Download to read offline




















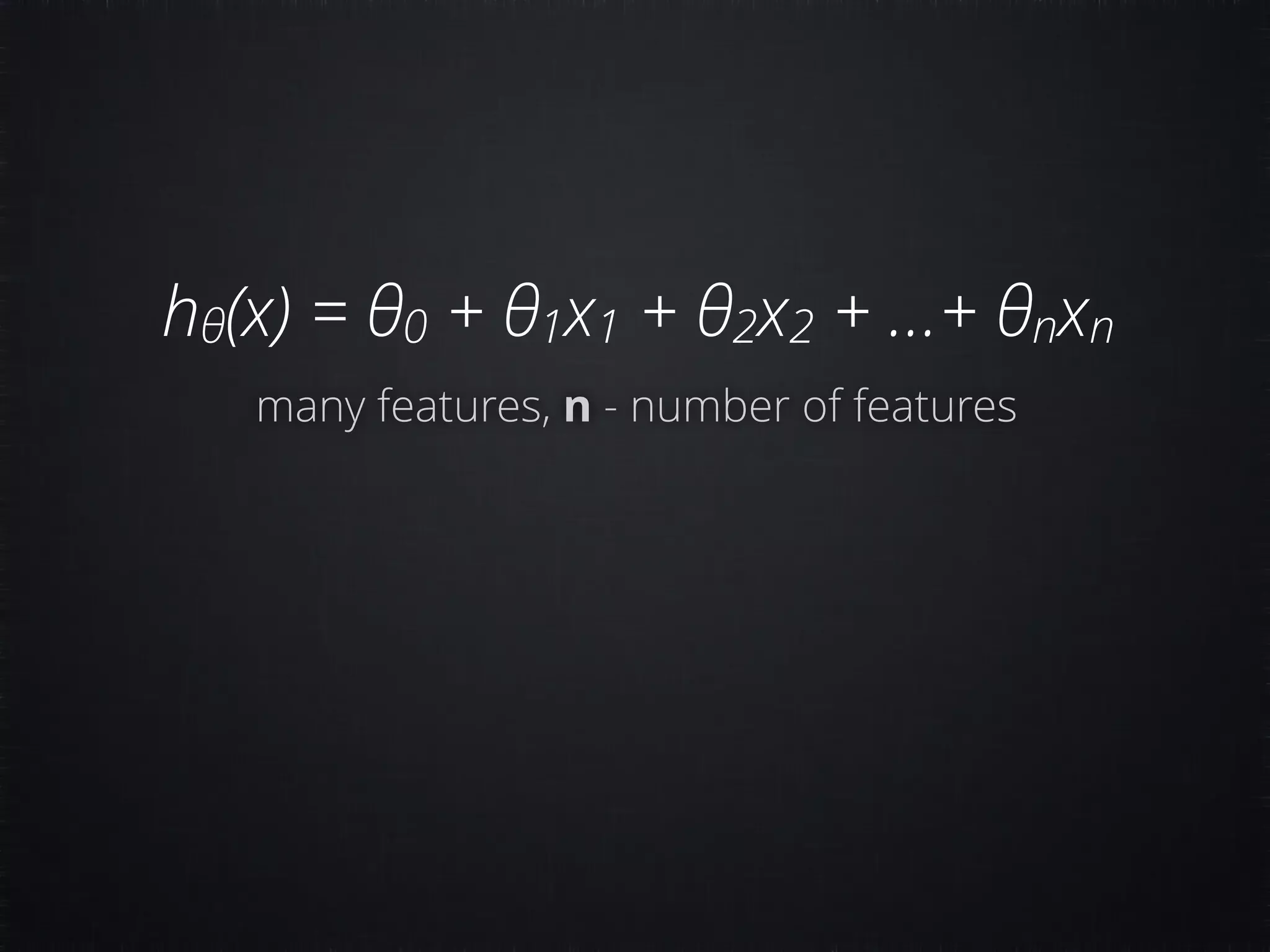


























![require './neural_network' LOCATIONS = [:home, :work, :tennis, :parents] LOCATIONS_INDEXED = LOCATIONS.map.with_index { |x, i| [x, i] }.to_h XX = [ # week 1 # 1st day of week, 8am [:work, 1, 8], [:tennis, 1, 17], [:home, 1, 20], [:work, 2, 8], [:home, 2, 18], [:work, 3, 8], [:tennis, 3, 17], [:home, 3, 20], [:work, 4, 8], [:home, 4, 18], [:work, 5, 8], [:home, 5, 18], [:parents, 7, 13], [:home, 7, 18], # week 2 [:work, 1, 8], [:home, 1, 18], [:work, 2, 8], [:home, 2, 18], [:work, 3, 8], [:tennis, 3, 17], [:home, 3, 20], [:work, 4, 8], [:home, 4, 18], [:work, 5, 8], [:home, 5, 18],](https://image.slidesharecdn.com/machine-learning-161208065538/75/Machine-Learning-Make-Your-Ruby-Code-Smarter-75-2048.jpg)
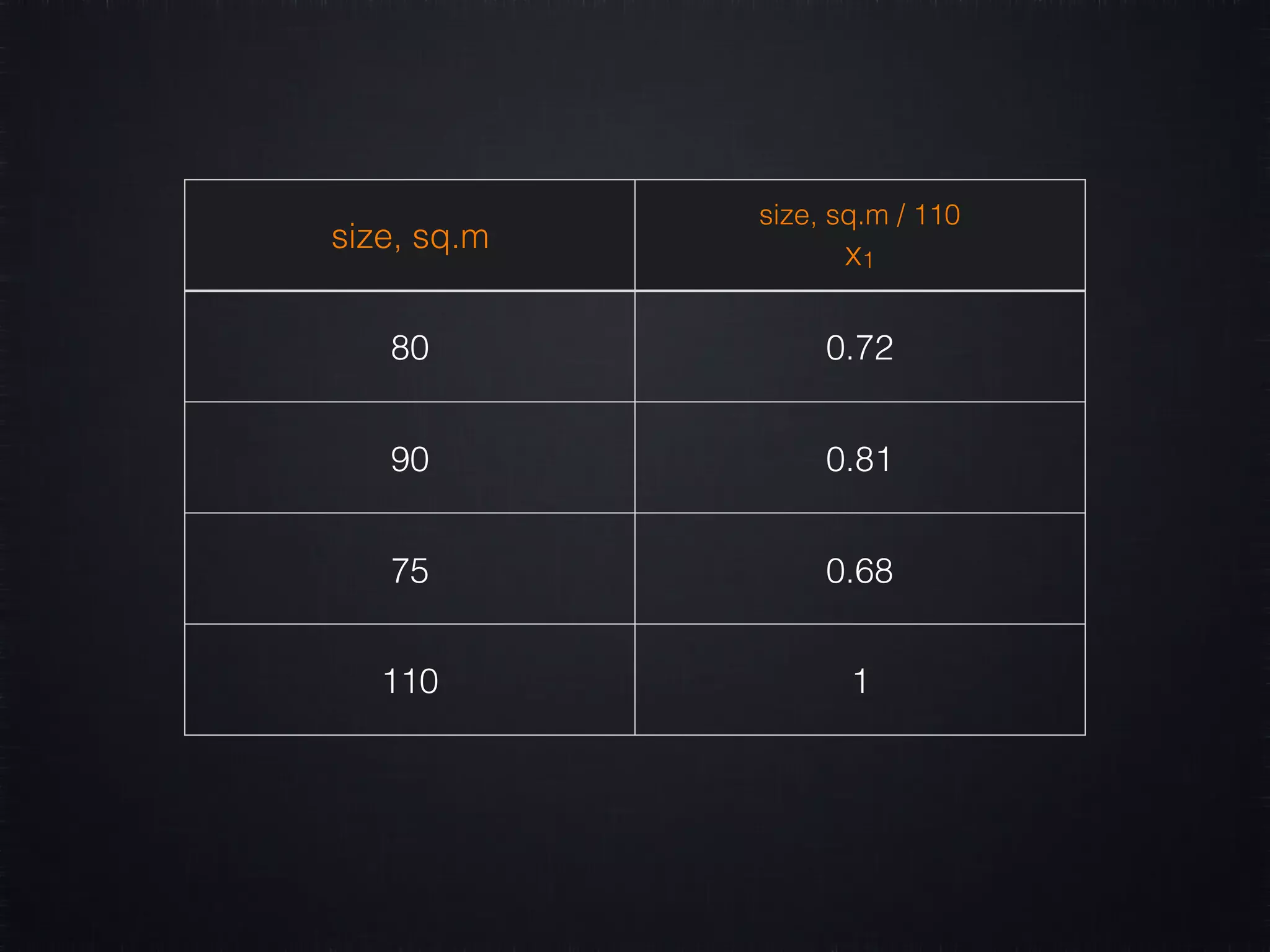
![XX.each do |destination, day, time| yy << LOCATIONS_INDEXED[destination] xx << [day.to_f/7, time.to_f/24] end features scaling](https://image.slidesharecdn.com/machine-learning-161208065538/75/Machine-Learning-Make-Your-Ruby-Code-Smarter-76-2048.jpg)

![[ [1, 16.5], [1, 17], [1, 17.5], [1, 17.8], [2, 17], [2, 18.1], [4, 18], [6, 23], [7, 13], ].each do |day, time| res = nn.predict_with_probabilities([ [day.to_f/7, time.to_f/24] ]).first. select {|v| v[0] > 0} # filter zero probabilities puts "#{day} #{time} t #{res.map {|v| [LOCATIONS[v[1]], v[0]]}.inspect}" end](https://image.slidesharecdn.com/machine-learning-161208065538/75/Machine-Learning-Make-Your-Ruby-Code-Smarter-79-2048.jpg)
![1 16.5 [[:tennis , 0.97]] 1 17 [[:tennis , 0.86], [:home , 0.06]] 1 17.5 [[:home , 0.52], [:tennis, 0.49]] 1 17.8 [[:home , 0.82], [:tennis, 0.22]] 2 17 [[:tennis , 0.85], [:home , 0.06]] 2 18.1 [[:home , 0.95], [:tennis, 0.07]] 4 18 [[:home , 0.96], [:tennis, 0.08]] 6 23 [[:home , 1.00]] [:work, 1, 8], [:tennis, 1, 17], [:home, 1, 20], [:work, 2, 8], [:home, 2, 18], [:work, 3, 8], [:tennis, 3, 17], [:home, 3, 20], [:work, 4, 8], [:home, 4, 18], [:work, 5, 8], [:home, 5, 18], [:parents, 7, 13], [:home, 7, 18], # week 2 [:work, 1, 8], [:home, 1, 18], [:work, 2, 8], [:home, 2, 18], [:work, 3, 8], [:tennis, 3, 17], [:home, 3, 20], [:work, 4, 8], [:home, 4, 18], [:work, 5, 8], [:home, 5, 18],](https://image.slidesharecdn.com/machine-learning-161208065538/75/Machine-Learning-Make-Your-Ruby-Code-Smarter-80-2048.jpg)



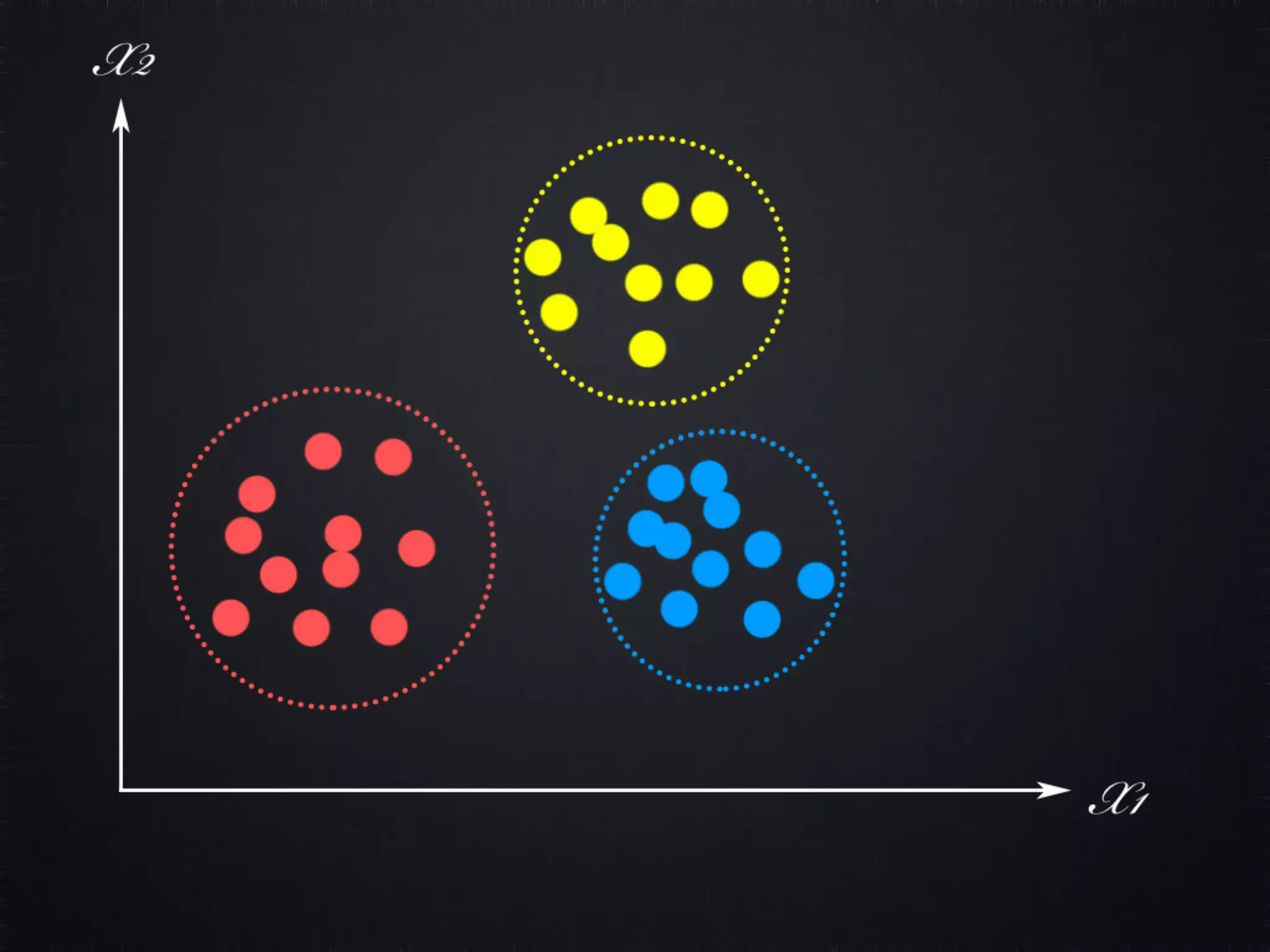

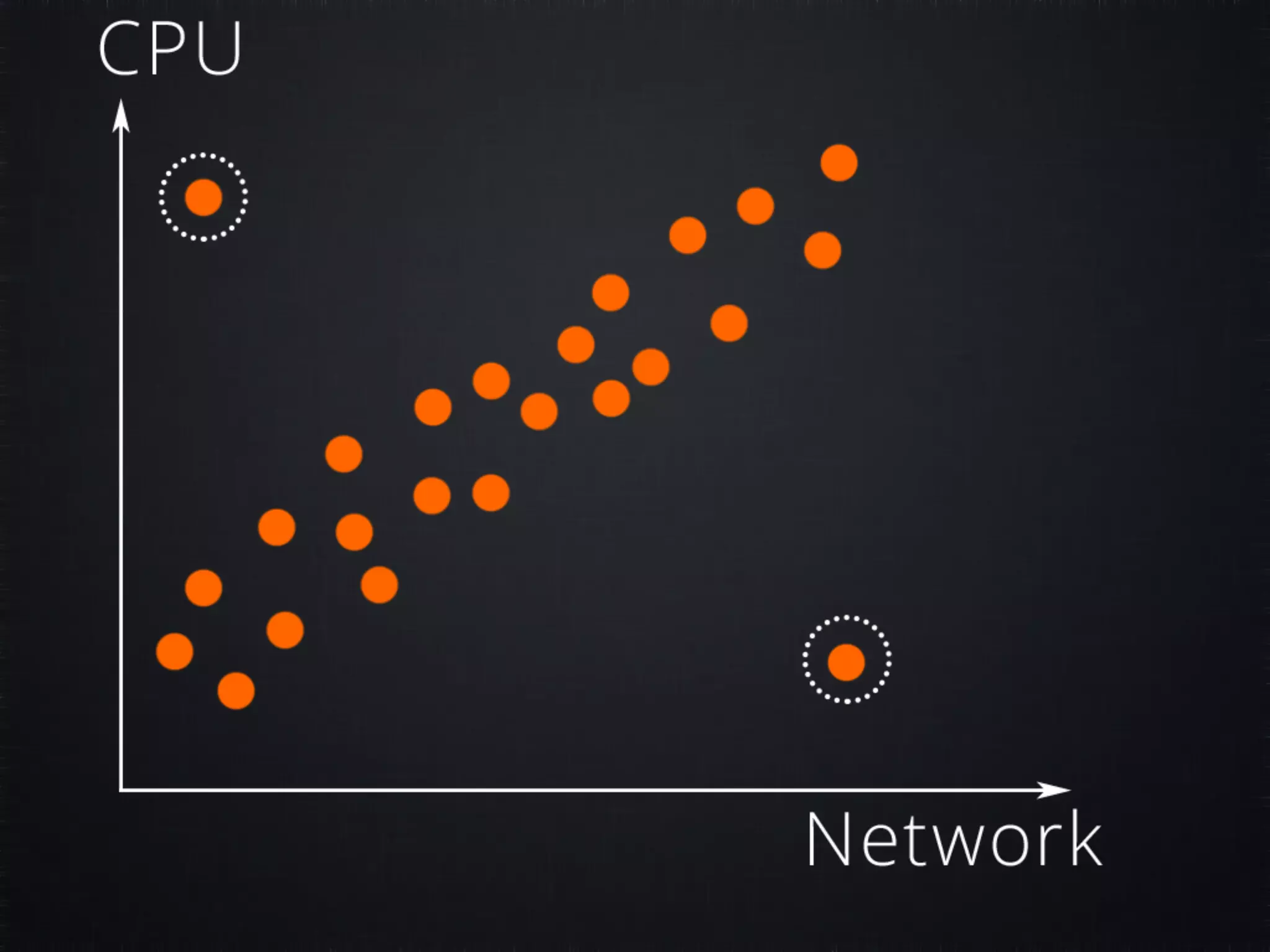

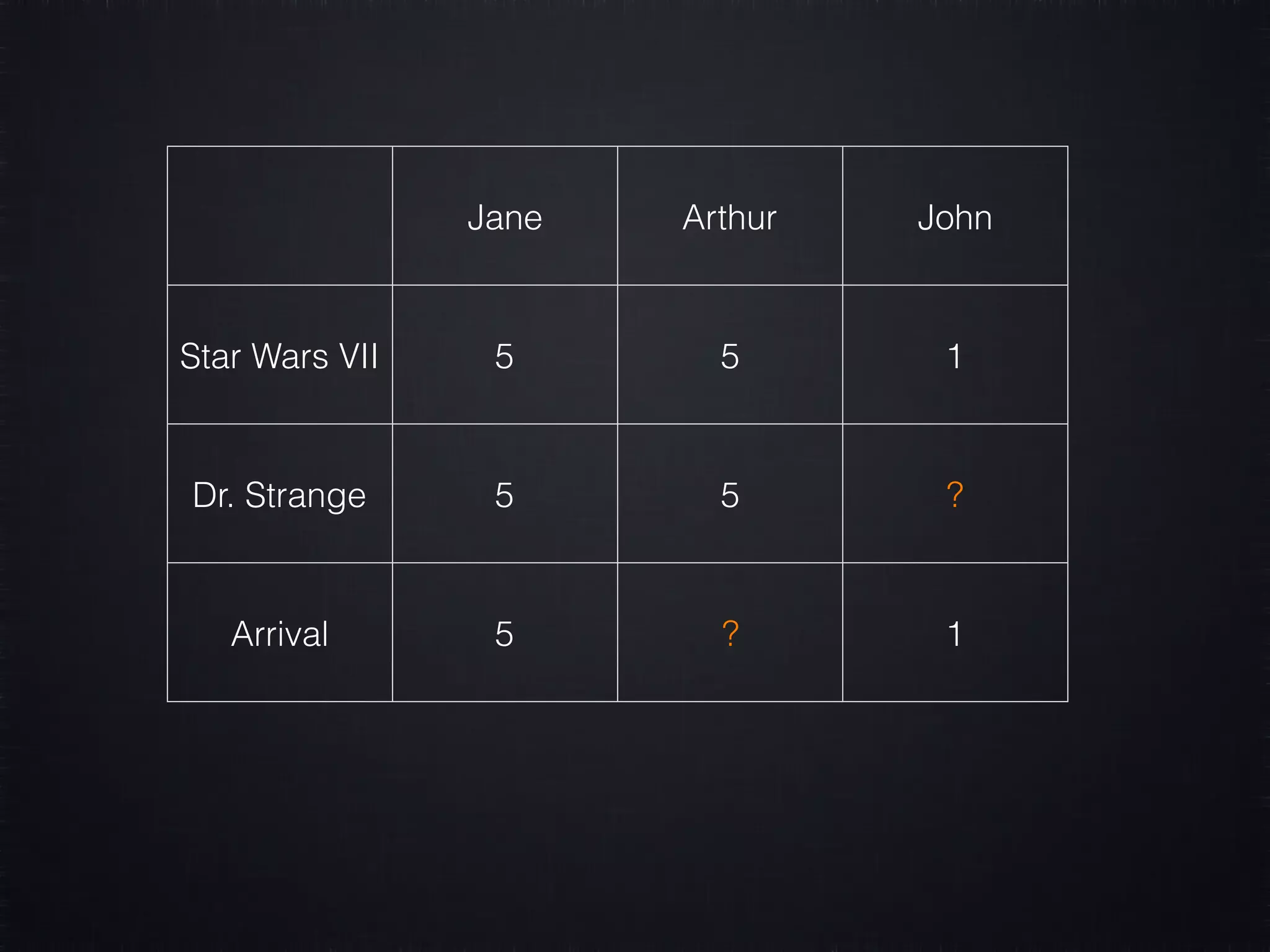






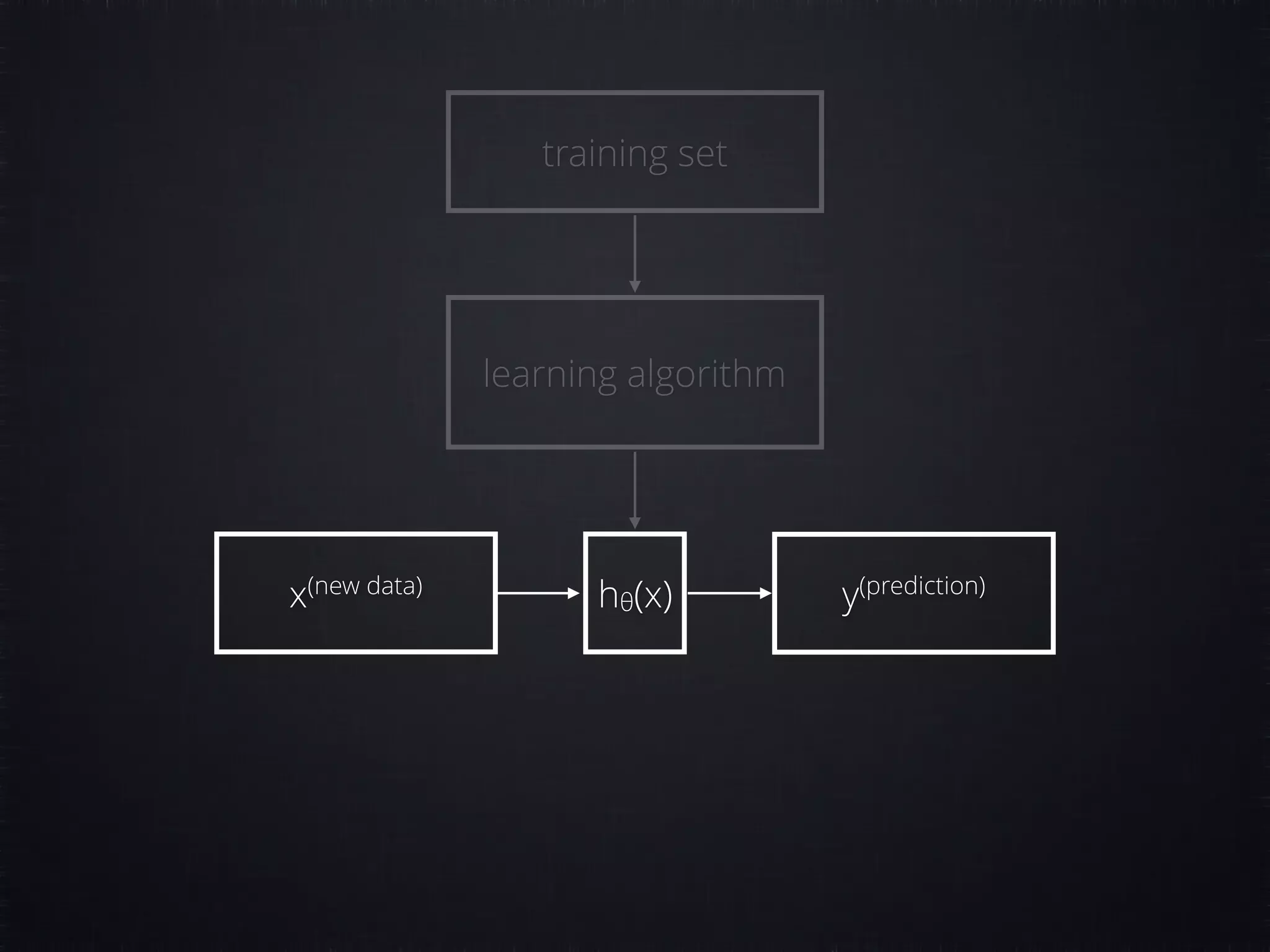
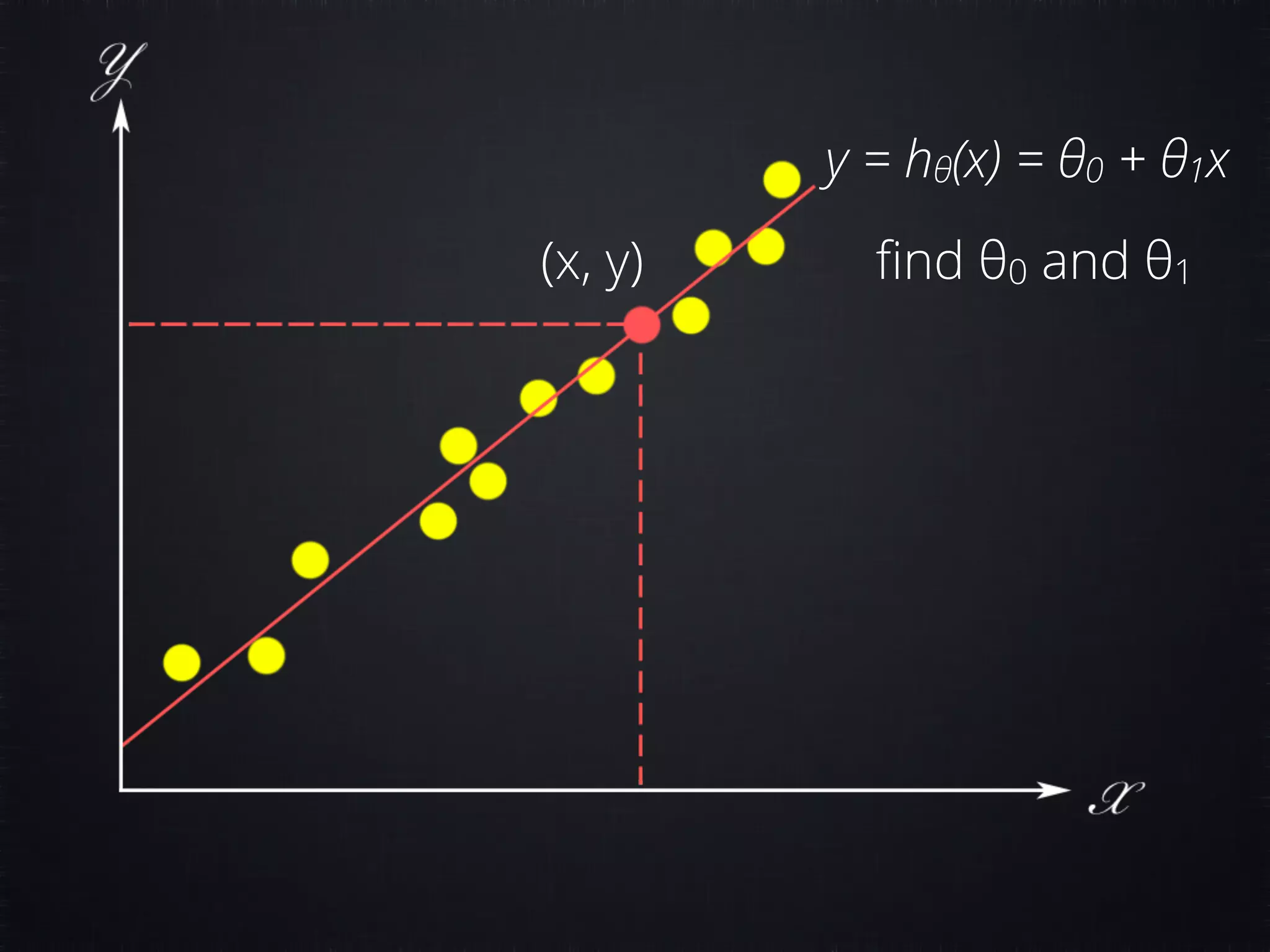
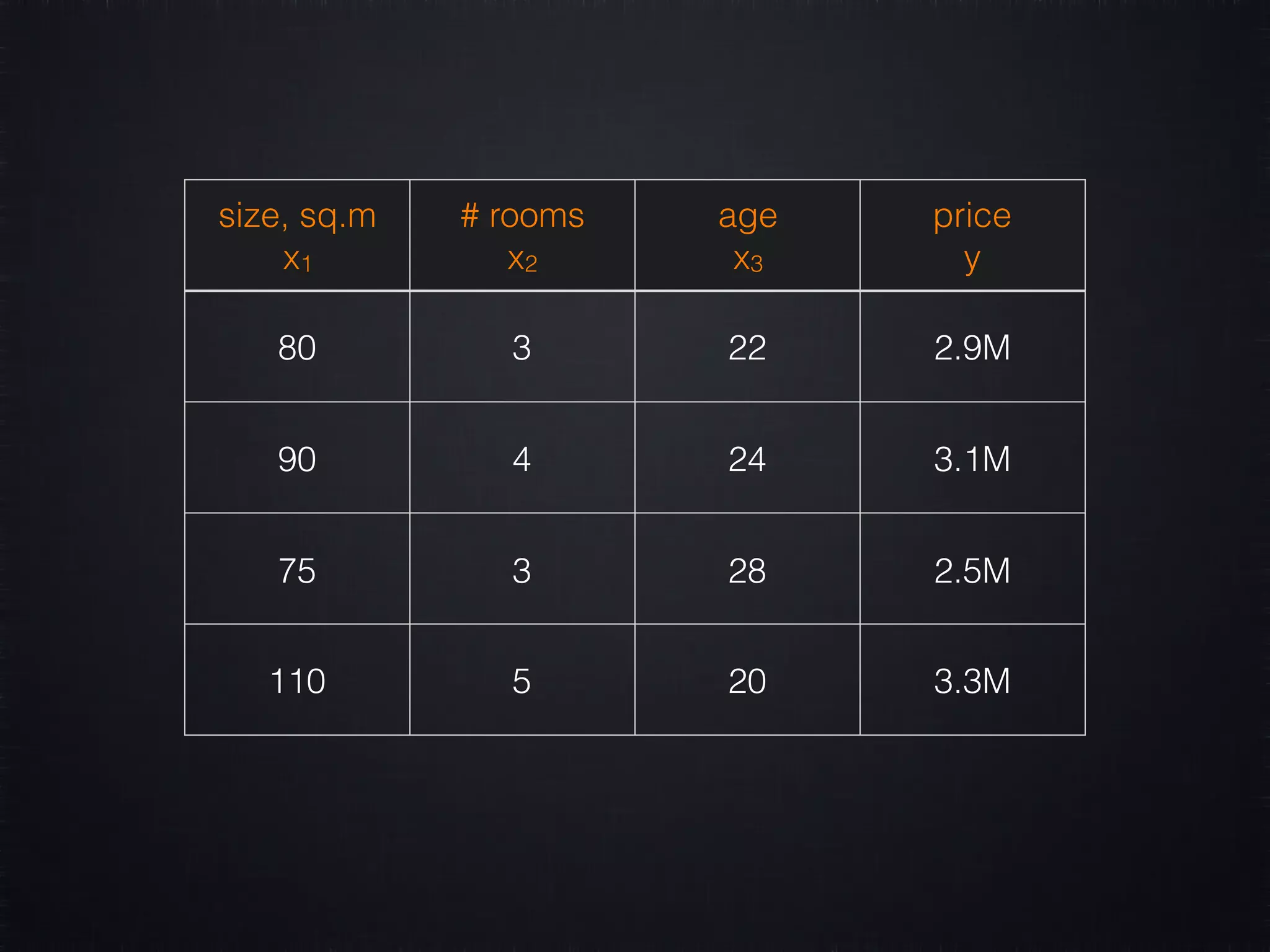
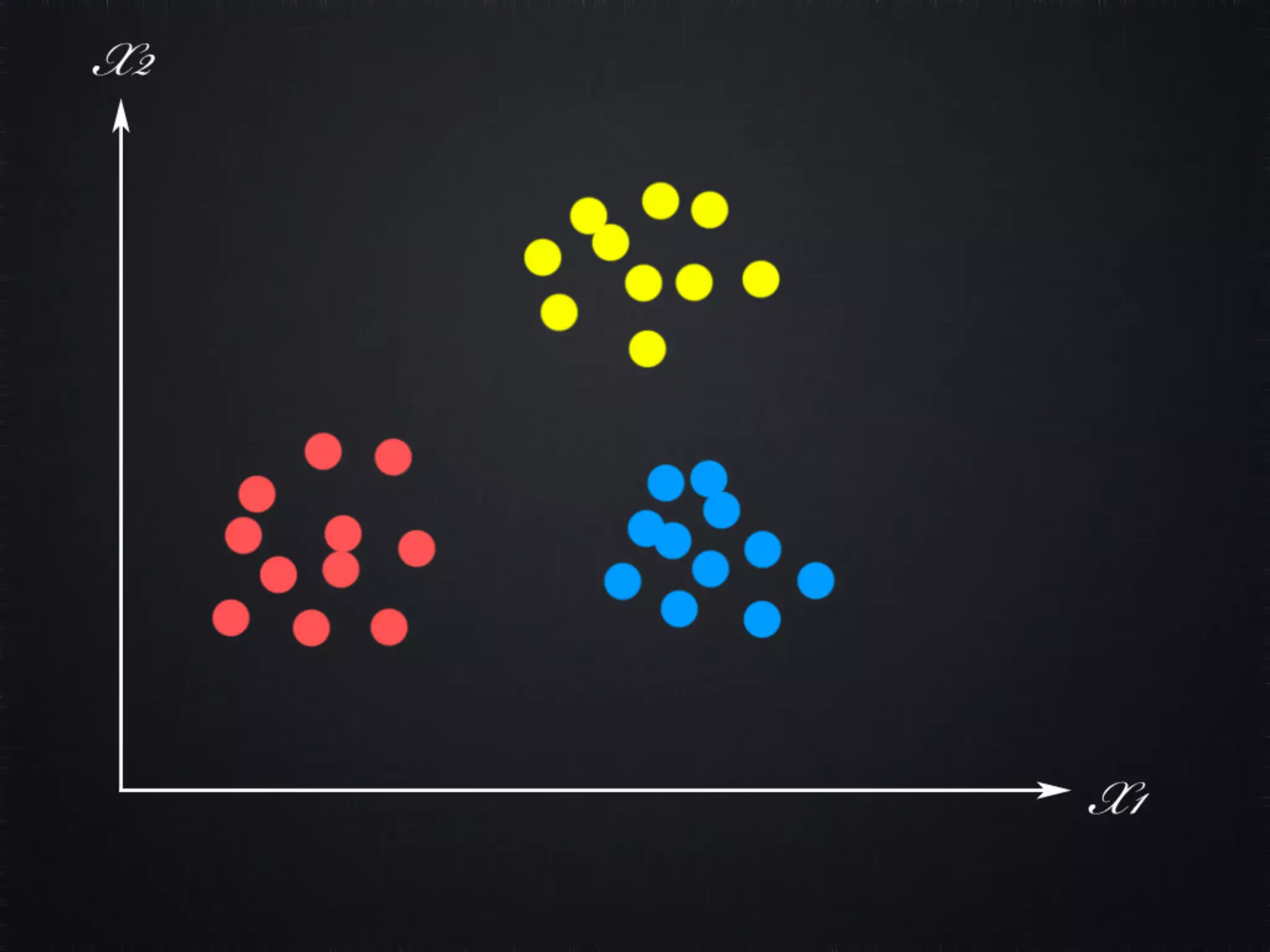
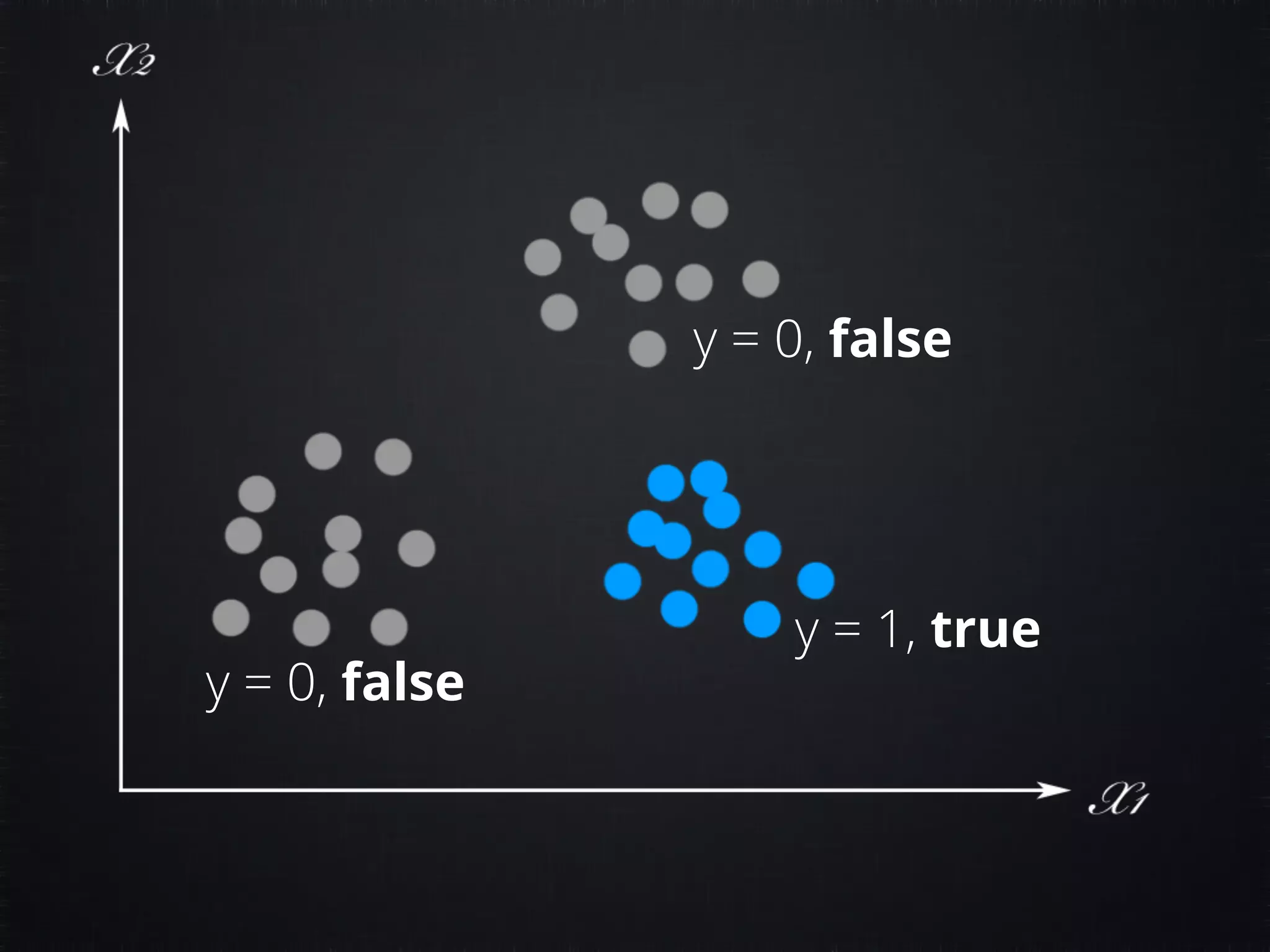
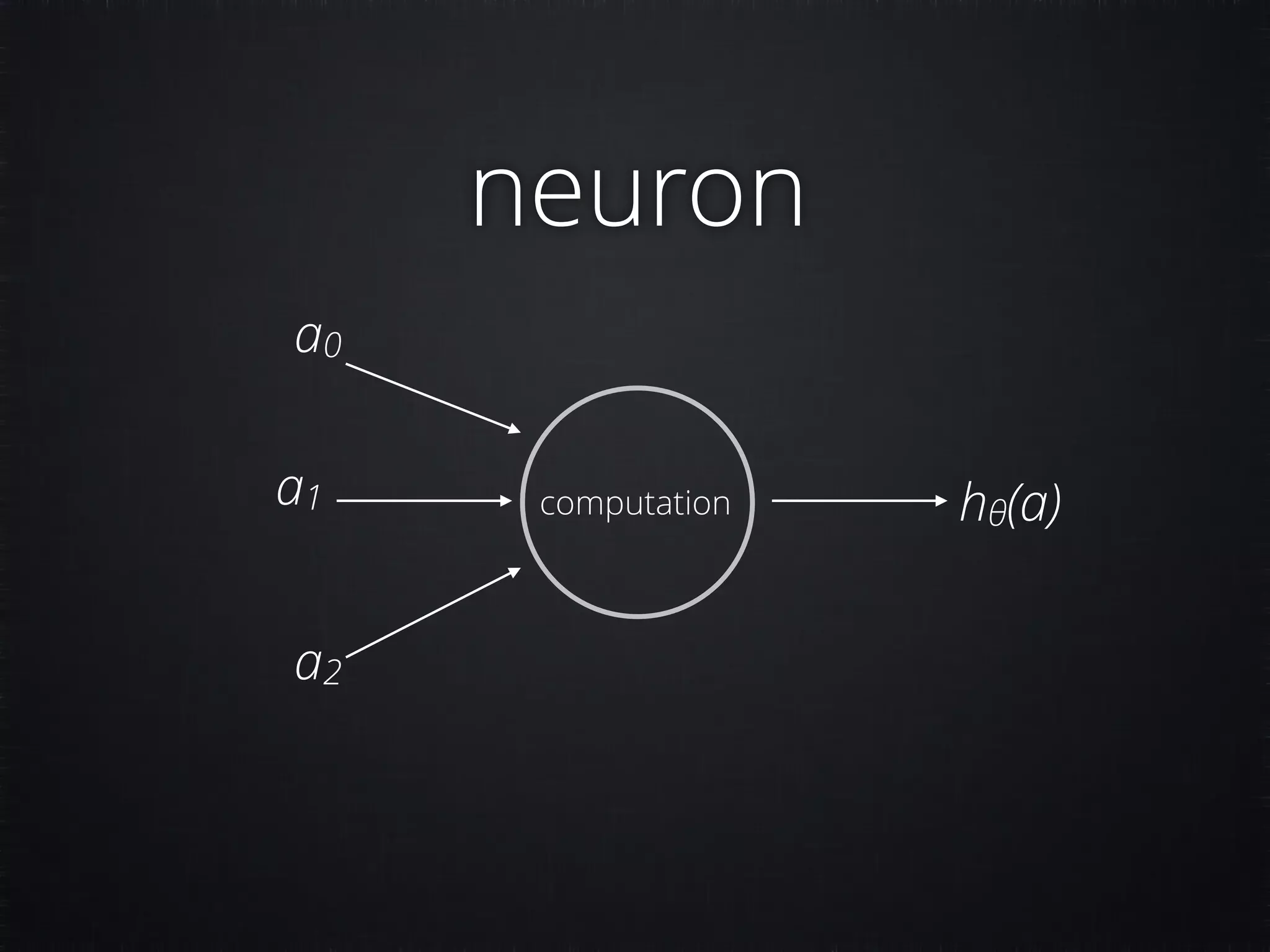
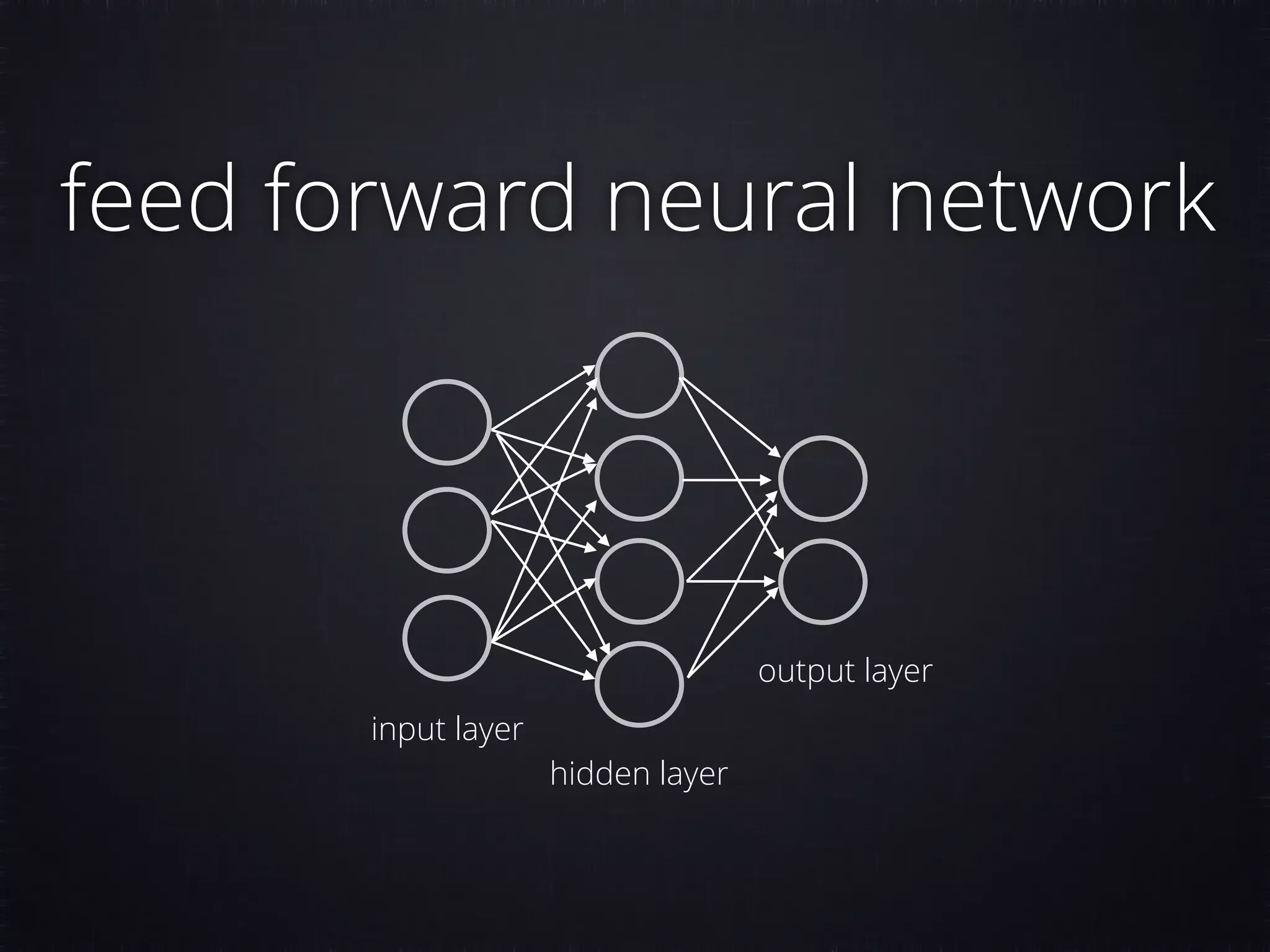
The document discusses concepts in machine learning (ML) and artificial intelligence (AI), explaining the differences between supervised and unsupervised learning, and detailing linear regression and logistic regression. It also covers neural networks, deep learning, and specific applications like recommendation systems and clustering. Additionally, it provides code examples, feature scaling techniques, and resources for further learning.