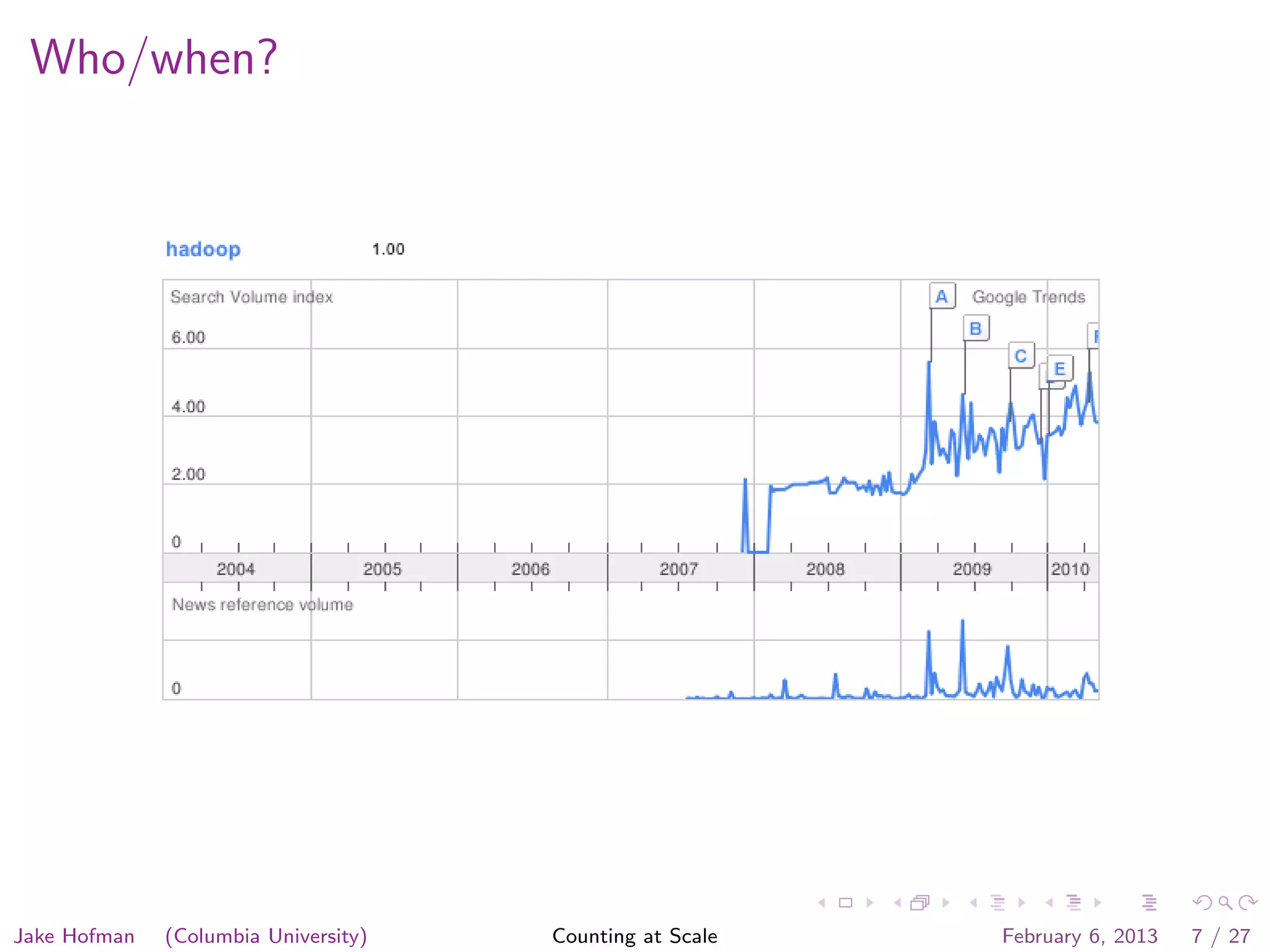
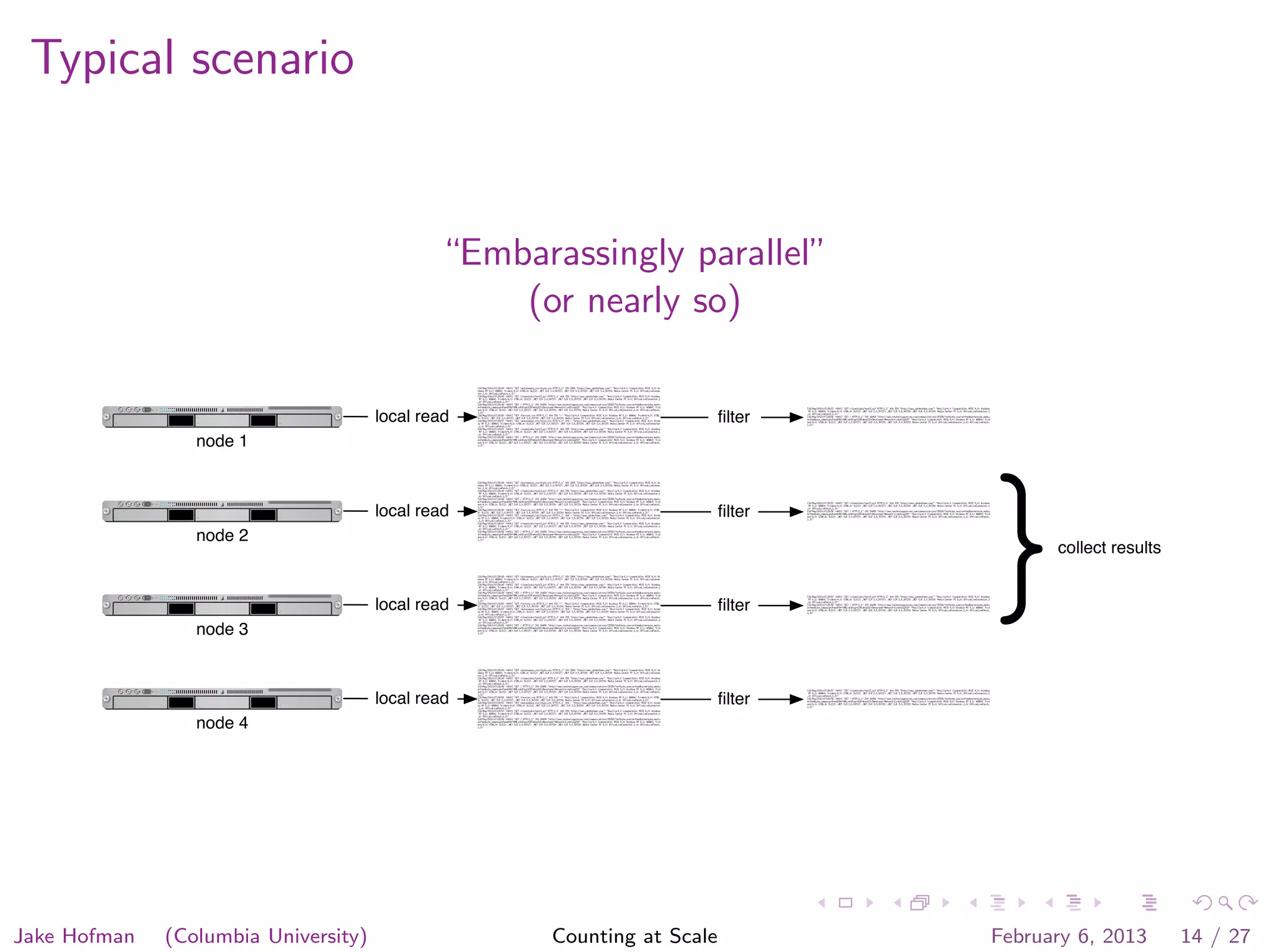
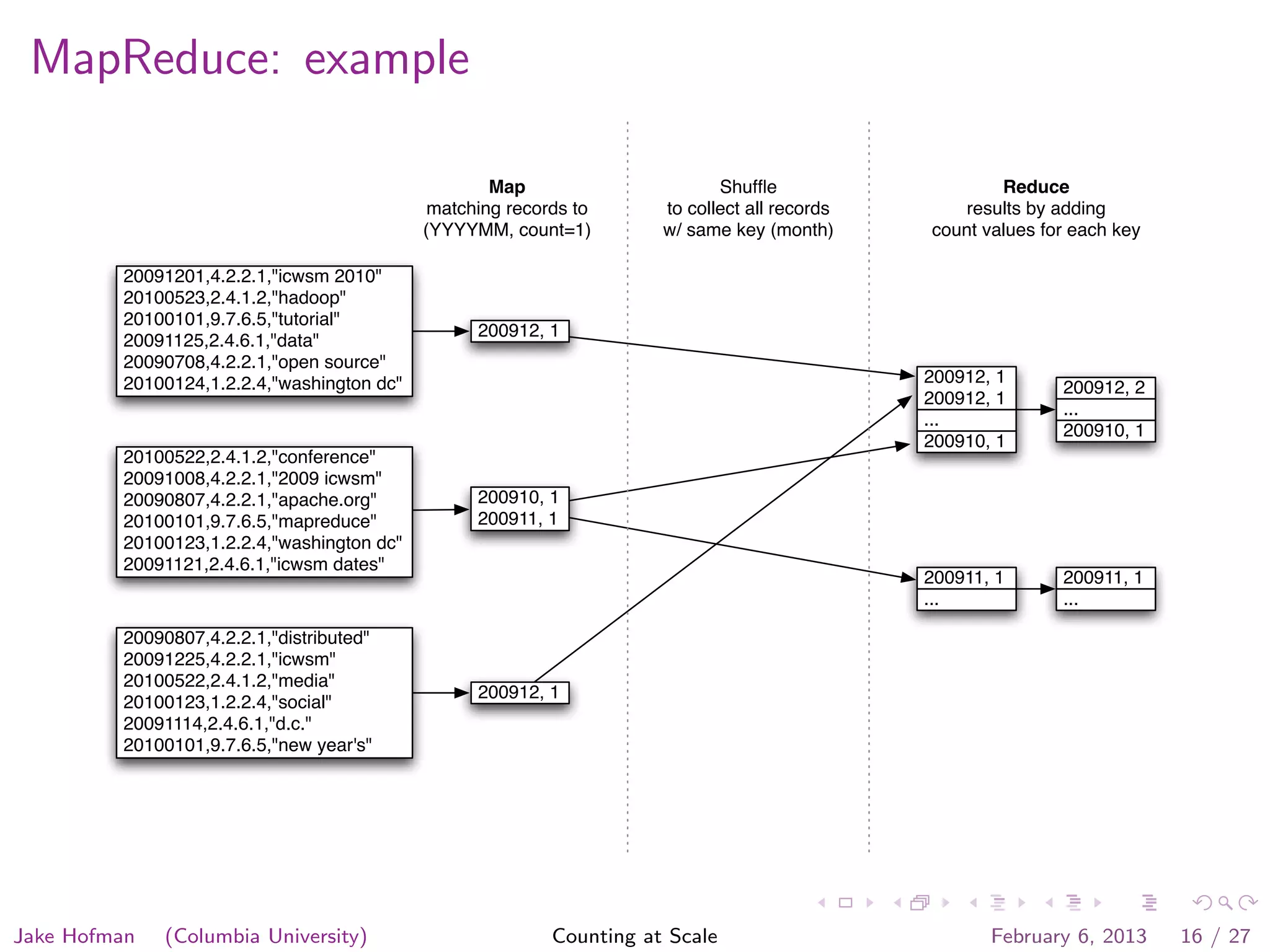
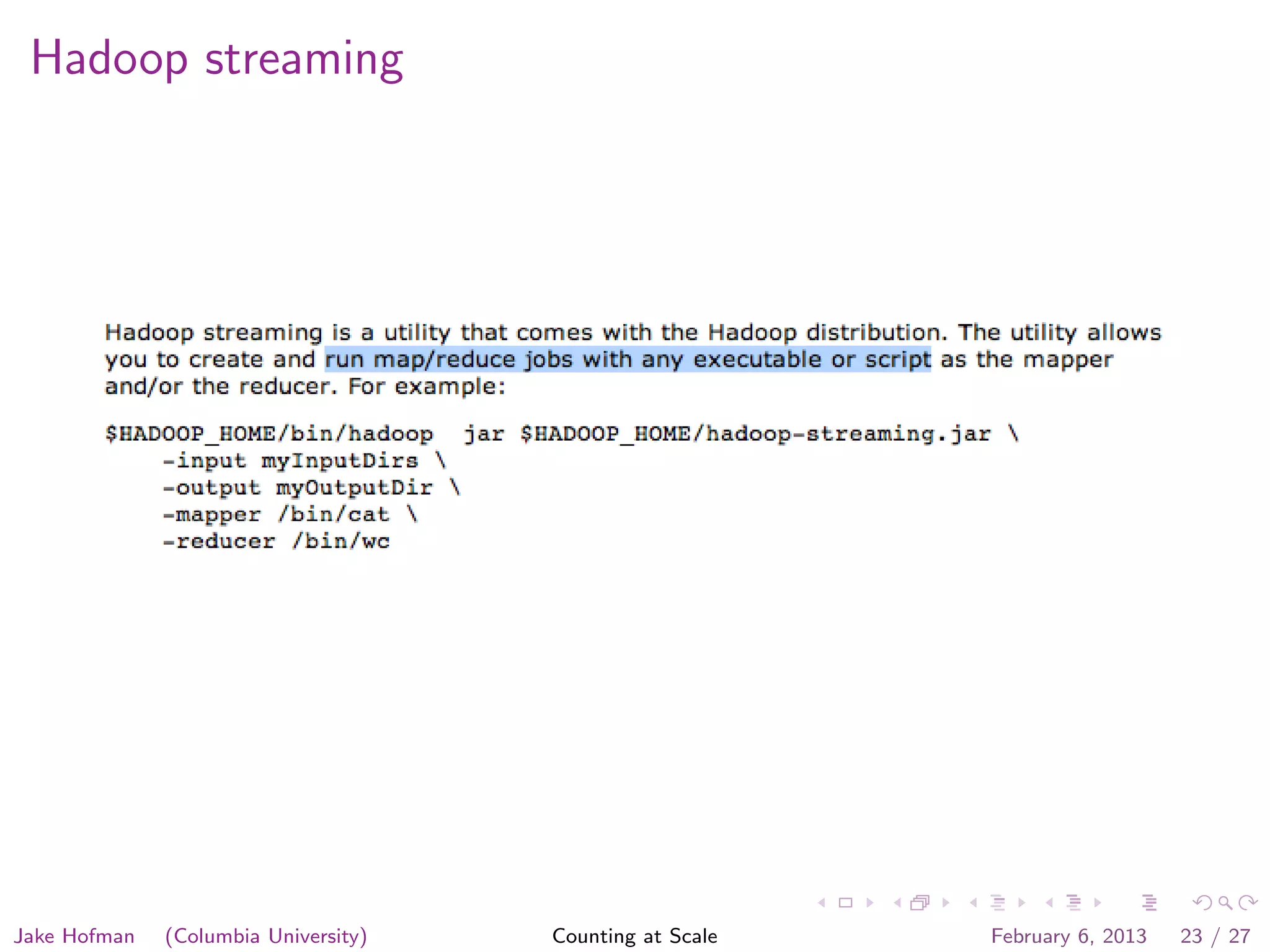
Jake Hofman of Columbia University gave a presentation on counting at scale using MapReduce. He began with an overview of MapReduce and how it allows programs to scale transparently by breaking large problems into smaller parallelized parts. He then demonstrated MapReduce through an example word counting problem, showing how the map and reduce functions work to distribute the work across nodes and aggregate the results. The presentation explained how MapReduce abstracts away the complexities of distributed and parallel processing.