

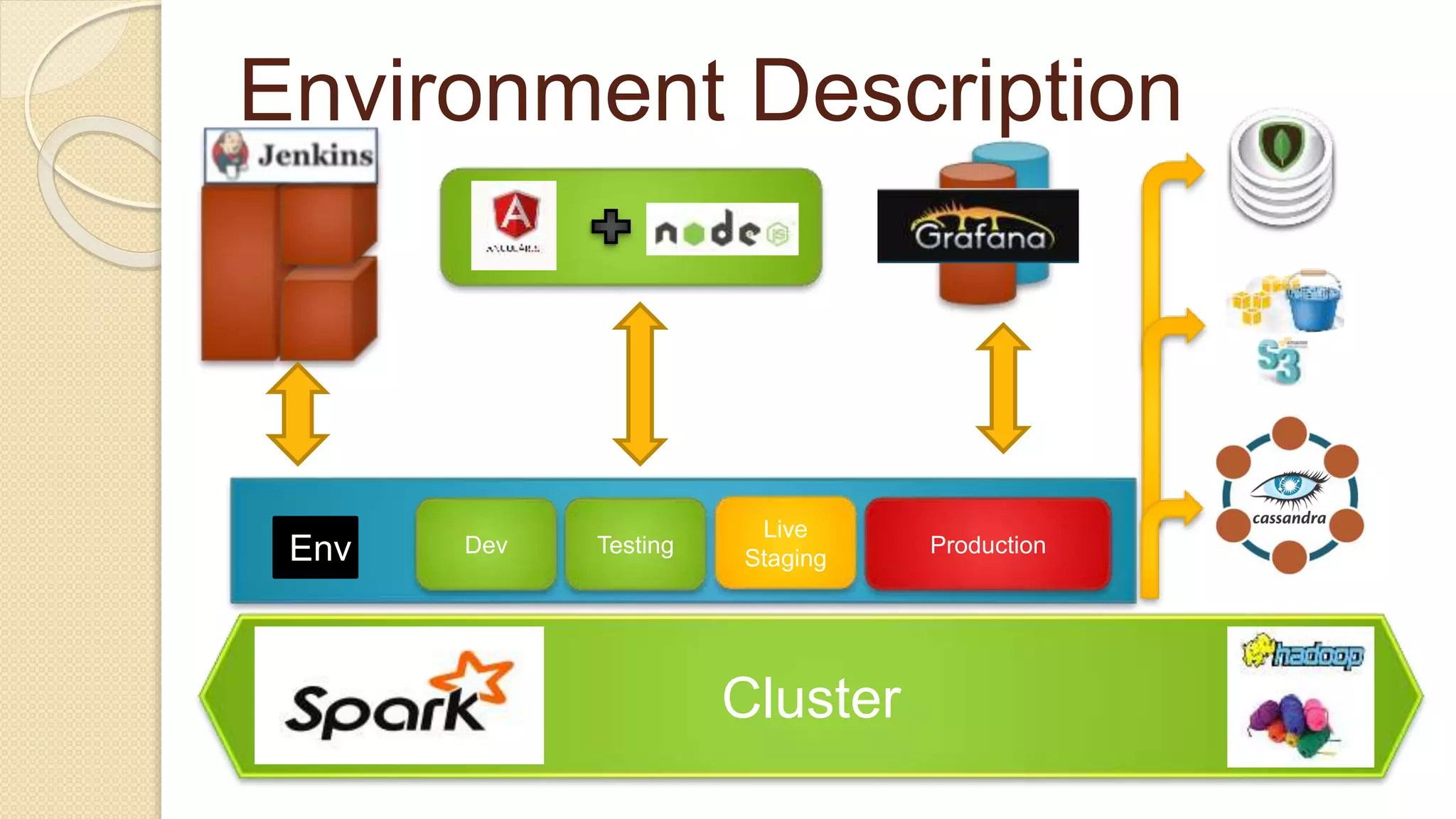

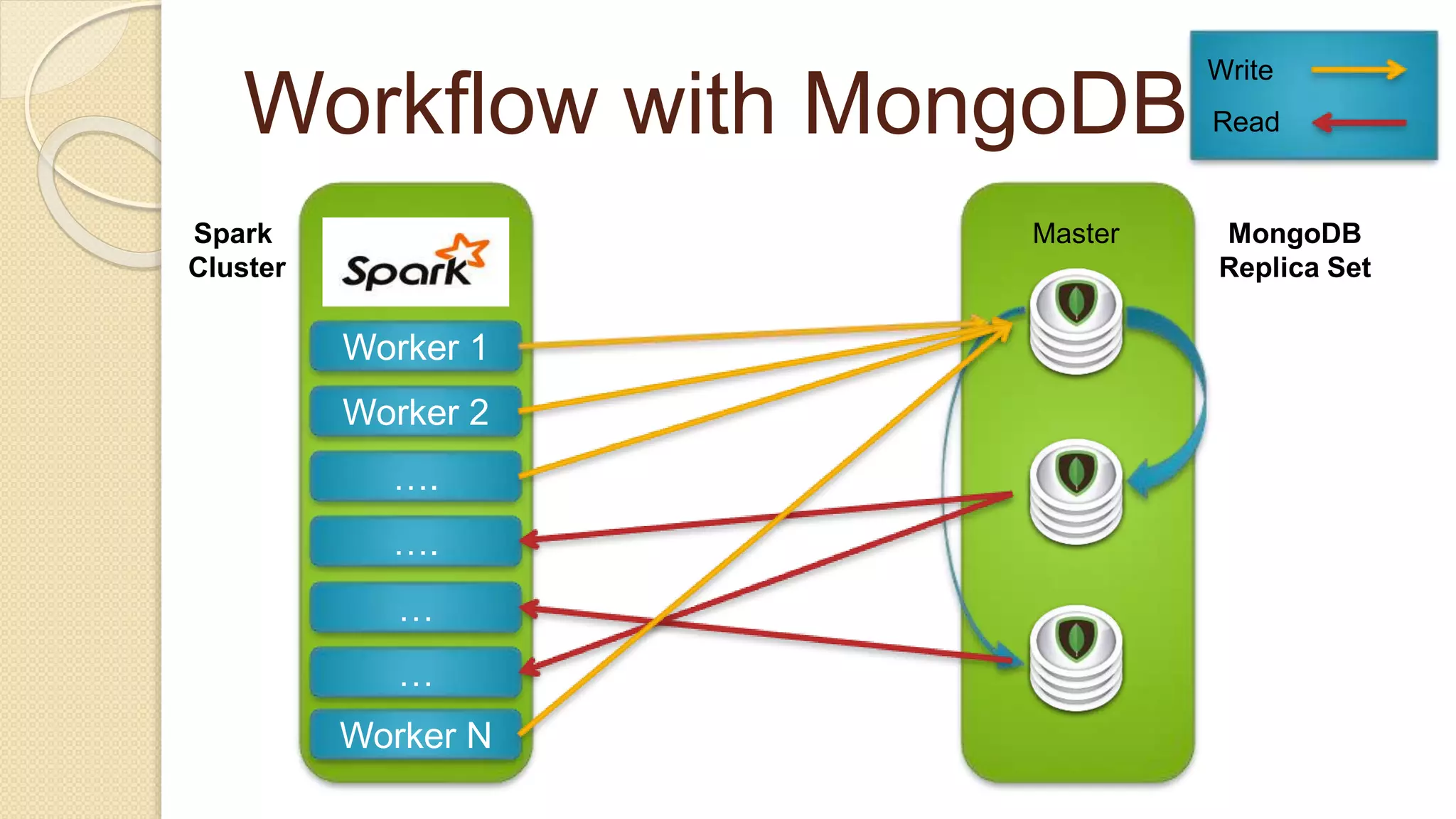




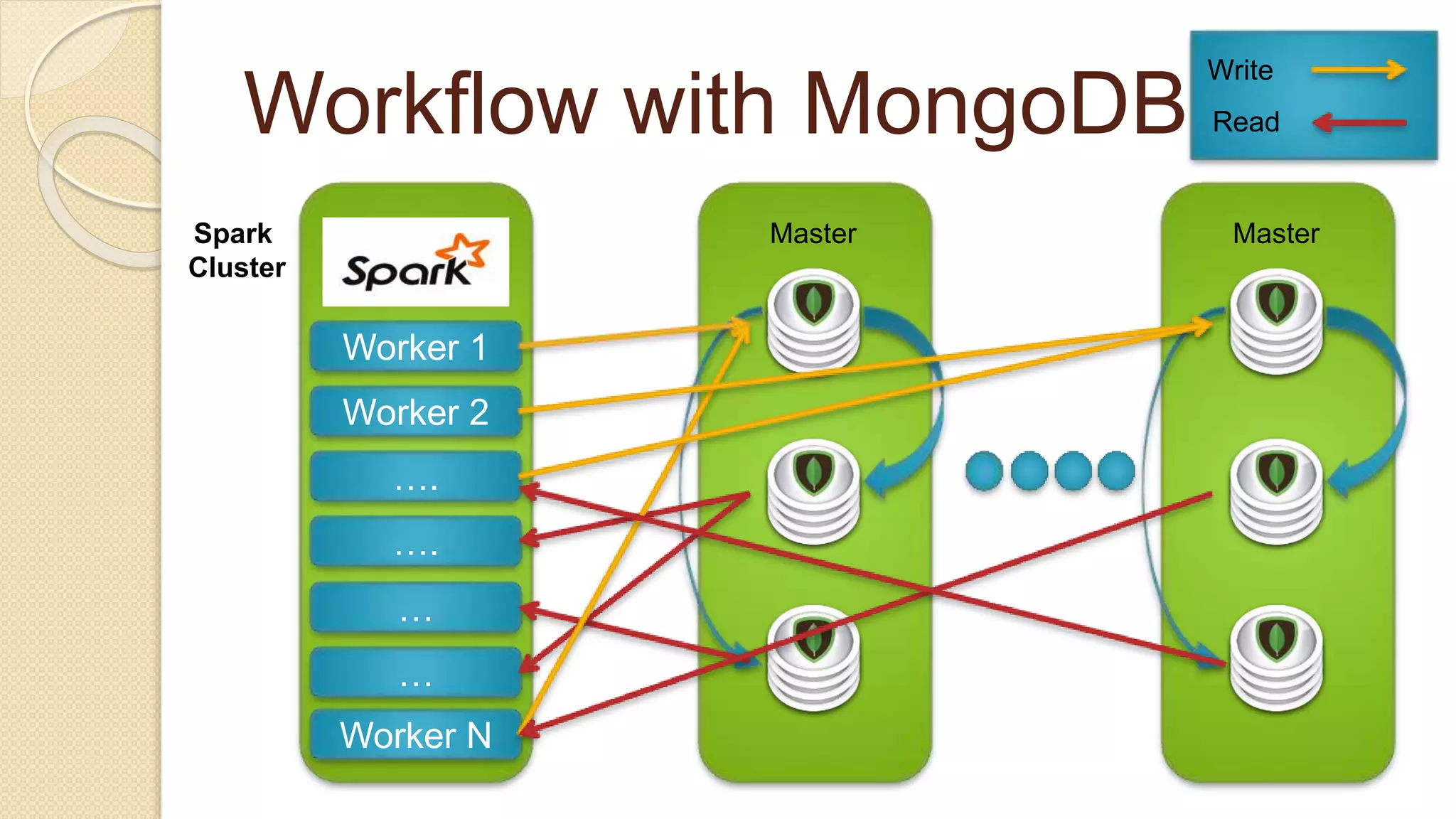




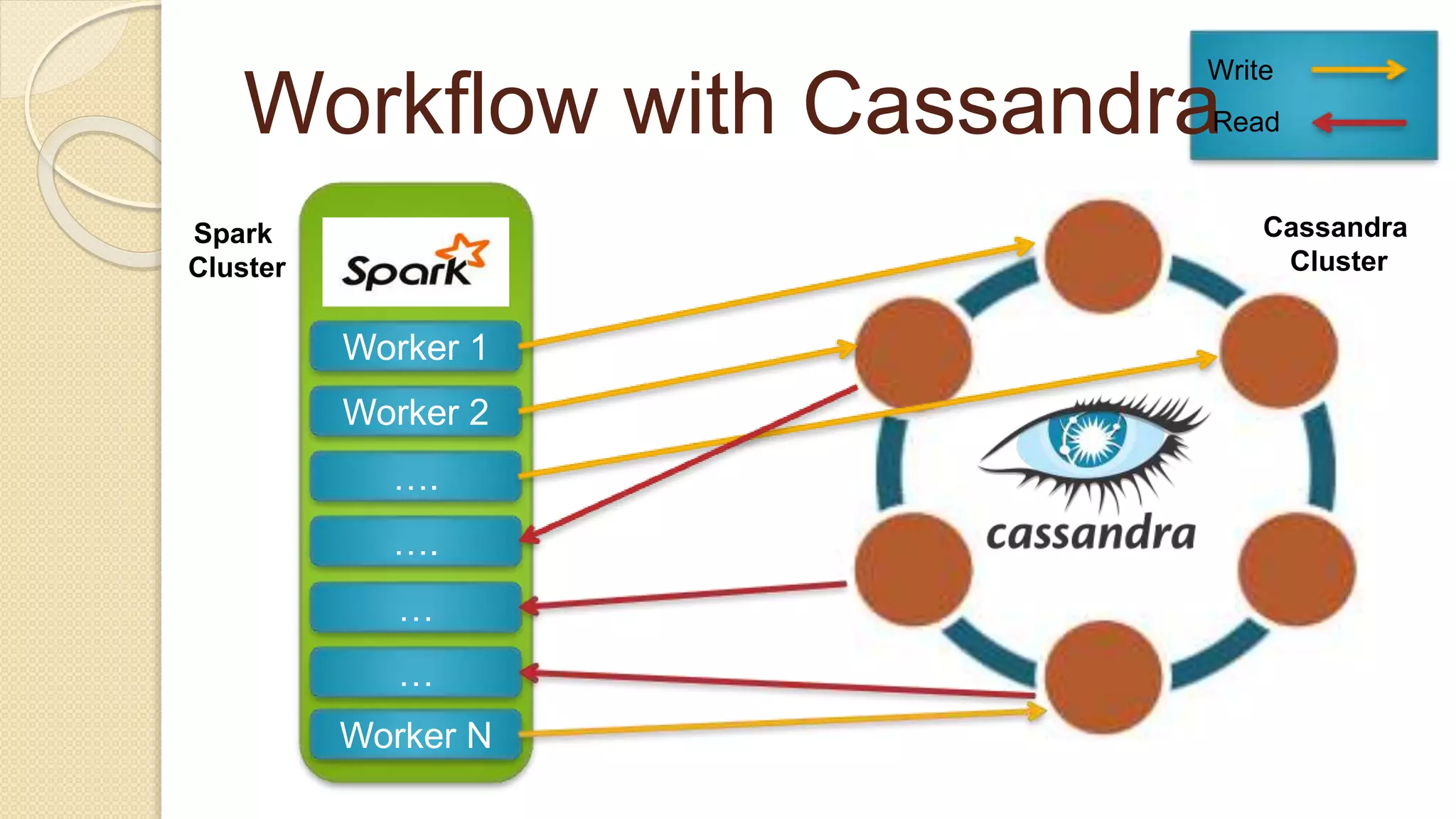





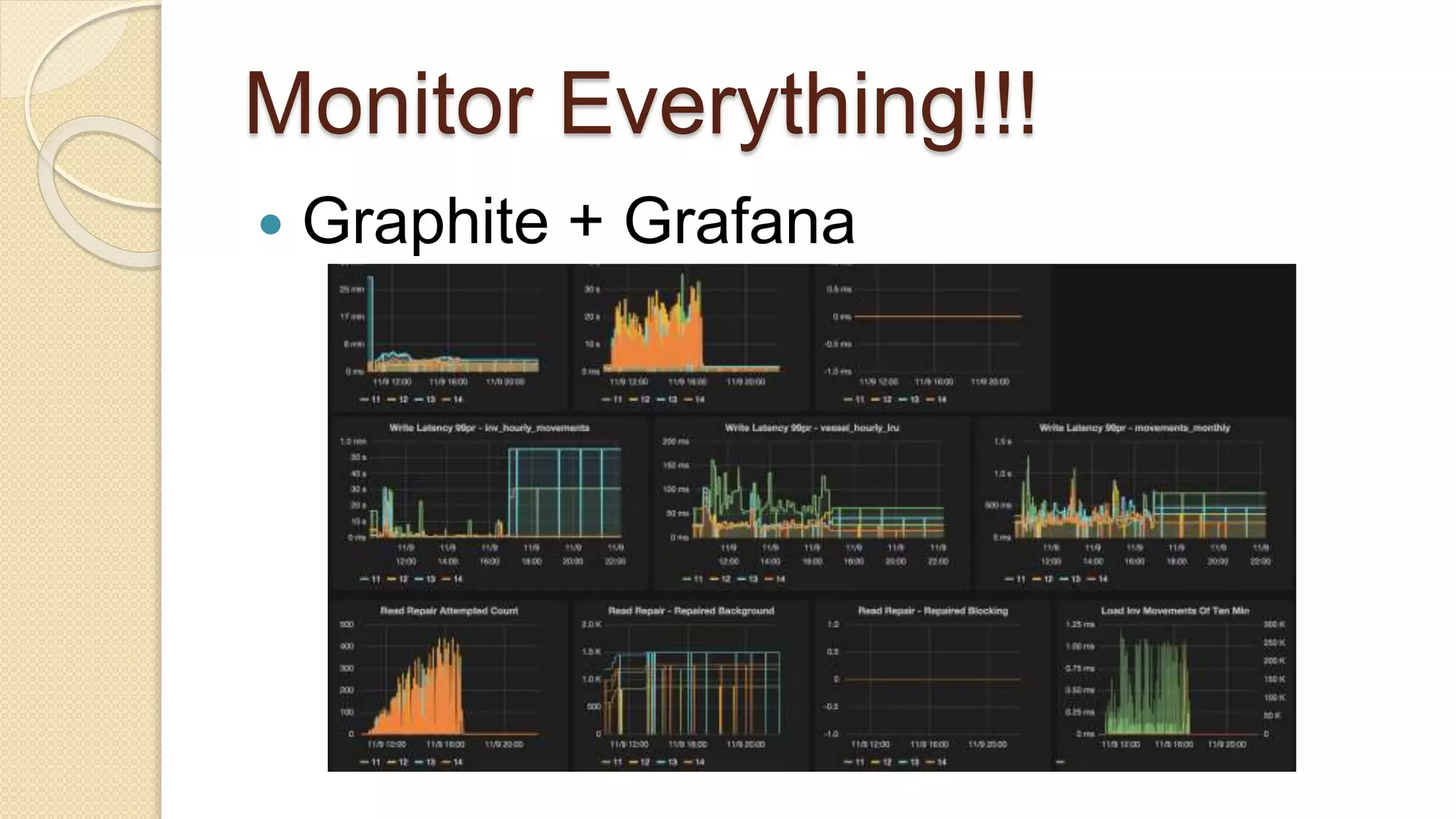







Demi Ben-Ari, a senior software engineer, discusses the transition from MongoDB to Apache Cassandra due to performance issues with batch job processing times. The solution involved writing to both databases simultaneously and leveraging Apache Cassandra's scalability and community support, resulting in performance improvements. Key lessons include the importance of monitoring, data modeling, and using prepared CQL statements for efficiency.