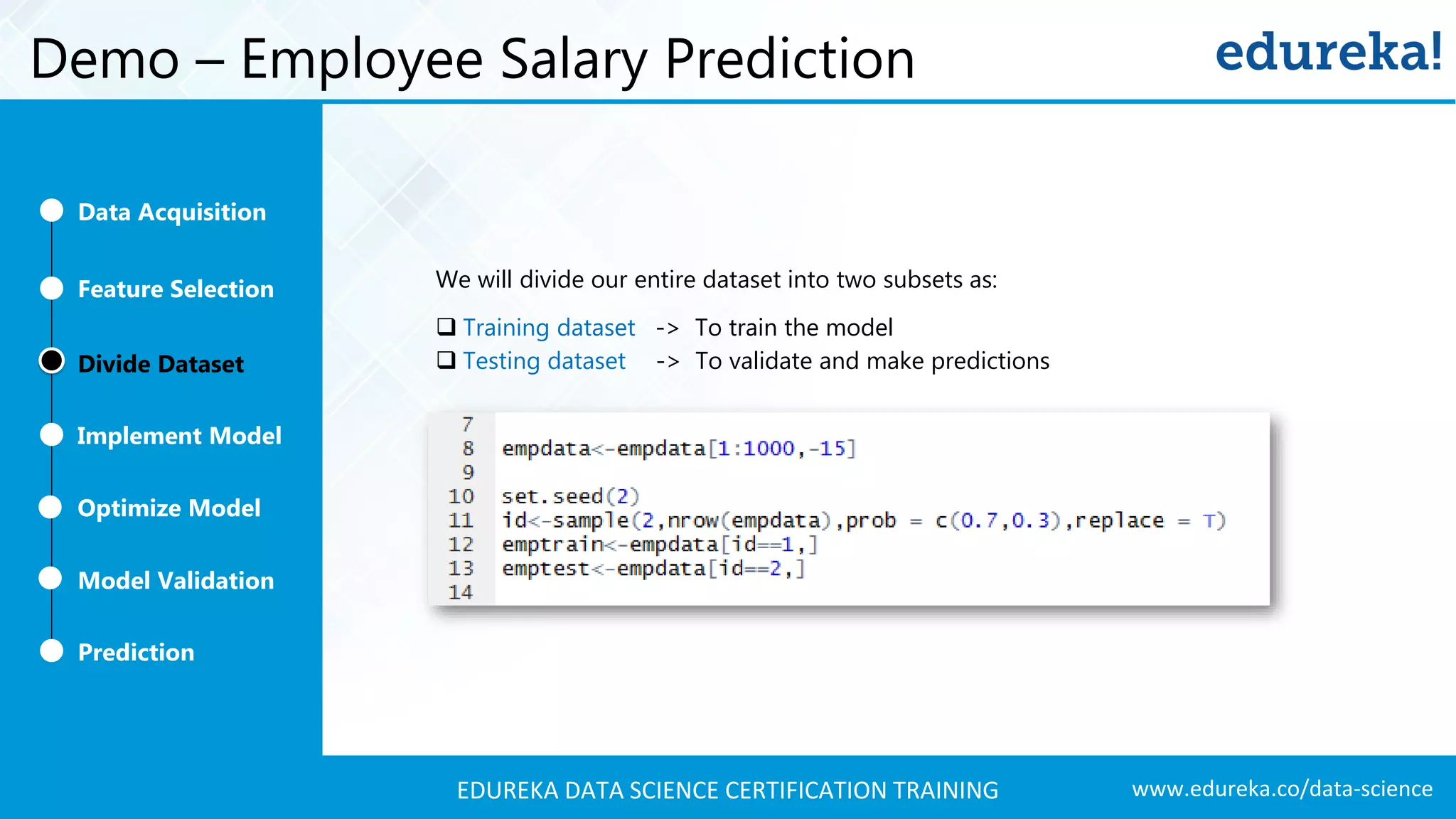
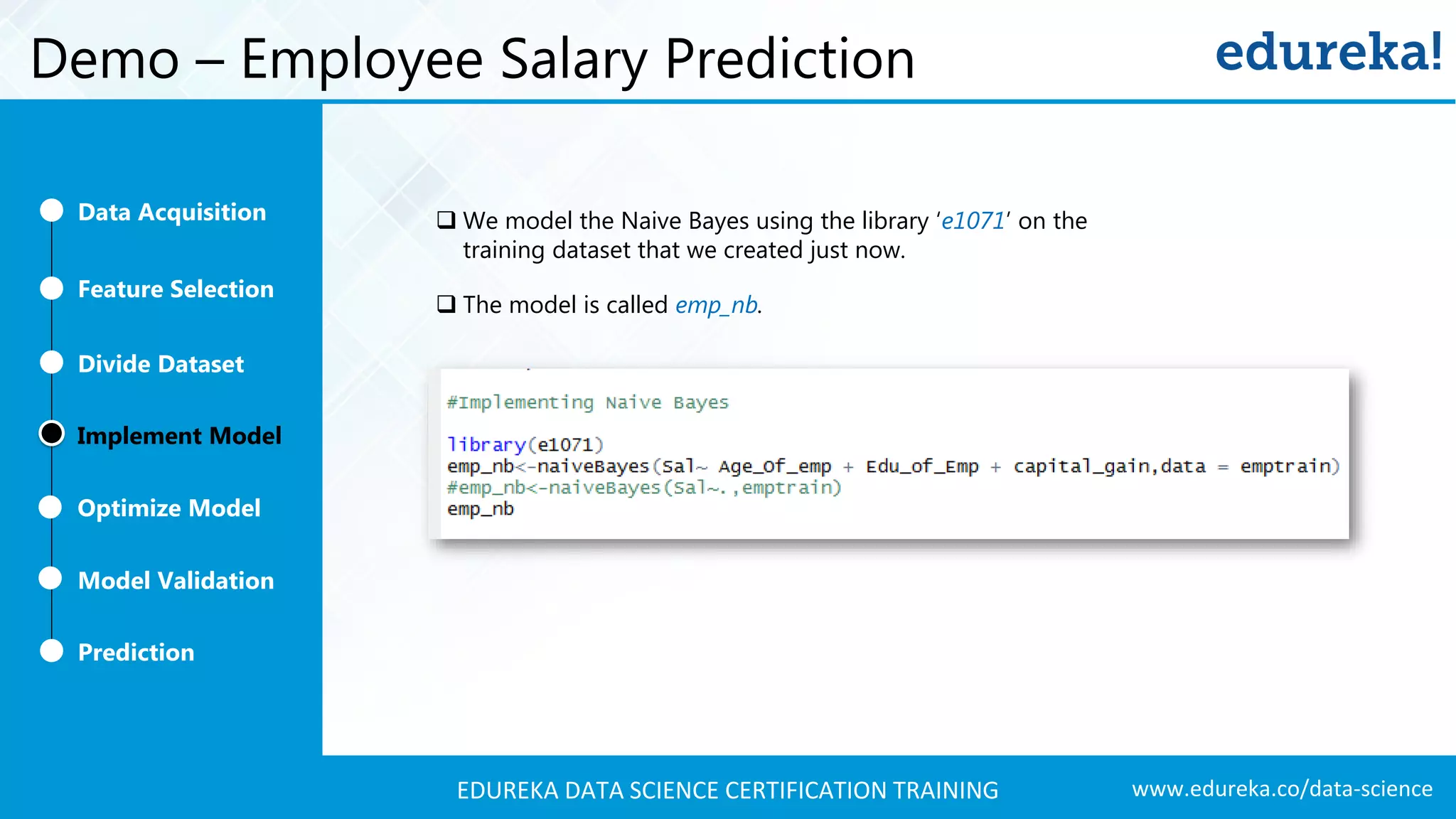
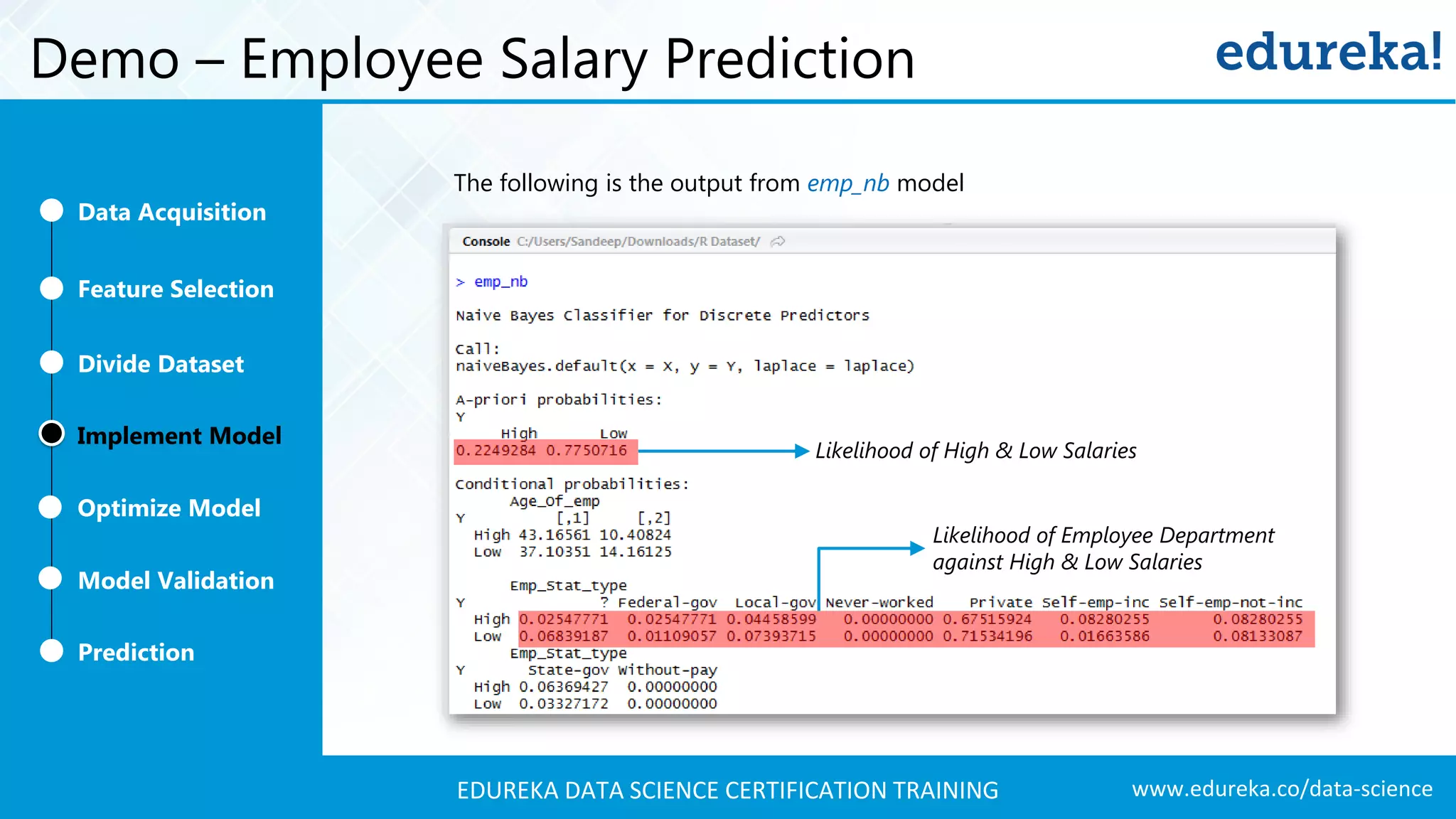
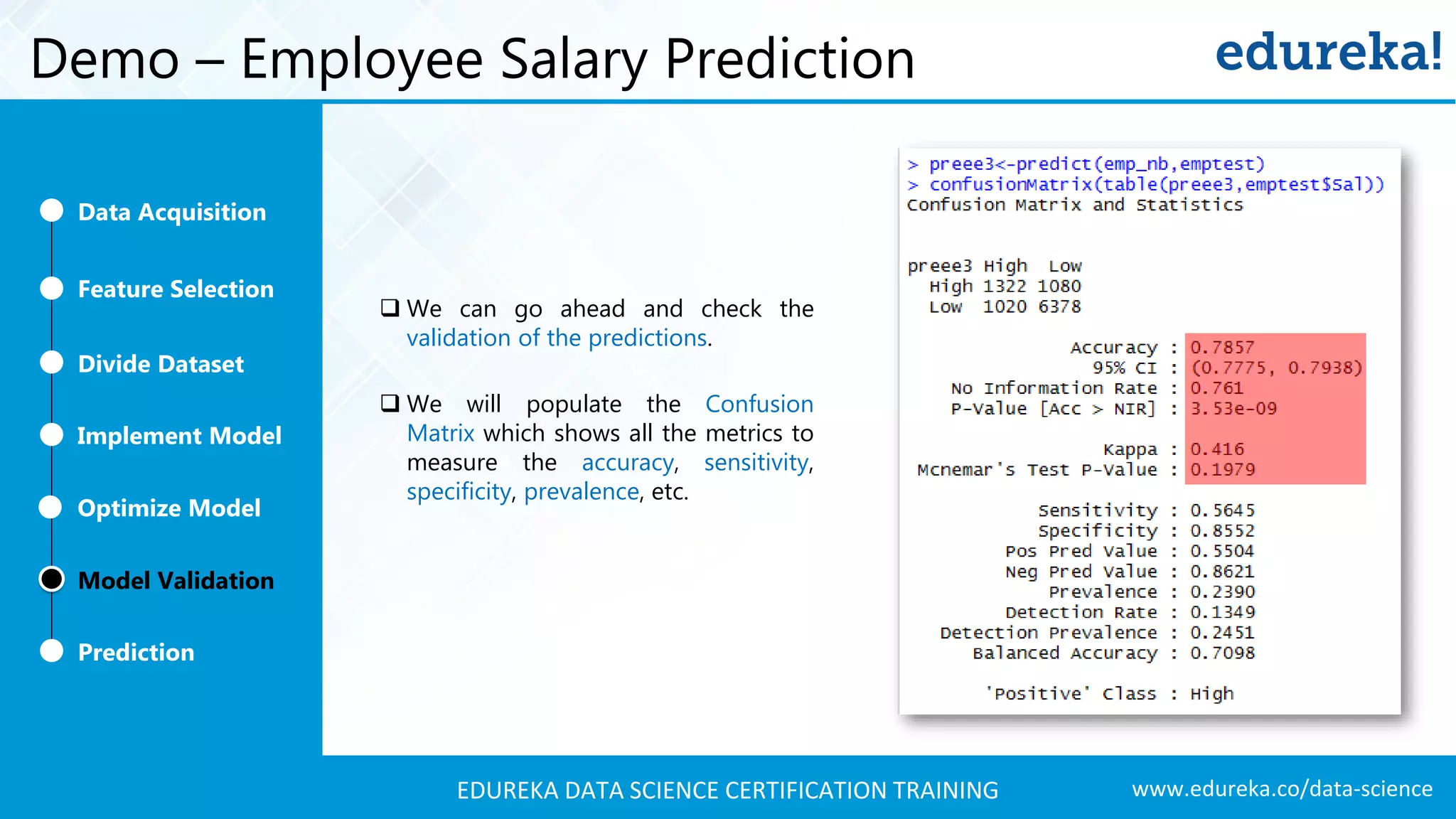
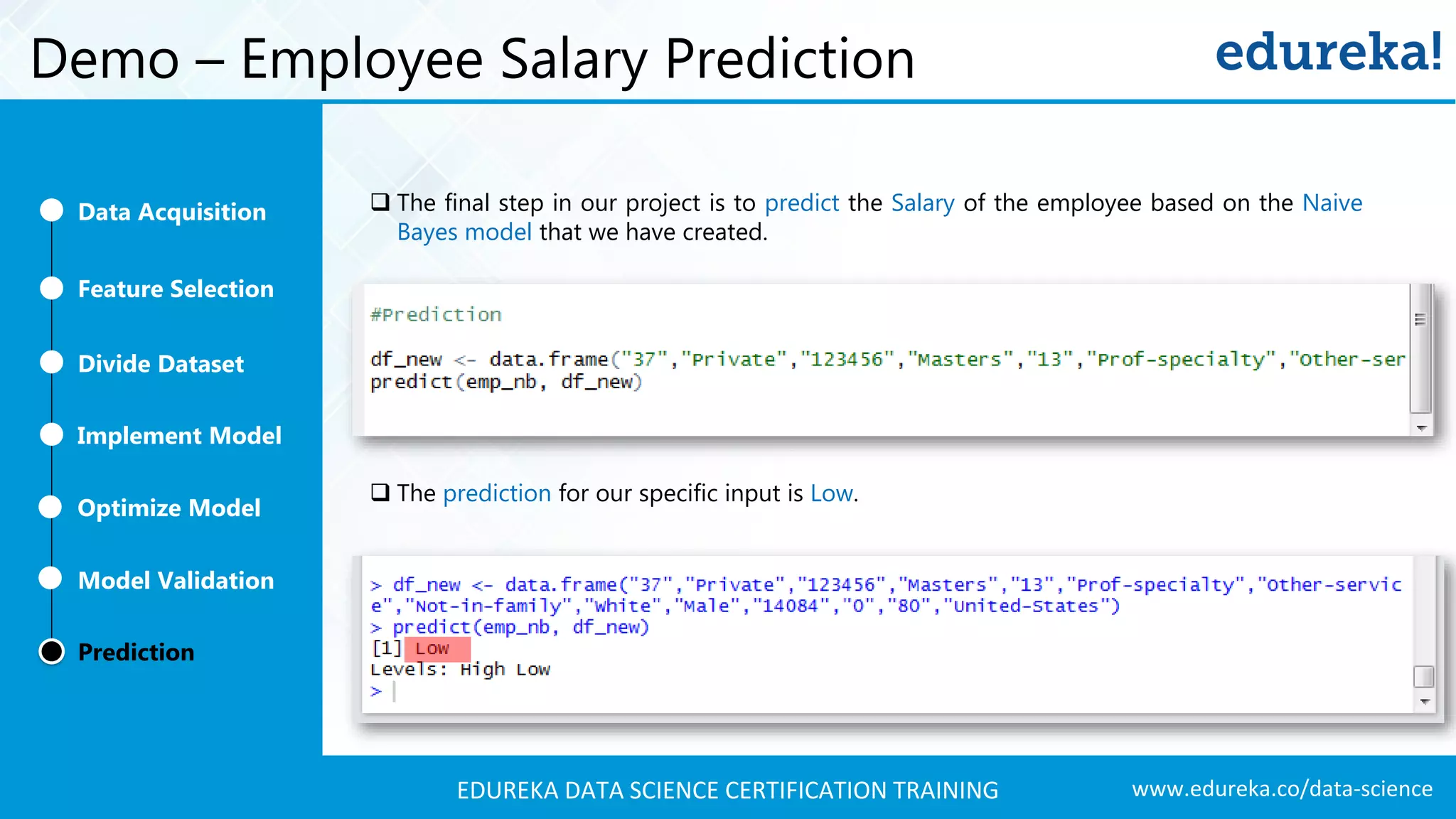
A comprehensive demo using Naive Bayes to predict employee salaries, detailing data acquisition, model building, optimization, and validation processes.
Summarization of the presentation covering all key points regarding Machine Learning, classification, and the Naive Bayes algorithm.