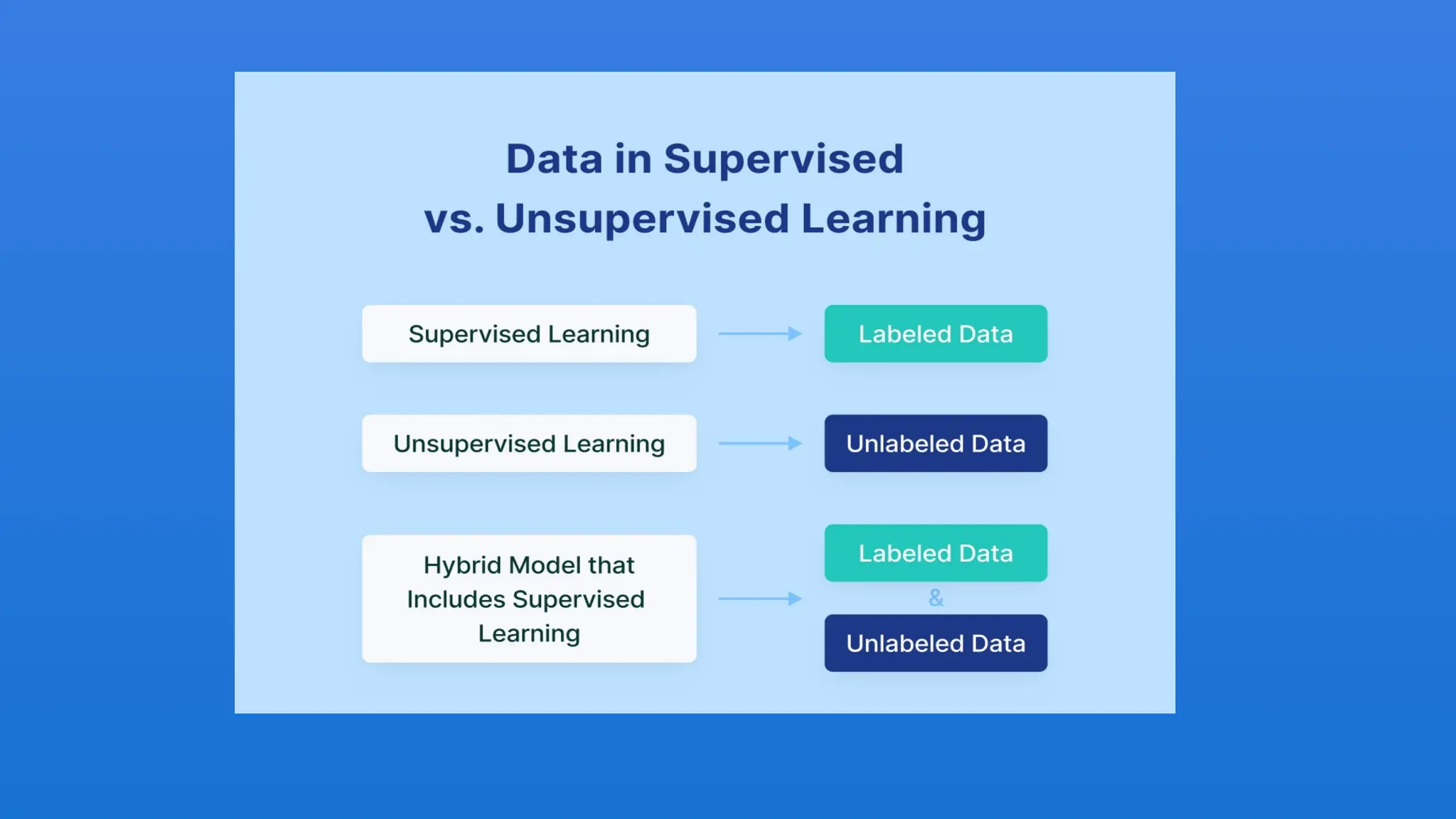
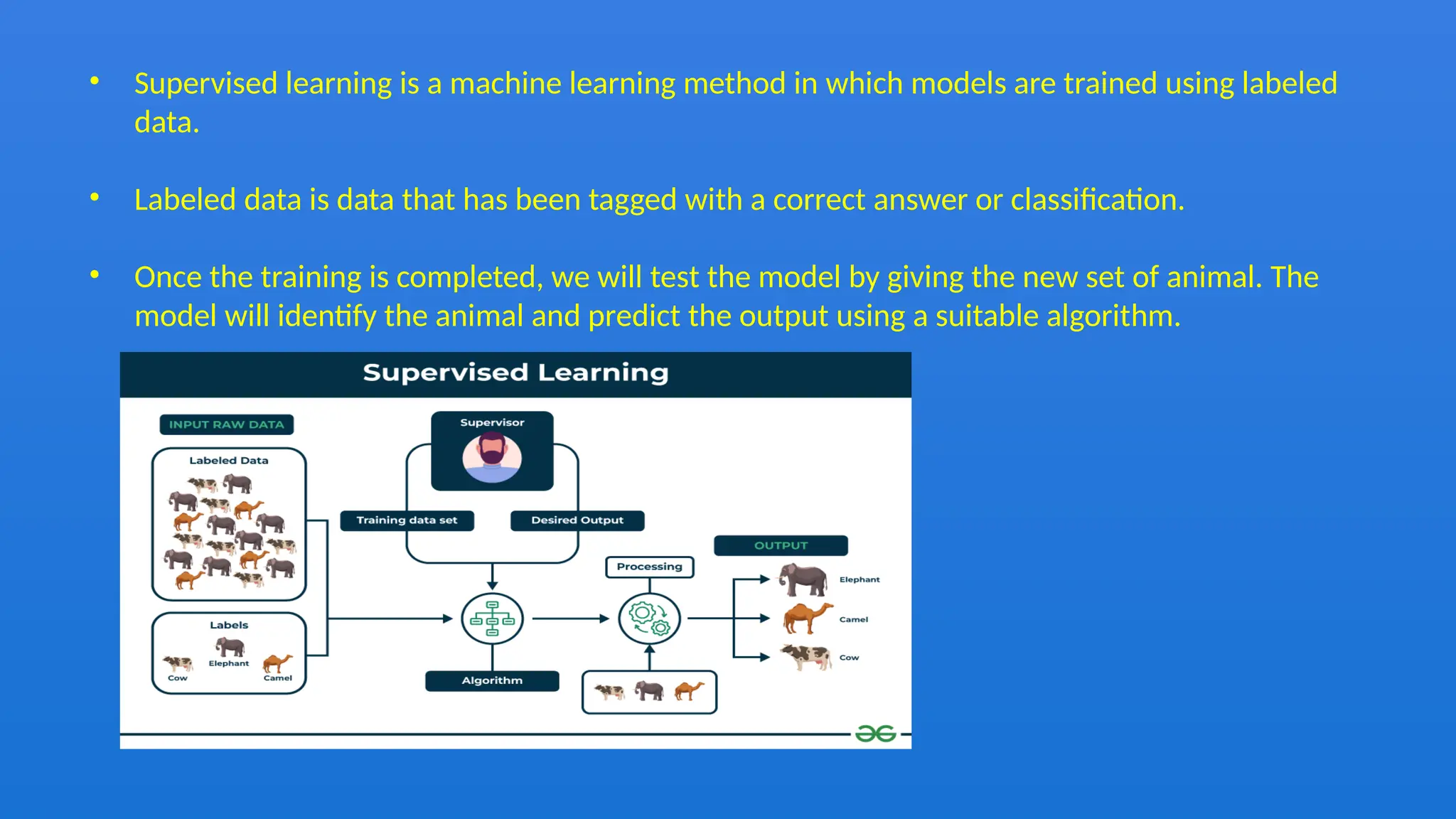
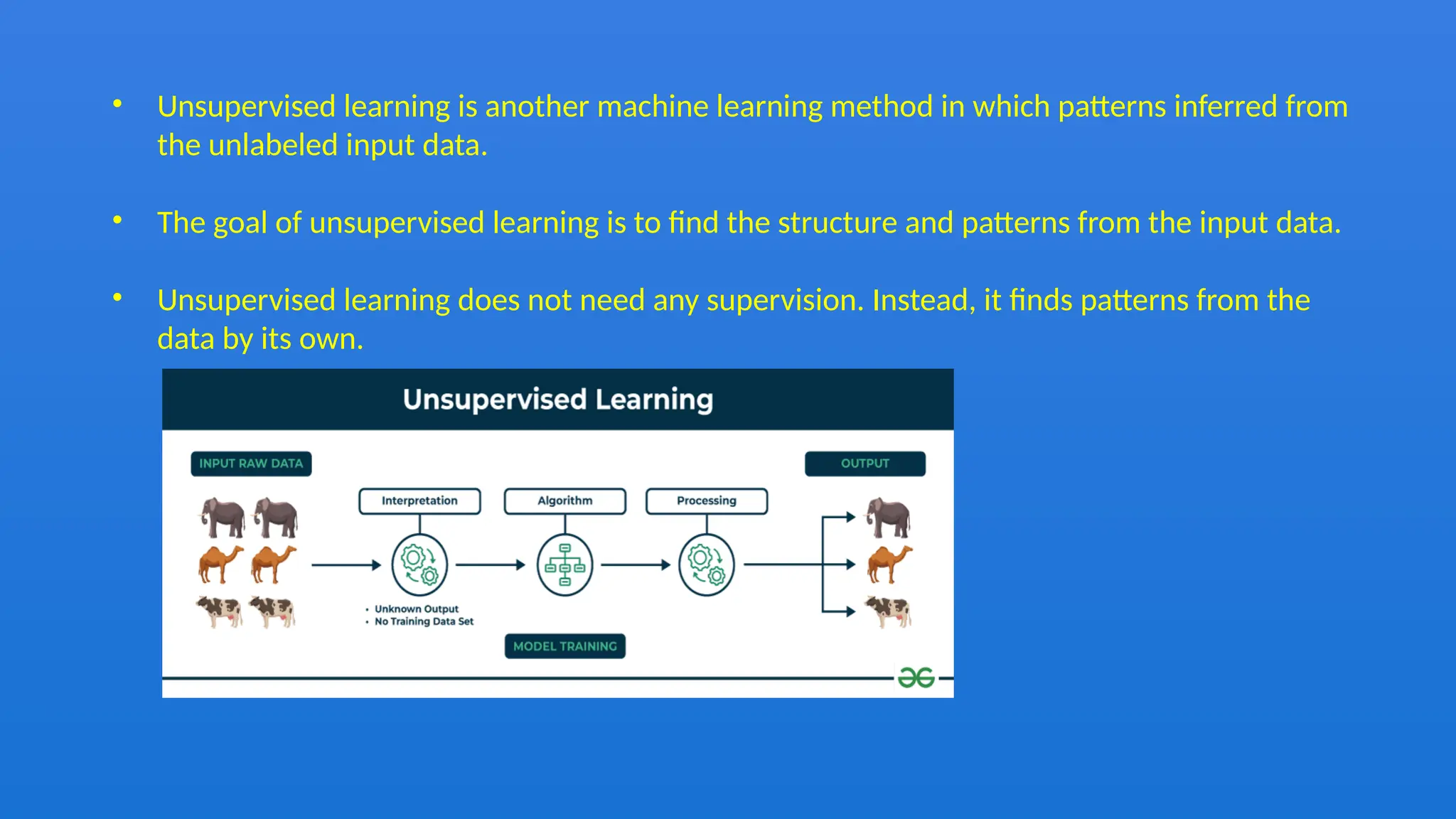
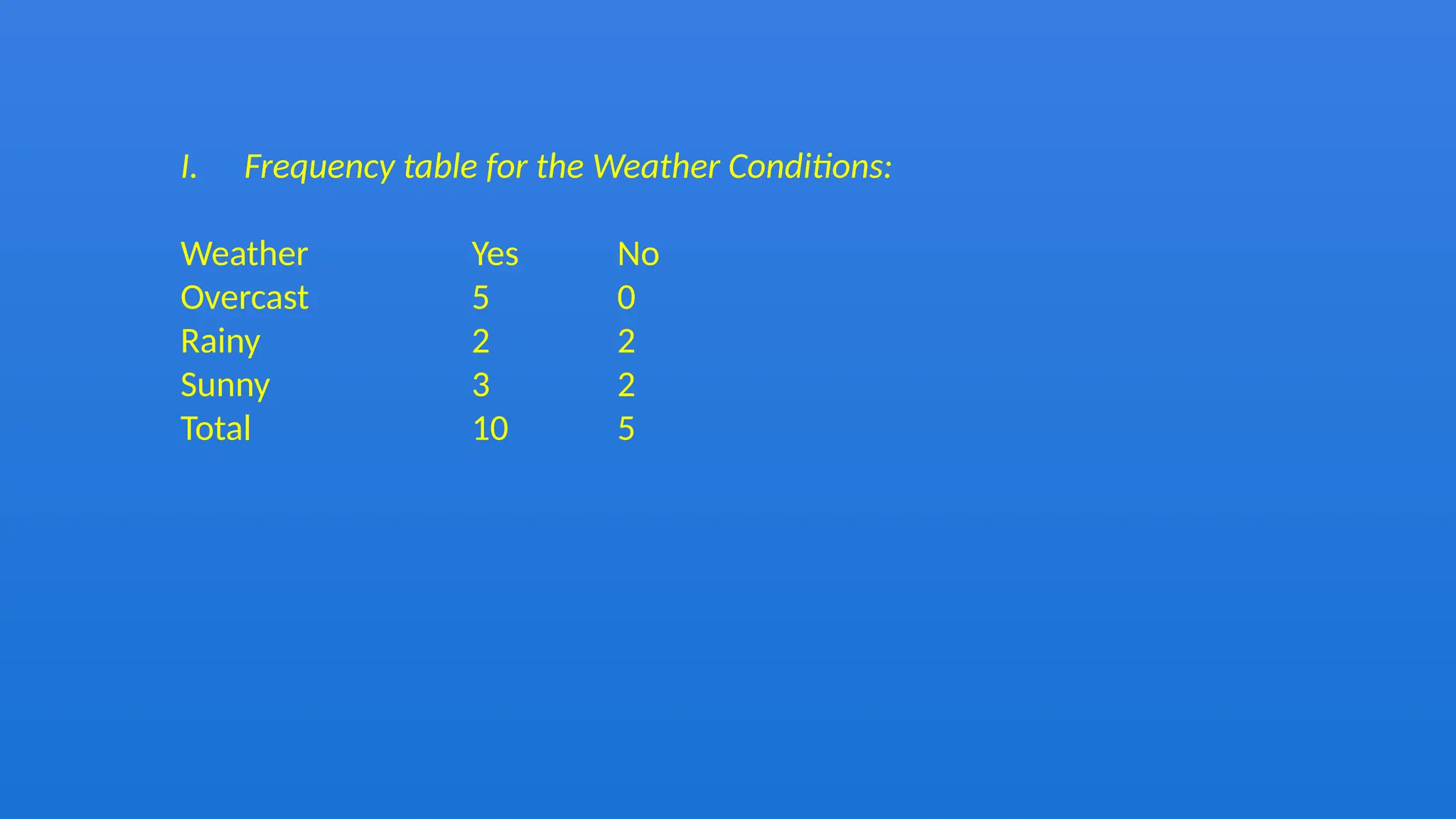
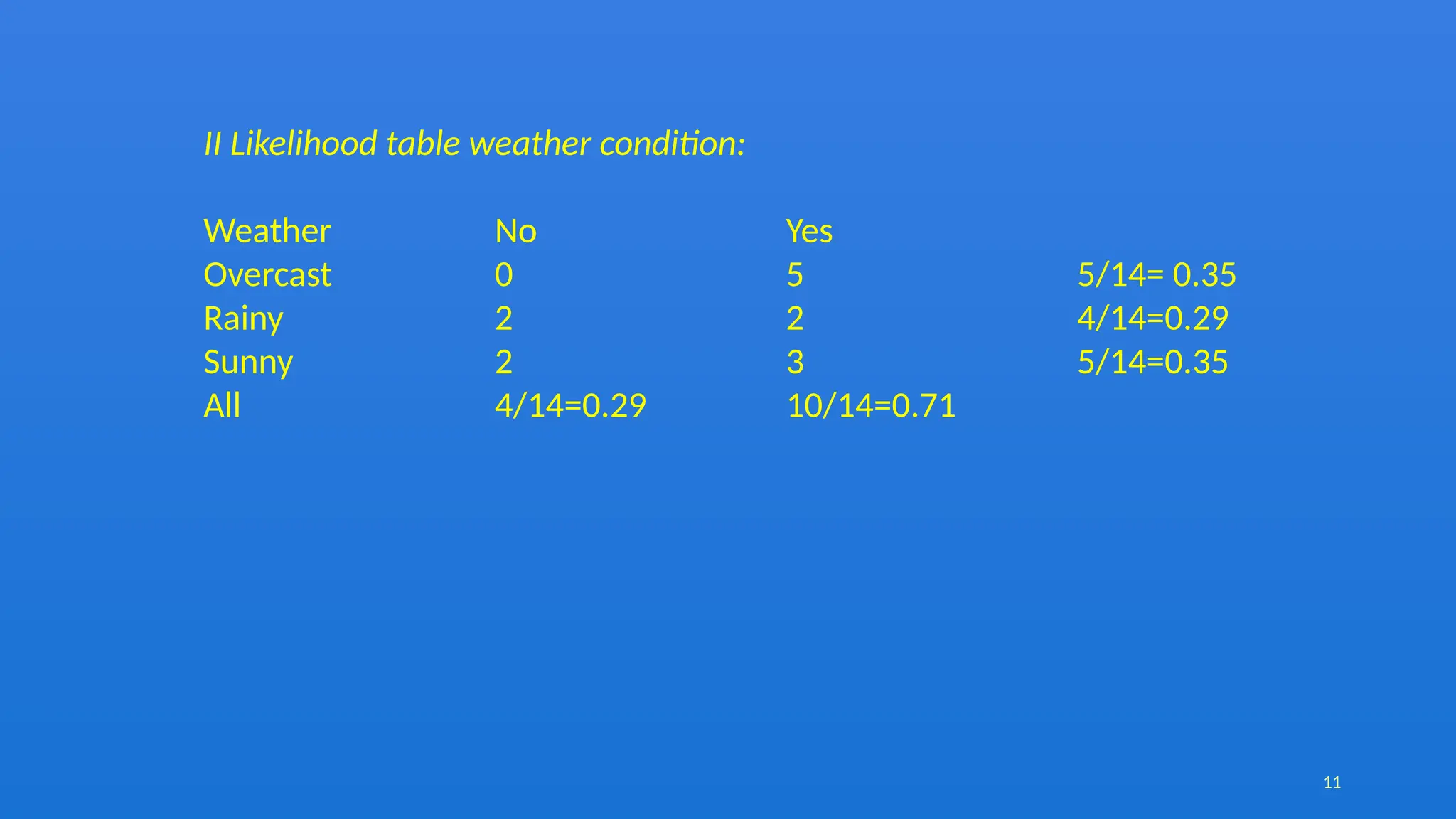
The document discusses the Naïve Bayes classifier, a supervised learning algorithm based on Bayes' theorem, often used for classification problems such as text classification. It highlights the distinction between supervised and unsupervised learning and explains the working of the Naïve Bayes classifier through examples, including a weather dataset scenario. Additionally, it outlines the advantages, disadvantages, and applications of the Naïve Bayes classifier, emphasizing its effectiveness in scenarios like spam filtration and sentiment analysis.